Matrix-Matrix Multiplications
and Fault Tolerance
on Hypercube Multiprocessors
Yuh-Rong Leu, Ing-Yi Chen* and Sy-Yen Kuo Department of Electrical Engineering
National Taiwan University Taipei, Taiwan, R.O.C.
*Department of Electronic Engineering Chung Yuan Christian University
Chungli, Taiwan, R.O.C.
Abstract
Several new algorithms for matrix-matrix multiplications on hypercube multiprocessors are presented and evaluated based on the number of multiplications, additions, and transfers. The matrices ~IIbe multiplied are uniformly distributed to all processors of a hypercube system. Each processor owns some submatrices which are derived by dividing the source matrices. Each submatrix multiplication can now be performed independently within a processor. AN the partial results are then summed up and transferred to a single processor. An orthogonal tree is used for effient communication. The time complsrity is O(log,p) i f p q processors are used. In addition. the UDD (Uniform Data Distribution) approach is employed when some processors do not workproperly and the faulty eflits have been detected. Two classes offault patterns are considered and evaluated.
1:
Basic Matrix-Vector Multiplication
A l g o r i t h mThe matrix-matrix multiplication algorithms presented in this paper are extensions of the matrix-vector multiplication algorithm in [l]. The basic matrix-vector multiplication can be described as the inner product of a vector with each row of a given matrix [3]:
IfA E R m X n h x ~ R " , then y = A . x. where y , =Z A,, 'x, , i = 1, ..., m.
fI
Altematives in viewing a matrix-matrix multiplication are listed below: If A E R B E R ' x 9 i C E K " I x 4 , then
(1) C = A B, where C,,
=&
A& Bb(2) C' = A '61'
In the above definitions, Akdenotes the k-th column ofA and A,denotes the k-th row ofA.
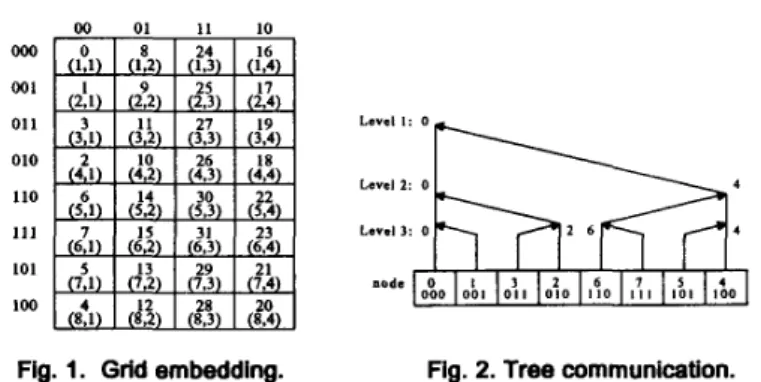
A common data mapping scheme for matrices is to use a two-dimensional grid embedding for the hypercube processors. To optimize the use of each processor, it is desirable to incorpo- rate all nodes (processors) into the grid and distribute the matrix elements as evenly as possi- ble among the nodes. A grid may be embedded on the hypercube using all nodes by numbering the processors according to the Gray code which is a binary number representation where only one bit is different for any two given consecutive numbers [4]. Fig. 1 illustrates such a Gray code numbering on a 5-D hypercube.
Acknowledgment: This research was supported by the National Science Council, Taiwan, R.O.C.
,
under Grant NSC 82-0404-E033-049-T and NSC 82-0408-E002-021.Session 5: Poster Session 00 01 I 1 10
177
OOO 001 01 1 010 110 111 I01 100 L0"Cl I : 0 Level 2: 0 L O V O l 3: 0 nodeFig. 1. Grid embedding. Fig. 2. Tree communication.
Suppose we need to sum up the values residing in the processors of column 1 in Fig. 1. The steps taken are shown in Fig. 2, where
+
indicates the data-flow direction. As soon as a pro- cessor receives data, it sums up the data with its own data.1. Distribute the matrix A and the vector x to each processor according to its position (iJ) in
2. Each processor computes sequentially the intermediate subvecrory,= A, x,.
3. Use the tree communication scheme row-wisely to gather and compute the resultant subvec- tors Y distributed on the first column-processors. The equation below describes this operation:
The basic matrix-vector multiplication algorithm can then be expressed as follows: the grid; thus, each processor acquires a portion of A (A,) and a poltion of x (x,).
P P
Yi =Z Aij. X j = Z . ~ , j
.
FI f l
4. Collect all Y,'s into processor (0,O) using the tree communication column-wisely.
2: Matrix-Matrix Multiplication Algorithms
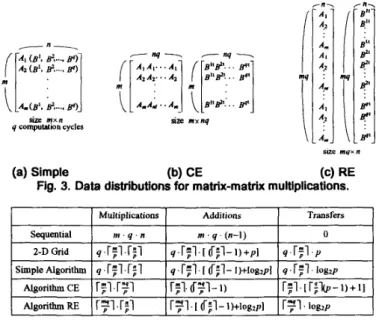
The first algorithm is a simple approach. The distributing method of this algorithm is simi- lar to the basic matrix-vector multiplication algorithm. In each computation cycle, only one column of matrix B is processed. Matrix A is distributed, and so each processor has a subma- trix A,,
.
Each E' is distributed across the processors of a row. C j is formed at the end of the j-th iteration. And in each iteration, a matrix-vector multiplication is performed as in the basic matrix-vector multiplication algorithm. So the entire matrix-matrix multiplication needs qcomputation cycles (see Fig. 3(a)).
The second one is named CE (Column-Expansion). In this algorithm, we use two aug- mented matrices each with m rows and nq columns. Each row of the augmented matrix con- sists of q copies of a row of matrix A. Associated with each copy is a column of matrix E (See Fig. 3@)). This algorithm is based on the fact that C, =Ai B j . After each processor has com-
pleted its own tasks of multiplications, additions, and transfers, the entries of each row of ma- trix C are distributed across the row-processors. So the tree communication scheme must be invoked to gather these data into the leftmost column-processors. In Fig. 3(b), B" stands for the transposed vector of B'sj-th column.
T h e third is the RE (Row-Expansion) algorithm. Algorithm RE still needs two aug- mented matrices
-
one formed by matrix A and the other by B. But instead of expanding by the column, we expand the matrices by the row. Thus we have two matrices, each of size178
I
Multiplications1
AdditionsInternational Conference
onApplication-Speciiic Array
ProcessorsTransfers
mqxn
.
The entries of these two matrices are then evenly distributed to all the processors. The computational mechanism is similar to that of the Simple Algorithm, but only one computa- tion cycle is required (see Fig. 3(c)). Fig. 4 gives the comparisons between previous and pro- posed algorithms.size m x n q computation cycles
s u e m q x n
Fig. 4. Comparisons for matrix-matrix multiplication
algorithms.
3: Redistribution under Multiple Faults
When some processors are faulty and the errors are detected, the jobs they are performing must be redistributed to other fault-free processors. This is the basic concept of load redis- tribution. We use the row/column UDD (Uniform Data Distribution) strategy, i.e. the work load of the faulty processors is first redistributed row-wisely and then column-wisely [2]. Two cases of multiple faults are considered in this section
-
either all faults are in one row or in one column.Assume there are r faulty processors in a row and totally 1) x p processors in the hypercube. Let: w be the width of the original largest submatrix,
h be the height of the original largest submatrix,
w,/be the width of submatrices distributed after row-wise UDD, h,/be the reduced height of submatrices in the row with faulty nodes,
h, be the increased hei ht of submatrices distributed to the remainin rows. Therefore, w
=r/l)l
and h=?m/pl
in the Simple Algorithm ; w =rnq/pfand h = rm/plin Algorithm CE; w =rn/p] and h =rmq/p] in Algorithm RE. The following equations must
hold in order for each node to have an equal number of data elements after the UDD (see Fig.
Session 5: Poster Session
179
w . h i = W t f . h l , h i , + ( p - l ) . h i = p . h w l f = w + r w / ( p - r ) .
hl,= hp@-r)l(p2 - r ) and wIf= w p / @ - r ) .
Assume there are c faulty processors in a column, and again, p x p processors in the hyper-
After a sequence of operations on the above equations, we get:
cube. Similarly, from Fig. S(b), we have: w . h i =Wlj.hl,
C . h i f + ( p - c ) . hi = p ' h W I f = w + w / ( p - 1).
After manipulating these equations, the final results are:
hl,=hp@- 1 ) / ( p 2 - c ) ; w ~ , = w P / @ - 1).
load of a faulty processor (ongmal block sue)
(a) Faults in a row (b) Faults in a column
Fig. 5. Matrix partitioning after rowlcolumn-UDD.
4:
Conclusions
In this paper, three algorithms for matrix-matrix multiplications are proposed and compared in terms of the number of multiplications, additions, and transfers. Furthermore, fault- tolerance issues for these algorithms are also discussed. These algorithms explore the connec- tivity of the hypercube and therefore are communication efficient. The transfer complexity of these algorithms is O(log,p) i f p x p processors are used. Overall, Algorithm RE behaves bet- ter than the other two algorithms with better load balance, and lower communication overhead.
References [ I ] [2] 131 141 151 161 171
A. C. Elster and A. P. Reeves, "Block-matrix Operatiuns Tlsing Orthogonal Trees," Proceeding 4 I h e Third International Confirence on Hypercihe Mitlfi/>r(~cess(>r~. SIAM, Pasadena, CA (January, 1988). A. C. Elster, M. Umit Uyar, and Anthnny P. Reeves, "Fault-Tolerant Matrix Operations on Hypercube Multiprocessors", Internutii>nul Conference on I'urullel Processing (1 989).
G. H. Golub and C . F. Van Loan. Mutrir Compittuftons. Johns Hopkins, Haltiiiiore, MD (1983). J. Salmon, "Binary Gray Codes and the Mapping of Physical Lattice into a Hypercube," Culfech Con-
current Processor Report (CCP) Hm-51, (1983).
S. L. Johnson. "Communication Efficient Basic Linear Algebra Computations on Hypercube Architec- ture," Journal of Puruliel und Distrilmred Compiiting, 4. pp. 133-1 72 (1 987).
0. A. Mcbryan a i d E. F. Van de Velde. "Matrix and Vector Operations on Hypercube Parallel Proces- sors," Purulld C m i p f i n g , 5,( l&2), pp. 117-125, North-Holland, (July 1987).
Angel L. Decegama, The fechndogv of Purulli4 Processing (Purullcl Pr(wcvstng Architecture und