國 立 交 通 大 學
資訊管理與財務金融學系
資訊管理碩士論文
結合行動智慧之群體商務組構機制
Combining Mobile Intelligence with Formation
Mechanism for Group Commerce
研究生:謝欣宸
指導教授:李永銘 博士
結合行動智慧之群體商務組構機制
Combining Mobile Intelligence with Formation Mechanism for
Group Commerce
研 究 生:謝欣宸 Student:Hsin-Chen Hsieh
指導教授:李永銘 Advisor:Yung-Ming Li
國立交通大學
資訊管理與財務金融學系
資訊管理碩士論文
A ThesisSubmitted to Institute of Information Management College of Management
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master
in
Institute of Information Management June 2014
Hsinchu, Taiwan, Republic of China
結合行動智慧之群體商務組構機制
學生:謝欣宸 指導教授:李永銘 博士 國立交通大學資訊管理研究所碩士班摘要
近年智慧型手機的崛起,造就行動商務的 Social、Local、Mobile 的整合概念(So-Lo-Mo)。目前的 So-Lo-Mo 服務只著重於個體使用者,而較少考慮群體服務之商機,而團 體商務的發展現況沒有辦法滿足即時性的團體購物需求,亦較少考量顧客之間的社群關 係。本研究將行動智慧與群體商務結合,並且考量偏好(preference)、情境(context) 與社會影響(social influence),讓顧客在現場欲購買商品或服務的瞬間,能透過行動裝 置即時找到附近具有潛在相同購買興趣的人組構群體(group formation)並且進行群體 購物,媒合供需兩端的需求,使得行動商務與團體商務的價值獲得突破性的提升。 關鍵詞:團體構成、團體商務、行動商務、So-Lo-Mo、社會影響Combining Mobile Intelligence with Formation
Mechanism for Group Commerce
Student: Hsin-Chen Hsieh Advisor: Yung-Ming Li Institute of Information Management
National Chiao-Tung University
ABSTRACT
The rise of smartphones brings new concept So-Lo-Mo (social-local-mobile) in mobile commerce area in recent years. However, current So-Lo-Mo services only focus on individual users but not a group of users, and the development of group commerce is not enough to satisfy the demand of real-time group buying and less to think about the social relationship between customers. In this research, we integrate mobile intelligence with group commerce and consider customers' preference, real-time context, and social influence as components in the mechanism. With the support of this mechanism, customers are able to gather near customers with the same potential purchase willingness through mobile devices when he/she wants to purchase products or services to have a real-time group-buying. By matching the demand and supply of mobile group-buying market, this research improves the business value of mobile commerce and group commerce further.
Keywords: Group formation, Group commerce, Mobile commerce, So-Lo-Mo, Social
致謝
光陰荏苒,回首時,碩士班兩年已經成為過去。在這兩年,學習和成長了許多,尤 其是最後的碩士論文,需要感謝許多人的幫忙,才能順利完成。 首先要感謝我的指導教授 李永銘老師的指導。李老師和我亦師亦友的關係,讓我 不只是向他學習如何做研究,並且也學習到老師的人生體驗和哲學。李老師是一位良師, 身懷理想抱負,並且努力付諸實踐、追求價值創造的個性,深深地影響我的思維方式, 開始懂得凡事都要思考價值,並且在做事的過程中都要追求能製作精緻的作品,做人處 事在各個面向追求盡善盡美,追求自我卓越成長。在學術研究的領域,李老師的教學風 格,能夠同時保持好的論文方向和學生能夠自由發揮創意的特質,是老師在深思熟慮之 後獨創的教學方式,讓我們學習獨立研究、獨立思考的能力,並且學習如何創新,以及 將創新研究出真實具體可行的研究成果。我在 IEBI 實驗室的這兩年,在李老師專業的 帶領之下,收穫豐收,順利畢業,並且能以自己具有交大資管碩士學歷與資質為傲。 實驗室的博士班學長姐們,也是幫助我非常多、需要致謝的人們。已經畢業的賴政 揚(無尾熊)學長,在我一開始煩惱要如何實作這深具創新性質的論文研究的時候,給 予我具體可行的建議,和我討論了兩個小時,讓我能夠初步的釐清論文的概念,縮短從 抽象到實務的過程,可以在起跑點走的順暢,十分感謝!李易霖學長會主動找我們這一 些碩二的同學們,親切地詢問有沒有任何問題,都可以請教他,雖然是上班族,也願意 和我們討論論文,是一位熱心的學長!林聯發(發哥)學長從碩一上學期開始,就常常 給予我們指導,在論文主題發想、系統架構與方法、實驗設計、驗證等等,只要是各種論文的問題,都可以面對面的找他討論,很用心地幫我們思考論文的問題和解決辦法, 真的是很謝謝發哥,也祝福發哥可以順利博士班畢業!白檸瑤學姐,數次在 Meeting 之 後,和我留在實驗室討論論文的實驗,親切地給我一些建議,在和學姐的討論中,都會 讓我更發想到有效的實驗設計,讓我的論文可以進展順利,非常謝謝她。劉智華學姐, 常常會和我們聊天,互相討論想法,讓我們能夠放鬆心情,面對未來的挑戰,非常感謝。 碩士班的同學們,張光宇(Alvin)謝謝你常常和我一起討論論文、從生活的大小事都 可以聊天,並且成為我們英文的指導小老師,我們一起吃飯、喝飲料、寫論文、口試, 是難忘的回憶!感謝傅渝婷身為實驗室的會計,協助我們購買實驗室的糧食,讓我們在 寫論文的時候,也能擁有好心情!謝謝謝復勛,我們常常一起討論論文的想法和遇到的 問題,讓我們更能夠釐清接下來應該怎麼做,謝謝!謝謝連銘彥,看你論文做的這麼認 真,也讓我變得更努力,我們在一起討論論文的過程中,一起成長、一起畢業,謝謝你! 碩一的學弟妹們,林彥丞感謝你常常會陪我一起玩,共創歡樂的研究生活,在口試的時 候幫助我採購食物,謝謝 Danny!黃智聖謝謝你常常陪我們一起玩樂,在口試的時候幫 忙我們準備食物,謝謝綠茶!李憶雯謝謝你也是常常和我們一起歡樂過生活,你寫給我 們的卡片真的很感動,實驗室如果沒有大天,真的是不行啦,謝謝實驗室有大天在!倪 敬媛謝謝你,和我們一起過著打鬧歡樂的生活,口試的時候特別幫我們去拿蛋糕的袋子, 實驗室有了你,一切都變得很溫馨和樂,謝謝你!其實不管是碩二還是碩一的人,都是 創造研究生的生活裡面重要的部分,還好有你們,我們才可以在歡樂的環境下,共同追 求學術上的成就,也都成為了好朋友。
謝謝所辦行政助理陳淑惠小姐,幫忙我們辦理了各種行政事務,謝謝你。感謝涂毓 能(仙貝),和你成為好朋友,共同分享研究生的大小事,讓心情可以放輕鬆,我們也在 互相幫忙對方的論文中,最後都可以順利畢業,謝謝! 最後,要感謝家父與家母,無怨無悔的支持我,讓我得以於政大資管系畢業後,還 能前往交大資管所就讀,追求更專業的學術知識,著實成長良多。如果沒有父母們的用 心栽培,我也無法成長到現在,並且能夠取得交通大學的碩士學歷;希望我在學期間的 努力,不管是優秀的在學成績、口試成績、取得畢業證書,能夠稍微回饋你們的用心良 苦,謝謝! 謝欣宸 2014 年 6 月 24 日 謹誌於 新竹 國立交通大學光復校區
INDEX
摘要... i
ABSTRACT ... ii
致謝... iii
INDEX ... vi
List of Equations ... viii
List of Tables ... ix
List of Figures ... x
Chapter 1 Introduction ... 1
1.1 Background ... 1
1.2 Motivation and Research Problems ... 2
1.3 Research Goals and Contributions ... 4
1.4 Thesis Outline ... 5
Chapter 2 Related Literatures ... 6
2.1 Mobile and Group Commerce ... 6
2.2 Context Awareness ... 7
2.3 Social Influence ... 8
Chapter 3 System Frameworks ... 10
3.1 Group Context Analysis Module ... 12
3.1.1 Travel Time Computing ... 13
3.2 Social Influence Analysis Module ... 14
3.2.1 Social Trust Computing ... 14
3.2.2 Social Closeness Computing... 16
3.3 Individual Preference Analysis Module ... 18
3.3.1 Product Tree Construction ... 19
3.3.2 Purchase Preference Computing ... 20
3.4 Group Formation Engine ... 22
3.4.1 Personal Weight Computing ... 23
3.4.2 Willingness Criteria Aggregation ... 25
3.4.3 Candidate Group Forming ... 26
3.4.4 Group Cohesion Computing ... 27
Chapter 4 Experiments ... 31
4.1 Data Collection ... 31
4.1.1 User Profile ... 33
4.1.2 Transaction Profile and Scenarios ... 33
4.1.3 ProductPlace Profile... 35
4.2 Experiment Process ... 36
4.3 Measurement Computing ... 37
4.3.1 Criteria Weight Computation ... 37
4.3.2 Willingness Computation ... 38
Chapter 5 Results and Evaluation ... 40
5.1 Accuracy of Contextual Group Formation ... 40
5.1.1 The Evaluation of Likeness ... 40
5.1.2 The Evaluation of Satisfaction ... 41
5.1.3 The Evaluation of Willingness ... 43
5.2 Accuracy of Willingness Criteria Aggregation ... 44
Chapter 6 Discussion and Conclusion ... 47
6.1 Research Summary ... 47
6.2 Research Contributions ... 48
6.3 Research Limitations ... 48
6.4 Future Works ... 49
List of Equations
Equation 1. The Set of Nearby People ... 13
Equation 2. Formula of Group Context ... 14
Equation 3. The Set of Friends of user i ... 15
Equation 4. Formula of Fiends Reviews ... 15
Equation 5. Formula of Social Trust ... 15
Equation 6. Min-Max Normalization ... 16
Equation 7. Computation of the Interaction on Social Media ... 17
Equation 8. The Set of Social Paths between Two People ... 18
Equation 9. The Set of Links in a Social Path ... 18
Equation 10. Formula of Social Closeness ... 18
Equation 11. Formula of Social Influence ... 18
Equation 12. Similarity between Product and User ... 22
Equation 13. Formula of Individual Preference ... 22
Equation 14. The Pairwise Matrix of Analytic Hierarchy Process ... 24
Equation 15. The Set of Relative Weights of Criteria ... 25
Equation 16. The Set of Personal Weights of Criteria ... 25
Equation 17. Formula of Personal Weight Computing ... 25
Equation 18. Formula of Willingness-to-Join... 26
Equation 19. The Set of Candidate Groups ... 26
Equation 20. Density of Groups ... 27
Equation 21. The Set of Ties between Group Leader and Group Members ... 29
Equation 22. The Set of Ties between Group Members ... 29
Equation 23. The Average of Ties between Group Leader and Group Members ... 29
Equation 24. The Average of Ties between Group Members ... 29
List of Tables
Table 1. Statistics of the User Network Constructed ... 33
Table 2. Places for Experiments ... 34
Table 3. Statistics of the Transactions in Three Scenarios ... 35
Table 4. Statistics of the Users in Three Scenarios ... 35
Table 5. Content of Questionnaire for Scenario 1 ... 37
Table 6. System Default Weight Values for Three Scenarios ... 38
Table 7. Statistical Verification Results of CSP Model on Likeness Score ... 41
Table 8. Statistical Verification Results of CSP model on Satisfaction Score ... 43
Table 9. Statistical Verification Results of CSP model on Satisfaction Score ... 44
List of Figures
Figure 1. An Illustration of Contextual Group Formation ... 10
Figure 2. The System Architecture of Contextual Group Formation Mechanism .. 11
Figure 3. The Illustration of Social Relations in a Social Network ... 16
Figure 4. The Example of ProductPlace Tree ... 20
Figure 5. The Hierarchy Decision Structure of Personal Weight Computing ... 24
Figure 6. Example of Candidate Groups of Initial Forming ... 27
Figure 7. The Example of Candidate Groups after the First Step ... 28
Figure 8. The Example of Candidate Groups of the Second Step ... 28
Figure 9. System Interface on an Android Smartphone ... 32
Figure 10. A Part of ProductPlace Tree ... 36
Figure 11. The Evaluation of Likeness of Group Activity ... 41
Figure 12. The Evaluation of Satisfaction with Service ... 42
Figure 13. The Evaluation of Willingness to Join a Group ... 43
Chapter 1
Introduction
1.1 Background
In recent years, group-buying market has been grown up for several years, making surprising revenues all around the world. In United States, The revenues of the largest group-buying website, Groupon, are $1.61 billion USD in 2011, $2.33 billion in 2012, and $2.573 billion in 2013, and it is still growing now [1]. In Austria, the group-buying market generated $504 million in 2012 and $115 million in Q1 2013 [2, 3]. In China, the turnover of group-buying industry reached to $3.52 billion USD in 2012 and $2.29 billion from Q1 to Q2 in 2013 [4], which is about to 66% of the annual turnover in 2012.
However, the development of group-buying market is restricted by some problems. Increasing competition is still continuous and make pressure on group-buying websites [5]. There are so many same products and services that customers can purchase through one group-buying websites or the other one. The current group-buying companies cannot provide real-time services. Consumers can browse the group-buying websites and apps for recreational or informational purposes, but cannot get the products and services at once after paying by credit cards or digital wallets. Group-buying companies cannot get the best use of impulse purchases through this non real-time business model, and about 22% customers have impulse purchases behavior over the Internet [6].
Mobile computing is a powerful solution to the problems of group-buying market. Many group-buying e-business companies provide mobile group-buying app services, such as Groupon, LivingSocial and taobao in China, to get the business trend of mobile commerce. Mobile transactions make the group-buying industry growing and increase customer satisfaction due to better service and customer confidence [5]. The number of mobile buyers
2012, and 79.4 million in 2013. By 2017, the number is predicted to rise to 138.8 million [7]. To combine mobile intelligence and group formation, customers can take the real-time group-buying services through the mobile devices in their hands, while they want to purchase big size products at a shopping mall, get group tickets to visit a museum and exhibition, have an afternoon tea, etc. With the mobile services, group-buying companies are able to provide real-time business model to make profits, vendors can have the benefit of selling wholesale commodities quickly and the customers also get benefit from reducing the cost of purchasing products and services.
1.2 Motivation and Research Problems
Group-buying websites face some problems. Due to the low entry barrier of the industry, numerous competitors in different countries have emerged rapidly and many sites are no longer active [8]. In June 2012, CNN Money News reported on Groupon’s precipitous stock declined and sent Groupon’s market cap below the $6 billion that Google offered as a buyout in late 2010 [9]. In August 2012, Forbes issued a report about Groupon’s problems and indicated that Groupon has an unsustainable business model for two reasons. First, Groupon is selling other companies’ products that have the upper hand in any deal negotiations. Second, Groupon have plenty of competitors. The business model also has a problem that if the minimum number of consumers signed up is not reached, then no one gets the Groupon offer [10]. Although some group buying sites introduce mobile app services into their service range, they cannot change the fact that customers are waiting for more customers to take part in the group-buying gathering, or the group-buying gathering will be closed if not reach the least threshold of the number of customers joined in the limited time period.
However, group-buying service with mobile computing can create an innovative service model that provides real-time group-buying services with higher willingness to impulse
purchase. There are three mobile advantages in group buying: (1) the benefit from real-time service: consumers are able to from a group buying by themselves at any time when they want to buy something and have the products or services at once after they pay by cash. They do not need to wait for delivery and the time to reach the minimum number of customers for a specific coupon. Stores can also benefit from the real-time group buying due to increasing sales and do not require to pay commission to group-coupon websites. For example, when a consumer wants to buy something at a local store, he/she can use app in the mobile device to sense people nearby who also likes the product or service and they can meet each other quickly to purchase together and enjoy the lower price due to group buying. The mobile group buying service can also discover the potential customers from one person to more people around, (2) the benefit from context awareness: the group-coupon website only use the location to classify their coupons, but it is less effective on increasing consumers’ purchase willingness. However, mobile devices provide the ability to context awareness, which can be used to detect who are around you by global positioning system and compute the travel time from one place to another, and (3) the benefit from social relations: customers are more likely to purchase products if there are friends in the group buying [11]. The synchronization between social media and mobile device brings a new opportunity to collect and analyze whether there are friends near the customer or not and utilize the like and check-in data on social media to analyze the purchase preference of customers. Customers can from a group-buying group with high cohesion by taking advantage of the power of social influence and we believe it can bring a new trend to mine nearby potential customers.
The proposed mechanism is going to utilize the three benefits from real time, context awareness, and social relations to conquer the problems which will be faced and listed below:
(1) How to improve group commerce from passively waiting for coupons to actively gathering nearby consumers to make a real-time group buying?
In the current circumstance, consumers need to wait for more people signing up the coupon. Using mobile technology, it is possible to gather more people actively and quickly by identifying the people nearby. So it is a problem that how to improve group commerce from passive to active real-time service.
(2) How to form groups with location-sensitive customers and high cohesion?
To identify the people nearby and invite them to join a group buying, we need to identify the locations of customers and their travel times to go together. After knew the nearby customers, it is important to select who are the suitable one to be the group members to form a group with high cohesion to have a better experience of the group buying service.
(3) How to utilize the power of social influence to increase the willingness to purchase?
In order to improve the motivation of nearby people to join a group, it is important to consider their preference and social relationships. People are more likely to purchase with friends than with strangers. It is a problem for this study that how to identify whether there are friends near the customer and how to increase the purchasing willingness for them to group buying.
1.3 Research Goals and Contributions
The objective of this study is to design a new contextual group formation mechanism to make everyone has the ability to enjoy real-time group buying at anywhere and anytime. A contextual group formation mechanism, analyzing the factors of context awareness, social influence and individual preference, is proposed to solve the problems by finding nearby consumers who are also interested in the product and geographically close to the customer who creates the group buy event to assure the success of real-time group-buying transactions by reaching the minimum number of buyers from people nearby. A group member list is generated for the customer who requires more people to join his/her group buy and the consumers in the
group member list will be invited to participate in the group buying.
The usage opportune moment of this mechanism can be extended to be the circumstance when someone needs to gather people quickly to do something together. Using this mechanism, not only customers but also vendors and shopkeepers can gather several consumers nearby to sell wholesale commodities with group discount. That benefits vendors to save advertising and marketing cost and make revenues.
There are several studies focusing on social intelligence or context-aware service separately. In this study, we combine social intelligence and context-aware service into mobile intelligence, which is a new research trend with strong potential impacts.
1.4 Thesis Outline
The remaining sections are described as follows. The literatures related to this research are reviewed in Chapter 2. The detailed description of the proposed mechanism is in Chapter 3. Chapter 4 delineates the experiments conducted based on the proposed mechanism. The evaluation of the experiments are described in Chapter 5. Finally, Chapter 6 concludes our research contributions and describes research limitations and the future works.
Chapter 2
Related Literatures
2.1 Mobile and Group Commerce
Mobile commerce (M-commerce) is the next generation of electronic commerce (e-commerce) beginning in 1997 the WAP (wireless application protocol) introduced [12] and is driven by the rapid proliferation of mobile devices, including personal digital assistants (PDAs), smartphones, tablets and other handheld devices [13]. M-commerce can be defined as any transaction with a monetary value, either direct or indirect, that is conducted over a wireless network [14].
Mobile devices provides a whole new set of service capabilities, including location-based service, context awareness, and push delivery [12]. The key benefit of mobile commerce is its ubiquitous access to information at anytime and anywhere [15], and vendors are more accessible to customers. Mobile commerce has generated interest in industry and enormous opportunities for business model innovation [12, 13]. Both the mobility and broad reach are the two major characteristics of mobile commerce: mobility is synonymous with portability, e.g., customers can conduct real-time business via mobile devices, and broad reach is implies that customers can be reached at any time and place via mobile devices [16].
Mobile commerce is also significantly influenced by the fast growth in social networking. Various social media have emerged and the research on how to combine mobile commerce and social commerce to generate new knowledge, business model and social implications is likely to be the near future of mobile commerce [12].
The phenomenon of group commerce is formed by consumer bundling that the existence of group forming strongly depends on new information technologies and the global proliferation of the Internet [17]. A well-known example of group commerce is Groupon launched in 2008. Groupon operates a group commerce market that connects merchants to
consumers by offering products and services at about 50% discount off the price [9, 18]. Every deal has to reach the minimum threshold size and the merchants may limit the maximum number of coupons sold [19]. Groupon provides a time-limited mechanism that increases customer’s sense of urgency and make a phenomena of panic buying [20, 21].
Group commerce is a popular business model with three-win situation which benefits sellers by lower marketing cost [22]. It also benefits customers by lower costs with large discount. Group commerce platforms get the largest discount from sellers to attract more customers and sells coupons at a price higher than it got from sellers [11].
However, the business model of group commerce is not sustainable enough, which has been described in section 1.2. In this research, considering geographic convenience, social influence and customer preference, we propose a contextual group formation mechanism to promote real-time group buying to improve the business model of mobile and group commerce.
2.2 Context Awareness
Context is any information that can be used to characterize the situation of an entity, where entity is a person, place, or object that is relevant to the interaction between a user and an application, including the user and the application themselves [23, 24]. Ryan et al. proposed that the types of context are location, environment, identity and time [25]. Schilit et al. defined the aspects of concept as where you are (location), who you are with (identity) and what resources are nearby (environment) [26]. This study adopts the categories of context are location, identity, activity and time which is suggested by Dey and Abowd because activity is about what is occurring in the situation and these four context types are primary for characterizing the situation of an specific entity [23].
Context awareness is to use context to provide relevant information and/or services to the user, where relevancy depends on the user’s task [23], which is first introduced by Want et al.
in 1992 [27]. Context awareness is well-known in ubiquitous computing, and context is the key to provide suitable services that are appropriate to the location, identity, activity and time [28]. Location is one kind of context that is most widely used for context-aware services [29].
The study considers (1) locations of users, (2) nearby people and (3) the circumstances of group buying as the contextual information to build a contextual group formation mechanism, which has the ability to gather nearby people at anytime and anywhere to enjoy real-time group buying.
2.3 Social Influence
Social influence has been widely used to explain collective and group behavior [30] and is defined as a process which individuals change and adapt their decisions and behaviors as a result of interactions with other group members [31]. Social influence is also defined as the degree to which people believe that important others in the same group would approve or disapprove of their behavior [32, 33]. Social influence is driven by social norms which define the acceptable and approved behaviors for the society or group which the individual belongs [34].
Social influence theory concentrates on the roles of social culture and social norms which is involved in interaction and communication within groups. Individuals in a group will adapt their behavior, attitudes and beliefs to the social context and to the reality of their own behavior and situation [35].
Social influence can be classified into three modes, including (1) compliance, (2) internalization and (3) identification [36]. Compliance is particular important in the initial decision making because the user has no relative usage experience and thus tends to depend more on second-hand information, which is particular from family or friends. Internalization is more important in deciding continuous group behavior, which is about the adoption of a
decision based on the similarity of the values of one group member with the values of other group members. A person will form an intention to participate in a group if realize that he/she is sharing common values or goals with other group members. Identification can be referred to cognition of awareness of one’s membership in the group, as well as the evaluation of self-worth and emotional involvement within the group [36-38].
In this study, we consider compliance and internalization modes of social influence, because it affects customers’ thoughts, behaviors and willingness to participate in a group buying. We analyze social trust and social closeness between users, who are the candidate group members, to arouse the motivation of users to use the mechanism and group buy with others.
Chapter 3
System Frameworks
The proposed contextual group formation mechanism is an innovative service model that customers can gather other nearby customers with certain social relations and similar preference at anywhere and anytime when they want to enjoy group buying, as illustrated in Figure 1, where the smile face is the group leader, who needs this mechanism to gather people nearby and thus creates a group buying event.
Figure 1. An Illustration of Contextual Group Formation
As a user uses this mechanism to create a group buying event to purchase something, he/she is the group leader. This mechanism will start to detect who are near the group leader and compute their degree of social influence and individual preference to the target product. Each user has three criteria of willingness to join a group or not: (1) group context, (2) social influence and (3) individual preference, and each criterion has its own weight for the user in a particular circumstance. Measuring the willingness-to-join of every person near the group leader, this mechanism takes top-k people with higher willingness as candidate group member to form several candidate groups. By computing the cohesion of each candidate groups, this mechanism selects a group with highest cohesion to provide the group member list to the group leader and invite all the group members to join the group buying.
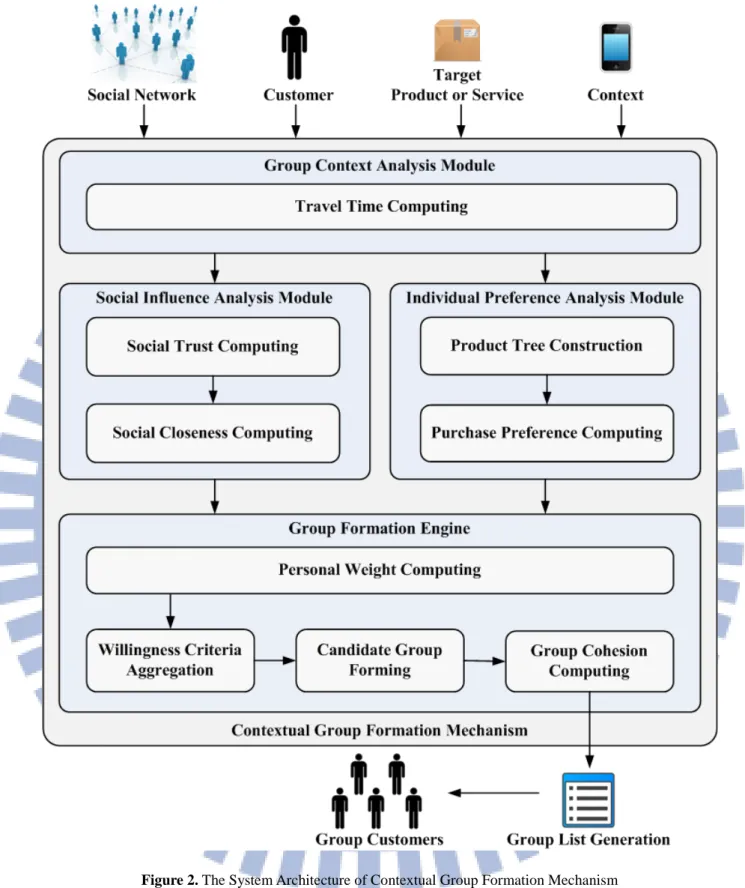
Figure 2. The System Architecture of Contextual Group Formation Mechanism
The main four modules in the system architecture are as follows:
(1) Group Context Analysis Module: The module is to detect who are nearby, which is measured by travel time, and then grade them with a value. It is the first module because
we only need to focus on nearby users in the other modules.
(2) Social Influence Analysis Module: The module utilizes social data to compute trust and closeness between nearby users to analyze who are trustable and close to the group leader, and then computes a value to every user nearby.
(3) Individual Preference Analysis Module: The module utilizes fan pages liked and check-ins on social media to analyze user purchase preference and then compute the similarity between user preference and the target product as a value to represent the degree how the user are interested in the target product.
(4) Group Formation Engine: The module combines the values of above three modules as group formation criteria, depending on personal weight of each user, to compute his/her willingness in joining the group buying. After we knowing the willingness of each user, the module generates several different candidate groups and computes the degree of cohesion of each candidate group to provide a group member list with highest cohesion to the group leader.
3.1 Group Context Analysis Module
The proposed mechanism provides a real-time service to gather people nearby with similar interest and certain social relations, so it is important to utilize the context data to be aware of the people around. If this mechanism invites someone far away from the group leader to participate in the group, he/she may not want to join the group due to far distance, even with a strong preference to the target product, on the other hand, if he/she is near the group leader, then he/she can go to there at once. In this group context analysis module, we take (1) user location and (2) nearby people as the context. The module uses the locations of users detected by mobile devices to find who are near the group leader.
3.1.1 Travel Time Computing
To get locations of mobile users, we use GPS (Global Positioning System) in mobile devices to receive longitude and latitude data of users. We consider the travel time but not distance between locations because distance cannot represent the real time spent that users may move by walking, driving or other methods.
We are able to get travel time and route between two locations of users by using Google Directions API [39]. We denote 𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇(𝑇𝑇, 𝑗𝑗) be the travel time from the user j (origin location) to the group leader i (destination location) in particular travel mode. We get the value of travel time by sending request with origin location, destination location and travel mode including walking, driving, bicycling or transit as parameters to Google Directions API, which will return the travel time in seconds. The travel time between user and the group leader is dynamic because it is possible that they are still moving and changing their locations.
To decide who are nearby people, we set the default maximum constraint of travel time to be 10 minutes, because we think if the user requires more than 10 minutes to go to the place, that is too long to be the real-time group-buying service what we want to provide. Users can change the default limit of travel time if needed. After get the travel times of users and filter out users far away from the group leader, we denote a set of people near the group leader i, 𝐽𝐽(𝑇𝑇) , as the Equation 1, where 𝑛𝑛 is the number of nearby people.
Equation 1. The Set of Nearby People
𝐽𝐽(𝑇𝑇) = {𝑗𝑗1(𝑇𝑇), 𝑗𝑗2(𝑇𝑇), … , 𝑗𝑗𝑛𝑛(𝑇𝑇)} (1)
Every person j in set 𝐽𝐽(𝑇𝑇) has his/her own 𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇(𝑇𝑇, 𝑗𝑗) , and we rank 𝑗𝑗𝑛𝑛(𝑇𝑇) according to 𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇(𝑇𝑇, 𝑗𝑗) in ascending order. We denote 𝑅𝑅𝑇𝑇𝑛𝑛𝑅𝑅(𝑗𝑗𝑛𝑛(𝑇𝑇)) as the rank of person 𝑗𝑗𝑛𝑛(𝑇𝑇) in 𝐽𝐽(𝑇𝑇) and then compute the score of this module for the group leader i and each nearby person j is measured by Equation 2.
Equation 2. Formula of Group Context
𝐺𝐺𝑇𝑇𝐺𝐺𝐺𝐺𝐺𝐺𝐺𝐺𝐺𝐺𝑛𝑛𝐺𝐺𝑇𝑇𝐺𝐺𝐺𝐺(𝑇𝑇, 𝑗𝑗) =𝑛𝑛 − 𝑅𝑅𝑇𝑇𝑛𝑛𝑅𝑅�𝑗𝑗𝑛𝑛𝑛𝑛(𝑇𝑇)� + 1, ∀𝑗𝑗𝑛𝑛(𝑇𝑇) ∈ 𝐽𝐽(𝑇𝑇) (2)
3.2 Social Influence Analysis Module
There are several situations of group buying, and customers want to enjoy group buying with various friends in different situations. For instance, if a customer wants to have a dinner at a restaurant with group discount, he/she may want to be with close friends but not strangers, on the other hand, if he/she wants to purchase large amount of commodities at a wholesale store, he/she may not care about with friends or not.
This module is to measure the degree of trust and closeness between two users. We denote 𝑆𝑆𝐺𝐺𝑆𝑆𝑇𝑇𝑇𝑇𝑇𝑇𝑆𝑆𝑛𝑛𝑆𝑆𝑇𝑇𝐺𝐺𝑇𝑇𝑛𝑛𝑆𝑆𝑇𝑇(𝑇𝑇, 𝑗𝑗) as the degree of social influence between the person j near the group leader i. We select Facebook to be the social data source because Facebook is one of the most popular social media in the world with 1.3 billion active users in Jan. 2014 [40].
3.2.1 Social Trust Computing
As a group leader uses this mechanism to gather nearby people to join his/her group buying, it is important to know whether the person is trustable or not. If users meet with malicious one and are harassed or cheated, we cannot control the situation but can avoid it to increase users’ willingness to take a grouping invitation.
In this section, we denote 𝑆𝑆𝐺𝐺𝑆𝑆𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝐺𝐺𝑆𝑆𝐺𝐺(𝑇𝑇, 𝑗𝑗) as a value that represents how nearby person
j is trustable to the group leader i. We use four kinds of social data to analyze it: (1) the number
of successful transactions of nearby person j denotes as 𝑆𝑆𝑇𝑇𝑇𝑇𝑇𝑇𝑛𝑛𝑆𝑆(𝑗𝑗), (2) the number of reports of nearby person j denotes as 𝑅𝑅𝑇𝑇𝐺𝐺𝐺𝐺𝑇𝑇𝐺𝐺𝑇𝑇𝑅𝑅(𝑗𝑗), (3) the total number of transactions of nearby person j denotes as 𝑇𝑇𝑇𝑇𝑇𝑇𝑛𝑛𝑆𝑆(𝑗𝑗) and (4) the number of good reviews given by the group leader
number of good reviews of nearby people base on friend referrals. That is to say, nearby candidate users who have received more good reviews will receive a higher score, and thus more likely to be recommended to a group leader for group formation.
All the transaction, report and review data are stored after a transaction is completed. In order to compute 𝐹𝐹𝑇𝑇𝑇𝑇𝑇𝑇𝑛𝑛𝑅𝑅𝑆𝑆𝑅𝑅𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝐹𝐹𝑆𝑆(𝑇𝑇, 𝑗𝑗), we denote 𝐹𝐹𝑇𝑇𝑇𝑇𝑇𝑇𝑛𝑛𝑅𝑅𝑆𝑆(𝑇𝑇) as a set of all the friends 𝑆𝑆𝑛𝑛(𝑇𝑇) of user i as Equation 3, where n is the number of friends.
Equation 3. The Set of Friends of user i
𝐹𝐹𝑇𝑇𝑇𝑇𝑇𝑇𝑛𝑛𝑅𝑅𝑆𝑆(𝑇𝑇) = {𝑆𝑆1(𝑇𝑇), 𝑆𝑆2(𝑇𝑇), … , 𝑆𝑆𝑛𝑛(𝑇𝑇)} (3)
Having Equation 3, 𝐹𝐹𝑇𝑇𝑇𝑇𝑇𝑇𝑛𝑛𝑅𝑅𝑆𝑆𝑅𝑅𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝐹𝐹𝑆𝑆(𝑇𝑇, 𝑗𝑗) can be measured by Equation 4. Equation 4. Formula of Fiends Reviews
𝐹𝐹𝑇𝑇𝑇𝑇𝑇𝑇𝑛𝑛𝑅𝑅𝑆𝑆𝑅𝑅𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝐹𝐹𝑆𝑆(𝑇𝑇, 𝑗𝑗) = � 𝑅𝑅𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝐹𝐹𝑆𝑆(𝑇𝑇, 𝑆𝑆𝑛𝑛(𝑇𝑇), 𝑗𝑗) 𝑓𝑓𝑛𝑛(𝑖𝑖)∈𝐹𝐹𝐹𝐹𝑖𝑖𝐹𝐹𝑛𝑛𝐹𝐹𝐹𝐹(𝑖𝑖)
(4)
Where 𝑅𝑅𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝐹𝐹𝑆𝑆(𝑇𝑇, 𝑆𝑆𝑛𝑛(𝑇𝑇), 𝑗𝑗) is the number of good reviews given by the group leader i and i’s friend 𝑆𝑆𝑛𝑛(𝑇𝑇) to the person j.
The value of 𝑆𝑆𝐺𝐺𝑆𝑆𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝐺𝐺𝑆𝑆𝐺𝐺(𝑇𝑇, 𝑗𝑗) is measured by Equation 5. If the candidate nearby user
j has no transaction or review data, we set 𝑇𝑇𝑇𝑇𝑇𝑇𝑛𝑛𝑆𝑆(𝑗𝑗) or 𝐹𝐹𝑇𝑇𝑇𝑇𝑇𝑇𝑛𝑛𝑅𝑅𝑆𝑆𝑅𝑅𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝐹𝐹𝑆𝑆(𝑇𝑇, 𝑗𝑗) as 1 to avoid
to divide by or multiply with 0. Equation 5. Formula of Social Trust
𝑆𝑆𝐺𝐺𝑆𝑆𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝐺𝐺𝑆𝑆𝐺𝐺(𝑇𝑇, 𝑗𝑗) = 𝑆𝑆𝑇𝑇𝑇𝑇𝑇𝑇𝑛𝑛𝑆𝑆(𝑗𝑗) − 𝑅𝑅𝑇𝑇𝐺𝐺𝐺𝐺𝑇𝑇𝐺𝐺𝑇𝑇𝑅𝑅(𝑗𝑗)𝑇𝑇𝑇𝑇𝑇𝑇𝑛𝑛𝑆𝑆(𝑗𝑗) ∗ 𝐹𝐹𝑇𝑇𝑇𝑇𝑇𝑇𝑛𝑛𝑅𝑅𝑆𝑆𝑅𝑅𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝐹𝐹𝑆𝑆(𝑇𝑇, 𝑗𝑗) (5)
The 𝑆𝑆𝐺𝐺𝑆𝑆𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝐺𝐺𝑆𝑆𝐺𝐺(𝑇𝑇, 𝑗𝑗) value should be normalized before going to the next step. We adopt min-max normalization approach because min-max normalization has higher efficiency than other normalization approach, such as z-score normalization and normalization by decimal scaling, and is more appropriate in real-time group-buying. The equation of min-max normalization is shown as Equation 6 and the 𝑆𝑆𝐺𝐺𝑆𝑆𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝐺𝐺𝑆𝑆𝐺𝐺(𝑇𝑇, 𝑗𝑗) value will be normalized
from 0 to 1.
Equation 6. Min-Max Normalization
𝑉𝑉′= 𝑉𝑉 − 𝑀𝑀𝑇𝑇𝑛𝑛(𝑆𝑆𝑇𝑇𝐺𝐺𝑣𝑣)
𝑀𝑀𝑇𝑇𝐺𝐺(𝑆𝑆𝑇𝑇𝐺𝐺𝑣𝑣) − 𝑀𝑀𝑇𝑇𝑛𝑛(𝑆𝑆𝑇𝑇𝐺𝐺𝑣𝑣) .(6)
Where V’ is the new value after normalization, V is the original value, Setv is a set which
contains all the Vs, Min(Setv) is the minimum value of Setv and Max(Setv) is the maximum value
of Setv.
3.2.2 Social Closeness Computing
It is usual that customers want to purchase something together with friends more than with strangers, so we consider the social relations between two users into this mechanism. In this section, we compute the degree of closeness between two users by using their social data collected from Facebook. In some cases, it is possible that the person near the group leader is not a direct friend, but an indirect friend, in other words, the person is friend of friend of the group leader (two-degree-relationship) or more degrees. We illustrate the situation as Figure 3.
Figure 3. The Illustration of Social Relations in a Social Network
Red (left) user icon represents the group leader, yellow (middle) ones represents social network of the group leader (including friends of the group leader, friends of friends of the group leader, and so on), and blue (right) one is the person near the group leader. The black solid arrow represents the friendship between two people. The size of the social network does not need to be too large, because it represents the group leader almost has no relation with the person. To define the maximum size of the network, we consider “six degrees of separation” theory to set the limit to six. Six degrees of separation is a theory that two people are able to
link each other less than or equal to six steps [41]. If the number of links between two people is larger than six, the value of social closeness between them is set to zero.
In order to compute the degree of closeness between the group leader to any person nearby, the interaction between users who are in the social network of the group leader is required on social media. The interaction between two users, who are denoted as 𝐺𝐺1 and 𝐺𝐺2 on social media is measured by (1) the number of the two users be tagged together in comments and posts, including statuses, check-ins and photos and we denote it as 𝑇𝑇𝑇𝑇𝑇𝑇(𝐺𝐺1, 𝐺𝐺2), (2) the number of comments written by the two users under a same post which is created by them and we denote it as 𝐺𝐺𝐺𝐺𝑇𝑇𝑇𝑇𝑇𝑇𝑛𝑛𝐺𝐺(𝐺𝐺1, 𝐺𝐺2) and (3) the number of likes given by the two users in comments and posts, including statuses, check-ins and photos which they own and we denote it as 𝐿𝐿𝑇𝑇𝑅𝑅𝑇𝑇(𝐺𝐺1, 𝐺𝐺2). The interaction between two users, 𝐺𝐺1 and 𝐺𝐺2, is measured by Equation 7.
Equation 7. Computation of the Interaction on Social Media
𝑆𝑆𝑛𝑛𝐺𝐺𝑇𝑇𝑇𝑇𝑇𝑇𝑆𝑆𝐺𝐺𝑇𝑇𝐺𝐺𝑛𝑛(𝐺𝐺1, 𝐺𝐺2) = 𝑇𝑇𝑇𝑇𝑇𝑇(𝐺𝐺1, 𝐺𝐺2) + 𝐺𝐺𝐺𝐺𝑇𝑇𝑇𝑇𝑇𝑇𝑛𝑛𝐺𝐺(𝐺𝐺1, 𝐺𝐺2) + 𝐿𝐿𝑇𝑇𝑅𝑅𝑇𝑇(𝐺𝐺1, 𝐺𝐺2) (7)
The 𝑆𝑆𝑛𝑛𝐺𝐺𝑇𝑇𝑇𝑇𝑇𝑇𝑆𝑆𝐺𝐺𝑇𝑇𝐺𝐺𝑛𝑛(𝐺𝐺1, 𝐺𝐺2) value should be normalized to be a value ranged from 0 to 1 before go to the next step. We also adopt min-max normalization approach to do it, which has been described as the Equation 6.
After described how to compute the interaction between two users, we are going to explain how to compute the social closeness value between the group leader and the person near the group leader.
We denote 𝑃𝑃𝑇𝑇𝐺𝐺ℎ𝑆𝑆(𝑇𝑇, 𝑗𝑗) as a set which contains all the social paths which are the routes to connect the group leader i with the nearby person j and each social path has a set of links, which connects two users in the particular social path and has its 𝑆𝑆𝑛𝑛𝐺𝐺𝑇𝑇𝑇𝑇𝑇𝑇𝑆𝑆𝐺𝐺𝑇𝑇𝐺𝐺𝑛𝑛(𝐺𝐺1, 𝐺𝐺2) value, denoted as 𝐿𝐿𝑇𝑇𝑛𝑛𝑅𝑅𝑆𝑆(𝐺𝐺1, 𝐺𝐺2). The length of a social path is denoted as 𝐿𝐿𝑇𝑇𝑛𝑛𝑃𝑃𝑇𝑇𝐺𝐺ℎ(𝑃𝑃𝑇𝑇𝐺𝐺ℎ𝑛𝑛(𝑇𝑇, 𝑗𝑗)), which is equal to the number of links in the social path. The two sets are shown as Equation 8
and 9, where n is the number of elements of the set. Equation 8. The Set of Social Paths between Two People
𝑃𝑃𝑇𝑇𝐺𝐺ℎ𝑆𝑆(𝑇𝑇, 𝑗𝑗) = {𝑃𝑃𝑇𝑇𝐺𝐺ℎ1(𝑇𝑇, 𝑗𝑗), 𝑃𝑃𝑇𝑇𝐺𝐺ℎ2(𝑇𝑇, 𝑗𝑗), … , 𝑃𝑃𝑇𝑇𝐺𝐺ℎ𝑛𝑛(𝑇𝑇, 𝑗𝑗)} (8)
Equation 9. The Set of Links in a Social Path
𝐿𝐿𝑇𝑇𝑛𝑛𝑅𝑅𝑆𝑆(𝐺𝐺1, 𝐺𝐺2) = {𝐿𝐿𝑇𝑇𝑛𝑛𝑅𝑅1(𝐺𝐺1, 𝐺𝐺2), 𝐿𝐿𝑇𝑇𝑛𝑛𝑅𝑅2(𝐺𝐺1, 𝐺𝐺2), … , 𝐿𝐿𝑇𝑇𝑛𝑛𝑅𝑅𝑛𝑛(𝐺𝐺1, 𝐺𝐺2)} (9)
The influence of 𝑆𝑆𝑛𝑛𝐺𝐺𝑇𝑇𝑇𝑇𝑇𝑇𝑆𝑆𝐺𝐺𝑇𝑇𝐺𝐺𝑛𝑛(𝐺𝐺1, 𝐺𝐺2) value of two users who are not direct friends with the group leader should be reduced according to its social degree far from the group leader. We denote 𝐷𝐷𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇�𝑇𝑇, 𝐿𝐿𝑇𝑇𝑛𝑛𝑅𝑅𝑛𝑛(𝐺𝐺1, 𝐺𝐺2)� as the social degree from the group leader i to the particular link 𝐿𝐿𝑇𝑇𝑛𝑛𝑅𝑅𝑛𝑛(𝐺𝐺1, 𝐺𝐺2).
The social closeness between the group leader i and the nearby person j can be measured by Equation 10 below, which value is equal to a particular social path with maximal value. The 𝑀𝑀𝑇𝑇𝐺𝐺() function is to find the maximal value of its parameter.
Equation 10. Formula of Social Closeness
𝑆𝑆𝐺𝐺𝑆𝑆𝑇𝑇𝑇𝑇𝑇𝑇𝐺𝐺𝑇𝑇𝐺𝐺𝑆𝑆𝑇𝑇𝑛𝑛𝑇𝑇𝑆𝑆𝑆𝑆(𝑇𝑇, 𝑗𝑗) = 𝑀𝑀𝑇𝑇𝐺𝐺 � 1 𝐿𝐿𝑇𝑇𝑛𝑛𝑃𝑃𝑇𝑇𝐺𝐺ℎ�𝑃𝑃𝑇𝑇𝐺𝐺ℎ𝑛𝑛(𝑇𝑇, 𝑗𝑗)�∗ � 𝑆𝑆𝑛𝑛𝐺𝐺𝑇𝑇𝑇𝑇𝑇𝑇𝑆𝑆𝐺𝐺𝑇𝑇𝐺𝐺𝑛𝑛(𝐺𝐺1, 𝐺𝐺2) 𝐷𝐷𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇�𝑇𝑇, 𝐿𝐿𝑇𝑇𝑛𝑛𝑅𝑅𝑛𝑛(𝐺𝐺1, 𝐺𝐺2)��, ∀ 𝐿𝐿𝑇𝑇𝑛𝑛𝑅𝑅𝑛𝑛(𝐺𝐺1, 𝐺𝐺2) ∈ 𝐿𝐿𝑇𝑇𝑛𝑛𝑅𝑅𝑆𝑆(𝐺𝐺1, 𝐺𝐺2) ∈ 𝑃𝑃𝑇𝑇𝐺𝐺ℎ𝑛𝑛(𝑇𝑇, 𝑗𝑗) ∈ 𝑃𝑃𝑇𝑇𝐺𝐺ℎ𝑆𝑆(𝑇𝑇, 𝑗𝑗) (10)
Finally, we have done social trust computing and social closeness computing, and then we combine them to calculate the social influence between the group leader i and nearby person j by using the Equation 11 below.
Equation 11. Formula of Social Influence
𝑆𝑆𝐺𝐺𝑆𝑆𝑇𝑇𝑇𝑇𝑇𝑇𝑆𝑆𝑛𝑛𝑆𝑆𝑇𝑇𝐺𝐺𝑇𝑇𝑛𝑛𝑆𝑆𝑇𝑇(𝑇𝑇, 𝑗𝑗) = 𝑆𝑆𝐺𝐺𝑆𝑆𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝐺𝐺𝑆𝑆𝐺𝐺(𝑇𝑇, 𝑗𝑗) ∗ 𝑆𝑆𝐺𝐺𝑆𝑆𝑇𝑇𝑇𝑇𝑇𝑇𝐺𝐺𝑇𝑇𝐺𝐺𝑆𝑆𝑇𝑇𝑛𝑛𝑇𝑇𝑆𝑆𝑆𝑆(𝑇𝑇, 𝑗𝑗) (11)
3.3 Individual Preference Analysis Module
his/her preference. It is important to discover users’ preference in a group buying event. When the group leader invites someone nearby to buy something together, if the person does not like it, then he/she may ignore the invitation. However, if the person also likes the product too, then he/she may join the group buying. To measure individual preference, we denote 𝑆𝑆𝑛𝑛𝑅𝑅𝑇𝑇𝑇𝑇𝑇𝑇𝑅𝑅𝐺𝐺𝑇𝑇𝑇𝑇𝑃𝑃𝑇𝑇𝑇𝑇𝑆𝑆𝑇𝑇𝑇𝑇𝑇𝑇𝑛𝑛𝑆𝑆𝑇𝑇(𝑗𝑗, 𝐺𝐺) to compute the similarity between the preference of person j near the group leader and the target product p, that is to say, the target product is sure ready for this module.
3.3.1 Product Tree Construction
Before computing the similarity between user preference and target product, we should identify the target product at first. To identify the target product, a tree structure is built to classify the target product. Products are hierarchical structures in the real world. For example, food can be divided into Chinese and American food, and restaurant can also be divided into Chinese and American restaurant. That is to say, each product can be related to a place where the product is sold.
In order to enhance the relationship and synchronization between products and places, we refer to the hierarchical categories of places on Facebook to construct a tree structure for the place tree and match the products to the categories which it belongs, see as Figure 4. We name the special tree “ProductPlace” tree and mark the index of each node to identify each category. The index is the number shown in each node. A product can belong to many categories in some cases. For example, people can buy burgers at American restaurant, burger restaurant and fast food restaurant.
Figure 4. The Example of ProductPlace Tree
3.3.2 Purchase Preference Computing
This computing method is to calculate the similarity between user preference and the target product by using the ProductPlace tree. We measure the purchase preference of a user by two kinds of social data: (1) pages: the pages that user likes on social media and (2) check-ins: check-in is the process whereby a person posts his/her location on a social network service. Check-in data show the preference of the user. For example, if a person has many check-ins at different restaurants, we can know that he/she likes to enjoy delicacies. We should transform the data types of the two kinds of data above because all the data should match the ProductPlace tree. Pages on Facebook have its own categories, and we can use its categories to match the ProductPlace tree. For example, “Costco” page is classified into “Shopping & Retail” category on Facebook and “McDonald’s” page is “Burger Restaurant” category. Check-ins on Facebook are tagged with a location, which is a page with its own categories too.
In order to know whether the user likes the target product or not, we calculate the similarity between the target product 𝐺𝐺 and preference of user 𝑗𝑗. We take the target product 𝐺𝐺 into the ProductPlace tree to identify and classify it clearly and create a new vector for the target product p which utilizes the index of nodes to represent the categories 𝐺𝐺 belongs and denote the vector as 𝐺𝐺⃑ which the value of each dimension is 1 if the category matches the node
Root 1 Restaurant 2 American 4 Burger 7 Japanese 5 Sushi 8 Sashimi 9 Museum 3 Ticket 6
or 0 if the category does not match the node. We take the place categories of the pages and check-ins data which the user 𝑗𝑗 likes and posted to match the ProductPlace tree to identify and classify them and also denote a vector as 𝚥𝚥⃑ to represent all the categories related with the pages and check-ins data, which the value of each dimension in 𝚥𝚥⃑ is the number of appearance of the category and sub-categories in pages and check-ins. The dimensions of the two vectors are the same to compute the similarity correctly.
Here is an example to show how to make the two vectors about target product and user preference by using the ProductPlace tree. We take “Sushi” as the target product 𝐺𝐺 and suppose the user j has 1 number of check-ins at an American restaurant, 2 number of that at a Japanese restaurant and 3 number of that at a museum. Then the two vectors 𝑆𝑆𝐺𝐺𝑆𝑆ℎ𝚤𝚤�����������⃑ and 𝚥𝚥⃑ with 9 dimensions (the order of dimensions depends on the index of nodes in ProductPlace tree) can be created as below. The nine dimensions are (1) Root, (2) Restaurant, (3) Museum, (4) American, (5) Japanese, (6) Ticket, (7) Burger, (8) Sushi and (9) Sashimi.
𝑆𝑆𝐺𝐺𝑆𝑆ℎ𝚤𝚤
�����������⃑(1, 1, 0, 0, 1, 0, 0, 1, 0) 𝚥𝚥⃑(6, 3, 3, 1, 2, 0, 0, 0, 0)
After having the two vectors about target product and user preference, we are going to compute the similarity between these two vectors. We modify Cosine Similarity method to create a new similarity equation because Cosine Similarity method has two defects and cannot be used into this mechanism: (1) if a user has many check-ins of different categories, the value of similarity will be reduced because the denominator of Cosine Similarity will be larger and cause distortion and (2) the value of Cosine Similarity will be normalized and make the value between 0 and 1 because of it denominator, but this neglects the influence of many pages liked and check-ins posted on the same category. We retain the numerator of Cosine Similarity using dot product but delete the denominator to create our similarity as Equation 12, where 𝐺𝐺⃑ is the 𝚥𝚥⃑ is the vector of preference of user j, to keep the features of
many pages and check-ins in the same or different categories. Equation 12. Similarity between Product and User
𝑆𝑆𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝐺𝐺𝑆𝑆(𝐺𝐺⃑, 𝚥𝚥⃑) = 𝐺𝐺⃑ ∙ 𝚥𝚥⃑ = � 𝐺𝐺⃑𝑖𝑖 ∗ 𝚥𝚥⃑𝑖𝑖 𝑛𝑛
𝑖𝑖=1
(12) We explain how the Equation 12 works by using the same example above.
𝑆𝑆𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝐺𝐺𝑆𝑆�𝑆𝑆𝐺𝐺𝑆𝑆ℎ𝚤𝚤�����������⃑, 𝚥𝚥⃑� = 6 + 3 + 2 = 11
If we add a user k into this example, the user k has 2 number of check-ins at an American restaurant, 1 number of that at a Japanese restaurant and 3 number of that at a museum, then the vector and similarity between target product and user k is:
𝑅𝑅�⃑(6, 3, 3, 2, 1, 0, 0, 0, 0)
𝑆𝑆𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝐺𝐺𝑆𝑆�𝑆𝑆𝐺𝐺𝑆𝑆ℎ𝚤𝚤�����������⃑, 𝑅𝑅�⃑� = 6 + 3 + 1 = 10
The result shows that the similarity is able to discriminate the difference of preference of different users and keep the features of many pages and check-ins data.
In the end of this section, we need to adopt the min-max normalization method which has described in Equation 6 to normalize the value of similarity after computed all the values of similarity of the candidate group members. We denote 𝑆𝑆𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝐺𝐺𝑆𝑆′(𝐺𝐺⃑, 𝚥𝚥⃑) as the normalized value and return it to be the value of individual preference analysis module as the Equation 13 below.
Equation 13. Formula of Individual Preference
𝑆𝑆𝑛𝑛𝑅𝑅𝑇𝑇𝑇𝑇𝑇𝑇𝑅𝑅𝐺𝐺𝑇𝑇𝑇𝑇𝑃𝑃𝑇𝑇𝑇𝑇𝑆𝑆𝑇𝑇𝑇𝑇𝑇𝑇𝑛𝑛𝑆𝑆𝑇𝑇(𝑗𝑗, 𝐺𝐺) = 𝑆𝑆𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝐺𝐺𝑆𝑆′(𝐺𝐺⃑, 𝚥𝚥⃑) (13)
3.4 Group Formation Engine
The group formation engine is to generate candidate groups and find the group with highest cohesion, which is appropriate to the circumstance of particular group buying, to the group leader. There are four parts in this module: (1) Personal Weight Computing is to compute
the weight values of three group formation criteria, including group context, social influence and individual preference, of a user in a particular circumstance, (2) Willingness Criteria Aggregation is to multiply the weight values of three criteria with its values to be the willingness of a user to join a group buying, (3) Candidate Group Forming is to generate several candidate groups according to the willingness of users and (4) Group Cohesion Computing is to compute the cohesion of candidate groups to find the one with highest cohesion.
The circumstances of group buying should be taken into consideration, because it may affect the willingness of users to join a group buying. For example, purchasing a plenty of products at a wholesale store, such as Costco, the group leader will dismiss the group after the transaction is completed. However, having a dinner gathering with friends at a restaurant with group discount, the group members will interact with each other for long time after the transaction is completed, which implies demand of social relations.
3.4.1 Personal Weight Computing
Each user has his/her own weights of criteria which affect the willingness to participate in a group or not. The measurement of willingness to join a group is various due to different circumstances. In this section, we compute the personal weights of three criteria which influence the willingness of a user to join a group in a specific situation.
We adopt the analytic hierarchy process (AHP) theory, a well-known structured technique for organizing and analyzing complex decision-making problems with multi criteria, which is proposed by Thomas L. Saaty in 1971 [42, 43], to compute the weights of the three willingness criteria: group context, social influence and individual preference towards a particular circumstance. We explain the detailed description as follows.
To apply AHP theory, we first define the problem to “whether to join a group or not” and then construct the hierarchy structure as the Figure 5.
Figure 5. The Hierarchy Decision Structure of Personal Weight Computing
There are three criteria in the hierarchy structure, which requires 𝐺𝐺23 = 3 comparisons and builds a pairwise matrix denoted as 𝑀𝑀𝐶𝐶𝐶𝐶𝐶𝐶 shown as Equation 14, where C implies group context, S implies social influence and P implies individual preference. The results of three comparisons between each criterion are on the upper triangle of the matrix and the values of the lower triangle are the reciprocal of the relative position on the upper triangle. The values on the diagonal line are 1 because they compare with themselves.
Equation 14. The Pairwise Matrix of Analytic Hierarchy Process
𝑀𝑀𝐶𝐶𝐶𝐶𝐶𝐶 = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ 11 𝐴𝐴𝐶𝐶𝐶𝐶 𝐴𝐴𝐶𝐶𝐶𝐶 𝐴𝐴𝐶𝐶𝐶𝐶 1 𝐴𝐴𝐶𝐶𝐶𝐶 1 𝐴𝐴𝐶𝐶𝐶𝐶 1 𝐴𝐴𝐶𝐶𝐶𝐶 1 ⎦⎥ ⎥ ⎥ ⎥ ⎤ (14)
Where 𝐴𝐴𝐶𝐶𝐶𝐶 represents the relative decision weight of group context similarity to social influence, 𝐴𝐴𝐶𝐶𝐶𝐶 represents the relative decision weight of group context similarity to individual preference, and 𝐴𝐴𝐶𝐶𝐶𝐶 represents the relative decision weight of social influence similarity to individual preference. These data has been collected from questionnaires in users’ first usage and its value may be affected by the circumstance. We define a set of this relative decision weights in a specific circumstance of a user j as 𝐴𝐴𝐶𝐶𝐶𝐶𝐶𝐶(𝑗𝑗) and this set can be indicated as Equation 15.
Equation 15. The Set of Relative Weights of Criteria
𝐴𝐴𝐶𝐶𝐶𝐶𝐶𝐶(𝑗𝑗) = {𝐴𝐴𝐶𝐶𝐶𝐶(𝑗𝑗), 𝐴𝐴𝐶𝐶𝐶𝐶(𝑗𝑗), 𝐴𝐴𝐶𝐶𝐶𝐶(𝑗𝑗)} (15)
We can compute the eigenvectors to obtain the weights of criteria by the eigenvalues after construct the pairwise matrix. We adopt average of normalized columns (ANC) method to get the eigenvectors because the pairwise matrix is not usually consistency matrix and use this ANC method can have higher accuracy of computing results then other methods when encounter non-consistency matrix [43]. We define a set containing the three weight values of the user j on the three criteria (group context, social influence and individual preference) as 𝑊𝑊𝐶𝐶𝐶𝐶𝐶𝐶(𝑗𝑗) and this set can be indicated as Equation 16.
Equation 16. The Set of Personal Weights of Criteria
𝑊𝑊𝐶𝐶𝐶𝐶𝐶𝐶(𝑗𝑗) = {𝑊𝑊𝐶𝐶(𝑗𝑗), 𝑊𝑊𝐶𝐶(𝑗𝑗), 𝑊𝑊𝐶𝐶(𝑗𝑗)} (16)
The weights of three criteria can be calculated by using the Equation 17. Equation 17. Formula of Personal Weight Computing
𝑊𝑊𝛼𝛼(𝑗𝑗) =13 �∑ 𝐴𝐴𝛽𝛽𝛽𝛽𝐴𝐴(𝑗𝑗) 𝛽𝛽𝛽𝛽(𝑗𝑗) 3 𝛽𝛽=1 3 𝛽𝛽=1 , ∀[𝑊𝑊𝛼𝛼(𝑗𝑗) ∈ 𝑊𝑊𝐶𝐶𝐶𝐶𝐶𝐶(𝑗𝑗)] & [𝐴𝐴𝛽𝛽𝛽𝛽(𝑗𝑗) ∈ 𝐴𝐴𝐶𝐶𝐶𝐶𝐶𝐶(𝑗𝑗)] (17)
These three weights of three criteria imply how the user j makes decision to whether to join a group buying with the invitation from the group leader or not.
3.4.2 Willingness Criteria Aggregation
Using the weight values of three criteria, this mechanism can have the ability to measure the willingness-to-join that the person j who is near the group leader i will want to join the group to purchase target product p together in a specific circumstance. We denote the willingness-to-join of person j as 𝐽𝐽𝐺𝐺𝑇𝑇𝑛𝑛𝑊𝑊𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑛𝑛𝑇𝑇𝑛𝑛𝑇𝑇𝑆𝑆𝑆𝑆(𝑇𝑇, 𝑗𝑗, 𝐺𝐺) and its value is calculated as the aggregation of the weight value of each criterion with the corresponding score of the criterion which calculated by the group context, social influence and individual preference analysis module. The value of 𝐽𝐽𝐺𝐺𝑇𝑇𝑛𝑛𝑊𝑊𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑛𝑛𝑇𝑇𝑛𝑛𝑇𝑇𝑆𝑆𝑆𝑆(𝑇𝑇, 𝑗𝑗, 𝐺𝐺) is measured as the Equation 18.
Equation 18. Formula of Willingness-to-Join
𝐽𝐽𝐺𝐺𝑇𝑇𝑛𝑛𝑊𝑊𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑛𝑛𝑇𝑇𝑛𝑛𝑇𝑇𝑆𝑆𝑆𝑆(𝑇𝑇, 𝑗𝑗, 𝐺𝐺) = 𝑊𝑊𝐶𝐶(𝑗𝑗) ∗ 𝐺𝐺𝑇𝑇𝐺𝐺𝐺𝐺𝐺𝐺𝐺𝐺𝐺𝐺𝑛𝑛𝐺𝐺𝑇𝑇𝐺𝐺𝐺𝐺(𝑇𝑇, 𝑗𝑗)
+𝑊𝑊𝐶𝐶(𝑗𝑗) ∗ 𝑆𝑆𝐺𝐺𝑆𝑆𝑇𝑇𝑇𝑇𝑇𝑇𝑆𝑆𝑛𝑛𝑆𝑆𝑇𝑇𝐺𝐺𝑇𝑇𝑛𝑛𝑆𝑆𝑇𝑇(𝑇𝑇, 𝑗𝑗)
+𝑊𝑊𝐶𝐶(𝑗𝑗) ∗ 𝑆𝑆𝑛𝑛𝑅𝑅𝑇𝑇𝑇𝑇𝑇𝑇𝑅𝑅𝐺𝐺𝑇𝑇𝑇𝑇𝑃𝑃𝑇𝑇𝑇𝑇𝑆𝑆𝑇𝑇𝑇𝑇𝑇𝑇𝑛𝑛𝑆𝑆𝑇𝑇(𝑗𝑗, 𝐺𝐺)
(18)
3.4.3 Candidate Group Forming
Now this mechanism has the ability to compute the willingness-to-join of everyone near the group leader who creates the group buying event in a specific circumstance. The number of people near the group leader may be very large, and it may be larger than the number of group members needed. For instance, the group leader needs 4 people to join his/her group buying, but the people nearby are about 20.
This mechanism requires this candidate group forming and next group cohesion computing approaches to solve the problem. We denote 𝑁𝑁𝐹𝐹𝐹𝐹 as the number of people required to the group buying (not including the group leader) and choose top-k people with higher willingness-to-join to the group. The number of people chosen is k at most (i.e. range from 1 to k), where k is equal to 𝑁𝑁𝐹𝐹𝐹𝐹 multiplies with a certain integer, because we need to consider the great diversity of the group members combination and its value of group cohesion and the higher ratio of willingness simultaneously, but we also need to limit the search range of people near the group leader. Therefore, a group leader can make about 𝐺𝐺𝑁𝑁𝑘𝑘𝑟𝑟𝑟𝑟 combinations for different groups. We denote 𝐺𝐺(𝑇𝑇, 𝑁𝑁𝐹𝐹𝐹𝐹) as a set containing all the candidate groups as following Equation 19 and send it to the next approach, group cohesion computing, to compute which is the best group that the group leader i wants.
Equation 19. The Set of Candidate Groups
3.4.4 Group Cohesion Computing
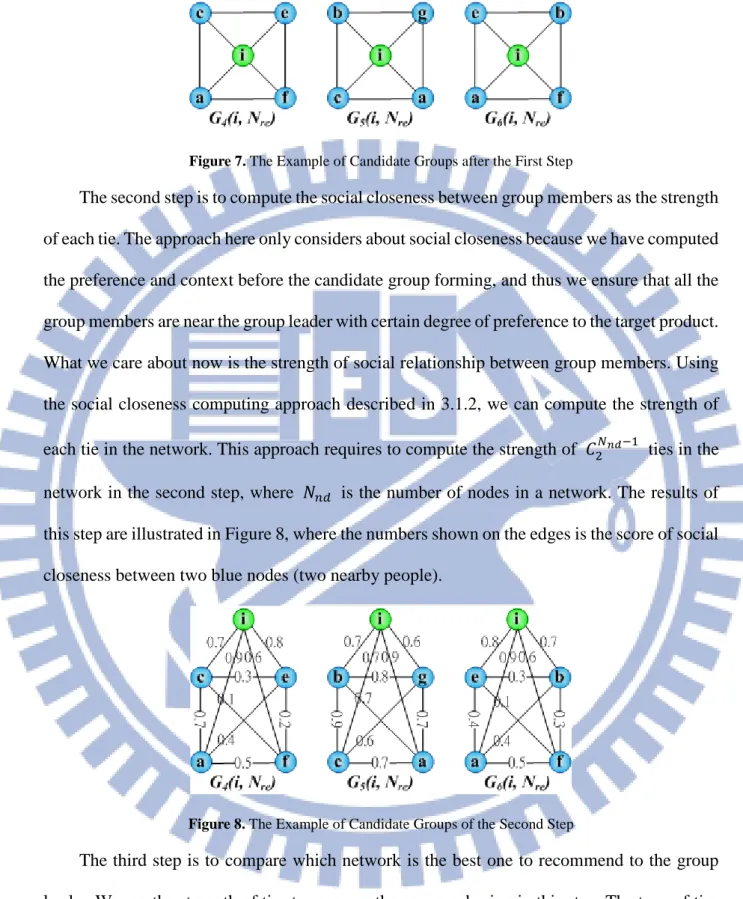
This group cohesion computing approach will run after receiving the 𝐺𝐺(𝑇𝑇, 𝑁𝑁𝐹𝐹𝐹𝐹) set from the candidate group forming approach. The 𝐺𝐺(𝑇𝑇, 𝑁𝑁𝐹𝐹𝐹𝐹) may have a great diversity of combinations. Examples of 𝑁𝑁𝐹𝐹𝐹𝐹 = 5 are illustrated in Figure 6.
Figure 6. Example of Candidate Groups of Initial Forming
The central green node is the group leader i and other blue nodes are the people near the group leader. Every node represents a person, and the edge between two blue nodes represents the friendship between two people on social media. If there is no edge between two blue nodes, it means that they are not friends. The candidate groups are an undirected and non-reflexive graph (or network) structure.
We measure the cohesion of these groups by three steps: (1) the density of network, (2) the social closeness between group members and (3) the average score of willingness-to-join and social closeness in the network.
The density of network can be measured by Equation 20 [44], where T is the number of ties and 𝑁𝑁𝑛𝑛𝐹𝐹 is the number of nodes in the network.
Equation 20. Density of Groups
𝐷𝐷𝑇𝑇𝑛𝑛𝑆𝑆𝑇𝑇𝐺𝐺𝑆𝑆(𝐺𝐺𝑛𝑛(𝑇𝑇, 𝑁𝑁𝐹𝐹𝐹𝐹)) =𝑁𝑁 2 ∗ 𝑇𝑇
𝑛𝑛𝐹𝐹 ∗ (𝑁𝑁𝑛𝑛𝐹𝐹− 1) (20)
Measuring the density of each candidate group, this mechanism filters the top groups with highest density to do the next step. Because it is possible that there are several groups with equal highest density, we need to do advanced filtering. For example, the density of each
Figure 7. The Example of Candidate Groups after the First Step
The second step is to compute the social closeness between group members as the strength of each tie. The approach here only considers about social closeness because we have computed the preference and context before the candidate group forming, and thus we ensure that all the group members are near the group leader with certain degree of preference to the target product. What we care about now is the strength of social relationship between group members. Using the social closeness computing approach described in 3.1.2, we can compute the strength of each tie in the network. This approach requires to compute the strength of 𝐺𝐺2𝑁𝑁𝑛𝑛𝑛𝑛−1 ties in the network in the second step, where 𝑁𝑁𝑛𝑛𝐹𝐹 is the number of nodes in a network. The results of this step are illustrated in Figure 8, where the numbers shown on the edges is the score of social closeness between two blue nodes (two nearby people).
Figure 8. The Example of Candidate Groups of the Second Step
The third step is to compare which network is the best one to recommend to the group leader. We use the strength of ties to measure the group cohesion in this step. The type of ties are not all the same because the ties from nearby people (blue nodes) to the group leader i (central green node) are measured by willingness-to-join and the other ties between nearby people (blue nodes) are measured by social closeness. Due to the different types of ties, we
need to calculate separately. We denote 𝑇𝑇𝑗𝑗𝑗𝑗 as a set of all the ties measured by
willingness-to-join and denote 𝑇𝑇𝐹𝐹𝑠𝑠 as a set of all the ties measured by social closeness. The representations of the two sets are Equation 21 and 22, where n and m is the total number of ties of the specific type.
Equation 21. The Set of Ties between Group Leader and Group Members
𝑇𝑇𝑗𝑗𝑗𝑗 = �𝑇𝑇𝑗𝑗𝑗𝑗1 , 𝑇𝑇𝑗𝑗𝑗𝑗2 , … , 𝑇𝑇𝑗𝑗𝑗𝑗𝑛𝑛�
(21) Equation 22. The Set of Ties between Group Members
𝑇𝑇𝐹𝐹𝑠𝑠 = {𝑇𝑇𝐹𝐹𝑠𝑠1, 𝑇𝑇𝐹𝐹𝑠𝑠2, … , 𝑇𝑇𝐹𝐹𝑠𝑠𝑚𝑚}
(22) Next to compute the average values of 𝑇𝑇𝑗𝑗𝑗𝑗 and 𝑇𝑇𝐹𝐹𝑠𝑠 using the Equation 23 and 24 as following.
Equation 23. The Average of Ties between Group Leader and Group Members
𝐴𝐴𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇�𝑇𝑇𝑗𝑗𝑗𝑗� =∑ 𝑇𝑇𝑗𝑗𝑗𝑗 𝑖𝑖 𝑛𝑛 𝑖𝑖=1 𝑛𝑛 (23)
Equation 24. The Average of Ties between Group Members
𝐴𝐴𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇(𝑇𝑇𝐹𝐹𝑠𝑠) =∑ 𝑇𝑇𝐹𝐹𝑠𝑠 𝑖𝑖 𝑚𝑚 𝑖𝑖=1 𝑇𝑇 (24)
The average of strength of ties can represent the average cohesion of the network. After get the average values of 𝑇𝑇𝑗𝑗𝑗𝑗 and 𝑇𝑇𝐹𝐹𝑠𝑠, we aggregate these two average values to compute the cohesion of the whole network by using the Equation 25. We decide to multiply these two average values because multiplying can make the higher value more higher, vice versa. It is useful to show the difference distinctly between each network.
Equation 25. Formula of Cohesion of Groups
𝐺𝐺𝐺𝐺ℎ𝑇𝑇𝑆𝑆𝑇𝑇𝐺𝐺𝑛𝑛�𝐺𝐺𝛼𝛼(𝑇𝑇, 𝑁𝑁𝐹𝐹𝐹𝐹)� = 𝐴𝐴𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇�𝑇𝑇𝑗𝑗𝑗𝑗� ∗ 𝐴𝐴𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇(𝑇𝑇𝐹𝐹𝑠𝑠),
∀𝐺𝐺𝛼𝛼(𝑇𝑇, 𝑁𝑁𝐹𝐹𝐹𝐹) ∈ 𝐺𝐺(𝑇𝑇, 𝑁𝑁𝐹𝐹𝐹𝐹)
(25)
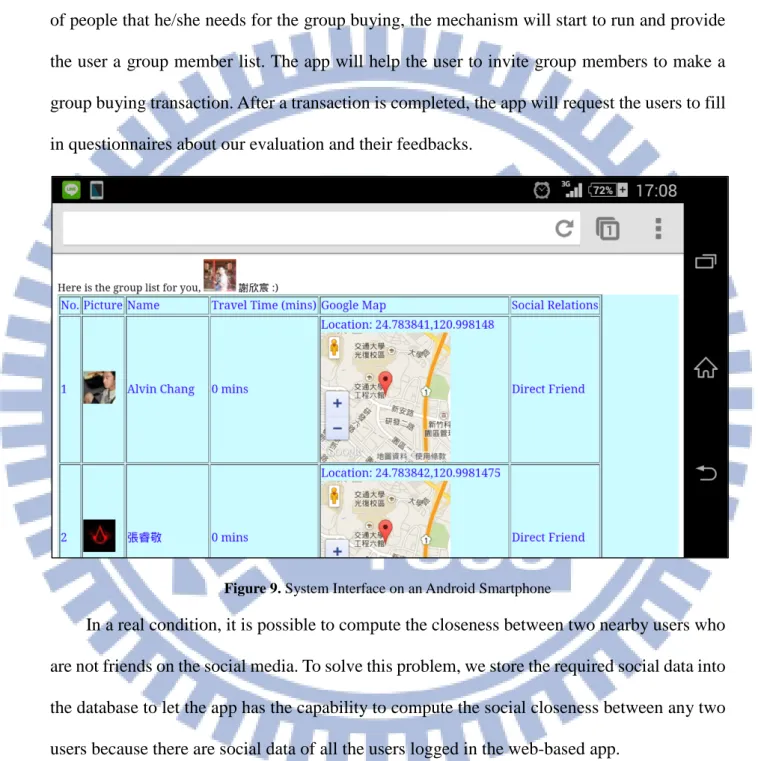
and inform the group members to meet themselves. The group list provides five types of information: (1) name, (2) profile picture, (3) relationship with the group leader, (4) location and (5) travel time. The group leader can gather the appropriate and nearby people to enjoy group buying by the group list, and the group members also benefit from group discount. We expect it will change the purchase behavior of humans in the real world.