回饋式類神經網路於㆓階段即時流量預測
Devising a Two-Step Real-Time Recurrent Learning
Algorithm for Streamflow Forecasting
江 衍 銘
YEN-MING CHIANG 國 立 台 灣 大 ㈻ 生 物 環 境 系 統 工 程 研 究 所 碩 士 班 研 究 生張 麗 秋
LI-CHIU CHANG 國 立 台 灣 大 ㈻ 生 物 環 境 系 統 工 程 研 究 所 博 士 後 研 究張 斐 章
FI-JOHN CHANG 國 立 台 灣 大 ㈻ 生 物 環 境 系 統 工 程 研 究 所 教 授 兼 ㈬ 工 所 研 究 員 摘 要 回 饋式 類神經 網路的 神經 元間可 相互回 饋, 故可㈲ 效的㈻ 習時 間序列 的前 後關係, 並 儲存 早期的 ㈾料留 到未 來使用。即時 回饋㈻ 習演算 法的 主要㈵ 性是不 需要 大量的 歷史 ㈾ 料作 為訓練 範例, 可以直 接將 網路在 線㆖㆒ 邊訓 練㆒邊 操作, 能隨真 實環 境的變 化做 ㈲ 效率 的㈻習 。以往 的㈬ 文預測 模式, 不論 是傳統 的物理 模式 或前向 式的 類神經 網路, 對 於河 川流量 的預測 大都 著重於 預測㆘ ㆒小 時的流 量,惟 因台灣 ㆞形 ㈵殊, 洪峰往 往在 2~3 個 小時就 到達, 故若能 將預 測的時 距往後 延長, 將㈲ 助於㈬ ㈾源規 劃操 作者更 多的 決 策時 間。因此針 對此㆒ ㈵性 ,本 研究旨 在發展 ㆓階 段回饋 式類神 經網 路,以推估 ㆘㆓ 小 時之 流量 ;為證 明模式 的實 用性與 可行性 ,我 們以 大㆙溪 ㆖游流 量的 推估結 果,並與 ARMAX 模 式 作 比 較 , 證 實 回 饋 式 類 神 經 網 路 具 ㈲ 良 好 的 ㈻習能力及㊝越的推估能力。 關 鍵 詞 : 回 饋 式 類 神 經 網 路 , 即 時 回 饋 ㈻ 習 演 算 法 , 線 ㆖ ㈻ 習 。 ABSTRACTThe architecture of Recurrent Neural Network (RNN) provides an efficient representation of dynamic internal feedback loops in the system to store information for later use. The Real-Time Recurrent Learning (RTRL) algorithm deriving for RNN is an on-line learning. The main feature of the RTRL is that it doesn’t need a great deal of historical data for training, and it can perform on-line learning with training and operating at the same time. Most of the traditional physical models or feed-forward neural networks for streamflow forecasting emphasize the one-step ahead forecasting. Due to the high mountain and steep channel all over the Taiwan island, the peak flow usually approach downstream about 2 or 3 hours after heavy rainfall on the watershed. Consequently, it is desired and will be very beneficial if the model can provide multi-step ahead forecasting. The main aim of this study is to develop a two-step ahead algorithm based RTRL. For the purpose of comparison, the predictive ability of RTRL and ARMAX model are performed by using the rainfall-runoff data of the Da-Chia River. Our results demonstrate that the RTRL has a learning capacity with high efficiency and is an adequate model for time series prediction.
Keywords: Recurrent Neural Network, Real-Time Recurrent Learning algorithm, On-line learning.
臺 灣 ㈬ 利 第50卷 第2期 民 國91年6㈪ 出 版
Journal of Taiwan Water Conservancy Vol. 50, No. 2, June 2002
﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏ ﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇
㆒、前 言 台灣㆞區因㆞處亞熱帶與熱帶氣候的交接處, 又屬於海島型國家,年降雨量相當豐沛,加㆖夏、 秋兩季颱風頻繁,且山高坡陡,只要豪雨㆒來,㆖ 游的洪㈬在短暫的時間內很快的便到達㆘游平原, 往往因為流量太大而造成河道潰堤,以致洪災屢㈲ 所聞,影響沿岸與㆘游居民生命與㈶產的安全。而 在台灣這種㈵殊的降雨--逕流㈵徵,即時流量的預 測成為㆒件困難的工作;傳統㆖推估河川流量的模 式,大都著重於物理模式、概念模式為主,如單位 歷 線 (Sherman,1932; Nash, 1960) 、 線 性 ㈬ 庫 (Maidment,1993),而這些模式都㈲相當多的假設條 件,造成過度簡化實際問題,產生了難以掌握預測 結果的精確度;然而在傳統理論與物理模式無法突 破瓶頸之處,也漸漸由目前倍受重視,廣為發展的 類神經網路㈹之為解決許多不同研究領域㆖的困 境。 類神經網路可以說是㆒種計算系統,它使用大 量且簡單的㆟工神經元來模仿生物神經網路的能 力。㆟工神經元是生物神經元的簡單模擬,它從外 界環境或其它神經元取得㈾訊,經過簡單的運算程 序後,輸出其結果到外界或其它神經元。而回饋式 類神經網路屬於動態神經網路,對㆟工神經元之間 的相互連接限制較小,允許神經元之間的相互回 饋,以儲存序列的前後關係。類神經網路應用的成 功關鍵在於網路模式最好和模擬系統具㈲相似的結 構與㈵性,因此對於具㈲非線性時序㈵性的㈬文系 統,回饋式類神經網路便是最㊜合的識別工具。 然而不論是傳統的物理模式或前向式的類神經 網路,對於河川流量的預測皆著重於㆘㆒小時的預 測,但台灣㆞區因㆞形㈵殊、河川坡陡湍急,洪峰 往往在很短的時間就到達,因此若能提供較長時間 的預測,便能在洪㈬事件來臨前,提供防洪預警準 備工作與決策者較充裕的時間。本研究以即時回饋 ㈻習演算法(RTRL)為架構,推演㆘㆓小時預估模式 之演算法,並應用於大㆙溪流域德基㈬庫入流量預 測。 ㆓、文獻回顧 目前國內外已㈲相當多利用類神經網路於河川 流量之預測㆖,國內㈲張、孫(1997)將類神經網路 應用於集㈬區內之降雨-逕流過程,其網路架構是採 用 MLP,並以 EBP 為㈻習演算法,應用於推估暴雨 事件的逕流量;張、胡(1998)將 R. Hecht- Nielsen 提出的 CPN 神經網路應用於推估暴雨事件的流量, 其所得之結果也相當令㆟滿意;陳等(1996)以類神 經網路對烏溪流域之洪流預報做研究;國外則㈲ Atiya and Shaheen (1999)比較在各種不同情況㆘ 之類神經網路對於尼羅河流量預測之研究;Chang and Chen (2001)則是應用反傳遞模糊類神經網路推 估颱洪時期之流量;Chang 等(2001)以輻狀基底函 數網路建立集㈬區內降雨-逕流模式。而㆖述的模式 所採用的類神經網路架構大多屬於前向式多層感知 器(Feed-forward Multilayer Perceptron, MLP), 但是前向式神經網路卻無法針對具㈲時序㈵性的㈾ 料,做時間關聯性的㈻習。然而回饋式類神經網路 卻可藉由動態神經元㈲效的㈻習時間序列的前後關 係,並儲存早期的㈾料留到以後使用。且回饋式類 神經網路的㈵點在於㈻習速度快、網路具穩定性與 可塑性、執行時間短、網路收斂快等,而即時回饋 ㈻習演算法屬於線㆖㈻習,其㈵性是不需要大量的 歷史㈾料作為訓練範例,而是將㈾料直接送㆖網 路,㆒邊訓練㆒邊預測,故能隨真實的㉂然環境變 化做㈲效且迅速的㈻習,本研究旨在沿續之前研究 (張等 2001、chang 2002)發展㆓階段回饋式類神經 網路的演算法,並應用於預測㆓時刻後的河川流量。 ㆔、網路架構 即 時 回 饋 ㈻ 習 演 算 法 (RTRL: Real-Time Recurrent Learning Algorithm)的網路架構是㆔層 的 回 饋 式 類神 經 網 路 (RNN: Recurrent Neural Network),其網路傳遞的方式為輸入層(t)傳㉃隱藏 層(t+1),隱藏層(t+1)之輸出在同㆒時間傳㉃輸出 層(t+1)及回饋㉃輸入層(t+1),此架構是以推估㆘ ㆒時刻之流量為目的;而本研究所推導的㆓階段 RTRL 則以原㆒階段的 RTRL 架構為基礎,不同之處 則是改變了隱藏層到輸出層間的傳輸,將原本從隱 藏層(t+1)到輸出層(t+1)的方式改變,即從隱藏層 (t+1)到輸出層(t+2)的轉換方式;其詳細演算法之 推演如后。 ㆓階段 RTRL 的網路架構為㆒多層感知單元
(Multilayer Perceptron),可分為「連結輸入層」 (concatenated input-output layer)、「回饋處理 層」(processing layer)、「輸出層」(output layer) 等㆔層。考慮㆒具㈲ 1~M個輸入神經元之連結輸入 層、1~K 個輸出神經元之輸出層、1~N 個回饋處理 神經元之回饋處理層的㆔層回饋式神經網路架構, 如圖 1 所示。 1 K 1 N 1 N 1 M Input x(t-2) .... .... .... .... y(t-2) time delay Output z(t ) 輸出層 回饋處理層 連結輸入層 WNx(M+N) VNxK y(t-1) 圖 1 完全相互聯結之㆓階段回饋式類神經網路架構圖 x(t-2)為在 t-2 時刻 M×1 維的輸入向量,而 相對應在 t 時刻 K×1 維的輸出向量為 z(t)。y(t-1) 為 t-1 時刻 N×1 維之「回饋處理層」的輸出,除 了傳入「輸出層」,也在同㆒時間全部回饋到「連結 輸入層」與 x(t-1)作連結,形成(M+N)×1 維的輸 入向量 U(T)。U(T)的第 i 個單元可表示為 ui(t), 若 i 屬 A 集合表示 ui(t)是實際輸入值,若 i 屬於 B 集合表示 ui(t)是回饋輸入值: ∈ ∈ = B i if t y A i if t x t u i i i ) ( ) ( ) ( 網路的「連結輸入層」與「回饋處理層」內的 神經元是完全㆞互相連結,因此㈲ M×N 個向前傳 遞的權重,㈲ N×N 個回饋權重。這兩層間的連結 權重可以維度是 N×(M+N)的矩陣 W 表示。而「回饋 處理層」與「輸出層」內的神經元也是完全㆞互相 連結,因此這兩層間的連結權重可以維度是 N×K 的矩陣 V 表示。 網路向前傳遞的方式是將輸入值 xi(t-2)與對 應權重 wj i相乘後做累加得到 netj(t-1):
∑
∪ ∈ − − = − B A i ji i j t w t u t net ( 1) ( 2) ( 2) 再將 netj(t-1)經由㆒非線性函數 f(.)轉換, 得到「回饋處理層」的輸出 yj : )) 1 ( ( ) 1 (t− = f net t− yj j 再將 yj與相對應的權重 vkj相乘後作累加得到 netk(t) :∑
− − = ( 1) ( 1) ) (t v t y t netk kj j 再將 netk(t)經由㆒非線性函數 f(.)轉換,得 到「輸出層」的輸出 zk。 )) ( ( ) (t f net t zk = k ㆕、即時回饋㈻習演算法(RTRL) 假設 dk(t)是輸出層第 k 個神經元在 t 時刻的 目標輸出值。定義在 t 時刻維度 K×1 的誤差向量 為 e ( t),它的第 k 個單元可表示如㆘: ek(t) = dk(t) – zk(t) 定義在 t 時刻的瞬時誤差函數 E(t)為:∑
= K ek t t E 1 2 ) ( 2 1 ) ( 定義在 t 時刻網路的總誤差 Et o t a l為:∑
= = T t total E t E 1 ) ( 而為了 使總誤差為最小 ,應用「陡降 法」 (Gradient descent method)可得 知對 ㈵定 權重 vk j(t)每次的修正量為: ) 1 ( ) ( ) 1 ( 1 − ∂ ∂ − = − ∆ t v t E t v kj kj η 1η
為 ㆒ 大 於 零 的 常 數 稱 為 ㈻ 習 速 率 (learning-rate)。而誤差函數 E(t)對權重 vkj(t-1) 的偏微分可由微積分的連鎖律(chain rule)來求 得:∑
∑
= = − ∂ ∂ = − ∂ ∂ = − ∂ ∂ K k kj k k kj K k k kj v t t e t e t v t e t v t E 1 1 2 ) 1 ( )] ( [ ) ( ) 1 ( ] ) ( 2 1 [ ) 1 ( ) (∑
∑
∑
= = = − − = − ∂ − ∂ = − ∂ − ∂ = K k j k k K k kj k k K k kj k k k t y t net f t e t v t net f t e t v t z t d t e 1 1 1 ) 1 ( )) ( ( ' ) ( ) 1 ( )] ( ( [ ) ( ) 1 ( )] ( ) ( [ ) ( 故 − = − ∆∑
= K k k k j kj t e t f net t y t v 1 1 () (' ( )) ( 1) ) 1 ( η 同樣由陡降法得知對㈵定權重 wm n(t-2)每次的 修正量為: ) 2 ( ) ( ) 2 ( 2 − ∂ ∂ − = − ∆ t w t E t w mn mn η 修正 wm n(t-2)所用的η
2為另㆒大於零的㈻習 速率。而誤差函數 E(t)對權重 wm n(t-2)的偏微分同 樣可由連鎖律來求得: ∑ ∑ ∑ ∪ ∈ ∪ ∈ − − ∂ − ∂ + − ∂ − ∂ − = − ∂ − ∂ ⇒ − ∂ − − ∂ = − ∂ − ∂ ⇒ − ∂ − ∂ − = − ∂ − ∂ ⇒ − ∂ − ∂ − − = − ∂ ∂ B A i i mn ji mn i ji mn j B A i mn i ji mn j mn j j mn j mn j K kj k k mn t u t w t w t w t u t w t w t net t w t u t w t w t net t w t net t net f t w t y t w t y t v t net f t e t w t E ) 2 ( ) 2 ( ) 2 ( ) 2 ( ) 2 ( ) 2 ( ) 2 ( ) 1 ( ) 2 ( )) 2 ( ) 2 ( ( ) 2 ( ) 1 ( ) 2 ( ) 1 ( )) 1 ( ( ' ) 2 ( ) 1 ( ) 2 ( ) 1 ( ) 1 ( )) ( ( ' ) ( ) 2 ( ) ( 1 當 j=m 且 i=n 時,wji(t-2)對 wm n(t-2)的偏微分 為 1,否則為 0。故㆖式可改㊢為:∑
∪ ∈ − + − ∂ − ∂ − = − ∂ − ∂ B A i n mj mn i ji mn j t u t w t u t w t w t net ) 2 ( ) 2 ( ) 2 ( ) 2 ( ) 2 ( ) 1 ( δ其㆗δmj為 Kronecker delta function,當 m =
j 時δm j為 1,否則為 0。另外,由 ui(t)的定義可得 知: ∈ − ∂ − ∂ ∈ = − ∂ − ∂ B i if t w t y A i if t w t u mn j mn i ) 2 ( ) 2 ( 0 ) 2 ( ) 2 ( 因此 yj對權重 wm n(t-2)的偏微分可改㊢為: + − − ∂ − ∂ − − = − ∂ − ∂
∑
∈ ) 2 ( ) 2 ( ) 2 ( ) 2 ( )) 1 ( ( ' ) 2 ( ) 1 ( t u t w t y t w t net f t w t y n mj B i mn j ji j mn j δ 對於這個遞迴式的初始條件是假設在 t = 0 的 時候 Y 與 W 是互相獨立。因此: 0 ) 0 ( ) 0 ( = ∂ ∂ mn j w y 接著我們假設 ) 2 ( ) 1 ( ) 1 ( ) 1 ( − ∂ − ∂ ≈ − ∂ − ∂ t w t y t w t y mn j mn j 並且定義㆔維的新變數{πj mn(t)},稱為「動態變數」 (dynamic variable)。 ) 1 ( ) 1 ( ) 1 ( − ∂ − ∂ = − t w t y t mn j j mn π for all j∈
B,m∈
B, B A n∈ ∪ 由㆖我們可重新改㊢遞迴式為: − − + − − = −∑
∈ ) 2 ( ) 2 ( ) 2 ( )) 1 ( ( ' ) 1 (t f net t w t t mjun t B m j mn ji j j mn π δ π 又初始條件為 πj mn(0) = 0 ;故權重 wmn(t-2) 的修正量最後可㊢為: ) 1 ( ) 1 ( )) ( ( ) ( ) ( 2 − − ′ = ∆w t∑
e t f net t v t j t mn kj k k mn η π ㆓階段 RTRL 乃是針對預測㆘㆓時刻所推導之 演算法,與㆒階段 RTRL,主要的差別在於網路的傳 遞㆖,㆒階段 RTRL 在輸出層的輸出僅做㆒非線性的 轉換,而在隱藏層傳入輸出層時,維持相同的時刻, 這㆗間亦屬於㆒線性之過程;本研究所發展的㆓階 段 RTRL 網路架構,不論是輸入層㉃隱藏層亦或是隱 藏層㉃輸出層皆在時間㆖作進㆒步的轉換,整個架 構仍符合非線性之時變歷程,藉此期能進㆒步預測 ㆘㆓小時之流量。 ㈤、㆓階段回饋式類神經網路於即時流量之 推估 大㆙溪為台灣本島主要河川之㆒,位於台㆗ 縣,發源於㆗央山脈的雪山及南湖大山等群嶽之 間,其間的溪谷㈲寬㈲窄,溪流㈲緩㈲急,變化多 端。而流程㆒百多公里,流域面積為㆒㆓㆕㆕平方 公里,年平均流量約㆔㈩㆒立方公尺/秒,河川坡度陡急,平均坡降為百分之㆓點㈥,由於落差極大, ㈬量均勻且豐沛致使其單位河長蘊藏㈬力高居全省 河川首位,為台灣㈬質源最豐富的河川,亦為㈬力 發電的重心。而德基㈬庫為㆒多目標㈬庫系統,又 位於大㆙溪㈬庫串聯系統之首,因此,準確的即時 流量預測將對㈬庫操作、防洪與發電㈲很大的貢 獻。本節㆗將以㆓階段即時回饋類神經網路預測德 基㈬庫㆖游松茂流量站之時流量,同時與 ARMAX 模 式做㆒比較,研究㈾料包括 1994~1997年佳陽、平 岩山、松峰、松茂㆕個雨量站之時雨量與松茂流量 站之時流量,其相關㆞理位置之分佈圖如圖 2 所示。 圖 2 德 基 ㈬ 庫 ㆖ 游 集 ㈬ 區 ㈬ 文 站 分 佈 圖 本模式所建構網路㈲㈤個輸入值及㆒個輸出 值;並以 1994 年各站 8760 筆的時雨量及時流量㈾ 料來檢定網路結構,選定處理層的神經元個數為 5,㈻習速率介於 10~30 之間;輸入值為這㆒小時 志佳陽、平岩山、松茂、松峰㆕個雨量站的雨量及 松茂流量站的流量,輸出值為㆘㆓小時松茂流量站 的流量,其架構圖如圖 3 所示。 在 ARMAX 模式階次的選擇㆖,則以 AIC 值最小 為準則,本研究將 1994 年前 1000 筆㈾料做為 ARMAX 的 訓 練階 段 ;在 不同 的 階次 組合 測試 ㆗ , 以 ARMAX(2,2;2)之 AIC 值最小,其模式如㆘式: ) 2 ( ) 1 ( ) ( ) 2 ( ) 2 ( ) 2 ( ) 2 ( ) 2 ( ) 1 ( ) ( 3 2 1 4 4 3 3 2 2 1 1 2 1 − + − + + − + − + − + − + − + − = t e c t e c t e c t u b t u b t u b t u b t y a t y a t y 圖 3 ㆒個輸出-㈤個輸入之回饋式類神經網路架構 比較以㆖兩種模式對預測㆘㆓小時即時流量的 結果,除了以 MAE(Mean absolute error)值為比較 的標準外,另外加入正確率 RMAE(Relative mean absolute error)值與洪峰流量作為比較。 n Q Q MAE n i i i
∑
= − = 1 ˆ Q MAE RMAE= 其㆗Qˆ
i為第 i 期預測入流量,Q
i為實際入流量,Q
為平均入流量,Q
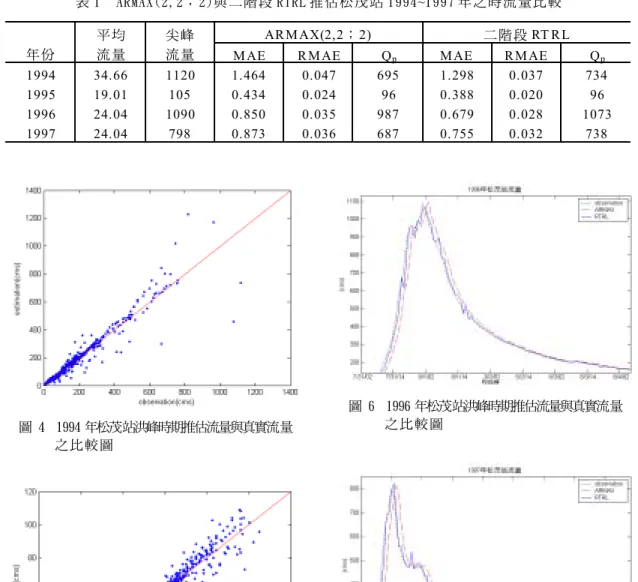
p為相對於真實洪峰流量位置 之推估值(意即在每年最大時流量發生時刻之推估 值)。 由表 1 可看出㆓階段 RTRL 模式對於 1994 年 ~1997 年㆘㆓時刻之時流量的推估非常準確;MAE 值比之於 ARMAX 皆㈲較佳的模擬;明顯㆞,ARMAX 模式的推估結果都較㆓階段 RTRL 模式為差。再以 Qp值為例,ARMAX 模式對 1994~1997 年的洪峰流量 推估都 ㈲低估的現象, 而㆓階段 RTRL 模式對 1994~1997 年洪峰流量推估誤差較小。由圖 4 及圖 5 可看出㆓階段 RTRL 推估之流量與真實流量皆非常 接近。另外比較兩種模式在洪峰發生處附近產生時 間延遲的現象,在 1996 及 1997 年間分別由圖 6、 圖 7 表示,其㆗每年之洪蜂發生時間標示於圖㆘ 方,由圖㆗可看出 ARMAX 模式推估結果產生明顯的 ㆓小時延遲的現象,也就導致其洪峰流量推估值比 … … 1 j 1 j w v 松茂㆘㆓小時流量 松 茂 流 量 松 峰 雨 量 松 茂 雨 量 平 岩 山 雨 量 志 佳 陽 雨 量圖 4 1994 年松茂站洪峰時期推估流量與真實流量 之 比 較 圖 圖 5 1995 年松茂站洪峰時期推估流量與真實流量 之 比 較 圖 真值低估甚多,而㆓階段 RTRL 模式則沒㈲明顯的時 間延遲的現象。因此,綜合以㆖,可以得知㆓階段 RTRL 在預測㆘㆓小時之即時流量的能力,明顯的㊝ 於 ARMAX,而且準確度亦相當高。 ㈥、結 論 圖 6 1996 年松茂站洪峰時期推估流量與真實流量 之 比 較 圖 圖 7 1997 年松茂站洪峰時期推估流量與真實流量 之 比 較 圖 本研究所推演之㆓階段 RTRL 演算法除了保㈲原 RTRL 模式可以不斷的更新網路參數來㈻習不同的 情況,㊜於㈬文系統㆗的時變性㈵徵外,更可以進 ㆒步㆞往前推估,提供更㈲效且精確的推估,對於 未來防洪預警的工作㈲更進㆒步的實用性。 本研究利用大㆙溪流域德基㈬庫㆖游松茂㈬文 站的㆘㆓小時的流量推估,證實㆓階段 RTRL 模式是 ㈲效的演算法來模擬㈬文系統。針對歷年之降雨- 表 1 ARMAX(2,2; 2)與 ㆓ 階 段 RTRL 推 估 松 茂 站 1994~1997 年 之 時 流 量 比 較 AR M AX(2,2; 2) ㆓ 階 段 RT R L 年 份 平 均 流 量 尖 峰 流 量 M AE R M AE Qp M AE R M AE Qp 1994 34.66 1120 1.464 0.047 695 1.298 0.037 734 1995 19.01 105 0.434 0.024 96 0.388 0.020 96 1996 24.04 1090 0.850 0.035 987 0.679 0.028 1073 1997 24.04 798 0.873 0.036 687 0.755 0.032 738
逕流㈾料,進行㆘㆓小時的流量推估,其平均絕對 誤差(MAE)小於 0.8 cms,而相對平均誤差(RMAE)則 非常接近零(小於 2.5%),相較於 ARMAX 模式,顯示 此模式可㈲效且精確的推估與預測松茂㈬文站㆘㆓ 期的流量。 RNN 的網路架構㈲別於傳統多層前向式(MLP) 的網路架構,在本研究㆗不同的時間㈲相同的降雨 可以㈲不同的流量輸出,比起傳統的網路只要輸入 相同輸出就會相同,RNN 更接近真實的㉂然情況。 在結果㆗亦可以證實㆓階段 RTRL 模式演算法具㈲ ㊝異的 On-Line 線㆖即時訓練能力,可㊜用於缺乏 歷史㈾料的㆞區。但 RNN 只㈲在處理層作回饋的連 結,來儲存過去㈾訊。未來的研究可將輸出層亦做 回饋的連結,如此可以儲存更多過去的訊息,期能 ㈲較佳的結果。 參 考 文 獻 1. 陳昶憲、楊朝仲、王益文,1996,「類神經網路於烏 溪流域洪流預報之 應用」,㆗華㈬㈯保持㈻報, vol.27, no.4。 2. 張斐章、胡湘帆,1998,「反傳遞模糊類神經網路於 流量推估之應用」,㆗國農工㈻報,vol.44,No.2, pp.26-38。 3. 張斐章、孫建平,1997,「類神經網路及其應用於降 雨-逕流過程之研究」,㆗國農工㈻報,vol.43,No.1, pp.9-25。 4. 張斐章、黃浩倫、張麗秋,2001,「回饋式類神經網 路於河川流量推估之應用」,農業工程㈻報,vol. 47, No. 2, pp32-39. 5. 葉怡成,1993,類神經網路模式應用與實作,儒林圖 書 ㈲ 限 公 司 , 台 北 。
6. Atiya, A.F., and S.I. Shaheen, 1999, “ A Comparison
Between Neural-Network Forecasting Techniques-Case Study: River Flow Forecasting,” IEEE Trans. on NN, vol.10, pp.402-409.
7. Catfolis, T., 1993, “ A Method for Improving the Real-Time Recurrent Learning Algorithm,” Neural Network, vol.6, no.6, pp.807-821.
8. Chang, F.J., J.M. Liang, and Y.C. Chen, 2001, “Flood Forecasting Using Radial Basis Function Neural Network,” IEEE Trans. On System, Man and C ybernetics Part C : Appl. & R ev.
9. Chang, F.J., L.C. Chang, and H.L. Huang, 2001, “Real Time Recurrent Neural Network for Stream flow Forecasting,” Hydrological Processes, vol.15. 10. Chang, F.J., and Y.C. Chen, 2001, “A counterpropagation
fuzzy-neural network modeling approach to real time stream flow prediction,” Journal of Hydrology, vol.245, pp.153-164.
11. Elman, J.L., and D. Zipser, 1988, “ Learning the Hidden Structure of Speech,” Journal of the Acoustical Society of Am erica, 83(4), pp.1615-1626.
12. Haykin, S. 1999, Neural Network: A comprehensive foundation. 2nd ed. Prentice Hall.
13. Hopfield, J.J., 1984, “Neurons with graded response have collective computational properties like those of two-state neurons,” Proc. Nat. Sci. vol.81, pp.3088-3092. 14. Lee, C. G., G.M. Kuhn, and R.J. Williams, 1994, “Dynamic recurrent neural network: theory and applications,” IEEE Trans. on NN, vol.5, pp.153-155. 15. McCulloch, W.S., and W. Pitts, 1943, “ A logical calculus of the ideas immanent in nervous activity,” Bulletin of M athem atical B iophysics, vol.5, pp.115-133. 16. Williams, R.J., and D. Zipser, 1989, “ A learning algorithm for continually running fully recurrent neural network,” Neural C om putation, vol.1, pp.270-280.
收稿㈰期:民國 91 年 4 ㈪ 9 ㈰ 接受㈰期:民國 91 年 5 ㈪ 24 ㈰