應用文本探勘技術於公開來源情報分析
51
0
0
全文
(2) 應用文本探勘技術於公開來源情報分析. 指導教授:楊新章 博士 國立高雄大學資訊管理學系. 學生:黃怡翔 國立高雄大學資訊管理學系碩士班. 摘要 在全球化以及知識經濟的時代下,情報的重要性越來越高,透過公開來源情 報分析可以迅速的了解國際形勢,得到一個國家之社會、經濟、文化等發展概況, 為國家、企業提供預警資訊,輔助決策者進行決策。 然而情報之分析仰賴大量具高度能力專家為之,隨著數位化時代的來臨,資 訊量急遽地增加,資訊的複雜度與多樣性亦大幅成長,已然超乎人類所能處理的 極限,僅靠人類的力量進行分析,顯然已無法滿足當今之需求。如何在數位化的 環境中,有效且快速的獲取有用情報,發展半自動乃至全自動之情報分析方法已 是不可或缺的。本研究的目的,在於運用文本探勘之技術,發展一自動化程序, 改善與建立針對公開來源情報處理之規範與流程。本研究將使用自我組織圖將訓 練文件進行分群後,針對分群結果,開發情報探勘之數種技術,據以偵測公開來 源情報中之有用資訊。本研究使用標準資料庫進行實驗,得到令人滿意的結果。 關鍵字:公開來源情報、文本探勘、自我組織圖. I.
(3) Analyzing Open Source Intelligence Based on Text Mining Techniques. Advisor: Dr. Hsin-Chang Yang Institute of Information Management National University of Kaohsiung Student: Yi-Shiang Huang Institute of Information Management National University of Kaohsiung. ABSTRACT In the age of globalization and knowledge economy, intelligence is become more and more important. Through the open source intelligence (OSINT) analysis can quickly understand the international situation, get a national overview of social, economic and cultural development and provide early warning for the state and enterprises to help people make decision. However, most of the OSINT processing is conducted manually which requires massive human effort and time cost. Automatic processing of OSINT is then unavoidable for modern applications. Although there exists software services to aid such automatic processing, the functionality and degree of automation are still immature and limited. In this work we developed an automatic processing approach for OSINT based on proposed text mining techniques. This approach may automatically identify interesting events from various aspects from which business could benefit. The major contribution of this work is that we have developed high-order mining techniques for OSINT, which will benefit domains like national security, personal knowledge management, with emphasis on business growth. Keywords: Text Mining, Open Source Intelligence, Self-Organizing Map. II.
(4) 目錄 摘要................................................................................................................................ I ABSTRACT ................................................................................................................. II 目錄............................................................................................................................. III 圖目錄......................................................................................................................... IV 表目錄........................................................................................................................... V 一、緒論........................................................................................................................ 1 1.1 研究背景.......................................................................................................... 1 1.2 研究動機.......................................................................................................... 2 1.3 研究目的.......................................................................................................... 3 1.4 研究架構.......................................................................................................... 4 二、文獻探討 ............................................................................................................... 5 2.1 情報.................................................................................................................. 5 2.2 公開來源情報 ................................................................................................. 7 2.3 情報分析........................................................................................................ 11 三、研究架構 ............................................................................................................. 13 3.1 前置處理........................................................................................................ 14 3.2 特徵淬取........................................................................................................ 14 3.3 分群與標記 ................................................................................................... 18 3.4 情報探勘........................................................................................................ 23 3.4.1 文件分群主題偵測 .................................................................................... 23 3.4.2 特定事件偵測 ............................................................................................ 24 四、實驗結果與評估 ................................................................................................. 26 4.1 前置處理........................................................................................................ 27 4.2 特徵萃取 ....................................................................................................... 27 4.3 分群與標記 ................................................................................................... 29 五、結論與分析 ......................................................................................................... 38 5.1 結論................................................................................................................ 38 5.2 未來研究方向與建議 ................................................................................... 39 參考文獻...................................................................................................................... 40 附錄.............................................................................................................................. 43. III.
(5) 圖目錄 圖 3-1 研究架構圖 ...................................................................................................... 13 圖 3-2 向量空間模型 .................................................................................................. 17 圖 3-3 二元化權重之向量空間模型 .......................................................................... 18 圖 3-4 自我組織圖架構 .............................................................................................. 19 圖 3-5 A.鄰近區域示意圖 .......................................................................................... 20 圖 3-5 B.鄰近區域縮小示意圖 .................................................................................. 20 圖 3-6 特定事件偵測 .................................................................................................. 24 圖 4-1 REUTERS-21578 資料集之文件範例 ........................................................... 26 圖 4-2 正規化後之文件 ............................................................................................. 27 圖 4-3 斷詞與詞性標記結果 ..................................................................................... 28 圖 4-4 字根還原、關鍵字選取後之結果 ................................................................. 29 圖 4-5 特定事件偵測之準確率 ................................................................................ 33 圖 4-6 新奇事件偵測準確度 ..................................................................................... 36 圖 4-7 採用新門檻值之新奇事件偵測準確度 ......................................................... 37. IV.
(6) 表目錄 表 1 自我組織圖統計資料 ........................................................................................ 30 表 2 特定事件偵測結果 ............................................................................................ 31 表 3 訓練資料集包含之類別 .................................................................................... 34 表 4 測試資料集包含之類別 .................................................................................... 35 表 5 新奇事件偵測結果 ............................................................................................ 35. V.
(7) 一、緒論 1.1 研究背景 情報(Intelligence)之蒐集與分析一直以來被認為在軍事與商業戰爭中是具有 關鍵性的角色。歷史上多有獲得關鍵情報而獲得軍事或商戰勝利的案例。情報之 用途,主要是能「料敵機先」 ,收「知己知彼,百戰百勝」之效。故情報之蒐集, 應具有可靠性與廣泛性,求來源之充足與正確,以利分析。情報之分析,則應具 有預測性,求關鍵事件之預知,而能防患未然。若能持續的、廣泛的、且可靠的 獲得情報,再加以進行準確分析,則不論在戰爭行為或商業利益上,皆可獲得巨 大的進展。故自古以來,情報的蒐集與分析一直備受(政治或企業)當權者重視。 情報管理為一循環過程,Johnston[1]認為完整的情報循環(intelligence cycle) 包含下列步驟:規劃與指引 (planning and direction)、蒐集(collection)、處理 (processing)、分析與產出(analysis and production)、發佈(dissemination)。上述流 程為一循環。若將情報循環視為一資訊系統,則規劃與指引步驟可視為系統之輸 入,發佈步驟可視為系統之輸出,其間之蒐集、處理、分析與產出步驟則可視為 資料處理過程。 在情報蒐集上,傳統以來,不論在軍事或商業上,情報大都藉由秘密、隱蔽 的管道獲得。主要的原因是具有價值的情報通常具有機密性與敏感性而不對外公 開。機密情報的取得因而時常經由不合法的方式取得,造成情報蒐集過程具有極 大風險。另一方面,秘密情報蒐集因管道之特殊與稀少性,加上反情報 (counter-intelligence)蒐集之可能,使得情報之可靠性亦時無保障。由於這些因素, 使情報蒐集之過程一直以來皆蒙上一層隱晦的面紗,情報蒐集者(情報員)之故 事亦在坊間多所流傳。由傳統管道所蒐集之情報,則具有資料量稀少、資料需驗 證、通訊管道難以建立等缺點。 相對於此,透過公開來源,如新聞、政府公報、企業財報、機關網頁等獲取 之情報,則稱之為公開來源情報。「公開」代表大眾可以付費方式或免費方式自 1.
(8) 由取得,乃相對於隱匿或機密而言。公開來源情報主要來自下列各來源:媒體、 網路社群、政府公開資料、觀察報告、學術專業會議、組織等。 美國國家情報總監(Director of National Intelligence)與國防部於美國 2006 年 會計年度之國防授權法案[2]中定義公開來源情報為「為特定聽眾之特定情報需 求,由公開資訊中進行即時的蒐集、利用、與發佈」。由此定義可知公開來源情 報需包含下列特性: 1.. 其情報來源為公開資料。. 2.. 其目的為提供特定情報需求。. 3.. 其運用過程包含蒐集、利用、與發佈。. 公開來源情報具有成本低、資訊即時、資訊量充足等優勢,是一個風險較小 的情報蒐集管道,且其分析所得的結果,對於整體的情報工作依然是具有貢獻的 [3]。另一方面,資訊科技的進步,讓公開來源情報變得無所不在、更容易取得 且更有價值,使得公開來源情報的獲取成本比以往任何時候都低廉。. 1.2 研究動機 公開來源情報在蒐集過程中和傳統方法最大的不同,在於傳統情報中蒐集過 程是最困難的一部份,特別是常常要自不合作的目標獲取情報,然而這部份對於 公開來源情報卻是最簡單且花費了最少成本的部份。公開來源情報最大的困難在 於自大量的資料中偵測出相關且可靠的來源。以往對公開來源情報的分析需仰賴 具備高度能力,足以立即處理這些資訊的專家為之。事實上,直至目前為止,公 開來源情報分析絕大部份仍需仰賴人力進行。 如前述,公開來源情報之分析目前皆由人力進行。然而人力之涵蓋範圍與即 時性皆有所限制。目前來自上述之公開來源資料量極為巨大,早已超乎人類可以 處理的極限。自動化的公開來源情報處理成為一必要且逐漸熱門之議題。然而自 動化處理需克服下列困難: 1.. 大量資料處理:公開來源之資料量十分巨大且格式不一致。因此不論. 2.
(9) 是線上或離線的處理皆十分困難。尤其是當資料來源是即時產生的 (如新聞),如何快速的擷取與處理大量資料是一頗為困難的問題。 2.. 情報分析:對於公開來源情報而言,情報來源不虞匱乏,甚至可以說 是多到氾濫。除了上述之資料處理困難外,如何自如此大量之資料中 過濾、偵測、摘錄出重要情報成為一十分困難之課題。傳統依人類智 慧之分析方法顯已不可行,一套半自動乃至全自動之情報分析方法將 是不可或缺的,惟該自動化方法必須克服大量資料與即時性要求。. 隨著資訊科技、網際網路的蓬勃發展,資訊量急速的成長,資訊的傳播與獲 取的管道也愈趨多樣化,使用者對於資訊的需求也越加的多樣與複雜化。在資訊 爆炸的環境下,充斥著大量的資訊,而使用者卻越來越難找到所需的資訊,這更 突顯了情報分析與研究的重要性。. 1.3 研究目的 自動化公開來源情報管理機制包含下列幾步驟: 1.. 規劃與指引:建立一使用者介面,接受使用者提供其情報分析需求。. 2.. 蒐集:建立一自動化機制,如代理人程式,以廣泛且精確的蒐集來自 各公開來源之情報資料。在自動蒐集過程中,須能因應不同需求自動 選取資料之來源。. 3.. 處理:針對蒐集後之資料中具有缺陷之資料進行清理與精煉。所要進 行的步驟包含取樣、斷詞、詞性標記與篩選、文字精煉(字根還原與 常用字刪除)、關鍵字選擇、維度縮減等。. 4.. 分析與產出:對所蒐集之文本型式公開來源情報進行探勘與分析。. 5.. 發佈:開發一使用者介面,主動或被動式的發佈產出之情報分析結 果。. 上述這些步驟都可以成為一個獨立的研究,本研究主要針對上述管理機制的 第四個步驟進行探討,針對公開來源情報中最容易取得且資料量最大的文本(text) 資料進行處理。本研究的目的為透過文本探勘技術進行情報探勘與分析之研究, 首先將收集到的文本資料進行分群,再發掘出每一分群的主題,而後再進行特定 3.
(10) 事件偵測即偵測出使用者有興趣的事件與新奇事件偵測即發掘出過去沒有被發 現的事件。. 1.4 研究架構 本論文共分為五個章節。第一章為緒論,說明本論文之研究背景、動機與 目的。第二章則針對公開來源情報的背景進行探討。第三章詳細說明本論文之研 究方法、架構與實驗設計。第四章為實驗結果,包含實驗資料來源、斷詞、字根 還原、停用字去除、特徵萃取,並根據前一章所提之實驗設計,進行實驗與評估 分析。最後第五章為結論與討論,針對研究成果進行討論。. 4.
(11) 二、文獻探討 2.1 情報 Johnston [1]將情報定義為「情報為瞭解或影響國外或國內實體之秘密性國家或團 體活動」 。由此定義可知情報的目標是為了瞭解或影響某些實體(entity),大多由. 政府或機關發動。例如美國的中央情報局會蒐集特定情報以瞭解某一恐怖組織之 動向。另一方面,他也定義情報分析(intelligence analysis)為「情報分析為運用個人 或群體認知方法在一秘密性社會文化意涵中進行資料權衡與假說驗證」 。因此情報分析. 必須在特定情境下對資料進行分析並對各種假設進行驗證。例如某一情報來源透 露一已知恐怖份子今日入境國內,則情報局之專家會分析此一情報之可信度,並 推測其是否會對國內造成危害。 情報管理為一循環過程,Johnston[1]認為完整的情報循環(intelligence cycle) 包含下列步驟: 1.. 規劃與指引(planning and direction):決定要監測與分析何事物。. 2.. 蒐集(collection):蒐集原始資料。. 3.. 處理(processing):精煉資料。. 4.. 分析與產出(analysis and production):將經處理後的資料轉換成情報完 成品,包含對情報進行整合、校勘、評估、與分析。. 5.. 發佈(dissemination):將處理結果提供予客戶。. 上述流程為一循環,當情報發佈後可再進行下一階段之情報循環。其中也可 以在完整循環中建立次循環,例如第 2-4 步驟。以下便針對此處理過程作一探討。. 2.1.1 情報蒐集 一般蒐集情報之方法,分為下列種類[4]: 1.. 人類情報(Human intelligence, HUMINT):指藉由人際間之接觸來獲取 情報,即俗稱之間諜活動。. 2.. 信號情報(Signal intelligence, SIGINT):指藉由截取信號以獲得情報。 5.
(12) 3.. 度量與簽章情報(Measurement and signature intelligence, MASINT):藉 由量測目標之參數並與目標之特徵(即簽章)比對以獲得情報。. 4.. 影像情報(Imagery intelligence, IMGINT):藉由分析衛星與空照圖以獲 取情報。. 5.. 地理空間情報(Geospatial intelligence, GEOINT):藉由分析地理空間資 訊以獲取情報。. 6.. 財務情報(Financial intelligence, FININT):指獲取對象之財務資訊以供 分析預測使用。. 7.. 技術情報(Technical intelligence, TECHINT):在軍事上,指蒐集外國軍 隊之武器與設備之情報。亦指國家階層上蒐集外國科技發展之情報。. 8.. 公開來源情報(Open source intelligence, OSINT):指自公開來源獲取情 報。. 以上之各種情報蒐集方法各有其應用領域與限制及其優劣點。一般而言,上 述各種情報蒐集方法皆需運用專業技術且需花費大量財力與人力,非一般個人或 企業所能負荷,因此多由國家級專門機構進行。然而其中之公開來源情報卻具有 成本低、資訊即時、資訊量充足等優勢,對情報蒐集而言成為一新興且具吸引力 之管道。. 2.1.2 情報處理 當獲得情報後,情報單位便需進行分析以供決策使用。分析之依據通常根據 情報的來源與內容。美國陸軍將情報的來源與內容依據其可靠程度各分成六個等 級[5]。在來源上,分為 A-F 六級,分別代表可信賴的(reliable)、經常可信賴的 (usually reliable)、相當可信賴的(fairly reliable)、有時可信賴的(not usually reliable)、 不可信賴的(unreliable)、與無法判別(cannot be judged)。在內容上,則分為 1-6 級,分別代表已確認(confirmed)、應該為真(probably true)、可能為真(possibly true)、 真實性存疑(doubtfully true)、不大可能(improbable)、與無法判別六級。對一情報. 6.
(13) 則可分別依其來源與內容進行分級。例如 A-1 級情報代表來源可信內容可確認之 高價值情報,E-5 則代表來源不可信賴且內容有誤之無價值情報。在進行情報分 析前,適當的情報品質分級應可有效的提升分析結果之品質。 情報分析是情報循環中,相當重要的一個步驟。傳統之情報分析通常為專業 人員進行。情報分析師依據其執行準則與流程[6]對情報進行分析。其間需運用 大量之分析技巧與個人經驗與智慧。此類技巧之運用與經驗之累積需耗費極大的 時間與心力,故無法大量為之。因此各國政府或企業莫不把具備高度分析能力之 情報分析師視為重要資產。誠然,一具有高度情報分析能力之人員可為機構帶來 巨大利益,然終就人力有限且訓練曠日費時,要依賴此方式進行情報分析僅國家 及大型企業具有能力進行。. 2.2 公開來源情報 公開來源情報並非一新的情報蒐集管道,早在 1941 年二次世界大戰時美國 中央情報局的外國廣播資訊服務(Foreign Broadcast Information Service, FBIS)便 依巴黎之柳橙價格(為一公開資訊)來判斷鐵路橋樑是否已被炸斷。近代的公開 來源情報開始於 1988 年美國葛雷將軍(Alfred M. Gray Jr.)提議將大部份的情報蒐 集放在公開來源上[7]。美國隨後於 2005 年在國家情報總監下設置公開來源中心 (Open Source Center)來蒐集來自「網際網路、資料庫、媒體、廣播、電視、視訊、 地理空間資料、攝影、與商業影像」之資訊。除了蒐集這些公開資訊外,它也負 責訓練足以運用這些資料的分析師。直至目前公開來源情報之應用性更因現今環 境而與日俱增。公開來源情報主要來自下列各來源: 1.. 媒體:報紙、雜誌、廣播、電視、網路媒介等。. 2.. 網路社群:社交網站、視訊分享網站、維基百科、部落格、社會性書籤 網站等。. 3.. 公開資料:政府公報、官方文件如財務報告、戶政資料、公聽會、國會 質詢、記者會、演講、環境影響評估等。. 7.
(14) 4.. 觀察報告:業餘無線電監聽者、飛機觀測者、公開之衛星圖與地圖等。. 5.. 學術專業:學術會議、學術組織、學術論文、專家等。. 公開來源情報優於傳統情報之處可由下列面向說明: 1.. 可信性(Credibility):公開來源情報之資料量大、穩定、且來自具聲譽來 源之情報大多頗為可信。由於資料來源不是單一來源,資料之正確性較 易驗證。. 2.. 強健性(Robustness):公開來源情報蒐集容易,即使單一管道中斷,亦 可由其他管道進行資料蒐集。. 3.. 即時性(Timeliness):公開來源情報經常是即時產生且可立即存取的,意 謂著我們可以立即的使用這些情報進行分析,也意味著在進行處理時必 須滿足及時(real time)的要求。. 4.. 匿名性(Anonymity):公開來源資料皆是公開的,不會有必須曝露資料 來源的顧慮。. 5.. 延續性(Sustainability):公開來源資料是持續性的建立與被蒐集的,我 們可以據以建立一事件之歷史並觀察其變化。. 公開來源情報之相關研究,早期大多僅限於其作業規範,並由國防單位進行。 例如美國國家情報總監下設公開來源中心,另北約組織(NATO)於 2001 年出版了 一有關公開來源情報之操作手冊[4],其中詳述了有關公開來源情報之各層面, 如資料來源、可用軟體、可用服務、及處理循環中各步驟之說明等。手冊中也提 供了廣泛的參加資料,如公開來源情報相關網站與訓練教材。本手冊是瞭解公開 來源情報之重要啟始知識。北約組織也另外出版了一本有關公開來源情報之文選 [8]。另針對網際網路之公開來源情報處理,北約亦發表了相關著作[9]。這一系 列著作可以說是瞭解公開來源情報的踏腳石。然而其中所敍述的,大多為描述公 開來源情報之規範與如何進行公開來源情報管理,對於自動化處理模式幾無著 墨。 美國國家情報總監辦公室(Office of the Director of National Intelligence, 8.
(15) ODNI)在 2007 年與 2008 年曾舉辦 Open Source Conference[10]。此會議並非學術 會議,其型式是以討論會的方式進行。在這個會議中討論了許多與公開來源相關 之議題,如公開來源之價值、如何建立早期預警、如何建立反情報、社交網路與 新科技的運用、國家安全與個人隱私之平衡、國外來源之存取、新興媒體之運用 等。其範圍大多仍侷限於情報界對於公開來源之運用及其影響之探討,較無學術 與技術面之討論。 近年來自動化公開來源情報處理吸引了來自於學術界,尤其是計算機領域學 者,的關注。和情報界不同的是,這些學者較關心的是如何設計一程序以取代人 力進行公開來源情報處理。由於情報分析可以說是要從資料中發掘出可用之情報, 與資料探勘之目的相近,因此很自然的可以引用資料探勘技術在公開來源情報之 處理機制上。然而這個想法直至近年才真正開始吸引一些學者投入並發表其研究 成果。事實上,應用資料探勘方法於公開來源情報之應用直至目前仍甚少被探索。 國際上也很少發表這方面的論文,證明此領域仍在嬰兒期。目前較相關之會議為 International Symposium on Open Source Intelligence and Web Mining (OSINT-WM)。這個會議主要便是希望藉由資料探勘方法,尤其是網路探勘(Web mining)技術與社交網路分析,進行公開來源情報之分析,可以說是目前世界上 少數聚集這方面研究之重要會議。 除了此會議之外,另有一些論文散見於不同的國際會議中。整理後得知,此 方面之研究大多以歐洲國家為主。以下則擇其重要之論文進行探討。 義大利的 SYNTHEMA 公司之 Baldini 等人於 2007 年開始發表了數篇論文描 述其所發展的公開來源情報處理平台 SPYWatch[11-13]。他們提出一架構來進行 公開來源情報之蒐集、處理、分析、產出、與發佈。此系統的核心技術在使用 K-means 演算法將文件分群後再進行分類。特點是本系統可處理來自不同語文文 件之情報。 奧地利的 Sail Technology 之 Pfeiffer 等學者[14]則發表了基於 MPEG-7 之處 理平台 Media Mining System。此系統之輸入可以為不同型式之公開來源資料, 9.
(16) 如衛星影像、電視影像、網頁與 RSS 輸入等。這些原始輸入隨後被處理以萃取 其內容。產出的內容則可在該公司之 Media Mining Server 中被檢索、分析與檢 視。Media Mining System 可用於早期預警、資訊分享、與風險評估上。 英國 Innovation Works 公司之 Vincen 等人[15]則提出一集中式架構以融合來 自不同來源的資訊以提供緊急服務所用。他們的技術主要的核心是使用機率加強 知識本體(probabilistic enhanced ontology)並配合多功能的服務介面與使用語意特 徵。本系統於發表時尚未成熟,其主要目標是要能夠達成情境認知(situation awareness)與影響評估(impact assessment)。 Badia 等學者[16]分析文字文件中的語句以獲得文件之時空資訊以提供公開 來源情報使用。他們先將語句轉換成主詞-動作-受詞的型式,再依據剖析程式 所提供之提示資訊與特定的語法樣式來找出語句中的時、空資訊。 美國德州的 Austin Info System 之 Palmer 早於 2005 年發表論文[17]則提出了 一語意比較量度以進行事件分析(event analysis)。他使用 Lavalette 分布取代了較 早所使用的語料庫分析[18]。他的系統主要的特點是可以偵測事件間之關聯。 歐盟執委會(European Commission)的聯合研究中心(Joint Research Centre, JRC)建立了一個二階段的事件淬取系統[19]。在第一階段中,他們建立了一稱為 歐洲媒體監測器(Europe Media Monitor, EMM)的新聞報導蒐集平台。這些新聞報 導會被分類與分群以供第二階段使用。在第二階段中,他們使用了兩個方法,其 一是 JRC 所發展的 NEXUS 系統[20-21]。此系統以分群為中心,採取簡淺語言學 方法來自某一主題群組中萃取資訊。其二是芬蘭赫爾辛基大學所發展了 PULS 系 統[22-23]。此系統則較為深入的分析新聞之內容,因而允許使用者自未明之新聞 中發掘事件。 Wiil 等人[24-25]以圖論的方法來來分析恐怖份子網路(Terrorist Network)。本 文之特殊性在於其分析著重於連結(link)而非傳統該類網路所著重之節點(node)。 Bartik[26]的研究試圖將文本資料進行分類。他除了使用傳統的 tf-idf 加權法來描 述文件內容外,也採用視覺特徵,即文字所出現的位置作為分類的依據。Dawoud 10.
(17) 等人[27]則結合數個社交網路分析常用的量度成為一全域性量度,以度量恐怖組 織之組織強度。Liu 與 Sandfort[28]則針對公開源碼,分析其與公眾參與對社會創 新的影響。雖然她們的研究亦與 Open Source 相關,但與此處之公開來源情報較 無關聯。Neri 等人[29]則以義大利總理之性醜聞為例,探討如何分析、標示、分 群新聞文件並發掘其隱含之關聯與情感方向。. 2.3 情報分析 如前文所述,情報分析主要就是從大量雜亂無章的資料中進行收集、整理、 分析,得到能輔助決策之情報。此目的與資料探勘極為相似,而公開來源情報的 來源與種類眾多,本研究將針對文本資料進行研究,利用文本探勘技術對情報分 析進行探討。 情報分析主要有幾個領域,事件偵測、事物關聯探勘、關鍵事物偵測、情報 可信度評估等[4]。 1.. 事件偵測:針對特定、新奇、異常事件進行發掘。. 2.. 事物關聯探勘:發掘事件或人物(通稱事物)間之關聯。例如恐怖份子 間是否有關聯(人物與人物間之關聯)、兩件爆炸案間是否有關聯(事 件間之關聯) 、恐怖份子與爆炸案間是否有關聯(人物與事件間之關聯) 等。. 3.. 關鍵事物偵測:關鍵事物指組織、團體、集合中之關鍵事件或人物。例 如一恐怖組織之領導者、一系列恐怖活動之主要事件等。. 4.. 情報可信度評估:來自公開來源之情報資訊,由於來源廣泛且即時,其 可信度常須加以釐清,以避免獲得錯誤情報,影響分析結果。. 情報分析之範疇相當廣泛,上述所提僅為幾個常見之分析,而本研究將以事 件偵測為主,透過文本探勘技術建立情報探勘之方法。 2.3.1 事件偵測 事件偵測(Event detection)可被定義為:「發現包含在連續的新聞串流之中有 11.
(18) 關新的或之前未發現的事件」[29-30]。事件偵測在過去有許多相關的研究,尤其 是由美國國防部高等研究計劃局(Defense Advanced Research Project Agency, DARPA)所主導之「主題偵測與追蹤(Topic Detection and Tracking, TDT)」計畫[31], 為多語言文本以及語音資料的相關研究,其中定義了五個與主題偵測與追蹤的相 關方向: 1.. 報導切割(Story Segmentation Task):將原始的資料切割單獨的新聞報 導。. 2.. 主題追蹤(Topic Tracking Task):找出新進的文件是否與先前的主題相 關。. 3.. 主題偵測(Topic Detection Task):偵測並組織相同主題之文件。. 4.. 第一則新聞偵測(First-Story Detection Task):判斷新進文件是否為新主 題或未討論過的主題。. 5.. 關聯檢測(Link Detection Task):判斷兩份文件是否討論相同主題。. 雖然定義了五種不同的研究方向,但每一項任務之研究,都有助於其他任務 之完成。其中和事件偵測較為相關的主題偵測與主題追蹤。主題偵測又可細分為 兩類:回顧偵測(retrospective detection)與線上偵測(on-line detection) [32]。回顧偵 測是指在給定的文件集中找出之前未發現的事件,透過分群之方法,將輸入的文 件集分群,而後得到新聞報導分群(story clusters),每一分群代表一個事件。線上 偵測則是從一連串蒐集到的即時新聞中找出新事件,將一連串依時間先後順序輸 入的文件,透過與現存之分群比對,來判定是否為新事件,若無法歸類於現存之 事件分群,則認定為新事件。回顧偵測、線上偵測與主題追蹤,過去經常使用 k-means、k-nearest neighbors 等演算法來進行分類、分群,然而其演算法易受離 群值影響需要相當精確的訓練資料集,且需要高度的計算量。故本研究將使用自 我組織圖(Self-organizing map)作為關聯性分析之方法,原因為其具有頗佳的分群 效能,且能將高維度資料間之拓樸關係呈現於二維的平面上。這點有利於我們去 發掘資料間之關聯,細節部分將於下一章描述。 12.
(19) 三、研究架構 本研究將發展一自動化公開來源情報探勘機制,其研究架構如圖 3-1 所示。 以下針對研究架構中之各步驟作說明。. 網頁. 新聞 公開來源資料. 前置處理. 清理後文件. 特徵淬取. 文件向量. 事件偵測 圖例 分析結果. 處理程序. 資料文件. 分析結果發佈. 圖 3-1 研究架構圖 13.
(20) 如前文所言,公開來源之情報來源十分廣泛,若以其發佈型式區分,可概分 為傳統媒體與電子媒體。此處之傳統媒體指以非電子方式發佈情報者,如報紙、 雜誌、電視、政府公報、廣播等。電子媒體則指發佈時便以電子形式進行,如部 落格、電子期刊、社交網站等。以自動化處理需求而言,電子媒體較為容易。傳 統媒體則需透過一數位化過程,如光學字元辨識、語音辨識等,將其數位化後方 能處理。然而由於愈來愈多的傳統媒體已經電子化,其間之分界已漸趨模糊。例 如大部份的主流報紙與雜誌皆已同時發行電子版。因此本研究將不針對僅以傳統 媒介發佈之媒體進行情報蒐集,只蒐集以電子形式且以文本型式表達之情報。 3.1 前置處理 蒐集之文件,具有不同的格式,亦包含許多無效的文件。本步驟將文件進行 正規化並篩選有效文件。各子步驟概述如下: A.. 文件正規化 首先必須將不同來源之文件轉換成相同型式,由於我們將只針對文字部份進. 行處理,因此本研究會將文件內各種型式之網頁標記(tag)、多媒體物件、無效字 元去除,淬取其中之文字部份,構成文本文件。在此無效字元包含控制字元與非 英文字元。 B.. 無效文件篩選 無效文件即對訓練無助益之文件,其存在將會增加訓練時間,同時可能會降. 低訓練品質。因此為了提升訓練品質,本研究會將這些無效文件篩除。本研究初 步定義之無效文件即正規化後文件容量過小(字數小於 20 字)之文件。 3.2 特徵淬取 一般而言,文件是由自然語言書寫而成,人們的想法與意見透過文字來表達, 然而自然語言文件內容並不容易由電腦直接進行處理,故必須從文件內容中淬取. 14.
(21) 出重要的特徵(feature)集合來代替原始文件,並將其轉換為向量型式,透過特徵 辨別之方法,將自然語言文件標示適當之主題。經由此步驟,可以使系統較容易 處理資料;反之,若缺少此步驟,則系統在處理資料上較為不易,且可能導致分 群、分類成效不彰。故此步驟之目的在於方便我們將所蒐集之文本資料轉換為適 合後續分群與分類訓練使用。以下將所需使用之程序進行說明: A.. 斷詞(segmentation): 文件本身是由許多的文字與詞彙組合而成,在自然語言(natural language)當. 中,許多描述式的詞彙對文件本身的涵義並無太大的影響;文件若無經過適當的 處理,便無法將文件導入分類、分群演算法中加以應用,且處理程序若不恰當, 亦會造成分類、分群的效果不佳。為實現文件分類、分群之工作,需透過斷詞與 斷句的程序,將文件拆解成文字、詞彙或關鍵字的集合,並剔除對文章涵義較薄 弱的文字,如無意義的符號與文字,再利用剩餘的詞彙作為文件的特徵進行文件 類別之辨別。文件特徵之萃取就是文件經由斷詞步驟將文件拆解成關鍵字之集合, 並初步剔除無意義的符號與文字。 此步驟將原始文件中以字元為基礎之表示法轉換為以字詞(word)為基礎之 表示法。拉丁語系之文件(如英文),字詞和字詞之間通常存在著分隔符號(如標點 符號與空白字元),因此,斷詞較為容易。本研究只針對單一語言文件進行處理, 在此以目標語言英文為例。因已存在許多可用斷詞程式,這部份基本上採取公開 原碼程式進行。本研究將使用 Stanford Natural Language Processing Group 所提供 的 Stanford Log-linear Part-Of-Speech Tagger[33]軟體進行斷詞。 B.. 字詞處理: 文件經由上述斷詞程序後所產生的字詞集合,可以用來代替原始文件,然而. 這些字詞並非皆同等重要的,有些字詞與該文件之意涵無顯著相關性,部分字詞 甚至不具意義;另一方面,過多的字詞將導致分類、分群之演算法效率不彰,故 必須選擇較具代表性的字詞做為文件的特徵,以簡化文件之表達與後續之處理, 15.
(22) 經過篩選後所餘之字詞,我們也稱之為關鍵字(keyword)。 傳統上,英文關鍵字之選擇包含幾個主要的步驟:停用字去除(stopword elimination)、關鍵字選取(keyword selection)、字根還原(stemming)等。首先,在 停用字去除上,停用字是指一些不具太多涵義而又經常出現的字,例如冠詞、介 系詞與連接詞等。本研究將採用標準之 Brown corpus 之停用詞集來剔除文件中 之停用詞。其次,為關鍵字選取,文件中的語句通常由不同詞性之字詞構成,其 中名詞被認為是具有最多意涵之詞性,故要進一步簡化關鍵字之數量時,通常會 選擇名詞做為關鍵字。本研究將使用 Stanford Natural Language Processing Group 所提供的 Stanford Log-linear Part-Of-Speech Tagger[33]來進行詞性標記,並選擇 名詞做為關鍵字。最後,字根還原部分,由於英文字詞通常會因數量、時態、詞 性等因素,而附加某些字首或字尾,透過字根還原程序可以將這些字首、字根去 除,使其還原為字根。本研究將採用著名之 Porter 字根還原演算法[34]進行字根 還原。 透過上述之標準字詞處理程序,可以簡化英文文件之表達,並降低關鍵字之 數量,亦即字彙集(vocabulary)之大小。 C.. 文件向量化: 文件簡化為關鍵字後,必須將其轉化為一向量以供後續程序使用。本研究將. 採用由 Salton[35]等人提出之向量空間模型(vector space model, VSM)進行轉換。 向量空間模型為目前廣為使用且受大部分研究者接受之方式,藉由關鍵字與文件 組合成之「關鍵字—文件」矩陣(term-document matrix),可利於機器方便閱讀並 加快系統之執行效能。圖 3-2 為一個具有 i 個關鍵字與 j 份文件之「關鍵字—文 件」矩陣。其中 wij 為關鍵字 i 在文件 j 中的權重值。. 16.
(23) Term1 Term2 Doc w11 w21 1 w12 w22 A Doc2 Doc j w1 j w2 j . Termi wi1 wi 2 wij . 圖 3-2 向量空間模型. 目前存在多種的權重值計算方式,傳統的向量空間模型以 tf-tdf 作為權重之 設定依據。 wij tf (i, j ) * idf (i). (1). 其中 tf (i, j ) 為關鍵字 Termi 在文件 d j 出現之頻率(term frequency,tf),這個數 字通常會被正規化,以防止它偏向長文件。. tf (i, j ) . ni , j. n. (2). k, j. k. 其中 ni,j 為關鍵字 Termi 在文件 d j 出現之次數,k 為文件 d j 中關鍵字索引,故分母 為 文 件 d j 中所有關鍵字的出現次數之總和。而 idf (i) 為反文件頻率 (inverse document frequency, idf),是衡量一個詞語普遍重要性的度量。. idf (i) logT ti . (3). 其中 T 為總文件數量,ti 為文件集中包含關鍵字 Termi 之文件個數。 另一種權重設定方式為二元化權重,若關鍵字出現在該文件中,則在該文件 向量中相對應的元素給予值 1;反之,若未出現於文件中,則給予值 0。如圖 3-3 之所示。. 17.
(24) Doc 1 B Doc2 Doc j . Term1 Term2 0 1 1 1 0 0. Termi 0 1 1 . 圖 3-3 二元化權重之向量空間模型 依據前述過程篩選後之關鍵字,利用向量空間模型將文件 dj 轉換為一向量 dj。在向量化的過程中,字詞之權重設定亦是考量的因素。本研究將採取第二種 方式設定權重,即二元化權重,根據字詞出現於文件與否,決定其所對應的向量 成份值為 0 或 1。 3.3 分群與標記 本步驟之目的在於找出文件間之關聯以提供給後續分析使用。目前已存在許 多資料分群方法,如常用之 k-means、k-nearest neighbors 等。本研究將選擇自我 組織圖(self-organizing map)作為關聯性分析之方法,原因為其具有頗佳的分群效 能,且能將高維度資料間之拓樸關係呈現於二維的平面上。這點有利於我們去發 掘資料間之關聯。 A. 自我組織圖訓練 自我組織圖演算法由 Kohonen[36]在 1982 所提出,為一種非監督式學習網路 模式。其能將文件分佈以視覺化方式呈現,把需要分析的文件進行自我組織圖訓 練後,能發掘出文件本身的特徵與關聯性,將具有相似主題的文件映射至相同或 鄰近位置的神經元上,所產生的映射圖能顯示出文件彼此間的關聯情形,使用者 可以透過圖上呈現的結果,快速的識別出文件與文件間以及文件與主題間的對應 關係。 自我組織圖的網路架構主要由輸入層、輸出層兩個部分組成,如圖 3-4 所示。 輸入層為網路的輸入變數,為一向量值。輸出層代表著訓練範例的分群結果,每 18.
(25) 一神經元代表一分群,神經元間之排列可以是一維、二維甚至多維,但通常以 NN 個的神經元所形成的二維矩形較為常用,不過實際上可依需求改為圓形、 三角型、六角型或任意形狀。輸入層之神經元與輸出層所有神經元間均有鏈結關 係,其強度以權值向量表示。. 輸出層 (神經元陣列,代表分群). 輸入層 (資料向量,代表輸入變數) 圖 3-4 自我組織圖架構 自我組織圖基本原理為模仿人類大腦結構,即大腦中具有相似功能的腦細胞 會聚集在一起的特性,與特徵映射的特性所發展出來的方法。自我組織圖具有以 下之特性: I. 維度縮減(dimensionality reduction) 自我組織圖模擬大腦特徵映射之特性,將原先以高維度特徵向量表示的 資料重新以低維度的方式表現,即把任意維度的輸入向量,映射在低維 度的輸出神經元陣列中,同常以一維或二維的拓樸網路來表示,如此可 易於了解文件間之群集關係。 II. 拓樸維持(topology preservation) 自我組織圖能將高維度資料所具有之關係映射於低維的特徵空間中,使 低維度的網路拓樸得以保有原本資料之對應關係。 以下介紹自我組織圖的基本名詞: I. 輸入層:為網路的輸入變數,也就是訓練範例的向量,其神經元的數目 依輸入向量維度而定。 II. 輸出層:為網路的輸出變數,即訓練範例的分群結果,通常為 N×N 個神 19.
(26) 經元形成的矩形。 III. 網路鏈結:輸入層中每個神經元與輸出層中每個神經元之鏈結,每一鏈 結皆依其權重表達神經元間之關連。 IV. 學習速率α(t):影響神經元突觸權重之調整速度,一般為介於 0 到 1 之 數值,會隨著訓練週期或時間增加而逐漸降低。 V. 鄰近中心:即優勝神經元,以該神經元為中心,在鄰近半徑區域內的神 經元之突觸權重皆會進行調整。 VI. 鄰近半徑:決定鄰近區域之大小,一開始可取較大的半徑值,隨著訓練 週期或時間增加臨近半徑會逐漸縮小。. 鄰近中心 (優勝神經元). 鄰近半徑 鄰近區域. 圖 3-5 a.鄰近區域示意圖. 第n次 第 n+1 次 第 n+2 次. 圖 3-5 b.鄰近區域縮小示意圖 自我組織圖的主要概念是透過計算文件向量與神經元突觸權重向量的距離 來映射文件至神經元上。根據文件在特徵向量上的相似程度,訓練出一個能表現 20.
(27) 整體性的特徵圖,特徵圖由多個排列成矩形的神經元組成,每個神經元具有一特 徵向量,初始時,隨機生成每個神經元的特徵向量,此時相鄰的神經元不一定相 似,之後開始進行學習,隨機輸入一文件向量,計算此文件向量與所有神經元的 距離,找出距離最近的神經元,即為獲勝神經元,此神經元與鄰近神經元可獲得 調整權重的機會,會往文件特徵向量的方向調整,使它們與文件特徵向量相似, 在經過多次的學習之後,相鄰的神經元會具有相似的特徵向量,而且與某些文件 特徵向量相似,故在完成訓練後,輸出層的神經元所呈現之拓樸結構能反映輸入 向量之分佈關係。自我組織圖的演算法為一疊代過程,其訓練過程描述如下: Step1:設定網路參數 設定訓練所需的參數,包含輸入層神經元數、輸出層神經元數、輸入文件向 量筆數、學習速率α(t)、學習次數 T,並以亂數設定鏈結權重向量 wi。 Step2:執行學習流程 Step2.1:自訓練文件向量中隨機挑選一文件向量 dj 進行訓練。 Step2.2:尋找優勝神經元。 計算 dj 與所有輸出神經元之距離,找出距離最小的神經元 c,c 即為優 勝神經元,其滿足下列公式,. d j w c min d j wi 1 i M. (4). 其中 wi 為第 i 個神經元的權重向量,M 為輸出神經元之總數。 Step2.3:更新鏈結權重的向量 鏈結權重向量調整的法則是將優勝神經元 c 與其鄰近區域內的神經元 皆進行調整,更新鏈結權重向量如下:. w lnew w lold (t )(d j w lold ), l N c. (5). 其中 Nc 為優勝神經元 c 之鄰近區域內的神經元集合,此鄰近區域將隨 著訓練周期增加而遞減,α(t)為訓練時間為 t 時的學習速率參數。 Step2.4:重複 Step2.1~ Step2.3 直到所有的文件向量都經過一次訓練。 21.
(28) Step3:檢查停止條件。 令 t=t+1,假如 t 達到了預先設定的總學習次數 T 時,則訓練完成;否則就 減少學習速率α(t),並縮減鄰近區域的範圍,回到 Step2 繼續執行訓練。 B. 標記(labeling) 經過自我組織圖的訓練後,將對神經元進行標記處理,並產生文件分群圖 (document cluster map, DCM)。所謂的標記處理即將先前文件於訓練完成之自我 組織圖之優勝神經元標示出來,如此便可以知道那些文件與文件間是相似的。我 們將文件分群圖之標記方法敘述如下: 在 DCM 中,概念上每一個神經元即代表一些文件的集合,且標記於此神經 元內的文件具有高度字詞同時出現(co-occurrence)的特性,因此被標記在同一或 鄰近神經元上的文件彼此間有一定程度的語意相似程度。 產生 DCM 所使用的方法為計算文件向量與各神經元突觸權重向量的距離。 我們將第 j 筆文件向量 dj 與所有神經元的突觸權重向量進行比較。假設第 j 筆文 件向量與第 i 個神經元的突觸權重向量距離為最小,則將此文件向量標記至此神 經元上。 我們將所有文件向量之標記神經元記錄下來,便可得到 DCM。先前提過本 文的文件向量是依各文件所包含的關鍵字來表示,因此具有多數相同關鍵字的文 件在理論上表示其相似程度很高,所以在標記的過程當中有很大的機會會被標記 在同一個神經元上,也就是說被標記在同一個神經元上的文件在語意上具有較高 的相似程度。因此包含相同字詞的文件會被標記在同一個或相鄰的神經元上。此 外,由於神經元數目通常會小於文件數目,所以會有多份文件被標記在同一神經 元上。因此一個神經元便構成一文件群集。透過這個過程,可以將相關的文件標 示於同一或鄰近神經元上,如此則可獲得文件之群集而完成分群,並獲得文件間 之關聯。. 22.
(29) 3.4 情報探勘 在大量的即時情報中,如何自其中發掘剛發生或即將發生的事件是一件很重 要情報分析任務,亦為進行早期預警(early warning)之重要步驟。本研究將使用 文本探勘方式,嘗試自公開來源情報中偵測出重要事件。我們將進行三種情報探 勘技術,分述如下。 3.4.1 文件分群主題偵測 我們可以發掘文件群組之重要關鍵字詞作為該分群主題。經由一字詞標記過 程,可以獲得一關鍵字詞分群圖(keyword cluster map, KCM)。與 DCM 不同的是, 在 KCM 中每一神經元內所包含的是一些字詞的群集,且這些字詞為其對應之文 件中的常用字詞,換句話說這些字詞在其被標記的神經元之突觸權重向量中具有 一定程度的權重值。 本文中的文件向量是以二元向量來表示,因此經由自我組織圖訓練後的突觸 權重向量理論上最好的情況應是 0 或 1,向量 0 代表字詞對於此神經元完全不重 要,相反的,向量 1 表示字詞對於此神經元具有很大的重要性;但事實的情況並 不會只出現 0 或 1 兩種極端情況,因為在訓練過程中每一神經元可能都會受到其 鄰近神經元之修正。所以本文設計以下方法來產生 KCM:檢視第 j 個神經元內 的突觸權重向量 wj,若某一字詞所對應之元素其值超過一預先設定之臨界值, 則將此字詞標記在此神經元上。這裡所提到的臨界值即一介於 0 到 1 之間的數值, 其中越接近於 1 表示此字詞在神經元中所代表的重要性越高,因此通常都設定為 一接近於 1 的數值,但具有彈性,可根據樣本資料的特性來調整臨界值的大小。 在標記處理之後,一個神經元會被數個字詞所標記,如此即形成了一個字詞 群集。在 KCM 裡,在文件中常常同時出現的字詞會被標記到相同或鄰近的神經 元上。例如,「微軟」與「比爾蓋茲」經常在一份文件中同時出現,所以它們會 被標記到相同或鄰近的神經元,因為它們所對應的元素在轉換成文件向量時都會 同時設定為 1,因此,神經元便會試著同時去學習這兩個字詞。相反的,不同時 23.
(30) 存在相同文件中的字詞在圖中就會被標記在距離較遠的神經元。如此我們就可以 依據兩個字詞在 KCM 中所對應的神經元來發掘它們彼此之間的關係。 3.4.2 特定事件偵測 特定事件指使用者事件設定之事件。例如,一金融業者會關心是否發生了有 關於歐元匯率之事件。他可以設定一些與此類事件相關之關鍵詞。我們則可以監 看新進文件以偵測該類事件是否發生。令 E = {ei} 為使用者所設定用來偵測某事 件的關鍵字詞集合。首先先發掘每一 ei 所屬之文件集合。令 Ci 為 ei 所屬之文件 集合。若 ei 為 KCM 中神經元 i 之關鍵字集合中之成員,Ci 即為該神經元所對應 之 DCM 中之文件分群。若 ei 出現在多個關鍵字詞群組中,選擇突觸權重向量中 具有最高之對應成份之分群為 Ci。決定了各事件關鍵字詞之對應文件群組後,可 以用下列方式來偵測特定事件。一新進文件 dI 首先依第一節所述進行前置處理 並轉換為一文件向量 dI 。此輸入文件向量再與文件分群圖中之所有神經元比較 以找出最近的文件分群 CI。若 CI 與任一事件分群(即 Ci)相同,則 DI 會被視 為使用者有興趣之特定事件文件。. 事件關鍵字 ei. Ci 新文件 dI. 圖 3-6 特定事件偵測 3.4.2 新奇事件偵測 在此新奇事件之定義為未能歸屬於任一文件群組之事件,其代表著此事件不 24.
(31) 曾出現過或之前未被注意到。偵測方法為當新進文件 dI 出現時,它的文件向量 會與自我組織圖中之所有神經元比較,即計算文件向量 dI 與每一神經元之突觸 權重向量 wj 之歐氏距離(Euclidean distance):. d I w j. 。. (6). dI 若 dI 與所有神經元之突觸權重向量 wj 之距離皆超過一門檻值,則我們便認為 dI 為一新奇事件,因其與任一文件群組皆不相似。. 25.
(32) 四、實驗結果與評估 本研究所使用之實驗資料集為 Reuters-21578,其內容為路透社自 1987 年 2 月至 1987 年 10 月中所收集之新聞,由 David D. Lewis[37]與路透社人員所整理 而成,總共為 21578 篇新聞文件。此資料集將文件區分為 135 個類別,然而其中 部分類別並不包含任何文件。我們使用其中的 Modified Apte Split 方法將其區分 為訓練資料與測試資料,其中各包含了 9603 與 3299 份文件。為了達到更好的效 果,捨棄了包含少於 20 份文件的類別,也捨棄了字數過少(少於 20 個字)與字數 過多的文件(多於 300 個字),經上述處理後訓練資料與測試資料各包含 5815 與 2355 份文件。再將這些文件依第三章所述方法轉為轉換為向量,在建立字彙集 時會捨棄只出現一次的關鍵字與不是名詞的字,再根據這些向量進行自我組織圖 訓練來進行分群與標記文件以建立文件分群圖,最後透過所得到的文件關聯來進 行本研究所提之三種偵測,並進行評估。圖 4-1 為 Reuters-21578 資料集之範例。. 圖 4-1 Reuters-21578 資料集之文件範例. 26.
(33) 4.1 前置處理 本研究前置處理步驟包含文件正規化與無效文件篩選,此步驟之目的是為了 將無效字元去除以得到文本文件,並剔除無效文件以提升訓練之品質。圖 4-2 為 正規化後之文件,去除各種型式之網頁標記(tag)、多媒體物件、無效字元,淬取 其中之文字部份所構成文本文件,其中無效字元指控制字元與非英文字元。之後 再將字數少於 20 或大於 300 的文件捨棄,以降低分群效果不佳之可能性。. 圖 4-2 正規化後之文件 4.2 特徵萃取 此步驟包含了斷詞、詞性標記、字根還原、停用字去除與關鍵字選取等步驟。 本研究採用 Stanford Natural Language Processing Group 所開發之 Part-Of-Speech Tagger[15]來進行斷詞與詞性標記。. 27.
(34) 圖 4-3 斷詞與詞性標記結果 圖 4-3 為斷詞與詞性標記結果,Part-Of-Speech Tagger 將文件中每個字的詞 性與標點符號標記出來,透過此步驟可以協助我們過濾標點符號與找出較具有語 意的詞彙。由於本研究是使用字詞之資訊進行分群,如訓練過程中,包含了一些 出現頻率較高但不具有檢索價值之詞彙,會影響對主題之辨認與學習。故必須於 訓練之前,將這些不具有檢索價值的詞彙過濾,此外,英文字詞因單複數與時態 之故,常會有同一個字以不同型態出現,如 story 和 stories,故在此透過 Porter 字根還原演算法[16]進行字根還原之步驟,將字彙的各種變化形式轉換回原來之 字根,此步驟同時亦可降低字彙集之大小。圖 4-4 為進行字根還原、關鍵字選取 後之結果,每個字詞後面的數字為此次字詞在該文件中的出現次數。經過關鍵字 選取程序後,共篩選出 2740 個關鍵字。. 28.
(35) 圖 4-4 字根還原、關鍵字選取後之結果 在完成前述步驟後,接著進行文件向量化,首先從文件集中進行特徵選取以 形成一字彙集,再利用 Salton[17]等人提出之向量空間模型將文件轉換成文件向 量,此一文件表示法可與自我組織圖結合,作為自我組織圖之輸入參數,而權重 部分則是採用二元布林值作為向量值,即文件中有出現該關鍵字則設值為 1 反之 為 0。 4.3 分群與標記 本研究使用 SOM 分群演算法對文件向量進行訓練,在完成訓練之後,將進 行一標記過程,把文件標記於自我組織圖中之優勝神經元上,如此便可得到一文 件分群圖,圖中每一神經元帶代表一個分群,由於文件是依據跟神經元距離之遠 近作為標記之準則,將文件標記在離最近之神經元上,從另一方面來說,被標記 在相同神經元上之文件,其相似度很高,故我們便可以得到文件之分群結果,從 而了解文件間的關聯。本研究的分群訓練其輸入為 Modified Apte Split 分割中屬 於訓練集合之文件,再根據前述所提之條件過濾,所得共 5815 份文件;從文件 在文件分群圖上的映射位置,亦可大約的表示出其文件間之關係,文件所屬的神 經元距離越近,代表著他們的關係越緊密。這是因為一般而言,擁有相似主題之. 29.
(36) 文件,其使用之文字亦會有相似的語言特徵,即有很大機會採用相同的詞彙,故 他們會擁有相似的特徵向量,在映射至分群圖時會被映射至相同或鄰近的神經元 上面。表 1 為自我組織圖之統計資料。本研究嘗試不同的參數範圍,自我組織圖 神經元數量由 100 至 225,學習速率由 0.2 至 1,最大訓練週期由 200 至 1000。 此表所顯示的為獲得最佳結果之自我組織圖。而後針對特定事件與新奇事件偵測 進行實驗,其結果分述如下。. 表 1 自我組織圖統計資料 參數. 值. 自我組織圖大小. 1010. 神經元突觸數量. 2740. 學習速率初始值. 0.4. 最大訓練週期. 600. 4.4 情報偵測 在得到文件分群結果後,便可依此文件間存在的關係,來進行各種事件偵測, 分述如下。 4.4.1 文件分群主題偵測 在進行事件偵測之前,先對文件分群進行主題偵測,發掘出文件群組中之重 要關鍵字,作為該分群之主題。由於文件分群圖上的每個群集,是由詞彙特徵相 似的文件所組成,在文件群集下之文件,所採用之詞彙有很大的重複性,且這些 常用的字詞能夠反映出該文件之主題,在訓練的過程中,亦會得到較高的權重值, 故我們可以透過神經元突觸向量中關鍵字權重值的大小來判定該關鍵字於此分 群的重要程度,而找出每一分群中較為重要的關鍵字作為分群之主題。以下為本 研究門檻值訂定方式,. 30.
(37) [max( w ij ) min( w ij )] 1 min( w ij ). (7). 其中1 為門檻值,wij 為神經元 i 中關鍵字 kj 對應的權重值。考量單一神經元內之 突觸權重,由於權重值越高代表其在神經元中的重要性越高,故這邊我們將1 的值設為 0.9。. 4.4.2 特定事件偵測 首先使用 Reuters-21578 資料集之類別關鍵字作為事件關鍵字。資料庫中超 過 20 份文件的類別共有 57 個,因此便以這些類別的主題作為事件關鍵字來測試 本文的方法。我們先以前述方法找出這些事件關鍵字所屬的文件分群。而後從測 試資料集中選取某一類別的文件,再將此文件之文件向量與所有神經元相比較, 若最相近者即為該類別之主題所屬之文件分群,則將其視為一成功的偵測。本研 究採用準確率做為評估偵測效能的指標,此指標定義如下:成功偵測數量/測試 文件數量,以本實驗結果為例,在門檻值為 0.3 時,測試文件數量為 2355 筆, 成功偵測數量為 593 筆,準確率=593/2355=25.18%,此指標顯示本實驗對於特定 事件的偵測能力。表 2 顯示實驗的結果。 表 2 特定事件偵測結果 描述. 值/結果. 測試文件數量. 2355. 測試主題(事件)數量. 57. 門檻值2. 0.3. 0.4. 0.5. 0.6. 0.7. 成功偵測數量. 593. 1034. 1497. 1890. 2135. 準確率. 25.18% 43.91% 63.57% 80.25% 90.66%. 最佳單一類別準確率. 59.56% 81.78%. 最差單一類別準確率. 0%. 0%. 31. 100%. 100%. 100%. 0%. 0%. 0%.
(38) 測試的文件數量一共有 2355 份文件分別來自 57 個類別,我們從一個類別中 抽出一份文件 dI 來計算他與所有文件分群的距離,當這份文件與文件分群的距 離小於一定範圍時,才認定此文件屬於該文件分群 C。 I 其範圍之訂定為 DCM 中, 所有文件與該文件分群之距離的一定比例下,如下所示: d I CI [max( di Ci ) min( di Ci )] * 2 min( di Ci ). (8). 其中2 為門檻值,Ci 為文件分群 Ci 之突觸權重向量,di 為該分群中的文件。 從表 2 中可以發現,當門檻值從 0.3 逐步調整到 0.7 時,其最差之準確率仍然為 0%,檢視測試資料集後我們發現,造成此結果的原因是因為,某些類別其文件 數量過少,如 retail 與 stg 這兩個類別,其在測試資料集中皆各只有一份文件存 在,故其準確率非 0%即 100%,致使最差準確率始終相當的低。各類別之特定 事件偵測準確率詳見附錄 1,圖 4-5 為各個類別於不同門檻值下之特定事件偵測 準確度。 假定有一金融業者,對金融領域相關事件有興趣,便可以透過特定事件偵測 來找出,首先使用者可以針對他有興趣的事件設定關鍵字,若使用者對 acq 此一 類別的事件有興趣,使用者在設定完 acq 的關鍵字後,便根據這些關鍵字透過上 一節所提之文件分群主題偵測,找出關鍵字所屬之文件分群,之後便監測這些分 群,根據特定事件偵測的結果,如果有文件被標記於受監測的分群上,即代表偵 測出使用者有興趣的事件,透過特定事件偵測可以降低使用者在龐大的訊息中, 尋找有興趣的事件所花費的時間,亦可滿足使用者對特定事件的情報需求。. 32.
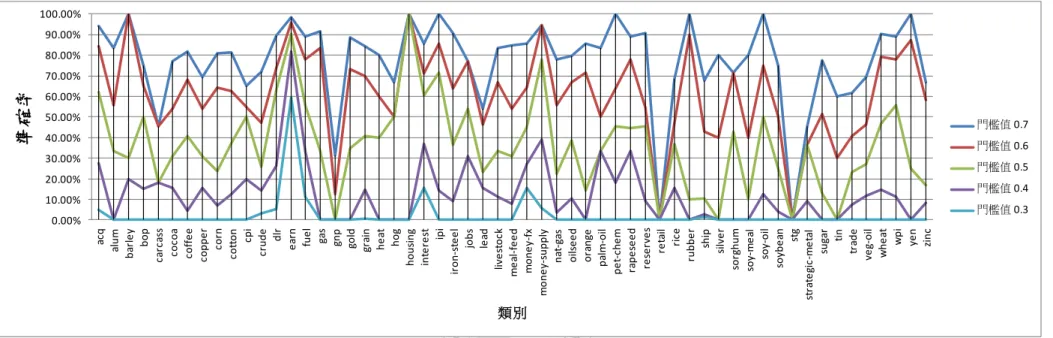
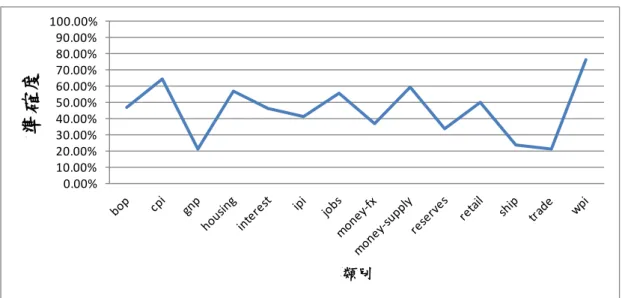
(39) acq alum barley bop carcass cocoa coffee copper corn cotton cpi crude dlr earn fuel gas gnp gold grain heat hog housing interest ipi iron-steel jobs lead livestock meal-feed money-fx money-supply nat-gas oilseed orange palm-oil pet-chem rapeseed reserves retail rice rubber ship silver sorghum soy-meal soy-oil soybean stg strategic-metal sugar tin trade veg-oil wheat wpi yen zinc. 準確率 100.00% 90.00%. 80.00%. 70.00%. 60.00%. 50.00%. 40.00% 門檻值 0.7. 30.00% 門檻值 0.6. 20.00% 門檻值 0.5. 10.00% 門檻值 0.4. 0.00% 門檻值 0.3. 類別. 圖 4-5 特定事件偵測之準確率. 33.
(40) 4.4.3 新奇事件偵測 要評估新奇事件偵測之效能較為困難,主要是因為我們必須另於訓練文件外 準備一組新奇文件。之前所使用的測試文件集並不能滿足新奇性的要求。一個簡 單的策略為假設屬於不同類別的文件即屬不相關,亦即對某一類別文件而言,其 他類別的文件即為新奇文件。根據這樣的假設,將訓練文件集依其類別切割。原 始的資料集共包含 8170 份訓練與測試文件。我們將其依類別重新切割為訓練與 測試文件集。訓練文件集包含 57 個類別中的 43 類別,共 6875 份文件。測試文 件集則包含剩餘的 14 個類別中的文件,共 1295 份文件。表 3 與表 4 分別顯示了 訓練資料與測試資料包含之類別,我們使用新的訓練文件集依據表 1 的參數重新 訓練自我組織圖。而後使用測試文件集中的文件來與自我組織圖中的神經元進行 比較以辨識其是否為新奇文件。. 表 3 訓練資料集包含之類別 acq. Dlr. livestock. alum. earn. meal-feed sorghum. yen. barley. fuel. nat-gas. soybean. zinc. carcass gas. oilseed. soy-meal. cocoa. gold. orange. soy-oil. coffee. grain. palm-oil. stg. copper. heat. pet-chem. strategic-metal. corn. hog. rapeseed. sugar. cotton. iron-steel rice. tin. crude. lead. veg-oil. rubber. 34. silver. wheat.
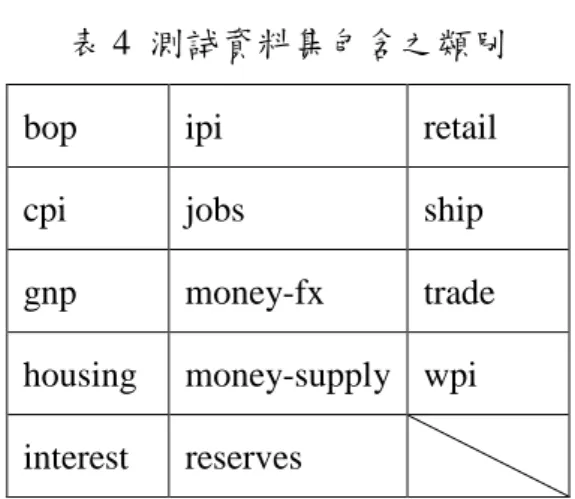
(41) 表 4 測試資料集包含之類別 bop. ipi. retail. cpi. jobs. ship. gnp. money-fx. trade. housing. money-supply wpi. interest. reserves. 表 5 為新奇事件偵測的結果,測試資料為表 4 中的 14 個類別之文件,這 14 個類別不參與自我組織圖之訓練,我們假定此 14 類別與訓練資料不相關,從其 中抽一份文件做為新進文件 dI ,將 dI 之文件向量與自我組織圖中所有神經元之 突觸權重向量比較,當距離皆超過一範圍時,則認定其為一新奇事件。. dI w j N. di w j max N . d wj min i N . d wj * min i 3 N . . (9). 其中 N 為神經元突觸數量,wj 為神經元 j 之突觸權重向量,di 為標記在神經元 j 中的文件,3 為門檻值。由表 5 可得知對於新奇事件的偵測都能夠有不錯的準確 率,各類別之新奇事件偵測準確率詳見附錄 2。圖 4-6 為各個類別之新奇事件偵 測結果。 表 5 新奇事件偵測結果 描述. 值/結果. 測試文件數量. 1295. 門檻值3 成功偵測數量 準確率 最佳單一類別準確率 最差單一類別準確率. 0.3. 0.4. 0.5. 1265. 1071. 703. 97.68% 82.70% 54.28% 100%. 97.01% 80.59%. 91.48% 59.57% 14.28%. 35.
(42) 100.00% 90.00% 80.00% 70.00%. 準確度. 60.00% 50.00% 40.00%. 門檻值 0.3. 30.00%. 門檻值 0.4. 20.00%. 門檻值 0.5. 10.00% 0.00%. 類別. 圖 4-6 新奇事件偵測準確度 由表 5 可知當門檻值較低時,代表測試文件只要與某一類別之文件有些許不 同,亦即頗為相似時,仍會被認為是新奇文件。反之,若門檻值較高,代表測試 文件與某類別的文件間要有較大的差異性才會被認為是新奇文件。由於本研究採 取只要不屬於同一類別的文件即為新奇文件的作法,但實際上不同類別的文件間 仍有可能具有相關性,故當門檻值較高時,要被偵測為新奇文件之可能性便較低, 造成準確率降低。由於本研究並未對不同類別文件間之相似度進行分析,故門檻 值及其準確度並無法提供確切之參考價值。為改善此一缺憾,一可能作法為計算 測試文件與各訓練類別間之平均相似度,再以此相似度作為門檻值。若準確率超 過 50%則可認為本方法可以成功的偵測新奇事件。. 36.
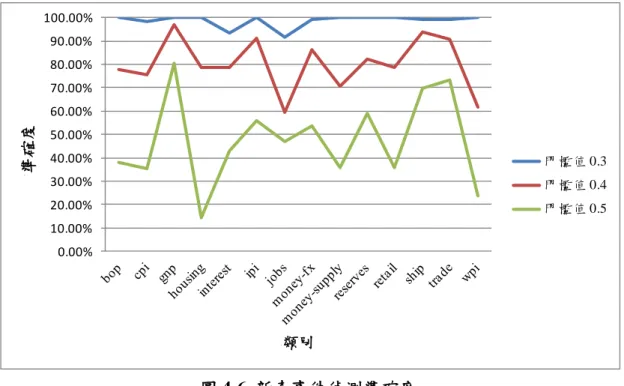
(43) 準確度. 100.00% 90.00% 80.00% 70.00% 60.00% 50.00% 40.00% 30.00% 20.00% 10.00% 0.00%. 類別. 圖 4-7 採用新門檻值之新奇事件偵測準確度. 圖 4-7 為考量測試文件與各訓練類別之相似度,經過計算得出門檻值為 7.0685,再依此門檻值進行新奇事件偵測之準確度,圖中準確率高的代表對此類 別之新奇事件之偵測能力較高,所以在 14 個類別當中,對 wpi、cpi 與 money-supply 此三個類別具有較佳的新奇事件偵測能力,而在準確率較低的部份如 gnp 類別, 因為其包含之文件與訓練文件間具有高度的相似度,較不易被判定為新奇事件, 故其準確率較低。 情報循環包含五大步驟,分別為規劃與指引、收集、處理、分析與產出、發 布,在收集後須評估情報的可信度,即針對來源與內容分別進行評估,然此為另 一研究領域不在本研究範圍內,本研究只針對分析與產出此一步驟進行探討,故 在一開始假定所有的資料皆為可信且有用的,在這樣的假設下進行事件偵測,偵 測所得到的結果,即是為了滿足使用者在特定事件上的情報需求,亦可以做為使 用者在進行決策時的輔助資訊。. 37.
(44) 五、結論與分析 5.1 結論 隨著資訊科技與網際網路的發達,公開來源情報的取得愈加容易,在全球化 與知識經濟的影響下,更突顯了取得情報的重要性,要如何快速的分析國際形勢、 了解社會、政治、經濟、文化之發展,仰賴於我們對公開來源情報之分析能力, 然傳統上情報之分析倚靠大量且具高度專業能力的專家為之,在步入數位化時代 後,資訊量急遽的增長,資訊的複雜度與多樣性亦隨之成長,已然超乎人類所能 處理之極限,單純靠人類的力量進行分析,顯然無法滿足當今的需求,故本研究 希望透過對於文本探勘技術之運用,來協助我們進行公開來源情報分析,以降低 在情報分析時對於人力之需求。 本研究藉由路透社文本集 Reuters-21578 進行文件之群集分析,並透過所獲 得之文件間的關聯,進行特定事件偵測與新奇事件偵測。特定事件偵測是指,偵 測出使用者所關注的事件,透過使用者設定與事件相關的關鍵字,我們可以監看 新進文件是否有該類事件發生。新奇事件偵測則是指能夠發掘出不曾出現過或是 之前未曾注意到的事件,換句話說,即是找出未能被歸屬任一文件分群之事件。 本研究使用自我組織圖做為文件分群之方法,在完成文件分群後,進一步分 析群集中的重要關鍵字,做為群集之主題關鍵字,透過主題關鍵字我們可以迅速 了解該群集之主題;此外,這一主題偵測之結果亦有助於我們進行特定事件之偵 測,由使用者選定有興趣之事件的關鍵字後,藉由主題偵測的結果來發掘與使用 者所選的關鍵字有關的文件分群,接著我們便可監看這些文件分群來得知是否有 使用者有興趣的事件發生。另外於新奇事件偵測,在完成自我組織圖之訓練後, 我們能將具有相關主題之文件群聚在一起,而形成一個個的主題分群,這是由過 去資料所形成的主題分群,故當有一個在歷史資料中沒有發生過或不曾被記錄的 事件發生時,我們便可以透過新奇事件之偵測來得知。上述為本研究架構中所提 出的情報偵測,本研究的目的在於有別於以往情報蒐集之危險與不易取得的困境,. 38.
(45) 故提出針對公開來源情報進行管理與分析之方法,以解決傳統情報之困難點,並 發展自動化的情報分析技術,降低情報分析上對於大量人力之需求。. 5.2 未來研究方向與建議 本研究採用路透社的 Reuters-21578 文本集作為實驗資料,然而該文本集中 各類別的文件數量極度不均,這在進行自我組織圖之訓練時,會導致神經元對某 些類別的訓練不足,故而導致在後續的事件偵測上,有些類別的偵測準確率較低, 對這些文件含量過低的類別,無法進行有效的偵測,故如能改以文件數量分布較 為平均的文本集進行訓練,相信能提高其偵測之準確度。 在未來的研究方向上,可以針對情報探勘的其他方向進行研究,如事件追蹤、 關鍵事物偵測等,此外,本研究僅針對單一語言進行分析,然有許多情報文件是 跨語言的,若發展多國語言文件的偵測方法,將可發掘發生在不同國家之重要事 件,且更具即時與豐富性。. 39.
(46) 參考文獻 [1] Johnston, R. “Analytic Culture in the US Intelligence Community: An Ethnographic Study”. Center for the Study of Intelligence, Central Intelligence Agency. https://www.cia.gov/library/center-for-the-study-of-intelligence/csi-publications/b ooks-and-monographs/analytic-culture-in-the-u-s-intelligence-community/full_tit le_page.htm. Retrieved 2010-12-9. [2] House of Representatives Report 109-89, National Defense Authorization Act for Fiscal Year 2006 (109th Congress 1st Session, May 20, 2005). [3] Richard A. Best, Jr., Alfred Cumming. “Open Source Intelligence (OSINT): Issues for Congress” Library of Congress Washington DC Congressional Research Service.2007. [4] NATO. NATO Open Source Intelligence Handbook, Supreme Allied Commander Atlantic, Norfolk, VA, 2001. [5] US Department of Army. FM 2-22.3 (FM 34-52) Human Intelligence Collector Operations, 2006. [6] Heuer, Richards J. Jr., "Psychology of Intelligence Analysis. Chapter 2. Perception: Why Can't We See What Is There To Be Seen?", History Staff, Center for the Study of Intelligence, Central Intelligence Agency, http://www.au.af.mil/au/awc/awcgate/psych-intel/art5.html. Retrieved 2010-12-9 [7] Gray, A. M. “Global Intelligence Challenges in the 1990's”, American Intelligence Journal, 1990, pp. 37-41. [8] NATO. NATO Open Source Intelligence Reader, Supreme Allied Commander Atlantic, Norfolk, VA, 2002. [9] NATO. Intelligence Exploitation of the Internet, Supreme Allied Commander Atlantic, Norfolk, VA, 2002. [10] Open Source Conference http://www.dniopensource.org/. Retrieved 2011-04-09. [11] Neri, F. and Priamo, A. “SPYWatch, Overcoming Linguistic Barriers in Information Management,” Proceedings of the 1st European Conference on Intelligence and Security Informatics, vol. 5376, Intelligence and Security Informatics, 2008, pp. 51-60. [12] Neri, F. and Geraci, P. “Mining Textual Data to Boost Information Access in OSINT,” in Proceedings of the 13th International Conference on Information Visualization, vol. IV, 2009, pp. 427-432. [13] Pfeiffer, M., Avila, M., Backfried, G., Pfannerer, N., and Riedler, J. “Next Generation Data Fusion Open Source Intelligence (OSINT) System Based on 40.
數據
![圖 4-4 字根還原、關鍵字選取後之結果 在完成前述步驟後,接著進行文件向量化,首先從文件集中進行特徵選取以 形成一字彙集,再利用 Salton[17]等人提出之向量空間模型將文件轉換成文件向 量,此一文件表示法可與自我組織圖結合,作為自我組織圖之輸入參數,而權重 部分則是採用二元布林值作為向量值,即文件中有出現該關鍵字則設值為 1 反之 為 0。 4.3 分群與標記 本研究使用 SOM 分群演算法對文件向量進行訓練,在完成訓練之後,將進 行一標記過程,把文件標記於自我組織圖中之優勝神經元上,如此便](https://thumb-ap.123doks.com/thumbv2/9libinfo/8789659.219717/35.892.274.624.105.502/我組為向量值即文件中有出現該關鍵字則設值反之本研究行一標記過.webp)
+3
相關文件
Mehrotra, “Content-based image retrieval with relevance feedback in MARS,” In Proceedings of IEEE International Conference on Image Processing ’97. Chakrabarti, “Query
in Proceedings of the 20th International Conference on Very Large Data
Lange, “An Object-Oriented Design Method for Hypermedia Information Systems”, Proceedings of the Twenty-seventh annual Hawaii International Conference on System Sciences, 1994,
Godsill, “Detection of abrupt spectral changes using support vector machines: an application to audio signal segmentation,” Proceedings of the IEEE International Conference
Shih and W.-C.Wang “A 3D Model Retrieval Approach based on The Principal Plane Descriptor” , Proceedings of The 10 Second International Conference on Innovative
[16] Goto, M., “A Robust Predominant-F0 Estimation Method for Real-time Detection of Melody and Bass Lines in CD Recordings,” Proceedings of the 2000 IEEE International Conference
編號 受訪者 年資 教育程度 園所職稱 園所班級 A 白鯨老師 25年 大學 葡萄幼稚園-白鯨班老師 6班 B 水獺老師 17年 大學 葡萄幼稚園-水獺班老師 6班 C 海豚老師 15年 大學
Wells, “Using a Maze Case Study to Teach Object-Oriented Programming and Design Patterns,” Proceedings of the sixth conference on Australasian computing education, pp. Line, “Age
