Hardware-Efficient Architecture Design of Tree-Depth Scanning and
Multiple Quantization Scheme for MPEG-4 Still Texture Coding
Hao-Chieh Chang, Zhong-Lan Yang, Chung-Jr Lian and Liang-Gee Chen
DSP/IC
Design Lab, Departmentof
Electrical EngineeringNational Taiwan University, Taipei,
Taiwan, R.O.C.
Email:
(howard,lgchen)@video.ee.ntu.edu.tw
ABSTRACT
This paper presents a hardware-efficient architecture of tree-
depth scanning (TDS) and multiple-quantization (MQ) scheme for MPEG-4 still texture coding. By means of the novel architecture. the TDS can achieve its maximal throughput to area ratio and minimal extemal memory access with only one wavelet-tree size on-chip memory. Besides. MQ adopts the proposed POT (power of 2) quantization. which is proved to have very similar performance with generic (user-defined coefticients) scalar quantization. to achieve the most cost- effective hardware implementation. The prototypinp chip has been implemented in a TSMC 0.35 Fm CMOS technology. This architecture can handle 30 4-CIF frames per second with 3 spatial layers and 3 SNR layers scalability at 100 MHz clock
frequency.
.
I. INTRODUCTION
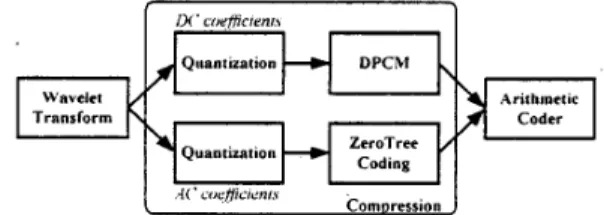
Recently, still texture coding [ 11-[4] becomes an important part of image technology because of the compression requirements of rapidly increasing Internet activities and image transmission demands. One traditional image compression algorithm, JPEG [j], can compress images with good quality at medium bit-rate. However, the image quality would become unacceptable at low bit-rate due to the block artifacts caused by block-based coding scheme. A newly finalized standard. MPEG-4 [6], can provide the solution for this drawback. MPEG-4 comprises a scalable still-texture coding tool. which employs the frame-based coding scheme. to avoid the blocking artifact at low bit-rate. The block diagram of MPEG-4 still texture coding-is shown in Fig. I . This tool can be divided into three major stages: wavelet transform, compression and entropy coding. The wavelet transform [7] decomposes the input image
into several subbands with various frequency
resolutions. The lowest frequency subband. i.e. in the top-left comer, is called DC band. The rest higher frequency subbands are called AC bands. The
DC
coefficients (i.e. wavelet coefficients in DC band) and AC coefficients are then quantized and compressed using DPCM coding and zerotree coding separately at the compression and entropy coding stages.
MPEG-4 still texture coding adopts the EZW-based [4] algorithm as the zerotree coding for AC coefficients. Many previous studies
[SI-[
1 I ] put their attention on the EZW [ I ] coding but the architecture designs of MPEG- 4 still texture coding are seldom mentioned currently. However. MPEG-4 is expected to dominate the multimedia communication technology in the near future and would be embedded in a variety of applications. such as mobile phones and digital cameras.In such portable or mobile devices, it could be expected that a dedicated hardware solution is the best candidate in the tradeoff of power. throughput and cost issues. This motivates us the attempt of optimizing the hardwire architecture design for the MPEG-4 still texture coding. Since architecture designs of wavelet transform and arithmetic coding are widely discussed, merely the architecture design of zerotree coding for MPEG-4 still texture coding is addressed in this paper.
( -
-1
ComnressionFigure 1. Block Diagram of MPEG-4 Still Texture Coding In this paper, we propose a novel architecture of tree- depth scanning and multiple quantization for MPEG-4 still texture coding. It is implemented by several design techniques, such as the symbol registration to decrease
the memory access for the recursive symbol
assignments of TDS and the POT quantization that can reduce the hardware complexity with negligible bit-rate increase. This design is also highly modularized such that it can be easily integrated with discrete wavelet transform and arithmetic coder to construct a complete MPEG-4 still texture encoder,
11. TREE-DEPTH SCANNING AND
MULTIPLE QUANTIZATION SCHEME
The zerotree coding algorithm exploits the self- similarity of the parent-children relationship to efficiently encode AC coefficients. The self-similarity means that if a coefficient is quantized to zero. it becomes "insignificant", and its descendants are also likely to be "insignificant". According to this self- similarity property. quantized AC coefficients can be efficiently represented by the following symbols: zerotree root (ZTR). isolated zero (IZ), value (VAL), value zerotree root (VZTR) and zerotree root descendant (ZTR-D). A ZTR denotes that a coefficient is the root of a zerotree. A ZTR can be decided if all its four children are also zerotree roots. An IZ implies that a coefficient is insignificant. but has non-zero descendants. A VAL symbol means that a coefficient has non-zero amplitude and non-zero descendants. A VZTR denotes a coefficient that is significant and all of its four children are zerotree roots. An additional11- 193
symbol. ZTR-D, which represents the descendant of a ZTR or VZTR, is introduced to indicate the different contest models of the arithmetic coder. The tree-depth scanning order is demonstrated in Fig. 2, in which all coet'ficients in the same wavelet tree are scanned before scanning the coefficients in the next wavelet tree. For example, indices 4, 5, .
.
.,
24 represent one wavelet tree. Coefficients in this tree are first encoded, then proceed to the next tree. indices 2 5 , 26,....
45. The tree-depth scanning method could provide the quality scalability.k25521- 2 1 8 1 1 7 5 1 7 6 238 2 3 9 I 3 1 3 4 3 5 I 9 3 9 4 9 7 9 8 ' 32 3 3 3 6 3 7 ' 95 96 9 9 1 0 0 ; 3 8 39 4 2 J 3 1 0 1 1 0 2 1 0 5 1 0 6 ,A0 4 1 4 J 4 5 1 0 3 101 1 0 7 1 0 8 156 1 5 7 16 0 1 6 1 2 1 9 2 2 0 2 2 3 2 2 4 1 5 6 1 5 9 1 6 2 1 6 3 221 222 ? 2 5 2 2 6 16.1 165 I 6 8 1 6 9 2 2 7 228 ? 3 1 2 3 2 I66 167 I70 ( 7 1 2 2 9 2 3 0 2 3 3 2 3 4
-
.--
, 1 1 4 ' 7 5 6 ' q 9 10 1 3 3 *-'w 1 3 0 1 9 3 e ' e t 8 , 7 7 1 1 1 2 1 5 * 2 5 , 8 8 4 6 109 1 3 1 1 3 2 ID4 1 9 5 1 7 1 8 21 1 1 5 % 2 1 4 172 2 3 5 1 3 3 1 3 4 196 197 1 9 2 0 2 3.---.
1 4 5 146 1 4 9 1 5 0 2 0 8 2 0 9 2 1 2 2 1 3 51 5 2 5 5 56 114 1 1 5 1 1 8 119 5 3 5 4 57 5 8 1 1 6 1 1 7 1 2 0 121 59 6 0 6 3 6 4 122 1 2 3 1 2 6 1 2 7 61 6 2 6 5 6 6 124 125 128 129 1 7 7 1 7 8 1 6 1 182 240 2 4 1 2 4 4 2 4 5 1 7 9 1 8 0 1 8 3 I 8 4 242 2 4 3 2 4 6 2 1 7 1 8 5 186 1 8 9 1 9 0 2 4 8 2 4 0 2 5 2 2 5 3 1 8 7 1 8 8 1 9 1 1 9 2 250 251 254 2 5 5 1 1 5 2 1 5 1 215 2 1 6 1 7 3 1 7 4 2 3 6I
2 3 7I
1 4 3 1 4 4 147 14'1 72 I I 2 2 I 8 0 I 2 4: 8 2 1 8 ; 7 4 ._I 140 198 1 4 2 200 1 4 8 206 7 3 7 6 77 7 5 7 8 7 9 8 1 8 4 8 5 8 3 8 6 8 7 199 2 0 2 2 0 3 201 2 0 4 2 0 5 2 0 7 2 1 0 2 1 1 ~~~ ~~Figure 2. Tree-Depth scanning order for a 16\16 coefficient map Lrith 3 l e ~ e l s of decomposition
S & A E Bitstreum
Multiple (successive) quantization is taken as the quantization scheme (see Fig. 3 ) in the MPEG-4 still texture coding. Each quantization step will generate one ( S N R ) scalability layer. Assume that there are N scalability layers. the MQ procedure is described as follows. The wavelet coefficients will be quantized with scalar quantizer Q,, at first quantization step, and then the reconstructed values are subtracted from the original wavelet coefficients to get the residuals. At the second step, these residuals are quantized by a finer quantizer
0,.
and the reconstructed values are subtracted from the residuals of the first quantization step. The following quantization steps are performed with finer quantizers ina similar way. This procedure will continue until the N,,,
quantization is performed on the coefficients. After the quantization of each scalability layer. the quantized coefficients of the current scalability layer will be assigned the corresponding symbols and the symbols are encoded by using the arithmetic coder.
111. DESIGN ANALYSIS AND
IMPLEMENTATION STRATEGY
In this section. we will highlight the architecture designo n the MQ scheme and TDS method. Since the 'TDS
method combined with MQ scheme leads to the
irregular data flow for various scalability requirements, the design effort should be spent on arranging data flow such that maximal hardware utilization can be achieved.
In addition, a mechanism that allows efficiently accessing the parent and children of each coeficient is also discussed. Moreover, POT quantization method is proposed to substantially reduce hardware complexity for division arithmetic of generic quantization with very few bit-rate increases.
,---.---.
L .
Figure 4. Block diagram of the proposed zerotree coding architecture
A.
Tree-Depth Scanning
Fig. 4 illustrates the block diagram of the zerotree coding. The AC coefficients are read out from external frame memory into on-chip tree memory first, and then they are quantized and assigned symbols at the symbol assignment (SA) stage. After that, they are stored back to tree memory. At the symbol generation ( S G ) stage, they are scanned again such that the final symbols for successive arithmetic coder car1 be generated. At the SA stage, each wavelet tree needs to be transversed twice
so
as to determine the required symbols for all coefficients. First pass assigns one of the four symbols for all the coefficients of current wavelet tree. After that, ;lie second pass determines the symbol ZTR-D to tne children of previous coefficients assigned as ZTR or
VZTR. Owing to the zerotree coding algorithm, top- down scanning order will lead to recursive nature in the
first
pass of
the SA stage. As a result. the bottom-up order is adopted for the first pa:js such that the recursive nature can be removed.The ZTR-D symbol would not be assigned until the locations of ZTR and VZTR are decided in the first pass. The straightforward implementation is to rescan the wavelet-tree and assign the ZTR-D in the second pass, but this will lead to 50% memory access increase. Another approach is to assign ZTR-D with VZTR or ZTR at the same time. That is. once a coefficient is marked VZTR or ZTR. its children are re-marked ZTR-D immediately. However. this leads to multiple memory accesses (one current coefficients and its four children) to on-chip memory at one cycle. To overcome this problem, a ZTR-D candidate symbol registration strategy is employed. A flag register is associated with each element of the tree buffer to indicate whether the element is a ZTR-D candidate at the SA stage. At the SG stage, we only need to check the flag register to judge whether a ZTR-D symbol should be output. This approach. which employs the time-multiplexing concept. can unfold the memory acces.jes in time domain to
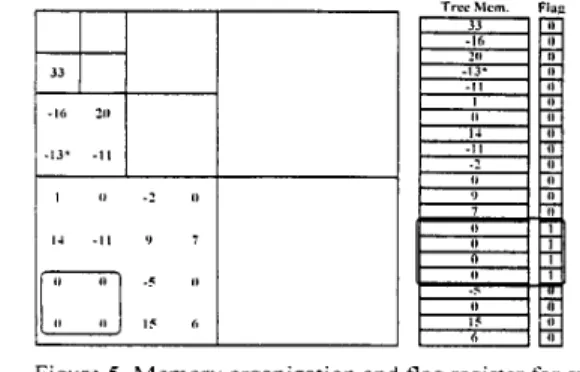
achieve the zerotree coding. Fi;;. 5 shows this ZTR-D candidate registration strategy.
Figure 3. Block Diapram ot' t h e Multiple (Successive)
Quantization Scheme
33 -16 ?I1 -13. - 1 1 I 11 - 2 11 I 4 - I 1 #> 7
[
:
:
]
I
:
1
Tree Mcm. FlagFigure 5 . Memory organization and flag register for symbol
registration
An on-chip memory is maintained to reduce the memory access to external frame memory at the SA stage. The minimal essential on-chip memory size is one wavelet tree. The tree-depth scan will lead to irregular data flow. However, by using a proper memory organization and addressing technique the irregular data flow can be effectively removed. Coefficients are stored in the on-chip memory with the same order as the tree- depth scanning method to facilitate the sequential data output order to the arithmetic coder at the SG stage. Since the scan order can be the bottom-up and top-down tree-depth scans at the SA stage, the entry point (first coefficient) address of each level should be indicated such that the other coefficients can be easily located. On the other hand. at the SA stage. the parent coefficient needs to be located to pass the significance information
of its children, and the ZTR-D assignment needs to locate the children of current coefficients. Namely, the parent and children of each coefficient may be accessed at the SA stage. For this. the symbol registration strategy can be applied both for ZTR-D assignment and significance information (zerotree root) passing. The following problem then becomes how to address the required parent or children locations in the tree buffer for the current coefficient. Actually. since the wavelet tree is a 4-ary tree. the locations of parent and children can be easily addressed by ( I ) and (2) respectively. Namely. with the proposed memory organization, no complicated addressing mechanism is required.
_" 55 5C - 35 -
.
30 -' 25 0 0 5 1 1 5 2 2 5 3 3 5 4 041 per OlxelFigure 6. A\ailable bit-rates for POT quantization
parenr iocnrron =
i
- I ( 1 )-I
\ \ h c r c i is the location o f t h s founh child
ci7ildren location = I x 4
+
Jwhere I I S the location of the parent. J = 1.2.3.4
( 2 )
B. POT Quantization Scheme
The hardware complexity of the quantization
implementation supporting user-defined coefficients (generic) is much higher than that of the quantization using constant coefficients. With the scalability features in MPEG-4, the number of quantization operations for each coefficient will be proportional to the number of scalability layers. This will lead to very high hardware complexity. As a consequence, the POT quantization scheme is proposed to reduce the hardware complexity. In this scheme, the quantization coefficients are constrained to only power of 2 integers. The division arithmetic is thus simplified to right-shift arithmetic.
However, the POT quantization leads to the
signification reduction of legal quantizers and thereby the available bit-rates. Fortunately. available bit-rates are concentrated in the low bit rate region although the number of bit-rates is limited, as shown in Fig. 6. Accordingly, the POT quantization still facilitates the low hardware complexity for the low bit-rate image coding and meets the low bit-rate goal. On the other hand, bit-rate variations are smaller than 4% if the quantization coefficients of the finest quantization stage are the same among different MQ combinations [I?]. This means that MQ scheme combined with the POT quantization has very similar performance if the finest quantization stage employs the same quantization coefficients.
C. Architectural Analysis
As mentioned previously. one two-port SRAM is employed as the on-chip wavelet-tree memory and one set of flag registers are associated with tree memory for symbol registration. The number of memory accesses to
the on-chip tree memory is twice per pixel in each scalability layer. Table 1 lists the comparison of memory access between several approaches. The memory access of the MPEG-4 VM is calculated from its recursive code. OZONE [9] and Bae's [ I O ] architecture also adopts one wavelet tree memory organization to reduce the memory access. The proposed symbol registration technique can further reduce the access. Thus. our design can have
27% reduction of memory accesses compared to
MPEG-4 VM, and 1 1 % reduction compared to OZONE and Bae's memory organization. In summary. except lighter on-chip tree memory access. ZTR-D assignment does not impose any burden on the tree memory due to the registration strategy. Besides, the memory addressing for TDS is simple and no complicated address generator is required.
IV. IMPELMENTATION
Since the zerotree coding did not involve many complex arithmetic operations but data assignment operations. this implementation is basically a memory dominant design. As a consequence. the memory resource allocation plays a very important role to achieve the hardware-efficient design. Because one wavelet-tree coefficients are processed in opposite order between SA
and SG stage, an extra tree buffer in between is required. Besides. for supporting the spatial scalability, the quantization order is opposite of the SA stage. Another extra tree memory is required to achieve the 100% utilization of each hardware modules. However, the cost of using two extra tree memories is too high. By
considering the throughput/cost tradeoff, the prototype implementation employs one tree memory. In such
implementation. half throughput performance is
achieved. The features o f the prototype chip are listed in Table 2 .
The entire architecture was d e s i g e d and verified
using RTL-Verilog. and synthesized with a 4-layer- metal O.35pm CMOS cell library using SYNOPSYS design complier. It was also fabricated using 0 . 3 5 ~
TSMC 1P4M CMOS technology. The chip size is
3.lx3.l mm'. and the post-sim clock frequency is
100MHz. At such rate, this chip can process 30 4-CIF frames per second with 5 spatial layers and 3 quality layers. Table 3 lists the specifications of the prototyping chip.
V.
CONCLUSIONS
In this paper. we have presented an efficient architecture of M Q scheme and TDS method for MPEG-4 still texture coding. By employing the proposed memory organization and symbol registration strategy. memory access can be reduced 20-30% compared with MPEG-4 VM. Moreover. the addressing technique based on the 4-ary property of wavelet tree scanning can reduce the hardware complexity. Besides, the MQ scheme combined with the POT quantization method is proposed to reduce the hardware complexity due to the removing of division arithmetic. By means of novel architecture and memory resource allocation. the best throughput/cost tradeoff is achieved. The prototyping chip is implemented using the TSMC O.35pm C M O S
technology. This architecture can process > O 4-CIF frames per second with 5 spatial layers and 3 S N R layers scalabilit? at 100 MHz clock frequency.
Quanrizarioii Scanning inerhod
Ma\ decoinp le\els
Ma\ spatial lavers
Ma\ S N R labers Quantization coeff
REFERENCES
I]. J . M. Shapiro. '-Embedded image coding using zerotree
of wavelet coefticients." IEEE Pansactions on Signnl
Processing. vo1.4 I. pp.34453462. Dec. 1993.
[2]. P. Srisram and M. W. Ma1,cellin. "Image coding using wavelet transforms and entropy-constraint trellis coded quantization." IEEE Transactions on Image Processing. vo1.4 pp.725-733. June 1995'.
[3]. S. A. Martucci. 1. Sodagar. T.Chiang. and Y. Q.
Zhang. "A zerotree wavelet video coder." IEEE
Pnnsnctions on Circuits and Svstenis for I ?de0
Technolog;L.. vo1.7. pp.109-1 18. Feb. 1997.
[4]. J. Liang. "The predictive embedded zerotree wavelet (PEZW) coder: Low complexit), image coding with versatile functionality." Proc. of' IEEE Conference on
.4coiistics. Speech and Signal Processing (IC.4SSP '99). pp. 1413-1416. 1999.
[ 51. Internntional Standard DIS I 0 9 18. Digirnl Conipression
and Coding oj'Continiioiis-lbne Still Images. ISO/IEC.
[6]. ISO.IEC FDIS 14496-2. lnforination Technolop
Generic Coding of .4iidio-I 'iszial Objects. Atlantic City:
ISO/IEC.
[ 7 ] . P. P. Vaidyanathan. Multirote syssrenis and jilter banks. Prentice Hall. Inc.. 1993.
[SI. J . M. Shapiro. "A fast technique for identifying zerotrees in the EZW algorithm." Proc. o f IEEE Conference on
.4cozistics. Speech and S i g r d Processing 1IC.4SSP '96).
[9]. B. Vanhoof. M. Peon. CI. Lafruit. .I. Bormans. L.
Nachtergaele. and I. Bolsenr;. "A scalable architecture for MPEG-4 wavelet quantization." Joirrnal of I ZSI Signal
Processing. ~01.23. no.1. pp.93-107. 1999.
[IO]. 1. Bae and V. K. Prasanna.. "A fast and area-efficient VLSl architecture tor embedded image coding." Proc. of-
IEEE Conjerence on Iniage processing IICIP). vol.3.
pp.23-26. I995
[ I I]. L. minn Ang. H. N. Cheung. and K. Eshraghian. -'VLSI
architecture of significance map coding of embedded zerotree Lbavelet coefficients." Proc. of- I€ € € .Asia-
Pacjfic Cor?f>rencr on Circ2,irs mid Svsteins. pp.627-630.
1998.
[I?]. Z. L. Yang. "Architecture Design for the Tree-Depth Scanning of MPEG-4 Still Texture Coding". inasrer
rhesis. Dept. of Elec. Eng. National Taiwan Universit?.
June 3000.
pp. 1444-1 448. 1996.
MQ ISQ included)
Tree-depth
Pouer ot 2 iniegeis
Table I . Comparison of memor! access beween several approaches
Memor? blemor) Normalizd Locate Locate
Size Access Access Parent Children
MPEG-4 VM 405.504 4.326.488 1 Recursive Eas!
OZONE [9] 34 1 3.628.152 0.82 Easy 1.4 A
Bar [IO] 34 I 3.628.152 0.82 Eas! N A
Proposed 34 1 3.228.98-1 0.73 Easy Eas!
Table 2. Features of the prototype chip Table 3. Specitication ofthe prolotype chip
Technolog!
Area
0 35 pin TSMC I P?bl CMOS
3098 4x309 I 2 pin- ( D i e l
231 1 212304 pin' (Ccmrel
3OOh transistors Linemop included)
I Jk Byres SRAM
Suppl! Voltaye 3 3 V
Colch Rate I00 M H z
Power 260 1nW.g 100 MHz
Picture Forinar K I F
Scalabilir!
Performance 30 fps
5 sparial and 3 S N R layers