Proceedings of the Sth'lnternational Conference on Neural Information Processing (ICONIP'OZ) , Vol. 2 Lip0 Wan& Jagath C. Rajapakse, Kunihiko Fukushlma, Soo-Young Lee, and Xin Yao (Editors)
A NOVEL LEARNING ALGORITHM FOR DATA CLASSIFICATION WITH
RADIAL BASIS FUNCTION NETWORKS
Yen-Jen Oyang, Shien-Ching Hwang, Yu-Yen Ou, Chien-Yu Chen, and Zhi-Wei Chen
Department of Computer Science and Information Engineering
National Taiwan University, Taipei, Taiwan,
R.
0. C.
{
yjoyang, yien, zwchen} @csie.ntu.edu.tw
{
schwang, cychen} @mars.csie.ntu.edu.tw
ABSTRACT
This paper proposes a novel learning algorithm for constructing data classifiers with radial basis function
(RBF) networks. The RBF networks constructed with the proposed learning algorithm generally are able to deliver the same level of classification accuracy its the
support vector machines (SVM). One important advantage of the proposed learning algorithm, in comparison with the support vector machines, is that the proposed learning algorithm normally takes far less time to figure out optimal parameter values with cross validation. A comparison with the SVM is of interest, because it has been shown in a number of recent studies that the
S V M
generally is able to deliver higher level of accuracy than the other existing data classification algorithms. The proposed learning algorithm worlks by constructing one RBF network to approximate the probability density function of each class of objects in the training data set. The main distinction of the proposed learning algorithm is how it exploits localdistributions of the training samples in determining the optimal parameter values of the basis functions. As the proposed learning algorithm is instance-based, the data reduction issue is also addressed in this paper. One interesting observation is that, for all three data sets used in data reduction experiments, the number of training samples remaining after a naive data reduction mechanism is applied is quite close to the number of support vectors identified by the SVM software.
Key terms: Radial basis function network, Data
classification, Machine learning.
1. INTRODUCTION
The radial basis function (RBF) network is a splxial type of neural networks with several distinctive features [12, 131. One of the main applications of IRBF networks is data classification. In the past few years, several learning algorithms have been proposed for data However, latest development in data classification has focused more on support vector machines (SVM) than on IZBF networks, because several recent studies have repo,rted that the SVM generally is able to deliver higher . classification with RBF networks [2, 4, 101.
classification accuracy than the other existing data classification algorithms [S, 9, 111. Nevertheless, the SVM suffers one major problem. That is, the time taken to carry out model selection for the SVM may be unacceptably long for some applications.
This paper proposes a novel learning algorithm for constructing RBF network based classifiers without incurring the same problem as SVM. Experimental results reveal that the RBF networks constructed with the proposed learning algorithm generally are able to deliver the same level of accuracy as the SVM [7]. Furthermore, the time taken to figure out the optimal
parameter values for a RBF network through cross validation is normally far less than that taken for a SVM.
The proposed learning algorithm works by constructing one RBF network based function approximator for each class of objects in the training data set. Each RBF network approximates the probability density function of one class of objects. The general form of the function approximators is as follows:
where
z
= ( z l , z 2 ,.
.
.,
z,)
is a vector in the m-dimensionalvector space and
lk
-
uhll is the distance between vectorsz
and uh. The function approximators are then exploited to conduct data classification. In some articles [151, a RBF network of the form shown inequation (1) is called a spherical Gaussian
RBF
network. For simplicity, such a RBF network is called spherical Gaussian function (SGF) network in this paper. The main distinction of the proposed learning algorithm is how the local distributions of the training samples are exploited. Because the proposed learning algorithm is instance-based, the efficiency issue shared by almost all instance-based learning algorithms must be addressed. That is, a data reduction mechanism must be employed to remove redundant samples in the training data set and, therefore, to improve the efficiency of the instance-based classifier. Experimental results reveal that the ndive data reduction mechanism employed in this paper is able to reduce the size of the training data set substantially with a minimum impact on classification accuracy. One interesting observation inthis regard is that, for all three data sets used in data reduction experiments, the number of training samples remaining after data reduction is applied and the number of support vectors identified by the SVM software are in the same order. In fact, in two out of the three cases reported in this paper, the differences are less than 15%. Since data reduction is a crucial issue for instance-based learning algorithms, further studies on this issue should be conducted.
In the following part of this paper, section 2 presents
an overview of how data classification is conducted with the proposed learning algorithm. Section 3 elaborates how the proposed learning algorithm works. Section 4 reports experiments conducted to evaluate the proposed learning algorithm. Finally, concluding remarks are
presented in section 5 .
2. OVERVIEW OF DATA CLASSIFICATION WITH THE PROPOSED LEARNING
ALGORITHM
This section presents an overview of how data classification is conducted with the proposed learning algorithm. Assume that the objects of concern are distributed in an m-dimensional vector space. Let
fi
denote the probability density function that corresponds to the distribution of class-j objects in the m-dimensional vector space. For each class of objects in the training data set, the proposed learning algorithm constructs a SGF network of form shown in equation (1) to approximate the probability density function of this particular class of objects. Letj j
denote the SGFnetwork based function approximator corresponding to class-j objects. Then, data classification is conducted by predicting the class of an incoming object located at
Y according to the likelihood function defined as follows:
n . A n
L j (v) = jf' (v) 3
where nj is the number of class-j training samples and n is the total number of samples in the training data set.
The essential issue of the proposed learning algorithm is how to construct the function approximator. Assume that the number of samples is sufficiently large. Then, by the law of large numbers in statistics [14], we can estimate the value of the probability density functionfi(si) at a class-j sample si as follows:
r
-
1-1where (i) R(si) is the maximum distance between si and its k, nearest training samples of the same class, (ii)
R(si)mn' is the volume of a hypersphere with radius
r(8
+
1)R(si) in an m-dimensional vector space, (iii)
r(.)
is the Gamma function [l], and (iv) kl is a parameter to be determined either through cross validation or by the user. Therefore, the ultimate goal of the learning process is toderive
3,
f2,
...
based on the estimated functionvalues at the training samples. Details of the proposed learning algorithm will be elaborated in the next section. One concern of applying equation (2) above is that
R(si) is determined by one single training sample and therefore could be unreliable, if the data set is noisy. In our implementation, we use
R(si)
defined in the following to replace R(si),where
i,,
iz,
...,
i ,
are the kl nearest training samplesof the same class as si. The basis of employing
R(si)
is elaborated in Appendix.3. APPROXIMATION OF PROBABILITY DENSITY FUNCTIONS
As mentioned earlier, the proposed learning algorithm constructs
a
SGF network based function approximator of form shown in equation (1) for each class of training samples. Assume that we now want to derive a function approximator for the set of class-j training samples {sl, s2,...,
si, ...). The proposed learning algorithm places one Gaussian function at each sample and sets w o in equation (1) to 0. The problem to be solved now is determining the optimal wh and ohvalues of each Gaussian function.In determining optimal parameter values for the Gaussian function centered at si, the proposed learning algorithm first conducts a mathematical analysis on a synthesized data set. The data set synthesized is based on two assumptions. First, the sampling density in the proximity of si is sufficiently high and, as a result, the variation of the probability density function in the proximity of si approaches 0. The second assumption is that si and its nearest samples of the same class are evenly spaced by a distance determined by the value of the probability density function at si. Fig. 1 shows an
example of the synthesized data set for a training sample in a 2-dimensional vector space. The details of the model are elaborated in the following.
" t "
Fig. 1. An example of the synthesized data set for a training sample in a 2-dimensional vector space.
(i) Sample si is located at the origin and the neighboring class-j samples are located at (h~b;., h2&,
...,
hm@, where h l , hZ,.
.
.,
h, are integers and b;. is the average distance between two adjacent class-j trainingsamples in the proximity of si. How
4
is determined will be elaborated later on.(ii) All the samples in the synthesized data set, incliuding
si, have the same function value equal toJ(si). The value offj(si) is estimated based on equation (2) in section 2.
The first phase of the proposed learning algorithm performs an analysis to figure out the values of wi and q that make function gi(.) defined in the following be a
constant function equal tofj(si),
La=-
k m -In other words,
for all x E R", where R is the set of real numbers.
we .will find that
gi(x) =&(si)- (3)
If we take partial derivatives of gi(xl, x2,
. .
.,
x,), thenagi(o,o
,...,
0)= o
andagi(*$&,
...,*
3)
2 - = 0axk ax h
for all 1 I h 2 m. It can be proved in mathematics that local maximums and local minimums of gj(.) are located
at (a1&, a24,
..., am4)
and ((b,++)Si,
(b2 ++)d\,...,
(b,
+$)Si),
where al, u2,...,
a, and bl, b2,...,
15, areintegers. Therefore, one empirical approach to make equation (3) above satisfied is to find appropriate iui and
q that make
We have
g,(O
)...,
O)=g,(k$)...,
ky)= 8, f j ( S i )Therefore, one of our goals is to find q such that
1
+
2f: z(2h)2 = 2f:z(2k+1)2
, which has only one numerical real root 0.861185. Let zo = 0.861185. Then, we have 2 c (z?)'-
z Y ) ~
)>
0 Furthermore, we have h=l h=O ee k=5 k=5 k=5<
2 ~ ; ~ = 6 . 4 6 6 4 ~ 1 0 - ~.
In summary, we have 0 < 1+
2%)
-
( 2 g10('~+')')
< 6.4664~10-'.Therefore, zo = 0.861185 is a good approximate root of equation (6). In fact, we can take more terms from both sides of equation (6) to obtain more accurate approximation.
Given that 0.861185 is a good approximate root of
equation (6) and that
z
= exp -2 , we need to setq = 0.914564 to make equation (5) satisfied. Next, we need to figure out the appropriate value of wi. According to equations (3) and (4a),
we need to set wi so that
(
h=l(
g?)
(7) fj(Si)-
- ( k ,+
1).r(7
+
1) w. = - (2.2925)" (2.2925)" . nj.
R(si)".
*The only remaining issue is to determine
4,
so that we can compute the value of q = 0.914564 accordingly. In this paper, we set4
to the average distance between two adjacent class-j training samples in the proximity of sample si. In an m-dimensional vector space, the number of uniformly distributed samples, N , in a hypercube with volume V can be computed by N =-
V ,a"
where a i s the spacing between two adjacent samples.
- 7
R(si )
J x
Therefore, we can compute
6
bysi
=d G m G
Let
z
= exp(
--
8
3
, then we can rewrite equation (5)as follows:
1 + 2 2 Z(2k)2 = 2
2
z(2k+1)2.
(6)
Since 0 <
z
< 1, if we want to find the root of equation (6), we can take a limited number of terms from both sides of the equation and find the approximate root. For example, if we take 5 terms from both sides of equation (6), then we havek=l k=O
In equations (7) and
(S),
parameter m is supposed to be set to the number of attributes of the data set. However, because some attributes of the data set may be correlated, we replace m in equations (7) and (8) by another value, denoted by hi in our implementation. The actual value of & is to be determined through cross validation. Actually, the process conducted to figure out optimal also serves to tune w i and q in our implementation. Once & is determined, we have the following approximate probability density function for class-j training samples {SI, s2,.
.
.,
si,.
,.
}:where p is a vector in the m-dimensional vector space,
nj is the number of class-j training samples, and 1.6210. R(si)
0. =
d-'
In fact, because the value of the Gaussian function decreases exponentially, when computing
j j
(p)according to equation (9), we only need to include a limited number of nearest training samples of ,U The number of nearest training samples to be included can be determined through cross validation.
As far as the time complexity of the proposed learning algorithm is concemed, for each training sample, we need to identify its k, nearest neighbors of the same class in the Iearning phase, where kl is a parameter in equation (2). If the kd-tree structure is employed [3], then the time complexity of this process is bounded by O(mn log n
+
kl n log n), where m is thenumber of attributes of the data set and n is total number of training samples. .In the classifying phase, we need to identify a fixed number of nearest training samples for each incoming object to be classified. Let k2
denote the fixed number. Then, the time complexity of the classifying phase is bounded by O(mn log n
+
k2clog n), where c is the number of objects to be classified.
''
-
4. EXPERIMENTAL RESULTS
evaluating the right-hand side i f equation (9).
The parameter that substitutes for m in equations (7)
This section reports the experiments conducted to evaluate the performance of the proposed learning algorithm. Table 1. lists the parameters to be tuned through cross validation in our implementation. In this paper, these parameters are set based on the 10-fold cross validation.
kl lThe parameter in equation (2).
, (The number of nearest training samples included in
[
I f 1 land(8).1
Table 1. The parameters to be set through cross validation in the proposed learning algorithm.
Tables 2 and 3 compare the accuracy of data classification based on the proposed learning algorithm, the support vector machine, and the KNN classifiers, over 9 data sets from the UCI repository [5]. The collection of benchmark data sets used is the same as that used in [9], except that DNA is not included. DNA is not included, because it contains categorical
data and an extension of the proposed learning algorithm is yet to be developed for handling categorical data sets. In Tables 2 and 3, the entry with the highest score in one row is shaded. The parenthesis in the entry
corresponding to the proposed algorithm encloses the values of the three parameters in Table 1. In these experiments, the SVM package used was LIBSVM [6]
with the radial basis kemel and the one-against-one practice was conducted.
Table 2 lists the results of the 6 smaller data sets, which contain no separate training and test sets. The number of samples in each of these 6 data sets is listed in the parenthesis below the name of the data set. For these 6 data sets, we adopted the evaluation practice used in [9]. That is, 10-fold cross validation is conducted on the entire data set and the best score is reported. Therefore, the numbers reported just reveal the maximum accuracy that can be achieved, provided that perfect cross validation algorithms are available to identify the optimal parameter values. As Table 2 shows, the data classification based on the proposed learning algorithm and the SVM achieve basically the same level of accuracy for 4 out of these 6 data sets. The two exceptions are glass and vehicle. The benchmark results of these two data sets suggest that both the proposed algorithm and the SVM have some blind spots, and therefore may not be able to perform as well as the other in some cases.
Table 3 provides a more informative comparison, as the data sets are larger and cross validations are conducted to determine the optimal parameter values for the proposed learning algorithm and the SVM. The two numbers in the parenthesis below the name of each data set correspond to the numbers of training samples and test samples, respectively. Again, the results show that the data classification based on the proposed learning algorithm and the SVM generally achieve the same level of accuracy. Tables 2 and 3 also show that the proposed learning algorithm and the SVM generally are able to deliver higher level of accuracy than the KNN classifiers.
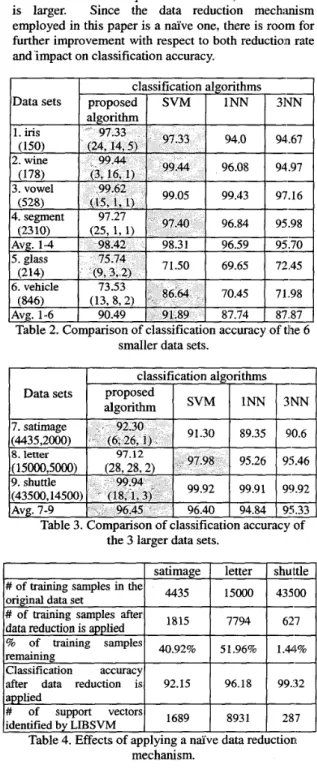
In the experiments reported in Tables 2 and 3, no data reduction is performed for the proposed learning algorithm. Table 4 presents the effect of applying a ndive data reduction algorithm. The ndive data reduction algorithm examines the training samples one by one in an arbitrary order. If the training sample being examined and all of its 10 nearest neighbors in the remaining training data set belong to the same class, then the training sample being examined is considered as redundant and is deleted. Since the proposed learning algorithm places one spherical Gaussian function at each training sample, removal of redundant training samples means that the SGF network constructed will contain less nodes and will operate more efficiently. As shown in Table 4, the naive data reduction algorithm is able to reduce the number of training samples substantially with a minimum impact on classification accuracy, less than 1% on average. The rate of data reduction depends on the characteristics
of the data set. For satimage and letter, about one half
of the training samples are removed, while over 98% of the training samples in shuttle are considered as
support vectors identified by the SVM software for designates the time taken to conduct 10-fold cross comparison. One interesting observation is that, for validation to figure out optimal parameter values. For
satimage and letter, the numbers of training samples SVM, we followed the practice suggested in [9]. In remaining after data reduction is applied and the this practice, cross validation is conducted with 225
numbers of support vectors identified by the SVM possible combinations of parameter values. For the software are almost equal. For shuttle, the difference proposed learning algorithm, cross validation was is larger. Since the data reduction mechinism conducted over the following ranges for the three employed in this paper is a ndive one, there is room for parameters listed in Table 1: kl: 1-30; k2: 1-30; hi :
further improvement with respect to both reduction rate 1-5.
and ‘impact on classification accuracy. In Table 5, Make classifier designates the time taken to construct a classifier based on the parameter values determined in the cross validation phase. For SVM, this is the time taken to identify support vectors. For the proposed learning algorithm, this is the time taken to construct the SGF networks. Test corresponds
to executing the classification algorithm to label all the objects in the test data set.
smaller data sets.
Table 5. Comparison of execution times in seconds.
As Table 5 reveals, the time taken to conduct cross validation for the SVM classifier is substantially higher than the time taken to conduct cross validation for the proposed learning algorithm. Furthermore, for both SVM and the proposed learning algorithm, once the optimal parameter values are determined, the times taken to construct the classifiers accordingly are insignificant in comparison with the time taken in the
the data classification phase is concerned, Table 5 shows that the performance of the SVM and that of the SGF network with data reduction applied are comparable. The actual execution time depends on the number of training samples remaining after data reduction is applied
or
the number of support vectors.3. Comparison Of Of cross validation phase. As far as the execution time of the 3 larger data sets.
5. CONCLUSION
In this paper, a novel learning algorithm for constructing data classifiers with RBF networks is proposed. The main distinction of the proposed learning algorithm is the way it exploits local distributions of the training samples in determining the optimal parameter values of mechanism. the basis functions. The experiments presented in this paper reveal that data classification with the proposed learning algorithm generally achieves the same level of data classification based on the proposed learning accuracy as the support vector machines. One algorithm and the SVM. important advantage of the proposed data classification
Table 4. Effects of applying a ndive data reduction1
Table 5 compares the execution times of c m i n g out
algorithm, in comparison with the support vector machine, is that the process conducted to construct a
RBF network with the proposed learning algorithm normally takes much less time than the process conducted to construct a SVM. As far as the efficiency
of the classifier is concerned, the ndive data reduction mechanism employed in this paper is able to reduce the size of the training data set substantially with a minimum impact on classification accuracy. One interesting observation in this regard is that, for all three data sets used in data reduction experiments, the number of training samples remaining after data reduction is applied is quite close to the number of support vectors identified by the SVM software.
As the study presented in this paper looks quite promising, several issues deserve further study. The first issue is the development of advanced data reduction mechanisms for the proposed learning algorithm. Advanced data reduction mechanisms should be able to deliver higher reduction rates than the ndive mechanism employed in this paper without sacrificing classification accuracy. The second issue is the extension of the proposed learning algorithm for handling categorical data sets. The third issue concerns why the proposed learning algorithm fails to deliver comparable accuracy in the vehicle test case, what the blind spot is, and how improvements can be made.
6. APPENDIX
Assume that
i1,i2,...,ik,
are the kl nearest training samples of si that belongs to the same class as si. If kl i ssufficiently large and the distribution of these kl samples in the vector space is uniform then we have
p R ( s )" z
k, =
r(t +
1) 'where p is the local density of samples
i,,
i2,
...,
ik,
in the proximity of si. Furthermore, we havekl
ih
- s i11
= f S t ) p(m
+
'h=l
2rm-'z:
where ~ is the surface area of a hypersphere
with radius r in an m-dimensional vector space. Therefore, we have
m + l 1 k l
CII
s^h -siII.
R ( s i ) = -.-
k1 h=l
The right-hand side of the equation above is then employed in this paper to estimate R(si).
7. REFERENCES
Proceedings of the 71h European Symposium on Artijkial Neural Network, pp. 399-404, 1999.
J. L. Bentley, "Multidimensional binary search trees used for associative searching,"
Communication of the ACM, vol. 18, no. 9, pp.
M. Bianchini, P. Frasconi, and M. Gori, "Learning without local minima in radial basis function networks," IEEE Transaction on Neural Networks,
vol. 6 , no. 3, pp. 749-756, 1995.
C. L. Blake and C. J. Merz, "UCI repository of bmachine learning databases," Technical report, University of California, Department of Information and Computer Science, Imine, CA, 1998.
C. C. Chang and C. J. Lin, "LIBSVM: a library for support vector machines," http://www.csie.ntu. edu.tw/-cjlirdlibsvm, 2001.
N. Cristianini and J. Shawe-Taylor, An
Introduction to Support Vector Machines,
Cambridge University Press, Cambridge, UK, 2000.
S. Dumais, J. Platt, and D. Heckerman, "Inductive learning algorithms and representations for text categorization," Proceedings of the International Conference on Information and Knowledge Management, pp. 148-154, 1998.
C. W. Hsu and C. J. Lin, "A comparison of
methods for multi-class support vector machines,"
IEEE Transactions on Neural Networks, vol. 13,
509-517,1975.
.
pp. 415-425,2002.
[lo] Y. S. Hwang and S. Y. Bang, "An efficient method to construct a radial basis function neural network classifier," Neural Networks, vol. 10, no. 8, pp.
[ l l ]
T.
Joachims, "Text categorization with support vector machines: learning with many relevant features," Proceedings of Eumpean Conference on Machine Leaming, pp. 137-142, 1998.[ 121 V. Kecman, Learning and Soft Computing: Support Vector Machines, Neural Networks, and F u u y
Logic Models, The MIT Press, Cambridge,
Massachusetts, London, England, 2001.
[13] M. J. L. Om, "Introduction to radial basis function networks," Technical report, Center for Cognitive Science, University of Edinburgh, 1996.
[14] A. Papoulis, Probability, Random Variables, and
Stochastic Processes, McGraw-Hill, 1991.
[15] B. Scholkopf, K. K. Sung, C. Burges, F. Girosi, P. Niyogi, T. Poggio, and V. Vapnik, "Comparing support vector machines with gaussian kernels to radial basis function classifiers," IEEE Transactions on Signal Processing, vol. 45, no. 11,
1495-1503,1997.
pp. 1-8, 1997.
[l]
[2]
E. Artin, The Gamma Function, New York, Holt, Rinehart, and Winston, 1964.
F. Belloir, A. Fache, and A. Billat, "A general approach to construct RBF net-based classifier,"