利用階層分解之視訊壓縮
82
0
0
全文
(2) 利用階層分解之視訊壓縮. 研究生:陳育信. 指導教授:莊仁輝 博士. 國立交通大學 資訊科學研究所. 摘要 本論文針對現行的視訊壓縮標準 H.264,探討前景和背景分析的應用,目的在透 過前景的影像品質、背景的資料量之降低,以及壓縮速度之提升等三方面,來改 善整體標準的壓縮效率。本論文對於 H.264 標準中可變區塊大小和失真模糊率的 兩種編碼工具進行調整與分析,並提出利用前景與背景遮罩來增加編碼效能,而 這個方法亦符合 H.264 標準內所規範的語法和語意,不會有相容性的問題。實驗 的結果也顯示,我們所提出的方法能相當有效的改善 H.264 的編碼效率。另外, 本論文亦提出一套自動視訊切割方法可供使用者使用,可以在攝影機運動的情況 下,切割出真實世界中運動的物體,實驗結果顯示,我們所提出的方法切割效果 良好。. i.
(3) Video Compression via Layer Decomposition. Student:Yu-Shin Chen. Advisor:Dr. Jen-Hui Chaung. Institute of Computer and Information Science Nation Chiao Tung University. ABSTRACT In this thesis we develop a method to improve the encoding performance of the H.264 video standard when the foreground and background models are given. The encoding performance is measured in three aspects: the PSNR, bit-rates and coding speed. By analyzing the variable block-size and rate-distortion coding tools of H.264, the proposed methods can enhance the video quality of the foreground objects and reduce the compression bit-rates of the background area. The syntax and semantics of the encoded bit-streams generated by our method also agree with H.264. Experimental results show that the proposed methods are quite effective in the performance improvement of the H.264 encoding. We also propose an automatic method for video segmentation which can find out the moving object in the video even when the video is taken by non-static camera. Experimental results show the correct segmentation rate are quite good. ii.
(4) 致謝 在這兩年的求學過程中,要感謝曾經幫助過我、教導過我的人。首先謝謝指 導教授莊仁輝老師,在兩年來的研究生涯中給予熱心的指導與教誨,老師常常在 百忙之餘仍費心的指導我,因此使我的論文能夠更加的豐富與完整。同時,也感 謝口試委員陳玲慧教授、雷欽隆教授和顏嗣鈞教授的建議和指教,使得本論文的 內容更加充實。 在交大的這些日子,認識了許許多多新的朋友,讓我的求學生涯更加的快樂 與順利,而實驗室裡的每一位同學、學長與學弟們也都很好相處,常常實驗室就 像一個大家庭般的熱鬧、溫馨;也謝謝大家這些日子來的幫忙與指教,才能讓我 在短短的兩年學到這麼多東西。. i.
(5) 目錄 第一章 簡介..................................................................................................................1 第二章 H.264/AVC 視訊壓縮標準..............................................................................3 2.1 簡介.................................................................................................................3 2.2 預測編碼 ( Prediction Coding ) ...................................................................4 2.2.1 畫面內的預測(Intra Prediction).....................................................4 2.2.2 畫面間的預測 (Inter Prediction )......................................................5 2.3 轉換、量化與熵編碼...................................................................................10 2.3.1 轉換(Transform)...........................................................................10 2.3.2 量化(Quantization).......................................................................10 2.3.3 熵編碼(Entropy coding)...............................................................11 第三章 前景與背景之訊切割與壓縮的相關研究探討............................................12 3.1 利用空間的資訊對靜態影像做切割...........................................................12 3.2 利用時空的資訊對視訊影像做切割...........................................................13 3.3 視訊壓縮的相關探討...................................................................................14 第四章 H.264 壓縮工具之分析、壓縮效能..............................................................15 4.1 RDO(Rate-Distortion Optimization)壓縮效能分析 ................................15 4.1.1 RDO 參數λ與畫面品質、資料量之關係.........................................16 4.1.2 RDO 參數λ與區塊大小之關係.........................................................19 4.2 使用前景與背景提升壓縮效能...................................................................25 4.2.1 前景與背景的使用觀念和流程........................................................25 4.2.2 前景畫面品質之提升........................................................................26 4.2.3 背景資料量之減少............................................................................30 4.2.3 前景與背景壓縮效能展示................................................................31 第五章 視訊影片中運動物體之自動切割................................................................34 5.1 視訊切割概念與流程...................................................................................36 5.2 區域運動估測與全域運動估測...................................................................37 5.2.1 區域運動估測使用區塊比對............................................................38 5.2.2 全域運動估測使用 PTZ 攝影機運動模型 ......................................39 5.3 自動區域運動估測與手動全域運動估測...................................................44 5.4 自動區域運動估測與半自動全域運動估測...............................................49 5.5 自動區域運動估測與自動全域運動估測...................................................52 5.6 結合小區域雜訊之去除之自動視訊切割方法...........................................59 5.7 不同參數設定的影響與實驗結果...............................................................60 5.7.1 運動向量差異 dmotion 之臨界值選取 ................................................60 5.7.2 參考畫面 It+1 的選取與切割結果之關係.......................................60 第六章 結論與未來展望............................................................................................70 ii.
(6) 表目錄 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表. 1:I、P 與 B 畫面所可以使用到的巨區塊(區塊)的種類 ..............................9 2:QP 量化對應值 ...............................................................................................11 3:平均 Frame Size 與 PSNR 之比較(Foreman) ...........................................18 4:RDO 不同參數之壓縮時間(Foreman 影片 11 張畫面) ...........................19 5:影片壓縮時間比較(59 張畫面).................................................................32 6:壓縮資料量與 PSNR 之比較(59 張畫面).................................................33 7:圖 26 (a) 與圖 26 (b) 的攝影機參數 ..........................................................41 8:訓練群終點誤差分佈(共 60 對)................................................................41 9:測試群終點誤差分佈(共 30 對)................................................................41 10:終點之誤差統計(共 450 對)....................................................................41 11:圖 27 (a) 與圖 27 (b) 所求得的終點誤差之統計(共 44 對)..............42 12:圖 28 (a) 與圖 28 (b) 的攝影機參數 ......................................................44 13:圖 28 (a) 與圖 28 (b) 所求得的終點誤差之統計(共 35 對) ................44 14:半自動全域運動估測計算出的攝影機參數................................................50 15:修正的偏差參數............................................................................................56 16:使用不同參考畫面時的切割正確率(共切割 50 張畫面)......................68 17:切割時間........................................................................................................69. iii.
(7) 圖目錄 圖 1:影片利用前景背景編碼的示意圖....................................................................1 圖 2:編碼流程示意圖................................................................................................3 圖 圖 圖 圖 圖 圖 圖 圖. 3:Macroblock:16×16、4×4, 2 種區塊大小.........................................................5 4:I4×4 的 9 種預測模式[3] .................................................................................5 5:I16×16 的 4 種預測模式[3] .............................................................................5 6:巨區塊的七種區塊尺寸....................................................................................6 7:切割畫面示意圖[3]..........................................................................................7 8:Direct Mode 示意圖[7] ....................................................................................8 9:區塊選擇流程圖................................................................................................9 10:H.264 之整數離散餘弦轉換[3]...................................................................10. 圖 圖 圖 圖 圖 圖. 11:不同λ對壓縮資料量大小的影響(Foreman) ...........................................17 12:不同λ對畫面的品質的影響(Foreman) ...................................................18 13:測試影片 Stefan、Foreman、Dancer...........................................................20 14:I-Frame 區塊大小分佈..................................................................................22 15:P-Frame 區塊大小分佈.................................................................................23 16:B-Frame 區塊大小分佈 ................................................................................24. 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖. 17:不同λ對應畫面之區塊切割(Foreman) ...................................................25 18:應用前景和背景編碼示意圖........................................................................26 19:Foreman 原始影像與前景和背景的切割圖 ................................................27 20:Foreman 影片前景部分的比較 ....................................................................28 21:Foreman 影片背景部分的比較 ....................................................................29 22:Mobile 影片中的兩張畫面 ...........................................................................35 23:運動向量示意圖............................................................................................35 24:視訊切割架構................................................................................................36 25:運動向量之差異性........................................................................................37 26:Zoom 影片中的手動標示點 .........................................................................40 27:Pan、Tilt、Zoom 影片中的手動標示點 ....................................................42 28:Mobile 影片中的手動標示點 .......................................................................43 29:全域運動估測流程圖....................................................................................44 30:自動區域運動估測與手動全域運動估測之視訊切割架構圖....................45 31:區域運動向量與全域運動向量....................................................................46. 圖 圖 圖 圖 圖. 32:16×16 區塊之區域運動向量與全域運動向量 ............................................47 33:Mobile 畫面之自動區域運動估測與手動全域運動估測 dmotion 值............48 34:Mobile 畫面切割結果之一 ...........................................................................48 35:自動區域運動估測與半自動全域運動估測之視訊切割架構圖................50 36:自動區域運動向量與半自動全域運動向量................................................51 iv.
(8) 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖. 37:Mobile 畫面之自動區域運動估測與半自全域運動估測 dmotion 值............51 38:Mobile 畫面切割結果之二 ...........................................................................51 39:自動視訊切割架構圖....................................................................................52 40:全域運動估計與偏差參數修正流程圖........................................................54 41:修正偏差參數所使用的對應點....................................................................55 42:Mobile 畫面之自動區域運動估測與自全域運動估測 dmotion 值................57 43:Mobile 畫面切割結果之三 ...........................................................................57 44:欲切割的 PTZ 影片 ......................................................................................58 45:PTZ 影片切割結果 .......................................................................................58 46:圖 44 使用全自動切割方法之 dmotion 值 .....................................................58 47:去除雜訊之切割............................................................................................59 48:Mobile 影片中的六張影像 ...........................................................................62 49:使用不同參考畫面所求得的區域運動向量與全域運動向量....................64 50:使用不同參考畫面所求得的 dmotion 分佈 ....................................................66 51:使用不同參考畫面之自動切割結果............................................................67. v.
(9) 第一章 簡介 由於科技的進步與資訊產業的蓬勃發展,多媒體應用日漸廣泛已成為生活中 不可以缺少的一部分,一般的影音資料如果未經壓縮,資料量將會非常龐大而難 以儲存與傳送,許多壓縮方法因此因應而生。針對視訊壓縮方面,H.264/AVC [1][2][3][4]是 2003 年所被提出的視訊壓縮標準,考慮使用者的需求與壓縮上 的彈性,本論文提出一個前景與背景的分析應用在現有 H.264/AVC 的壓縮標準 上,使得整體壓縮時間減少而著重部分畫面品質提升,並且有助於壓縮資料的儲 存、傳送與利用。 由 ISO Motion Picture Experts Group(MPEG 組織)和 ITU-T Video Coding Experts Group(VCEG 組織)所成立的 Joint Video Team(JVT 組織),提出的 H.264/AVC(Advanced Video Coding) (或 MPEG4 Part 10/AVC)標準,為本論文 所要探討的對象。本論文將針對現行的視訊壓縮標準 H.264,探討前景和背景的 應用,目的在透過前景的影像品質的提升、背景的資料量之降低,以及壓縮速度 之提升等三方面,來改善整體標準的壓縮效率。 對於本論文所提出的視訊壓縮方法,使用者可以依據需求分別定義前景與背 景,一般而言,前景是影片中重要的部分,可能是物體移動的部分,或是觀看者 仔細注意的畫面部分;而背景可能以靜態區域為主,或是整段影片中觀看者較不 注意的部分。. 圖 1:影片利用前景背景編碼的示意圖 1.
(10) 對於整個視訊壓,其過程分為編碼流程(Encoding Process)和解碼流程 (Decoding Process)2 部分,分別用編碼器(Encoder)和解碼器 (Decoder) 來實作,而本論文所討論的對象是編碼過程。圖 1 為我們如何利用前景和背景 來編碼的示意圖,其中是把影片的內容,區分為 2 個部分後,在編碼器中以不同 的編碼流程來處理,達到不同的編碼效能和編碼品質。 本論文中所提出的編碼方法可以使用切割好的前景與背景遮罩作為輔助的 壓縮資訊,另外,本論文也提出一套自動視訊切割方法可供使用者使用。對於前 景 與 背 景 的 分 析 , 分 別 找 出 適 合 前 景 與 背 景 的 區 塊 大 小 與 Rate-Distortion Optimization [5][6][7]參數,來提升前景影像品質、降低背景資料量,並減少壓 縮速度。視訊切割方面則是利用物體的運動資訊,切割出與攝影機運動不一致的 物體。 經過本論文所提出的方法壓縮後的影片,皆可以使用在一般的 H.264 解碼器 上,不會有相容性的問題,因為本論文的壓縮方法皆符合 H.264 標準所定義的語 法(Syntax)和語意(Semantics),而本論文所考量壓縮效能的依據有:訊號雜 訊比(SNR,Signal to Noise Ratio) 、位元速率(Bitrate) 、編碼速度(Coding Speed)… 等。 本論文共分成六章,第二章是 H.264 視訊壓縮標準及其壓縮原理的簡介。第 三章是“前景和背景的應用”與“視訊切割”之相關研究討論。第四章討論本論文所 提出的“前景背景應用方法”與實驗結果。第五章為本論文所提出的自動視訊切割 方法與實驗結果。第六章為結論,並且探討一些將來可能繼續研究的方向和應用。. 2.
(11) 第二章 H.264/AVC 視訊壓縮標準 2.1 簡介 MPEG 的全名為“ Motion Picture Expert Group”,是由 IEC/ISO 在 1988 年成 立的組織,主要的工作是制定標準化的數位視訊壓縮演算法。它分別在 1991、 1994、1998 年了制定 MPEG-1 [8]、MPEG-2 [9]、MPEG-4 [10]等視訊壓縮標準。 對於資料的日漸龐大,相較於其他的視訊壓縮標準,ITU-T Video Coding Experts Group(VCEG)希望建立一個效率加倍的標準,而提出了 H.26L。2001 年,VCEG 和 MPEG 共同合作組織了 Joint Video Team(JVT)並且在 2003 完成 了整個新的視訊壓縮標準 H.264/AVC(或稱 MPEG-4 Part10 或是 MPEG-4 /AVC) 。 在 MPEG 壓縮標準中,只定義了視訊資料經壓縮後的位元串列的語法和語 意,以及解碼的程序;對於編碼的過程,在標準內並沒有明確的制定,主要可提 供編碼器設計者根據編碼速度、品質和複雜度來做取捨,只要編碼後的位元串列 符合 MPEG 標準定義的語法和語義即可。 預測. 轉換. 量化. (Prediction). (Transform). (Quantization). 熵編碼 (Entropy coding). 圖 2:編碼流程示意圖. 現今的視訊壓縮標準大多採用圖 2 所示的編碼流程,在編碼的過程中,一 個巨區塊(Macroblock)為編碼的基本單位,一個巨區塊大小為 16×16 像素,每 一個畫面在壓縮時都會被區分成為 M×N 個巨區塊(M 與 N 為正整數) ,而在 H.264 中每一個巨區塊都可能再細分成數個區塊(Block) 。有了以上的基本觀念,我們 將在接下來的小節中,依序對 H.264 的預測、轉換、量化、熵編碼等步驟做介紹。 3.
(12) 2.2 預測編碼 ( Prediction Coding ) 視訊影片通常具有空間與時間上的相似性,此為視訊壓縮中重要的概念。就 空間上而言,相鄰的像素通常在色彩或灰階強度上會非常相似,此時就可以利用 周圍已編碼過的像素來預測尚未編碼的像素;當然,在某些特別的情況中可能空 間上的相似性不高(如物體的邊緣),但大多數情況是具有空間上相似的特性。 由於影片是由多張靜態影像的連續播放,為了使人眼觀看感覺流暢,相鄰的二張 畫面當中,大部份的場景也都有極高的相似性或不變性,連續兩張畫面中的物體 可能只有些微的運動差異,利用這種時間上的相似性,只要知道物體的運動便可 由上張畫面找到相似物體。利用空間相似性來預測稱為“畫面內的預測”(Intra Prediction) ,利用時間相似性的預測則稱為“畫面間的預測”(Inter Prediction) 。. 2.2.1 畫面內的預測(Intra Prediction) 使用 Intra Prediction 的畫面稱為 I 畫面(Intra-Coded Frame)。對於 I 畫面中 的巨區塊,如圖 3 所示,H.264 可以直接使用 16×16 巨區塊壓縮或再切割成 16 個 4×4 區塊做壓縮;此兩種區塊又分別可稱為 I16×16(Intra 16×16)與 I4×4(Intra 4×4)區塊。利用空間上的相似性,I4×4 有九種預測模式可使用,I16×16 有 4 種 預測模式可使用,分別如圖 4、圖 5 所示。編碼器會對每一種預測模式算出預 測區塊的像素值,並計算預測區塊與真實區塊之誤差;之後,編碼器再挑選誤差 最小之模式為最佳的預測模式。計算預測區塊的公式可在[4]找到,因為解碼器 也可以藉由同樣的公式計算出預測區塊,所以需要傳送的部分只有最佳預測模 式、區塊編碼種類(區塊形狀)與預測誤差值(或稱為 Residual)。. 4.
(13) 圖 3:Macroblock:16×16、4×4, 2 種區塊大小. 圖 4:I4×4 的 9 種預測模式[3]. 圖 5:I16×16 的 4 種預測模式[3]. 2.2.2 畫面間的預測 (Inter Prediction ) 除了 I 畫面以外,有兩種畫面會使用 Inter Prediction 預測方式,分別稱為 P 畫面(Predictive-Coded Frame)與 B 畫面(Bidirectional-Coded Frame),其中的 差異在於 P 畫面只能參考之前的畫面,而 B 畫面則可以參考之前與之後的畫面。 對於目前要壓縮的巨區塊(Current Macroblock) ,編碼器會透過運動估測(Motion. 5.
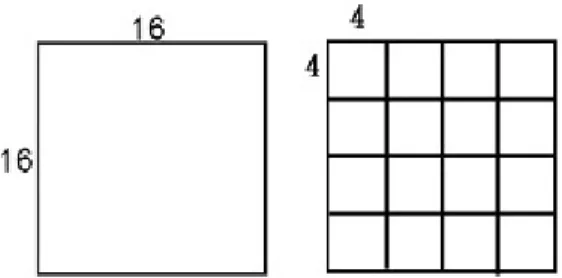
(14) Estimation)找到參考畫面(Reference Frame)中最相似的區塊當作預測區塊。“目 前要壓縮的區塊”與“預測區塊”之相對位移稱之為運動向量(Motion Vector)。類 似於 Intra Prediction,編碼器只需要傳送運動向量與預測誤差,因為解碼器可以 經由運動向量找到參考畫面中的預測區塊,再加上預測誤差就可以得到原本的真 實區塊。在運動估測中通常會設定一個搜尋範圍,搜尋範圍越大可能會找到更相 似區塊而減少預測誤差,但是搜尋時間也會因此會變大,而記錄運動向量所需要 的資料量也可能會變大。. 運動估測是以區塊比對為基礎,H.264 提供了七種不同尺寸的區塊作為運動 估測之使用,並且每一種尺寸的區塊都需要記錄一個自己的運動向量。如圖 6 所示,一個巨區塊共可以有四種切割方式,分別可能為 16×16, 8×16, 16×8 或 8×8,當巨區塊被切割為 4 個 8×8 的區塊時,每個 8×8 區塊又可以有各自的四種 切割方式。. 圖 6:巨區塊的七種區塊尺寸. 因為區塊大小非固定,所以區塊的編碼種類也需要被傳送。如果選擇一種較 大的區塊(如 16×16、16×8、8×16)來對巨區塊作切割,則巨區塊所需要的運 動向量個數較少,因此運動向量資料量會變少,但預測誤差的資料量有可能會比. 6.
(15) 較多(因為誤差可能變大)。如選擇一個較小的區塊(如 4×8、8×4、4×4 等) , 雖然可以使得預測誤差資料量變小,但是因為區塊變小會增加的運動向量的總資 料量,這些都是會影響到資料壓縮的效果。一般來說,較平滑的畫面通常用較大 的區塊而較多細節部分的畫面則用較小的區塊會使的整體資料量較小,如圖 7 的影像即為一種可能的區塊組合樣式,較平滑的地方考慮使用較大的區塊,邊緣 與輪廓等區域則可以考慮用小區塊組合而成。. 除了上述的七種區塊大小外,P 畫面還有一種區塊模式,當一個巨區塊沒有 編碼後剩下的預測誤差需要傳送,並且也不需要傳送運動向量的資訊時候,叫做 Skip Mode,此種類在解碼的過程中,並不使用到運動向量來表示預測後的結果, 是直接複製參考畫面中對應位置之區塊來當作預測區塊。另外,在 B 畫面也有 一種特別的區塊模式叫做 Direct Mode,此種模式會利用參考畫面的時間距離比 率(Temporal Distance Scaling)來產生運動向量。. 圖 7:切割畫面示意圖[3]. 7.
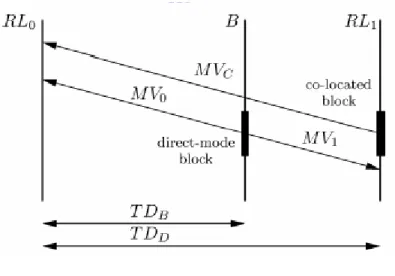
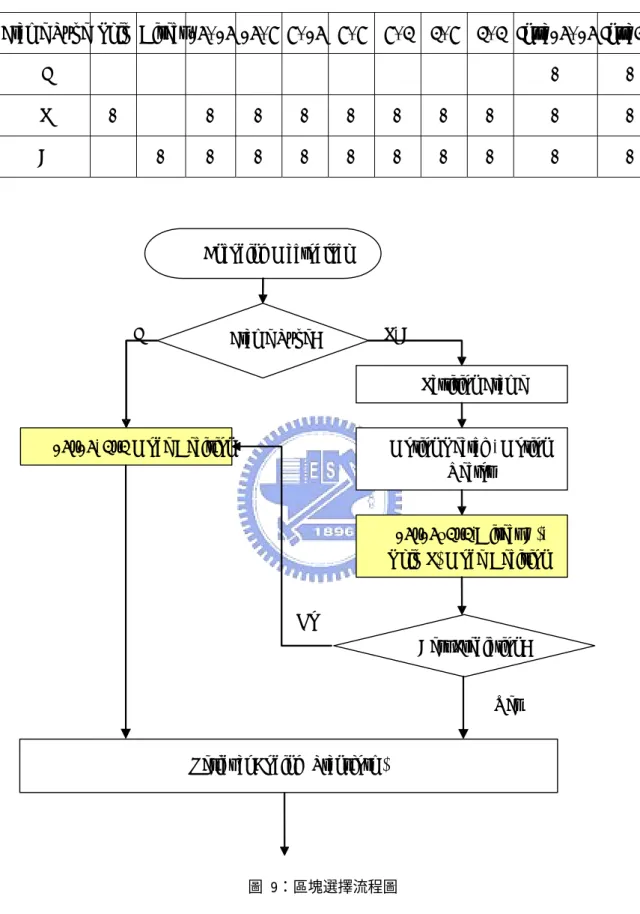
(16) 圖 8 為 Direct Mode 示意圖, (MV0 , MV1)分別表“目前要壓縮的區塊”之向 前參考與向後參考運動向量。為了要求得這兩個運動向量,必須要由“向後參考 畫面”(RL1)中相同位置(Co-located)的巨區塊之運動向量“MVc”推導。若向 前參考畫面為(RL0),向後參考畫面為(RL1),則二運動向量的求法為. MV0=(TDB/TDD)*MVC. (2.1). MV1=(TDD - TDB / TDD)* MVC. (2.2). 其中 TDD 表示 RL0 與 RL1 在時間上的差值,TDB 表示目前此 B 畫面與 RL0 的差 值。. 圖 8:Direct Mode 示意圖[7]. 在 H.264 標準中,P 和 B 畫面,也可以使用 2.2.1 小節的 Intra Prediction 的 2 種區塊大小以及多種預測模式,當編碼器認為 Inter Prediction 預測方式之巨方塊 誤差太大時便會使用 Intra Prediction 的預測方式。表 1 為 I、P 與 B 畫面所可以 使用到的巨區塊(區塊)的種類之整理表列。圖 9 則為預測編碼時最佳區塊種 類的選擇流程,其中何者為最佳的預測模式由編碼器的設計者決定,這是因為 H.264 標準只定義解碼器的規範,而 H.264 也提供了一種方法,這個方法可以在 H.264 原始碼 JM 版本[11]找到。 8.
(17) 表 1:I、P 與 B 畫面所可以使用到的巨區塊(區塊)的種類. Frame Type Skip Direct 16×16 16×8 8×16 8×8. 8×4. 4×8. 4×4 Intra16×16 Intra4×4. I P. √ √. B. √. √. √. √. √. √. √. √. √. √. √. √. √. √. √. √. √. √. √. Encoding Macroblock. I. √. P, B. Frame Type?. Partition Frame. 16x16, 4x4 Mode Decision. Motion S earch , Motion Vector. 16x16~4x4,D irect(B), S kip(P) Mode Decision. No Best Prediction? Yes Residual Coding (Transform). 圖 9:區塊選擇流程圖. 9.
(18) 2.3 轉換、量化與熵編碼 2.3.1 轉換(Transform) 一般影像經過傅立葉轉換(Fourier Transform)或餘弦轉換(Cosine Transform) 後,大部分的資料量都會集中在低頻的部分,高頻的部分則會留下較少的資料 量,藉由這個的特性可以讓量化步驟更有效的處理資料。相較於之前的壓縮標準 使用 8×8 區塊的浮點數離散餘弦轉換,H.264 則是使用了 4×4 區塊的整數離散餘 弦轉換,使用較小的區塊減少了方塊與漣漪的現象,整數轉換則減少了浮點數轉 換在電腦實作上誤差的累積。如圖 10,一個巨區塊可以被分成 16 個 4×4 區塊, 每個區塊都會進行整數離散餘弦轉換,其中每個 4×4 區塊轉換後的 DC 成分即是 原來區塊所有元素的平均值。在 H264 中新增了 Hadamard 轉換,H.264 會將 16 個 DC 成分集合成新的 1 個 4×4 區塊,對此 4×4 區塊進行 Hadamard 轉換進一步 消除空間上的重複性,關於 H.264 中轉換方法的詳細介紹可以在[3][4]中找到。. 圖 10:H.264 之整數離散餘弦轉換[3]. 2.3.2 量化(Quantization). 量化是一種失真的壓縮方法,資料經過量化之後即不可能恢復成原始資料,. 10.
(19) 表 2.2 為 H.264 所提供的量化參數(QP)表,每一個量化參數對應到一個量化 位階(QStep) ,每當量化參數增加 6 時,量化位階呈 2 倍成長,而當量化參數越 高時代表失真越嚴重,但是壓縮後的資料量也會較小。在這個步驟中所要量化的 資料是經過整數離散餘弦轉換後的結果,當決定好量化參數之後,對每一個 4×4 區塊的量化參數就是固定的,但是在細節上,另外會有個權重調節低頻與高頻部 分的量化比例,對於低頻的部分量化程度會比較低,失真度較小,高頻部分則量 化程度較高,失真度較高。在前一小節提到,經過轉換後的高頻部分是對應到空 間域上變化較快的細節,而人的視覺系統對空間域上變化較快的細節比較不敏 感,所以在實際壓縮中容許的失真度可以較高,也因此量化程度較高;而低頻的 部分若失真太嚴重人眼感覺較敏銳,因此量化程度必須較小,關於 H.264 中量化 方法的詳細介紹可以在[3][4]中得到。. 表 2:QP 量化對應值. QP. 0. 1. 2. 3. QStep 0.625 0.6875 0.8125 0.875. 4. 5. 6. 1. 1.125. 1.25. 7. 8. 1.375 1.625. 9. 10. 11. 12. …. 1.75. 2. 2.25. 2.5. …. QP. …. 18. …. 24. …. 30. …. 36. …. 42. …. 48. …. 51. QStep. …. 5. …. 10. …. 20. …. 40. …. 80. …. 160. …. 224. 2.3.3 熵編碼(Entropy coding). 視訊壓縮的最後一個步驟是熵編碼,H.264 中支援了 2 種熵編碼來進一步使 得資料量變小,分別為 CAVLC(Context-Adaptive Variable-Length Coding)和 CABAC(Context-Adaptive Binary Arithmetic Coding)[3][4],主要的概念是利 用較少的位元來表示出現機率較高的符號,出現機率較低的符號則用較多的位元 表示,如此一來整體的資料量較小,其中 CABAC 的方法複雜度較高壓縮效果也 比較好。 11.
(20) 第三章 前景與背景之訊切割與壓縮的相關 研究探討 針對單一畫面中物體之切割,已經有許多方法被提出,這些方法可以根據不 同的影像特徵(如顏色、紋理、灰階強度) ,切出符合這些特徵的物體,然而切 割結果的穩定度相依於影像的特性而有好壞之分。在視訊檔案之中,單獨使用空 間資訊所產生的切割結果略顯薄弱,如果可以加入時間域上的資訊(如運動資 訊),便可增加切割的強固性。. 3.1 利用空間的資訊對靜態影像做切割 一種常見的方法則是以區域為基礎(如 Region Growing)[12],找出空 間上特徵相同的區域,但此方法對於邊界的切割較不穩定,因為對於臨界值的選 取亦較困難。為了切割出物體的輪廓,Snake Model[13]亦經常被使用。Snake Model 的缺點是必須要先以人工的方式,在物體的周圍圈出一個初始輪廓,然後 根據 Snake Model 的內部力與外部力去逼近物體的輪廓。另外 Snake Model 也常 常需要調整內部力與外部力的權重參數,以便適應不同特徵的影像。另外分水嶺 演算法(Watershed algorithms)[14]亦經常被使用,分水嶺演算法是利用注水原 理,從低處的像素開使用高處成長,而高處的地方通常是影像中的物體邊界,因 此在物體邊緣處停止注水可以找到物體的切割。J. Malik 提出了使用 Normalized Cuts[15]來切割影像,主要的觀念是把一張畫面建構成一個加權圖,每個像素與 像素之間會依照其相似關係而有一個權重。在切割的時候,一次的切割會切出兩 群物體,其考慮的依據是去掉加權較小的邊並使同一群內的物體有最大的加權, 如此一來比較相似的像素會被切割在一起,然而使用 Normalized Cuts 切割影像 的時候,同一個物體有可能被切成幾個破碎的部分。 12.
(21) 3.2 利用時空的資訊對視訊影像做切割. 為了切割視訊影像,時域上的資料是非常有用的資訊,畫面中的物體運動是 最常被拿來使用的。針對攝影機為固定的情況下,切割的方法會比攝影機在運動 的情況簡單,最常使用的方法是連續兩張畫面的相減,用此可以偵測出畫面中有 物體運動的區域,做為初步切割的結果。[16] [17]同樣是利用了兩張畫面間的 差異對物體做切割,為了增加可靠性,[16] [17]會累多張積畫面的差異資訊再 做切割。[18][19]推導了機率函數,將影片中相似的位置、顏色、運動等,判斷 出相似的部分作群集,對不同特性的物體作切割。而[20]同樣是使用 Normalized Cuts 的方法,只是在建構加權圖時,考慮了運動的資訊做權重。. 在攝影機不為靜止的狀況,對視訊畫面切割最為困難,[21]使用了物體追蹤 與圖形識別的方法來切割運動的物體,此方法的好處是在物體有變形或者遮蔽 時,仍然可已有不錯的切割效果,但是第一次步驟必須先用另外的方法做一個初 始的切割,之後才可以使用物體追蹤的方式。[21]中並沒有提到一個強固的初始 切割方法,而初始切割的好壞大大的影響了後續切割的結果,這一部分是仍需要 改進的地方。[22]使用了仿射模型(Affine Model)來估測物體的運動,他的做 法是每塊區域估計一組仿射參數,之後再合併仿射參數較像的鄰近區域。但是實 際合併區域的時候,有可能屬於同一個物體卻不會被合併情況發生,因此造成同 一個物體會被切割成許多的區塊。[23]同樣也利用了運動的資訊作為運動物體之 切割,為了增加運動資訊的強固性,[23]所提出的方法必須要累積數張畫面間的 運動資訊。接下來,求出具有不同運動之物體個數,並給每一個物體設定一組初 始的仿射參數,來代表每一個物體。最後,推導出一個機率函數,函數所定義的 是每一個像素屬於某個物體的機率,因此可以把每一個像素分類,對不同的物體 作切割。[23]所提出的方法中,初始仿射參數的設定是一個重要的部分,另外,. 13.
(22) 具有不同運動的物體個數之求得也相當重要,由於這一方面的方法不穩定,造成 有些的運動物體並沒有被切割出來。. 3.3 視訊壓縮的相關探討. 與壓縮效能相關的研究有可調式編碼(Rate Control Coding)[24],在編碼 時所考慮了的應用環境因素來調整編碼的效果,也就是彈性的使用多種編碼方 式,再依據當時的一些條件,如: 頻寬、解析度等等的要求來進行編碼控制,這 類方法著重在原來標準內的編碼工具的功能調整。另外在 MPEG4 包含了 Sprite Coding[25]的編碼技術,目的是對於每個畫面中重複出現的部分只做一次處理, 進而減少重複編碼的情況產生,如此一來,便可以減少整體的壓縮時間與壓縮後 的資料量,當每個畫面間的重複部分越大時,壓縮的資料量更會明顯的減少。然 而在進行 Sprite Coding 時,必須要有每張畫面切割好的遮罩當作輸入以做為輔助 的編碼工具,如此壓縮的資料量與畫面的品質才會好,因此對於 Sprite Coding 的壓縮技巧上,視訊切割是一個重要的步驟。[26]提出了對 I 畫面的預測模式做 改善,可以在畫面品質沒有大量減少與資料量沒有大量增加的情況下減少 I 畫面 的壓縮時間;與[26]所提出的方法不同的是,本論文所提出的方法是針對 P、B 畫面的區塊選擇作改善,以減少壓縮的時間。. 在本章,我們介紹了不同的切割方法與其在壓縮上的應用,本論文亦提出了 一套視訊切割與壓縮的方法,並利用在現今視訊壓縮標準 H.264 上,其最後的目 的希望能夠提升壓縮資料的訊號雜訊比(PSNR)、降低位元率(Biterate)與加 快編碼速度(Coding Speed)。. 14.
(23) 第四章 H.264 壓縮工具之分析、壓縮效能 之提升與前景背景之應用 在此章將介紹、分析 H.264 多重區塊尺寸與 Rate-Distortion Optimization (RDO)[5][6][7]等編碼工具對於壓縮效能之影響並將其應用在我們所提出的前 景與背景壓縮方法。本章考慮的壓縮效能包含訊號雜訊比(PSNR)、位元率 (Biterate)與編碼速度(Coding Speed)。 在第二章的介紹中得知,H.264 提供多種不同的區塊大小與多種預測方向的 選擇,這些都是 H.264 比之前的壓縮標準在壓縮效能上大大提升的原因之一。另 外 H.264 額外提供 RDO 來做為 Intra Prediction、Inter Prediction(Motion Estimation)的預測工具,其基本想法是想在影像品質與位元率之間取得一個平 衡。 對於上述 H.264 壓縮工具, H.264 提供使用者在區塊大小上的選擇有相當 大的彈性,RDO 編碼工具亦可以選擇是否加入編碼流程之中。. 4.1 RDO(Rate-Distortion Optimization)壓縮效能分析 在 RDO 編碼過程中,所針對的 Rate 和 Distortion 的部份,是以下列方程式 為主要依據: Cost = D(B, Bˆ |Q)+ λ·R(B | Q). (4.1). 其中 Cost 為此巨區塊編碼方式的代價,Q 是給定的量化參數,B 是指原始影像 中正在被處理的一個巨區塊, Bˆ 是原始巨區塊 B 經過編碼再解碼後的重建區塊,. D 為估計失真度的函數,通常以 PSNR 當比較標準,R 為估計壓縮資料量的函數 15.
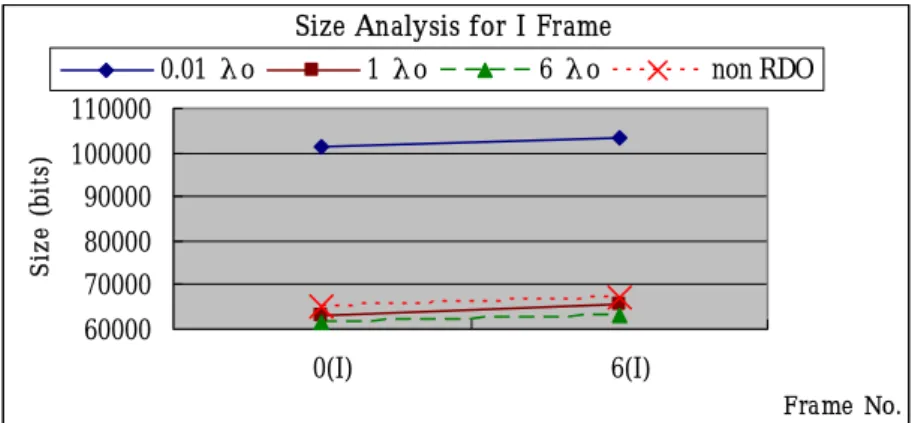
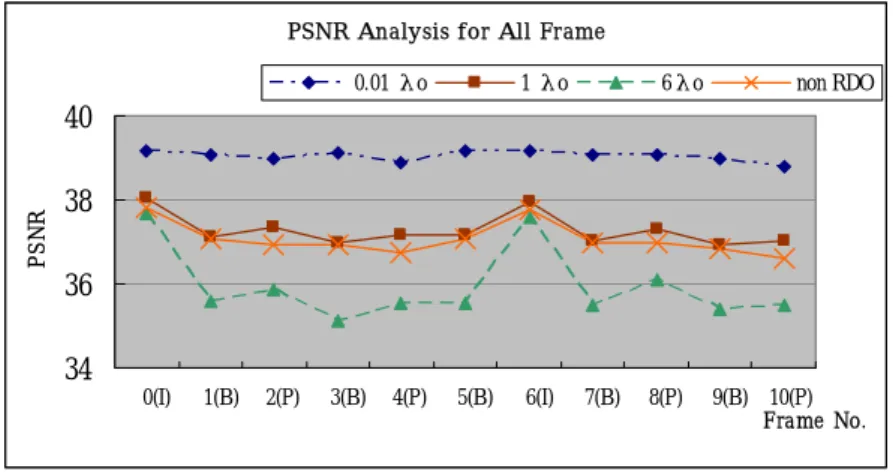
(24) [5][6][7],通常以 Bitrate 作衡量,λ 則是一個比例常數,藉由這個比例常數的 調整,便可以對於畫面的品質和位元速率來做一個控制。當λ越小時,PSNR 值 會越高,但壓縮率較低;而λ越大,壓縮率高,PSNR 值相對較低。. 4.1.1 RDO 參數λ與畫面品質、資料量之關係 在這一小節,我們將驗證(4.1)式中 RDO 參數λ與畫面品質、位元率之關係。 在 H.264 的參考原始碼中,預設的參數 I、P 畫面λ0 = 27.41、B 畫面λ0 = 73.11。 我們以標準的λ=1λ0 來當作比較的基礎,此一數據將與λ=0.01λ0、λ=6λ0 以及不使 用 RDO 工具的壓縮方式相互比較。本章節實驗所做的一些設定所列如下:. z. 影片 Foreman、壓縮 11 張畫面、序列格式 IBPBPBIBPBP. z. I、P 畫面λ0 = 27.41、B 畫面λ0 = 73.11. z. I、P、B 之 QP=28. z. P、B 的參考畫面 1 張. z. H.264 原始碼 JM 7.3[11]. z. Windows XP Professional 、Visual C++ 6.0. z. Pentum4-2.4GHz、256MB RAM. 首先比較λ=1λ0、λ=0.01λ0、λ=6λ0 對壓縮效能的影響。圖 11 為不同λ對壓 縮資料量大小的影響,圖 11(a)為 I 畫面之統計,圖 11(b)與圖 11(c)則 分別為 P 畫面和 B 畫面之統計,I、P 與 B 畫面的共同結果是當λ越小時,壓縮率 越低,λ越大則壓縮率越高。圖 12 為不同λ對畫面品質在 PSNR 上的影響,當λ 越小時,PSNR 值會越高,λ越大,PSNR 越低。. 16.
(25) Size Analysis for I Frame 0.01 λo. 1 λo. 6 λo. non RDO. Siz e (bits). 110000 100000 90000 80000 70000 60000 0(I). 6(I) Fra me No.. (a) I Frame Size Analysis for P Frame. Size (bits). 0.01 λo. 0.1 λo. 6λo. non RDO. 80000 70000 60000 50000 40000 30000 20000 10000 2(P). 4(P). 8(P). 10(P). Fra me No.. (b) P Frame Size Analysis for B Frame. Siz e (bits). 0.01 λo. 1 λo. 6 λo. non RDO. 60000 50000 40000 30000 20000 10000 0 1(B). 3(B). 5(B). 7(B). 9(B). Fra me No.. (c) B Frame 圖 11:不同λ對壓縮資料量大小的影響(Foreman). 17.
(26) PSNR Analysis for All Frame 0.01 λo. 1 λo. 6λo. non RDO. PSNR. 40 38 36 34 0(I). 1(B). 2(P). 3(B). 4(P). 5(B). 6(I). 7(B). 8(P). 9(B) 10(P) Fra me No.. 圖 12:不同λ對畫面的品質的影響(Foreman). 表 3:平均 Frame Size 與 PSNR 之比較(Foreman) (a) 平均數據 I Frame. P Frame. B Frame. Ave.Size(Bits) Ave.PSNR(db) Ave.Size(Bits) Ave.PSNR(db) Ave.Size(Bits) Ave.PSNR(db) 0.01λ0. 102300. 39.16. 77118. 39.06. 53229. 38.97. 1λ0. 64200. 37.59. 16993. 37.01. 91889. 37.36. 6λ0. 62112. 36.48. 12614. 35.40. 847689. 36.05. Non RDO. 66272. 37.42. 17088. 36.95. 11189. 36.99. (b) 以 1λ0 為基準之比較 I Frame. P Frame. B Frame. Ave.Size(Bits) Ave.PSNR(db). Ave.Size(Bits) Ave.PSNR(db). Ave.Size(Bits) Ave.PSNR(db). 0.01λ0-1λ0 38100(60.34%). 1.57. 59681(342.28%). 2.05. 44040(479.28%). 1.61. -2088(-3.25%). -1.11. -4822(-27.65%). -1.61. -712(-7.75%). -1.31. 6λ0-1λ0. 表 3 為不同λ之數據比較,表 3(a)是使用不同的λ參數之平均數據,另外 以 1λ0 為基準,將 0.01λ0、6λ0 相對於 1λ0 的數據統計於表 3(b)中。在 I 畫面 中,0.01λ0 比 1λ0 約提升了 1.57db 的 PSNR,但是多花了 60.34%的資料量。對 P 畫面,0.01λ0 比 1λ0 約提升了 2.05db 的 PSNR,但是多花了 342.28%的資料量。 對 B 畫面,0.01λ0 比 1λ0 約提升了 1.62db 的 PSNR,但是多花了 479.28%的資料 量;P、B 畫面雖然提高了較多的 PSNR 值,但是也花了更多倍的資料。. 18.
(27) I 畫面中,6λ0 比 1λ0 約省了 3.25%的資料量,但是損失了 1.11db 的 PSNR。 P 畫面中, 6λ0 比 1λ0 約省了 27.65%的資料量,但是損失了 1.61db 的 PSNR。對 B 畫面,6λ0 比 1λ0 約省了 7.75%的資料量,但是損失了 1.31db 的 PSNR。P 畫面 省下了最多資料量,但是損失的 PSNR 也是最多。. 接下來我們比較使用預設的λ=1λ0 與不使用 RDO 之壓縮效能上的差異。由 表 3(a)可知,在不使用 RDO 工具的情況下,所需要的資料量比 1λ0 的 RDO 略大,PSNR 則略為 1λ0 的 RDO 低,也就是說不使用 RDO 的情況,在壓縮率與 失真度的表現上都較差;但是,RDO 為了達到更精準的估量,必須花費更多的 計算時間,表 4 即為不同參數下,H.264 壓縮 11 張影片所要花費的時間,使用. RDO 工具大約要比不使用 RDO 工具多花上 2.5 倍以上的時間。. 表 4:RDO 不同參數之壓縮時間(Foreman 影片 11 張畫面). Coding Parameter. 0.01λ0. 1λ0. 6λ0. Non RDO. Coding Time (sec). 107.032. 110.575. 103.860. 40.437. 4.1.2 RDO 參數λ與區塊大小之關係 本小節將分析不同λ與所使用區塊大小之關係,我們使用了三種不同特性的 影片當作測試,分別為 Stefan、Foreman、Dancer。Stefan 影片具有較多的細節區 域,Dancer 影片大部分是非常平滑的區域,而 Foreman 特性則介於兩種影片之 間,我們所使用的三種影片顯示在圖 13,至於本小節實驗的其他參數與環境相 關設定則與 4.1.1 小節相同。. 19.
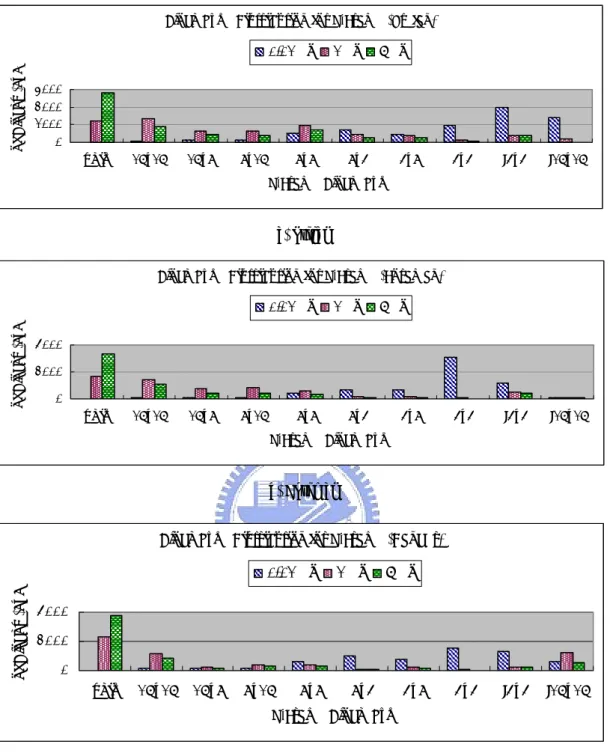
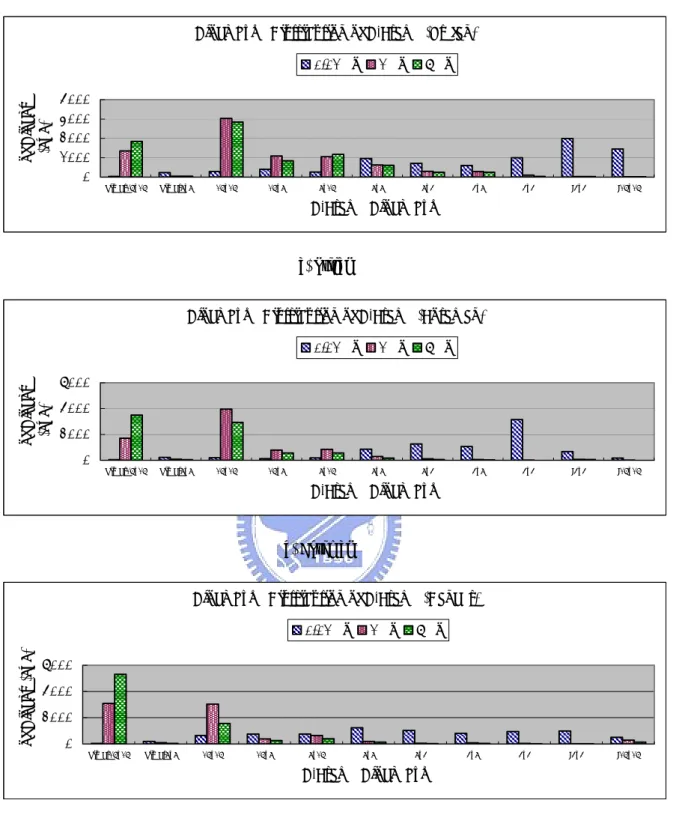
(28) (a) Stefan. (b) Foreman. (c) Dancer. 圖 13:測試影片 Stefan、Foreman、Dancer. 圖 14 為我們針對 I 畫面所統計的結果,不同λ有不同的區塊大小分佈。0.01λ0 的 RDO 為了畫面品質之提升,比 1λ0 的 RDO 使用了更多的 I4×4 區塊;而 6λ0 的 RDO 為了壓縮率之提升,會比 1λ0 的 RDO 增加一點點 I16×16 區塊的用量。 雖然 Stefan、Foreman、Dancer 三個測試影片在 6λ0 的 RDO 都增加了 I16×16 區 塊的用量,但是在 Stefan、Foreman 整體使用 I4×4 區塊的比例仍然比 I16×16 區 塊多很多。在第二章曾提到過,經過預測編碼完所要傳輸的資料包含:1.最佳預 測模式、2.區塊編碼種類(區塊形狀)與 3.預測誤差值,其中區塊編碼種類所需 要的資料量是固定的,而最佳預測模式與預測誤差則和區塊大小有很大的相關。 區塊為 I4×4 時,因為區塊較小且預測模式較多(共九種) ,所以預測誤差會較小, 但是相較於 I16×16 區塊只要傳送一個預測模式,16 個 I4×4 的區塊則要傳送 16 個表示預測模式的資料量(因為一個 16×16 區塊可以切割成 16 個 4×4 區塊) 。因 為 Dancer 影片平滑的區域相當多,使用 I16×16 區塊時之預測誤差已經相當小, 所以不需要使用大量的 I4×4 區塊;而在 Stefan、Foreman 影片,6λ0 的 RDO 則選 擇使用較多 I4×4 區塊使得壓縮資料量會較少。. 20.
(29) 圖 15 是針對 P 畫面的情況所統計出不同λ對應的區塊大小分佈,0.01λ0 的. RDO 為了畫面品質之提升,比 1λ0 的 RDO 使用了更多的 4×4 與 Intra 區塊(I4×4 或 I16×16) ;而 6λ0 的 RDO 為了壓縮率之提升,會比 1λ0 的 RDO 增加了更多 Skip. Mode 的使用量,由圖 15 可得知,6λ0 的 RDO 之區塊使用量前兩名為 Skip Mode 與 16×16 區塊。圖 16 所討論的是 B 畫面,其中區塊分佈的關係大致上與 P 畫面 類似,只是 B 畫面沒有 Skip Mode 區塊,取而代之的是 Direct Mode 區塊。. 經由以上的實驗結果可以發現 P、B 畫面中,當λ越小畫面品質要求越高時,. RDO 越傾向使用較小的區塊;當λ越大壓縮倍率要求越高,RDO 則傾向使用較 大的區塊與特殊模式區塊。在 I 畫面中,當λ越小時,RDO 一樣傾向於使用較小 的區塊,但是當λ越大壓縮倍率要求越高時,RDO 使用區塊尺寸的選擇則與影片 的特性有很大的相關。而不使用 RDO 工具時,雖然其 PSNR 與位元壓縮率的分 佈與 1λ0 的 RDO 相似,但其在 P、B 畫面區塊大小之選擇上,與 1λ0 的 RDO 還 是存在著些許的差異;正因為在區塊大小上 1λ0 的 RDO 有做些細部的挑選,以 致於 1λ0 的 RDO 在 PSNR 與位元壓縮率都有較好的結果。. 圖 17 為不同λ對應畫面之區塊切割,我們把實際區塊的選擇結果畫在影像 上。此圖所顯示的是 Foreman 的第三張影像(Frame Number=2,Frame Type=P), 圖中黑色的方格代表各式區塊的大小及形狀種類,灰色的為 Intra Prediction 的區 塊,而紅色則為 P、B 畫面的 Skip 或是 Direct 區塊種類。從圖中更可以明顯的感 覺到不同λ與區塊大小的關係,本小節的結果將會被下一小節所參考,並且加入 前景與背景的使用來提升壓縮效能。. 21.
(30) Block Type Distribution of I-Frame (Stefan). # of Blocks (8x8). 0.01 λo. 1 λo. 6 λo. 4000 3000 2000 1000 0 I4x4. I16x16 I-Frame Block Type (a) Stefan. Block Type Distribution of I-Frame (Foraman). # of Blocks (8x8). 0.01 λo. 1 λo. 6 λo. 4000 3000 2000 1000 0 I4x4. I16x16 I-Frame Block Type (b) Foreman. Block Type Distribution of I-Frame (Dancer). # of Blocks (8x8). 0.01 λo. 1 λo. 6 λo. 3000 2000 1000 0 I4x4. I16x16 I-Frame Block Type (c) Dancer. 圖 14:I-Frame 區塊大小分佈 22.
(31) Block Type Distribution for P-Frame (Stefan). # of Blocks (8x8). 0.01 λo. 1 λo. 6 λo. 3000 2000 1000 0 skip. 16x16. 16x8. 8x16. 8x8. 8x4. 4x8. 4x4. I4x4. I16x16. 4x4. I4x4. I16x16. 4x4. I4x4. I16x16. P-Frame Block Type. (a) Stefan Block Type Distribution for P-Frame (Foraman). # of Blocks (8x8). 0.01 λo. 1 λo. 6 λo. 4000 2000 0 skip. 16x16. 16x8. 8x16. 8x8. 8x4. 4x8. P-Frame Block Type. (b) Foreman Block Type Distribution for P-Frame (Dancer). # of Blocks (8x8. 0.01 λo. 1 λo. 6 λo. 4000 2000 0 skip. 16x16. 16x8. 8x16. 8x8. 8x4. P-Frame Block Type. (c) Dancer 圖 15:P-Frame 區塊大小分佈. 23. 4x8.
(32) Block Type Distribution of B-Frame (Stefan). # of Blocks (8x8). 0.01 λo 4000 3000 2000 1000 0. direcr16x16. direct8x8. 16x16. 16x8. 8x16. 1 λo. 8x8. 6 λo. 8x4. 4x8. 4x4. I4x4. I16x16. 4x4. I4x4. I16x16. B-Frame Block Type. (a) Stefan Block Type Distribution of B-Frame (Foraman). # of Blocks (8x8). 0.01 λo. 1 λo. 6 λo. 6000 4000 2000 0. direcr16x16. direct8x8. 16x16. 16x8. 8x16. 8x8. 8x4. 4x8. B-Frame Block Type. (b) Foreman Block Type Distribution of B-Frame (Dancer). # of Blocks (8x8). 0.01 λo. 1 λo. 6 λo. 6000 4000 2000 0. direcr16x16. direct8x8. 16x16. 16x8. 8x16. 8x8. 8x4. B-Frame Block Type. (c) Dancer 圖 16:B-Frame 區塊大小分佈. 24. 4x8. 4x4. I4x4. I16x16.
(33) (a) 使用 0.01λ0 壓縮. (b) 使用 1λ0 壓縮. (c) 使用 6λ0 壓縮. (d) 不使用 RDO 壓縮. 圖 17:不同λ對應畫面之區塊切割(Foreman). 4.2 使用前景與背景提升壓縮效能 這個章節,我們將應用已經切割好的前景與背景到編碼流程之中,針對不同 的需求使用前景與背景,可以達成壓縮效能的提升。. 4.2.1 前景與背景的使用觀念和流程 一般而言,觀看者在觀看一段影片的時候,可能只有某些事件的發生或動作 會被觀看者特別注意,因此能有效的將這些區域區分出來,並加以用不同方式去 壓縮,就可以達到重點區域的品質提升,而整體所耗費的資源下降。圖 18(a) 25.
(34) 為一般視訊編碼方式,圖 18(b)中為我們所提出的想法,藉由原來影像與前景 和背景分割的 2 元黑白影像,一起進入編碼器編碼,來改善壓縮效能。我們定義 使用者特別注重畫面品質的部分為前景;相較於前景,比較不需要高畫面品質的 部分定義為背景;對於背景,我們要求較高的壓縮倍率,即較少的資料量。為了 符合前景與背景需求,在編碼的時候,前景與背景會使用不同的壓縮參數與方法 編碼。. Encoder. Bitstream. The original method. Bitstream. The proposed method. (a)一般編碼方式. Encoder. (b)我們使用的編碼方式 圖 18:應用前景和背景編碼示意圖. 4.2.2 前景畫面品質之提升 在進行壓縮時,針對前景的部分,目的是容許資料量的增加而提升畫面的品 質;本小節以 Foreman 影片作為實驗對象,針對圖 19(a)Foreman 的原始影像, 我們加入了圖 19(b)前景與背景的切割圖作為輔助編碼的工具,並總共壓縮 59 張畫面,至於本小節實驗的其他參數與環境相關設定則與 4.1.1 小節相同。. 26.
(35) (a)原始影像. (b)前景與背景的切割圖. 圖 19:Foreman 原始影像與前景和背景的切割圖. 圖 19(b)中白色的區域代表所定義的前景,黑色的區域則定義為背景,因 為 H.264 壓縮是以巨區塊為基本單位,所以一旦某個巨區塊裡包含白色的前景像 素,則整個巨區塊皆會被當成前景區塊來壓縮,其餘不屬於前景的巨區塊則當成 背景壓縮。經過 4.1.2 小節的分析,可知道在 P 與 B 畫面中,0.01λ0 的 RDO 為 了畫面品質之提升,會大量使用 4×4、I4×4 與 I16×16 區塊,因此我們在不開啟. RDO 工具的情況下,指定 P 與 B 畫面前景的部分只能使用 4×4 區塊做編碼(不 考慮特殊模式) ,而 I 畫面因為只有兩種區塊大小可以選擇,所以並不特別指定; 此一方法稱做“指定模式”方法(Assign Mode),實驗的結果如圖 20(a)所示。 由圖 20(a)可以發現,指定區塊的結果雖然可以和不使用 RDO 工具的效能相 似,但還是比 1λ0 的 RDO 效能差。. 在容許資料量增加而提升畫面的品質的前提下,我們提出了混和指定區塊與 使用 RDO 工具的方法。我們指定 P 與 B 畫面前景的部分只能使用 4×4 的區塊, 並同時使用 0.1λ0 的 RDO,而 I 畫面因為只有兩種區塊大小可選擇,所以並不特 別指定區塊,只使用 0.1λ0 的 RDO 壓縮 I 畫面的前景,由圖 20(b)中可以看 出我們的方法可以比 1λ0 的 RDO 大多提升 PSNR 0.5∼1.25db。針對前景部分所 使用的方法如下所列: 27.
(36) z. 圖 20(a)所使用的 3 個方法:. z. . 1. 使用 1λ0 的 RDO. . 2. 不使用 RDO. . 3. I 不指定,P 與 B 只能使用 4×4 區塊 (Assign Mode). 圖 20(b)所使用的 2 個方法: . 1. 使用 1λ0 的 RDO. . 2. 我們的方法[27]: . I:只使用 0.1λ0 的 RDO. . P、B:指定使用 4×4 區塊並使用 0.1λ0 的 RDO Foreground PSNR Comparisions (Foreman) 1 λo. Assign Mode. non RDO. 39.5. 39. PSNR. 38.5. 38. 37.5. 37. 36.5. 36. I BP BP B I BP BP B I BP B P B I BP B P B I BP B P B I BP B P B I BP B P B I BP BP B I B P BP B I B P BP. Frame Type. (a) PSNR-1 Foreground PSNR Comparisions (Foreman) 1 λo. Our Method. 41 40.5. PSNR. 40 39.5 39 38.5 38 37.5 37 36.5 I BP B P B I B P BP B I BP BP B I BP BP B I BP BP B I BP B P B I B P BP B I BP B P B I BP BP B I BP BP. Frame Type. (b) PSNR-2 圖 20:Foreman 影片前景部分的比較. 28.
(37) Back g r o u n d Size ( Fo r eman ) 1 λo. Assign mode. non RDO. 50000 45000 40000. Size (Bits). 35000 30000 25000 20000 15000 10000 5000 0 I BP BP BI B P B P B I B P B P BI BP BP BI BP BP BI B P B P B I B P B P BI BP BP BI BP BP B I B P B P. Frame Type. (a) Size-1 Background Size (Foreman) 1 λo. 6 λo + Assign 16x16. non RDO. 50000 45000 40000. Size (Bits). 35000 30000 25000 20000 15000 10000 5000 0 I B P B P B I B P B P B I B P B P B I B P B P B I B P B P B I B P B P B I B P B P B I B P B P B I B P B P B I B P B P. Frame Type. (b) Size-2 Background Size (Foreman). 1 λo. Our Method. 50000 45000 40000. Size (Bits). 35000 30000 25000 20000 15000 10000 5000 0 I B P B P B I B P B P B I B P B P B I B P B P B I B P B P B I B P B P B I B P B P B I B P B P B I B P B P B I B P B P. Frame Type. (c) Size-3 圖 21:Foreman 影片背景部分的比較 29.
(38) 4.2.3 背景資料量之減少 在進行視訊壓縮時,背景是較不重要的部分,因此可以容忍畫面品質的犧 牲,以達到減少資料量的目的。在 4.1.2 小節的分析,可以知道在 P 與 B 畫面 中,6λ0 的 RDO 為了壓縮率之提升會大量使用 Skip Mode 與 16×16 區塊。對於. Foreman 影片,首先考慮 P 與 B 畫面之背景部分只能使用 16×16 的區塊,而 I 畫面不指定區塊,結果如圖 21(a)所示。圖 21(b)為 P 與 B 畫面之背景部 分使用 16×16 的區塊,並同時使用 6λ0 的 RDO,而 I 畫面一樣不指定區塊,但 是會使用 6λ0 的 RDO 壓縮 I 畫面的背景之結果。正如預期的,不管有沒有使用. 6λ0 的 RDO,只固定使用 16×16 的區塊並不會減少很多的資料量,甚至比不使用 RDO 還差,因為壓縮後資料量是由運動向量與預測誤差的資料量總和所組成, 16×16 的區塊雖然有較少的運動向量個數,但是預測誤差卻可能因此而增大。考 慮資料量的減少,針對不同區域的影像特性使用適當的區塊大小才是最佳的壓縮 方式。. 我們進一步的改善這個方法,我們給予 6λ0 的 RDO 在背景的部分有兩種選 擇,一種為 16×16 的區塊,另一種為 Skip 或 Direct Mode,結果如圖 21(c)所 示,在大部分的情況下,我們可以比 1λ0 的 RDO 使用更少的資料量。針對背景 部分所使用的方法如下所列:. z. 圖 21(a)所使用的 3 個方法: . 1. 使用 1λ0 的 RDO. . 2. 不使用 RDO. . 3. I 不指定,P 與 B 只能使用 16×16 區塊(Assign Mode). 30.
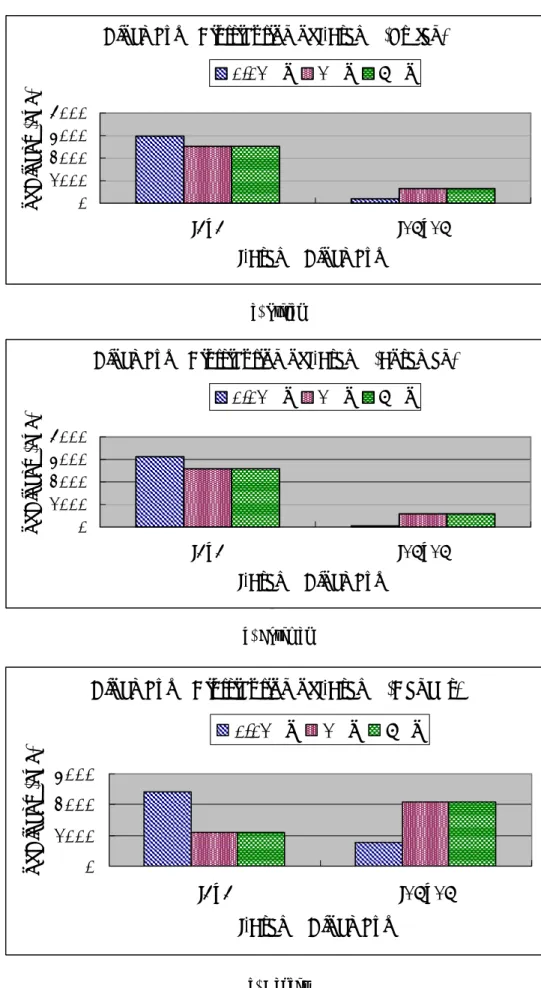
(39) z. 圖 21(b)所使用的 3 個方法: . 1. 使用 1λ0 的 RDO. . 2. 不使用 RDO. . 3. I:只使用 6λ0 的 RDO, P 與 B:指定使用 16×16 區塊與 6λ0 的 RDO ( 6λ0+Assign 16×16). z. 圖 21(c)所使用的 2 個方法: . 1. 使用 1λ0 的 RDO. . 2. 我們的方法[27]: . I:只使用 6λ0 的 RDO. . P、B:指定可使用 16×16 或 skip/direct mode 區塊並開啟 6λ0 的 RDO. 4.2.3 前景與背景壓縮效能展示 從前兩小節的結果可得知,我們的方法可以針對不同的需求而改善壓縮效 能,本小節將把前景與背景的資料同時呈現,並附上完整的實驗數據。. 在壓縮影片所需要花費的時間上,不論是哪種測試影片,我們的方法與不使 用 RDO 所花費的時間接近,使用 1λ0 的 RDO 之壓縮時間則為我們方法的 2.5 倍以上,實驗的結果顯示在表 5,由此可知我們的方法比單純只使用 RDO 工具 節省了相當多的時間。. 最後,壓縮效能數據(包含 Size 與 PSNR)呈現在表 6 中。關於前景之畫 面品質,我們的方法在 Foreman、Stefan、Dancer 三個測試影片中比 1λ0 的 RDO. 31.
(40) 提升了 0.93db、0.32db、0.32db,同時也比不使用 RDO 工具好;然而,為了畫 面品質之提升,我們的方法在 Foreman、Stefan、Dancer 三個測試影片中,前景 部分會比 1λ0 的 RDO 多用了 2.3、1.4、1.6 倍的資料量。其中要注意的是,在同 樣的參數同樣的方法下,提升 PSNR 值的程度與畫面特性有關。. 表 5:影片壓縮時間比較(59 張畫面) (a)Foreman Coding Parameter. 1λ0. Our Method. Non RDO. Coding Time (sec). 553.192. 218.113. 204.516. (b)Stefan Coding Parameter. 1λ0. Our Method. Non RDO. Coding Time (sec). 753.128. 286.169. 226.952. (c)Dancer Coding Parameter. 1λ0. Our Method. Non RDO. Coding Time (sec). 484.390. 189.649. 144.156. 在背景的部分,我們的方法在 Foreman、Stefan、Dancer 三個測試影片中, 會比 1λ0 的 RDO 省下 7.1%、1.5%、10.8%的資料量,而耗損的 PSNR 值分別為. 0.99db、1.88 db、2.4 db。至於整張畫面的總資料量就與前景背景所佔的比例、 前影背景畫面的影像特性有關。. 針對前景的 PSNR 提升與背景壓縮資料量的減少,我們的方法皆比標準 1λ0 的 RDO 好,其中整體所花費的資料量增加主要是使用在前景 PSNR 的提升,而 我們的方法所花費的壓縮時間比標準 1λ0 的 RDO 少很多,與不開啟 RDO 的情況 接近。. 32.
(41) 表 6:壓縮資料量與 PSNR 之比較(59 張畫面) (a)Foreman Foreground of Frame. Background of Frame. Whole Frame. Ave. PSNR (db). Total Size (bits). Ave. PSNR (db). Total Size (bits). Total Size (bits). 1λ0. 37.52. 634315. 36.29. 608598. 1174048. Our Method. 38.45. 1459147. 35.30. 565450. 2024597. Non RDO. 37.30. 662309. 36.47. 653861. 1316170. (b)Stefan Foreground of Frame. Background of Frame. Whole Frame. Ave. PSNR (db). Total Size (bits). Ave. PSNR (db). Total Size (bits). Total Size (bits). 1λ0. 34.67. 640358. 35.80. 2658979. 3309337. Our Method. 34.99. 905867. 33.92. 2617962. 3523829. Non RDO. 34.43. 670723. 35.61. 2781574. 3452297. (c)Dancer Foreground of Frame. Background of Frame. Whole Frame. Ave. PSNR (db). Total Size (bits). Ave. PSNR (db). Total Size (bits). Total Size (bits). 1λ0. 35.60. 1062529. 43.56. 192451. 1254980. Our Method. 35.92. 1697418. 41.16. 171672. 1853411. Non RDO. 35.38. 1492036. 43.07. 269959. 1761995. 33.
(42) 第五章 視訊影片中運動物體之自動切 割 對於第四章所提出壓縮方法,除了要壓縮的影片外,另外需要輸入前景與背 景遮罩來當作壓縮的輔助工具。在本章節,我們提出了一個視訊檔案的自動切割 方法來產生前景與背景遮罩,在此,定義只因為攝影機之移動而運動的區域為背 景(真實世界中靜止的物體),而除了攝影機運動外,尚有自身運動之物體則歸 類為前景(真實世界中運動之物體),我們的方法可以在攝影機不為靜止的情況 下,自動切割出真實世界中的運動物體。在我們所提出的方法裡,被切割的影像 中之背景部分必須為最大的一群,如此才可以更準確的切割視訊檔案。. 在攝影機不為靜止的影片中,如果有獨立運動的物體,則攝影機之運動與物 體之運動會有其差異存在,若物體本身是靜止不動時,此時實際物體被攝影機拍 攝的影像才會與攝影機運動一致。圖 22 為 MPEG 組織所提供的測試影片 Mobile, 影片中獨立運動的物體有月曆、球與火車。假如圖 22(a)為目前要作切割處理 的視訊畫面,而圖 22(b)為其鄰近時間點的參考畫面,則我們必須要求得圖 22 (a)與圖 22(b)間各物體的運動資訊才能對視訊畫面做切割。圖 22(a)與 圖 22(b)間的運動情況如圖 23(a)所示,可以看出圖 23(a)中的運動只有 在部分的區域具有一致性,因為所拍攝的場景中有許多不同運動的物體存在。假 設畫面中拍攝的所有物體均為靜止,則物體看起來會運動只是因為攝影機之運動 造成,物體的運動趨勢(此時只有攝影機運動)可能如圖 23(b)所示。如果能 夠找出圖 23(a)與圖 23(b)間運動的不同之處,就能分辨出何者為真實世界 中靜止之物體,何者為運動之物體。. 34.
(43) 為了切割靜止與獨立運動的物體,我們利用了上述的觀念於我們的方法之 中,做為視訊切割的基礎。本章所使用的方法是基於“攝影機運動估測模型”,在 後續的小節會介紹視訊切割所需要的攝影機運動估測模型,並應用此模型到我們 所提出的視訊切割方法中,進而達成視訊切割的目的。. (a) 處理畫面. (b) 參考畫面 圖 22:Mobile 影片中的兩張畫面. (a). (b) 圖 23:運動向量示意圖. 35.
(44) 5.1 視訊切割概念與流程 視訊切割的流程如圖 24 所示,每次的輸入共兩個畫面,分別為“所要切割 的畫面” It 與其鄰近的“參考畫面” It+1 。圖 24 演算法的第一個步驟是區域運動 估測(Local Motion Estimation),區域運動估測是要發現兩張畫面間每個物體的 位移。估測區域運動的方法有許多種,手動標示對應點即為一種較準確的方法, 其他方法如所 2.2.2 小節所提到的區塊比對方法或光流估測(Optical Flow)[28] 皆為一種可行的方法。. It. It+1. Local Motion Estimation. Global Motion Estimation. Motion Difference Analysis. Frame Segmentation. 圖 24:視訊切割架構. 圖 24 中 視 訊 切 割 的 第 二 步 驟 為 全 域 運 動 之 估 測 ( Global Motion ,所謂的全域運動是以攝影機的觀點做宏觀的計算,希望得到所有的 Estimation) 物體在只有攝影機運動影響下的運動資訊(即把真實世界中所有物體皆當成靜止 不動),在這部分會藉由攝影機運動參數來估測畫面中整體運動的情況。切割畫. 36.
(45) 面時,每個部分都要估測出其區域運動與全域運動,區域運動與全域運動的關係 有兩種,一種為圖 25(a)所示,區域運動與全域運動差異較小,另外一種情況 為圖 25 (b)所示,區域運動與全域運動差異較大。若區域運動與全域運動差 異較小,則此部分為背景的機率較大,在真實世界中可能是靜止的物體;若區域 運動與全域運動差異較大,則此部分可能為我們所定義的前景,因為物體不單只 有攝影機運動,還有自身的運動。因此,為了進行視訊切割,必須要找出整張畫 面中所有的區域運動及所有的全域運動才能做進一步的切割。在演算法的第三個 步驟是要分析區域運動與全域運動的差異性,並訂定好評斷區域運動與全域運動 之差異的臨界值,此臨界值會用來當作切割為背景或前景的標準。在演算法的最 後一個步驟會根據前一步驟所訂定的標準來切割影像,若某一部份之區域運動與 全域運動之差異大於所訂定的臨界值,則切割為前景,反之,切割為背景。. (a) 運動差異小. (b) 運動差異大. 圖 25:運動向量之差異性. 5.2 區域運動估測與全域運動估測 在前一小節中介紹了視訊切割的概念與流程,本小節會針對前一小節所提到 的區域運動估測與全域運動估測再做進一步的介紹。. 37.
(46) 5.2.1 區域運動估測使用區塊比對 在區域運動估測必須要找出兩張畫面中具有運動關係的對應點,考慮一般的 視訊壓縮皆以“區塊比對為基礎”,為了視訊切割可以進一步的整合到視訊壓縮之 中,本論文皆使用“區塊比對”當作“區域運動估測”之方法。區塊比對的一項優點 就是較為簡單,但是也有其缺點,所列如下:. 1. 遮蔽或消失:兩張影像中欲尋找對應關係的對應點,可能會因為遮蔽的 現象而找不到真正有對應關係的點。另外若某物體原本在畫面裡,在下 一個時刻卻移出了畫面,在這種情況下是無法找到正確的對應點。 2. 扭曲或變形:物體本身有嚴重的扭曲或變形,對應點也沒辦法找的很好。 3. 模稜兩可或物體邊緣:區塊比對是以灰階值的大小差異為判斷標準,找 出灰階值差異最小的區塊。當區塊比對的區塊太小時,在很大的平順的 區域中,由於灰階值差異太接近,可能會有對應點誤判的情形產生。另 外當所使用的區塊太大時,在物體的邊緣常常會包含多個物體,因為每 個物體的運動不一定一致,所以針對一個區塊只找一個對應點可能會有 錯誤的情況產生。. 4. 搜尋範圍:區塊比對時,搜尋的範圍不能無限制的擴張以免增加運算的 複雜度;一般來說,搜尋的範圍在 16 個像素值最常被拿來使用,但在某 些情況下實際物體的運動會超過 16 個像素,所以可能也無法找到最佳的 對應點。. 雖然區塊比對有上述的缺點,但是因為其演算法較為簡單,且視訊壓縮標準 中也使用區塊比對,所以我們仍然使用區塊比對來估計區域運動。本論文所使用 的區塊比對皆以 16×16 區塊為單位,而搜尋範圍均設定為±16 個像素。 38.
(47) 5.2.2 全域運動估測使用 PTZ 攝影機運動模型 全域運動估測時,本論文使用了Peter J. Ramadge等人 [29][30]所提出的攝 影機運動估測模型,此模型基本假設是攝影機運動只能有放大、縮小、上下或左 右傾斜攝影,但是攝影機的中心必須固定於定點不可有平移運動,我們簡稱此模 型為PTZ(Pan、Tilt、Zoom)運動參數模型,我們以此模型來近似一般攝影機運 動之模型。. x′ = y′ =. p1 x + p2 y + p3 p5 x + p 6 y + 1. − p 2 x + p1 y + p4 p5 x + p 6 y + 1. (5.1). PTZ 運動估測模型如(5.1)式所示,其中(x , y)與( x ′ , y ′ )分別為相 鄰兩張畫面中具有運動對應關係的兩個點之影像座標,而 p1 、 p2 、 p3 、 p4 、 p5 與. p6 代表著運動模型的六個參數,此模型之推導可以在[29]中得到,值得注意的 是座標(0,0)對應到的是影像畫面的中心。. 在本小節,我們使用兩段符合 PTZ 運動的影片來驗證 PTZ 模型的準確度, 為了估計攝影機的運動及其運動參數,每次共需要兩張畫面。在第一段影片中, 物體均靜止不動,而攝影機則是單純的只有縮小的動作, 圖 26(a)與圖 26 (b)分別為影片中攝影機運動前與攝影機運動後的兩張畫面,兩張畫面中各自 有 90 個數字,代表著我們在兩張畫面中手動標示的 180 的點,以圖 26(a)中 數字 1 的點為例,當攝影機經過運動後,圖 26(a)中數字 1 的位置會移動到圖 26(b)中數字 1 的位置,我們稱這樣的兩個點為一對“對應點”,其他數字也有 同樣的對應關係,所以兩張畫面中共有 90 對具有對應關係的對應點,另外,為 了稱呼方便,在圖 26(a)中的點皆稱為起點,在圖 26(b)中的點皆稱為終點。. 39.
(48) 為 了 估 計 PTZ 模 型 參 數 , 所 使 用 的 方 法 為 “ 非 線 性 回 歸 ” ( Nonlinear. Regression) 。將圖 26 中 90 對“對應點”隨機分為 60 對與 30 對兩群,其中 60 對 的一群是做為估計攝影機參數使用,稱為訓練群(Training Set) ,而 30 對的一群 則是要驗證算出來的攝影機參數,稱為測試群(Testing Set) 。把訓練群當作非線 性回歸的輸入,經過非線性回歸的計算,會求出表 7 的六個相機參數,用此六 個參數即可以描述圖 26 (a)與圖 26(b)之間的攝影機運動。. (a) 處理畫面 It. (b) 參考畫面 It+1 圖 26:Zoom 影片中的手動標示點. 假設圖 26 (a)中有一起點座標為(x , y),對應到圖 26 (b)終點座標 ( x′ , y′ ) ;若將起點座標與表 7 的六個運動參數帶入(5.1)式,可求得新的終 。距離誤差(5.2)式可用來計算所求得的終點座標( xn′ , y ′n ) 點座標( xn′ , y ′n ) 相對於手動標示座標( x ′ , y ′ )之準確性,其誤差的單位為像素。表 8 統計出 60 對訓練群的終點誤差分佈情形,從表 8 可以看出經由攝影機參數所估得的終點 誤差都小於兩個像素以下。表 9 統計出 30 對測試群的終點誤差分佈情形,可以 看到誤差也在兩個像素以下。. err = | x ′ - xn′ | + | y ′ - y ′n | 40. (5.2).
(49) 表 7:圖 26 (a) 與圖 26 (b) 的攝影機參數. P1. P2. P3. P4. P5. P6. 0.962542. -0.000416. -0.094951. 0.176463. 0. 0.000026. 表 8:訓練群終點誤差分佈(共 60 對). 0<err≦0.5 0.5<err≦1.0 1.0<err≦1.5 1.5<err≦2.0 Number of pairs. 9. 32. 16. 2<err. Total. 0. 60. 2<err. Total. 0. 30. 3. 表 9:測試群終點誤差分佈(共 30 對). 0<err≦0.5 0.5<err≦1.0 1.0<err≦1.5 1.5<err≦2.0 Number of pairs. 8. 10. 8. 4. 估計攝影機的運動及其運動參數時,每次共需要兩張畫面及畫面中的對應點 關係,為了進一步測試 PTZ 模型的誤差,我們總共估計了 5 組攝影機參數,此 五組攝影機參數所造成的終點誤差之分佈統計於表 10 中,表中的 f0 ∼ f1 代表 所估測的攝影機參數是畫面 0 與畫面 1 之間的參數,f1 ∼ f2 代表所估測的攝影 機參數是畫面 1 與畫面 2 之間的參數,其他以此類推。表 10 中實驗結果顯示, 終點誤差皆小於 2 個像素以下,這代表著當拍攝影片時的攝影機若約略符合 PTZ 運動模型,則計算出來的攝影機參數之精準度在兩個像素以內,另外誤差小於 1.5 像素的佔了全部的 94%,誤差小於 1 個像素的則佔了 70%。. 表 10:終點之誤差統計(共 450 對). 0<err≦0.5 0.5<err≦1.0 1.0<err≦1.5 1.5<err≦2.0. 2<err. Total. f0 ∼ f1. 17. 42. 24. 7. 0. 90. f1 ∼ f2. 20. 41. 22. 7. 0. 90. f2 ∼ f3. 27. 40. 21. 2. 0. 90. f3 ∼ f4. 23. 40. 20. 7. 0. 90. f4 ∼ f5. 20. 45. 19. 6. 0. 90. 24%. 46%. 24%. 6%. 0%. 41.
(50) 在我們拍攝的第二段影片中,物體一樣都靜止不動,而攝影機除了縮小的動 作外還有往左傾斜攝影,圖 27(a)與圖 27(b)分別為影片中攝影機運動前與 攝影機運動後的兩張畫面。在圖 27 的兩張影像中標示了 44 對“對應點”,將 44 對“對應點”隨機分為訓練群 24 對與測試群 20 對,而誤差函數同樣使用(5.2) 式。訓練群與測試群的誤差結果統計在表 11 中,由表 11 可得知終點誤差也都 小於兩個像素,而誤差小於 1.5 像素的佔了全部的 91%,誤差小於 1 個像素的則 佔了 71%。. (a) 處理畫面 It. (b) 參考畫面 It+1. 圖 27:Pan、Tilt、Zoom 影片中的手動標示點. 表 11:圖 27 (a) 與圖 27 (b) 所求得的終點誤差之統計(共 44 對). 0<err≦0.5. 0.5<err≦1.0. 1.0<err≦1.5. 1.5<err≦2.0. 2<err. Training set. 5. 12. 5. 2. 0. Testing set. 6. 8. 4. 2. 0. 25%. 46%. 20%. 9%. 0%. 圖 28 是 MPEG 組織所提供的測試影片 Mobile 的手動標示點,本章節的實 驗會對圖 28(a)的畫面做切割。Mobile 影片的攝影機運動除了縮小以外,尚 會往左平移,因此,Mobile 影片的攝影機運動並不完全符合 PTZ 攝影機運動模 型,但是在此我們同樣用 PTZ 攝影機運動模型來近似其攝影機運動,並估計其 42.
(51) 誤差。為了計算攝影機參數,分別在圖 28 兩張畫面中的背景部分手動標示了 35 對“對應點”,如圖 28(a)與圖 28(b)所示。將 35 對“對應點”隨機分為訓練 群 25 對與測試群 10 對,訓練群所求得的攝影機參數如表 12 所示,並且利用測 試群來驗證終點的誤差,誤差函數同樣使用(5.2)式。誤差的結果統計在表 13 中,由表 13 可得知終點誤差也都小於兩個像素,而誤差小於 1.5 像素的佔了全 部的 94%,誤差小於 1 個像素的則佔了 71%。全域運動估測流程如圖 29 所示, 而估計全域運動的方法總結如下:. 1. 找到具有運動關係的對應點。 2. 輸入對應點並利用非線性回歸求得攝影機參數。 3. 將 It 上起點座標與攝影機參數帶入(5.1)式,求出全域運動在 It+1 上的 終點座標。. (a) 處理畫面 It. (b) 參考畫面 It+1. 圖 28:Mobile 影片中的手動標示點. 43.
(52) 表 12:圖 28 (a) 與圖 28 (b) 的攝影機參數. P1. P2. 0.986704. P3. 0.000443. P4. 2.848848. P5. P6. 0.155756. 0. 0. 表 13:圖 28 (a) 與圖 28 (b) 所求得的終點誤差之統計(共 35 對). 0<err≦0.5. 0.5<err≦1.0. 1.0<err≦1.5. 1.5<err≦2.0. 2<err. Training set. 5. 12. 6. 2. 0. Testing set. 6. 2. 2. 0. 0. 31%. 40%. 23%. 6%. 0%. 圖 29:全域運動估測流程圖. 5.3 自動區域運動估測與手動全域運動估測. 圖 30 為自動區域運動估測與手動全域運動估測之視訊切割架構圖,為了對 圖 28(a)的 Mobile 畫面做切割,首先使用 16×16 大小的區塊比對方法求得圖 28 (a)It 與圖 28(b)It+1 間的區域運動向量,因為 Mobile 為 325×288 的影像,所 以一張影像共可切割成 396 個 16×16 的區塊。對於影像中的每一個區塊都必須使 用區塊比對求得一個區域運動向量,所以對於一張畫面共有 396 的區域運動向 44.
(53) 量。區域運動向量的起點為 It 畫面中現在處理區塊的左上角點座標,比對到 It+1 畫面中,區塊的左上角座標則為終點,以( xl′ , yl′ )表示。圖 31(a)即為圖 28 (a)參考圖 28(b),利用區塊比對後所找出的 396 個區域運動向量。. 圖 30:自動區域運動估測與手動全域運動估測之視訊切割架構圖. 45.
數據
![圖 7:切割畫面示意圖[3]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8255349.171863/15.892.158.711.543.1048/圖7切割畫面示意圖3.webp)
+7

相關文件
‘Desmos’ for graph sketching and ‘Video Physics’ for motion analysis were introduced. Students worked in groups to design experiments, build models, perform experiments
Tying in with the modules and topics in the school-based English Language curriculum, schools are encouraged to make use of the lesson plans in the resource
Ongoing Projects in Image/Video Analytics with Deep Convolutional Neural Networks. § Goal – Devise effective and efficient learning methods for scalable visual analytic
– Assume that there is no concept with significan t correlation to Mountain..
– evolve the algorithm into an end-to-end system for ball detection and tracking of broadcast tennis video g. – analyze the tactics of players and winning-patterns, and hence
Visit the following page and select video #3 (How warrant works) to show students a video introducing derivative warrant, then discuss with them the difference of a call and a
Trace of display recognition and mental state inference in a video labelled as undecided from the DVD [5]: (top) selected frames from the video sampled every 1 second; (middle) head
(2) We emphasized that our method uses compressed video data to train and detect human behavior, while the proposed method of [19] Alireza Fathi and Greg Mori can only
