行政院國家科學委員會專題研究計畫 成果報告
產品回收及再利用考量下企業採購決策及再製造決策之研
究(第 2 年)
研究成果報告(完整版)
計 畫 類 別 : 個別型 計 畫 編 號 : NSC 95-2416-H-004-050-MY2 執 行 期 間 : 96 年 08 月 01 日至 97 年 07 月 31 日 執 行 單 位 : 國立政治大學資訊管理學系 計 畫 主 持 人 : 林我聰 計畫參與人員: 碩士班研究生-兼任助理人員:林尚達 碩士班研究生-兼任助理人員:吳三裕 碩士班研究生-兼任助理人員:李惠卿 博士班研究生-兼任助理人員:李亞暉 博士班研究生-兼任助理人員:鄧廣豐 報 告 附 件 : 出席國際會議研究心得報告及發表論文 處 理 方 式 : 本計畫可公開查詢中 華 民 國 97 年 10 月 27 日
摘要
全球化的影響下,企業在獲取有限資源的競爭上日趨激烈,再加上環保意 識的抬頭及相關環保法令的要求,企業從其原物料的取得到產品設計、生產、配 送等供應鏈的活動上都需加上環保的考量,以符合綠色供應鏈(Green Supply Chain)的要求。此外,企業於微利時代中希望透過提高客戶服務,來產生差異 化,因此企業對於運籌管理(Logistics Management)亦從原本僅著重於原物料 採購、產品製造至配送顧客處的正向運籌管理(Forward Logistics Management),延伸至注重產品退貨、維修、回收、再製造(Remanufacturing) 及再利用的逆向運籌管理(Reverse Logistics Management)。而由於產品的回 收、再製造,並成為原物料重新投入供應鏈中(再利用),因此,對於企業的原 物料採購決策上產生重大的影響 - 原物料取得來源包含:(1)向原始供應商處 採購的新品(新零件),及(2)再製造中心所提供可再利用的回收品(再生零 件);後者相對而言,充滿了高度的不確定性(產品回收量、回收品可再利用率 等均不確定)。本研究藉由 CPFR(Collaborative Planning, Forecasting and
Replenishment)流程模型,探討當製造商零件的供貨來源有兩種時:(1)向外部 供應商訂購的新零件、(2)由再製造中心利用回收品進行再製造生產的再生零 件,在符合相關環保法令規範及考量因應不確定性之備料庫存等成本最小下,提 出一製造商、外部供應商與再製造中心三者的協同運作機制與訂單預測模型,產 生回收再製造量及新零件訂單預測量的建議值。同時本研究並依上述所提出之協 同運作機制與訂單預測模型,建立一決策支援系統雛型,提供決策者於考量產品 回收及再利用時,能做出符合企業效益的回收再製造及新零件訂購決策,減少企 業面對環保法令規範與客戶要求下,帶給企業管理上的衝擊。 關鍵詞:逆向運籌、CPFR、再製造、訂單預測、存貨管理
Abstract
Due to the markets are trending towards globalization, how to effectively use global resources becomes a key managerial issue, and all enterprises activities from raw-material purchase, products design to finished-product delivery have to consider the government’s decree and environmental consciousness to accord with the request of green supply chain. In addition, if enterprises want to make a difference between them and competitors, they can extend their logistics services from traditional forward logistics services to reverse logistics services (including products return, repair, recovery, remanufacturing and reuse). Owing to the products recovery,
remanufacturing and reuse, enterprises have strong impact on their raw-material acquiring and purchase activities (The sources of raw material can be from original raw material suppliers that provide new parts and from remanufacturing centers that provide remanufacturing parts. The quantities of raw material from remanufacturing centers are very highly uncertain).
In this research, to consider the conformity with government’s decree and minimalization of the total cost, we propose a collaborative mechanism and order forecasting model based on the CPFR (Collaborative Planning, Forecasting and Replenishment) for the manufacturer/enterprise, its original raw material suppliers and remanufacturing centers to decide the remanufacturing quantity of
remanufacturing parts from remanufacturing centers and the order quantity of new parts from original raw material suppliers. This research also builds a prototype of the decision support system based on the proposed collaborative mechanism and order forecast model to help making remanufacturing decisions for remanufacturing pars and ordering decisions for new parts.
Keywords:Reverse Logistics, CPFR, Remanufacturing, Order Forecasting, Inventory Management
目 錄
第一章 緒論...9 1.1 研究背景...9 1.2 研究動機...11 1.3 研究目的...13 1.4 研究方法與研究範圍...13 1.5 報告架構...14 第二章 文獻探討...16 2.1 協同規劃、預測與補貨...16 2.1.1 協同規劃、預測與補貨之定義...16 2.1.2 CPFR 之處理流程...18 2.1.3 CPFR 之效益...20 2.2 預測方法...21 2.2.1 預測概論...21 2.2.2 預測方法選擇與趨勢...23 2.2.3 因果分析-多元回歸分析...25 2.3 最佳演算法...27 2.3.1 最佳演算法之比較...27 2.3.2 演化策略法之介紹...29 2.3.3 編碼與適應函式...30 2.3.4 重組...30 2.3.5 突變...31 2.3.6 選擇與終止...32 2.4 逆向運籌管理...342.4.1 逆向運籌定義...34 2.4.2 逆向運籌的存貨管理...35 2.4.3 決定性存貨管理...36 2.4.4 隨機存貨管理...40 2.5 模糊理論...44 2.5.1 模糊理論之介紹...44 2.5.2 模糊控制系統...46 2.5.3 模糊化...47 2.5.4 模糊規則庫...50 2.5.5 推理引擎...51 2.5.6 解模糊化...53 2.5.7 小結...53 第三章 研究步驟與研究模型建置...55 3.1 研究步驟與流程...55 3.2 混合預測整體模型架構...58 3.2.1 步驟一 多元回歸模型變數建立...59 3.2.2 步驟二 模糊物料訂購總量模型...63 3.2.3 步驟三、四 演化策略法求最佳化之混合預測模型...74 第四章 實驗設計...79 4.1 實驗績效與驗證...79 4.2 資料來源與使用之分配...79 4.3 模糊物料訂購總量績效驗證...81 4.3.1 1-28 週系統參數績效驗證...81 4.3.2 演化代數選擇...81 4.3.3 突變率...85 4.3.4 模糊物料訂購總量模型績效...87
4.4 多元回歸...93 4.4.1 多元回歸參數分析...93 4.4.2 演化策略模型...94 4.4.3 績效檢視...96 第五章 結論與未來研究方向...100 5.1 研究結論...100 5.2 未來研究方向...101 參考文獻...102 計畫成果自評...106
圖 目 錄
圖 1-1 再製造策略下 CPFR 預測訂單模型關係架構圖...14 圖 1-2 研究架構與步驟示意圖...15 圖 2-1 CPFR 九大步驟...18 圖 2-2 企業預測模型採用狀況...24 圖 2-3 離散重組示意圖...31 圖 2-4 中間產物形示意圖...31 圖 2-5 演化流程圖...33 圖 2-6 再製造活動存貨系統...36圖 2-7 Serviceable and recoverable stock corresponding to the (1,R)...38
圖 2-8 Serviceable and recoverable stock corresponding to the (P,1)...39
圖 2-9 溫士城的存貨管理研究...42
圖 2-10 push control...43
圖 2-11 simple pull control...43
圖 2-12 general pull control...43
圖 2-13 模糊控制器架構圖...46 圖 2-14 π 曲線形函數...47 圖 2-15 梯形函數...48 圖 2-16 圖 2-16 三角形函數 l...49 圖 2-17 高斯分佈函數...49 圖 2-18 模糊推論示意圖...52 圖 3-1 研究模型建置圖...55 圖 3-2 本研究步驟之流程...57 圖 3-3 本研究之模型流程圖...59 圖 3-4 模糊物料訂購總量模型研究範圍...65
圖 3-5 模糊物料訂購總量模型操作流程...73 圖 3-6 多元回歸參數演化流程圖...78 圖 4-1 資料區間規劃圖...80 圖 4-2 第 1 週演化代數之績效收斂趨勢...82 圖 4-3 第 2 週演化代數之績效收斂趨勢...82 圖 4-4 第 3 週演化代數之績效收斂趨勢...82 圖 4-5 第 4 週演化代數之績效收斂趨勢...83 圖 4-6 第 5 週演化代數之績效收斂趨勢...83 圖 4-7 第 6 週演化代數之績效收斂趨勢...83 圖 4-8 第 7 週演化代數之績效收斂趨勢...84 圖 4-9 第 8 週演化代數之績效收斂趨勢...84 圖 4-10 第 9 週演化代數之績效收斂趨勢...84 圖 4-11 第 10 週演化代數之績效收斂趨勢...85 圖 4-12 演化訓練最佳代數圖...96
表 目 錄
表 1-1 協同預測方法相關研究...12 表 2-1 CPFR 九大流程步驟...19 表 2-2 預測模型特性整理...22 表 2-3 因果預測函數型態...25 表 3-1 參數說明表...67 表 4-1 突變率績效排名表之ㄧ...86 表 4-2 突變率績效排名表之二...86 表 4-3 各週次模擬成本與變動範圍表...87 表 4-4 第 21 週集群分析...88 表 4-5 第 22 週集群分析...89 表 4-6 第 23 週集群分析...89 表 4-7 第 24 週集群分析...90 表 4-8 第 25 週集群分析...90 表 4-9 第 26 週集群分析...91 表 4-10 第 27 週集群分析...91 表 4-11 第 28 週集群分析...92 表 4-12 各週次平均總成本集群資訊...92 表 4-13 回歸分析參數表...94 表 4-14 演化模型第一期初始值...95 表 4-15 演化訓練突變率前測實驗...96 表 4-16 四週預測之十次實驗績效...97 表 4-17 八週預測之十次實驗績效...98 表 4-18 平均預測模型績效檢視...99第一章、 緒論
1.1 研究背景
台灣是個以製造業為主並高度仰賴貿易的國家,所以生產的產品大部分外銷 到歐美各地。面對著國際大廠與主要通路商的成本領導壓力下,製造業的利潤空 間逐漸被壓縮;處於供應鏈中游階段廠商必須提高其供應鏈管理效率,降低運籌 成本、提供差異化或加值服務以爭取訂單。1998 年所提出的協同規劃、預測與 補貨(Collaborative Planning, Forecasting and Replenishment, CPFR )在國 外發展多年,目前全球已有上百家知名企業成功採用,並獲得實際的效益,如: Wal-Mart、IBM、HP、Johnson & Johnson 等公司。企業導入 CPFR 就像打破企業 之間無形的藩籬,讓整個供應鏈就像一個虛擬企業,與貿易夥伴共同參與規劃、 預測及補貨作業。 目前國內外廠商在推動 CPFR 不遺餘力,在正向運籌方面的協同已經蓬勃發 展多年,許多研究報告也紛紛提出,CPFR 有助於 1. 降低訂 單 出 錯 的 機 會 ;2. 改 善 預 測 的 準 確 性 及 適 時 ;3. 縮 短 訂 單 週 期,提升庫存周轉率,提升平均客 單價;4. 降低促銷品過期報廢金額、降低促銷缺貨率;5. 提 供 自 動 預 警 及 預 測 供 應 的 短 缺 可 能 性 ; 6. 協 同 合 作 尋 找 最 佳 的 組 件 及 原 料 採 購 安 排 。MaCarthy and Golicic (2002)、 Helms et al.(2000)學 者 在 探 討 協 同 預 測 績 效 與 效 益,注 重 在 導 入 研 究 所 帶 來 的 效 益。Aviv(2002)、黃 蘭 禎 (2004)研 究 中 主 要 探 討 預 測 方 法 為 主 。但隨著各國法令限制在全球化的 影響下,面對日漸減少的有限資源,以及社會環保意識抬頭以及相關法令規範。 企業必須從新思考整個產品流程設計,從產品設計、原物料的取得、產品製造、 配送、甚至回收,整條供應鏈的運作設計上都必須加上環保這個因素去加以考 量。在歐洲地區,歐盟訂定「廢棄電子電機設備指令」WEEE(Waste Electronics
and Electrical Equipment),針對電子產品的廢棄物問題,要求製造商必須負 責回收環保方面問題,提出有效循環利用機制,以減少每年應電子設備廢棄物所 帶來的汙染,法規裡要求歐盟會員國將 WEEE 納入該國法規;各企業廠商須在 2005 年八月底前完成相關配套(包含 collection, inspection, recycle,
disposal),企業須負起處理這些產品的責任,減少廢棄產品對環境的影響,相 關歐盟法令還包含「危害物質限用指令」(RoHS)、「包裝廢棄物指令」(PPW)全球 的製造商必須符合這項法令才能講產品出口到歐盟 。根據經濟部工業局於 2006 年初公布的調查數據,歐盟實施 RoHS 環保指令後,將波及國內十大產業,約 34,533 家廠商,受影響產值更將高達 2,446 億元。此外根據經濟部的評估,WEEE 與 RoHS 指令將使台灣約有 44 項的電機電子產品在輸出歐盟時受到管制,占了歐 盟管制 81 項產品的一半以上,這些輸往歐盟屬於十大類管制的電機電子產品在 2005 年產值約為 2,025 億元,國內產業受影響的程度可見一般。 另外伴隨產品生命週期縮短和產品淘汰速度增快,企業在面對複雜的市場若 不能精準預測產品的生命週期與需求量,常常造成大量生產囤積品。尤其以電子 性產品方面若不能在當季售出,不僅本身公司會造成巨大的存貨成本壓力,後續 滯銷品處理也需付出高額費用。根據統計美國每年消費性電子產業退貨額達 150 億美元來自於商品的退貨、生產過剩、報廢與回收等隱藏性損失,使得各企業營 運成本提高。企業除了加強品質管理與 CPFR 協同預測機制降低因生產過剩缺失 外,亦可在對這些滯銷產品、退貨產品做妥善處理,將回收品透過產品復原活動 加以復原其價值。與其將產品直接丟棄,不如當作另一原物料管道的取得,降低 原物料取得成本,充分利用回收品剩餘價值,將可替企業帶來可觀的效益。 所以面臨法令與回收復原活動雙重新因素下,CPFR 中對於訂單預測在考慮逆 向運籌下實行再製造策略下如何創造新的契機;根據訂單預測動態調整訂購數 量,以降低不確定因素影響,所以建立買賣雙方可達成共識的訂單預測模型是非 常重要的。
1.2 研究動機
長久以來企業對於運籌的觀點只單方面的考慮產品的研發設計、採購、生產 製造、運輸,配銷,藉由最佳化上述流程以提升產品整體價值,即所謂的正向供 應鏈;但隨著環保法令限制、產品生命週期縮短、消費者環保意識抬頭、地球資 源有限影響下,必須將正向運籌延伸至包含產品的回收、分類,復原,丟棄處理 等逆向運籌的處理活動,將產品的生命從產出到死亡提供完整運籌模型。許多研 究報告中也提出,實行逆向運籌有助於企業從中獲利與節省成本。 在 CPFR 流程中多數研究著重在正向供應鏈的協同預測的架構、導入效益與 預測方法等議題,但對於當企業活動中包含逆向運籌-再製造活動策略下時的協 同預測方法少有提之,因此與其相關之研究探討有其必要性;並且在預測模型建 置上,大多數以內部企業銷售預測與存貨需求預測為主,少數有針對 CPFR 中的 訂單預測方面來提出協同訂單模型之文獻;且在供應鏈中屬於生產製造階段的中 游廠商,需要面對未來環保法規及綠色意識地壓力,所以製造商有其必要將回收 活動納入 CPFR 預測方法,精確的控管物料需求量,協調物料供應、製造活動與 再製造活動三者之間的運作;一方面能使存貨可以達到有效控管以因應回收所帶 來的相關存貨成本壓力;另一方面回收品的前置時間皆會高於正常的採購流程 (Inderfurth and Van Der Laan, 2001),但若在法令規定最小回收量要求下, 廠商就不能直覺的從新物料來源來進行採購,必須以符合生產時程與低成本要 求,在物料供應商和再製造中心間來源作零件數量取捨,同時也能規避來自於法 令罰則的懲罰。表 1-1 協同預測方法相關研究 作者 研究內容與重點 Aviv(2002) 透過自我共同相關(Auto-correlated)需求模型來探討聯合預 測與補貨流程之效益 Holmstrom et al.(2002) 針對零售商與配銷商,在品類管理前提下,提出可以適用於大 規模協同合作的「商品等級-佔有率(Rank-share)」預測方法, 提供由上而下的集合銷售預測 李順益(2002) 利用灰色理論中灰預測的簡易、少數據之特性,來設計一套有 效的短期預測架構,並探討灰色預測應用於短期預測之適用性 黃蘭禎(2004) 透過混合性架構,結合時間序列和多元回歸模型預測方法且利 用基因演算法來提供協同銷售預測模型 曾永勝(2005) 利用類神經網路找出適合混合性預測架構解釋變數,且利用演 化策略演算法,求得符合協同銷售預測特性與需求之預測模型 陳寬茂(2005) 透過時間序列和多元回歸模型與演化策略法三階段預測方 法,建構出協同訂單預測模型 【資料來源:黃蘭禎(2004)、曾永勝(2005)、陳寬茂(2005)】 現今預測方法之研究,如表 1-1 所示,包括了時間序列分析、多元回歸分析、 基因演算法、灰色理論等,期望以更加的預測模型為企業提供更準確的資訊。羅 慕君(2004)指出企業的訂單預測主要利用歷史資訊,透過簡單的預測方法在加上 內部人工的產能預估產生。黃蘭禎(2004)、曾永勝(2005)與陳寬茂(2005)三位在 混合預測模型上,步驟上採用時間序列方式,再加入事件影響因子並透過多元回 歸分析求參數解,最後使用最佳演算法進行求解。然而在將回收活動考慮進來同
時,來自回收數量因素上,時間變異呈現高度不確定性,時間序列模型在估計預 測容易造成缺失;實際的生產活動與復原活動的交錯進行,也在時間序列以及多 元回歸分析中難以解釋。所以本研究希望如何在協同機制下加入再製造策略活 動,考慮實際工廠運作情形;滿足需求的前提下,配合逆向運籌下的存貨管理政 策使存貨成本最小化。使得未來訂購零件不確定性增添下,希望能藉由新的短期 訂單方法能找出最佳的預測值幫助企業與供應商能加強協同規劃,提升供應鏈競 爭力。
1.3 研究目的
本研究主要以 CPFR 流程中之訂單預測階段為主題,基於上述背景動機,將 生產製造情形、逆向運籌活動和事件因子、供應鏈績效因素等整合,建構出具有 協同機制的採購計量模型。在逆向運籌需求的趨勢下,產品回收及再利用勢必將 成為企業不可免除的問題,而回收與再利用衍生的作業成本,也將對企業帶來不 小成本負擔;且相關法令規範的也使得企業不得不將逆向運籌活動納入營運活動 範疇。 所以本研究的目的就是探討基於前述背景與動機,當回收量與需求量為不確 定情況要求下,建立具有產品回收與再利用考量下與物料供應商的採購決策模 型。1.4 研究方法與研究範圍
本研究的主要目的是希望能找出當製造商擁有回收機制下,如何透過結合 CPFR 流程步驟下發展出適合的協同訂單預測方法。使得供應鏈中各成員所觀察 到的,相互分享之訊息、事件納入模型考量中,得以提供供應鏈中單一最佳化訂 單預測量。此外供應鏈成員也可以進一步利用此模型來分析各訊息與事件對訂單 預測量可能之影響與決策績效。基於上述方法與概念,本研究模型將透過文獻探討方式,蒐集有關存貨管 理、協同預測與逆向運籌等相關領域;歸納出當企業流程中引進回收活動時,物 料提供商和製造商進行協同訂單預測之影響因子,作為模型的解釋變數。透過「模 型推導」研究方法,將存貨管理之經濟訂購量概念與多元回歸分析法結合,並透 過最佳演算法加以輔助;推導出多元回歸預測模型。最後採用實驗方法,以假設 資料進行統計分析,透過資料之測試,以最小平方誤差(MSE)等指標來驗證模型 績效,進而提出驗證結果與建議。 本研究偏向短期預測訂單模型,以快速反應市場需求,將製造商、再製造中 心及物料供應商關係架構如圖 1-1 所示;在再製造活動驅使下考量其訂單之特性 與因素影響,三者如何透過 CPFR 機制發展其適用的訂單預測模型,完成補貨程 序。 再製造中心 物料供應商 CPFR 製造中心 訂單預測量 再製造中心 物料供應商 CPFR 製造中心 訂單預測量 圖 1-1 再製造策略下 CPFR 預測訂單模型關係架構圖
1.5 報告架構
本研究報告共分五章,如圖 1-2 所示,第一章為緒論,描述本研究之背景、 動機、目的、研究流程與研究方法。第二章為文獻探討,針對本研究主題「逆向 運籌下 CPFR-訂單預測模型探討」;探討供應鏈、存貨管理、逆向運籌、預測方法論、CPFR 相關議題。第三章為說明本研究之預測模型建構、實驗設計、績效 指標以及操作性定義。發展一個適用整合正逆向運籌的訂單預測模型,考量可能 發生的各種不確定因素,以求出一個具參考的模型。第四章為本研究之實驗過 程、結果與分析;說明本研究與傳統方式預測方法優。最後,第五章提出本研究 之結論、貢獻及對未來研究之建議。 第一章、緒論 (背景、動機、目的、研究方法) 第二章、文獻探討 (供應鏈、CPFR、逆向物流等) 第三章、研究步驟與研究模型建置 (研究流程、模型架構、績效衡量指標) 第四章 、實驗分析與模型績效驗證 (資料敘述與分析、實驗設計) 第五章、結論與建議 (研究結論、貢獻、未來研究的建議) 第一章、緒論 (背景、動機、目的、研究方法) 第二章、文獻探討 (供應鏈、CPFR、逆向物流等) 第三章、研究步驟與研究模型建置 (研究流程、模型架構、績效衡量指標) 第四章 、實驗分析與模型績效驗證 (資料敘述與分析、實驗設計) 第五章、結論與建議 (研究結論、貢獻、未來研究的建議) 圖 1-2 研究架構與步驟示意圖
第二章、 文獻探討
2.1 協同規劃、預測與補貨
2.1.1 協同規劃、預測與補貨之定義協同規劃、與預測補貨 CPFR(Collaborative Planning, Forecasting and Replenishment)源自於 1995 年九月由 Wal-Mart 和其供應商針對零售業供應鏈問 題所發展出來的方法論,裡面參與成員包含了軟體公司、顧問公司集與 Wal-Mart 的供應商。此指導原則是冀望透過協同分享預測,增進零售商與製造商因需求不 確定所造成的長鞭效應,影響整個供貨問題,造成整體在需求鏈上的銷售損失以 及生產過剩的成本損失。之後 CPFR 發展透過 26 個領導廠商成立 VICS 協會共同 制定指導原則,透過網路應用以及相關支援的應用軟體共同承擔風險,在 1998 年公佈的一連串指導原則(處理流程),共訂定了九大步驟協助企業間如何在規 劃、預測與補貨等方面進行合作。 聯合通商與 EANTAIWAN(2002)對 CPFR 之定義為「正式規範兩個企業夥伴間 的處理流程,雙方需先同意接受協同合作計畫和預測,監控全程一直至補貨之間 的運作是否成功,然後確認異常狀況,最後採取可行方案加以解決」。 VICS(2002)定義為「CPFR 是一套藉由企業與交易夥伴, 透過分享預測相關 資訊,來追求供應鏈協同合作的方法。而透過此一方法,可以使雙方的預測績效 提升」。 Seifert(2002)對 CPFR 定義為「供應鏈中所有參與者間的計畫,目的在透過 共同管理規劃流程及分享資訊,來改善彼此的關係」。 林振成(2003) 對 CPFR 定義為「一個企業間協同流程,使價值鏈參與者透過 事先規劃及同意異常狀況處理規則,以控制供需間預期心理的過度或不當反應,
減低供需之差異,進而共同分享市場潛能與風險」。 Schroder(2002)透過高度的信任、與有品質的資訊分享來達到可衡量的改 進,其目標為增加需求預測和補貨規劃之正確性。CPFR 是由一連串的企業流程 所組成,將供應鏈中交易伙伴共同擬定之企業目標及方法、聯合銷售及作業性計 畫、電子化整合及更新銷售預測及補貨計劃連貫起來。 因此 CPFR 之協同合作(Collaboration)概念需要資訊技術去建立、讓合作 夥伴運用網際網路分享預測和結果資訊,增加商品的可利用率與銷售量。供應鏈 中的合作一直被視為一種主要的企業流程,而 CPFR 正是一種能夠使彼此交易夥 伴之間達成雙贏局面,亦即客戶滿意度,成本及收益能夠同時達到最佳化之最成 功的機制;再者 CPFR 也是一個指引架構,提供出一個參考架構、模型以及技術, 讓合作夥伴可以一同進行計畫評估與決策。為了提昇成員彼此間的相互信任程 度,CPFR 重新定義了商務流程,以確保體系成員間在協同運作的過程中,任何 成員都不會有突如其來的意外狀況發生;也正因為如此,愈來愈多的企業及組織 正走向 CPFR 的懷抱以享受其所帶來的好處。
2.1.2 CPFR 之處理流程 CPFR 為一連串的企業流程所組成,而這一連串的流程乃是由供應鏈中互相 的交易夥伴共同擬定之企業目標及方法、共同發展之聯合銷售及作業性計劃,和 電子化的整合及更新銷售預測,訂單預測及補貨計劃」。彼此夥伴之間的溝通更 加的密切,其意味著:當需求改變時,促銷或是策略變動、聯合銷售預測及訂單 預測,補貨計劃更能適時且迅速的調整至合理的水平,而能減少雙方因為變動而 造成的成本損失。透過 CPFR 活動可達到改善需求預測、產品在對的時間點配送 至對的目的地、降低整個供應鏈的存貨水準,避免缺貨現象、改善顧客服務水準。 增進整條供應鏈效益。 在 CPFR 流程模型中,包含了三大階段及九大步驟,分別為規劃階段、預測 階段和補貨階段。 圖 2-1 CPFR 九大步驟 【資料來源:http://www.vics.org/】
表 2-1 CPFR 九大流程步驟 階段 流程步驟 規劃 發展前端協議 制定聯合商業計畫 預測 銷售 預測 制定銷售預測 界定找出影響銷售預測之例外狀況,並列出例外商品項目 針對例外商品項目,協同解決該例外狀況 訂單 預測 制定訂單預測 界定找出影響訂單預測之利外狀況,並列出例外商品項目 針對例外商品項目,協同解決該例外狀況 補貨 產生訂單 【資料來源:http://www.vics.org/】
2.1.3 CPFR 之效益 實行 CPFR 好處,可歸納成,王立志(2006): 1. 對零售商而言:銷售量增加、服務水準提升、訂單回應時間縮短和產品存貨 數、報廢數及不良品數目均下降。 2. 對製造商而言:銷售量增加、訂單滿足率提升、產品存貨量減少、週轉時間 加快及產能使用減少。 3. 共享的供應鏈效益:增強夥伴關係、提供自上游到下游的銷售分析和訂單預 測量、利用行銷點資料、季節活動、促銷、新品介紹以及商店開幕等資訊來改進 預測的準確性、透過除去或預先排除問題來進行需求鏈管理、在未來的必要條件 和規劃中接受協商合作,可獲得共同規劃出來的計畫,便於進行促銷管理;整合 規劃、預測和運籌活動;提供有效率的型錄管理,並了解顧客的採購偏好;提供 關鍵績效指標的分析(例如:預測準確度、預測經驗、產品前置時間、存貨週轉 次數、缺貨比率)來減少供應鏈中缺乏效率部份,並改善顧客服務及增加銷售量 和獲利能力。 而根據 CPFR 網站的調查,CPFR 可以為導入的廠商帶來的效益平均為:銷售 成長 2%至 25%、預測準確度提升 10%至 15%及服務水準成長 0.5%至 2%。 因此 CPFR 指導方針中制訂一套循序漸進的方法,先從協同規劃開始,再經過協 同預測,最終達到協同補貨。此商業流程的主要特色,仍在於促使供應鏈體系的 成員,在「商務夥伴」關係架構下,能夠根據彼此之間的互信程度來共用特定的 企業資訊,以在供應鏈體系內發揮各自的核心競爭力,分擔整體供應鏈成敗共同 責任,並且同享成果。
2.2 預測方法
2.2.1 預測概論 于宗先將預測定義為「對未被觀察事象的一種說明」。所謂未被觀察的事象 不僅指未來的事象,也指已發生的事象。如果所涉及的包括這兩種事象,則稱為 廣義的預測。如果所涉及的僅是未來的事象,則稱為狹義的預測。預測是利用現 代科學理論和方法,結合人類的豐富經驗與判斷,根據相關數據資料透過系統化 的步驟計算與分析,去探討未來事物發展之可能趨勢,以變作為未來行動分針。 Delurgio(1999)認為預測是對未來值或狀況機率上的估計或敘述,但好的規劃和 控制要求預測要包括平均值、範圍和對該範圍的機率估算等項目,預測被強調不 應該只是個單一值,而是一個值域。大部分的預測運用中,此方面的決策會嚴重 影響到定價與促銷的決策,也可能對生產控制、存貨控制等產生重大影響。基本 上預測可分為管理者規劃系統,或者是幫助規劃系統使用。規劃系統主要提供長 期性計畫,包含地點設置的選擇、未來提供的產品種類;規劃系統使用主要運用 在中短期的計畫,包含了生產需求規劃、預算編列及存貨控制等。 目前產業界都是應用預測的手法來預測公司未來長短程的銷售量,然後再利 用這些預測數據,加上公司的營運策略來事先規劃長程的產能擴充計劃及短程的 生產計劃。如此一來便能使得客戶訂單在交期準確性上,得到一個較令人滿意的 結果。預測是一種資料探勘的相關技術,通常都是利用各種統計或回歸 (Regression)的方法,從過去的歷史資料中找出有用的趨勢或是模型,然後利用 這些趨勢或模型來求得下一期間或週期的預測值。 預測分類主要可分為區分成定性分析與定量分析兩大類。一般而言預測過程 利用人的因素、個人意見、直覺等主觀投入因素,缺乏準確數字描述可被稱為定 性分析;而定量分析則是利用客觀性資料或者歷史數據,避免因為強烈主觀因素 造成預測偏差。Gorden(1997)將預測方法分為三類、判斷法、時間序列與因果法。依 Chamber(1971)等之區分預測的方法可以分為三大類:定性分析(Qualitative Methods)、時間序列分析及投影法(Time Series Analysis & Projection)與因 果分析法(Causal Methods)。DeLurgio(1999)亦將預測方法區分為單變數(時間 序列)、多重變數(因果預測)與定性預測三類。呂柏賢(1999)將預測方法分成 有很多種,主要有統計方法、定性分析、經濟模型、因果分析法與人工智慧法。 表 2-2 預測模型特性整理 模型型態 預測方法 適用時機 判斷預測法 (Judgmental) 貝氏法(Baysian) 德菲法(Delphi) 1. 歷史資料缺乏 2. 要求快速的預測結果 時間序列(Time Serials) 簡單移動平均(Simple
Averages) 移動平均(Moving Averages) 指數平滑(Exponential Smoothing) 線性趨勢(Linear trend) 1. 資料模型呈現平滑與 持續特性 2. 資料模型呈現季節特 性 3. 資料量可得且適足 4. 環境穩定變化慢 5. 過去發生事件會在未 來持續發生 因果關係 (Cause-and-effect) 回歸分析(Regression) 計量經濟分析 (Econometric) 輸入輸出分析 (Input-out) 類神經網路 1. 資料模型出現凸點或 outliers 2. 資料模型出現季節性 3. 模型的自變數與因變 數有強而穩定關係 【資料來源:黃蘭禎(2004)】
2.2.2 預測方法選擇與趨勢 Levary 和Han(1995)條列了選擇各項技術預測方法的先決條件;而影響技 術預測方法選用的因素則有以下六點: 1. 技術的研發成本:當新的技術發展的過程中,累積花費的金錢愈多,實現的 機會就會增加,同時發展的時間就愈短,而這些金錢的花費通常與技術發展所帶 來的可能利益、及其對社會潛在的影響有關。 2. 資料的取得:不同預測方法的應用資料數量也會有差異。 3. 資料的有效性:資料的品質、深入程度也是技術預測方法上的考量因素。 4. 技術發展的不確定性:不同的預測方法適合不同種類的問題,在不確定的情 況下,必須選擇最好方案。 5. 技術世代間隔:如果新技術發展與現存的技術愈相近,其成功的機會將會增 加,同時其發展時間也會縮短。 6. 技術發展變數因子:當技術發展時遭受到的不確定變數增多時,預測活動所 考慮因素變得複雜;通常難以利用單種預測方法,有可能需要多種方法交互運用。
Makridakis and Wheelwright(1997)針對一般預測方法進行實證研究歸,納 以下結論: 1. 在預測方法選擇上,並沒有相關研究證明哪種預測方法較好,需針對問題模 型提出一套預測方法。 2. 定性分析研究上的預測準確度較低,且花費成本較高。 3. 計量經濟模型預測結果並沒有比時間序列預測來的準確,但它可提供各變數 因果關係。
4. 無論何種預測方法,簡單的預測方法並未絕對比複雜的方法準確性低。 5. 實證結果顯示,給予所有的資料相同權數的簡單最小平均法,其預測準確性 低於依據資料的新舊特性給予較高、低權數的折扣平均法。 Mentzer et al.(1995)在對 478 家公司的問卷調查中發現,「移動平均法」 與「指數平滑法」是實務界最熟悉的預測方法,且兩者亦分別為預測週期「三個 月以內」及「三個月至兩年」中,被採用最多的預測方法,另其中「指數平滑法」 更是最受業界滿意的預測技術。 Makridakis et al.(2000)研究發現沒有一種方法對所有的時間序列或預測 時間範圍擁有絕對的優勢,也就是某種預測方法會在某些時段表現最好,但在其 他時段卻不盡然,且複雜的方法並不會顯著地比簡單的方法精確。 Jain(2002)研究中針對 1236 家企業調查,發現 61.33%採用時間序列分析, 22.65%採用因果分析、13.92%採用判斷分析法、2.10%採用其他自行建構方法。 如圖 圖 2-2 企業預測模型採用狀況 【資料來源:黃蘭禎(2004)】 Ozturkmen(2000)、Charles(2002)與 Jain(2002)研究中皆認為,利用單一預 測方法考因素過於簡化,未能解決由產業環境變化所帶來不穩定的因素,應合併 各種多種預測方法,擷取各方法之所長,提升其預測準確性。黃蘭禎(2004)、曾 永勝(2005)與陳寬茂(2005),研究中也分別証實了利用混合式的預測方法可以有 效提升其預測結果。
由上述相關的文獻中,當我們在設計預測模型中,必須針對其研究主題加以 定義分析,選擇適當預測方法。本研究問題中主要針對再製造策略活動下的訂單 預測,由上述的文獻中提到針對環境不確定的情況下,利用混合式的預測方法可 以獲得較佳結果。因此本研究的訂單預測,採用因果分析為基礎,結合傳統中存 貨管理經濟訂購量的概念,提供較佳解釋與預測準確性,並可以進一步提供事件 影響分析量。 2.2.3 因果分析-多元回歸分析 在一般的多元迴歸分析預測函數中,依其複雜性有一般線性回歸、非線性回 歸;為了操作方便,非線性回歸須轉換為線性,轉換後以半對數(Semi-log)線性 回歸和雙對數(Double-log)線性回歸模型中為常見。這些線性回歸模型定義如 下: 1. 一般多元線性回歸模型:Y =β0+
∑
βi∗Xi 2. 半對數線性回歸模型:lnY =β0+∑
βi∗Xi 3. 雙對數線性回歸模型:lnY =β0+∑
βi∗Xi+∑
βj∗lnXj 其中 Xi,Xj皆為解釋變數;βj為解釋變數之係數;Y 為回歸函數的應變變數 表 2-3 因果預測函數型態 作者 函數型態Venkatesh and Lakshman(1996) 雙對數線性 Mulhern et al.(1998)
Blatterg and Wisniewski(1989) Mulhern and Leone(1991)
Bolton(1989) 呂百舟(2000)
半對數線性
Venkatesh and Lakshman(1996)認為銷售量函數以半對數方法表示並不太恰 當。他認為銷售量之解釋變數,其解釋變數並非全部都可用指數表示之,統計模 型中,對於質化因子(如品牌、顏色、性別等)多以虛擬變數(Dummy Variable) 「1」或「0」來表示該特徵值的有無。這些指標性變數,以指數來表示還算恰當。 但對於談性、邊際效果之解釋(如價格彈性)在轉換半對數形式後,會有過分高估 之現象,使用雙對數線性形式可減輕這現象。 本研究中,主要針對訂單預測模型設計,其中包含許多指標性變數與一般性 變數(如庫存策略與訂單週期),若用半對數線性函數並不恰當,易發生變數影響 效果被低估或高估之現象,故採用雙對數線性函數形式以減輕此現象。
2.3 最佳演算法
2.3.1 最佳演算法之比較 一、 演化策略法之特色 吳子逢(2003)傳統的演化策略是一個有效的最佳化搜尋方法,它的優點 是: 1. 多點搜尋容易維持條件限制下合理的解; 2. 變數為實數型有利於連續型變數問題直接設計; 3. 容易加入啟發性 (Heuristic) 知識; 4. 有能力找到全域近似最佳解 (Global Near-optimum);演化策略在每一 迭代中只有針對現有的解產生若干個突變運算,係採用高斯分布隨機產 生再測試的方法產生新解。 二、 基因演算法的特色 張育瑋(2003)基因演算法跟一般的最佳化方法所不同之主要特性分述如下: 1. 基因演算法的運算,主要在參數經過編碼的位元字串上,而非參數本 身,所以在搜尋分析上不受參數連續性的限制。 2. 基因演算法採用隨機多點同時搜尋(多點跳躍演化)的方式(複製、交 配、突變),因此可以避免侷限在區域的較佳解上,而得到問題的較佳 解,且較傳統如模擬退火法類的單點依序搜尋方式為佳。 3. 基因演算法運算時只需訂定問題要求的目標函數(Objective Function)為適應函數,並不需其他的輔助資訊(如函數的微分性、連 續性),所以適合各類問題的目標函數。三、 模擬退火法之特色 黃肆海(2003)模擬退火法可視為一種機率登山搜尋的演算法,它結合了最陡 坡降與隨機程序的方法,在搜尋的過程中,通常是以隨機的方式來尋找。 1. 模擬退火法其演算程式較其他啟發式演算法易撰寫與理解,沒有複雜的 運算; 2. 在整個搜尋過程中,僅需考慮目標函數值本身,不需考慮目標函數值的 一階或多階微分值; 3. 此外,設計變數值可為離散值,不一定為連續值,隨機選取的初始設計 變數對搜尋結果影響不大。 模擬退火法搜尋方式是單點搜尋,沒有設計變數的訊息交換,搜尋速度比基 因與演化策略法慢。其中最大的缺點在於模擬退火法算是所有最佳化方法中待設 定參數最多的一個,且參數的選定深受函數的影響,並左右著搜尋結果的好壞。 而基因演算法主要編碼方式以整數型態為主要方式。因此本研究採用演化策略法 因為在於其研究發展完全建立在嚴密的數值分析與機率理論上,其搜尋能力的分 析在 Arnold(2002)、Beyer(1995, 2001, 2002)均有詳細探討研究。在連續型變 數應用問題上,演化策略的表現較優於演化規劃,在球體模型(Sphere Model) 的 參數最佳化實驗上也比傳統基因演算較佳,所以演化策略的應用多半在於連續函 數問題的最佳解設計上。
2.3.2 演化策略法之介紹
1964 年,德國人 Rechenberg 為了解決流體力學中模型控制問題而發展出了 演化策略法。演化策略法基本上屬於人工智慧(Artificial Intelligence, AI) 領域中的一種,以生物學家達爾文(Darwin)提出的「物競天擇,適者生存」的進 化論(Evolutionism)為基礎模型。進化論大意是說,生態中各生命個體在有限資 源情況下,為了求取生存與子嗣延續,必需透過競爭與自然演化生物演化機制以 求物種延續,失敗者將被淘汰而勝利者留下。類似許多的進化論演化式計算模型 方法已經被發展出來。
1.遺傳演算法(Genetic Algorithm, GA) 。 2.演化策略(Evolutionary Strategy, ES) 。
3. 演化式規劃(Evolutionary Programming, EP) 。
4. 適應動態環境學習的分類系統(Classifier System, CS) 。 GA 為主要演化式演算法的基本型,各種演化式計算模型都是由 GA,加強、 延伸而來的。ES 與 GA 最大不同之處在於 ES 中個體的染色體是以實數所表現, 而非如遺傳演算法一般,以位元為基本單位;利用實數表示時染色體可能為問題 之可能解同時,這樣可避免在合適度評估時做數值轉換。 最早的 ES 為隨機搜尋只有突變與選擇機制並不包含重組,稱為「1+1演 化策略」( (1+1)-ES, 單成員的 ES,運算過程透過一個父解經由突變機制(利用 平均值為 0,標準差為 s)產生一個下代(子解),接著透過適應函數比較父代與子 代,在進行下代演化)。隨後發展了族群式演化策略,((μ+λ)演化策略 和(μ, λ)演化策略),並加入新的演化運算元-重組機制(Recombination),使控制演 化的策略參數隨著各單元一同演化。此兩種不同 ES 主要差異為(μ+λ)-ES, μ 個父代產生λ的子代,且從這μ+λ個解中挑選最佳的μ個為父,再進行下一代 運算;而 (μ,λ)-ES, μ個父代中產生λ>μ個子代後,並只考慮新產生的子 代,選出最佳μ個做為父代,再進行下一代運算)。ES 至此奠定雛型。 最早的演算法演化策略的重要機制:編碼型式 (Representation) 與適應函
式(Fitness Function) 、重組 (Recombination) 、突變 (Mutation) 及選擇 (Selection)。 2.3.3 編碼與適應函式 演化策略的應用多半在於連續函數問題的最佳解設計上。我們必須將問題編 碼成 n R Xr∈ 形式,其中 n 為問題變數個數。之後我們給定一個目標函式 R R f : n → ,且適應函式 Φ 原則與目標函式一致Φ
( )
ar = f(xr), 其中xr 為ar組 成之一,即ar=(x1,x2,...,xn,α1,α2,...αm),x為變數α 為策略參數,(α 是問題變 數的標準差以作為突變機制的依據)α 個數1≤m≤n,在問題描述中必須定義清 楚,之後我們可以利用適應函式 Φ 作為演化依據。 假設我們針對 4 個實數變數進行計問題為佳化設計,第一部主要是進行變數 編碼rx∈(
x1,x2,x3,x4)
,接著給定目標函式f( rx)∈R,接著設定策略參數α ,最後 組成適應函式Φ(
x1,x2,x3,x4,α1,α2,α3,α4)
。 2.3.4 重組(recombination) 當演化策略法為(μ+λ)-ES 和(μ,λ)-ES 會多出重組步驟與 GA 步驟中的交 配相同,主要是為了讓父代個體染色體互相交換有用的資訊,使子代染色體獲得 更高的合適度,以改善父代染色體。除了目標變數進行重組運算外,策略參數也 可隨著各單元一同演化。演化策略有許多種重組方式,一般可以分為離散型式 (Discrete) 及中間產物型式(Intermediate) ,其運算方法如下: 一、 離散型式 從父代中集合中選取兩組解,p1{10,20,30,40,50}與 p2{12,24,28,44,48},接下 透過離散重組式{1,1,2,2,1}(選擇子代解變數繼承的對象,1 代表由 p1 選取 2 代表由 p2 選取),產出子代{10,20,28,44,50}。如下圖所示:圖 2-3 離散重組示意圖 二、 中間產物型 中間產物主要是利用加權平均的概念運算,如下圖中中間產物運算子 {0.4,0.3,0.6,0.6,.5}意味著新子代的各個變數的解是經由父代依比例產生; child 中的第一個變數 11.2 即是10×0.4+12×
(
1−0.4)
計算求得。 50 40 30 20 10 48 44 28 24 12 中間產物={0.4,0.3,0.6,0.5,0.5} 11.2 22.8 29.2 42 49 p1 p2 child 50 40 30 20 10 48 44 28 24 12 中間產物={0.4,0.3,0.6,0.5,0.5} 11.2 22.8 29.2 42 49 p1 p2 child 圖 2-4 中間產物形示意圖 2.3.5 突變 在演化策略法中,若各子代來自於父母的基因組合時,染色體的內容即是問 題的可能解,可避免個體在合適度評估時做數值轉換,但只進行重組運算時無法 產生差異度較大的子代,容易陷入區域最佳解(Local Solution)中,因此適當的 突變有助於子代邁向全域最佳解(Global Solution);其中不僅目標變數可以藉 50 40 30 20 10 48 44 28 24 12 離散重組={1,1,2,2,1} 10 20 28 44 50 p1 p2 child 50 40 30 20 10 48 44 28 24 12 離散重組={1,1,2,2,1} 10 20 28 44 50 p1 p2 child由突變機制最佳化,策略參數也可透過突變獲得一組效率最高的演化參數。 突變公式如下:
( )
( )
(
0,1 0,1)
exp ' ' N N i i =σ ⋅ τ⋅ +τ ⋅ σ i=1,2,3,...,nσ ) 1 , 0 ( . ' ' N x xj = j +σj j=1,2,3,...,n i σ 為父代中第 i 個策略參數 ' i σ 為子代中第 i 個策略參數 j x 為父代中第 j 個目標變數 ' j x 為子代中第 j 個目標變數 1 2 − = nτ 全域學習率(Global Learning Rate),n=目標變數個數
1 ' = 2 −
n
τ 區域學習率(Local Learning Rate),n=目標變數個數
2.3.6 選擇與終止 選擇機制在演化策略中方式是決定論的 (Deterministic) ,可以分為((μ +λ)演化策略 和(μ,λ)演化策略),主要差異在主要分別在於(μ+λ)ES 中,在於父代經過重組與突變後產生λ個子代,之後再進行適性函數評估時,會 將父代與子代(μ+λ)同時進行考慮選出μ個為下一代的父集合;(μ,λ)ES 則是在評估時只考慮λ個子代,之後選出μ個為下一代的父代;演化流程圖如圖 2-5。 在正常運作下,要中止演化,通常有下列方式,視資料與問題複雜度設定之。
1. 設定演化代數; 2. 設定演化時間; 3. 設定每袋合適性之差異程度,當差異小到預設值時。 產生初代母體族群 由母體中挑選父代 行重組運算,產生 子代 進行子代突變 適應函數評估值 選擇下世代父解 是否到達演 化終止條件 最佳解 Y N 產生初代母體族群 由母體中挑選父代 行重組運算,產生 子代 進行子代突變 適應函數評估值 選擇下世代父解 是否到達演 化終止條件 最佳解 Y N 圖 2-5 演化流程圖
2.4 逆向運籌管理(Reverse Logistics Management)
2.4.1 逆向運籌定義 當運籌逐漸發展成一新興領域後,由於消費意識的抬頭與顧客滿意度要求的 提升,由製造端到消費端單方面的正向運籌服務,已不敷需要。不良品的退貨、 產業界所提供的滿意保證、維修、和其他的回收因素,使得由顧客端將產品退回 到製造端的逆向運籌變得越來越重要。美國逆向物流協會(Reverse Logistics Executive Council, RLEC)將逆向物流定義為:逆向物流是一種物品移動的過程 中, 從最終目的地移動至其他地點, 主要是為了獲得在其他方面無法得到的價 值, 或是為了對產品做適當的處置。【資料來源:洪維謙(2006)】依據美國物流管理協會的研究報告中對於逆物流之定義:「以廣義的觀點說
明產源減量(Source Reduction) 、再生(Recycling) 、替代(Substitution)、 物料再利用(Reuse)及清理(Disposal)等方法進行之物流相關活動,在物流程序 中扮演物品再生、廢棄物清理(Waste Disposal)及有害物質(Hazardous Materials)管理的角色。以下是幾位學者對於逆向運籌之定義: Stock(1992):逆向運籌是一種扮演產品退回、資源減量、再生(Recycling)、 物料替代、循環再利用、廢棄物清理、翻新(Refurbishing)、維修(Repair)、再 製造(Remanufacturing)的活動;且認為逆向運籌管理是一種系統性的商業模 型,也就是說企業採用最佳的運籌管理方式,已完成整個供應鏈的循環並且使企 業能從中獲利。【資料來源:林坤德(2004)】
Carter and Ellram (1998) 認為逆向運籌狹義的定義為透過配銷的網路系 統將所銷售的產品進行回收的過程。但是以逆向運籌廣義的定義而言,逆向運籌 還包括了使正向供應鏈的使用物料數量減少,以使得回收的物料數量也跟著減少 以及使得產品可以再使用和再生處理可以更方便。Dowlatshahi(2000)定義逆向
運籌為重新設計供應鏈,使產品或零件再製造、循環利用以及丟棄處理活動下能 被有效率管理,並且有效地利用資源。Fleischmann(2000)重新定義逆向運籌, 他認為所謂的逆向運籌:即是從顧客端回流的商品,再次做適當處理與製作,然 後重新在市面上銷售的程序。 簡而言之,逆向運籌是當商品到達其使用年限、維修,損壞退回或商業退回 (時裝、化妝品等)等因素時,從終端使用者手上移至其他地點進行處理活動,使 商品可重新獲得其價值和提供適當產品廢棄處置。 根據一項保守的估計,逆向運籌計算起來大概佔運籌總成本的4%(Rogers, 2001)。在零售業和製造業裡,逆向運籌的成本被估計佔總運籌成本的5%-6% (Raimer, 1997)。對照Daugherty的觀察研究指出,平均來說逆向運籌的成本 佔企業運籌總成本的9.49%(Daugherty et al, 2001)。因此逆向運籌必將成為 許多企業裡的關鍵性問題。【資料來源:鄭偉平(2005)】 因此隨著社會發展,逆向運籌的經濟價值也逐步得到顯現,國外許多知名企 業把逆向運籌強化成其競爭優勢,作為增加顧客價值、提高供應鏈整體績效的重 要手段,其中Chone(1988)逆向運籌主要目在於達成企業在經濟上以及環保上的 目標。同時在研究中並提到企業使用再製造方式的話,一年可以節省40 ~ 60% 的 成本。另外Marien(1998)研究中發現產業已經了解到實施逆向運籌有助於企業活 得良好的競爭優勢。 2.4.2 逆向運籌的存貨管理 同步化的生產和再製是目前實務上的生產趨勢,然而當一般產品和再製品的 前置時間不同時,會造成決策者不知道要如何決定最佳物料訂購量和再製品生產 量,才可使總存貨成本達到最小化,而使存貨的控制出現困難。傳統零件存貨策 略考量方式主要依據需求透過經濟訂購量模型(EOQ)可求出經濟訂購量;然而當 企業活動中包含了再製造策略,存貨考量因素並非如傳統單階層,而是分成兩段
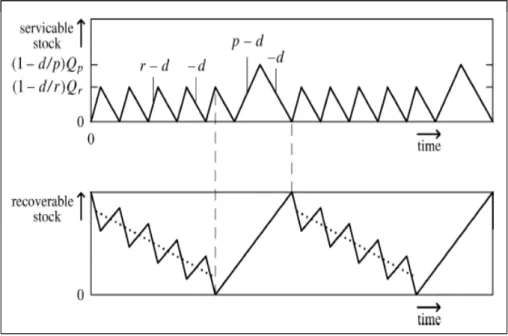
式存貨,供給一般需求存貨又稱為可服務存貨(Serviceable Inventory)與回收 品存貨又稱為可復原存貨(Recoverable Inventory)。 End-user remanufacturing manufacture 需求 可服務存貨 可復原存貨 回收 supplier End-user remanufacturing manufacture 需求 可服務存貨 可復原存貨 回收 supplier 圖 2-6 再製造活動存貨系統 在零件可再製造情況下,企業引進再製造活動策略下,可服務存貨供給來源 有可分作兩方面,一是項零件供應商訂購新零件以滿足需求,另一則是透過零件 再製活動,將其物料恢復其價值(假設再製零件與新零件並無差異),這時產生了 新問題,需要向供應商訂購新零件多少?在可復原存貨方面,由於回收活動存在 著回收數量不確定、回收時間不確定和回收品質不確定性,除了數量與時間因素 會造成生產控制上問題,回收品質更是嚴重影響到再製造活動成本;因此衍生出 如何再製造批量問題?所以有許多學者開始研究相關逆向運籌下帶來的相關存貨 管理研究。 2.4.3 決定性存貨管理 第一個研究此問題的是 Schrady(1967),在研究中他將需求與回收被假設為 一常數,並且製造與再製造中心皆是無限的生產率。他分析傳統經濟訂購量問題 利用淨需求(需求-回收)解決再製造活動下產生的問題,主要目標最小化每單位 時間總成本。他透過不同的可服務存貨與可復原存貨持有成本以及替代訂購方 式,發展出在一個在生產批量中包含許多個復原批量模型(1, R)短期策略,求得
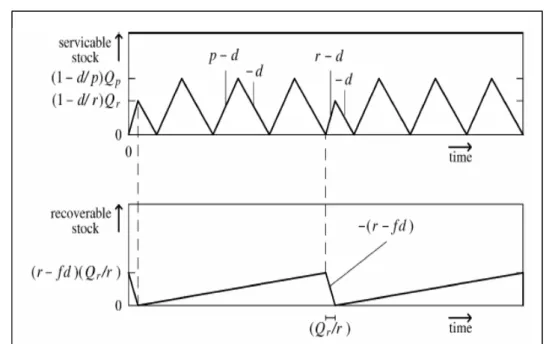
最佳經濟訂購量與復原批量。 Richter(1996)探討 EOQ 模型在可以被滿足的再生產品及維修之靜態需求 模型。假設回收產品、維修率及其他可能丟棄的機率,討論設置的變化、收集期 間的長度和最小浪費丟棄率。求解最佳的控制參數值和探討相互依賴的回收率。 Teunter(2001)將 Schrady(1967)中提出的(1, R)再製造策略的模型一般 化,並延伸了 Schrady(1967)架構模型得出(P, 1)固定生產 P 次的生產活動裡包 含一次的復原活動的策略短期生產模型在模型中多了回收品丟棄的選擇策略,在 模型中也是透過使用不同的生產與復原的持有成本率。
Nahmias and Rivera(1979) 利用有限的復原率去研究 Schrady(1967)的模 型變動,其中假設生產率與復原率一樣是無限,且復原率會大於需求率,並且推 導出(1, R)批量的最佳公式。其研究與 Koh et al.(2002)一樣假設生產率是無 限但在復原率卻是有限的情況,不過不同的是 Koh et al.的研究中允許復原率 可以小於或大於需求率,且考慮(1, R) (P, 1)策略。 Koh et al.(2002)在需求為固定時,市場需求可由可復原產品以及採購新產 品共同滿足。在此模型中假設一定的比率從顧客手中回收並且等待復原在使用。 在他們研究模型假設一次復原活動週期中夾雜多個訂購活動又或者一個新產品 訂購活動周期中夾雜了許多個復原活動。在當中批量與實值變數可以輕易的被分 析模型計算出,但整數變數與訂購次數與復原設置次數無法由此分析模型求解。 在這個研究模型中屬於一決定性模型,主要目標在固定設置與訂購成本與變動存 貨成本間取捨求得最佳化。在此模型中可同時求的採購的經濟訂購量與最佳的復 原產品的存貨水準以便啟動復原程序。其中模型情形類似 Mabini et al.(1992)、Richter(1996)和 Schrady(1967)三位學者,但此三位在模型中皆假 設復原能力是無限的,換句話說他們可直接將 Recoverable Items 直接轉換成 Serviceable Items。但在實際情況下產品復原能力(Recoverable Capacity)應
是被限制的,在轉換過程應該是逐漸是轉換而非一次性。在此模型中將此問題考 慮進去。
Teunter(2004)模型中提到,需求率與回收片段(Deterministic)是決定性 的,裡面相關的適當成本為訂購復原批量成本(Ordering Recovery Lots),訂購 生產成本(Ordering Production Lots), 倉庫可復原持有成本 Holding
Recoverable Items in Stock, 倉庫持有新或復原產品成本(Holding
New/Recovered Items in Stock). 在這模型中希望求出最佳的新產品或復原產 品的生產/採購批量。在研究中討論的對象放在原設備廠商(Original Equipment Manufactures)的 Product Recovery. 回收活動不考慮 Disposal 項目。解決決 定性的生產/採購與復原的(Production/Procurement and Recovery )最佳化批 量問題。
圖 2-7 Serviceable and Recoverable Stock Corresponding to the (1,R)
圖 2-8 Serviceable and Recoverable Stock Corresponding to the (P,1)
【資料來源:Teunter(2004)】
Teuntera and Vlachosb(2002)研究一個單一產品的混合式生產系統
(Manufacturing and Remanufacturing)研究中假設再製造活動是有利益的且在 平均情況下需求大於回收,利用模擬的方法,探討不同的需求、回收、製造活動 與再製造活動,在回收活動中包含有無拋棄選擇(Disposal Option),對於成本 影響變化的大小。從研究中發現當需求率十分緩慢(每年的需求少於 10 個),或 再製造活動成本比製造活動加上丟棄選擇活動昂貴(或至少是這些成本的 90%),又或者復原率是非常高(至少大於百分之 90)處於此情況下,回收品拋棄 選擇的策略是不需要的,再製造活動可以導致大量成本下降到達百分之三;當然 更多的成本降低是可以被期望的,如果回收率遠遠大於需求率。另外研究中也發 現,並非每種情況都要考慮 Disposal 策略必須視情況而定;更有些特殊情況, 當需求可以直接被回收品滿足時,這種混合式生產系統(Hybrid Production System)在未來中將被淘汰。如果再製造活動是沒有利益可言的強況下,使用拋 棄選擇策略來達大規模的成本下降,可以被考慮的。
林坤德(2006),問題主要探討當製造商的原料零組件可由兩階存貨政策的供 給情況下(一是由供應商訂購,另一是由再製造中心利用回收品製造生產),在研 究中採用連續盤存制,當再製造中心的回收量到達一定水準存量時,即將立即將 再製造品立即轉變成零組件。在此研究模型假設並不考慮到丟棄處理選項,強調 全部物品皆可回收,也為一決定性模型。市場的需求率與回收率都為固定,回收 品從再製造中心進行復原活動到製造中心,以及訂購新零件到製造商的前置時間 皆為 0,模型中藉由計算全年的總成本(全年再製造中心設置成本、全年零件訂 購成本,以及回收品總持有成本與製造商總持有成本)。求出最佳再製造批量與 訂購批量。 2.4.4 隨機存貨管理 Heyman(1977)研究中假設透過永續檢查模型,研究中認為需求量與回收量並 非常態,應該回隨著時間有不同的情況,所以假設兩者相互獨立分配的假設,沒 有固定成本,且前置時間為零情況下,透過隨機模型將回收量與需求量假設互相 獨立分配下,希望藉著考慮在擁有丟棄機制情況下求得持有成本與生產成本中, 獲得平衡已達成存貨成本最小化。【資料來源:溫士城(2006)】
Muckstadt 和 Isaac(1981)研究中假設前置時間非零、需求與回收為 Poisson 分配,並考慮存貨持有成本、修改訂單成本及固定採購成本,證明在上述的前提 假設下(s,Q)是最佳的存貨管理模型。【資料來源:溫士城(2006)】
Fleischmann et al.(1997)在逆向運籌機制下,製造、再製、丟棄、購買新 品數量上的控制,應用不同的存貨管理模型並分析比較不同的存貨管理模型下總 成本的變化。
Van Der Laan and Salomo(1997) 研究控制系統何時清理廢棄物是最經濟, 以及為何要執行的原因,並比較 Push-disposal 與 Pull-disposal 模型差異。 使用模擬方法考慮 Push 和 Pull 的不同運送法則下,並考慮是否丟棄廢棄物,
及其最佳決策配置。研究結果為當再製造的存貨價值低於可服務的存貨價值可採 用 Pull-disposal,其他都應該採用 Push-disposal 較適合。
Inderfurth and Van Der Laan(2001)在傳統隨機存貨模型中,加入逆向 運籌存貨的考量下,回收數量的不確定性和回收品修復數量的不穩定性會讓存貨 模型變的複雜與困難,當回收品數量不足需求時可購買新品來替代,也因如此購 買的前置時間就顯得相當重要,所以在不同的隨機模型中找出最佳的前置時間。
Fleischmann and Kuik(2003)的研究裡,發現之前大多數的隨機存貨管理模 型,對於回收品處理方式以負需求考慮,但在此研究中只利用正需求模型探討以 簡化數學模型複雜,採用單一階層存貨模型,考慮需求量與回收量彼此獨立且在 不考慮丟棄處理機制情況下,發現採用(s, S)的存貨策略能達到最小總成本。 溫士城(2006)研究模型中研究對象強調逆向運籌中的回收品的再製活動為 研究對象,在有兩組零組件供貨來的情況下(一是回收品經過再製造的零組件, 另一是向外部供應商訂購全新的零組件),探討單一產品、連續週期、且需求率 與回收率為隨機模型下透過模糊控制與基因演算法計算,再製造批量與訂購批 量,已達總成本最小化。
圖 2-9 溫士城(2006)的存貨管理研究
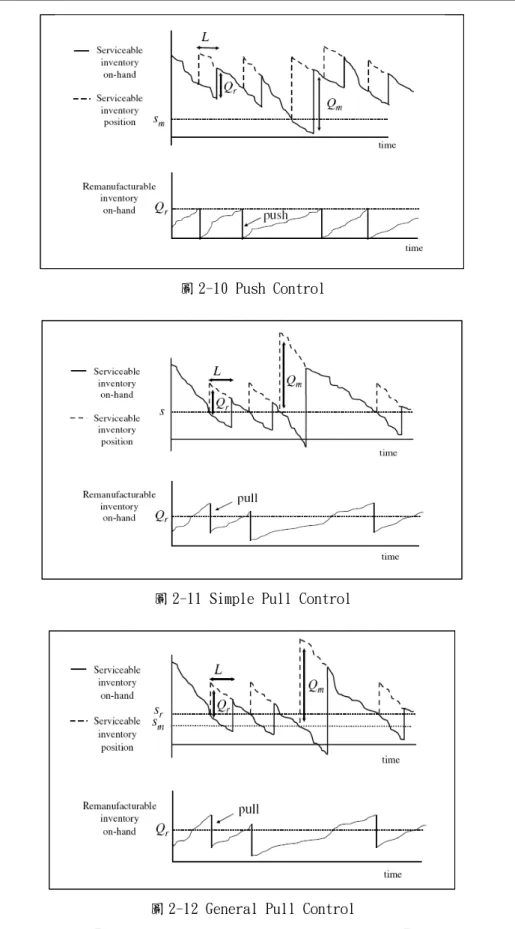
Van Der Laan and Teunter(2006)考慮製造與再製造活動的的存貨政策。透 過費用極小化的成本目標下,對於全部的政策,提出一個簡單的緊密正式的公式 去估計最佳策略參數(最佳訂購量與最佳訂購水準),並利用啟發式方法去了解求 解過程。模型中將生產與再製造活動的前置時間皆為相等的非零常數,除此之外 也考慮了設置成本,持有成本、以及復原活動設置成本等;為了控制此複雜的系 統,考慮了多方面的存貨政策。在生產活動策略上都採相似的(s,Q)方式,復原 活動訂購上則採用 Push or Pull 策略。所有的目的就是在成本最小的情況下計 算出一個公式去針對策略參數的估計。在裡面分別發展了三種形式的存貨政策, Push、Simple Pull 和 General Pull,發現 General Pull 效率最好。
圖 2-10 Push Control
圖 2-11 Simple Pull Control
圖 2-12 General Pull Control
2.5 模糊理論
2.5.1 模糊理論之介紹 自然界存在的許多現象無法透過明確的定義的概念,如天氣很「熱」、好 「遠」、這人好「高」或你太「胖」了等…這些抽象字眼。當人們要做決策時, 若手中掌獲的資訊是這些抽象化的字眼,要如何去量化它是個重要的議題。因此 模糊理論在 1967 年由美國電子控制專家的 L.A.Zadeh 提出,它一種將模糊概念 量化的表達工具,可用來表達無法明確定義的模糊性概念。Fuzzy 理論在人類思 維與電腦運算之間搭起了一道橋樑,是以往數學理論所辦不到的。由於真實世界 並非二值邏輯理論 (非 1,即 0),當事件本身具有含糊概念時便無法解釋。Zadeh 透過模糊集合理論,將一事件利用「歸屬函數」描述之關聯程度;模糊集合可視 為傳統集合的擴展,它取無限點的「歸屬函數」值來描述一個集合。 傳統集合(crisp set) ⎩ ⎨ ⎧ ∉ ∈ = A x A x x A , 0 , 1 ) ( μ 模糊集合 ) 1 ) ( ⎪ ⎪ ⎩ ⎪ ⎪ ⎨ ⎧ < ≤ − − ≤ ≤ ≤ ≤ − − = d x c c d x d c x b b x a a b a x x A ρ 模糊理論實際上是模糊集合、模糊關係(Fuzzy Relation)、模糊邏輯(Fuzzy Logic)、模糊控制(Fuzzy Control)、模糊量測(Fuzzy Measure)...等理論之泛 稱。。1974 年英國倫敦大學 Mamdani 教授首度成功的將模糊控制理論應用於蒸 氣引擎的鍋爐燃燒的操作上,其後,模糊控制應用逐漸受世界各國重視,尤其在 近幾年中,Fuzzy 理論已經成功地應用在各種領域之中,如影像辨識、自動控制 等領域,王文俊(1997) 模糊理論發展至今已接近三十年,應用的範圍非常廣泛,從工程科技到社會人文科學,都可以發現模糊理論研究的蹤跡與成果;在工程方 面,有型樣辨識、統明確集合普通的集合理論基於二值邏輯,亦即集合的界線必 須是非常明確的。
2.5.2 模糊控制系統 模糊控制系統與傳統控系統不同的差異在於控制器的設計。模糊系控制器設 計理念模糊控制乃建立在人類經驗基礎上,透過語言所組成的條件式,進而設計 出一控制器來實踐人的經驗,即可模仿人類的思維方式及操作策略,驅使控制器 代替人類對複雜受控系統進行控制;而傳統控制器主要是經由一定的數學模型去 控制。因此面對複雜且人性化的控制器,利用傳統方法難以設計出良好系統,必 須透過經驗與規則控制為基礎,依據人類下決策的近似推理模型,將這些條件式 控制規則轉化成自動控制策略,獲得控制效果。1974 年,E.H.Mamdani 利用模 糊邏輯的方式,成功地完成蒸汽引擎的控制後,證實利用語言寫出來的條件式, 只要有適當的演算法,控制效能也能非常完美,並從此開啟了一個新的控制時 代。模糊控制的基本特點是不依賴受控系統的數學模型,而是利用專家的經驗、 知識與受控系統輸出訊號所推論決定的,在不確定、非線性過程或對象控制中, 比傳統控制系統的可適用性控制具有更好的強健性。 一般模糊系統包括四個部分:1. 模糊化(Fuzzifierion)、2.
模糊規則庫(Fuzzy Rule Base)、3. 推理引擎(Inference Engine)、4. 解模糊 化(Defuzzifierion)。結構如下 模糊化 推理引擎 受控系統 解模糊 模糊規則庫 模糊控制器 模糊變數 條件式 明確資訊輸出 模糊變數 語意輸入 模糊化 推理引擎 受控系統 解模糊 模糊規則庫 模糊控制器 模糊變數 條件式 明確資訊輸出 模糊變數 語意輸入 圖 2-13 模糊控制器架構圖
2.5.3 模糊化(Fuzzifierion) 糊控制系統所接受控體傳回來的狀態變數(State Variables),進行量化 (Quantization)工作,以便將輸入變數的值轉換到相對應的論域。因為控制規則 是以口語形式寫成,為了讓系統了解外部輸入的變數,以利語言化條件式控制規 則的判讀;因此將資料透過歸屬函數的轉換,將輸入值映射至模糊集合空間為整 個模糊控制系統第一步驟。典型的連續性隸屬函數有三角形(Triangular Shape) 函數、梯形(Trapezoid Shape)函數、π 曲線形函數、S 函數、Z 函數、指數函 數等。 1 .π 曲線形函數: 形狀有如倒吊的鐘,故又有「吊鐘形(Bell Shape)函數」之稱。函數表示方式為:
(
)
⎪ ⎪ ⎩ ⎪⎪ ⎨ ⎧ ≥ + + ≤ − − = c x b c b c c x Z c x c b c b c x S c b x ), , 2 , ; ( ), , 2 , ; ( , , π c c-b c+b 1 c c-b c+b 1 圖 2-14 π曲線形函數 其中參數 b 稱為π 曲線形函數的帶寬。π 曲線形函數常用以表達「x 大約是 c」這樣的模糊概念。2. 梯形函數 形狀有如梯形,函數表示方式為 ⎪ ⎪ ⎪ ⎩ ⎪ ⎪ ⎪ ⎨ ⎧ ≤ ≤ ≤ − − ≤ ≤ ≤ ≤ − − ≤ = x d d x c c d x d c x b b x a a b a x a x x A 0 1 0 ) ( φ b a c 1 X a
φ
d b a c 1 X aφ
d 圖 2-15 梯形函數 3. 三角形函數 形狀有如三角形,函數表示方式為 ⎪ ⎪ ⎪ ⎩ ⎪⎪ ⎪ ⎨ ⎧ ≤ ≤ ≤ − − ≤ ≤ − − ≤ = x c c x b b c x c b x a a b a x a x x A 0 0 ) ( ωb a c 1 X A
ω
b a c 1 X Aω
圖 2-16 三角形函數 4. 高斯分佈函數 又稱常態分配函數形狀有點類似π 曲線形函數,只是涵蓋的範圍延伸至正負 無限大。一般以兩個參數即可完全描述出指數函數的特性: ( ) 2 2 ) , , (x μ σ =e−x−μ σ N A N 1 μ A N 1 μ 圖 2-17 高斯分佈函數 μ表示指數函數的中心點,而σ 則描述函數延展的程度。此函數常被用於適 應性的模糊控制系統中。 歸屬函數的取得,是決定系統成敗的關鍵,其對系統的成效有很大的影響, 但目前並無一個較系統化的作法可輕易的取得這歸屬函數。歸屬函數的取得大致有下列方法溫士城(2006) 1. 利用模糊統計試驗加以確定 2. 利用機率統計的結果予以推理確定 3. 模糊德爾菲法 4. 自我學習獲得(ANN,GA) 5. 基本上是以個人的主觀而隨意決定的 由於企業包含再製造活動的相關研究方面資料甚少,且專家不易取得,所以 透過人工智慧,自我學習可得較佳情況。
2.5.4 模糊規則庫(Fuzzy Rule Base) 主要包含規則庫與資料庫兩種: 1. 模糊規則庫:是整個控制器核心部份,主要提供決策判斷的準則。規則的建 立主要來自於人類的經驗與智慧將它語意化,並以 if –then 的條列形式儲存, 設計的好壞影響到整個控制效果。一般形式如下表示: m j n i j Action than i Situation if < > =1,2,3,..., =1,2,3,.., 其中 i 代表發生可能情況,j 代表相對應的動作。 規則庫產生的方式 一般有下面幾種方法: (a) 直接轉換操作員的操作技巧與經驗為模糊語言控制規則。 (b) 根據受控體對控制輸入與系統輸出的反應去歸納受控行為,以試誤法進行設 計。 (c) 經由控制系統本身進行學習或修正控制規則(ANN, GA)。
由於企業包含再製造活動的相關研究方面資料甚少,且專家不易取得,所以 透過人工智慧,自我學習可得較佳情況。 2. 資料庫:儲存必要的變數資料,好使模糊控制器能判定輸入變數在模糊集合 的定義。換句話說,在資料庫中存放的資料,便是有關如何將明確集合的資料轉 換成模糊集合的數值,亦即轉換成隸屬函數。 2.5.5 推理引擎(Inference Engine) 推理引擎是怎個控制的決策中心,模擬人類思考判斷的方式,將模糊化後的 變數搭配規則庫的條件式,透過推論過程求得輸出值。最為下階段解模糊化的輸 入值。以下根據林思宏(2000)研究中提出主要常見的推理引擎。 以推論的合成規則為基礎的方法(直接法); 以真理值空間為媒介的方法(間接法); 高木管野的模糊推論法(特別法)。