行政院國家科學委員會專題研究計畫 成果報告
子計畫一:寬頻網際網路中路由選徑技術與 QOS 訊務控制之
研究設計(3/3)
計畫類別: 整合型計畫 計畫編號: NSC91-2219-E-009-034- 執行期間: 91 年 08 月 01 日至 92 年 07 月 31 日 執行單位: 國立交通大學電信工程學系 計畫主持人: 張仲儒 計畫參與人員: 林立峰、黃鏗銘、黃慶喜、丁崇光、陳柏翰、鄭永宏、吳育葵、 顏寧佑 報告類型: 完整報告 處理方式: 本計畫可公開查詢中 華 民 國 93 年 2 月 16 日
計畫中文摘要
由於網際網路的蓬勃發展,使得網際網路上的訊務量急遽增加,且跨網域 的比重也驟然提升甚多,除了最初且最基本的數據通訊之外,也加入了語音或影 像等即時性類型的服務,故其需要高速的頻寬、有效的 QoS 運作架構與訊務控 制機制來確保使用者的服務品質可以獲得保障。 為了解決寬頻的問題,本計畫擬從兩方面來著手:一是直接針對路由器本 身著手,增加路由器路由選徑 (Routing) 的處理速度,即是要發展出高速的路由 選徑機制;另一方面則是藉著改變架構,利用第二層網路的高速交換(Switch) 動 作來取代第三層的 IP 位址路由選徑動作,使可以獲得等效於加快路由選徑速度的效果,我們可以將其視為一種虛擬的路由選徑(Virtual Routing) 方式,如 IETF 所提出的MPLS(Multi-Protocol Label Switch) 技術。
在提供服務品質保證方面,目前IETF 已經針對這方面(服務品質保證)的
需求成立了相關的Working Group。其中的 DiffServ 並不針對 per-flow 的訊務提 供服務品質保證,而是將訊務分為幾種不同的等級種類(Class),再對每一種類提 供不同的服務品質。因此DiffServ 在實際的運作方式上,必須在路由器上對訊務 進行分類(Classify)的動作並施予不同的排程(Schedule)處理;同時也必須引入連 線導向(電信)網路中訊務控制的概念。 所以在網際網路服務品質保證機制方面,我們將針對 DiffServ 的架構以及 其中所必需的訊務控制,配合我們既有多年來在ATM 網路上發展訊務控制機制 的經驗,擬設計出適合於網際網路中,特別是具有IntServ、DiffServ、或 MPLS 等相關 QoS 機制的網際網路環境之呼叫允諾控制法,對新進的連線作系統資源 的確認,再決定是否接受此連線的訊務,以更進一步確保能提供各種類的訊務所 要求的QoS。在設計呼叫允諾控制法的同時,也投入標準中並未明確定義的使用 參數控制機制的研究,對訊務進行監控以確保進入網路的連線訊務的合法性,維 持呼叫允諾控制的正常運作。 最後我們將利用乏晰控制和類神經網路理論,選擇適當的乏晰控制器與類 神經網路架構,發展出各相對應的乏晰和類神經訊務控制法則。並完成系統模擬 程式的撰寫,利用電腦模擬的方式來驗證所獲得研究成果的正確性。 關鍵詞: 路由選徑、多協定標記交換、差異化服務/差別服務、訊務控制、呼 叫允諾控制、使用參數控制
Abstract
With the blooming of Internet application services, the Internet traffic flow increases dramatically and the traffic flow from inter-network transmission also increases rapidly. Not only the basic data transmission but also some multimedia services (such as: voice, real-time video services) are also carried on the Internet. Henceforth, to provide the QoS-provisioning services, the larger bandwidth capacity, effective QoS-provisioning service framework, and traffic control mechanisms are the primary requirements in the design of the Internet.
For the issue of larger bandwidth capacity, 2 solutions are proposed in this project: faster routing and virtual routing. For the faster routing, a better routing path search scheme is proposed to speed up the performance of the router. The virtual routing technique is to apply the high speed layer-2 switching mechanism on the router to replace the original layer-3 routing mechanism, such as: IETF’s MPLS (multi-Protocol Label Switch).
As to the QoS-provisioning services, the DiffServ (differentiated Service) service model is considered. An IETF Working Group is dedicated to the research of DiffServ service model. The goal of DiffServ is not to provide QoS-provisioning services on the pre-flow basis; instead, on the class basis. The DiffServ defines several service classes and each class has its own QoS requirements. Therefore, when the DiffServ services are provided on the Internet, the routers must classify all the input traffic and assign different scheduling priority level. Also, it is necessary to add the call control mechanism that has been well-developed in the connection-oriented network.
Broadband Network Lab has devoted to the research of the traffic control mechanism on the ATM network for a long time and gained some precious experiences. Based on those experiences, an appropriate call admission control (CAC) scheme is proposed for the traffic control of the DiffServ. Moreover, the proposed CAC scheme can also applied to other Internet QoS-provisioning services, such as: IntServ, DiffServ, MPLS and etc. On the receiving of new connection request, the CAC will check if there is available system resource for the new request. In such way, network can provide QoS guarantee for both the existing connections and new connection. Also, we will study the Internet usage parameter control (UPC) mechanism that is not clearly defined in the IETF specification. By monitoring the
traffic flow, the UPC can make the validation of the connection, such that the CAC will operate properly.
Finally, we will apply the fuzzy logic control and neural network mechanism on the CAC and UPC schemes. By choosing proper fuzzy logic controller and neural network architecture, we will propose the corresponding fuzzy and neural network traffic control rules. To verify the proposed schemes, we will build system simulation environment and simulate the schemes by software.
Keywords: Routing, Multi-Protocol Label Switch (MPLS), DiffServ, Call Admission Control (CAC), Usage Parameter Control (UPC)
目錄
一、 計畫緣由及目的... 1
二、 研究方法、成果與討論... 8
1. 高速的路由選徑機制... 8
1-1. 高速單一路由選徑(Unicast Routing)機制-階層式分群解析架構........ 8
1-2. 高速單一路由選徑(Unicast Routing)機制-TCAM-based 架構... 15
1-3. 高速群播路由選徑(Multicast Routing)機制.... 20
2. MPLS 網路之 VC-Merge 機制的效能分析... 22
3. MPLS 網路之路徑保護及快速回復(Path Recovery) 機制... 27
4. DiffServ 網路中精確的訊務監控調節(Traffic Contioner)機制.... 34
5. 高速 IP 封包分類(Packet Classification) 機制... 41
三、 參考文獻... 46
四、 計畫成果自評... 50
五、 附錄... 53
一、計畫緣由及目的
從 1969 年發展至今的網際網路(Internet),已經由最初實驗性的研究成果, 在歷經幾次的變革之後普及至教育和商業環境;更由於其跨網路、跨地域(無遠 弗屆)、極富有彈性(Flexibility) 與可能性(Possibility) 的特點,吸引了愈來愈多 人投入此一新的網路世界,然而它的成功卻也加速顯現其發展的瓶頸。擁有超過 兩千萬個節點及上億使用者的 Internet,必須進行大幅度的改造,才能進一步像 電話一樣普及,事實上這些改造的研發工作也從未間斷。1996 年 10 月,全美三 十四所大學宣佈合作建造 Internet2,加速此迫切的改造。1997 年 2 月克林頓 (Clinton) 政府也提出新世代網際網路 NGI (Next Generation Internet) 五年計畫 (1998-2003),以配合延伸 Internet2 的構想。架構出網際網路的網際網路協定(IP Protocol) 原本只是適用於數據 (Data) 通訊的第三層網路協定,並藉著路由器連接不同的網路/網域形成一非通訊連線 導向(Connectionless) 的廣域網路。其目的,主要是希望透過一致的定址方式與 有效率的路徑演算機制,達成不同網路中各通訊端點之間資料的傳輸、遞送,而 此也已滿足一般數據資料通訊的需求。然而在網際網路蓬勃發展之際,也使得許 多非單純數據傳輸的應用,例如語音或影像等具備即時 (Real-time) 傳輸要求的 服務也採用IP Protocol 進入網際網路中,再加上多媒體技術的突飛猛進與其服務 的普及,使得對網路頻寬與服務品質的需求也相對應地提升,這是當初設計時所 始料未及的,但也正是這些各式各樣的應用帶動了網際網路的蓬勃發展與目前的 成功。所以,為了確保目前和未來可能的各項應用與服務能夠在網際網路上運作 順暢甚或具有一定的品質,以維持網際網路的永續發展,有許多的改革動作也應 運而生,其中最主要的即是在「高速頻寬傳輸」與「服務品質保證(QoS guarantee) 運作機制」上的研究。 在高速寬頻傳輸方面,除了在實體網路的傳輸鍊路(Link)傳輸頻寬與設備處 理速度的提升之外,最重要的關鍵與瓶頸還是在於構成網際網路的核心設備-第 三層路由器(Router) 的路由選徑(Routing) 處理速度。網際網路可以說是 OSI 通 訊協定堆疊架構中第三層的網路系統,藉著路由器連接不同的(區域)網路/網 域以形成廣域的網路系統。在以往網際網路與其上的應用仍未如今日如此普及之 際,多數的訊務仍屬與區域子網路的範圍,藉由路由器連往其他網路的跨網路訊 務並不多,子網路的內部訊務與跨網域訊務量呈現80/20 的比值(80%為子網域 訊務,20%為跨子網域訊務)。由於近年來網際網路上服務的多元化使得網路訊 務量暴增,網路的流量不再遵守過去的80/20 定律,而演變成 20/80 的分佈,使 得路由器的負載量增加。再加上多媒體技術的突飛猛進與其服務的普及,使得這 些跨網路的訊務也多屬於多媒體通訊的訊務,對頻寬與網路服務品質保證的需求 也相對應地提升。這些現象皆會增加路由器的負擔,使得傳統路由器的效能成為
網路上的瓶頸。因此,提升路由器的處理速度以解決此問題成為一必然的趨勢。 目前在這方面的研究可以分成兩大類:一是直接針對路由器本身著手,實際增加 路由器路由選徑 (Routing) 的運算速度。這部分除了直接提高硬體運作平台速度 的方式之外,即是要發展出有效率的路由選徑運算方法。傳統上主要是以純軟體 操作方式的角度,來設計出一較佳的路由資訊的資料結構(Data Structure) 以及相 對應的比對搜尋演算法(Algorithm),而近幾年來,開始發展出硬體架構導向 (Hardware-oriented) 觀念的路由選徑機制,即是期望所設計的路由比對搜尋演算 法能夠適合以實際的硬體邏輯&運算電路來予以實現,以較軟體操作程序高速的 硬體運作方式來提升路由選徑的速度,亦即提升路由器的處理速度。在超高速 Gigabit 網路的路由器裡,假設網路每秒可傳送 1 Giga bits 的資料量,若在網路 上平均每個封包的大小為512 bits,則每個封包大約只允許 500 ns 的處理時間, 這還不包括在封包進來路由器時的佇列延遲問題,而現今的路由器大多無法達到 此一速度的要求。因此在本計畫中,我們將對既有的路由選徑的方式(路由表格 查詢法,Routing Table Lookup)與前述幾種路由選徑速度提升的方法或架構進行
研究,以提出符合Gigabit 超高速網路中的高速路由選徑的方法。此外,隨著多 樣化的即時(Real-time) 影音多媒體通訊服務的蓬勃發展,使得網際網路上的群 播路由(Multicast Routing) 技術日益重要,以節省網路上所需流通的訊務資料量 我們希望藉由上述在設計傳統Unicast 路由選徑方法的技術以及經驗,能經由簡 易的修改應對而快速地實現群播功能所需的群播路由(Multicast Routing) 機制。 另一類提升路由器處理速度的方式,則是藉著改變IP 網路的運作架構,利 用連結導向(Connection-oriented) 的第二層(電信)網路的高速交換(Switch) 動 作來取代第三層非連結導向(Connectionless) 的 IP 協定網路的路由選徑動作,使 可以獲得等效於在第三層 IP 網路上加快路由選徑運算速度的效果,我們也可以
將其視為一種虛擬的路由選徑(Virtual Routing) 方式,如 IETF 所提出的多協定標 記交換技術(Multi-Protocol Label Switch, MPLS) 技術。MPLS 可以視為是將 IP 路由器(Router) 建立在第二層網路的交換器(Switch) 上,或者可以說是將原本單 純的 IP 路由器功能加以擴充,包含進第二層網路的交換器(Switch) 功能,並依
照IP 封包的終點位址,在 IP 封包上加上一個較短的、屬於第二層交換網路的交
換標籤(label),之後便能夠使此擴充功能的路由器直接透過其第二層的交換機能 依照這個短標籤,而不是傳統的IP Longest Prefix Matching 方式,迅速的交換 IP
封包,改善IP 封包路由交換的性能。而這種結合傳統第三層 IP 路由選徑以及第
二層高速交換機制的路由器可以稱之為交換路由器(Switch Router);而此種 IP 封 包路由交換技術也可稱之為IP Switch 技術。
目前在以第二層交換網路技術實現的MPLS 網路中,以 ATM (Asynchronous Transfer Mode) 網路被視為是最好的實現平台,採取結合 IP 與 ATM 交換網路的
模式來提供最高性能的IP 封包轉送能力,而其中用於取代 IP 路由選徑的交換用
Identifier/Virtual Circuit Identifier),並以 ATM-LSR (Label Switching Router) 做為 實際封包路由轉送的關鍵設備。ATM-LSR 的硬體架構主要是延襲自 ATM 交換 機,並再擴充結合 IP 路由器的功能與 MPLS 網路所專有的標記交換協定(Label Switch Protocol) 等能力。
在MPLS 網路的基本運作中,一個 Switch Router 處的一個交換用短標籤即 是對應至一組{Source IP (SIP), Destination IP (DIP)}連線路由。此短標籤如同傳 統交換網路的交換用短標籤一般,是屬於「區域性(Local)」以及「可重複利用 (Re-usable)」的資源,以增加系統所能夠支援的同時在線(on-line)的 IP 連線路由 數量,提升網路規模。為了能夠進一步充分利用有限的標籤資源,讓有限的標籤 資源能支援更多的同時在線(on-line) IP 連線路由,提高 MPLS 網路規模的擴充性 (Scalability),一個重要的功能便是標記整合(Label-merge)機制:在一 Switch Router 中將多個前往相同目的網路或節點的 IP Route 轉換、對應(mapping)、整合成相 同的短標籤,如此一個標籤便只對應至一個目的網路或節點{Destination IP (DIP)}。而必須注意的是,一旦將多個 IP Route 以相同的 Label 整合之後,原本 各IP Route 訊務流中的 Data 便無法再在此一標籤交換網路的層次予以分離,必 須要至此一整合標籤的IP Route 的終端節點上將 Data 還原至 IP 封包的層次後, 才能夠再依據其不同的 Destination IP 資訊進行不同的路由轉送。而實現在以 ATM 技術為基礎的 MPLS 網路時,所對應的 Label-merge 技術即為 VC-merge: 將對應至不同IP Route 的交換短標籤 VPI/VCI 整合對應成同一個 VPI/VCI。但由 於ATM 網路的封包(稱為 Cell)容量較 IP 封包小,因此大多數的 IP 封包會被 分割成多個ATM Cell 來傳送,如此當啟動 VC-merge 功能時會產生問題:若在 交換器處逕行將個別抵達的ATM cell 的 VPI/VCI 標籤進行 VC-merge 的轉換與 整合,原本分屬於不同VPI/VCI route 中不同 IP 封包的多個 Cell,有可能會被以 相同的 VPI/VCI 但交錯的(Interleaving) 順序送出,則導致在共同的目的節點處 無法以傳統ATM 的 cell 接收與重組機制將資料正確地還原成上層的 IP 封包,以 順利地分離出經由 Label-merge 或 VC-merge 機制融合的訊務。一簡單的解決方 案是Frame-level Interleaving,即是在 ATM-LSR 交換機的 Input 端設置封包重組 緩衝器(Reassembly Buffer, RB),把屬於同一 IP 封包的多個 ATM cell 收集完整 後,再進行 VC-merge 的 VPI/VCI 標籤轉換,並以連續輸出(back-to-back) 的方 式將屬於同一IP 封包的 cell 送出,待同屬一個 IP 的 cell 都送出後,再進行下一
組屬於同一 IP 封包的 cell 輸出。然而,勢必將會因為重組緩衝器的設置而增加
了ATM-LSR 的記憶體需求,也可能影響資料傳輸的延遲(Delay)。因此在本計畫 中,我們探討具有 VC-merge 能力的 ATM-LSR 交換機的性能:分析 VC-merge 的 ATM-LSR 所需的緩衝器和 cell blocking 機率之間的關係,以提供實際 ATM-LSR 設計上的參考,並和傳統不具有 VC-merge 能力的 ATM Switch 性能作 比較,試著去探討具有VC-merge 能力的 ATM-LSR 交換機需要比傳統的 ATM 交
換機具備多少緩衝器資源,是否需提供額外的大量緩衝器以達到和傳統ATM 交
此外,近年來諸如語音、影像等即時性服務在網際網路上逐漸成為重要的 網路應用型態,其需要仰賴寬頻高速的網路傳輸以維持良好的品質表現,而在此 同時,MPLS 技術的提出的確適時為網際網路提供了高速且低延遲的訊務傳輸能 力,但相對的,當高速的 MPLS 網路發生傳輸路徑錯誤或損壞的時候,往往也 會造成更嚴重的影響(例如更大量的資料遺失),尤其對於即時性服務而言更是 如此。因此我們針對 MPLS 網路,在其傳輸路徑保護(Protection) 以及發生錯誤 (failure) 時之路徑回復(Path Recovery) 機制方面進行深入的研究,提出一套有效
的路徑保護/回復機制,以便於 MPLS 網路傳輸路徑發生錯誤或損壞時還能夠 維持部分基本的通訊,並可以快速而正確地恢復既有的通訊,降低 MPLS 網路 上傳輸路徑錯誤或損壞所帶來的影響,減少封包遺失率,並期望能夠進一步達到 動態負載平衡的附加效益,使系統資源做最佳的利用,如此便可有效的提高網路 的資料輸出率(throughput)。此外,我們另一項著手的重點便是針對此機制發展出 一套系統化的方法,讓業者在採用此方法時可以根據其需求與使用者付費原則, 評估採用不同複雜度的運作形式與保護程度,在成本與演算法完整性之間取得一 平衡點。最後我們以 ns-2 此套網路模擬軟體進行該路徑回復機制的效能評估與 驗證,以貼近實際的運作狀況與結果。 提升網路頻寬或可稍微改善服務品質(QoS),但由於既有的網際網路協定本 質上是屬於盡力式(Best-effort)的服務,所以仍無法從根本上做有效地改進,必須 要再配合其他的機制來達成服務品質保證,如此也才能夠確保頻寬獲得最有效益 的利用。目前這仍是屬於新的研究領域,相關標準並未完備,而相關研究論文數 量 也 不 多 , 有 許 多 值 得 研 究 的 課 題 和 空 間 。 目 前 網 際 網 路 的 標 準 組 織 IETF(Internet Engineering Task Force) 已經針對這方面(服務品質保證)的需求 成立了相關的Working Group,制定了一些關於網際網路服務品質保證的訊務控 制機制或運作架構等解決方案,例如:RSVP(Resource Reservation Protocol,資源 保留協定)、IntServ(Integrated Service,整合服務)[23-26]、DiffServ(Differentiated Service, 差別服務)[28-33]、QoS Routing(服務品質路由選徑) ……等等。
IntServ 主要是想針對 per-flow 的單一訊務提供服務品質保證 [23]。在 IntServ 中,除了保留原有基本 Best-effort 方式的服務之外,另外定義了兩種新 的、具有品質保證的服務方式:Guaranteed 以及 Controlled-Load 服務 [24-25]。 引入電信網路通訊連線前呼叫允諾控制(CAC, Call Admission Control) 的觀念, 其必須配合RSVP 對 per-flow 做到在通訊之前,先根據其服務品質要求,在通訊
路徑上的每一個路由器保留足夠的資源,來更進一步達成具有 QoS 的服務。雖
然IntServ 的架構(ISA, Integrated Service Architecture) 已經趨於成熟,但是由於 其針對 per-flow 的訊務提供服務品質保證的特性,在原本即不具備 flow 識別功
能的IP 網路上則必須透過額外的 flow 識別分類機制來輔助,若要能夠支援足夠
數量的同時在線(on-line) flow 的訊務流,則必須要有足夠大的 flow 識別記憶體
所有的訊務控制機制都必需要做到per-flow 的處理方式,也使得網路設備的工作 量與複雜度都增加,負荷(Loading)變重,因而導致其擴充性(Scalability) 不佳: 當實行的網路規模不大(例如在一區域網路中)的時候還能夠維持服務品質,但 是當實行的網路範圍擴大時,負擔便會急速增加而不易維護,故目前不適宜在廣 域網路或骨幹網路上實施。 DiffServ [28] 可以說是在對 IP Network 上服務品質的迫切需求,以及希望 能獲得儘早實現的壓力下應運而生的。DiffServ 可以視為是 IntServ 的改良版本, 它並不針對per-flow 的訊務提供服務品質保證,而是將訊務區分為有限的幾種不 同的服務等級(Service Class),而每一個服務等級即對應至一種訊務服務品質,然 後只針對個別Service Class 的整合訊務進行 QoS 的處理,而不再對其中單一的 per-flow 訊務進行處理,如此便能夠解決 IntServ 中 per-flow 處理方式的複雜度所 造成的網路 Scability 受限的問題,加速具 QoS 保證的網際網路的實現。目前 DiffServ 相關的 RFC 在 Best-effort 之外共定義了 5 個 Service Class [28-33] 並可 區分為兩大類,分別是Expedited Forwarding (EF) Service [29-30] 以及 Assured Forwarding (AF) Service [31-32]。這兩大類的服務所要求的服務品質並不相同, 其中 Expedited Forwarding (EF) 服務所欲達成的 QoS 是比較嚴格的,要求 Delay、Jitter、Loss 都必須獲得保障;而 Assured Forwarding (AF) 服務則可以容 許較大的Traffic Burst,故只要求 Loss。為實現 DiffServ 此網際網路 QoS 架構, IETF 也在相關的 RFC 中定義 DiffServ 網路設備應具備的元件以及其系統架構參 考模型 [28],其中以「訊務封包分類器(Packet Classifier)」與「訊務監控調節器 (Traffic Conditioner)」為基礎關鍵元件,是為其他 QoS 訊務控制、處理機制(例 如:CAC 連線允諾控制機制、Scheduling 排程控制、流量控制、壅塞控制等 Per-Hop Behavior)運作的基礎。與 IntServ 處相同的地方是,在原本即不具備 flow 識別
功能的IP 網路上則必須透過額外的 flow 識別分類機制來輔助,才可能進一步進
行以 flow 為基礎的訊務控制機制並達成 QoS 服務品質保證的目的,而 Packet Classifier 即是負責此一 flow 識別分類機制的元件。而與 IntServ 中的 flow 識別 分類機制不同之處在於,DiffServ 的 Packet Classifier 並非以「1 identification rule-to-1 flow」的方式用於鑑別出單一連線的 Traffic flow,而是以「multiple identification rules-to-1 service class flow」此含有後續匯整功能的識別方式,亦即 「分類(Classification)」的方式,辨識並區隔出不同 Service Class 的訊務,以便接 下 來 能 夠 透 過 不 同 的 訊 務 處 理 方 法 而 達 到 差 別 化 服 務 品 質 的 目 的 。Packet Classifier 的分類法則可以是多樣的,根據 IP 封包中不同的欄位(例如:Source IP、 Destination IP、Transport-layer Port、ToS/DSCP……等)與其上記載的訊息,或 單一欄位、或多欄位組合的條件方式進行訊務的分類。而其效能訴求主要是簡單 而高速的運作速度,並期望具備較小的記憶體需求。
至於DiffServ 的另一個基礎關鍵元件-訊務監控調節器則是對進入 DiffServ 網路的訊務進行監控,確保其各 Service Class 訊務的統計特性皆能夠符合其 Traffic Profile 協議的條件。圖 0(a)所示即是訊務封包分類器(Packet Classifier)與 訊務監控調節器(Traffic Conditioner)於一 DiffServ 網路設備中的運作邏輯關係架 構。此外訊務監控調節器也會針對所監控的訊務,根據其符合 Traffic Profile 的 程度狀況(Conforming Degree) 或是其封包內容的重要性,對其封包進行多層次 的標記並對應至不同程度的Dropping Precedence,以提供並輔助當網路壅塞情形 發生而啟動 Packet Dropping 機制時,欲達成差異化 Packet Dropping 所需要的 Packet Dropping 優先順序的參考依據。目前 IETF 已對各 Service Class 的訊務定 義了3 個基本且必要的 Packet Dropping Precedence,分別具有 High、Medium、 Low 三種 Dropping 機率,因此訊務監控調節器也將配合分別以紅色(Red)、黃色 (Yellow)、綠色(Green) 三種顏色來進行標記。圖 0(b)與(c)分別顯示了一訊務監 控調節器的功能架構圖,以及定義在 DSCP 處的 Service Class 與 Color(或稱 圖 0: (a) Classifier 與 Traffic Conditioner (TC) 之運作邏輯關係架構, (b) Traffic
Conditioner 之功能架構圖, (c) DSCP 欄位與各 Service Class 標記代碼示意圖
TC TC TC Classifier TCAF4 TCAF1 EF AF1 AF4 Meter Marker Shaper or Dropper Traffic Conditioner (TC) Traffic Profile (from Classifier) Pre-defined Rules Header Payload AF1 0 0 1 0 1 0 0 0 1 1 0 0 0 0 1 1 1 0 AF2 0 1 0 0 1 0 0 1 0 1 0 0 0 1 0 1 1 0 AF3 0 1 1 0 1 0 0 1 1 1 0 0 0 1 1 1 1 0 AF4 1 0 0 0 1 0 1 0 0 1 0 0 1 0 0 1 1 0 EF 1 0 1 1 1 0 DSCP CU DS Field DS Field
IPv4: “TOS” octet IPv6: “Traffic Class” octet
metering state info.
makes the notation 0 1 2 3 4 5 6 7 Traffic/packet info. Network Node (Edge Router) Pre-defined Rules/Polices TC TCEF (a) (b) (c)
Dropping Precedence)的整合性標示定義。一網路訊務進入 DiffServ 的 Edge 設 備時,會先由 Packet Classifier 進行分類以識別出其中各封包所屬的 Service Class,接下來訊務監控調節器中的 Meter 會對各 Service Class 的訊務封包進行統 計並分別與其 Traffic Profile 比對,並將此結果傳送至 Marker;Marker 在得到 Meter 所做的訊務統計與其和 Traffic Profile 之間的比對數據後,會根據事先定義 好的決策法則(Decision Rule) 進行訊務封包的實際標記動作,而此標記如同圖 0(c)所示,是包含了該訊務封包所屬的 Service Class 以及所對應 Dropping Precedence 的顏色標記。訊務監控調節機制的效能訴求,則是期望能夠達到在確 保訊務特性符合 Traffic Profile 規範的同時,精確地讓系統資源獲得充分且最佳 的利用,並進一步保障其中各 micro-flow 連線標記的公平性(Fairness)。由於 DiffServ 的各項訊務處理或 QoS 控制機制皆是以一 Service Class 的訊務流為基 礎,即使能夠達成預定的訊務控制目標,卻也不能完全保障此時Service Class 中 各 micro-flow 連線所實際獲得的 QoS 能和控制目標相當,如此將導致 DiffServ
此項網際網路 QoS 架構方案無法獲得廣大的採用與實現。因此若能夠同時在
micro-flow 的連線標記公平性上有所改善,則將使各 micro-flow 實際所得到的網 路資源和QoS 也較為公平,如此才能夠有效提升 DiffServ 網際網路 QoS 架構的 可行性與使用效益。
接下來我們將分別就本計畫在「高速頻寬傳輸」與「服務品質保證運作機 制」上的各項具體研究成果,進行方法說明與成果討論,
二、研究方法、成果與討論
1. 高速的路由選徑機制
這部分主要是發展適合硬體實現(Hardware-oriented) 的高速路由選徑方 法,期以硬體的運作方式加速路由選徑的運算速度,以滿足Gigabit 超高速網路 環境下以及未來更寬頻的網際網路應用的需求。1-1. 高速單一路由選徑(Unicast Routing) 機制-階層分群解析架構
經過歸納與研究分析的結果,適合硬體實現的路由選徑方法應具備有下列 的特性與概念:「固定資料長度」的資料運算動作,以及「規則化」的、「反覆運 作」的處理程序(Process),而「階層式分群解析」(或稱「多層次群組解析」)的 方法即具備有上述的末兩項特點,再配合上以階層式的多元完全展開樹(Trie) 來做為其將整個IP 位址進行多層次的 IP 位址區段分群的參考架構後,便具備有 「固定資料長度」的資料運算動作的條件,因而極適合於做為採用實際的硬體邏 輯&運算電路來實現的路由選徑機制。「階層式分群解析」的方式是:將整個IP 位址進行多個層次的 IP 位址區段分群-先進行第一層次的較粗略分群,再依據 實際路由表格中路由字首(Route Prefix) 的資訊,針對有需要做進一步細部分群 解析的群組(即包含一個以上,對應至更小範圍 IP 位址區段的路由字首)進行 下一層次更精細的分群展開,如此反覆運作至每一分群中沒有對應至更小範圍IP 位址區段的路由字首為止。接下來將每一層次的每一IP 位址區段分群與該 IP 位 址區段路由選徑的結果進行對應並以表格紀錄(「分群-路由結果」對應表格): 若為毋須再進行下一階段細部分群解析的群組,將必然可以對應至一個該 IP 位 址區段的(共同)路由選徑結果(即封包的輸出埠(output port));若為需要再進一 步細部分群解析的群組,則可以對應至一個「必須進行下一層次更細部分群解析」 的指示,並且指向連結至該進一層次的「分群-路由結果」對應表格。進行實際 路由選徑的應用時,只要將所欲查詢的目的IP 位址(Destination IP Address) 與各 層次的IP 位址區段分群進行比對,尋找其所屬的最細的分群,待確定目的 IP 屬 於何層次的某一分群後,即可以由該層次的「分群-路由結果」對應表格直接查 表得知其路由結果輸出埠。而此「比對」動作是規則地、次第從第一層分群開始, 再視需要逐步往分群更精細的層次檢視、比對。由於是將路由選徑之搜尋演算動 作化為「規則」化的、「反覆運作」的多層次比對與查表動作,因此已具備適合 硬體實現的初步條件了。因此我們將以「階層式分群解析」的方式為主,來發展適合硬體實現的高 速路由選徑方法。而我們所提出的作法,是以階層式的多元完全展開樹(Trie) 來做為「階層式分群解析」方法中,將整個IP 位址進行多層次的 IP 位址區段分 群的參考架構—也就是使每層次的IP 位址區段分群恰好為一 N-bit (1≤N<16) 的 完全展開樹(Trie),如此一分群的 IP 位址區段範圍皆可以用一個 IP 位址字首 (Prefix) 的形式來表示(例如:140.113/16)—再依據實際路由表格中路由字首 (Route Prefix) 的資訊,進行實際階層式的多元完全展開樹的建置工作,在每一 層次中,僅針對有需要做進一步細部分群解析的群組(即包含一個以上對應至更 長路由字首的次IP 位址區段)進行下一層次更精細的 N’-bits Trie (1≤N<16)的分 群展開(以上的敘述可以參見圖 0 所示)。每一層次皆對應至一組表格,紀錄此 層次中各分群IP 位址區段(Segment) 及其所對應的路由選徑結果,或是必須進行 下一層次更細部分群解析的指示。而針對有需要才進一步細部分群解析的方式也 比起純粹的(階層式)多元完全展開樹方法大大減少所需的記憶體容量。實際應 用於進行路由選徑查詢動作時,即是將所欲查詢封包的目的 IP 位址(Destination IP Address) 與各層次的分群進行比對:由第一層次分群開始,直至其所屬的分 群不再有進一步的分群解析為止,此時只要查詢該層次的「分群-路由結果」對 應表格即可得到該封包的路由輸出埠。而由於我們是以階層式的多元完全展開樹 圖 0: Trie-based 階層式分群解析路由方法 ∗ 001∗ 010∗ 011∗ 100∗ 101∗ 110∗ 111∗ 000∗ ∗(default Route) 0 ∗ 11 ∗ 1 2 3 4 Prefix Output Port
001 1∗ 5 001 10 10∗ 6 101 01 ∗ 7 001 ∗ ∗(default Route) 0 ∗ 11 ∗ 1 2 3 4 Prefix Output Port
001 1∗ 5 001 10 10∗ 6 101 01 ∗ 7 001 ∗ 2 N1 2 2 1 N2 3 3 4 4 N3 5 1 7 1 1 5 5 6 5 01 01 100 (MSB) (LSB) 000 001 010 011 100 10 1 110 11 1 00 01 10 10 00 01 10 10 00 01 10 10 Routing Table (路由表格)
Data Structure of the Corresponding Memory Usage Destination IP Addr. of incoming IP Header (if necessary) Compare Compare Compare
Full Expansion of IP(v4) Address
0.0.0.0 28.28.28.28 01 01 100 (MSB) (LSB) 01 01 100 (MSB) (LSB) Address Decoder (定址電路) (MSB) (LSB) (MSB) (LSB) 11 11 11
(Trie),來做為其將整個 IP 位址區段進行多層次分群的參考架構,每層次的 IP 位址區段分群恰好為一N-bit (1≤N<16) 完全展開樹(Trie),因此可以如同圖 0 右
半部份所示,進一步將目的IP 位址在各層次的「分群比對」動作,轉換為 N-bit
固定長度的「定址」動作,而所定址到的記憶體內容即儲存該階層中該 IP 位址
群組(Segment) 的路由選徑結果(output port),或是指向儲存著下一層次分群解析
的路由選徑結果的 Pointer,如此也相當於將原本分群比對之後的「分群-路由結 果」表格的查詢動作也一併整合進來了。也就是說,只要透過反覆的(固定資料 長度的)定址動作,即可以得到路由選徑的結果。至此,我們已將傳統路由選徑 之搜尋演算動作,轉化為一套系統化的階層式路由資料結構,與一「規則」化的、 「反覆運作」的多層次「定址」動作,而這些都可以採用實際的硬體邏輯&運算 電路來加以實現並獲得加速的效果,例如其中的定址動作便能夠採用定址電路來 達成。此時Routing 的速度則完全取決於「記憶體定址」的「存取次數」與「定 址電路運作速度」。 為了決定實際運作時,所使用的實際階層分群(參數)的設定,包含階層 數目與每一階層中的分群大小(因為每一階層是為一個N-bit 的多元展開樹,所 以這裡也相當於是在決定每一階層的N 值大小,亦即多元展開樹的大小),以及 所需要的記憶體容量大小,因此我們進一步探討 Routing Table 的特性,並再深 入瞭解所設計方法的特點,以及兩者之間的關係。對於每一種路由選徑方法而 言,不同的 Routing Table 資料皆會因為其中路由字首數據的不同,諸如路由字 首數量多寡、分佈的型態/趨勢、分佈的量值大小差異,造成其不同的運作記憶 體容量需求。在觀察我們所設計的路由選徑方法之後發現,對於一筆 Routing Table 資料而言,不同的階層分群方式會影響儲存路由結果的資料結構所需要的 記憶體容量,這也表示我們可以藉由適當地設定階層分群方式,來獲得最小記憶 體容量。透過初步的檢驗程序發現,增加分群階層數可以使每一階層的完全展開 樹規模較小,相對上每一分群範圍較廣,因此可以較有效率地針對有需要再進一 步分群解析的 Subnet 才進行下一階層的展開,所以可以相當有效地減少記憶體 需求,然而卻有平均記憶體存取次數隨之遞增的缺點,因而我們必須在分群階層 數與記憶體存取次數之間權衡一最佳點。此外觀察也發現,記憶體容量需求也並 非隨著階層數的增加而永遠呈等速率地減少,而是會趨向一飽和值。因此在綜合 考量階層數變化對於記憶體容量以及存取次數的效應之後,我們決定採用5 層次 的分群解析架構。
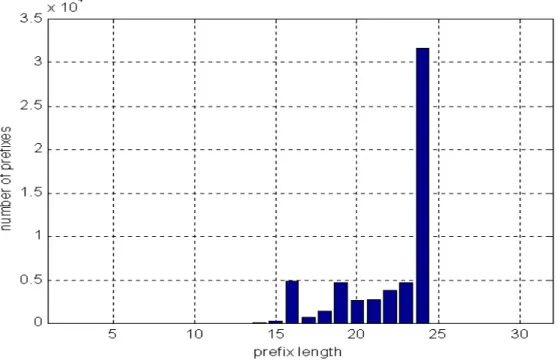
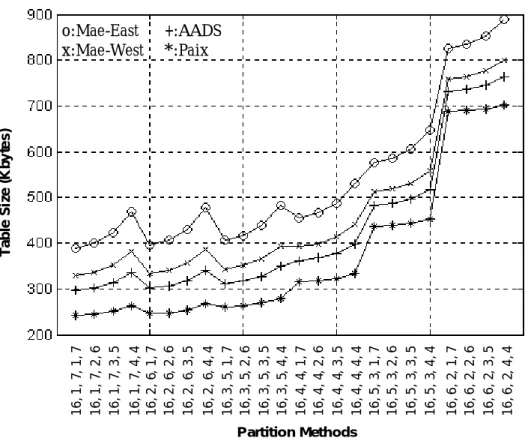
最後我們更進一步地分析實際Routing Table 中路由字首的分佈狀況,作為 階層式多元完全展開樹各層次中分群的依據,期望能以對應路由字首分佈特性來 最佳化的分群設計,獲得更有效率的記憶體使用。圖 0 為一般 Routing Table 中 普遍的路由字首分佈狀態統計圖,從圖上可見大多數的路由字首長度集中在 16 bits 至 24 bits 之間,因此若是在此長度之間有一個階層分界展開點,便可以在此 階層的展開中完成大多數的路由選徑查詢動作(如果實際的 IP 封包標頭的目的 IP 位址不特別集中在長度超過 24 bits 的路由字首的話)。而根據之前分群階層數 考量與決策過程的經驗來看,如果在 1 至 15 bit 的字首長度之間定有分層展開 點,則應該可以有較小的記憶體容量需求,然而卻也會因而增加平均記憶體存取 次數。在同樣權衡記憶體大小與平均存取次數後之後,我們擬定以 16 bits 的路 由字首長度做為第一分群階層的展開,期望以此展開長度在第一次的分群展開中 便能夠完成大多數的路由選徑查詢,並進一步如圖 0 所示檢驗多種分群組合方 式,最後我們擬定用於Unicast Routing 的 32-bit IPv4 位址而言的最佳 IP 位址階 層分群方式為「16-1-7-1-7」,因為此方式可以得到最佳的表現:平均記憶體存取 次數較小,以及最小的記憶體需求。
圖 0: Routing Table 中路由字首的分佈狀態圖
最後,我們採用一簡單的位元圖(Bit Map) 壓縮法(Compression Bit Map, CBM) 將儲存路由結果的資料結構做壓縮,以進一步減少所需的儲存記憶體空 間。而我們所設計的階層式分群解析法原本在運作架構特性上就相當適合模組化 的運作,可以將每一個階層的分群解析路由查詢動作都視為一獨立而完整的運作 模組,因此透過適當的電路規劃與安排,可以達成硬體上超管線式(Pipeline) 平 行多工架構的運作方式及其優點,當有 IP 路由選徑查詢進入第二階層後,便可 以馬上接受下一 IP 路由查詢的要求,維持高度的路由查詢 Throughput,使每個 封包路由選徑動作所要存取記憶體的平均次數減少至極致,可達到相當於在一次 的記憶體存取動作與時間,便可以完成一筆IP 路由選徑查詢的動作,此時 Routing 的速度將幾乎完全取決於記憶體存取定址的硬體定址電路運作速度。 圖 0: 不同的 IP 位址 (32-bit IPv4) 階層分群方式及其所需之記憶體容量
(對不同ISP/NSP 的 Routing Table 而言)
16, 1, 7 , 1, 7 16, 1, 7 , 2, 6 16, 1, 7 , 3, 5 16, 1, 7 , 4, 4 16, 2, 6 , 1, 7 16, 2, 6 , 2, 6 16, 2, 6 , 3, 5 16, 2, 6 , 4, 4 16, 3, 5 , 1, 7 16, 3, 5 , 2, 6 16, 3, 5 , 3, 5 16, 3, 5 , 4, 4 16, 4, 4 , 1, 7 16, 4, 4 , 2, 6 16, 4, 4 , 3, 5 16, 4, 4 , 4, 4 16, 5, 3 , 1, 7 16, 5, 3 , 2, 6 16, 5, 3 , 3, 5 16, 5, 3 , 4, 4 16, 6, 2 , 1, 7 16, 6, 2 , 2, 6 16, 6, 2 , 3, 5 16, 6, 2 , 4, 4 Partition Methods Ta bl e S iz e ( K b y te s ) o:Mae-East +:AADS x:Mae-West *:Paix
圖 0 所示即為我們所設計的快速路由選徑機制的硬體邏輯架構。從表 0 的 模擬結果看來,目前我們所設計適合於IPv4 Unicast 的高速路由選徑方法相較於 其他類似概念的方法 [3],僅需要不到 400 Kbytes 的記憶體空間,而且透過硬體 上Pipeline 平行多工的方式,可達到每個封包在平均一次記憶體定址存取的動作 即可以獲得路由選徑結果。未來我們將考量實際商用化系統環境與規格(速度與 記憶體容量需求)進行調整與最佳化設計,改進其路由表格資訊更新(Routing Table Update)時所必須對應的相關資料結構與內容的替換或更新,提出更有效 率的方式。除此之外也擬配合次世代網際網路的潮流,進一步發展適用於 IPv6 環境的高效能路由選徑技術。 圖 0: 快速路由選徑機制的硬體邏輯架構
綜合上述的內容來看,我們在高速路由選徑法之研究設計方面,藉由適當 的查詢架構與路由表格結構的設計,快速而硬體架構導向的路由查詢演算法得以 實現,配合上實際硬體化操作與超管線(Pipeline) 平行多工運作架構的設計,使 得路由選徑查詢得以達到平均約一次記憶體存取動作即可完成的高通透率 (Throughput),可以向上支援至超高速乙太網路(Gigabit Ethernet) 甚或更高速網 際網路頻寬的需求。根據階層式分群解析概念,配合壓縮化完全展開樹以及 Compression Bit Map 壓縮法而發展出來的路由選徑方法,確實能使路由選徑機制 運作所需的記憶體容量降低許多,相對於平面展開式的壓縮方式,更小的記憶體 容量亦更有利於硬體架構的設計與運作,甚至可以將記憶體與周邊相關的邏輯電 路整合入同一單晶片中,成為一獨立的硬體路由選徑搜尋引擎,除了可以更大幅 提升速度之外,也符合系統化晶片(System on Chip, SoC) 的發展潮流與趨勢。另 外,我們也將所設計的方法針對Routing Table 中,大量的路由字首長度大於 24 的此種特殊路由字首分佈情況做進一步的檢驗與分析,發現其所造成的記憶體容 量需求成長的幅度相當低,並未隨之成比例地大量增加,從此結果也可見我們的 方法還具有相當的空間擴展性的優勢。藉由對單一路由(Unicast Routing) 之選徑 技術研究,我們可以很快進入多點群播路由(Multicast Routing) 及下一代網際網 路IPv6 之相關路由選徑技術的研究,甚至是封包分類器(Packet Classifier) 中複 雜度更高、查詢參照資訊(欄位)更多的查表搜尋演算機制的設計。
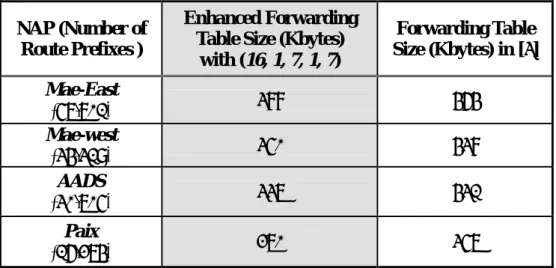
表 0: 路由選徑方法所需記憶體容量之比較
NAP (Number of Route Prefixes )
Enhanced Forwarding Table Size (Kbytes)
with (16, 1, 7, 1, 7) Forwarding Table Size (Kbytes) in [3] Mae-East (57,701) 388 464 Mae-west (34,319) 350 438 AADS (30,705) 337 431 Paix (16,274) 270 357
1-2. 高速單一路由選徑(Unicast Routing) 機制-TCAM-based 架構
除了上述根據階層式分群解析概念,配合壓縮化完全展開樹而發展出來的 硬體架構導向的路由選徑方法之外,另一類硬體化操作的路由選徑機制,即是著 眼於因半導體製程技術的進步而開發出來的TCAM (Ternary Content Addressable Memory) 記憶體特性,而採用其為基礎的路由選徑方法,可稱之為「直接 TCAM 路由比對方法 (Direct TCAM Match)」。因此在本計畫中,我們也提出一套採用 TCAM 記憶體特性的硬體化操作路由選徑機制。相較而言,如上一節中採取階 層式分群解析概念,或以完全展開樹為基礎的這一類方法 [2, 3, 6],相當於是 將原本路由選徑所需要的查詢演算方式進行轉換,成為一些單純、規律的邏輯電 路運作和記憶體存取動作的操作程序,之後只要將IP 封包標頭的 Destination IP 位址輸入,透過此規則化的操作程序即可以獲得路由選徑的結果。由於並不是直 接透過一般 IP 路由選徑搜尋演算方法的過程,而是間接地透過轉換後的規則化 操作程序即可獲得等效於路由選徑搜尋演算法的結果,因此也被歸類稱為「間接 路由查詢方法(Indirect Lookup)」。 隨著半導體技術的進步,記憶體的種類與功能也不斷推陳出新,除了運作 速度與記憶容量之單位面積密度的提升與價格的下降之外,也從最初單純的資料 儲存目的發展至以專屬或特殊應用為主的功能性記憶體,「內容定址記憶體 (Content Addressable Memory, CAM)」即是做為「資料搜尋」用途的專門記憶 體。其應用的方式為:記憶體中的每一個儲存單位存入的為某一應用的一筆候選 內容資料以及該內容的相關聯數據資料,待該應用需要進行內容搜尋的時候,僅 需將該內容輸入記憶體做為定址用途,CAM 記憶體自動會將內容比對吻合的該 儲存單位的內容相關聯數據資料輸出。省去在傳統記憶體架構的操作程序中,必 須自行將記憶體中的候選內容資料一一定址取出並分別比對,再將內容吻合項目 的相關聯數據資料另外定址讀出所必須花費的時間。而具三元資料比對能力的 TCAM (Ternary CAM) 記憶體的提出,更是讓 CAM 記憶體的資料搜尋能力因為 具備更彈性的應用方式而進一步提升:儲存的內容可以包含don’t care 萬用字元 (*),因此可做到多對一的模糊化搜尋方式,也就是一筆候選內容可以包含多個 可能性,輸入資料時不再需要完全吻合候選內容才會得到輸出,只要與候選內容 近似,在其包含的可能性範圍內,就可以得到相對應的關聯數據輸出。這樣的資 料搜尋應用方式與IP 路由選徑有著相近似的運作方式(Routing Table 中每一筆 路由字首資料皆可視為是以萬用字元對應至一 IP 位址區段,也就是多個 IP 位 址,而同一IP 位址可能會被多個路由字首所對應的 IP 位址區段範圍所涵蓋。當
欲查詢某一IP 位址的路由結果時,根據 Longest Prefix Match 的原則,即是將包
含到此待查 IP 位址的所有路由字首都搜尋出來並比較其字首長度,而以最長字
首所對應的路由結果做為此待查IP 位址的路由選徑查詢結果),因而使得TCAM
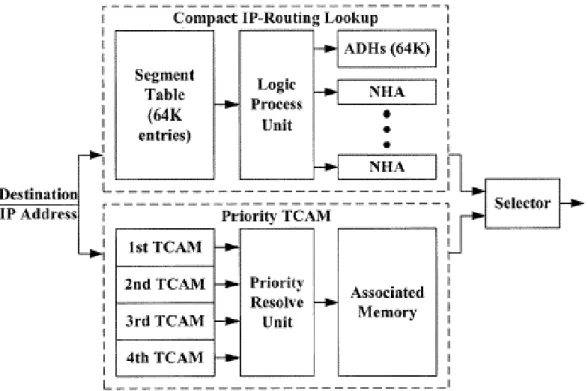
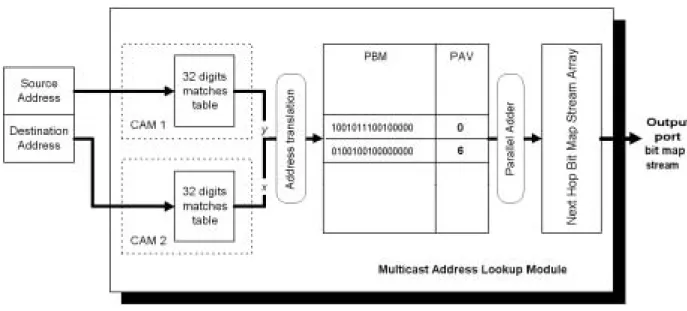
以TCAM 為基礎的 IP 路由選徑方法即是一個硬體化操作的路由選徑方式, 具備有多方面的優點:由於屬於硬體的運作架構,所以運作的速度相當快;也因 為其本身的操作特性即相當符合 IP 路由選徑搜尋演算模式,所以僅需要搭配相 當簡單的周邊邏輯電路便能夠進行路由選徑查詢的應用,而運作所需要的資料結 構的建立與更新速度也很簡單、迅速,可以直接使用 Routing Table 的路由字首 資料而不需做任何轉換或處理的動作,所需要額外的記憶體容量也很小。然而其 目前唯一、也屬重大的缺點是,價格仍然過高,使得其雖然具備執行路由選徑機 制最佳且優秀的能力條件,但是真正商用化的路由器仍未見有採用其做為路由選 徑機制的應用。在本研究中,我們提出了一個整合直接 TCAM 路由比對和間接 路由查詢方法的路由選徑演算法,而設計的主要動機與概念便是:充分利用 TCAM 的特性並兼顧其價格缺點,整合間接路由查詢方法,並採用兩者平行處 理、分工合作的概念,截長補短—以間接路由查詢方法彌補 TCAM 因價格高而 數量不足,無法完全負擔路由選徑搜尋應用需求的缺點;利用少量的 TCAM 搭 配Priority 處理邏輯單元,來負擔部分(路由字首長度較長的)路由資訊的路由 選徑應用,減少間接路由查詢方法所需負責的路由資訊數量,因而降低其記憶體 需求。而此新的複合式路由選徑方法,最多只需要2 次的記憶體查詢時間,便可 以得到路由選徑的結果,而且也一併減少路由搜尋資料表的更新時間。其較細部 的設計與運作程序如下面的內容所述。 令li和hi表示路由器 (Router) 路由表格中第 pi筆路由字首的長度及其對應 的路由器輸出埠。我們所設計採用 TCAM 記憶體特性的硬體化操作路由選徑方 法的架構圖如圖 0 所示:上半部是為一個既有的間接路由查詢方法,處理 li小 於或等於24 的路由字首 pi,下半部即是直接TCAM 路由比對方法,處理 li大於 24 的路由字首 pi。此兩部份在實際的操作中是為平行處理的運作方式,對於一 筆輸入欲進行路由選徑查詢的 IP 位址,會同時被輸入至兩部份。若只有上半部
分的Indirect Lookup 有輸出,則 Selector 單元會將此結果直接做為自己的輸出,
成為該待查 IP 路由選徑的最終結果;若上下兩部份都分別得到路由選徑的結
果,則Selector 單元將會因為 Longest Prefix Match 的路由選徑原則,而以下半部 分Direct TCAM Lookup 的結果做為自己的輸出,同時也表示是該待查 IP 路由選 徑的最終結果。上半部的Segment Table 是存放以 IP 位址的前 16 位元為第一分 群解析階層展開後的每一分群IP Segment 所對應的路由結果 Pointer;而邏輯處 理單元(Logic Process Unit) 則是根據 Segment Table 所輸出的路由結果 Pointer, 進一步指向ADH (Associated Default Hop) 取得對應的路由選徑結果(也就是路
由輸出埠),或是指向儲存著下一層次分群解析的路由選徑結果的 NHA (Next
Hop Array)。而下半部的 1st、2nd、3rd 和 4th TCAM 表示 4 群 TCAMs 硬體單元, 分別儲存並處理Routing Table 中字首長度為 25 至 26 bits、27 至 28 bits、29 至 30 bits 和 31 至 32 bits 的路由字首,並依序具有由小至大的輸出優先權;Priority Resolve Unit 單元則如同一個 Filter,依 1st、2nd、3rd 和 4th TCAM 的實際輸出
TCAM 皆無有效輸出,則 Priority Resolve Unit 便以一個預設輸出代替; Associated Memory 存放四個 TCAM 中所有(長度大於 24 bits 的)路由字首所對 應的路由選徑結果(也就是路由輸出埠),並會根據Priority Resolve Unit 的結果, 輸出所對應的路由選徑結果;若Priority Resolve Unit 的輸出是為預設輸出,則 Associated Memory 將不會有輸出。
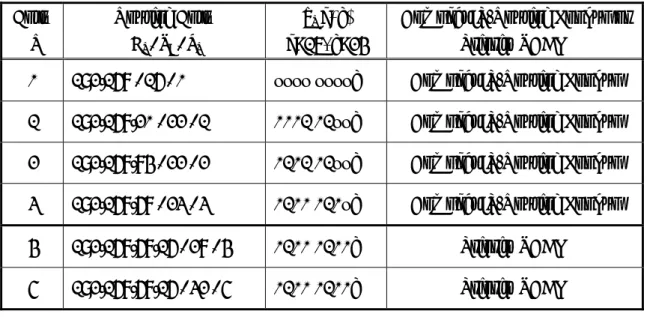
令pi (x, y)表示 pi 的 x 位元至 y 位元。表 0 顯示 IP segment 192.168 的對應
路由表。因為192.168 IP segment 的最大長度 li為32 bits。因此若利用傳統上單
純的間接路由查詢方式Huang’s scheme [3] 來查詢的話,此 192.168 IP segment 需要 2(32-16) 個對應的 NHA 路由器輸出埠 entry。利用我們提出的複合式路由選 徑查詢方法(如表 0 的最後一個欄位所示):我們把li大於24 bits 的路由字首 pi,
用直接TCAM 路由比對方法來處理;把 li小於或等於24 bits 的路由字首 pi,才由
間接路由查詢方法來處理。因此在間接路由查詢方法這部分只需要2(23-16)個(因 為把li大於或等於24 bits 的路由字首 pi排除,最大的li為23 bits)對應的 NHA
路由器輸出埠entry,大幅降低 NHA 路由器輸出埠 entry 的記憶體需求,同時也
把最長的IP 路由選徑查詢的時間降低在 2 次記憶體存取的時間內。
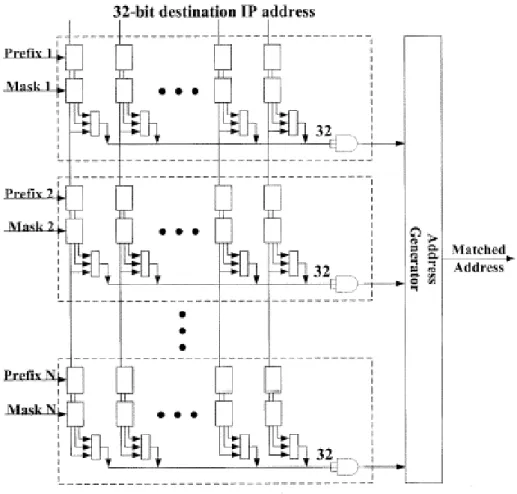
不僅如此,我們還進一步提出一個「同值位元整合壓縮法(Common Bit Integration)」,來改善間接路由查詢方法的(NHA)記憶體需求。以表 0 中 entry 1 至 entry 3(li小於或等24 bits 的路由字首)為例,其第 17、19、21 和 22 位元 是相同的,因此我們只需紀錄第18、20 和 23 位元的 3-bit 的 pattern 即可,因此 對應的NHA 路由器輸出埠 entry 可進一步由原來的 2(23-16)減少至2(23-16-4) = 23, 更進一步減低所需要的記憶體大小。 圖 0 表示 TCAM 硬體單元的架構圖。TCAM 硬體單元由路由字首 pi暫存
器,對應的pi mask bit pattern、32 個 3 位元比較器,和 1 個 32 位元的 AND 邏輯
運算單元所構成。由於 TCAM 硬體單元完全是由硬體構成,因此以其為基礎的
路由選徑方法比起同為硬體操作架構的間接路由查詢方法而言,仍是具有較快的 運作速度。
以網際網路上運作的實際IP 路由表為例,表 0 列出三個大型 ISP 處的實際 Routing Table 的資料,以及兩種具代表性的間接路由查詢方法(Huang’s scheme
及 Chen’s scheme)與我們提出的複合式路由選徑查詢方法對記憶體需求的比
較。由表中可見,增加少量的 TCAM 硬體單元,所需的記憶體可大幅降低,不
僅使 IP 路由輸出埠的查詢時間降低在 2 次的記憶體讀取的時間內,亦可降低更
新搜尋的資料表的時間。
表 0: Routing prefixes of the 192.168 segment Entry i Routing Entry Pi / l I / hi pi(x, y) x=17, y=24
Compact IP-Routing Lookup or Priority TCAM
0 192.168 / 16 / 0 xxxx xxxxb Compact IP-Routing Lookup 1 192.168.20 / 22 / 1 0001 01xxb Compact IP-Routing Lookup 2 192.168.84 / 22 / 2 0101 01xxb Compact IP-Routing Lookup 3 192.168.68 / 23 / 3 0100 010xb Compact IP-Routing Lookup 4 192.168.68.16 / 28 / 4 0100 0100b Priority TCAM 5 192.168.68.16 / 32 / 5 0100 0100b Priority TCAM
1-3. 高速群播路由選徑(Multicast Routing) 機制
群播路由選徑(Multicast Routing) 與一般單一路由選徑(Unicast Routing) 的 不同點在於:一個Multicast IP 即代表著一個唯一的 Multicast Group,其包含(對 應到)多個分佈在不同區域的主機(Host),並非如其他(一般的)Unicast IP 多半 是以一個連續的區段(Segment) 為單位,來指派、對應到某一區域的單一主機。 所以, 在路由表格中,Multicast 的 Routing entry 是以(單一)完整長度的路由 字首來呈現,與一般Unicast 的 Routing entry 是以不完全長度的字首來代表一個
連續 IP 位址區段的形式有所不同; 同時,其路由選徑結果也不再只是對應到
單一的輸出埠,而可能是一「組」的多個輸出埠; 另外一個與Unicast Routing
形式上較大的不同是,為了讓 Multicast 的運作更有彈性,可以自由地根據不同
的資料發送端來設定不同的資料群播遞送的方式,Multicast Routing 採取多(雙) 欄位資料搜尋比對的路由選徑動作,除了Multicast 的 Destination IP 之外,也必 須同時根據Source IP 位址來決定路由結果輸出埠為何。因此,Multicast Routing 的關鍵技術是為一個高速的多欄位資料完全相符(Exactly Match) 的比對搜尋機 制,並且能同時迅速地解析出所需要進行封包轉送的多個路由輸出埠。從高速單 一路由選徑方法的設計經驗得知,內容定址記憶體 CAM 和 TCAM 本身即可視 為一個簡單而易於實現的硬體架構的資料比對搜尋裝置,而CAM 的運作方式即 相當於一個資料完全相符(Exactly Match) 的比對搜尋機制,因此相當適合應用在 表 0: 各種路由選徑方法所需記憶體容量之比較
AADS Mae-West PAIX
Prefixes 33,931 37,523 18,569 Segments 5,813 6,126 3,571 Length>24 431 433 443 Huang’s [3] 599K 610K 507K Chen’s [6] 659K 781K 543K Priority TCAM IP-Routing Lookup 423K +431 TCAM 463K +433 TCAM 377K +443 TCAM
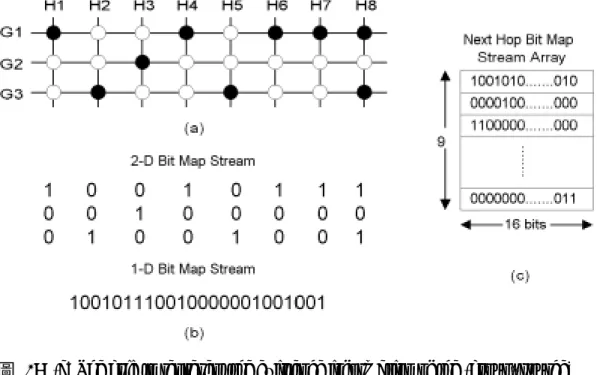
高速硬體化操作的 Multicast Routing 路由選徑機制的設計中;此外,有鑑於 Compression Bit Map (CBM) 的概念對於單一路由選徑機制運作所需的資料結構 記憶體空間上的壓縮有很大的幫助,因此我們同樣將此概念應用在群播路由 (Multicast Routing) 的選徑機制設計上,以有效降低、控制路由表格的大小。綜 合上述的考量,我們提出一套以CAM 為基礎,並採用 CBM 技術為輔的高速硬 體化操作的Multicast Routing 路由選徑方法。此方法的群播路由查詢速度可以相 當快,一次群播路由查詢只需要三次的記憶體存取次數(Memory Accesses,再加 上管線式(Pipeline) 運作架構的可行性,也同樣能使得平均查詢次數降至一次的 記憶體存取次數。其細部的設計與運作如下面的內容所述。 整個群播路由表格的組成基本上包含來源位址(Source Address)、目的位址 (Destination Address) 以及由此兩個位址所決定出唯一的一組輸出埠號碼(Output Port Numbers)。根據群播路由查詢法則,當路由器收到一個封包,發現其目的位 址為群播網際網路位址(Multicast IP Address) 後,接著必需檢查其來源位址,確 定這是此群播組(Multicast Group) 裡的成員,以及是哪一位成員所發出的封包, 由這兩個位址便可決定出一組輸出埠號碼;每一個號碼表示路由器必須要複製一 份此封包往這個輸出埠送。基本上,我們以底下所示的方式表示一個群播組和其 所包括的成員: Group G1: Sources H1, H4, H6, H7, H8. Group G2: Sources H3. Group G3: Sources H2, H5, H8. Gx 表示目的位址,Hx 表示來源位址。根據這個法則,我們把路由器上經 由路由協定(Routing Protocol) 所獲知的來源位址和目的位址(這裡特別是針對對 應至Multicast Group 的 Multicast IP 位址)作成一個二維空間的棋盤狀對應表, 此表格的縱軸表示來源位址,橫軸表示目地位址,而兩軸的交叉點基本上有一個 圓圈,黑色圓圈表示這是一個有效的群播組和組員的關係,(群播組(Multicast Group), 組員(Membership Source)),白色圓圈則表示是一個無效的群播組和組員 的關係,如圖 0(a) 所示。將這些圖形資訊做一個二進位數字編碼,黑色圓圈為 1,白色圓圈為 0,便可形成如圖 0(b) 的一串二進位數字串列。接著我們將此種 Bit Map 的資訊編碼方式也同樣運用在路由輸出埠組上,我們將每一個有效的 (Multicast Group, Membership Source)關係所對應的輸出埠號碼組作以 Next Hop Bit Map Stream 的形式來表示,每一筆 Next Hop Bit Map Stream 的每個位元 依序對應到一個輸出埠,而以其位元值表示是否要複製一份封包往這個輸出埠 送,位元1 表示需要,位元 0 表示不需要,如圖 0(c) 表格中每一個 Entry 所示。 最後再將所有有效的(Multicast Group, Membership Source)所對應到的 Next Hop Bit Map Stream 以一個如圖 0(c) 所示的 Next Hop Bit Map Stream Array 陣列來依 序置放,做為查詢之用。
進行Multicast Routing 路由選徑查詢時,先要根據封包標頭的(Source IP, Destination IP)資訊在這個二維空間棋盤狀對應表中尋找其對應的圓圈的幾何位
置,接著再從棋盤最左上邊的第一個交會點開始計算到此對應位置前位元值為1
的個數是多少,此數目即代表從棋盤狀對應表左上角第一個交會點算起有效的 (Multicast Group, Membership Source)關係組數,將這個數目對應到存有輸出 埠資訊的Next Hop Bit Map Stream Array 陣列中的位置,如此便可快速取得所需 要的路由資訊。為使路由速度更快,在查詢由來源位址和目的位址所組成的幾何 位置資訊上,採用「內容定址記憶體Content Addressable Memory (CAM)」的方 式來實作,並將原本圖 0(b) 的二進位數字串列作一個簡單切割以利實作上匯流 排的資料寬度需求,形成如圖 0 的系統架構圖;這個架構適用於管線運作方式, 因此也可大幅提高整體路由查詢的資料輸出率(Throughput)。
圖 0: (a) The grid to represent the existence information of the (group, source) pairs, (b) The pair bit map streams, (c) The next hop bit map stream array.
2. MPLS 網路之 VC-Merge 機制的效能分析
在此,我們主要是設計一套有效的系統效能分析演算方法,針對VC-merge
的ATM-LSR 所需的緩衝器和 cell blocking 機率之間的關係進行分析,試著去探 討具有VC-merge 能力的 ATM-LSR 交換機需要比傳統的 ATM 交換機具備多少緩 衝器資源,這其中包含了Frame-level Interleaving 機制所需要的 ATM cell 重組緩 衝器以及ATM-LSR 原本既有的輸出緩衝器(Output Buffer, OB)。
圖 0 顯示一個具有 VC-merge 能力的 ATM-LSR 交換器架構;包含了 N 個輸 入/N 個輸出的 ATM cell 交換單元及 N 個輸出模組(Output Module) 單元。圖 0 進一步顯示輸出模組的架構,包含了 M 個重組緩衝器(Reassembly Buffer)、具 VC-merge 功能方塊、S 個依服務等級不同的輸出緩衝器(Output Buffer) 及 ATM cell 服務的輸出排序等。
圖 0: Block diagram of the output module
RB 1 RB 2 RB 3 RB M VC Merge (by Pointer Transfer)
OBs (Output Buffers) RBs (Reassembly
Buffers)
Service Class 1 Queue
Service Class S Queue
Cell Service Scheduler (WFQ or DiffServ) OUTPUT LINK
圖 0: Block diagram of a VC-merging capable ATM-LSR
Input Ports Output Module Output Module Output Module Output Module 1 2 3 N
Switch Fabric Output Ports
1
2
3
圖 0(d) 為傳統不具 VC-merge 能力的 ATM-LSR 交換機形式,即便是欲前 往相同目的網路或節點的IP Route,其相對應的 ATM cell 在交換後仍是採用不同 的 VPI/VCI 以區隔出其為分屬不同 IP Route 的訊務流,如此即便是對應至不同 IP Route 中 IP 封包的 ATM cell 有任意交錯傳輸的現象也沒有關係;圖 0(a)、(b) 及(c) 顯示三種不同型態的 VC-merge 形式:(a)是為 Full VC-merge,對於欲傳輸 至相同目的網路或節點的 IP Route,將其所屬的 ATM cell 皆轉換成一致的 VPI/VCI 進行傳輸,(b)和(c)則為在進行 VC-merge 時,除了一致的目的網路或節
點之外,額外考慮IP Route 不同的服務品質或其他屬性,將欲前往相同目的網路
或節點而且屬性相同的IP Route,其所屬的 ATM cell 才會在交換後轉換成一致的 VPI/VCI 進行傳輸,此種 VC-merge 方式則稱為 Partial VC-merge。在此種 VC-merge 方式中,VC-merge 後不同 VPI/VCI 的 ATM cell 可以任意交錯傳輸沒 關係,但是相同VPI/VCI 的 ATM cell 仍是必須要遵循 Frame-level interleaving 機 制,不可與對應至不同IP Route 中某一 IP 封包的 ATM cell 交錯。圖 0 中的縮小 數字表示起始的VCI,底線代表 ATM EOM (End of Message) cell。例如 52代表
EOM cell,原先 VCI=2 經過 ATM-LSR 交換機後轉成 VCI=5。
圖 0: Three types of VC-merging and one type of non-VC-merging 1 1 1 4 4 4 2 2 3 3 1 2 3 4 5 5 5 5 Input Cell Stream to a Specific Port In Out VCI Table Output Cell Stream of a Specific Port 1 1 1 4 4 4 2 2 3 3 1 2 3 4 6 5 6 5 Input Cell Stream to a Specific Port In Out VCI Table Output Cell Stream of a Specific Port 61 54 61 54 61 63 52 52 63 54
(a) Full VC-merge
(c) Partial VC-merge with multiple output buffers
54 54 51 51 51 53 53 52 52 54 81 81 63 54 72 54 63 72 81 54 54 54 61 61 61 63 63 52 52 54 1 1 1 4 4 4 2 2 3 3 1 2 3 4 8 7 6 5 Input Cell Stream to a Specific In Out VCI Table Output Cell Stream of a Specific Port 1 1 1 4 4 4 2 2 3 3 1 2 3 4 6 5 6 5 Input Cell Stream to a Specific Port In Out VCI Table Output Cell Stream of a Specific Port
(b) Partial VC-merge with Single output buffer
我們所設計的分析方法主要是參考論文[7]的方法並加以改進:在我們提出 的系統中,放寬[4]的 Input Model,可允許 Cell-interleaving 的 Input Pattern,並且 允許Partial VC-merge 的運作方式。我們建立一個排隊理論數學模式 D-BMAP/D/1 來分析輸出模組的機率分佈。D-BMAP/D/1 的排隊理論模式為:
M 個 IP Stream 可模擬成 M 個 ON-OFF sources,ON 的時間和 OFF 的時間為 幾何分佈(Geometrical Distribution);
在 ON 的時段裡,IP Stream 會產生 1 個 ATM cell 的機率為 r。在 OFF 的時段 裡,IP Stream 不會產生任何一個 1 個 ATM cell。參數(1/r)代表 ATM cell interleaving 的程度;
輸出服務模式為每個 ATM time slot 處理完 1 個 ATM cell。
研究結果顯示,相較於論文[7] D-BMAP (Discrete – Batch Markovian Arrival Process)/D/1 的排隊理論模式,我們所設計的分析方法其計算複雜度可由 O(M4) 減少為(M2),其中 M 為所模擬的 ON-OFF Source 的個數,並且更進一步多引進 了一個參數 r,來描述 IP 封包的 interleaving 程度,使得數學模型更接近實際的
情況,所得的分析結果也較為接近實際。複雜度較低的結果,使得對較大的Buffer
Size 分析也能夠得到較高的 Cell Loss Prob.的準確度(尤其 Cell Loss Prob.通常低 於 10-6 以下)。我們也利用了 Moment-Generation Function 的理論方法來近似 D-BMAP/D/1 的排隊理論模式,求得一個精確度蠻高的、接近前述所設計的分析 方法結果的輸出緩衝器(Output Buffer) 中 ATM cell 數量分佈的數學近似方程 式,可更快速計算Cell Loss Prob.。分析及模擬結果顯示 ATM-LSR 交換機需要 具備比傳統 ATM 交換機多 50-70%的緩衝器資源來支援 ATM cell 重新組合使 用,以及避免VC-merge 後無法在目的網路或節點處分離出不同 IP Route 訊務的 問題。
圖 0 顯示透過數學分析及電腦模擬一個支援 VC-merge 功能的 ATM-LSR 其
總緩衝器 overflow 機率分佈的結果。可以發現,我們的數學分析結果和電腦模
擬結果相當一致。由圖 0 我們可得到以下結論:
1. 具有 VC-merge 能力的 ATM-LSR 交換機較傳統 ATM 交換機需要較大的緩衝 器資源。如圖 0 中顯示在 overflow 機率為 10-5次方的假設下,傳統ATM 交 換機需要約390 個 ATM cell 緩衝器;ATM-LSR 交換機需要至少 520 個 ATM cell 緩衝器。
2. 在細胞交錯 cell-interleaving 愈嚴重的情況下(r 參數愈小),需要更多的重組緩 衝器來重組IP 封包,因此需要更多的緩衝器資源。在一般的 cell-interleaving 程度的訊務下,約需要比傳統ATM 交換機增加 50%-70%的緩衝器資源。
圖 0: Overflow probability of the total buffer versus buffer threshold 0 100 200 300 400 500 600 700 10-5 10-4 10-3 10-2 10-1 Buffer Thresholds T B O v e r fl ow P r ob a b il it y (256,1/16) (16,1) (M,r)=(16,1), (32,1/2), (64,1/4) (M,r)=(128,1/8), (256,1/16) Simulation Non-VC-merging
3. MPLS 網 路 之 路 徑 保 護 (Protection) 及 快 速 回 復 (Path
Recovery) 機制
這部分的研究主要在於提出一套有效的 MPLS 網路之路徑保護/回復機 制,以便於MPLS 網路傳輸路徑發生錯誤或損壞時還能夠維持部分基本的通訊, 並可以快速而正確地地恢復既有的通訊,降低 MPLS 網路上傳輸路徑錯誤或損 壞所帶來的影響,減少封包遺失率,並期望能夠進一步達到動態負載平衡的附加 效益,使系統資源做最佳的利用,如此便可有效的提高網路的資料輸出率 (throughput)。 一個完整的路徑保護/回復機制應包含有幾個要素:單一或多條的工作路 徑(Working path) 與備援路徑(Backup path)、路徑狀態監控/錯誤偵測和警告通 知機制、以及路徑回復程序啟動時,切換到Backup path 的機制。IETF 提出了兩 種 路 徑 保 護 / 回 復 機 制 的 運 作 模 型(Model) [12, 9] , 也 可 做 為 許 多 Path Protection/Recovery 方法的兩大分類依據,其主要是根據 Backup path 建立的時間 點做為區隔:如表 0 所示,在路徑發生錯誤之前即預先規劃並建立好 Backup path 的方式稱之為「Protection Switch Model」;相對的,在路徑發生錯誤之後才開始 建立適當 Backup path 的方式便稱為「Re-Routing Model」。「Protection Switch Model」由於採取事先規劃並建立好 Backup path 的方式,因此當發生路徑錯誤 時可以迅速地切換至Backup path 以回復正常通訊,然而由於相關的系統頻寬資 源也會是在建立Backup path 時即被保留,等待路徑發生錯誤時可以立即切換專表 0: 兩種 Path Protection/Recovery Model 之比較
Recovery
Model Backup Path Type
Backup Path Establish Point Switch -over Processing Recovery Time Resource Utilization/ Optimization Establish-On-Demand (Simple-Dynamic,
Shortest-Dynamic) Slowest High
Re- Routing Pre-Qualified After Fault Local Medium Medium 1+1 (Haskin Algorithm,
Makam Algorithm) Fast Lowest
Protection Switch 1:1, 1:n, m:n* Before Fault Head-end Fast Low
用,造成系統資源的使用效率最低,因為需要預先保留做為備援專用的相當數量
的資源在一般時候是閒置的。也由於必須耗費較多系統資源,因此 Backup path
多半僅在靠近通訊兩方的頭端(Head-end) 網路節點建立。「Re-Routing Model」的 傳統方式(如Simple-Dynamic 和 Shortest-Dynamic)是當路徑錯誤時才開始搜尋 並建立適當的Backup path,因此路徑回復(切換至 Backup path)的速度較慢, 但也因為不事先保留資源所以可以讓系統資源做最有效的利用,而且可以在距離 路徑錯誤當地(Local) 的最近或較近的節點(LSR)即進行路徑回復,不需要再 回到頭端節點才來進行,對路徑錯誤的反應速度較快且靈活度佳。其在路徑錯誤 的Local 節點建立至通訊終端的 Backup path 的方式,也對於路徑回復後因路徑 錯誤影響而需要重送的資料量減少。而分類上仍歸屬於「Re-Routing Model」的 Pre-Qualified 方式則其實是介於兩類方法間的機制,兼具兩者的優點,其關鍵在 於:以Re-Routing Model 為主,但是引用 Protection Switch Model 預先建立 Backup path 的觀念,在路徑錯誤發生之前先搜尋、規劃好可作為備援 Backup path 的數 個候選路徑,一旦路徑錯誤發生時即能夠透過簡單的資源保留與設定的動作,便 可迅速地建立Backup path 並恢復原有的通訊。由於並未在事先建立 Backup path 並保留資源,僅是預先搜尋、規劃候選Backup path 而已,因此資源仍可做充分 的利用而不浪費,並且也可以預先在Working path 沿線的各個 LSR 節點上分別 搜尋、規劃至通訊終端節點的Backup path,保有 Re-Routing Model 中在路徑錯
誤的最近幾個 LSR 處即可以快速反應的優點。如此再配合上前述當錯誤發生時
可節省搜尋時間並快速建立Backup path 的優點,更加使 Path Recovery 的速度獲 得更大幅度的提升。
著眼於兩種Path Protection/Recovery Model 各有其優缺點,因此我們嘗試結 合兩邊的優點,以屬性介於兩者之間的Re-Routing Model 作法中 Pre-Qualified 類 型的網路路徑錯誤復原演算法為主,提出一套高速而最佳的路徑保護/回復機制 的方法。然而在實際的操作上,由於Pre-Qualified 方法對於 Backup path 的形式 與數量並沒有明確的定義或限制,因此我們可以,也有必要根據Pre-Qualified 方 法的原則,設計、定義出一套適當並有效率的實際運作方式。如同之前內容所提, 除了在通訊的起迄的兩終端LSR 節點之間於通訊開始之前預先規劃 Backup path 之外,我們也在Working path 沿線的各個 LSR 節點上分別搜尋至通訊終端節點 的Backup path,然而此種 Backup path 的搜尋動作並不需要在通訊開始之前就進 行完畢,可以在通訊開始之後才進行,以避免過多通訊前的程序延遲了通訊開始 的時間,而且也不要求每一個沿線LSR 節點都必須要找到 Backup path。若發生 路徑錯誤時其最近一LSR 節點無法或尚未搜尋到 Backup path,便可通知其上游 (Up-stream) LSR 節點進行 Backup path 的建立與通訊的恢復;若此上游 LSR 節點 亦尚未搜尋到適當的Backup path,便可以再往其上游的 LSR 節點進行通知,直 到有上游LSR 已經找到 Backup path,或是到最上游的通訊終端 LSR 節點處為止 (這裡必定有Backup path,是通訊開始前即預先搜尋、規劃好的)。由於在搜尋 到Backup back 之後,並不需要在路徑錯誤發生前對其所需的資源加以保留,然
![圖 0 所示即為我們所設計的快速路由選徑機制的硬體邏輯架構。從表 0 的 模擬結果看來,目前我們所設計適合於 IPv4 Unicast 的高速路由選徑方法相較於 其他類似概念的方法 [3],僅需要不到 400 Kbytes 的記憶體空間,而且透過硬體 上 Pipeline 平行多工的方式,可達到每個封包在平均一次記憶體定址存取的動作 即可以獲得路由選徑結果。未來我們將考量實際商用化系統環境與規格(速度與 記憶體容量需求)進行調整與最佳化設計,改進其路由表格資訊更新(Routing Table Upda](https://thumb-ap.123doks.com/thumbv2/9libinfo/8422428.180606/18.892.146.775.128.745/所示上平行多工方式可達到每個封包在平均一次體定記憶求進行調.webp)