1
行政院國家科學委員會補助專題研究計畫成果報告
機率式建模技術與自然語言的標記、認知和教學
計畫類別:▓個別型計畫 □整合型計畫
計畫編號:NSC 97-2221-E-004-007
-MY2
執行期間: 97 年 8 月 1 日至 100 年 1 月 31 日
執行機構及系所:國立政治大學資訊科學系
計畫主持人:劉昭麟
共同主持人:蔡介立(國立政治大學心理系)、高照明(國立台灣大學外語系)
計畫參與人員:賴敏華、田侃文、黃志斌、黃昭憲、莊怡軒、陳建良、
張裕淇、蔡家琦、王瑞平
成果報告類型(依經費核定清單規定繳交):□精簡報告 ▓完整報告
(為避免重複,期中報告已經呈報之成果將不再贅述)
本計畫除繳交成果報告外,另須繳交以下出國心得報告:
□赴國外出差或研習心得報告
▓赴大陸地區出差或研習心得報告
▓出席國際學術會議心得報告
□國際合作研究計畫國外研究報告
處理方式:
除列管計畫及下列情形者外,得立即公開查詢
□涉及專利或其他智慧財產權,□一年□二年後可公開查詢
中 華 民 國 100 年 4 月 1 日
2
國科會補助專題研究計畫成果報告自評表
請就研究內容與原計畫相符程度、達成預期目標情況、研究成果之學術或應用價值(簡
要敘述成果所代表之意義、價值、影響或進一步發展之可能性)、是否適合在學術期
刊發表或申請專利、主要發現或其他有關價值等,作一綜合評估。
1. 請就研究內容與原計畫相符程度、達成預期目標情況作一綜合評估
▓
達成目標
說明:
延續之前的相關研究,本研究案完成了一項以機率模型建構學生學習模型的研究,並且發表一系列之相關學術會 議論文和包含一篇 IJAIED 之兩篇長篇期刊論文。在認知與教學方面,藉由此研究案的資助,我們陸續發表於國 際間卓俱聲望的學術研討會,例如 ACL 和 COLING。2. 研究成果在學術期刊發表或申請專利等情形:
論文:
▓
已發表 □未發表之文稿 □撰寫中 □無
專利:□已獲得 □申請中
▓
無
技轉:□已技轉 □洽談中
▓
無
其他:(以 100 字為限)
主要論文發表如下。
1. C.-L. Liu. Selecting Bayesian-network models based on simulated expectation, Behaviormetrika, 36(1), 1‒25. 2009.
2. C.-L. Liu. A simulation-based experience in learning structures of Bayesian networks to represent how students learn composite concepts, International Journal of Artificial Intelligence in Education, 18(3), 237‒285. 2008. 3. C.-L. Liu, M.-H. Lai, Y.-H. Chuang, and C.-Y. Lee. Visually and phonologically similar characters in incorrect
simplified Chinese words, Proceedings of the Twenty Third International Conference on Computational Linguistics (COLING'10), posters, 739‒747. 2010.
4. C.-L. Liu, K.-W. Tien, M.-H. Lai, Y.-H. Chuang, and S.-H. Wu. Capturing errors in written Chinese words, Proceedings of the Forty Seventh Annual Meeting of the Association for Computational Linguistics (ACL'09), short papers, 25‒28. 2009.
3. 請依學術成就、技術創新、社會影響等方面,評估研究成果之學術或應用價值(簡
要敘述成果所代表之意義、價值、影響或進一步發展之可能性)
(以 500 字為限)
本研究於 2007 年底提案之時,即已著手進行以機率式模型建構學生學習模型之相關研究,而且也正著手進行 關於漢字錯字分析的基礎工作。經過兩年的努力之後,我們完成了以機率式模型建構學生學習模型的探索,瞭解了 其中的困難之處,並且將所得的經驗發表於一系列之國際學術會議以及兩篇國際學術期刊論文之中。 語言教學方面,我們從 2007 年的初步探索,歷經 2008 年和 2009 年多位同學的持續努力,我們完成了以倉頡 詳馬來捕捉形體相近漢字的相關研究,並且完成了數個實際的應用,過程中的相關成果均發表於 ACL 年會之中。 至 2010 年,我們將相關研究經驗擴大到簡體漢字,相關結果也發表於 COLING 年會。 在認知科技方面,我們的成果仍屬初階,目前只獲得少量的眼動資料,雖然已經啟動相關研究,但是仍然沒有 建立精確的眼動軌跡與漢字閱讀歷程的關係。這一部份的成果現在只發表在 2010 年 TAAI 年會的國際議程中。我們 希望能夠在這一方面繼續努力。 除了發表論文之外,這一研究計畫對於社會最實際的貢獻在於搭配 2010 到 2011 年的後續計畫中,我們實際地 建立了一個可以輔助孩童學習漢字的軟體,並且實際在台北市某國小實地測試,而且證明該軟體對於學習成效的明 顯助益。 由於計畫主持人於 2010 年中出國短期訪問直到 2011 年一月初才返國,基於須要準備不少工作,並且有一些計 畫工作的延遲,所以計畫工作遲到 2010 年下半年方才結束,導致報帳與相關結案作業均相當延遲。3
中文摘要
本研究案於撰寫計畫申請書時,預計進行兩大類工作。第一類是利用貝氏網路來建構學生學習歷程的模型,第二類工作 則是利用計算語言學處理自然語言的技術,來開發可以協助電腦輔助語文教學的軟體。以下我們分類說明這兩年期的計畫 中,我們所發表的 19 篇論文。雖然我們著墨的應用領域不少,但是都是基於應用人工智慧與計算語言學的相關技術來作有 用的應用。 經過兩年的努力,雖然我們又發掘了更多先前沒有想到且值得深入的議題,但是我們相信我們的工作目標已經完成相當 高的比例。在過去兩年之間,我們共發表三篇國際學術期刊論文,六篇國際學術會議論文與十篇國內學術會議論文。比較具 有代表性的長篇期刊論文發表於 International Journal of Artificial Intelligence in Education (IJAIED),此外我們也在 2009 發表 了一篇 ACL 短文論文、在 2010 年發表的一篇 COLING 的海報論文。雖然這樣的結果顯然不是最佳的可能成果,不過希望可 以算是不錯的成果。 除了 IJAIED 論文與另一篇發表於 Behaviormetika 的論文之外,這兩年論文主要的議題都是關於應用計算語言學來協助 建構電腦輔助教學的軟體的議題。我們主要集中於研究包含簡體字和繁體字的中文錯字。錯字的來源可能源於發音相近的 字,也可能源於字形相近的字。我們延伸的倉頡碼的原始概念,建立了倉頡詳碼,然後應用倉頡詳碼的概念來計算中文近形 字。再輔以網路搜尋技術的協助,我們發現一個很好的方法可以複製人們常寫錯的漢字。在這樣的基礎之上,我們開發了兩 個應用軟體,一個是協助老師出中文改錯字試題的軟體,另一個則是輔助小學生學習漢字的遊戲軟體。這一方面的論文發表 於 IC1、IC2、IC4、IC5、IC6 和 J1(請參閱本報告中之論文列表)。基於這一些國際會議的論文的整合結果,在進一步利用 2010 年七月之後的資助之下,我們已經整理成期刊論文,並且被 ACM 的 Transaction on Asian Language Information Processing 接受發表。DC1 的內容,則是利用過去計算相近漢字的技術,用來輔助心理語言學專家建構一個有助於學生學習漢字的遊戲 軟體。 在學生學習歷程的機率式建模和中文錯字之外,我們還有餘力作更多的相關研究。IC3 和 DC7 是關於如何運用自然語言 處理技術,來協助教師編輯句子重組試題的研究成果。DC2 和 DC5 是利用語句分析技術來探討閱讀測驗難度的問題。 DC4 是關於如何利用文字處理技術來猜測中文短句中的情緒。 DC3、DC6 和 DC8 都是關於機器翻譯的相關技術。DC3 則是偏向於如何利用機器翻譯技術來輔助英文試題的中譯工作。 DC9 是延續多年以前關於中文訴訟文書的國科會研究計畫的末尾結束工作。 DC10 則是一個電腦遊戲的設計。這樣的發展有助於我們累積發展輔助語文學習的遊戲設計。 在人員訓練方面,本計畫執行期間合計畢業七位碩士班研究生,目前均順利就業或者服役中。英文摘要
At the time the proposal for the research project was drafted, we planned two types of research work. The first was to apply Bayesian networks as the language for modeling students’ learning procedures. The second one was to employ techniques of natural language processing for assisting the construction of software for computer-assisted language learning. After two years of work, we have published 19 papers based on our findings. Although these papers cover a wide range of applications, they share the same technical foundations: artificial intelligence and computational linguistics.
After two years of work, we are afraid that we have encountered more challenges than we thought, and we have learned a lot from this experience. Despite the challenges, we have worked hard enough to find some useful results. The results were published in three international journal articles, six international academic conferences papers, and 10 domestic academic conferences papers. Among these publications, we thought the long article published in the International Journal of Artificial Intelligence in Education (IJAIED) is quite representative. In addition, we published our results, as short papers, in the most prestigious conferences in the field of Computational Linguistics, i.e., ACL 2009 and COLING 2010. Although we cannot say that such results are perfect, we hope that these accomplishments are reasonable for the resources that we were granted.
The papers that we published in IJAIED and Behaviormetrika were about student modeling with Bayesian networks. The target problem was about modeling the learning procedure with which students learn composite concepts.
At almost the same time that we finished the work on student modeling, we began to work on the issues related to incorrect Chinese characters in text. The majority of our recent publications surround this research topic, and we tried to work on both traditional and simplified Chinese characters. Both intuition and our experience show that the sources of incorrect characters are related to phonological and visual similarity between Chinese characters. In order to enable computers to find visually similar characters, we extend the original Cangjie codes to capture the detailed structures of Chinese characters. Some similarity measures were proposed for the task, and experimental results have proven their effectiveness. With the help of Web-based statistics that we collected from portals like Google, we were able to reproduce incorrect words at very high rate.
Based on such a computing tool, we have built a system that can help teachers to compile test items for word corrections of Chinese characters. We have also employed the tool to build a game-based learning environment to help students learn to read Chinese characters.
For the research direction about incorrect Chinese characters, we have published papers IC1, IC2, IC4, IC5, IC6, and J1 (please refer to the papers listed below). In addition, with the support of an NSC project that began from August 2010, we have actually extended the work reported in the conference papers, and have a journal paper accepted by the ACM Transaction on Asian Language Information Processing. A portion of our experience in building a game-based environment for learning Chinese characters was reported in DC1. This game was based on research results of psycholinguistics, and the latest experiments, those we conducted in 2011, proved the effectiveness of the games.
We have conducted some more exploration that we did not mention in the original proposal. We applied techniques for sentence manipulation to help teachers build test items for scrambled sentences, and the results were reported in IC3 and DC7. We tried to learn
4
about how the texts for reading comprehensions were chosen by analyzing the linguistic structures of the texts, and the results were reported in DC2 and DC5.
DC4 reported how we may infer the emotion carried by short Chinese sentences.
DC3, DC6, and DC8 were related to techniques of machine translation (MT). DC3, in particular, was related how we may apply MT techniques for translating English test items into their Chinese counterparts.
DC9 was a piece of work that related to a previous NSC research project of ours. It reported an information retrieval system for Chinese indictment documents.
DC10 provided our experience in using machine learning techniques in game design. It was one of our first attempt to build a game, and was educational for us to build the game for learning Chinese characters.
中文關鍵詞
貝氏網路、機率式建模、學生學習歷程、中文錯字、改錯字試題、句子重組、心理語言學、中文字學習遊戲
英文關鍵詞
Bayesian Networks, Probabilistic Modeling, Learning Style Modeling, Incorrect Chinese Characters, Word Correction Tests, Scrambled Sentence Tests, Psycholinguistics, Games for Learning Chinese Characters
報告內容:包括前言、研究目的、文獻探討、研究方法、結果與討論(含結論與建議)…等。
由於本研究案發表許多論文,如果要瞭解個別研究工作的參考文獻、研究方法與結果等細節,煩請參考下面表列之各論 文。個別計畫的工作內容與關連性已經在前面的摘要中概述。
計畫執行期間之內所發表之論文
期刊論文
J1. Chao-Lin Liu, Jen-Hsiang Lin, and Yu-Chun Wang. Applications of NLP techniques to computer-assisted authoring of test items for elementary Chinese, US-China Education Review, 7(3), 42ԟ52. David Publishing Company, USA, March 2010.
J2. Chao-Lin Liu. Selecting Bayesian-network models based on simulated expectation, Behaviormetrika, 36(1), 1ԟ25. The Behaviormetric Society of Japan, Japan, April 2009.
J3. Chao-Lin Liu. A simulation-based experience in learning structures of Bayesian networks to represent how students learn composite concepts, International Journal of Artificial Intelligence in Education, 18(3), 237ԟ285. IOS Press, The Netherlands, September 2008.
國際學術會議論文
IC1. Shih-Hung Wu, Yong-Zhi Chen, Ping-Che Yang, Tsun Ku, and Chao-Lin Liu. Reducing the false alarm rate of Chinese character error detection and correction, Proceedings of the First CIPS-SIGHAN Joint Conference on Chinese Language Processing (CLP'10), 54ԟ61. Beijing, China, 28-29 August 2010.
IC2. Chao-Lin Liu, Min-Hua Lai, Yi-Hsuan Chuang, and Chia-Ying Lee. Visually and phonologically similar characters in incorrect simplified Chinese words, Proceedings of the Twenty Third International Conference on Computational Linguistics (COLING'10), posters, 739ԟ747. Beijing, China, 23-27 August 2010.
IC3. Chao-Lin Liu, Chih-Bin Huang, Ying-Tse Sun, and Wei-Ti Kuo. Computer assisted creation of items for scrambled sentence tests, Proceedings of the Seventeenth International Conference on Computers in Education (ICCE'09), 117ԟ121. Hong Kong, China, 30 November-4 December 2009.
IC4. Chao-Lin Liu, Kan-Wen Tien, Min-Hua Lai, Yi-Hsuan Chuang, and Shih-Hung Wu. Phonological and logographic influences on errors in written Chinese words, Proceedings of the Seventh Workshop on Asian Language Resources (ALR7), the Forty Seventh Annual Meeting of the Association for Computational Linguistics (ACL'09), 84ԟ91. Singapore, 2-7 August 2009. IC5. Chao-Lin Liu, Kan-Wen Tien, Min-Hua Lai, Yi-Hsuan Chuang, and Shih-Hung Wu. Capturing errors in written Chinese words,
Proceedings of the Forty Seventh Annual Meeting of the Association for Computational Linguistics (ACL'09), short papers, 25ԟ28. Singapore, 2-7 August 2009.
IC6. Chao-Lin Liu, Kan-Wen Tien, Yi-Hsuan Chuang, Chih-Bin Huang, and Juei-Yu Weng. Two applications of lexical information to computer-assisted item authoring for elementary Chinese, Lecture Notes in Computer Science 5579: Proceedings of the Twenty Second International Conference on Industrial Engineering & Other Applications of Applied Intelligent Systems (IEA/AIE '09), 470ԟ480. Tainan, Taiwan, 24-27 June 2009.
國內學術會議論文
DC1. Chia-Ling Lee, Yu-Chi Chang, Chia-Ying Lee, and Chao-Lin Liu. 結合認知理論之電腦輔助漢字教學遊戲, Proceedings of the 2010 Taiwan Academic Network Conference (TANET'10), CD-ROM. Tainan, Taiwan, 27-29 October, 2010. (in Chinese)
5
DC2. Chao-Shainn Huang, Wei-Ti Kuo, Chia-Ling Lee, Chia-Chi Tsai, and Chao-Lin Liu. 以語文特徵為基之中學閱讀測驗短文 分級 (Using linguistic features to classify texts for reading comprehension tests at the high school levels), Proceedings of the Twenty Second Conference on Computational Linguistics and Speech Processing (ROCLING XXII), 98ԟ112. Nantou, Taiwan, 1-2 September 2010. (in Chinese)
DC3. Chao-Shainn Huang, Yu-Chi Chang, Chao-Lin Liu, and Yuen-Hsien Tseng. 以共現資訊為基礎增進中學英漢翻譯試題與解 答之詞彙對列 (Using co-occurrence information to improve Chinese-English word alignment in translation test items for high school students), Proceedings of the Twenty Second Conference on Computational Linguistics and Speech Processing (ROCLING XXII), 128ԟ142. Nantou, Taiwan, 1-2 September 2010. (in Chinese)
DC4. Ying-Tse Sun, Chien-Liang Chen, Chun-Chieh Liu, Chao-Lin Liu, and Von-Wun Soo. 中文短句之情緒分類 (Sentiment classification of short Chinese sentences), Proceedings of the Twenty Second Conference on Computational Linguistics and Speech Processing (ROCLING XXII), 184ԟ198. Nantou, Taiwan, 1-2 September 2010. (in Chinese)
DC5. Wei-Ti Kuo, Chao-Shainn Huang, Min-Hua Lai, Chao-Lin Liu, and Zhao-Ming Gao. 適用於中學英文閱讀測驗短文分類的 特徵比較, Proceedings of the Fourteenth Conference on Artificial Intelligence and Applications (TAAI'09), CD-ROM. Taichung, Taiwan, 30-31 October 2009. (in Chinese)
DC6. Kan-Wen Tien, Yuen-Hsien Tseng, and Chao-Lin Liu. 中英文專利文書之文句對列(Sentence alignment of English and Chinese patent documents), Proceedings of the Twenty First Conference on Computational Linguistics and Speech Processing (ROCLING XXI), 85ԟ99. Taichung, Taiwan, 1-2 September 2009. (in Chinese)
DC7. Chih-Bin Huang, Chao-Lin Liu, Wei-Ti Kuo, Ying-Tse Sun, and Min-Hua Lai. 電腦輔助句子重組試題編製(Computer assisted test-item generation for sentence reconstruction), Proceedings of the Twenty First Conference on Computational Linguistics and Speech Processing (ROCLING XXI), 165ԟ178. Taichung, Taiwan, 1-2 September 2009. (in Chinese)
DC8. Yuen-Hsien Tseng, Chao-Lin Liu, and Ze-Jing Chuang. 專利雙語語料之中、英對照詞自動擷取 (Automatic term pair extraction from bilingual patent corpus), Proceedings of the Twenty First Conference on Computational Linguistics and Speech Processing (ROCLING XXI), 279ԟ292. Taichung, Taiwan, 1-2 September 2009. (in Chinese)
DC9. Chia-Liang Lan, Min-Hua Lai, Kan-Wen Tien and Chao-Lin Liu. 訴訟文書檢索系統, Proceedings of the Thirteenth Conference on Artificial Intelligence and Applications (TAAI'08), 305ԟ312. Yilan, Taiwan, 21-22 November 2008. (in Chinese)
DC10. Zeng-Hong Lin and Chao-Lin Liu. 任意棋盤的 Othello 遊戲, Proceedings of the Thirteenth Conference on Artificial Intelligence and Applications (TAAI'08), 443ԟ449. Yilan, Taiwan, 21-22 November 2008. (in Chinese)
6
在期中報告中我們已經附上當時已經發表的論文,以下我們再附上
兩篇更新的論文。分別是前面論文表列中的 IC2 和 IC3。
Visually and Phonologically Similar Characters in Incorrect
Simplified Chinese Words
Chao-Lin Liu† Min-Hua Lai‡ Yi-Hsuan Chuang↑ Chia-Ying Lee↨ †‡↑Department of Computer Science; †↨Center for Mind, Brain, and Learning
National Chengchi University
↨Institute of Linguistics, Academia Sinica
{†chaolin, ‡g9523, ↑g9804}@cs.nccu.edu.tw, ↨[email protected]
Abstract
Visually and phonologically similar cha-racters are major contributing factors for errors in Chinese text. By defining ap-propriate similarity measures that consid-er extended Cangjie codes, we can identi-fy visually similar characters within a fraction of a second. Relying on the pro-nunciation information noted for individ-ual characters in Chinese lexicons, we can compute a list of characters that are phonologically similar to a given charac-ter. We collected 621 incorrect Chinese words reported on the Internet, and ana-lyzed the causes of these errors. 83% of these errors were related to phonological similarity, and 48% of them were related to visual similarity between the involved characters. Generating the lists of phono-logically and visually similar characters, our programs were able to contain more than 90% of the incorrect characters in the reported errors.
1
Introduction
In this paper, we report the experience of our studying the errors in simplified Chinese words. Chinese words consist of individual characters. Some words contain just one character, but most words comprise two or more characters. For in-stance, “卖” (mai4)1 has just one character, and
“语言” (yu3 yan2) is formed by two characters. Two most common causes for writing or typing incorrect Chinese words are due to visual and phonological similarity between the correct and
1 We show simplified Chinese characters followed by
their Hanyu pinyin. The digit that follows the symbols for the sound is the tone for the character.
the incorrect characters. For instance, one might use “划” (hwa2) in the place of “画”(hwa4) in “刻画形象” (ke1 hwa4 xing2 xiang4) partially because of phonological similarity; one might replace “拙” (zhuo2) in “心劳力拙” (xin1 lao2 li4 zhuo2) with “绌” (chu4) partially due to visu-al similarity. (We do not claim that the visuvisu-al or phonological similarity alone can explain the observed errors.)
Similar characters are important for under-standing the errors in both traditional and simpli-fied Chinese. Liu et al. (2009a-c) applied tech-niques for manipulating correctness of Chinese words to computer assisted test-item generation. Research in psycholinguistics has shown that the number of neighbor characters influences the timing of activating the mental lexicon during the process of understanding Chinese text (Kuo et al. 2004; Lee et al. 2006). Having a way to compute and find similar characters will facilitate the process of finding neighbor words, so can be in-strumental for related studies in psycholinguistics. Algorithms for optical character recognition for Chinese and for recognizing written Chinese try to guess the input characters based on sets of confusing sets (Fan et al. 1995; Liu et al., 2004). The confusing sets happen to be hand-crafted clusters of visually similar characters.
It is relatively easy to judge whether two cha-racters have similar pronunciations based on their records in a given Chinese lexicon. We will discuss more related issues shortly.
To determine whether two characters are vi-sually similar is not as easy. Image processing techniques may be useful but is not perfectly feasible, given that there are more than fifty thousand Chinese characters (HanDict, 2010) and that many of them are similar to each other in special ways. Liu et al. (2008) extend the Cangjie codes (Cangjie, 2010; Chu, 2010) to en-code the layouts and details about traditional
Chinese characters for computing visually simi-lar characters. Evidence observed in psycholin-guistic studies offers a cognition-based support for the design of Liu et al.’s approach (Yeh and Li, 2002). In addition, the proposed method proves to be effective in capturing incorrect tra-ditional Chinese words (Liu et al., 2009a-c).
In this paper, we work on the errors in simpli-fied Chinese words by extending the Cangjie codes for simplified Chinese. We obtain two lists of incorrect words that were reported on the In-ternet, analyze the major reasons that contribute to the observed errors, and evaluate how the new Cangjie codes help us spot the incorrect charac-ters. Results of our analysis show that phonolog-ical and visual similarities contribute similar por-tions of errors in simplified and traditional Chi-nese. Experimental results also show that, we can catch more than 90% of the reported errors.
We go over some issues about phonological similarity in Section 2, elaborate how we extend and apply Cangjie codes for simplified Chinese in Section 3, present details about our experi-ments and observations in Section 4, and discuss some technical issues in Section 5.
2
Phonologically Similar Characters
The pronunciation of a Chinese character in-volves a sound, which consists of the nucleus and an optional onset, and a tone. In Mandarin Chi-nese, there are four tones. (Some researchers in-clude the fifth tone.)
In our work, we consider four categories of phonological similarity between two characters: same sound and same tone (SS), same sound and different tone (SD), similar sound and same tone (MS), and similar sound and different tone (MD).
We rely on the information provided in a lex-icon (Dict, 2010) to determine whether two cha-racters have the same sound or the same tone. The judgment of whether two characters have similar sound should consider the language expe-rience of an individual. One who live in the southern and one who live in the northern China may have quite different perceptions of “similar” sound. In this work, we resort to the confusion sets observed in a psycholinguistic study con-ducted at the Academic Sinica.
Some Chinese characters are heteronyms. Let C1 and C2 be two characters that have multiple
pronunciations. If C1 and C2 share one of their
pronunciations, we consider that C1 and C2
be-long to the SS category. This principle applies when we consider phonological similarity in oth-er categories.
One challenge in defining similarity between characters is that the pronunciations of a charac-ter can depend on its context. The most common example of tone sandhi in Chinese (Chen, 2000) is that the first third-tone character in words formed by two adjacent third-tone characters will be pronounced in the second tone. At present, we ignore the influences of context when determin-ing whether two characters are phonologically similar.
Although we have confined our definition of phonological similarity to the context of the Mandarin Chinese, it is important to note the in-fluence of sublanguages within the Chinese lan-guage family will affect the perception of phono-logical similarity. Sublanguages used in different areas in China, e.g., Shanghai, Min, and Canton share the same written forms with the Mandarin Chinese, but have quite different though related pronunciation systems. Hence, people living in different areas in China may perceive phonologi-cal similarity in very different ways. The study in this direction is beyond the scope of the current study.
3
Visually Similar Characters
Figure 1 shows four groups of visually similar characters. Characters in group 1 and group 2 differ subtly at the stroke level. Characters in group 3 share the components on their right sides. The shared component of the characters in group 4 appears at different places within the characters.
Radicals are used in Chinese dictionaries to organize characters, so are useful for finding vi-sually similar characters. The characters in group 1 and group 2 belong to the radicals “田” and “ ”, respectively. Notice that, although the radical for group 2 is clear, the radical for group 1 is not obvious because “田” is not a standalone compo-nent.
However, the shared components might not be the radicals of characters. The shared compo-nents in groups 3 and 4 are not the radicals. In
many cases, radicals are semantic components of Chinese characters. In groups 3 and 4, the shared components carry information about the pronun-ciations of the characters. Hence, those charac-ters are listed under different radicals, though they do look similar in some ways.
Hence, a mechanism other than just relying on information about characters in typical lexicons is necessary, and we will use the extended Cang-jie codes for finding visually similar characters.
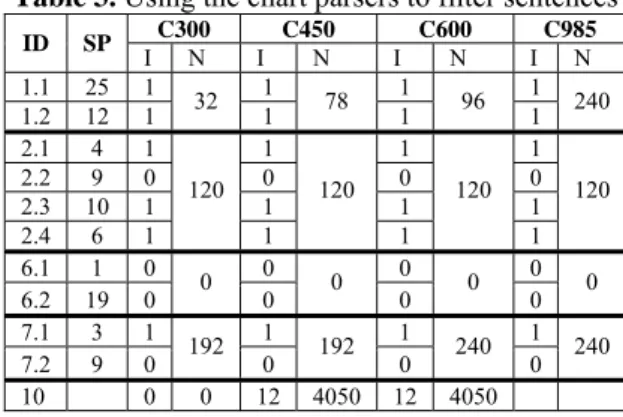
3.1 Cangjie Codes for Simplified Chinese
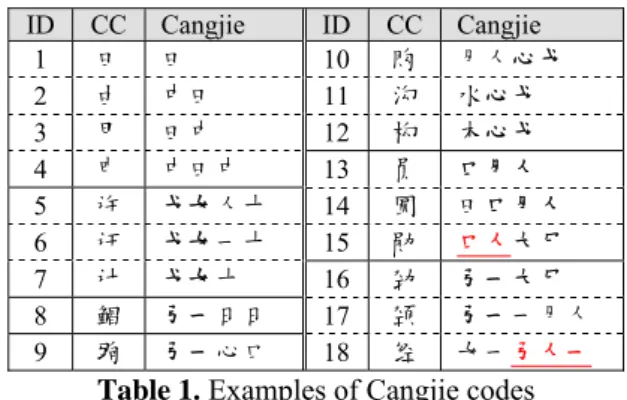
Table 1 shows the Cangjie codes for the 13 characters listed in Figure 1 and five other characters. The “ID” column shows the identification number for the characters, and we will refer to the ith character by c
i, where i is the
ID. The “CC” column shows the Chinese characters, and the “Cangjie” column shows the Cangjie codes. Each symbol in the Cangjie codes corresponds to a key on the keyboard, e.g. “田” and “ 中 ” collocate with “W” and “L”, respectively. Information about the complete correspondence is available on the Wikipedia2.
Using the Cangjie codes saves us from using image processing methods to determine the de-grees of similarity between characters. Take the Cangjie codes for the characters in group 2 (c5, c6,
and c7) for example. It is possible to find that the
characters share a common component, based on the shared substrings of the Cangjie codes, i.e., “戈女”. Using the common substring (shown in black bold) of the Cangjie codes, we may also find the shared component “勾” for characters in group 3 (c10, c11, and c12), the shared component
“员” in c13 and c14, the shared component “力” in
c15 and c16, and the shared component “ ” in c16
and c17.
Despite the perceivable advantages, these original Cangjie codes are not good enough. In order to maintain efficiency in inputting Chinese characters, the Cangjie codes have been limited to no more than five keys. Thus, users of the Cangjie input method must familiarize them-selves with the principles for simplifying the Cangjie codes. While the simplified codes help the input efficiency, they also introduce difficul-ties and ambiguidifficul-ties when we compare the
2en.wikipedia.org/wiki/Cangjie_input_method#Keyboard_la yout ; last visited on 22 April 2010.
jie codes for computing similar characters. The prefix “弓一” in c16 and c17 can represent “ ”,
“鱼” (e.g., c8), and “马” (e.g., c9). Characters
whose Cangjie codes include “弓一” may con-tain any of these three components, but they do not really look alike.
Therefore, we augment the original Cangjie codes by using the complete Cangjie codes and annotate each Chinese character with a layout identification that encodes the overall contours of the characters. This is how Liu and his col-leagues (2008) did for the Cangjie codes for tra-ditional Chinese characters, and we employ a similar exploration for the simplified Chinese.
3.2 Augmenting the Cangjie Codes
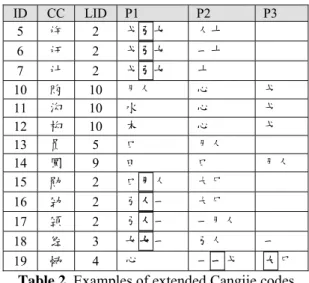
Figure 2 shows the twelve possible layouts that are considered for the Cangjie codes for simplified Chinese characters. Some of the layouts contain smaller areas, and the rectangles show a subarea within a character. The smaller areas are assigned IDs between one and three. Notice that, to maintain read-ability of the figures, not all IDs for subareas are shown in Figure 2. An example character is provided below each layout. From left to right and from top to bottom, each layout is assigned an identification number from 1 to 12. For example, the layout ID of “国” is 8. “国” has two parts, i.e., “囗” and “玉”.
Researchers have come up with other ways to
ID CC Cangjie ID CC Cangjie 1 田 田 10 购 月人心戈 2 由 中田 11 沟 水心戈 3 甲 田中 12 构 木心戈 4 申 中田中 13 员 口月人 5 许 戈女人十 14 圆 田口月人 6 讦 戈女一十 15 勋 口人大尸 7 计 戈女十 16 劲 弓一大尸 8 鲳 弓一日日 17 颈 弓一一月人 9 驹 弓一心口 18 经 女一弓人一
Table 1. Examples of Cangjie codes
decompose individual Chinese characters. The Chinese Document Lab at the Academia Sinica proposed a system with 13 operators for describ-ing the relationships among components in Chi-nese characters (CDL, 2010). Lee (2010b) pro-pose more than 30 possible layouts.
The layout of a character affects how people perceive visual similarity between characters. For instance, c16 in Table 1 is more similar to c17
than to c18, although they share “ ”. We rely on
the expertise in Cangjie codes reported in (Lee, 2010a) to split the codes into parts.
Table 2 shows the extended codes for some characters listed in Table 1. The “ID” column provides links between the characters listed in both Table 1 and Table 2. The “CC” column shows the Chinese characters. The “LID” column shows the identifications for the layouts of the characters. The columns with headings “P1”, “P2”, and “P3” show the extended Cangjie codes, where “Pi” shows the ith part of the Cangjie
codes, as indicated in Figure 2.
We decide the extended codes for the parts with the help of computer programs and subjec-tive judgments. Starting from the original Cang-jie codes, we can compute the most frequent sub-strings just like we can compute the frequencies of n-grams in corpora (cf. Jurafsky and Martin, 2009). Computing the most common substrings in the original codes is not a complex task be-cause the longest original Cangjie codes contain just five symbols.
Often, the frequent substrings are simplified codes for popular components in Chinese charac-ters, e.g., “ ” and “ ”. The original codes for “ ” and “ ” are “戈弓女” and “弓人一”, but they are often simplified to “戈女” and “弓一”, respec-tively. When simplified, “ ” have the same Cangjie code with “戉”, and “ ” have the same Cangjie code with “马” and “鱼”.
After finding the frequent substrings, we veri-fy whether these frequent substrings are simpli-fied codes for meaningful components. For mea-ningful components, we replace the simplified codes with complete codes. For instance the Cangjie codes for “许” and “讦” are extended to include “弓” in Table 2, where we indicate the extended keys that did not belong to the original Cangjie codes in boldface and with a surrounding box. Most of the non-meaningful frequent sub-strings have two keys: one is the last key of a
part, and the other is the first key of another part. They were by observed by coincidence.
Although most of the examples provided in Table 2 indicate that we expand only the first part of the Cangjie codes, it is absolutely possible that the other parts, i.e., P2 and P3, may need to be extended too. c19 shows such an example.
Replacing simplified codes with complete codes not only help us avoid incorrect matches but also help us find matches that would be missed due to simplification of Cangjie codes. Using just the original Cangjie codes in Table 1, it is not easy to determine that c18 (“经”) in Table
1 shares a component (“ ”) with c16 and c17 (“劲”
and “颈”). In contrast, there is a chance to find the similarity with the extended Cangjie codes in Table 2, given that all of the three Cangjie codes include “弓人一”.
We can see an application of the LIDs, using “劲”, “颈” and “经” as an example. Consider the case that we want to determine which of “颈” and “经” is more similar to “劲”. Their extended Cangjie codes will indicate that “颈” is the an-swer to this question for two reasons. First, “劲” and “颈” belong to the same type of layout; and, second, the shared components reside at the same area in “劲” and “颈”.
3.3 Similarity Measures
The main differences between the original and the extended Cangjie codes are the degrees of details about the structures of the Chinese cha-racters. By recovering the details that were ig-nored in the original codes, our programs will be
ID CC LID P1 P2 P3 5 许 2 戈弓女 人十 6 讦 2 戈弓女 一十 7 计 2 戈弓女 十 10 购 10 月人 心 戈 11 沟 10 水 心 戈 12 构 10 木 心 戈 13 员 5 口 月人 14 圆 9 田 口 月人 15 勋 2 口月人 大尸 16 劲 2 弓人一 大尸 17 颈 2 弓人一 一月人 18 经 3 女女一 弓人 一 19 恸 4 心 一一戈 大尸
better equipped to find the similarity between characters.
In the current study, we experiment with three different scoring methods to measure the visual similarity between two characters based on their extended Cangjie codes. Two of these methods had been tried by Liu and his colleagues’ study for traditional Chinese characters (Liu et al., 2009b-c). The first method, denoted SC1, con-siders the total number of matched keys in the matched parts (without considering their part IDs). Let ci denote the ith character listed in Table
2. We have SC1(c15, c16) = 2 because of the
matched “大尸”. Analogously, we have SC1(c19,
c16) = 2.
The second method, denoted SC2, includes the score of SC1 and considers the following conditions: (1) add one point if the matched parts locate at the same place in the characters and (2) if the first condition is met, an extra point will be added if the characters belong to the same layout. Hence, we have SC2(c15, c16) =SC1(c15,
c16)+1+1=4 because (1) the matched “大尸”
lo-cate at P2 in both characters and (2) c15 and c16
belong to the same layout. Assuming that c16
be-longs to layout 5, than SC2(c15, c16) would
be-come 3. In contrast, we have SC2(c19, c16)=2. No
extra weights for the matching “大尸” because it locates at different parts in the characters. The extra weight considers the spatial influences of the matched parts on the perception of similarity.
While splitting the extended Cangjie codes in-to parts allows us in-to tell that c15 is more similar
to c16 than to c19, it also creates a new barrier in
computing similarity scores. An example of this problem is that SC2(c17, c18)=0. This is because
that “弓人一” at P1 in c17 can match neither “弓
人” at P2 nor “一” at P3 in c18.
To alleviate this problem, we consider SC3 which computes the similarity in three steps. First, we concatenate the parts of a Cangjie code for a character. Then, we compute the longest common subsequence (LCS) (cf. Cormen et al., 2009) of the concatenated codes of the two cha-racters being compared, and compute a Dice’s coefficient (cf. Croft et al., 2010) as the similari-ty. Let X and Y denote the concatenated, ex-tended Cangjie codes for two characters, and let
Z be the LCS of X and Y. The similarity is
de-fined by the following equation.
S Y
X Z
DiceLCS , whereSis thelength ofstring 2
(1)
We compute another Dice’s coefficient be-tween X and Y. The formula is the similar to (1), except that we set Z to the longest common
con-secutive subsequence. We call this score LCCS
Dice . Notice that DiceLCCSDiceLCS ,
1
LCCS
Dice , and DiceLCS1 . Finally, SC3 of two
characters is the sum of their SC2, 10DiceLCCS,
and 5DiceLCS. We multiply the Dice’s
coeffi-cients with constants to make them as influential as the SC2 component in SC3. The constants were not scientifically chosen, but were selected heuristically.
4
Error Analysis and Evaluation
We evaluate the effectiveness of using the pho-nologically and visually similar characters to captures errors in simplified Chinese words with two lists of reported errors that were collected from the Internet.
4.1 Data Sources
We need two types of data for the experiments. The information about the pronunciation and structures of the Chinese characters help us gen-erate lists of similar characters. We also need reported errors so that we can evaluate whether the similar characters catch the reported errors.
A lexicon that provides the pronunciation in-formation about Chinese characters and a data-base that contains the extended Cangjie codes are necessary for our programs to generate lists of characters that are phonologically and visually similar to a given character.
It is not difficult to acquire lexicons that show standard pronunciations for Chinese characters. As we stated in Section 2, the main problem is that it is not easy to predict how people in differ-ent areas in China actually pronounce the charac-ters. Hence, we can only rely on the standards that are recorded in lexicons.
With the procedure reported in Section 3.2, we built a database of extended Cangjie codes for the simplified Chinese. The database was de-signed to contain 5401 common characters in the BIG5 encoding, which was originally designed for the traditional Chinese. After converting the traditional Chinese characters to the simplified counterparts, the database contained only 5170
different characters.
We searched the Internet for reported errors that were collected in real-world scenarios, and obtained two lists of errors. The first list3 came
from the entrance examinations for senior high schools in China, and the second list4 contained
errors observed at senior high schools in China. We used 160 and 524 errors from the first and the second lists, respectively, and we refer to the combined list as the Ilist. An item of reported error contained two parts: the correct word and the mistaken character, both of which will be used in our experiments.
4.2 Preliminary Data Analysis
Since our programs can compare the similarity only between characters that are included in our lexicon, we have to exclude some reported errors from the Ilist. As a result, we used only 621 er-rors in this section.
Two native speakers subjectively classified the causes of these errors into three categories based on whether the errors were related to phonologi-cal similarity, visual similarity, or neither. Since the annotators did not always agree on their clas-sifications, the final results have five interesting categories: “P”, “V”, “N”, “D”, and “B” in Table 3. P and V indicate that the annotators agreed on the types of errors to be related to phonological and visual similarity, respectively. N indicates that the annotators believed that the errors were not due to phonological or visual similarity. D indicates that the annotators believed that the errors were due to phonological or visual similar-ity, but they did not have a consensus. B indi-cates the intersection of P and V.
Table 3 shows the percentages of errors in these categories. To get 100% from the table, we can add up P, V, N, and D, and subtract B from the total. In reality there are errors of type N, and Liu and his colleagues (2009b) reported this type of errors. Errors in this category happened to be missing in the Ilist. Based on our and Liu’s
3www.0668edu.com/soft/4/12/95/2008/2008091357140.htm ; last visited on 22 April 2010.
4gaozhong.kt5u.com/soft/2/38018.html; last visited on 22 April 2010.
servations, the percentages of phonological and visual similarities contribute to the errors in sim-plified and traditional Chinese words with simi-lar percentages.
4.3 Experimental Procedure
We design and employ the ICCEval procedure
for the evaluation task.
At step 1, given the correct word and the cor-rect character to be intentionally replaced with incorrect characters, we created a list of charac-ters based on the selection criterion. We may choose to evaluate phonologically or visually similar characters. For a given character, ICCEv-al can generate characters that are in the SS, SD,
MS, and MD categories for phonologically simi-lar characters (cf. Section 2). For visually simisimi-lar characters, ICCEval can select characters based
on SC1, SC2, and SC3 (cf. Section 3.3). In addi-tion, ICCEval can generate a list of characters
that belong to the same radical and have the same number of strokes with the correct character. In the experimental results, we refer to this type of similar characters as RS.
At step 2, for a correct word that people origi-nally wanted to write, we replaced the correct character with an incorrect character with the characters that were generated at step 1, submit-ted the incorrect word to Google AJAX Search
P V N D B
Ilist 83.1 48.3 0 3.7 35.1 Table 3. Percentages of types of errors
Procedure ICCEval Input:
ccr: the correct character; cwd: the correct word; crit: the selec-tion criterion; num: number of re-quested characters; rnk: the cri-terion to rank the incorrect words;
Output: a list of ranked candidates for ccr
Steps:
1. Generate a list, L, of charac-ters for ccr with the specified criterion, crit. When using SC1, SC2, or SC3 to select visually similar characters, at most num characters will be selected. 2. For each c in L, replace ccr in
cwd with c, submit the resulting incorrect word to Google, and record the ENOP.
3. Rank the list of incorrect words generated at step 2, using the criterion specified by rnk. 4. Return the ranked list.
API, and extracted the estimated numbers of pages (ENOP) 5 that contained the incorrect words. In an ordinary interaction with Google, an ENOP can be retrieved from the search results, and it typically follows the string “Results 1-10 of about” on the upper part of the browser
window. Using the AJAX API, we just have to parse the returned results with a simple method.
Larger ENOPs for incorrect words suggest that these words are incorrect words that people frequently used on their web pages. Hence, we ranked the similar characters based on their ENOPs at step 3, and return the list.
Since the reported errors contained informa-tion about the incorrect ways to write the correct words, we could check whether the real incorrect characters were among the similar characters that our programs generated at step 1 (inclusion tests). We could also check whether the actual incorrect characters were ranked higher in the ranked lists (ranking tests).
Take the word “和蔼可亲” as an example. In the collected data, it is reported that people wrote this word as “和霭可亲”, i.e., the second charac-ter was incorrect. Hoping to capture the error,
ICCEval generated a list of possible substitutions
for “蔼” at step 1. Depending on the categories of sources of errors, ICCEval generated a list of
characters. When aiming to test the effectiveness of visually similar characters, we could ask IC-CEval to apply SC3 to generate a list of
alterna-tives for “蔼”, possibly including “霭”, “谒”, “葛”, and other candidates. At step 2, we created and submitted query strings “和霭可亲”, “和谒 可亲”, and “和葛可亲” to obtain the ENOPs for the candidates. If the ENOPs were, respectively, 410000, 26100, and 7940, these candidates would be returned in the order of “霭”, “谒”, and “葛”. As a result, the returned list contained the actual incorrect character “霭”, and placed “霭” on top of the ranked list.
Notice that we considered the contexts in which the incorrect characters appeared to rank. We did not rank the incorrect characters with just the unigrams. In addition, although this running example shows that we ranked the characters directly with the ENOPs, we also ranked the list
5According to (Croft et al., 2010), the ENOPs may not re-flect the actual number of pages on the Internet.
of alternatives with pointwise mutual information: ) Pr( ) Pr( ) Pr( , X C X C X C PMI , (2)
where X is the candidate character to replace the correct character and C is the correct word ex-cluding the correct character to be replaced. To compute the score of replacing “蔼” with “霭” in “和蔼可亲”, X = “霭”, C=“和□可亲”, and (CX)
is “和霭可亲”. (□ denotes a character to be
re-placed.) PMI is a common tool for judging collo-cations in natural language processing. (cf. Ju-rafsky and Martin, 2009).
It would demand very much computation ef-fort to find Pr(C). Fortunately, we do not have to consider Pr(C) because it is a common denomi-nator for all incorrect characters. Let X1 and X2
be two competing candidates for the correct cha-racter. We can ignore Pr(C) because of the fol-lowing relationship.
Pr(Pr( ) ) ) Pr( ) Pr( , , 2 2 1 1 2 1 X X C X X C X C PMI X C PMI Hence, X1 prevails if scoreC, X1 is larger.
) Pr( ) Pr( , X X C X C score (3)In our work, we approximate the probabilities used in (3) by the corresponding frequencies that we can collect through Google, similar to the methods that we used to collect the ENOPs.
4.4 Experimental Results: Inclusion Tests
We ran ICCEval with 621 errors in the Ilist. The
experiments were conducted for all categories of phonological and visual similarity. When using SS, SD, MS, MD, and RS as the selection crite-rion, we did not limit the number of candidate characters. When using SC1, SC2, and SC3 as the criterion, we limited the number candidates to be no more than 30. We consider only words that the native speakers have consensus over the causes of errors. Hence, we dropped those 3.7% of words in Table 3, and had just 598 errors. The ENOPs were obtained during March and April 2010.
Table 4 shows the chances that the lists,
gen-SS SD MS MD Phone
Ilist 82.6 29.3 1.7 1.6 97.3
SC1 SC2 SC3 RS Visual Ilist 78.3 71.0 87.7 1.3 90.0 Table 4. Chances of the recommended list
erated with different crit at step 1, contained the
incorrect character in the reported errors. In the Ilist, there were 516 and 3006 errors that were
related to phonological and visual similarity, re-spectively. Using the characters generated with the SS criterion, we captured 426 out of 516 phone-related errors, so we showed 426/516 = 82.6% in the table.
Results in Table 4 show that we captured phone-related errors more effectively than visual-ly-similar errors. With a simple method, we can compute the union of the characters that were generated with the SS, SD, MS, and MD criteria. This integrated list suggested how well we cap-tured the errors that were related to phones, and we show its effectiveness under “Phone”. Simi-larly, we integrated the lists generated by SC1, SC2, SC3, and RS to explore the effectiveness of finding errors that are related to visual similarity, and the result is shown under “Visual”.
4.5 Experimental Results: Ranking Tests
To put the generated characters into work, we wish to put the actual incorrect character high in the ranked list. This will help the efficiency in supporting computer assisted test-item writing. Having short lists that contain relatively more confusing characters may facilitate the data prep-aration for psycholinguistic studies.
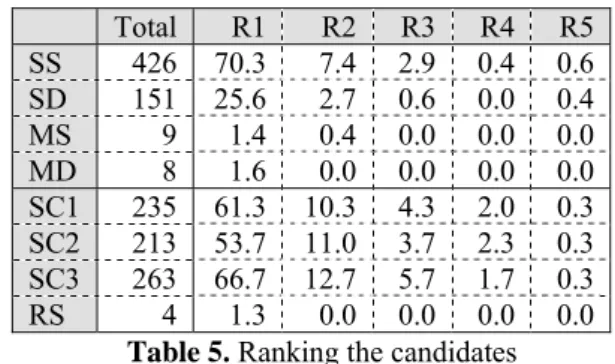
At step 3, we ranked the candidate characters by forming incorrect words with other characters in the correct words as the context and submitted the words to Google for ENOPs. The results of ranking, shown in Table 5, indicate that we may just offer the leading five candidates to cover the actual incorrect characters in almost all cases.
The “Total” column shows the total number of errors that were captured by the selection crite-rion. The column “Ri” shows the percentage of all errors, due to phonological or visual similarity, that were re-created and ranked ith at step 3 in
ICCEVAL. The row headings show the selection
criteria that were used in the experiments. For instance, using SS as the criterion, 70.3% of ac-tual phone-related errors were rank first, 7.4% of the phone-related errors were ranked second, etc. If we recommended only 5 leading incorrect
6The sum of 516 and 300 is larger than 598 because
some of the characters are similar both phonologically and visually.
racters only with SS, we would have captured the actual incorrect characters that were phone re-lated 81.6% (the sum of R1 to R5) of the time. For errors that were related to visual similarity, recommending the top five candidates with SC3 would capture the actual incorrect characters 87.1% of the time. Since we do not show the complete distributions, the sums over the rows are not 100%. In the current experiments, the worst rank was 21.
We also used PMI to rank the incorrect words. Due to page limits, we cannot show complete details about the results. The observed distribu-tions in ranks were not very different from those shown in Table 5.
5
Discussion
Compared with Liu et al.’s analysis (2009b-c) for the traditional Chinese, the proportions of errors related to phonological factors are almost the same, both at about 80%. The proportion of errors related to visual factors varied, but the av-erages in both studies were about 48%. A larger scale of study is needed for how traditional and simplified characters affect the distributions of errors. Results shown in Table 4 suggest that it is relatively easy to capture errors related to visual factors in simplified Chinese. Although we can-not elaborate, we can-note that Cangjie codes are can-not good for comparing characters that have few strokes, e.g., c1 to c4 in Table 1. In these cases,
the coding method for Wubihua input method (Wubihua, 2010) should be applied.
Acknowledgement
This research was supported in part by the research contract NSC-97-2221-E-004-007-MY2 from the Na-tional Science Council of Taiwan. We thank the ano-nymous reviewers for constructive comments. Al-though we are not able to respond to all the comments
Total R1 R2 R3 R4 R5 SS 426 70.3 7.4 2.9 0.4 0.6 SD 151 25.6 2.7 0.6 0.0 0.4 MS 9 1.4 0.4 0.0 0.0 0.0 MD 8 1.6 0.0 0.0 0.0 0.0 SC1 235 61.3 10.3 4.3 2.0 0.3 SC2 213 53.7 11.0 3.7 2.3 0.3 SC3 263 66.7 12.7 5.7 1.7 0.3 RS 4 1.3 0.0 0.0 0.0 0.0
in this paper, we have done so in an extended version of this paper.
References
Cangjie. 2010. Last visited on 22 April 2010: en.wikipedia.org/wiki/Cangjie_input_method. CDL. 2010. Chinese document laboratory, Academia
Sinica. Last visited on 22 April, 2010; cdp.sinica.edu.tw/cdphanzi/. (in Chinese)
Chen, Matthew. Y. 2000. Tone Sandhi: Patterns across Chinese Dialects, (Cambridge Studies in Linguistics 92). Cambridge University Press. Chu, Bong-Foo. 2010. Handbook of the Fifth
Genera-tion of the Cangjie Input Method. last visited on 22 April 2010: www.cbflabs.com/book/5cjbook/. (in Chi-nese)
Cormen, Thomas H., Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. 2009. Introduction to Algorithms, third edition. MIT Press.
Croft, W. Bruce, Donald Metzler, and Trevor Stroh-man, 2010. Search Engines: Information Retrieval in Practice, Pearson.
Dict. 2010. Last visited on 22 April 2010, www.cns11643.gov.tw/AIDB/welcome.do
Fan, Kuo-Chin, Chang-Keng Lin, and Kuo-Sen Chou. 1995. Confusion set recognition of on-line Chinese characters by artificial intelligence technique. Pat-tern Recognition, 28(3):303ԟ313.
HanDict. 2010. Last visit on 22 April 2010, www.zdic.net/appendix/f19.htm.
Jurafsky, Daniel and James H. Martin. 2009. Speech and Language Processing, second edition, Pearson. Kuo, Wen-Jui, Tzu-Chen Yeh, Jun-Ren Lee, Li-Fen
Chen, Po-Lei Lee, Shyan-Shiou Chen, Low-Tone Ho, Daisy L. Hung, Ovid J.-L. Tzeng, and Jen-Chuen Hsieh. 2004. Orthographic and phonological processing of Chinese characters: An fMRI study. NeuroImage, 21(4):1721ԟ1731.
Lee, Chia-Ying, Jie-Li Tsai, Hsu-Wen Huang, Daisy L. Hung, Ovid J.-L. Tzeng. 2006. The temporal signatures of semantic and phonological activations for Chinese sublexical processing: An even-related potential study. Brain Research, 1121(1):150-159. Lee, Hsiang. 2010a. Cangjie Input Methods in 30
Days 2. Foruto. Last visited on 22 April 2010: in-put.foruto.com/cccls/cjzd.html.
Lee, Mu. 2010b. A quantitative study of the formation of Chinese characters. Last visited on 22 April 2010: chinese.exponode.com/0_1.htm. (in Chinese)
Liu, Chao-Lin, and Jen-Hsiang Lin. 2008. Using structural information for identifying similar Chi-nese characters. Proc. of the 46th
Annual Meeting of the Association for Computational Linguistics, short papers, 93ԟ96.
Liu, Chao-Lin, Kan-Wen Tien, Yi-Hsuan Chuang, Chih-Bin Huang, and Juei-Yu Weng. 2009a. Two applications of lexical information to computer-assisted item authoring for elementary Chinese. Proc. of the 22nd Int’l Conf. on Industrial En-gineering & Other Applications of Applied Intel-ligent Systems, 470ԟ480.
Liu, Chao-Lin, Kan-Wen Tien, Min-Hua Lai, Yi-Hsuan Chuang, and Shih-Hung Wu. 2009b. Cap-turing errors in written Chinese words. Proc. of the 47th Annual Meeting of the Association for Compu-tational Linguistics, short papers, 25ԟ28.
Liu, Chao-Lin, Kan-Wen Tien, Min-Hua Lai, Yi-Hsuan Chuang, and Shih-Hung Wu. 2009c. Phono-logical and logographic influences on errors in written Chinese words. Proc. of the 7th
Workshop on Asian Language Resources, the 47th Annual Meeting of the ACL, 84ԟ91.
Liu, Cheng-Lin, Stefan Jaeger, and Masaki Nakagawa. 2004. Online recognition of Chinese characters: The state-of-the-art. IEEE Transaction on Pattern Analysis and Machine Intelligence, 26(2):198ԟ213. Wubihua. 2010. Last visited on 22 April 2010:
en.wikipedia.org/wiki/Wubihua_method.
Yeh, Su-Ling, and Jing-Ling Li. 2002. Role of struc-ture and component in judgments of visual simi-larity of Chinese Characters. Journal of Expe-rimental Psychology: Human Perception and Per-formance, 28(4):933ԟ947.
KONG, S.C., et al. (Eds.), ICCE2009; ©2009 Asia-Pacific Society for Computers in Education.
Computer Assisted Creation of Items for
Scrambled Sentence Tests
Chao-Lin Liu
Chih-Bin Huang Ying-Tse Sun
Wei-Ti Kuo
Department of Computer Science, National Chengchi University, Taiwan {chaolin,96753014,93703038,94703041}@nccu.edu.tw
Abstract. We apply techniques of natural language processing to support the creation of special scrambled sentences that allow only specific word orders. The scrambled sentences are useful for students to practice their knowledge about grammars. It takes two steps to create a test item for scrambled-sentence tests. We create a set of grammatical alternative sentences from the target sen-tence, and make sure that students will rebuild the target sentence by pegging some of the words in the target sentence. The proposed methods can automatically and effectively peg words to single out a specific sentence from a set of sentences. We also employ the Stanford parser and propose a practi-cal heuristic principle to help teachers exclude a potentially large number of alternative grammatipracti-cal orderings of a set of words in the scrambled sentence.
Keywords: scrambled sentence tests, computer assisted item generation, grammar learning, natural language processing
1
Introduction
Techniques that were originally designed for natural language processing (NLP) have proved to be instru-mental for applications for computer assisted language learning (CALL) [1, 3, 7]. In this paper, we report an application of NLP techniques for grammar learning.
Word orders are important in conveying the correct meaning in almost all languages, so learning the cor-rect word orders are crucial even for beginning learners of languages (cf. some examples at
http://www.manythings.org/ss/ and http://www.msrossbec.com/scrambleintro.shtml). Placing students in
actual conversations is common for students to practice knowledge of word orders. However, some students might not be ready for such challenging field tests, so a less stressful environment is necessary for those who are not completely ready for direct conversations.
Constructing sentences from scrambled sentences offers an alternative for students of intermediate com-petence. In these practices, sentences are segmented and scrambled to create a set of words or phrases, and students have to reconstruct the original sentences with the given text segments. Taking advantage of the information contained in parse trees, Liu et al. [5] segmented the sentences into different numbers of pieces to make the test items adaptive to students’ competence levels.
A sentence can be segmented at coarse or fine levels, and a student may find two or more grammatical orders of the resulting segments. When a teacher prefers to avoiding multiple answers to a test item, just segmenting the sentences based on parse trees become insufficient, and more techniques are in need.
The safest way to make sure that there is only way to build a sentence from a set of words is to rule out all but the target sentence by pegging some words. Given a set of sentences, it is not very difficult to find such words to be anchored. Our experience show that the task of generating all grammatical permutations of a set of words turns out to be more challenging that it appears [1, 4].
In Section 2, we present more background information about the work on scrambling sentences for grammar learners. In Section 3, we propose methods to select and peg some words for a set of sentences to achieve a unique ordering. In Section 4, we attempt to employ the Stanford parser (http://nlp.stanford.edu:8080/parser/) to find all grammatical arrangements of a set of words and phrases. With such a capability, we will reduce the burden of teachers. In Section 5, we report the results when we repeated the work reported in the previous section with a categorical parser. In Section 6, we propose a prac-tical heuristic to solve the discussed problems.
KONG, S.C., et al. (Eds.), ICCE2009; ©2009 Asia-Pacific Society for Computers in Education.
2
Problem Definition
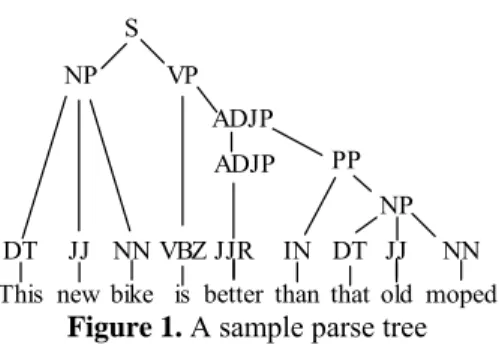
We employ parsing techniques to split a given sentence. Fig-ure 1 shows a parse tree, produced by the Stanford parser, for “The new bike is better than that old car”. This sentence can be split in multiple ways, e.g., {“this new bike”, “is better than”, “that old car”} or {“this”, “new”, “bike”, “is better than”, “that”, “old”, “car”}. An instance of sentence recon-struction practice is to provide the segments {“is better than”, “this new bike”, “that old car”} to students and expect them to come up with the original sentence.
Splitting the given sentence at different granularities offers a way to control the difficulty of the test items, and is a useful
strategy in adaptive assessment. Rebuilding the sentence from {“is better than”, “this new bike”, “that old car”} is easier than rebuilding the sentence from {“this”, “new”, “bike”, “is better than”, “that”, “old”, “car”}. Splitting the sentence into more segments, all else being equal, generally makes the task of recon-struction of the sentence more challenging. Hitting the correct order from 3!(=6) arrangements by chance is more likely to occur than hitting the correct order from 7!(=5040) arrangements by chance.
There might be different ways to rebuild a correct sentence for a given segmentation of the original sen-tence. When we segment the original sentence into more segments, we may have allowed more possible an-swers. For instance, we may build at least 48 sentences from {“this”, “new”, “bike”, “is”, “better”, “than”, “that”, “old”, “car”} (cf. Table 1 on the next page).
When we would like the students to practice a particular sentence pattern, we may want to force the stu-dents to rebuild the sentence in a specific manner, e.g., assertive sentences vs. yes/no questions. One may rely on the contextual information to exclude some of the syntactically acceptable arrangements as Liu et al. [5] suggested. If the sentence in Figure 1 was preceded by an utterance that involved a new bike in a conver-sation, then “this old bike” would become less plausible in the expected ordering.
An automatic method to fix some of the words at their original locations makes certain that there is ex-actly one acceptable solution. If we split the sentence in Figure 1 into nine words, there will be at least 48 grammatical arrangements. If we fix “new”, “that” and “car” at the second, the seventh and the ninth words in the sentence, respectively, there will be only way rebuild the sentence.
In addition, when preparing a test item, a teacher typically provides only one sentence—The one the teachers would like the students to rebuild. To facilitate the preparation of test items, we attempt to find all of the alternative arrangements of the words that constitute the given sentence. For the sentence used in Fig-ure 1, we would like to create sentences like “This new car is better than that old bike” and “Is this new bike better than that old bike” for the teachers, and help the teachers rule out these grammatical alternatives by pegging some selected words.
3
Pegging Words for a Unique Order
Assume that we have a way to find all grammatical arrangements of the words for a sentence like the one shown in Figure 1. We present algorithms to select and fix the words that will single out the desirable ar-rangements. It is very likely that, for educational purposes, a teacher may want to fix certain words of her/his choices. The user interface of our system certainly can accommodate this need, but we will not consider this need when discussing the design of the internal algorithm.
Assume that there are m tokens, w1, w2, …, wi, …, wm, in
a given sentence, sg, and that we have a set of n sentences,
S={s1, s2, …, sj, …, sn}, that are formed with those m tokens
in sg. Hence, we have sgS. Figure 2 shows the algorithm
that will find the minimum number of words to peg and to allow sg to be the answer to the sentence reconstruction task.
In the algorithm, we identify the sentences that share the same tokens at the same positions as sg. The sentences that
meet such criteria are called “surviving” sentences. The al-gorithm aims at reducing the number of surviving sentences by pegging more and more tokens. By construction, the al-gorithm will iterate at most (m-1) times, when it chooses to peg (m-1) tokens. In addition, when it happens to peg (m-1) tokens, sg will be the last sentence in S at Step 5.
We enumerated 48 grammatical arrangements of the words in the sentence in Figure 1, and we list the sentences in Table 1. We ran the Word-Pegging algorithm with these
VP NP ADJP ADJP PP This DT new JJ bike NN better JJR than IN NP that DT old JJ moped NN is VBZ S
Figure 1. A sample parse tree
Algorithm: Word-Pegging Input: S = {s1, s2, …, sj, …, sn} and
sg = w1w2…wi…wm; where sgS
Output: the set of indexes of tokens to be pegged Steps:
1. Set W to
2. If kW, set ck to the number of sentences in
S whose k-th token is the same as wk. If kW,
set ck to (n+1)
3. Find the index v in [1,m], such that cvis the
smallest among all cu for any u≠v (more
dis-cussion about the choice of v in the paper) 4. Add v to W. Remove from S the sentences
whose v-th token is not the same as wv
5. If there is only one sentence in S, return W; otherwise, return to Step 2