應用平行語料建構中文斷詞組件 - 政大學術集成
86
0
0
全文
(2) 應用平行語料建構中文斷詞組件 Applications of Parallel Corpora for Chinese Segmentation. 研 究 生:王瑞平. Student:Jui-Ping Wang. 指導教授:劉昭麟. Advisor:Chao-Lin Liu. 資訊科學系 碩士論文. y. ‧. Nat. A Thesis. 學. ‧ 國. 立. 治 國立政治大學 政 大. io. sit. submitted to Department of Computer Science. er. National Chengchi University. a. n. v l C in partial fulfillment of the requirements ni hfore the n gdegree c h i Uof Master in Computer Science. 中華民國一百零一年八月 Aug 2012.
(3) 致謝. 在作為研究生的這兩年中,體驗到了許多大學時未曾接觸過的新事物,也學習到了不少 新知識。首先我要感謝我的指導教授 劉昭麟老師;對於不夠主動積極的我,是老師讓 我瞭解主動積極的態度的重要性。在作研究方面,謝謝老師不厭其煩地糾正我所犯下的 許多錯誤,並引導我到正確的方向。真的很感謝老師這兩年來的教誨與照顧。. 政 治 大 學長、裕淇學長與怡軒學姐,在我遇到挫折時,因為有學長姐的鼓勵,所以使我能繼續 立. 在 MIG 實驗室度過的這段時間,感謝各位 MIG 成員對我的關懷與照顧。謝謝建良. ‧ 國. 學. 向前邁進。謝謝同學柏廷、家琦,當我在課業或研究等事情上遇到困難時,總是能給予 我最大的幫助。謝謝學弟瑋杰、孫暐的關心與在實驗室的大小事情上的協助。謝謝大學. Nat. y. ‧. 部成員的恰恰、刀片、翅膀、鴻源的幫忙。. sit. 然後我要感謝媽媽對我無微不至的照顧;聽到妳對我說「早點休息」時,心裡總是. al. n 最後也感謝口試委員. er. io. 覺得很溫暖。也謝謝姊姊給我的鼓勵,讓我能更堅定地朝完成研究所學業的目標前進。. v i n 高照明老師 的指導。 C h 與 張嘉惠老師 engchi U 2012 年 7 月. 王瑞平. 機器智能實驗室. i.
(4) 應用平行語料建構中文斷詞組件. 摘要. 在本論文,我們建構一個基於中英平行語料的中文斷詞系統,並 透過該系統對不同領域的語料斷詞。提供我們的系統不同領域的 治. 政. 大. 立 中英平行語料後,系統可以自動化地產生品質不錯的訓練語料,. ‧ 國. 學. 以節省透過人工斷詞方式取得訓練語料所耗費的時間、人力。. ‧. 在產生訓練語料時,首先對中英平行語料中的所有中文句,. Nat. io. sit. y. 透過查詢中文辭典的方式產生句子的各種斷詞組合,再利用英漢. er. 翻譯的資訊處理交集型歧異,將錯誤的斷詞組合去除。此外本研. al. n. v i n Ch 究從中英平行語料中擷取新的中英詞對與未知詞,並分別將其擴 engchi U 充至英漢辭典模組與中文辭典模組,以提升我們的系統之斷詞效 能。 我們透過兩部分的實驗進行斷詞效能評估,而在實驗中會使 用三種不同領域的實驗語料。在第一部分,我們以人工斷詞的測 試語料進行斷詞效能評估。在第二部分,我們藉由漢英翻譯的翻. ii.
(5) 譯品質間接地評估我們的系統之斷詞效能。由實驗結果顯示,我 們的系統可以有一定的斷詞效能。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. iii. i n U. v.
(6) Applications of Parallel Corpora for Chinese Segmentation. Abstract. In this paper, we construct a Chinese word segmentation system which based on Chinese-English Parallel Corpus to save time and manpower, and the corpora in. 政 治 大. different domains can be segmented by our system.. 立. By providing Chinese-English Parallel Corpus to our system, training. ‧ 國. 學. corpus can be automatically produced by our system. Then segmentation model. ‧. can be trained with the produced training corpus. We use Chinese translation of. sit. y. Nat. words in English parallel sentences to solve overlapping ambiguity. We extract. io. er. translation pairs and unknown words from Chinese-English Parallel Corpus. In evaluation, two different experiments are conducted, and experimental. al. n. v i n data in three domains are C used segmentation performance in two U h etonevaluate i h gc. experiments. In the first experiment, manually annotated Chinese sentences are used as testing data. In the second experiment, segmentation performance is indirectly indicated by translation quality. Experimental results show that our system achieves acceptable segmentation performance.. iv.
(7) 目錄 第一章 緒論 .......................................................................................................................... 1 1.1 研究背景與動機 ........................................................................................................ 1 1.2 研究方法 .................................................................................................................... 2 1.3 論文架構 .................................................................................................................... 3. 政 治 大. 第二章 文獻探討 ................................................................................................................. 5. 立. 2.1 中文斷詞之相關研究 ................................................................................................ 5. ‧ 國. 學. 2.1.1 法則式斷詞法之相關研究 .............................................................................. 5. ‧. 2.1.2 統計式斷詞法之相關研究 .............................................................................. 5. y. Nat. al. er. io. sit. 2.1.3 斷詞歧異性問題與未知詞問題之相關研究 .................................................. 8. v. n. 2.1.4 斷詞標準不一問題之相關研究 ...................................................................... 8. Ch. engchi. i n U. 2.2 基於英漢雙語平行語料進行斷詞的相關研究 ........................................................ 9. 第三章 系統架構 ............................................................................................................... 11 3.1 系統流程與架構 ...................................................................................................... 11 3.2 斷詞模型訓練工具 .................................................................................................. 12. 第四章 辭典模組介紹與加入近義詞 .......................................................................... 13 4.1 辭典模組介紹 .......................................................................................................... 13. v.
(8) 4.2 加入近義詞之英漢合併辭典建置 .......................................................................... 14 4.2.1 利用一詞泛讀尋找近義詞 ............................................................................ 14 4.2.2 利用E-HowNet尋找近義詞 .......................................................................... 15 4.2.3 辭典建置流程 ................................................................................................ 22. 第五章 產生訓練語料 ...................................................................................................... 23. 政 治 大 5.2 利用英漢翻譯的資訊處理交集型歧異 .................................................................. 26 立 5.1 產生各種斷詞組合 .................................................................................................. 23. ‧ 國. 學. 5.3 擷取中英詞對與未知詞 .......................................................................................... 28. ‧. 5.3.1 擷取「候選中英遺留詞對」與「候選中文遺留字詞」 ............................ 28. sit. y. Nat. 5.3.2 利用可能性比例與共現頻率進行篩選 ........................................................ 29. er. io. 5.3.3 利用詞性序列規則進行篩選 ........................................................................ 32. al. n. v i n Ch 實驗結果與分析 ................................................................................................. 36 engchi U. 第六章. 6.1 實驗語料來源 .......................................................................................................... 36 6.2 擷取中英詞對與未知詞之實驗 .............................................................................. 38 6.2.1 擷取中英詞對之實驗 .................................................................................... 38 6.2.2 擷取未知詞之實驗 ........................................................................................ 41 6.3 以人工斷詞測試語料評估斷詞效能之實驗 .......................................................... 45 6.3.1 實驗流程設計 ................................................................................................ 46 vi.
(9) 6.3.2 實驗結果與分析 ............................................................................................ 49 6.4 以漢英翻譯的翻譯品質評估斷詞效能之實驗 ...................................................... 54 6.4.1 實驗流程設計 ................................................................................................ 55 6.4.2 實驗結果與分析 ............................................................................................ 57. 第七章 結論與未來展望 ................................................................................................. 62. 政 治 大 7.2 未來展望 .................................................................................................................. 63 立 7.1 結論 .......................................................................................................................... 62. ‧ 國. 學. 參考文獻 ............................................................................................................................... 65. ‧. 附錄Ι 不同領域語料之斷詞效能(以詞數表示) .............................................. 70. sit. y. Nat. io. n. al. er. 附錄Ⅱ 口試問題與建議之記錄 ................................................................................... 72. Ch. engchi. vii. i n U. v.
(10) 圖目錄. 圖 3.1 系統的流程與架構 ....................................................................................................... 11 圖 4.1 輸入“quietness”的中文翻譯後一詞泛讀回傳之近義詞群 ........................................ 15 圖 4.2 E-HowNet 詞彙的定義結構之範例一 ......................................................................... 16. 政 治 大. 圖 4.3 E-HowNet 詞彙的定義結構之範例二 ......................................................................... 16. 立. 圖 4.4 義原於{entity|事物}中的距離之範例 ........................................................................ 18. ‧ 國. 學. 圖 4.5 計算𝑊𝑓之範例詞彙 .................................................................................................... 19. ‧. 圖 4.6 計算詞彙相似度之兩種情形的範例 .......................................................................... 21. y. Nat. er. io. sit. 圖 4.7 藉由表示式相似度計算取得中文翻譯近義詞集之流程 .......................................... 22 圖 5.1 產生句子的各種斷詞組合的步驟 .............................................................................. 23. n. al. Ch. engchi. i n U. v. 圖 5.2 產生「貼近市場需求,」之 Vi .................................................................................. 24 圖 5.3 各階段的 Candi 的內容 ............................................................................................... 25 圖 5.4 處理交集型歧異的整體流程 ...................................................................................... 27 圖 5.5 建立詞性序列規則表的步驟 ...................................................................................... 33 圖 5.6 利用詞性序列規則篩選候選中文遺留字詞之範例 .................................................. 35 圖 6.1 產生訓練語料之方式 .................................................................................................. 46 圖 6.2 加入的未知詞與辭典詞彙衝突的情況下對斷詞結果之影響 .................................. 52 viii.
(11) 圖 6.3 在訓練斷詞模型時加入辭典與未加入辭典的情況下所得之斷詞結果 ................... 53 圖 6.4 得到斷詞模型的流程 .................................................................................................. 55 圖 6.5 測試語料與英漢訓練語料之中文句的斷詞流程 ...................................................... 56 圖 6.6 得到翻譯結果的流程 .................................................................................................. 56. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. ix. i n U. v.
(12) 表目錄. 表 4.1 中文辭典模組之辭典詞彙數統計 .............................................................................. 13 表 4.2 英漢辭典模組之辭典詞彙數統計 .............................................................................. 13 表 5.1 PAT-tree 抽詞程式所擷取出之結果 ........................................................................... 29. 政 治 大. 表 5.2 候選中英遺留詞對之共現頻率與−2logλ對應表 ...................................................... 31. 立. 表 5.3 詞性序列規則表的內容格式 ...................................................................................... 34. ‧ 國. 學. 表 6.1 實驗語料句數統計 ...................................................................................................... 36. ‧. 表 6.2 繁體中文類型的實驗語料之統計 .............................................................................. 36. y. Nat. al. er. io. sit. 表 6.3 Chinese Broadcast Conversation Parallel Text - Part 1、Part 2 語料之統計資料....... 37. v. n. 表 6.4 候選中英遺留詞對數量統計 ...................................................................................... 38. Ch. engchi. i n U. 表 6.5 以不同的共現頻率作為門檻值之篩選結果(新聞語料) ...................................... 39 表 6.6 以不同的共現頻率作為門檻值之篩選結果(科學人) .......................................... 39 表 6.7 以不同的共現頻率作為門檻值之篩選結果(廣播會話語料) .............................. 39 表 6.8 以不同的共現頻率作為門檻值之篩選結果(C300) ............................................. 40 表 6.9 以不同的共現頻率作為門檻值之篩選結果(C220) ............................................. 40 表 6.10 被加入至英漢辭典模組的各語料之候選中英遺留詞對 ........................................ 41 表 6.11 候選中文遺留字詞數量統計 .................................................................................... 42 x.
(13) 表 6.12 以通過不同門檻值之詞性序列規則進行篩選的結果(新聞語料) .................... 43 表 6.13 以通過不同門檻值之詞性序列規則進行篩選的結果(科學人) ........................ 43 表 6.14 以通過不同門檻值之詞性序列規則進行篩選的結果(廣播會話語料) ............ 43 表 6.15 以通過不同門檻值之詞性序列規則進行篩選的結果(C300) ........................... 44 表 6.16 以通過不同門檻值之詞性序列規則進行篩選的結果(C220) ........................... 44 表 6.17 被加入至中文辭典模組的各語料之候選中文遺留字詞 ........................................ 45. 政 治 大 表 6.18 不同領域語料之斷詞效能 ......................................................................................... 48 立. ‧ 國. 學. 表 6.19 未利用與利用英漢翻譯資訊處理交集型歧異所得到之斷詞結果 ......................... 50 表 6.20 未加入與加入未知詞與中英詞對所得到之斷詞結果 ............................................. 51. ‧. sit. y. Nat. 表 6.21 Tseng.PatentMT 的結果之翻譯品質 ......................................................................... 57. n. al. er. io. 表 6.22 C300、C220 之漢英翻譯實驗結果 ........................................................................... 58. i n U. v. 表 6.23 科學人、新聞語料、廣播會話語料之漢英翻譯實驗結果 .................................... 59. Ch. engchi. xi.
(14) 第一章 緒論. 1.1 研究背景與動機. 詞為最小有意義且能夠自由運用的語言單位[2],而英文與中文在取得句子中的詞的方法 上有所不同:在英文可以用空白去斷出英文句中的各個詞,中文則需要透過斷詞這個步. 政 治 大 料進行中文斷詞處理才能進行後續的工作,所以對於中文自然語言處理,中文斷詞是一 立 驟來取得中文句中的各個詞。因為在機器翻譯、資訊檢索等相關領域上,都需要先對語. 項非常重要且基礎的工作。. ‧ 國. 學. 中文斷詞技術大致上可以分為法則式斷詞法以及統計式斷詞法。近來許多採用統計. ‧. 式斷詞法的研究,都能獲得不錯的斷詞效能。不過統計式的斷詞法在訓練斷詞模型時會. sit. y. Nat. 需要大量的訓練語料,而因為通常透過人工斷詞所得到的訓練語料才能有較高的品質,. al. er. io. 所以高品質的訓練語料往往不易取得。此外在不同的需求下,使用者可能會提供不同領. v. n. 域的語料給斷詞系統,所以一個中文斷詞系統會需要對不同領域的語料皆有不錯的斷詞. Ch. engchi. i n U. 效能。但若是使用某一個領域的語料所訓練出的斷詞模型,去對其他不同領域的測試語 料進行斷詞的話,可能會因為斷詞模型與其他不同領域的測試語料之間的性質差異大, 導致斷詞效能不佳。因此本研究建構一個基於中英平行語料的斷詞系統;提供我們的系 統各個不同領域之中英平行語料,就可自動化地得到品質不錯之訓練語料,以節省透過 人工斷詞得到訓練語料所需的大量人力與時間;之後該系統會利用所得之訓練語料去訓 練斷詞模型,並以斷詞模型對該領域的語料進行斷詞。 中文斷詞存在以下兩個重要問題:斷詞歧異性問題、未知詞問題。斷詞歧異性問題 是指當一個中文字串可以被斷成數種的斷詞組合時,則包含該字串的句子在斷詞後可能 會被斷成不符合句意的錯誤斷詞結果,進而影響斷詞效能。斷詞歧異性問題包含組合型 1.
(15) 歧異(combination ambiguity)和交集型歧異(overlapping ambiguity),在本研究中我們只著 重處理交集型歧異。交集型歧異是當一個中文字串「ABC」可以被斷成「AB/C」及「A/BC」 時(A、B、C 皆為單一中文字,AB 與 C 之間的斜線代表詞彙間的斷詞點) ,則「AB」、 「BC」會有共同的交集「B」,如此就會形成交集型歧異,而我們稱「ABC」為交集型 歧異字串。為了提升斷詞效能,本研究透過英漢翻譯的資訊去處理交集型歧異。未知詞 指的是未收錄於辭典中的詞彙,例如人名、地名、組織名等。在日常生活中人們會不斷 創造出新的詞彙,因此不太可能存在一部辭典能包含所有新的詞彙,故未知詞經常會出. 政 治 大 升斷詞效能,則處理未知詞問題會是必要的工作。本研究則透過詞性序列規則去篩選出 立 現在文章中。斷詞系統在對未知詞斷詞時通常會出現錯誤斷詞的情形,所以如果想要提. 未知詞。. ‧ 國. 學 ‧. 1.2 研究方法. y. Nat. sit. 我們的系統之大略架構為:首先藉由中英平行語料來自動化地得到品質不錯的訓練語. er. io. 料,並利用該訓練語料訓練斷詞模型。之後透過斷詞模型對測試語料斷詞。. al. n. v i n 在處理交集型歧異時我們會利用英文詞彙的中文翻譯進行對應;而因為英漢辭典中 Ch engchi U. 的英文詞彙之中文翻譯有限,所以為了提升利用英漢翻譯的資訊去處理交集型歧異的效 果,本研究透過 E-HowNet[24]與一詞泛讀[11]去取得英文詞彙的中文翻譯近義詞,以擴 充英文詞彙之中文翻譯數量。在產生訓練語料時,我們對中文語料中的句子,透過查詢 中文辭典的方式,得到該句的各種斷詞組合。之後利用英漢翻譯的資訊去處理交集型歧 異,將英文詞彙的中文翻譯對應到的斷詞組合視為正確斷詞組合,並去除錯誤的斷詞組 合,藉此提升訓練語料的品質。利用英漢翻譯的資訊去處理交集型歧異的原因是:透過 英文詞彙的中文翻譯,可以挑選出符合英文陳述的正確中文斷詞組合。得到訓練語料後, 我們利用 LingPipe 中文斷詞器[31]及史丹佛中文斷詞器(Stanford Chinese Segmenter)[38] 訓練斷詞模型。 2.
(16) 我們從中英平行語料中擷取未知詞,藉此處理未知詞問題,以提升我們的系統之斷 詞效能;我們從中英平行語料中擷取新的中英詞對來提升利用英漢翻譯的資訊去處理交 集型歧異的效果,並藉此提升我們的系統之斷詞效能。以下則為擷取中英詞對與未知詞 之大略流程:首先對所有中英平行句對,利用英文詞彙的中文翻譯對中文句斷詞後,在 英文句會有「英文遺留字詞」 ,中文句會有「中文遺留字詞」 。透過 PAT-tree 抽詞程式對 「中文遺留字詞」進行初步詞彙擷取並以停用詞列表過濾後,就得到「候選中文遺留字 詞」;而我們把由「英文遺留字詞」與「候選中文遺留字詞」所構成的詞對稱為「候選. 政 治 大 將通過篩選的「候選中英遺留詞對」視為正確詞對,加入至英漢辭典模組;利用詞性序 立. 中英遺留詞對」。之後利用可能性比例與共現頻率對「候選中英遺留詞對」進行篩選,. 列規則對「候選中文遺留字詞」進行篩選,將通過篩選的「候選中文遺留字詞」視為未. ‧ 國. 學. 知詞,加入至中文辭典模組。. ‧. 為了評估我們的系統之斷詞效能,本研究共使用科學文章類型的科學人、C300、C220. sit. y. Nat. 及新聞文章類型的新聞語料與會話文章類型的廣播會話語料這三種不同領域之各個語. al. er. io. 料進行實驗,而關於各種語料的來源會在後續章節詳述。本研究之實驗則分為兩大部分。. v. n. 在第一部分,因為我們沒有測試語料之斷詞標準答案,所以我們對測試語料進行人工斷. Ch. engchi. i n U. 詞以作為斷詞標準答案,並透過召回率、精確率、F1-measure 三個評估指標進行斷詞效 能評估。在第二部分,我們利用統計式機器翻譯系統「Moses」[33]進行漢英翻譯實驗, 並藉由翻譯品質的好壞,來間接地評估斷詞效能之好壞。. 1.3 論文架構. 在第一章我們介紹研究背景與動機、研究方法,第二章回顧中文斷詞之相關研究與基於 英漢雙語平行語料進行斷詞的相關研究,第三章針對辭典模組與加入近義詞之英漢合併 辭典建置進行介紹,第四章說明我們的系統的架構與介紹訓練斷詞模型的工具,第五章 詳述產生訓練語料的方法,第六章說明實驗語料的來源及介紹以人工斷詞測試語料評估 3.
(17) 斷詞效能、以漢英翻譯的翻譯品質評估斷詞效能這兩部分實驗的實驗流程與實驗結果分 析,第七章為結論與未來展望。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 4. i n U. v.
(18) 第二章 文獻探討 本章共分為兩小節。在 2.1 節回顧中文斷詞之相關研究,2.2 節介紹基於英漢雙語平行語 料進行中文斷詞的相關研究。. 2.1 中文斷詞之相關研究. 政 治 大 關研究,2.1.3 節回顧處理斷詞歧異性、未知詞問題之相關研究,2.1.4 節為斷詞標準不 立 本節共分為四個小節。在 2.1.1 節、2.1.2 節分別回顧法則式斷詞法、統計式斷詞法之相. 一問題之相關研究。. ‧ 國. 學 ‧. 2.1.1 法則式斷詞法之相關研究. y. Nat. sit. 法則式的斷詞法會利用辭典,並搭配規則進行斷詞。Chen[19]提出了利用經驗法則. n. al. er. io. (heuristic rules)處理斷詞歧異性問題的方法。該方法當斷詞歧異性問題發生時,會根. i n U. v. 據辭典及 determinative-measure compounds rule 產生以該字詞開頭的連續三個詞的所有. Ch. engchi. 詞組。產生所有詞組後,會利用六條經驗法則去挑選符合規則的詞組。. 2.1.2 統計式斷詞法之相關研究. 在統計式斷詞法中,有許多研究將中文斷詞視為字元標記的工作,而在其中較廣泛被使 用的技術有條件隨機域模型(Conditional Random Fields)、隱藏式馬可夫模型(Hidden Markov Models)、感知器(Perceptron)等。以下為統計式斷詞法之相關研究介紹。. 5.
(19) Wang 等[40]結合 character-based discriminative model 和 character-based generative model 這兩種模型以進行斷詞;該研究中提到了比起使用單一模型,如果將兩種模型結 合,能夠有更好的斷詞效能。 Jiang[28]使用 cascaded linear model 進行斷詞與詞性標記(POS tagging);cascaded linear model 為兩層的結構,在內層利用以字元為基礎的(character-based) 感知器作為核 心,並在外層的線性模型(linear model) ,將感知器的輸出結果作為特徵(feature),搭配 語言模型(language model)等其他特徵一起去訓練模型。結果顯示比起單獨使用感知. 政 治 大. 器的斷詞模型,cascaded linear model 不管在斷詞還是結合斷詞與詞性標記的工作上都能. 立. 有更好的正確率。. ‧ 國. 學. 以下介紹國內一些採用統計式的斷詞法的研究。詹嘉丞[14]提出一個針對非繁體中 文字進行處理的方法,使得斷詞系統遇到非繁體中文字也能斷詞。該研究利用判斷模組. ‧. 處理中文人名與日文人名,並將繁簡日韓漢字對應到繁體字,以便之後能使用繁體的已. y. Nat. er. io. %。. sit. 知詞進行候選詞判斷。在斷詞效能上,採用 bigram 機率模型時,F-Measure 可以達到 94.16. al. n. v i n 朱怡霖[6]採用交疊式(interleaving)方式將中文斷詞與專有名詞辨識兩項工作整合。 Ch engchi U. 與管流式(pipeline) 方式不同,採用交疊式方式,會把所有候選詞保留住,並利用人名、. 地名、組織名等辨識模組辨識出可能的候選詞,到最後再選出由候選詞組成的斷詞組合 中的最佳斷詞組合。 林筱晴[8]認為與傳統語料庫相比,web 擁有更大的資料量,且具有即時性;所以該 研究將 web 當成一個大型語料庫,將搜尋引擎所提供的 page count 作為詞頻套用至 likelihood ratio test,以辨識人名、地名、組織名這三種型態的未知詞;在斷詞歧異性問 題方面,則是利用 word-based bigram model 進行處理。. 6.
(20) 利用隱藏式馬可夫模型進行中文斷詞時,許多研究會使用外部資源或是結合其他的 機器學習演算法來提高斷詞效能。但林 千翔[9]不使用任何外部資源,而是應用特製化 (specialization)的概念,將長詞優先斷詞法與隱藏式馬可夫模型結合,使得隱藏式馬 可夫模型能夠帶有斷詞歧義性及未知詞的資訊,進而提升斷詞效能。 羅永聖[18]透過兩階段的方式進行斷詞。在第一階段,透過查詢辭典得到斷詞候選 句後,利用條件隨機域模型從斷詞候選句中去除機率較低的句子;在第二階段會利用語 言規則處理人名、二字詞拆解等問題,最後再利用條件隨機域模型選出最好的候選句做 為最後的斷詞結果。. 立. 政 治 大. 上述提到的研究中,有部分研究透過查詢辭典並搭配規則的方式來產生所有的斷詞. ‧ 國. 學. 組合[8][14][18],並在產生所有斷詞組合後,利用馬可夫 bigram 機率模型去處理斷詞歧 異性問題[8][14],或利用條件隨機域模型去處理斷詞歧異性問題[18];他們的作法是透. ‧. 過機率模型算出所有斷詞組合的機率,再選擇所有斷詞組合中機率值最高的斷詞組合作. y. Nat. al. er. io. 而是利用英漢翻譯的資訊去找出正確的斷詞組合。. sit. 為正確的斷詞組合。而與他們的作法不同,我們產生各種斷詞組合後,不透過機率模型,. n. v i n 綜觀上述所提到的各種統計式的斷詞法,幾乎都會需要使用大量的訓練語料;而因 Ch engchi U. 為現在公開提供使用的人工斷詞的訓練語料不多,所以他們所使用的訓練語料大多是中 研院平衡語料庫[3]或 SIGHAN Bakeoff 2[37]所公開的 4 種訓練語料(由中央研究院 (Academia Sinica)、香港城市大學(City University of Hong Kong)、北京大學(Peking University)及微軟亞洲研究院(Microsoft Research)所提供)。我們希望能透過系統化的 流程來自動地產生訓練語料,這樣在訓練斷詞模型時就可以不用侷限於少數幾種公開提 供使用的語料。. 7.
(21) 2.1.3 斷詞歧異性問題與未知詞問題之相關研究. 在處理斷詞歧異性問題的研究中, Li[30]等人利用非監督式(unsupervised)訓練的方 法處理交集型歧異。該研究利用非監督式的方式去訓練 Naive Bayesian 分類器,將判斷 交集型歧異的問題轉換成二元分類的問題後,搭配 ensemble learning,藉由多數的分類 器的投票結果去決定最後的斷詞結果。之後利用 5759 筆人工標記的交集型歧異字串的 測試集進行實驗,結果顯示該方法能夠有 94.3%的正確率。. 政 治 大. 以下介紹一些處理未知詞問題的研究。利用以辭典為基的斷詞法對未知詞進行斷詞. 立. 的話,未知詞會被切成幾個較小的單位,而 Chen 等人[20]觀察到大多數的未知詞的詞構. ‧ 國. 學. 中都會包含單字詞。不過單字詞除了可能是未知詞的一部份之外,也有可能是單獨使用 的已知詞。所以他們利用以語料庫為基的學習法(corpus-based learning approach)去產生. ‧. 偵測單獨使用的已知詞的規則,符合規則的單字詞為單獨使用的已知詞,而不符合規則. y. Nat. er. io. sit. 的單字詞即為未知詞的一部份。. Chen 等人[21]在 2002 年的研究中提出了一種擷取未知詞的方法;該研究在擷取未. al. n. v i n 知詞時,會針對屬於未知詞一部份的單字詞,判斷該單字詞是否可以和相鄰的詞彙進行 Ch engchi U 合併。該研究使用「形態規則」(morphological rules)與「統計規則」(statistical rules)去 擷取未知詞,並利用結構正確性(structure validity)、句法正確性(syntactic validity)、區域 一致性 (local consistency)三條準則去驗證所擷取出的結果是否為未知詞。. 2.1.4 斷詞標準不一問題之相關研究. 由於「中文詞」的定義每個人並不相同,且不同的工作可能適合不同的斷詞標準,所以 各個斷詞系統之間或各個人工標記語料庫(manually annotated corpora)之間可能擁有不. 8.
(22) 同的斷詞標準。以下介紹處理各個人工標記語料庫之間斷詞標準不一的問題之相關研 究。 為了處理人工標記語料庫之間斷詞標準不一的問題,Jiang[29]提出了自動化地將斷 詞標準轉換成另一種斷詞標準的方法。Jiang 使用以來源語料庫(source corpus)所訓練的 來源分類器(source classifier)對目標語料庫(target corpus)斷詞,將該斷詞結果作為引導資 訊(guide information),使用引導資訊與目標語料庫訓練出目標分類器(target classifier)。 之後以目標分類器將句子從來源語料庫的斷詞標準轉換成目標語料庫的斷詞標準。. 政 治 大 2.2 基於英漢雙語平行語料進行斷詞的相關研究 立. ‧ 國. 學. 在進行漢英或英漢機器翻譯時,需要先對英漢雙語平行語料中之中文語料進行斷詞,才. ‧. 能進行後續的動作,故對漢英或英漢機器翻譯工作而言,中文斷詞是重要的工作;而在. y. Nat. 進行漢英或英漢機器翻譯時,有些研究在對中文語料斷詞時會運用英漢雙語平行語料中. n. er. io. al. sit. 的英漢雙語資訊,藉此提升翻譯的品質。. v. Huang[26]使用基於chinese language model與bilingual STM的模型去進行斷詞。在訓. Ch. engchi. i n U. 練的過程,利用IBM model 2去估算翻譯機率(translation probability) 以及對列機率 (alignment probability),以建立bilingual STM。實驗結果顯示使用bilingual segmentation 演算法的召回率(recall)為0.794,比起單語(monolingual)的斷詞工具Ketitool的召回 率來得更好。在中翻英的工作上,使用bilingual segmentation演算法所得到的BLEU分數 為0.235,也優於使用Ketitool的BLEU分數(0.223)。 Ma[32]提出了一種適用於不同領域的雙語平行語料的斷詞法。該方法為:首先建立 1 對 n 關係的雙語辭典(bilingual 1-to-n dictionary),該辭典的格式為一個英文詞彙對列 至多個中文字。該研究將中文句斷成由中文字組成的字串後,再查詢 1 對 n 關係的雙語. 9.
(23) 辭典,若辭典的某詞對的英文詞彙有包含在英文句,且該英文詞彙所對列到的多個中文 字有包含在中文句,則將該多個中文字結合成一個中文詞彙。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 10. i n U. v.
(24) 第三章 系統架構 在本章我們於 3.1 節介紹我們的系統之流程與架構,於 3.2 節介紹訓練斷詞模型時所使 用的軟體工具。. 3.1 系統流程與架構. 政 治 大 介紹;首先,將從中英平行語料中所篩選出的候選中英遺留詞對擴充至英漢辭典模組, 立 本系統的整體架構與流程如圖 3.1 所示,而流程中各步驟的詳細說明會在後續章節加以. 將從中英平行語料中所篩選出的候選中文遺留字詞擴充至中文辭典模組。提供本系統中. ‧ 國. 學. 英平行語料後,我們透過查詢中文辭典模組中的辭典之方式,對語料中的每一句中文句. ‧. 產生該句的各種斷詞組合。而為了得到較少錯誤的訓練語料,我們藉由查詢英漢辭典模. n 中英平行語料. 英漢辭典模組. 中文辭典模組. i n U. v. 利用英漢翻譯資訊去處理 交集型歧異,並去除錯誤 斷詞組合. C產生斷詞組合 hengchi. 英文句. 訓練斷詞模型 LingPipe中文斷詞器 或 史丹佛中文斷詞器. (b). 未斷詞之中文 測試語料. 候選中英 遺留詞對. er. io. al. 中文句. sit. y. Nat. 候選中文 遺留字詞. (a). 斷詞模型. 斷詞後待評 估之語料. 斷詞模型. 圖 3.1 系統的流程與架構 11. 訓練語料.
(25) 組中的辭典之方式來利用英漢翻譯的資訊去處理交集型歧異,將所產生的斷詞組合中的 錯誤斷詞組合去除。得到訓練語料後,我們利用 LingPipe 中文斷詞器及史丹佛中文斷詞 器訓練斷詞模型;透過上述兩種工具去訓練斷詞模型時,除了提供這兩種工具訓練語料 之外,也可以加入外部辭典一起訓練。最後利用所得到的斷詞模型將未斷詞測試語料進 行斷詞,得到已斷詞之語料。. 3.2 斷詞模型訓練工具. 政 治 大. 本研究利用史丹佛中文斷詞器以及 LingPipe 中文斷詞器這兩種軟體工具進行斷詞模型. 立. 的訓練。. ‧ 國. 學. 史丹佛中文斷詞器是基於條件隨機域實做而成的斷詞器。我們將訓練語料提供給史. ‧. 丹佛中文斷詞器進行訓練,在訓練完成後會得到斷詞模型。而在 2008 年 5 月 21 號之後. y. Nat. 的版本,史丹佛中文斷詞器可以在訓練斷詞模型時藉由加入外部辭典的方式來增加. er. io. sit. lexicon–based features 至條件隨機域模型中。藉由增加 lexicon–based features,可以增加 斷詞器斷詞時的一致性(consistency)[22]。. n. al. Ch. engchi. i n U. v. LingPipe 中文斷詞器在進行斷詞時會將詞彙間未正確插入空白的情形視為錯誤,並 透過斷詞模型,將空白插入至兩詞彙間以修正該錯誤。我們將訓練語料提供給 LingPipe 中文斷詞器進行訓練,就可以得到斷詞模型。而 LingPipe 中文斷詞器也可於訓練斷詞模 型時加入外部辭典,以提供更多資訊給斷詞模型。. 12.
(26) 第四章 辭典模組介紹與加入近義詞 本章共分為兩個節次。在 4.1 節介紹我們的系統之辭典模組,4.2 節介紹加入近義詞的方 法與「加入近義詞之英漢合併辭典」的建置。. 4.1 辭典模組介紹. 政 治 大 辭典與專業辭典兩種類別。英漢辭典模組中的專業辭典類別包含「英漢技術名詞辭典」, 立 我們的系統之辭典模組包含英漢辭典模組與中文辭典模組,而這兩個模組中都包含一般. 中文辭典模組中的專業辭典類別包含「中文技術名詞辭典」、世界人名翻譯大辭典,關. ‧ 國. 學. 於「英漢技術名詞辭典」與「中文技術名詞辭典」的建置會在下一段落說明。而英漢辭. ‧. 典模組中的一般辭典類別包含「加入近義詞之英漢合併辭典」與懶蟲簡明英漢詞典[17],. y. Nat. 關於「加入近義詞之英漢合併辭典」的建置會在 4.2 節詳細說明。中文辭典模組的一般. n. al. er. io. sit. 辭典類別則包含教育部國語辭典[13]、成語詞典[7]及高級漢語大詞典[13]。中文辭典模. v. 表 4.1 中文辭典模組之辭典詞彙數統計 辭典類別 一般辭典 一般辭典 一般辭典 專業辭典 專業辭典. C h中文辭典模組 engchi 辭典名稱. i n U. 中文詞彙數 教育部國語辭典 157704 成語詞典 13947 高級漢語大詞典 54467 中文技術名詞辭典 804053 世界人名翻譯大辭典 648612. 表 4.2 英漢辭典模組之辭典詞彙數統計 辭典類別 一般辭典 一般辭典 專業辭典. 英漢辭典模組 辭典名稱 英文詞彙數 加入近義詞之英漢合併辭典 99805 懶蟲簡明英漢詞典 英漢技術名詞辭典. 121525 586075 13. 中文詞彙數 3729292 323766 804053.
(27) 組之辭典詞彙數統計、英漢辭典模組之辭典詞彙數統計分別如上頁表 4.1、表 4.2 所示。 本研究從國家教育研究院學術名詞資訊網[12]下載了 138 個技術名詞檔案,並將其 整合成「英漢技術名詞辭典」 。 「英漢技術名詞辭典」的內容格式為一個英文技術名詞對 應一個中文技術名詞的形式,而「中文技術名詞辭典」是只取「英漢技術名詞辭典」中 的中文技術名詞整合而成。. 4.2 加入近義詞之英漢合併辭典建置. 政 治 大 當中文句出現交集型歧異時,我們會利用英漢辭典中的英文詞彙之中文翻譯去進行比對, 立 所以為了提高利用英漢翻譯的資訊去處理交集型歧異的效果,會須要增加英文詞彙的中文. ‧ 國. 學. 翻譯詞彙數目;我們參考[10]的作法將牛津現代英漢雙解詞典[1]和 Dr.eye 譯典通線上字典. ‧. [23]合併成「英漢合併辭典」 ,以增加英文詞彙的中文翻譯詞彙數目。除了利用英漢辭典的. y. Nat. 中文翻譯詞彙,本研究也加入中文翻譯詞彙的近義詞,來擴充英漢辭典的中文翻譯詞彙之. er. io. sit. 數目。本研究使用中央研究院現代漢語一詞泛讀系統(以下簡稱一詞泛讀)及 E-HowNet 去尋找中文翻譯詞彙的近義詞。. n. al. Ch. engchi. i n U. v. 我們於 4.2.1 節中介紹利用一詞泛讀尋找近義詞的方法,4.2.2 節中介紹利用 E-HowNet 尋找近義詞的方法,4.2.3 節介紹建置「加入近義詞之英漢合併辭典」的流程。. 4.2.1 利用一詞泛讀尋找近義詞. 本研究參考[10]的作法去利用一詞泛讀取得近義詞。將中文詞彙輸入至一詞泛讀,一詞 泛讀會傳回該詞彙的近義詞群。我們把英文詞彙的各個中文翻譯輸入至一詞泛讀,將一 詞泛讀傳回的各個中文翻譯的近義詞群合併後,即為該英文詞彙的中文翻譯近義詞集。 以下以單字“quietness”為例進行說明,而“quietness”的中文翻譯為「安靜」 、 「肅靜」 、 「平 靜」與「樸素」。我們將「安靜」、「肅靜」、「平靜」與「樸素」逐一輸入至一詞泛讀, 14.
(28) 一詞泛讀回傳之「安靜」的近義詞群 安定、平靜、平安、安靜、安寧、安樂、風平浪 靜、安居樂業、安靖、康樂、安謐、平靖、民康 物阜、安生、安堵、安瀾、物阜民豐、消停、寧 靖、清淨、幽靜、清幽、清靜…. “quietness” “ 的中文翻譯 安靜 肅靜 平靜 樸素. 一詞泛讀回傳之「肅靜」的近義詞群 安靜、寧靜、冷靜、靜、寂靜、清淨、幽靜、清 幽、清靜、沉靜、恬靜、靜謐、靜悄悄、沉寂、 鴉雀無聲、岑寂、僻靜、死寂、悄無聲息、冷寂、 夜闌人靜、寂然、肅靜、萬籟俱寂…. 一詞泛讀. 治 政 安定、平靜、平安、安靜、安寧、安樂、風平浪 大 一詞泛讀回傳之「平靜」的近義詞群. 立. ‧ 國. 學. 靜、安居樂業、安靖、康樂、安謐、平靖、民康 物阜、安生、安堵、安瀾、物阜民豐、消停、寧 靖 一詞泛讀回傳之「樸素」的近義詞群. ‧. 樸素、純樸、樸實、素樸、質樸、樸質、簡樸、 質樸無華. y. Nat. sit. 圖 4.1 輸入“quietness”的中文翻譯後一詞泛讀回傳之近義詞群. n. al. er. io. 而一詞泛讀回傳的結果如圖 4.1 所示。最後把系統傳回的這四個中文翻譯的近義詞群合 併,就會得到“quietness”的中文翻譯近義詞集。. Ch. engchi. i n U. v. 4.2.2 利用 E-HowNet 尋找近義詞. 在 E-HowNet 中,用來定義及描述詞彙之語義(概念)的單位為義原或簡單概念(simpler concept) , 而 以 下 將 介 紹 E-HowNet 詞 彙 之 定 義 結 構 。 下 頁 圖 4.2 、 圖 4.3 中 的 TopLevelDefinition 和 BottomLevelExpansion 標記中含有描述詞彙語義的表示式,而 BottomLevelExpansion 表示式是 TopLevelDefinition 表示式之更細一步的意義擴充[10]; BottomLevelExpansion 表示式可以有以下幾種構成方式:由一個上位詞概念與許多特徵 所構成、由一個概念所構成、由一個義原所構成[25]。由一個上位詞概念與許多特徵所 15.
(29) <Word item = "懼高症"> <WordFreq>7</WordFreq> <WordSense id="1"> <English>acrophobia</English> <Phone>ㄐㄩˋ. ㄍㄠ ㄓㄥˋ</Phone>. <PinYin>ju4 gao1 heng4</PinYin> <SyntacticFunction> <POS>Nad</POS> <Freq>7</Freq> </SyntacticFunction> <TopLevelDefinition>. 治 政 大 </TopLevelDefinition> 立 <BottomLevelExpansion>. {disease|疾病:CoEvent={fear|害怕:cause={high|高}}}. ‧ 國. 學. {disease|疾病:CoEvent={fear|害怕:cause={high|高}}}. </BottomLevelExpansion> </WordSense>. ‧. </Word>. Nat. sit. n. al. er. io. <Word item = "樹幹">. y. 圖 4.2 E-HowNet 詞彙的定義結構之範例一. Ch. <WordFreq>56</WordFreq> <WordSense id="1">. engchi. i n U. v. <English>tree trunk</English> <Phone>ㄕㄨˋ. ㄍㄢˋ</Phone>. <PinYin>shu4 gan4</PinYin> <SyntacticFunction> <POS>Nab</POS> <Freq>56</Freq> </SyntacticFunction> <TopLevelDefinition>{BodyPart({tree|樹})}</TopLevelDefinition> <BottomLevelExpansion>{BodyPart({tree|樹})}</BottomLevelExpansion> </WordSense> </Word>. 圖 4.3 E-HowNet 詞彙的定義結構之範例二 16.
(30) 構成之構成方式如上頁圖 4.2 所示,BottomLevelExpansion 表示式中的義原「disease|疾 病」為「懼高症」的上位詞概念,而「CoEvent={fear|害怕:cause={high|高}}」 、 「cause={high| 高}」為其特徵。此外在 E-HowNet 中含有兩種關係:語意角色(Semantic Role)以及函數 (function)。函數可以將一個概念轉換成另一個新的概念,如在上頁圖 4.3「樹幹」之 BottomLevelExpansion 表示式部分,函數 BodyPart( )可以將義原 tree|樹所構成的概念, 轉 換 成 另一個新的概念。語意角色則是用來建構兩個參數間的主題關係(thematic relation)、性質屬性(property attribute)[25]。. 政 治 大 透過計算兩詞彙的概念語義運算式之相似度的方式來得到兩個詞彙之間的相似度,本研 立 在詞彙的相似度計算上,我們參考了 Liu 與 Li[16]於 2002 年提出的方法。Liu 與 Li. ‧ 國. 學. 究則透過計算兩詞彙的 BottomLevelExpansion 表示式之相似度的方式來得到兩個詞彙之 間的相似度。我們的想法為:因為 BottomLevelExpansion 表示式是用來描述詞彙之語義,. ‧. 所以兩個互為近義詞的詞彙應該會有相似的 BottomLevelExpansion 表示式。. y. Nat. sit. 在本研究中我們只會利用 BottomLevelExpansion 表示式去計算詞彙相似度,而不會. n. al. er. io. 利用到 TopLevelDefinition 表示式,所以在本章以下內容中我們將 BottomLevelExpansion. i n U. v. 表示式簡稱為「表示式」。在計算表示式之相似度時我們首先會對表示式進行擷取。為. Ch. engchi. 了簡化計算的複雜度,我們不從表示式中擷取結構較複雜的特徵,而僅擷取義原、由義 原與修飾義原之函數所構成之組合(以下簡稱義原函數組合)來代表該表示式。例如對 於上頁圖 4.2 中的詞彙「懼高症」 ,我們會擷取「懼高症」之上位詞概念「disease|疾病」 與特徵中的義原「fear|害怕」、「high|高」,對於上頁圖 4.3 中的詞彙「樹幹」會擷取 「BodyPart({tree|樹})」這個義原函數組合。 首先在義原的相似度計算上,我們沿用 Liu 與 Li 在 2002 年所使用的公式,即以下 公式(1): 𝑆𝑖𝑚(𝑝1 , 𝑝2 ) =. 𝛼 𝑑+𝛼. 17. (1).
(31) 公式(1)中的𝑝1 、𝑝2 為兩個義原,α則是可調節的參數。在廣義知網知識分類體系. (E-HowNet Taxonomy)中包含了兩棵子樹(subtree):{entity|事物}、{relation|關係},義. 原為{entity|事物}中的節點,函數則為{relation|關係}中的節點。我們將 d 定義為 𝑝1、𝑝2 在 {entity|事物}中的路徑長度(d 為一整數),若以圖 4.4 中的義原「sky |空域」、「the Pacific Ocean |太平洋」為例,則這兩個義原的 d 為 3。 Liu 與 Li 將義原的相似度計算作為概念語義運算式的相似度計算之基礎,但我們發 現若只以義原的相似度計算作為表示式之相似度計算之基礎,可能會將相似度不高的詞. 政 治 大 表示式之相似度為 為「speak|說」 ,若只以義原作為表示式相似度計算之基礎,則這兩個詞彙的 立 彙當做近義詞。例如以下頁圖 4.5(b)中的兩個詞彙為例,因為「出聲」、「口吻」的義原皆. ‧ 國. 學. 1,所以相似度不高的「出聲」會被視為「口吻」之近義詞。因此本研究在計算表示式相似. 度時,不只以義原作為表示式相似度計算之基礎,而另外考慮了函數對於概念的影響,以. ‧. 義原或義原函數組合的相似度計算作為表示式相似度計算之基礎。義原或義原函數組合. n. al. Ch. 𝛼 𝑑+𝛼. engchi. er. io. 𝑆𝑖𝑚(𝑐1 , 𝑐2 ) = 𝑊𝑓 ×. sit. y. Nat. 的相似度之計算則如公式(2)所示。. i n U. v. 圖 4.4 義原於{entity|事物}中的距離之範例. 18. (2).
(32) (a) <Word item = "兵士"> <BottomLevelExpansion>{member({army|軍隊})}</BottomLevelExpansion> </Word> <Word item = "兵種"> <BottomLevelExpansion>{kind({army|軍隊})}</BottomLevelExpansion> </Word> (b) <Word item = "出聲"> <BottomLevelExpansion>{speak|說}</BottomLevelExpansion> </Word>. 政 治 大 <BottomLevelExpansion>{style({speak|說})}</BottomLevelExpansion> 立. <Word item = "口吻">. 學. ‧ 國. </Word>. 圖 4.5 計算𝑊𝑓 之範例詞彙. ‧. 1 , 如果𝑐1 及𝑐2 皆為義原. (3). io. al. 𝑆𝑖𝑚(𝑓1 , 𝑓2 ) =. 𝛼 𝑓𝑑 + 𝛼. sit. y. 𝛿, 如果𝑐1 及𝑐2 其中之一為義原函數組合. er. Nat. 𝑊𝑓 = �𝑆𝑖𝑚(𝑓1 , 𝑓2 ), 如果𝑐1 及𝑐2 皆為義原函數組合. (4). n. v i n Ch 上頁公式(2)中的𝑐1 、𝑐2 為義原或義原函數組合,𝑊 e n g c h i U 𝑓 的計算方式則如公式(3)所示。. 當𝑐1 及𝑐2皆為義原時,我們將𝑊𝑓 設為 1,此時公式(2)等同於計算義原相似度的公式(1)。 當𝑐1 及𝑐2 皆為義原函數組合時(如圖 4.5 (a)之 member({army|軍隊})、kind({army|軍隊})),. 則𝑊𝑓 的值為𝑐1之函數(𝑓1 )與𝑐2 之函數(𝑓2 )間的相似度𝑆𝑖𝑚(𝑓1 , 𝑓2 ),而函數間的相似度可由 公式(4)得到;公式(4)中的𝑓1 、𝑓2 為兩個函數,𝑓𝑑 定義為𝑓1 、𝑓2 在{relation|關係}中的路徑. 長度(𝑓𝑑 為一整數)。當𝑐1 或𝑐2 的其中之一為義原函數組合時(如圖 4.5 (b)之 speak|說、. style({speak|說})),則因為該義原函數組合對應到義原,所以該義原函數組合中的函數. 所對應的函數為空,此時我們參考 Liu 與 Li 的作法,將𝑊𝑓 的值設為常數𝛿(任一非空值. 與空值的相似度)。. 19.
(33) 以下介紹詞彙的表示式相似度之計算方法。當兩個詞彙的表示式皆為義原或義原函 數組合時,則詞彙的表示式相似度可由公式(2)得到。當兩個詞彙中至少一個詞彙之表示 式是由一個上位詞概念與許多特徵構成時,我們利用公式(5) 計算詞彙的表示式的相似 度。當詞彙之表示式是由一個上位詞概念與許多特徵構成時,我們覺得表示式中的上位 詞概念是描述此詞彙之概念的主要部分,所以將上位詞概念稱為「主要概念描述」,而 由各個特徵中的義原或義原函數組合所構成的集合則稱為「次要概念描述」。在公式(5) 中的𝑆𝑖𝑚1 (𝑆𝑆1 , 𝑆𝑆2 )為兩個詞彙表示式的「主要概念描述」的相似度,𝑆𝑖𝑚2 (𝑆𝑆1 , 𝑆𝑆2 )為兩. 政 治 大 覺得「主要概念描述」的重要性大於「次要概念描述」 ,所以設定𝛽 立. 個詞彙表示式的「次要概念描述」的相似度。在公式(5)中的權重𝛽𝑖 的設定上,因為我們 1. ‧ 國. 𝑆𝑖𝑚(𝑆𝑆1 , 𝑆𝑆2 ) = � 𝛽𝑖 𝑆𝑖𝑚𝑖 (𝑆𝑆1 , 𝑆𝑆2 ) 𝑖=1. 學. 2. > 𝛽2, 𝛽1 + 𝛽2 = 1 。 (5). y. ‧. Nat. = 𝛽1 𝑆𝑖𝑚1 (𝑆𝑆1 , 𝑆𝑆2 ) + 𝛽2 𝑆𝑖𝑚2 (𝑆𝑆1 , 𝑆𝑆2 ). er. io. sit. 我們在利用公式(5)計算詞彙相似度時會分成以下兩種情形進行計算,下頁圖 4.6 則 為這兩種情形的範例,在圖中沒有用灰底標示的部分是主要概念描述,有用灰底標示的. al. n. v i n 部分則是次要概念描述。情形 C 1:當兩個詞彙的表示式的構成方式都是由一個上位詞概 hengchi U. 念與許多特徵構成時(如圖 4.6 中的「僕人」、「女傭」兩詞彙),則兩詞彙表示式的 𝑆𝑖𝑚1 (𝑆𝑆1 , 𝑆𝑆2 )可由公式(2)得到,在𝑆𝑖𝑚2 (𝑆𝑆1 , 𝑆𝑆2 )計算上,我們沿用[16]中的集合的相. 似度計算之演算法進行計算,而集合中的元素為義原或義原函數組合。情形 2:當一個 詞彙的表示式是由一個上位詞概念與許多特徵構成,另一個詞彙的表示式是由一個義原 或義原函數組合構成時(如圖 4.6 中的「僕人」 、 「假冒」兩詞彙) ,我們將由一個義原或 義原函數組合構成的表示式中的義原或義原函數組合視為「主要概念描述」,將該表示 式的「次要概念描述」視為空值;兩詞彙表示式的𝑆𝑖𝑚1 (𝑆𝑆1 , 𝑆𝑆2 )也是由公式(2)得到,. 而因為我們定義集合與空值的相似度為常數δ,所以𝑆𝑖𝑚2 (𝑆𝑆1 , 𝑆𝑆2 )為δ。 20.
(34) 僕 人 之 表 示 式 : {human| 人 :predication={engage| 從 事 :content={affairs| 事 務:CoEvent={engage|從事}},location={family|家庭},agent={~}}} 女 傭 之 表 示 式 : {human| 人 :predication={engage| 從 事 :content={affairs| 事 務},location={family|家庭},agent={~}},gender={female|女}} 假冒之表示式:{fake|偽} (情形 1). 主要概念描述. 次要概念描述. 僕人之擷取後的表示式:. human|人. engage|從事、affairs|事務、family|家庭. 女傭之擷取後的表示式:. human|人. engage|從事、affairs|事務、family|家 庭、female|女. (情形 2). 政 治次要概念描述 大. 主要概念描述. 立. 假冒之擷取後的表示式:. fake|偽. engage|從事、affairs|事務、family|家庭. 圖 4.6 計算詞彙相似度之兩種情形的範例. ‧. ‧ 國. human|人. 學. 僕人之擷取後的表示式:. 介紹了計算兩詞彙的表示式相似度之計算方法後,以下我們透過下頁圖 4.7 中的英. Nat. sit. y. 文詞彙“servitor”為例,說明如何取得英文詞彙的中文翻譯近義詞集。首先對“servitor”. n. al. er. io. 的所有中文翻譯之表示式與所有 E-HowNet 中文詞彙之表示式進行擷取,而擷取後的表. i n U. v. 示式如圖 4.7 中灰底標記所示。之後將“servitor”的所有中文翻譯之表示式,一一與所. Ch. engchi. 有 E-HowNet 中文詞彙之表示式計算相似度後,將相似度高於門檻值的 E-HowNet 中文 詞彙視為近義詞。 以下為我們設定各個公式中所存在之可調節的參數與相似度之門檻值的過程。在各 個公式中所存在之可調節的參數分別為:𝛼、𝛿、𝛽1、𝛽2。我們將𝛼的值限制在 1.6 或 2.0, 𝛿的值限制在 0.05 或 0.1 或 0.2,因為我們設定𝛽1 > 𝛽2 , 𝛽1 + 𝛽2 = 1,所以將(𝛽1 , 𝛽2 )的. 值限制在(0.9,0.1)、(0.8,0.2)、(0.7,0.3)、(0.6,0.4)這四種。相似度之門檻值則限制在 0.9、 0.8、0.7。之後針對在不同的𝛼、δ、(𝛽1 , 𝛽2 )、相似度之門檻值設定下所得的結果,我. 們用人工方式比較結果中的部分英文詞彙之中文翻譯近義詞,以選出較佳的參數組合。 最後我們設定𝛼為 1.6,𝛿為 0.05,𝛽1為 0.6,𝛽2為 0.4,相似度之門檻值為 0.9。 21.
(35) servitor之中文翻譯:僕人 主要概念描述: human|人 次要概念描述: engage|從事, affairs|事務, family|家庭. servitor之中文翻譯:侍從 主要概念描述: human|人 次要概念描述: TakeCare|照 料, MakeLiving|謀生. E-HowNet 中文詞彙:女傭 主要概念描述: human|人 次要概念描述: engage|從事, affairs|事務, family|家庭, female|女 中文詞彙:假冒. 表示式相似 度計算. fake|偽 .. 中文詞彙:抹布 主要概念描述: tool|用具 次要概念描述: .wipe|擦拭 ... 門檻值篩選. servitor之中文翻譯近義詞集. 立. 僕, 廝, 婢, 男僕, 僕從, 僕役, 傭 人, 僱傭, 僮僕, 下女, 下人, 佣 人, 使女, 侍女, 侍僕, 女佣, 女傭, 奴僕, 女僕, 從者, 隨從. 政 治 大. ‧ 國. 學. 圖 4.7 藉由表示式相似度計算取得中文翻譯近義詞集之流程. ‧. 4.2.3 辭典建置流程. sit. y. Nat. n. al. er. io. 以下為建置「加入近義詞之英漢合併辭典」之流程:我們對「英漢合併辭典」中的各個. i n U. v. 英文詞彙,依照在 4.2.1、4.2.2 節所述的方法從一詞泛讀及 E-HowNet 取得該詞彙的中. Ch. engchi. 文翻譯近義詞集後,我們把從一詞泛讀及 E-HowNet 得到的中文翻譯近義詞集與「英漢 合併辭典」的英文詞彙之中文翻譯詞彙進行整合,就完成「加入近義詞之英漢合併辭典」 的建置。. 22.
(36) 第五章 產生訓練語料 第五章主要介紹產生訓練語料與擷取中英平行語料中的中英詞對與未知詞的方法。5.1 節介紹產生句子的各種斷詞組合的方法,5.2 節介紹如何利用英漢翻譯的資訊處理交集 型歧異,並去除錯誤的斷詞組合,5.3 節介紹擷取中英詞對與未知詞的方法。. 5.1 產生各種斷詞組合. 政 治 大 中文句可以看成是由字所組成的字串,而隨著組合成句子的詞彙的不同,會形成不同的 立. 斷詞組合。因此我們針對未斷詞語料中的每句中文句,透過查詢中文辭典的方式,產生. ‧ 國. 學. 由不同的詞彙所組成的句子之各種斷詞組合,藉此得到訓練語料。我們產生中文句的各. ‧. 種斷詞組合的目的為希望在訓練斷詞模型的過程中,透過大量語料的統計現象,來得到. y. Nat. 較佳的斷詞模型。我們將句子表示成字串 C1:n (C1:n = C1 C2…Cn),並依照圖 5.1 的步. er. io. sit. 驟來產生句子的各種斷詞組合。以下為圖 5.1 中 Vi 與 Candi(i=1 to n)的定義。Vi 為詞 彙集合,在 Vi 內會存放句子中所有以 Ci 開頭的詞彙。Candi 為候選集合,在 Candi 內會. al. n. v i n 針對句子中的每一個字C C (i=1 h e ntogn)查詢中文辭典模組的辭典中是否包含句 i U h c 子中以該字開頭的不同長度之字串(字串的長度為 1 to n-i+1) ,若包含則將該. 1.. i. 字串加入 Vi 。 2.. 將 i 的初始值設為 1。. 3.. (a).如果 V1 中的某一詞彙等同於 C1:i,則把該詞彙加入至 Candi。 (b). for j =1 to i-1, i > 1 如果 Candj 中的某一斷詞組合加上 Vj+1 中的另一詞彙後,不含有「包含 單字詞的詞彙組合」 ,並且等同於 C1:i,則把該斷詞組合加入至 Candi。. 4.. 如果 i 不等於 n,則把 i 遞增 1,並重回到步驟 3。如果 i 等於 n,則 Candi 內的所有斷詞組合即為該句子的各種斷詞組合。 圖 5.1 產生句子的各種斷詞組合的步驟. 23.
(37) 存放字串 C1:i 的各種斷詞組合。 在上頁圖 5.1 步驟 3(b)中提到的「包含單字詞的詞彙組合」的定義為:當某詞彙組 合中包含單字詞,且該詞彙組合可以結合成一個詞彙時,則該詞彙組合為「包含單字詞 的詞彙組合」 。例如「科學/家」這一個詞彙組合包含了單字詞「家」,且「科學/家」可 以結合成詞彙「科學家」 ,則「科學/家」為「包含單字詞的詞彙組合」 。我們發現若句子 內含有許多「包含單字詞的詞彙組合」時,會產生大量的斷詞組合。如「一家民間公司 提議用鐵粉在部分海洋施肥」這句中文句,包含了「一/家」、「民/間」、「公/司」、「提/. 政 治 大 除含有「包含單字詞的詞彙組合」之斷詞組合的情況下,最後該中文句會產生 256 組的 立 議」、「鐵/粉」、「部/分」、「海/洋」、 「施/肥」這些「包含單字詞的詞彙組合」,而在不去. ‧ 國. 學. 斷詞組合。若語料中的許多中文句都會產生大量的斷詞組合,就會使得訓練語料變得過 於龐大,造成在訓練斷詞模型時會消耗大量時間、資源。因此在步驟 3(b)我們不將含有. ‧. 「包含單字詞的詞彙組合」的斷詞組合加入 Candi,藉此去除含有「包含單字詞的詞彙. sit. y. Nat. 組合」之斷詞組合。. n. al. er. io. 以下我們以「貼近市場需求,」這一句子為例,對產生句子的各種斷詞組合的步驟. C1:貼. C2:近. Ch. i n U. 字串 C e n g c hC i:場 C :市 1:i. 3. 4. v. C5:需. C6:求. C7:,. 查詢中文辭典中是否包含句子中以 Ci 開頭的不同長度之字串,若包含則將該字串加入 Vi. 詞彙集合 Vi V1. V2. V3. V4. V5. V6. V7. 貼. 近. 市. 場. 需. 求. ,. 貼近. 市場. 需求. 市場需求. 圖 5.2 產生「貼近市場需求,」之 Vi 24.
(38) i=1. i=2. i=3. i=4. i=5. Cand1 貼. Cand2 貼近. Cand3 貼近 市. Cand4 貼近 市場. Cand5 貼近 市場 需. i=7. i=6. Cand7 貼近 市場 需求 ,. Cand6 貼近 市場 需求. 貼近 市場需求 ,. 貼近 市場需求. 圖 5.3 各階段的 Candi 的內容. 政 治 大 文辭典模組的辭典中是否包含句子中以該字開頭的不同長度之字串。若以「貼」為例, 立 進行說明。在上頁圖 5.1 中步驟 1,會針對「貼」、「近」、「市」…「,」一一去查詢中. ‧ 國. 學. 會查詢辭典中是否包含「貼」 、 「貼近」 、 「貼近市」等字串,若辭典中有包含,則表示該 字串為一詞彙,所以該字串會被加入至 V1;此外若 Ci 為標點符號,我們則把它視為存. ‧. 在於辭典中的單字詞,將其加入至 Vi。最終的 Vi 則如上頁圖 5.2 所示。. y. Nat. sit. 在圖 5.1 步驟 3 中的 i 代表不同的階段,而在各個階段會產生字串 C1:i 之各種斷詞. n. al. er. io. 組合。在 i 等於 1 時,在步驟 3(a)會檢查 V1 中是否有詞彙等同於 C1:1,而因為 V1 中的. i n U. v. 「貼」等同於 C1:1,所以會被加入至 Cand1。i 等於 2 時,在步驟 3(a)會查詢 V1 中是否. Ch. engchi. 有詞彙等同於 C1:2,而 V1 中的「貼近」等同於 C1:2,所以會被加入至 Cand2;在步驟 3(b),「貼」加上「近」後會形成「貼 近」,為含有「包含單字詞的詞彙組合」的斷詞 組合,所以「貼 近」不會被加入至 Cand2。重複執行步驟 3、步驟 4 到 i 等於 6 時,在 步驟 3(b),Cand5 中的「貼近 市場 需」加上「求」後會含有「需 求」這個「包含單字 詞的詞彙組合」,所以不會被加入至 Cand6;而 Cand4 中的「貼近 市場」加上 V5 中的 「需求」會等同於 C1:6,所以會被加入至 Cand6; Cand2 中的「貼近」加上 V3 中的「市 場需求」會等同於 C1:6,所以也會被加入至 Cand6。重複執行步驟 3、步驟 4 到 i 等於 7, 則 Cand7 內的所有斷詞組合就是句子之各種斷詞組合。圖 5.3 則是各階段的 Candi 的內 容。 25.
(39) 5.2 利用英漢翻譯的資訊處理交集型歧異. 在產生句子的各種斷詞組合後,本研究利用英漢翻譯的資訊去處理交集型歧異。我們利 用英漢翻譯的資訊去處理交集型歧異的原因為:當一個句子有交集型歧異時,透過英文 詞彙的中文翻譯,可以挑選出符合英文陳述的正確斷詞組合。例如有交集型歧異的句子 「一旦有機會」可以被斷成「一旦/有機/會」 、 「一旦/有/機會」 ,而透過英文詞彙“chance” 的中文翻譯「機會」可以挑選出正確的斷詞組合「一旦/有/機會」 。挑選出正確的斷詞組. 政 治 大. 合之後,我們會去除錯誤的斷詞組合,以得到較少錯誤的訓練語料。. 立. 在對交集型歧異進行處理前,需要先取得英文句中的各個詞彙的中文翻譯集合,而. ‧ 國. 學. 以下說明取得英文句中的各個詞彙的中文翻譯集合的流程。首先我們透過英文句中的空 白對英文句進行斷詞,以取得句子中的各個詞彙。英漢辭典模組的各辭典中之英文詞彙. ‧. 大多以原形表示,但英文句中的各個詞彙並不一定為原形,而可能為不同的時態(如過. y. Nat. sit. 去式、未來式等),或者是複數形態或大寫形態。所以為了讓英文句中的非原形之詞彙. n. al. er. io. 也可以對應到辭典中的詞彙,我們利用史丹佛剖析器[5]對英文句中的各英文詞彙進行詞. i n U. v. 幹還原(lemmatization)後,再到英漢辭典模組中的一般與專業辭典類型的各辭典中查詢. Ch. engchi. 該詞彙的中文翻譯。之後取一般辭典類型的各辭典中查詢到的中文翻譯與專業辭典類型 的各辭典中查詢到的中文翻譯的聯集,作為該英文詞彙的中文翻譯集合。 以下介紹處理交集型歧異的方法。給定含有交集型歧異字串「ABC」 (A、B、C 皆 為單一中文字,而「ABC」可以被斷成「A/BC」或「AB/C」)的中文句之各個斷詞組合 與該中文句所對應的英文句,我們利用英文句中的各個詞彙之中文翻譯集合的中文翻譯 去對應斷詞組合中的中文詞彙;如果某個英文詞彙的中文翻譯集合之中文翻譯對應到斷 詞組合中的詞彙 AB,則將包含「AB/C」的斷詞組合視為正確斷詞組合,而包含「A/BC」 的斷詞組合則是錯誤斷詞組合,所以我們會去除包含「A/BC」的錯誤斷詞組合。. 26.
(40) 輸入 英文句:Even those projects can induce earthquakes, although most are small. 斷詞組合 1:即便/是/這/類/工程/都/可能/引發/地震/,/不過/大半/規模/不大/。 斷詞組合 2:即/便是/這/類/工程/都/可能/引發/地震/,/不過/大半/規模/不大/。. 步驟 1:利用史丹佛剖析器對英文句中之各詞彙進行詞幹還原 even、those、project、 can、 induce、 earthquake、 although 、most、 be、 small. 步驟 2:至英漢辭典模組中的一般與專業辭典類型的辭典中查詢英文句中各詞彙的中文翻 譯,取各辭典中查詢到的中文翻譯的聯集,作為該詞彙的中文翻譯集合 even:縱使、縱然、即便…. 政 治 大 induce:勸誘、促使、導 those:那些、那. can:可能、會、 可以…. 立. 致…. project:計劃、方案、事業… earthquake:地震、 大動盪、 天搖地動…. although:雖然、儘管、即使… most:至多、 頂多、最… be:位於、身處、是…. ‧ 國. 學. small:小的、少的、小型的…. ‧. 步驟 3:利用英文句中的各詞彙之中文翻譯集合的中文翻譯去對應斷詞組合中的詞彙,將 錯誤斷詞組合去除. Nat. io. sit. /。. y. 正確斷詞組合:<even/即便>即便/是/這/類/工程/都/可能/引發/地震/,/不過/大半/規模/不大. n. al. er. 錯誤斷詞組合:即/便是/這/類/工程/都/可能/引發/地震/,/不過/大半/規模/不大/。. Ch. e n g輸出 chi. i n U. v. 即便/是/這/類/工程/都/可能/引發/地震/,/不過/大半/規模/不大/。 圖 5.4 處理交集型歧異的整體流程. 以下藉圖 5.4 說明處理交集型歧異的整體流程。中文句「即便是這類工程都可能引 發地震,不過大半規模不大。」包含了交集型歧異字串「即便是」 (「即便是」可以被斷 成「即便/是」及「即/便是」),而圖 5.4 中的斷詞組合 1、斷詞組合 2 為該中文句的各個 斷詞組合。經過步驟 1 及步驟 2 後,我們取得了英文句中各詞彙的中文翻譯集合,如“even” 的中文翻譯集合包含「縱使」 、 「縱然」 、 「即便」等詞彙。在步驟 3 正確斷詞組合的部分, 我們標記<詞幹還原後的英文詞彙/中文詞彙>的意思是利用左側的詞幹還原後的英文詞 彙之中文翻譯集合中的中文翻譯,可以對應到右側的中文詞彙,例如< even/即便>的意思 27.
(41) 是 “even”是經過詞幹還原後的詞彙,而“even”的中文翻譯集合中的中文翻譯會對應到 「即便」 ;因為“even”的中文翻譯集合中的中文翻譯可以對應到斷詞組合 1 中的「即便」, 所以在步驟 3 我們將包含「即便/是」的斷詞組合視為正確斷詞組合,並去除包含「即/ 便是」的錯誤斷詞組合。. 5.3 擷取中英詞對與未知詞. 本研究從中英平行語料中擷取新的中英詞對,以擴充英漢辭典模組的詞對數量,藉此提. 政 治 大. 高利用英漢翻譯資訊處理訓練語料中的交集型歧異之效果,與提升我們的系統之斷詞效. 立. 能。此外本研究也從中英平行語料中擷取未知詞,藉此處理訓練語料中的未知詞問題,. ‧ 國. 學. 以提升我們的系統之斷詞效能。在擷取中英平行語料中的中英詞對與未知詞時,首先我 們會從語料中擷取「候選中英遺留詞對」、「候選中文遺留字詞」。之後對於「候選中英. ‧. 遺留詞對」,我們利用可能性比例(likelihood ratios)與詞對之共現頻率進行篩選;若通過. y. Nat. sit. 篩選,則將該詞對視為新的中英詞對,擴充至英漢辭典模組中。另外我們也利用詞性序. n. al. er. io. 列規則對「候選中文遺留字詞」進行篩選,通過篩選的「候選中文遺留字詞」則視為未 知詞,擴充至中文辭典模組中。. Ch. engchi. i n U. v. 本節共分為三個節次,在 5.3.1 節介紹如何從語料中擷取「候選中英遺留詞對」 、 「候 選中文遺留字詞」 ,在 5.3.2 節詳細說明如何利用可能性比例與詞對之共現頻率對「候選 中英遺留詞對」進行篩選,在 5.3.3 節詳細說明如何利用詞性序列規則對「候選中文遺 留字詞」進行篩選。. 5.3.1 擷取「候選中英遺留詞對」與「候選中文遺留字詞」. 我們首先藉由查詢英漢辭典模組的方式來取得英文句的各個詞彙之中文翻譯集合,之後 再利用英文句的各個詞彙之中文翻譯集合的中文翻譯對中文句進行斷詞。在斷詞後,中 28.
(42) 表 5.1 PAT-tree 抽詞程式所擷取出之結果 擷取出之結果. 詞頻. 劍橋. 10. 會不. 10. 歐斯. 10. 確的. 10. 飛利浦. 9. 火劫學說. 8. 政 治 大 文遺留字詞」。對於中文句中的所有「中文遺留字詞」,我們使用 PAT-tree 抽詞程式[35] 立. 文句會有未被斷詞的「中文遺留字詞」 ,英文句會有無法在中文句中找到對應詞彙的「英. ‧ 國. 學. 進行初步的詞彙擷取。我們發現利用 PAT-tree 抽詞程式所擷取出的結果中,許多錯誤的 結果都會含有停用詞,如表 5.1 中的「會不」 、 「確的」 ;因此對於以 PAT-tree 抽詞程式所. ‧. 擷取出的結果,我們藉由停用詞列表將其中包含停用詞的結果去除後,我們稱其餘的結. sit. y. Nat. 果為「候選中文遺留字詞」。由同一平行句對的「候選中文遺留字詞」及「英文遺留字. io. er. 詞」所產生的詞對則稱為「候選中英遺留詞對」。然後因為我們希望得到的是新的中英. al. n. 詞對與未知詞,所以我們去除包含於英漢辭典模組中的辭典之「候選中英遺留詞對」及. i n C 包含於中文辭典模組中的辭典之「候選中文遺留字詞」 hengchi U 。. v. 5.3.2 利用可能性比例與共現頻率進行篩選. 因為可能性比例可用於分析兩個詞的關連度[34],而由較有關連的「候選中文遺留字詞」 與「英文遺留字詞」所形成的「候選中英遺留詞對」有較大的機會為正確的中英詞對, 所以本研究利用可能性比例對「候選中英遺留詞對」進行篩選。. 29.
(43) 我們首先對「候選中文遺留字詞」 (c)與「英文遺留字詞」 (e)進行 H1、H2 兩個 假設: H1: 𝑃(𝑒|𝑐) = 𝑝 = 𝑃(𝑒|𝑐̅) H2: 𝑃(𝑒|𝑐) = 𝑝1 ≠ 𝑝2 = 𝑃(𝑒|𝑐̅) 𝑝=. 𝐹𝑒 𝑁. 𝑝1 =. 𝑝2 =. 立. (6) (7) (8). 𝐹𝑐𝑒 𝐹𝑐. (9). 政 治 大. 𝐹𝑒 − 𝐹𝑐𝑒 𝑁 − 𝐹𝑐. (10). ‧ 國. 學. H1 表示兩個詞之間是獨立的,H2 表示兩個詞之間是相依的。𝐹𝑒為在所有英文句中. 「英文遺留字詞」出現的句數,𝐹𝑐為在所有中文句中「候選中文遺留字詞」出現的句數,. ‧. 𝐹𝑐𝑒 為「候選中英遺留詞對」的共現頻率(共現頻率為候選中英遺留詞對中的中文詞與. 英文詞共同出現的句對數,而中文詞與英文詞共同出現的意思是:中文詞出現在某平行. y. Nat. sit. er. io. 句對的中文句,且英文詞也出現在該句對的英文句),𝑁為中英平行語料的總句數。. 我們利用可能性比例檢驗 H1、 H2;假設機率分佈為 binomial distribution,則. al. n. b(𝑘, 𝑛, 𝑥) =. �𝑛𝑘�𝑥 𝑘 (1. − 𝑥). 𝑛−𝑘. Ch. 。. engchi. i n U. v. 而可能性比例的公式如下:. Likelihood ratio (𝑐, 𝑒) = logλ = log. b(𝐹𝑐𝑒, 𝐹𝑐, 𝑝)b(𝐹𝑒 − 𝐹𝑐𝑒, 𝑁 − 𝐹𝑐, 𝑝) b(𝐹𝑐𝑒, 𝐹𝑐, 𝑝1 )b(𝐹𝑒 − 𝐹𝑐𝑒, 𝑁 − 𝐹𝑐, 𝑝2 ). = logL(𝐹𝑐𝑒, 𝐹𝑐, 𝑝) + logL(𝐹𝑒 − 𝐹𝑐𝑒, 𝑁 − 𝐹𝑐, 𝑝). −logL(𝐹𝑐𝑒, 𝐹𝑐, 𝑝1 ) − logL(𝐹𝑒 − 𝐹𝑐𝑒, 𝑁 − 𝐹𝑐, 𝑝2 ). 在公式(11)中,L(𝑘, 𝑛, 𝑥) = 𝑥 𝑘 (1 − 𝑥)𝑛−𝑘 。. 30. (11).
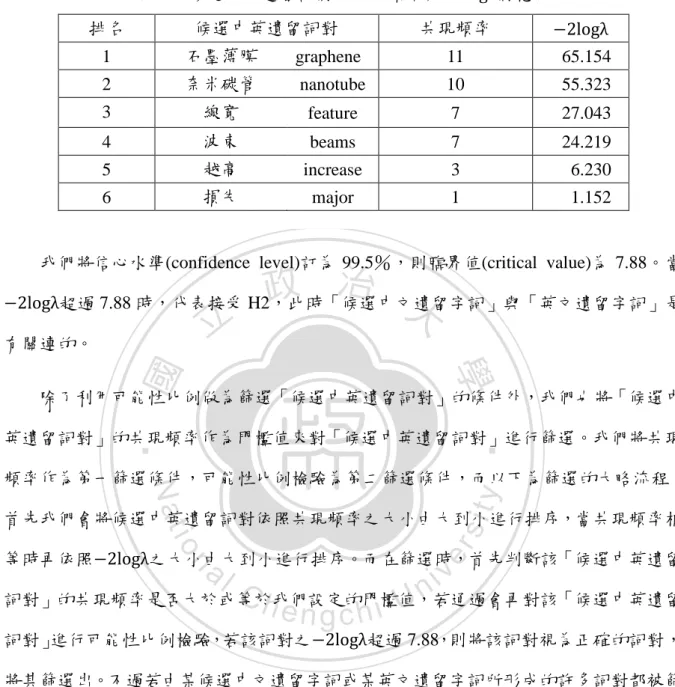
(44) 表 5.2 候選中英遺留詞對之共現頻率與−2logλ對應表 排名. 候選中英遺留詞對. 共現頻率. −2logλ. 1. 石墨薄膜. graphene. 11. 2. 奈米碳管. nanotube. 10. 3. 線寬. feature. 7. 27.043. 4. 波束. beams. 7. 24.219. 5. 越高. increase. 3. 6.230. 6. 損失. major. 1. 1.152. 65.154 55.323. 我們將信心水準(confidence level)訂為 99.5%,則臨界值(critical value)為 7.88。當. 政 治 大. −2logλ超過 7.88 時,代表接受 H2,此時「候選中文遺留字詞」與「英文遺留字詞」是. 立. 有關連的。. ‧ 國. 學. 除了利用可能性比例做為篩選「候選中英遺留詞對」的條件外,我們也將「候選中. ‧. 英遺留詞對」的共現頻率作為門檻值來對「候選中英遺留詞對」進行篩選。我們將共現. sit. y. Nat. 頻率作為第一篩選條件,可能性比例檢驗為第二篩選條件,而以下為篩選的大略流程:. io. er. 首先我們會將候選中英遺留詞對依照共現頻率之大小由大到小進行排序,當共現頻率相 等時再依照−2logλ之大小由大到小進行排序。而在篩選時,首先判斷該「候選中英遺留. al. n. v i n Ch 詞對」的共現頻率是否大於或等於我們設定的門檻值,若通過會再對該「候選中英遺留 engchi U 詞對」進行可能性比例檢驗,若該詞對之−2logλ超過 7.88,則將該詞對視為正確的詞對, 將其篩選出。不過若由某候選中文遺留字詞或某英文遺留字詞所形成的許多詞對都被篩 選出的話,則我們只取包含該候選中文遺留字詞或英文遺留字詞的排名最高之詞對。 以下透過表 5.2 說明如何利用可能性比例與共現頻率進行篩選,而表 5.2 中的候選 中英遺留詞對已依照上一段落所述方法依序依照共現頻率、−2logλ大小由大到小進行排 序。假設將共現頻率的門檻值設為 3,則表 5.2 中的詞對“越高 increase”雖然共現頻率 大於或等於 3,但因進行可能性比例檢測後其−2logλ小於 7.88,所以該詞對會被視為錯 誤的詞對。而「石墨薄膜 graphene」 、 「奈米碳管 nanotube」 、 「線寬 feature」 、 「波束 beams」 31.
數據
相關文件
Lange, “An Object-Oriented Design Method for Hypermedia Information Systems”, Proceedings of the Twenty-seventh annual Hawaii International Conference on System Sciences, 1994,
[23] Tiantong You, Hossam Hassanein and Chi-Hsiang Yeh, “PIDC - Towards an Ideal MAC Protocol for Multi-hop Wireless LANs,” Proceedings of the IEEE International Conference
Godsill, “Detection of abrupt spectral changes using support vector machines: an application to audio signal segmentation,” Proceedings of the IEEE International Conference
Shih and W.-C.Wang “A 3D Model Retrieval Approach based on The Principal Plane Descriptor” , Proceedings of The 10 Second International Conference on Innovative
D.Wilcox, “A hidden Markov model framework for video segmentation using audio and image features,” in Proceedings of the 1998 IEEE Internation Conference on Acoustics, Speech,
[16] Goto, M., “A Robust Predominant-F0 Estimation Method for Real-time Detection of Melody and Bass Lines in CD Recordings,” Proceedings of the 2000 IEEE International Conference
Harma, “Automatic identification of bird species based on sinusoidal modeling of syllables,” in Proceedings of IEEE International Conference on Acoustics, Speech,
Li, The application of Bayesian optimization and classifier systems in nurse scheduling, in: Proceedings of the 8th International Conference on Parallel Problem Solving
