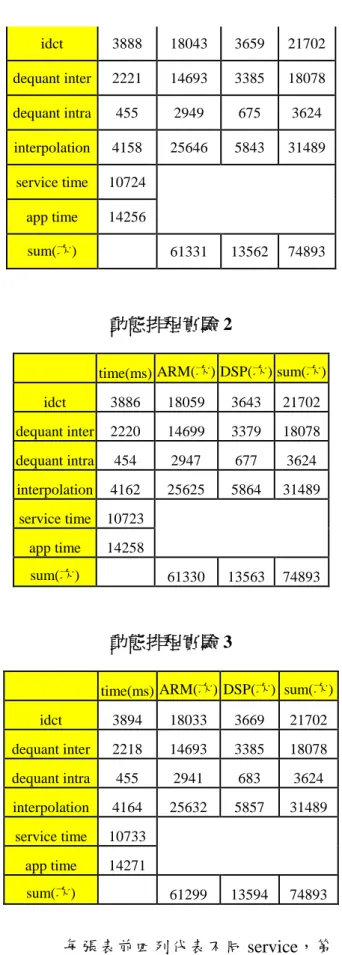
行政院國家科學委員會專題研究計畫 成果報告
子計畫二:多媒體通訊數位基頻 SoC 加速架構及嵌入式作業
系統界面的研究(3/3)
計畫類別: 整合型計畫 計畫編號: NSC94-2220-E-009-008- 執行期間: 94 年 08 月 01 日至 95 年 07 月 31 日 執行單位: 國立交通大學資訊工程學系(所) 計畫主持人: 蔡淳仁 計畫參與人員: 王岳宜、蕭哲民、蘇郁淵、李國丞、林君玲 報告類型: 完整報告 處理方式: 本計畫可公開查詢中 華 民 國 95 年 10 月 31 日
行政院國家科學委員會專題研究計畫成果報告
MPEG-4/21 SOC
設計及新世代行動通訊之研究-子計畫二:多媒體通訊數位基頻 SoC 加速架構及嵌入式作業系統
界面的研究(3/3)
計畫編號:NSC 94-2220-E-009-008
執行期限:94 年 8 月 1 日至 95 年 7 月 31 日
主持人:蔡淳仁 國立交通大學資訊工程系
參與人員:王岳宜、蕭哲民、蘇郁淵、李國丞、林君玲
國立交通大學資
訊工程系
中文摘要
本子計畫的主要目的是在研究多媒體數位通訊基頻 SoC 的應用程式加速架構,以及 異質多核心的作業系統分工排程器的設計。傳統的通訊基頻晶片,只提供 layer 2 以下 的運算功能,以及語音壓縮解壓縮功能。但為了有效支援新一代多媒體通訊應用,許多 基頻晶片大廠如 TI、Freescale、及 Qualcomm 都已經推出了整合多媒體甚至 Java 加速 功能的單一基頻晶片。在三年的整合計畫中,本計畫主要的完成項目有下面幾項。首先 是設計了一個多標準視訊編碼硬體加速 SoC 平台,以利軟硬體協同設計。這個平台有別 於以往針對單一多媒體壓縮標準而做的純硬體佈線的設計。本平台的架構設計是以能直 接支援 MPEG 正在發展中的 Reconfigurable Video Coding (RVC) 的技術為目標。其次本 計畫在異質多核心的作業系統分工排程器的設計方面,完整地在 TI OMAP OSK5912 平 台上發展完成了一套 Heterogeneous Multi-Processor (HMP) 的動態工作切割排程作業系 統核心,以善用 arm 以及 dsp 雙核心效能,並證明在複雜的多媒體應用上,其效能會比 業界慣用的動態工作切割排程雙核心系統好。最後,本計畫也研究了適用手機的 Java VM 環境的加速功能。本計畫以一套公開 RTL 程式碼的、功能類似 KVM 的 Java Processor -JOP 為出發點,設計了一套創新的 Dynamic Code Optimization 的加速機制,把 JOP 在 Spartan III FPGA 上的效能提昇超過 10%。整體而言,本子計畫大體完成了最初計畫 提案中每一項提到的可以整合到基頻晶片的應用程式加速功能。關鍵詞:多媒體通訊、嵌入式作業系統、數位基頻晶片、可動態調整視訊編碼器、Java 處理器
Abstract
The goal of this project is to design an application acceleration architecture that can be integrated into a multimedia communication baseband SoC, and a OS kernel scheduler for dynamic partitioning of tasks for heterogeneous multi-core systems. Conventional baseband processor only provides computational acceleration for speech codecs and network protocol stacks at layer-2 and below. However, in order to support new multimedia communication applications efficiently, new chip venders such as TI, Freescale, and Qualcomm have all announced baseband chipset with multimedia acceleration capabilities. For the past three years, our project team has completed the following major tasks. First of all, we have designed a multi-format video codec acceleration SoC platform. The platform is different from the conventional codec SoC that is hard-wired for a particular codec. Instead, we have followed the latest Reconfigurable Video Codec Framework Standard that is being developed within MPEG. Secondly, we have designed a dynamic task partitioning OS kernel scheduler for heterogeneous multi-processor (HMP) platforms. The design is completely implemented in a embedded prototyping board based on TI-OMAP 5912. We have also shown that for complex multimedia applications, this dynamic partitioning approach can outperform the traditional static partitioning approach. Finally, we have also investigated techniques to accelerate hardware-based Java Runtime environment. The project team developed an innovative Dynamic Code Optimization for Java processors. The proposed technique is implemented for an open source Java processor, JOP, on Spartan III FPGA and obtains over 10% performance gain. In summary, we have accomplished all the goals listed in the original project proposal.
Keywords: multimedia communication, embedded OS, digital baseband processor, reconfigurable video coding, Java processors
目錄
一、 前言 ... 2 二、 研究目的 ... 2 三、 文獻探討 ... 4 四、 結果與討論 ... 4 五、 計劃成果自評 ... 4 附錄一、 可重組的視訊加速 SoC 平台 ... 6 附錄二、 異質多核心作業系統動態分工排程器 ... 12 1. 簡介 ... 12 2. 相關研究 ... 13 2.1 多核心平台排程演算法 ... 13 2.2 對稱式多核心平台與非對稱式多核心平台 ... 14 2.3 同質多核心平台系統下的非對稱式排程 ... 15 2.4 動態式分工及排程 ... 16 2.5 共享資源控制 ... 17 2.6 靜態式分工 ... 18 3. 理論與實作背景 ... 183.1 OMAP 5912 Application Processor ... 19
3.2 OMAP 5912 Starter Kit:OSK 5912 (OMAP 5912 OSK) ... 19
3.3 eCos ... 20
3.4 eCos Overview ... 20
3.5 Configure Tool ... 20
3.6 Component ... 20
i. HAL ... 21
ii. The Kernel ... 23
iii. The Scheduler ... 24
a. Multilevel Queue Scheduler ... 24
b. Bitmap Scheduler ... 24
iv. Synchronization Mechanisms ... 24
v. Threads and Interrupt Handling ... 25
vi. RedBoot ... 25
3.7 移植 eCos 到 OMAP 5912 ... 26
4. 異質多核動態分工排程器設計 ... 27
4.1 Scheduler API ... 27
4.2 Service Registrar 和 Core Service Table ... 28
4.3 Dispatcher ... 28 4.4 Task Dispatcher ... 29 4.5 Task Terminator ... 30 4.6 Loading Tables ... 30 4.7 雙核心溝通方法 ... 31 4.8 DSP API ... 32 5. 實驗結果 ... 32 5.1 實驗環境 ... 32 5.2 動態排程實驗 ... 33 5.3 相異處理器實驗 ... 34 5.4 相異 bit rate 實驗 ... 36 5.5 DSP delay 實驗 ... 37
6. 結論與展望 ... 38
7. 參考文獻 ... 39
附錄三、 Java 處理器加速機制的設計 ... 41
1. Introduction ... 41
1.1 Why Dynamic Code Optimization (DCO) ... 41
1.2 Dynamically-Typed OO Languages ... 41
1.3 Dynamic Message Sending ... 41
1.4 DCO for Java VM Using HW/SW Co-design Approach ... 43
2. Related Work ... 43
2.1 Previous DCO Mechanisms ... 43
2.2 Lookup Cache Mechanism in Smalltalk-80 ... 43
2.3 Inline Cache Mechanism in Smalltalk-80 ... 44
2.4 Polymorphic Inline Cache in SELF System ... 45
2.5 Java Virtual Machine Reference Implementation ... 46
2.6 Sun’sK VirtualMachineReferenceImplementation ... 49
3. Proposed Dynamic Code Optimization System ... 50
3.1 Data Structure Using in Our Dynamic Code Optimization ... 50
i. Data Arrangement in the External Memory ... 50
ii. Method Cache ... 51
iii. Runtime Data Structure ... 52
a. Stack Frame ... 52
b. Data layout ... 53
c. Runtime Class Structure ... 53
3.2 The Proposed Dynamic Code Optimization Scheme ... 53
i. Analysis of Bytecode Execution Frequency ... 54
ii. Access Time of External Memory & Internal Memory ... 54
iii. Architecture Overview ... 55
3.3 Implementation Details ... 56
i. Hardware Modules ... 56
ii. Software Modules ... 57
4. Performance Study ... 58
4.1 Xilinx Spartan-3 Development Board ... 58
4.2 Java Benchmark Programs ... 58
i. Sieve of Eratosthenes ... 58
ii. Kfl ... 58
iii. UDP/IP ... 59
4.3 Experiment Results ... 59
i. Execution Time ... 59
ii. Power consumption ... 59
iii. Microcode Execution Cycles ... 60
iv. External Memory Access Times ... 61
5. Conclusion and Future Work ... 61
一、 前言
本報告是過去三年的整合計畫的完整 報告。在三年的整合計畫中,本子計畫大 體完成了最初計畫提案中每一項提到的可 以整合到基頻晶片的應用程式加速功能。 首先,我們設計了一個多標準視訊編碼硬 體加速 SoC 平台。並在 ARM Integrator 的 SoC Emulation Platform 上驗證了這個平 台。這個平台有別於以往業界針對單一多 媒體壓縮標準而做的純硬體佈線的設計。 本平台的架構設計是以能直接支援 MPEG 正 在 發 展 中 的 Reconfigurable Video Coding (RVC) 的技術為目標。其次本計畫 在異質多核心的作業系統分工排程器的設 計方面,完整地在 TI OMAP OSK5912 平 台 上 發 展 完 成 了 一 套 Heterogeneous Multi-Processor (HMP) 的動態工作切割 排程作業系統核心,以善用 arm 以及 dsp 雙核心效能,並證明在複雜的多媒體應用 上,其效能會比業界慣用的動態工作切割 排程雙核心系統好。最後,本計畫也研究 了適用手機的 Java VM 環境的加速功 能。本計畫以一套公開 RTL 程式碼的、功 能類似 KVM 的 Java Processor-JOP 為出 發點,設計了一套創新的 Dynamic Code Optimization 的 加 速 機 制 , 把 JOP 在 Spartan III FPGA 上的效能提昇超過 10%。二、 研究目的
未來行動通訊網路及相關應用一定會 成為後 PC 時代的主要科技產業.雖然各 種寬頻行動網路(CDMA-2000, WLAN, UMTS/WCDMA)的架設已慢慢成熟,電 信業者也推出各種行動數據服務,但行動 寬頻網的主要訴求:多媒體通訊應用,卻遲 遲不能起飛。其中最主要的理由是多媒體 手機的設計一直無法達到理想的境界。由 於多媒體資料的傳輸及處理具有高運算量 的特性,手機的體積又要越做越小,耗電 量又要低,因此一個專為多媒體演算法及 傳輸協定設計的低耗電整合式系統晶片 (System-on- Chip, SoC)是手機及行動通 訊設備的關鍵元件。而想要把複雜的數顆 晶片整合到一顆系統晶片,最大的挑戰, 除了硬體線路的整合,還包含了內嵌韌體 的整合。以國外一流大廠的手機為例,最 早的多媒體手機大概要用到十多顆晶片, 而最新的手機大概只用到五、六顆晶片, 最主要的關鍵,就是把不同網路的基頻晶 片和應用處理器整合在一起。過去台灣工 業界在 IC 元件設計方面算是具世界水 準,但是對於高度整合系統晶片所需的複 雜韌體的設計則較缺乏經驗。因此在系統 設計上,有時甚至於會“棄軟從硬”,一 些用韌體可達到的功能,反而用硬體線路 來取代,這樣的做法,也許可以減少需要 同時維護軟硬體的麻煩,但是卻阻礙了系 統晶片的彈性和成長空間。 Audio interface Microphone ADC RF interface Analog baseband DSP ASIP Digital baseband GPP Receive Synthesizer Modulator Power antenna Display Keypad SIM Card Radio subsystem 圖一、二代手機架構 傳統的二代手機包含了射頻模組、類 比基頻模組、數位基頻模組、和耗電管控 模組等等(圖一)。其中,數位基頻帶模組 是負責語音編碼、容錯編碼、通訊協定處 理、短訊服務處理、及使用者界面等工作。 在架構上,一般是採用了双處理器核心的 設計。也就是包含一個低效能嵌入式通用 微處理器(GPP)核心加上一個訊號處理 器(DSP)核心。其中 GPP 所執行的任務 包含了 layer 2/3 通訊協定的處理、簡訊服 務處理、人機界面、及簡單的手機作業系 統等,而 DSP 所處理的工作包含 layer 1 通訊協定、語音壓縮解壓縮等等。這樣的 架構應付傳統的語音通訊需求已經足夠, 但卻不足以滿足多媒體通訊在效能上的要 求。特別是如果把低耗電的要求再加上 去,更是一個複雜的問題。為了在傳統手 機架構上很快加入多媒體的功能,國外手 機晶片大廠的做法是另外在系統中加入一 顆應用程式處理器(Application Processor) (如圖二)。在這邊要特別強調的是,對多媒體手機而言,應用程式處理器的存在只 是一個過度時期的需求。如果我們仔細分 析一下應用程式處理器的架構,其實跟(數 位)基頻處理核心是十分接近的,除了有 一個通用微處理器外,也常常包含一個 DSP 核心及一些多媒體加速邏輯。那麼, 為什麼不乾脆擴充基頻處理核心的能力來 取代掉應用程式處理器的功能呢?一開始 的多媒體手機不這樣做,最主要的理由並 不是硬體架構上難以達成這樣的目標,而 是在韌體的整合上有其困難度。 Audio interface Microphone ADC RF interface Analog baseband DSP ASIP Digital GPP Receiver Synthesizer Modulator Power amp antenna Display Keypad SIM Card Radio subsystem Image sensor Multimedia Accelerator Processor cores bluetooth GPS transceiver receiver application processor 圖三、初期多媒體手機架構 以現在的行動多媒體應用硬體架構而 言,有以下的特點是過去嵌入式作業系統 設計時所沒有考量到的。第一、現今的 GPP 核心(通常為 RISC 架構)效能比起早期 的雙核基頻晶片的 GPP 核心要強多了,而 且也常常內建一些訊號處理的加速指令, 第二、新的嵌入式多媒體應用,常常要同 時執行好幾個弱即時(soft real-time)的多媒 體工作(包含視訊、音效、繪圖等等),因 此,傳統上,針對單一時刻只執行單一耗 計算量的工作的異質核心軟體分割方法 (software partition,如圖二),常常在動態 執行的狀況下不能達到最佳效能及工作分 配(load balancing),第三、多媒體應用的瓶 頸往往是卡在記憶頻寬上,因此,新一代 的嵌入式系統記憶體架構往往採用了異質 分 散 式 記 憶 體 架 構 (heterogeneous distributed memory blocks),配合較有彈性 的 晶 片 內 嵌 元 件 的 連 結 通 道 (interconnect),這也是在過去的作業系統 的記憶體管控模組所沒有的設計。 總結一下前面的討論,當嵌入式系統 的設計越趨複雜,系統晶片的整合度越 高,有效率的嵌入式系統和系統晶片的軟 韌體開發將會是未來這個領域的技術重心 所在。然而嵌入式軟體的開發並不能直接 根據 PC 經驗而有樣學樣,必須根據新應 用來思考新方向,特別是在嵌入式作業系 統的設計上,不僅是要重新思考排程器 (scheduler) 和 記 憶 體 管 控 模 組 (memory manager)的架構,甚至於應該重新設計程 式設計模式,才能達到最佳效果。 另外,在多媒體硬體加速架構方面, 過去的業界習慣針對一個多媒體標準進行 純硬體最佳化的設計。但是由於現在的數 位多媒體的標準一直在演進中(如 video codec 從 早 期 的 MPEG-1/2 到 現 在 的 MPEG-4, H.264, 及 WMV 9,傳輸協定也 會從早期的 MPEG-2 transport 慢慢往 IP network 的方向走 , 而 Java profiles 及 presentation scripting language 如 SMIL
等標準也一直在增訂中)。在過去採用純硬 體佈線(hardwired)的方式設計系統的年 代,升級到支援新標準的平台往往只能透 過購買全新的硬體設備來達成。在未來服 務導向的時代,這樣的設計只會增加使用 者的負擔而阻礙新服務的推出,因此現在 一個設計完善的多媒體平台一定要具有高 度使用者擴充性。換句話說,當新服務推 出時,使用者不需要購買一個新的設備, 只要升級現有平台的韌體或可程式化邏輯 元件就可達到享用新服務的目的。 基於以上的理念,配合 MPEG 正在制 訂 中 中 的 Reconfigurable Video Coding (RVC) 標準,在 FPGA 的發展板上設計一 個具擴充性的多媒體加速平台。這個平台 的 開 發 採 用 先 進 的 軟 硬 體 協 同 設 計 (hardware/software co-design)概念.以 最少的硬體設備達到最大的應用軟體效 能。並維持軟硬體的可擴充性。 另外,Java 幾乎已經是嵌入式系統的 應用程式的標準環境了。在手機上,Java 應用程式必須符合 CLDC/MIDP/KVM 的 規範。由於早期手機的 Java 環境都是用內 嵌式處理器來執行軟體 VM 模擬器,所以 效能不彰,而使得應用程式的開發受限。 雖然目前有一些 Java 加速器的設計,但在 手機上除了 ARM 的 Java 副處理器之外,
都不算成功。我們在此計畫中,也花時間 研究一個接近手機用 KVM 的公開硬體程 式碼的 Java 處理器,並研究手機 Java 環 境的效能加速法。
三、 文獻探討
本計畫的總合成果主要有三大方向, 首先是以可擴充的視訊加速平台、在異質 雙核心平台上設計的動態分工排程作業系 統、以及手機用的 Java Processor 的加速。 關於這三個研究方向的文獻探討,請參見 綜合報告之後的成果報告一、二、和三。四、 結果與討論
在可擴充的視訊加速平台的架構設計 方面,我們是以能直接支援 MPEG 正在發 展中的 RVC Framework 的技術為目標。 在 RVC 的架構中,視訊編碼的工具(如 IDCT、VLC)是獨立掛在(軟體或硬體) 平台上的一些 Functional Units。而這些 Functional Units 可 以 透 過 一 個table-driven 的 Finite State Machine (FSM) 來控制組成一個特定的 data path 來處理某 一個視訊標準。如果這個 FSM 是以軟體實 作,那個這個加速平台就可以做到動態重 組成 H.264 或 MPEG-4 等不同視訊標準的 功能。至於我們在這部份研究的詳細報 告,請參見附錄一。 另外,在異質雙核心平台上設計的動 態分工排程作業系統的設計方面。我們特 別設計了一個程序排程器,可以動態根據 RISC core 和 DSP core 的負荷,來決定要 叫用那一個版本的執行碼(RISC 或 DSP) 來完成工作。另外,在動態分工的應用上, 我們除了完成了 MPEG-4 的 encoder 和 decoder , 另 外 也 完 成 了 H.264 的 Intra encoder。關於這個異質雙核心平台的動態 分工排程器的詳細報告,請參見附錄二。 最後,在 Java 處理器的加速研究方 面,我們設計利用硬體記錄了每一個 byte code 的執行次數,對重覆執行,而且需要 做動態 resolution 的指令,進行 dynamic code optimization 的動作。根據實驗,這樣 的系統設計,可以得到相當不錯的加速。 這部份的詳細報告,請參見附錄三。
五、 計劃成果自評
總合三年的成果,和原計畫提出的目 標相當吻合。在達成預期目標情況方面有 以下數點: 1. 多 媒 體 雙 核 心 系 統 中 , 在 TI OMAP OSK5912 平台上發展一套 Heterogeneous Multi-Processor (HMP) 的動態工作切割排程作業 系統核心。在開發這個技術的過程 中,我們有以下成果: I. 發展自己的 DSP scheduler 來幫助作 task 的排程。II. Porting eCos 到 TI omap 平台
上,並開發雙核心有效的溝 通協定。 III. 設 計 一 個 可 以 配 合 eCos MLQ scheduler 的動態分工 模組。 IV. 設 計 新 的 異 質 多 核 心 的 新 Programming model。 V. 實作出支援動態分工應用程 式的開發工具。 2. 視訊編碼硬體加速平台上,實作出 以下 IPs: I. Motion-estimation:計算到達 到 1/4 pel , 參 考 多 個 reference frames 以 及 所 有 sub block 模式
II. H.264 deblocking filter III. MPEG4 IDCT
IV. H.264 transform/inverse
transform unit
V. H.264 quantizer and
de-quantizer
VI. H.264 intra predictor
發展中的 Reconfigurable Video Coding (RVC) 的架構為主要的 設計目標,以期能支援不同視訊 壓縮法的解碼器的動態產生。由 於 RVC 為目前 MPEG 工作中的 項目,所以目前的設計都是以軟 體(C model 或其它 behavioral model 的模擬平台,如 Moses for
CAL 來進行研究)。本團隊因為 積極參與 MPEG 標準的制訂,所 以能隨時根據最新的結果來修正 設計這個平台。
3. 實 作 出 Java Dynamic Code
Optimization for Java Processor 的 軟硬體系統。
附錄一、可重組的視訊加速 SoC 平台
I. INTRODUCTION
Most multimedia devices today have to support multiple codec standards. Take
video codecs for example, a portable
multimedia player usually supports the playback of the MPEG-1/2, MPEG-4 SP, WMV, and H.264/MPEG-4 Part 10 video contents. In order to reduce system cost, a single-chip SoC solution that supports all these standards is a sensible approach. From IC designers’ point of view this is not a serious problem since most (if not all)
popular video codecs share the same
block-based motion compensated transform coding data flow. In addition, many coding tools have similar architecture. However, there are some application issues that makes
traditional codec design approaches
unsatisfactory [1].
A major problem with existing
approach of defining a codec standard is the lack of flexibility when new applications emerge. A video codec is composed of several coding tools (e.g. DCT/IDCT, MC, VLC/VLD, etc.). However, for a codec standard, the conformance point is defined at codec-level, instead of tool-level. Different profiles/levels are created for each codec to address the need of different classes of applications. This approach works fine in the past since the application scenarios were quite simple (e.g. DVD, DTV). However,
with the exponential growth of new
multimedia applications, the old approach of defining conformance point at codec-level becomes awkward. Quite often, a new application designer finds it impossible to
find a reasonable codec profile@level to fit the target application well. For example, the FMO tool of H.264 is useless for many applications but a decoder may still need to support it simply because it is included in AVC baseline profile. In general, application environment is changing faster than an international standard can catch up that there should be a more efficient way of allowing a codec to adapt to new applications while maintaining interoperability among different solutions.
MPEG has recognized this issue and started a new work item called Video Coding Tools Repository (VCTR) in 2004. After some investigations, the direction and benefit of VCTR is becoming clear [2].
Later, this effort becomes the
Reconfigurable Video Coding (RVC)
framework in 2006 [3]. This new framework defines the conformance point at tool-level. Therefore, in principle, an RVC-enabled codec can negotiate on-the-fly with the video bitstream encoder/sender about which coding tools is required and how the data path can be wired among these coding tools in order to decode the video bitstream. After the setup stage, the decoder can decode the bitstream correctly. With this approach, an SoC can support multiple codec standards as well as creating customized codecs in real
time as long as it contains all the
standard-conforming tools that is necessary
to decode bitstreams from different
encoders.
So far, the RVC framework is still in development. Most of the investigations are done using C models and behavioral model
simulators such as Moses [4]. In this report, SoC architecture that can be used to implement the RVC framework is proposed. The report is organized as follows. The RVC framework is introduced in section II. The SoC architecture for direct support of RVC is presented in section III. Some comparisons of the RVC architecture to a common hard-wired solution is also given in
this section. Section IV studies an
implementation to get an idea on the cost for such flexibility. Finally, some discussions are given in section V.
II. MPEG RVC FRAMEWORK
The concept of MPEG RVC framework can be illustrated in Fig. 1. The key difference between RVC and the old MPEG codec standards is that the interface of each coding tools is defined precisely so that they can be used (like LEGO blocks) to build various codecs. The decoder configuration describes how input bitstream can be parsed so that the raw input data to each coding tools can be extracted. A decoder description language is under development so that the configuration of a specific codec (such as H.264) can be described using a (small)
configuration bitstream. The decoder
configuration bitstream will be processed by an RVC decoder before decoding of a video
bitstream conforming to the described
standard. Note that after processing a configuration bitstream, the RVC decoder will generate a Global Control Unit (GCU) that governs the operation of the coding tools.
In principle, the configuration
description tells the RVC decoder how to wire the coding tools to form a data path. In
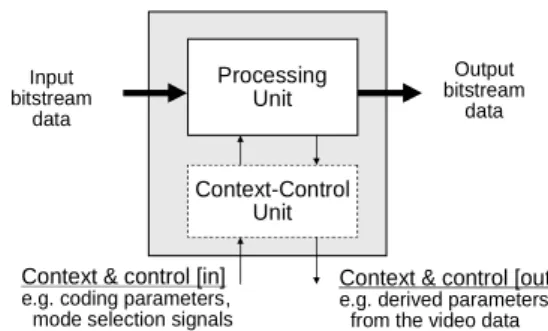
the RVC framework, each coding tools is called a functional unit (FU) and is specified in Fig. 2 [1]. In Fig. 2, a control signal is a signal embedded in the video bitstream (for example, the width and height of the video
frame). A context signal is a signal
generated from the processing of bitstream
data (for example, the AC prediction
direction in the MPEG-4 Part 2 video standard). The context-control unit reads in the context and control signals generated by previousFU’sand generates(orpasseson) some context and control signals to the next FU’sbased on theresultoftheprocessing unit.
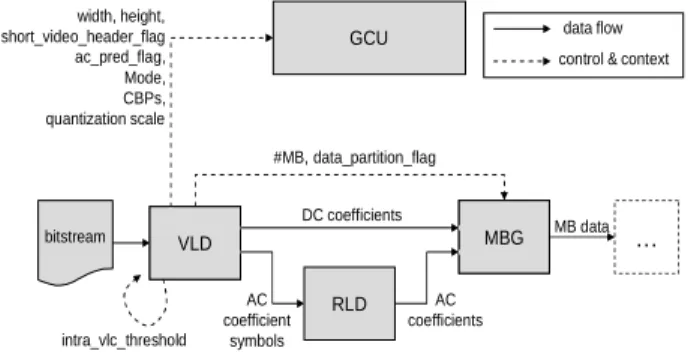
A partial example of a configured RVC codec that behaves like an MPEG-4 Simple Profile video decoder is shown in Fig. 3. In Fig. 3, VLD is the FU for variable length decoding, RLD is the FU for run-length decoding, and MBG is the 8x8 block coefficients composition FU.
88 IDCT 44 GBT 44
intra-prediction ¼-Pel MC ½-Pel MC H.264 Decoder
Configuration and API
MPEG-4 Decoder Configuration and API
Tools in RVC Toolbox Applications Old MPEG conformance point New RVC conformance point
Fig. 1. Concept of MPEG RVC framework
Processing Unit Input bitstream data Output bitstream data
Context & control [in]
e.g. coding parameters, mode selection signals
Context & control [out]
e.g. derived parameters from the video data
Context-Control Unit
8 RLD DC coefficients AC coefficient symbols MBG MBG data flow bitstream … AC coefficients GCU VLD VLD width, height, short_video_header_flag ac_pred_flag, Mode, CBPs, quantization scale intra_vlc_threshold
control & context
#MB, data_partition_flag
MB data
Fig. 3. Example of RVC configuration
III. SOC ARCHITECTURE FOR RVC Since the specification of the video decoder
configuration language and the actual
mechanism of a GCU are still under
development at MPEG, this report proposes a potential VLSI architecture that is suitable for supporting the RVC framework and perform some early analysis on such architecture. The RVC framework actually fits the platform-based design principle of SoC quite well. For maximal flexibility, the GCU will be implemented in software and running on the processor core of an SoC. Each coding tool can be implemented as an IP on the bus with limited configurability via a private register file. The proposed architecture is show in Fig. 4.
In Fig. 4, the coding tools are not attached to the main system bus (AMBA AHB) directly. A local bus, MMB, is used to off-load the bandwidth from the main system bus. Here, MMB stands for Multi-Media Bus. In our implementation, the bus protocol of MMB is a simplified version of AHB. A two-way DMA is used to transfer data between external SDRAM and internal SRAM banks. The DMA can be
invoked from either the ARM core or the coding tool IPs (as long as the tool is implemented as an
MMB master).Thereason formultipleSRAM’s
on the MMB is to reduce the memory bandwidth requirement for parallel operations of the coding tools. RVC Coding Toolbox DMA H.264 ILF ARM SDRAM SRAM 1 AHB MMB H.264 CAVLD DMA Register file DMA Register file H.264 TQ H.264 INTRA H.264 CABAC MPEG-2 IDCT SRAM 2 SRAM 3
Fig. 4. SoC architecture for RVC framework
ARM memory AHB Deblocking filter INTRA Decode MC TQ–1 CAVLD
Fig. 5. Hard-wired decoder example
Although local bus and multiple SRAM banks are used to alleviate the bandwidth issue, the performance of this architecture still cannot match that of a hard-wired architecture. For example, a hard-wired H.264 baseline decoder may have a tighter MB decoding pipeline as shown in Fig. 5. There are two main advantages of the architecture in Fig. 5. First of all, the decoding pipeline is controlled by a hard-wired FSM with cycle-based synchronization. On the other hand, for the RVC framework, the controller will be implemented in software, and
9
hence, cannot guarantee cycle-based operation of
the pipeline. Another advantage of the
hard-wired approach is that it does not require excessive accesses to external memory.
It is important to point out that the purpose of the RVC framework is not to obtain the most efficient design of a single codec, but to allow a flexible and extensible design of codec systems. Multi-standard codec support (or even generate customized codec on-the-fly) can be achieved by configuring a new GCU via decoder description bitstreams. In the next section, we will study an
actual implementation of the proposed
architecture in Fig. 4 to get an idea about the cost one has to pay for such flexibility.
IV. IMPLEMENTATION STUDY OF THE PROPOSED SYSTEM
In this section, an implementation of the
proposed system architecture (Fig. 4) is
investigated. The implementation is based on an SoC emulation platform, the ARM Integrator [6]. The platform is composed of a main board, an ARM 9 processor core module, and a Xilinx VirtexE XCV2000E FPGA logic module. The platform adopts the AMBA bus protocol. The RVC coding toolbox logic of the proposed system is implemented in the FPGA. The local bus protocol, MMB, of the toolbox logic is a reduced version of AHB with much less wires and a minimal implementation of bus arbiter and decoder.
In the proposed system architecture, the finite state machine (FSM) that drives the operation of the coding tool FUs is implemented
in software. As a result, the codec pipeline is not executed in a lock step fashion but instead driven by the software FSM via control signals. Each coding tool FU (please refer to Fig. 2) is implemented so that the input bitstream data is coming from a SRAM bank on the MMB and the output bitstream data will be stored in another SRAM bank on the MMB. Block RAMs of the Virtex II FPGA and the ZBT SRAM of the ARM Integrator are used for this purpose. Table I and Table II list the required memory for the input data and output data. It is obvious that such implementation is not as efficient as a tightly-coupled pipeline [5] where different pipeline stages are connected via registers or FIFO.
On the other hand, since the system control FSM is implemented in software, the Global Control Unit of the MPEG RVC framework can be dynamically implemented using this FSM. Therefore, any video decoders can be emulated on-the-fly by the proposed architecture as long as all the coding tools required by the target
codec are supported by the architecture.
Therefore, the proposed architecture is very flexible and scalable. It is important to point out that in order to support dynamic reconfiguration of the RVC decoder, the software-based system FSM shall not be a hard-coded FSM. Instead, it should be implemented as a table-driven FSM where the table content can be modified by the RVC decoder configuration bitstream.
The implementation of the processing unit and context-control unit of a coding tool FU
follows traditional hard-wired IP design
10
implemented as a data path and the
context-control unit is a hard-wired FSM with
register files for memory-mapped I/O
configuration and signaling. Currently, most of the FUs supported in the proposed platforms are for H.264. The synthesis report of some of the implemented FUs is shown in TABLE III.
V. CONCLUSIONS
This report introduces the MPEG RVC framework and proposes an SoC architecture to
support the framework. Since the RVC
framework is still under development at MPEG. There is not much research on how the
framework can be efficiently supported using an SoC platform design paradigm. The table-driven software FSM for dynamic generation of a GCU and the decoder configuration language is still yet to be defined by MPEG. However, based on our study, the proposed architecture is very feasible for practical SoC implementation of the RVC framework. Although a reconfigurable video codec cannot compete with a hard-wired codec for performance given current VLSI implementation technology, it is much more scalable in the sense that any new codecs (coding tools) can be added into the platform with minimal effort.
TABLE I. The data size from external of the FUs in the proposed RVC architecture Data form External Memory
Luma Chroma Total Cycles
Intra
predictor(input)
256 bytes 128 bytes 384 bytes 96
Luma Chroma Block info Total Cycles
Deblocking filter(input)
384 bytes 256 bytes 120 bytes 760 bytes 190
TABLE II. The data size from internal memory of the FUs in the proposed RVC architecture Data from Internal Memory
Residual Luma Residual Chroma Total Cycles
Intra predictor(outpu t) 256 bytes 128 bytes 384 bytes 96 Trans.&quant. Luma Trans.&quant Chroma Total Cycles TQ/TQ-1(outpu pt) 512 bytes 256 bytes 768 bytes 192
Luma Chroma Total Cycles
11
bytes
Deblocked Luma Deblocked Chroma Total Cycles
Deblocking filter(output)
256 bytes 128 bytes 384
bytes
96
residual data MVD Total Cycles
CAVLC(input) 768 bytes 64 bytes 832
bytes
208
TABLE III. The Synthesis Report of some Logics
Module name H.264 Transform Quantizer Intra predictor 1 (other modes) Intra predictor 2 (DC mode) Inloop Filter CAVLC* MPEG-2 IDCT Clock rate 72MHZ NA 198 MHZ 158 MHZ 60MHZ 50MHZ 77MHZ
Logic size 252 LUTS
197 LUTS with MULT18X18
LE
879 LUTS 188 LUTS 3105 LUTS
3125 LUTS 3232 LUTS Bandwidth 16/18 (output/clk) 1/1 (output/clk) 4/1 output/clk 1/1 output/clk (I4MB) 1/5 output/clk (I16MB) 2/1 (output/clk) depend on content 64/158 (output/clk) Memory usage 1 (16x16 bit) 96 words by 14 bits 52 words by 5 bits 52 words by 3 bits NA NA 16x384 bits 128x22-bi t 16x16-bit 64x16 bit
*CAVLC is based on a Spartan II FPGA device, and the others are based on a VirtexE FPGA device
REFERENCES
[1] E. S. Jang, K. Asai, and C.-J. Tsai, Study of Video Coding
Tool Repository v5.0, MPEG Meeting Document N7329,
Poznan, July 2005.
[2] C.-J. Tsai, Suggestions on the Direction of VCTR, MPEG
Input Document M12074, Busan, April, 2005.
[3] ISO/IEC MPEG Video Group, Final Call for Proposals on
Reconfigurable Video Coding, MPEG Meeting Document N8070, Montreux, April 2006.
[4] J. Janneck et al., Moses Tool Suite, https://sourceforge.net/projects/mosestoolsuite/.
[5] T.-C Chen, Y.-W. Huang, and L.-G.Chen,“Analysisand design of macroblock pipelining for H.264/AVC VLSI architecture,”Proc. of IEEE ISCAS 2004, Kobe, 2004.
附錄二、異質多核心作業系統動態分工排程器
1. 簡介 在街頭上,隨處可見用手機在聊天談 事情的人們;或是掛著耳機,利用 mp3 播 放器在聆聽音樂的青少年;上班族也幾乎 用 PDA 取代了以往紙本記事的習慣。如此 廣大流行的手持式裝置,如今越來越擴展 它的應用層面,例如手機支援百萬像素的 拍照功能,使手機也有了數位相機的能 力;3G 的影像電話功能,不只是對話,也 能同時看到對方的表情,讓遠距溝通變得 更生動;mp3 播放器的文字瀏覽,秀圖系 統甚至影片播放功能,令單純聽音樂的 mp3 播放器提高其附加價值,搖身一變成 為微形的數位娛樂中心;另外 PDA 的衛星 定位導航功能,打破了我們一向認為 PDA 只不過是個可以帶著走的超小型桌上電腦 的既有想法,發揮了在移動力上的特性。 相信未來必定會推出更強大更高品質的應 用,使得嵌入式系統的複雜度迅速地提 升,相對的嵌入式系統的工作效能也必需 提高。 為了諸如此類眾多新的功能,以多媒 體應用來說,嵌入式系統必需完成極大量 的多媒體資料處理工作;換句話說,嵌入 式系統要在相同甚至更短的時間內,處理 更大量的資料,做更多的運算工作。提高 嵌入式系統的能力是必要的。就過去電腦 系統的發展史來看,提高系統的能力不外 乎是提高處理器的能力為主,而處理器的 能力就直接關係到它每秒可以運算的次 數,每秒可以執行的計算量,亦即處理器 的頻率。然而目前利用此一概念發展的單 一核心嵌入式平台己不敷使用。 考慮手持裝置的特性:輕巧以及移動 力佳。嵌入式平台便有了體積上的限制, 其中便影響到一個重要的耗電量的問題。 體積上的考量,手持裝置無法配置大容量 大體積的電池,同時顧及其移動的特性, 也無法接受一再需要補充電力的要求。提 高核心頻率會消耗大量電力,這一點會成 為嵌入式平台的致命傷,再者,高核心頻 率相伴而來的是產生許多的熱量,散熱方 面也是一個難題。在現今市場上,整體行 動裝置效能的提升不是利用提高核心頻率 的方法,而是以增加核心數(處理器數量) 來平衡高核心頻率需求及大耗電量和高熱 能產生的缺點。這種多個處理器的架構, 我 們 稱 之 為 多 核 心 架 構 (multiprocessor architecture)。 事實上,異質多核心架構在嵌入式系 統的發展己被業界廣泛地使用,例如德州 儀 器 公 司 的 OMAP(Open Multimedia Application Platform),以及 Freescale 的 MXC 。 在 非 對 稱 式 多 核 心 系 統 晶 片 (system-on-chip: SoC)架構裡,會有顆一般 功能的處理器(general purpose processor: GPP)核心,做為嵌入式系統作業系統的控 制核心,配上一顆數位訊號處理器(digital signal processor: DSP)核心。DSP 可以大量 即時處理多媒體資料,如 MPEG 1、MPEG 2、MPEG 4 或是音訊資料等等。以德州儀器 公 司 的 OMAP 5912 OSK (OMAP
Starter Kit)為例 [1],其 GPP 採用 ARM 公 司 ARM926EJS,DSP 則是德儀自行研發 的 TMS320C55X。研發人員可以依照資料 處理的性質,將工作分配給 OMAP 架構微 處理器中的 ARM 微處理器或者是 DSP 微 處理器去處理。非對稱式多核心架構可有 效 率 利 的 處 理 嵌 入 式 系 統 上 的 工 作 (task),發揮系統的最大效能,特別是對於 多媒體的應用程式有令人亮眼的表現。 現 存 的 即 時 作 業 系 統 (real-time operating system)對於非對稱式多核心架 構 大 部 份 是 採 用 靜 態 式 分 工 (statically partitioned)的方法。所謂靜態式分工方法 是系統設計時研發人員就做好工作的分 配,屬於控制流程的工作就交由 GPP 執 行,屬於多媒體運算處理的工作多交由 DSP 執行。在這種分工架構之下,有兩個 不同的 schedulers 為兩顆核心獨立運行已 分配好的工作。換句話說,兩顆核心各自 處理已分配好份內的工作,完成之後,在 下一個工作來臨之前是閒置的狀態,因為
在獨立的視野裡,已是最好的效能發揮。 這類型的分工方式在傳統行動通訊平台及 應用程式環境下是相當有效的法。過去常 用的 GPP 核心在特殊工作處理的功能性 和速度都有所不足,意即 GPP 沒辦法勝任 DSP 的工作。並且過去的嵌入式應用程式 環境通常是單純的前景/背景(foreground/ background)工作模式,所以不需用到複雜 的動態排程。 但是新一代多媒體應用會拓展到更寬 廣的層面,再加上硬體裝置上有了新的提 升。首先,多媒體應用程式已經複雜到一 個境界,為了提升系統效能和減低能量的 消耗,必需用動態調整兩顆核心的工作量 取代系統設計時做好的工作分配。其次是 GPP 的能力已被大幅提高,可以幾乎和 DSP 等速地處理某些多媒體資料,換句話 說, 在這些情況下,GPP 可以用來分擔 DSP 的工作負載。接著是多媒體應用程式 在記憶體和計算量的需求己經大大超越過 往,多媒體資料經常會被包裝成運輸串流 (transport stream),往返於兩顆核心之間, 但是在執行時核心之間溝通的成本並非固 定,譬如傳輸時電力的消耗與總電量的關 係、工作有沒有完成時間的限制(deadline) 等……,有太多因素要考量,是不可能在 系統設計時就預測到並且做好資料傳輸的 設定。著眼於系統效能,靜態式分工系統 設計不再合適,即時作業系統排程器在設 計上要有新的突破。 考慮以上種種原因,我們便提出一種 新的動態精細分工式(tightly-coupled)作業 系統排程器[21],[22],這種新的排程法會 由單一排程器監控各顆異質核心的工作狀 態,並能動態地分配工作給當下最合適的 處理器核心。排程視野的廣度上,由系統 設計時就定好的靜態工作分配延伸到執行 時的動態分配;而深度上,考量整個系統 即時的狀況,做出最適當的工作分配並減 少微處理器的閒置浪費,取得比靜態式分 工系統更大的效能發揮。 2. 相關研究 這一章將會介紹此領域的相關研究。 依順會介紹多核心平台著名的排程演算 法,對稱多核心平台及非對稱式多核心平 台,非對稱式多核心平台系統的排程,動 態排程,共享資源的控制,非對稱式系統 晶片 SoC,和靜態式分工系統。 2.1 多核心平台排程演算法 多核心處理器架構排程器的研究越來 越受到重視。過去十多年來,在實用上, 多核心排程演算法的發展重點是放在對稱 式 多 核 心 系 統 (symmetric multiprocessor system)上。多核心排程技巧在同質多核心 平 台 部 份 可 以 被 分 成 兩 類 , partition
scheduling 和 global scheduling[23] 。
Partition scheduling 是指每一個核心有自 己的工作駐列(task queue),包括 ready 駐 列和 wait 駐列。工作排程的考慮會以各自 區域的 priority 為主,與其他處理器獨立。 每一個工作一旦被分配到一個處理器,在 其生命週期內都不會移到別的處理器。 Global scheduling 則是將所有準備完成的 工作放在一個共同的 priority 駐列。最高 priority 的工作會被挑選放到一個工作量 較低的處理器執行。這種 scheduling 模式 在同質多核心的系統上表現較前者佳。 以下簡單列出一些常用的多核心排程 演算法[3]: Rate monotonic: 每一個週期性的工 作有固定的 priority,priority 的順序是 根據該工作的執行頻率高低而定,例 如要等待 interrupt 的工作,其 priority 相對較低。在 1973 年,Liu 和 Laylan 證明這個演算法是固定 priority 演算 法中最理想的一種。
Earliest Deadline First: 這種演算法可 將週期性和非週期性的工作一起排 程,主要概念是越早結束的工作越先 執行。M. L. Dertouzos 在 1974 年證 實當瞬間有許多工作等待執行時,此 演算法是最有效率的。 Deadline Monotonic: D.M.結合上述 兩種演算-- priority的給定除了根據該 工作的執行頻率外,另外會再考慮 deadline 越早,priority 越高。 Background Scheduling: 此種演算法 同時處理 soft real-time aperiodic task
和 hard real-time periodic task。兩種型 式的工作分別置入兩個不同的駐列。 此演算法實用上雖沒有很高的利用 性,但其優點在於實作很簡單。 Pooling Server: P.S.可處理非週期性 的工作。每個時間區塊一過,server 便服務下一個時間區塊可以執行的工 作。若沒有工作在等待被執行,則會 閒置 server,等到下一個時間間隔再 甦醒。 Deferrable Server: 此演算法類似上 一個,但是若下一個時間區塊沒有等 待被執行的工作,則 server 服務可能 被服務的工作,而不是閒置 sever。 Sporadic Server: S.S.使用於非週期 性工作,可以增進其反應時間,使得 非週性工作的效能追上週期性工作的 效能。
Dynamic Sporadic Server: 這個演算 法利用 deadline 調整 priority,增進 Sporadic Server 的效能。
Robust Earliest Deadline: 這是 1995 年 Buttazzo 和 Stankovic 發展的演 算法,作用於 over loading 環境中的非 週期性工作。此演算法不只可以減少 deadline 預測錯誤,也可降低系統 over loading 的程度。
Constant Bandwidth Server: 這是在 1998 年 Buttazzo 和 Abeni 發展的演 算法,用來解決即時多媒體應用的問 題。例如在串流影音的系統中,對串 流 資 料 的 傳 輸 和 處 理 的 delay 和 jitter,必須要控制在一定的範圍內。 Adaptative Bandwidth Reservation : Abeni 和 Buttazzo 在 1999 年提出對 constant bandwidth server 的改良。對 於執行時間未知的工作所能分配到的 處 理 器 的 頻 寬 可 以 經 由 Adaptative Bandwidth Reservation 來控制。在這 裡,頻寬(bandwidth)一詞指的是處理 器分配給工作的時間或是工作被執行 的週期。 2.2 對稱式多核心平台與非對稱式多 核心平台 前面提到目前實用上多核心作業系統 的排程演算法大部份都是以對稱式的多核 心平台為目標,比方說,Satoshi Kaneko et al 在 2004 提出的一個多核心平台[4]。這 個 600MHz 單晶片多核心平台包括兩個 M32R 32-bit CPU 核心,一個 512-KB 共用 的 SRAM,和一個內部分享的 pipeline bus。
這個平台是由 0.15um CMOS 製程製 造,適用於嵌入式系統。此多核心平台是 對 稱 式 的 多 程 序 處 理 平 台 , 並 且 支 援 modified-exclusive-shared-invalid (MESI) 的快取統一協定。該系統繼承了先前單晶 片多核心平台的諸項優點,並針對嵌入式 處理器做了最佳化,以使得系統效能增加 的同時也能減低電力的消耗。為了增加核 心的效能,他們在平台內部置入一個共享 的 pipeline bus。此 bus 的特性是低延遲和 每秒 4.8 G-bit 的大頻寬。此外也用多個低 耗電技術,例如擁有不同使用電力的模型 選擇: 睡眠模式、工作模式、和等待模式。 不同系統情況下,不同核心甚至週邊有不 同 的 模 式 選 擇 , 以 達 到 最 高 的 省 電 約 18.4%。使得此多核心平台在 600MHz 1.5V 之下功作僅消耗 800 mW,待機時更只耗 1.5mW。 有些應用,如 3G 通訊和嵌入式多媒 體應用,會同時執行控制的工作和大量資 料處理的工作。一般實作上,為了逹到最 佳 的 性 能 / 秏 電 量 比 值 , 異 質 多 核 心 (Heterogeneous Multi-Processor)的架構是 一般業界常用的設計方法[1], [13]。例如飛 利 浦 半 導 體 部 門 發 展 了 一 套 Silicon System Platform (SSP)。SSP 是零件的工具 箱,是一種一般性、開放性和可程式化的 架 構 。 主 要 用 來 產 生 有 軟 體 和 硬 體 IP blocks 的特定應用產品領域。過往研發新 產品,可能必需打造整個新平台架構,付 多相當的成本花費。利用 SSP 概念,為新 應用產品而修改的架構會比試著去產生整 個新架構更有實作的效率。使用 SSP 設計 產品的速度很快而且技術風險低,因為架 構中軟體硬體的功能性己經驗證過,而且 還可以結合其他工作元件更容易達到設計 的目標。同時其中有很大的空間讓設計團 隊創造不同市場需求的產品;一系列的產 品由入門到進階的產品,只需在平台上增
減功能區塊,就可有效地減少開發時間及 成本花費。日後使用者甚至可以隨著更新 軟體的版本來增強或增加產品的功能性。 飛利浦的 Nexperia 平台是一個單晶片系統 的 SSP,用來開發數位視訊產品。Nexperia 平台上主要包括 MIPS 處理器和飛利浦的 TriMedia VLIW 媒體處理器,及其他 IP 元 件。結合 MIPS 及 TriMedia 兩種不同的計 算核心,整合成單晶片系統。飛利浦利用 此平台創造出多功能的機上盒,它可以即 時解碼多個視訊串流、執行數位錄製、壓 製訊號用於視訊電話、瀏覽網站和收發電 子郵件等多項功能。其他如德州儀器(TI), 飛思卡爾(Freescale)和 Toshiba 等知名大廠 都有自己的異質多核心平台,本論文在 TI OMAP 上實作,稍後章節將會詳細介紹 OMAP 平台。 在軟體的開發過程中,軟體測試是很 重要而且很昂貴的一部份。有一種軟體測 試的方法稱之為資料流測試(Data Flow Testing),使用資料流測試可以決定一個軟 體的測試是否充份且完整。Harrold 提出一 個新的方法把整個資料流測試工作量切割 成適當的大小[5]。這些測試的工作量可以 靜態地也可以動態地接受排程。也可以改 變成適合共用式記憶體或分散式記憶體的 環境。在[5]中把資料流測試演算法實作出 單一核心平台的版本和多核心平台的版 本,並根據大量的軟體實驗來驗證資料流 演算法的正確性。另外,這些實驗也可證 實多核心平台的效能優於單核心平台。平 均效能上多核心平台比單核心平台加速 1.7 倍。 Annavaram 等人討論過非對稱式多 核心系統的效能優於對稱式多核心系統的 看法[6]。激發此篇論文的研究動機有下例 三點:首先,單晶片多核心平台上 CPU 核 心的數目增加,同時間可以執行的運算量 上升。第二,可以利用單晶片多核心架構 優點的多執行緒軟體變得更流行。因為演 算法的性質,這些多執行緒程式被分階段 連續的執行。然而Amdahl’slaw指出平行 化程式的加速將會被計算的連續部份限 制。第三,不斷增加的晶片整合層級和逐 步降低使用的電壓結合使得如何減少電量 的耗損成為首要注重的設計限制。此論文 的目標是最小化多執行緒程式的執行時 間。該執行緒包含平行處理和連續處理的 階段,同時也保要有多核心單晶片的電力 消耗限制。為了減少 Amdahl’s law 影 響,在論文中對於電量花費的計算是根據 可獲得的平行度來決定處理的指令數,並 以這些指令花費的電量為準。使用該等 式,電力 = 每個指令的能量(Energy per Instruction: EPI) * 每秒指令數(Instructions per second: IPS)。假設電力固定的情況 下,因此限制平行量的多核心單晶片是低 IPS,會花較多的 EPI。相反地,高平行量 時,會花較少的 EPI。根據[6]的實驗,在 相同的耗電量前題下,一個複雜的系統在 使用非對稱式多核心、多執行緒執行時, 會比對稱式多核心系統增加百分之三十八 的效能。 隨著近年來多媒體裝置的流行,多執 行緒平台研究關注的焦點已由對稱式多核 心系統轉移到非對稱式多核心系統。非對 稱式多核心系統比對稱式多核心系統有更 佳的效能/時脈比,因此在多不同工作執行 時非對稱式多核心系統更適合嵌入式裝 置。 2.3 同質多核心平台系統下的非對稱 式排程 前面提過,異質多核心平台在處理通 訊及多媒體相關工作時可以得到最佳的效 能/時脈比,但目前並沒有論文是針對異質 多核心平台探討動態自動排程的設計。不 過倒是有不少論文是針對同質多核心平台 研究非對稱式動態自動排程的可行性。 Wendorf 等人 提出多個工作分配和排程 方法[7],範圍由非對稱 master/slave 排程 到對稱式排程。他們在許多情況下測試這 些分配和排程方法。對於非對稱系統,結 果顯示 OS Preempt 策略幾乎在所有的清 況下都有最高的效能。作業系統的工作的 priority 相對高於一般應用程式,而在兩者 有相同 priority 時,作業系統的工作可以較 優先得到處理器的使用權,稱之為 OS Preempt。相對於其他策略 OS Preempt 可 以減少時間耗損百分之三十到百分之六 十。在許多測試情況下非對稱的系統和對
稱式的系統幾乎有一樣的效能,甚至前者 有優於後者的情況。重要的是,在對稱式 系 統 中 , 作 業 系 統 工 作 因 functionality partition 仍需在全部可以使用的處理器中 選擇執行者,相較之下非對稱式系統指定 單一處理器微理作業系統工作,更容易實 作。結果也指出,在不同工作分配和排程 演算法下,process switch overhead 和多處 理器之間的對於分享資源的競爭是決定系 統效能的因素中相對較不重要的。
Greenberg 提 出 了 一 個 簡 單 的
master-slave 架構[8]。在一些電腦作業系統 下,一個程序(process)可以在 user mode 或 是 system mode 的模式下執行。一個 user mode 的程序可以在執行中進行一個系統 呼叫(system call)變成 system mode。這個 程 序 在 結 束 這 些 呼 叫 後 便 回 到 user mode。在 master-slave 的多核心架構下, 系統呼叫如 kernel call 只可以在 master 核 心執行,剩下的呼叫就被視為如 user call, 和 其 它 工 作 一樣可以在 master 核心或 slave 核心執行。當 slave 核心上的 user mode 程序欲使用 kernel call,slave 核心會 將該程序交給 master 核心處理,而非由 slave 核心處理。在 Greenberg 提出的設計 中,工作會先在兩個駐列等待。一個駐列 稱為 master 駐列,另一個則稱為 slave 駐 列。Master 駐列的工作都是在系統模式, 而 salve 駐列上的工作都是在使用者模 式。 如前所述 master 駐列是只在 master 核 心 執 行 的 駐 列 ,slave 駐列卻是可在 master 核心或 salve 核心執行。此論文利用 兩種簡單又實作的排程演算法來平衡排程 的彈性和 queue-switching 的成本花費。最 後並提出一個分析公式,用來測量硬體和 work load 參數,同時考量 master-slave 系 統的電力和限制,並進而尋找到非對稱式 多核心系統中最佳 slave 核心的數量。 2.4 動態式分工及排程 許多對時間有嚴格要求的應用都需要 動 態 排 程 方 能 達 到 預 定 的 效 能 。 Manimaran 等人把一個系統的效能定義 為該系統能在 deadline 之前完成的工作所 佔的百分比[9]。在這篇論文中,他們提出 在多核心系統上使用的一種演算法,可以 動態地對可執行的即時工作進行排程,並 具有容錯的功能。系統的運作是基於以下 兩個限制條件: 一、每一個工作一旦分配 給 處 理 器 以 後 , 是 不 會 被 打 斷 的 (non-preemptive)。二、每個工作有兩種版 本,這個假設是用來改善處理器錯誤的問 題並可以得到較高的效能。 系統的內有 N 個處理器和 N+1 個駐 列,其中包含了 N 個 local 駐列和一個 global 駐列。每一個處理器和一個 local 駐 列為一個組合。排程器自 global 駐列中取 得最高 priority 的工作,動態地依系統狀態 和各個處理器的狀態,決定將置入哪一個 local 駐列。提出的演算法有下列三個技 巧: 1)距離概念:決定 task 駐列中兩個工 作版本的相對位置。 2)彈性的系統復原:在效能和容錯等 級的取捨。 3) 資 源 的 回 收 : 回 收 被 判 定 為 deadlock 的工作和己完成的工作所分配到 的資源。 利用動態排程方法和上述技巧系統的 效能和容錯性達成應用上時間的限制。 Avritzer 等人發展出一個效能分析模 組[10]。該模組對使用 load sharing 演算法 的高度非對稱系統做效能的評估。load sharing 演算法是基於全系統的狀態進行 排程工作。load sharing 演算法有兩種實作 的層級,第一種層級在作業系統內部,稱 為 kernel 層級或 shell 層級。第二種層級 為使用者層級,在 shell 的前端。前者雖有 效率上的優點,但是異質機器之間的相容 性 使 得 實 作 上 十 分 困 難 。 雖 然 後 者 的 overhead 比前者大,但有三個理由令此論 文決定使用後者實作。第一、不必考慮異 質機器的相容性,容易實作。第二、對機 器和使用者 load sharing 會透明化。第三、 使用者利用 shell 前端控制可以決定要不 要加入負載分享的機制當中。 Load sharing 的主心概念是要儘可能
縮短整個系統的反應時間,執行方法是把 工作分配給利用率低的機器。動態的 load sharing 可分成由傳送者初始化的型態和 由接收者初始化的型態兩種。傳送者初始 化的型態使用時機是系統負載不高時,接 收者初始化的型態是系統呈現高負載時使 用。此論文提出了一個分界型(threshold type)的 load sharing 演算法,此演算法會 隨著某些分界值的變動而調整最適當的工 作參數,例如每個機器上的工作數量。實 作上該演算法的模型是建立以全系統為視 野的全系統狀態馬克夫鏈和並計算出能在 最差狀況下逹到最小 latency 的系統。此論 文的結論指出在非對稱式的環境下,小心 地動態調整 load sharing 的演算法,會比靜 態設定 load sharing 的演算法的效能有大 幅增進。 2.5 共享資源控制 Majumdar 提到多核心系統上程序之 間會有競爭分享的資源[11],例如變數就 會儲存在分享記憶體上。保持資料一致性 的機制不可缺少,如此才能確保系統的正 確性。可是這種機制又通常會降低系統效 能。這篇論文研究以多核心平台為基礎的 應用程式為對象,如電話交換器和即時資 料庫,控制分享資源的競爭以達到高度 throughput 及高度 scalability。將己存在的 程式改成 re-entrance 或是將程序做適當的 排程是兩種可實行的控制記憶體競爭方 法。此論文著重於第二種方法。對數種控 制資源競爭的排程演算法量化其結果,可 以了解系統內部的行為和每一種演算法最 重要的特性。結合數種排程演算法的特性 的優點,衍生出混合式的控制資源競爭排 程演算法: Hybrid-K。Hybrid-K 可以把所 有程序執行時間縮短為依序執行每個程序 所花費執行時間的 1/K。參數 K 代表系統 增加的處理器數目。因此增進的效能會依 K 的增加而上升。然而需要注意的一點是 實驗使用的處理器數目最大只到 10,因此 K 大於 10 的情況尚待驗證。 Saewong 等人指出如何安排同時存 取多個資源[12],這是眾所皆知的一個 NP complete 的問題。在分散式即時系統之 中,通常都是用 Decoupling 的方法來管理 點對點延遲的系統。不幸地,當利用單獨 的核心來管理多個資源時,Decoupling 的 方法就會失敗。利用單獨核心管理資源方 式的優點是可以減少衝突以全系統的觀點 來分配資源的使用。例如控制核心可以利 用裝置驅動程式、檔案系統或協定服務 (protocol service)來控制相關的資源。控制 核心我們稱之為 host 核心。Host 核心具有 兩個角色:其一,host 核心如一般的核心 可執行應用程式。其二,host 核心可以控 制和管理其他 time-shared 的資源。此論文 研究協同排程的控制和受控制資源的問 題 , 提 出 合 作 排 程 伺 服 器 (Cooperative Scheduling Server :CSS)。 CSS 是一個專用的伺服器,利用固定 的一個處理器來控制眾多可以分享的資 源,例如: 磁碟機和程序之間的溝通。下 列兩個概念是 CSS 的目標基礎。首先,在 一個控制器上(如 CPU)先執行一個非週 期性的伺服器,該伺服器可以處理所有局 部資源的使用要求。這表示 conjunctive admission control 是在控制端和受控制端 一起實行的。接著,在應用程式層級的時 間限制被分割進入多個階段,每一個階段 都會被保證在一個特定的資源上完成。 Real time file system (RTFS)是一個即時的 檔案系統,它可以提供在 CPU 低負載時, 對磁碟頻寬的保證。有了 file system CSS (FSCSS) , 磁 碟 頻 寬 的 保 證 也 可 以 在 高 CPU 負載和高磁碟工作量下達成。以下列 出協同排程演算法設計需要考慮到的因 素。第一、資源異質性產生的排程失誤問 題。依受控資源的觀點,host 核心必須確 保 這 些 資 源 相 對 活 動 不 能 被 其 他 更 高 priority 的活動過份地延遲。依 CPU 的觀 點,native CPU application 又必須保有完 成的時間限制。因此會有 confliction 和
scheduling miss 。 第 二 、 conjunctive
admission control;每一個受控制資源的 admission control 必須不只是考慮自己擁 有資源的存取,還有 host 核心的可獲得 性。因此,要保證即時的服務,協同排程 的允許控策略需要搭配資源存取資料的反 應時間和處理器排程器去分配 CSS 程序 的反應時間。第三、分享資源的同步問題。 資源的存取可以平行化處理。資源和 host
核心做好同步,可以允許每個資源達到最 大平行化。 第四、有效的資源利用。即時 排程的主要目標是達到高利用率和對於應 用程式的 deadline 保證。因此,除了保證 多資源存取的 deadline 之外,系統應該提 供整個系統資源的高利用率。 2.6 靜態式分工 一般的異質雙核心系統架構(比如由 Ferrari 等人提出的 The Janus system[14], 是由一個一般功能處理器和一個特殊功能 處理器所組成。這兩個運算單元共同使用 一個公用匯流排(bus),而且可以自由地使 用 RAM 和 ROM 等記憶體。而其他週邊 輸出輸入設備則由一般功能處理器控制。 通常這兩顆處理器是建構在單一晶片上, 可以完全分享整個架構上的記憶體空間, 也可以將處理器之間的溝通所需的成本忽 略成極小。如此的設計通常會將一般功能 處理器視為 master 處理器,而特殊功能處 理器便視為 DSP。 然而這些系統大多是設計成靜態式分 工的方法。Gai 等人曾討論由 GPP 和 DSP 非對稱架構多核心排程的問題[15]。在這 篇論文中,DSP 被當成是類似有計算能力 的資源,在 DSP 上執行的工作,都是由 GPP 一次一個分配過去。等到 DSP 完成工 作,再回到 GPP 繼續下一個工作。如此設 計是因為 DSP 對某些工作的能力比 GPP 有效率很多,DSP 在這些工作上所省下的 時間和單獨由 GPP 執行整個工作所花的 時間相較,會大於 GPP 的閒置和兩個核心 的溝通所需的時間。這種方式的實作方法 是由兩個 task 駐列來完成。一個是 GPP 駐 列,存放一般的工作,並由 GPP 負責執 行。另一個則是 DSP 駐列,存放給 DSP 執行的工作。當 DSP 閒置時即是可以接受 新工作,排程器選擇在這兩個駐列的頂端 有最高 priority 的工作。若是選擇到 GPP 駐列,就由 GPP 來執行工作,反之 GPP 便將 DSP 駐列上的工作傳給 DSP 執行。 而當 DSP 正在工作,排程器只選擇 GPP 駐列上最高 priority 的工作交由 GPP 執行。 由過去的研究顯示,非對稱式多核心 平台的優點及可行性十分明顯,而且同一 個工作如果能動態根據不同核心來排程, 也會大大提昇效能。下一章,我們將提出 精細分工的工作模型和相關背景。 3. 理論與實作背景 我們以動態精細分工工作模型為概 念,實作出非對稱式異質多核心平台排程 器。所謂動態精細分工系統和目前廣為使 用的靜態式分工(statically partitioned)系統 是相對的。在靜態式分工系統中,一項工 作會分配到哪一個處理器是在系統設計時 就決定好的。為了提高整體系統的效能, 我們提出了動態精細分工工作模式。假設 在系統平台上有兩個處理器核心,分別是 GPP 核心以及 DSP 核心。新的工作被執行 前,在 GPP 上的排程器將監看每個處理器 核心的執行時期狀態,和決定哪一個核心 較適合執行該工作,再動態地分配給 GPP 或 DSP 執行,減少處理器核心閒置的時 間,提高處理器核心利用率,進而縮短全 部工作執行時間,增加整個系統平台的效 能,這種工作模式我們稱之為精細分工工 作模型。 本 篇 論 文 提 出 的 排 程 器 是 實 作 於 OMAP5912 OSK 平台上,使用的作業系統 在 ARM 處理器核心部分是以 eCos 2.0 版 本為基礎進行修改,在 DSP 處理器核心的 排程核心是由我們自行設計的。在本章 中,我們會介紹 OMAP 5912 應用處理 器 (OMAP 5912 Application Processor)和 OMAP 59120 發展板(OMAP 5912 Starter Kit: OSK 5912) , 以及嵌入式作業系統 eCos 2.0 版本。過去,本驗室也曾開發過 在 Linux 下利用 DSP Gateway 及 TI 發展 的 DSP/BIOS 排程器[21]。根據過去的實 驗結果,利用 DSP Gateway 的溝通機制成 本太高,每秒傳輸只有 3 MBytes,不合乎 精細分工系統的需求,因此我們在本論文 中改用較為精簡的 eCos 作業系統,並提出 有效率的 mailbox 和 shared memory 的溝通 機制,以證實精細分工系統可以得較高的 效能。所有 eCos 移植到 5912 OSK 的過程 將在下一章說明。本論文研究實作的細節 會在第五章詳細介紹。
3.1 OMAP 5912 Application Processor
OMAP5912 應用處理器是一塊高度 整 合 的 SoC , 包 括 的 重 要 元 件 有 : GPP-ARM 核心、DSP 核心、和 Traffic controller 等等。OSK 5912 為使用 OMAP 5912 應用處理器的發展平台。 OMAP5912 應用處器整合 ARM 926 EJ-S RISC 核心和 TI TMS320C55x DSP 核心。ARM9 RISC 核心在嵌入式系統被廣 為使用,C55x DSP 核心對於數位訊號處 理 展 現 高 效 能 和 低 耗 電 的 特 性 。 因 此 OMAP5912 應用處理器適合多媒體嵌入 式裝置,經由切割每個應用程式為眾多工 作和適切地分配工作給兩個處理器核心執 行可以有優秀的效能表現。 Fig. 6 為 OMAP 5912 功能區塊圖
[1] 。 MPU(ARM9) 、 MPU peripheral
bridge 、 Memory traffic controller 以 及 system DMA 四者透過 MPU BUS 溝通。 MPU 由 MPU bridge 透過 public/ private peripheral bus 和其週邊溝通。DSP 透過
public/ private peripheral bus 和 其
peripheral 溝通。此外 DSP 可藉由 DSP MMU 或是 MPU Interface 和系統其他部份 做溝通。
Fig. 6. OMAP 5912 功能區塊圖
OMAP5912 應用處理器 DSP 的記憶 體包括內部記憶體 DARAM 和 SARAM。 ARM 定義一個 word 等於 4 個 byte,採 byte addressing,所有週邊和擴充的 memory 以 及 control register 都由 32 位元來定位。DSP 定義一個 word 等於 2 個 byte,是採 word addressing。 當 ARM 對應一塊實體記憶體到 DSP 的記憶體空間,DSP 可以透過 DSP MMU 來存取該塊記憶體,同時在 ARM 的虛擬 記憶中有一塊配置為 DSP 記憶體空間, 也會被對應到該塊實體記憶體。 在 OMAP5912 應用處理器上 Memory traffic controller 是一個很重要的內外部記 憶體存取元件。Memory traffic controller 可以令 DSP 和 ARM 利用 TI OCP (Open Core Protocol)存取內部共用記憶體或週邊 裝置,存取外部記憶體可利用兩種高速記 憶介面來完成,分別為 External Memory Interface Fast(EMIFF)和 External Memory Interface Slow(EMIFS)。 EMIFF 相較 EMIFS 是較快速的記憶 體 裝 置 , 在 OSK 5912 發 展 板 上 對 應 EMIFF 配置的記憶體是 SDRAM,最大可 支援到 64 M Bytes。存取資料的寬度和位 址的寬度都是 16 bits,也提供了兩個 bank 選擇位元,亦即可以將 SDRAM 分成四個 區域來使用。使用者的應用程式預設是諸 存到此 SDRAM。 EMIFS 所 連 接 的 外 部 裝 置 記 憶 是 NOR FLASH。透過介面可以 8 bits / 16 bits / 32bits 的寬度在每個 NOR FLASH 晶片上 存取資料,其使用的位址寬度為 25 bits。 OSK 5912 發展板上共有四塊外部 FLASH 晶片,每塊晶片最大容量為 64 M Bytes, 所 以 可 使 用 的 總 記 憶 體 容 量 為 128 M Bytes。此四塊 NOR FLASH 分別為 CS0, CS1, CS2, 和 CS3。Boot ROM 位於 CS0, 系統開發者設計的 boot-loader 或作業系 統則是存放在 CS3。經過設定,啟動的模 式可以利用 CS0 的 boot ROM 或是 CS3 的 boot-loader 開機。
3.2 OMAP 5912 Starter Kit:OSK 5912 (OMAP 5912 OSK) OSK 5912 是對軟體和硬體做高度整 合的平台,主要可做為視訊 圖片訊號處理 裝置和行動溝通裝置。可以使用一般的嵌 入式作業系統做為 OSK 5912 上 ARM 處 理器的作業系統,而 TI 提供 DSP/BIOS 做 為 DSP 處 理 器 的 即 時 核 心 (real-time kernel)。Fig. 7 為 OSK 5912 正視圖[19]:
Fig. 7. OSK 5912 正視圖 Hardware Features 如下: ARM 926EJS 處理器核心運行於頻率 192 MHz。 Texas Instruments TMS320C55x 運行 於頻率 192 MHz。 內建音訊編碼解碼器 TLV320AIC23 codec
64 Mega Bytes DDR RAM
256 Mega Bytes on board Flash ROM 10 MBPS Ethernet port
On board IEEE 1149.1 JTAG connector for optional emulation
Software Features 如下:
Compatible with MontaVista's Linux for OSK5912
Compatible with OMAP Code
Composer Studio from Texas
Instruments 3.3 eCos OSK 5912 所採用的原始作業系統是 MontaVista Linux,但是根據我們去年的經 驗,Linux 配合 DSP Gateway 的效能表現 無法達到精細分工系統所需的要求,故本 論文沒有採用原始發展系統所採用的整合 軟體。接下來介紹 ARM 端採用的 eCos 作 業系統。在下一章我們會討論如何將 eCos 移植到 OSK5912 的平台下。 3.4 eCos Overview eCos 是 一 個 開 放 程 式 碼 , 可 設 定 (configurable),可移植和免費的嵌入式即 時作業系統。eCos 的一項重大的技術革新 是設定系統(configuration system)。設定系 統允許應用程式設計者對 run time 元件加 入或調整所需的功能和實作方式。傳統 上,作業系統會限制實作的方法,無法選 擇。設定系統使得 eCos 開發者創造符合特 定應用程式的特定作業系統,也使得 eCos 適合更大範圍的嵌入式應用。設定系統的 使用可以保證資源的最小化,和其他不需 要的功能和特徵都可以被移除。如此便利 性的因素是 eCos 它是一個元件架構的系 統。eCos 被設計為可以移植到許多目標架 構和目標平台,包括 16 32 64 位元架構和 MPU, MCU, DSP。eCos 支援許多不同平 台架構,如 ARM、Intel StrongARM 及 XScale、Fujitsu FR-V、Hitachi SH2/3/4、 Hitachi H8/300H 、 Intel x86 、 MIPS 、 Matsushita AM3x 、 Motorola PowerPC 、 Motorola 68k/Coldfire、NEC V850 和 Sun SPARC,其他尚包括許多流行的架構和發 展板。 3.5 Configure Tool 嵌入式系統正被推動朝著更小更快更 便宜更精緻,所以更需方便地控制系統內 所有的軟體。有不同的方法可以控制應用 程式內元件的特性。eCos 元件控制的哲學 是為了減少系統大小,對資源最自由的配 置。持著此設計哲學,最小化的系統不必 支援某些複雜系統上才有的強大功能。有 一種在 run time 控制軟體元件的方法,例 如 動 態 連 結 程 式 庫 (Dynamic Link Libraries),不必預先對元計做設定,但是 這個方法會會導致程式大小增加。另一種 方法是在 link time 時,當需要某個特殊功 能元件就會被包入,反之則除去,例如 GNU linker。這方法的特性是擁有某元件 的全部功能或都不擁有。Compile time 的 元件控制,使得系統開發者可以建立特定 應用程式需要的元件,可以保持所有的程 式碼都是系統所需要的。對於嵌入式系統 來說,這是解決程式碼多寡的好方法。eCos 有一套十分方便的 configure tool,讓系統 開發者在 compile time 決定所需的元件和 元件的能力,而不必動手修改元件的程式 本體。 3.6 Component 要了解 eCos,則了解元件的基礎架構 非常重要。元件基礎架構專為滿足嵌入式 系統和嵌入式設計的相關需求而存在。設 計的 eCos 元件基礎架構可以控制元件達