行政院國家科學委員會專題研究計畫 成果報告
演化式計算與群體智慧應用於排程問題(2/2) 研究成果報告(完整版)
計 畫 類 別 : 個別型
計 畫 編 號 : NSC 95-2221-E-011-081-
執 行 期 間 : 95 年 08 月 01 日至 96 年 07 月 31 日 執 行 單 位 : 國立臺灣科技大學工業管理系
計 畫 主 持 人 : 廖慶榮
計畫參與人員: 碩士班研究生-兼任助理:阮曉健、程哲廞、趙謙文、徐千淇 博士後研究:曾兆堂
處 理 方 式 : 本計畫涉及專利或其他智慧財產權,1 年後可公開查詢
中 華 民 國 96 年 10 月 20 日
行政院國家科學委員會補助專題研究計畫成果報告
※※※※※※※※※※※※※※※※※※※※※※※※※※
※ ※
※ 演化式計算與群體智慧應用於排程問題(2/2) ※
※ ※
※※※※※※※※※※※※※※※※※※※※※※※※※※
計畫類別:;個別型計畫 □整合型計畫 計畫編號:NSC-94-2213-E011-034
NSC-95-2811-E011-006
執行期間: 94 年 8 月 1 日至 95 年 7 月 31 日(第一年)
執行期間: 94 年 8 月 1 日至 96 年 7 月 31 日(全案二年)
計畫主持人:廖慶榮 教授
計畫參與人員:曾兆堂、阮曉健、程哲廞、趙謙文、徐千淇
本成果報告包括以下應繳交之附件:
□赴國外出差或研習心得報告一份
□赴大陸地區出差或研習心得報告一份
□出席國際學術會議心得報告及發表之論文各一份
□國際合作研究計畫國外研究報告書一份 執行單位:台灣科技大學工業管理系
中 華 民 國 96 年 7 月 31 日
1
行政院國家科學委員會專題研究計畫成果報告
演化式計算與群體智慧應用於排程問題
Evolutionary Computation and Swarm Intelligence for Scheduling Problems
計畫編號:NSC-94-2213-E-011-034 NSC-95-2811-E-011-006 執行期限:94 年 8 月 1 日至 96 年 7 月 31 日 主持人:廖慶榮 教授 台灣科技大學工業管理系
計畫參與人員:曾兆堂 台灣科技大學工業管理系博士後研究 阮曉健 台灣科技大學工業管理系碩士班 程哲廞 台灣科技大學工業管理系碩士班 趙謙文 台灣科技大學工業管理系碩士班 徐千淇 台灣科技大學工業管理系碩士班
中文摘要
粒子群最佳化演算法(Particle Swarm Optimization;PSO)是一個集合演化式計算 與群體智慧的共通啟發式演算法,它啟發自鳥群或魚群的行為。目前粒子群最佳化演算 法應用在排程問題上的研究是相當罕見。因此,本研究設計三種不同的粒子群最佳化演 算法,來求解典型之流程型工廠、批量流之流程型工廠以及多工處理之多階混合流程型 工廠等三類排程問題。本研究主要區分為以下三個部份:
第一部份:PSO 求解流程型工廠排程問題
針對此問題,我們發展出一個間斷型粒子群最佳化演算法(Discrete Particle Swarm Optimization;DPSO),該演算法延伸自間斷版本的粒子群最佳化演算法。在演算法中,
我們重新定義粒子及速度且發展一個有效的方法使粒子移動至新的順序。實驗結果證明 我們提出的間斷型粒子群最佳化演算法非常具有競爭力。
第二部份:PSO 求解批量流之流程型工廠排程問題
針對此問題,首先我們提出一個淨移動利益演算法(Net Benefit of Movement;
NBM),求得一個已知順序下的最佳子批量配置。其次,我們改善第一部份提出的 DPSO
演算法以搜尋最佳的順序。此新的DPSO 演算法引入基因演算法中的繼承機制,改善粒
子的建構方式。實驗結果顯示,改善後DPSO 演算法,在此排程問題上呈現最好的績效。
第三部份:PSO 求解多工處理之多階混合流程型工廠排程問題
針對此問題,我們再提出一個新 PSO 的演算法。該演算法主要延伸自連續版本的
PSO 演算法,並引入一個新的粒子編碼方式並找出最好的粒子速度方程式及鄰域拓撲機
制。實驗結果證明,我們所提出的PSO 演算法有很好的求解效果。
關鍵詞:粒子群最佳化演算法、演化式計算、群體智慧、排程、流程型工廠
Abstract
Particle Swarm Optimization (PSO) is a novel metaheuristic which combines Evolutionary Computation and Swarm Intelligence. It is inspired by the flocking behavior of birds. The applications of PSO to scheduling problems are extremely few. In this research, we focus on the application of PSO to solve the flowshop, lot streaming flowshop, and multistage hybrid flowshop with multiprocessor task scheduling problems. The research includes the following three parts:
Part I. Particle swarm optimization for flowshop scheduling problem.
For flowshop scheduling, we present a PSO algorithm, extended from discrete PSO. In the proposed algorithm, the particle and the velocity are redefined, and an efficient approach is developed to move a particle to the new sequence. Computational results show that the proposed PSO algorithm is very competitive.
Part II. Particle swarm optimization for lot-streaming flowshop scheduling problem.
To solve this problem, we first propose a so-called net benefit of movement (NBM) algorithm, which is much more efficient than the existing linear programming model for obtaining the optimal starting and completion times of sublots for a given job sequence. A new discrete particle swarm optimization (DPSO) algorithm incorporating the NBM algorithm is then developed to search for the best sequence. The new DPSO improves the existing DPSO by introducing an inheritance scheme, inspired by a genetic algorithm, into particles construction. Computational results show that the proposed DPSO algorithm is very competitive for the problem.
Part III. Particle swarm optimization for hybrid flow-shop scheduling with multiprocessor tasks.
In this research, we address the problem by using particle swarm optimization (PSO), a novel metaheuristic inspired by the flocking behavior of birds. The proposed PSO algorithm has several features, such as a new encoding scheme, an implementation of the best velocity equation and neighborhood topology among several different variants, and an effective incorporation of local search. The results show that the proposed PSO algorithm outperforms all the existing algorithms for the considered problem.
Keywords: Particle swarm optimization; Evolutionary computation; Swarm intelligence;
Scheduling; flowshop
Part I. Particle swarm optimization for flowshop scheduling problem 1. Introduction
Particle Swarm Optimization (PSO), originally designed by Kennedy and Eberhart (1995), is an emerging population-based optimization method. Since 2002, PSO has been growing rapidly with over 100 published papers every year. All the related research has totaled over 300 papers until 2004 (Hu et al., 2004). PSO has been applied successfully to continuous nonlinear functions (Kennedy and Eberhart, 1995), neural networks (Van den Bergh and Engelbrecht, 2000), nonlinear constrained optimization problems (El-Galland et al., 2001), etc. Most of the applications have been concentrated on solving continuous optimization problems, but the studies of PSO on discrete optimization problems are relatively few. In this research, we will develop a PSO algorithm for the flowshop scheduling problem, a class of important discrete optimization problems.
In the PSO literature, the research on scheduling is extremely few. Tasgetiren et al.
(2004a) first developed a PSO algorithm for the single machine total weighted tardiness problem. They used the smallest position value (SPV) rule, a non-decreasing order mechanism, to convert a position vector to a job permutation. Also, a well-known local search method, called variable neighborhood search (VNS), was applied to improve the solution.
With the same approach, Tasgetiren et al. (2004b) solved two permutation flowshop problems with the criteria of makespan minimization and maximum lateness minimization, respectively.
Both their algorithms with and without VNS were experimented on the benchmark problems given by Demirkol et al. (1998) and both showed their advantages over the respective genetic algorithms (GA) proposed by themselves.
It is noted that the above scheduling research on PSO is an extension from the continuous version of PSO (i.e., the original PSO). To solve discrete optimization problems, Kennedy and Eberhart (1997) also developed a discrete version of PSO, which however has seldom been utilized. Adopting a different approach from Tasgetiren et al. (2004a,b), this research attempts to develop an algorithm for the flowshop scheduling problem based on discrete PSO.
The proposed PSO algorithm has several features including the construction of a particle sequence and a new neighborhood structure of particles, among others.
To evaluate the performance of the discrete PSO algorithm for flowshop scheduling, we will conduct a series of experiments in this research. First, we will compare our discrete PSO algorithm with the continuous PSO algorithm of Tasgetiren et al. (2004b). The two algorithms will be used to solve the makespan minimization problem in a flowshop, studied by Tasgetiren et al. (2004b). Second, we will make a comparison between PSO and GA, another population-based metaheuristic. A recent GA algorithm of Etiler et al. (2004) is chosen and the comparative study is made based on the well-known benchmark problems given by Taillard (1993). Third, as Pinedo (2002) indicates, population-based algorithms are well suited for multi-objective scheduling problems because they are already designed to carry a population of solutions from one generation to next generation. Hence, we will select a GA algorithm, developed by Sridhar and Rajendran (1996), for a triple-objective flowshop scheduling problem for comparison. Finally, to improve our PSO algorithm we will attempt to incorporate a local search scheme into the algorithm. The best upper bounds on total flow time reported by Rajendran and Ziegler (2004) are utilized for the relative performance evaluation.
The structure of this research is organized as follows. In the next section, we introduce the background of PSO. The structure of the proposed PSO algorithm is presented in Section
3. A series of comparative experiments are conducted in Section 4 to evaluate the performance of the proposed algorithm. Finally, conclusions are given in Section 5.
2. Introduction to PSO
2.1 Background of PSO
PSO is inspired by observing the bird flocking or fish school (Kennedy and Eberhart, 1995). Scientists found that the synchrony of flocking behavior was through maintaining optimal distances between individual members and their neighbors. Thus, velocity plays the important role of adjusting each other for the optimal distance. Furthermore, scientists simulated the scenario in which birds search for food and observed their social behavior. They perceived that in order to find food the individual members determined their velocities by two factors, their own best previous experience and the best experience of all other members (Kennedy and Eberhart, 1995). This is similar to the human behavior in making decision where people consider their own best past experience and the best experience of how the other people around them have performed (Kennedy et al., 2001).
According to the above concept, Kennedy and Eberhart (1995) developed the so-called PSO for optimization of continuous nonlinear functions. They discussed the application of PSO to the training of artificial neural network weights, and also demonstrated the good performance of PSO on a benchmark function for genetic algorithms. In their paper, birds are called particles, each representing a potential solution. To find the optimal solution, each particle adjusts its flying according to its own flying experience and its companions’ flying experience. Shi and Eberhart (1998) named the former the cognition part and the latter the social part.
For the social part, Eberhart and Kennedy (1995) developed the so-called gbest and lbest models for the neighborhood structure of particles. In the gbest model, the companions’ flying experience is obtained in the population, i.e., the original PSO version. In the lbest model, the companions’ flying experience is obtained in the local neighborhood.
2.2 Discrete PSO
In the above discussion, PSO is restricted in real number space. However, many optimization problems are set in a space featuring discrete or qualitative distinctions between variables. To meet the need, Kennedy and Eberhart (1997) developed a discrete version of PSO. Discrete PSO essentially differs from the original (or continuous) PSO in two characteristics. First, the particle is composed of the binary variable. Second, the velocity must be transformed into the change of probability, which is the chance of the binary variable taking the value one.
The following notation is needed in discrete PSO. Denote by N the number of p particles in the population. Let Xit =( ,x xit1 it2,...,xiDt ), {0,1}xidt ∈ , be particle i with D bits at iteration t, where X being treated as a potential solution has a rate of change called velocity. it Denote the velocity as Vit =(v vit1, it2,...,viDt ), vidt ∈ Let R. Pit =(pit1,pit2,...,piDt ) be the best solution that particle i has obtained until iteration t , and Pgt =(ptg1,pgt2,...,pgDt ) be the best solution obtained from P in the population (gbest) or local neighborhood (lbest) at iteration it
t .
As in continuous PSO, each particle adjusts its velocity according to the cognition part and the social part. Mathematically, we have
1
1 1( ) 2 2( )
t t t t t t
id id id id gd id
v =v− +c r p −x +c r p −x (1) where c is the cognition learning factor, 1 c is the social learning factor, and 2 r and 1 r 2 are random numbers uniformly distributed in [0,1] . Eq. (1) specifies that the velocity of a particle at iteration t is determined by the previous velocity of the particle, the cognition part, and the social part. The values c r (k k k =1, 2) determine the weights of the two parts, where their sum is usually limited to 4 (Kennedy et al., 2001).
By Eq. (1), each particle moves according to its new velocity. Recall that particles are represented by binary variables. For the velocity value of each bit in a particle, Kennedy and Eberhart (1997) claim that higher value is more likely to choose 1, while lower value favors the 0 choice. Furthermore, they constrain the velocity value to the interval [0, 1] by using the following sigmoid function:
( ) 1
1 exp( )
t
id t
id
s v = v
+ − (2) where ( )s vidt denotes the probability of bit x taking 1. To avoid (idt s vidt ) approaching 0 or 1, a constant Vmax is used to limit the range of v . In practice, idt Vmax is often set at 4, i.e.,
max max
[ , ]
t
vid ∈ −V +V (Kennedy et al., 2001).
Kennedy et al. (2001) give the pseudo code of discrete PSO as follows (for maximization problem):
Loop
For i=1 to N p
If (G Xit)>G P( )it then // ( )G evaluates objective function For d =1 to D bits
pidt =xidt //p is best so far idt Next d
End if
g = //arbitrary i For j= indexes of neighbors (or population)
If G P( )jt >G P( )gt then g= // g is index of best performer in j neighborhood (or population) Next j
For d =1 to D
vidt =vidt−1+c r p1 1( idt −xidt )+c r p2 2( tgd −xidt ) vidt ∈ −[ Vmax,+Vmax]
If random number<s v( )idt then xidt+1= ; else 1 xidt+1= 0 Next d
Next i Until criterion
3. The proposed PSO algorithm
The flowshop scheduling problem can be described as follows: given n jobs and m machines. The job sequence is the same for each machine and the machine sequence is the same for each job, i.e., the permutation schedule. Each machine can process only one job at a time. The ready times of all jobs are zero. No job splitting is allowed; that is, once a job is
started, it will be worked on continuously until completed. The processing times of n jobs on each machine are given and known with certainty. The setup time and the transportation time are negligible. The objective is to find a job sequence π that minimizes the desired criterion.
It is most common to choose the makespan or the total flow time as the criterion. This is because the makespan represents the degree of the resource utilized by the system, and the total flow time represents the work-in-process inventory. Both are what the decision maker is concerned about. The scheduling problems are NP-hard in general (Garey et al., 1976).
In this research, we extend the discrete PSO of Kennedy and Eberhart (1997) to solve the flowshop scheduling problem. Clearly, the discrete particle needs to be redesigned to represent a sequence of n jobs, and the velocity has to be redefined. To move a particle to a new sequence, an efficient approach also needs to be developed. Details are given in what follows.
In the proposed PSO algorithm, a particle represents a sequence and is encoded into a
“job-to-position” scheme. There are N particles in population. A particle i at iteration t p can be denoted as Xit =(xit11,xit12,...,xinnt ), {0,1}xijk∈ , where xijkt equals 1 if job j of particle i is placed in the kth position of the sequence and 0 otherwise.
The search mechanism of DPSO iteratively explores a solution space according to the adjustment for the velocity of particle. For the flowshop problem, the velocity, called velocity trail, of particle i at iteration t is defined as Vit =(vit11,vit12,...,vinnt ),vijkt ∈R, where vijkt is the velocity value for job j of particle i placed in the kth position at iteration t . Each particle possesses a velocity trail, which can be regarded as the frequency-based memory (Onwubolu, 2002). The frequency-based memory records the number of times that a job visits a particular position. At each iteration, two kinds of frequency information, pbest and gbest, are recorded into the velocity trail, which is calculated by the following equation:
1
1 1( ) 2 2( )
t t t t t t
ijk ijk ijk ijk gjk ijk
v =wv− +c r p −x +c r p −x (3) The w in Eq. (3) is the inertia weight, c is the cognition learning factor, 1 c is the social 2 learning factor, r and 1 r are random numbers uniformly distributed in [0,1] , 2
11 12
( , ,..., ), {0,1}
t t t t t
i i i inn ijk
P = p p p p ∈ denotes the binary value of the best solution until iteration t , and Pgt =(pgt11,ptg12,...,ptgnn),pijkt ∈{0,1} denotes the associated binary value obtained from particles in the population at iteration t . A constant Vmax is often used to limit the range of vijkt , i.e., vijkt ∈ −[ Vmax,+Vmax] (Kennedy et al., 2001).
To construct a new particle i , job j chosen from the set of unscheduled jobs is placed in position k (k =1, 2,..., )n according to the following probability function until a complete sequence is constructed:
( ) ( , )
( )
t t ijk
i t
ijk j F
q j k s v
s v
∈
= ∑ (4)
The s( ) in Eq. (4) is a sigmoid function which constrains the velocity value to the interval [0,1], s v( ijkt ) represents the probability of xijkt taking the value 1, F is a set including the first f unscheduled jobs as present in the best sequence obtained so far. The parameter f is to be determined by experiments.
The outline of the proposed PSO algorithm is given as follows:
Step 1. (Initialization) Randomly generate initial particles.
Step 2. (Fitness) Evaluate the fitness of each particle in the swarm.
Step 3. (Update) Calculate the velocity trail of each particle by Eq. (3).
Step 4. (Construction) Each particle applies Eq. (4) to select the next position repeatedly until a complete sequence is constructed.
Step 5. (Termination) Stop the algorithm if the stopping criterion is satisfied; return to Step 2 otherwise.
We attempt to incorporate a local search scheme into the proposed PSO algorithm (called PSO-LS) to improve its performance. The local search scheme is a combination of IT (interchange) and IS (insertion). First, IT is implemented, with the first-improvement strategy, until no better sequence is found. After that, IS is applied to complete the local search. The movement for both forward and backward interchanges and insertions is restricted to a maximum of 12 nearest positions. The local search is combined into the PSO procedure as follows. To start with, a local search is first employed to each particle. In the loop of the DPSO algorithm, the local search is carried out once for every fixed number (the number of jobs) of iterations.
4. Computation results
Three sets of computational experiments were conducted to test the performance of the proposed PSO algorithm. The first set compares our algorithm with the continuous PSO algorithm of Tasgetiren et al. (2004b). The second sets draw a comparison with GA, another population-based metaheuristic, for flowshop scheduling with single objective. The third set examines the performance of the algorithm with the incorporation of local search technique.
All the algorithms were coded in Visual C++ and run on a Pentium IV 3.2 GHz PC.
4.1. Comparison with continuous PSO
Tasgetiren et al. (2004b) developed a continuous PSO algorithm for the makespan minimization problem in a flowshop. We will compare our PSO algorithm with their algorithm. The comparative experiments were conducted on the benchmark instances for flowshop scheduling with makespan given by Demirkol et al. (1998) in accordance with Tasgetiren et al. (2004b).
We solve the 40 benchmark instances by using each of the two PSO algorithms, where each instance is tested for 10 trials. We use the percentage relative increase (PRI) in makespan as the performance measure, i.e.,
( )
PRI A U 100
U
= − ×
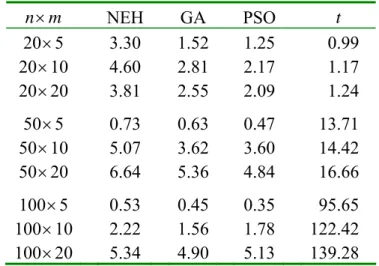
where U represents the best upper bound, A represents the makespan value generated by the respective algorithm. For each instance, the average (μPRI), standard deviation (σPRI), and minimum (min ) of PRI are computed. The results are given in Table 1, which gives PRI the mean μPRI (avg), mean σPRI (std), and mean minPRI (min), along with the number of iterations (iter.) and average computation time ( t ). It can be observed that the proposed PSO algorithm outperforms the algorithm of Tasgetiren et al. for all the combinations. For the mean μPRI (avg), there is an average difference of 1.46. With the increase in the number of jobs, the difference is slightly raised. The proposed PSO algorithm is also superior in terms of std and min.
However, it is observed in Table 1 that our algorithm requires more computation time.
Table 1 Comparison with the algorithm of Tasgetiren et al.
Algorithm of Tasgetiren et al. Proposed PSO n m× Np×iter. avg std min t Np×iter
.
avg std min t
20×15 40×1000 −6.04 1.11 −7.68 0.50 20×1000 −6.76 0.57 −7.64 1.01 20×20 −4.34 1.20 −6.15 0.61 −5.65 0.47 −6.27 1.12 30×15 60×1000 −6.73 1.27 −8.58 1.28 20×1500 −8.56 0.67 −9.61 3.02 30×20 −5.41 0.96 −6.71 1.55 −6.34 0.61 −7.33 3.25 40×15 80×1000 −7.22 1.12 −8.67 2.53 20×2000 −8.94 0.63 −10.02 6.76 40×20 −5.15 0.85 −6.56 2.99 −6.63 0.66 −7.52 7.57 50× 15 100× 1000 −6.15 0.97 −7.56 4.34 20× 2500 −7.85 0.53 −8.64 12.66 50×20 −6.75 0.96 −8.19 5.11 −8.74 0.52 −9.62 13.06 Average −5.97 1.06 −7.51 2.36 −7.43 0.58 −8.33 6.06
Table 2 Comparison with the algorithm of Tasgetiren et al.
for the same computation time
Increase no. of iterations Increase population size n m× Np×iter. avg std min t Np×iter. avg std min t 20×15 40×2500 −6.54 0.84 −7.68 1.24 100×1000 −6.47 1.09 −7.93 1.25 20×20 −4.93 0.89 −6.20 1.53 −4.92 1.20 −6.30 1.54 30×15 60×2500 −7.22 1.05 −8.75 3.16 150×1000 −7.37 1.19 −9.05 3.29 30×20 −5.67 1.01 −7.44 3.84 −5.79 0.98 −7.56 3.96 40×15 80×2500 −7.80 1.02 −9.31 6.29 200×1000 −8.06 0.99 −9.74 6.41 40×20 −5.60 1.13 −7.39 7.45 −5.61 0.88 −6.87 7.58 50×15 100×2500 −6.47 0.84 −7.70 10.84 250×1000 −6.71 0.87 −7.92 11.07 50×20 −7.23 1.10 −8.81 12.74 −7.18 0.94 −8.43 12.90 Average −6.40 1.00 −7.86 5.89 −6.44 1.03 −7.86 6.00 To be fair, we allow the number of iterations or the population size for the algorithm of Tasgetiren et al. to increase so as to achieve the same computation time as ours. The new results are given in Table 2, which shows that the proposed PSO algorithm is still superior but the difference is reduced.
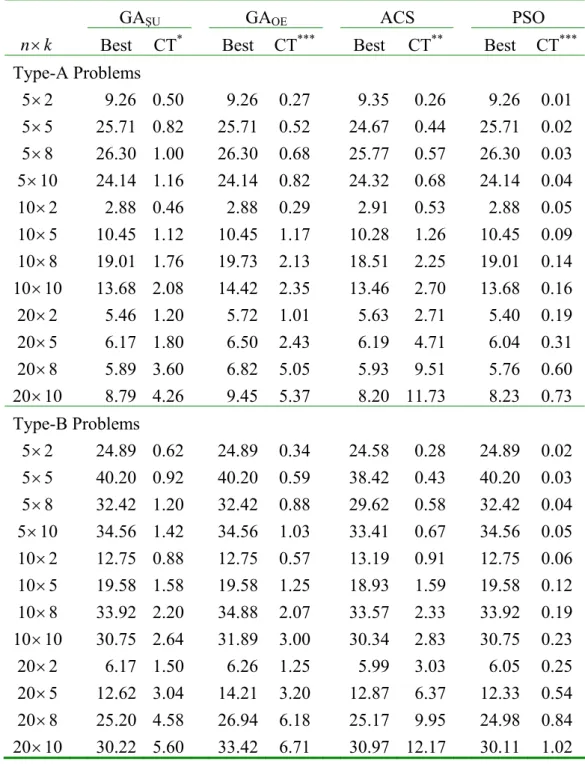
4.2. Comparison with GA for single-objective flowshop
We now present the comparative analysis between the proposed PSO algorithm and GA for flowshop scheduling with makespan criterion. A recent implementation of GA developed by Etiler et al. (2004) is selected for comparison. The experiments were conducted on the benchmark problems, given by Taillard [24], with m=5, 10, 20 and n=20, 50, 100. There were 10 instances for each problem size and 90 problem instances in all. The problem instances and their best upper bounds can be downloaded from http://ina.eivd.ch/
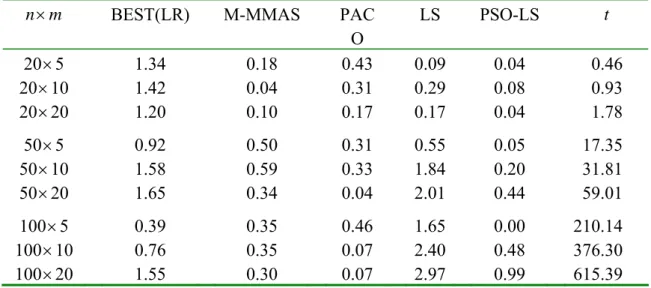
collaborateurs/etd/. The results are summarized in Table 3, which gives the mean μPRI (avg) yielded by PSO, GA, and NEH (1983). We note that NEH is a constructive heuristic and it can generate the solution in a very short time. It is observed from the table that the proposed PSO algorithm performs best for most problems, while GA is the best for two large-sized problems (100 10× and 100 20× ).
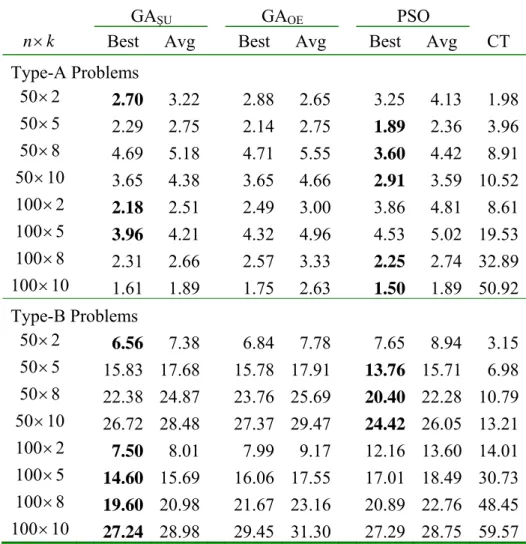
4.3. Performance of PSO with local search
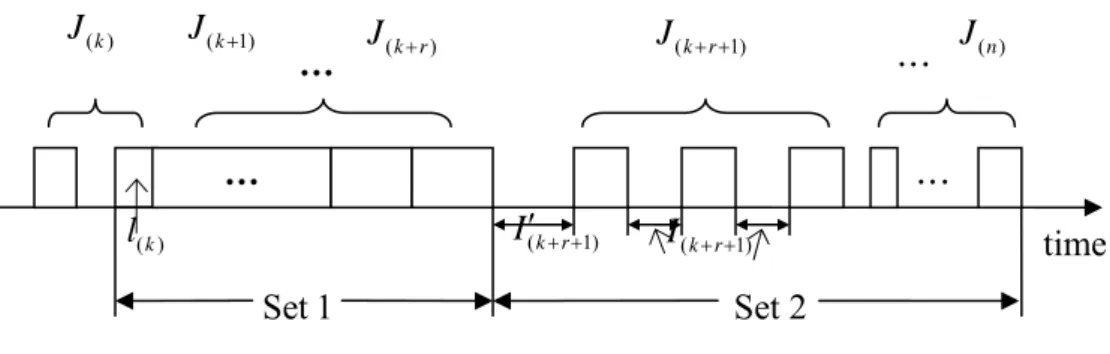
We now attempt to incorporate a local search scheme into the proposed PSO algorithm (called PSO-LS) and observe its performance for flowshop scheduling with total flow time criterion. We will compare its solutions with the best upper bounds on total flow time reported by Rajendran and Ziegler (2004), which developed two ant-colony algorithms, called M-MMAS and PACO. The comparative experiments will be carried out on the benchmark problems of Taillard (1993).
The computational results are summarized in Table 4, which gives the mean value of RPI in total flow time yielded by BEST(LR) (2001), M-MMAS, PACO, LS, PSO-LS, respectively.
It is observed that both M-MMAS and PACO outperform other algorithms for most problems.
Although our PSO-LS performs well for some problems, the results are obtained by taking more iterations and more computation times. We note that both M-MMAS and PACO are the latest versions of ant-colony algorithms, which have been applied to the scheduling problems for about ten years. Nevertheless, PSO has just been employed in solving scheduling problems for one or two years, and thus it still has potential to be developed as a good solution approach for the scheduling problem. In addition, LS in Table 4 denotes the implementation of our local search without using any other solution methods. To have a fair comparison between LS and PSO-LS, LS was run to attain the same computation time as PSO-LS. It is observed that PSO-LS is superior to LS in all the problems, which indicates that the particles are truly led to good intermediate solutions by PSO.
Table 3 Comparison with GA of Etiler et al. for single- objective flowshop
n m× NEH GA PSO t
20×5 3.30 1.52 1.25 0.99
20×10 4.60 2.81 2.17 1.17
20×20 3.81 2.55 2.09 1.24
50×5 0.73 0.63 0.47 13.71
50×10 5.07 3.62 3.60 14.42
50×20 6.64 5.36 4.84 16.66
100×5 0.53 0.45 0.35 95.65
100×10 2.22 1.56 1.78 122.42 100×20 5.34 4.90 5.13 139.28
Table 4 Relative performance of different algorithms for flowshop scheduling with total flow time
n m× BEST(LR) M-MMAS PAC
O
LS PSO-LS t
20×5 1.34 0.18 0.43 0.09 0.04 0.46
20×10 1.42 0.04 0.31 0.29 0.08 0.93
20×20 1.20 0.10 0.17 0.17 0.04 1.78
50×5 0.92 0.50 0.31 0.55 0.05 17.35
50×10 1.58 0.59 0.33 1.84 0.20 31.81
50×20 1.65 0.34 0.04 2.01 0.44 59.01
100×5 0.39 0.35 0.46 1.65 0.00 210.14
100×10 0.76 0.35 0.07 2.40 0.48 376.30
100×20 1.55 0.30 0.07 2.97 0.99 615.39
5. Conclusions and future studies
The main aim of this research is to develop a PSO algorithm for flowshop scheduling.
The proposed algorithm is extended from the discrete version of PSO, where the particle and velocity are redefined. Applying an efficient approach to the construction of sequence, the particle is moved to the new sequence. We have also designed a new neighborhood structure in the social part to further improve the algorithm.
To verify the performance of the proposed PSO algorithm, a series of experiments have been conducted in this research. First, we have demonstrated by experiments that the extended discrete PSO algorithm performs better than the extended continuous PSO algorithm of Tasgetiren et al. (2004b). In the second experiments, the proposed algorithm has been further compared with GA in solving the flowshop scheduling problem with single objective.
The experimental results have shown the superiority of the proposed algorithm over GA by allowing GA to have the same computation time. Finally, we have incorporated a local search scheme into the proposed algorithm (called PSO-LS). The computational results have shown that the local search can be really guided by PSO in our approach. We have also found that the two ant-colony algorithms--M-MMAS and PACO-- outperform PSO-LS in general.
Although PSO-LS has performed better for some problems, the results are obtained by taking more computation times. It should be noted that both M-MMAS and PACO are the latest versions of ant-colony algorithms, which have been applied to the scheduling problem for about ten years. Nevertheless, PSO has just been employed in solving scheduling problems, and thus it still has potential to be developed as a good solution approach for the scheduling problem.
It can be seen from our PSO algorithm that the velocity trail is gradually accumulated by the individual’s own experience and individual’s companions’ experience. This social behavior of sharing useful information among individuals in order to find the optimal solution is the merit of PSO over more classical metaheuristics. The simplicity is also another advantage of PSO--the main search procedure can be described in one straightforward formula (i.e., velocity updating equation) (Kennedy et al., 2001).
PSO has been applied successfully to many continuous optimization problems, but its
applications to discrete optimization problems are few. In this research, we have demonstrated that the discrete version of PSO can be applied to the flowshop scheduling problem, a class of discrete optimization problems, and the extended algorithm is very competitive. Future research may be conducted to further investigate the applications of discrete PSO to other scheduling problems. It is also worthwhile to design other versions of PSO to continue pursuing the best performance of PSO in solving flowshop scheduling problems.
References
Demirkol, E., Mehta, S. and Uzsoy, R., Benchmarks for shop scheduling problems. European Journal of Operational Research, 1998, 109, 137-141.
Eberhart, R.C. and Kennedy, J., A new optimizer using particle swarm theory, in Pceedings of the Sixth International Symposium on Micromachine and Human Science, 1995, pp.
39-43.
El-Galland, AI., El-Hawary, M.E. and Sallam, A.A., Swarming of intelligent particles for solving the nonlinear constrained optimization problem. Engineering Intelligent Systems for Electrical Engineering and Communications, 2001, 9, 155-163.
Etiler, O., Toklu, B., Atak, M. and Wilson, J., A genetic algorithm for flow shop scheduling problems. Journal of the Operational Research Society, 2004, 55, 830-835.
Garey, M.R., Johnson, D.S. and Sethi, R., The complexity of flowshop and jobshop scheduling. Mathematics of Operations Research, 1976, 1, 117-129.
Hu, X., Shi, Y. and Eberhart, R.C., Recent advances in particle swarm, in Proceedings of the IEEE Congress on Evolutionary Computation, 2004, pp. 90-97.
Kennedy, J. and Eberhart, R.C., Particle swarm optimization, in Proceedings of IEEE International Conference on Neural Networks, Piscataway, 1995, pp. 1942-1948.
Kennedy, J. and Eberhart, R.C., A discrete binary version of the particle swarm algorithm, in Proceedings of the World Multiconference on Systemics, Cybernetics and Informatics, 1997, pp. 4104-4109.
Kennedy, J., Eberhart, R.C. and Shi, Y., Swarm Intelligence, 2001 (Morgan Kaufmann: CA).
Liu, J. and Reeves, C.R., Constructive and composite heuristic solutions to the F||∑Ci scheduling problem. European Journal of Operational Research, 2001, 132, 439-452.
Nawaz, M., Enscore, E.E. and Ham, I., A heuristic algorithm for the m-machine, n-job flowshop sequencing problem. OMEGA, 1983, 11, 91-95.
Onwubolu, G.C., Emerging Optimization Techniques in Production Planning and Control, 2002 (Imperial College Press: London).
Pinedo, M., Scheduling: Theory, Algorithm, and System, 2nd ed., 2002 (Prentice-Hall:NJ).
Rajendran, C. and Ziegler, H., Ant-colony algorithms for permutation flowshop scheduling to minimize makespan/total flowtime of jobs. European Journal of Operational Research, 2004, 155, 426-438.
Shi, Y. and Eberhart, R.C., A modified particle swarm optimizer, in Proceedings of the IEEE congress on Evolutionary Computation, Piscataway, 1998, pp. 69-73.
Sridhar, J. and Rajendran, C., Scheduling in flowshop and cellular manufacturing systems with multiple objectives--a genetic algorithmic approach. Production Planning and Control, 1996, 7, 374-382.
Taillard, E., Benchmarks for basic scheduling problems. European Journal of Operational Research 1993, 64, 278-85.
Tasgetiren, M.F., Sevkli, M., Liang, Y.C. and Gencyilmaz, G., Particle swarm optimization
algorithm for single machine total weighted tardiness problem, in Proceeding of the IEEE congress on Evolutionary Computation, 2004a, pp. 1412-1419.
Tasgetiren, M.F., Liang, Y.C., Sevkli, M. and Gencyilmaz, G., Particle swarm optimization algorithm for makespan and maximum lateness minimization in permutation flowshop sequencing problem. in Proceeding of the Fourth International Symposium on Intelligent Manufacturing Systems, 2004b, pp. 431-441.
Van den Bergh, F. and Engelbrecht, A.P., Cooperative learning in neural network using particle swarm optimizers. South African Computer Journal, 2000, 26, 84-90.
Part II. Particle swarm optimization for lot-streaming flowshop scheduling problem
1. Introduction
In a traditional flowshop, each job must be processed on every machine and all jobs must follow the same machine sequence (route). One of the common restrictions made in most research studies is that a job cannot be transferred to the next machine before its processing is finished. This need not be the case in many practical situations because a job may be split into a number of smaller sublots. When a job sublot is completed, it can be immediately moved to the next machine. By splitting jobs, the idle time on successive machines can be reduced. The job splitting into sublots process is usually called “lot streaming”, which was first introduced by Reiter (1966). Some studies showed that lot streaming can significantly improve the schedule performance with respect to the makespan (Potts and Baker, 1989; Baker and Pyke, 1990). In recent years, lot streaming has received extensive attention and been applied to the flowshop scheduling problem. A complete survey can be found in Chang and Chiu (2005).
For the lot-streaming problem of a single job in a flowshop, the objective is to simply determine the optimal sublot sizes. Potts and Baker (1989) considered a flowshop with makespan criterion and indicated when it is sufficient in a single-job model to use the same sublot sizes for all machines. Trietsch and Baker (1993) reviewed the different forms of single-job lot streaming existing in the literature and generalized some important structural insights. To minimize the total flow time, Kropp and Smunt (1990) presented optimal sublot size policies and two heuristic methods for a single job in a flowshop. Bukchin et al. (2002) identified the optimal solution properties and developed a solution procedure to minimize the total flow time in a two-machine flowshop with detached setups and batch availability.
For the lot-streaming problem with n jobs (j=1,..., )n in a flowshop with makespan criterion, we need to simultaneously obtain the best job sequence and the optimal sublot allocation (sublot starting and completion times). Potts and Baker (1989) showed that it is not possible to solve the n-job problem simply by applying lot streaming individually to the single-job problem. Vickson and Alfredsson (1992) modified Johnson’s rule to obtain the optimal solutions for the two-machine and special three-machine problems with unit-size sublots. Kalir and Sarin (2001) investigated equal-size sublots and developed a bottleneck minimal idleness heuristic to generate solutions that were very close to the optimum. To the best of our knowledge, the n-job model in a flowshop with total flow time criterion was not considered in the literature.
With the advent of just-in-time (JIT), the criterion involving both earliness and tardiness penalties has received significant attention. Yoon and Ventura (2002a) examined lot-streaming flowshop scheduling with respect to earliness and tardiness penalties. For a given job sequence, they presented linear programming (LP) models to obtain the optimal sublot allocation for cases where the buffers between successive machines have limited or infinite capacities and the sublots have equal sizes or are consistent. For the case with equal-size sublot and infinite capacity buffer, sixteen pairwise interchange methods obtained by combining four rules to generate initial sequences with four neighborhood search mechanisms are considered. The experimental results showed that the best performance was obtained using a non-pairwise interchange mechanism and the smallest overall slack time rule to generate the initial sequence. Later, Yoon and Ventura (2002b) provided a genetic algorithm (GA) that incorporated the LP and pairwise interchange method for the lot-streaming flowshop scheduling with equal-size sublot and infinite capacity buffer. Their
computational results showed that the proposed GA, called the hybrid genetic algorithm (HGA), works well for this type of problem.
Particle swarm optimization (PSO), proposed by Kennedy and Eberhart (1995), is a novel metaheuristic. To address various types of optimization problems, both the continuous and discrete versions of PSO have been developed (Kennedy and Eberhart, 1995; Kennedy and Eberhart, 1997). Since then, PSO has been successfully applied to many continuous and discrete optimization problems (Kennedy and Eberhart, 1995; Van den Bergh and Engelbrecht, 2002; Clerc, 2004; Allahverdi and Al-Anzi, 2006).
The literature on PSO applied to the scheduling problem is limited. Tasgetiren et al.
(2004a, 2004b, 2007) proposed PSO algorithms extended from the continuous version (Kennedy and Eberhart, 1995). They used the smallest position value (SPV) rule, borrowed from the random key representation of GA, to convert the continuous position values into a discrete job sequence. Their PSO algorithms with local search were effectively applied to solve single machine and flowshop scheduling problems. On the other hand, two discrete PSO (DPSO) algorithms exist in the literature for solving flowshop scheduling problems.
Rameshkumar et al. (2005) proposed a DPSO algorithm where new operations based on job transpositions are provided to compute particle velocity and update particle positions. Liao et al. (2007) also developed a DPSO algorithm based on the discrete PSO version (Kennedy and Eberhart, 1997). In their DPSO algorithm, the particle and the velocity are redefined and an efficient approach is developed to move a particle to the new job sequence.
In this research, we address the lot-streaming flowshop scheduling problem with the objective of minimizing the total weighted earliness and tardiness. As in Yoon and Ventura (2002b), we assume equal-size sublots and infinite capacity buffers. Trietsch and Baker (1993) reviewed three types of sublots including equal-size, consistent and variable sublots. They indicated that it may be more attractive to use equal-size sublots in some applications, such as an application described by Kalir and Sarin (2001) for scheduling surface mount technology (SMT) flow line.
The problem solving process is separated into two phases. In the first phase, we provide a so-called net benefit of movement (NBM) algorithm to determine the optimal sublot allocation for a given sequence. The NBM algorithm is much more efficient than the LP model by Yoon and Ventura (2002b). In the second phase, we propose a discrete PSO (DPSO) algorithm to find the best sequence. The proposed DPSO will be compared with the HGA of Yoon and Ventura (2002b).
2. Lot streaming in a flowshop
In this section, we formally define the addressed problem. The following notation is used throughout the part II of research:
n number of jobs m number of machines J j job j (j=1, 2,..., )n
π a processing sequence of jobs
( )k
J job placed in the kth position in a sequence s j number of sublots for job j
t ij processing time of job j on machine i lt ij sublot processing time of job j on machine i
d j due date of job j
C j completion time of job j
T j tardiness of job j , max(0,Tj = Cj−dj) E j earliness of job j , Ej =max(0,dj−Cj) αj earliness penalty of job j
βj tardiness penalty of job j
( )k
l last sublot of J( )k on the last machine
( )k
e starting time of l( )k
( )k
UNB net benefit by moving l( )k one time unit
The problem considered in this research can be stated as follows. There is a flowshop with n jobs and m machines. Each job must be processed on each one of the m machines in series. Job j can be split into s equal sublots where j s is the same for all j machines. This type of sublots is called equal-size sublots in the lot streaming realm. Both the setup time and the sublot transportation time are ignored. The objective is to minimize the total weighted earliness and tardiness, i.e.,
1
min ( ) n ( j j j j)
j
f π α E β T
= ∑= + (1)
The problem can be divided into two subproblems. The first subproblem is to find the optimal starting and completion times for each sublot on each machine for a given sequence. The second one is to search for the best sequence with minimum total weighted earliness and tardiness. The two subproblems are clearly dependent, and hence it is rather difficult to determine the optimal schedule for the problem.
3. Optimal sublot allocation for a given sequence
As a subproblem for the considered problem, we need to determine the optimal starting and completion times of each sublot on each machine for a given sequence. Yoon and Ventura (2002b) presented an LP model for this purpose. Due to a large computational effort for the LP model, which is used in their GA, only small-size problems with at most 15 jobs are solved. In this section, we develop an efficient algorithm which can serve the same purpose but requires much less computation time. The developed algorithm can be easily incorporated into any metaheuristic and thus large-size problems can be solved.
The proposed algorithm uses the concept of net benefit of movement (NBM) to determine whether a considered sublot should be moved. At the beginning of the algorithm, each sublot is started as soon as possible in the flowshop for a given sequence. Thus, a backward movement is not allowed, and we need only to consider a forward movement to minimize the objective function.
The job completion time is determined using the last sublot for the job on the last machine. When the optimal starting and completion times for all of the last sublots on the last machine are obtained, the optimal schedule can be generated by delaying processing other sublots on each machine as much as possible without affecting the starting times for these last sublots. Based on the above discussion, we can focus our attention on scheduling the last sublots for jobs on the last machine (l( )k ,k=1, 2,...,n).
The basic idea of the NBM algorithm can be briefly explained as follows. The algorithm