建置圖書館書籍推薦系統:資料探勘之應用
陳垂呈1、陳幸暉2 1. 南台科技大學 資訊管理系 2. 國立高雄師範大學 教育學系親職教育研究所 E-mail: [email protected]摘 要
本研究以讀者之借閱資料為探勘的資料來源,每一筆借閱資料記錄讀者曾經借閱的書籍項目及其借閱 的次序,並以某 k 本書籍為探勘的目標,k≥1,利用分群化(clustering)技術分別從以下兩方面建置此 k 本 書籍適性化推薦:一是只考量書籍項目是否出現在借閱資料中,依據借閱資料之間的借閱相似度,文中設 計一個方法將借閱資料歸屬於與中心點具有最大借閱相似度的群組,並經由反覆的分群化計算,以達到整 體借閱相似度總和為最大值的目標,然後從群組中分別發掘此 k 本書籍各適性化推薦的讀者;二是考量書 籍項目具有借閱次序,文中修改前面推薦的方法,依據借閱資料之間的次序借閱相似度,文中設計一個方 法將借閱資料歸屬於與中心點具有最大次序借閱相似度的群組,並經由反覆的分群化計算,以達到整體次 序借閱相似度總和為最大值的目標,然後從群組中分別發掘具有借閱次序之此 k 本書籍各適性化推薦的讀 者。本研究根據所提出的方法,設計與建置一個圖書館書籍推薦探勘系統,其探勘結果對規劃書籍推薦適 性化的讀者,可以提供相當有用的參考資訊。 關鍵詞:資料探勘、分群化、借閱資料、圖書館1. 前 言
圖書館藉由資訊技術的支援,可以輕易、快速儲存讀者的借閱資料,這些借閱資料可能來自於讀者曾 經借閱的書籍記錄、讀者填寫的興趣資料與人口統計資料、或是網頁的瀏覽記錄等。如何利用這些大量的 借閱資料,深入分析讀者的借閱行為,以改善與讀者之間的關係,並提供讀者最貼切的借閱服務、進而提 升讀者的滿意度與利用率,是圖書館管理者必須思考的問題之一。 資料探勘(data mining)是從大量資料中找出有用的資訊與知識,目前已應用在許多領域中[1],並已 被證明可以有效應用在產品行銷、銷售及顧客服務上,是企業提升經營優勢與競爭力的重要工具之一[2, 3]。 本研究將以讀者之借閱資料為探勘的資料來源,每一筆借閱資料記錄讀者曾經借閱的書籍項目及其借閱的 次序,並以某 k 本書籍為探勘的目標,k≥1,分別以 b1, b2, …, bi, …, bk表示之,1≤i≤k,在發掘書籍 bi適性 化推薦之讀者的過程中,對於曾經借閱書籍 bi 的讀者,視為對書籍 bi 有興趣的已知讀者,對於潛在讀者則 利用分群化(clustering)技術分別從以下兩方面進行發掘計算: (1) 只考量書籍項目是否出現在借閱資料中:文中先挑選 k 筆借閱資料其必須分別包含書籍 b1, b2, …, bk, 分別設定為一群組的中心點,設計一個分群化方法將借閱資料歸屬於與中心點具有最大借閱相似度的 群組,並達到整體借閱相似度總和為最大值的分群化目標,然後從群組中分別發掘此 k 本書籍各適性 化推薦的讀者。 (2) 考量書籍項目具有借閱次序:文中先挑選 k 筆借閱資料其必須分別包含書籍 b1, b2, …, bk,分別設定為 一群組的中心點,修改前面的分群化方法,將借閱資料歸屬於與中心點具有最大次序借閱相似度的群 組,並達到整體次序借閱相似度總和為最大值的分群化目標,然後從群組中分別發掘具有借閱次序之此 k 本書籍各適性化推薦的讀者。 本研究根據所提出的方法,設計與建置一個書籍推薦探勘系統,其探勘結果對圖書館規劃書籍適性化 推薦的讀者,必可以提供相當有用的參考資訊。 本論文的架構如下:下一節中說明資料探勘技術、及其在書籍借閱應用上的相關研究;第 3 節中考量 書籍項目是否出現在借閱資料中,設計一個方法發掘書籍適性化推薦的讀者;第 4 節中考量書籍項目具有 借閱次序,設計一個方法發掘具有借閱次序之書籍適性化推薦的讀者;第 5 節中依據所提出的方法,設計 與建置一個書籍推薦探勘系統;最後在第 6 節中做一結論。
2. 相關研究
資料探勘(data mining)是從大量資料中挖掘出潛在有用的資訊與知識,發現專家尚且未知的新關係, 以提供企業管理人員決策支援的參考。資料探勘可完成以下任務或更多:關聯規則(association rules)、分 群(clustering)、分類(classification)、次序相關分析(sequential pattern analysis)及預測(prediction)等 [1],利用資料探勘於企業從事行銷決策及市場預測等活動時,可以提供非常有價值的參考資訊[2, 3]。 辜曼蓉(1999)曾指出圖書館的核心價值是讀者和服務人員之間的互動,而館藏和資訊傳播則扮演提 升圖書館服務品質的輔助角色[4]。因此,針對不同讀者需求資訊的差異性下,善用個人化服務技術調整圖 書館的資訊服務,是圖書館管理重要的服務方式之一[5, 6],其目的是將最貼切的館藏資訊主動傳達給讀者 個人,進而提升館藏資料的利用率與圖書館的管理績效。 對於圖書館的書籍借閱而言,管理人員往往不知書籍適合的讀者在那,導致圖書館只能被動等待讀者 來借閱書籍,而面對圖書館大量的書籍,也容易造成讀者搜尋書籍資料的困擾與不便。如此被動的圖書館 經營方式,對提升書籍借閱率將無法提供有用的效益。目前已有許多利用資料探勘應用於圖書館經營服務 的相關研究,其包含有:[7]利用 k-means 的方法找出學習社群,以支援電子圖書館的個人化服務;[8]利用 關聯規則提升數位圖書館的個人化服務及管理;[9]提出利用資料探勘發掘讀者的社群關係,進而達到吸引 讀者借閱書籍,以提升圖書館的借閱率與讀者忠誠度等目的;[10]利用資料探勘找出讀者與書籍之間的一般 化關聯規則,做為讀者之新書推薦的依據;[11]以模糊理論(fuzzy)與資料探勘分析讀者的借閱資料,進 而提供相關的書籍推薦給讀者參考。 物件分群化是以相似度做為分群的依據,分群化的研究主要可分為以下幾種:分割式(partitioning)、 階層式(hierarchical)、格子基礎(grid-based)、密度基礎(density-based)與模型基礎(model-based)等[1]。 Berry and Linoff(1997)曾描述:「想對資料進行分析、了解資料意涵並描繪出最好的利用方式,分群化分 析(cluster analysis)是一個很好的開始方法」[2]。本研究將修改分割式分群化的方法,做為分群化借閱資 料的方法依據。眾多分割式分群化演算法中,較著名的有 PAM(Partitioning Around Medoids)[12]、k-means [13, 14] 及 CLARANS [15]等,其目的是分群成使用者所指定的 k 個群組,此分割方式可將每一物件歸屬於最相似的 群組中。PAM 演算法由 Kaufman 和 Rousseeuw(1990)所提出[12],為了將全部物件分群成 k 個群組,PAM 演算法是先為每個群組決定一個代表物件(representative objects),此代表物件稱之為 medoid,一旦把 k 個 medoids 選定之後,就依據相似度來決定非 medoid 物件是屬於那一個群組,其相似度是以物件彼此之間的 距離(Euclidean distance)來表示,d(Oa, Ob)表示物件 Oa與 Ob之間的距離。例如 Oi為 medoid,而 Oj為非
medoid 物件,如果 d(Oj, Oi)=min{d(Oj, Oe)},Oe表示所有的 medoids,則 Oj歸屬於 Oi群組。
對任一個非 medoid 物件 Oj而言,當一個 medoid Oi被一個非 medoid 物件 Oh取代時,所造成的改變成
Cjih = d(Oj, Om) – d(Oj, On) Om表示以 Oh取代 Oi之後,與 Oj具有最大相似度(最短距離)的 medoid; On表示以 Oh取代 Oi之前,與 Oj具有最大相似度(最短距離)的 medoid。 以 Oh取代 Oi成為 medoid 之後,所造成的總改變成本為: TCih = C
∑
jih j 若 TCih>0 時,表示以 Oh取代 Oi之後的總距離相較於取代前大,則 Oi將不會被 Oh所取代。以 TCih為分群 化的衡量依據,說明 PAM 演算法如下: PAM () { 任意選取 k 個物件做為 medoids,並計算分群後的總距離; TCih=0; while TCih<0 { 對所有 Oi與 Oh的組合計算出其 TCih; 選出 TCih為最小值的 Oi與 Oh配對; if TCih>=0 break; } 完成分群; } 本研究將以分群化方法做為探勘資料的方法依據,以某 k 本書籍為探勘的目標,k≥1,分別從以下兩方 面發掘書籍適性化推薦:一是發掘此 k 本書籍各適性化推薦的讀者;二是發掘具有借閱次序之此 k 本書籍 各適性化推薦的讀者。3. 發掘書籍適性化推薦之讀者
本章節以讀者之借閱資料為探勘的資料來源,每一筆借閱資料包含讀者曾經借閱的書籍項目,以並某 k 本書籍為探勘的目標,k≥1,此 k 本書籍分別以 b1, b2, …, bi, …, bk表示之,1≤i≤k。對於曾經借閱書籍 bi的 讀者,視為對書籍 bi有興趣的已知讀者,對於潛在讀者則設計一個分群化方法,從借閱資料中找出書籍 bi 與其他書籍之間的關聯性,以判斷推薦借閱書籍 bi的讀者具有那些的傾向特徵,以做為發掘適合借閱之讀 者的依據。本章節共分為兩小節如下:第 3.1 節中設計一個分群化方法發掘書籍適性化推薦的讀者;第 3.2 節中以一實例做說明。 3.1 探勘方法 文中定義以下借閱相似度做為借閱資料歸屬於那一群組的依據: 借閱相似度={借閱資料∩群組中心點}的書籍項目數量/群組中心點的書籍項目數量例如一筆借閱資料為{ABC},一個群組中心點為{ABDEF},其借閱相似度=2/5=40%。計算借閱資料與 各群組中心點之間借閱相似度,然後將借閱資料歸屬於借閱相似度最大的群組中。在每次分群化之後計算 整體借閱相似度的總和,若目前分群化的整體借閱相似度總和大於之前的分群,則將目前分群的中心點取 代之前的中心點。 由於欲探勘 k 本書籍各適性化推薦的讀者,文中先挑選 k 筆借閱資料其必須分別包含書籍 b1, b2, …, bk, 並分別設定為一群組的中心點。若某一書籍 bi未曾被借閱過,即沒有借閱資料包含書籍 bi,則以與書籍 bi 性質最相近且曾經被借閱的書籍取代之。依據借閱相似度的大小將借閱資料 Tj歸屬於群組中,分別以 b 1-群組、b2-群組、⋅⋅⋅、bk-群組表示之,1≤j≤m,表示共有 m 筆的借閱資料,分群化的過程可表示為: Clustering (b1, b2, …, bk) { if k=1 { 將包含書籍 b1的借閱資料歸屬於 b1-群組; break; } else { 挑選 k 筆借閱資料其必須分別包含書籍 b1, b2, …, bk做為群組中心點; d1=計算分群後的整體借閱相似度的總和; d=d1; /*表示分群化之後減之前整體借閱相似度總和的差值*/ while d>0 { 挑選任一包含書籍 bi的借閱資料取代原先 bi-群組的中心點,1≤i≤k; 計算分群化之後的整體借閱相似度的總和; d2=選出整體借閱相似度總和為最大值的中心點組合; d=d2-d1; if d≤0 { 保留之前的分群; Break; } else { 將目前分群的中心點取代之前的中心點; d1=d2; } } 完成分群; } 經由上述分群化步驟,可將借閱資料歸屬於最適合的群組,並達到整體借閱相似度總和為最大值的目 標。在 bi-群組中計算除了書籍 bi之外各項書籍出現的比率值為:各項書籍出現在 bi-群組中的數量/bi-群組 包含的借閱資料數量,然後將比率值最大的書籍稱為「推薦因子」,做為發掘書籍 bi適性化推薦之讀者的依 據。藉由 bi-群組的借閱傾向特徵,文中定義書籍 bi適性化推薦的讀者如下: 書籍 bi適性化推薦的讀者:若讀者的借閱資料中包含「推薦因子」的書籍且未曾借閱書籍 bi,表示為
潛在對書籍 bi有興趣者,則為書籍 bi適性化推薦的讀者。 根據以上的探勘計算,即可分別發掘 k 本書籍各適性化推薦的讀者。在實際的應用中,對於設定「推 薦因子」的書籍項目數量,可依據應用上的須要而彈性調整。 3.2 實例說明 文中以一實例說明發掘某一書籍適性化推薦之讀者的探勘過程。表 1 為借閱資料庫 D1,其包含 4 筆的 借閱資料,其中{A, B, C, D, E}表示書籍項目的集合,{T1, T2, T3, T4}表示借閱資料的集合,假設欲探勘之書 籍為 A 及 B。 表 1 借閱資料庫 D1 借閱資料編號 書籍項目 T1 AD T2 BE T3 ACE T4 BCE 首先挑選包含書籍 A 的借閱資料 T1、及包含書籍 B 的 T2分別一群組的中心點,選經由演算法 Clustering() 的計算,可得到以下兩個群組: A-群組={T1, T3}及 B-群組={T2, T4}
在 A-群組中除了書籍 A,計算其它書籍出現的比率值為:C=1/2=50%; D=1/2=50%; E=1/2=50%,其中 挑選書籍 C 為「推薦因子」,可發掘書籍 A 適性化推薦的讀者為:T4。 在 B-群組中除了書籍 B,計算其它書籍出現的比率值為:C=1/2=50%; E=2/2=100%,其中書籍 E 具有 最大的出現比率值,因此以書籍 E 為「推薦因子」,可發掘書籍 B 適性化推薦的讀者為:T3。
4. 發掘具有借閱次序之書籍適性化推薦的讀者
讀者借閱的書籍記錄中,除了儲存借閱的書籍項目,也伴隨儲存借閱的日期時間。因此若考量讀者借 閱的時間性,則從讀者的借閱資料中,可顯示出讀者是依本身的興趣或是書籍的特性而有次序借閱書籍項 目。此章節以讀者之具有書籍次序的借閱資料為探勘的資料來源,並以某 k 本書籍為探勘的目標,k≥1,此 k 本書籍分別以 b1, b2, …, bi, …, bk表示之,1≤i≤k。對於曾經借閱書籍 bi的讀者,視為對書籍 bi有興趣的已 知讀者,對於潛在讀者則設計一個分群化方法,從借閱資料中找出書籍 bi與其他書籍之間的次序關聯性, 以判斷推薦借閱書籍 bi的讀者具有那些的傾向特徵。本章節共分為兩小節如下:第 4.1 節中設計一個分群 化方法發掘具有借閱次序之書籍適性化推薦的讀者;第 4.2 節中以一實例做說明。 4.1 次序探勘方法 文中定義以下次序借閱相似度的計算,做為借閱資料歸屬於那一群組的依據: (1) 在不考量借閱次序的情況下,計算 s={借閱資料∩群組中心點}的書籍項目,s≥0; (2) 計算 s 中書籍項目的次序子集合; (3) 只考量書籍借閱的次序性,而非前後次序的相鄰性,找出一個包含書籍項目最大的次序子集合 smax,其包含於借閱資料與群組中心點;
(4) 序借閱相似度=smax的書籍項目數量/群組中心點的書籍項目數量。
例如一筆借閱資料為{ABC},一個群組中心點為{BDCEA},其 s={ABC},s 的次序子集合={A, B, C, AB, BA, AC, CA, BC, CB, ABC, ACB, BAC, BCA, CAB, CAB},找出 smax={BC},因此序借閱相似度=2/5=40%。
計算借閱資料與各別群組中心點之間次序借閱相似度,然後將借閱資料歸屬於次序借閱相似度最大的群組 中。在每次分群化之後計算整體次序借閱相似度的總和,若目前分群化的整體次序借閱相似度總和大於之 前的分群,則將目前的中心點取代之前的中心點。 由於欲探勘具有借閱次序之 k 本書籍各適性化推薦的讀者,文中先挑選 k 筆借閱資料其必須分別包含 書籍 b1, b2, …, bk,並分別設定為一群組的中心點。然後再利用前一章節的分群化方法,依據次序借閱相似 度的大小將借閱資料 Tj歸屬於群組中,分別以 b1-次序群組、b2-次序群組、⋅⋅⋅、bk-次序群組表示之,1≤j≤m, 表示共有 m 筆的借閱資料。經由反覆的分群化計算,以達到整體次序借閱相似度總和為最大值的目標。 分群化之後,在 bi-次序群組中計算借閱書籍 bi之前各項書籍出現的比率值為:借閱書籍 bi之前各項書 籍出現在 bi-群組中的數量/bi-次序群組包含的借閱資料數量,將比率值最大的書籍稱為「次序推薦因子」, 做為發掘具有借閱次序之書籍 bi適性化推薦的讀者的依據。藉由 bi-次序群組的借閱傾向特徵,文中定義具 有借閱次序之書籍 bi適性化推薦的讀者如下: 具有借閱次序之書籍 bi適性化推薦的讀者:若讀者的借閱資料中包含「次序推薦因子」的書籍且未曾借 閱書籍 bi,表示為潛在對書籍 bi有興趣者,則為具有借閱次序之書籍 bi適性化推薦的讀者。 根據以上的探勘計算,即可發掘具有借閱次序之 k 本書籍各適性化推薦的讀者。在實際的應用中,對於 設定「次序推薦因子」的書籍項目數量,可依據應用上的須要而彈性調整。 4.2 實例說明 文中以一實例說明發掘具有借閱次序之書籍適性化推薦的讀者的探勘過程。表 2 為借閱資料庫 D2,其 包含 4 筆的借閱資料,其中{A, B, C, D, E}表示書籍項目的集合,{T1, T2, T3, T4}表示借閱資料的集合,假設 欲探勘之書籍為 B。 表 2 借閱資料庫 D2 借閱資料編號 書籍項目 T1 AE T2 EB T3 CA T4 AEB 經由演算法 Clustering( )的計算,將包含書籍 B 的借閱資料歸屬於 B-次序群組,可得到以下結果: B-次序群組={T2, T4} 在 B-次序群組中計算借閱書籍 B 之前各項書籍出現的比率值為:A=1/2=50%; E=2/2=100%,其中書 籍 E 的出現比率值為最大,因此以書籍 E 為「次序推薦因子」,可發掘具有借閱次序之書籍 B 適性化推 薦的讀者為:T1。
5. 建置書籍推薦探勘系統
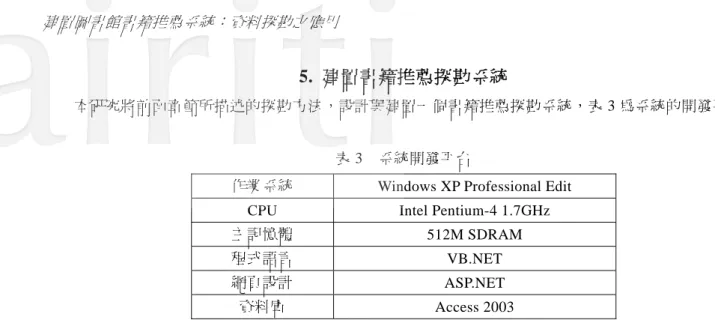
本研究將前面章節所描述的探勘方法,設計與建置一個書籍推薦探勘系統,表 3 為系統的開發平台。
表 3 系統開發平台
作業系統 Windows XP Professional Edit CPU Intel Pentium-4 1.7GHz 主記憶體 512M SDRAM 程式語言 VB.NET 網頁設計 ASP.NET 資料庫 Access 2003 文中以南部某一科技大學圖書館讀者的借閱資料為例,共有 2000、2001、2002、2003、2004 及 2005 等六年的借閱資料,各年份曾經借閱過書籍之讀者的人數分別為 967、2172、4424、7050、9350 及 8666 位, 以做為所設計之探勘方法的資料來源。文中以前五年(2000-2004)讀者之借閱資料做為探勘計算的訓練資 料,若去除重複的讀者,則在這五年中共有 16033 位不同的讀者曾經借閱過書籍。以最後一年(2005)讀者之 借閱資料做為探勘計算的驗證資料,其中在前五年也有出現的讀者共有 6532 位。 圖 1 為借閱資料的原始資料,包含有書籍的「條碼號」、「讀者編號」、「借閱日期」、「借閱時間」、「歸 還日期」、「歸還時間」、及「書名」等欄位資料,這些原始資料是以每一本書籍為一個記錄儲存。在探勘計 算之前須先將相同讀者曾經借閱的書籍記錄彙整成一筆的借閱資料。 圖 1 原始借閱資料 本研究以前五年的借閱資料做為探勘的訓練資料,以找出書籍推薦的讀者傾向特徵。接下來說明以訓 練資料做為資料來源的探勘過程。圖 2 為點選「推薦方式」→「一般性探勘」功能的探勘畫面,在「書籍 編號」欄位中填入欲探勘的書籍編號。經由第 3 節所描述之方法的探勘過程,可在「群組」欄位中顯示出 符合條件的讀者編號,並在「適性化推薦的讀者」欄位中顯示出探勘的結果,如圖 2。
圖 2 發掘書籍適性化推薦之讀者的執行畫面 圖 3 為點選「推薦方式」→「次序性探勘」功能的探勘畫面,在「書籍編號」欄位中填入欲探勘的書 籍編號。經由第 4 節所描述之方法的探勘過程,可在「群組」欄位中顯示出符合條件的讀者編號,並在「適 性化推薦的讀者」欄位中顯示出探勘的結果,如圖 3。 圖 3 發掘具有借閱次序之書籍適性化推薦的讀者的執行畫面 本研究以最後一年(2005)的借閱資料做為探勘的驗證資料,以評估在前面訓練資料中所探勘之推薦讀者 的結果成效。文中隨機挑選前五年曾經被借閱的書籍 100 本為例,然後分別發掘每一本書籍適性化推薦的 讀者、及具有借閱次序之適性化推薦的讀者,這些推薦的讀者在最後一年的借閱資料中是否出現這本書籍, 可做為評估推薦的讀者是否有效的依據。 本探勘系統之評估驗證資料的執行過程如下:圖 4 為點選「推薦方式」→「一般性探勘」功能的探勘
畫面,並點選「2005 書籍推薦評估」→「開始」功能。首先計算每一本書籍利用第 3 節探勘方法所推薦的 讀者,其中只要有至少一位推薦的讀者在最後一年也曾借閱這本書籍、或是推薦的讀者都未出現在最後一 年,即定義為「推薦出現」,否則為「推薦未出現」。經由以上的計算,可得到「推薦出現」比率值為 16%, 即這 100 本書籍中有 16 本是「推薦出現」。 圖 4 評估書籍適性化推薦之讀者的執行畫面 圖 5 為點選「推薦方式」→「次序性探勘」功能的探勘畫面,並點選「2005 書籍推薦評估」→「開始」 功能。首先計算每一本書籍利用第 4 節探勘方法所推薦的讀者,其中只要有至少一位推薦的讀者在最後一 年也曾借閱這本書籍、或是推薦的讀者都未出現在最後一年,即定義為「推薦出現」,否則為「推薦未出現」。 經由以上的計算,可得到「推薦出現」比率值為 12%,即這 100 本書籍中有 12 本是「推薦出現」。 圖 5 評估具有借閱次序之書籍適性化推薦的讀者的執行畫面
本探勘系統若能對訓練資料所找出之讀者做實際的推薦,讓讀者接受到書籍推薦的訊息、及延長驗證 的期間,其「推薦出現」比率值應可更為提高。
6. 結 論
本研究以讀者之借閱資料為探勘的資料來源,並以某 k 本書籍為探勘的目標,k≥1,利用分群化方法分 別從以下兩方面發掘 K 本書籍各適性化推薦的讀者:一是只考量書籍是否出現在借閱資料中;二是增加考 量書籍具有借閱次序。文中所設計的分群化方法除了保留原先 PAM 演算法的精神,在每次分群計算中取代 原先中心點的借閱資也具備群組的獨特性,根據所提出的方法,設計與建置一個書籍推薦探勘系統。從資 料的蒐集、分析、方法的設計、及結果推導出的讀者傾向特徵,顯示本研究所提出之探勘方法具有圖書館 實務上的應用價值。參考文獻
[1] Han, J. and Kamber, M., Data Mining: Concepts and Techniques, 2nd Ed., Morgan Kaufmann, 2006.
[2] Berry, M. J. A. and Linoff, G. S., Data Mining Techniques for Marketing, Sales, and Customer Support, New York: John Wiley, 1997.
[3] Hui, S. C. and Jha, G., “Data Mining for Customer Service Support,” Information and Management, vol. 38, pp. 1-13, 2000.
[4] 辜曼蓉,「讀者資訊尋求行為與以讀者為中心的圖書館行銷」,書府,第二十卷,81-111 頁,1999。
[5] 卜小蝶,「淺析個人化服務技術的發展趨勢對圖書館的影響」,國立成功大學圖書館館刊,第二期,63-73 頁,1998。
[6] Ou, J., Lin, S. and Li, J., “The Personalized Index Service System in Digital Library,” Proceedings of the Third International Symposium on Cooperative Database Systems for Advanced Applications, 2001.
[7] 陳慶瑄,「學習社群對電子圖書館個人化服務之影響」,國立中正大學,資訊管理研究所碩士論文,2000。 [8] 孫冠華,「應用資料探勘技術於數位圖書館之個人化服務及管理」,南華大學,資訊管理學研究所碩士論文,2003。 [9] 吳安琪,「利用資料探勘的技術及統計的方法增強圖書館的經營與服務」,國立交通大學,資訊科學研究所碩士論 文,2001。 [10] 洪志淵,「圖書流通記錄之一般化相關規則找尋之研究」,國立中山大學,資訊管理研究所碩士論文,2001。 [11] 張苑菁,「以模糊理論建構之圖書推薦系統」,淡江大學,資訊工程研究所碩士論文,2001。
[12] Kaufman, L. and Rousseeuw, P. J., Finding Groups in Data: an Introduction to Cluster Analysis, John Wiley & Sons, 1990.
[13] Alsabti, K., Ranka, S. and Singh, V., “An Efficient K-Means Clustering Algorithm,” Proceedings of the PPS/SPDP Workshop on High Performance Data Mining, 1998.
[14] Dubes, R. C. and Jain, A. K., Algorithms for Clustering Data, Prentice Hall, 1988.
[15] Ng, R. T. and Han, J., “Efficient and Effective Clustering Methods for Spatial Data Mining,” Proceedings of the 20th International Conference on Very Large Data Bases, pp. 144-155, 1994.