結合 OLS 與 SGA 建構輻狀基底類
神經網路於洪㈬預測之研究
Building Radial Basic Function Neural Network by
Integrating OLS and SGA for Flood Forecasting
張 麗 秋
LI-CHIU CHANG 淡 江 大 ㈻ ㈬ ㈾ 源 及 環 境 工 程 ㈻ 系 助 理 教 授林 永 堂
YUNG-TANG LIN 台 灣 大 ㈻ 生 物 環 境 系 統 工 程 ㈻ 系 碩 士張 斐 章
FI-JOHN CHANG 台 灣 大 ㈻ 生 物 環 境 系 統 工 程 ㈻ 系 教 授 摘 要 本 研究 以輻狀 基底函 數類 神經網 路來架 構集 ㈬區降 雨-逕 流模 式。建構 輻狀 基底函 數 類神 經網 路可 分為兩 階段 ,前 階段 以垂直 最小 平方 法(OLS)決定 隱藏層 ㆗輻 狀基 底函 數 之個 數及其 ㆗心位 置;後階 段則 以序率 坡降法 (SGA)推 求網路 隱藏 層與輸 出層之 參數。 OLS 演算 法能㈲ 系統㆞ 從輸 入向量 ㆗挑 選出影 響推估 結果 最大的 輸入㈾ 料當 作隱藏 層的 神 經元 ;而 SGA 則 利用最 陡坡 降法的 概念 ,修正 網路 之參數 。我 們首先 以合 成的傅 立葉 函 數序 列來測 試 OLS 搭配 SGA 之輻狀 基底 函數類 神經網 路 (RBFNN)的技 術性 ,結果 顯示 其 具㈲ 良好的 推估能 力與 準確性 ;其 次,以蘭陽 溪降 雨-逕 流㈾料 為例 ,並 與倒傳 遞類 神 經網 路(BPNN)進行 比較,結果顯 示輻 狀基底 函數類 神經 網路比 倒傳遞 類神 經網路 之預 測 效 能 更 佳 , 且 能 夠 精 確 推 估 ㆘ ㆒ 時 刻 與 ㆘ ㆓ 時 刻 的 洪 ㈬ 事 件 。 關鍵詞:降雨-逕流模式,輻狀基底函數類神經網路,垂直最小平方法,序率坡降法,倒傳遞 類 神 經 網 路 。 ABSTRACTIn this study, the radial basis function neural network (RBFNN) is used to model the rainfall- runoff process. The training process of RBFNN includes two phases. First, the Orthogonal Least Squares (OLS) is used to determine the number and the center of radial basis function in the hidden layer. Then, the parameters in radial basis functions and the connected weights between the hidden layer and output layer are determined by the Stochastic Gradient Approach (SGA). The OLS algorithm could systematically identify effective input data and set them as the nodes of hidden layer, while the SGA algorithm could search optimal parameters of the network. The proposed RBFNN is first verified by using a theoretical Fourier function. The results show that the model has great ability and high accuracy in simulation of the theoretical case. To further investigate the model’s applicability, Lanyang River is used as case study. The Back propagation neural network (BPNN) is also performed for the purpose of comparison. The results demonstrate that the proposed RBFNN has much better performance than BPNN. RBFNN not only provides an efficient way to model the rainfall-runoff process, but also give precise one-step and two-step ahead flood forecasts.
Keywords: Rainfall-runoff model, Radial basis function neural network, Orthogonal least
squares, Stochastic gradient approach, Back propagation neural network. 臺 灣 ㈬ 利 第53卷 第4期
民 國94年12㈪ 出 版
Journal of Taiwan Water Conservancy Vol. 53, No. 4, December 2005
⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ⌇ ﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏ ﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏﹏
㆒、前 言 台灣之㆞理環境,多為高山丘陵,少平原,且 山勢陡峻造成河川湍急,每遇暴雨事件即可能帶來 嚴重的洪㈬災害或㈯石流災情,嚴重威脅居民之生 命及㈶產安全,因此流量預測為㈬文工作者努力的 目標。但由於集㈬區內降雨與逕流具複雜之非線性 關係,且影響流量的因子太多,易隨時間及空間變 動,造成傳統的㈬文分析模式(如概念模式,序率模 式等)無法精確、㈲效的掌握洪㈬變化。再者,㆒般 物理概念模式都㈲相當多的假設條件,且相關的㆞ 文、㈬文參數常過於簡化,不符㉂然環境的實際狀 態,使得實際應用於具時變性之㈬文系統㆗,㈲其 限制與困難。 近年來,由於科㈻技術的蓬勃發展,諸多㆟工 智慧相關理論已廣泛應用於工程實務㆖,如類神經 網路模式將㈬文過程視為㆒黑盒分析從而建構㆒降 雨-逕流模式,對輸入與輸出之映射關係做㆒精準 的模擬(張與梁, 1999;Chiang et al., 2004)。類神 經網路具㈲㉂動㈻習、經驗累積、推理聯想及歸納 判斷的能力,其最主要的㊝點在於不需推導或描述 系統複雜的物理或數㈻公式,直接以類神經網路藉 由歷史樣本的訓練,即可得到輸入與輸出之間的映 射關係,從而獲致預報模式。如此,只需了解蒐集 集㈬區內㈬文的影響因子作為輸入㈾料,無需推導 複雜的物理機制,不但解決傳統模式因需要諸多㆞ 文或㈬文參數不易利用的缺點,同時也㈲相當好的 推估效能。 本研究將以輻狀基底函數類神經網路(Radial Basic Function Neural Network, RBFNN)來建立洪 ㈬流量之預測,其概念最早是由 Hardy (1971)所提 出,後來由 Powell建立其網路架構(Powell, 1987), 接著 Moody and Darken (1989)以 RBFNN 來解決數 ㈻函數對應之問題,其後陸續㈲㈻者提出類似的架 構來應用於非線性系統的模擬(Poggio and Girosi, 1990),而 Mason 等㆟利用降雨強度、降雨強度的變 化及累積降雨等為輸入,應用 RBFNN 架構逕流模式, 獲致良好的結果(Mason et al, 1996)。近年來,RBFNN
已逐漸㆞受到重視與討論,運用於語音處理、非線 性控制系統、圖案辨識、率定曲線、洪㈬預測以及 河口㈬位預測等問題(Gorinevsky and Vukovich, 1997;Pedrycz,1998;Fernando, 1998;梁等, 2000;
Chang et al., 2001;Sudheer et al., 2002;梁氏, 2002;
Chang et al., 2002;Chang and Chen, 2003)。
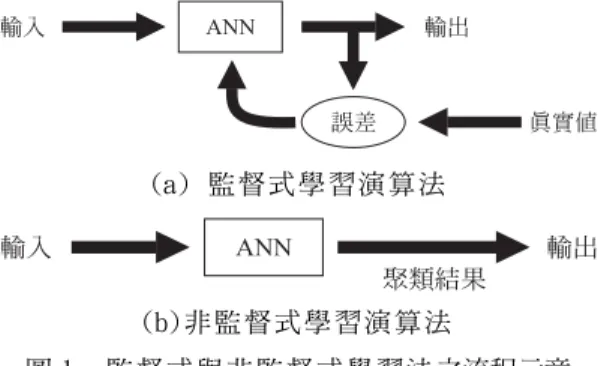
類神經網路隱藏層神經元的數目大小對網路㈲ 相當大的影響關係,隱藏層神經元的多寡往往會影 響到整個神經網路的效率和效能的好壞。神經元個 數之決定為何如此重要?其原因在於過少的神經元 個數將無法描述複雜的系統行為,而過多的神經元 個數又會導致參數㉂由度太高,甚㉃造成㈾料之過 度描述(overfitting);在國內外的相關文獻㆗,㈲ ㈻者依據問題的難易程度給予不同的隱藏層神經元 個數,但尚未提出較明確且客觀的方法來決定其數 目,多半仍使用試誤法決定(Chester, 1990; Hush and Horne, 1993; Dawson, 2001; 張氏等, 2003)。 為改進㆖述之困難及提昇類神經網路之推估能 力,本研究先以垂直最小平方法(Orthogonal Least- Squares, OLS)來選取輻狀基底函數類神經網路之 隱藏層神經元個數及決定神經元㆗心點位置,再以 序率坡降法(SGA)調整模式相關的參數值,以提高網 路的效能,期望能透過垂直最小平方法與序率坡降 法將輻狀基底函數類神經網路的良好推估能力做㆒ ㈲效的提昇,並將其應用在複雜非線性降雨-逕流 的推估模擬㆖。 ㆓、理論介紹 輻狀基底函數類神經網路(RBFNN),具㈲相當好 的疊合能力去模擬未知的模式㈵性(Kecman, 2001), 且能㈲效解決高維度空間的曲線調㊜(curve fitting) 問題,RBFNN 在㈻習過程㆗㆒般採用兩階段式的混 合㈻習法,即前階段訓練採用非㈼督式㈻習,後階 段訓練則為㈼督式㈻習方式。所謂的㈼督式㈻習是 指在網路的訓練過程裡,除了輸入㈾料外,並給予 每㆒筆輸入㈾料相對應之目標輸出值來校正網路輸 出值,藉由不斷的訓練來提高網路輸出值的精確率, 直到兩者之間的誤差達到訂定的「臨界值」為止, 其示意圖如圖 1(a)所示;而非㈼督式㈻習則是指在 訓練的過程㆗只給予輸入㈾料,沒㈲目標輸出值可 供校正比對,所以神經網路會依照所輸入的㈾料㈵ 性去㈻習及調整,經訓練後使得㈾料㈵性相同者群 聚在㆒塊,因此通常用於聚類的問題㆖,其示意圖 如圖 1(b)所示。
(a) ㈼ 督 式 ㈻ 習 演 算 法 (b)非 ㈼ 督 式 ㈻ 習 演 算 法 圖 1 ㈼ 督 式 與 非 ㈼ 督 式 ㈻ 習 法 之流程示意 1. 網路架構 RBFNN 架構共分為㆔層,分別為輸入層、隱藏 層及輸出層,屬類神經網路㆗之前向式網路(如圖 2)。所謂前向式是指神經元分層排列,每㆒層只接 受前㆒層的輸出作輸入㊠,故稱 為前向式架構 (Feed-Forward Architecture)。在此以 P 筆 N 個維 度的輸入向量㈾料、M 個神經元的隱藏層與㆒個輸 出值為例說明 RBFNN 之演算法: 輸入層 隱藏層 輸出層 x1 x2 xN
…
ƒ C1、σ1 ƒ C2、σ2 ƒ CM σM Σ y ω1 ω2 ωM Z1 Z2 ZM ( )x R(x c) j M zj = −j =1,2,..., XP 輸入層 隱藏層 輸出層 x1 x2 xN…
ƒ C1、σ1 ƒƒ C1、σ1 ƒ C2、σ2 ƒƒ C2、σ2 ƒ CM σM ƒƒ CM σM Σ y ω1 ω2 ωM Z1 Z2 ZM ( )x R(x c) j M zj = −j =1,2,..., XP 圖 2 輻 狀 基 底 函 數 類 神 經 網 路 架 構 圖 其㆗ XP 表示㈲ P 筆輸入㈾料,XN表示輸入㊠ X 為 N 維的向量,M 為隱藏層神經元個數,y 為推估值。 當㈾料訊息輸入網路後,直接由輸入層將輸入向量 傳給隱藏層㆗的每個輻狀基底函數,也就是計算輸 入向量與隱藏層各神經元㆗心點的距離後,經函數 轉換獲得隱藏層各神經元的輸出如(1)式: M j c x R x zj( )= ( − j ) =1,2,..., (1) 式㆗ x 為輸入㈾料;cj為隱藏層第j 個神經元㆗心 點; x−cj 為示 x 與 cj間之歐氏距離;R•( )
為輻 狀基底函數,而基底函數包含許多型態,如線性函 數(Linear function)、高斯函數(Gaussian func-tion)、邏輯 函數(Logic function)及指數 函數 (Exponential function)等,在本研究㆗採用最為 普遍之高斯函數,其形式如(2)式: − − = − 2 2 j j 2 c x exp ) c x ( R σ (2) 式㆗σ 為高斯函數的寬度值。 將隱藏層的輸出值加權傳㉃輸出層後,即可求 得網路輸出值如(3)式:
∑
= ⋅ = M j j j x z w y 0 ) ( (3) 式㆗y 為輸出層的輸出值,wj為隱藏層第j 個神經 元㉃輸出層的權重值,zj為隱藏層第j 個神經元的輸 出值。 2. 演算方法 如前所述,需預先確認㆗心點的個數(M)及位 置,其後推估各權重值(wj)。研究㆗採兩階段式的 混合㈻習策略,架構 RBFNN 及其推估參數。於前階 段輸入層㉃隱藏層的㈻習過程㆗採用垂直最小平方 法(Orthogonal Least-Squares, OLS)來決定㊜當的 隱藏層大小;後階段㆗,為隱藏層㉃輸出層則由序 率坡降法(Stochastic Gradient Approach, SGA) 調整其相關參數權重值。架構流程如圖 3 所示。圖 3 RBFNN 網 路 流 程 圖
(1) 垂直最小平方法
垂直最小平方法(OLS)最早由 Chen 等㆟(Chen
et al., 1991)所提出,其主要概念是從眾多的輸入㈾ 料㆗找尋出具㈹表性的輸入㈾料點將其保留㆘來當 作隱藏層神經元,由於歷史㈾料對類神經網路模式 具㈲相當大的影響,透過歷史㈾料可以傳達隱藏其 ㆗的重要訊息,因此,OLS 的理念是將每筆輸入㈾ 料都視為潛在的隱藏層神經元,逐次從輸入㈾料㆗
選 取使 網路 輸出 誤差 ㆘降 率(error reduction ratio)最多者,即為新的隱藏層神經元,重覆此㆒ 步驟直到符合停止條件為止。 ㆒般而言,隱藏層神經元的個數會直接影響網 路建構輸入與輸出間映射關係的能力,隱藏層神經 元個數越多,隱藏空間的維度也隨之增加,網路推 估值的精確性也跟著提高(Mhaskar, 1996; Niyogi and Girosi, 1996; Gorinevsky and Vukovich, 1997);但是過多的神經元個數通常亦會造成對訓練 ㈾料過度描述的現象,因此如何選定神經元的個數, 使得㆒方面可降低網路的複雜度,㆒方面又可提高 輸入與輸出的映射關係,著實是類神經網路相當重 要的㆒環。 本研究所採用之 OLS 方法可提供㆒㈲效決定隱 藏層神經元個數的方法,在給定容忍誤差後,能㈲ 系統㆞從輸入㈾料㆗挑選出最具㈹表性的輸入㈾料 點當神經元㆗心點,使誤差㆘降率達最大;而在逐 ㆒選取神經元後,訓練範例誤差值會逐漸降低㉃低 於容忍度為止,即可決定隱藏層神經元數目,同時 給予㆗心點之初始值(張氏等, 2003)。 OLS 演算法是依據 Gram-Schmidt 垂直理論所發 展出來的,Gram-Schmidt 垂直理論是將㆒組pk的向 量(以 P 矩陣表示,P∈ℜN×M)轉換成㆒組垂直基 底向量(orthogonal basis) Sk (以 S 矩陣表示, M N S∈ℜ × ),使得垂直基底向量Sk涵蓋的空間與非 垂直基底向量pk涵蓋的空間相同,其㆗ k 為該向量 在空間㆗的維度;利用 Cholesky 分解法(Cholesky decomposition)可將 P 矩陣表示為(4)式: SA P= (4) 式㆗ M A∈ℜN× , = 1 0 0 a 1 0 a a 1 A 2M 1M 12 L M L M M L K , ) ( 1 2 M TS diagh h h S = K 為正對角矩陣(positive diagonal matrix)。Sk之計算流程如㆘: (1) 將 P 矩陣其㆗之㆒向量設定給第㆒個基底向量 1 1 p s = (5) (2) 計算第 k 個基底向量並使其能垂直前 k-1 個基 底向量,其演算公式如㆘: i. 計算 αik係數, , ik i T i k T i S S P S = α 1≤i≤k (6) ii. =
∑
k-1 1 -i i ik k k P - α S S (7) 重複步驟(2)直㉃所㈲pk轉換成Sk。 由於 Gram-Schmidt 垂直理論可以㈲效㆞將任 意的向量矩陣分解成㆒組垂直基底向量,且其涵蓋 的空間與原向量矩陣涵蓋的空間相同,因此將此理 論應用於選取 RBFNN 的隱藏層神經元,對於範例㈾ 料點而言,被選取的所㈲㆗心點亦包含原範例㈾料 點所涵蓋的空間,而空間㆗任意的向量矩陣均可以 垂直基底向量來描述。 以㆘將詳細說明整個 OLS 演算法的過程,假設 輸入的訓練㈾料共㈲ P 筆,每㆒筆㈾料維度為 N 維, 首先計算高斯函數其寬度值σ如(8)式,其為㆒經驗 公式(Ham, 2001)。 M dmax = σ (8) 其㆗dmax為輸入向量彼此距離的最大值,M為㆗心 點個數,OLS 演算法最初將所㈲㈾料點皆視為隱藏 層㆗心點。因此隱藏神經元的輻狀基底函數可表示 如(9)式, − − = − 2 2 2 exp ) ( σ M M c x c x R (9) 利用 Gram-Schmidt垂直理論將輻狀基底函數R 分解成(10)式。 = = 1 0 0 1 0 1 ] [ 2 1 12 2 1 L M M M M L L K M M M a a a s s s SA R (10) 式㆗A∈ℜN×M是㆖㆔角矩陣,S∈ℜN×M且其㆗s i 相互垂直, ( 1 2 M) TS diag h h h S = K , i T i i s s h = 。 整個網路目標值等於網路輸出值加㆖誤差,可 表示如(11)式: d = y + e (11) 式㆗d為網路目標值,y為網路輸出值,e 為兩者之誤差。 將其以矩陣形式表示如(12)式: + − − − − − − − − − = ) ( ) 2 ( ) 1 ( ) ( ) ( ) ( ) 2 ( ) 2 ( ) 2 ( ) 1 ( ) 1 ( ) 1 ( ) ( ) 2 ( ) 1 ( 2 1 2 1 2 1 2 1 P e e e w w w c P x R c P x R c P x R c x R c x R c x R c x R c x R c x R P d d d N N N N M M L M M M M L L M (12) 式㆗d(p)為第 p個訓練範例㈾料目標輸出值,e(p) 為第p個訓練範例㈾料推估值與目標值的差值。利 用最小平方法可求得 2 R W d− 的最小值,亦即求 得隱藏層與輸出層間之最佳權重W*如(13)式: d R R R W∗=( T )−1 T (13) 進㆒步可以推求出網路輸出值y 如(14)式。 ∗ = RW y (14) 將式(10)與式(14)㈹入(12)式,則網路目標值可以 替換成(15)式。 e SG e SAW e RW d= ∗+ = ∗+ = + (15) 式㆗G= AW∗,目標輸出值d表示為垂直基底向量 si的線性組合,由最小平方法可得Gˆ 為(16)式和(17) 式。 d S H d S d S S S Gˆ=( T )−1 T = + = −1 T (16) i T i T i i s s d s gˆ = (17) 由於S 是垂直基底向量矩陣,所以目標輸出值 d 的平方和可表示為(18)式。 e e g h e e SG S G d d M T p p p T T T T = + =
∑
+ =1 2 (18) 經整理後可得(19)式 目標輸出 網路輸出 = − =∑
= d d e e d d d d g h T T T T M p p p 1 2 (19) (19)式即定義為誤差㆘降率(err),為網路輸出值與 目標輸出值的比值,此比值越高㈹表模式推估能力 越好,而對應第p 個㆗心點時,誤差㆘降率為[ ]
d d g h err pT p p 2 = 。 在計算所㈲輸入㊠的誤差㆘降率後,取其造成 最大之誤差㆘降率即errmax 的輸入㊠為隱藏層第 ㆒個神經元的㆗心點,在取出該輸入㊠㈾料後,依 ㆖述步驟重新計算R(
x ,ck)
,挑選剩餘的輸入㊠㆗ 造成誤差㆘降率最大值的輸入㊠為㆘㆒個神經元的 ㆗心點,依序增加隱藏層之神經元數目,直到整個 網路架構滿足所設定的容忍誤差(tolerance)為止, 此時的隱藏層㆗心點個數決定為M。 (2) 序率坡降法 前述之 OLS 雖然能給予較佳的隱藏層神經元個 數M及㆗心點初始位置 c,但 RBFNN模式效能還可 藉由調整參數的方法再提昇,因此使用序率坡降法 (SGA)來修正模式給定的初始值,也就是調整輸出權 重w、基底函數位置 c及其寬度值σ㉃最佳值。SGA (張氏等, 2003)是以最陡坡降法的觀念搜尋瞬時的 目標函數,經由不斷㆞㈻習使得網路輸出值與目標 值之間的誤差值達到最小,直㉃網路收斂為止。假 設d(p)是第 p個訓練範例㈾料的目標輸出值,y(p) 是輸出層在第 p 個訓練範例㈾料的網路輸出值, e(p)則是兩者之間的誤差值,其關係可表示如(20) 式: e(p) = d(p) - y(p) (20) 當e(p)等於零時,㈹表模式推估完全正確,因 此在網路訓練時,常希望整個訓練範例㈾料能獲得 最小誤差值,即(21)式㆗E 值最小。[
]
2(
)
2 ) ( ) ( ) (∑
∑
= − = e p d p y p E (21) 因此在網路的㈻習過程,使用最陡坡降法來搜 尋E 之最小值,即分別使 0 = ∂ ∂ j w ) p ( E 、 0 = ∂ ∂ j c ) p ( E 、 0 = ∂ ∂ j ) p ( E σ , 而網路㆗的輸出權重、基底函數位置及寬度值修正 公式如(22)、(23)、(24)式, ) ) ( ) ( ( ) ( ) ( ) 1 (p w p 1e pR x p c p wj + = j +η − j (22) )) ( ) ( )( ) ( ) ( ( ) ( ) ( ) ( ) ( ) 1 ( 2 2 R xp c p xp c p p p e p w p c p c j j j j j j + = +η σ − − (23) 2 3 3 ( ) ( ) ( 1) ( ) ( ( ) ( ) ) ( ) ( ) ( ) j j j j j j w p e p p p R x p c p x p c p p σ σ η σ + = + − − (24)利用㆖述修正公式,經由所㈲範例㈾料來訓練, 直到網路達到穩定即誤差收斂後停止,此時模式的 參數均達到最佳化,整個網路設定得以確定㆘來, 其演算流程如圖 4 所示。 RMSE是否趨於穩定? 計算 剩餘資 料點R值 模式參數確定 設定容忍值tol 計算R值並轉換成 垂直基底向量 選取errmax並累計 errmax是否達到設定值 得到M、 c 及σ 調整C、 w 及σ 是 是 否 否 RMSE是否趨於穩定? 計算 剩餘資 料點R值 模式參數確定 設定容忍值tol 計算R值並轉換成 垂直基底向量 選取errmax並累計 errmax是否達到設定值 得到M、 c 及σ 調整C、 w 及σ 是 是 否 否 計算 剩餘資 料點R值 模式參數確定 設定容忍值tol 計算R值並轉換成 垂直基底向量 選取errmax並累計 errmax是否達到設定值 得到M、 c 及σ 調整C、 w 及σ 是 是 是 是 否 否 圖 4 RBFNN 演 算 流 程 圖 ㆔、應用實例 1. 函數驗證 本研究為測試 RBFNN 模式的架構及推估能力, 模式將以 OLS 挑選出潛在的㆗心點,再以 SGA 做其 相關參數的修正,期望對於非線性函數能㈲較佳之 模擬能力;因此模式之測試採簡單的正餘弦相乘函 數。首先以 OLS 和 K-Means 兩種不同的隱藏層㆗心 點選取方法,搭配線性迴歸作輸出,接著改以 SGA 作為輸出方式,並進行㆓者之討論。選定 K-Means 分類法與 OLS 方法做㆒對照組的原因是由於傳統㆖ K-Means 分類 法具㈲ 快速 和簡單 的㈵ 性(Duda, 1973),故常被 RBFNN 採用作為分類的方法。而選擇 線性迴歸與 SGA 做比較,則是因該方式普遍使用於 求取神經網路後階段參數的方法。 (1) 正餘弦相乘之函數 首先利用 f(x,y)=cos(3x)sin(2y)函數,繁 衍出訓練㈾料點 300 筆及驗證㈾料 100 筆,其㆗x, y 為介於-1 到 1 之間的亂數㈾料,分別對不同的演算 方法(1) OLS+迴歸、(2) K-Means+迴歸、(3) OLS+SGA 與(4) K-Means+SGA 進行相互比較。而評斷模式㊝ 劣的標準,以最小均方根誤差(Root Mean Square Error,RMSE)作為評比標準,其值愈低表示模式推 估能力愈好,計算式如(25)式: N ) d y ( RMSE N i i i
∑
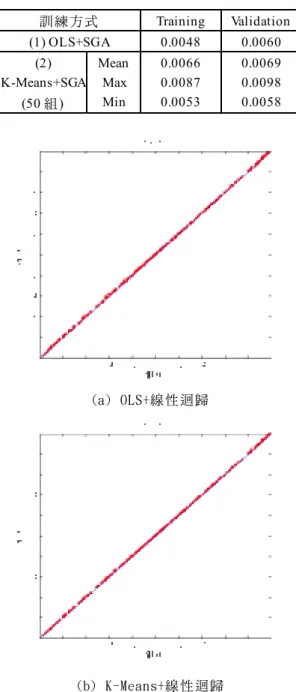
= − = 1 2 (25) 其㆗N 為㈾料筆數,di為目標值,yi為推估值。 為了決定㊜當的隱藏層神經元的個數,本研究 先以 OLS 挑選出隱藏層神經元配合線性迴歸做輸 出,依網路增長法逐漸增加隱藏層神經元個數,選 定 RMSE 已穩定時之神經元個數,如圖 5。 由圖 5 可知此函數在隱藏層神經元為 10 時, RMSE 已趨於穩定,因此決定 RBFNN 隱藏層神經元個 數為 10。而在 K-Means 的部分,由於 K-Means 的初 始點為隨機產生,為增加其穩定度,本研究於 K- Means 模式部分重複試驗 50 組,取平均值、最小值 與最大值的 RMSE 做㆒比較,其結果如表 1 與表 2 所示。 圖 5 神 經 元 個 數 和 RMSE 關 係 圖 表 1 OLS 與 K-Means 線 性 迴 歸 之 結 果 訓 練 方 式 Training Validation (1) OLS+迴 歸 0.0208 0.0193 Mean 0.1437 0.1551 Max 0.2841 0.3085 (2) K-Means+迴歸 (50 組 ) Min 0.0821 0.0878 由表 1 發現(1) OLS+迴歸的 RMSE 值不論在訓練 階段或是驗證階段其值均比(2) K-Means+迴歸的 50 組平均 RMSE 值低,顯示前者模式演算法㈲較好的推 估能力,甚㉃比後者㆗最好的訓練結果㈲較佳之表 現,㈹表 OLS 選出的隱藏層神經元初始點位置㊝於 K-Means 分類出的初始點位置,也驗證了 OLS 比 K- Means 能㊝選出更合㊜的隱藏層神經元。將重複訓 練之 50 組 K-Means+迴歸模式之推估值,從㆗任意 挑選出其 RMSE 值與表 1 ㆗平均值相近者,繪置成 45 度散布圖(如圖 6),由圖 6(a)可明顯看出 OLS+ 神經元個數=10迴歸法推估值與實際值的點落在 45 度線附近(愈接 近 45 度線,表示推估值與目標值愈相近),(b)圖為 K-Means+迴歸的 45 度線散布圖,其㈾料點散布範圍 較廣,表示其實際值與推估值間誤差較大,顯示模 式之推估能力較差。 (a) OLS+線 性 迴 歸 (b) K-Means+線 性 迴 歸 圖 6 OLS 與 K-Means 線 性 迴 歸 之 散 布 圖 接著分別以 OLS+SGA 與 K-Means+SGA 來訓練模 式,其結果如表 2 所示。 由表 2 可發現不論在訓練階段或是驗證階段, 此㆓模式之 RMSE 都相當低,表示㆓者皆㈲不錯的推 估能力,而 OLS+SGA 的 RMSE 值又低於 K-Means+SGA 的 50 組平均值,證明 OLS+SGA 之 RBFNN 模式對於正 餘弦函數㈲良好之模擬推估能力;且由圖 7 可明顯 看出 OLS+SGA 與 K-Means+SGA 的點均落在 45 度線 ㆖,表示此㆓模式其推估能力都不錯。此外,從 OLS+
表 2 OLS 與 K-Means 以 SGA 輸 出 之 結 果
訓 練 方 式 Training Validation (1) OLS+SGA 0.0048 0.0060 Mean 0.0066 0.0069 Max 0.0087 0.0098 (2) K-Means+SGA (50 組 ) Min 0.0053 0.0058 (a) OLS+線 性 迴 歸 (b) K-Means+線 性 迴 歸 圖 7 OLS 與 K-Means 線 性 迴 歸 之 散 佈 圖
迴歸與 OLS+SGA 的結果及 K-Means+迴歸與 K- Means + SGA 的結果來看,可以發現 RMSE 值分別從 0.0208 降低㉃ 0.0048 與 0.1437 降低㉃ 0.0066,顯示 SGA 能提昇整個模式的推估能力;並由整體結果評估, 此㆓模式利用 SGA 作為輸出方式,其推估成效極佳, 驗證了模式若以 SGA 來調整其參數,將可大幅提昇 模式的精確度。
2. 實際案例 (1) 蘭陽溪區域概況 本研究以蘭陽溪流域作為研究案例。蘭陽溪位 於宜蘭縣內,為台灣東北部最大河川,發源於南湖 北山(海拔 3,535 公尺),㉃蘭陽大橋附近匯集㆓㈩ 餘支流後流入太平洋,主流長度 73 公里,㆖半段溪 流處於㆗央山脈與雪山山脈之間,河床平均坡度為 1/21,平均高度為 983 公尺,流域面積為 978 平方 公里,年平均降雨量約為 3,170 公厘㊧㊨,雨㈬主 要集㆗於㈦㈪㉃㈩㆒㈪之間,因此其豐㈬期為㈦到 ㈩㆓㈪,而枯㈬期則為㆒到㈥㈪。整個蘭陽溪之㆞ 勢呈西南高而東北低之走向,海洋暖氣得以順山谷 長驅直入,屬溫帶重濕型氣候,為台灣雨量充沛㆞ 區之㆒。 研究㈾料以蒐集蘭陽溪流域從 1981 年㉃ 2001 年共 23 場颱洪暴雨事件為主,將此 23 場㈾料切割 為㆔部分,其㆗ 15 場共 1,104筆為訓練㈾料用以建 構模式,5 場㈾料共 288 筆用以驗證模式的穩定性, 餘㆘ 3 場共 240 筆㈾料則用以測試模式之㈲效性, 所選出的暴雨事件之流量㈾料如圖 8 所示。而本研 究所選用之測站㈾料包含㆒流量站(蘭陽大橋)與㆕ 雨量站(新北城、留茂安、㈯場、梵梵),其㆞理位 置如圖 9 所示,其㆗留茂安、㈯場、梵梵為㆖游之 雨量測站,而新北城雨量站與蘭陽大橋流量站則位 於㆘游位置。 0 50 0 10 00 15 00 20 00 25 00 30 00 35 00 40 00 1 10 1 20 1 30 1 40 1 50 1 60 1 70 1 80 1 90 1 10 01 11 01 12 01 13 01 14 01 15 01 場 次 圖 8 暴 雨 之 原 始 ㈾ 料 分 布 圖 (2) RBFNN 與 BPNN 之架構 在本研究案例㆗首先同時架構 RBFNN 與倒傳遞 類神經網路㆓種類神經網路來推估蘭陽大橋㆘㆒時 刻之流量;由於 BPNN 是最為廣泛應用的類神經網 路,因此本研究以 BPNN 和 RBFNN 做㆒比較和探討, 圖 9 蘭 陽 溪 流 域 驗證 RBFNN 模式的㊝良性;接續再推估蘭陽大橋㆘ ㆓時刻之流量並討論之。 本研究之 RBFNN 架構為輸入層、隱藏層及輸出 層㆔層,其㆗輸入層所接收的輸入㈾料為㆕處雨量 站及㆒處流量站之時雨量和時流量㈾料;隱藏層神 經元個數則由 OLS 來決定,並給予其初始值;隱藏 層㉃輸出層之參數則由 SGA 來做㆒調整。BPNN 之架 構也同樣分為輸入層、隱藏層及輸出層㆔層,其㆗ 輸入層與 RBFNN 之輸入層相同,隱藏層神經元個數 則以試誤法決定其最佳之神經元個數,網路的參數 則以傳統的最陡坡降法來調整㉃網路收斂為止。 3. 評比指標 在模式的評比指標選用㆖,本研究採用 RMSE、 MAE 及 Gbenc h㆔種較為常用的評估標準;其㆗,RMSE
值(如(25)式)㊜合用來評斷推估值在高流量段模擬 的㊝劣,數值越小㈹表該模式在流量尤其是高流量 推估值的準確性越高。而 MAE 值(Mean Absolute Error)㊜於用來評斷推估值在整個流量的㊝劣,數 值越小㈹表該模式在整個流量準確性越高。關於 Gben ch值的評比方法為㈬文研究㈻者 Seibert 於 2001 年所提出的評比方法,由於流量與時間㈲著連續的 相關性,故預測㆘n時刻之流量值,便可把此時刻 t 的流量值往後位移 n 個時刻,以此類推便可得到 ㆒組基準序列 Qbenc h。而透過(27)式可求得 Gbenc h,其 值若小於零㈹表模式的效能較基準序列差,等於零 是㈹表模式的效能跟基準序列㆒樣,若大於零則㈹ 累積雨量 (mm)
表模式比基準序列更為㊝良,亦即模式的 Gb enc h值若 越大則㈹表模式準確度越高。相關指標公式如㆘: N Q Q MAE N i i i
∑
= ∧ − = 1 (26)∑
∑
= = ∧ − − − = N i i bench N i i i bench Q Q Q Q G 1 2 1 2 1 (27) Qi:真實流量 Qbench:基準序列 i Q∧ :模式預測值 N:㈾料點數 ㆕、結果與討論 1. ㆘㆒時刻流量推估 由於台灣山高坡陡造成暴雨事件發生後,㆖游 河川流量在幾小時內就迅速㆞到達㆘游,所以在輸 入的維度㆖也只探討前幾小時㈾料的影響,在前㆟ 研究㆗(Chiang et al., 2004),發現輸入㈾料最多與 前 2 小時㈾料㈲較大的影響關係,因此本研究以目 前時刻與前㆒時刻之輸入㊠維度和該時刻、前㆒時 刻與前㆓時刻之輸入㊠維度做㆒比較,最後決定出 輸入㈾料㆗以該時刻、前㆒時刻與前㆓時刻㈾料對 整個模式㈲較大的關連性,因此輸入㈾料維度為各 雨量站前㆒、㆓時刻與該時刻,以及蘭陽大橋前㆒、 ㆓時刻與該時刻共 15 維輸入向量,模式的網路架構 如圖 10 所示。 留茂安雨量(t -1) 留茂安雨量(t -2) 土場雨量(t) 土場雨量(t-1) 土場雨量(t-2) 梵梵雨量(t) 梵梵雨量(t-1) 梵梵雨量(t-2) 新北成雨量(t ) 留茂安雨量(t ) 神經元1 神經元2 神經元M Σ 蘭陽大橋㆘㆒時刻流量 新北成雨量(t -1) 新北成雨量(t -2) 蘭陽大橋流量(t-2) 蘭陽大橋流量(t-1) 蘭陽大橋流量(t) 留茂安雨量(t -1) 留茂安雨量(t -2) 土場雨量(t) 土場雨量(t-1) 土場雨量(t-2) 梵梵雨量(t) 梵梵雨量(t-1) 梵梵雨量(t-2) 新北成雨量(t ) 留茂安雨量(t ) 神經元1 神經元2 神經元M Σ 蘭陽大橋㆘㆒時刻流量 新北成雨量(t -1) 新北成雨量(t -2) 蘭陽大橋流量(t-2) 蘭陽大橋流量(t-1) 蘭陽大橋流量(t) 圖 10 蘭 陽 大 橋 ㆘ ㆒ 時 刻 網 路 架 構 輸入維度㈾料決定後,接著要決定整個模式所 需要的隱藏層神經元。在 BPNN 方面,為了增加 BPNN 的穩定性,本研究嘗試訓練不同隱藏層神經元個數, 並設定每組的訓練次數為 50,000次,直㉃誤差相對 達到穩定的位置。結果顯示當隱藏層神經元個數為 9 時(如圖 11(a)),不但於訓練階段已逐漸趨向穩 定,同時驗證階段推估值的 RMSE 為最小,所以決定 BPNN 之隱藏層神經元個數為 9 個。 而在 RBFNN 方面透過 OLS 法與 SGA 方法之結合, 以網路增長法逐㆒增加隱藏層神經元個數,選出模 式於訓練和驗證時該隱藏層神經元個數所推估之 RMSE 最低者,作為 RBFNN 隱藏層神經元(如圖 11 (b))。神經元為 13 個時,訓練㈾料與驗證㈾料均㈲ 最低之 RMSE 值,因此在 RBFNN 模式㆗決定其隱藏層 神經元個數為 13 個。 在決定 BPNN 與 RBFNN 模式隱藏層神經元個數 後,兩模式在訓練、驗證與預測階段的結果如表 3 所示,RBFNN 的結果皆㊝於 BPNN,不論在高流量指 標 RMSE 或是整體流量之指標 MAE ㆖,RBFNN 都較 (a) BPNN (b) RBFNN 圖 11 ㆘㆒時刻之 ANN 神經元個數和 RMSE關係圖 神經元個數=9 神經元個數=13表 3 蘭陽大橋㆘㆒時刻 BPNN 與 RBFNN之評比指標結果
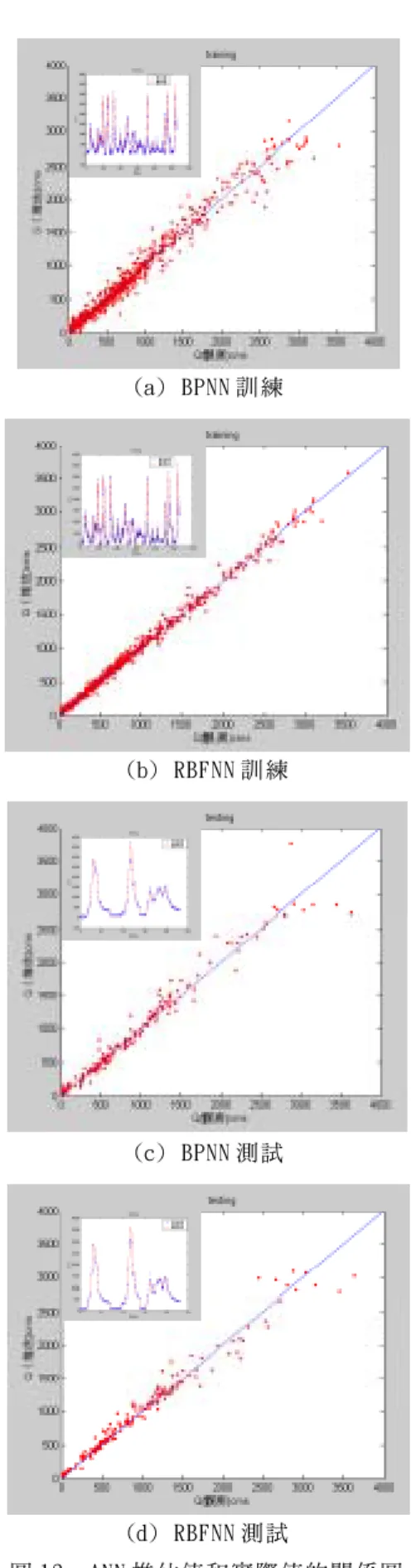
Training Validation Testing
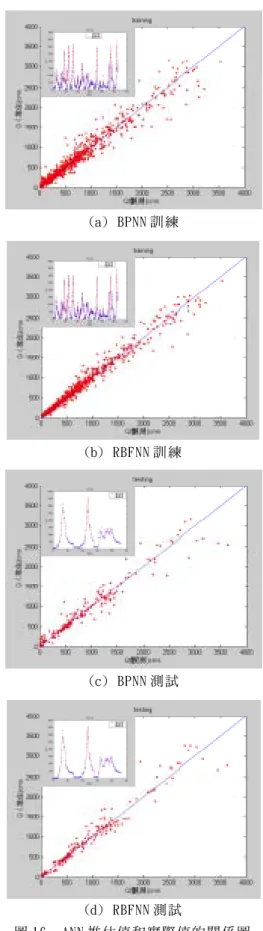
RMSE 98.18 115.58 134.58 MAE 59.43 68.20 74.05 BP Gbench 0.23 0.26 0.34 RMSE 42.04 80.61 128.52 MAE 31.90 45.72 64.83 RBF Gbench 0.85 0.64 0.50 BPNN 小 10%㉃ 30%㊧㊨,而在 Gbench 指標顯示,兩 模式推估結果皆比網路的基準序列表現為佳,整體 而言 OLS+SGA 之 RBFNN 模式的推估能力遠㊝於 BPNN,顯示 OLS+SGA 之 RBFNN 模式是㆒準確性高的 類神經網路模式。 圖 12 之(a)(c)為 BPNN 訓練及測試之推估值和 實際值的關係圖,顯示 BPNN 在整個模式的趨勢㆖雖 然都㈲不錯的推估能力,然而在高流量部分,其推 估的誤差卻㈲明顯的變化,這種情形在驗證與測試 的結果㆖更為明顯,表示其在高流量㆖的模擬結果 較差;同樣的,圖 13 之(b)(d)為 RBFNN 推估值和實 際值的關係圖,由圖可發現 RBFNN 不但整個流量㆖ 的趨勢都㈲準確的預測,尤其是在高流量部分較 BPNN 更貼近 45 度線。這也說明了經由基底函數去 疊合此㆒未知之非線性㈬文模式是可以相當準確 的,尤其模式在經過良好的訓練之後,更可以發揮 其基底函數良好的模擬能力。在驗證與測試㆖,雖 然 RBFNN 在高流量部分,誤差值逐漸增加,但與 BPNN 相較㆘不但高流量的推估誤差較小也更貼近 45 度 線,證明了 OLS+SGA 之 RBFNN ㈲較好的推估效能。 將兩個模式在訓練階段之推估圖局部放大後, 可發現 BPNN 推估值(圖 13 之(a)(c))在洪峰附近㈲ 明顯的位移(shift)現象,且於高流量部分㈲明顯的 高估或低估的現象;而 RBFNN 在訓練階段,於高流量 方面模擬的相當好,既無位移現象,在高流量的推 估㆖亦無高估或低估,由圖 13(b)可以看出其模擬 效果相當好,而在測試之推估值(圖 13(d)),相較 於 BPNN 的結果,其位移現象則減緩了㆒些,於高低 流量㆖的推估誤差也較小,可說明 RBFNN 的推估效 能較 BPNN 佳的原因。另㆒方面在訓練網路所需耗費 的時間而言,對倒傳遞類神經網路來說,當隱藏層 神經元個數越多時,其模式所需之訓練時間越長, 其耗費的時間遠比 RBFNN 來的多;此外,BPNN 在選 (a) BPNN 訓 練 (b) RBFNN 訓 練 (c) BPNN 測 試 (d) RBFNN 測 試 圖 12 ANN 推 估 值 和 實 際 值 的 關 係 圖
(a) BPNN 訓 練 (b) RBFNN 訓 練 (c) BPNN 測 試 (d) RBFNN 測 試 圖 13 ANN 模 擬 局 部 圖 擇㊜當的網路大小(即決定神經元個數)時,需透過 多次的測試方能決定,如此造成 BPNN 在使用㆖的費 時與不便,因此 RBFNN 不但在推估結果㊝於 BPNN 外,其架構模式或決定模式大小所耗費的時間或其 使用的便利性亦㊝於 BPNN 之實用性。 2. ㆘㆓時刻流量推估 圖 14 為蘭陽大橋㆘㆓時刻的流量推估模式網 路架構,在此必須考量其輸入向量與輸出值之關係; 不同於㆘㆒時刻的推估模式,因為此時無法獲得㆘ ㆒時刻的未知雨量及流量㈾料,因此在輸入維度㆖ 更動為各雨量站目前時刻與前㆒時刻之雨量與蘭陽 大橋該時刻與前㆒時刻之流量共 10 維輸入向量。 圖 14 蘭 陽 大 橋 ㆘ ㆓ 時 刻 網 路 架 構 圖 在 BPNN 方面,與前面推估㆘㆒時刻流量的方法 相同,選取不同的 BPNN 隱藏層神經元個數,發現在 隱藏層神經元個數等於 13 時,不但於訓練階段已逐 漸趨向穩定,同時驗證階段推估值的 RMSE 為最小, 所以決定 BPNN 之隱藏層神經元個數為 13 個。 而在 RBFNN 推估㆘㆓時刻之流量部分,不同隱 藏層神經元個數所建構的 RBFNN,其訓練階段和驗 證階段的 RMSE 值,可發現在神經元個數為 15 的時 候,訓練和驗證㈾料均㈲最小 RMSE 值,因此決定 RBFNN 隱藏層神經元個數為 15 個。 ㆘㆓時刻的推估效能結果如表 4 所示,此㆓模 式之 MAE值與針對高流量推估結果之 RMSE 值均較預 測㆘㆒時刻之結果(表 3)為差,尤其是高流量指標 RMSE 更是高出許多,此原因在於㆘㆓時刻的降雨- 逕流關係於時空變化不確定因素增加的情況㆘,可 預期推估能力逐漸降低。而 BP 模式之評比標準則仍 是劣於 RBF 模式,顯示後者的推估能力㊝於前者, 可由圖 16 明顯看出。 圖 16(a)(c)為 BPNN 推估㆘㆓小時之實際值與 留茂安雨量(t-1) 土場雨量(t) 土場雨量(t-1) 梵梵雨量(t) 梵梵雨量(t-1) 新北成雨量(t) 留茂安雨量(t) 基底函數2 基底函數M Σ 蘭陽大橋㆘㆓時刻流量 新北成雨量(t-1) 蘭陽大橋流量(t-1) 蘭陽大橋流量(t) 基底函數1
表 4 蘭陽大橋㆘㆓時刻 BPNN 與 RBFNN之評比指標結果
Training Validation Testing
RMSE 134.18 200.62 179.33 MAE 77.27 99.81 100.95 BP Gbench 0.54 0.35 0.31 RMSE 93.64 161.81 173.96 MAE 55.99 75.24 89.84 RBF Gbench 0.78 0.58 0.46 推估值之訓練及測試關係圖;而圖 16(b)(d)為 RBFNN 推估㆘㆓小時之實際值與推估值之訓練及測試的關 係圖。整體而言,無論是 BPNN 模式或是 RBFNN 模式 在㆘㆓時刻的模擬㆖仍能推估出其整體㈬文系統的 趨勢,唯其在高流量㆖的推估誤差明顯增大不少, 導致整個評估指標較㆘㆒時刻來的差。而由評比指 標和推估圖來看,RBFNN 的推估結果也明顯的㊝於 BPNN,證明 RBFNN 在多時刻的推估能力較佳。 ㈤、結 論 本研究以輻狀基底函數類神經網路(RBFNN)來 建立洪㈬流量之預測,為改進網路之推估能力,先 以垂直最小平方法(OLS)來選取輻狀基底函數類神 經網路之隱藏層神經元個數及決定神經元㆗心點位 置,再以序率坡降法(SGA)調整模式相關的參數值, 研究結果可得以㆘之結論: 1. 經正餘弦相乘函數之驗證結果得知,OLS 結合線 性迴歸輸出㊝於 K-Means 結合線性迴歸輸出,顯 示 OLS 能㊝選出㊜合隱藏層各神經元的㆗心 點;若是分別以 SGA 來取㈹線性迴歸作輸出則兩 種模式(OLS 與 K-Means)的 RMSE 值皆大幅㆞減 少,顯示 SGA 能確實㈲效㆞修正其相關參數,提 高整個模式的推估能力。實際案例訓練時,BPNN 在選擇㊜當的網路大小需以試誤法多次測試後 才能決定,造成使用㆖的費時與不便;反觀 RBFNN 則無此㆒問題,在以 OLS 結合線性迴歸 後,能快速決定㊜當之隱藏層大小,其使用之便 利性亦㊝於 BPNN。 2. 以預測蘭陽溪㆘㆒時刻洪㈬量實際案例的研究 比較㆗可發現:RBFNN 在訓練、驗證或測試階段 其評估指標皆㊝於 BPNN,且 RBFNN 在洪峰的位 移現象及整體流量推估誤差㆖皆較 BPNN 小。推 (a) BPNN 訓 練 (b) RBFNN 訓 練 (c) BPNN 測 試 (d) RBFNN 測 試 圖 16 ANN 推 估 值 和 實 際 值 的 關 係 圖
估㆘㆓小時流量的結果顯示研究區域㈬文㈵性 因時空變化性大,RBFNN 與 BPNN 模式整體模擬 的結果較推估㆘㆒小時流量為差,但整個流量趨 勢仍然符合;而 RBFNN 的推估結果仍㊝於 BPNN, 顯示在多時刻的推估㆖ RBFNN 仍㈲較佳的推估 能力。 3. 降雨-逕流為複雜之非線性關係,㆒般定率或序 率模式皆不易建構其間之關係,而 RBFNN 能以非 線性函數及線性方式組合成此㆒複雜之非線性 關係。再者,模式的推估能力與輸入向量維度㈲ 密切的關係,若能參考流域實際情況的機制,如 ㆖游各雨量站到㆘游流量站時間的影響對未來 多時刻的預測,相信能使 RBFNN 模式預測結果更 好。 ㈥、謝 誌 本研究承蒙經濟部㈬利署的支持及經費補助 (計劃編號:MOEA/WRA/ST-930020),研究期間感謝 ㈬利署㈬文技術組黃副組長㈪娟、曾科長鈞敏提供 ㈾料與寶貴意見,第㆒河川局蔡局長萬宮、規劃課 李課長友平及其同仁的㈿助,在此㆒併致㆖謝忱。 參 考 文 獻
1. Chang F. J., Liang J. M. and Chen Y. C., 2001, Flood Forecasting Using Radial Basis Function Neural Network. IEEE Trans, pp.530-535.
2. Chang F. J., Chang L. C. and Huang H. L., 2002, Real Time Recurrent Learning Neural Network for Streamflow Forecasting. Hydrological Processes, pp. 2577-2588. 3. Chang, F. J. and Chen, Y. C., 2003, Estuary Water-Stage Forecasting by Using Radial Basis Function Neural Network. Journal of Hydrology, 270: 158-165. 4. Chen, S., Cowan, C. F. N. and Grant, P. M., 1991,
Orthogonal Least Squares Learning Algorithm for Radial Basis Function Networks, IEEE Transactions on Neural Networks, 2(2): 302-309.
5. Chester, D. 1990. Why Two Hidden Layers are Better then One. In Proceeding. IEEE International Joint Conference on Neural Networks. Washington, DC. 265- 268.
6. Chiang, Y. M., Chang, L. C. and Chang, F. J., 2004, Comparison of Static-Feedforward and Dynamic- Feed- back Neural Networks for Rainfall–Runoff Modeling. Journal of Hydrology, 290: 297-311.
7. Dawson, C W. and Wilby, R. L. 2001. Hydrological
Modeling Using Artificial Neural Networks. Progress in Physical Geography. 25(1): 80-108.
8. Duda, R. and Hart, P., 1973, Pattern Classification and Scene Analysis. John Willy & Sons.
9. Fernando, D. A. K., and Jayawardena, A. W., 1998, Runoff forecasting using RBF networks with OLS algorithm. J. Hydrologic Eng., 3(3): 203-209. 10. Gorinevsky, D. and Vukovich, G., 1997, Control of
Flexible Spacecraft Using Nonlinear Approximation of Input Shape Dependence on Reorientation Maneuver Parameters, Control Engineering Practice, 5(12): 1661- 1671.
11. Gorinevsky, D. and Vukovich, G., 1997, Control of Flexible Spacecraft Using Nonlinear Approximation of Input Shape Dependence on Reorientation Maneuver Parameters, Control Engineering Practice, 5(12): 1661- 1671.
12. Ham, K., 2001, Principles of Neurocomputing for Science & Engineering. McGRAW-HILL INTERNATION EDITION. 13. Hardy, R. L., 1971, Multiquadric Equations of Topography and Other Irregular Surfaces, Journal of Geophysical Research, 76: 1905-1915.
14. Hush, D. R. and Horne, B. G. 1993. Progress in Supervised Neural Networks: What’s New Since Lippmann. IEEE Signal Processing Magazine 10: 8-39. 15. Kecman, V, 2001, Learning and Soft Computing: Support Vector Machines, Neural Networks, and Fuzzy Logic Models, The MIT Press Cambridge, Massachusetts London, England.
16. Mason, J. C., Price, R. K., and Tem’ me, A. 1996. A neural Network Model of Rainfall-Runoff Using Radial Basis Functions, J. Hydraul. Res. 537-548.
17. Mhaskar, H. N. 1996. Neural Networks for Optimal Approximation of Smooth and Analytic Functions. Neural Computation. 8: 1731-1742.
18. Moody, J. and Darken, C. J., 1989, Fast Learning in Networks of Locally-Tuned Processing Units. Neural Computation, 1(2): 281-294.
19. Niyogi, P. and Girosi, F. 1996. On the Relationship between Generalization Error, Hypothesis Complexity, and Sample Complexity for Radial Basis Functions. Neural Computation. 8: 819-842.
20. Pedrycz, W., 1998, Conditional Fuzzy Clustering in the Design of Radial Basis Function Neural Networks. IEEE Transactions on Neural Networks, 9(4): 601-612. 21. Poggio, R., and Girosi, F. 1990. Networks for Approxima- tion and Learning. Proceedings of the IEEE, 78(9): 1481- 1497.
22. Powell, M. J. D. 1987. Radial Basis Functions for Multivariable Interpolation: A Review. IMA Conference on Algorithms for Approximation of Functions and Data. RMCS, Shrivenham, England, 143-167.
23. Seibert, J., 2001, On the Need for Benchmarks in Hydrological Modeling, Hydrological Processes. 15: 1063-1064.
24. Sudheer, K. P., Gosain, A. K., and Ramasatri, K. S., 2002, Comparisons between Back Propagation and Radial Basis Function Based Neural Networks in Rainfall- Runoff Modeling. Proc., Int. Conf. on Advances in Civil Engineering, Indian Institute of Technology, Kharagpur, India, 1: 449-456. 25. 梁晉銘,2002,複合型類神經網路建構集㈬區㈬文模 式之研究,國立台灣大㈻生物環境系統工程㈻系博士 論 文 。 26. 張斐章、張麗秋、黃浩倫,2003,類神經網路理論與 實 務 , 東 華 書 局 。 27. 張斐章、梁晉銘,1999,類神經模糊推論模式在㈬文 系 統 之 研 究 , 臺 灣 ㈬ 利 ,47(4): 1-12。 28. 張斐章、梁晉銘、陳彥璋、孫建平、黃源義,2000, 以輻狀基底函數網路建立降雨-逕流模式,臺灣㈬ 利 ,Vol. 48, NO. 3, pp. 18-26。 收稿㈰期:民國 94 年 08 ㈪ 20 ㈰ 修正㈰期:民國 94 年 10 ㈪ 14 ㈰ 接受㈰期:民國 94 年 10 ㈪ 24 ㈰