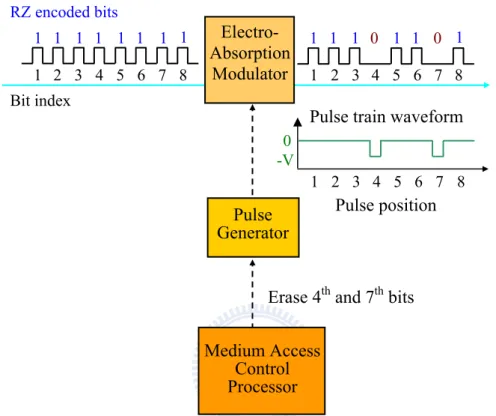
國立交通大學資訊學院
資 訊 工 程 學 系
博士論文
全光分波多工封包交換都會環狀網路之
光標頭處理及存取控制系統的設計與實現
Design and Experimentation of an
Optical-Header Processing and Access Control
System for a Packet-Switched WDM Metro
Ring Network
研 究 生:王雅纖
指 導 教 授:楊啟瑞 博士
全光分波多工封包交換都會環狀網路之
光標頭處理及存取控制系統的設計與實現
Design and Experimentation of an
Optical-Header Processing and Access Control
System for a Packet-Switched WDM Metro
Ring Network
研 究 生:王雅纖
Student: Ya-Shian Wang
指導教授:楊啟瑞 博士
Advisor: Dr. Maria C. Yuang
國立交通大學 資訊學院
資訊工程學系
博士論文
A Thesis
Submitted to Department of Computer Science
College of Computer Science
National Chiao Tung University
in partial Fulfillment of the Requirements
For the Degree of
Doctor of Philosophy
in
Computer Science
February 2010
Hsinchu, Taiwan, R.O.C.
中 華 民 國 九 十 九 年 二 月
全光分波多工封包交換都會環狀網路之
光標頭處理及存取控制系統的設計與實現
研究生:王雅纖 指導教授:楊啟瑞 博士
國立交通大學 資訊工程學系
Abstract in Chinese
下一世代全光都會型網路(metropolitan area networks; MANs)旨在支援各類 型要求高頻寬之網路應用程式以及訊務特性趨於動態變化之網路應用程式,全光 封包交換技術(optical packet switching; OPS),能夠滿足此類網路之需求,被視為 是未來全光都會網路的一個典範。此篇論文提出之全光標頭交換與存取控制系統 (optical-header processing and access control system; OPACS) 設計與實現,是應用 在全光分波多工(wavelength division multiplexing; WDM)封包交換都會環型槽狀 網路。OPACS 的設計具有兩項獨一無二的特色。首先, OPACS 設計之內頻控 制(in-band)分時多工(time division multiplexing; TDM)全光標頭訊號技術,每個訊 槽包含控制標頭以及資料負載,藉由波長與時間之轉換,OPACS 使所有全光平 行控制標頭可在成本效益考量下,進行標頭的接收、修改、以及重送。再者, OPACS 系統提出之多用途媒介存取控制(medium access control ; MAC) 設計,稱 為分散式多重粒度與視窗預訂(distributed multi-granularity and multi-window reservation; DMGWR),DMGWR 的動態頻寬配置設計,特別適合應用在訊務量 很高且訊務特性趨於動態變化之網路。基本上, DMGWR 為了確保每個網路節 點能夠公平地存取網路頻寬,要求網路節點傳送資料前必須先提出預約需求,並 藉由全域分散式佇列(global distributed queue)來達到網路頻寬公平性之配置。 DMGWR 的多重粒度設計,讓節點可以一次預約多個訊槽。DMGWR 的多重視 窗設計,當節點還有資料須要傳送(如大量突發訊務),即便節點原預約資料還未
傳送完畢前,當預約次數還在系統視窗範圍(window size)內時,都能再提出新的 預約需求。透過實驗模擬結果得知,相對於現存的兩種主要動態頻寬配置 HORNET DQBR 以及 WDMA 網路,OPACS 可以達到更為優異的系統輸出、頻 寬效率、接取延遲、公平性以及大量突發訊務適應性表現。實驗結果也顯示,全
光標頭交換能夠在一完全同步的方式進行標頭的刪除與整合,證明OPACS 系統
Design and Experimentation of an
Optical-Header Processing and Access Control
System for a Packet-Switched WDM Metro
Ring Network
Student: Ya-Shian Wang Advisor: Dr. Maria C. Yuang
Department of Computer Science National Chiao Tung University, Taiwan
Abstract
Optical packet switching (OPS) has been considered to be a promising paradigm to support a wide range of applications with different time-varying and high bandwidth demands for future optical metropolitan area networks (MANs). This thesis presents the design of an experimental optical-header processing and access control system (OPACS) for an OPS WDM metro slotted-ring network. OPMACS is endowed with two distinctive features. First, OPMACS has been designed for a dual unidirectional slotted ring network using in-band signaling control. Each control header is in-band time-division-multiplexed with its corresponding payload within a slot. OPACS enables the optical headers across all parallel wavelengths to be efficiently received, modified, and re-transmitted by means of a wavelength-time conversion technique. Moreover, OPACS embodies a versatile medium access control (MAC) scheme, referred to as the distributed multi-granularity and multi-window reservation (DMGWR) mechanism, which is particularly advantageous for traffic of high and varying loads and burstiness. Basically, DMGWR requires each node to make reservation requests prior to transmissions while maintaining a distributed queue for ensuring fair access of bandwidth. By “multi-granularity”, each node can
make a reservation of multiple slots at a time. By “multi-window”, each node is allowed to have multiple outstanding reservations within the window size. Simulation pit the OPACS network against two other existing networks, simulation results show that the OPACS network outperforms these networks with respect to throughput, access delay, and fairness under various traffic patterns. Experimental results demonstrate that all optical headers are removed and combined with the data in a fully synchronous manner, justifying the viability of the system.
CONTENTS
ABSTRACT IN CHINESE ... I ABSTRACT ... III LIST OF FIGURES...VII LIST OF TABLES ... IX SYMBOLS ... X ACRONYMS ... XI CHAPTER 1. INTRODUCTION...11.1OPTICAL NETWORKS:AN OVERVIEW...1
1.2MOTIVATION AND OBJECTIVES...3
1.3ORGANIZATION OF THE THESIS...7
CHAPTER 2. OPS-BASED METRO RING NETWORKS...8
2.1OPTICAL HEADER PROCESSING TECHNIQUES...8
2.2EXPERIMENTAL TESTBEDS FOR PACKET-SWITCHED RING METRO WDM NETWORKS...13
2.3EXISTING MAC PROTOCOLS FOR OPS-BASED WDMMETRO RING NETWORKS...19
2.3EXISTING MAC PROTOCOLS FOR OPS-BASED WDMMETRO RING NETWORKS...20
2.4DISCUSSIONS...32
CHAPTER 3. THE OPACS SYSTEM ARCHITECTURE ...36
3.1SYSTEM ARCHITECTURE...36
3.2NODE ARCHITECTURE...39
CHAPTER 4. FAIRNESS CONTROL FOR THE OPACS MAC PROTOCOL ...42
4.1OPACSFAIRNESS CONTROL PROTOCOL:DMGWRDESIGN PRINCIPLES...42
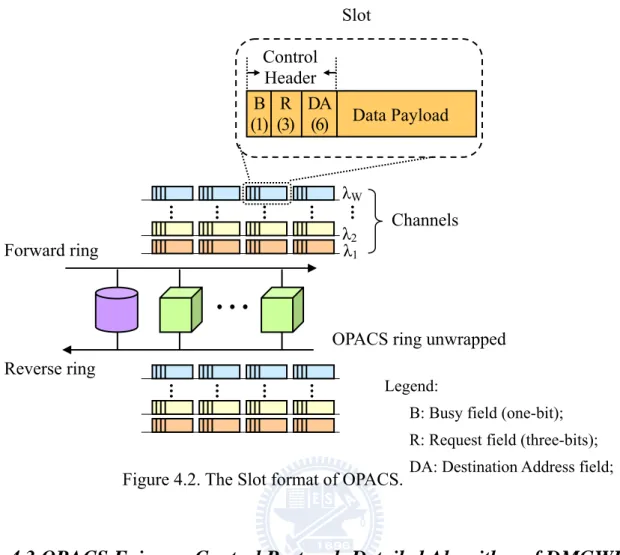
4.2SLOT FORMAT OF OPACS...45
4.3OPACSFAIRNESS CONTROL PROTOCOL:DETAILED ALGORITHM OF DMGWR ...46
4.4OPACSFAIRNESS CONTROL PROTOCOL:CONTENTION-FREE PACKET SELECTION SCHEMES...52
CHAPTER 5. SIMULATION RESULTS ...54
5.1SIMULATION MODEL...54
5.2PERFORMANCE METRICS...56
5.3PERFORMANCE COMPARISONS...57
5.4PERFORMANCE STUDY...69
5.5DISCUSSIONS...77
6.1EXPERIMENTAL NODE SETUP...79
6.2EXPERIMENTAL RESULTS...80
CHAPTER 7. CONCLUSIONS AND FUTURE WORK...85
7.1CONCLUSIONS...85
7.2FUTURE WORKS...86
APPENDIX ...88
REFERENCES ...94
List of Figures
Figure 2.1. In-band header control architecture... 9
Figure 2.2. Out-Of-band header control architecture... 9
Figure 2.3. General node architecture of HOPSMAN ...18
Figure 2.4. The control slot format of WDMA protocol...27
Figure 2.5. The Cycle and slot structures of PQOC...30
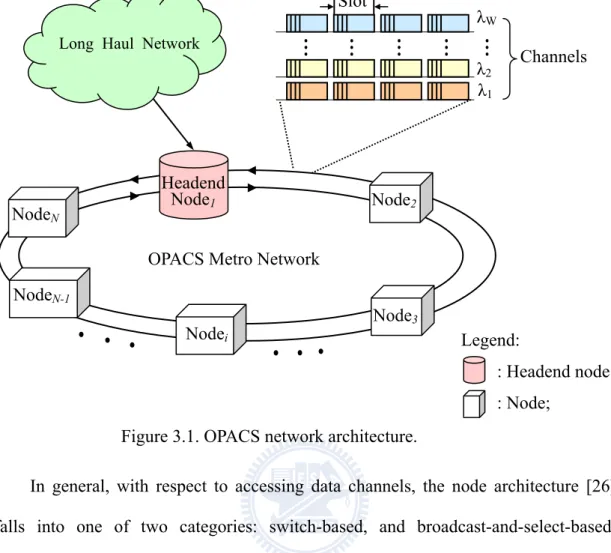
Figure 3.1. OPACS Network Architecture ...36
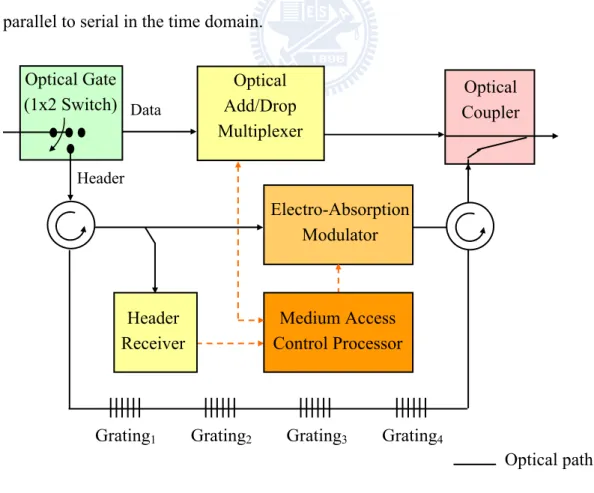
Figure 3.2. OPACS- system architecture (W=4)...38
Figure 3.3. Electro-Absorption Modulator- an example... 40
Figure 4.1. The dual ring unwrapped, while focusing on the contention for Node N. ...41
Figure 4.2. The DMGWR slot format... 45
Figure 4.3. The DMGWR scheme: Idle state ...46
Figure 4.4. The DMGWR scheme: Ready state ...47
Figure 4.5. The DMGWR scheme: Active state ...48
Figure 4.6. The DMGWR algorithm...50
Figure 5.1. Throughput comparison...57
Figure 5.2. Aggregate throughput comparison under various loads and number of wavelengths...61
Figure 5.3. Access delay comparison under various burstiness and load...62
Figure 5.4. Comparisons of delay Fairness under various inter-nodal distance ...63
Figure 5.5. Comparisons of delay fairness under various burstiness... 63
Figure 5.6. Delay comparisons for network with malicious nodes...64
Figure 5.7. Performance comparisons for network with malicious nodes...65
Figure 5.8. The impact of wavelength sharing on throughput performance under the same sharing ratio ... 65
Figure 5.9. The impact of wavelength sharing on throughput performance with the same number of wavelengths...66
Figure 5.10. The impact of multi-window design on delay...67
Figure 5.12. Delay performance comparison under various loads and burstiness...71
Figure 5.13. Delay fairness comparison under various multi-granularity ...72
Figure 5.14. Receiver contention probability comparison...73
Figure 5.15. Normalized throughput fairness comparison for packet selection strategies ...74
Figure 5.16. Delay performance comparison for packet selection strategies under various number of wavelengths ...74
Figure 6.1. Experimental node setup ...78
Figure 6.2. Experimental results- signal traces observed at stages (a)-(g) ...80
Figure 6.3. The second experimental results ...82
Figure A.1 The idle state of DQDB scheme ...87
List of Tables
Table 1. Experimental testbeds comparisons ...32 Table 2. Fairness MAC protocols comparisons ...34 Table 3. Multi-channel dynamic bandwidth allocation schemes comparisons...77
Symbols
N Number of nodes W Number of wavelengths D Inter-nodal distance L Offer load B Burstinessα Probability of changing from State H to Ľ in a slot β Probability of changing from State Ľ to H in a slot
λH Probability of changing from State H to Ľ in a slot
λĽ Probability of changing from State Ľ to H in a slot
Acronyms
ADM Add/Drop Multiplexer
ASK Amplitude Shift Keying
ATMR Asynchronous Transfer Mode Ring AWG Arrayed Waveguide Gratings
CD Countdown Counter
CSMA/CA Carrier Sense Multiple Access with Collision Avoidance DAVID Data And Voice Integration over DWDM
DMGWR Distributed Multi-Granularity and Multi-Window Reservation DSWR Distributed Single-Window Reservation
DPSK Differential Phase Shift Keying DQDB Distributed Queue Dual Bus
DQBR Distributed Queue Bidirectional Ring EAM Electro-Absorption Modulator FBG Fiber Bragg Gratings
FCFS First Come First Serve FIFO First In First Out
FSK Frequency Shift Keying HOL Head-Of-Line
HORNET Hybrid Optoelectronic Ring Network
IP Internet Protocol
MAN Metropolitan Area Network
M-ATMR Multiple Asynchronous Transfer Mode Ring MMPP Markov Modulated Poisson Process
MMR Muliple MetaRing
MTIT Multitoken Interarrival Time NRS The total Number of Reserved Slots NRZ NonReturn to Zero
OCS Optical Circuit Switching
OCSS Optical Carrier Suppression and Separation OPS Optical Packet Switching
OPACS Optical-Header Processing and Access Control System PQOC Probabilistic Quota plus Credit
PRQ Pending Request Queues PSK Phase-Shift Keying RAM Random Access Memory
RingO The Italian Ring Optical Network RQ Request Counter
RZ Return to Zero
SCM SubCarrier Multiplexed SDH Synchronous Digital Hierarchy SOA Semiconductor Optical Amplifier SONET Synchronous Optical Network SRR Synchronous Round Robin TDM Time Division Multiplexing VOQ Virtual Output Queue
WDM Wavelength Division Multiplexing WDMA WDM Access Protocol
WS Window Size
Chapter 1. Introduction
1.1 Optical Networks: An Overview
Over the last decade, advances in Internet technology brought about the proliferation of Internet-based multimedia applications, such as IPTV, remote terminal services, and on-line gaming. These applications virtually require the satisfaction of different time-varying and high bandwidth demand and stringent delay-throughput performance. Optical wavelength division multiplexing (WDM) [1-5] has been shown successful in providing virtually unlimited bandwidth to support a large amount of steady traffic based on the optical circuit switching (OCS) paradigm for long-haul backbone networks. Future optical networks, especially metropolitan area networks (MANs) [4-5] and local area networks (LANs) networks, are expected to flexibly and cost-effectively satisfy a wide range of applications having time-varying and high bandwidth demands and stringent delay requirements.
Regarding MANs, some slightly different optimization parameters are required [5,6]: (1) Flexible upgrade: The pace of bandwidth demand in metro calls for new solutions, much more flexible and scalable than traditional synchronous optical network/synchronous digital hierarchy (SONET/SDH) rings. Scalability is not just reaching huge capacities, but more being able to upgrade smoothly the system during operation with limited initial investment cost. WDM is obviously entering this market, and is expected to contribute to the network scalability. (2) Optimized resource utilization: Data traffic burstiness is obviously higher than in the backbone due to less efficient statistical multiplexing in a network much closer to the access and usually with simpler topologies. Next-generation metropolitan solutions will need to propose more sophisticated bandwidth and resource allocation management schemes, to
propose bandwidth-flexible services at affordable costs. (3) Cost per transferred bit: Cost is clearly of major importance in metropolitan area networks. Capacity and flexibility obviously have to be traded off with the added cost, although higher utilization of available resources will drive it down. (4) Transparency: Since a much greater variety of protocols coexist in the metropolitan market, compared to the core, a high level of transparency with respect to these protocols is expected to preserve the past investment of network operators.
Such facts bring about the need of exploiting the optical packet-switching (OPS) [2-5] paradigm that takes advantage of statistical multiplexing (i.e., fine-grained on-demand channel allocation) to efficiently share wavelength channels among multiple users and connections. OPS [2-5] has thus been considered to be a preeminent paradigm capable of supporting such applications over future optical WDM MANs. It is worth noticing that the OPS technique studied here excludes the use of optical random access memory (RAM) [4] and precise optical packet time synchronous technology, which is a significant technological limitations OPS faces.
In general, a WDM OPS switch consists of four parts: the input interface, switching fabric, output interface, and control unit [2-5]. The input interface is mainly used for packet delineation and alignment, packet header information extraction and packet header removal. The switch fabric is the core of the switch and is used to switch packets optically. The output interface is used to regenerate the optical signals and insert the packet header. The control unit controls the switch using the information in the packet headers. Because of synchronization requirements, optical packet switches are typically designed for fixed-size packets.
When a packet arrives at a WDM optical packet switch, it is first processed by the input interface. The header and payload of the packet are separated, and the header is converted into the electrical domain and processed by the control unit electronically.
The payload remains an optical signal throughout the switch. After the payload passes through the switching fabric, it is recombined with the header, which is converted back into the optical domain at the output interface.
1.2 Motivation and Objectives
Numerous topologies and architectures [7-32] for OPS WDM MANs have been proposed in recent years. Of these proposals, the structure of slotted rings [7-28] receives the most attention. While most of the work [13,14,16-26] is simulation driven, only a handful [7-11,25-32] undertakes experimental prototypes. Two key challenges pertaining to OPS-based WDM networks are the header control and medium access controls. The header control can be in-band [25-32], where both header and payload are modulated and transported via the same wavelength, or out-of-band [7-24], where control headers are carried via a dedicated control wavelength. While both control methods have their merits, from a carrier’s perspective, an out-of-band control system appears impractical due to the additional cost of a fixed transceiver on each node.
In addition, in-band control has several advantages over out-of-band control. First, in a mesh network, a layer-two wavelength switch can switch the header and payload together to an output port without examining the header. With out-of-band control, complicated control signal processing and routing are needed (e.g., optical burst switching) because the header and payload are carried on different wavelengths. Second, in-band headers can be used as a performance monitoring signal. Physical impairments on the payload can be monitored by detecting header signal's quality. Third, because all wavelengths’ control information has to fit within a time slot, out-of-band control requires a costly high-data-rate control wavelength in order to support more channels, resulting in a scalability problem. Thus, this work focuses on
the in-band header control and processing.
There are three basic in-band header control techniques: subcarrier multiplexed (SCM) [25-28,33-50], orthogonal modulation [51-64], and time-domain-multiplexing (TDM) [26-28,65-67]. With the SCM technique, the header information can be carried on a subcarrier frequency that is separated from the baseband payload frequency. SCM requires stringent wavelength accuracy and stability if a fixed optical notch filer (e.g., a fiber Bragg grating) is used to remove the header at each node. Most traditional SCM methods cannot potentially scale up well with the payload data rate because an expanding baseband may eventually overlap with the subcarrier frequency. The optical carrier suppression and separation (OCSS) technique [33], however, was shown to be able to generate the header at very high subcarrier frequency and with high bit rate and extinction ratio. Nevertheless, SCM still requires stringent wavelength accuracy and stability while using a fixed optical filter to remove the header at each node.
The orthogonal modulation technique, which includes amplitude shift keying (ASK) [38], frequency shift keying (FSK) [54], ASK/differential phase shift keying (DPSK) [55,56], and DPSK/FSK [57], exhibits severe transmission system penalty due to the inherently low extinction ratio of a high-speed payload signal. Finally, with the TDM technique, the header and payload are serially connected in the time domain, interspaced with an optical guard time to facilitate header extraction and modification. The bit rates of the header and payload can either be the same [65], or different [66,67]. Generally, traditional TDM-based approaches require an extremely precise control timing and alignment to perform header erasing and rewriting operations. The first goal of this work is to propose a simple and highly efficient TDM-based optical header processing scheme. As will be demonstrated, in our system optical headers can also be easily modified by taking advantage of the particularly notable MAC design.
Another key performance-enhancing feature pertaining to OPS-based networks is the design of the medium access control (MAC) mechanism. The MAC scheme should be designed to offer fair and versatile bandwidth allocation, achieving satisfied throughput and delay performance under a wide range of traffic loads and burstiness. Moreover, the MAC protocol should take into account the scalability problem with respect to the number of wavelengths. While numerous MAC protocols for OPS-based slotted-ring networks have been proposed in the literature [10-14], our second goal is to explore a variant of a reservation-based mechanism, IEEE 802.6 Distributed Queue Dual Bus (DQDB) [72], for the multi-channel WDM metro networks. In single-channel DQDB, each node must issue a reservation request prior to the transmission. To ensure that packets are sent in the order they arrived at the network, DQDB requires each node to maintain a distributed queue via a Request (RQ) and a CountDown (CD) counters. DQDB was shown to achieve superior throughput and delay performance, nevertheless undergoes the unfairness problem due to long propagation delay under heavy traffic conditions.
In this WDM-DQDB line of work, the WDM Access (WDMA) [13] protocol simply extends the basic single-channel DQDB to the multi-channel case, namely, each node maintains a single distributed queue for all of the wavelengths. Due to the use of a tunable transceiver, WDMA adopts the retransmission mechanism if the receiver contention problem occurs. With such a simple design, WDMA unfortunately results in access unfairness and inefficiencies for multi-channel networks under varying traffic patterns and burstiness. The hybrid optoelectronic ring network (HORNET) [10] employs a distributed queue bidirectional ring (DQBR) protocol. Due to the use of fixed-tuned receivers, HORNET statically assigns each node a wavelength as the home channel for receiving packets. Such static wavelength
assignment results in poor statistical multiplexing gain and bandwidth efficiency. As a result of the home-channel design, DQBR treats wavelengths independently and requires each node to maintain a distributed queue for each wavelength. Moreover, each node is allowed to issue multiple independent single-slot requests. With DQBR, HORNET achieves acceptable utilization and fairness at the expense of high control complexity for maintaining the same number of counter pairs as that of wavelengths. Such a design gives rise to a scalability problem. Moreover, the design of permitting unlimited multiple requests with single slot granularity per request unfortunately results in unfairness problems.
A novel OPACS (optical-header processing and access control system) for a 10-Gb/s optical packet-switched [26-28] WDM metro ring network is presented in this dissertation. OPACS has two prominent features that set it apart from existing related work. First, OPACS is designed for a dual unidirectional ring network using in-band signaling control. Each control header is time-division-multiplexed with its corresponding data packet within a slot. By making use of signal gating and wavelength-time conversion techniques, OPACS enables the optical headers across all parallel wavelengths to be efficiently received, modified, and re-transmitted. Second, taking diverse traffic patterns and burstiness into account, OPACS employs a variant of the DQDB scheme, referred to as the distributed multi-granularity and multi-window reservation (DMGWR) scheme. By “multi-granularity”, DMGWR permits each node to reserve different amounts of bandwidth (slots) at a time. By “multi-window”, DMGWR allows each node to have multiple outstanding reservations within the window size. From numerical results that pit the DMGWR network against two other existing networks (WDMA-based and HORNET), we show that the OPACS network outperforms both networks with respect to throughput, access delay, and fairness under various traffic patterns. Experimental results
demonstrate that all optical headers are removed and combined with the data in a fully synchronous manner, justifying the viability of the system.
1.3 Organization of the Thesis
The remainder of this thesis is organized as follows. Chapter 2 provides a review of existing related optical header processing techniques, experimental testbeds, existing related MAC protocols and fairness control schemes for OPS-based WDM metro ring networks. Chapter 3 presents the OPACS system architecture and node architecture. Chapter 4 introduces the design concepts and detailed operations of the MAC protocol. Chapter 5 evaluates comparatively the performance of the protocol introduced in Chapter 4. Chapter 6 presents the experimental setup and results. Finally, conclusion remarks of this thesis and some future works are provided in Chapter 7.
Chapter 2. OPS-based Metro Ring Networks
This chapter provides a review of existing optical header processing techniques, experimental testbed systems, and the existing MAC protocols related to OPS based metro ring networks. Following a short introduction, in-band header control techniques are investigated. In general, the low-speed label associated with a high-speed payload is extracted, processed, and replaced at every intermediate network-switching node. Meanwhile, the high-speed payload is optically switched (controlled by the electrically processed label) to an appropriate output fiber as an entirely untouched entity. The subsequent section will assess four experimental testbed systems that are relevant to this work. The third subsequent section will provide a review of existing MAC protocols and fairness control schemes for OPS-based WDM metro ring networks. The access control techniques are investigated by means of the different buffer selection strategies to achieve high channel utilization and low access delay. Furthermore, fairness control mechanisms are described in the next subsequent sections with particular emphasis on static bandwidth allocation control schemes and explicit dynamic bandwidth allocation schemes.
2.1 Optical Header Processing Techniques
The header control can be in-band [25-32], where both header and payload are modulated and transported via the same wavelength (see Figure 2.1), or out-of-band [7-24], where control headers are carried via a dedicated control wavelength, as depicted in Figure 2.2. Both control methods have their merits, from a carrier’s perspective, an out-of-band control system appears impractical due to the additional cost of a fixed transceiver on each node.
In an in-band based OPS network [4,33], the optical data packets contain a payload and a header or label. Optical header control technique is an important aspect of OPS and it involves the extraction and processing of the headers so that the packets can be routed to their correct destinations. In an OPS network, the optical packets are first encapsulated with optical labels as they enter the network. Once they are in the network, only the optical header undergoes OE conversion in the OPS router, so that the packet’s routing information and other auxiliary data, such as the wavelength and the bit rate of the payload, can be
Figure 2.1.In-band header control architecture. . . . Control Header . . . Slot λ1 Channels λ2 λW
Figure 2.2. Out-of-band header control architecture. . . . Control Channel Data Channels λ0 λ1 λW λW-1 Slot Slot . . .
determined. Since the payload remains in optical form from source to destination, it can be encoded at very high bit rate using any modulation format. To make the header control procedure very efficient, the header must be easily separated from the payload and it has to be processed at very high speeds.
Basically, the optical header scheme [4] should: 1) impose a minimum overhead to the data networking capacity, 2) support simple header replacement techniques, 3) maintain high signal fidelity across fiber transmission and cascaded nodes, and 4) impose low crosstalk between the header and the payload. Many in-band optical header processing techniques have been proposed and exhibit different strengths and limitations. There are three basic techniques: subcarrier multiplexed (SCM) [25-28,33-50], orthogonal modulation [51-64], and time-domain-multiplexing (TDM) [26-28,65-67].
2.1.1 Subcarrier Multiplexing (SCM) Header Technique
One of the most popular optical header techniques is based on subcarrier multiplexing (SCM) [25-28, 33-50] of the header with the data payload on the baseband. Initially, double-sideband SCM optical header techniques were widely utilized; however, the double-sideband SCM signal multiplexing studied in the mid 1980s [44], [45] for video transmission was known to cause RF fading, causing signal reception problems at particular distances in the network. RF fading is a result of the coherent interference between the carrier and the two sidebands, which constructively or destructively interfere depending on their relative phases determined by the initial phase conditions and the total dispersion (the product of the dispersion coefficient and the fiber transmission length).
ability to support a coarse alignment between the label and the payload, allowing a more asynchronous replacement of the SCM-encoded label [33]. This feature is significant, considering that chromatic dispersion may affect the arrival times of the header and payload signals; in addition, the low-cost electronic devices involved in the label processing may undergo frequency drifting.
To defeat the RF fading effect, a number of new techniques including carrier suppression method in optical header extraction and replacement [51] as well as single-side optical labeling technique with carrier suppression [33] have been investigated. Both techniques utilized relatively simple optical filtering techniques such as fiber Bragg gratings (FBGs) or arrayed waveguide gratings (AWG) for separating subcarrier components and showed successful penalty-free operations. Cascaded optical router operation [49], polarization and dispersion dependent fiber transmission, and first field trial across 477 km have been demonstrated [50] using the double-sideband optical header technique.
2.1.2 Orthogonal Modulation Header Technique
One of the most innovative optical header technologies employs the header and the data information modulated in orthogonal modulation formats of each other (e.g., in amplitude and phase domains) [55-57]. It is also possible to place two levels of labels [56] in the phase and wavelength domains for the amplitude-domain data. Demonstrated techniques involved ON–OFF keying intensity modulated (OOK-IM) data payloads with frequency shifted keying (FSK) headers [57] as well as 2.5-Gb/s OOK-IM headers with 40-Gb/s return-to-zero differential phase-shift keying (RZ-DPSK) data payloads [53]. Chi et al. [51] showed a header (label) replacement technique involving SOA, EAM, and highly nonlinear fiber for 10-Gb/s IM data
payloads and two-level optical headers (labels) at 2.5-Gb/s DPSK and the wavelength domain. In both cases of ASK labels and FSK/phase-shift keying (PSK) labels, there are tradeoff considerations related to extinction ratios in the two orthogonal domains. Likewise, crosstalk rejections in real systems become difficult since the two domains are coupled due to, for example, frequency chirping caused during amplitude modulation and vice versa. Zhang et al. [57] used integrated EAM-DFB lasers for FSK label modulation, where offsetting amplitude modulations in EAM cancel the unintentional amplitude modulation during FSK label modulation. Additional orthogonal modulation schemes include polarization modulations [59,60], wavelength-shifted keying for pulse position modulation [63], and embedded DPSK label in ASK data payload [64].
2.1.3 Time Division Multiplexed (TDM) Technique
Initial OPS technologies including TDM OPS technologies utilized a time-division-multiplexed (TDM) labels header technique, similar to the synchronous optical network/synchronous digital hierarchy (SONET/SDH) overhead. The label and the payload are serial in the time domain, interspaced with an optical guard time to facilitate label extraction and processing. They primarily pursued synchronous and fixed-length packet switching mainly because the TDM label already required relatively strict timing control. The KEOPS utilized the header line rate of 622 Mb/s and the flexible payload line rate of up to 10 Gb/s [65]. Both headers and payloads are led by synchronization bits to facilitate burst mode clock recovery. Upon reading the packet headers, all packets were synchronized by the optical synchronizer in the OPS system. Time domain header replacement requires time switching to remove the old header and to attach a new header to the payload. Since the header format includes a
small number of header bits (typically less than 100 bits), the overhead is very small, especially if a large data payload format (> 15 000 bytes) is adopted. Like in other OPS technologies, typical line rates for the header can be much lower than those for the data payload, and thus, relatively simple electronics can process the header and look up the forwarding table after reading the optical header content using a burst-mode optoelectronic receiver.
The bit rates of the label and the payload can be the same [65] or different [26-28,]. This method is straightforward to implement at the transmitter end, since the label and the payload are both in baseband formats and use the same wavelength channel. It also provides possibilities for all-optical regeneration and label processing [67]. However, the label receiving may require sophisticated synchronization and timing control. In some cases, accurate control signals have to be generated at each hop to inform the label processors of the temporal positions of the labels. In other cases, different power levels or coding formats (such as return to zero (RZ) and non return to zero (NRZ)) are taken to distinguish the label and the payload. Relatively complicated signaling or receiver designs make this bit-serial method difficult for practical applications. Moreover, the label and the data payload occupy separate time spaces, limiting the available data throughput.
2.2 Experimental Testbeds for Packet-Switched Ring Metro WDM
networks
Numerous topologies and architectures for OPS-based WDM metro ring networks have been proposed and exhibit different strengths and limitations. Of these proposals, the structure of slotted rings [7-32] receives the most attention. While most of the work [13-24] is simulation driven, only a handful [8-12,25] undertakes
experimental prototypes. In this section we survey four of the most recent experimental testbed systems relevant to this work for packet-switched ring metro WDM networks: HORNET [10, 25], RingO [12], DAVID [9], and HOPSMAN [7, 8].
2.2.1 Hybrid Optoelectronic Ring NETwork (HORNET)
The original version of Hybrid Optoelectronic Ring NETwork (HORNET) is a unidirectional WDM ring network [25]. Each node is equipped with one fast tunable transmitter (TT) and one fixed-tuned burst mode receiver (FR). The HORNET node structure consists of three subsections: slot manager, smart drop, and smart add module. The header control of HORNET is in-band SCM-based control. The destination address of a packet is modulated onto a SCM tone using a combination of ASK and FSK. For carrier senseing, the slot manager taps off some optical power for subcarrier recovery to perform two functions in parallel. It monitors the subcarriers (carrier sense) and relays the wavelength occupancy information to the smart add. It also demodulates the subcarrier (FSK demodulation) that corresponds to the nodes drop wavelength, recovers the address, and informs the smart drop whether the incoming packet is destined for itself or for a downstream node. The smart drop module drops a fixed wavelength using a circulator and a fiber Bragg grating. The dropped wavelength is detected inside a burst mode receiver that recovers the packet bit clock. It then uses the address information provided by the slot manager to switch the received packet either to the LAN or to a retransmit queue, where it waits to be multihopped to a downstream node. The smart add module chooses a transmission wavelength depending on the destination node of the queued packet and the wavelength availability information from the slot manager to avoid collision avoidance. It then tunes the fast tunable laser transmitter to the target wavelength and
modulates the packet on to the optical carrier. Access to all wavelengths is governed by means of a Carrier Sense Multiple Access with Collision Avoidance (CSMA/CA) protocol.
As extended the first version of unidirectional TT-FR, the second version of HORNET is a bi-directional WDM slotted ring network [10]. The HORNET architecture is designed to cost-effectively scale beyond 1 Tb/s while efficiently transporting bursty and randomly fluctuating traffic. Each node is equipped with one tunable transmitter and one fixed-tuned receiver for each ring. A node contains a wavelength drop for the node’s drop-wavelength on each ring, a tunable transmitter subsystem for each ring, a wavelength add and drop for the control channel wavelength on each ring, and a node controller. The node’s protocols are implemented in programmable logic devices (PLDs) on the node-controller circuit board clocked at 125 MHz. A Gigabit Ethernet (GbE) chip set is used for the transmission and reception of the control channel in the testbed. Gain-clamped semiconductor optical amplifiers (GC-SOAs) are used to provide linear gain in the testbed. The header control of HORNET is out-of-band control. The extended HORNET version proposed a distributed control-channel based MAC protocol, called Distributed Queue Bidirectional Ring (DQBR).
2.2.2 Ring Optical Network (RingO)
The Italian Ring Optical Network (RingO) [12] project used a unidirectional slotted WDM /Time division multiplexing (TDM) architecture. The node structure based on AWGs, was first proposed because of the major flexibility given by fully demultiplexing all channels on separate fibers. In addition, the node is equipped with an array of fixed-tuned transmitters and one fixed-tuned receiver. The number of
nodes in the first RingO version is equal to the number of wavelengths. Thus, each node has its own dedicated wavelength for packet reception. All wavelengths are slotted with the slot length equal to the transmission time of a fixed-size packet plus guard time. Each node performs λ-monitoring to check the wavelength occupation state on a slot-by-slot basis to avoid channel collision. Such a simple design gives rise to a scalability problem.
The second RingO node design is based on an add–drop filter, allowing for better cascadability and less stringent physical constraints. While this structure is similar to the first version for network functionalities, it is significantly different from the physical layer point of view. The input–output optical path is greatly simplified, and consists only of a passive optical splitter and a fixed add–drop filter tuned on the wavelength that must be received locally. This setup greatly reduces node attenuation, self-filtering, and PDL effects, and allows a higher node cascadability.
2.2.3 Data And Voice Integration over DWDM (DAVID)
The European IST project proposed DAVID (Data And Voice Integration over DWDM) networks [9]. The DAVID MAN consists of a number of unidirectional slotted WDM rings of metropolitan dimensions, which collect traffic from several ring nodes. These nodes provide an electro/optical interface to edge routers/switches at the end of access networks via a variety of legacy interfaces (e.g., Gigabit Ethernet in business areas, PONs in mixed or residential areas, cable head-ends, or any other legacy system). The WDM rings are interconnected to other rings via a bufferless hub, and to a mesh of packet-switched OPRs in the core creating the complete optical WAN. The rings can be either physically disjoint, or be obtained by partitioning the optical bandwidth into disjoint portions.
In DAVID, a broadcast-and-select architecture, which ensures nonblocking performance, is chosen, using semiconductor optical amplifier (SOA) technology [21]. A major issue in every packet switched network is contention resolution. In electronic routers this problem is tackled using random access memory (RAM), which is unfeasible in the optical domain. Since all optical buffers today are technologically hard to realize, there seems to be a consensus that they should be avoided as much as possible or at least be limited to a minimum. As stated before, the MAN is completely bufferless in the optical domain. In the WAN, a shared recirculating FDL buffer is used to help solving contention, where exploitation of the wavelength domain does not suffice.
The hub node is used to forward optical packets between ring networks, as well as to interconnect the metro area to the backbone through an electronic Gateway. The hub is an SOA-based optical packet switch capable to cope with a very high level of traffic (Terabit/s). The lack of real optical memories is compensated through the use of an extended multi-ring MAC protocol. The optical hub is, thus, bufferless and its structure is similar to the one of the optical packet router in the backbone but with reduced targeted final capacity. The main difference between the hub and the OPR is at the control level: the optical hub is configured by a controller which exploits the control channels of each connected ring network, in order to calculate the switching permutation. The hub comprises synchronization stages, a space switching stage, a wavelength switching stage, and regeneration stages if required (depending on the power budget). Each WDM channel operates at 10 Gb/s that with 32 wavelengths per ring and a channel spacing of 100 GHz, occupy 24 nm of bandwidth per ring; this corresponds to a reasonable optical bandwidth for the introduction of a SOA-based technology. The maximum capacity of one ring becomes 320 Gb/s.
an optical part. The electronic part realizes the adaptation with client layers, which. is performed in the traffic manager board (TMB). Specific burst mode transceivers (BMTs) are used to send/receive optical packets to/from the optical packet ring networks.
2.2.4 High-Performance Optical Packet-Switched WDM Metro ring Network (HOPSMAN)
The High-Performance Optical Packet-Switched WDM Metro ring Network (HOPSMAN) [7,8] testbed system has a scalable architecture in which the node number is unconstrained by the wavelength number. It encompasses a handful of nodes (called server nodes) that are additionally equipped with optical slot erasers capable of erasing optical slots resulting in an increase in bandwidth efficiency.
Nodes in HOPSMAN are interconnected via a single unidirectional fiber that carries multiple WDM data channels (10-Gb/s) and one control channel (2.5-Gb/s) containing the status of data channels. Channels are further divided into synchronous time slots. Nodes are equipped with one fixed transmitter/ receiver for accessing the control channel; and one or multiple tunable transmitter(s)/receiver(s) for dropping/ adding packets from/to data channels on a slot basis.
HOPSMAN has three types of nodes- POP-node (P-node), Ordinary-node (O-node), and Server-node (S-node). A P-node is a gateway between HOPSMAN and long-haul networks, and typically includes multiple tunable transmitters/receivers. An O-node is a regular node with one tunable transmitter/receiver. Finally, an S-node is an O-node but additionally equipped with a slot-eraser device, making bandwidth reusable and thus achieving greater bandwidth efficiency. Notice revealed by our study that, bandwidth efficiency improves greatly with only a few S-nodes in a network.
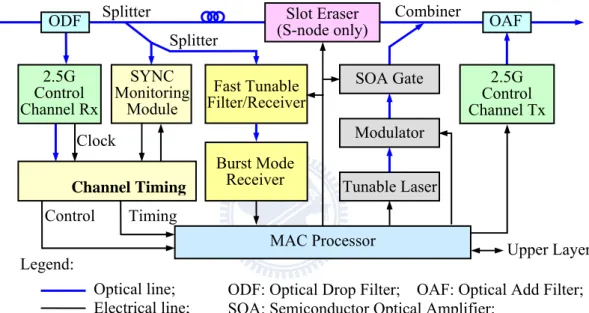
The HOPSMAN node architecture is shown in Figure 2.3. First, a fixed optical drop filter extracts the control channel information. In coordination with the SYNC Monitoring Module, the Channel Timing Processor is responsible to identify the beginning of a control/data slot. Notice that, the slot boundaries of the control and data channels are aligned during transmissions. With status of data channels, the MAC Processor mainly performs the MAC scheme, namely the determination of the add/drop/erase operations and the status updates of the associated control channel mini-slots. channel slot signal is transmitted via the fixed transmitter and combined with data channel slots via the optical add filter (OAF).
Figure 2.3. General node architecture of HOPSMAN. Clock
Splitter
ODF (S-node only)Slot Eraser OAF
2.5G Control Channel Rx Modulator SOA Gate MAC Processor Tunable Laser Combiner 2.5G Control Channel Tx SYNC Monitoring Module Channel Timing Timing Fast Tunable Filter/Receiver Upper Layer Burst Mode Receiver Splitter Control Optical line; Electrical line; Legend:
ODF: Optical Drop Filter; OAF: Optical Add Filter; SOA: Semiconductor Optical Amplifier;
2.3 Existing MAC protocols for OPS-based WDM Metro ring networks
Another key performance-enhancing feature pertaining to OPS-based networks is the design of the medium access control (MAC) mechanism. In general, for various node configurations of transmitters and receivers, access contentions can be either channel collisions or receiver collisions [6]. When a node inserts a packet on a given wavelength while another packet is currently passing the ring on the same wavelength, a channel collision occurs and both packets are disrupted. Receiver collisions are also known as destination conflicts when the destination node does not know about the transmission or another packet is currently received on a different wavelength. Clearly, both channel and receiver collisions have a detrimental impact on the throughput-delay performance of the network.The degradation of network performance due to channel or receiver collisions can be mitigated or completely avoided at the MAC protocol level. Clearly, MAC protocols are required to govern, mitigate or even completely prevent access conflicts on the WDM channels shared among competing nodes. Numerous MAC protocols and fairness schemes for OPS based WDM metro ring networks have been proposed and exhibit different strengths and limitations.
2.3.1 MAC Protocols for OPS-based WDM Metro ring networks
This subsection describes four of the most recent MAC protocols of slotted OPS-based ring networks. Most of proposed protocols [17-24,32] provide collision-free transmission through various buffer selection policies or packet selection strategies to resolve contention conflicts among competing nodes. Basically, these protocols can achieve high channel utilization and low access delay and allow for relatively simple access schemes.
2.3.1.1 Synchronous Round Robin (SRR) Ptotocol
The Synchronous Round Robin (SRR) protocol is kind of destination stripping for a unidirectional WDM ring network ith fixed-size time slots. Each node is equipped with one tunable transmitter and one fixed-tuned receiver (TT-FR). In SRR [23], each node has (N – 1) separate first-in-first-out (FIFO) VOQs, one for each destination. SRR adopts an a priori access strategy. Specifically, each node scans the VOQs in a round robin manner on a per-slot basis, looking for a packet to transmit. When the current slot is occupied, that is, a transmission is not possible as it would result in a channel collision, then no packet is transmitted from the selected VOQ. For the transmission attempt in the next slot, the next VOQ is selected according to the round-robin scanning of SRR. If the selected VOQ is nonempty, the first (oldest) packet is transmitted. If the selected VOQ is empty, SRR selects the first packet from the longest queue among the remaining VOQs to transmit.
Under heavy uniform load conditions, when all VOQs are non-empty, the SRR scheduling algorithm converges to round-robin TDMA. For uniform traffic, SRR asymptotically achieves a bandwidth utilization of 100 percent. However, the presence of unbalanced traffic leads to wasted bandwidth due to the nonzero probability that the a priori access strategy selects a wavelength channel whose slot is occupied while leaving free slots unused. It was shown that a posteriori access strategies avoid this drawback, resulting in an improved throughput-delay performance, albeit at the expense of increased complexity.
SRR achieves good performance requiring only local information on the backlog of the VOQs, which also avoids the well-known head-of-line (HOL) blocking problem. Owing to destination stripping, slots can be spatially reused several times as they propagate along the ring. On the other hand, slot reuse raises fairness control
problems, particularly for nonuniform traffic. A node to which a large amount of slots is directed generates a large amount of free slots, and nodes immediately downstream are in a favorable position with respect to other nodes.
2.3.1.2 Multitoken interarrival time (MTIT) Protocol
The Multitoken Interarrival Time (MTIT) access protocol is a token-based access scheme for a CC-FTW-FRW unidirectional WDM ring network [32]. For each data channel, every node has one fixed-tuned transmitter, one fixed-tuned receiver, and one on-off optical switch. A dedicated wavelength is used as the control channel for the purpose of access control and ring management. The on-off switches are used to control the flow of optical signals through the ring and prevent re-circulation of the same packet on the ring. Once transmitted by the source node, the packet makes one round trip in the ring and is removed from the network by the same source node, that is, MTIT employs source stripping.
Channel access is regulated by a multitoken approach. Each channel is associated with one token that circulates among the nodes on the control channel and regulates access to the corresponding data channel. The MTIT protocol controls the token holding time by means of a target token interarrival time with value (TTIT). The TTIT is agreed upon by all nodes connected to the ring at the configuration time of the system. Upon a token arrival, the node is allowed to hold the token for a period of time equal to TTIT – TIAT, where TIAT is the actual token interarrival time between that token’s arrival time and the arrival time of the token held previously. If the token holding time is up, then the node must finish the currently ongoing packet transmission and release the token. If TIAT exceeds TTIT, then the token is late and must be released immediately. In any case, if a node has no packets to transmit, then
that node must release the token immediately. Since MTIT uses source release, it can guarantee fair access to the ring if the nodes’ timers operate within a certain timing tolerance and the maximum packet length is bounded.
With the FTW-FRW node structure, MTIT avoids receiver collisions and allows each node to simultaneously use multiple data wavelength channels. However, the number of transceivers at each node is rather large. MTIT achieves low access delay due to the fact that a node has the opportunity to grab a token more frequently than in conventional token rings where a node has to wait one round-trip time for the next token. A unique feature of MTIT is its capability to self-adjust the relative positions of tokens along the ring circumference and maintain an even distribution of the token position. As a result, the variance of the token inter-arrival time is low, guaranteeing to every node a consistent channel access delay in support of high-priority traffic. On the other hand, the capacity of MTIT is smaller than that of destination-stripping ring networks since source stripping does not allow for spatial wavelength reuse. For uniform traffic it was shown that MTIT achieves high bandwidth efficiency and low access delay for varying packet sizes even in relatively large (thousands of kilometers) networks.
2.3.1.3 Posteriori VOQ Selection Protocols
Bengi and van As [21,22] proposed several posteriori buffer selection schemes for the HORNET architecture [25]. Each node is equipped with one fixed-tuned transmitter and one tunable receiver (FT-TR). In an empty-slot protocol, each unused slot on any wavelength channel can be used for packet transmission by a source node. However, when more than one wavelength channel carries an empty slot in the current slot period, one packet (or equivalently, one VOQ) corresponding to one of the
empty channels has to be chosen according to a prescribed selection rule. Due to the short time between channel inspection and packet transmission, the a posteriori packet selection process has to be performed at a high speed in the electronic domain, which increases the processing complexity compared to an a priori packet selection scheme. Five different a posteriori VOQ selection strategies are described and examined:
• Random Selection: The VOQ from which a packet is to be transmitted is selected randomly according to a uniform distribution.
• Longest Queue Selection: The longest VOQ is chosen upon buffer contention. • Round-Robin Selection: The VOQ is chosen in a round robin fashion.
• Maximum Hop Selection: The packet (VOQ) associated with the maximum hop distance between source and destination node is selected when buffer contention arises.
• C-TDMA Selection: The channel-oriented TDMA (C-TDMA) scheme first attempts to select the packet according to a round-robin policy. If that selection would prevent a transmission, either due to an empty VOQ or an occupied slot, then the longest VOQ that allows for a packet transmission is chosen. This scheme is largely equivalent to the SRR scheme with a posteriori access It was found that the random and round-robin buffer selection schemes provide a satisfactory compromise between performance and implementational complexity.
2.3.1.4 Source Stripping and Destination Stripping Protocols for TT-FRW
Another approach, proposed by Jelger and Elmirghani [17-19], is the use of source stripping and destination stripping protocols for the HORNET architecture [25]. Packets are buffered in a single FIFO transmit queue at each node. In the proposed
source-stripping scheme, a sender must not reuse the slot it just marked empty. The destination stripping mechanism prevented a node from reusing a slot on its assigned wavelength as soon as it was marked empty in order to prevent a single node from starving the entire network. However, this mechanism failed to achieve a complete fairness across all of the nodes sharing the same wavelength, particularly when the network traffic pattern was unbalanced.
By means of simulation it was shown that destination stripping outperforms source stripping in terms of throughput, delay, and packet dropping probability. With only one tunable receiver at each node, receiver collisions can occur. Receiver collisions can be avoided in a number of ways. In one approach, arriving packets that find the destination’s receiver busy re-circulate on the ring until the receiver of the destination is free, that is, is tuned to the corresponding wavelength [17-19]. Alternatively, receiver collisions can be completely avoided at the architecture level by replacing each node’s tunable receiver with an array of W fixed-tuned receivers, each operating at a different wavelength (FT-FRW). Another proposal to resolve receiver contention is based on optical switched delay lines (SDLs). A destination node puts all simultaneously arriving packets except one into optical delay lines such that packets can be received sequentially.
2.3.2 Fairness Control Protocols for OPS based Metro Ring Networks
Although selection policies (described in the previous subsection) achieve high network efficiency, yet they do not address the inherent fairness issues among ring nodes. As several ring nodes share common channels, upstream nodes may grab all the available bandwidths, and the downstream nodes would possibly starve. In general, fairness control schemes limit the transmission of upstream nodes in an attempt to
keep enough bandwidth for downstream nodes. Existing fairness control schemes can be categorized into two classes: static bandwidth allocation control and reservation-based fairness control. Basically, the static bandwidth allocation mechanisms regulate the access by providing equal access opportunity to all competing nodes. Contrastingly, various dynamic bandwidth allocation fairness control mechanisms attempt to improve the deficiency and ultimately solve the instability of the static-based fairness protocols.
This subsection describes the fairness protocols of slotted OPS-based ring networks. To avoid starvation, the transmission rate of nodes has to be controlled in order to achieve fairness among all nodes. However, restricting nodes in their transmission decreases channel utilization. In general, there is a tradeoff between fairness and channel utilization.
2.3.2.1 Multi-MetaRing (MMR) Protocol
The Multi-MetaRing (MMR) [14, 15] algorithm adapts a mechanism originally proposed for the single-channel MetaRing [71] high-speed electronic metropolitan area network. Fairness in the MetaRing is achieved by circulating a control message, named SAT (short for SATisfied). Each node is assigned a maximum number of packets to be transmitted between two SAT visits; this maximum number of packets is the node’s quota or credit. Each node normally forwards the SAT message on the ring with no delay, unless it is not SATisfied in the sense that it has not transmitted the permitted number of packets since the last time it forwarded the SAT. The SAT is delayed at unSATisfied nodes until SATisfaction is obtained, that is, either the node packet buffer is empty or the permitted number of packets has been transmitted.
transmissions of all nodes on all wavelength channels. Each node can transmit up to K packets to each destination since the last SAT visit. Each SATisfied node forwards the SAT to the upstream node. Thus, the SAT logically rotates in the opposite direction with respect to data (although the physical propagation is co-directional). With this scheme the SAT propagation delays are very large since the SAT message has to traverse almost the entire network to reach the upstream node. Alternatively, the MMR Multiple SAT (MMR-MS) scheme uses one SAT message for each wavelength. It was shown in that this MMR-MS scheme is generally the preferable extension of the MetaRing fairnesscontrol scheme to a WDM ring.
2.3.2.2 Multiple ATMR (M-ATMR) Protocol
The access protocol discussed earlier suffers from fairness problems due to destination stripping. In [21, 22] Bengi and van As adopted an extension of the well-established Asynchronous Transfer Mode Ring (ATMR) [70] fairness protocol to the multiple channel WDM ring case. This extension is M-ATMR. In M-ATMR each node receives a prescribed number of transmission credits for each destination. When a node has used all its credits or has nothing to send, it transitions into the inactive state. In order to properly apply the credit reset mechanism, every node has to know which node was the last active node. To achieve this, each active node overwrites a so-called busy address field in the header of every incoming slot with its own address. (The busy address field may be included in the SCM header of each WDM wavelength channel.) Thus, a node receiving a slot with its own busy address knows that all the other nodes are inactive. If the last active node detects inactivity of all the other nodes, it generates a reset immediately after its own transmission. The reset mechanism causes the nodes to reset their credits to the predefined values. In this
manner, it is guaranteed that every node uses a maximum number of slots between two subsequent reset cycles. It was shown in [] that the M-ATMR fairness protocol applied for best-effort traffic provides throughput and delay fairness for both uniform and client/server traffic scenarios.
2.3.2.3 WDM Access (WDMA) Protocol
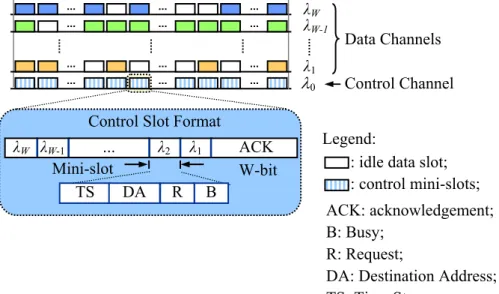
The WDM Access (WDMA) [13] protocol simply extends the basic single-channel DQDB [72] to the multi-channel case, namely, each node keeps a record of RQ and CD counters to maintain a single distributed queue for all of the wavelengths. Each node is equipped with one tunable transmitter and one tunable receiver (TT-TR) for each ring. WDMA adopts the retransmission mechanism if the receiver contention problem occurs. As shown in Figure 2.4, each control slot in WDMA consists of a Busy bit, a Request bit, a Destination Address (DS) field, and a Timestamp (TS) field. When a new packet arrives at a node, a unique timestamp is assigned to it. Similar to DQDB, each node issues a request bit in a minislot on the reverse ring. Then the node calculate the values of RQ and CD counters. As the vlaue
Figure 2.4 . The control slot structures of WDMA. W-bit
Control Slot Format
TS λW-1 λW … λ2 λ1 ACK Control Channel Data Channels λ0 λ1 λW
: idle data slot; : control mini-slots; Legend: λW-1 ACK: acknowledgement; B: Busy; R: Request;
DA: Destination Address; TS: Time Stamp;
Mini-slot
of CD counter changes to zero, the request reaches the top of distributed queue. The node waits for the next idle data slot to send the packet by setting Busy bit to one and writing the destination address and timestamp of the packet into the DA and TS fields. To receive data, each node constantly monitors the control channel. In case of destination conflict where more than one packet is addressed to the same destination in a slot, the packet with the smallest timestamp wins the contention. The headend exiamines each control slot by computing the results of receiver-contention according to the timestamp ordering, and writing receiver-contention into the acknowledge field in the next slot. With such a simple design, WDMA unfortunately results in access unfairness and inefficiencies for multi-channel networks under varying traffic patterns and burstiness.
2.3.2.4 Distributed Queue Bidirectional Ring (DQBR) Protocol
The extended version of HORNET [10] employs a distributed queue bidirectional ring (DQBR) protocol, which is a variant of DQDB [72] protocol. The DQBR fairness protocol works as follows. In each control-channel frame, a bit stream of length W bits, called the request bit stream, follows the wavelength-availability information. When a node on the network receives a packet in VOQw, the node notifies the upstream nodes about the packet by setting bit w in the request bit stream in the control channel that travels upstream with respect to the direction the packet will travel. All upstream nodes take note of the requests by incrementing a counter called a request counter (RC). Each node maintains a separate RC for each wavelength. Thus, if bit w in the request bit stream is set, RC w is incremented. Each time a packet arrives at VOQ w, the node stamps the value in RC w onto the packet and then clears the RC. The value of this stamp is called the wait counter (WC). After
the packet reaches the head of the VOQ, if the WC equals n it must allow n empty frames to pass by for downstream packets that were generated earlier. When an empty frame passes by the node on wavelength w, the WC for the packet at the head of VOQ w is decremented (if the WC equals zero, the RC w is decremented). Not until the WC equals zero can the packet be transmitted. The counting system ensures that the packets are sent in the order in which they arrived in the network.
Due to the use of fixed-tuned receivers, HORNET statically assigns each node a wavelength as the home channel for receiving packets. Such static wavelength assignment results in poor statistical multiplexing gain and bandwidth efficiency. As a result of the home-channel design, DQBR treats wavelengths independently and requires each node to maintain a distributed queue for each wavelength. Moreover, each node is allowed to issue multiple independent single-slot requests. With DQBR, HORNET achieves acceptable utilization and fairness at the expense of high control complexity for maintaining the same number of counter pairs as that of wavelengths. Such a design gives rise to a scalability problem. Moreover, the design of permitting unlimited multiple requests with single slot granularity per request unfortunately results in unfairness problems.
2.3.2.5 Probabilistic Quota plus Credit (PQOC) Protocol
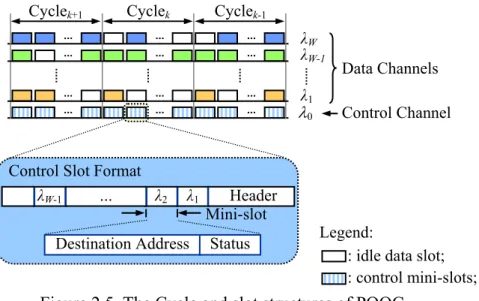
The HOPSMAN [7,8] employs a MAC scheme, called Probabilistic Quota plus Credit (PQOC). First, a cycle (see Figure 2.5) is composed of a pre-determined, fixed number of slots. In general, PQOC allows each node to transmit a maximum number of packets (slots), or quota, within a cycle. Most importantly, even though the total bandwidth is equally allocated to every node via the quota, unfairness surprisingly appears when the network load becomes high. This is because upstream nodes can
access empty slots first, resulting in an increasing tendency for downstream nodes to encounter available empty slots that are located vertically around the back of the cycle. This issue, as well as the vertical-access constraint, gives rise to poorer delay-throughput performance for downstream nodes. To resolve the unfairness problem, the quota is exerted in a probabilistic rather than a deterministic fashion, as “probabilistic quota” implies. In other words, rather than transmitting packets immediately if there remains quota, each node makes the transmission decision according to a probability, e.g., the quota divided by the cycle length. Note that, using the probability, a node may end up making fewer packet transmissions than its quota. The problem can be simply resolved by enforcing a packet transmission in a subsequent slot time with an idle slot. Such an approach evenly distributes idle slots within the entire cycle at all times and thus eliminates unfairness against downstream nodes.
Furthermore, if a node cannot use up its entire quota in a cycle, i.e., has fewer packets than its quota, the node yields the unused bandwidth (slots) to downstream nodes. By doing so, the node earns the same number of slots as credits. These credits allow the node to transmit more packets beyond its original quota in a limited number
Figure 2.5. The Cycle and slot structures of PQOC. Mini-slot
Control Slot Format
Destination Address Status
λW-1 … λ2 λ1 Header
Cyclek+1 Cyclek Cyclek-1
Control Channel Data Channels
λ0
λ1
λW
: idle data slot; : control mini-slots; Legend:
of upcoming cycles, called the window. That is, the credits are only valid when the number of elapsed cycles does not exceed the window. The rationale behind this design is to regulate a fair use of unused remaining bandwidth particularly in the metro environment with traffic of high burstiness. Notice that there are system tradeoffs in PQOC involving the cycle length and window size. For example, the smaller the cycle length, the better the bandwidth sharing; the larger the window size, the better the bursty-traffic adaptation, both at the cost of more frequent computation. The determinations of the cycle length and window size, which are beyond the scope of this article, can be dynamically adjusted in accordance with the monitored traffic load and burstiness via network management protocols.
2.4 Discussions
The testbeds described in this charpter follow the same goal that overcome the emerging metro gap between high-speed local clients (and networks) and the very-high-speed backbone networks. To overcome this metro gap, the ring networks need to efficiently use the wavelength resources, to be easily upgradeable (and scalable), and to flexibly support varying traffic loads and packet formats in a fair and cost effective manner.
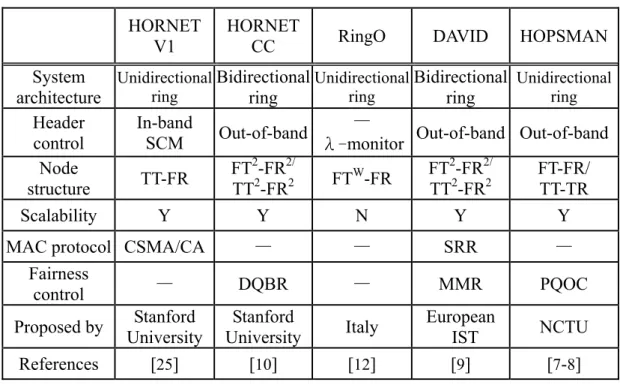
Toward this end, in Table 1 we contrast the experimental testbed networks in terms of header control, node structure, scalability, and packet removal, as well as support for MAC and fairness control. We see from Table 1 that among the networks not having a control channel, the TT-FR node structure is most common. Notice that although fast tunable transmitters [68] with a laser tuning time up to several nano-seconds have emerged, fast tunable receivers [69] operating in the nano-second order remain virtually unavailable. We see from the table that all protocol-oriented and concept-oriented research efforts (as well as the HORNET testbed) allow for easy
scalability in the number of nodes. The proof-of-concept testbed RINGO, on the other hand, are at present limited to as many nodes as there are wavelength channels.
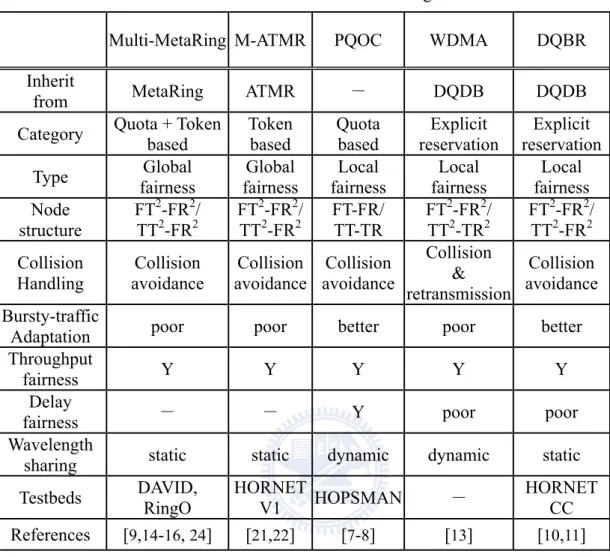
Table 2 shows a summary of various fairness control protocols in terms of fairness category, fairness type, node structure, collision handling, burst-traffic adaptation, throughput fairness, delay fairness, wavelength sharing, as well as adapted by the testbed network. In the quota-based schemes, each node is allocated a quota that is the maximum transmission bound within a variable-length cycle. Most of the research work focuses on the dynamic adjustment of the cycle length. ATMR [70] allows the last active node to initialize a reset-signal rotating on the ring to inform all nodes to re-start a new cycle. MetaRing [71] uses a token-based signal circulating around the ring. When a node receives the token, it either forwards the token and thus starts a new cycle immediately, or holds the token until the node has no data to send or the quota of previous cycle expires. These schemes were shown to achieve high network utilization and great fairness. However, they cause cycle lengths to prolong several ring times, resulting in a large maximum delay bound and delay jitter, and thus
Table 1. Experimental testbeds comparisons HORNET
V1
HORNET
CC RingO DAVID HOPSMAN
System architecture Unidirectional ring Bidirectional ring Unidirectional ring Bidirectional ring Unidirectional ring Header control In-band SCM Out-of-band —
λ-monitor Out-of-band Out-of-band Node structure TT-FR FT2-FR2/ TT2-FR2 FTW-FR FT2-FR2/ TT2-FR2 FT-FR/ TT-TR Scalability Y Y N Y Y
MAC protocol CSMA/CA — — SRR —
Fairness
control — DQBR — MMR PQOC
Proposed by University Stanford UniversityStanford Italy European IST NCTU