Abstract—Data clustering is a powerful technique designed
specifically for discerning the structure of and simplifying the complexity of large scale data. It is a technique commonly used for statistical data analysis, and is also used in many other fields, including machine learning, data mining, pattern recognition, image analysis, and bioinformatics, in which the distribution of information can be of any size and shape. An improved technique combining linearly decreasing weight particle swarm optimization (LDWPSO) with an acceleration strategy is proposed in this paper. Accelerated linearly decreasing weight particle swarm optimization (ALDWPSO) searches for cluster centers in an arbitrary data set and can effectively indentify the global optima. ALDWPSO is tested on six experimental data sets, and its performance is compared to the performance of PSO, NM-PSO, K-PSO, K-NM-PSO, LDWPSO and K-means clustering. Results indicate that ALDWPSO is both robust and suitable for solving data clustering problem.
Index Terms—data clustering, linearly decreasing weight,
particle swarm optimization.
I. INTRODUCTION
Machine learning techniques are mainly categorized into two kinds, supervised learning and unsupervised learning. Clustering analysis is a typical and very popular unsupervised learning technique. Clustering analysis is the process of grouping a set of objects into clusters so that objects within a cluster are similar to each other but are dissimilar to objects in other clusters [1] [2] [3]. When used on a set of objects, it helps identify some inherent structures present in the objects. The purpose of cluster analysis is to classify the clusters into subsets that have some meaning in the context of a particular problem. More specifically, a set of patterns, usually vectors in a multi-dimensional space, are grouped into some clusters. When the number of clusters, K, is known a priori, clustering may be formulated as the distribution of n objects in an N-dimensional space among K groups in such a way that the objects in the same group are more similar in some sense than those in the different groups [4]. This involves minimization of some extrinsic optimization criteria. The well-known K-means [5] algorithm, which has been successfully applied to many practical
C. H. Yang is with the Network Systems Department, Toko University, 61363, Chiayi, Taiwan. (phone: 886-7-3814526#5639; e-mail: [email protected]).
C.H. Yang is also with the Electronic Engineering Department, National Kaohsiung University of Applied Sciences, 80778, Kaohsiung, Taiwan.
C. J. Hsiao is with the Electronic Engineering Department, National Kaohsiung University of Applied Sciences, 80778, Kaohsiung, Taiwan. (phone: 886-7-3814526#5654; e-mail: [email protected]).
L. Y. Chuang is with the Chemical Engineering Department, I-Shou University, 84001, Kaohsiung, Taiwan. (e-mail: [email protected]).
clustering problems, suffers from several drawbacks due to its choice of initializations. The objective function of the K-means is not convex and hence it may contain many local minima. In recent years, many clustering algorithms based on evolutionary computing, such as genetic algorithms [6] [7] and particle swarm optimization [8], have been introduced. Genetic algorithms typically sets out with some candidate solutions to the optimization problem, and then the candidates evolve towards a better solution through selection, crossover and mutation. Particle swarm optimization (PSO) is a population-based algorithm [9]. It simulates the behavior of naturally occurring swarm, e.g., a school fish, to achieve a self-evolving system. It searches automatically for the optimum solution in the search space, and the involved search process is not random. Depending on the nature of different problems, a fitness function decides the best way to conduct the search. The PSO algorithm has rapidly become popular and has been applied in neural network optimization [10], data clustering [11] [12], engineering design [13], etc. Although evolutionary computation techniques do eventually locate the desired solution, practical use of these techniques in solving complex optimization problems is severely limited by the high computational cost associated with the slow convergence rate.
PSO applied to the clustering multi-dimensional space has shown outstanding performance. However, the rate of convergence when searching for global optima is still not sufficient [14]. A linearly decreasing weight particle swarm optimization (LDWPSO), in which a linearly decreasing inertia factor is introduced into the velocity update equation of the original PSO [15] is proposed in this study to solve this problem. The performance of LDWPSO is significantly improved over the original PSO because LDWPSO effectively balances the global and local search abilities of the swarm. The accelerated linearly decreasing weight particle swarm optimization (ALDWPSO) algorithm can be adapted to cluster arbitrary data by evolving the appropriate cluster centers in an attempt to optimize a given clustering metric. Results of the conducted experimental studies on a variety of data sets taken from several real-life situations demonstrate that ALDWPSO is superior to the K-means, PSO, LDWPSO, K-PSO, and K-NM-PSO algorithms.
This work is organized as follows. In Section 2, the PSO algorithm, linearly decreasing weight and ALDWPSO clustering are described. In Section 3, experimental results and a discussion thereof are provided. Finally, concluding remarks are offered in Section 4.
II. METHODS
Accelerated Linearly Decreasing Weight Particle
Swarm Optimization for Data Clustering
Cheng-Hong Yang, Member, IAENG, Chih-Jen Hsiao and Li-Yeh Chuang
Proceedings of the International MultiConference of Engineers and Computer Scientists 2010 Vol I, IMECS 2010, March 17 - 19, 2010, Hong Kong
ISBN: 978-988-17012-8-2
ISSN: 2078-0958 (Print); ISSN: 2078-0966 (Online)
A. Particle Swarm Optimization
The robust and efficient PSO evolutionary computation learning algorithm was developed by Kennedy and Eberhart (1995) [9]. In the original PSO, each particle is analogous to an individual fish in a school of fish. It is a population-based optimization technique, where a population is called a swarm. A swarm consists of N particles moving around in a D-dimensional search space.
The position of the ith particle can be represented by xi =
(xi1, xi2, …, xiD). The velocity for the ith particle can be written
as vi = (vi1, vi2, …, viD). The positions and velocities of the
particles are confined within [Xmin, Xmax]D and [Vmin, Vmax]D,
respectively. Each particle coexists and evolves simultaneously based on knowledge shared with neighbouring particles. It makes use of its own memory and knowledge gained by the swarm as a whole to find the best solution.
The best previously encountered position of the ith particle
is denoted its individual best position pi = (pi1, pi2,..., piD), a
value called pbesti. The best value of the all individual pbesti
values is denoted the global best position g = (g1, g2, …, gD)
and called gbest. The PSO process is initialized with a population of random particles, and the algorithm then executes a search for optimal solutions by continuously updating generations. At each generation, the position and velocity of the ith particle are updated by pbesti and gbest of
the swarm population. The update equations can be formulated as:
old
id d old id id old id new id x gbest r c x pbest r c v w v 2 2 1 1 (1) new id old id new id x v x (2)where r1 and r2 are random numbers between (0, 1), and c1
and c2 are acceleration constants that control how far a
particle moves in a single generation. Velocities new id
v and voldid
denote the velocities of the new and old particle, respectively.
old id
x is the current particle position, and new id
x is the new, updated particle position. Eberhart et al. [16] [17] suggested values of c1 = c2 = 2. The inertia weight w controls the impact
of the previous velocity of a particle on its current one. It is defined in Eq. (3). 0 . 2 5 . 0 rand w (3)
In Eq. (3), rand is a randomly generated number between zero and one.
B. Linearly Decreasing Weight Particle Swarm Optimization
Shi and Eberhart proposed a linearly decreasing weight particle swarm optimization (LDWPSO), in which a linearly decreasing inertia factor was introduced into the velocity update equation of the original PSO [15]. The performance of LDWPSO is significantly improved over the original PSO because LDWPSO effectively balances the global and local
search abilities of the swarm. In LDWPSO, wLDW is the
inertia weight which linearly decreases from 0.9 to 0.4 through the search process [15]. The equation for the linear decrease can be written as:
min max max min max w Iteration Iteration Iteration w w w i LDW (4)In Eq. (4), wmax is 0.9, wmin is 0.4 and Iterationmax is the
maximum number of allowed iterations.
C. ALDWPSO Clustering
Although PSO has been successfully applied to many practical clustering problems, its convergence rate is rather slow and the global search ability for optimum solutions needs to be improved. We thus propose a combination of a linearly decreasing weight and an acceleration strategy to improve the performance of PSO. ALDWPSO consists of four major processes, namely the encoding and initialization of the particle, the acceleration strategy, the velocity and position update, and the fitness evaluation. The ALDWPSO procedure for data clustering is described below:
Step1). Initial population and encoding: 3N particles are randomly generated, where each particle represents a feasible solution (cluster center) of the problem. N is computed as follows:
d
K
N
(5)where d is the data set dimension and K is the anticipated number of clusters.
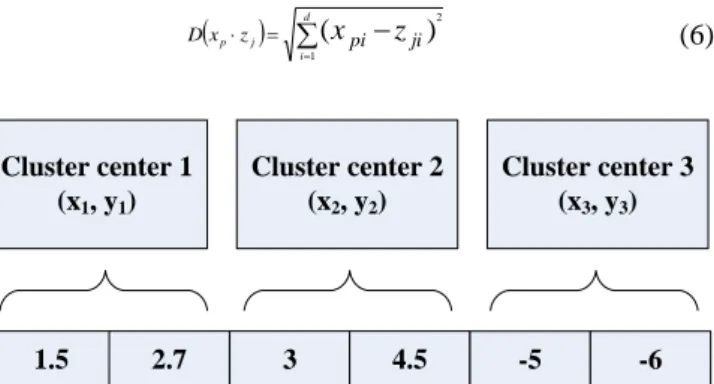
A possible encoding of a particle for a two-dimensional problem with three clusters is illustrated in Fig. 1. The three cluster centers represented by this particle are (1.5, 2.7), (3, 4.5), and (-5, -6).
Step2). Acceleration strategy: In the initial steps, one-third of the particles are used to accelerate the convergence rate of the particles. The one-third of particles has been set after several experiments. The distances between data vectors within a cluster and the center of the cluster are defined in Eq. (6). The acceleration strategy recalculates the cluster center vectors using Eq. (7) and yields mean centers. The mean clusters then replace the original centers. The new position of the particle is thus given by:
d i j p z pi ji x D x z 1 2 ) ( (6) Cluster center 1 (x1, y1) Cluster center 3 (x3, y3) Cluster center 2 (x2, y2) 1.5 2.7 3 4.5 -5 -6
Fig. 1. Encoding of a single particle in PSO Proceedings of the International MultiConference of Engineers and Computer Scientists 2010 Vol I,
IMECS 2010, March 17 - 19, 2010, Hong Kong
ISBN: 978-988-17012-8-2
ISSN: 2078-0958 (Print); ISSN: 2078-0966 (Online)
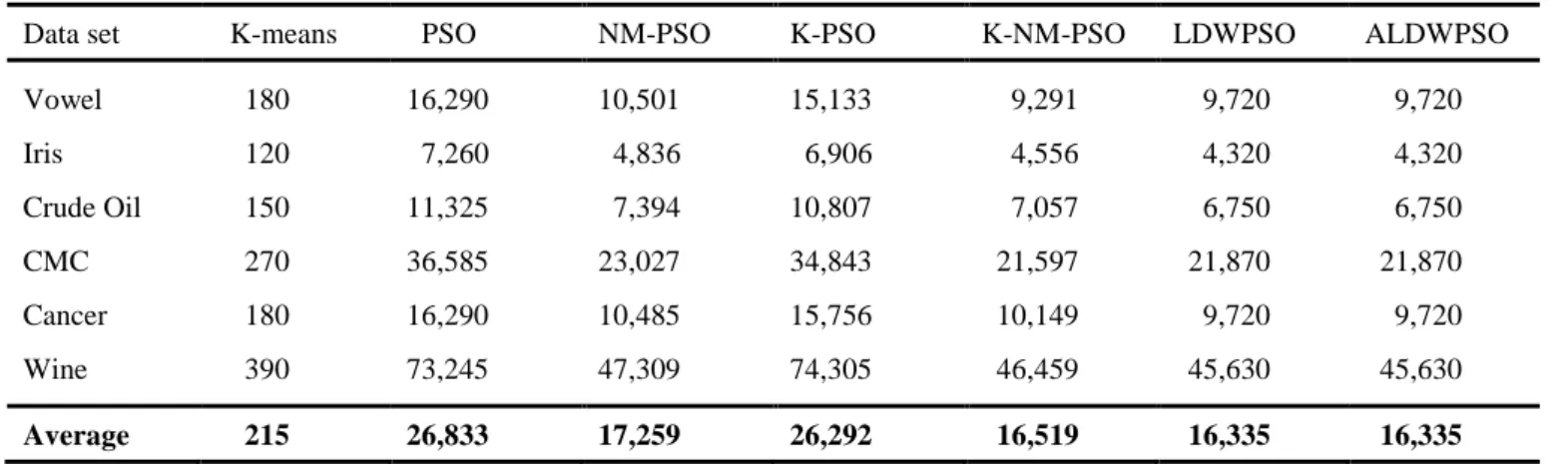
Table 5.The number of function evaluations for each clustering algorithm
Data set K-means PSO NM-PSO K-PSO K-NM-PSO LDWPSO ALDWPSO
Vowel 180 16,290 10,501 15,133 9,291 9,720 9,720 Iris 120 7,260 4,836 6,906 4,556 4,320 4,320 Crude Oil 150 11,325 7,394 10,807 7,057 6,750 6,750 CMC 270 36,585 23,027 34,843 21,597 21,870 21,870 Cancer 180 16,290 10,485 15,756 10,149 9,720 9,720 Wine 390 73,245 47,309 74,305 46,459 45,630 45,630 Average 215 26,833 17,259 26,292 16,519 16,335 16,335
Legend : The best average values are indicated in bold type. The results for K-means, PSO, NM-PSO, K-PSO, K-NM-PSO can be found in [14].
SO, K-PSO, and K-NM-PSO, and produce better outcomes than the other methods. K-NM-PSO is a hybrid technique that combines the K-means algorithm, Nelder-Mead simplex search [18], and PSO. In a direct comparison the performance of ALDWPSO proved to be better than the performance of K-NM-PSO. All the evidence of the simulations demonstrates that ALDWPSO converges to global optima with a smaller error rate and fewer function evaluations, which leads naturally to the conclusion that ALDWPSO is a viable and robust technique for data clustering.
IV. CONCLUSIONS
This article proposes a novel method for solving data clustering problem called ALDWPSO. The performance of the ALDWPSO clustering algorithm has been demonstrated on six publicly available data sets. ALDWPSO uses minimum intra-cluster distances as the metric, and searches the robust data cluster centers in an N-dimensional Euclidean space. Under the same metric, PSO, NM-PSO, K-PSO, and K-NM-PSOSO need more iterations to achieve a global optimum. The K-means algorithm may get stuck in a local optimum, depending on the choice of the initial cluster centers. The experimental results indicate that ALDWPSO reached a minimal error rate faster than the other methods, and thus reduces computational cost. In the future, we will employ ALDWPSO to other clustering problem in bioinformatics. We intend to develop a hybrid technique based on other clustering algorithms to enhance the performance of ALDWPSO.
REFERENCES
[1] J. Han, M. Kamber, and A. K. H. Tung, “Spatial clustering methods in data mining: A survey,” In H. J. Miller & J. Han (Eds.). Geographic data mining and knowledge discover, London: Taylor & Francis, 2001.
[2] A. K. Jain, M. N. Murty, and P. J. Flynn, “Data clustering: a review,” ACM Computing Surveys, 1999, vol. 31, pp.264–323.
[3] L. Rokach, and O. Maimon, “Clustering methods in Maimon, O. and Rokach, L. (Eds.): Data Mining and Knowledge Discovery Handbook,” Springer, New York. 2005, pp. 321–352.
[4] M. R. Anderberg, “Cluster Analysis for Application,” Academic Press, New York, 1973.
[5] J. B. MacQueen, “Some methods for classification and analysis of mul- tivariate observations,” In: Proceedings of the Fifth Berkeley Symp. Math. Stat. Prob., vol.1, 1967, pp. 281-297.
[6] C. A. Murthy, and N. Chowdhury, “In search of optimal cluaters using genetic algorithms,” Pattern Recognition Letters. 1996, vol. 17, pp. 825–832.
[7] S. Bandyopadhyay, and U. Maulik, “An evolutionary technique based on K-means algorithm for optimal clustering in RN,” Information Science, 2002, vol. 146, pp. 221–237.
[8] S. Paterlini, and T. Krink, “Differential evolution and particle swarm optimization in partitional clustering,” Computational Statistics and Data Analysis, 2006, vol. 50, pp. 1220-1247.
[9] J. Kennedy, and R. C. Eberhart, “Particle swarm optimization.” Proceedings of the IEEE International Joint Conference on Neural Network, 1995, vol.4, pp. 1942-1948.
[10] R. C. Eberhart, Y. Shi, “Evolving Artificial Neural Networks.” in Proceeding of International Conference on Neural Networks and Brain, Beijing, P.R.C. 1998, pp. 5-13.
[11] D. W. Merwe, A. P. Engelbrecht, “Data Clustering Using Particle Swarm Optimization,” in Proceedings of IEEE Congress on Evolutionary Computation (CEC), Canberra, Australia. 2003, pp. 215-220.
[12] M. G. Omran, A. P. Engelbrecht, and A. Salman, “Particle Swarm Optimization Method for Image Clustering,” International Journal on Pattern Recognition and Artificial Intelligence 19, 2005, pp. 297-321. [13] Q. He, L. Wang, “An effective co-evolutionary particle swarm optimization for constrained engineering design problems,” Engineering Applications of Artificial Intelligence 20, 2007, pp. 89-99.
[14] Y. T. Kao, E. Zahara, and I. W. Kao, “A hybridized approach to data clustering,” Expert Systems with Applications. 2008, vol. 34, pp. 1754-1762.
[15] Y. Shi, and R.C. Eberhart, “Empirical study of particle swarm optimization,” Proc. of Congress on Evolutionary Computation, Washington, DC, 6-9 July 1999, pp. 1945-1949.
[16] R. C. Eberhart, and Y. Shi, “Tracking and optimizing dynamic systems with particle swarms,” In Proceedings of the Congress on Evolutionary Computation. 2001, pp. 94-97.
[17] X. Hu, and R. C. Eberhart. “Tracking dynamic systems with PSO: where’s the cheese?,” In Proceedings of the Workshop on Particle Swarm Optimization, 2001.
[18] J. A. Nelder, and R. Mead, “A simplex method for function minimization,” Computer Journal. 1965, vol. 7, pp. 308-313. Proceedings of the International MultiConference of Engineers and Computer Scientists 2010 Vol I,
IMECS 2010, March 17 - 19, 2010, Hong Kong
ISBN: 978-988-17012-8-2
ISSN: 2078-0958 (Print); ISSN: 2078-0966 (Online)