2006IEEE International Conference on Systems, Man, and Cybernetics
October8-11, 2006,
Taipei,
TaiwanPossibilistic C-Shell Clustering with Inter-Cluster Constraints
Tsaipei
Wang, Member,IEEE, andJames M. Keller, Fellow,IEEEAbstract-This paper describes our analysis of using extra constrainttermsregarding relations between cluster prototypes in possibilistic c-shell clustering. The extra constraints are
implemented as additional terms in the cost function. This allows users of these algorithms to incorporate additional knowledge regarding properties cluster prototype into the clustering process. Ouranalysis here focusesontheuse ofone extra term for locating circles (shell clustering with circular
prototypes)with similar radii. An adjustable factor is used to
control the strength of this constraint. For possibilistic
clustering, this couples the update procedure of the otherwise independent prototypes. Our experiments, using both simulation and real image data, indicate that this is especially
useful in locating actual clusters when the available data are
noisy.
I. INTRODUCTION
THE ability to locate specific shapes in images is important formany image analysis problems. Fuzzyand possibilistic c-shell clustering algorithms have been demonstrated to performwell for the task oflocating lines, circles, and quadric curves in 2-D images (orhyperplanes, hyperspheres, and hyperquadric surfaces in higher dimension data) [1-4], rectangles [5], and template-based shapes [6]. Examples of their application to real-world image analysis are in [7,8]. Among the two (fuzzy and possibilistic) approaches, the
possibilistic
approach is moreimmune tothe effect of noisepoints, and isthe basis ofour
algorithm discussed in this paper. Compared with the generalized Houghtransform [9] ortemplate
matching,
shell clustering hasmuchsmallermemoryandtimerequirements,
and the precision of prototype parameters is not limited tothe bin size in the Hough transform or the parameter resolution of thetemplates [2].
Existing c-shell clustering algorithms allow the specification of the number and type of prototypes, the initial conditions (membership values or prototypes), and a
distance or similaritymeasure between prototypes and data points. They do not allow the inclusion of additional constraintsonclustercharacteristics in the
clustering
process. However, insomeparticularapplicationstheremay be other desirablepropertiesfortheclusteringresults. Forthese cases,we present here the idea of introducing
approximate
constraints on cluster prototype parameters thatcorrespond
tothedesired clusterproperties. Sincefuzzyand
possibilistic
Tsaipei Wang is with theDepartment ofComputerScience, National Chiao Tung University, Hsinchu, Taiwan (phone: +886-3-5712121
ext.56689;e-mail:wangts(cs.nctu.edu.tw).
J. M. Keller is with the Department of Electrical and Computer Engineering, University of Missouri-Columbia, Columbia, MO 65211,
USA.
clustering algorithms identify the clusters through minimization of cost functions, it seems natural to try to incorporate these additional constraints on cluster parameters in the cost functions, and this is the approach we describein this paper.
There are many different types of additional constraints, depending on the particular applications and the extra information we know about the desired clusters. Such constraints can also be applied to the relations between clusters. For example, in c-shell clustering, we may want linear/planar prototypes that are approximately parallel to each other, or circular prototypes with similar radii. Different constraints mean different constraint terms added to the cost function. Here we focus on one example, where
we look for circular prototypes that have similar radii, and
use thisexample to illustrate someproperties ofusing such additionalconstraints. In the following, section II describes theformulation of the original and our modified possibilistic c-shell clustering (PCSC) algorithms for circles. Section III contains simulation results, and section IV describes an application in a real world scenario. Section V is our conclusion and discussion.
IL.
DESCRIPTION OFALGORITHM A. The OriginalPCSCforCirclesThe original PCSC algorithm, presented in [2], is an extension ofthepossibilisticc-means (PCM) algorithm[10] with shell-shapedprototypes. Here we limit our description to circle prototypes only. The following distance measure betweenapointxjandacircleprototype
{c1,
ri},
ct2~~ 2 2
dij2=(|Xi
C1 (1)is used to allow an analytical form for updating the prototypes, avoidingthe numerical methodsused by [4] for the original fuzzy c-shell clustering. The objective function of PCM is
C N C N
J= z
uijmdy:
+zlz(1 -uq)m.
(2)i=lj=1 i=1 j=1
Here
uj1
is the possibilistic membership of vector Xj in prototype{ci, rj},
N is the number of vectors, C is the number of clusters, andql
and m are two parameters that determine thedependenceofuij
ondcj.
Theupdateequations for the possibilistic membership values and the prototypesU"j = I+ i m and
2(ff)
1wi respectively, where -2cj Pi= T 2 , -Ci Ci-ri N m X[
1 Hi]1Y
Li
iXjI'
m2UJ(XjX)
andXjm(XjTXj
j=1 j=1These update equations are derived by
setting
to zero the derivatives of theobjective functionJrelativetou1j
andpi.
We can perform the original PCSC
algorithm
using
the procedurebelow:1.Initialize the prototypes.
2. Repeat until convergence or for a
predefined
number of iterations2.1. Calculate cluster
membership
U={uij}
using (3).2.2. Updatethe prototypesusing (4).
Convergence can be defined as when the
changes
of prototypesbetween iterations fall below a preset threshold.B. The
Modified
PCSCfor CirclesSince we are considering circle prototypes with similar radii, weadd an extra termJctotheoriginal costfunction J in(2)totakeradiussimilarityintoaccount:
J'=
J+Jc
(5)For the purpose of simplicity, let us consider only two
clusters now. Let
(cl,r1)
and (c2,r2) represent the respective prototypes. For the constraint of radius similarity, we can usethefollowingform forJ,:
2
_2
2c=
-a(r2
-r2
)
(6)
Here a is zero or a positive number
indicating
how strong theconstraintis. The selection ofits value willbe discussed later.The next step is to derive theupdate equations. With the added term Jc, we are not able to derive a
single
equation like (4) that simultaneously updates both the center and radius of a prototype. It is necessary to differentiate J relative to the center and radius ofa prototype separately, and minimizeJbysetting these derivativestozero:al N (
2_2
=-2j(ui)m(Xj -ci)ixj-ci
ri2
)0(7)
andail
a(ri2
) =-2L(Ur2J )rx2)-Ci| ri+2a
(ri2
-r3-i2
)=O.Here i 1,2.
Equations (7) and (8) do not allow us to obtain simple closed-form update equations for the prototype parameters, c1, r1, c2 and r2. This is because both r1 and r2 appear together due to the added term
J,
Therefore, an iterative method isnecessary for finding the solutions. Similar to[4],
we choose to solve (7) and (8) using Newton's method. There are 6 quantities to be optimized simultaneously (2 each forclandc2 for two-dimensional data, and one each for r,andr2).The procedure and stopping criteria of themodified PCSC algorithm are similar to those of the original PCSC, except that we update the prototypes by solving (7) and (8) using Newton's method. To reduce the amount of computation time,we further limit the prototype parameterupdating step toonly one iteration of Newton's method. This was indicated in [11] to still give goodclustering results, which we find to bethecase.
In order to gain some insight into the effect of thenew
parameter a, let us first consider a "perfect" scenario where the data points fall exactly on two circles and are evenly spaced in each circle, with
(cl*,r
*)
and(c2*,r2*)
being the centers and radii of the two underlying circles. In addition, these two circles are assumed to be well separated so their corresponding data points can be treated as two separate sets (calledX(1) andX(2)below), with themembership ofa data pointin one settothe cluster of theothersetassumed tobezero. This makes the clustering process more like two
separateclusteringprocessesofX(l) andX(2) coupled only by the constraint term
J,
For this special case, one solution to (7) is when
ci=ci,
regardless of the value of
ri.
This can be understood by consideringthe assumedsymmetry. When c,ci,
all thexj
in X(i)have thesamedij:
dij2 k
[(i)2
-2]i
forxj
inX(i),
which is independent ofj. This makes the memberships
uj
independent ofj
as well. (We will use u(l) and U(2) to represent thej-independent memberships.) Combine these with theassumption ofevenly spacedXj,
and wecan seethat the summation in (7) becomes zero whenci=ci*.
Since we have notmadeanyassumption regardingthe prototyperadii, this proves thatcl=cl*
isasolution.Our next task is to solve for
r,
and r2 givencl=cl*
and C2 C2. First, from (8) we can obtain the following relation betweenr1 andtheother parameters:2 a2 +
E
(U(l))m
Xj
-c1l2
Xjc (l, a X((U) )) XjeX(]) (9)LetN1 andN2 are thenumber of data points in X(1) and X(2), (8) respectively, and
N1'=Nl(u(,))m
andN2'=N2(u(2))m be the total membership in the two individual clusters. By into (9) substitutingxj
cl|=xj
-c |=- forxjinX(i), we geta2
+N,1(*)2
2 - r2±iv1tr1}
(IOa)
and similarly 2*2+
r2arI
+N2(r2)
(lOb)
a±N2'
We can further derive separateexpressions
(rj)2
and(r2)2 asweightedaverages of(rl )2and
(r2
*)2:
2
(aN2
')(r )2
+(a+N2
')N1'
*)
2 r,2 = 2 r2 2r)
( a) (aN2')+(at+N2')Nl' and 2(aN,')(r>
)2±(a
N1')N2
(r2 (br2
=.i2r
(Ilb)
(aN1
')+(a+N')N2'
This implies that solutions of both ri and
r,
have values betweenr1*
andr2*.
When acO,wehaverl=rl*
andr2=r2*
asexpected. When ais much larger than N1 and N2 (andN1' andN2'as
well),
it turnsoutthatr,and r2 become identical:r]2, r22
N1 (r1)i N2'(r2)2 (12)N1 +
N21
Equations (1 1)and(12)are notsolutions of
r,
and r2. This isbecause N,' actually depends on r1 through d112 andu().
Aspecial case whenwe can obtain
simple analytical
solutions forr1
andr2 iswhen we set71
J24oo,
and from(3)wehaveuij-1.
This in turn makesNj'
-N. This allowsus to compute analytical solutions of r1 and r2directly using (11),
withNl'
and N2' replaced by N1 and N2. Inaddition,
because membership values are constant, these solutions will notchange between iterations of the
clustering algorithm.
Inotherwords, theycorrespondtothe prototypes found
by
ourmodifiedPCSCalgorithmunder theconditionsabove. Inthe followingwecontinueto assume
Ni'=N1.
The purpose of thederivationsabove istounderstandhow the relations between rl, r2,
rl*
andr2*
are affectedby
the relations between a, N1 and N2. Oneinteresting
aspect tolook at isthe ratio between
[(ri)2_(r
*)2]
and[(r2
*)2
-(rl
)2].
This isa measure of how much the radius ofaprototype is affected by the difference between the twounderlying
circles. We caneasily obtainthisratio
by
subtract(r1
*)2
from bothsidesof( lla):rl2
*)2
aN2 (ri ) -(ri) __13 *2*2I
a(r*)2_
(r1*)2
aN2 +(a-+N2)N andsimilarly,
2 *)2(r2)
(r2)
- aN1 (I3b) *2 *2(r1
)
_(r2
)
aN++(aNc+
N)N2
We candrawafew observations for
special
casesof(13):
(1) The ratio in(13a)is closeto onewhenoN2
>>(c-N2)NI
(i.e., afterdividedbyaNIN2,
Nl-'>>a-+N2-
').
Thisoccurs whenboth aandN2aremuchlargerthanN1.
Inthis case,we haverP:-r2
.Onthe otherhand,
theratio in(3.33b)
is closetozero under the same condition because
aNV
<<aN2
<(a-+N1)N2,
resulting inr2=r2*.
Oneobservation we can drawis that, when a is large compared with the number of data points, and there are many more data points in one set than the other, both prototypes will have radius similar to that of the underlying circle of the larger data set.
(2) When
a>»N2=N1,
both ratios in (13) become 1/2, giving2 2
ri r2
[(rl*)2+(r2*)2]/2.
This means that bothprototypes
end up with the same radius when oc is very large and both sets have the same number of data points.
(3) The ratio in (13a) is close to zero when cxN2<<
(oaIN2)N1
(i.e.,
after dividedby
aNIN2,
Nl-l<<
-±+N2-
).
Thisoccurswhen either aorN2is much smaller thanN1. In this case, we have
rl-rl,
meaning that r1 is barely affected by the extra constraint.Overall, for the extra constraint to significantly affect the clustering result, ashould be large compared with either N2 orN1.
For more thorough investigation of how the relations between a;
N,
and N2 affect the clustering result, we plot in Fig. 1 r1 (solid lines) and r2 (dashed lines) relative torl*
andr2*
as functions of a for a few different combinations ofN1
and N2, computed from(11). The radii of underlying circles in this simulation are set tor1
10 andr2*
=20. We can see thatr1=rl
* andr2=r2*
when a-0, and that both r1 and r2appear to move toward the same value when ais increased. In addition, this value shifts toward
r1
* whenN1/N2
increases, and toward
r2*
whenNI/N2
increases.III. SIMULATION RESULTS
Inthis sectionourmodified PCSC algorithm is appliedto two dimensional simulation data. The assumption of independent sets of data for individual clusters is used throughout this section just for illustration purpose. This assumption does not affect the actual usage of thealgorithm because in the possibilistic approach to clustering, each prototype is updated independently regardless of what happens with the other prototypes, except for our added inter-cluster constraints.
Forcomparisonwiththe derivation in theprevious section, we start with the "perfect" scenario. We plot in Fig. 1
r1
(squares) and r2 (circles) obtained by applyingourmodified PCSC algorithm,instead ofusingtheanalytical results, for a few different values of a. The simulation results areobtained with perfect initialization (initial prototypes overlapping with underlying circles of the data points),
qV500000,
andm=1.5. The value ofq is made verylargesothat allmembership values will be closetoone, asassumed for the analytical results. We can see the prototype radii obtainedthrough clusteringare consistentwiththeanalytical results.
Fig. 2 contains the datapoints and prototypes found with various combinations of a,
N1
and N2. Parameter valuesqr500000
andm=1.5
are used. The small dots are data points and the large circles are prototypes found. Fig. 2(a) and (b)havecr0,
and the prototypes found matchperfectlyN2= 100 20 15 10 20 rIl -o c m -1 (a)
le
.1
.1
,.."i 0'-.,',:
I (c) .4''
.. .~ ~ ~ ~~ 04 Co 0 Tl-0 100 200 0 100 200 0 100 200a
Fig. 1. Radii ofprototypes found by PCSCrelative totheradii of
underlying circles ofthe data points,asfunctions of a, N1 andN,. Eachindividualplotcorrespondstoadifferent combination ofN, and N,. Radii ofunderlying circlesarer, =10andr,=20.The solidand
dashedlines areanalytical resultsfor r1 and r,,respectively,and the
small squares and circles are simulated results for r1 and r,,
respectively.
with the underlying circles ofthe data points. In Fig. 2(c),
we have ao0 and
N,.N2,
but both prototypes match perfectly with the underlying circles and have the sameradius because we have set rl
*r2
Fig. 2(d)-(f) correspondto a>0,
N1.N2,
andrlJ*r2*.
InFig. 2(d),wehaveN2>N,,
and the resulting prototypes match better with X(2). This is reversedinFig. 2(e).Fig. 2(f)is thesame asFig.2(d)except that ais larger, causing the two prototypes to have evencloser radii. The changeis moreevident forX(1), which has lessdata points.
Itmay seem strangethattheextra constrainttermactually makes the prototypes different from the underlying circles with differentradii, suchas inFig. 2(e). The
analysis using
the perfect scenario is to help us understand the relations between ocandotherparameters. Amorepracticaluseofthe modified PCSC algorithm is to more accurately locate the prototypes that are expected to have similar radii when the data arenoisy. For example, assume thatX(l)
contains only datapointsalongacircle;
we can find thisunderlying
circle withPCSC easily. Intheotherhand, forexample, letX(2) beso noisy that simply clustering its data points produces a
prototypeverydifferent from theunderlying cluster. Insuch cases,we canthink ofthe"coupled"
clustering
ashaving
the prototype for X(l) pullingthe prototype forX(2) along inthe clusteringprocess.The scenario in the last paragraph is illustrated with simulated data in Fig. 3. HereX(1) and X(2) have the same
number of data points
(N,=N2=48),
but X(2) contains only part ofa circle (16 points)and therest arenoise points (32 points). The underlying circles have the same radius,r*
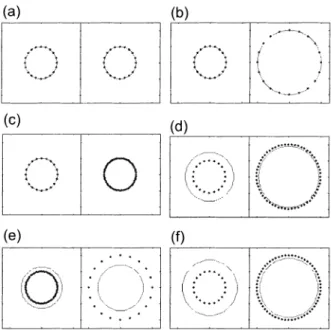
=r2 =8,and arecentered at (0,0). We applyourmodifiedPCSC algorithm using different values of c, Fig. 3(a)-(d) correspond to cc = 0, 5, 20, and 400, respectively. Initial
(d)
(e)
(f)(1II~~~~~~~~~~~~~~~~~4
Fig.2. Simulation exampleof PCSC withconstraintusingnoiseless
data.The smalldotsaredatapointstobeclustered,andthe circlesare
foundprototypesfoundby ouralgorithm. Both axesofeach small rectangle have ranges of -25 to 25. Parameters used are: (a) rj=r =10,N=N,=20, cr=0; (b)rl=10,r,*=20,N,=N,=20, a-0; (c)
r==r,=10,N1=20,N,=60, cr20; (d)rl =10, r,=20,N1=20,N,=60, c-20; (a) r*=10,r,*=20,N1=60, N,=20,a-100; (a) r'=10, r, =20,
N,=20, N,-60, cr100.Theleftandrightrectangles of each of(a)-(d) correspondtoparameters withsubscripts1and2,respectively.
prototypes are set to be the underlying circles so that no erroris causedby bad initialization. Thevalue ofq is set to
(r1
*)4/2;2000.
The solidcirclesare thefinalprototypesafter 10iterations of ouralgorithm, and the dashed circles arethe underlying circlesoverlapped withX(2) forcomparison. The actual centers and radii of the prototypes found are also listed in Table 1. It is evident that,by increasing oc, we are abletobetteridentifytheunderlying circlesinthenoisydataset(X(2)) through clustering. Forthetwo larger oxvalues, the prototypesfoundforcluster #2 are so close totheunderlying circlesthattheyarealmostinseparable.
To more systematically investigate the power of the constraint term in locatingthe correct underlying circles for this scenario, we repeat for 100 times the sameexperiment
as in Fig. 3 with the same underlying circles but different, randomly generated noise points. Furthermore, the initial prototypes have randomly selected centers within r1
*14=2
from (0,0) and radii of between 8±2. We include the variation in initialization to make the experiment more
realistic. The statistics is listed in Table 2. The quantity "radius error" is the absolute radius difference between the prototypes found and the underlying circles. The quantity "deviation"represents themaximum separation between the final prototype and the underlying circle and is used as a measureofhow accurately theclustering algorithm finds the underlying circle. Cluster #1, which corresponds to the noiseless set of data points (X(1)), remains very close to the
underlying circle for all a values. On the other hand, for cluster #2,which corresponds to the noisy set of data points (X(2)), both deviation and radius error are significantly reduced when a is increased. Even a--1, which is much smaller than both N1 and N2, results in significantly more accurateprototypes than when a-0.
(b)
Fig. 3. Simulationexampleof PCSC withconstraintusingonesetof noiselessdata and one set ofnoisy data.Thesmall dotsaredatapoints
to be clustered, and the circlesare found prototypes found by our
algorithm. Both axesofeachsmallrectanglehave ranges of -20to
20. (a)-(d)correspondtoc-0, 5, 20,and400,respectively. Theleft
andrightrectanglesof eachof(a)-(d)correspondtoparameters with
subscriptsI and2,respectively.
TABLE I
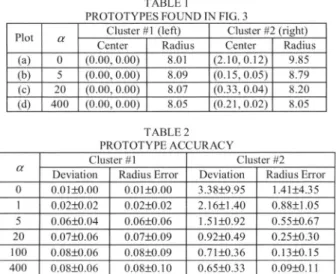
PROTOTYPESFOUND IN FIG. 3
Cluster#1(left) Cluster #2(right) Center Radius Center Radius (a) 0 (0.00,0.00) 8.01 (2.10,0.12) 9.85 (b) 5 (0.00, 0.00) 8.09 (0.15,0.05) 8.79 (c) 20 (0.00,0.00) 8.07 (0.33, 0.04) 8.20 (d) 400 (0.00,0.00) 8.05 (0.21,0.02) 8.05 TABLE 2 PROTOTYPEACCURACY Cluster#1 Cluster#2
a Deviation RadiusError Deviation RadiusError 0 0.01±0.00 0.01±0.00 3.38±9.95 1.41±4.35 1 0.02±0.02 0.02+0.02 2.16+1.40 0.88+1.05 5 0.06±0.04 0.06+0.06 1.51+0.92 0.55+0.67 20 0.07+0.06 0.07±0.09 0.92±0.49 0.25+0.30 100 0.08±0.06 0.08+0.09 0.71+0.36 0.13+0.15 400 0.08±0.06 0.08+0.10 0.65+0.33 0.09±0.11
Accuracy ofprototypes foundbyourPCSC algorithm usingoneset
ofnoiseless dataandone setofnoisydata. TABLE 3 PROTOTYPEACCURACY
ar Deviation Radius Error 0 1.60+2.66 0.59+0.88 1 1.32+1.44 0.48±0.60 5 1.12+0.82 0.42±0.49 20 1.04+0.77 0.39+0.45 100 1.03+0.69 0.40+0.45 400 1.03+0.69 0.39+0.45
Accuracy ofprototypes foundbyourPCSC
algorithmusingtwosetsofnoisydata.
Fig. 4. Processing ofeyeimages in with the PCSC algorithm with constraint. (a) The eye images. (b) The detected potential pupil boundary pixels of (a). (c) and (d)arethesame as(a) and (b), with solid anddashed circlesindicating pupil boundary locations obtained withouralgorithm and by manuallabeling,respectively. (e) and (f
arethesameas(c) and(d),exceptthattheoriginal PCSC is used.
Itis also interestingtoinvestigate the performance ofour
algorithm whenbothX(1) andX(2)arenoisy. Forthispurpose
we repeatthe experiment with both X(1) andX(2) consisting of24 points along apartial circle and 24 noise points. The
statistics of 100randomized trials are listed in Table 3; the
parameters and initialization conditions are the same as
those used in generating Table 2. While there is still some
improvement in accuracy here with increased a, this
improvement is evidently less dramatic as compared to the results in Table 2 even with verylarge a. Thereduction in
deviation and radius error seems to level offat larger a,
indicating that we can not achieve better accuracy by increasing a.
IV. EXAMPLEFORREAL IMAGE DATA
Afterall theexperiments with simulated data,weshowan
example of the application ofourmodified PCSCalgorithm on real data. Here the goal is to simultaneously find the
pupils, whicharecircles,from apairofeyeimages obtained in a screening test [12]. The procedure to extract the pupil boundary pixelsfromtheimagesisgiven in[13].
Fig. 4showsa casewhere the contrastbetween thepupils
andsurrounding regions is verylow in one eye. Fig. 4(a)is
the original eye images and Fig. 4(b) shows the extracted
boundary pixels, which serve as the data points in shell
clustering. InFig. 4(c) and4(d)thecircles(pupil boundaries)
obtainedthroughthe originalPCSC areoverlappedwith the
images in Fig. 4(a) and4(b).Thesolid circles indicatingthe
pupil boundaries found by our algorithm and the dashed circles indicating manually labeled pupil boundaries. The
boundaryof the darkerpupilisnotcorrectlylocated because
(a)
(c)
(b)
(d)
thealgorithm is affected by data pointsthat donotfallon the [12] G. W. Cibis, "Video Vision Development Assessment(VVDA): pupil*bundary.The parameters used for PCSC here are Combiningthe
Bruckner
Testwith EccentricPhotorefraction forDynamicIdentificationofAmblyogenicFactors",Trans. Am.
m=1.5 and
qr2OOO.
In Fig. 4(e) and4(f)
we plot the Ophthalmol.Soc., vol. 84, pp.643-685, 1994.clustering resultswith themodifiedPCSC using a-100. We [13] T. Wang, "Eye Location and Fixation Estimation Techniquesfor
Automated Video Vision Development Assessment", Master'sThesis, can see that the new algorithm gives much more accurate Dept.Comp. Eng.Comp. Sci., University ofMissouri-Columbia,
pupilboundary locations. Columbia, MO,2002.
V. CONCLUSION
We present in this paper the use ofextra cost function terms as a method for incorporating additional desired properties ofclusterprototypes. The focus of our analysisis on the locating circular prototypes with similar radii, although the generalapproach certainlyisnotlimitedtothis case. The effect of the constraint
strength
factorix,
asanalyzed insections IIandIII, should be
applicable
toother cases with constraints on relations among clusters. We believe that this approach can enhance theapplicability
of clustering in various applications. Possible directions of future research include the investigation regarding other types of constraints, the effect of adjusting oa between iterations, and the effectonoverlappedclusters.ACKNOWLEDGMENT
The authors would like to thank Dr. Gerhard Cibis of Children'sMercyHospital, KansasCity, Missouri, USA, for fruitfulcollaboration andthe use ofimage data.
REFERENCES
[1] R.Krishnapurum,H.Frigui,and0.Nasraoui,"AFuzzyClustering AlgorithmtoDetectPlanar andQuadricShapes",Proc.NAFIPS, 1992, pp. 59-68.
[2] R.Krishnapurum,H.Frigui,and0. Nasraoui,"Fuzzyand Possibilistic ShellClustering Algorithms and Their ApplicationtoBoundary
Detectionand SurfaceApproximation-PartI",IEEE. Trans. Fuzzy
Systems, vol.3, pp.2943, 1995.
[3] R.Krishnapurum,H.Frigui, and0. Nasraoui,"Fuzzy andPossibilistic
ShellClustering Algorithmsand TheirApplicationtoBoundary
Detection andSurfaceApproximation-PartII",IEEE. Trans. Fuzzy
Systems,vol. 3, pp.44-60, 1995.
[4] R. N. Dave, "FuzzyShell-Clustering and Application to Circle Detection inDigitalImages", Int.J.Gen. Syst.,vol. 16, pp. 343-355, 1990.
[5] F.Hoeppner,"Fuzzy shellclustering algorithmsinimage processing: fuzzy c-rectangular and 2-rectangular shells",IEEETrans.Fuzzy
Systems,vol. 5, 599-613, 1997.
[6] X.-B.Gao,W.-X.Xie,J.-Z.Liu,and J.Li, "Template based fuzzy c-shellsclusteringalgorithmandits fastimplementation",Proc. IEEE Int'lConfiSignalProcessing, 1996, pp. 1269-1272.
[7] I. Gathand D. Hoory,"DetectionofElliptic Shells Using Fuzzy
Clustering: ApplicationtoMRIImages", Proc. ICPR, 1994, pp. 251-255.
[8] A.W.C.Liew and H.Yan, "An adaptivespatial fuzzyclustering
algorithm for 3-D MR image segmentation", IEEE Trans. Medical Imaging, vol. 22, pp. 1063-1075, 2003.
[9] R. C. Gonzales and R.E.Woods, Digital Image Processing (2nd Ed.), PrenticeHall, 2002.
[10] R.Krishnapurumand J. M.Keller, "APossibilisticApproach to
Clustering",IEEETrans. FuizzySystems,vol. 1, pp.98-110,1993.
[11] J.C. Bezdek and R.J.Hathaway,"Numerical convergence and
interpretationof thefuzzy c-shells clustering algorithm", IEEE Trans. NeuralNetworks, vol. 3, pp. 787-793, 1992.