MPT-based branch-and-bound strategy for
scheduling problem in high-level synthesis
P.-Y. HsiaoG .-M. WU J.-Y.Su
Indexing terms: Scheduling problem, High-level synthesis, M P T
Abstract: A branch-and-bound algorithm based on a maximum possibility table (MPT) is proposed to solve scheduling problems in high- level synthesis. Six efficient priority rules are developed as bounding functions in the algorithm. Extensions for real-world constraints are also considered, including chained operations, multicycle operations, mutually exclusive operations and pipelined data paths. Experimental results indicate that the MPT-based algorithm returns competitive scheduling results at significant savings in execution time as compared with other methods.
1 Introduction
High-level syntheses are performed to transform algo- rithmically specified behaviours of digital systems into register-transfer level structures [l, 21. There are three major phases in high-level synthesis. The first phase, called compilation, compiles the formal language into an internal representation. Control/data flow graphs (CDFGs) are the most frequently used representations. The second phase, called scheduling, assigns the opera- tions into control steps according to certain constraints while minimising corresponding objective functions. The third phase, called allocation, tries to share hard- ware resources, such as functional units, storage and communication paths, while minimising costs as much as possible. However, the interrelationship between scheduling and allocation is very close. An optimal schedule is not guaranteed to provide an optimal syn- thesis result after subsequent allocation operations. For practical considerations, using many interleaved sched- uling and allocation iterations with a fast heuristic algorithm, instead of searching for a single optimal solution, will obtain a more satisfactory synthesis result
During the last decade, many systems using different scheduling techniques have been proposed. When resources are unconstrained, the simplest scheduling technique, as soon as possible (ASAP), and the comple- [31.
0 IEE, 1998
IEE Proceedings online no. 19982347
Paper first received 1st July 1996 and in final revised form 11th March I997
The authors are with the Department of Computer and Information Science, National Chiao Tung University, Republic of China
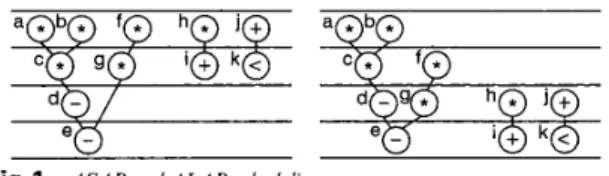
mentary as late as possible (ALAP), as shown in Fig. 1, may be used along with the corresponding description of the computation set from the example of the HAL [4] system. Scheduling problems with limited resources have already been shown to be NP-hard and thus, for most systems, analytic methodology must depend on heuristic techniques. The class of algorithms including SLICER [5] and MAHA [6] is based on list scheduling techniques. List scheduling manages all operations in topological order, using the precedences dictated by data and control dependencies in the CDFGs. The force-directed scheduling (FDS) [7] algorithm is the pri- mary scheme within the HAL system. In this algo- rithm, the cost of hardware resources can be reduced by conducting operations concurrently. The ASCAM [8] algorithm considers evaluated costs as major con- cerns in updating probability values. The FAMOS [3] algorithm is based on the scheme proposed by Kernighan and Lin to escape local minima traps [9]. It also includes various selection functions developed to define hardware resource costs. A global scheduling algorithm with code-motions has been proposed by Rim [16]. Instead of using heuristic algorithms to schedule operations, mathematical descriptions of scheduling objectives and constraints are derived from ALPS [lo] and can be successfully translated into inte- ger linear programming (ILP) formulations. Therefore, ALPS obtains solutions at the expense of execution time because ILP is, by nature, an exponential-time algorithm.
XI = X+ dx;
uI = U- (3*x*u*dx)- (3*y*dx); yl = y+ u*dx;
c = XI < a:
Fig. 1 A S A P und A L A P scheduling
In this paper, a branch-and-bound algorithm based on a maximum possibility table (MPT) [l 11 is proposed to solve scheduling problems in high-level synthesis. Six efficient priority rules are developed as bounding func- tions within our MPT-based algorithm.
2 Preprocess
For internal representations, we create maximum possi- bility tables (MPTs) instead of distribution graphs.
425
-
operation type *
node a c b f g hlMPT*I d e i j k
I
MPT*+ - >
Fig.2 MPTgraphfor Fig. 1
ope-ation type *
nsde b f g h MPT*
Definitio,r 2.2: Given a CDFG, the freedom of path A
equals n if, and only if, the mobility of each operation within path A involves n C-steps.
For example, the freedom of path (h, i) in Fig. 1 equals 3.
Definition 2.3: The critical path of a given CDFG is
defined as the single path of the CDFG with the long- est delay time.
+ - > i j k MPT*
-+
* -
0 1 0 0 Mznzt = 0 1 1 0 1 0 - 1 1- Fig. 3 MPTgraph without critical path nodesFor example, (a, c, d, e ) or (b, c, d, e ) can be consid- ered to be critical paths, as shown in Fig. 1. Using the critical path (a, e, d, e ) with four control steps, we now assume five control steps as the time constraint. This time constraint thus has one control step more than the 426
critical path. MPT graphs without critical-path nodes can be constructed, as shown in Fig. 3.
Using these constructed MPTs, we first consider the maximal multiplier possibilities. C-step.2 has the maxi- mal cost in MPT*. Therefore, whenever possible we must try to eliminate multiplication operations from C- step.2 when scheduling the critical path. The critical- path schedule for the five control-step time constraint is shown in Fig. 4.
C-step 1
"0
C-step 2\
\C-step 4 C-step 5
many possible alternative assignments for each opera- tion, as the tree structure in Fig. 5 shows.
Fig. 5 Alternative assignments for each operation
As shown in Fig. 5 , Minit describes the distributions of operations after the critical path has been found. Associated with the CDFG shown in Fig. 1, where the time constraint is assumed to be four control steps, there is only one possible noncritical path assignment from Minit such as assigning 0pn.b to C-step.1. After 0pn.b has been manipulated, there are two available ways to assign the following opn.g, C-step.2 (Mg,2) or C-step.3 (Mg,3). After previous assignments have been made, there are two possible assignments for opnf MJ2 or M L l , for Mg,3 and Mg,2, respectively. Therefore, there are exponentially many possible paths to con- sider. To select the most efficient path, we propose a heuristic solution based on the following six priority rules and corresponding bounding functions to remove undesirable branches from the M i j graph.
Table 1
Name of PR Descriptive outline Precedence constraint
Lowest cost matrix among current candidates M i n i m u m value of MPT items
Lowest-cost ancestor min(COST(backtrack( 1, Mi,$)), matrix
Backtrack among min(MPT(backtrack(> 1, Mi,j))), ancestors until the
MPT value can be determined Latest C-step
(C-step.i) < (C-step.j) Vopni
-
opnj, Si s (C-step.i) s Li, Si s (C-step.j) s Lj min(COST(Mi,j)),Si s (C-stepd s Limin(MPT(C-step.i)), Si s (C-step.i) s Li
Si s (C-step.i) s Li
Si s (C-step.i) s Li
If candidates cannot be eliminated by R I through R5, select matrix corresponding t o latest C-step where Si, Si: the C-step that 0pn.i or 0pn.j assigned t o by ASAP.
Li, Lj: the C-step that 0pn.i or 0pn.j assigned t o by ALAP. Mino: finding the m i n m u m value.
COSTO: evaluating the total cost. MPTO: getting the element value of MPT.
Backtrack(n0, Mi,j): Backtrack t o no-th ancestor of Mi,j.
Section. The corresponding bounding functions are also listed in Table 1. For convenience of presentation, ancestor matrices are represented as Mc,p, Mc,p+,, ...,
Mc,q, and the operation mobility 0pn.c is between p and
q. By sequentially applying these six priority rules (PR1 through PR6), we can guarantee that only one ancestor matrix, called the consulting matrix, should be referred. Using this consulting matrix, we can further construct the corresponding Mi,j and update the MPT.
3.1
PR?: precedence constraint
Operation assignments must not violate data dependen- cies. That is, the associative relation between 0pn.i and o p n j in CDFG must be always preserved.
3.2
PR2: choose the lowest cost matrix from
among current candidates
M i j is made the consulting matrix if it has the lowest cost function among all candidate matrices, as deter- mined by
C O S T ( K , , )
= Mopn(l)*
cost1+
Mopn(2)*
costa+
.
' .+
Mopn(k)*
costk(3) where costk is the area-associated cost of type k opera- tion.
Mf.3 Mg.2
U + U +
construcf
-
-Fig. 6 Sample illustration of priority rules
Fig. 6 illustrates construction MJ3 by referring to
Mg,2 or Mg,3, where opnfis a multiplier needing to be
assigned at C-step.3. Reference to Mg,2, shows that three multipliers and two adders will be consumed. However, reference to Mg,3, shows that four multipliers and two adders will be required. Precision demands selection of the former case.
Mf.3 MB.3
3
gj.;%r??.$
5
Fig. 7 Sample illustration of priority rules
3 Priority rules and bound functions for 3.3
PR3: minimum value of MPT items
scheduling
In this Section, we present detailed descriptions of six priority rules concerning the assignment of operations based on the derived representation from the previous
This rule selects the reference matrix with the minimum MPT value. This approach reduces the impact of unscheduled nodes as much as possible. In Fig. 7, we refer to Mg,2 and Mg,3 to construct ML3, with equiva- lent cost consumption. We can check the constructed
informai.ion representation
MPT*
to determine whetherMPT*(~:I
=5
is larger than MPT*(%) = 3; ifso,
wewill
select Mg,2 to construct MJ3 to reduce the impact on nodes not yet scheduled.
3.4 P/?4: lowest-cost ancestor matrix
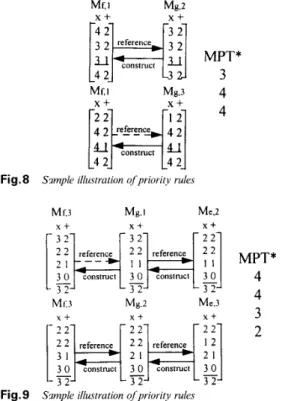
This rule identifies the lowest-cost matrix from among ancestor matrices. As shown in Fig. 8, we refer to Mx,2 or Mx,3 to construct Mr: I . They have equivalent sched-
uled M J l costs and MPT*. However, the cost consump- tion resilting from Mx,2 is lower than that resulting from M g , 3 , therefore we will select Mg,2 to construct
Mf, I
MPT*
3
Mf.1 M8.3
4
4
Fig. 8 Srrmple i h t r a t i o n of priority rules
Mf.3 Mg. I Me.2 X +
MPT*
44
3 2 3 2 MU Mg.2 Me.3 T + X + X +3
- 3 2 3 2 2 2 3 0 3 22
Fig. 9 Srrmple illustration of priority rules
3.5
Pt75: backtrack among ancestors until the
MPT
value can be determined
This rule backtracks among ancestors of candidate matrices until PR3 is able to determine an appropriate selection. As shown in Fig. 9, we would like to con- struct M f 3 , but we cannot distinguish between M g , l and Mg,2 by applying PRl through PR4. Hence, we back- track among ancestor matrices to Me,2 and Me,3, where MPT(3) < MPT(2), after which the former can be abandoned.
3
Fig. 10
428
Sample illustration of priority rules
3.6
PR6: latest C-step selection
If
an appropriate selection cannot made using PRl through PR5, the latest C-step is then considered. This rule is derived from the ALAP algorithm. As shown in Fig. 10, M g , , and Mx,2 have passed R I through R5. We would then select Mg,2 to construct M J ~ since its corresponding C-step occurred later than Mg, ] .A complete description of our algorithm is presented below. Note that the six priority rules must be checked in sequence.
Branch-Bound-SCHEDULE() {
Take the data flow graph, assignment delays and cost values of each operation;
Use ASAP and ALAP to determine the mobility of all operations;
Find the critical path;
Create MPTs for noncritical path nodes. Schedule the critical path;
WHILE (there are nodes remain unassigned)
select a path A with the smallest degree of freedom; SCHEDULE(A); END
1
SCHEDULE(A) BEGINselect node i which is the leaf node of path A; WHILE(i is not NULL)
FOR j = mobility-start(i) TO mobility-
end(i) using PRI, PR2,
...,
PR6 to select the consulting matrix;IF (operation i is assigned to C-step j , all data dependencies are not violated) THEN using consulting matrix to construct
Mi,j i = leaf node of path A; remove i from A; update the MPT;
END
WHILE (there are paths related to path A that are unscheduled) select one path B
among them with the smallest degree of free- dom;
SCHEDULE(B); END
END
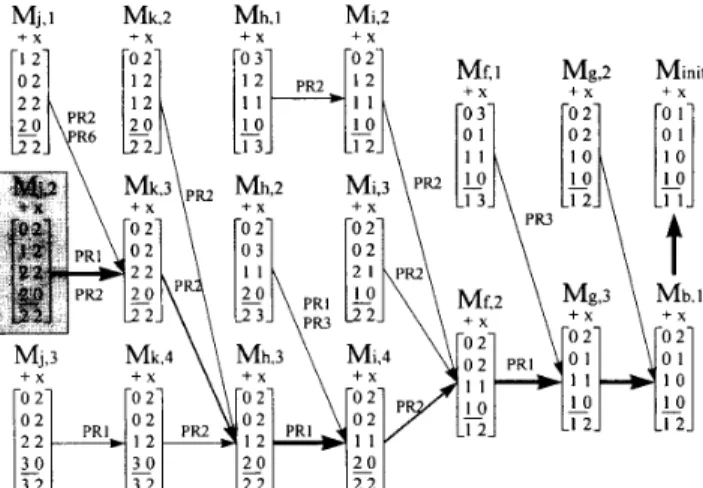
The result derived from our algorithm on the example from HAL is shown in Fig. 11. We assume that the available functional units are multipliers and ALUs (the ALU is capable of performing addition, subtrac- tion and comparison), and that the multiplier costs are higher than the costs of the ALUs. It is not difficult to see that the critical path is (a, c, d, e). Minit is the initial potential cost matrix after the critical path has been scheduled. The initial MPT* = (3,3,2,0) and MPT+ = (1,3,3,2); neither of these MPT graphs include the criti- cal path. The arrows point out the matrices associated with the consulting direction. PR1, PR2,
...,
PR6 along with the arrows are used as referential bases. When 0pn.b can only be assigned to C-step.1, we assign 0pn.b to C-step.1 and refer to Minit to construct Mb,l with the first element in the second column increased by oneMj.1 M k . 2 Mh.1 Mi2
+ X + X + X + X
Mtl Mg,2 Minit
Fig. 11 Procedures derived by our MPT-bused algorithm for H A L example
and the last element in the second column changed to 2. MPT* must be updated to (2,3,2,0). The o p n f can follow assignment to C-step.2 or C-step.1. Since it is assigned to C-step.2, it can refer by Mg,3 only, because according to PRI, 0pn.g and opnfhave data dependen- cies. As it is assigned to C-step. 1, the candidate matri- ces Mg,2 and Mg,3 have the same costs as the candidate matrices. Now, MPT* = (2,2,1,0) and the third element is smaller than the second element. Therefore,
Mf;,
can refer to M g , 3 according to PR3. Using the proposed methodology, the final solution is indicated by the shadowed block. We can backtrack indexes to obtain the optimal solution, as shown by the thick arrows;multipliers and two ALUs are required for the imple- mentation.
For the computational complexity consideration of the proposed algorithm, the associated MPTs can be created in linear time and initialisation of the critical path also consumes linear time. Let S be the number of control steps and N be the total number of noncritical path nodes. Consider PR5 is backtracking behaviour, which may require O(iV). In the worst case, the entire time complexity will be bounded by O(S2N2).
they are Mj,2> Mk.3, M i , 4 > Mf;2> Mg,3> Mb,1. That is, two
4 Extensions for real-world constraints
In previous Sections, we assumed that one clock cycle is required for each operation, but that is not always true in real situations. In this Section we must extend the previous algorithm to accommodate real world situations.
The conditional construct is similar to the ‘if-then- else’ or ‘case’ statement within the programming language. Inherently, it results in several mutually exclusive branches. Mutually exclusive operations can easily be handled by referring to them as only one operation if they use the same type of functional unit, even though they are assigned to the same control step.
Operations that require multiple control steps to exe- cute are also considered. For nonpipelined implementa- tion, when the operation is assigned, the functional unit cannot be shared by other operations until the assigned operation has been completed. Assume that M i j indi- cates that operation i is necessarily assigned from C- step4 to C-step.(j
+
di - l), where di represents the propagation delay of operation i. Then, a new MPT, called MC-MPT, must be redefined as follows:IEE Proc.-Comput. Digit. Tech., Vol 145, No. 6 , November 1998
j + d , - l
M C - M p T t y p e ( c ) , j = M p T t y p e ( c ) , k
k = j
Therefore, PR3 and PR5 must be modified to choose the smallest MC-MPT. Specifically, the corresponding hardware use costs must be modified for each propaga- tion C-step following assignment.
For functional units that provide chaining functions, we can chain several operations in one cycle if their total running time is less than the cycle time. We can further formulate a chaining problem as a multicycle problem by reducing the cycle time. The greatest com- mon divisor of the functional unit’s propagation delay time is selected as the new cycle time; a multicycle strategy can then be used to solve the chaining prob- lem.
For pipelined data-path systems, execution of multi- ple tasks can be conducted concurrently. For a given latency L , operations assigned to C-step(i
+
p L ) (for p = 0, 1, 2,...
and i = 0, 1, 2,...,
L - 1) cannot share a functional unit because they are executed simultane- ously. Consequently, the MPT in PR3 and PR5 must be changed to the sum of MPTs (SMPT) over C-stepj+
p L (p = 0, 1, 2, ...) as follows:sMPTtype(c),j =
c
M P T t y p e ( c ) ,7 ( r - j ) m o d L = O , l < r L swhere
s denotes t h e number of
C-steps
PR3 is then modified as follows:
S M p T t y p e ( c ) , j 1 = min ( s M P T t y p e ( c ) , p + k )
O l k l p L
Table 2: Information on computers
Method Computer MIPS
MAHA [61 FDS 171 ALPS [IO] FAMOS 131 SEHWA [I51 Kung 1121 Komi [ I 3 1 Achatz [I41 MPT [ours] VAX-I I D 5 0
Xerox 1108 LISP machine VAX-11/8800 SUN 4/280 VAX-I I D 5 0 nla SUN SPARC SUN SPARC-2 SUN SPARC-IPC 1 nla 12 10 1 n/a 25 12.5 14 429
Table 3: Experimental results for MAHA example
CPU time CPU time Cycles Operlcycle Adds Muls (unnormalised)
(normalised) System MAHA 8 1 1 1 160s 2857 4 3 2 3 160s 2857 FDS 8 1 1 1 50 s nla 4 2 2 2 25s nla 3 3 3 3 35s nla APLS 8 1 1 1 0.26s 55.7 4 2 2 2 0.08s 17.1 3 3 3 3 0.23s 49.3 FAMOS 8 1 1 1 0.033s 5.9 4 2 2 2 0.05s 8.9 3 3 3 3 0.033s 5.9 MPT(ours) 8 1 1 1 0.004s 1 4 2 2 2 0.004s 1 3 3 3 3 0.004s 1 2 4 4 4 0.004s 1 5 Experimental results
Our MPT-based system has been implemented and tested in C language on a Sun SPARC-IPC. To verify the efficiency of the proposed algorithm, results from other approaches are described, and are compared with ours in Tables 3-6. For comparison with other meth- ods, we have normalised the CPU time for each method using the MIPS information shown in Table 2. Note that the required resource results for ALPS in these Tables are optimal, since they are obtained using ILP.
The first example, taken from MAHA, contains chained (operations involving fewer than eight cycles. The experimental results for this example are summa- rised in Table 3. The same required resource cost opti- misations, can be derived using FDS, ALPS, FAMOS and our MPT-based approach. However, a significant time saving is achieved by our MPT-based algorithm.
Table 4: E.xperimental results for FDS example
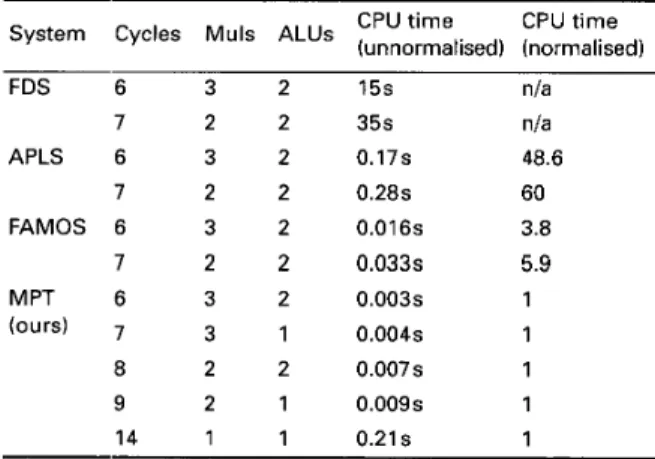
FDS 6 3 2 15s nla 7 2 2 35s nla 7 2 2 0.28s 60 FAMOS 6 3 2 0.016s 3.8 7 2 2 0.033s 5.9 APLS 6 3 2 0.17s 48.6 MPT 6 3 2 0.003s 1 (ours) 3 1 0.004s 1 8 2 2 0.007s 1 9 2 1 0.009s 1 14 1 1 0.21 s 1
The second example is differential equation taken from FDS that contains multicycle operations and has a critical path six cycles long. In this example, multipli- cation WE.S assumed to have a delay of two cycles, while
addition was given a delay of half a cycle. The corre- sponding scheduling results for the second example are
Table 5: Experimental results for fifth order elliptic filter example
CPU time CPU time System Cycles ALUs (unnormalised) (normalised) Kung Komi Achatz FDS APLS FAMOS M PT (ours) 17 4 4 17 3 3 18 2 2 21 2 1 17 3 3 18 2 2 2 1 21 17 3 3 18 3 2 19 2 2 2 1 21 17 3 3 2 2 18 21 2 1 17 3 3 18 2 2 2 1 21 17 3 3 18 2 2 21 2 1 28 1 1 nla 4.2s 15.3s 22.2s Is 5s 26s 60s 180s 420s 780 s 0.26s 3.1s 34.5s 0.067s 0.101s 0.783s 0.009s 0.013s 0.023s 0.108s nla 883 2101 1723 99.2 343 1009 nla nla nla nla 24.8 204 1285 5.3 5.6 24.3 1 1 1 1
shown in Table
4;
our MPT-based extension algorithm for multicycle operations derived in section IV was applied for resource scheduling. Considering resource costs, our MPT-based approach had one multiplier growth and one ALU decrement for the case involving seven cycles. However, a significant time saving was also achieved by our MPT-based algorithm.The third example is a fifth-order elliptic digital filter [I21 that contains 26 additions and eight multiplica- tions. For this example, multiplication was assumed to take two cycles, and addition was assumed to have a one-cycle requirement. The critical path was 17 cycles long. The MPT-based solution obtained for 17 control steps is shown in Fig. 12; it requires three multipliers
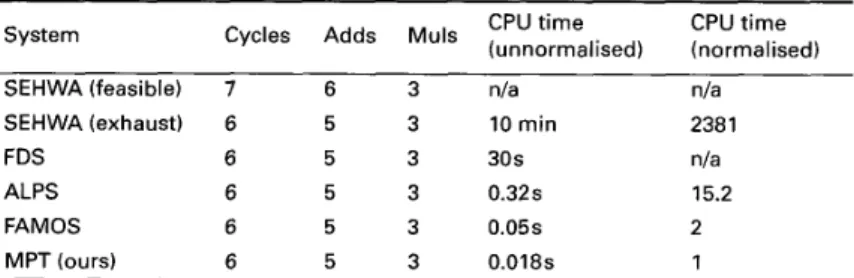
Table 6: Experimental results for SEHWA example
System CPU time CPU time
(unnormalised) (normalised) Cycles Adds Muls
SEHWA (feasible) 7 6 3 n/a n/a
FDS 6 5 3 30s n/a
ALPS 6 5 3 0.32s 15.2
FAMOS 6 5 3 0.05s 2
MPT (ours) 6 5 3 0.018s 1
SEHWA (exhaust) 6 5 3 10 m i n 2381
and three ALUs. All scheduling results for the third example are shown in Table 5, along with two other ILP-based methods derived by H. Kmi et al. [13] and Achatz [ 141, respectively. Our MPT-based algorithm was able to obtain the optimal solutions for each criti- cal-cycle consideration in significantly less execution time.
Fig. 12 17 C-steps scheduling for fifth-order elliptic filter
The fourth example is a pipelined 16-point digit FIR filter adopted from SEHWA [15]. For this example, multiplication was assumed to take 80ns and addition to take 40ns. Cycle time was 100ns. The latency for the pipelined data path was equal to three cycles. The cor- responding scheduling results for this example are shown in Table 6. A significant time saving was achieved by our MPT-based algorithm, and an optimal solution was obtained.
Average normalised execution time can be expressed as geometric mean. The formula for the geometric mean is
APLS, 6 times than FAMOS, 1473 times than Komi, and 325 times than Achatz. The comparisons presented in these examples show the ALPS scheduling algorithm to be an optimal approach to using the ILP method. Moreover, our MPT-based algorithm can achieve near optimal scheduling of hardware resources in signifi- cantly shorter CPU times than any of the previous approaches we tested.
6 Conclusions
We create MPT graphs instead of the distribution graphs used in most previous scheduling systems. The MPT graphs indicate maximal degrees of concurrence among the similar operations in each control step. We preprocess the nodes among the critical path using a simple method that removes a subset of the total number of nodes from the computationally more expensive parts of the algorithm. The kernel of our method can be classified as a branch-and-bound algo- rithm. To improve the computation time, we propose six priority rules to serve as our bounding functions. Extensions for real-world constraints are also consid- ered in our algorithm, including chained operations, multicycle operations, mutually exclusive operations, and pipelined data paths. Our algorithm guarantees to achieve near-optimal hardware resources usage in sig- nificantly shorter CPU times than other approaches tested.
7 References
1 MCFARLAND, M.C., PARKER, A.C., and CAMPOSANO, R.: ‘The high-level synthesis of digital systems’, Proc. IEEE, 1990, DE MICHELI, G.: ‘Synthesis and optimization of digital circuits’ (McGraw-Hill, 1994)
PARK, I.C., and KYUNG, C.M.: ‘FAMOS: an efficient schedul- ing algorithm for high-level synthesis’, ZEEE Trans., 1993, CAD- 4 PAULIN, P.G., KNIGHT, J.P., and GIRCZYC, E.F.: ‘HAL: A multi-paradigm approach to automatic data path synthesis’. Pro- ceedings of 23rd Design automation conference, 1986, pp. 263-270
5 PANGRLE, B.M., and GAJSKI, D.D.: ‘Slicer: a state synthe- sizer for intelligent silicon compilation’. Proceedings of IEEE international conference on Computer design, 1987
6 PARKER, A.C.: ‘MAHA: A program for datapath synthesis’. Proceedings of 23rd Design automafion conference, 1986, pp. 263- 270
78, pp. 301-318 2
3
12, pp. 1437-1448
7 PAULIN, P.G., and KNIGHT, J.P.: ‘Force-directed scheduling for the behavioural synthesis for ASIC’s’, IEEE Trans., 1989, C A M , pp. 661-679
CIVERA, P., MASERA, G., PICCININI, G., and ZAMBONI, M.: ‘Algorithms for operation scheduling in VLSI circuit design’,
8
I E E Pr&, 1993, 140, pp, 339-346
9 KERNIGHAN, B,W,, and LIN,
s,:
‘An efficient heuristic proce- dure for partitioning graph’, Bell Syst. Tech. J., 1970, 49, (2), pp. 291-30810 HWANG, C.-T., LEE, J.-H., and HSU, Y-C.: ‘Formal approach to the scheduling program in high-level synthesis’, IEEE Trans.,
-
where execution time ratio, is the execution time, nor- malised to the reference system, for the ith example of a total of IZ in the workload. Comparing the time per-
formance of systems with geometric mean, our algo-
rithm is 2875 times than MAHA, 103 times than 1991, CAD-10, pp. 464475
I 1 HSIAO, P.Y., WU,,G.M., HO, M.H., and. CHANG, C.J.: 14 ACHATZ, H.: ‘Extended Oil LP formulation for the scheduling problem in high-level synthesis’. Proceedings of EDAC-93, 1993, pp. 226231
15 PARK, N., and PARKER, A.C.: ‘SEHWA: a software package for synthesis of pipelines from behavioural specifications’, IEEE
Trans., 1988, CAD-7, pp, 356-370
16 RIM, M., FA”, Y., and JAIN, R.: ‘Global scheduling with code-motions for high-level synthesis applications’, IEEE Trans., MPT based scheduling for high-level synthesis’. International
symposium on V L S I technical systems and applicutions, 1995, pp. 63-67
12 KUNG, S.Y., WHITEHOUSE, H.J., and KAILATH, T.: ‘VLSI and moiern signal processing’ (Prentice Hall, Englewood Cliffs, NJ, 1985), pp. 258-264
13 KOMI, H., YAMADA, S., and FUKUNAGA, K.: ‘A scheduling method by stepwise expansion in high-level synthesis’. Proceedings
of IEEE conference on Computer-aided design, 1992, pp. 234-237 1995, VLSI-3, pp. 379-392