Incremental Mining of Ontological Association Rules in
Evolving Environments
Ming-Cheng Tseng1and Wen-Yang Lin2
1Refining Business Division, CPC Corporation, Taiwan
2Dept. of Comp. Sci. & Info. Eng., National University of Kaohsiung, Taiwan 1[email protected],2[email protected]
Abstract. The process of knowledge discovery from databases is a knowledge intensive, highly user-oriented practice, thus has recently heralded the development of ontology-incorporated data mining techniques. In our previous work, we have considered the problem of mining association rules with ontological information (called ontological association rules) and devised two efficient algorithms, called AROC and AROS, for discovering ontological associations that exploit not only classification but also composition relationship between items. The real world, however, is not static. Data mining practitioners usually are confronted with a dynamic environment. New transactions are continually added into the database over time, and the ontology of items is evolved accordingly. Furthermore, the work of discovering interesting association rules is an iterative process; the analysts need to repeatedly adjust the constraint of minimum support and/or minimum confidence to discover real informative rules. Under these circumstances, how to dynamically discover association rules efficiently is a crucial issue. In this regard, we proposed a unified algorithm, called MIFO, which can handle the maintenance of discovered frequent patterns taking account of all evolving factors: new transactions updating in databases, ontology evolution and minimum support refinement. Empirical evaluation showed that MIFO is significantly faster than running our previous algorithms AROC and AROS from scratch.
Keywords: Association rules, rule maintenance, database update, support constraint refinement, ontology evolution.
1
Introduction
Data mining is to discover useful patterns. One of the most important patterns is to find association rules from a database [1]. An association rule is an expression of the form X Y, where X and Y are sets of items. Such a rule reveals that transactions in the database containing items in X tend to also contain items in Y. And such information is very useful in many aspects of business management, such as store layoutplanning,targetmarketing,understanding customer’sbehavior,etc.
As pointed out in the literature [6], the data mining process is knowledge intensive since it requires domain knowledge to decide what kind of data should be used or
which information is the most useful, thus has recently heralded the development of incorporating ontology (domain knowledge) [14] into the process of data mining. In the past few years, there has been researches investigated the problem of mining association rules with classification or composition information [5][7][10][17]. In our recent study, we have considered this problem from a more unified viewpoint. We proposed two effective algorithms, called AROC and AROS [21], for mining association rules that exploit the ontological information not only presenting classification but also composition relationship.
The real world, however, is not static. New transactions are continually added into the database over time, and the ontology of items is evolved accordingly. Furthermore, the analysts would need to repeatedly adjust the constraint of minimum support and/or minimum confidence to discover real informative rules. All of these changes would invalidate previously discovered association rules and/or introduce new ones. Under these circumstances, it is a crucial task to find a method to effectively update the discovered association rules when new transactions are added to the original database along with the ontology evolution and/or minimum support refinement.
In this paper, we consider the problem and propose a unified algorithm, called MIFO, which can handle the maintenance of discovered frequent patterns on taking account of all evolving factors: new transactions updating in databases, ontology evolution, and minimum support refinement. Empirical evaluation showed that MIFO is significantly faster than running our previous algorithms AROC and AROS afresh.
The remainder of this paper is organized as follows. First, related work is presented in Section 2. Section 3 introduces and formalizes the problem for maintenance of association rules with ontological information. In Section 4, we describe the main ideas in the design of the proposed algorithm MFIO. In Section 5, we describe the experiments and discuss the results. Finally, conclusions and future work are given in the last section.
2
Related Work
If concept hierarchy or taxonomy is taken as a kind of ontology, then the research of incorporating ontology into data mining can be traced back to 1995 when Han & Fu [7] and Srikant & Agrawal [17] proposed to combine conceptual hierarchy knowledge to mine so-called multilevel association rules and generalized association rules, respectively.
In [10], Jea et al. considered the problem of discover multiple-level association rules with composition (has-a) hierarchy and proposed a method. Their approach is similar to [17], and was later extended by Chien et al. [5] to fuzzy association rules.
The problem of incremental updating association rules was first addressed by Cheung et al. [2]. By making use of the discovered frequent itemsets, the proposed FUP algorithm can dramatically reduce the efforts for computing the frequent itemsets in the updated database. They further examined the maintenance of multi-level association rules [3], and extended the model to incorporate the situations of deletion and modification [4]. Since then, a number of techniques have been proposed to improve the efficiency of incremental mining algorithm [9][13][15][19]. All of
these approaches, however, did not consider the issue of incorporating ontological information. In [20], we have extended the problem of maintaining generalized associations incrementally to that incorporates non-uniform minimum support.
3
Problem Statement
Let I{i1, i2,…,im} be a set of items, and DB{t1, t2,…,tn} be a set of transactions,
where each transaction titid, Ahas a unique identifier tid and a set of items A (A
I). To study the mining of association rules with ontological information from DB, we
assume that the ontology of items, T, is available and is denoted as a graph on IE, where E{e1, e2, …, ep} represents the set of extended items derived from I. There
are two different types of edges in T, taxonomic edge (denoting is-a relationship) and
meronymic edge (denoting has-a relationship). We call an item j a generalization of
item i if there is a path composed of taxonomic edges from i to j, and conversely, we call i a specialization of j. On the other hand, we call item k a component of item i if there is a path composed of meronymic edges from i to k, and we call i an aggregation of k. For example, in Figure 1(a) I{HP DeskJet, Epson EPL, Sony VAIO, IBM TP}, and E {Printer, PC, Ink Cartridge, Photo Conductor, Toner Cartridge, S 60GB, RAM 256MB, IBM 60GB}.
Note that, in Figure 1(a),someitem like“Ink Cartridge”could beacomponentof “HP DeskJet”orbe a primitive item purchased directly. To differentiate between these, when an item a serves as a component item, we append an asterisk to the item a (a*), and when a* appears in the association rule, it should be interpreted as “Aggregation (Assembly, Product) of item”. For example, rule IBM TP Ink Cartridge* reveals that people who purchase “IBM TP”are likely to purchase the “Product of Ink Cartridge”.
Definition 1. Given a set of transactions DB and an ontology T, an ontological
association rule is an implication of the form, A B, where A, B I E, A B , and no item in B is a generalized item or a component of any item in A, and vice versa. The support of this rule, sup(A B), is equal to the support of A B. The confidence of the rule, conf(A B), is the ratio of sup(A B) versus sup(A), i.e., the percentage of transactions in DB containing A that also contain B.
According to Definition 1, an itemset is not only simply composed of primitive purchased items in the ontology but also composed of extended items in higher or lower levels of the ontology. In this regard, we have to take the extended items of items in a transaction into account while determine the support of an itemset. In addition, the condition that no item in A is a generalization or a component item of any item in B is essential; otherwise, a rule of the form, a generalization(a) or a
component(a), always has 100% confidence and is trivial.
In reality, frequencies of items occur not evenly, that is, some items appear very frequently while others rarely emerge in the transactions. Following the concept in [12], we assume that the user can specify different minimum supports to different items in the ontology, as defined below:
Definition 2. Let ms(a) denote the minimum support of an item a in IE. An itemset
A{a1, a2,…,ak}, where aiI E, is frequent if the support of A is equal to or
larger than the lowest value of minimum support of items in A, i.e., sup(A)ms(A)
minaiAms(ai).
The problem of updating the frequent itemsets with the incremental transactions, the new ontology and the new multiple minimum support setting can be defined as follows.
Definition 3. Let DB denote the original database, db the incremental database, T the
old ontology, T* the new ontology, msoldold multiple minimum support setting, msnew
new multiple minimum support setting, A an itemset, and LDB the set of frequent itemsets in DB. The updated extended database UE* is the union ofED* and ed*, i.e., UE*ED* + ed*, where ED* and ed* are the extension of DB and ed with extended items in T*, respectively. The problem of updating the frequent itemsets with the new ontology T* and the new multiple minimum support setting msnew is, given the
knowledge of DB, db, T, T*, LDB, msold and msnew, to find LUE*{A | supUE*(A)
msnew(A)}.
Example 1. Consider Figure 1, which depicts the situation that an original database DB is added with an incremental database db along with the old ontology T replaced
by the new ontology T*, where a new primitive item “Gateway GE”along with a new component “Q 60GB”and a new category “Desktop PC”are added, and item “Sony VAIO”is reclassified as “Desktop PC”accordingly. Assume that the analyst has discovered a set of frequent itemsets LDBin DB with respect to the old ontology T and minimum support setting msold. Then the problem of interest can be regarded as
discovering the new set of frequent itemsets LUE*from the updated database UE* with respect to the new minimum support setting.
Sony VAIO, Ink Cartridge 6
IBM TP, HP DeskJet, Ink Cartridge 5
HP DeskJet 4
IBM TP, HP DeskJet, Ink Cartridge 3
Sony VAIO, IBM TP, Epson EPL 2
IBM TP, Epson EPL, Toner Cartridge 1
Items Purchased TID
Sony VAIO, Ink Cartridge 6
IBM TP, HP DeskJet, Ink Cartridge 5
HP DeskJet 4
IBM TP, HP DeskJet, Ink Cartridge 3
Sony VAIO, IBM TP, Epson EPL 2
IBM TP, Epson EPL, Toner Cartridge 1
Items Purchased TID
IBM 60GB, Toner Cartridge 10
Q 60GB, Toner Cartridge 9
IBM TP, HP DeskJet, S 60GB, Toner Cartridge 8
Gateway GE, IBM 60GB, Toner Cartridge 7
Items Purchased TID
IBM 60GB, Toner Cartridge 10
Q 60GB, Toner Cartridge 9
IBM TP, HP DeskJet, S 60GB, Toner Cartridge 8
Gateway GE, IBM 60GB, Toner Cartridge 7 Items Purchased TID Original database (DB ) Incremental database (db) Composition Classification Photo Conductor Toner Cartridge HP DeskJet Printer Epson EPL -Ink Cartridge -RAM 256MB IBM 60GB Sony VAIO PC IBM TP S 60GB -IBM TP PC IBM 60GB S 60GB Sony VAIO RAM 256MB Desktop PC Gateway GE Q 60GB Photo Conductor Toner Cartridge HP DeskJet Printer Epson EPL -Ink Cartridge -Old ontology ( T ) New ontology (T*)
4
Maintenance of Frequent Itemsets with Ontological
Information
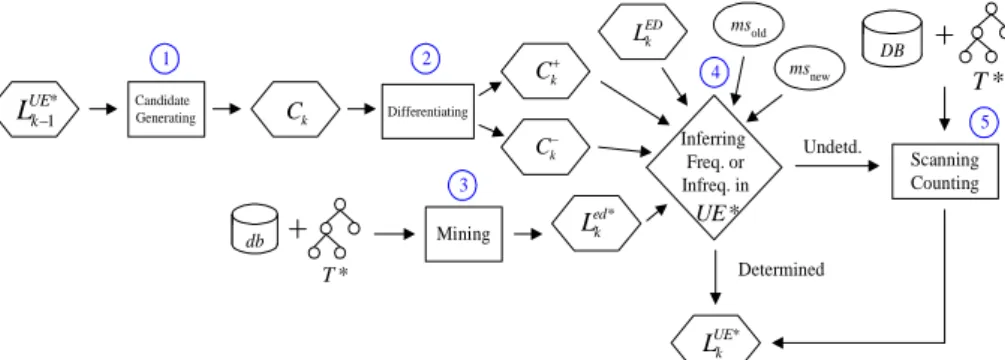
A straightforward way to find updated ontological frequent itemsets would be to run one of our previous proposed algorithms, AROC or AROS, for finding frequent itemsets in the updated extended database UE*. This simple way, however, ignores that some of the discovered frequent itemsets are not affected by incremental transactions, minimum support update and/or ontology evolution; that is, these itemsets survive in the ontology evolution and remain frequent in UE* under the minimum support update. If we can identify the unaffected itemsets, then we can avoid unnecessary computations in counting their supports. In view of this, we adopt an Apriori-like maintenance framework depicted in Figure 2.
ED k L Candidate Generating Ck Differentiating k C k C Mining Inferring Freq. or Infreq. in * UE * UE k L Determined Undetd. * T DB db * T * ed k L 1 3 2 4 5 Scanning Counting * 1 UE k L msold msnew
Fig. 2. Proposed framework for updating the frequent ontological k-itemsets. Each pass of mining the frequent k-itemsets involves the following main steps: 1. Generate candidate k-itemsets Ck.
2. Differentiate in Ckthe affected itemsets (Ck) from the unaffected ones (
k
C ).
3. Scan the incremental database db with the new taxonomy T*, and apply one of our previous algorithms AROC and AROS to find ed*
k
L .
4. Incorporate LEDk *, Ledk*,Ck,Ck, msoldand msnewto determine whether a candidate
itemset is frequent or not in the resulting database UE*.
5. Scan DB with T*, i.e., ED*, to count the support of itemsets that are undetermined in Step 4.
Below, we elaborate on each of the kernel steps, i.e., Steps 2 and 4.
4.1 Differentiation of Affected and Unaffected Itemsets
Definition 4. An item (primitive or extended) is called an affected item if its support
would be changed with respect to the ontology evolution; otherwise, it is called an unaffected item.
Consider an item xT T*, and the three independent subsets T T*, T*T and
or not. The case that x is a renamed item is neglected for which can be simply regarded as an unaffected item.
1. xT T*. In this case, x is an obsolete item. Then the support of x in the updated database should be counted as 0 and so x is an affected item.
2. x T*T. In this case, x denotes a new item, whose support may change from zero to nonzero. Thus, x should be regarded as an affected item.
3. x T T*. This case is more complex, depending on whether x is a primitive, generalized and/or component item, as clarified in the following lemmas.
Lemma 1. Consider a primitive item xI I*. Then countED*(x)countED(x) if x
II*.
Lemma 2. Consider an extended item xT T*. If pspcT(x)paggT(x)pspcT*(x)
paggT*(x), then countED*(x)countED(x), where pspcT(x) andpspcT*(x) denote the
sets of primitive specialized items of x in T and T*, respectively, and where paggT(x)
and paggT*(x) denote the sets of primitive aggregation items of x in T and T*,
respectively.
For example, consider the new ontology T* in Figure 1. The generalized item “PC” is an unaffected item since its primitive specializations, {Gateway GE, Sony VAIO, IBM TP} do not change after the ontology evolution. The component item “RAM 256MB”is also an unaffected item since its primitive aggregations, {Gateway GE, Sony VAIO, IBM TP}, do not change after the ontology evolution.
Definition 5. For a candidate itemset A, we say A is an affected itemset if it contains
at least one affected item.
Lemma 3. Consider an itemset A. Then A is an unaffected itemset with countED*(A)
countED(A), if A contains unaffected items only, and countED*(A)0 if A contains at
least one obsolete item x, for xT T*, or if A contains at least one new primitive item.
4.2 Inference of Frequent and Infrequent Itemsets
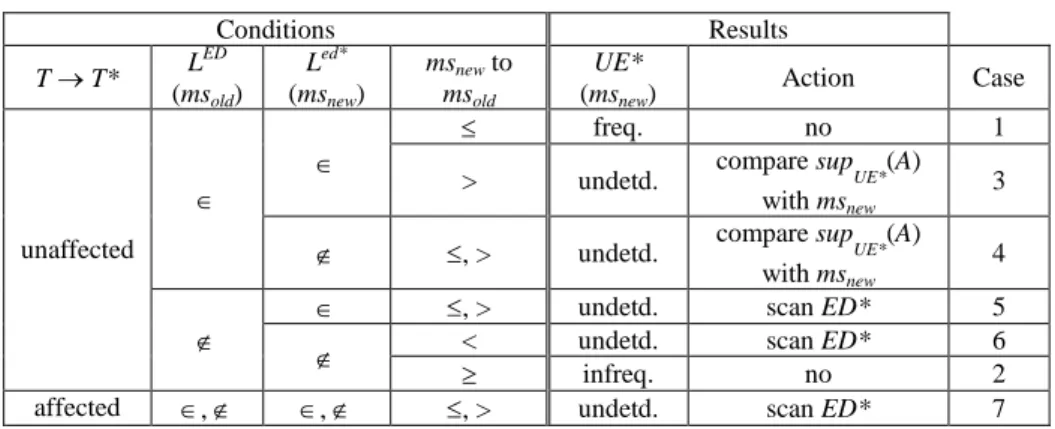
Now that we have clarified how to differentiate the unaffected and affected itemsets and how to deal with the effect of minimum support refinement, we will further show how to utilize this information to determine in advance whether or not an itemset is frequent before scanning the extended database ED*, and show the corresponding actions in counting the support of itemsets. Taking account of all three evolving factors, i.e., incremental database update, ontology evolution and/or minimum support refinement, we devise that there are seven situations of itemset updates, as summarized in Table 1.
Note that only Cases 5, 6 and 7 require an additional scan of ED* to determine the support counts of A in UE*. In Case 3, after scanning ed* and comparing the support of A with msnew, even if A is frequent in ed*, A may become infrequent in UE* under
msnew> msold. In Case 4, after scanning ed* and comparing the support of A with msnew,
even if A is infrequent in ed*, no matter what msnewis, A may become frequent in UE*.
Cases 3 and 4. In Case 5, A is infrequent in ED, but frequent in ed*; therefore, no matter what msnew is, A may become frequent in UE*. After scanning ed* and
comparing the support of A with msnew, if A is frequent in ed*, we have to rescan ED*
to decide whether A is frequent or not in UE*. In Case 6, A is infrequent in ED and
ed*; however, msnew< msold, A may become frequent in UE*. After scanning ed* and
comparing the support of A with msnew, even if A is infrequent in ed*, since msnew<
msold, we have to rescan ED* to decide whether A is frequent or not in UE*. For Case
7, since A is an affected itemset, its support counts could be changed in ED*. No matter what msnewis, we need to further scan ED* to decide whether it is frequent or
not.
Table 1. Seven cases for frequent itemsets inference.
Conditions Results T T* L ED (msold) Led* (msnew) msnewto msold UE* (msnew) Action Case freq. no 1
> undetd. compare supUE*(A)
with msnew
3
,> undetd. compare supUE*(A)
with msnew
4
,> undetd. scan ED* 5
< undetd. scan ED* 6
unaffected
infreq. no 2
affected , , ,> undetd. scan ED* 7
*Note: Abbreviation “undetd.”represents “undetermined”.
5
Experimental Results
In order to examine the performance of MFIO, we conducted experiments to compare it with that of applying AROC and AROS afresh respect to the new environment. A synthetic dataset of 200000 transactions, generated by the IBM data generator [1], with artificially-built ontology composed of 362 items that are divided into 30 groups, each of which consists of four levels with average fanout of 5.
The efficiency of the algorithms is evaluated from three aspects: the effect of varying minimum support refinement, that of varying incremental size, and that of ontology evolution degree. Here, the evolution degree is measured by the fraction of extended items that are affected by the ontology evolution.
All programs were implemented with the Visual C++ programming language and all experiments were performed on an Intel Pentium-IV 2.80GHz with 2GB RAM, running on Windows 2000. In the implementation of each algorithm, we also adopted two different support counting strategies: one with the horizontal counting [1] and the other with the vertical intersection counting [16]. For differentiation, the algorithms with horizontal counting are denoted as AROC(H), AROS(H) and MFIO(H), while the algorithms with vertical intersection counting are denoted as AROC(V), AROS(V) and MFIO(V). In addition, each performance aspect for MFIO(V) and MFIO(H) was
examined under two extreme cases of support refinement: (1) all items having less new minimum supports, i.e., msnewmsold,denoted as MFIO1(V) and MFIO1(H); and
(2) all items having larger new minimum supports, i.e., msnewmsold,denoted as
MFIO2(V) and MFIO2(H), which can be used as an indication of the performance bounds of our MFIO algorithm.
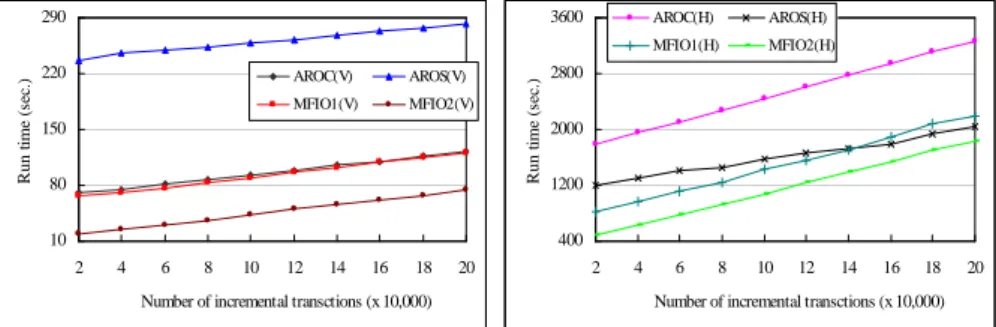
We first compared the three algorithms under varying incremental size at the multiple minimum support setting (CLS), msoldCLS + 0.05% for MFIO1 and msold
CLS 0.05% for MFIO2 with constant evolution degree 1.8%. The other parameters are set to default values. The results depicted in Figure 3 show that all algorithms exhibit linear scalability, and that MFIO1(H) performs slower than AROS(H) for incremental size over 140,000, because undetermined candidates requiring rescanning the original database increases under msnew msold, and
processing time is proportional to the number of transactions.
10 80 150 220 290 2 4 6 8 10 12 14 16 18 20
Number of incremental transctions (x 10,000)
R u n ti m e (s ec .) AROC(V) AROS(V) MFIO1(V) MFIO2(V) 400 1200 2000 2800 3600 2 4 6 8 10 12 14 16 18 20
Number of incremental transctions (x 10,000)
R u n ti m e (s ec .) AROC(H) AROS(H) MFIO1(H) MFIO2(H)
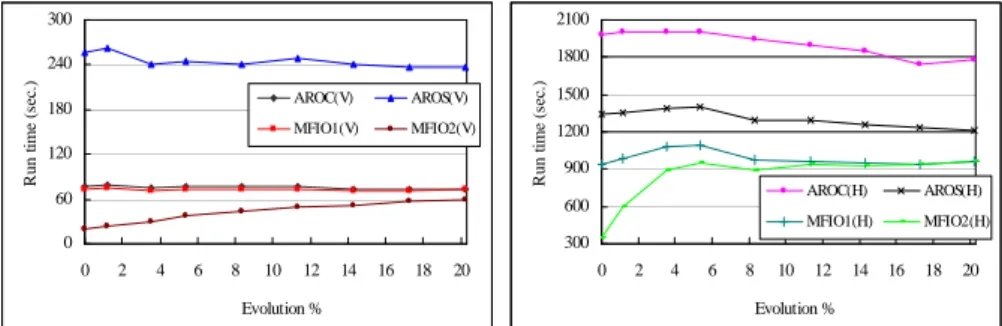
Fig. 3. Performance evaluation for varying incremental transaction size under multiple minimum supports with (a) vertical intersection counting; and (b) horizontal counting. Next, we examined the effect of varying the degrees of ontology evolution. The other parameters were set as before. As the results in Figure 4 show, algorithm MFIO is heavily affected by the degree of evolution, whereas AROC and AROS exhibit steady performance. When the degree of evolution decreases, the performance gap between MFIO2(V) and AROC(V) and that between MFIO2(H) and AROC(H) increases since the number of affected candidates decreases and so does the possibility of rescanning original database. On the contrary, when the degree of ontology evolution increases, the advantage of reusing original frequent itemsets for MFIO(V) and MFIO(H) disappears gradually. This is because most original frequent itemsets turn out to be affected itemsets, and provoke rescanning the original database.
6
Conclusions and Future Work
In this paper, we have investigated the problem of maintaining discovered association rules with ontological information in an evolving environment. We have considered all possible evolving factors that would affect the feasibility of discovered itemsets, including transaction update, ontology evolution and/or minimum support refinement. To facilitate and accelerate the mining process, we have differentiated affected
itemsets from unaffected ones, dealt with minimum support refinement and incremental transactions, and further utilized this information to determine in advance whether or not an itemset is frequent so that this approach can provide another opportunity for candidate pruning and alleviation of database rescan. Finally, we proposed a unified maintaining algorithm, MIFO, for maintaining discovered frequent itemsets. Empirical evaluation showed that the algorithm is very effective and has good linear scale-up characteristic, as compared with applying our previous proposed mining algorithms AROC and AROS from scratch. In the future, we will extend this work to other types of ontology that consists of more complicated semantic relationships [18], and develop other categories of association mining algorithms such as FP-growth [8]. 0 60 120 180 240 300 0 2 4 6 8 10 12 14 16 18 20 Evolution % R u n ti m e (s ec .) AROC(V) AROS(V) MFIO1(V) MFIO2(V) 300 600 900 1200 1500 1800 2100 0 2 4 6 8 10 12 14 16 18 20 Evolution % R u n ti m e (s ec .) AROC(H) AROS(H) MFIO1(H) MFIO2(H)
Fig. 4. Performance evaluation for different evolution degrees under multiple minimum supports with (a) vertical intersection counting; and (b) horizontal counting.
Acknowledgements
This work is partially supported by National Science Council of Taiwan under grant No. NSC95-2221-E-390-024.
References
1. Agrawal, R., Srikant, R.: Fast Algorithms for Mining Association Rules. In: Proc. of 20th Int. Conf. on Very Large Data Bases, pp. 487--499 (1994)
2. Cheung, D.W., Han, J., Ng, V.T., Wong, C.Y.: Maintenance of Discovered Association Rules in Large Databases: An Incremental Update Technique. In: Proc. of 12th Int. Conf. on Data Engineering, pp.106--114 (1996)
3. Cheung, D.W., Ng, V.T., Tam, B.W.: Maintenance of Discovered Knowledge: A Case in Multi-Level Association Rules. In: Proc. of 2nd Int. Conf. on Knowledge Discovery and Data Mining, pp. 307--310 (1996)
4. Cheung, D.W., Lee, S.D., Kao, B.: A General Incremental Technique for Maintaining Discovered Association Rules. In: Proc. of 5th Int. Conf. on Database Systems for Advanced Applications, pp. 185--194 (1997)
5. Chien, B.C., Wang, J.J., Zhong, M.H.: Mining Fuzzy Association Rules on Has-a and Is-a Hierarchical Structures. International Journal of Advanced Computational Intelligence & Intelligent Informatics 11(4), pp.423--432 (2007)
6. Fayyad, U., Piatetsky-Shapiro, G., Smyth, P.: The KDD Process for Extracting Useful Knowledge from Volumes of Data. Communications of the ACM 39(11), pp. 27--34 (1996) 7. Han, J., Fu, Y.: Discovery of Multiple-Level Association Rules from Large Databases. In:
Proc. of 21st Int. Conf. on Very Large Data Bases, pp. 420--431 (1995)
8. Han, J., Pei, J., Yin, Y.: Mining Frequent Patterns without Candidate Generation. In: Proc. of 2000 ACM SIGMOD Int. Conf. on Management of Data, pp. 1--12 (2000)
9. Hong, T.P., Wang, C.Y., Tao, Y.H.: A New Incremental Data Mining Algorithm Using Pre-Large Itemsets. Intelligent Data Analysis 5(2), pp. 111--129 (2001)
10. Jea, K.F., Chiu, T.P., Chang, M.Y.: Mining Multiple-Level Association Rules in Has-a Hierarchy. In: Proc. of Joint Conf. on AI, Fuzzy System, and Grey System (2003)
11. Lin, W.Y., Tseng, M.C.: Automated Support Specification for Efficient Mining of Interesting Association Rules. Journal of Information Science 32(3), pp. 238--250 (2006) 12. Liu, B., Hsu, W., Ma, Y.: Mining Association Rules with Multiple Minimum Supports. In:
Proc. of 1999 Int. Conf. on Knowledge Discovery and Data Mining, pp. 337--341 (1999) 13. Ng, K.K., Lam, W.: Updating of Association Rules Dynamically. In: Proc. of 1999 Int.
Symposium on Database Applications in Non-Traditional Environments, pp. 84--91 (2000) 14. OWL Web Ontology Language Use Cases and Requirements,
http://www.w3.org/TR/webont-req/ (2004)
15. Sarda, N.L., Srinivas, N.V.: An Adaptive Algorithm for Incremental Mining of Association Rules. In: Proc. of 9th Int. Workshop on Database and Expert Systems Applications, pp. 240--245 (1998)
16. Savasere, A., Omiecinski, E., Navathe, S.: An Efficient Algorithm for Mining Association Rules in Large Databases. In: Proc. of 21st Int. Conf. on Very Large Data Bases, pp. 432--444 (1995)
17. Srikant, R., Agrawal, R.: Mining Generalized Association Rules. In: Proc. of 21st Int. Conf. on Very Large Data Bases, pp. 407--419 (1995)
18. Storey, V.C.: Understanding Semantic Relationships. Very Large Databases Journal 2(4), pp. 455--488 (1993)
19. Thomas, S., Bodagala, S., Alsabti, K., Ranka, S.: An Efficient Algorithm for the Incremental Updation of Association Rules in Large Databases. In: Proc. of 3rd Int. Conf. on Knowledge Discovery and Data Mining, pp. 263--266 (1997)
20. Tseng, M.C., Lin, W.Y.: Maintenance of Generalized Association Rules with Multiple Minimum Supports. Intelligent Data Analysis 8, pp. 417--436 (2004)
21. Tseng, M.C., Lin, W.Y., Jeng, R.: Mining Association Rules with Ontological Information. In: Proc. of 2nd Int. Conf. on Innovative Computing, Information and Control, pp. 300--303 (2007)