API 参考
文档版本 01
发布日期 2022-02-17
版权所有 © 华为技术有限公司 2022。 保留一切权利。
非经本公司书面许可,任何单位和个人不得擅自摘抄、复制本文档内容的部分或全部,并不得以任何形式传 播。
商标声明
和其他华为商标均为华为技术有限公司的商标。
本文档提及的其他所有商标或注册商标,由各自的所有人拥有。
注意
您购买的产品、服务或特性等应受华为公司商业合同和条款的约束,本文档中描述的全部或部分产品、服务或 特性可能不在您的购买或使用范围之内。除非合同另有约定,华为公司对本文档内容不做任何明示或暗示的声 明或保证。
由于产品版本升级或其他原因,本文档内容会不定期进行更新。除非另有约定,本文档仅作为使用指导,本文 档中的所有陈述、信息和建议不构成任何明示或暗示的担保。
华为技术有限公司
地址: 深圳市龙岗区坂田华为总部办公楼 邮编:518129
网址:
https://www.huawei.com
客户服务邮箱:
[email protected]
客户服务电话:4008302118目 录
1 使用前必读... 1
1.1 概述... 1
1.2 调用说明...2
1.3 终端节点...2
1.4 基本概念...4
2 API 概览... 6
3 如何调用 REST API... 7
3.1 构造请求...7
3.2 认证鉴权...9
3.3 返回结果... 11
4 如何调用 WebSocket API... 13
5 实时语音识别接口... 15
5.1 接口说明... 15
5.2 Websocket 握手请求...15
5.2.1 流式一句话... 15
5.2.2 实时语音识别连续模式...18
5.2.3 实时语音识别单句模式...20
5.3 实时语音识别请求... 22
5.3.1 实时语音识别工作流程...22
5.3.2 开始识别... 23
5.3.3 发送音频数据... 26
5.3.4 结束识别... 26
5.4 实时语音识别响应... 27
5.4.1 开始识别请求响应... 27
5.4.2 事件响应... 28
5.4.3 识别结果响应... 29
5.4.4 错误响应... 31
5.4.5 严重错误响应... 32
5.4.6 结束识别请求响应... 33
6 一句话识别...35
6.1 http 接口...35
6.2 websocket 接口... 41
7 录音文件识别接口... 51
7.1 录音文件识别...51
7.2 录音文件识别状态查询... 59
8 录音文件识别极速版接口... 64
9 语音合成接口...70
9.1 语音合成... 70
10 实时语音合成接口...78
10.1 Websocket 握手请求... 78
10.2 实时语音合成请求... 81
10.2.1 开始语音合成请求... 81
10.3 实时语音合成响应... 83
10.3.1 开始合成响应...83
10.3.2 语音合成结果响应... 84
10.3.3 语音合成结束响应... 84
10.3.4 语音合成错误响应... 85
10.3.5 严重错误响应...86
11 热词管理接口...87
11.1 创建热词表... 87
11.2 更新热词表... 90
11.3 查询热词表信息...92
11.4 删除热词表... 94
11.5 查询热词表列表...96
12 附录... 100
12.1 示例音频... 100
12.2 获取项目 ID... 100
12.3 获取帐号 ID... 101
12.4 获取 AK/SK... 102
12.5 公共请求参数...103
12.6 公共响应参数...104
12.7 状态码...104
12.8 错误码...106
12.9 配置 OBS 访问权限... 110
13 修订记录... 112
1 使用前必读
1.1 概述
欢迎使用语音交互服务(Speech Interaction Service ,简称SIS)。
语音交互服务(Speech Interaction Service,简称SIS)是一种人机交互方式,用户通 过实时访问和调用API获取语音交互结果。支持用户通过语音识别功能,将口述音频、
普通话或者带有一定方言的语音文件识别成可编辑的文本,同时也支持通过语音合成 功能将文本转换成逼真的语音等提升用户体验。适用场景如语音客服质检、会议记 录、语音短消息、有声读物、电话回访等。
语音交互(实时语音识别、一句话识别、录音文件识别、语音合成)服务所提供的API 为自研API。
表1-1 实时语音识别接口说明
接口类型 说明
实时语音识别接口 华为云提供的Websocket接口,主要用于实时语音识 别。音频分片传输,服务器端可以返回中间临时转写结 果,在最后返回最终转写结果。
表1-2 一句话识别接口说明
接口类型 说明
一句话识别 一句话识别接口,用于短语音的同步识别。一次性上传 整个音频,响应中即返回识别结果。
表1-3 录音文件识别接口说明
接口类型 说明
录音文件识别 录音文件识别接口,用于转写不超过5小时的音频。由于 录音文件转写需要较长的时间,因此转写是异步的。
表1-4 语音合成接口说明
接口类型 说明
语音合成/实时语音合成 语音合成,依托先进的语音技术,使用深度学习算法,
将文本转换为自然流畅的语音。用户通过实时访问和调 用API获取语音合成结果,将用户输入的文字合成为音 频。通过音色选择、自定义音量、语速、音高等,可自 定义音频格式,为企业和个人提供个性化的发音服务。
1.2 调用说明
SIS服务提供了两种接口,包含REST(Representational State Transfer)API,支持您 通过HTTPS请求调用,调用方法请参见如何调用REST API。也包含WebSocket接口,
支持Websocket协议,调用方法请参见如何调用WebSocket API。
调用所需示例音频参见示例音频。
说明
调用接口的时候,无需开通服务,可直接调用。此时请按照实际需要选择计费方式,计费是按照 调用接口的次数或者时长来计算费用,具体计费价格参见语音交互价格计算器。
支持两种计费方式:
● 按需计费,默认计费方式为“按需计费”。
● 折扣套餐包方式,是用户可以购买套餐包,扣费时调用次数会先在套餐包内进行抵扣,抵扣 完后的剩余调用量默认转回按需计费方式。
1.3 终端节点
终端节点即调用API的请求地址,不同服务不同区域的终端节点不同。
目前语音交互服务一句话识别、录音文件识别支持以下地区和终端节点:
说明
当前服务仅支持北京和上海区域,后续会陆续上线其他区域。
● 华北-北京一,该区域资源有限,当前仅支持已选择该区域的老用户使用,新用户不可见,后 续该区域不可用。
● 华北-北京四,推荐的区域,支持一句话识别、录音文件识别、实时语音识别、语音合成和口 语测评和热词等接口。
● 华东-上海一,推荐的区域,支持一句话识别、录音文件识别、实时语音识别、语音合成和热 词等接口 。
一句话识别,录音文件识别支持服务终端:
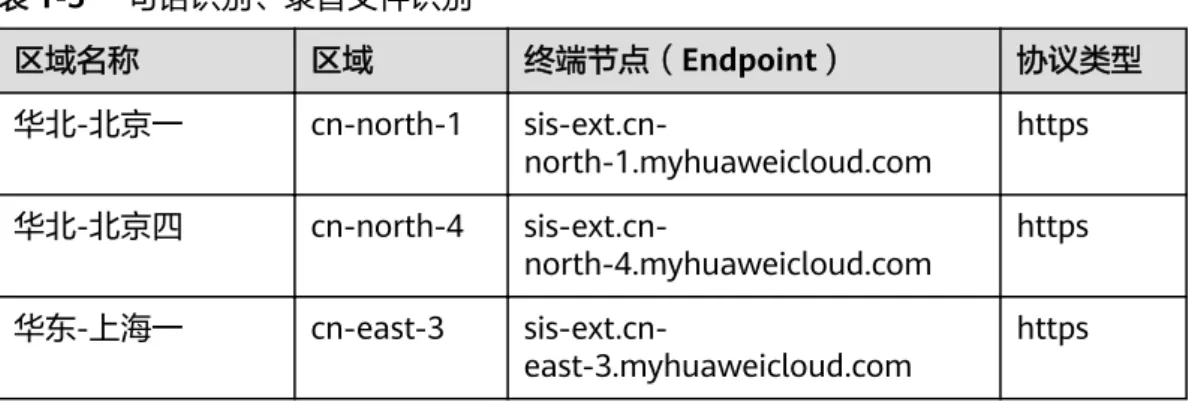
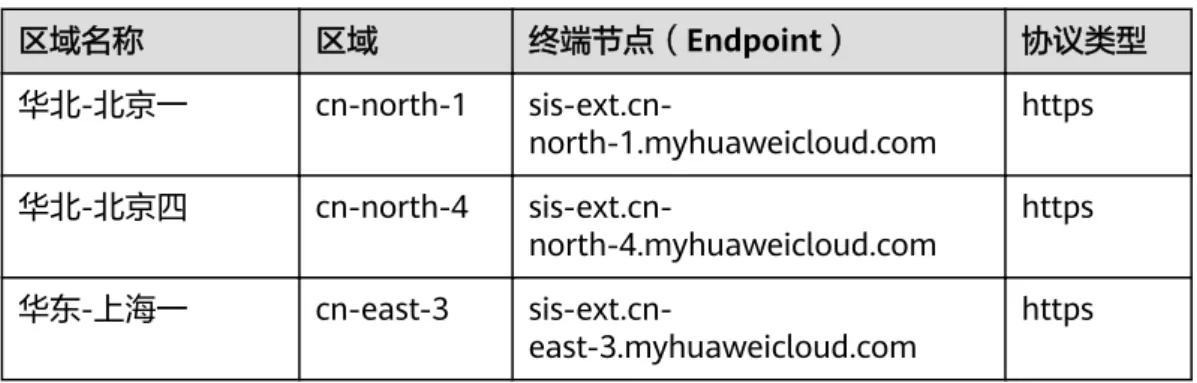
表1-5 一句话识别、录音文件识别
区域名称 区域 终端节点(Endpoint) 协议类型
华北-北京一 cn-north-1 sis-ext.cn-
north-1.myhuaweicloud.com https 华北-北京四 cn-north-4 sis-ext.cn-
north-4.myhuaweicloud.com https 华东-上海一 cn-east-3 sis-ext.cn-
east-3.myhuaweicloud.com https
实时语音识别( RASR)支持服务终端:
表1-6 实时语音识别
区域名称 区域 终端节点(Endpoint) 协议类型
华北-北京一 cn-north-1 sis-ext.cn-
north-1.myhuaweicloud.com Websocke t
华北-北京四 cn-north-4 sis-ext.cn-
north-4.myhuaweicloud.com Websocke t
华东-上海一 cn-east-3 sis-ext.cn-
east-3.myhuaweicloud.com Websocke t
语音合成支持服务终端:
表1-7 语音合成
区域名称 区域 终端节点(Endpoint) 协议类型
华北-北京一 cn-north-1 sis-ext.cn-
north-1.myhuaweicloud.com https 华北-北京四 cn-north-4 sis-ext.cn-
north-4.myhuaweicloud.com https 华东-上海一 cn-east-3 sis-ext.cn-
east-3.myhuaweicloud.com https
热词(一句话识别、录音文件识别、实时语音识别中的热词)支持服务终端:
表1-8 热词:
区域名称 区域 终端节点(Endpoint) 协议类型
华北-北京一 cn-north-1 sis-ext.cn-
north-1.myhuaweicloud.com https 华北-北京四 cn-north-4 sis-ext.cn-
north-4.myhuaweicloud.com https 华东-上海一 cn-east-3 sis-ext.cn-
east-3.myhuaweicloud.com https
1.4 基本概念
● 帐号
用户注册华为云时的帐号,帐号对其所拥有的资源及云服务具有完全的访问权 限,可以重置用户密码、分配用户权限等。由于帐号是付费主体,为了确保帐号 安全,建议您不要直接使用帐号进行日常管理工作,而是创建用户并使用他们进 行日常管理工作。
● 用户
由帐号在IAM中创建的用户,是云服务的使用人员,具有身份凭证(密码和访问 密钥)。
在我的凭证下,您可以查看帐号ID和用户ID。通常在调用API的鉴权过程中,您需 要用到帐号、用户和密码等信息。
● 区域(Region)
从地理位置和网络时延维度划分,同一个Region内共享弹性计算、块存储、对象 存储、VPC网络、弹性公网IP、镜像等公共服务。Region分为通用Region和专属 Region,通用Region指面向公共租户提供通用云服务的Region;专属Region指只 承载同一类业务或只面向特定租户提供业务服务的专用Region。
详情请参见区域和可用区。
● 可用区(AZ,Availability Zone)
一个AZ是一个或多个物理数据中心的集合,有独立的风火水电,AZ内逻辑上再将 计算、网络、存储等资源划分成多个集群。一个Region中的多个AZ间通过高速光 纤相连,以满足用户跨AZ构建高可用性系统的需求。
● 项目
华为云的区域默认对应一个项目,这个项目由系统预置,用来隔离物理区域间的 资源(计算资源、存储资源和网络资源),以默认项目为单位进行授权,用户可 以访问您帐号中该区域的所有资源。如果您希望进行更加精细的权限控制,可以 在区域默认的项目中创建子项目,并在子项目中购买资源,然后以子项目为单位 进行授权,使得用户仅能访问特定子项目中资源,使得资源的权限控制更加精 确。
图1-1 项目隔离模型
2 API 概览
SIS服务提供了两种接口,包含REST(Representational State Transfer)API,支持您 通过HTTPS请求调用,请参见表2-1。也包含WebSocket接口,支持Websocket协议,
请参见表2-2。
表2-1 REST API 功能
接口 功能 API URI
一句话识别接口
一句话识别
POST /v1/{project_id}/asr/short-audio 录音文件识别接录音文件识别
接口
识别接口:POST /v1/{project_id}/asr/transcriber/jobs
状态查询:GET /v1/{project_id}/asr/
transcriber/jobs/{job_id}
语音合成接口
语音合成接口
POST /v1/{project_id}/tts表2-2 WebSocket API 功能
接口 功能 API URI
实时语音识别接
口(请求)
开始识别
支持三种模式的请求消息:● 流式一句话
WSS /v1/{project_id}/rasr/short- stream
● 实时语音识别连续模式
WSS /v1/{project_id}/rasr/continue- stream
● 实时语音识别单句模式
WSS /v1/{project_id}/rasr/sentence- stream
发送音频数据
结束识别
3 如何调用 REST API
3.1 构造请求
本节介绍REST API请求的组成,并以调用一句话识别接口说明如何调用API。
您还可以通过这个视频教程了解如何构造请求调用API:https://
bbs.huaweicloud.com/videos/102987 。
请求 URI
请求URI由如下部分组成。
{URI-scheme} :// {Endpoint} / {resource-path} ? {query-string}
表3-1 请求 URI
参数 说明
URI-scheme 传输请求的协议,当前所有API均采用HTTPS协议。
Endpoint 承载REST服务端点的服务器域名或IP,不同服务在不同区域,
Endpoint不同,可以从终端节点中获取。例如,一句话识别服务在
“华北-北京四”区域的Endpoint为“sis-ext.cn- north-4.myhuaweicloud.com”。
resource-
path 资源路径,即API访问路径。从具体API的URI模块获取,例如“一句 话识别”API的resource-path为的“/v1/{project_id}/asr/short- audio”。其中“project_id”需要替换成用户的项目ID,可参考获
取项目ID。
query-string 查询参数,可选,查询参数前面需要带一个“?”,形式为“参数 名=参数取值”。例如“录音文件识别状态查询” 中
“job_id=123”表示查询“job_id”为123的任务结果。
例如,在“华北-北京四””区域调用一句话识别API,则需要使用“华北-北京四”区 域的Endpoint(sis-ext.cn-north-4.myhuaweicloud.com),拼接起来如下所示。
https://sis-ext.cn-north-4.myhuaweicloud.com/v1/{project_id}/asr/short-audio
图3-1 URI 示意图
说明
为查看方便,每个具体API的URI,只给出resource-path部分,并将请求方法写在一起。这是因 为URI-scheme都是HTTPS,而Endpoint在同一个区域也相同,所以简洁起见将这两部分省略。
请求方法
HTTP请求方法(也称为操作或动词),它告诉服务你正在请求什么类型的操作。
● GET:请求服务器返回指定资源。
● PUT:请求服务器更新指定资源。
● POST:请求服务器新增资源或执行特殊操作。
● DELETE:请求服务器删除指定资源,如删除对象等。
● HEAD:请求服务器资源头部。
● PATCH:请求服务器更新资源的部分内容。当资源不存在的时候,PATCH可能会 去创建一个新的资源。
在一句话识别的URI部分,您可以看到其请求方法为“POST”,则其请求为:
POST https://sis-ext.cn-north-4.myhuaweicloud.com/v1/{project_id}/asr/short-audio
请求消息头
附加请求头字段,如指定的URI和HTTP方法所要求的字段。例如定义消息体类型的请 求头“Content-Type”,请求鉴权信息等。
如下公共消息头需要添加到请求中。
● Content-Type:消息体的类型(格式),必选,默认取值为“application/
json”。
● X-Auth-Token:用户Token,可选,当使用Token方式认证时,必须填充该字 段。用户Token请参考认证鉴权中的“Token认证”。
添加消息头后的请求如下所示:
POST https://sis-ext.cn-north-4.myhuaweicloud.com/v1/{project_id}/asr/short-audio Content-Type: application/json
X-Auth-Token: MIINRwYJKoZIhvcNAQcCoIINOD...
请求消息体
请求消息体通常以结构化格式发出,与请求消息头中Content-type对应,传递除请求 消息头之外的内容。若请求消息体中参数支持中文,则中文字符必须为UTF-8编码。
每个接口的请求消息体内容不同,也并不是每个接口都需要有请求消息体(或者说消 息体为空),GET、DELETE操作类型的接口就不需要消息体,消息体具体内容需要根 据具体接口而定。
对于一句话识别接口,您可以从接口的请求部分看到所需的请求参数及参数说明。将 消息体加入后的请求如下所示,其中“data”参数表示将音频转化为Base64编码字符 串。POST https://sis-ext.cn-north-4.myhuaweicloud.com/v1/{project_id}/asr/short-audio
Content-Type: application/json
X-Auth-Token: MIINRwYJKoZIhvcNAQcCoIINOD...
{ “data”: “encode audio by Base64”, “config”: {
“audio_format”: “wav”,
“property”: “chinese_8k_common”
} }
到这里为止这个请求需要的内容就具备齐全了,您可以使用curl、Postman或直接编 写代码等方式发送请求调用API。对于一句话识别接口,您可以从响应消息部分看到返 回参数及参数说明。
3.2 认证鉴权
调用接口有如下两种认证方式,您可以选择其中一种进行认证鉴权。
● Token认证:通过Token认证通用请求。
● AK/SK认证:通过AK(Access Key ID)/SK(Secret Access Key)加密调用请求。
Token 认证
说明
Token的有效期为24小时,需要使用同一个Token鉴权时,可以缓存起来,避免频繁调用。
Token在计算机系统中代表令牌(临时)的意思,拥有Token就代表拥有某种权限。
Token认证就是在调用API的时候将Token加到请求消息头,从而通过身份认证,获得 操作API的权限。
获取用户Token接口请求构造如下,您可以从接口的请求部分看到所需的请求参数及参 数说明。获取Token消息头只需填写“Content-Type”,将消息体加入后的请求如下所 示。
加粗的斜体字段需要根据实际值填写,其中
username
为用户名,domainname
为用 户所属的帐号名称,********
为用户登录密码。username,domainname和project name的获取方法参见获取用户名、用户ID、项目名称、项目ID。获取Token的终端节点和
projectname
需与SIS服务终端节点保持一致。当访问华北-北 京四的终端节点(即sis-ext.cn-north-4
.myhuaweicloud.com)时,获取Token请使用 终端节点https://iam.cn-north-4
.myhuaweicloud.com,projectname
对应使用cn- north-4
。Token可通过调用获取用户Token接口获取,调用本服务API需要project级别的 Token,即调用获取用户Token接口时,请求body中auth.scope的取值需要选择 project,如下所示。
POST https://iam.cn-north-4.myhuaweicloud.com/v3/auth/tokens Content-Type: application/json
{ "auth": { "identity": { "methods": [ "password"
],
"password": { "user": {
"name": "username", "password": "********", "domain": {
"name": "domainname"
} } } }, "scope": { "project": {
"name": "projectname"
} } } }
如下图所示,返回的响应消息头中“x-subject-token”就是需要获取的用户Token。获 取Token之后,您就可以使用Token认证调用SIS服务API。
图3-2 获取用户 Token 响应消息头
获取Token后,再调用其他接口时,您需要在请求消息头中添加“X-Auth-Token”,
其值即为Token。例如Token值为“ABCDEFJ....”,则调用接口时将“X-Auth-Token:
ABCDEFJ....”加到请求消息头即可,如下所示。
Content-Type: application/json X-Auth-Token: ABCDEFJ....
您还可以通过这个视频教程了解如何使用Token认证:https://
bbs.huaweicloud.com/videos/101333 。
AK/SK 认证
说明
AK/SK签名认证方式仅支持消息体在12M以内,12M以上的请求请使用Token认证。
AK/SK认证就是使用AK/SK对请求进行签名,在请求时将签名信息添加到消息头,从而 通过身份认证。
● AK(Access Key ID):访问密钥ID。与私有访问密钥关联的唯一标识符;访问密钥 ID和私有访问密钥一起使用,对请求进行加密签名。
● SK(Secret Access Key):与访问密钥ID结合使用的密钥,对请求进行加密签名,
可标识发送方,并防止请求被修改。
使用AK/SK认证时,您可以基于签名算法使用AK/SK对请求进行签名,也可以使用专门 的签名SDK对请求进行签名。详细的签名方法和SDK使用方法请参见API签名指南。
须知
签名SDK只提供签名功能,与服务提供的SDK不同,使用时请注意。
AK/SK获取方式请参考获取AK/SK。
3.3 返回结果
状态码
请求发送以后,您会收到响应,包含状态码、响应消息头和消息体。
状态码是一组从1xx到5xx的数字代码,状态码表示了请求响应的状态,完整的状态码 列表请参见状态码。
对于SIS服务接口,如果调用后返回状态码为“200”,则表示请求成功。
响应消息头
对应请求消息头,响应同样也有消息头,如“Content-type”。SIS服务响应消息头无 特殊用途,可用于定位问题使用。
响应消息体
响应消息体通常以结构化格式返回,与响应消息头中Content-type对应,传递除响应 消息头之外的内容。
对于一句话识别接口,返回如下消息体。格式请具体参考一句话识别响应消息部分。
{ "trace_id": "567e8537-a89c-13c3-a882-826321939651", "result":{
"text": "欢迎使用语音云服务。", "score": 0.9
}}
当接口调用出错时,会返回错误码及错误信息说明,错误响应的Body体格式如下所 示。
{ "error_msg": "***", "error_code": "SIS.0001"
}
其中,error_code表示错误码,error_msg表示错误描述信息。
4 如何调用 WebSocket API
前提条件
在调用实时语音识别的Websocket接口之前,您需要完成Token认证,详细操作指导请 参见认证鉴权。
接口使用介绍
实时语音识别接口使用Websocket协议承载,客户端与服务端交流流程如图4-1所示。
分为三个主要步骤:
1. WebSocket握手。
2. 基于WebSocket协议进行实时语音识别。
3. 关闭WebSocket连接。
其中,基于WebSocket协议进行实时语音识别时,需要客户端首先发送转写开始消 息,然后持续发送语音数据至服务端,最后发送结束消息,在此期间客户端会持续收 到服务端发送的转写结果或事件,客户端根据所收到的相应消息做对应处理。实时语 音识别接口的具体细节请参见接口说明章节。
图4-1 客户端与服务端交流流程
5 实时语音识别接口
5.1 接口说明
实时语音识别接口基于Websocket协议实现。分别提供了“流式一句话”、“实时语 音识别连续模式”、“实时语音识别单句模式”三种模式。
三种模式的握手请求wss-URI不同,基于Websocket承载的实时语音识别请求和响应的 消息格式相同。
开发者可以使用java、python、c++等开发语言支持Websocket的对应软件包或库接 口,与实时语音识别引擎握手连接,并发送语音数据和接收转写结果,最后关闭 Websocket连接。
● 获取Websocket握手请求wss-URI请参见Websocket握手请求。
● 获取实时语音识别请求消息格式信息请参见实时语音识别请求。
● 获取实时语音识别响应消息格式请参见实时语音识别响应。
客户端通过Websocket协议访问实时流转写接口时,连接时长不能超过5小时。超过5 小时的Websocket连接,服务端会自动断链。
5.2 Websocket 握手请求
5.2.1 流式一句话
功能介绍
流式一句话模式的语音长度限制为一分钟,适合于对话聊天等识别场景。
该接口支持用户将一整段语音分段,以流式输入,最后得到识别结果。实时语音识别 引擎在获得分段的输入语音的同时,就可以同步地对这段数据进行特征提取和解码工 作,而不用等到所有数据都获得后再开始工作。因此这样就可以在最后一段语音结束 后,仅延迟很短的时间(也即等待处理最后一段语音数据以及获取最终结果的时间)
即可返回最终识别结果。这种流式输入方式能缩短整体上获得最终结果的时间,极大 地提升用户体验。
wss-URI
● wss-URI格式
wss /v1/{project_id}/rasr/short-stream
● 参数说明
表5-1 参数说明
参数名 是否必选 说明
project_id 是 项目编号。获取方法,请参见获取项
目ID。
● 请求示例(伪码)
wss://{endpoint}/v1/{project_id}/rasr/short-stream Request Header:
X-Auth-Token:
MIINRwYJKoZIhvcNAQcCoIINODCCDTQCAQExDTALBglghkgBZQMEAgEwgguVBgkqhkiG...
说明
“endpoint”即调用API的请求地址,不同服务不同区域的“endpoint”不同,具体请参见 终端节点。
● Python3语言请求代码示例
# -*- coding: utf-8 -*-
# 此demo仅供测试使用,强烈建议使用sdk。需提前安装websocket-client, 执行pip install websocket- client
import websocket import threading import time import json def rasr_demo():
url = 'wss://{{endpoint}}/v1/{{project_id}}/rasr/short-stream' # endpoint和project_id需替换 audio_path = '音频路径'
token = '用户对应region的token' header = {
'X-Auth-Token': token }
with open(audio_path, 'rb') as f:
data = f.read() body = {
'command': 'START', 'config': {
'audio_format': 'pcm8k16bit', 'property': 'chinese_8k_common' }
}
def _on_message(ws, message):
print(message) def _on_error(ws, error):
print(error)
ws = websocket.WebSocketApp(url, header, on_message=_on_message, on_error=_on_error) _thread = threading.Thread(target=ws.run_forever, args=(None, None, 30, 20))
_thread.start() time.sleep(1)
ws.send(json.dumps(body), opcode=websocket.ABNF.OPCODE_TEXT) now_index = 0
byte_len = 4000
while now_index < len(data):
next_index = now_index + byte_len if next_index > len(data):
next_index = len(data)
send_array = data[now_index: next_index]
ws.send(send_array, opcode=websocket.ABNF.OPCODE_BINARY) now_index += byte_len
time.sleep(0.05)
ws.send("{\"command\": \"END\", \"cancel\": \"false\"}", opcode=websocket.ABNF.OPCODE_TEXT) time.sleep(10)
ws.close()
if __name__ == '__main__':
rasr_demo()
● Java语言请求代码示例
import okhttp3.OkHttpClient;
import okhttp3.Request;
import okhttp3.Response;
import okhttp3.WebSocket;
import okhttp3.WebSocketListener;
import okio.ByteString;
import java.net.URL;
/** * 此demo仅供测试使用,强烈建议使用SDK
* 使用前需已配置okhttp、okio jar包。jar包可通过下载SDK获取。
*/public class RasrDemo { public void rasrDemo() { try {
// endpoint和projectId需要替换成实际信息。
String url = "wss://{{endpoint}}/v1/{{project_id}}/rasr/short-stream";
String token = "对应region的token";
byte[] data = null; // 存放将要发送音频的byte数组 OkHttpClient okHttpClient = new OkHttpClient();
Request request = new Request.Builder().url(url).header("X-Auth-Token", token).build();
WebSocket webSocket = okHttpClient.newWebSocket(request, new MyListener());
webSocket.send("{\"command\": \"START\", \"config\": {\"audio_format\": \"pcm8k16bit\",
\"property\": \"chinese_8k_common\"}}");
webSocket.send(ByteString.of(data));
webSocket.send("{ \"command\": \"END\", \"cancel\": false}");
Thread.sleep(10000);
webSocket.close(1000, null);
} catch (Exception e) { e.printStackTrace();
}
}
class MyListener extends WebSocketListener { @Override
public void onOpen(WebSocket webSocket, Response response) { System.out.println("conneected");
}
@Override
public void onClosed(WebSocket webSocket, int code, String reason) { System.out.println("closed");
}
@Override
public void onFailure(WebSocket webSocket, Throwable t, Response response) { t.printStackTrace();
}
@Override
public void onMessage(WebSocket webSocket, String text) { System.out.println(text);
}
} public static void main(String[] args) { RasrDemo rasrDemo = new RasrDemo();
rasrDemo.rasrDemo();
}}
5.2.2 实时语音识别连续模式
功能介绍
连续识别模式的语音总长度限制为五小时,适合于会议、演讲和直播等场景。
连续识别模式在流式识别的基础上,结合了语音的端点检测功能。语音数据也是分段 输入,但是连续识别模式将会在处理数据之前进行端点检测,如果是语音才会进行实 际的解码工作,如果检测到静音,将直接丢弃。如果检测到一段语音的结束点,就会 直接将当前这一段的识别结果返回,然后继续检测后面的语音数据。因此在连续识别 模式中,可能多次返回识别结果。如果送入的一段语音较长,甚至有可能在一次返回 中包括了多段的识别结果。
由于引入了静音检测,连续识别模式通常会比流式识别能具有更高的效率,因为对于 静音段将不会进行特征提取和解码操作,因而能更有效地利用CPU。而流式识别通常 和客户端的端点检测功能相结合,只将检测到的有效语音段上传到服务器进行识别。
wss-URI
● wss-URI格式
wss /v1/{project_id}/rasr/continue-stream
● 参数说明
表5-2 参数说明
参数名 是否必选 说明
project_id 是 项目编号。获取方法,请参见获取项目ID。
● 请求示例(伪码)
wss://{endpoint}/v1/{project_id}/rasr/continue-stream Request Header:
X-Auth-Token:
MIINRwYJKoZIhvcNAQcCoIINODCCDTQCAQExDTALBglghkgBZQMEAgEwgguVBgkqhkiG...
说明
“endpoint”即调用API的请求地址,不同服务不同区域的“endpoint”不同,具体请参见 终端节点。
● Python3语言请求代码示例
# -*- coding: utf-8 -*-
# 此demo仅供测试使用,强烈建议使用sdk。需提前安装websocket-client, 执行pip install websocket- client
import websocket import threading import time import json def rasr_demo():
url = 'wss://{{endpoint}}/v1/{{project_id}}/rasr/continue-stream' # endpoint和project_id需替换 audio_path = '音频路径'
token = '用户对应region的token' header = {
'X-Auth-Token': token
}
with open(audio_path, 'rb') as f:
data = f.read() body = {
'command': 'START', 'config': {
'audio_format': 'pcm8k16bit', 'property': 'chinese_8k_common' }
}
def _on_message(ws, message):
print(message) def _on_error(ws, error):
print(error)
ws = websocket.WebSocketApp(url, header, on_message=_on_message, on_error=_on_error) _thread = threading.Thread(target=ws.run_forever, args=(None, None, 30, 20))
_thread.start() time.sleep(1)
ws.send(json.dumps(body), opcode=websocket.ABNF.OPCODE_TEXT) now_index = 0
byte_len = 4000
while now_index < len(data):
next_index = now_index + byte_len if next_index > len(data):
next_index = len(data)
send_array = data[now_index: next_index]
ws.send(send_array, opcode=websocket.ABNF.OPCODE_BINARY) now_index += byte_len
time.sleep(0.05)
ws.send("{\"command\": \"END\", \"cancel\": \"false\"}", opcode=websocket.ABNF.OPCODE_TEXT) time.sleep(10)
ws.close()
if __name__ == '__main__':
rasr_demo()
● Java语言请求代码示例
import okhttp3.OkHttpClient;
import okhttp3.Request;
import okhttp3.Response;
import okhttp3.WebSocket;
import okhttp3.WebSocketListener;
import okio.ByteString;
import java.net.URL;
/** * 此demo仅供测试使用,强烈建议使用SDK
* 使用前需已配置okhttp、okio jar包。jar包可通过下载SDK获取。
*/public class RasrDemo { public void rasrDemo() { try {
// endpoint和projectId需要替换成实际信息。
String url = "wss://{{endpoint}}/v1/{{project_id}}/rasr/continue-stream";
String token = "对应region的token";
byte[] data = null; // 存放将要发送音频的byte数组 OkHttpClient okHttpClient = new OkHttpClient();
Request request = new Request.Builder().url(url).header("X-Auth-Token", token).build();
WebSocket webSocket = okHttpClient.newWebSocket(request, new MyListener());
webSocket.send("{\"command\": \"START\", \"config\": {\"audio_format\": \"pcm8k16bit\",
\"property\": \"chinese_8k_common\"}}");
webSocket.send(ByteString.of(data));
webSocket.send("{ \"command\": \"END\", \"cancel\": false}");
Thread.sleep(10000);
webSocket.close(1000, null);
} catch (Exception e) { e.printStackTrace();
}
} class MyListener extends WebSocketListener { @Override
public void onOpen(WebSocket webSocket, Response response) { System.out.println("conneected");
}
@Override
public void onClosed(WebSocket webSocket, int code, String reason) { System.out.println("closed");
}
@Override
public void onFailure(WebSocket webSocket, Throwable t, Response response) { t.printStackTrace();
}
@Override
public void onMessage(WebSocket webSocket, String text) { System.out.println(text);
}
} public static void main(String[] args) { RasrDemo rasrDemo = new RasrDemo();
rasrDemo.rasrDemo();
}}
5.2.3 实时语音识别单句模式
功能介绍
单句模式自动检测一句话的结束,因此适合于需要与您的系统进行交互的场景,例如 外呼、控制口令等场景。
实时语音识别引擎的单句识别模式,和连续识别模式类似,也会进行语音的端点检 测,如果检测到静音,将直接丢弃,检测到语音才会馈入核心进行实际的解码工作,
如果检测到一段语音的结束点,就会将当前这一段的识别结果返回。和连续识别不同 的是,在单句模式下,返回第一段的识别结果后,将不再继续识别后续的音频。这主 要是用于和用户进行语音交互的场景下,当用户说完一句话后,往往会等待后续的交 互操作,例如聆听根据识别结果播报的相关内容,因而没有必要继续识别后续的音 频。
wss-URI
● wss-URI格式:
wss /v1/{project_id}/rasr/sentence-stream
● 参数说明
表5-3 参数说明
参数名 是否必选 说明
project_id 是 项目编号。获取方法,请参见获取项目ID。
● 请求示例(伪码)
wss://{endpoint}/v1/{project_id}/rasr/sentence-stream Request Header:
X-Auth-Token:
MIINRwYJKoZIhvcNAQcCoIINODCCDTQCAQExDTALBglghkgBZQMEAgEwgguVBgkqhkiG...
说明
“endpoint”即调用API的请求地址,不同服务不同区域的“endpoint”不同,具体请参见 终端节点。
● Python3语言请求代码示例
# -*- coding: utf-8 -*-
# 此demo仅供测试使用,强烈建议使用sdk。需提前安装websocket-client, 执行pip install websocket- client
import websocket import threading import time import json def rasr_demo():
url = 'wss://{{endpoint}}/v1/{{project_id}}/rasr/sentence-stream' # endpoint和project_id需替换 audio_path = '音频路径'
token = '用户对应region的token' header = {
'X-Auth-Token': token }
with open(audio_path, 'rb') as f:
data = f.read() body = {
'command': 'START', 'config': {
'audio_format': 'pcm8k16bit', 'property': 'chinese_8k_common' }
}
def _on_message(ws, message):
print(message) def _on_error(ws, error):
print(error)
ws = websocket.WebSocketApp(url, header, on_message=_on_message, on_error=_on_error) _thread = threading.Thread(target=ws.run_forever, args=(None, None, 30, 20))
_thread.start() time.sleep(1)
ws.send(json.dumps(body), opcode=websocket.ABNF.OPCODE_TEXT) now_index = 0
byte_len = 4000
while now_index < len(data):
next_index = now_index + byte_len if next_index > len(data):
next_index = len(data)
send_array = data[now_index: next_index]
ws.send(send_array, opcode=websocket.ABNF.OPCODE_BINARY) now_index += byte_len
time.sleep(0.05)
ws.send("{\"command\": \"END\", \"cancel\": \"false\"}", opcode=websocket.ABNF.OPCODE_TEXT) time.sleep(10)
ws.close()
if __name__ == '__main__':
rasr_demo()
● Java语言请求代码示例
import okhttp3.OkHttpClient;
import okhttp3.Request;
import okhttp3.Response;
import okhttp3.WebSocket;
import okhttp3.WebSocketListener;
import okio.ByteString;
import java.net.URL;
/** * 此demo仅供测试使用,强烈建议使用SDK
* 使用前需已配置okhttp、okio jar包。jar包可通过下载SDK获取。
*/public class RasrDemo {
public void rasrDemo() { try {
// endpoint和projectId需要替换成实际信息。
String url = "wss://{{endpoint}}/v1/{{project_id}}/rasr/sentence-stream";
String token = "对应region的token";
byte[] data = null; // 存放将要发送音频的byte数组 OkHttpClient okHttpClient = new OkHttpClient();
Request request = new Request.Builder().url(url).header("X-Auth-Token", token).build();
WebSocket webSocket = okHttpClient.newWebSocket(request, new MyListener());
webSocket.send("{\"command\": \"START\", \"config\": {\"audio_format\": \"pcm8k16bit\",
\"property\": \"chinese_8k_common\"}}");
webSocket.send(ByteString.of(data));
webSocket.send("{ \"command\": \"END\", \"cancel\": false}");
Thread.sleep(10000);
webSocket.close(1000, null);
} catch (Exception e) { e.printStackTrace();
} }
class MyListener extends WebSocketListener { @Override
public void onOpen(WebSocket webSocket, Response response) { System.out.println("conneected");
}
@Override
public void onClosed(WebSocket webSocket, int code, String reason) { System.out.println("closed");
}
@Override
public void onFailure(WebSocket webSocket, Throwable t, Response response) { t.printStackTrace();
}
@Override
public void onMessage(WebSocket webSocket, String text) { System.out.println(text);
}
} public static void main(String[] args) { RasrDemo rasrDemo = new RasrDemo();
rasrDemo.rasrDemo();
}}
5.3 实时语音识别请求
5.3.1 实时语音识别工作流程
实时语音识别分为开始识别、发送音频数据、结束识别,断开连接四个阶段。
● 开始阶段需要发送开始指令,包含采样率,音频格式,是否返回中间结果等配置 信息。服务端会返回一个开始响应。
● 发送音频阶段客户端会分片发送音频数据,服务会返回识别结果或者其他事件,
如音频超时,静音部分过长等。
● 音频发送结束后,客户端会发送结束请求,服务端会返回end响应。
● 实时语音识别必须客户端要主动断开连接。当服务端超过20s没有收到客户的任何 数据时,会返回error事件,并主动断开。
图5-1 工作流程
5.3.2 开始识别
功能介绍
当wss握手请求收到成功响应后,客户端到服务端的通信协议会升级为Websocket协 议。通过Websocket协议,客户端发送开始识别请求,用于配置实时语音识别的配置 信息。
请求消息
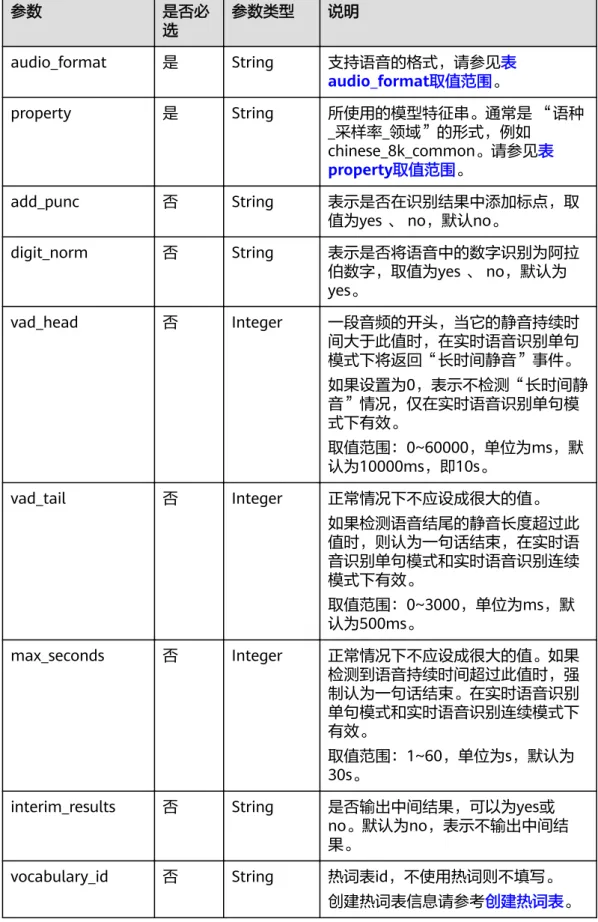
表5-4 参数说明
参数名 是否必
选
参数类型 说明
command 是 String 需设置为START,表示开始识别请 求。
config 是 Object 配置信息。结构信息请参见表 config
数据结构。
表5-5 config 数据结构
参数 是否必
选
参数类型 说明
audio_format 是 String 支持语音的格式,请参见表
audio_format取值范围。
property 是 String 所使用的模型特征串。通常是 “语种 _采样率_领域”的形式,例如
chinese_8k_common。请参见表
property取值范围。
add_punc 否 String 表示是否在识别结果中添加标点,取 值为yes 、 no,默认no。
digit_norm 否 String 表示是否将语音中的数字识别为阿拉 伯数字,取值为yes 、 no,默认为 yes。
vad_head 否 Integer 一段音频的开头,当它的静音持续时 间大于此值时,在实时语音识别单句 模式下将返回“长时间静音”事件。
如果设置为0,表示不检测“长时间静 音”情况,仅在实时语音识别单句模 式下有效。
取值范围:0~60000,单位为ms,默 认为10000ms,即10s。
vad_tail 否 Integer 正常情况下不应设成很大的值。
如果检测语音结尾的静音长度超过此 值时,则认为一句话结束,在实时语 音识别单句模式和实时语音识别连续 模式下有效。
取值范围:0~3000,单位为ms,默 认为500ms。
max_seconds 否 Integer 正常情况下不应设成很大的值。如果 检测到语音持续时间超过此值时,强 制认为一句话结束。在实时语音识别 单句模式和实时语音识别连续模式下 有效。
取值范围:1~60,单位为s,默认为 30s。
interim_results 否 String 是否输出中间结果,可以为yes或 no。默认为no,表示不输出中间结 果。
vocabulary_id 否 String 热词表id,不使用热词则不填写。
创建热词表信息请参考创建热词表。
参数 是否必 选
参数类型 说明
need_word_info 否 String 表示是否在识别结果中输出分词结果 信息,取值为“yes”和“no”,默 认为“no”。
表5-6 property 取值范围
property取值 说明
chinese_8k_common 支持采样率为8k的中文普通话语音识别。
chinese_16k_common 支持采样率为16k的中文普通话语音识别。
chinese_16k_general 支持采样率为16k的中文普通话语音识别,同时 可识别一些简单的方言。
若选择此参数,暂不支持vad_tail、
max_seconds参数。
格式仅支持pcm16k16bit,区域仅支持cn- north-4。支持连续模式和流式一句话模式。
sichuan_16k_common 支持采样率为16k的中文普通话与四川话方言语 音识别。区域仅支持cn-north-4。
cantonese_16k_common 支持采样率为16k的粤语方言语音识别。区域仅 支持cn-north-4。
shanghai_16k_common 支持采样率为16k的上海话方言语音识别。区域 仅支持cn-north-4。
chinese_16k_court 支持采样率为16k的庭审会议语音识别。区域仅 支持cn-north-4。
chinese_16k_it 支持采样率为16k的IT会议语音识别。区域仅支 持cn-north-4。
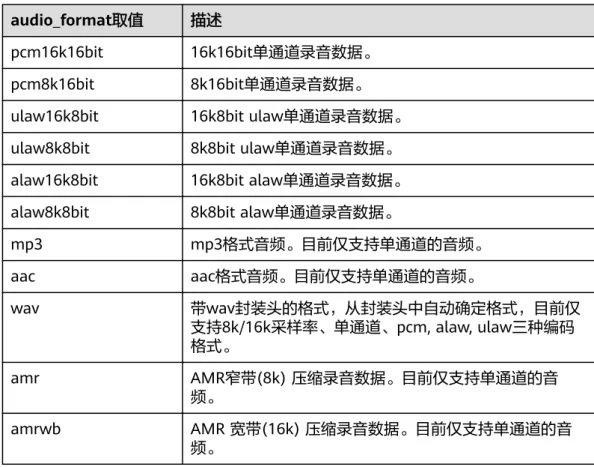
表5-7 audio_format 取值范围
audio_format取值 说明
pcm16k16bit 16k16bit单通道录音数据。
pcm8k16bit 8k16bit单通道录音数据。
ulaw16k8bit 16k8bit ulaw单通道录音数据。
ulaw8k8bit 8k8bit ulaw单通道录音数据。
alaw16k8bit 16k8bit alaw单通道录音数据。
alaw8k8bit 8k8bit alaw单通道录音数据。
说明
目前仅支持裸音频格式,仅支持pcm编码的wav格式,不支其他wav头或者arm格式的编码。
示例
{ "command": "START", "config":
{ "audio_format": "ulaw8k8bit", "property": "chinese_8k_common", "add_punc": "yes",
"vad_tail": 400, "interim_results": "yes", "need_word_info": "yes"
}}
状态码
状态码请参见状态码。
错误码
错误码请参见错误码。
5.3.3 发送音频数据
在收到“开始识别”的响应之后,可以开始发送音频数据。为节省流量,音频以二进 制数据帧形式(binary message)的方式发送。
音频数据将分片发送,也即在获得一定量音频数据的同时就可以发送一个binary message,每个分片建议在50ms~1000ms之间,建议在需要实时反馈的情况下 100ms,不需要实时反馈的情况下500ms。
5.3.4 结束识别
功能介绍
对于识别中的对话,需要在Websocket上发送“结束识别”的请求来取消或结束识 别。 "结束识别"请求使用文本类型的数据帧(text message)发送,命令和参数以json 字符串的形式提供。
请求消息
表5-8 参数说明
参数名 是否必
选
参数类型 说明
command 是 String 设置为END,表示结束识别请求。
参数名 是否必 选
参数类型 说明
cancel 否 Boolen ● true:表示取消识别,也即丢弃识别中和 未识别的语音数据并结束,不返回剩余的 识别结果。
● false:表示继续处理识别中和未识别的语 音数据直到处理完所有之前发送的数据。
默认是false。
示例
{ "command": "END", "cancel": false }
状态码
状态码请参见状态码。
错误码
错误码请参见错误码。
5.4 实时语音识别响应
5.4.1 开始识别请求响应
由于WebSocket是全双工的,因此响应就是从服务器端发送给客户端的消息,但也并 不是所有的请求信息都有一条对应的响应。服务器端收到“开始识别”请求时,会给 出如下响应消息,以json字符串形式放置在text message中。
响应消息
表5-9 响应参数
参数名 参数类型 说明
resp_type String 参数值为START,表示开始识别响应。
trace_id String 服务内部的令牌,可用于在日志中追溯具 体流程。
示例
{ "resp_type": "START",
"trace_id": "567e8537-a89c-13c3-a882-826321939651"
}
状态码
状态码请参见状态码。
错误码
错误码请参见错误码。
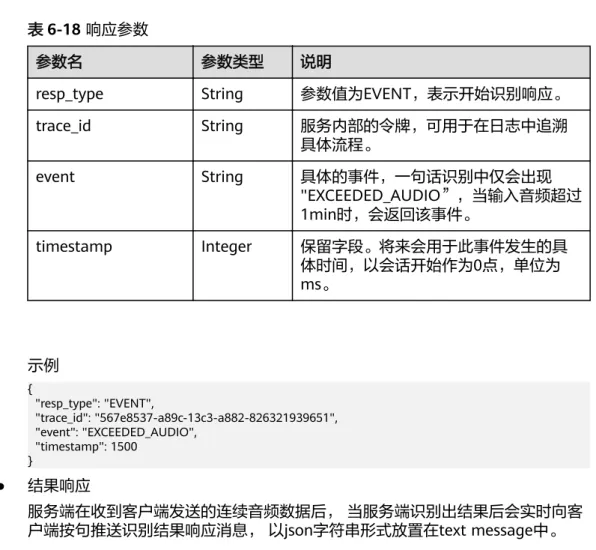
5.4.2 事件响应
服务器端检测到某些事件时,会给出如下响应消息,以json字符串形式放置在text message中。
响应消息
表5-10 响应参数
参数名 参数类型 说明
resp_type String 参数值为EVENT,表示开始识别响应。
trace_id String 服务内部的令牌,可用于在日志中追溯具 体流程。
event String 具体的事件,详细参数可参见event取值范
围及其说明。
timestamp Integer 保留字段。将来会用于此事件发生的具体 时间,以会话开始作为0点,单位为ms。
event 取值范围及其说明
表5-11 event 取值范围
事件 说明
VOICE_START 检测到句子开始。
VOICE_END 检测到句子结束。
EXCEEDED_SILENCE 静音超长,也即没有检测到声音。
EXCEEDED_AUDIO 输入音频超长。指一通会话的总的音频长度大于 后台配置的最大允许长度(比如5h)。
● 在流式一句话模式下:
– 不会返回VOICE_START、VOICE_END、EXCEEDED_SILCENCE事件。
– 返回EXCEEDED_AUDIO事件后,后续音频将被忽略,不会再识别。
● 在实时语音识别单句模式下:
– 返回VOICE_START事件,表示检测到语音,此时IVR可以做打断。
– 返回VOICE_END事件后,表示一句话结束,后续的音频将被忽略,不会再进 行识别。
– 只会返回最多一组VOICE_START和VOICE_END事件。
– 如果返回EXCEEDED_SILENCE事件,表示超过vad_head没有检测到声音,通 常表示用户一直没有说话。此时后续的音频将被忽略,不会再进行识别。
– 返回EXCEEDED_AUDIO事件后,后续音频将被忽略,不会再识别。
● 在实时语音识别连续模式下:
– 不会返回VOICE_START、VOICE_END、EXCEED_SLIENCE事件。
– 返回EXCEEDED_AUDIO事件后,后续音频将被忽略,不会再识别。
示例
{ "resp_type": "EVENT",
"trace_id": "567e8537-a89c-13c3-a882-826321939651", "event": "VOICE_END",
"timestamp": 1500 }
状态码
状态码请参见状态码。
错误码
错误码请参见错误码。
5.4.3 识别结果响应
服务端在收到客户端发送的连续音频数据后, 当服务端识别出结果后会实时向客户端 按句推送识别结果响应消息, 以json字符串形式放置在text message中。
响应消息
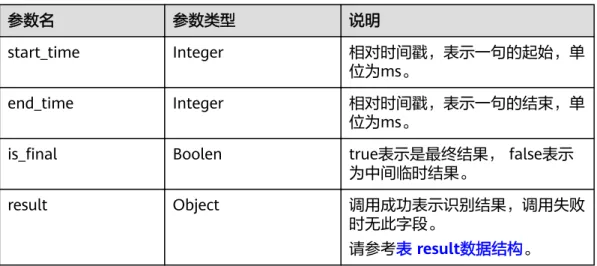
表5-12 响应参数
参数名 参数类型 说明
resp_type String 参数值为RESULT,表示识别结果响应。
trace_id String 服务内部的令牌,可用于在日志中追溯具体流 程。
segments Array of objects 多句结果。
请参考表 segment 数据结构。
表5-13 segment 数据结构
参数名 参数类型 说明
start_time Integer 相对时间戳,表示一句的起始,单 位为ms。
end_time Integer 相对时间戳,表示一句的结束,单 位为ms。
is_final Boolen true表示是最终结果, false表示 为中间临时结果。
result Object 调用成功表示识别结果,调用失败
时无此字段。
请参考表 result数据结构。
表5-14 result 数据结构
参数名 参数类型 说明
text String 识别结果。
score Float 识别结果的置信度,取值范围:0~1。此值 仅会在最终结果时被赋值,在中间结果时统 一置为“0.0”。
说明
目前置信度作用不是太大,请勿过多依赖此值。
word_info Array of
Object 分词输出列表。
表5-15 word_info 数据结构
参数名 是否必选 参数类型 说明
start_time 否 Integer 起始时间 end_time 否 Integer 结束时间
word 否 String 分词
示例
{ "resp_type": "RESULT",
"trace_id": "567e8537-a89c-13c3-a882-826321939651", "segments":
[ {
"start_time": 100, "end_time": 1500, "is_final": false,
"result":
{
"text": "第一句中间结果", "word_info": [
{
"start_time": 100, "end_time": 800, "word": "第一"
}, {
"start_time": 800, "end_time": 1000, "word": "句"
}, {
"start_time": 1000, "end_time": 1500, "word": "结果"
} ],
"score": 0.0 }, }, ]}
状态码
状态码请参见状态码。
错误码
错误码请参见错误码。
5.4.4 错误响应
错误响应,通常是指不影响流程,但当前会话无法再进行下去的错误,包括如下情 况:
● 配置串错误,包括存在不识别的配置串,或者配置串值的范围不合法。
● 时序不正确,比如连续发送两次“开始识别”指令。
● 识别过程中发生错误,比如音频解码发生错误。
出现错误响应时,如果已经在一个会话中了,会再发送一个“结束识别”的响应,表 示识别会话结束。如果会话还没有开始,那么发送此错误响应后不做其它操作。此后 的音频数据都被忽略,直到收到下一个“开始识别”请求。
响应消息
表5-16 响应参数
参数名 参数类型 说明
resp_type String 参数值为ERROR,表示错误响应。
trace_id String 服务内部的跟踪令牌,可用于在日志中追 溯具体流程。
在某些错误情况下,可能没有此字段。
参数名 参数类型 说明
error_code String 错误码列表。详细错误码解释,请参见错
误码。
error_msg String 返回错误信息。
示例
{ "resp_type": "ERROR",
"trace_id": "567e8537-a89c-13c3-a882-826321939651", "error_code": "SIS.0002",
"error_msg": "***"
}
状态码
状态码请参见状态码。
错误码
错误码请参见错误码。
5.4.5 严重错误响应
严重错误,通常指流程无法继续的情况。比如当出现客户端分片音频间隔超时(例如 20s)。
出现严重错误响应时,流程不再继续,服务器端会主动断连。
响应消息
表5-17 响应参数
参数名 参数类型 说明
resp_type String 参数值为FATAL_ERROR,表示开始识别响 应。
trace_id String 服务内部的令牌,可用于在日志中追溯具 体流程。
error_code String 错误码列表。详细错误码解释,请参见错
误码。
error_msg String 返回错误信息。
示例
{ "resp_type": "FATAL_ERROR",
"trace_id": "567e8537-a89c-13c3-a882-826321939651", "error_code": "SIS.0002",
"error_msg": "***"
}
状态码
状态码请参见状态码。
错误码
错误码请参见错误码。
5.4.6 结束识别请求响应
服务器端收到“结束识别”请求时或语音识别过程中发生错误,服务端会向客户端推 送如下响应消息,以json字符串形式放置在text message中。
响应消息
表5-18 响应参数
参数名 参数类型 说明
resp_type String 参数值为END,表示结束识别响应。
trace_id String 服务内部的令牌,可用于在日志中追溯具 体流程。
reason String 结束原因,详情请参见表 结束原因表。
表5-19 结束原因表
参数名 说明
NORMAL 正常结束。
CANCEL 用户取消,也即客户端发送“结束识别”指令时
cancel参数为true。
ERROR 识别过程中发生错误。
示例
{ "resp_type": "END",
"trace_id": "567e8537-a89c-13c3-a882-826321939651", "reason": "NORMAL",
}
状态码
状态码请参见状态码。
错误码
错误码请参见错误码。
6 一句话识别
6.1 http 接口
功能介绍
一句话识别接口,用于短语音的同步识别。一次性上传1min以内音频,能快速返回识 别结果。该接口的使用限制请参见约束与限制,详细使用指导请参见SIS服务使用简介 章节。
调试
您可以在API Explorer中调试该接口。
URI
POST /v1/{project_id}/asr/short-audio
表6-1 路径参数
参数 是否必选 参数类型 描述
project_id 是 String 项目编号。获取方法,请参见获取项目
ID。
请求参数
表6-2 请求 Header 参数
参数 是否必选 参数类型 描述
X-Auth-
Token 是 String 用户Token。
Token认证就是在调用API的时候将Token 加到请求消息头,从而通过身份认证,获 得操作API的权限,响应消息头中X- Subject-Token的值即为Token。
表6-3 请求 Body 参数
参数 是否必选 参数类型 描述
config 是
Config
object 配置信息。
data 是 String 语音数据,Base64编码,要求Base64编 码后大小不超过4M,音频时长不超过1分 钟。
表6-4 Config
参数 是否必选 参数类型 描述
audio_form
at 是 String 支持语音的格式,请参考表
audio_format取值范围。
property 是 String 所使用的模型特征串,通常是 “语种_采 样率_领域”的形式,采样率需要与音频 采样率保持一致,取值范围请参考表
property取值范围。
add_punc 否 String 表示是否在识别结果中添加标点,取值为
“yes”和“no”,默认为“no”。
digit_norm 否 String 表示是否将语音中的数字识别为阿拉伯数 字,取值为“yes” 和 “no”,默认为
“yes”。
vocabulary
_id 否 String 热词表id,不使用则不填写。
创建热词表信息请参考创建热词表。
need_word
_info 否 String 表示是否在识别结果中输出分词结果信 息,取值为“yes”和“no”,默认为
“no”。
表6-5 audio_format 取值范围 audio_format取值 描述
pcm16k16bit 16k16bit单通道录音数据。
pcm8k16bit 8k16bit单通道录音数据。
ulaw16k8bit 16k8bit ulaw单通道录音数据。
ulaw8k8bit 8k8bit ulaw单通道录音数据。
alaw16k8bit 16k8bit alaw单通道录音数据。
alaw8k8bit 8k8bit alaw单通道录音数据。
mp3 mp3格式音频。目前仅支持单通道的音频。
aac aac格式音频。目前仅支持单通道的音频。
wav 带wav封装头的格式,从封装头中自动确定格式,目前仅 支持8k/16k采样率、单通道、pcm, alaw, ulaw三种编码 格式。
amr AMR窄带(8k) 压缩录音数据。目前仅支持单通道的音 频。
amrwb AMR 宽带(16k) 压缩录音数据。目前仅支持单通道的音 频。
表6-6 property 取值范围 property取值 描述
chinese_8k_common 支持采样率为8k的中文普通话语音识别。
chinese_16k_common 支持采样率为16k的中文普通话语音识别。
chinese_16k_general 支持采样率为16k的中文普通话语音识别,同时可识别一 些简单的方言。
格式仅支持pcm16k16bit、mp3、wav,区域仅支持cn- north-4。
sichuan_16k_common 支持采样率为16k的中文普通话与四川话方言识别。区域 仅支持cn-north-4。
cantonese_16k_comm
on 支持采样率为16k的粤语方言识别。区域仅支持cn- north-4。
shanghai_16k_commo
n 支持采样率为16k的上海话方言识别,区域仅支持cn-
north-4。
响应参数
状态码: 200
表6-7 响应 Body 参数
参数 是否必选 参数类型 描述
trace_id 是 String 服务内部的令牌,可用于在日志中追溯具 体流程,调用失败无此字段。
在某些错误情况下可能没有此令牌字符 串。
result 是
Result
object 调用成功表示识别结果,调用失败时无此 字段。
表6-8 Result
参数 是否必选 参数类型 描述
text 是 String 调用成功表示识别出的内容。
score 是 Float 调用成功表示识别出的置信度,取值范 围:0~1。
word_info 否 Array of
WordInfo
objects分词信息列表。
表6-9 WordInfo
参数 是否必选 参数类型 描述
start_time 否 Integer 起始时间 end_time 否 Integer 结束时间
word 否 String 分词
状态码: 400
表6-10 响应 Body 参数
参数 参数类型 描述
error_code String 调用失败时的错误码。 调用成功时无此字段。
error_msg String 调用失败时的错误信息。 调用成功时无此字段。
请求示例
说明
“endpoint”即调用API的请求地址,不同服务不同区域的“endpoint”不同,具体请参见终端 节点。
● 请求示例(伪码)
POST https://{endpoint}/v1/{project_id}/asr/short-audio Request Header:
Content-Type: application/json X-Auth-Token:
MIINRwYJKoZIhvcNAQcCoIINODCCDTQCAQExDTALBglghkgBZQMEAgEwgguVBgkqhkiG...
Request body:
{ "config":
{ "audio_format": "ulaw8k8bit", "property": "chinese_8k_common", "add_punc": "yes",
"need_word_info": "yes"
}, "data": "/+MgxAAUeHpMAUkQAANhuRAC..."
}
● Python3语言请求代码示例
# -*- coding: utf-8 -*-
# 此demo仅供测试使用,强烈建议使用sdk。需提前安装requests,执行pip install requests import requests
import base64 import json def sasr_demo():
url = 'https://{{endpoint}}/v1/{{project_id}}/asr/short-audio' # endpoint和project_id需替换 token = '用户对应region的token'
file_path = '将要识别音频的路径' with open(file_path, 'rb') as f:
data = f.read()
base64_data = str(base64.b64encode(data), 'utf-8') header = {
'Content-Type': 'application/json', 'X-Auth-Token': token
} body = {
'data': base64_data, 'config': {
'property': 'chinese_8k_common', 'audio_format': 'pcm8k16bit' }
}
resp = requests.post(url, data=json.dumps(body), headers=header) print(resp.text)
if __name__ == '__main__':
sasr_demo()
● Java语言请求代码示例
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.HttpURLConnection;
import java.net.URL;
/** * 此demo仅供测试使用,强烈建议使用SDK
*/public class SasrDemo {
public void sasrDemo() { try {
// endpoint和projectId需要替换成实际信息。
URL url = new URL("https://{{endpoint}}/v1/{{project_id}}/asr/short-audio");
String token = "对应region的token";
String audioBody = "8k wav格式audio对应base64编码";
HttpURLConnection connection = (HttpURLConnection)url.openConnection();
connection.setRequestMethod("POST");
connection.setDoInput(true);
connection.setDoOutput(true);
connection.addRequestProperty("Content-Type", "application/json");
connection.addRequestProperty("X-Auth-Token", token);
OutputStreamWriter osw = new OutputStreamWriter(connection.getOutputStream(), "UTF-8");
String body = "{\"data\":\"" + audioBody + "\", \"config\": { \"audio_format\": \"wav\", "
+ "\"property\":\"chinese_8k_common\"}}";
osw.append(body);
osw.flush();
InputStream is = connection.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is, "UTF-8"));
while (br.ready()) {
System.out.println(br.readLine());
}
} catch (Exception e) { e.printStackTrace();
}
} public static void main(String[] args) { SasrDemo sasrDemo = new SasrDemo();
sasrDemo.sasrDemo();
}}
响应示例
状态码:200 成功响应示例
{ "trace_id": "567e8537-a89c-13c3-a882-826321939651", "result":{
"text": "欢迎使用语音云服务。", "score": 0.9,
"word_info": [ {
"start_time": 150, "end_time": 570, "word": "欢迎"
}, {
"start_time": 570, "end_time": 990, "word": "使用"
}, {
"start_time": 990, "end_time": 1380, "word": "语音"
}, {
"start_time": 1380, "end_time": 1590, "word": "云"
}, {
"start_time": 1590, "end_time": 2070,
"word": "服务"
} ] }}
状态码:400 失败响应示例
{ "error_code":"SIS.0001", "error_msg":"***"
}
状态码
状态码请参见状态码。
错误码
错误码请参见错误码。
6.2 websocket 接口
功能介绍
一句话识别websocket接口支持识别1min以内的音频,交互过程如图 客户端和服务端
交互流程所示,主要分为开始识别、发送音频数据,结束识别、断开连接四个步骤。
websocket接口同http接口一致按次计费,只要建立连接成功,发送音频,服务开始识 别,则本次调用计费生效。如果用户发送错误end请求或者持续20s未发送音频而产生 了报错,该次调用依然认为生效。如果连接成功后未发送音频直接断开,或者请求字 段不正确而产生异常,则认为本次调用无效,不会纳入计费次数。
图6-1 客户端和服务端交互流程
wss-URI
● wss-URI格式
wss /v1/{project_id}/asr/short-audio
● 参数说明
表6-11 参数说明
参数名 是否必选 说明
project_id 是 项目编号。获取方法,请参见获取项
目ID。
开始识别
● 功能介绍
当wss握手请求收到成功响应后,客户端到服务端的通信协议会升级为Websocket 协议。通过Websocket协议,客户端发送开始识别请求,用于配置一句话识别的 配置信息。
● 请求消息