行政院國家科學委員會專題研究計畫 成果報告
資料探勘之敏感資料保護技術研發 研究成果報告(精簡版)
計 畫 類 別 : 個別型
計 畫 編 號 : NSC 97-2221-E-011-092-
執 行 期 間 : 97 年 08 月 01 日至 98 年 07 月 31 日 執 行 單 位 : 國立臺灣科技大學資訊工程系
計 畫 主 持 人 : 戴碧如
計畫參與人員: 碩士班研究生-兼任助理人員:林柏佑 碩士班研究生-兼任助理人員:姜弘霖 碩士班研究生-兼任助理人員:林楊澤 碩士班研究生-兼任助理人員:鍾至衡 碩士班研究生-兼任助理人員:姜禮翔
報 告 附 件 : 出席國際會議研究心得報告及發表論文
處 理 方 式 : 本計畫涉及專利或其他智慧財產權,2 年後可公開查詢
中 華 民 國 98 年 10 月 28 日
行政院國家科學委員會補助專題研究計畫 ■ 成 果 報 告
□期中進度報告 資料探勘之敏感資料保護技術研發
計畫類別:■ 個別型計畫 □ 整合型計畫 計畫編號:NSC 97-2221-E-011-092-
執行期間: 97 年 8 月 1 日至 98 年 7 月 31 日
計畫主持人:戴碧如 共同主持人:
計畫參與人員: 林柏佑、姜弘霖、林楊澤、姜禮翔、鍾至衡
成果報告類型(依經費核定清單規定繳交):■精簡報告 □完整報告
本成果報告包括以下應繳交之附件:
□赴國外出差或研習心得報告一份
□赴大陸地區出差或研習心得報告一份
■出席國際學術會議心得報告及發表之論文各一份
□國際合作研究計畫國外研究報告書一份
處理方式:除產學合作研究計畫、提升產業技術及人才培育研究計畫、列管計畫 及下列情形者外,得立即公開查詢
■涉及專利或其他智慧財產權,□一年□二年後可公開查詢
執行單位:
中 華 民 國 98 年 7 月 31 日
I
(一)計畫中文摘要
隨著電腦與網路技術的日新月異及大量普及,人們產生與獲取資料越來越快 速便捷,因而對於分析處理大量資料的技術更加重視,以至帶動了各式資料探勘 相關技術的研究發展,其中頻繁項目集的探勘可以應用在很多不同的領域上,也 是常常被使用於交易資料庫分析的技術。但是隨著技術日漸進步,所帶來隱私的 議題也越來越受到關注。過去保護交易資料庫內敏感資訊的技術,都是以單一的 最小支持度或是隱私係數來作為保護的基準,並且嘗試取得「機密資訊保護」和
「非機密資訊保存」之間的平衡點。但是在實際生活中,不同的項目集可能需要 運用不同的最小支持度去判斷他是否為頻繁的,而在靈活的最小支持度設定下,
過去針對單一門檻值下頻繁項目集特性而設計的方法都不再適用,因此在本計畫 中,我們加入多門檻值的設定,考量在多門檻值下頻繁項目集的特性,提出一個 新的淨除演算法來保護機密的資訊,使得對敏感資訊的保護能更切合於它本身的 特性,並藉此達到在修改過後的資料庫內保留更多的非機密資訊,亦即降低資訊 遺失的程度。最後會對所提出之方法進行效率、擴充性和對資料庫影響最小化等 各方面作最佳化的研究。
(二) 計畫英文摘要
Frequent pattern mining is one of popular research topics in the data mining area.
With the advance of these techniques, privacy issues attract more and more attentions in recent years. In this field, previous works hide sensitive information based on a uniform support threshold or using a privacy disclosure parameter. The challenge is how to achieve a balance between the information preservation and the sensitivity protection. However, in practical applications, we probably need to apply different support thresholds on different itemsets to reflect their significance respectively. In this project, we design new hiding strategies to hide sensitive patterns with multiple support thresholds. With flexible user-defined multiple support thresholds, the hiding result is expected to be closer to user requirements and real applications. Besides, after hiding sensitive patterns and rules, the revised dataset is expected to preserve most information of the original dataset. Furthermore, in this project, we also try to extend our method to optimize the efficiency, the scalability, and the preservation of information while hiding sensitive patterns.
II
目錄
目錄 ... II
一、前言 ... 1
二、研究目的 ... 1
三、文獻探討 ... 2
四、研究方法 ... 3
淨除演算法 ... 3
敏感項目集表 ... 4
樣式表 ... 4
選擇策略及更新步驟 ... 5
五、結果與討論 ... 6
參考文獻 ... 8
計畫成果自評 ... 10
附件一、已報表之國際會議論文:
Ya-Ping Kuo, Pai-Yu Lin and Bi-Ru Dai, "Hiding Frequent Patterns under Multiple Sensitive Thresholds," Proceedings of the 19th International Conference on
Database and Expert Systems Applications (DEXA 2008), Turin, Italy, September 1-5, 2008. (Lecture Notes in Computer Science 5181 Springer 2008, ISBN
978-3-540-85653-5) (EI)
附件二、可供推廣之研發成果資料表
1
一、前言
近年來隨著網際網路的普及以及資料庫技術的純熟,資料的產生與收集都更 加便利,除了組織和公司團體都各自擁有了大量的資料累積,個人用戶也成為各 式資料來源的貢獻者,造就了資料量快速且大量成長的現象,但是這一堆未經過 處理的資料通常不適合直接地運用於一些商業決策或醫學、股票、環境等應用上 面,因此,資料擁有者對於進一步之資料分析處理技術的需求日漸增加,也使得 資料探勘(data mining)相關技術更加受到重視[1]。過去有許多學者對資料探勘下 了很多不同的定義,又可以把它稱為資料庫的知識挖掘,簡稱為 KDD (Knowledge Discovery in Databases)。一般而言,資料探勘指得是從大量資料當中萃取出合適 的資料,進行資料處理、挖掘,以找出專家未知的或是有趣的、有用的、潛在的 資訊,作為決策的參考依據。
隨著資料探勘技術日漸提昇,我們可以從雜亂無章的資料當中探索出更多有 用的資訊,但是同時也面臨到一個值得重視的問題⎯⎯隱私(Privacy)。從資料庫 當中分析萃取出來的資訊有時候可能是一些公司組織的機密,或是牽涉到個人的 隱私權,所以在探尋隱含的有用資訊之際,同時也要能確保不會洩漏出機密或敏 感的資訊。然而,保護機密資訊的方式,若只是單純地將機密資訊從資料庫裡刪 除,再釋放出修改過的資料庫,很有可能經由推論或探勘的方法,從非機密的資 訊中推演得知機密資訊,因此,在設計資料保護機制時,不但要考慮到機密的資 訊必須避免經由資料探勘的技術被獲取,還要更進一步考慮,從所有的非機密資 訊當中應該都不可以推得機密的資訊。除此之外,資料探勘分析的目的是希望取 得有用的資訊來幫助制定決策或是其他運用方面,所以在保護機密資訊的同時,
也必須注意到原本資訊保存的最大化,並且盡量不要產生額外的非真實資訊,以 確保原本資料庫本身的價值。
二、研究目的
計劃中,我們針對從交易資料庫中隱藏敏感項目集的問題上,在[2]中已經 完整的解釋隱藏敏感項目集的動機及重要性。正如以下所述,假設大部份的顧客 買牛奶通常也會買 Green Paper 這家造紙公司的紙。如果另一家造紙公司 Dedtrees Paper 從一個超級市場的資料庫中探勘出這樣的一個法則,然後發布一個促銷活 動「如果你買 Dedtrees Paper 的紙,再買牛奶,你的牛奶將會得到 50 元的折扣」
接著 Green Paper 造紙公司的銷售量就會因為這樣的一個商業策略而降低。出於 這個原因 Green Paper 造紙公司不會想要提供較低的價格給超級市場。另一方 面,Dedtrees Paper 造紙公司已經達到他的目的也再也不會有意願提供較低的價 格給超級市場。那超級市場就會遭遇到相當嚴重的損失,因此在公佈資料庫之前 必須先對敏感資料做淨除動作。
2
之前大部份的淨除演算法並沒有考慮以下的問題,而是只使用一個使用者自 定的最小支持度門檻值。首先,對每個不同的項目集,使用單一支持度門檻值在 實際的應用中並不合理。比如高價格產品或是最近新產品的支持度,像電腦的支 持度本身就會比水這類一般及普遍的產品低。但這樣並不代表說後者較前者來得 有重要性。如果我們將所有敏感項目集的支持度都降到同一個最小支持度門檻值 下,可能會導致一些項目集過度的保護或一些項目集沒有做到充分的保護。此 外,若競爭對象探勘時所使用的支持度門檻值小於我們原先在隱藏所使用的支持 度門檻值,那公佈出去的資料庫將會洩露所有的敏感資訊。相反地,如果隱藏資 料庫時所使用的門檻值太小,那公佈的資料庫將有可能遺失太多的資訊,而變成 沒有利用價值,使得接下來的探勘工作無法運行。此外,若一些較一般的項目及 特殊的項目出現在資料庫中的頻率很近似的話,此時競爭對象就會推測有一些敏 感的資訊已被隱藏。
因此,基於隱私保護及資訊保留的考量下,給予每個項目集一個特定的門檻 值 是 很 重 要 的 。 由 於 上 述 原 因 , 在 [3] 中 提 出 了 使 用 透 露 門 檻 值 (Disclosure thresholds)的演算法。他是根據敏感項目集在資料庫中的分佈來降低其支持度。
也使用一個透露門檻值直接控制隱私和資訊保留之間的平衡。 然而,此方法沒 有考慮不同的敏感項目集在不同的應用上的特性,或是不同使用者的個人需求。
而完全是依賴資料庫的分佈來對非高頻項目集及高頻項目集做淨除動作。
在本計畫中,我們加入多門檻值的設定,考量在多門檻值下頻繁項目集的特 性,提出一個新的淨除演算法來保護機密的資訊,使得對敏感資訊的保護能更切 合於它本身的特性,並藉此達到在修改過後的資料庫內保留更多的非機密資訊,
亦即降低資訊遺失的程度。
三、文獻探討
隱藏高頻項目集和關聯法則一開始是由[4]所提出,作者證明了要找到一個 最佳的淨除方法是一個 NP-hard 的問題,同時也提出了一個啟發式的方法藉由刪 除資料庫中交易資料的項目來達到隱藏敏感高頻項目集。近年來,越來越多的研 究學者開始注意到隱私的議題。後來的方法大致可分為以下兩種策略:資料修改 (data modification)及資料重建(data reconstruction)。
資料修改:這一群演算法的概念是變動原資料庫使得敏感資訊沒辦法在新資 料庫中被探勘出來。這些演算法選擇部份項目成為移除項目(victim item),移除 或是插入它們到一些交易資料中[5]。在[3]中,作者發表了一個新的方法,此方 法使用了透露參數(disclosure parameter)來取代支持度門檻值直接控制隱私要求 及資訊保留之間的平衡。以透露參數作為基礎,每個敏感項目集的支持度都被降 低相同的比例。IGA 演算法[4]一開始先將敏感項目集做分群,接著基於減低對 資料庫副作用的考量來選擇移除項目,在[6]這個論文中,提出 border-based 的概 念來有效率的評估任何修改對資料庫的影響。藉由這種為了降低副作用的貪婪選
3
擇方式,使得資料庫的品質及相關聯的高頻項目集能夠被完好的維護。在[4]中,
作者提出一個演算法可以用來抵擋向前推論攻擊(forward inference attack)。藉由 乘上原資料庫矩陣,然後一起作一次的淨除。這個方法擁有更好的效能。最近的 研究大部份都是注重在最小化對資料庫的副作用[7][8]。這些方法分別減少了對 交易資料及項目的修改來限制對資料庫所產生的副作用。
資料重建:這一類演算法的動機在於先前基於資料庫作修改的方法花太多時 間在掃描資料庫上而且也不能直接控制公佈資料的資訊。因此資料重建這一類演 算法,使用基於資訊考量的方法,直接重建包含資料庫擁有者所要保留的資訊的 新資料庫,再將其公佈出去。一般的情,在原資料庫中的高頻項目集是被視為一 種知識。反向高頻項目集探勘(inverse frequent set mining)問題在[9]中第一次被提 出,也被證明為是一個 NP-hard 的問題。因而,大部份的學者應用這樣的概念到 隱私的議題和演算法的基準[10]。在[11]中,作者提出一個 constraint inverse itemset lattice mining 技術來自動產生簡單的、可公佈的且可分享的資料集。他指 出如果存在一個可行的支持度集合,他們可以藉由一對一的對映產生包含一些高 頻項目集的新資料庫。在[12]中,作者提出 FP-tree-based 的方法用來做 inverse frequent set 探勘。且新產生的資料庫完全滿足全部所給的限制。然而,此方法沒 有提供完整和良好的隱藏。他只有控制非敏感項目集的支持度數量跟原資料庫中 的一模一樣,但出現頻率並沒有滿足原來的限制。針對此議題,現在最重要的問 題是要如何找出可行的支持度集並且對映到適合的資料集。
此外,多重支持度門檻值的概念在[13]第一次被提出。由於觀察到的現象,
發現不同項目集的支持度在實際情況下不會完全相同。我們使用一些已有的多重 支持度門檻值的規範來當作衡量我們演算法的基準,會在下一章介紹。
四、研究方法
淨除演算法
圖表 1:淨除演算法架構
我們的淨除演算法架構如圖表 1 所示,主要包含了三個元件:敏感項目集表
4
(sensitive pattern table)、樣式表(template table)、淨除動作表(action table)。第一、
先藉由掃描資料庫以取得敏感項目集的支持度(support)以及其敏感的交易資 料。接著再依據最小門檻值建立一個敏感項目表來儲存每一個敏感項目集所需降 低的支持度數量。第二、我們對每一個敏感項目集產生相對應的樣式表,每個樣 式表包含所有可能被選擇用來隱藏相對應敏感項目集的移除項目(victim item)。
再依減少對資料庫產生副作用的隱藏策略從樣式表中選擇一個樣式出來。接著找 出對應的交易資料,其交易資料的數量足夠用來將此樣式所含蓋的敏感項目集給 刪除,將此產生出的記錄放入淨除動作表。然後所有元件的資訊都會更新,以上 兩個步驟選擇以及更新會一直重覆直到所有的敏感項目集都被隱藏起來。最後我 們依據淨除動作表找出相對應的交易資料及移除其指定的移除項目來完成淨 除,整個淨除演算法只需要掃描資料庫兩次。
敏感項目集表
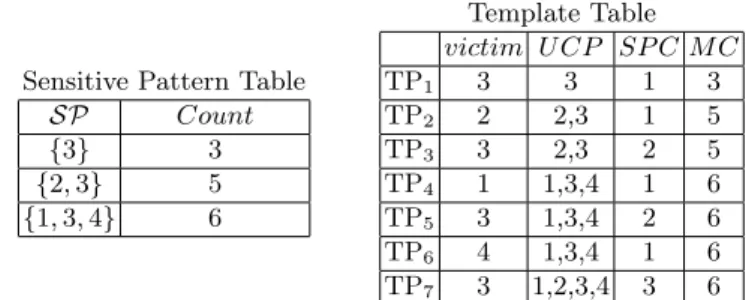
(a) 敏感項目集表 (b) 樣式表 表格 1:敏感項目集表及所對應的樣式表
在敏感項目集表中包含了兩個欄位,分別是敏感項目集(SP)和其所需的移除 數量(Count),如表格 1(a)所示,敏感項目集的移除數量也表示了要讓該項目集成 為非頻繁項目集所需降低的最少支持度數量。
樣式表
一開始的樣式表是根據敏感項目集表所建立的,如表格 1 所描述的。一個樣 式是以下列的形式所表示的:< TPID, victim, UCP, SPC, MC >,其中 TPID 是樣 式的識別子(TemPlate unique IDentifier),而 victim 是經過考慮要從相對應的交易 資料中選定一個移除項目。對於一個長度為 k 的敏感項目集,會有 k 個項目能夠 成為移除項目,因此我們可以對不同的項目產生 k 個樣式。以{1, 3, 4}為例,能 夠產生出分別對應項目{1},{3},{4}的樣式。樣式中的 UCP 必須包含在所選擇 用來刪除的交易資料中。同時也是所有能夠被此樣式淨除的敏感項目集的聯集。
這就意謂著當我們選出一個包含此 UCP 的敏感交易資料,且在此交易資料中刪 除移除項目,而每個所對應的敏感項目集支持度將會下降。舉例來說,在表格 1(b)中,TP1是刪除有包含{3}的交易資料中的{3}來隱藏{3}這個敏感項目集。TP3
5
是刪除有包含{2, 3}的交易資料中的{3}來隱藏{2, 3}這個敏感項目集。SPC 是代 表可被此樣式所淨除的敏感項目集數量。舉例來說,像在表格 1(b)中的 TP3可以 同時隱藏兩個敏感項目集{2, 3}、{3},所以此樣式的 SPC 為 2。接著 MC 代表 當要隱藏此樣式所對應的敏感項目集時,所需要降低支持度的最少數量。因此,
樣式的 MC 為所有此樣式所對應的敏感項目集中的最大修改數量。例如在表格 1(b)中,TP3的 MC 為 max{3, 5}=5。
不只是以上所介紹的樣式,另外我們藉由產生接合樣式(joint template)來包 含更多的敏感項目集。若任兩個樣式,它們擁有相同的移除項目且各自的 UCP 沒有互相包含的話,我們可以將其接合起來成為一個新的樣式。而此新樣式的 SPC 及 MC 則會依據對應的敏感項目集計算得出。如表格 1 所示,TP3和 TP5可 以結合產生 TP7,其 UCP 為{1, 2, 3 ,4}是{2, 3}與{1, 3, 4}的聯集。而 TP7的 SPC 將會是 3,因為從包含{1, 2, 3, 4}的交易資料中移除{3}這個項目可以同時讓 3 個 敏感項目集的支持度下降,分別是{3}、{2, 3}及{1, 3, 4}。而 TP7 的 MC 為 max{3, 5, 6} = 6。因此,TP7成為比 TP3、TP5還要好的選擇,因為 TP7的 SPC 大於 TP3 和 TP5能夠同時隱藏更多的敏感項目集。
選擇策略及更新步驟
我們隱藏策略的本質為「使副作用達到最小」,我們在每一回合選擇 SPC 為 最大的樣式,如果有超過一個以上的樣式擁有相同的 SPC,就會去選擇擁有最小 MC 的樣式。若仍然還有超過一個以上有相同的 MC,那就選擇一個其移除項目 的支持度為所有資料庫中最小的樣式,最後若上述的所有情況無法解決的話就使 用亂數的機制來挑選。在選完樣式之後,藉由一開始所建立的交易資料索引找出 所有相對應的敏感交易資料,如果找出的敏感交易資料數量大於所選樣式 MC,
就選擇前 MC 個較短的交易資料移至淨除動作表中進行淨除。反之所有相對應的 交易資料將會被淨除。接著根據所淨除的交易資料數量,更新 Count,MC 會被 重新計算。若有些敏感項目集被此樣式給隱藏起來,則 SPC 和 UCP 也會改變。
當一個樣式的 SPC 變成零的時候,我們從樣式表裡移除此樣式。
為了要提升演算法的效能,我們提出修改邊緣項目集(border itemests)的概 念,以減少不必要的工作。由於頻繁項目集的單調特性,隱藏一個敏感項目集也 會同時隱藏其擴展項目集(superset itemsets),因此在淨除過程中,我們僅僅只需 刪除沒有敏感子項目集(subset itemsets)的敏感項目集。這樣的一個項目集也被稱 為邊緣項目集。例如,如果{1, 2, 3}、{1, 3}和{1}為三個敏感項目集,其中{1}就 為邊緣項目集。只要敏感項目集中的邊緣項目集都被隱藏,我們就能保護所有的 敏感項目集的資訊。然而這樣的技術不能應用在隱藏敏感項目集在多重最小門檻 值的情況下,當一個敏感項目集的擴展集所設定的門檻值小於他自己的門檻值的 話,只隱藏邊緣項目集並不能保證能保護所有的敏感頻繁項目集。以上面的例子 來看,如果最小門檻值對應到{1, 2, 3}、{1, 3}和{1},分別為 2、4 和 3。那麼{1}
6
和{1, 2, 3}就是需要修改的邊緣項目集。若這些邊緣項目集被隱藏,那麼所有敏 感的資訊都能被保護。
五、結果與討論
在這一部份,我們要展示我們所提出淨除演算法的效能(performance)以及可 擴展性(scalability)。我們使用支持度限制[14](support constraint)以及最大限制 [15](maximum constraint)來給定每一個敏感項目集不同的最小門檻值。除此之 外,為了要能夠與項目群集演算法[16](Item Grouping Algorithm, IGA)做比較,我 們讓演算法與 IGA 使用相同的透露門檻值(Disclosure thresholds)來呈現在單一最 小門檻值狀況下的效能。這些限制如同以下說明:
透露門檻值:這是設計用來讓我們的方法能與 IGA 在單一支持度門檻值下 比較。因此,最小門檻值設定如下方所示需與 IGA 相同:
α
×
=s ( ) )
(X up X st
α的設定相同於 IGA 所使用的透露門檻值。
支持度限制:與[14]所提出的相類似,我們一開始先將資料庫裡的支持度範 圍分割為若干區間,每一個區間有相同的數量的項目,以便所有的區間 Bi在第 i 個區間都能包含所有的項目。接著,在這個架構的支持度限制是由所有區間的可 能組合而產生。支持度限制的支持度門檻值SCk(B1,...Br)≤θk如以下所定義:
} 1 ), ( ...
) (
{rk 1 S Bi S Br min × × ×
= −
θ
其中S(Bi)代表在B 中項目支持度最小的數量,而i r 是一個大於 1 的正整數。r 值 較大的話可以用來降低S(Bi)×...×S(Br)減少的速度,我們可以改變 r 值來產生不 同的支持度限制。
最大限制:我們使用與[17]相同的公式,來給定每個項目不同的支持度門檻 值。
⎩⎨
⎧ × × >
= otherwise.
, )
( if ) ) (
( minsup
minsup X
sup X
X sup
st ρ ρ
其中 0 ≦ρ≦ 1,且 sup(i)表示在資料集中此項目 i 的支持度,若ρ設為零,所 有項目的最小支持度門檻值皆相同。那這一情況就與單一最小門檻值的情況一 樣。
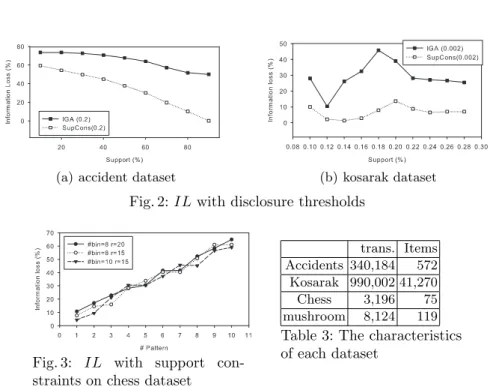
我們使用兩個不同特性的資料集分別是 accidents [18]和 kosarak,並且使用 透露門檻值的方式與 IGA 比較我們的方法。另一方面,考慮到探勘多重門檻項 目集的時間復雜度,不失其一般性,兩個較小的實際資料集 chess 和 mushroom [19]
也用來衡量我們的隱藏方法。
7
我們採用兩種衡量指標,資訊遺失(information loss, IL)和隱藏失敗(hiding failure)來評估我們刪除策略的效能。資訊遺失(IL)是指在淨除過程中被隱藏的非 敏感項目集所占的百分比,如同下列式子所示:
|)
|
| (|
|))
|
| (|
|)
|
| ((|
s
s s
P FP
P P F P
IL FP
−
− ′
− ′
= −
其中|FP 為在原資料庫 D 中頻繁項目集的數量,| |P 為在原資料庫 D 中敏感項s | 目集的數量。另外|F ′ 和P | |P′ 分別為在新資料庫 Ds| ’中頻繁項目集的數量以及在 新資料庫 D’中敏感項目集的數量。隱藏失敗(HF)是仍然在新資料庫 D’出現的敏 感項目集所占的百分比,以下列方式表示:
|
|
|
|
s s
P HF P′
=
在單一最小門檻值的情況下,P 包含任何一個敏感項目集的擴展集。然而在多重s 最小門檻值的情況下,一個頻繁項目的子項目集不一定是高頻的。
首先,我們在單一最小門檻值的情況下,同時評估我們的演算法以及 IGA 效能。我們分別設定透露門檻值為 0.2 及 0.002 來隱藏在 accidents 及 kosarak 資 料集中的敏感項目集。敏感項目集是由高頻項目集中隨機挑選出來,挑選出來的 項目集其支持度分別大於 20%及 0.2%,隨後我們對新的資料庫分別以 10% 到 90%及 0.1% 到 0.28%的支持度門檻值探勘高頻項目集。資訊遺失的結果如圖表 2 所示。資訊遺失的趨勢與測試的資料集特性有很高的關聯性。我們可以觀察到 我們的方法有達到較好的資料保護。大部份隱藏失敗都為零,除了將 accidents 的最小支持度門檻值設在 10%時,IGA 的隱藏失敗為 0.0057%而我們的方法則為 0.325%。
圖表 2:資訊遺失與透露門檻值
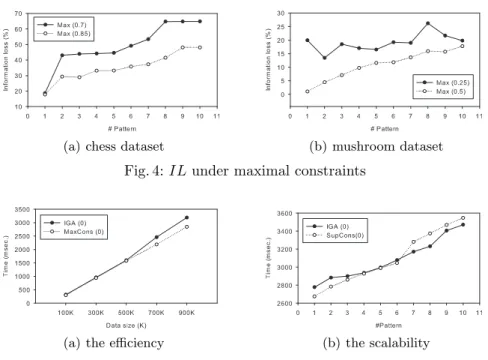
我們在相同的資料庫以及相同的敏感項目集下與 IGA 比較執行時間以及可 擴展性,。且兩個方法的透露門檻值參數α都設為零,當此參數設為零時,代表 要完全隱藏。我們隱藏 6 個長度為 2~6 且彼此互斥的敏感項目集,同時也改變 資料集的大小由 10 萬筆資料到 90 萬筆。結果如圖表 3(a)所示。接著我們再改變 所隱藏的敏感項目集數量由 1 個敏感項目集到 10 個敏感項目集,項目集都是隨 機挑選的。其結果如果圖表 3(b)所示。我們可以觀察到執行時間與資料庫的資料 筆數以及敏感項目集數量呈線性關系。可得知我們的方法如同 IGA 達到了很好 的可擴展性。並且實現了更好的資訊保護及提供了能夠隱藏敏感項目集在多重最
8
小門檻值下的能力。資訊遺失的結果如圖表 4(a)及 4(b)所示,由於從 chess 資料 集中所選出的敏感項目集其支持度較高,使得要隱藏一個項目集需要有更多的項 目被刪除,導致資訊遺失量變高,所有的隱藏失敗皆為零。我們可以觀察到資訊 遺失會隨著最大限制 r 值的下降以及所需隱藏敏感項目集數量的增加而上升。
圖表 3:在 kosarak 資料集下與 IGA 做比較
圖表 4:資訊遺失與最大限制
我們介紹了隱藏高頻項目集在多重最小門檻值下的概念,提出新的,在多重 最小門檻值的情況下的隱藏演算法,此隱藏演算法也可適用在實際的應用中。我 們按照過去的經驗藉由一連串實驗來驗證我們方法的效能、可擴展性。我們的實 驗結果展現出我們的方法是有效的且相較於 IGA 在單一支持度門檻值下有明顯 的改進。此外我們能在多重最小門檻值下隱藏資料庫的敏感資訊。
參考文獻
[1] Jiawei Han and Micheline Kamber. Data Mining: Concepts and Techniques, 2nd edition, Morgan Kaufmann, 2006
[2] Clifton, C., Marks, D.: Security and Privacy Implication of Data Mining. In: ACM SIGMOD Workshop on Data Mining and Knowledge Discovery, pp. 15–19 (1996)
[3] Oliveira, S.R.M., Za´ıane, O.R.: A Unified Framework for Protecting Sensitive Association Rules in Business Collaboration. Int. J. of Business Intelligence and Data Mining 1(3), 247–287 (2006)
[4] Atallah, M., Bertino, E., Elmagarmid, A., Ibrahim, M., Verykios, V.: Disclosure Limitation of Sensitive Rules. In: Proc. of the IEEE Knowledge and Data
9
Exchange Workshop, pp. 45–52 (1999)
[5] Verykios, V.S., Elmagarmid, A., Bertino, E., Saygin, Y., Dasseni, E.: Association Rule Hiding. IEEE Transactions on Knowledge and Data Engineering 16(4), 434–447 (2004)
[6] Xingzhi, S., Yu, P.S.: A Border-Based Approach for Hiding Sensitive Frequent Itemsets. In: Proc. of 5th IEEE Int. Conf. on Data Mining, pp. 426–433 (2005) [7] Wu, Y.H., Chiang, C.M., Chen, A.L.P.: Hiding Sensitive Association Rules with
Limited Side Effects. IEEE Transactions on Knowledge and Data Engineering 19(1), 29–42 (2007)
[8]Gkoulalas-Divanis, A., Verykios, V.S.: An Integer Programming Approach for Frequent Itemset Hiding. In: Proc. of Int. Conf. on Information and Knowledge Management, pp. 748–757 (2006)
[9] Mielikainen, T.: On Inverse Frequent Set Mining. Proc. of the 2nd IEEE ICDM Workshop on Privacy Preserving Data Mining (2003)
[10] Wu, X., Wu, Y., Wang, Y., Li, Y.: Privacy-Aware Market Basket Data Set Generation: A Feasible Approach for Inverse Frequent Set Mining. Proc. 5th SIAM Int. Conf. on Data Mining (2005)
[11] Chen, X., Orlowska, M., Li, X.: A New Framework of Privacy Preserving Data Sharing. Proc. of IEEE 4th Int. Workshop on Privacy and Security Aspects of Data Mining (2004) 47–56
[12]Guo, Y.: Reconstruction-Based Association Rule Hiding. Proc. of SIGMOD 2007 Ph.D. Workshop on Innovative Database Research (2007)
[13] Liu, B., Hsu, W., Ma, Y.: Mining Association Rules with Multiple Minimum Supports. Proc. of the 5th ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining (1999) 337–341
[14]Wang, K., He, Y., Han, J.: Pushing Support Constraints into Association Rules Mining. IEEE Transactions on Knowledge and Data Engineering 15(3) (2003) 642–658
[15] Lee, Y.C., Hong, T.P., Lin, W.Y.: Mining Association Rules with Multiple Minimum Supports Using Maximum Constraints. Int. Journal of Approximate Reasoning on Data Mining and Granular Computing 40(1–2) (2005) 44–54 [16] Blake, C.L., Merz, C.J.:UCIRepository of machine learning databases
[http://www.ics.uci.edu/ mlearn/MLRepository.html]. Irvine, CA:University of
10
Califarnia, Dept. of Inf. and CS., (1998)
[17] Liu, B., Hsu, W., Ma, Y.: Mining Association Rules with Multiple Minimum Sup- ports. Proc. of the 5th ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining (1999) 337–341
[18]Geurts, K., Wets, G., Brijs, T., Vanhoof, K.: Profiling High-Frequency Accident Locations Using Association Rules. Proc. of the 82th Annual Transportation Research Board (2003) 18
[19]Blake, C.L., Merz, C.J.:UCIRepository of machine learning databases
[http://www.ics.uci.edu/ mlearn/MLRepository.html].Irvine, CA: University of Califarnia, Dept. of Inf. and CS., (1998)
計畫成果自評
本計畫與原計畫書中第一年之進度大致相符,我們針對多重支持度門檻值設 計一個新的淨除演算法來保護機密的頻繁項目集,使得對敏感資訊的保護能更切 合於它本身的特性,並藉此達到在修改過後的資料庫內保留更多的非機密資訊,
亦即降低資訊遺失的程度。由於過去大部份的敏感項目集淨除演算法都是將所有 的敏感項目集降低到單一的門檻值下,但這樣子情況並不適合運用在實際的應用 上。然而,此敏感項目集淨除演算法,能夠依照敏感項目集在資料庫中的分布,
將其各自的支持降低到所指定的不同門檻值底下。此研究成果可實作在資料庫 上,在公佈資料庫時應用此方法,來產生具隱私保護的資料庫。部分研究成果已 發表於國際會議:
Ya-Ping Kuo, Pai-Yu Lin and Bi-Ru Dai, "Hiding Frequent Patterns under Multiple Sensitive Thresholds," Proceedings of the 19th International Conference on Database and Expert Systems Applications (DEXA 2008), Turin, Italy, September 1-5, 2008.
(Lecture Notes in Computer Science 5181 Springer 2008, ISBN 978-3-540-85653-5) (EI)
附件一
Hiding Frequent Patterns under Multiple Sensitive Thresholds
Ya-Ping Kuo, Pai-Yu Lin, and Bi-Ru Dai
Department of Computer Science and Information Engineering, National Taiwan University of Science and Technology, Taipei, Taiwan. R.O.C.
{m9515063,m9615082}@mail.ntust.edu.tw, [email protected]
Abstract. Frequent pattern mining is a popular topic in data mining.
With the advance of this technique, privacy issues attract more and more attention in recent years. In this field, previous works based hiding sensi- tive information on a uniform support threshold or a disclosure threshold.
However, in practical applications, we probably need to apply different support thresholds to different itemsets for reflecting their significance.
In this paper, we propose a new hiding strategy to protect sensitive frequent patterns with multiple sensitive thresholds. Based on different sensitive thresholds, the sanitized dataset is able to highly fulfill user re- quirements in real applications, while preserving more information of the original dataset. Empirical studies show that our approach can protect sensitive knowledge well not only under multiple thresholds, but also un- der a uniform threshold. Moreover, the quality of the sanitized dataset can be maintained.
Keywords: privacy, frequent pattern hiding, multiple threshold, sensi- tive knowledge, security, data sanitization.
1 Introduction
Frequent pattern and association rule mining play the important roles in data mining [1]. By this technique, we can discover interesting but hidden information from database. This technique has been applied to many application domains, such as the analysis of market basket, medical management, stock, environment, business, etc., and brings great advantages. However, most database owners are unwilling to supply their datasets to analysis, since some sensitive information or private commercial strategies are at the risk of being disclosed from the min- ing result. Therefore, although many benefits can be provided by this technique, it causes new threats to privacy and security. For above reason, the database should be processed before releasing so that it can contain the most of original non-sensitive knowledge and the least of sensitive information for the owner.
Intuitively, the database owner can permit only partial access of dataset for analysis or directly remove all sensitive information from the mining result of database. However, it is possible that the adversary still can infer sensitive item- sets or high-level items from non-sensitive patterns or low-level items. For exam- ple, suppose that {1} is the sensitive pattern and the set of all frequent patterns
2
are {{1}, {1, 2}, {2, 3}}. If we directly remove {1} and release {{1, 2}, {2, 3}}, the adversary may still be able to infer that {1} is frequent. That is because of the monotonic property of frequent patterns, which means that all non-empty subsets of a frequent pattern must be frequent. Hence the challenge is how to protect sensitive information from being attacked by inference.
1.1 Motivations
In this paper, we focus on the problem of hiding sensitive frequent itemsets from a transaction database. The motivation and the importance of hiding sensitive itemsets have been well explained in [2] as stated below. Suppose that most people who purchase milk usually also purchase Green paper. If the Dedtrees paper company mines this rule from the database of a supermarket and issues a coupon, “if you buy the Dedtrees paper, you will get a 50 cents off discount of one milk,” then the sales of Green paper will be reduced by the above com- mercial strategy. For this reason, the Green paper company would not like to provide a lower price to the supermarket. On the other hand, the Dedtrees paper company has already achieved its goal, and is unwilling to provide a lower price to supermarket anymore. Then, the supermarket will suffer serious losses. Hence the database should be sanitized for such sensitive information before releasing.
Most of previous sanitization algorithms only use one user-predefined sup- port threshold without considering the following issues. First, using a uniform support threshold with different patterns is not always reasonable in real life.
For instance, the supports of high price or the latest products, such as com- puters, are intrinsically lower than those of general or common products, such as water, but it does not imply the latter ones are more significant than the former ones. If we decrease the supports of all sensitive itemsets to be smaller than the same threshold, it may cause some itemsets are overprotected and some are not protected sufficiently. Furthermore if the support threshold used by the adversary in mining is smaller than the one used in hiding, the released database will disclose all sensitive information. On the contrary, if the support threshold which is used for hiding is too small, the released database is possible to lose too much information and becomes useless for subsequent mining. In addition, if the general items and the particular items have similar frequencies in database, the adversary will infer that some sensitive knowledge has been hidden. Therefore, based on the consideration of both privacy protection and information preserva- tion, it is important to assign each itemset a particular threshold. For the above reasons, an algorithms using a disclosure threshold has been proposed [17]. It decreases the supports of sensitive patterns according to their distribution in database and uses a disclosure threshold directly to control the balance between privacy and knowledge discovery. However, the method does not consider the characteristics of different sensitive itemsets in different applications or the per- sonalized requirements of different users. It totally relies on the distribution of database to do the same degree of sanitization with infrequent sensitive patterns and more frequent sensitive patterns.
3
1.2 Contributions
In this paper, we propose a new strategy, which combines the sanitization algo- rithm and the concept of multiple support thresholds [14], to solve the problem which is mentioned above. Before sanitizing, the database owner can specify the support threshold, called sensitive threshold, for each sensitive pattern based on his/her domain knowledge. Then our algorithm will decrease the support of each sensitive pattern to be below its sensitive threshold, respectively. Under multi- ple thresholds, the database owner can directly decide the sanitization degree of different patterns hence the protected database can much more satisfy the demand of the database owner. Consequently, the proposed strategy is able to reduce the probability of privacy breach and preserve as much information as possible.
The main contributions of this paper are as follows: (1) a new hiding strat- egy with multiple sensitive thresholds, which is more applicable in reality, is suggested; (2) the proposed algorithm can achieve better privacy protection and information preservation; (3) The new metrics are presented to measure perfor- mance for hiding frequent patterns under multiple sensitive thresholds because of the difference between under multiple thresholds and a uniform one, while the sets of the patterns which need to be hidden by user-predefined are the same.
The rest of this paper is organized as follows. The preliminary knowledge is stated in Section 2. In Section 3, we introduce our sanitizaion framework, the whole sanitization process, and some techniques which improve performance and efficiency. Some related hiding algorithms are reviewed in Section 4. The new metrics, experimental results and discussion are presented in Section 5. In the last part, Section 6 presents our conclusions.
2 Preliminaries
Before presenting our hiding strategy and framework, we introduce the prelim- inaries of frequent patterns, the transaction database, and the related concepts of privacy and multiple thresholds briefly.
Frequent pattern and Transaction database. Let I = {1, . . . , n} be a non-empty set of items. Each non-empty subset X ⊆ I is called a pattern or an itemset. A transaction is a pair of itemset t ⊆ I with a unique identifier Ti, called the transaction identifier or TID. A transaction database D = {T1, . . . , TN} is a set of transactions, and its size is |D| = N . We assume that the itemsets and the transactions are ordered in lexicographic order. A transaction t sup- ports X, if X ⊆ t. Given a database D, the support of an itemset X, denoted sup(X), is the number of transactions that support X in D. The frequency of X is sup(X)/|D|. An itemset X is said to be frequent if sup(X)/|D| is larger than the user-predefined minimum support, denoted as minsup, 0 ≤ minsup ≤ 1.
Sensitive itemset, sensitive threshold, and sensitive transaction. Let D be a transaction database, FP be a set of frequent patterns, and {sp1, . . . , spi}
∈ SP be a set of patterns that need to be hidden based on some security require- ments. A set of frequent patterns which are able to infer any patterns in SP,
4
I and X I is the set of all items; X is an itemset, X ⊆ I (Ti, t) The transaction itemset t with its TID Ti
sup(X) The support of X
minsup The user-predefined minimum support threshold sp1, . . . , spi∈ SP The set of patterns that need to be hidden
Ps The set of sensitive patterns which can infer any patterns in SP Ts(X) The set of sensitive transactions of X
st(X) The sensitive threshold of X TPk The unique identifier of template
SP C The number of sensitive patterns covered of a template M C The minimal count of the transactions need to be modified
Table 1: The summarization of notations used in the paper
denoted as Ps, is said to be sensitive. ∼ Ps is the set of non-sensitive frequent patterns such that Ps∪ ∼ Ps= FP. As long as a transaction supports any item- sets, it is said to be sensitive, denoted as Ts, and the set of sensitive transactions of X is denoted as Ts(X). The support threshold used for hiding is named sen- sitive threshold. The sensitive threshold of a sensitive pattern X is denoted as st(X).
3 The Template-Based Sanitization Process
The main goal of this work is to hide sensitive information in database so that the frequent itemset mining result of new released dataset will not disclose any sensitive patterns. The challenge of this problem is to find out the balanced so- lution between the privacy requirement and the information preservation. We suggest assigning different sensitive threshold to each sensitive itemset to mini- mize the side effects with the dataset. Formally, the problem definition is stated as follows:
Frequent pattern hiding with multiple sensitive thresholds. Given a database D and the set of patterns to be hidden, {sp1, . . . , spi} ∈ SP, with their sensitive thresholds, st(sp1), . . . , st(spi), the problem is how to transform D to D0 such that Ps will not be mined from D0, and ∼ Ps can still be contained in D0. Finally, D0 can be released without violating the privacy concern.
In our sanitization process, we remove some items for each sensitive itemset from its corresponding sensitive transactions. Since a uniform sensitive threshold is usually not suitable for real cases, we apply the concept of multiple sensitive thresholds for hiding sensitive itemsets so that the itemsets with higher occur- rences in reality can preserve more information. Moreover, the itemsets with lower occurrences in reality can reach better protection. Note that we will not focus on the determination of sensitive thresholds since they largely depend on applications and users requirements. Database owners can decide the sensitive threshold based on existing schemes [8][14][18] or any preferred settings.
5
Sensitive Pattern
Transaction Index
Original Database
New Database
Template Table
Action Table Threshold
Sensitive Calculate
Inverted file
Mining
Build/
Update
Retrieve
Modify & Output Fig. 1: The sanitization framework
In this section, our framework and the whole sanitization process of hiding frequent patterns are presented. We propose a template-based framework which is similar as [5] but different strategy on choosing an optimal hiding action with minimal side effect. The proposed method hides the sensitive itemset by decreasing its support. We apply the template to evaluate the impact of choosing different items to be victims and different hiding order of sensitive itemsets.
In order to reach minimum side effect, we would like to choose the optimal modification of a template which can hide most sensitive itemsets and sanitize least sensitive transactions at the same time. In addition to promote efficiency, we suggest a revised border-based method to reduce the redundant work on hiding and rely on the inverted file and pattern index to speed up the renovation of each component in our sanitization process. The summarization of notations used in this paper is shown as Table 1.
3.1 The Sanitization Framework
The framework of our sanitization process is illustrated as Fig. 1. It mainly consists of three components: sensitive pattern table, template table, and ac- tion table. At first, the database is scanned to find all supports and sensitive transactions of sensitive itemsets, and then the sensitive pattern table is built that stores the number of supports should be decreased based on the sensitive threshold for each sensitive itemsets. Secondly, we generate the corresponding templates for each sensitive itemset that contains all probable choices of vic- tim items for hiding this itemset. Next, a template is selected from template table according to the hiding strategy of minimizing side effects for the original database. Then we search out the corresponding sensitive transactions enough to be modified for hiding all sensitive patterns covered by this template and then put all pairs,(victimitem, T ID), to action table. Then, the information of all components is updated. The choosing and updating process will repeat until all sensitive itemsets are hidden. Finally, we remove each victim item from its pair transaction in the action table. Note that the whole sanitization framework only needs to scan the database twice.
6
Sensitive Pattern Table
SP Count
{3} 3
{2, 3} 5
{1, 3, 4} 6
Template Table victim U CP SP C M C
TP1 3 3 1 3
TP2 2 2,3 1 5
TP3 3 2,3 2 5
TP4 1 1,3,4 1 6
TP5 3 1,3,4 2 6
TP6 4 1,3,4 1 6
TP7 3 1,2,3,4 3 6
Table 2: The sensitive pattern table and the corresponding template table
3.2 Sensitive Pattern Table
There are two attributes contained in the sensitive pattern table, each sensitive itemset and its Count, as shown in Table 2. The Count of a sensitive pattern indicates that the minimal number of support which is required to be decreased will make this pattern to be infrequent. Based on multiple sensitive thresholds, we propose the lemma of Count as follow:
Lemma 1. Given a sensitive pattern spi, the minimal number of transactions that should be sanitized for hiding this pattern is computed as spi.Count = bsup(spi) − st(spi) + 1c
Proof. To hide a sensitive pattern spi, its support, sup(spi), should be decreased to be below its sensitive threshold, st(spi). Hence removing some victim items contained in spi from the corresponding sensitive transactions will make spi to be infrequent. Let spi.Count be the minimal number of sanitized transac- tions as sup(spi) < st(spi). Because sup(spi) − spi.Count < st(spi), and then spi.Count > sup(spi) − st(spi). Therefore spi.Count = the interger part of ((sup(spi) − st(spi)) + 1) = bsup(spi) − st(spi) + 1c ut
3.3 Template Table
The initial template table should be built according to the sensitive pattern table, as depicted in Table 2. A template is represented in the form: < TPID, victim, U CP, SP C, M C >, where TPID is the template unique identifier, and victim is the chosen item that is considered to be removed from the corresponding sensitive transactions. For a sensitive itemset with length k, there are k items that can be victims. Hence we can generate k templates with different victims. Take {1, 3, 4}
as example, three templates with the victims, {1}, {3}, and {4} are produced, respectively. The U CP of a template represents the itemset must be contained in the corresponding transactions and it is the union of all corresponding sensitive patterns which can be sanitized by this template. It means that if the victim is deleted from the corresponding sensitive transactions which contain the U CP , the support of each corresponding sensitive pattern is decreased. For instance in
7 Table 2, TP1for hiding {3} is to delete {3} from the transactions containing {3};
TP3 for hiding {2, 3} and {3} is to delete {3} from the transaction containing {2, 3}, etc. The SP C, stands for the number of the sensitive patterns which can be sanitized by this template. For example, the TP3 in Table 2 can hide two sensitive patterns {3} and {2, 3} at the same time, so its SP C is 2. The M C indicates the minimal number of the support should be decreased, such that all corresponding sensitive patterns of this template are hidden. Hence the M C is the maximum Count among all corresponding sensitive patterns of this template. For instance, the M C of TP3 in Table 2 is max{3, 5} = 5.
Not only are those templates introduced above, but also we generate joint templates to cover more sensitive patterns. If any two templates have the same victim, and their U CP do not contain each other, we can join them to be a new template. The U CP of the new joint template is the union of the U CP s of all combined templates. Then the SP C and the M C are computed according all corresponding sensitive patterns. As shown in Table 2, TP3 and TP5can be combined to generate TP7. The U CP , the union of {2, 3} and {1, 3, 4}, is {1, 2, 3, 4}. Then the SP C of TP7will be 3 because removing {3} from transaction containing {1, 2, 3, 4} can decrease the supports of three sensitive patterns, {3}, {2, 3}, and {1, 3, 4}. The M C of TP7 is max{3, 5, 6} = 6. Consequently, TP7
becomes a better choice than TP3and TP5because the SP C in it is larger than the others, thus TP7can hide more patterns at the same time. We use the hash table to avoid generating the same template with existing ones, and transfer the pattern index from binary to decimal to be the hash key. We can compute the SP C and the M C of all templates refer to the sensitive pattern table, and the computation algorithm is similar in [5].
3.4 Choosing Strategy and Updating Process
Based on the essence of our hiding strategies - “minimizing side effect”, we choose the template having the largest SP C at each round. If there exists more than one template having the same SP C, the template with the smallest M C is selected. If there still exists more than one, we choose the template which has the victim with the lowest support in the database. Finally, if the tie is still not solved, a random choice will be picked. After choosing the template, the corresponding sensitive transactions are found out by the transaction index. If the number of the sensitive transactions is larger than the M C of the chosen template, we choose the first M C shortest transactions to move to action table for sanitizing; otherwise all corresponding sensitive transactions will be sanitized.
By the number of sanitized transactions, the Count and the M C are recomputed.
If some patterns are hidden by this template, the SP C and the U CP should be changed. As the SP C of a template becomes zero, we remove this template from template table. Lastly, the TID of sanitized transactions are removed from the transaction index of the corresponding sensitive patterns of this template.
In order to achieve better hiding performance, the number of the victim items in one transaction is not restricted.
8
3.5 Performance and Efficiency Improvement
In order to promote the performance and efficiency of our framework, we propose the concept of revised border itemsets for reducing redundant work. Because of the monotonic property of frequent patterns, hiding a sensitive pattern will hide all supersets of this pattern. Hence in the sanitization process, we merely need to hide the sensitive patterns which have no sensitive subsets. Such itemset is said to be a border itemset. For instance, if the {1, 2, 3}, {1, 3} and {1} are three sensitive patterns, then {1} is a border itemset but {1, 2, 3}, {1, 3} are not. As long as the border itemsets of the sensitive patterns have been hidden, we can protect all sensitive information. However this technique cannot be applied to the situation of hiding frequent patterns with multiple sensitive thresholds. While the sensitive threshold of the super-itemset is smaller than that of the itemset, focusing on hiding the border itemset cannot guarantee the protection of all sensitive frequent patterns. Therefore, we take all the itemsets which have no sensitive subsets with lower support thresholds than themselves to be the revised border itemset. In the above example, if the sensitive thresholds of {1,2,3}, {1,3}, and {1} are 2, 4, and 3, respectively, then {1} and {1,2,3} are revised border itemset. If the revised border itemsets are hidden, all the sensitive knowledge will be protected. In addition, the techniques of pattern index [5] and inverted file are also applied in our framework for increasing efficiency.
4 Related Works
The problem of hiding frequent patterns and association rules was proposed in [9] firstly. The authors proved that finding an optimal sanitization for hiding frequent patterns is an NP-hard problem and proposed a heuristic approach by deleting items from transactions in the database to hide sensitive frequent patterns. In recent year, more and more researchers start paying attention to privacy issues. The consequent approaches can be classified into two categories:
data modification, and data reconstruction.
Data modification. The main idea of this group is to alter original database such that the sensitive information is not able to be mined in new database. So as to decrease the support or confidence of sensitive rules below the user-predefined threshold, these algorithms choose some items as victims and delete or insert them in some transactions [6]. In [17], the authors present a novel approach us- ing a disclosure parameter instead of the support threshold to directly control the balance between privacy requirement and information preservation. Based on the disclosure parameter, the support of each sensitive pattern is decreased by the same proportion. The proposed IGA algorithm groups sensitive patterns first, and then chooses the victim items based on the minimal side effects for database. In [7], the border-based concept was proposed to evaluate the impact of any modification on the database efficiently. The quality of database and relative frequency of each frequent itemset can be well maintained by greedily selecting the modifications with minimal side effect. In [4], the authors propose