行政院國家科學委員會專題研究計畫 成果報告
以音樂動機探勘為導向的電腦音樂作曲(第 2 年)
研究成果報告(完整版)
計 畫 類 別 : 個別型 計 畫 編 號 : NSC 98-2221-E-004-007-MY2 執 行 期 間 : 99 年 08 月 01 日至 101 年 01 月 31 日 執 行 單 位 : 國立政治大學資訊科學系 計 畫 主 持 人 : 沈錳坤 計畫參與人員: 碩士班研究生-兼任助理人員:鄭世宏 碩士班研究生-兼任助理人員:范斯越 碩士班研究生-兼任助理人員:黃柏堯 報 告 附 件 : 出席國際會議研究心得報告及發表論文 公 開 資 訊 : 本計畫涉及專利或其他智慧財產權,2 年後可公開查詢中 華 民 國 101 年 06 月 26 日
中 文 摘 要 : 電腦自動作曲是人類的夢想。目前有關電腦自動作曲的研 究,根據作曲規則產生的方式,大致可以分為外顯規則與內 隱規則兩種做法。內隱規則是由樣本資料中學習作曲規則。 現有內隱規則的研究都是採用 Bottom-Up Approach。本研究 提出 Top-Down Approach 的方法,利用 Data Mining 的技 術,提供使用者由音樂資料庫中選取多首音樂,系統從中探 勘出音樂動機、曲式、曲風樣式,並自動產生與使用者選取 的音樂風格相近的音樂。本計畫提出探勘由重複樣式音樂動 機、分析曲式結構、探勘曲風的方法,並提出根據曲式、音 樂動機、曲風產生新的音樂的作法。實驗顯示測試者不易區 別作曲家的作品與本系統產生的音樂。 中文關鍵詞: 電腦自動作曲, 資料探勘, 音樂動機探勘, 重複樣式 英 文 摘 要 : Computer music composition is the dream of computer
music researchers. In this research, a top-down approach is investigated to discover the rules of musical composition from given music objects and to create a new music object of which style is similar to the given music objects based on the discovered composition rules. The proposed approach utilizes the data mining techniques in order to discover the
styled rules of music composition characterized by music structures, melody styles and motifs. A new music object is generated based on the discovered rules. To measure the effectiveness of the proposed approach in computer music composition, a method similar to the Turing test was adopted to test the differences between the machine-generated and human-composed music. Experimental results show that it is hard to distinguish between them. The other
experiment showed that the style of generated music is similar to that of the given music objects. 英文關鍵詞: algorithmic composition, data mining, motif mining,
目錄
摘要... 1
Abstracts ... 2
1. Introduction ... 3
2. Related Work ... 4
2.1 Composing with Explicit Rules ... 4
2.2 Composing with Implicit Rules... 5
2.3 Discussions ... 6
3 System Architecture and Main Melody Extraction ... 6
4 Analysis and Learning ... 8
4.1 Music Structure Analysis and Structure Rule Learning ... 8
4.2 Melody Style Analysis and Melody Style Rule Learning ... 12
4.3 Motif Mining and Motif Selection Rule Learning ... 15
(1) Repetition ... 15 (2) Sequence... 15 (3) Contrary motion ... 15 (4) Retrogradation ... 15 (5) Augmentation or Diminution ... 16 5 Music Generation ... 16 6 Experiments ... 18 6.1 Turing-like Test... 19
6.2 Effectiveness Evaluation for Styled Composition ... 19
6.3 Efficiency Evaluation of Music Generation ... 20
6.4 Case Study ... 20
7 Conclusions ... 21
以音樂動機探勘為導向的電腦音樂作曲
摘要
電腦自動作曲是人類的夢想。目前有關電腦自動作曲的研究,根據作曲規則產生的方式, 大致可以分為外顯規則與內隱規則兩種做法。內隱規則是由樣本資料中學習作曲規則。現 有內隱規則的研究都是採用 Bottom-Up Approach。本研究提出 Top-Down Approach 的方 法,利用資料探勘技術,提供使用者由音樂資料庫中選取多首音樂,系統從中探勘出音樂 動機、曲式、曲風樣式,並自動產生與使用者選取的音樂風格相近的音樂。本計畫提出探 勘由重複樣式音樂動機、分析曲式結構、探勘曲風的方法,並提出根據曲式、音樂動機、 曲風產生新的音樂的作法。實驗顯示測試者不易區別作曲家的作品與本系統產生的音樂。
A Motivic Pattern Mining Approach
for Computer Music Composition
Abstracts
Computer music composition is the dream of computer music researchers. In this research, a top-down approach is investigated to discover the rules of musical composition from given music objects and to create a new music object of which style is similar to the given music objects based on the discovered composition rules. The proposed approach utilizes the data mining techniques in order to discover the styled rules of music composition characterized by music structures, melody styles and motifs. A new music object is generated based on the discovered rules. To measure the effectiveness of the proposed approach in computer music composition, a method similar to the Turing test was adopted to test the differences between the machine-generated and human-composed music. Experimental results show that it is hard to distinguish between them. The other experiment showed that the style of generated music is similar to that of the given music objects.
1. I
NTRODUCTIONComputer music generation is the dream of computer music researchers. The process of producing musical content consists of two major steps: composition and arrangement. First, composers create original melodies with chords in the basic structure. Next, arrangers rewrite and adapt the original melodies and chords specifying harmonies, instrumentation, style, dynamics, and sequence. After these two steps, performance, recording, mixing, and audio mastering are conducted to produce the music for the general listener. Composing needs most originality and shows the most valuable part among these processes.
Machine-generated music compositions have been investigated for a long time. Current research on computer composition may be classified under two approaches based upon the method used to generate the compositional rules. In the explicit approach, the compositional rule is specified by humans while in the implicit approach the composition rule is derived from sample music. Therefore, in the implicit approach, training data is required in order to discover the compositional rules.
Figure 1: Flow chart of computer-generated music composition.
As shown in Figure 1, there are four design issues regarding the implicit approach: feature extraction, feature analysis, rule learning and music generation. Feature extraction concerns the extraction of low-level music features from sample music. Feature analysis obtains the high-level semantic information from low-level music features. Rule learning discovers the patterns (compositional rules) in terms of the high level semantic information from the set of sample music. Finally, music generation employs the discovered patterns to generate music.
A musical work, the result of a composer’s skillful training, is expected to possess rich compositional information. In a set of musical works from whether composed by the same composer or collected from an audience’s personal preference, this set of musical works must share the commonly compositional patterns. From the rich background and nature of extant musical works, this study seeks to discover more about their compositional rules. Data mining technique is applied since it has been the adaptive ability to discover variant patterns.
In this project, the implicit approach to computer music composition based on the discovered musical patterns from music examples is investigated. The developed approach takes a set of user-specified music examples as input and generates music with a style similar to that of the user-specified music set. While most of previous works on algorithmic music composition adopt the bottom-up approach, this project develops a
top-down approach that composers might prefer for music composition. A new framework considering the
properties of music structures, melody styles and motif development is proposed. Furthermore, most of previous works characterize the melody style as repetition or statistics of notes which are in the level of musical surfaces, the proposed approach models melody styles in terms of melody features hidden from the melody surfaces. More specifically, the proposed approach is developed based on the data mining techniques in order to discover music style patterns. With respect to the algorithmic compositional models, the proposed approach is a hybrid model with a learning procedure. Finally, we examine proposed system by a critical approach which is similar to Turing-test.
The remainder of this report is organized as follows. In the next section, there is a review of previous work on computer music composition. Section 3 provides the system architecture and feature extraction of the proposed approach. Feature analysis and rule learning are described in Section 4. Section 5 presents the method of music generation. Next, in Section 6, the experiments are presented. At last, the conclusion is drawn in Section 7.
2. R
ELATEDW
ORKThere exist many systems for computer music composition. Basically, there are two different types of computer music composition systems. One is the algorithmic composition which generates music automatically while the other is the computer-aided composition which serves as a tool to help the composer to generate music. Although the first commonly recognized algorithmic composition system pioneered in the mid 1950s, there is no universal classification for different approaches of algorithmic composition. In this section, we review approaches of algorithmic composition according to the method used to obtain the composition rules as mentioned in Section. 1.
2.1 Composing with Explicit Rules
Early work on the generation of computer music focuses on compositions with rules explicitly specified by composers.
Stochastic system generates the sequence of musical parameters by selection from a given set according to specified probability distribution function. This random process fulfils the expectation of musicians. Therefore, the compositional rule is embedded within the stochastic process itself. Hidden Markov Model (HMM) is probably the most common approach of stochastic process for music composition. Especially, in Markov model, the probability of future events depends on past events. This fulfils the sequence requirement of melody. An example is CAMUS which consults a user-specified Markov table to control rhythm and the temporal organization of note group [33].
The hierarchical structure of musical thought has a strong similarity to linguistics. While formal grammars and finite automata are normally utilized for representation of the laws of formation of a language, some music composition mechanisms are developed based on formal grammars or automata. BP2 is an example of software developed for composing using grammars. Production rules whose terminal nodes correspond to sound objects are employed to generate music with constraint-satisfaction programming [4].
Artificial life is a discipline that studies natural living systems by computer simulation of their biological aspects. Cellular automata and genetic algorithms (GA) are two common approaches for algorithmic music composition. A cellar automata consists of an array of cells that change states according to evolution rules.
While cellar automata generates tremendous amount of patterns, music composition can be modeled as a pattern propagation process. CAMUS, which consults Markov chains to generate rhythm, is a cellar automata music generator. It utilizes both Game of Life and Demon Cyclic Space automation to produce triple of notes and to determine the orchestration, respectively, in parallel [31].
Music composition can be treated as a combinatorial optimization problem. Therefore, it is natural to develop music composition mechanism based on genetic algorithm. In GA, initially, a population of entities is randomly created. Reproduction which involves mutation process is performed to create the next generation. This reproduction process repeats until the population passes the evaluation specified as the fitness function. In terms of music composition based on GA, musical phrases, with a higher, post-evaluation fitness value, are selected for creating the next generation. The desired musical phrase is generated gradually after each round. Therefore, the fitness function acts as the compositional rules. One GA-based example is offered by J. A. Biles who proposed the GenJam system that generates jazz solos [5]. Another was designed by G. Papadopoulos et al. [36] who utilized the genetic algorithm to generate jazz melody. The major difference between these two approaches lies in the fitness function. The fitness function of the former is evaluated interactively by human while that of the latter is evaluated against eight characteristics of the melody. More discussions on GA-based music composition can be found in [7][50].
The particle swarm system, SWARMUSIC [6], employs particle motion to produce musical material by mapping particle position onto a MIDI event. This system can also improvise and interact with users in real-time. Similar idea is employed to generate music by simulating moves of artificial ants on a graph where vertices represent notes and edges represent possible transitions between notes [23]. Another interesting approach is developed recently in the field of artificial chemistry. To compose music using the virtual model of the chemical system, molecules and chemical equations are designed to implement a set of musical rules. The implemented system based on a non-deterministic algorithm successfully generates musical phrases [34][45].
2.2 Composing with Implicit Rules
Recent work on computer-generated musical composition has been attempted to learn the features or rules of composition from examples of musical work implicitly.
Some approach comes with the development of the machine learning technology. Reagan [38] adopted decision tree classifier to discover the common properties of the meta-level features from the examples labeled as scores and to composes music using these features. At the IRCAM research center, S. Dubnov et al. proposed a machine learning methods for musical style learning from examples [20][29]. Two different approaches, incremental parsing and prediction suffix tree are utilized to model patterns and to inference new music. Both approaches try to model musical repeating patterns in an approximate way.
D. Conklin [12] proposed the use of statistical model to capture music styles from a corpus of music work. Several methods for sampling from a statistical model along with the pattern-based sampling are investigated. Hidden Markov Model has been applied with success to implicit music composition. Cybernectic Composer is an earlier example based on HMM to generate music in different styles [3]. Farbood and Schoner present an algorithmic composition system which generates Palestrina-style music [22]. Palestrina was a famous sixteenth-century composer whose work is seen as a summation of Renaissance polyphony. Given counterpoint examples, the system infers the probability tables of Markov model and
composes a counterpoint line given a cantus firmus. In most HMM-based approaches, each state represents a note. Recent approach treats each state as the patterns extracted from examples [48]. Therefore, this approach learns the composition rules from examples implicitly using sequences of patterns.
The artificial neural network (ANN) has been used in the last years for music composition. It resembles the activities of human brain structure. In this computation, the process is performed by a set of several simple units, the neurons, connected in a network by weights. The parameters of the network are adjusted by learning from examples. The most recent research is conducted by Correa et al. Both supervised and unsupervised approaches were proposed to learn aspects of music structure and to compose new melody, by using Back-Propagation-Through-Time and Self Organizing Maps neural networks. [10][17].
D. Cope [13][14][15][16] has conducted a series of work in algorithmic composition, whose basic idea is from Mozart’s dice game. The basic approach is to extract signatures which are short musical passages from existing works by pattern matching techniques first. Then the extracted signatures are replicated and recombined to create a reasonable melody by evaluation against augment transition network borrowed from natural language processing. The composition process also takes other musical properties into consideration, such as phrase structures, texture, earmarks and unifications. The music produced by this kind of approaches has demonstrated an elegant result.
2.3 Discussions
All of the above-mentioned researches belong to the bottom-up approach where smaller segments are extended to compose higher level musical sections for the entire work. Furthermore, most approaches focus on learning patterns of note sequences while music structures and motives are not considered. In the majority of previous approaches, no special attention has been paid to the beginning and ending of generated melody, to say nothing of music structures. Motif is an important element in music composition. In the bottom-up approach, simple notes instead of motives are used as the basic units of melody. The top-down approach, on the other hand, starts by developing a composition plan and proceeds to refine this plan. This approach forces the composition to be creative within formal constraints, such as musical structure. While most, if not all, of the bottom-up approaches, deal with algorithmic composition as a problem solving task, the top-down approaches treat it as a creative process. Composers might prefer the top-down approach that helps the composer to be creative within the formal constraints of generative process. Compared with the above-mentioned bottom approaches, our proposed framework is a top-down approach that analyzes and learns the musical structure style, discovers the motives and the melody style from examples first. Then a new music object is generated by settling on the musical structure, determining the melody style and generating melody sequence.
3 S
YSTEMA
RCHITECTURE ANDM
AINM
ELODYE
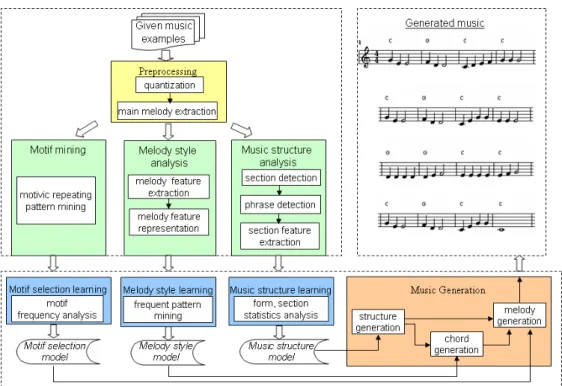
XTRACTIONFigure 2 shows the system architecture and the process flow of the proposed music system. Given a set of music in MIDI format, the main melody extraction component extracts the main melody which is a monophonic melody. Then, each extracted melody is analyzed using the music structure analysis component, the melody style analysis component and the motif mining component individually. All analysis steps are off-line processes, namely, all music objects in database can be analyzed before using system. In contrast, the learning and the generation procedures are performed after the music objects are specified by the user. The
structure analysis component detects the musical section-phrase structure, extracts section features and generates the section sequences for the structure learning component. The structure learning component generates the music structure model by statistics analysis of section and phrase features. The melody style analysis component extracts the melody style by finding accompanied chords and generates different melody style representations for the melody style learning component. The melody style learning component discovers the melody style model by frequent pattern mining techniques. The motif mining component finds the set of motives which constitute the potential candidates by motivic repeating pattern mining technique for the motif selection learning component. The motif selection learning component generates the motif selection model by frequency analysis of extracted motives. Finally, after these analysis and learning processes, the three models (music structure model, melody style model and motif selection model) are established. These three models involve the music style of the selected music objects. In the music generation component, a new music object is generated based on these three models.
Figure 2: The system architecture and process flow of the proposed approach.
Melody is the essential element of music composition. The main melody extraction component consists of two steps. In the first step, quantization is performed. In digital music processing, quantization is the process to align music notes to a precise setting. This is achieved by setting the timing grid and moving each note to the closest point on the timing grid. In our system the timing grid is set to a quarter of a beat and quantization is applied to both MIDI’s Note-On messages and Note-Off messages. Figure 3 illustrate an example of quantization process.
Figure 3: An illustration of quantization.
Figure 4: An example of All-mono method to extract the main melody.
The next step extracts the monophonic melody from the polyphonic melody. Uitdenbogerd et al. [46] have presented four melody extraction methods: All-mono, Entropy-channel, Entropy-part and Top-channel. According to their experimental result, All-mono method, adopted in this research, obtains the best accuracy. All-mono combines all the music tracks and among the simultaneous notes, includes the highest notes as the main melody. In Figure 4, the first staff (Figure 4(a)) shows an example of polyphonic segment while the second staff (Figure 4(b)) shows the extracted main melody using All-mono.
4 A
NALYSIS ANDL
EARNING4.1 Music Structure Analysis and Structure Rule Learning
Musical structure can be regarded as a hierarchical structure similar to the structure of an article. In our approach, a music object is composed of sections and a section is composed of one or more phrases [19]. The structure analysis component discovers the section-phrase hierarchical structure of a music object while the structure learning component analyzes common characteristics from structures of given music examples. Some researchers have devoted to the investigation of music segmentation techniques for symbolic music [8][11][32][44][49]. Most work focuses on the extraction of phrases. Takasu et al. proposed the phrase extraction method based on some heuristic rules and extended the work to classify phrases into two classes: theme phrases and non-theme phrases based on the decision tree algorithm [44]. Chen et al. adopted a similar approach to extract phrases and to group similar phrases for sentence extraction [11]. Nevertheless, to the best of our knowledge, nobody has focused on the detection of musical sections which constitute the musical form. Therefore, we present a heuristic method for section detection.
is performed. To find the section structure in music, first we discover repeating patterns over main melody. A repeating pattern is a sequence of notes repeats several times in a music object. The main melody is a note sequence where a note can be parameterized with several property values such as pitch, duration and velocity. Velocity is only relevant to music performance. Therefore only pitch and duration are considered for the structure analysis. The repeating patterns over pitch-duration sequence are discovered by repeating pattern mining techniques. Over the past few years, several algorithms have been proposed to mine repeating patterns in a sequence [25][27][30]. Suffix tree is a well-know data structure originally developed for string matching. It is also utilized to find the repeating patterns by storing the suffix information [30]. There may exist a large number of repeating patterns in a sequence. Therefore, the concept of non-trivial repeating patterns was introduced by Hsu et al. [25]. A repeating pattern is non-trivial if and only if there does not exist another superstring with the same frequency. Hsu et al. proposed two different approaches, correlative matrix and string-join, to mine non-trivial repeating patterns [25]. In the former approach, a data structure called correlative matrix is constructed by lining up the note sequence the horizontal and vertical dimensions respectively to keep the intermediate information of substring matching. Each cell of this matrix denotes the length of a founded repeating pattern. After the construction of this matrix, the repeating frequencies of all repeating patterns can be derived by computing the non-zero-cells in the matrix. The latter approach, string-join, utilizes the anti-monotony property to avoid generating large amount of candidates. In this approach, shorter patterns are joined into longer ones and the non-qualified candidates are pruned out. Here, we employ the correlative matrix technique to find the repeating patterns.
A B C B NTRP 0 NTRP 1 NTRP 2 NTRP 3 NTRP 4 NTRP 5 C NTRP 0 NTRP 1 NTRP 2 NTRP 3 NTRP 4 NTRP 5 beat bar 1 1 5 2 9 3 13 4 17 5 21 6 25 7 29 8 33 9 37 10 41 11 45 12 49 13 53 14 57 15 61 16
Figure 5: The instances of repeating patterns in the main melody of “Little Bee.”
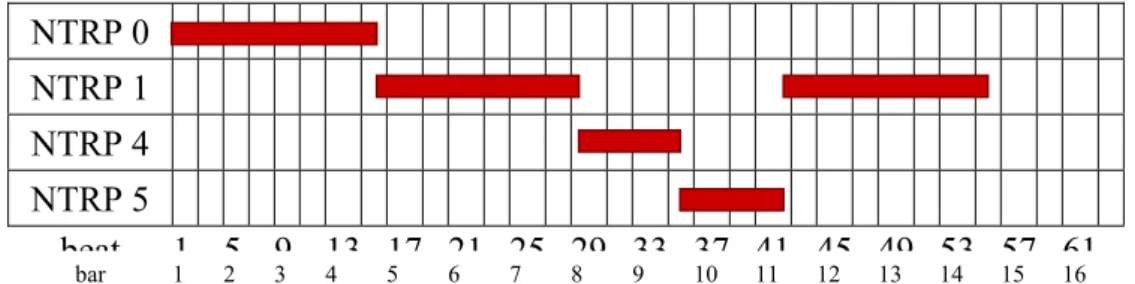
Each repeating pattern appears several times. Figure 5 illustrates the instances of non-trivial repeating patterns after correlative matrix technique has been applied to the musical piece “Little Bee.” Repeating patterns with durations shorter than two bars are not shown here. In Figure 5, each strip denotes an instance of a non-trivial repeating pattern. There are six non-trivial repeating patterns. For example, the first pattern NTRP0 has three instances. One starts at the first bar, another starts at the fifth bar, and the other starts at the thirteenth bar.
Algorithm Pattern-Selection
Input: A set of n phrase, P = {pi =(li, ri) 1 i n}
Output: The subset Q of P such that the total duration is maximized
1) Sort the left positions and the right positions of the phrases into a 1-dimension array T of 2n elements 2) Create a 1-dimension array S of 2n elements
3) for i 1 to 2n //initializing value for S 4) Si 0
5) for i 2 to 2n //fill up array in order 6) if T(i) is the right end of a phrase pk = (lk, rk)
7) f lk 8) d rk - lk 9) Si max{Sf -1+ d, Si-1} 10) else 11) Si Si-1 12) i 2n; Q {};
13) While (i 2) //backtracking s2n to extract phrases 14) if ( Si≠ Si-1 )
15) let pk be the phrase ends at Ti
16) Add pk to Q
17) i lk
18) else 19) i i-1
20) return Q
Figure 6: Pattern-selection algorithm.
As not all instances of repeating pattern are required for section structure detection, appropriate instances need to be selected. First, in our proposed approach, all the instances of the repeating patterns with durations shorter than two bars are filtered out. Then we attempt to extract the musical sections by finding the set of non-overlapping repeating pattern instances such that the total length of the selected instances is maximized.
We modify the algorithm for exon-chaining problem developed in the field of bioinformatics [26]. Given a set of weighted intervals in a chain, the exon-chaining problem attempts to find a set of non-overlapping intervals such that the total weight is maximal. This algorithm can be modified to accommodate the pattern selection problem by replacing the weight of an interval with its duration. As the detailed pattern-selection algorithm in Figure 6 shows, given n pattern instances, this problem can be solved using dynamic programming in a one dimension array S of 2n elements, n of which corresponds to the starting (left) positions
of the instances and n of which corresponds to the ending (right) positions of the phrases. For the sake of simplicity, it is assumed that all instances are distinct. This algorithm starts by sorting the starting and ending positions of all instances into a one dimension array T of 2n elements. The i-th element of S, Si, represents the
maximum duration for the set of instances which ends before the position Ti. The set of instances, which ends
before or at Ti, to maximize the total duration either excludes the instance ends at Ti, or includes the instance
ends at Ti to the maximum set of phrases which ends before the left position of this instance (Figure 6, lines 5
to 11). This leads to the following formula
otherwise , , at starting instance an of position ending the is if , -, max{ 1 1 1 i i f i f i f i i S S T T T T S S S
The set of selected phrases can be derived by backtracking the array S (Figure 6, lines 13 to 20). To describe the computation of this algorithm, Figure 7 gives the example corresponding to the pattern instances in “Little Bee.” In this example, the duration of each instance is measured in beats. The circled instances constitute the set which maximizes the total duration.
The next step of section structure detection is to find the section boundary based on the selected pattern instances. Each selected instance corresponds to a section. Initially, the starting and ending positions of a section are set to those of corresponding instance. Then each section is shrunk or expanded by adjusting the starting position to the nearest starting position of an odd numbered bar. For example, the second section in Figure 8 is shrunk by adjusting its starting position to the first beat of the fifth bar. At last, each section is expanded by aligning its ending position to meet the starting position of the next section. For example, in Figure 8, the ending position of the first section is set to the end of the fourth bar.
Figure 7: An illustration of example of pattern selection corresponding to Figure 5.
NTRP 0 NTRP 1 NTRP 4 NTRP 5 beat 1 5 9 13 17 21 25 29 33 37 41 45 49 53 57 61 bar 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Figure 8: The selected pattern instances of the example in Figure 5.
The second step in music structure is phrase detection. To obtain the number of phrases in a musical section, the LBDM (Local Boundary Detection Model) approach developed by Cambouropoulos et al. [8] is used to segment a section into phrases. Previous experiments have adopted LBDM as representative of the melodic feature-based algorithms for melody segmentation [32]. LBDM extracts the pitch interval sequence, the inter onset interval sequence and the reset sequence from the main melody. Then these three sequences are integrated into the sequence of boundary strength values measured by the change rule and the proximity rule. The resulting peaks of the boundary strength value sequence are regarded as the phrase boundaries.
The final step in music structure analysis is to extract features for each section, including section labeling. Each section is labeled such that all the instances of the same repeating pattern are labeled with the same symbol. For example, in Figure 8, the labeled sequence becomes ABCDB. The second and the fifth section correspond to the same repeating pattern, so do the third and the fourth section. At last, the structure analysis component outputs a section sequence where the section is parameterized by label, numberOfOccurrences,
numOfPhrases and length. While the attribute label denotes which label it is, the attribute numberOfOccurrences denotes the number of appearances of the same label. The attribute numOfPhrases
denotes the number of phrases in this section and the attribute length denotes the length of the section measured in beats.
In the learning step, the probability distribution of section sequences along with associated meters is derived to model the style of musical form. Moreover, the conditional probability Prob(numOfPhrases|label,
numberOfOccurrences) of the number of phrases given a label and an occurrence value is derived. So does
the conditional probability that Prob(length|label, numberOfOccurrences) of the section length given a label and an occurrence value.
4.2 Melody Style Analysis and Melody Style Rule Learning
After the analysis of the musical structure, the melodies are segmented into sections. The segmented melodies are collected for the purpose of melody style mining. The design issues regarding melody style mining techniques are melody feature extraction, melody feature representation and melody style mining/classification algorithms. In a sense, most works on algorithmic music composition may be regarded as approaches to model melody styles and to generate note sequences based on the models. For example, the HMM-based approach models melody style as Hidden Markov Model where the probability of next note depends on one or more previous notes. In addition, there exist some researches on melody style analysis from symbolic music [9][18][28][39][40][41]. The work developed in MIT Media Lab. [9] employed Hidden Markov Model to model and classify the melodies of Irish, German and Austrian folk song. Melodies are represented as a sequence of absolute pitches, absolute pitches with duration, intervals and contours. Another research in CMU utilized the naïve classifier, linear and neural network respectively to recognize music style for interactive performance systems [18]. Thirteen statistical features derived from MIDI are identified for learning of music style. Kranenburg and Backer extracted 20 low level characteristics of counterpoint for polyphonic music style recognition. The K-means clustering, the k-nearest-neighbor and C4.5 classification algorithms are employed to obtain music styles [28]. In [39], 28 statistics of melody content, such as number of notes, pitch range, average of note duration, number of diatonic notes, are developed for feature representations of automatic music style recognition from symbolic representation of melodies. The Bayesian classifier, the k-nearest neighbor and the self-organizing map are applied to perform music style learning.
Most of these approaches characterize the melody style as repetition of notes or statistics of pitches which are in the level of musical surfaces. However, stylistic features that characterize the music are usually hidden from the melody surface.
We have proposed the music style mining technique to construct the melody style model for a set of music objects [40][41]. The basic idea is to utilize the chord based on harmony to extract the melody features. A chord is comprised of a number of pitches sounded simultaneously. Accompanying chords can be used as the melody feature to characterize the melody style. Figure 9 illustrates the reason why we choose chord as the feature for melody style mining. Figure 9(a) and Figure 9(b) show two different music segments. These two segments are quite similar in terms of either note sequence or interval contour. However, the music style and feelings of them are quite different. On the contrary, both music segments composed by Bach shown in Figure 9(c) and Figure 9(d) are of the same style. The chords assigned to these two music segments are the same.
Figure 9: Examples of music segments and assigned chords [40].
To match up the chords and melody, we have developed the chord assignment method based on the music theory. This algorithm starts by the determination of the chord sampling unit. Then, for each sampling unit, sixty common chords are selected as the candidates. Each candidate is scored based on harmony and chord progression rules. The chord with the highest score is assigned to the respective sampling unit. The detailed algorithm can be found in our previously published paper [40][41].
After determining the chord respective to each sampling unit, the melody feature can be represented in the following different ways.
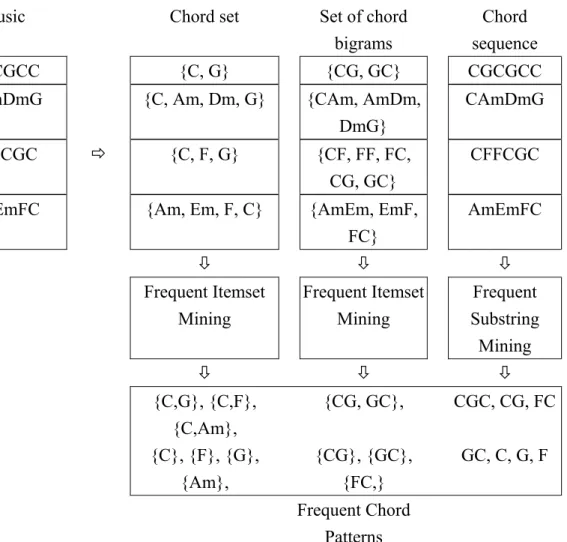
(1) Chord sequence: the feature of a melody is represented as a sequence of chords.
(2) Set of chord bi-grams: the feature of a melody is represented as a set of bi-grams of chords. A bi-gram is an adjacent pair of chords extracted from a chord sequence.
(3) Chord set: the feature of a melody is represented as a set of chords.
For instance, assume that in a melody of four sampling units, the chords with the highest scores are C, G, G, and C respectively. The melody feature is represented by the chord set {C, G}, the set of chord bi-grams {CG, GG, GC}, and the chord sequence <CGGC>.
In order to obtain the interesting hidden relationships between chords and music styles, we adopted two melody mining methods with respect to the melody feature representations.
Frequent Itemset If the feature of a melody is represented as a set of chord or a set of chord bi-grams, the concept of frequent itemset mining in the association rule mining is utilized. In our work, each item
corresponds to a chord or a chord bi-gram. An itemset is frequent if the number of music examples that contain this itemset is larger than a specified minimum support minsup. Assume that there exists a frequent itemset {C, F, G} from a set of lyric-style melody examples, this represents that a great part of lyric-style melody examples consist of chords C, F and G together. The Apriori algorithm is employed to find the frequent itemsets [1]. Apriori is a well-known data mining approach originally developed for the discovery of frequent itemsets from a database of itemsets. The classic Apriori algorithm for the discovery of frequent itemsets makes multiple passes over the database. In the first pass, the support of each individual item is calculated and those above the minsup are kept as a seed set. In the subsequent pass, the seed set is used to generate new potentially frequent itemsets, namely candidate itemsets. Then the support of each candidate itemset is calculated by scanning the database. The candidates with support no less than the minsup are the frequent itemsets and are fed into the seed set that will be used for the next pass. The process continues until no new frequent itemsets are found.
Frequent Substring If the feature of a melody is represented as a sequence of chords, to find the ordered patterns, we mine the frequent substring, by modifying the concept of sequential pattern mining in sequence data mining techniques. The substring is consecutive, which differs from the sequential patterns. A substring is frequent if the number of music examples, which are the superstrings of this substring, is larger than a specified minimum support. The frequent substring is found by modifying the join step of the Apriori-based sequential mining algorithm [2].
Music Chord set Set of chord
bigrams
Chord sequence
CGCGCC {C, G} {CG, GC} CGCGCC
CAmDmG {C, Am, Dm, G} {CAm, AmDm,
DmG}
CAmDmG
CFFCGC {C, F, G} {CF, FF, FC,
CG, GC}
CFFCGC
AmEmFC {Am, Em, F, C} {AmEm, EmF,
FC} AmEmFC Frequent Itemset Mining Frequent Itemset Mining Frequent Substring Mining {C,G}, {C,F}, {C,Am}, {CG, GC}, CGC, CG, FC {C}, {F}, {G}, {Am}, {CG}, {GC}, {FC,} GC, C, G, F Frequent Chord Patterns
Given a set of music examples, the discovered frequent chord patterns constitute the music style model of user specified examples. Figure 10 gives an example of melody style mining. In this example, there are four music sections which are transformed into chord sequences. Given the minimum support 50%, eighteen frequent chord patterns are discovered and constitute the music style model.
4.3 Motif Mining and Motif Selection Rule Learning
In musicology, a motive is a salient recurring segment of notes that may be used to construct all or some of the melody and themes. Motif development is the compositional procedure in which complete work or sections are based a thematic motif [43]. There are several ways for developing a motif. Some of the major ways to develop a motif are repetition, sequence, contrary motion, retrograde, augmentation and diminution, as Figure 11 shown.The following are a brief description for each kind of motif developments.
Figure 11: Examples of the development of motif: (1) Repetition, (2) Sequence, (3) Contrary Motion, (4) Retrograde, (5) Augmentation and Diminution.
(1) Repetition
The repetition is the exact repeating, where Fig. 11(1) is an example. Exact repetition is a motif development usually seen in composing and is usually used by composers to impress the audience.
(2) Sequence
The sequence refers to the moving of a motive in pitch in a constant level. It is a specialization of transposition. Figure 11(2) shows an example where the motive is moved downwards by two semitones.
(3) Contrary motion
Contrary motion performs notes within the original motif but in reverse contour while rhythm remains unchanged. More exactly, the contrary here indicates a pitch interval of two consecutive notes when the original motif is equal to the negative pitch interval of the two notes in derived motif. For example, in Figure 11(3), the interval sequence, in semitones, of the original motive is <2, 2, 1, -3, 2, -4> while that of the first variation is <-2, -2, -1, 3, -2, 4>.
(4) Retrogradation
example in Figure 11(4), the first measure is an original motif and the second measure is the one that performs the retrograde variation. The rhythm of the derived motif isn’t changed. However, the pitch sequence is varied from the original <65, 65, 67, 71, 72, 72> to <72, 72, 71, 67, 65, 65>.
(5) Augmentation or Diminution
Composers using augmentation or diminution motif development will keep the original melody with the rhythm scale enlarged (augmentation) or shrunk (diminution) proportionally. More precisely, augmentation involves an extended duration of each note in a motif while diminution involves a reduction in the duration of each note in a contrary motif. For example, in Figure 11(5), the first measure is an original motif, while the second and the third measures are the result of augmentation and diminution respectively.
To discover the motifs which are not necessarily exact repetition, the conditions of substring matching in each cell of the correlative matrix need to be modified in order to accommodate the motivic variations. For example, to discover the retrogradation, each cell of the correlative matrix should consult the lower-right cell, rather than the upper-left cell in exact repetition finding. More details concerning the motif finding algorithms can be found in earlier work completed by the authors [24].
The motif selection model describes the importance of motifs. Let Freqm,music denote the frequency of a
motif m appearing in music object music. The formula is normalized as Equation 1 and this is denoted as
Support(m, music). For a motif m in a given music database DB, its support are summed up and denoted as ASupport(m, DB). Finally, the ASupport is normalized as Equation 3 and it is denoted by NSupport(m,DB),
where Min(DB) and Max(DB) represent the minimum and maximum ASupport of motives in DB, respectively. music
motif motif music music m Freq Freq music m Support( , ) , , (1) DB am am m Support DB m ASupport( , ) ( , ) (2) ) 1 ) ( ) ( ( ) 1 ) ( ) , ( ( ) ,
(m DB ASupportm DB MinDB MaxDB Min DB
NSupport (3)
5 M
USICG
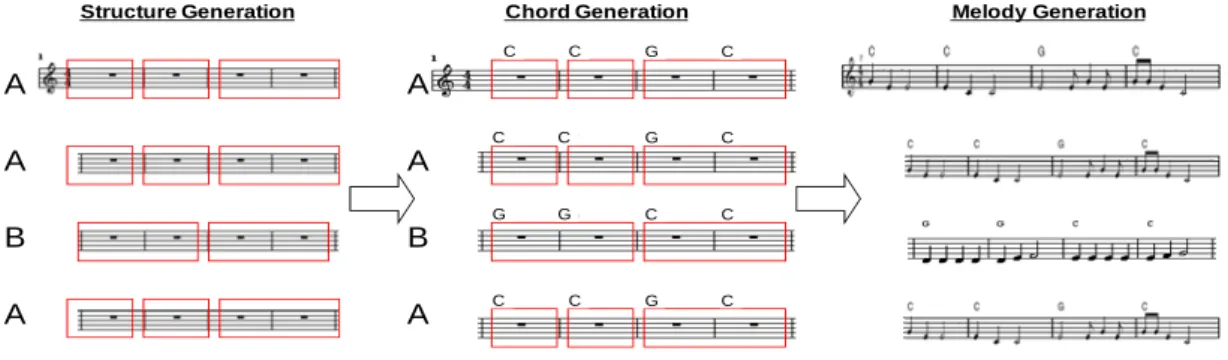
ENERATIONIn this section, the method used to generate music from the three models constructed in the previous steps is discussed. The flow chart is shown in the music generation component of Figure 2, and Figure 12 is an example of music generation.
Structure Generation Chord Generation Melody Generation
A A B A A A B A C C G C C C G C G G C C C C G C
Figure 12: An example of music generation.
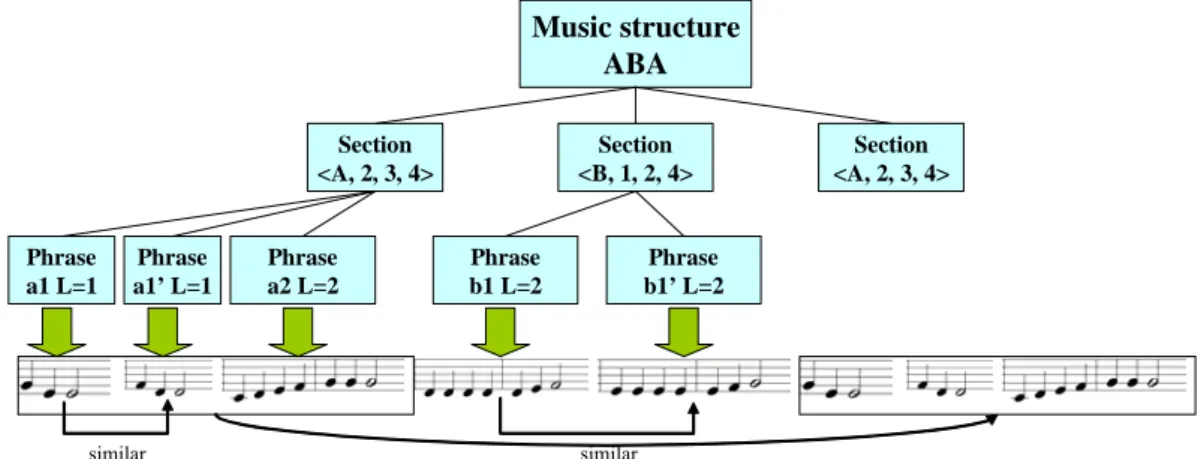
first generates the music structure expressed as a sequence of parametric sections, top level structure. As an example in Figure 14, the structure model generates the sequence of the sections <(A,3,3,4), (A,3,3,4), (B,1,2,4), (A,3,3,4)>. For the description of each attribute, refer to the last paragraph in Sec. 4.2. According to these attributes, the system allocates phrases in each section which forms the second level. In general, the length of a phrase composed by musicians is a power of two bars [43]. Richard Strauss, describing his method of composing, has written “…a motif or a melodic phrase of two to four bars occurs to me immediately. I put
this down on paper and then expand it straightaway into a phrase of eight, sixteen, or thirty-two bars… ”
Therefore, given the length of a section and the required number of phrases, we design a heuristic algorithm, phrase allocation algorithm shown in Figure 13, to allocate phrases. The basic idea of this algorithm is to allocate the phrases such that each is of length power of 2. As an example in Figure 12, the length of the section A is four and the number of phrases is three. The algorithm allocates three phrases of length one, one, and two in order, respectively. Note that if any label of the section is equal to ‘A’, it is applied similar arrangement of section A, directly.
Algorithm Phrase-Allocation Input: length (length of a section)
numberOfPhrases (number of phrases in this section)
Output: {phrasei.length|1 i numberOfPhrases }
1) aveLength = length/numOfPhrases
2) find x such that aveLength-2x is minimum
3) for (i=1; i numberOfPhrases-1; i++) 4) phrasei.length = 2x
5) phrasei.length= length-2x×(i-1)
Figure 13: Phrase-Allocation algorithm.
After the determination of section-phrase structure, the chord generation component generates the chord for each bar based on the music style model. As stated in section 4.2, the music style model consists of frequent chord patterns. The chord generation component randomly generates several chord sequences. The greater the number of frequent chord patterns contained in a randomly generated chord sequence, the higher the score of the chord sequence. The chord sequence with the highest score is assigned to the respective bar.
After the structure and chord information are determined, the melody generation component works as follows. For each phrase, the melody generation component selects a motif from the motif selection model. In general, the duration of a motif is shorter than that of a phrase. The selected motif is developed (repeated) based on the major ways of motif development mentioned in section 4.3.
To ensure that the motif-developed sequence is harmonic to the determined chord sequence, an evaluation function is employed to measure the harmonization between a motif sequence and a chord sequence. This evaluation function is, in fact, the inverse function of the chord assignment algorithm mentioned in section 4.2. In melody style mining, given a melody, the chord assignment algorithm tries to find the best accompanied chord sequence. In contrast, in melody generation, given a chord sequence, the evaluation function tries to find the best accompanied motif sequence. If the developed motif sequence is
judged to be disharmonious, the melody generation component selects another motif from the motif selection model and develops the motif variation. This process is repeated until a harmonious motif sequence is produced. Music structure ABA Section <A, 2, 3, 4> Section <B, 1, 2, 4> Phrase a1 L=1 Phrase a1’ L=1 Phrase a2 L=2 Section <A, 2, 3, 4> Phrase b1’ L=2 Phrase b1 L=2 similar similar
Figure 14: An example of music structure generation and melody generation.
Note that, from the perspective of music structure, some sections are associated with the same label. For instance, the example shown in Figure 14 contains sections one and three which are both associated with label “A.” For those phrases contained in the repeated section, the motif sequences are simply duplicated from the motif sequences generated in the phrases of the previous section of the same label.
Finally, the melody generation component concatenates the motif sequences along with the corresponding chord sequences to compose the music.
6 E
XPERIMENTSTo demonstrate the performance of the proposed top down approach for algorithm music composition, we have implemented a music composition system on the World Wide Web (http://avatar.cs.nccu.edu.tw/
~stevechiu/cms/experiment2). Our music composition system was implemented in Java along with jMusic [42] and Weka [51]. Both jMusic and weak are open source packages. jMusic is a Java library written for musicians. It is designed to assist the compositional process by providing an environment for musical exploration, musical analysis and computer music education. jMusic supports music data structure based upon note/sound events, and provides methods for organizing, manipulating and analyzing musical data. Weka is a collection of libraries for data mining tasks. It contains tools for data pre-processing, classification, regression, clustering, association rules, and visualization. In our implementation, jMusic is utilized to extract MIDI messages, maintain music data structure and output MIDI message. The chord assignment algorithm in the melody style analysis component is also developed in jMusic. Weka is used to implement the music style mining component.
Little attention in the research literature has been paid to the problem of evaluating the music generated by systems for algorithmic music composition. This comes from the fact that evaluation of aesthetic value in works of art often comes down to individual subjective opinion. The majority of music composition systems proposed in the research literature evaluate the performance by presenting the examples of composed music works only. Some researches performed qualitative analysis by asking subjects about the preference of the generated music works. Only few researches have conducted experiments for quantitative analysis of performance by asking subjects to discriminate system generated music from human composed music.
However, to the best of our knowledge, there exists no research on algorithmic composition which performs comparative analysis of performances among different systems. This is partly owing to the availability or implementation of other music composition systems.
To evaluate the effectiveness and efficiency of the proposed music generation approach, three experiments were performed. One experiment is a test designed to discriminate system-generated music from conventionally-composed music. Another experiment is to test whether the music style of the generated music is similar to that of the given music objects. Moreover, to evaluate the efficiency of the proposed approach, the other experiment was conducted to measure the elapsed time of music generation. At last, a case study is given to demonstrate an example generated by our system.
6.1 Turing-like Test
It is difficult to evaluate the effectiveness of a computer-generated music composition system because the evaluation of effectiveness in works of art often comes down to subjective opinion. In 2001, M. Pearce addressed this problem and proposed a method to evaluate the computer music composition system [37]. This study has adopted this method to design the necessary experiments.
Table 1: The results of the discrimination test.
SD: the standard deviation, DF: the degree of freedom, t: t statistic.
Mean SD DF t P-value
All subjects 0.522 0.115 35 1.16 0.253
All subjects except experts
0.503 0.106 31 0.166 0.869
The proposed system can be considered successful if the subjects cannot distinguish the system-generated music from the human-composed music. There were 36 subjects, including four well-trained music experts. The prepared dataset consisted of 10 machine-generated music objects and 10 human-composed music objects. The latter comprised “Beyer 8”, “Beyer 11”, “Beyer 35”, “Beyer 51”, “Through All Night”, “Beautiful May”, “Listen to Angle Singing”, “Melody”, “Moonlight”, and “Up to Roof.” These music objects are all piano music containing melody and accompaniment. These 20 music objects were sorted randomly and displayed to the subjects. The subjects were asked to listen to each music object and to determine whether it is system-generated or human-composed music. The proportions of correctly discriminated music were calculated from the obtained result (Mean is the average of the accuracy). The significant test was performed with the one-sample t-test against 0.5 (the expected value if subjects discriminated randomly).
The results of the experimental test are shown in Table 1. The results show that it is difficult to discriminate the system-generated music objects from the human-composed ones. All the subjects (including the experts) displayed a higher degree of discrimination because some of them possess extensive musical backgrounds.
6.2 Effectiveness Evaluation for Styled Composition
system-generated music is similar to that of the given music. The proposed system was demonstrated for the subjects on the world-wide web: http://avatar.cs.nccu.edu.tw/~stevechiu/cms/experiment2. For each round of music generation, subjects were asked to give a score, from 0 to 3, to denote the degree to which they felt it was dissimilar or similar. Each subject repeated this process three times. A total of 31 subjects performed the test with a resulting mean score of 1.405 and a standard deviation of 0.779.
6.3 Efficiency Evaluation of Music Generation
To evaluate the response time of the developed music composition system, the third experiment was conducted. The experiment was conducted on an IBM desktop computer with a 2.4 Ghz Intel(R) Pentium(R) quad-core processor with 4 gigabytes main memory running Linux 2.6 operating system.
There are 39 music objects collected from the Internet. The average number of notes per music in database was 145.2. The analysis component, especially the motif mining, takes most of the execution time in the whole process. While the analysis component was executed offline instead of online, the elapsed time for learning step and generating a new music object is shown in Figure 15 as a function of the number of selected music examples. It can be seen that with the increasing number of selected music examples, the elapsed time of on line processing takes less than 10 milliseconds.
Figure 15: Elapsed time of the online process of our system. 6.4 Case Study
The results of the proposed approach are shown by using an example. Using six music objects as input, “Beyer 55,” “Grandfather’s clock,” “Little Bee,” “Little Star,” “My Family,” and “Ode to Joy,” the obtained result is an AABA form. The resulting phrase arrangements are 1-1-2 in Section A and 2-2 in Section B. At the melody style mining step, the following patterns were discovered: {{C}, {G}, {C, G}}, {(G, C), (C, G)}, {<C, G>, <G, C>, <C, G, C>}. Furthermore, the chord generation component was found to generate the chord progressions <C, C, G, C> in Section A and <C, G, G, C> in Section B. The motif selection model chose a motif “sol-mi-mi” for generating the first phrase and the melody generation component develops this motif for the second phrase melody in Section A. Finally, the resulting musical composition is shown in Figure 16.
Figure 16: An example of composed music using the proposed approach.
7 C
ONCLUSIONSIn this research, we have proposed a top-down approach for a music compositional system. Data mining techniques have been utilized to analyze and discover the common patterns or characteristics of music structure, melody style and motifs from the given musical pieces. The patterns discovered and the characteristics which constitute music structure, the melody style, and the motif selection model. The proposed system generates music based on these three models. The experimental results show that it is not easy to distinguish the system-generated music from the human-composed music. Future work includes of embedding other compositional elements such as rhythmic development, mode, and tone color into the composition process.
References
[1] R. Agrawal and R. Srikant, Fast Algorithms for Mining Association Rules, In Proc. of International Conference on Very Large Data Bases VLDB'94, 1994.
[2] R. Agrawal and R. Srikant, Mining Sequential Patterns, In Proc. of IEEE International Conference on Data Engineering ICDE’95, 1995.
[3] C. Ame and M. Domino, Cybernetic Composer: An Overview. In M. Balaban, K. Ebcioglu, and O. Laske, ed., Understanding Music with AI. AAAI Press, 1992.
[4] B. Bel, Migrating Musical Concepts: An Overview of the Bol Processor, Computer Music Journal, Vol. 22, No. 2, 1998.
[5] J. A. Biles, GenJam: A Genetic Algorithm for Generating Jazz Solos, In Proc. of International Computer Music Conference, ICMC'94, 1994.
[6] T. M. Blackwell and P. Bentley, Improvised Music with Swarms, In Proc. of the Congress on Evolutionary Computation CEC’02, 2002.
[7] A. R. Brown, Opportunities for Evolutionary Music Composition, In Proc. of Australasian Computer Music Conference ACMA'02, 2002.
[8] E. Cambouropoulos, The Local Boundary Detection Model (LBDM) and its Application in the Study of Expressive Timing, In Proc. of International Computer Music Conference ICMC'01, 2001.
[9] W. Chai and B. Vercoe, Folk Music Classification Using Hidden Markov Models, In Proc. of the International Conference on Artificial Intelligence ICAI’01, 2001.
[10] C. C. J. Chen and R. Miikkulainen, Creating Melodies with Evolving Recurrent Neural Network, In Proc. of International Joint Conference on Neural Networks IJCNN'01, 2001.
[11] H. C. Chen, C. H. Lin, and A. L. P. Chen, Music Segmentation by Rhythmic Features and Melodic Shapes, In Proc. of IEEE International Conference on Multimedia and Expo ICME’04, 2004.
[12] D. Conklin, Music Generation from Statistical Models, In Proc. of the Symposium on Artificial Intelligence and Creativity in the Arts and Sciences AISB'03, 2003.
[13] D. Cope, The Algorithmic Composer, A-R Editions, 2000.
[14] D. Cope, Recombinant Music Using the Computer to Explore Musical Style, IEEE Computer, Vol. 24, No. 7, 1991.
[15] D. Cope, Experiments in Musical Intelligence, A-R Editions, 1996.
[16] D. Cope, Computer Modeling of Musical Intelligence in EMI, Computer Music Journal, Vol. 16, No. 2, 1992.
[17] D. C. Correa, A. L. M. Levada, J. H. Saito and J. F. Mari, Neural Network Based Systems for Computer-Aided Musical Composition: Supervised x Unsupervised Learning, In Proc. of ACM Symposium Applied Computing SAC'08, 2008.
[18] R. Dannenberg, B. Thom, and D. Watson, A Machine Learning Approach to Musical Style Recognition, In Proc. of International Computer Music Conference ICMC’97, 1997.
[19] C. T. Davie, Musical Structure and Design, Dover Publications, 1966.
[20] S. Dubnov, G. Assayag, O. Lartillot and G. Gejerano, Using Machine-Learning Methods for Musical Style Modeling, IEEE Computer, Vol. 36, No. 10, 2003.
[21] D. Espi, Ponce de Leon,P. J., C. Perez-Sancho, et al, A Cooperative Approach to Style-Oriented Music Composition, In Proc. of International Workshop on Artificial Intelligence and Music MUSIC-AI'07, 2007.
[22] M. Farbood, Analysis and Synthesis of Palestrina-Style Counterpoint Using Markov Chains, In Proc. of International Computer Music Conference ICMC'01, 2001.
[23] C. Guéret, N. Monmarché and M. Slimane, Ants Can Play Music, In Proc. of Ant Colony Optimization and Swarm Intelligence ANTS'04, 2004.
[24] M. C. Ho and M. K. Shan, Theme-based Music Structural Analysis, submitted to IEEE Multimedia, 2007.
[25] J. L. Hsu, C. C. Liu and A. L. P. Chen, Efficient Repeating Pattern Finding in Music Database, IEEE Transaction on Multimedia, Vol. 3, No. 3, 2001.
[26] N. C. Jones and P. A. Pevzner, An Introduction to Bioinformatics Algorithms, The MIT Press, 2004. [27] I. Karydis, A. Nanopoulos and Y. Manolopoulos, Finding Maximum-length Repeating Patterns in Music
Databases, Multimedia Tools and Applications, Vol. 32, No. 1, 2007.
[28] P. van Kranenburg and E. Backer, Music Style Recognition- A Quantitative Approach, In Proc. of Conference on Interdisciplinary Musicology CIM’04, 2004.
[29] O. Lartillot, S. Subnov, G. Assayag and G. Bejerano, Automatic Modeling of Musical Style, In Proc. of International Conference in Computer Music ICMC'02, 2002.
[30] Y. L. Lo, W. L. Lee and L. H. Chang, True Suffix Tree Approach for Discovering Non-trivial Repeating Patterns in a Music Object, Multimedia Tools and Applications, Vol. 37, No. 2, 2008.
[31] K. McAlpine, E. R. Miranda and S. Hoggar, Composing Music with Algorithms: A Case Study System, Computer Music Journal, Vol. 23, No.2, 1999.
[32] M. Melucci and N. Orio, A Comparison of Manual and Automatic Melody Segmentation, In Proc. of International Symposium on Music Information Retrieval ISMIR’02, 2002.
[33] E. R. Miranda, Composing Music with Computers, Focal Press, 2001.
[34] T. Miura and K. Tominaga, An Approach to Algorithmic Music Composition with an Artificial Chemistry, In Proc. of the German Workshop on Artificial Life, 2006.
[35] K. Muscutt, Composing with Algorithms: An Interview with David Cope, Computer Music Journal, Vol. 31, No. 3, 2007.
[36] G. Papadopoulos and G. Wiggins, A Genetic Algorithm for Generation of Jazz Melodies, In Proc. of Software Technology and Engineering Practice STEP'98, 1998.
[37] M. Pearce and G. Wiggins, Towards A Framework for the Evaluation of Machine Compositions, In Proc. of Symposium on Artificial Intelligence and Creativity in the Arts and Sciences AISB'01, 2001.
[38] P. Reagan, Computer Music Generation via Decision Tree Learning, Master Thesis, Department of Computer Science, Carnegie Mellon University, USA, 1999.
[39] P. J. Ponce de Leon and J. M. Inesta, Pattern Recognition Approach for Music Style Identification Using Shallow Statistical Descriptors, IEEE Transactions on Systems, Man, and Cybernectics,-Part C: Applications and Reviews, Vol. 37, No. 2, 2007.
[40] M. K. Shan, F. F. Kuo, and M. F. Chen, Music Style Mining and Classification by Melody, In Proc. of IEEE International Conference on Multimedia and Expo ICME’02, 2002.
[41] M. K. Shan and F. F. Kuo, Music Style Mining and Classification by Melody, IEICE Transactions on Information and System, Vol. E86-D, No. 4, 2003.
[42] A. Sorensen and A. R. Brown, Introducing jMusic, In Proc. of the Australasian Computer Music Conference, 2000.
[43] L. Stein, Structure & Style: The Study and Analysis of Musical Forms, Summy-Birchard Music, 1979. [44] A. Takasu, T. Yanase, T. Kanazawa, and J. Adachi, Music Structure Analysis and Its Application to
Theme Phrase Extraction, In Proc. of European Conference on Research and Advanced Technology for Digital Libraries ECDL’99, 1999.
[45] K. Tominaga and M. Setomoto, An Artificial-Chemistry Approach to Generating Polyphonic Musical Phrases, Lecture Notes in Computer Science, Vol. 4976, 2008.
[46] A. L. Uitdenbogerd and J. Zobel, Melodic Matching Techniques for Large Music Databases, In Proc. of ACM International Conference on Multimedia MM'99, 1999.
[47] P. E. Utgoff and P. B. Kirlin, Detecting Motives and Recurring Patterns in Polyphonic Music, In Proc. of International Computer Music Conference ICMC’06, 2006.
[48] K. Verbeurgt, M. Dinolfo and M. Fayer, Extracting Patterns in Music for Composition via Markov Chains, In Proc. of International Conference on Innovations in Applied Artificial Intelligence, 2004.
[49] T. Weyde, J. Wissmann, and K. Neubarth, An Experiment on the Role of Pitch Intervals in Melodic Segmentation, In Proc. of International Symposium on Music Information Retrieval ISMIR’07, 2007.
[50] G. Wiggins, G. Papadopoulos, S. Phon-Amnuaisuk and A. Tuson, Evolutionary Methods for Musical Composition, In Proc. of Anticipation Music and Cognition CASYS'98, 1998.
[51] I. H. Witten and E. Frank, Data Mining: Practical Machine Learning Tools and Techniques, CA: Morgan Kaufmann, 2005.
國科會補助專題研究計畫項下出席國際學術會議心得報告
日期: 年 月 日
一、參加會議經過
ACM International Conference on Information and Knowledge Management, CIKM 是 ACM 結合資料庫
(Database)、資料探勘(Data Mining)、資訊擷取(Information Retrieval)、知識管理(Knowledge Management)
領域的權威會議。歷年的 CIKM 都有不少精彩的研究成果發表。本屆會議共收到 918 篇來自全球五大 洲的論文投稿,所發表的論文包括了 134 篇 Full Paper 的 Oral Presentation、93 篇 Short Paper 的 Oral Presentation、98 篇 Poster 海報論文。其中,Full Oral Presentation Paper 的 Accepting Rate 為 15%,Short
Oral Presentation Paper 的 Accepting Rate 為 10%,Poster 海報論文的 Accepting Rate 為 10%,累計 Full
Paper, Short Paper, Poster 的 Accepting rate 為 35%。今年的會議為第二十屆在英國的哥拉斯哥舉行,由
格拉斯哥大學主辦。台灣今年有台大電機系陳銘憲教授、台大資工系的吳家麟教授、台大資工系的陳 信希教授、台大資工系的鄭卜任教授、連同敝實驗室共 6 篇論文在 CIKM 發表。敝實驗室此次投稿了 2 篇論文,一篇結合 Social Media 與 Music Playlist 的 Social Music Recommendation,一篇則是
Context-based People Search in Labeled Social Networks。前者很可惜在實驗部分由於資料來源的關係,
計畫編號 NSC-98-2221-E-004-007-MY2
計畫名稱
以音樂動機探勘為導向的電腦音樂作曲
出國人員
姓名
沈錳坤
服務機構
及職稱
政治大學資訊科學系教授
會議時間
100 年 10 月 24 日至 100 年 10 月 28 日會議地點 英國格拉斯哥
會議名稱
(中文) 第 20 屆國際計算機學會資訊與知識管理會議
(英文) 20
thACM International Conference on Information and Knowledge
Management, ACM CIKM, 2011.
發表論文
題目
(中文) 社群網絡上以情境為導向的人名搜尋
(英文)
Context-based People Search in Labeled Social Networks
不夠完整。後者則獲評審肯定。
今年的 Keynote speech 包括 MIT 的 Professor David R. Karger 主講 Creating User Interfaces that Entice People to Manage Better Information、University of Melbourne 的 Professor Justin Zobel 主講 Data, Health,
and Algorithmics: Computational Challenges for Biomedicine、來自義大利 Università di Roma La Sapienza
的 Professor Maurizio Lenzerini 主講 Ontology-based Data Management。與我的研究關係密切的是 Professor David R. Karger 的主題演講。雖然對於這些議題都不陌生,但 Prof. Karger 完整的整理與介紹
令人對於相關議題有整合而嚴謹的體會。尤其,對於 Collaborative Filtering, Social Media 有精闢的分析。 他也點出幾個重要研究議題。對於我們正研究的 Social Computing、Social Music Recommendation 之研 究有很大的幫助。
我的報告安排在 25 日下午的 Query Answering and Social Search 這 Session。Session Chair 是來自於 Indian University 的 Prof. Yuqing Wu。Prof. Wu 的研究專長在 XML Database,尤其是 XML 的 Query
Processing。之前曾研讀過其相關論文,其實驗室發展的系統也有在這次會議的 Demo。這場主要的論
文都偏重在 Search。我們發表的論文主要是利用 Social Context 協助使用者在 Social Networks 上的搜 尋,我們將此 Social Search Problem 轉換為 Team Formation 的問題,並提出在大量 Social Networks 上 的演算法。我們的報告獲得在場學者踴躍的討論,大家對於以 Context 輔助 Social Network 上的搜尋很 感興趣,唯一感到可惜的是有位學者誤解我們的研究是解決 Namesake 的問題。
另一場印象深刻的主題是 26 日下午的 Session: Social Networks and Communities。尤其第一篇發表 的論文: Discovering Top-k Teams of Experts with/without a Leader in Social Networks,與我近年的研究興 趣息息相關。雖然作者沒有出席,而是由另一篇論文的作者代為報告,但其問題定義的變形非常有創 意。很可惜的是可能因為原作者沒出席,因此沒有獲得現場學者的關注。
今年在會議的前一天與後一天分別有 10 場 Tutorial 與 15 場 Workshop。雖然 Tutorial 中包括來自於 Yahoo! Research 的 Information Retrieval Challenges in Computational Advertising、UC Santa Barbara 的
Information Diffusion in Social Networks: Observing and Affecting What Society Cares About、與 Big Data
相關的 Large-Scale Array Analytics: Taming the Data Tsunami,但受限於經費限制而沒能參加。
二、與會心得
權威會議。由每年發表的論文可以觀察這些領域的研究發展趨勢。這幾年逐漸可以觀察出產業界的大 量資料對於這些領域的影響。除了 Microsoft Research, Google Research, Yahoo! Research 因為有大量使 用者資料而有不少研究論文發表,很多研究的實驗也都以大量資料來驗證。
此外,27 日的 Industrial Event 中我印象最深刻的是來自於 Google 的 Ed Chi 介紹 Model-Driven Research in Social Computing。這與我目前有關 Social Network 有密切的關係,Ed Chi 點出目前 Social
Network 上有關 Information Diffusion 的 Theory of Influential 的盲點,並提出一些 Model-Driven 的 Issues。
這次會議如同 ACM KDD, IEEE ICDM,逐漸有 Social Network 的相關論文,只是這方面的成長數量 沒有其他會議明顯。希望明年會議將會有更多結合 Social Network 的相關論文。
三、考察參觀活動(無是項活動者略)
這次會議的舉行地點雖然是在格拉斯哥的 Crowne Plaza,但基於對亞當史密斯的崇仰,特別到主辦 單位格拉斯哥大學參觀。除了看到亞當史密斯的雕像,也參觀了大學的博物館。對於格拉斯哥大學在 啟蒙時代,所扮演的角色與對社會的影響,印象深刻。同時,由倫敦回國前一天,也拜訪了 University of College London (UCL)的 Cancer Institute,因為敝實驗室畢業的系友(大學部專題學生,後來在中研院
TIGP 獲得博士學位)詹博士正在此進行有關生物資訊的博士後研究。與其詳談研究工作情形,深深體
會到 Data Science 在 Bioinformatics 扮演的角色。


![Figure 9: Examples of music segments and assigned chords [40].](https://thumb-ap.123doks.com/thumbv2/9libinfo/8304279.174256/16.892.205.692.380.594/figure-examples-music-segments-assigned-chords.webp)