以自動摘要提昇中文文件分類之效能
89
0
0
全文
(2) Automatic Summarization as a Basis for Improving the Classification Effectiveness of Chinese Documents Advisor: Dr. Wen-Feng Hsiao By: Kia-Fan Liu. A Thesis Submitted to the Graduate Program of Information Management in Partial Fulfillment of the Requirements for the Degree of Master of Science in Information Management. National Pingtung Institute of Commerce Pingtung, Taiwan, R.O.C. July, 2006.
(3) 國立屏東商業技術學院 資訊管理系 所( ) ( 碩) 士 論 文 94. 以自動摘要提昇中文文件分類之效能. 劉凱帆 撰.
(4) 以自動摘要提昇中文文件分類之效能 研究生: 劉凱帆. 指導教授: 蕭文峰. 國立屏東商業技術學院資訊管理系(所) 摘要 「摘要」通常代表一篇文章之核心概念。本研究提出以文件摘要來 進行特徵字選取,以替代現行之維度縮減法;此方法可減少向量的維 度,以及選取出較具代表性的特徵字。實驗結果顯示,以文件摘要進行 特徵字選取可得到不錯的中文文件分類的效能,其正確性優於以 Information Gain 挑選特徵字的 KNN 分類器。另外,當以類別為向量單 位時其分類效果又比以文件為向量單位的結果要好;此呼應模式選取準 則中的正確性與精簡性(或優雅性)。 另外,由於文件作者的用詞習慣可能不盡相同,相同概念可能以不 同詞彙表達,如此可能造成分類上的偏誤。因此本研究亦探討同義詞對 分類正確性之影響。由實驗結果顯示,同義詞對提昇分類的正確性並無 正面效果。其原因可能在於同義詞之距離計算不夠周延,後續研究將探 討更合理的計算方式。 最後,本方法所衍生的好處是同時產生文件的指示性(indicative)摘 要,可供使用者快速知曉其文件之概念。 關鍵字:自動摘要、中文、文件分類、特徵詞選取、同義詞. I.
(5) Automatic Summarization as a Basis for Improving the Classification Effectiveness of Chinese Documents Student :. Kia-Fan Liu. Advisor :. Dr. Wen-Feng Hsiao. Information Management, National Pingtung Institute of Commerce. Abstract A “summary” usually represents the core concept of an article. Therefore, instead of using some feature selection methods to reduce the size of keyword vector, we proposed using the summary of an article to generate its corresponding keyword vector. This method, we believe, can both reduce the dimensionality of the keyword vector and extract more representative keywords. The experimental results show that our method does obtain a good performance for Chinese documents classification. Its accuracy outperforms KNN classifiers which employs Information Gain as the criterion of feature selection. Furthermore, the accuracy of our method achieves maximum when using class-based keyword vector instead of document-based keyword vector. This result corresponds to the criteria of parsimoniousness and elegance in model selection. Owing to different writing styles, different authors might choose different terms to express the same concepts. This, however, might incur the classification bias. In this study we also investigate the effect of the synonyms (defined by thesaurus) on the classification. The experiment results show that no positive effects exist in synonyms on improving the classification accuracy. The reason might be attributed to the poor similarity metrics defined in calculating the distance between two terms. Future research might consider devising a more reasonable metrics. Finally, a by-product of our proposed method is that it can generate indicative summaries of those documents. Thus, readers can easily grasp the concepts of those documents by our method. II.
(6) Keywords: Automatic Summarization, Chinese, Text Categorization, Feature Selection, Synonyms. III.
(7) 誌謝 又見鳳凰花開時,轉眼間即將結束兩年的學習生涯,回首來時路, 從懵懂無知到略有所悟,百感交集,點滴在心頭。 兩年學習生涯中,令我最感不虛此行的,便是能接受 蕭文峰老師 的指導,在論文研究期間,蕭老師給予學術專業的傳授及對論文細心的 指正,除學業及課業上的教導之外,其做人處事之態度也是學生所難望 及項背;老師自稱是博「土」,但樸實中有幽默,令枯燥無味的研究增 添了許多樂趣。其次要感謝師範大學 蔡蓉青教授、中山大學 張德民教 授及靜宜大學 楊子青教授,在百忙之中,仍撥冗擔任學生之口試委員, 並給予不少寶貴的意見,因為有老師們的指正,本篇論文才能更趨完整。 此外,還要感謝屏東商業技術學院所有的同窗好友、學弟靖良、顯 堂及中山大學的伙伴們,陪伴著我兩年屏東的研究生活,在生活及研究 上不吝給予我幫助,因為有他們,在研究與休閒娛樂各方面給予完整的 奧援,心中只有無限感激,在此獻上我最高的謝意。 最後要感謝的是我的父母以及家人,沒有他們對我的關心以及提供 我無虞的生活,及無後顧之憂的專心在學業上,我也不能一路的順利升 學。也感謝我的女朋友雅文,在我遇到瓶頸遲滯不前時給我加油打氣, 陪伴我渡過一個又一個的難關。. 謹將此論文獻給我親愛的家人以及所有關心我、幫助我的人。. IV.
(8) 目錄 1. 2. 緒論 ................................................................................................................................. 1 1.1. 背景和動機......................................................................................................................................... 1. 1.2. 目的..................................................................................................................................................... 3. 文獻探討 ......................................................................................................................... 5 2.1. 3. 文件分類............................................................................................................................................. 5. 2.1.1. 預處理 ....................................................................................................................................... 6. 2.1.2. 維度縮減(Dimensionality Reduction, DR)................................................................................ 6. 2.1.3. 產生向量模型(vector space model).......................................................................................... 8. 2.1.4. 使用分類器 ..............................................................................................................................11. 2.2. 摘要獲取的相關技術....................................................................................................................... 13. 2.3. 字彙不匹配問題............................................................................................................................... 17. 2.3.1. 同義詞 ..................................................................................................................................... 17. 2.3.2. 相關詞 ..................................................................................................................................... 20. 研究方法 ....................................................................................................................... 21 3.1. 預處理............................................................................................................................................... 21. 3.2. 特徵詞選取....................................................................................................................................... 22. 3.3. 文件相似比對改進........................................................................................................................... 26. 3.3.1. 4. 5. 同義詞詞典比對改進 ............................................................................................................. 26. 系統實作與實驗結果與分析 ....................................................................................... 30 4.1. 系統雛型介紹................................................................................................................................... 30. 4.2. 中文實驗測試集............................................................................................................................... 32. 4.3. 文件分類的效能指標....................................................................................................................... 33. 4.4. 自動摘要之結果............................................................................................................................... 35. 4.5. 實驗設計與結果............................................................................................................................... 38. 4.5.1. 實驗一 ..................................................................................................................................... 38. 4.5.2. 實驗二 ..................................................................................................................................... 45. 4.5.3. 實驗三 ..................................................................................................................................... 48. 4.5.4. 實驗四 ..................................................................................................................................... 51. 4.5.5. 實驗五 ..................................................................................................................................... 65. 結論及未來研究方向 ................................................................................................... 69 5.1. 結論................................................................................................................................................... 69. 5.2. 未來研究方向................................................................................................................................... 70. V.
(9) 6. 參考文獻 ....................................................................................................................... 71. 7. 附錄 ............................................................................................................................... 74. VI.
(10) 圖目錄 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖. 2-1 文件分類流程圖...................................................................................................... 5 2-2 向量空間模型示意圖.............................................................................................. 8 2-3 K個最鄰近法示意圖[8] ......................................................................................... 12 2-4 支援向量機分類模型............................................................................................ 13 2-5 詞頻與鑑別力的相關圖 [21] ............................................................................... 14 2-6 計算句子的重要性 [21] ....................................................................................... 15 2-7 《同義詞詞林》語義分類樹形圖 [5] ................................................................. 18 3-1 本研究文件分類流程............................................................................................ 21 3-2 特徵字擷取方法.................................................................................................... 22 3-3 文件相似度計算(未考量同義詞計算) ................................................................. 26 3-4 文件相似度計算流程圖........................................................................................ 27 3-5 文件相似度計算(利用同義詞) ............................................................................. 29. 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖. 4-1 主系統的操作畫面................................................................................................ 31 4-2 主系統的分類結果畫面........................................................................................ 31 4-3 摘要篩選比例 30%,不同向量單位之比較 ....................................................... 42 4-4 摘要篩選比例 40%,不同向量單位之比較 ....................................................... 43 4-5 以類別向量在不同摘要篩選比例之比較............................................................ 44 4-6 只考量名詞與同時考量名詞和動詞的比較........................................................ 47 4-7 交叉驗證法的分類結果比較表(Macro-F) ........................................................... 49 4-8 交叉驗證法的分類結果比較表(Accuracy).......................................................... 50 4-9 分類器分類結果比較圖(資料集A) ...................................................................... 56 4-10 分類器分類結果比較圖(Accuracy) (資料集A) ................................................. 56 4-11 分類器分類結果比較圖(Macro-F) (資料集A)................................................... 57 4-12 分類器分類結果比較圖(資料集B) .................................................................... 64 4-13 分類器分類結果比較圖(Accuracy) (資料集B) ................................................. 64 4-14 分類器分類結果比較圖(Macro-F) (資料集B)................................................... 65. VII.
(11) 表目錄 表 表 表 表 表 表 表 表 表 表 表 表. 2-1 特徵字選取方法[28] ............................................................................................... 7 4-1 中文測試資料集.................................................................................................... 32 4-2 混淆矩陣(Confusion Matrix)................................................................................. 33 4-3 新聞全文範例........................................................................................................ 35 4-4 新聞 20%摘要範例............................................................................................... 36 4-5 ICIM2006 作者撰寫摘要 ....................................................................................... 36 4-6 ICIM2006 自動摘要範例(前 500 字) .................................................................... 36 4-7 以文件為向量,訓練資料為 30%,摘要比例為 30%及 40%之分類結果..... 39 4-8 以文件為向量,訓練資料為 50%,摘要比例為 30%及 40%之分類結果..... 39 4-9 以文件為向量,訓練資料為 70%,摘要比例為 30%及 40%之分類結果..... 40 4-10 以類別為向量,訓練資料為 30%,摘要比例為 30%及 40%之分類結果... 40 4-11 以類別為向量,訓練資料為 50%,摘要比例為 30%及 40%之分類結果 ... 41. 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表. 4-12 以類別為向量,訓練資料為 70%,摘要比例為 30%及 40%之分類結果... 41 4-13 摘要篩選比例 30%,不同向量單位之比較 ..................................................... 42 4-14 摘要篩選比例 40%,不同向量單位之比較 ..................................................... 42 4-15 以類別為向量,在不同摘要比例下,不同訓練資料比例之分類結果........... 43 4-16 訓練資料為 30%分類結果................................................................................. 45 4-17 訓練資料為 50%分類結果................................................................................. 46 4-18 訓練資料為 70%分類結果................................................................................. 46 4-19 只考量名詞與同時考量名詞和動詞的比較...................................................... 47 4-20 交叉驗證測試資料集.......................................................................................... 49 4-21 交叉驗證法的分類結果比較表.......................................................................... 49 4-22 在資料集A下,本研究分類器分類結果 ........................................................... 52 4-23 在資料集A下,SVM分類器分類結果 .............................................................. 53 4-24 在資料集A下,KNN分類器分類結果 .............................................................. 54 4-25 分類器分類結果比較表 (資料集A) .................................................................. 55 4-26 在資料集B下,本研究分類器分類結果 ........................................................... 58 4-27 在資料集B下,SVM分類器分類結果 .............................................................. 60 4-28 在資料集B下,KNN分類器分類結果 .............................................................. 62 4-29 分類器分類結果比較表(資料集B) .................................................................... 63 4-30 用於同義詞實驗之資料集.................................................................................. 66 4-31 加入同義詞典方法下,某一文件與政治和財經比較結果.............................. 67 4-32 以類別為特徵向量單位,未採用同義詞詞典之分類結果.............................. 67. 表 4-33 以文件為特徵向量單位,未採用同義詞詞典之分類結果.............................. 67 表 4-34 加入同義詞詞典比較結果表.............................................................................. 68 表 7-1 程式模組說明........................................................................................................ 74 VIII.
(12) 表 7-2 流程說明................................................................................................................ 75 表 7-3 程式指令說明........................................................................................................ 76 表 7-4 圖形介面分類器使用說明.................................................................................... 77. IX.
(13) 1 緒論 文件分類(text categorization)是將文件依其內容與性質加以分類,以 方便使用者按類瀏覽及選擇文件。例如,Yahoo!奇摩股市將網頁連結依 行業別(電子、金融、化學、航運、…)加以分類、購物網站依商品型態(家 電、禮品、玩具、精品、男裝、女裝、…)分類等。這些分類可幫助使用 者/消費者快速找到其想要的資訊以進行比較與選擇。傳統由人類專家執 行文件分類的方式已不符合時間及成本的考量。另一方面,人工檢閱的 缺點除了速度慢以外,還包括個人主觀與意識型態的差異性,將可能導 致文件分類的標準不一致;利用技術和機器可以有效解決人為產生的偏 差,另外處理資訊的速度,人工檢閱是無法相比。因此,一種有效而分 類結果令人滿意的自動分類方法是很重要的。 1.1 背景和動機 近年來,大量數位文獻不斷地增加,文件分類因此逐漸視為一種有 效資訊檢索的方案,其可提供使用者依主題查詢而不必受限於文件用 詞。故許多學者紛紛投入自動分類的研究,例如,Bayesian分類器[17]、 決策樹(decision tree)[25]、K個最鄰近法(k-nearest neighbor)分類器[27]、 等等。 大多數的文件分類演算法都需透過學習訓練文件的特徵來建構出 1.
(14) 對應的模型。然而,由於文件中的自然語言,屬非結構化的資料(不似資 料庫中的資料有固定數目及事先就定義好的屬性),較難以描述,故需透 過文件索引法(document indexing),將文件映射成一組特徵字向量(term vector)。在普通大小的資料集中,中文的特徵字數量可能會很大,輕易 達 到 10 6 或 是 甚 至 更 多 [29]( 中 文 特 徵 字 將 更 多 ) 不 像 文 件 檢 索 (text retrieval),在文件分類時,若詞彙空間的維度高某些演算法將無法處理。 例如,KD-trees在維度高於 10 以上的速度會變得相當慢[31]。因此,在 進行文件分類之前,通常必須先經過維度縮減的前處理。 傳 統 用 於 維 度 縮 減 的 方 法 有 兩 類 , 一 是 進 行 特 徵 字 選 取 (term selection),將重要具代表性的特徵字選出;另一方式是進行特徵字擷取 (term extraction),由舊有特徵字組合成新的特徵字。這些努力雖能改善 文件分類的效率及有效性,但其缺點在於這些運算相當耗費資源,且這 些辛苦獲得之特徵字向量並無法再利用。另一方面,我們也無法由這些 獲得的特徵字來瞭解某一篇文件的主要概念。此外,特徵字向量長度決 定不易,維度縮減演算法的一個潛在問題是會造成資訊遺失(information loss)。 最後,在文件分類比對部分,常用的是特徵向量(feature vector)來 比對,但是特徵字比對的過程,會產生「字彙不匹配」(vocabulary mismatch)的問題,主要是因為只考量用詞是否一樣。但對於詞義相同但 2.
(15) 詞彙字串不同時,就會忽略掉了。而這樣的忽略明顯地會影響到分類正 確性。 1.2 目的 過去研究[24]指出由少量但具代表性的資料所建立的模型並不會比 大量資料所建立模型差(當同時考量資料蒐集成本、模式建立成本、及預 測錯誤之成本時)。因此,為了解決上述所提的問題,相對於採用特徵字 選取或特徵字擷取來進行維度縮減,本研究提議從文件中先自動產生摘 要,並擷取其特徵字,以進行中文文件分類。自動產生摘要的目的有二: 一、可成為該文件的指示性(indicative)摘要 1,可提供使用者在依主題查 詢時,可快速知曉其文件之概念;二、可進一步減少特徵字數量,以達 成維度縮減。現行維度縮減之解決方法都是從統計的角度去考量,極少 從自然語言中語法概念方面去作考量。在語法概念上,一個句子必須有 兩個部分:一部分叫作主語,表示意思中的「甚麼」,通常為名詞;另 一部分叫作述語,通常為動詞,表示這個甚麼「怎麼樣」。因此,本研 究從自然語言中語法概念的角度來進行,評估句子中動詞及名詞之數量 及所在位置來決定句子的重要程度。依句子之重要程度降冪排序,挑選 其中之前θ 2 %成為摘要,並由摘要中萃取關鍵字組成特徵向量以利分類. 1 2. 所謂指示性摘是依斷句來挑選,相對於一般摘要其差別在於無文章結構,前後句並無連貫。. θ在本研究實驗中,設定為 30%、40% 3.
(16) 學習。其次,本研究另一目的在於瞭解在文件分類的特徵字比對上,考 量同義詞是否能提升特徵字比對結果,以改善「字彙不匹配」的問題。 在後續的章節中,我們將說明,由摘要產生特徵向量的作法具相當的可 靠性及穩定性。. 4.
(17) 2 文獻探討 由於文件的特性是以自然語言表達,通常沒有共同的結構,也沒有 固定的長度,屬非結構化資料。Heart [19]認為文件探勘與資料探勘最主 要的差異在於資料探勘能發掘資料背後隱藏的規則;而文件探勘僅能將 文件歸入事先定義好的類別。例如內容為基準(content-based)的新聞文件 分類就屬於文件分類的一種。Sebastiani [28]認為把用自然語言編寫的文 件,根據其表達主題分類至事 先定義好的類別中即為文件分類 (text classification)。人工文件分類是根據專家知識事先定義出每一類別的分類 規則,並透過人工的方式來加以歸類。而機器學習技術領域中的文件分 類,是藉由一些事先定義好類別的文件,讓系統自動從這些文件中學習 每類的特徵,並利用這些特徵做為分類的依據。 2.1 文件分類. 圖 2-1 文件分類流程圖. 5.
(18) 文件分類的流程大致可分為五個程序(如圖 2-1所示),分別為: 2.1.1 預處理 文件分類的第一步是預處理,預處理則是將文件進行轉換,使轉換 成符合分類器之格式。文件轉換通常有下列類型[10]:移除HTML(或是其 它的)標籤、移除停用字(stop words)、進行字根還原(word stemming)、詞 性的標記,以及中文文件需要的斷詞處理。 2.1.2 維度縮減(Dimensionality Reduction, DR) 文件分類會面臨特徵空間過大的問題,因此需藉特定的方法使維度 縮減。維度縮減的好處就是可以減少模型的過適(overfitting)問題。維度 縮減可由兩種主要方式來達成[28]: 1) 特徵字選取技術(term selection) 特徵字選取就是試圖從文件集中移除不具資訊(non-informative)的 字詞,以改善分類的有效性和減少計算的複雜度。最常使用的是以文件 頻率(Document Frequency)來挑選。其它用以選取特徵字的方法尚包括: DIA相關因子(Darmstadt Indexing Approach association factor)、資訊增益 (information gain)、相互資訊量(mutual information)、卡方值(chi-square)、 NGL係數(Ng, et al., 1997)、相關分數(relevancy score)、機遇比(odds ratio)、GSS係數(Galavotti, 2000),如表 2-1所示。其中 P ( t k , c i ) 表示一 6.
(19) 個隨機文件x,特徵字 t k 並發生在文件x中且文件x屬於特定類別 ci 的機 率, t k 則表示並無發生在文件x中,另外 Tr 則代表訓練文件數目。. 表 2-1 特徵字選取方法[28] Function. Denoted by. Mathematical form. DIA association factor. z ( t k , ci ). Information gain. IG (tk , ci ). Mutual information. MI (t k , ci ). Chi-square. χ 2 (t k , ci ). NGL coefficient. NGL(tk , ci ). Relevancy score. RS (tk , ci ). log. Odds ratio. OR(tk , ci ). P (tk ci ) ⋅ (1 − P (tk c i )) (1 − P (tk ci )) ⋅ P (tk c i ). GSS coefficient. GSS (t k , ci ). P(ti , ci ) ⋅ P(tk , ci ) − P(ti , ci ) ⋅ P(t k , ci ). P (c i t k ) ∑. ∑ P(t , c) ⋅ log. c∈{ci , ci }t ∈{t k , t k }. log. P(t , c) P(t ) ⋅ P(c). P (t k ,c i ) P (t k ) ⋅ P ( c i ). [. Tr ⋅ P (ti , ci ) ⋅ P (t k , ci ) − P (ti , c i ) ⋅ P (t k , ci ). [. P (t k ) ⋅ P (t k ) ⋅ P (ci ) ⋅ P (c i ). Tr ⋅ P(ti , ci ) ⋅ P(tk , ci ) − P(ti , c i ) ⋅ P(t k , ci ). ]. 2. ]. P(tk ) ⋅ P(t k ) ⋅ P(ci ) ⋅ P (c i ). P (t k ci ) + d P (t k c i ) + d. 2) 特徵字擷取技術(term extraction) 特徵字擷取試圖產生具有較佳效果之合成(synthetic)的特徵字,其最 主要目的在於解決一詞多義、同形異義、同義詞、及原來的詞可能並不 是文件內容表達法最佳維度等問題。其方法大致為兩種:(i)從舊的特徵 集擷取出新的特徵集,以分佈分群法(distributional clustering)達成。(ii) 依據新合成的維度將原先的文件特徵字轉換成其它的特徵字,以隱含語 意索引法(Latent Semantic Indexing)達成[28]。. 7.
(20) 2.1.3 產生向量模型(vector space model) 將非結構的文件轉換成結構化的向量空間,由於處在同一個空間之 中,因此文件在下一階段就可以彼此間可相互比較。 文件是許多的詞彙所形成的集合,其中包含部份較具鑑別力的索引 詞。通常將一個文件挑選出詞彙並重組成一個詞表,其詞表並以陣列的 形式儲存。一個詞即代表向量中的一個維度,而一個維度指的是一個特 徵,在文件探勘中,特徵則指一個特徵詞。而每一維度上的值則代表該 文件在這個維度上的重要程度。這個值稱為詞的「權重」,由這些權重 所組合成特徵向量(Feature Vector)則代表在向量空間中的一篇文件,此方 法稱向量空間模型(vector space model)。例如,圖 2-2所示,將兩文件中 的出現的字進行交集,此集合就稱之向量空間,在此用詞頻來表示該字 的權重。. 圖 2-2 向量空間模型示意圖 所有的文件向量可組合成一個矩陣 A,其數學表示法如下: 8.
(21) Di =< wi1 , wi 2 ...win >. D1 ⎡ w11 D2 ⎢ w21 ⎢ . ⎢ . A= ⎢ . ⎢ . . ⎢ . ⎢ Di ⎣ wi1. . . . w1n ⎤ . . . . ⎥ ⎥ . . . . ⎥ ⎥ . . . . ⎥ . . . . ⎥ ⎥ . . . win ⎦. w12 . . . . .. Di表示第i篇文章,wij表示第j個特徵在第i文章的權重值。 以下介紹六種不同的計算權重的方法[10]: 1) Boolean weighting 這是屬於最簡單的方法,就是將文件出現的詞的權重設為1,未出 現則設為0。 ⎧1 if f ij > 0 Wij = ⎨ ⎩0 otherwise Wij 表示詞的權重, f ij 表示出現的頻率。. 2) Word frequency weighting 另一個簡單的方法,就是使用詞在文件中頻率。 Wij = f ij Wij 表示詞的權重, f ij 表示出現的頻率,圖 2-2權重屬此種方法。. 9.
(22) 3) TFIDF weighting(Term Frequency Inverse Document Frequency) 這改善了前兩方案未考慮詞在所有文件中的頻率。 ⎛N⎞ Wij = f ij ∗ log⎜ ⎟ ⎜n ⎟ ⎝ j⎠ Wij 表示詞的權重, f ij 表示出現的頻率,N表示文件的總數, n j 表. 示詞 j 在全部文件中所出現的次數。 4) TFC weighting (Term Frequency Count) 由於TFIDF weighting未考慮文件的長度不同,TFC weighting 相似 於 TFIDF weighting 除了長度的正規化當作分母。. Wij =. ⎛N⎞ f ij ∗ log⎜ ⎟ ⎜n ⎟ ⎝ j⎠ ⎛N⎞ ∑i=1[ f ij ∗ log⎜⎜ n ⎟⎟] ⎝ j⎠. 2. M. M 表示全部文件中詞的數目,Wij 表示詞的權重, f ij 表示出現的頻. 率,N表示文件的總數, n j 表示詞 j 在全部文件中所出現的次數。 5) LTC weighting (Logarithm term count ) 與前者稍微不同的是用詞頻對數代替原本的詞頻,減小了詞頻差 距很大對 Wij 的影響。. 10.
(23) Wij =. ⎛N⎞ log( f ij + 1.0) ∗ log⎜ ⎟ ⎜n ⎟ ⎝ j⎠ ⎛N⎞ ∑i=1[log( f ij + 1.0) ∗ log⎜⎜ n ⎟⎟] ⎝ j⎠. 2. M. 6) Entropy weighting 這方法是基於資訊理論概念,也是最複雜權重方案。 N ⎡ f ⎛ ⎛ f ij ⎞⎤ ⎞ 1 ij Wij = log( f ij + 1.0) ∗ ⎜1 + ⎢ log⎜⎜ ⎟⎟⎥ ⎟ ∑ ⎜ log( N ) j =1 ⎢ n j ⎟ ⎝ n j ⎠⎦⎥ ⎠ ⎣ ⎝. Wij 表示詞的權重,表示出現的頻率,N表示文件的總數, n j 表示 詞 j 在全部文件中所出現的次數。. 其中. N ⎡ f ⎛ f ij ⎞⎤ 1 ij ∑ ⎢ log⎜⎜ ⎟⎟⎥ 是詞 j 的entropy,若詞平均分散在 log( N ) j =1⎢⎣ n j ⎝ n j ⎠⎥⎦. 所有文件中,則其值為-1;若只有出現在單一文件中則其值為0。 2.1.4 使用分類器 當文件經過轉換,有了比較基準之後,便可以透過一些演算法來找出 文件相似度,此處說明本研究相關之分類器。 1) K個最鄰近法(K-Nearest-Neighbor,KNN) 最鄰近法是一種以案例基礎(example-based)的機器學習法,不需要訓 練階段的方法,它是利用經由測試樣本四周K個最近的訓練樣本來確定此 樣本,其中測量最近的方式是利用距離或相似度測量。但若只找最相近 11.
(24) 的單一案例,極可能會受到雜訊的干擾而影響到分類結果,因此會選擇 一個以上的案例,判別其中那種類別為多數則可歸類之,其定義如下 [27]:假設有個欲查詢的文件 q 及查詢參數k,該文件 q 與 Ο 集合的距離小 於與 Ο′ 集合的距離,那麼就表示 Ο 集合為物件q的K個最近鄰居,其中DB 表所有的文件corups。. ∀o ∈ NN q (k ). O. ∀o'∈ DB − NN q ( k ). O’. ⇒ d (o, q) < d (o' , q) 圖 2-3 K個最鄰近法示意圖[8] 2) 支援向量機(Support Vector Machine) 支援向量機是一種統計基礎的機器學習法。主要的目標是在高維度 的 特 徵 空 間 中 找 出 一 個 最 大 邊 際 超 平 面 (Maximum Margin Hyperplane )。而落在邊際(Margin)的點,則稱支援向量。其表示式如下:. y = w ⋅ x + b ,而超平面為 w ⋅ x + b = 0 其中,y 為分類結果,x 為特徵向量,w 為特徵向量 x 的權重。. 12.
(25) w ⋅ x + b = +1 Margin. w ⋅ x + b = −1 Support Vector Hyperplan w ⋅ x + b. =0. 圖 2-4 支援向量機分類模型 Joachims [20]主張SVM在文件分類上提供兩個重要的優點: z 不須特徵字選擇:因為 SVM 比較不會產生模型過適(over-fitting)問 題並且能排列出重要的維度。 z 不須大量的參數調整:預設的參數值也顯示其可提供最好的效能。 上述是一般文件分類之基本流程,本研究提議以摘要來獲取關鍵 字,故接下來介紹摘要獲取的相關技術。 2.2 摘要獲取的相關技術 由於句子是最基本的概念單位,因此一種直覺的方式是由選擇文件 中重要句子來組成摘要。Luhn [21]提議句子的重要性可從其鑑別詞 (significant words)所佔的「比重」來評估。其中,鑑別詞可由測量各詞出 現在文章中的頻率來決定。其基本理由在於文章的作者使用不同的詞來 表達相同的概念的機率是很小的;即使文章作者努力的選擇同義詞來替. 13.
(26) 換,很快地就會用完同義的候選詞而落入重覆使用的循環中。Luhn的實 驗(圖 2-5)顯示出高頻字往往是一般用詞(如,停用字等),因此而對於文 章是較少鑑別力。而低頻字通常是較不重要的概念,故出現次數不高。 因此選擇則是詞頻介於C、D門檻值之間的詞來做為鑑別詞集。. D. C FREQUENCY WORDS. 圖 2-5 詞頻與鑑別力的相關圖 [21] Luhn[21]提議句子重要性的計算可根據句子中首次出現鑑別詞的位 置以及最後一個鑑別詞的位置做為計算的範圍,將其中的鑑別詞個數平 方並除以該範圍內所有詞的個數。以圖 2-6為例,其範圍內有四個鑑別 詞和三個未具鑑別力的詞,計算的方式就是四的平方除於七,四捨五入 後即是 2.3,該值即代表該句子重要性指標。. 14.
(27) 圖 2-6 計算句子的重要性 [21] 在中文自動摘要方面,許多研究[3,13,14,15,16] 提議鑑別詞的計算應 以名詞與動詞為主。其根據的理由是,如果將文件中的冠詞、副詞、以 及介系詞等詞彙刪除,讀者仍然能夠知道這份文件的表達概念,因此說 明了名詞與動詞相當重要。本研究由擴充Chen and Chen[3,13,14,15]之方 法來計算句子的重要性,以獲得文件之摘要。以下介紹Chen and Chen所 提的方法,從他們的論文整理有出四種詞彙的統計值如下:(1) 詞彙的重 要性、(2) 詞彙的重複性、(3) 詞彙的共現性及(4) 詞彙的距離。 作者認為詞彙重要性是針對文件而言,並非詞彙本身重要與否。因此 IDF才能代表詞彙對文件的重要程度。當訓練資料的數量夠大時,IDF值 具有相當高的穩定性,因此可以計算詞彙的重要性,其中IDF值愈大,表 示愈重要。IDF可以使用下列的數學式計算求得。 IDF(w) = log((P-O(w))/O(w)) P 是某一文件集合的文件總數,O(w)是包含詞w的文件總數(重複性)。 15.
(28) 由於作者認為概念一致的文件資料,作者使用的詞組必然趨向某一個 語意範疇。以統計的角度,表示該語意範疇的詞彙一起出現的機率比較 大。判斷那些詞組屬於同樣的語意範疇則是利用大規模的語料庫計算詞 的共現程度。使用共現資訊(Mutual Information,簡稱MI)計算詞的共現, 其數學式如下所示: MI(t i , t j ) = log. P(t i , t j ) P(t i ) P(t j ). 共現資訊的含義是,當詞 t i 與詞 t j 頻繁一起在語料庫出現,其聯合機率 P ( t i , t j ) 會大於 P ( t i ) P ( t j ) ,因此 MI(t i , t j ) 會大於0;當詞 t i 與詞 t j 出現的方式. 是背道而馳時, MI(t i , t j ) 會甚小於0,舉例來說,若詞 t i 機率為0.8、詞 t j 機 率為0.9,當詞 t i 與詞 t j 頻繁在一起時,聯合機率 P ( t i , t j ) 為0.8,其MI為 log(0.8/(0.9*0.8))=log(1.11)=0.515;當詞 t i 與詞 t j 出現背道而馳時,聯合機 率 P ( t i , t j ) 為0.2,其MI為log(0.2/(0.9*0.8))=log(0.277)= -1.848。 作者認為詞的位置也很重要。基於文件是有生命的文字組合的觀點, 相關的詞組其出現的距離不會太長。因為,若相隔太遠,彼此之間的影 響效果就大打折扣,就應該不會是作者的用意。引入距離的因素,比較 能夠確實反應撰寫行為。距離的計算可採用如下的方式,首先為每一個 名詞與動詞設定一個編號,以下面這一段文字為例: 據 內蒙古1 自治區2 林業廳3 消息4 , 中國5 政府6 自 第十 個. 16.
(29) 五年 計畫7 以來 , 全 區8 的 國家級9 自然10 保護區11 由 十 個 增 加12 到 二十 個 , 數量13 居14 中國15 各 省16 市區17 之 首 。 詞彙X與Y 的距離D(X,Y)可以用以下的方式計算: D(X,Y) = ABS(C(X)-C(Y)) ABS 為絕對值函數,C(X)代表詞彙X的編號,如C(消息) = 4,而C(計 畫) = 7,所以D(消息,計畫) =3。 作者計算句子的重要性是依上述的資訊計算後再結合位置、首次出 現、線索詞等資訊,來計算每句子的分數,最後從分數高者選擇。 2.3 字彙不匹配問題 過去用於解決字彙不匹配問題之方法有二:(1)同義詞( synonyns),由 同義詞詞典定義;(2)相關詞(related terms),由詞的分群分佈而得。 2.3.1 同義詞 劉群、李素建[4]認為詞相似度主要用於衡量文件中詞的可替換程 度;而在資訊檢索中,相似度更要能反映文件或者使用者查詢在意義上 的符合程度。相似度是一個數值,一般而言,其取值範圍在[0,1]之間。 一個詞語與其本身的語義相似度為 1。如果兩個詞語在任何上下文中都 不可替換,那麼其相似度為 0。. 17.
(30) 計算相似度上,通常是計算詞語之間的距離。兩個詞語之間距離越 大,其兩者相似度則越低;反之,若兩個詞語之間距離越小,其相似度 則越大。二者之間建立一種簡單的對應關係。這種對應關係需要符合幾 個條件,其條件定義如下[4]:兩個詞語之間距離為 0 時,其相似度為 1, 兩個詞語之間距離為無窮大時,其相似度為 0,兩個詞語的距離越大, 其相似度越小。 計算詞語之間距離的方法,一般而言是利用一部同義詞詞典 (thesaurus)。同義詞詞典都是將所有的詞語組織在一棵或幾棵樹狀的層 次結構中如圖 2-7所示。在樹狀的層次結構中,詞語視為一個節點,而 任何兩個節點之間只有一條路徑,而這條路徑的長度就可以作為這兩個 詞語之間距離的一種衝量。. A B. C. D. 圖 2-7 《同義詞詞林》語義分類樹形圖 [5] 其計算方式如下,假設兩個詞語W1和W2,且W1和W2存在同義詞詞 18.
(31) 典中。 t ' (W1 ) = t ' (W2 ) 則代表這兩個詞語都在同一個樹狀結構內,而兩個 詞語在這個樹狀結構中的路徑距離為 dist (W1 ,W2 ) 。舉例來說,圖 2-7中 第五層的兩個節點A、B其距離為 2 個單位長(dist(A, B)=2);A、D其距 離為 6 個單位長(dist(A, D)=6);D、B間距離為 6 個單位長(dist(D, B)=6); 有趣的是,同義詞間的距離並不符合遞移性公理,dist(A,B)≠dist(A,D) + dist(D,B)。接著根據下列eq. 1的公式,就可以算出得到這兩個詞語之間 的相似度,其中α是一個可調節的參數,其含義是:當相似度為 0.5 時的 詞語距離值[22]。. ⎧α / α + dist (W1 , W2 ) t ' (W1 ) = t ' (W2 ) sim (W1 , W2 ) = ⎨ t ' (W1 ) ≠ t ' (W2 ) ⎩ 0, W1 , W2 ∈ WS ' , WS 表示同義詞詞典. 19. ---------eq. 1.
(32) 2.3.2 相關詞. 一種常見的計算相關詞的方法是詞的分佈分群法(term distributional clustering)[12]。在分佈分群法(distributional clustering),用以測量兩個詞 的分配(term distributions)的方法是Kullback-Leibler (KL) divergence。對於 詞 Wt 與詞 Ws ,它們的KL divergence可表示為 D(P(C| Wt )||P(C| Ws )),其定 |C |. P(c j | wt ). j =1. P(c j | ws ). 義為 ∑ P (c j | wt ) log(. ) ,其中|C|為類別的數目,P( C j | Wt )則代表是. Term Wt 在 C j 類別的機率是多少。為了避免KL divergence的非對稱性 3. (nonsymmetric)的問題,這裡所使用的是權重平均的KL divergence定義如. 下: P( wt ) • D( P(C | wt ) || P(C | wt ∨ ws )) + P( ws ) • D( P(C | ws ) || P(C | wt ∨ ws )) ,其中 P (C | wt ∨ ws ) 定義為. P( wt ) P ( ws ) p (C | wt ) + p(C | ws ) 。基於KL P( wt ) + P( ws ) P ( wt ) + P( ws ). divergence,我們將詞進行分群,然而分群首先要先選擇群心M個,其中 M個則是由各類別平均挑選出來,即是 M | C | 個詞。各類別挑選方式則是 依Mutual information選出 M | C | 個詞。群心選取完畢之後,將所有訓練文 件 不 重 覆 以 及 排 除 群 心 的 詞 集 合 , 將 每 一 個 詞 依 據 權 重 平 均 的 KL divergence的測量全部分到每一群之中。. 3. KL divergence非對稱性(nonsymmetric)指 20.
(33) 3 研究方法 如前所述,為了改善文件分類的有效性,本研究由特徵字選取加以 改進。我們採用之文件分類流程如圖 3-1所示,包括訓練階段(分類器建 置)及測試階段(未知文件之分類)。在訓練階段包括預處理、特徵選取、 及分類器產生(本研究採用KNN分類器);在測試階段,未分類之文件同樣 經過預處理、特徵選取(產生文件向量)、接著由KNN分類器中選取K個最 相近之文件,並由投票法(多數決)來決定此未知文件所屬類別。各階段主 要工作分述如下:. 圖 3-1 本研究文件分類流程 3.1 預處理. 此階段包括移除 HTML 的標籤(網頁文件)及其它格式設定(Word 檔 或 PDF 檔),以獲得純文字資料。接著對所獲得之文字集合進行中文斷. 21.
(34) 詞 、斷句、及詞性的標記等處理。 3.2 特徵詞選取. 由於Chen and Chen [14]之方法的目的是產生摘要而非應用於文件分 類,因此本研究根據他們方法的主要概念來設計計算句子的重要性的方 法,以獲得文件之摘要。其中鑑別詞的計算同時考慮句中之名詞與動詞 (Chen and Chen之方法僅考慮名詞的重要性),其原因在語法概念上,一個 句子必須有兩個部分:一部分叫作主語,表示意思中的「甚麼」,通常 為名詞;另一部分叫作述語,通常為動詞,表示這個甚麼「怎麼樣」。 因此這種分析方式較符合自然語言中語法概念[2]。詳細流程及計算步驟 如圖 3-2所示:. 圖 3-2 特徵字擷取方法. 22.
(35) Setp1 計算文章名詞與動詞的IDF值. 在判斷某一名詞或動詞是否為鑑別詞時,可依此名詞或動詞是否具 區辨力(用以區辨不同文件或不同類別)來考量,故可由計算該詞之 IDF (inverse document frequency)值獲得。詳細計算公式如下所示。. ⎛N⎞ W ij = log ⎜ ⎟ ⎜n ⎟ ⎝ j⎠. -------- eq. 2. 其中, Wij 表示詞的權重, N 表示文件的總數, n j 表示詞 j 在全部文 件中所出現的次數。 Setp2 計算句子中名詞與其它名詞、動詞之間距離. 基於文件是有生命的文字組合觀點,相關的詞組其出現的距離應不 會太長,否則彼此之間的連貫性及語氣效果就會大打折扣。因此,引入 距離的因素,比較能夠確實反應撰寫行為(參考[14] ,不同之處是本方 法是各個字都會編號。)。詞彙X與Y距離D(X,Y)可以用以下公式求得: D(X,Y) = ABS(C(X)-C(Y)) ---------eq. 3 其中,ABS(•)表絕對值,C(•)代表詞彙•的編號。. 以下面這一段文字為例: 據1 內蒙古2 自治區3 林業廳4 消息5 , 中國6 政府7 自8 第 十9 個10五年11 計畫12 以來13, 全 區14 的15 國家級16 自然17 保. 23.
(36) 護區18 由19 十20 個21 增加22 到23 二十24 個25 ,數量26 居27 中國28 各29 省30 市區31 之32 首33 。 故,D(消息,計畫) = ABS(C(消息)- C(計畫)) =ABS(-7) =7 Setp3 計算句子的名詞與動詞強度(Connective Strength, CS) CS(n) = SNN(n)+SNV(n). --------- eq. 4. CS(v) = SVN(v)+SVV(v). --------- eq. 5. 根據Chen and Chen [14],句子的重要性可由名詞與其它名詞的強度 及名詞與動詞間的強度來獲得,即CS(n)(參考eq. 4)。其中SNN(ni) (eq. 6) 為名詞ni與其他名詞nj的強度(由IDF(•)及距離D(•,•)算得)。SNV(ni) (eq. 7) 為名詞ni與其他動詞vj的強度。由於動詞本身亦含有豐富資訊(參考[2]), 故本研究據此加入動詞的強度對句子重要性的計算(參考eq. 5)。SVN(vi) (eq. 8為動詞vi與其他名詞nj的強度;SVN(vi) (eq. 9)為動詞vi與其他動詞 vj的強度。 SNN(n i ) = ∑ j. SNV(n i ) = ∑ j. SVN(v i ) = ∑ j. SVV(v i ) = ∑ j. IDF(n i ) × IDF(n j ). ---------eq. 6. D(n i , n j ) IDF(n i ) × IDF(v j ). ---------eq. 7. D(n i , v j ) IDF(v i ) × IDF(n j ). ---------eq. 8. D(v i , n j ) IDF(v i ) × IDF(v j ). ---------eq. 9. D(v i , v j ). 24.
(37) Setp4 計算句子重要程度. 假設一個句子 S i 包含m個名詞(nj)和n個動詞(vk),其句子權重 ES(s i ) 可由eq. 10求得。 m. n. j. k. ES(si ) = ∑ CS(n j ) + ∑ CS(vk ). ----- eq. 10. Setp5 產生摘要並轉成候選特徵詞表. 欲產生摘要,只須將句子依重要程度值排序(採降冪排序),並從中 挑選出前θ%即可(θ為參數值,依應用領域不同而變,例如手機簡訊之摘 要可能限制在 50-100 字內)。在摘要(前θ%之句子)中之所有字詞,成為 當然之候選特徵詞表。以摘要來產生特徵向量的作法,本研究非第一人 ([24]使用摘要進行英文文件分類其效果比使用全文還要好),但用於中文 文件分類則尚未見諸於文獻中。 Setp6 挑選特徵詞. 候選特徵詞表必須進一步移除停用字(包括定詞、後置定詞、介詞、 語助詞、連接詞、及量詞),並以 IDF 門檻值來挑出最終侯選字。欲組 成特徵向量,本研究採用兩種作法,其一是以各文件為單位,每個文件 自成一個向量,在同一空間向量比較;另一則是以類別為單位,一個類 別一個向量。此處,我們採 TFIDF 當成特徵向量權重。. 25.
(38) 3.3 文件相似比對改進. 在文件比對部分,常用的是特徵向量(feature vector)來比對,但是特 徵字比對的過程,一般只有考量用詞是否一樣。一旦詞義相同但用詞不 同時,就會忽略掉了。而這樣的忽略是有可能會影響到後續處理的正確, 如圖 3-3則是一般的計算方式,其中特徵字的權重為TF值,這兩個相似 向量相比之後,相似度值卻是為0(在此若分母為0時,則會判定相似度為 0)。因此,本研究引用了同義詞詞典[6]來改進,其步驟詳細說明如下:. 類別向量空間模型 a 壯漢. 成年人. 船民. 農婦. 2. 2. 2. 1. -Vector:(2,2,2,1) 文件 b : 男子、壯丁、水上居民、女人 壯漢 成年人 船民 農婦. 0. 0. 0. 0. Let d a = (2,2,2,1) and d b = (0,0,0,0). da × db = 2 × 0 + 2 × 0 + 2 × 0 + 2 × 0 = 0 | d a |= 2 2 + 2 2 + 2 2 + 12 = 3.605 | d b |= 0 2 + 0 2 + 0 2 + 0 2 = 0 similarity =. -Vector:(0,0,0,0). da × db 0 = =0 | d a || d b | 3.605 × 0. 圖 3-3 文件相似度計算(未考量同義詞計算). 3.3.1 同義詞詞典比對改進. 為了解決字彙不匹配問題。因此,本研究引用了同義詞詞典[6]來改 進。流程如圖 3-4所示,其步驟詳細說明如下:. 26.
(39) 圖 3-4 文件相似度計算流程圖. Setp1 先挑出文件與特徵向量模型的相同字. 根據特徵向量模型選出在文件中出現相同的字,本研究視為其詞相似 度為1,不需再計算,另外也可減少計算成本。 Setp2 計算文件與特徵向量剩餘字的相似度. 設文件a和特徵向量模型b,各剩餘m和n個詞,則兩文件中特徵字詞 組之間的相似值之計算如下: 假設兩個詞 ati 和 btj 存在同義詞詞典中,表示為 a ti , btj ∈ WS ' 。且若兩 個詞語在同一個樹狀結構內,表示為 t ' (ati ) = t ' (btj ) ,而兩個詞語在這個 樹狀結構中的路徑距離為 dist (ati , btj ) ,根據下列公式,就可以算出得到這 兩個詞語之間的相似度[22],其中α值根據[4]設為 1.6。. 27.
(40) 其中《同義詞詞林》按照樹狀的層次結構把所有收錄的詞條組織到 一起,把詞彙分成大、中、小三類,大類有 12 個,中類有 97 個,小類 有 1,400 個[5]。因此,兩詞語若不在相同的大類時,本研究視其兩詞語 不在同一個樹狀結構內即 t ' (ati ) ≠ t ' (btj ) 。 ⎧α / α + dist (W1 , W2 ) t ' (W1 ) = t ' (W2 ) sim (W1 , W2 ) = ⎨ t ' (W1 ) ≠ t ' (W2 ) ⎩ 0, W1 , W2 ∈ WS ' , WS表示同義詞詞典. Setp3 排序並挑出相似度較高的特徵字詞組. 計算特徵字詞組相似度之後,選出文件特徵與向量模型中特徵一起出 現在同義詞典中的詞組集,接著對應每一個向量模型的特徵選出相似度 最高的特徵字詞組,並相似度超過門檻值β(後續實驗將設為0.4和0.9)以 上,將其列入到同義詞詞組表中以加入計算。 Setp4 計算文件相似度. 計算文件相似度時,本研究採用cosine方式測量,其公式如下: n. d × db = Sim( Da , Db ) = cos θ = a | d a || d b |. ∑W k =1. ak. × Wbk. n. n. 1. 1. (∑ Wak )(∑ Wbk ). 文件相似度計算時,除了相同用詞之外,並挑出出現在同義詞詞組 表的詞,然後,在特徵向量中,其詞之權重計算方式為:將該詞之原先. 28.
(41) 權重乘上相似值。相似度計算方式如圖 3-5所示,其中本研究計算方式 為圖 3-5,圖 3-3則是一般的計算方式。假設類別向量空間模型為a和文 件為b皆有描述人的概念,在詞相似度計算時,壯漢和男子、成年人和 壯丁、船民和水上居民、農婦和女人,這四組相似度皆為為 1.0 ,並且 其特徵字的權重為TF值時。在圖 3-3計算方式,文件b中男子、壯丁、 水上居民、女人權重皆為零,且相似度值計算後為零,在圖 3-5計算方 式,加入同義詞的算法之後,文件b中男子、壯丁、水上居民、女人, 這四個權重皆變為 1,且該文件相似度值計算後為 0.971。因此,圖 3-5 計算方式,較能比較符合文件的相似度。 類別向量空間模型 a 壯漢. 成年人. 船民. 農婦. 2. 2. 2. 1. -Vector:(2,2,2,1) 文件 b : 男子、壯丁、水上居民、女人 壯漢 成年人 船民 農婦. 1. 1. 1. -Vector:(1,1,1,1). 1. Let d a = (2, 2, 2, 1) and d b = (1, 1,1, 1) d a × d b = 2 × (1 * 1.0) + 2 × (1 * 1.0) + 2 × (1 * 1.0) + 1 × (1 * 1.0) = 7 | d a |= 2 2 + 2 2 + 2 2 + 12 = 3.605 | d b |= 12 + 12 + 12 + 12 = 2 similarity =. da × db 7 = = 0.971 | d a || d b | 3.605 × 2. 圖 3-5 文件相似度計算(利用同義詞). 29.
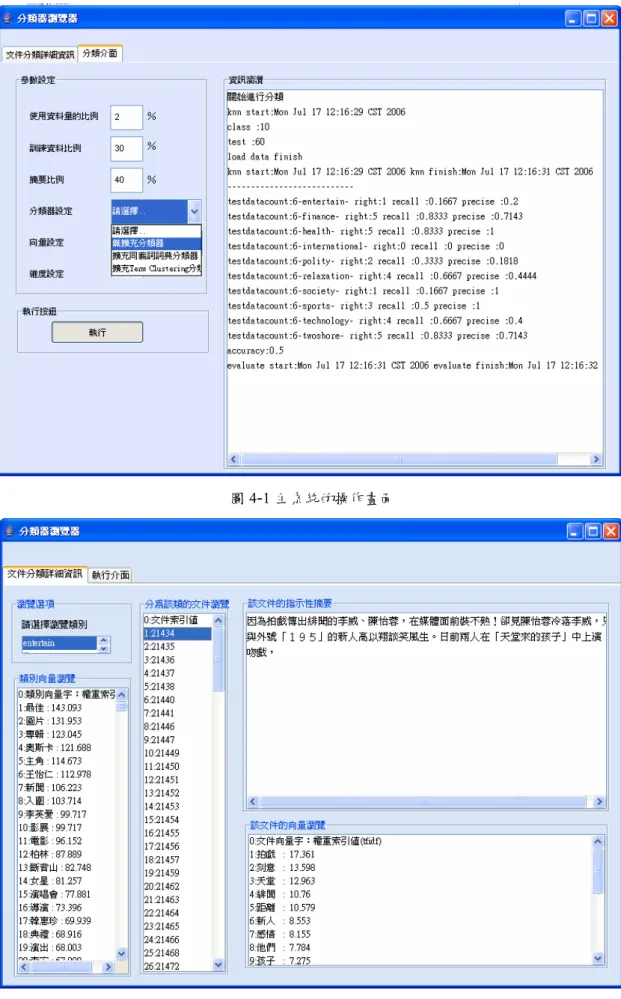
(42) 4 系統實作與實驗結果與分析 本章介紹本研究開發之雛型系統並說明實驗設計採用的效能指標及 實驗結果與分析。 4.1 系統雛型介紹. 本研究之分類器的主要操作畫面如圖 4-1所示,左邊為參數設定的介 面,右邊則是顯示分類的結果,圖 4-2則顯示分類結果的畫面。選擇類別 瀏覽之後會顯示出類別的向量以及分為該類的文件。點選某一文件則會 出現百分之二十全文之指示性摘要(系統摘要篩選比例為0.4%,在瀏覽界 面中則僅呈現前20%,若前20%超過500字以上,則顯示前500字)以及文 件的篩選出特徵字。詳細之程式模組與使用手冊,請參閱附錄。本研究 秉持開放原始碼之精神,相關程式碼可於http://einstein.npic.edu.tw:9212 /projects/SUMBACC/ 下載,冀能對研究社區知識的累積有所助益。本系 統「以摘要為基礎的中文分類器」簡稱SUMBACC(SUMmarization-BAsed Chinese Classifier, SUMBACC)。. 30.
(43) 圖 4-1 主系統的操作畫面. 圖 4-2 主系統的分類結果畫面. 31.
(44) 4.2 中文實驗測試集. 本研究收集2006/2/2至2006/2/14之yahoo電子新聞中的10個群組共 4319篇報導(以下稱資料集A),以及 ICIM2006 中 13 個 議 題 共 211 篇 論 文 (以下稱資料集B)。各資料集之類別分佈如表 4-1所示。其中yahoo電子新 聞之格式為HTML,故研究者以JAVA撰寫相關程式,擷取新聞之文字內 容。而ICIM之論文槌式為pdf,故我們先將之轉成純文字的格式(txt)。 表 4-1 中文測試資料集 yahoo news2/2~2/14. ICIM2006 PAPER. 類別. 文件數. 類別. 文件數. 政治. 415. 決策支援智慧型系統. 32. 運動. 450. 其他資訊管理相關議題. 6. 財經. 442. 知識經濟與創新. 18. 影視. 407. 商業智慧與資料探勘. 17. 科技. 440. 軟體工程. 12. 兩岸. 447. 資訊安全管理. 17. 休閒. 438. 資訊系統應用. 21. 社會. 420. 資訊科技創新與應用. 24. 國際. 414. 資訊科技與社會. 17. 健康. 446. 資訊教育. 6. TOTAL. 4319. 電子商務. 9. 網路技術與應用. 22. 數位內容與學習. 10. TOTAL. 211. 32.
(45) 4.3 文件分類的效能指標. 在資訊檢索系統中,文件分類的評估一般來說是由實驗結果來評估而 非是分析式(例如,證明系統是正確和完整的)。文件分類的實驗評估通常 是測量它的效用(effectiveness)而非是它的效率(efficiency)[28]。因此,為 了了解實驗效果的優劣好壞,資訊檢索(information retrieval)領域中最常 見的方式就是精確率(precision, P)及召回率(recall, R)[23]。但是同時有好 幾個類別要一起考量,因此則有 macro-average 平均方法[28]。為了在精 確度及召回率中取得平衡,可以使用F-measure,在多類別要全部分析時, 並可以利用上述的macro-average來求出macro-F。最後,並計算整體的正 確率(accuracy)。故本研究將使用這五種指標來判別文件分類效果好壞。 表 4-2 混淆矩陣(Confusion Matrix) 專家判斷 +. -. +. a. b. -. c. d. 分類器判斷. 如表 4-2的混淆矩陣(decision confusion matrix),混淆矩陣中包含a, b, c, d 四種類別預測的結果,其中a表示分類模型準確地預測屬於該類別的 資料個數,d表示不屬於該類的文件,沒有被模型分為該類的資料個數準 確地預測屬於該類別的資料個數。b表示不屬於該類的文件,被模型分為 33.
(46) 該類的資料個數,也就是將實際不屬於該類別的資料預測為該類別;c則 是模型錯誤地將該類別預測為其它類別的資料個數。精確度表示在所有 被模型預測為正當郵件類別的資料中正確的百分比;召回率則定義為實 際為正當郵件類別的資料中被模型準確地預測出的百分比。而F-measure 是調和平均數,綜合了回應率與精確率,本研究則是由實驗結果,將各 類別相關的P 與R,求出macro-average之後,再得到macro-F。七個評估 準則的計算方式如下: Pr ecision =. Re call =. a a+b. a a+c. ------- eq. 12. 1 m a ∑ m i =1 a + b. ------- eq. 13. 1 m a Marco Re call = ∑ m i =1 a + c. ------- eq. 14. Macro Pr ecision =. F=. Accuracy= Macro-F =. ------- eq. 11. 2 pr p+r. ------- eq. 15. a+d a +b+c +d. ------- eq. 16. 2 * ( Macro Pr ecision) * ( Macro Re call) ( Macro Pr ecision + Macro Re call ). 34. ------- eq. 17.
(47) 4.4 自動摘要之結果. 本研究採用中央研究院詞庫小組所研發之中文斷詞系統[1]進行斷詞 與斷句等預處理。其中,句子的定義不僅是句號,也可能還包括逗號、 分號、問號及驚嘆號。因此句子的長度並不會過長,如此一來,句子中 雜訊就不會過多,且產生的摘要也較符合真實情境(例如,某些句子僅某 些部份是重要的,如果整句選為摘要反而容易失焦)。我們從資料集取出 一則新聞及ICIM2006的某一篇論文進行比較。表 4-3、表 4-5為資料集 中之某則電子新聞之全文及論文作者所撰寫的摘要;表 4-4、表 4-6則為 本研究從這兩篇文章所萃取出之摘要。可明顯看出,所獲得之摘要雖不 若人工摘要之完整與優雅,但足以成為該文件的指示性(indicative)摘要, 供使用者快速知曉其主要概念。 表 4-3 新聞全文範例 加入華納唱片快1年的蕭亞軒,新專輯的發行已延宕到3月,不料有周刊報導,她 的發片計劃可能遙遙無期,因為華納嫌她太難「搞」,早悄悄轉賣她的唱片約。 8日華納發表聲明否認,並表示對這張專輯寄予厚望,是只許成功的力作。 目前在紐約錄音兼度假的蕭亞軒,新專輯的發行又要延宕?據壹周刊報導,她的 發片日遙遙無期,其實不是先前媒體所說的預算太少,而是她和經紀公司「大熊星」 都太難搞了,與華納唱片鬧不愉快。 此外,壹周刊還指出,她預計在3月發行的新專輯,華納決定將發片案丟出去。. 35.
(48) 表 4-4 新聞 20%摘要範例 加入華納唱片快1年的蕭亞軒,她的發片計劃可能遙遙無期,因為華納嫌 她太難「搞」,8日華納發表聲明否認,並表示對這張專輯寄予厚望,目前在 紐約錄音兼度假的蕭亞軒,其實不是先前媒體所說的預算太少,. 表 4-5 ICIM2006 作者撰寫摘要 本研究提出以文件摘要來進行特徵字選取,以替代現行之維度縮減法。此 方法可減少向量的維度,以及選取出較具代表性的特徵字;經實驗證實,以文 件摘要來進行特徵字選取可有效提升中文文件分類的精確率(precision)和回收 率(recall)(比傳統以 TFIDF 進行特徵向量選取要佳);且依訓練文件數量的多 寡,有不同的改善效果,在訓練文件較少時效果愈顯著。顯示本研究所提方法 有相當的穩健性及可靠性。另外,當以類別為向量單位時其分類效果又比以文 件為向量單位的結果要好;此呼應模式選取準則中的正確性與精簡性(或優雅 性)。最後,本方法所衍生的好處是同時產生文件的指示性(indicative) 摘要, 可供使用者快速知曉其文件之概念。. 表 4-6 ICIM2006 自動摘要範例(前 500 字) 以自動摘要為基礎之中文文件分類器蕭文峰. 劉凱帆屏東商業技術學院. 資訊管理系所屏東商業技術學院資訊管理系所 [email protected].以替代現 行之維度縮減法。以及選取出較具代表性的特徵字;經實驗證實,以文件摘要 來進行特徵字選取可有效提升中文文件分類的精確率 (precision) 和回收率. (recall)(比傳統以 TFIDF 進行特徵向量選取要佳);且依訓練文件數量的多寡, 在訓練文件較少時效果愈顯著。當以類別為向量單位時其分類效果又比以文件 為向量單位的結果要好;此呼應模式選取準則中的正確性與精簡性 ( 或優雅 36.
(49) 性)。Yahoo!奇摩股市將網頁連結依行業別(電子、金融、化學、航運、…)加以 分類、購物網站依商品型態(家電、禮品、玩具、精品、男裝、女裝、…)分類 等。貝氏(Bayesian)[9]、決策樹(decisiontree)[23]、決策法則(decisionrule)、迴歸 法(regressionmethod)、Rocchi 法(Rocchiomethod)、類神經網路(neuralnetworks)、 支援向量機法(supportvectormachine)、k 個最鄰近法(k-nearestneighbor)[17]等。. 37.
(50) 4.5 實驗設計與結果. 本研究總共設計了五個實驗,第一個實驗為參數調整,分別探討以 文件為單位之特徵向量和以類別為單位之特徵向量,何者分類效果較 佳;以及其對應的摘要篩選比例。實驗二進一步探討加入動詞的考量的 摘要篩選法是否優於僅考量名詞的篩選法(由分類正確率來比較)。實驗三 及實驗四之目的則在瞭解本研究所提方法與其它方法之優劣。然囿於時 間及運算成本,欲以全部資料進行嚴謹的交叉驗證測試將不可行 4 。因 此,在實驗三中我們先以較小的資料量進行五等份之交叉驗證(5-fold cross validation),比較SVM、KNN與本研究分類器之分類正確性。實驗 四再以保留法(holdout method),分別以資料集A及資料集B比較SVM、 KNN與本研究的分類器。最後,實驗五則是探討同義詞擴充對分類正確 性之影響。 4.5.1 實驗一. 在實驗一之目的在於瞭解以文件為特徵向量單位和以類別為特徵向 量單位(整個類別以一個向量表示) 5 ,何者之分類效果較佳。此處,當文 件為特徵向量單位時,分類器會選取最相近之35篇文件(i.e., KNN的參數. 4. 本研究以Java撰寫對應程式,平均而言完整地執行一個資料集(約 10MB的資料)所需時間約需 6 個 小時。 5 向量權重皆以TFIDF表示,資料集則以 2006/2/2 至 2006/2/14 電子新聞資料集進行實驗(資料集A)。. 38.
(51) K取35),並依類別加總相似度,選取相似度最高之類別做為預測值。實 驗測試摘要篩選比例(θ)方式為,由於在[9]中摘要篩選比例效果最好是 40%,因此本研究先測試摘要比例為30%及40%時(全文的30%與40%) 6 , 不同訓練資料比例(30%、50%、70%)下,以文件或類別為向量單位何者 表現會較佳。詳細的比較結果請參考表 4-7~表 4-12所示。 表 4-7 以文件為向量,訓練資料為 30%,摘要比例為 30%及 40%之分類結果 取前 30%全文摘要. 取前 40%全文摘要. 類別 文件數 分類正確 Recall Precision. 類別 文件數 分類正確 Recall Precision. 政治. 290. 227. 0.78. 0.60. 政治. 290. 230. 0.79. 0.61. 運動. 315. 304. 0.97. 0.94. 運動. 315. 306. 0.97. 0.93. 財經. 309. 224. 0.72. 0.63. 財經. 309. 229. 0.74. 0.63. 影視. 284. 228. 0.80. 0.81. 影視. 284. 238. 0.84. 0.80. 科技. 308. 202. 0.66. 0.62. 科技. 308. 207. 0.67. 0.63. 兩岸. 312. 169. 0.54. 0.60. 兩岸. 312. 171. 0.55. 0.63. 休閒. 306. 173. 0.57. 0.75. 休閒. 306. 182. 0.59. 0.76. 社會. 294. 185. 0.63. 0.61. 社會. 294. 188. 0.64. 0.64. 國際. 289. 144. 0.50. 0.65. 國際. 289. 141. 0.49. 0.65. 健康. 312. 249. 0.80. 0.80. 健康. 312. 249. 0.80. 0.83. TOTAL. 3019. 2105. 70%. 70% TOTAL. 2141 71%. 71%. Accuracy. 70%. 3019. Accuracy. 71%. 表 4-8 以文件為向量,訓練資料為 50%,摘要比例為 30%及 40%之分類結果 取前 30%全文摘要. 取前 40%全文摘要. 類別 文件數 分類正確 Recall Precision. 6. 類別 文件數 分類正確 Recall Precision. 政治. 207. 163. 0.79. 0.71. 政治. 207. 163. 0.79. 0.73. 運動. 225. 218. 0.97. 0.94. 運動. 225. 219. 0.97. 0.94. 財經. 221. 172. 0.78. 0.73. 財經. 221. 173. 0.78. 0.72. 影視. 203. 168. 0.83. 0.86. 影視. 203. 175. 0.86. 0.86. 科技. 220. 156. 0.71. 0.69. 科技. 220. 158. 0.72. 0.70. 摘要為全文的濃縮,應朝愈精簡愈佳,故本研究加入 30%的測試。. 39.
(52) 兩岸. 223. 134. 0.60. 0.69. 兩岸. 223. 129. 0.58. 0.70. 休閒. 219. 151. 0.69. 0.76. 休閒. 219. 159. 0.73. 0.77. 社會. 210. 142. 0.68. 0.61. 社會. 210. 140. 0.67. 0.61. 國際. 207. 119. 0.57. 0.66. 國際. 207. 124. 0.60. 0.67. 健康. 223. 180. 0.81. 0.79. 健康. 223. 181. 0.81. 0.79. TOTAL. 2158. 1603. 74%. 74% TOTAL. 1621 75%. 75%. Accuracy. 74%. 2158. Accuracy. 75%. 表 4-9 以文件為向量,訓練資料為 70%,摘要比例為 30%及 40%之分類結果 取前 30%全文摘要. 取前 40%全文摘要. 類別 文件數 分類正確 Recall Precision. 類別 文件數 分類正確 Recall Precision. 政治. 124. 91. 0.73. 0.72. 政治. 124. 91. 0.73. 0.75. 運動. 135. 131. 0.97. 0.93. 運動. 135. 131. 0.97. 0.92. 財經. 132. 110. 0.83. 0.74. 財經. 132. 108. 0.82. 0.74. 影視. 122. 95. 0.78. 0.86. 影視. 122. 101. 0.83. 0.89. 科技. 132. 96. 0.73. 0.72. 科技. 132. 98. 0.74. 0.71. 兩岸. 134. 86. 0.64. 0.69. 兩岸. 134. 89. 0.66. 0.70. 休閒. 131. 104. 0.79. 0.75. 休閒. 131. 110. 0.84. 0.77. 社會. 126. 90. 0.71. 0.67. 社會. 126. 90. 0.71. 0.68. 國際. 124. 69. 0.56. 0.63. 國際. 124. 69. 0.56. 0.66. 健康. 133. 106. 0.80. 0.85. 健康. 133. 107. 0.80. 0.86. TOTAL. 1293. 978. 75%. 76% TOTAL. 994 77%. 77%. Accuracy. 76%. 1293. Accuracy. 77%. 表 4-10 以類別為向量,訓練資料為 30%,摘要比例為 30%及 40%之分類結果 取前 30%全文摘要. 取前 40%全文摘要. 類別 文件數 分類正確 Recall Precision. 類別 文件數 分類正確 Recall Precision. 政治. 290. 220. 0.76. 0.70. 政治. 290. 219. 0.76. 0.71. 運動. 315. 306. 0.97. 0.94. 運動. 315. 307. 0.97. 0.95. 財經. 309. 226. 0.73. 0.66. 財經. 309. 231. 0.75. 0.66. 影視. 284. 263. 0.93. 0.77. 影視. 284. 266. 0.94. 0.76. 科技. 308. 203. 0.66. 0.69. 科技. 308. 203. 0.66. 0.71. 兩岸. 312. 178. 0.57. 0.67. 兩岸. 312. 181. 0.58. 0.67. 休閒. 306. 215. 0.70. 0.74. 休閒. 306. 224. 0.73. 0.77. 社會. 294. 182. 0.62. 0.64. 社會. 294. 185. 0.63. 0.65. 國際. 289. 168. 0.58. 0.70. 國際. 289. 165. 0.57. 0.69. 健康. 312. 264. 0.85. 0.82. 健康. 312. 266. 0.85. 0.84. 40.
(53) TOTAL. 3019. 2225. 74%. Accuracy. 74%. 73% TOTAL. 3019. 2247 74% Accuracy. 74%. 74%. 表 4-11 以類別為向量,訓練資料為 50%,摘要比例為 30%及 40%之分類結果 取前 30%全文摘要. 取前 40%全文摘要. 類別 文件數 分類正確 Recall Precision. 類別 文件數 分類正確 Recall Precision. 政治. 207. 155. 0.75. 0.80. 政治. 207. 156. 0.75. 0.80. 運動. 225. 219. 0.97. 0.95. 運動. 225. 220. 0.98. 0.96. 財經. 221. 173. 0.78. 0.75. 財經. 221. 173. 0.78. 0.74. 影視. 203. 186. 0.92. 0.78. 影視. 203. 190. 0.94. 0.80. 科技. 220. 159. 0.72. 0.77. 科技. 220. 158. 0.72. 0.79. 兩岸. 223. 141. 0.63. 0.71. 兩岸. 223. 142. 0.64. 0.72. 休閒. 219. 180. 0.82. 0.80. 休閒. 219. 191. 0.87. 0.81. 社會. 210. 141. 0.67. 0.64. 社會. 210. 139. 0.66. 0.64. 國際. 207. 133. 0.64. 0.73. 國際. 207. 132. 0.64. 0.72. 健康. 223. 190. 0.85. 0.82. 健康. 223. 193. 0.87. 0.84. TOTAL. 2158. 1677. 78%. 77% TOTAL. 1694 78%. 78%. Accuracy. 78%. 2158. Accuracy. 78%. 表 4-12 以類別為向量,訓練資料為 70%,摘要比例為 30%及 40%之分類結果 取前 30%全文摘要. 取前 40%全文摘要. 類別 文件數 分類正確 Recall Precision. 類別 文件數 分類正確 Recall Precision. 政治. 124. 87. 0.70. 0.78. 政治. 124. 91. 0.73. 0.78. 運動. 135. 127. 0.94. 0.96. 運動. 135. 129. 0.96. 0.96. 財經. 132. 104. 0.79. 0.79. 財經. 132. 103. 0.78. 0.82. 影視. 122. 109. 0.89. 0.83. 影視. 122. 110. 0.90. 0.83. 科技. 132. 100. 0.76. 0.79. 科技. 132. 102. 0.77. 0.80. 兩岸. 134. 93. 0.69. 0.72. 兩岸. 134. 95. 0.71. 0.73. 休閒. 131. 117. 0.89. 0.81. 休閒. 131. 120. 0.92. 0.83. 社會. 126. 95. 0.75. 0.67. 社會. 126. 94. 0.75. 0.70. 國際. 124. 77. 0.62. 0.71. 國際. 124. 77. 0.62. 0.71. 健康. 133. 112. 0.84. 0.82. 健康. 133. 115. 0.86. 0.85. TOTAL. 1293. 1021. 79%. 79% TOTAL. 1036 80%. 80%. Accuracy. 79%. 1293. Accuracy. 41. 80%.
(54) 綜括而言,以類別為向量單位之分類器顯著優於以文件為向量單位 之分類器(就macro-recall及macro-precision二者皆然)(參考 表 4-13與 表 4-14之數據,或圖 4-3及圖 4-4之比較圖)。其原因可能在於,當以類別為 特徵向量單位時該類別之特徵詞全部聚在一起,描述類別的資訊更加完 整,因此分類效果也比較好。 表 4-13 摘要篩選比例 30%,不同向量單位之比較 摘要篩選. 篩選比例 30%. (文件向量). (類別向量). Marco-Recall Marco-Precision Marco-Recall Marco-Precision. 訓練文件比例. 30%. 1330 份. 70%. 70%. 74%. 73%. 50%. 2161 份. 74%. 74%. 78%. 77%. 70%. 3026 份. 75%. 76%. 79%. 79%. 表 4-14 摘要篩選比例 40%,不同向量單位之比較 摘要篩選. 篩選比例 40%. (文件向量). (類別向量). Marco-Recall Marco-Precision Marco-Recall Marco-Precision. 訓練文件比例. 30%. 1330 份. 71%. 71%. 74%. 74%. 50%. 2161 份. 75%. 75%. 78%. 78%. 70%. 3026 份. 77%. 77%. 80%. 80%. 80% 1330份. 75%. 2161份 70%. 3026份. 65% Marco-Recall. Marco-Precise. Marco-Recall. (文件向量). Marco-Precise. (類別向量). 圖 4-3 摘要篩選比例 30%,不同向量單位之比較 42.
(55) 85% 80%. 1330份. 75%. 2161份. 70%. 3026份. 65% Marco-Recall. Marco-Precise. Marco-Recall. (文件向量). Marco-Precise. (類別向量). 圖 4-4 摘要篩選比例 40%,不同向量單位之比較. 為進一步瞭解不同摘要篩選比例(10%, 20%, 30%, 40%)及不同訓練 資料比例(20%, 30%, …, 80%)的分類效果,本研究採用接受者操作曲線 (ROC curve)分析。詳細的數據如表 4-15及圖 4-5所示,可知摘要篩選比 例愈高或訓練資料愈多,模式的正確率愈高(當然其計算成本也相對的較 高)。但由數據中我們也可觀察出,當摘要比例由30%提昇為40%時,其 正確率提昇皆不足1%;顯示正確率提昇的效益已不足彌平摘要比例增加 的成本,因此本研究之後續實驗皆將摘要比例固定為40%。 表 4-15 以類別為向量,在不同摘要比例下,不同訓練資料比例之分類結果 訓練資料比例 (%) 摘要篩選比例. 20. 30. 40. 50. 60. 70. 80. 0.1. 59.360% 65.585% 66.820% 69.741% 71.460% 73.163% 73.050%. 0.2. 66.600% 71.017% 73.310% 75.255% 76.040% 76.489% 78.860%. 0.3. 69.320% 73.700% 76.320% 77.711% 78.360% 78.964% 80.720%. 0.4. 70.370% 74.429% 76.940% 78.499% 79.350% 80.124% 81.770%. 43.
(56) 90% 80% 70%. Accuracy. 60%. 0.1. 50%. 0.2. 40%. 0.3 0.4. 30% 20% 10% 0% 0. 10. 20. 30. 40. 50. 60. 70. 訓練資料比例(%). 圖 4-5 以類別向量在不同摘要篩選比例之比較. 44. 80.
(57) 4.5.2 實驗二. 實驗二的目的在於瞭解加入動詞考量的摘要篩選法是否能提昇中文 分類的效能(原摘要篩選法僅考量名詞)。實驗設定如下:摘要篩選比例(θ) 固定為40%,以2006/2/2至2006/2/1之yahoo電子新聞中的十個類別為資料 集,訓練資料比例設為30%、50%、及70%。 實驗結果如表 4-16~表 4-18所示。綜合而言(圖 4-6)隨著訓練資料的 比例增加,加入了動詞考量的分類結果會比較好。也說明了考量動詞對 於描述句子的概念較完整,此呼應第三章的論點:加入動詞較能符合自 然語言中的語法概念,因此提高分類的效能。因此,後續實驗所採用之 摘要篩選法將同時考量名詞與動詞。 表 4-16 訓練資料為 30%分類結果 考量名詞與動詞. 只考量名詞 類別 文件數 分類正確 Recall Precision. 類別 文件數 分類正確 Recall Precision 政治. 290. 219. 0.76. 0.71. 政治. 290. 218. 0.75. 0.71. 運動. 315. 307. 0.97. 0.95. 運動. 315. 305. 0.97. 0.95. 財經. 309. 231. 0.75. 0.66. 財經. 309. 231. 0.75. 0.66. 影視. 284. 266. 0.94. 0.76. 影視. 284. 263. 0.93. 0.77. 科技. 308. 203. 0.66. 0.71. 科技. 308. 199. 0.65. 0.71. 兩岸. 312. 181. 0.58. 0.67. 兩岸. 312. 182. 0.58. 0.67. 休閒. 306. 224. 0.73. 0.77. 休閒. 306. 229. 0.75. 0.77. 社會. 294. 185. 0.63. 0.65. 社會. 294. 187. 0.64. 0.66. 國際. 289. 165. 0.57. 0.69. 國際. 289. 167. 0.58. 0.70. 健康. 312. 266. 0.85. 0.84. 健康. 312. 268. 0.86. 0.83. TOTAL 3019. 2247. 74%. 74%. TOTAL 3019. 2249. 74%. 74%. Accracy 74.43%. Accracy 74.49%. 45.
(58) 表 4-17 訓練資料為 50%分類結果 考量名詞與動詞. 只考量名詞. 類別 文件數 分類正確 Recall Precision. 類別 文件數 分類正確 Recall Precision. 政治. 207. 156. 0.75. 0.80. 政治. 207. 154. 0.74. 0.81. 運動. 225. 220. 0.98. 0.96. 運動. 225. 219. 0.97. 0.96. 財經. 221. 173. 0.78. 0.74. 財經. 221. 174. 0.79. 0.74. 影視. 203. 190. 0.94. 0.80. 影視. 203. 188. 0.93. 0.80. 科技. 220. 158. 0.72. 0.79. 科技. 220. 159. 0.72. 0.80. 兩岸. 223. 142. 0.64. 0.72. 兩岸. 223. 141. 0.63. 0.71. 休閒. 219. 191. 0.87. 0.81. 休閒. 219. 192. 0.88. 0.81. 社會. 210. 139. 0.66. 0.64. 社會. 210. 141. 0.67. 0.65. 國際. 207. 132. 0.64. 0.72. 國際. 207. 131. 0.63. 0.72. 健康. 223. 193. 0.87. 0.84. 健康. 223. 193. 0.87. 0.82. TOTAL. 2158. 1694. 78%. 78% TOTAL. 2158. 1692. 78%. 78%. Accracy 78.50%. Accracy 78.41%. 表 4-18 訓練資料為 70%分類結果 考量名詞與動詞. 只考量名詞. 類別 文件數 分類正確 Recall Precision. 類別 文件數 分類正確 Recall Precision. 政治. 124. 91. 0.73. 0.78. 政治. 124. 90. 0.73. 0.78. 運動. 135. 129. 0.96. 0.96. 運動. 135. 128. 0.95. 0.96. 財經. 132. 103. 0.78. 0.82. 財經. 132. 105. 0.80. 0.82. 影視. 122. 110. 0.90. 0.83. 影視. 122. 112. 0.92. 0.85. 科技. 132. 102. 0.77. 0.80. 科技. 132. 101. 0.77. 0.81. 兩岸. 134. 95. 0.71. 0.73. 兩岸. 134. 93. 0.69. 0.72. 休閒. 131. 120. 0.92. 0.83. 休閒. 131. 120. 0.92. 0.83. 社會. 126. 94. 0.75. 0.70. 社會. 126. 95. 0.75. 0.70. 國際. 124. 77. 0.62. 0.71. 國際. 124. 76. 0.61. 0.70. 健康. 133. 115. 0.86. 0.85. 健康. 133. 114. 0.86. 0.82. TOTAL. 1293. 1036. 80%. 80% TOTAL. 1293. 1034. 80%. 80%. Accracy 80.12%. Accracy 79.97%. 46.
(59) 表 4-19 只考量名詞與同時考量名詞和動詞的比較 訓練文件比例. Accuracy 考量名詞與動詞 只考量名詞. 30%. 74.429%. 74.495%. 50%. 78.499%. 78.406%. 70%. 80.124%. 79.969%. 81.0% 80.0%. Accuracy. 79.0% 78.0% 考量名詞與動詞. 77.0%. 只考量名詞. 76.0% 75.0% 74.0% 73.0% 1. 2. 3. 訓練資料比例. 圖 4-6 只考量名詞與同時考量名詞和動詞的比較. 47.
(60) 4.5.3 實驗三. 瞭解本研究所提方法與其它方法之優劣,實驗三先以小樣本進行五 等份之交叉驗證(5-fold cross validation),比較SVM、KNN與本研究分類 器之分類正確性。其中,KNN與SVM分類器是由中文自然語言處理開放 平台網站 7 所取得的。此兩個分類器皆以Information Gain進行特徵選取, 因為在[32]的研究指出Information Gain是個相當穩健的特徵選取法。然而 相對地,本研究之分類器則以摘要法來選取特徵。如前述,本研究之摘 要篩選比例設定為40%,並且以類別為特徵向量單位。資料集是由資料 集A取出類別區隔比較明顯的五類(如表 4-20所示)進行測試。資料集分成 5個等份(5-fold),必須重覆5次訓練和測試,每次以其中1個等份(fold)為 測試資料,其它資料為訓練資料,以評估模式的正確率;如此重覆5次後, 將5次的正確率平均求得此模式正確率的估計值。然而,由於KNN與SVM 分類器所需要的資料格式是簡體中文,故其次料必須先利用簡繁轉換程 式將資料集轉換成簡體中文才能使用。實驗結果如表 4-21及圖 4-7與圖 4-8所示。綜合而言,本研究所提方法在平均正確率及Macro-F皆與SVM 分類器沒有顯著差異,但顯著優於以Information Gain為特徵選取之KNN 分類器。如此說明了本研究所提方法之可行性。. 7. 中文自然語言處理開放平台網站 http://www.nlp.org.cn. 48.
數據
![表 2-1 特徵字選取方法[28]](https://thumb-ap.123doks.com/thumbv2/9libinfo/9012236.298094/19.892.164.752.313.725/表21特徵字選取方法28.webp)
![圖 2-6 計算句子的重要性 [21]](https://thumb-ap.123doks.com/thumbv2/9libinfo/9012236.298094/27.892.299.623.113.349/圖26計算句子的重要性21.webp)

+7






相關文件
Mehrotra, “Content-based image retrieval with relevance feedback in MARS,” In Proceedings of IEEE International Conference on Image Processing ’97. Chakrabarti, “Query
in Proceedings of the 20th International Conference on Very Large Data
(1999), "Mining Association Rules with Multiple Minimum Supports," Proceedings of ACMSIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego,
Lange, “An Object-Oriented Design Method for Hypermedia Information Systems”, Proceedings of the Twenty-seventh annual Hawaii International Conference on System Sciences, 1994,
Muraoka, “A Real-time Beat Tracking System for Audio Signals,” in Proceedings of International Computer Music Conference, pp. Goto, “A Predominant-F0 Estimation Method for
Shih and W.-C.Wang “A 3D Model Retrieval Approach based on The Principal Plane Descriptor” , Proceedings of The 10 Second International Conference on Innovative
D.Wilcox, “A hidden Markov model framework for video segmentation using audio and image features,” in Proceedings of the 1998 IEEE Internation Conference on Acoustics, Speech,
Wells, “Using a Maze Case Study to Teach Object-Oriented Programming and Design Patterns,” Proceedings of the sixth conference on Australasian computing education, pp. Line, “Age
