Schema Integration For Object-Relational Databases With Data Verification
8
0
0
全文
(2) We apply bottom-up approach to integrate existing database schema into a global schema [11], which will be evolved into a modified global schema. We can integrate the existing database schemas in pairs by discovering their relationship as follows: 1. Compare the database schema, 2. Seek users’ confirmation. 3. Conflicts resolutions 4. Merge Entities/Classes and Relationships/Associations 5. Verify the result schema by Data Exhaustive Search Algorithms (DESA) the data occurrences in the database 3. Schema Integration Schema integration provides a global view of multiple schemas. Our approach uses a bottom up approach to integrate existing database into a global database by pairs. The main objective is to provide an integrated schema based on user requirement with no loss of information. The general algorithm is as follows: Begin For each existing database do Begin If its conceptual schema does not exist then reconstruct its conceptual schema by reverse engineering; For each pair of existing database schema A and schema B do begin Resolve semantic conflicts between schema A and schema B; /*step1*/ Merge classes/entities and relationship relations between schema A and B; /*step2*/ end end end The input schemas must analysis in pairs and resolve semantic conflicts in different areas. Conflicts are resolved using well-define semantic rules [11] with user supervisions. Classes/Entities are merged by union or abstractions like subtype, generalization, aggregation and others. To demonstrate this step, EER and OMT diagrams are used to represent the conceptual schema of relational and object oriented respectively. [7-9, 21] We apply a method which is similar to the assertion-based approach. We first define corresponding assertions for DBA to specify the semantic correspondences among component object-oriented schemas as follows:. 1) Class-equivalent – Two classes are classequivalent if they are semantically equivalent. Their semantic domains are the same. For example class Student in schema A and class Student in schema B are classequivalent. 2) Class-correspondent – Two classes are class-correspondent if they are semantically related but not equivalent. Three kinds of classes correspondences are identified: class-containment, class-overlap and classdisjointness. For example, class Woman and class Person are class-containment. Class Student and class Teacher are class-overlap. Class Male and Class Female are classdisjointness. 3) Attribute-equivalent – Two attributes are attribute-equivalent if they are semantically equivalent. For example, Student.name and S-name are attribute equivalent. 4) Attribute-set-equivalent – Two attribute sets are attribute-set-equivalent if they are semantically equivalent. For example, attribute set (City, Street, No) and attribute Address are attribute-set-equivalent. 5) Attribute-set-class-equivalent – An attribute set and a class are attribute-set-classequivalent if the attribute set and the class are semantically equivalent. For example, attribute set (blood-type) and Class Blood are attribute-set-class-equivalent. 6) Attribute-class-set-equivalent – An attribute and a set of classes are attribute-class-setequivalent if the attribute is semantically equivalent to a division characteristic of a class. For example, attribute Person.sex and a set of classes (Male, Female) are attributeclass-set-equivalent because the division characteristic of class Person for the subclasses is sex. The details of each of the above steps are demonstrated as follows. (Refer to [11] for detail demonstration in relational schema and [15] for Object schema) Step 1. Identify and resolve the semantics integrity conflicts among input schemas. Input: Schema A and B with entities/classes and attributes in conflicts to each other on semantics Output: Integrated Schema Y after data transformation In dealing with definition related conflict like inconsistency in keys or synonyms/homonyms in names, user supervision is essential. For.
(3) instance, two entities may have some candidate keys overlapping with each other but using different key as the primary key. User has to clarify in this kind of situation. On the other hand, for conflicts arising from structural differences. The goal here is to capture as much information from the input schemas as possible. The most conservative approach is to capture the superset from the schemas. For example, in dealing with cardinality, the cardinality of the same relationship relation in schema A is 1:1 while the other one in Schema B is 1:n. Since a 1:n relationship is the superset of a 1:1 relationship, the 1:n cardinality is used for the integrated relation. Another example is the participation constraint. If the same relationship relation in different schemas have different level of participation constraints, partial participation always override total participation in the integrated schema. It is because total participation is a subset of partial participation. When dealing with data type and subtype conflict, association/relationship relation is used for resolution. To illustrate this, assume we have an attribute Department of the entity School in one schema and an entity Department in another schema. To resolve the data type conflict, a 1:n relationship is formed in the integrated schema to link up these two entities. Step 2. Merge classes/entities relationship relations Input: existing schema A and B Output: merged (integrated) schema X. THEN cardinality(A1, A2) ← 1:n; ELSE IF (class(A1) = class(B1)) ∧ (class(A2) = class(B2)) ∧ (cardinality(A1, A2) = 1:1 or 1:n) ∧ (cardinality(B1, B2) = m:n) THEN cardinality(A1, A2) ← m:n; Sub-step 2.2 Merge classes/entities Subtype Relationship IF domain(A) ⊂ domain(B) THEN begin Class(X1) ← Class(A) Class(X2) ← Class(B) Class(X1) isa Class(X2) End;. by. Sub-step 2.3 Merge entities/classes by Generalization IF ((domain(A) ∩ domain(B)) ≠ 0) ∧ ((I(A) ∩ I(B))=0) THEN begin Class(X1) ← Class(A) Class(X2) ← Class(B) Domain(X) ← domain(A) ∩ domain(B) (I (X1) ∩ I(X2))=0 end ELSE IF ((domain(A) ∩ domain(B)) ≠ 0) ∧ ((I(A) ∩ I(B)) ≠ 0) THEN begin Class(X1) ← Class(A) Class(X2) ← Class(B) domain(X) ← domain(A) ∩ domain(B) (I (X1) ∩ I(X2)) ≠ 0 end;. and. Classes/Entities are merged using the union operator if their domain is the same. Otherwise, abstractions are used under careful user supervision. By examining the same keys with the same entity name in different database schemas, we can merge the entities by union. The integrated entity takes all the attributes from both entities. Abstractions like generalization; aggregation are used in merging entities/classes in different input schemas when they fulfill the semantic condition. The details are as follows and summarized in Table 1. Sub-step 2.1 Merge relationship associations by capturing cardinality IF (class(A1) = class (B1)) ∧ (class(A2) = class (B2)) ∧ (cardinality(A1, A2) = 1:1) ∧ (cardinality(B1, B2) = 1:n). Sub-step 2.4 Merge classes/entities by Aggregation Aggregation [25] is an abstraction in which a relationship among objects is represented by a higher level, aggregate object. In relational terminology, aggregation consist of an aggregate entity which is an association of a relationship set with corresponding entities into a single entity set. This aggregate entity is treated as a single unit without concern for the details of its internal structure. [6, 16] In the object-oriented view, aggregation provides a convenient mechanism for modeling the relationship IS_PART_OF between objects. [14] By extending the semantics of slot values, an attribute stores either the reference of another object or a copy of that object to make it a composite value. An object becomes dependent upon another if the dependent object is referred by an attribute in the ‘parent’ object. When an object is deleted, all dependent objects it related to are also deleted. [13] Since the.
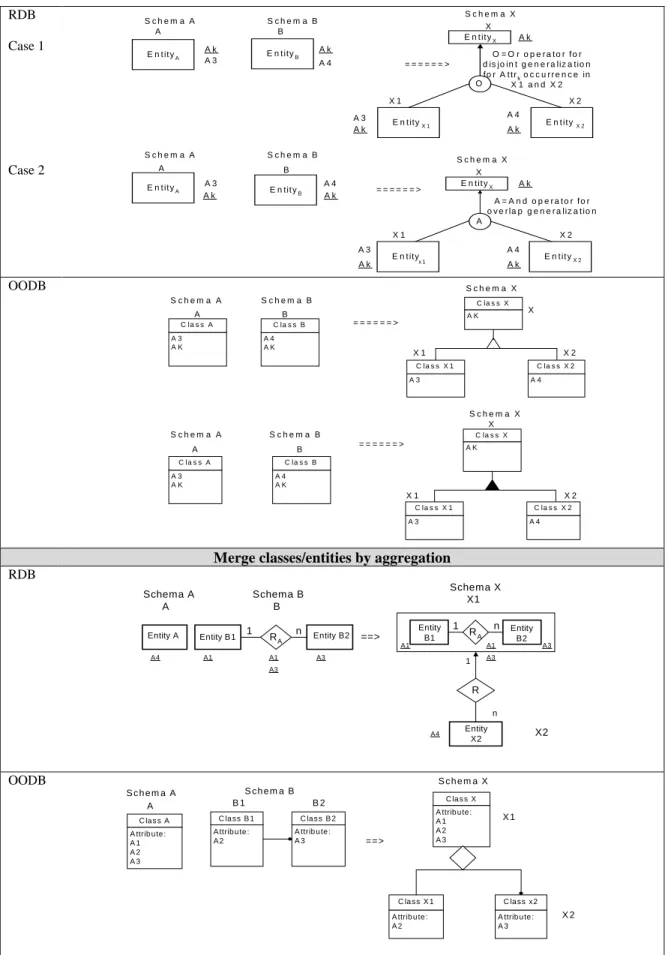
(4) implementations of this abstraction are different in relational and OO model, the merging procedure are different as well.. Object Oriented View of Aggregation If Domain (Key(B1)) ⊂ Domain (Attr(A)) AND Domain (Key(B2)) ⊂ Domain (Attr(A)) THEN begin aggregation(X1) ← Class(A) Class(X2) ← Class(B1, association, B2) End;. Relational View of Aggregation IF relationship(B) →→ class(A) /* MVD → means multi-value dependency */ THEN begin aggregation(X1) ← (class B1, relationship B, class B2 ) class(X2) ← class(A) cardinality (X1, X2) ← 1:n end;. Merge relationship associations by capturing cardinality RDB Case1. Schema A 1. Entity x. R. 1. Schema B. Entity y. A1. A2. Case2. R. 1. Entity y A2. Entity x. ====>. Entity x. A2. m. R. n. Attribute: A1 A2. Attribute: A3 A4. Entity y. ====>. S c he m a A. A ttribu te : A3 A4. R. n. Entity y A2. Transform ed Schem a A' Class x. Attribute: A1 A2. ====>. Attribute: A3 A4. T ran s fo rm e d S c he m a A ' C la s s x Y. A ttribu te : A1 A2. m. Class x. Attribute: A3 A4. C las s x. Entity y. A1. S c h em a B C la s s Y. n. A2. Entity x. C lass x. Attribute: A1 A2. R. Transformed Schema A'. A2. C lass x. 1. A1. Schem a B C lass x. A ttrib ute : A1 A2. Entity y. A1. Schem a A Class x. C la s s x. Transformed Schema A'. Schema B. A1. Case2. R. n. A1. Schema A 1. Entity x. OODB Case1. Entity x. 1. C la s s x. A ttribu te: A3 A4. C las s Y. A ttrib u te: A1 A2. ====>. A ttrib ute: A3 A4. Merge class/entities by subtype relationships RDB. S chem a A A A1. E n tity x. S ch e m a X. S chem a B B A1. E n tity y. A2. A3. A1. ==>. A2. OODB. X1. X2. E n tity x. E n tity y. Schem a X Schem a A A Class x. Schem a B B Class y. A1 A2. A1 A3. Class x A1 A3. X1. ==> Class y A2. Merge classes/entities by generalization. X2. A1 A3.
(5) RDB Case 1. S chem a A A. Schem a X X E n t it y X Ak. S chem a B B Ak A3. E n t it y A. Ak. E n t ity B. A4. O = O r o p e ra to r fo r d is jo in t g e n e r a liz a tio n fo r A t t r k o c c u r r e n c e in O X 1 and X 2. ======>. X1 A3 Ak S chem a A. Case 2. X2 A4. E n t ity X 1. Ak. S chem a B. A. Schem a X X E n tit y X. B A3 Ak. E n t it y A. A4 Ak. E n tit y B. E n t it y. ======>. X2. Ak. A = A n d o p e ra to r fo r o v e r la p g e n e r a liz a t io n A X1 A3. X2 A4. E n t ity. x1. Ak. E n t it y X 2. Ak. OODB. Schem a X S chem a A. S chem a B. A. B. C la s s A. C la s s X. ======>. C la s s B. A3 AK. X. AK. A4 AK. X1. X2. C la s s X 1. C la s s X 2. A3. A4. Schem a X X S chem a A. S chem a B. A C la s s A. C la s s X. ======>. B. AK. C la s s B. A3 AK. A4 AK. X1. X2. C la s s X 1. C la s s X 2. A3. A4. Merge classes/entities by aggregation RDB Schema A A Entity A A4. Schema X X1. Schema B B Entity B1. 1. A1. RA A1. n. Entity B2. Entity B1. ==>. 1. n. RA. A1. A1. A3. Entity B2. A3. A3. 1. A3. R n A4. OODB. Entity X2. X2. Schem a X Schem a A A C la s s A A ttrib u te : A1 A2 A3. S ch e m a B B1 C la ss B 1 A ttrib u te : A2. C la s s X. B2. A ttrib u te : A1 A2 A3. C la s s B 2 A ttrib u te : A3. ==>. C la ss X 1 A ttrib u te : A2. X1. C la ss x2 A ttrib u te : A3. Table 1 Merge classes/entities and relationship relations. X2.
(6) 4. Verification of the global schema To discover and verify the abstractions and data semantics in the input schemas and integrated schema. After data integration, data mining algorithms are employed to “mine” these abstractions from the physical data to verify the correctness of the integrate schema based on the user requirement. These algorithms are used to provide verification and confirmation of schema integration by making intelligent guesses from the physical data in finding the abstractions. The intention for using these algorithms assists the user in finding the true data semantics from the integrated schema. The result from the algorithms may not agree with the userspecification in some cases. For example, in extracting the types of generalization (overlap or disjoint) from the data, the physical data may appear as disjoint at some particular database states while the relationship is defined as overlap by the user. In such case, if the userspecification and the result from the algorithm are not contradicted to each other, let user clarify them. However, if the user-specification violate the semantics in the physical data. It will be overruled by the result from the algorithm. Since the input schemas may be in relational view or object oriented view, we provide the algorithms for both views.. Given two classes and their reference attributes C1, Ref(C1), C2, Ref(C2) in an OO schema S, we can locate its cardinality as: For i = 1 to 2 do begin Select Ref(Ci), Ci from S; max(i) = 1 While not end of instance(Ref(Ci)) do Begin If instance(Ref(Ci)) = NULL then Minimun = True; Else If Ref(Ci) is a set reference max(i) = n; End; End ; If Minimum then Card(i) = (0, max(i)); Else Card(i) = max(i); End; End /* For loop */ Let Cardinality (C1, C2) = card(1) : card (2). 1) Verifying algorithm for cardinality Relational View Given relations and their primary keys R1, PK(R1), ...RS, PK(RS) in a relational schema S, we can locate its cardinality as: Select PK(R) from R; Let i = 1; While not at end of instance(Pki(R)) do Begin Select Count(FK(Rj)) = Ci from Rj where FK(Rj)= Instance(Pki(R)); Let i = i + 1; End; Let minimum(Rj) = minimum(C1,…Cn); Let maximum(Rj) = maximum(C1,..Cn); If Minimum(Rj) = 0 Then cardinality (R, Rj) = 1: (0, n) Else If maximum (Rj) = 1 Then cardinality (R, Rj) = 1: 1 Else cardinaliy (R, Rj) = 1:n; If cardinality (R, Rj) = n:1 and cardinality (R, Rh) = n: 1 Then cardinaltiy (Rj, Rh) = m:n. If ISA-relationship (Rj1, R) = True and … and ISA-relationship (Rjn, R) = True Then Generalization (R, Rj1, …Rjn) := Disjoint; For h := 1 to n do Select PK(Rjh) from Rjh; For k := 1 to n do begin for m := 1 to n do begin if k < m then begin Select Count(*)=Allcount from PK(Rm) where PK(Rm) is in PK(Rk); If Allcount > 0 then Begin Generalization (R, Rj1, …, Rjn) := Overlap; Exit; end; end; end; end. Object Oriented View. 2). Verifying algorithm for disjoint generalization Relational View Given a superclass relation and its primary key: R, PK(R), referring to its subclass relations and their primary key: Rj1, PK(Rj1), …Rjn, PK(Rjn), their generalization can be located as:. Object Oriented View Given a superclass and its OID: C, OID(C), referring to its subclass and their OID: Cj1, OID(Cj1), …Cjn, OID(Cjn), their generalization can be located as:.
(7) If ISA-relationship (Cj1, C) = True and … and ISA-relationship (Cjn, C) = True Then Generalization (C, Cj1, …Cjn) := Disjoint; For h := 1 to n do Select OID(Cjh) from Cjh; For k := 1 to n do begin for m := 1 to n do begin if k < m then begin Select Count(*)=Allcount from OID(Cm) where OID(Cm) is in OID(Ck); If Allcount > 0 then begin Generalization (C, Cj1, …, Cjn) := Overlap; Exit; end; end; end; end; The above algorithm takes O(mn) times for two subclasses with n-tuple and m-tuple respectively. For vast amount of data, a more efficient algorithm in identifying disjoint generalization is desirable. One can sort the keys (for relational view) or OID (for OO view) of the two subrelations/sub-classes using efficient sorting algorithms like radix sort or merge sort. (Which takes O(n) and O(n log n) respectively) Then merge the two lists together and halt on duplication of data. The halt in the merge procedure indicate overlap generalization. In worst case analysis, (i.e. overlap generalization) the merge only takes O(max(m,n)) and the whole process takes maximum O(max(m,n)) to complete. (With Radix sort) 3). Verification algorithm for aggregation Relational View Given an aggregate relation with its primary keys, AR, PK(AR) referring to its component relations with its foreign key, CR1,…,CRn, FK(CR1),…,FK(CRn) from schema S, the aggregation can be located as: Let i = 1; IF PK(AR) = FK(CRi) then Select FK(CRi) from S; While not at the end of instance(FK(CRi)) do Begin Select Count(FK(CRi)) = Ci from CRi where Instance(FK(CRi)) = NULL; End; Let i = i + 1; End; For i = 1 to n IF Ci > 0. THEN Aggregation (AR, CRi) = False; ELSE Aggregation (AR, CRi) = True; End; Next; Object Oriented View Given an aggregate class with its reference attribute pointers, AC, Ref1(AC),…,Refn(AC) referring to its component classes with its OID, CC1,…,CCn, OID(CC1),…, OID(CCn) from schema S, the aggregation can be located as: For i = 1 to n For j = 1 to n IF Refi(AC) = OID(CCj) THEN /* Reference attribute refer to the component class */ Select Refi(AC) from AC; While not at the end of instance(Refi(AC)) do Begin Select Count(Refi(AC)) = Cj from AC where Instance(Refi(AC)) = NULL; End; Break; End; Next; Next; For j = 1 to n IF Cj > 0 THEN Aggregation (AR, CCj) = False; ELSE Aggregation (AR, CCj) = True; End; Next; 5. CONCLUSION This paper proposes a methodology to integrate existing object-relational database schemas in both relational and object oriented view to facilities different application requirements. The main objective of this methodology is to integrate existing source schemas to fulfill user requirement with no loss of information. A bottom-up schema integration technique is used to integrate existing object-relational schemas. Data Exhaustive Search Algorithms are used to verify the semantic correctness with regards to the user requirement after data integration. The next logical enhancement of this research is to apply the algorithm to different OO modeling standard like the ODMG and UML. 6. REFERENCE [1] Batini, C., Lenzerini, M. and Navathe, S. (1986) A Comparative Analysis of Methodologies for Database System Integration, ACM Computing Survey, Vol 18, No 4..
(8) [2] Batini, C., Ceri, S. and Navathe, S.(1992) Conceptual Database Design: An Entity-Relationship Approach, The Benjamin/Cummings Publishing Company, Inc, p 227-243. [3] Boudjlida, N. and Perrin, O. (1995) A Formal Framework and a Procedural Approach for Data Integration. In Proceedings of the International Conference on Systems Integration, ICSI'94, pages 476--485, São Paulo, Brazil, August 1994. IEEE Comp. Society Press. [4] Boudjlida, N., Bouneffa, M. A., and Perrin, O. (1995) Data Integration in a LegacySystems Migration Process. Research Report 95R-394, CRIN-UHP Nancy 1, January 1995 [5] Elmagarmid, A., Rusinkiewicz, M., Sheth, A. (1999) Management of Heterogeneous and Autonomous Database Systems, Morgan Kaufmann Publishers, Inc. [6] Elmasri R. and Navathe, S.(2000) Fundamentals of Database Systems, Benjamin/Cummings pub. [7] Fong, J,(1992) Methodology for schema translation from hierarchical or network into relational, Information and Software Technology, p159-174, Vol 34, No 3, 1992. [8] Fong, J. and Kwan I. (1994) A Reengineering Approach for Object-Oriented Database Design Proceeding of First IFIP/SQI International Conference on Software Quality and Productivity pp139-147 Chapman and Hall 1994 [9] Fong, J. (1995) Mapping Extended Entity Relationship Model to Object Modeling Technique. SIGMOD Record 24(3): 18-22 (1995) [10] Fong J. and Huang, S.M. (1997) Information Systems Reenineering, Springer 1997 [11] Fong, J., Karlapalem, K., Li, Q., and Kwan, I.,(1999) Methodology of Schema Integration for New Database Applications: A Practitioner’s Approach, Journal of Database Management, Vol. 10, No. 1, pp. 3-18. [12] Fong, J. and Huang, S. (1999b) Architecture of a Universal Database: A Frame Model Approach, International Journal of Cooperative Information Systems, Vol. 8, No. 1, pp.47-82. [13] Gray, P.M.D., Kulkarni, K.G., and Paton, N.W. (1992) Object-Oriented Databases: A Semantic Data Model Approach, Prentice Hall International, UK 1992 [14] Hughes, John G. (1991) ObjectOriented Databases (1991) Prentice Hall International, UK 1991. [15] Koh, J-L., Chen, Arbee (1993) Integration of Heterogeneous Object Schemas, on the Proceedings of 12th International Conference on the ER Approach Arlington, Texas USA, December 1993 Springer-Verlag [16] Korth, H. and Silberschatz, A.(1997)Database System Concepts (3rd edition), McGraw-Hill. [17] Kwan, I. and Fong, J.,(1999) Schema integration methodology and its verification by use of information capacity, Information Systems, Vol 24, No 5, pp. 355-376. [18] McLoed, D. and Heimbigner, D.(1980) A Federated Architecture for Database Systems, Proceedings of the AFIPS National Computer Conference, vol 39, AFIPS Press, Arlington, VA. [19] R.J.Miller, Y.E.Ioannidis, and R. Ramakrishnan (1993) The use of Information capacity in schema integration and translation, Proceedings of the 19th International Conference on Very Large Data Base, Dublin, Ireland, pp. 120-133, Morgan Kaufmann. [20] Navathe, S., Sashidhar, T., and Elmasri, R. (1984) Relationship merging in schema integration. Proceedings of the 10th International Conference on Very Large DataBase, Singapore, pp. 27-90, Morgan Kaufmann. [21] Narasimhan, B., Navathe, S. and Jayaraman, S. (1993) On Mapping ER and Relational Models into OO Schemas, Proceedings of the 12th International Conference on the ER Approach, pp402-413, SpringerVerlag [22] Özsu, M. and Valduriez, P. (1991) Principles of Distributed Database Systems, Prentice-Hall International Edition, pp.428-430. [23] Rosenthal, A. and Reiner, D., (1987) Theoretically sound transformations for practical database design. Proceedings of the International Conference on the Entity-Relationship Approach, New York, pp. 115-131. [24] Sheth A. and Larson, J.(1990)Federated Database Systems for Managing Distributed Heterogeneous, and Autonomous Databases, ACM Computing Survey, Vol 22, No 3. [25] Smith, J.M., and Smith, D.C.P. (1977) Database Abstractions: Aggregation and Generalization, ACM Trans. On Database Systems 2, No. 2 [26] UNISQL, (1999) http://www.unisql.com/kcompub/new/en_sqlove r.htm.
(9)
數據
相關文件
• Consider an algorithm that runs C for time kT (n) and rejects the input if C does not stop within the time bound.. • By Markov’s inequality, this new algorithm runs in time kT (n)
• Consider an algorithm that runs C for time kT (n) and rejects the input if C does not stop within the time bound.. • By Markov’s inequality, this new algorithm runs in time kT (n)
• Suppose, instead, we run the algorithm for the same running time mkT (n) once and rejects the input if it does not stop within the time bound.. • By Markov’s inequality, this
Each of the chapters begin with the primary objective of the Zen school and then goes on to analyze the failings of the contemporary Zen schools. The treatise puts forth the view
Geometry gml:CurvePropertyType ISO 19136-1 捷運系統名稱 xs:string XML Schema 捷運線段名稱 xs:string XML Schema 捷運類型代碼 xs:integer XML Schema 測製年月
Then, we tested the influence of θ for the rate of convergence of Algorithm 4.1, by using this algorithm with α = 15 and four different θ to solve a test ex- ample generated as
Like the proximal point algorithm using D-function [5, 8], we under some mild assumptions es- tablish the global convergence of the algorithm expressed in terms of function values,
Looking back, the Life Buddhism advocated by Master Taixu established the basic conceptual framework for the theoretical system of Humanistic Buddhism of his disciple,
