Implementing digital copyright on
the internet through an enhanced
creative common licence protocol
Chyan Yang
Institute of Business and Management & Institute of Information Management,
National Chiao Tung University, Taipei, Taiwan
Hsien-Jyh Liao
Institute of Information Management, National Chiao Tung University,
Taipei, Taiwan, and
Chung-Chen Chen
Information Management Department, National Kinmen Institute of Technology,
Kinmen, Taiwan
Abstract
Purpose – The purpose of this paper is to explain the Creative Common license (CC license) a digital copyright license, which can clearly express the scope of copyright granted by the owners and therefore help users, including crawlers and software robots, to comprehend the scope of authority and then collect digital contents via the internet legally. However, both the complex format and difficulty in embedding the digital codes in a binary file impede the spread of CC licenses. This paper seeks to propose a new protocol CCFE, based on the CC license, to solve the above problems.
Design/methodology/approach – Instead of embedding the CC licensing information in the body of a CC file, CCFE attaches the authentication information in the file extension. The syntax of CCFE to verify the validity of CCFE is illustrated.
Findings – CCFE allows the authorization data to be embedded and is consequently preserved in the process of duplication and transmission. Thus the portability of the authentication method is magnified. In addition, users can use general search engines, like Google, to find the CC licensed documents.
Originality/value – The paper points out the disadvantages of the current CC license and explains a new protocol. Furthermore, it explains how this new paradigm can be used for constructing an online digital library and how librarians can use software robots to collect digital contents on the internet within copyright guidelines.
Keywords Copyright law, Licensing, Digital libraries, Search engines Paper type Research paper
Introduction
An efficient and appropriate format to express the scope of licensing of digital copyright may improve the distribution and reuse of digital works. According to current copyright law, such as 17 U.S.C. 106, authors automatically own the copyright of their works right after they finished them; and no one can reproduce, modify or distribute the works without the owners’ permission.
The current issue and full text archive of this journal is available at www.emeraldinsight.com/0264-0473.htm
The authors thank the anonymous reviewer for his valuable comments on the draft of this article.
EL
27,1
20
Received 2 November 2007 Revised 4 December 2007 Accepted 10 December 2007The Electronic Library Vol. 27 No. 1, 2009 pp. 20-30
q Emerald Group Publishing Limited 0264-0473
However, in the internet world, copyright regulations give rise to certain ambiguities and contradictions. For example, when an author uploads his works on a web site, any reader may easily come to a conclusion that these works are made available for reading by any person visiting that web site. On the other hand, some readers may have doubts about downloading, reproducing and modifying the contents. This concern is based on the fact that some owners may authorize the online users or readers to read, reproduce and modify the works, but another author may not. Even for experienced information professionals or attorneys, figuring out what is and is not allowed is difficult and time-consuming.
This problem becomes more complex because online digital libraries or internet archives (Blake, 2004) use software agents to retrieve documents, images, audio recordings and other information objects available on publicly accessible web sites. To illustrate: Citeseer.ist (1997) is a well known and popular online digital library. A large number of academic papers related to computer science can be searched (Giles et al., 1998). One important part of Citeseer is the software robot (“crawler” or “spider”) (Raghavan and Garcia-Molina, 2001). This software robot can retrieve and store all related papers in Adobe Portable Document Format (PDF) or PostScript (PS) format from a web site. Citeseer then indexes these documents. Users may search Citeseer for documents pertinent to their area of research, and users may download one or more documents as required. Since few software robots are able to differentiate between a copyrighted document and a document that has been posted by an author for general use, they simply automatically retrieve all papers from the internet.
Now the question is, “Should digital libraries, like Citeseer, distribute all collected papers as complete contents or just their abstracts?” And: “Can digital libraries reproduce papers whenever the papers are needed or only one copy is allowed?” Online digital libraries are likely to violate one or more copyright regulations. Few libraries have sufficient staffs to examine each digital document, find the copyright holder, and then seek permission to include that document in an online collection. Although there have been no lawsuits filed against online digital libraries, Google has become entangled in litigation over copyright (Field, 2006).
Digital librarians and researchers have doubts about what is and what is not permissible for digital content accessible via the internet. One solution is for authors to set forth a license that states what is permitted. The General Public license (GPL) is one of the most widely used licenses for software (Free Software Foundation, 1989). Another successful example is GNU Free Document License (GFDL) (Free Software Foundation, 2000); Wikipedia has adopted the GFDL to guide its users (Wikipedia, 2001). Although both GPL and GFDL are reasonably popular in some specific fields, there is no common license which can be used in a variety of works, ranging from documents, audio, video, or other binary files.
The Creative Common license (hereinafter, CC license) is a license for the purpose of granting some or all of the authors’ rights to the public. CC license is not limited to software or documents. This license is designed for a broad range of contents, including but not limited to documents, animation files, and other types of information objects. CC license is now popular with the number of documents licensed under CC license and known as CC licensed documents has been increasing in recent years. One significant boost to CC licensing is Google’s and Yahoo!’s inclusion of support to allow users to search only CC licensed documents (Google, 2007; Yahoo, 2007). These two
Digital copyright
on the internet
systems combined process nearly 80 per cent of English language queries worldwide, these companies’ support has been a positive step forward for the CC license (ClikZ Network, 2007).
Table I shows the number of documents collected by Google and Yahoo! June 2007. Google has processed more than 32 billion web pages and 30 billion non-text objects and makes available about 20 billion web pages for public queries. Yahoo! has about 20 billion pages in its web index. What is clear is that the number of CC license documents accounts for less than 1 per cent of the total documents in these two systems.
Google now permits searching for images and YouTube.com videos. However, the public search system uses metadata for the image and YouTube.com indexes. Google has developed technology that permits the text in an audio or video file to be extracted and indexed. This advanced system was not available to the public as of 20 November 2007. Yahoo! offers a similar image search facility, but the company has withdrawn its podcast search system. Thus, CC license data is generally restricted to text documents. Despite the maturing of the public search systems’ services, queries for certain file types are less robust than text queries. It is worth noting that Google’s “advanced search” functions allow a user to search for text within Microsoft Word files, Adobe PDF files, Adobe Postscript files, and a handful of others. While encouraging, more work is needed to even the search playing field for content in certain file types. Although progress is being made, the present CC license method is perceived by some as too complex to use for both text file and binary files. For the CC license method to gain more adherents, the CC licensing framework begs for improvements and enhancements for users, web search systems, and digital libraries.
We will turn our attention to the CC license in Section 2 of this paper. We aim to allow the reader to understand the basic concept of CC license and want to call attention to the problems and difficulties of the current CC licensing framework, which we will discuss in Section 3. We will place emphasis on searching and “pulling out” or limiting a result set to CC licensed files. Next, we propose a new protocol, called the CC File Extension (CCFE). Our research suggests that the CCFE will help address the challenges and complexities of the present CC license. Finally, we will discuss some unsolved problems and suggest some additional issues that invite future research. Overview of CC License
Creative Common (CC) is an organization which designed the CC license (Creative Commons, 2002). It gives authors a way to grant some or all of their copyrights to the public. The first CC licenses appeared in December 2002. The guiding principle of the CC license is to complement copyright law rather than competing with it (Lessig, 2004). The present CC license can be used in a wide variety of works, including audio, video, images, and texts. The first option is called the “Commons Deed.” This CC license is a basic, human-readable, plain-language summary that states what a user may do with the content. The second option is called the “Legal Code.” This CC license is an
Google Yahoo!
Number of all pages CC only Number of all pages CC only 20 billion 58,500,000 20 billion 18,400,000 Table I.
The number of web pages and CC page in Yahoo! and Google (on 2007/6/3)
EL
27,1
authentication document. It uses formal and explicit legal terms. The “Legal Code” gives the scope of licensing for a work. The third option is the “Digital Code.” This CC license is machine-readable metadata or a “digital signature” of the license. A software robot can process these metadata and tag the document as governed by the CC license. The key point is that an author may use one of these options, or mix and match them to suit the author’s needs. Figure 1 shows an example of CC license of a document in all three ways.
The conditions of the CC license can be categorized into three types. First, there is Permission which describes the rights granted by the license. Second, there is Prohibition, which states those actions prohibited by the license. Finally, there is the Requirement, which describes restrictions imposed by the license. Mixing and matching all these conditions produces a number of different combinations. The CC license is considered much easier to use and understand than other licenses, like GPL (Lin et al., 2006). In addition, the CC license’s official web site provides an online license software “wizard” to help authors to choose the most appropriate license. The author answers three questions about the rights they want to grant (Creative Commons, 2007). To sum up, the CC license seeks to notify the user that the CC licensed work is available. However, certain rights have been reserved. From this perspective, the CC licensed works are distinguished from the public domain works (Loren, 2007). Problems of current CC license framework
The three formats of CC license framework – commons-deed, legal-code and digital-code – are sufficient to cover most of the needs of readers, law experts and computer programs. Nevertheless, the present CC license contains some roadblocks that now hamper the spread of CC license (Gonza´lez, 2006). In this section, we will identify several issues in the CC license. We want to focus on the digital-code, since that is most relevant to automatically-constructed digital collections.
In general, the digital-code of the CC license takes the form of HTML tags embedded in the body of a CC licensed document (Wikipedia, 2007a). The following example shows a section of the digital-code for the “Attribution-Noncommercial-Share Alike” CC license:
, a rel ¼ “license” href ¼ “http://creativecommons.org/licenses/by-nc-sa/3.0/us/” . , img alt ¼ “Creative Commons License” style ¼ “border-width:0” src ¼ “http://i. creativecommons.org/l/by-nc-sa/3.0/us/88x31.png” /.
, /a .
Figure 1. An example of the three formats of CC license
Digital copyright
on the internet
, br / . This work is licensed under a , a rel ¼ “license”
href ¼ “http://creativecommons.org/licenses/by-nc-sa/3.0/us/” . Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States License , /a . .
Our research has revealed three “issues” with the CC license’s approach to digital-code. First, authors may find the syntax of the code too complex or too time consuming to create and embed in a work. The modest use of the CC license is stark evidence that this is a significant barrier to most authors. Next, the syntax is not easily portable in binary files. Finally, a search engine such as Google’s Googlebot can not easily identify the CC license tag in a binary file without file transformation. File transformation adds to the computational cost of indexing and is not generally looked on with favor by commercial enterprises. Let’s look at each issue in more depth.
Problem 1: The syntax of digital-code in CC is too complex for people to write
Based on the sample of digital-code above, non-programmers will be baffled by the syntax in the code snippet. In fact, CC’s designers are aware of this issue. The CC license’s web site provides a user-friendly tool that can generate the needed digital-code. Once the code has been produced, an author needs to cut and paste the generated digital-code into their files. The syntax of the CC license code is meant for an indexing subsystem, not a human. Some humans may be uncomfortable with the extra step the CC license system requires to place the needed instructions in a document file. Problem 2: It is hard to embed CC license into binary files
Anchored in hypertext mark-up language (HTML) and its variants, the digital-code of the CC license is text. Embedding text in a binary file is problematic. The file may be corrupted, or a conversion process is needed which adds another manual step to the process. Therefore, the CC license does not address the issue of placing the instructions in an audio, video, PDF, or Microsoft PowerPoint files. At this time, there are two methods to describe the CC license for binary files. The first method is an author may use a software program such as CcPublisher to embed CC license declaration segment into the body of a binary file (CcPublisher, 2007). The second one is not recommended by CC organization: the author embeds the digital-code into a host HTML or XML file and the host file calls the binary file type (Flickr, 2004). A software robot “reads” the host file and then accesses the binary file pointed to in the HTML or XML “wrapper”. The obvious problem with the first work around is that the author must handle the additional processes manually. The second work around creates a problem with what we call “portability”. When a user copies the binary file, the wrapper or host file can be detached, thus the CC license is disconnected from the binary component.
Problem 3: Most search engines cannot search CC licensed binary files
Even as problematic as the hurdles put in the path of the author wanting to use the CC license for binary files, indexing robots launched by Google, Microsoft, and Yahoo!, among others, are not programmed to recognize the CC license embed in a binary file. Today, these robots are “blind” to embedded CC license information. Of course, it is possible to design a search engine which can process the license description in the host HTML files. Commercial search engines have certain priorities, and, at this time, adding support for embedded CC license data in binary files is not an urgent matter.
EL
27,1
For example, on 4 December 2007, we used Google’s CC search interface to search for CC licensed PDF files. Although there are 790 articles found in the search results, none of the documents in the result list is a Adobe PDF file. The result list includes only the files with a URL ending in “PDF”. Obviously, the CC license is rare in binary files. Google is either not able to recognize or does not process included CC license data. In fact, at this time, we cannot retrieve any CC licensed Adobe PDF or Microsoft PowerPoint (PPT) file in Google. A digital library wanting to search for documents with a CC license cannot perform this function with Google’s, Microsoft’s or Yahoo!’s syntax. It goes without saying that this technical limitation in the search engines restricts the development of CC license and online digital libraries.
Resolving problems with CC file extension protocol
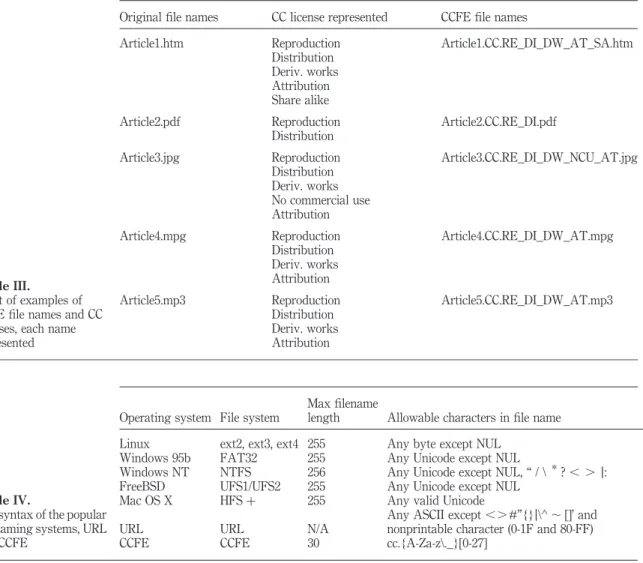
In order to resolve the above problems, we wish to propose a new protocol called the CC File Extension (CCFE). In the CCFE method, the CC license is embedded into the file name, not the body of the file. The method applies to any file type, not just binary files. Both people and programs can read the file extension and access the CC license information. The CC license information is therefore preserved in the process of duplication and transmission. The method addresses the problem of license portability. In order to embed CC license into file names, we propose a set of abbreviations to express the CC license’s conditions. A CC condition can be expressed as two letters. For example, the abbreviation of “CU” at column 2 in Table II means “Allow commercial-use” of this file. A negative condition can be expressed by prefixing the letter “N” to the appropriate two letter code. The letter “N” is a mnemonic to help the author and may be interpreted as a “no”. For example, “NCU” means “Commercial- use is not allowed. “NDW” means the author does not allow anyone to adapt his works. A ”DW” means any user modification of the file is allowed. Table II shows the set of abbreviations to express the CC license’s conditions.
CCFE extends each file name with a CC license part. The CC license part is a file extension with the “.CC. , conditions_list . ” syntax. The , condition_list . part in CCFE is a list of conditions. For example, the string ClintonDebate. CC.RE_DI_DW_AT.mpg makes explicit the author’s intentions regarding reuse. Each condition is separated with an underline “_”. Therefore, a file with “.CC.RE_DI_DW_NCU” license part means this CC licensed file is in the condition “the author allows reproduction, distribution and modification, but commercial usage is disallowed”. The Only limitation of our method is that the CCFE only works on file
Conditions Permitted abbreviation Prohibited abbreviation
Reproduction RE NRE
Distribution DI NDI
Derivative works DW NDW
Commercial use CU NCU
Notice NO NNO
Attribution AT NAT
Share alike SA NSA
Source code SC NSC
Table II. A table of letters and icons representing CC conditions
Digital copyright
on the internet
systems which support a long file name. Table III shows additional examples of CCFE file names
Since there are only two special symbols used in CCFE: the period symbol “.” and the underline symbol “_”, our method is compatible with most widely spread operating systems, such as UNIX, Linux, Apple OS X, and Microsoft Windows. Furthermore, CCFE may also be inserted into a URL without an encoding step.
Table IV provides several examples of the method in the syntax of popular file systems. First, the maximum length of the CC condition element in CCFE is only 30 letters (27 for the combination of all conditions and three for the heading “cc.”). There are some variations in the maximum length of file names in each operating system (Wikipedia, 2007b). For most modern operating systems, the maximum file length is longer than 255. We believe that the CCFE extensions require a modest portion of the
Original file names CC license represented CCFE file names
Article1.htm Reproduction Distribution Deriv. works Attribution Share alike Article1.CC.RE_DI_DW_AT_SA.htm Article2.pdf Reproduction Distribution Article2.CC.RE_DI.pdf Article3.jpg Reproduction Distribution Deriv. works No commercial use Attribution Article3.CC.RE_DI_DW_NCU_AT.jpg Article4.mpg Reproduction Distribution Deriv. works Attribution Article4.CC.RE_DI_DW_AT.mpg Article5.mp3 Reproduction Distribution Deriv. works Attribution Article5.CC.RE_DI_DW_AT.mp3 Table III. A set of examples of CCFE file names and CC licenses, each name represented
Operating system File system
Max filename
length Allowable characters in file name
Linux ext2, ext3, ext4 255 Any byte except NUL Windows 95b FAT32 255 Any Unicode except NUL
Windows NT NTFS 256 Any Unicode except NUL, “ / \ *? , . j:
FreeBSD UFS1/UFS2 255 Any Unicode except NUL Mac OS X HFS þ 255 Any valid Unicode
URL URL N/A
Any ASCII except , . #”{}j\^ , []’ and nonprintable character (0-1F and 80-FF) CCFE CCFE 30 cc.{A-Za-z\._}[0-27]
Table IV.
The syntax of the popular file naming systems, URL and CCFE
EL
27,1
filename of these operating systems. URLs have no file name length restriction in the RFC1738 standard. Most browsers and web servers have some restrictions in practice, but the maximum filename length is always longer than 255 (RFC1738, 1994). So the CCFE filename length is not material in the internet environment. Second, the last column in Table IV shows the allowable characters in directory entries. Most modern file systems allow dot and underline symbol and most operating system allow dot and underline symbol in the interface of file system. There is no prohibited letter in CCFE. CCFE is, therefore, compatible with Linux, Microsoft Windows, BSD, and internet file and path naming conventions.
The application of CCFE
Using general purpose search engines to search CCFE license
The designers of search engines pay most of their attention on returning relevant results quickly (Brin and Page, 1998; Yang et al., 2007). General purpose search engines have not been designed to meet the needs of professional researchers. Sometimes specialists need to search for specific topics and may have to locate documents suitable for inclusion in a digital archive, inclusion in a collection, distribution to students, or modification. For example, architects working for a construction company may need images of other structures to include in a brochure about a new building. Ideally, an architect could use a search engine like Microsoft Live or Google to locate images. However, to locate a CC licensed pictures which permit commercial use, web search engines are almost useless. Nevertheless, if CC license conditions are embedded in the CCFE file name as we propose, the architect can use existing search engines’ advanced search functions to limit the query to images and other binary files with a CC license. To verify the efficacy of our approach, we put 25 CCFE named files, including 22 PDF files and three DOC files, on our web site http://ccc.kmit.edu.tw/ as test data. We allowed 30 days to elapse so that the Googlebot had time to index these files. When the files appeared in the Google index, we designed and ran different queries using the Google search syntax. The queries we tested were:
. The first query is “di site:ccc.kmit.edu.tw”. This query asks Google to look in our
web site for files CCFE file names which authorize users to distribute content. Google located six files, but only three of them are CCFE named files; the other three were files which contained the string “di”. We were able to scan the result list and identify the CCFE files by their file names.
. Then we created the query for rights to reproduce and distribute the files. . At last, we created the query for permission to share and reproduce content.
Google’s engine allowed us to locate the matching files. Table V presents all the searching queries and results. Our test shows that a public search engine – in this case Google – allows users to pinpoint CCFE compliant file names.
Query Query for Google Result file number CCFE file
Query1 di site:ccc.kmit.edu.tw 6 3
Query2 re di site:ccc.kmit.edu.tw 3 2
Query3 re sa site:ccc.kmit.edu.tw 4 2
Table V. Querying Google for the test CCFE files
Digital copyright
on the internet
Therefore, if people obey the CCFE name conventions for CC licensed files, the limitations of the present CC license method are overcome. More importantly, the hurdles of copying strings, the complexity of converting the license for binary files, or the work around involving a separate HTML or XML file are eliminated.
Applications for digital libraries
The usefulness of this proposed method for digital libraries is obvious. Furthermore, we are confident that most authors familiar with the CC license can create a CCFE file name. No tools are needed other than the information presented in this article. For a user unable to create a file name, we can envision a simple web forms that allows the user to click on the rights. The web page then displays the file name for these choices. The file name approach requires no changes to search engine crawlers. Authors can explicitly present rights without complex steps. The method allows any user to locate CC licensed files regardless of the file type.
A digital library can automate the acquisition of CC licensed files, confident that no copyright violations will be inadvertently made. Librarians can effectively and correctly categorize these documents by the rights explicitly granted by the authors. CCFE allows online multimedia digital libraries to be assembled with text, images, and other information objects.
Conclusion and future works
A librarian experienced with online digital collection development will understand the scope and implications of our method of implementing a CC license. As we mentioned above, the implementation method of the current CC licensing framework is too complex to be widely used. CCFE attaches the license data via the file name itself. Most search engines can allow users to limit their queries to CC license files without any changes to their existing software or systems. Finally, CCFE works on text and binary files, a feature simply not supported by the present CC license method.
Keeping the disadvantages of the CC license in mind, we proposed the CCFE protocol for authors to publish the file on web in CC license. CCFE is much easier and clearer than the original CC license. Once the files in CCFE are published on the web, digital library applications, such as Citeseer, can get all these files for people to read, reproduce, and modify, without undo concern about potential legal problems. Online digital libraries based on CCFE need require significant effort. Furthermore there are some legal issues swirling around the notion of the CC license (Loren, 2007); nevertheless, we believe CCFE can play important role in the future.
References
Blake, M. (2004), “Archive of web sites”, The Electronic Library, Vol. 22 No. 5, p. 462.
Brin, S. and Page, L. (1998), “The anatomy of a large-scale hypertextual web search engine”, Proceedings of the 7th International World Wide Web Conference, Brisbane, Australia, April 14-18, 1998, available at: http://citeseer.ist.psu.edu/brin98anatomy.html (accessed July 3, 2007).
CcPublisher (2007), available at http://wiki.creativecommons.org/CcPublisher (accessed 3 December 2007).
Citeseer.ist (1997), available at: http://citeseer.ist.psu.edu/ (accessed 3 July 2007).
EL
27,1
ClikZ Network (2007), US Search Engine Rankings, September 2007, available at: www.clickz. com/3627655 (accessed 3 December 2007).
Creative Commons (2002), History, available at http://creativecommons.org/about/history (accessed 3 July 2007).
Creative Commons (2007), available at http://creativecommons.org/license/?lang ¼ en (accessed 3 July 2007).
Field, B.A. (2006), Blake A. Field v. Google Inc., available at: http://w2.eff.org/IP/blake_v_google/ google_nevada_order.pdf (accessed July 3, 2007).
Flickr (2004), available at www.flickr.com/creativecommons/ (accessed 3 July 2007).
Free Software Foundation (1989), “General Public License – GPL”, available at www.gnu.org/ copyleft/gpl.html (accessed 3 July 2007).
Free Software Foundation (2000), GNU Free Documentation License, available at www.gnu.org/ licenses/fdl.html (accessed 3 July 2007).
Giles, C.L., Bollacker, K.D. and Lawrence, S. (1998), “CiteSeer: an automatic citation indexing system”, Proceedings of the 3rd ACM International Conference on Digital Libraries, Pittsburgh, PA, June 23-26, 1998, available at: http://citeseer.ist.psu.edu/giles98citeseer. html (accessed July 3, 2007).
Gonza´lez, A.G. (2006), “Open science: open source licenses in scientific research”, N.C. J.L. & Tech, Vol. 7 No. 2, pp. 11-26.
Google (2007), available at www.google.com/advanced_search?hl ¼ en (accessed 3 July 2007). Lessig, L. (2004), Free Culture: How Big Media Use Technology and the Law to Lock Down Culture
and Control Creativity, Penguin Press, New York, NY.
Lin, Y.H., Ko, T.-M., Chuang, T.-R. and Lin, K.-J. (2006), “Open source licenses and the creative commons framework: license selection and comparison”, Journal of Information Science and Engineering, Vol. 22 No. 2, pp. 1-17.
Loren, L.P. (2007), “Building a reliable semicommons of creative works: enforcement of creative commons licenses and limited abandonment of copyright”, George Mason Law Review, Vol. 14 No. 2, p. 271.
Raghavan, S. and Garcia-Molina, H. (2001), “Crawling the hidden web”, Proceedings of the 27th International Conference on Very Large Data Bases (VLDB), Rome, 11-14 September, 2001, available at: http://dbpubs.stanford.edu:8090/pub/2000-36 (accessed July 3, 2007). RFC1738 (1994), available at ftp://ftp.rfc-editor.org/in-notes/rfc1738.txt (accessed July 3, 2007). Wikipedia (2001), GNU Free Documentation License, available at http://en.wikipedia.org/wiki/
GNU_Free_Documentation_License (accessed 3 July 2007).
Wikipedia (2007a), “Resource description framework”, available at http://en.wikipedia.org/wiki/ Resource_Description_Framework (accessed 3 December 2007).
Wikipedia (2007b), “Comparison of file systems”, available at: http://en.wikipedia.org/wiki/ Comparison_of_file_systems (accessed 3 December 2007).
Yahoo! (2007), available at: http://search.yahoo.com/cc (accessed 3 July 2007).
Yang, C., Yang, K-C. and Yuan, H-C. (2007), “Improving the search process through ontology-based adaptive semantic search”, The Electronic Library, Vol. 25 No. 2, p. 234.
About the authors
Chyan Yang received his PhD in Computer Science from the University of Washington, Seattle. He also holds a Master in Information Science from Georgia Institute of Technology, a MBA in Management Science from National Chiao Tung University and received his BS in EE from
Digital copyright
on the internet
National Chiao Tung University. Between 1987 and 1992 he worked as an assistant professor in the Department of Electrical and Computer Engineering at the US Naval Postgraduate School at Monterey, California. From 1992-1995 he was with the Institute of Management Science, National Chiao Tung University, Taiwan as an associate professor. Chyan Yang is now a Professor in the Institute of Business and Management, National Chiao Tung University, Taiwan. He has been an IEEE senior member since 1992 and has worked as an adviser to several IT companies. With more than 60 journal papers and 90 conference papers published, his current research interests include information management, and strategic management.
Hsien-Jyh Liao is a PhDstudent of Institute of Information Management, National Chiao Tung University. He also received his BS and Master degrees in Computer and Information Science from National Chiao Tung University. He holds a Master in Law from SooChow University. Then he passed the bar exam and, since 2001, he has been a prosecutor, serving in the Taoyuan District Prosecutor Office, Taiwan.
Chung-Chen Chen received his PhD and MS degree in Computer Engineering from the National Taiwan University, Taiwan. He also received his BS in Computer and Information Science from National Chiao Tung University. Chung-Chen Chen is now an assistant professor in the Information Management Department, National Kinmen Institute of Technology, Taiwan. His recent research interests are network programming and information retrieval).
EL
27,1
30
To purchase reprints of this article please e-mail: reprints@emeraldinsight.com Or visit our web site for further details: www.emeraldinsight.com/reprints