Proceedings o f t b e ZOO3 IEEE
lnternifionsl Conference on Robotics & A ~ t o r n a t i o n
Taipei, Taiwan, September 14-19, ZOO3
EMG
Classification for Prehensile Postures Using Cascaded Architecture
of
Neural Networks with Self-organizing Maps
Han-Pang Huang', Yi-Hung Liu", Li-Wei Liu", and Chun-Shin Wong**
Robotics Laboratory, Department of Mechanical EngineeringNational Taiwan University, Taipei, 10660, Taiwan TELFAX: (886) 2-23633875, E-mail: hanpane@,ntu.edu.tw 'Professor and correspondence addressee, Graduate student f.
Abstract
Electromyograph (EMG) features have the properties of large variations and nonstationarity. An important issue in the classification of EMG is the classifier design. The major goal of this paper is to develop a classifier for the classification of eight kinds of prehensile postures to achieve high classification rate and reduce the online learning time. The cascaded architecture of neural networks with feature map (CANFM) is proposed to achieve the goal. The CANFM is composed of two kinds of neural networks: an unsupervised Kohonen's self-organizing map (SOM), and a supervised multi-layer feedfonvard neural network. Experimental results show that by extracting EMG features, forth-order autoregressive model (ARM) and histogram of EMG signals (IEMG), as inputs, the proposed CANFM can obtain and remain higher classification rates compared with other classifiers, including k-nearest neighbor method (K-NN), fuzzy K-NN algorithm, and hack-propagation neural network (BPNN) in several online testing.
Keywords: EMG classification, prosthetic hand, self-organizing map (SOM), and neural networks.
1.
Introduction
EMG classification for controlling a prosthetic hand is one of the most difficult panem recognition problems because there often exist large variations in EMG features. Hence, how to select a suitable classifier that can handle large variations existed in EMG features to remain high classification rates and can have fast response to output posture command in the online process is very important.
The k-nearest neighbor (K-NN) algorithm and neural networks were frequently selected as the classifiers in the ENG classification in the practical use [1][7][14][16]. The K-NN algorithm is based on the distance (e.g. Euclidean distance) similarity matching [ 9 ] . It has the merits of simplicity. However, it cannot handle features with complexity since there are no machine learning techniques involved.. Besides, the back-propagation neural network (BPNN) appears more robust to solve complex classification problems since BPNN can learn the relationship between inputs and desired outputs of training patterns by gradient descent technique and back-propagation algorithm [6][1 I]. However, if number of inputs increases, the complexity of network structllre will increase exponentially. In [I], they took the
hack-propagation algorithm to train fuzzy rules to build a fuzzy inference based neural network classifier to handle the variation property. In [4], they combined the linear discriminant algorithm (LDA) with the principal component analysis (PCA) to classify EMG signals based on wavelet features. However, for some other features (e.g. time-domain features), using the LDA may not he a good solution due to the high interclass ambiguities. Moreover, the required time for classification is another consideration.
To handle complicated EMG classification problems accurately and eficiently, we develop a new cascaded architecture of neural networks with feature map (CANFM) to classify EMG signals. In the proposed classifier architecture, CANFM, the dimension of feature space is first reduced by the unsupervised neural network, Kohonen's self-organizing map (SOM). No maner how many features are used, each group of features in high dimension from a channel (an EMG surface electrode) can be transformed into two-dimensional (2-D) coordinates by the 2-D Kohonen's SOM. Aside from the benefit of reduction in input dimension, SOM can remove some noisy data and can absorb the large variations appear in original features. Thus, it can avoid the subsequent training process being over-oriented to the training patterns. The further classification will he performed by a supervised multi-layer neural network trained by hack-propagation algorithm (BPNN). The classification process by the CANFM is performed on the digital signal processor (DSP) based EMG classification system.
2.
EMG
Data Acquisition
2.1 Prehensile Postures and Sensor Locations
In this paper, eight types of prehensile postures to be classified are selected for the reason that they are typical postures for most frequent use of human beings. The eight postures are power grasp (PG), hook grasp (HG), wrist flexion (WF), lateral pinch (LP), flattened hand (FH), centralized grip (CEG), three-jaw chuck (TJC), and Cylindrical grasp (CYG), and they are listed in Table 1 .
In order to obtain the meaningful EMG signals for eight kinds of prehensile postures, the placement of EMG surface electrodes is important. According to the relations between the muscle location and the prehensile postures [SI, the three EMG surface electrodes are placed on palmaris longus, extensor digitorum and flexor carpi ulnaris and therefore three channels are used (see Fig. 1)
Table 1 Eight kinds ofpostures to be classified Posture
types
Fig. 2 Po m r Hook Wri.1 Lateral
C a w W'aV neeon pinch
Pormre Flattened Centralized Three-jaw Cylindrical
2.2 EMG Feature Extractions
Some EMG features, such as integral of EMG (IEMG) [7][16], waveform length (WL) [7][16], variance (VAR) [14][15][16], zero crossing (ZC) [7][15][16], slope sign changes (SSC) [7][16], Willison amplitude (WAMP) [14][16], autoregressive model (ARM) [14][5][16] and histogram of EMG (HEMG) [14], have been proposed. In this paper, we select the ARM and HEMG as the EMG features through some testing and evaluation.
,
Flexor c a r ~ i ulnansPalman* long"*
Fig. 1. The placements of EMG surface electrodes A. Autoregressive Model (ARM)
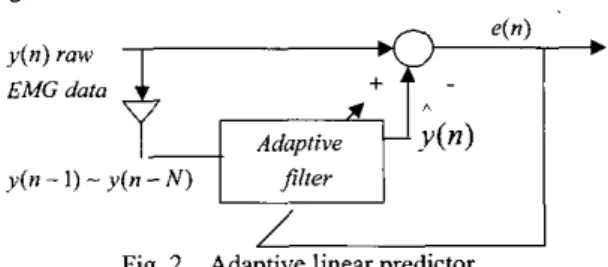
It is difficult to analyze the EMG signal because of its naNre of nonlinearity and nonstationarity However, in a short time period the EMG signal can be regarded as a stationary Gaussian process and can he represented by an autoregressive model (ARM). ARM is used to identify the EMG time series as
where yk is the Mh output of ARM and emgk.,is the (k-i)th sample data out of N samples of EMG raw data. M is the order of ARM, ai are the estimate of the ARM parameters and uaX is the white noise. The ARM parameters a, can be calculated via the adaptive least mean square method (LMS). The adaptive AR method that is similar to the adaptive predictor predicts the input EMG sample according to previous input samples by minimizing the output error. The adaptive predictor stmcture is shown in
Fig. 2 Adaptive linear predictor
The criterion of the adaptive LMS method is to minimize a mean square error function E[e2(n)] that can be given as
e ( n ) = y ( n ) - y ( n ) = y ( n ) - C o j y ( n - i ) = A ~ Y ( ~ ) (2) where A represents the linear prediction vector, Y(n) is theinput signal vector by
N i=l
thus
E [ e 2 ( n ) ] = ArE[Y(n)Yr(n)]A (4) In order to minimize Ere2@)] with respect to prediction vector A , the gradient of E[e2(n)] is used to obtain the optimum as
2
JA ( 5 )
~- - 2 E [ Y ( n ) Y T ( n ) ] A = 2 E [ Y ( n ) e ( n ) ]
The prediction vector A can be updated by the following steepest-descent algorithm:
A ( . + I ) = A ( n ) - p - = A ( n ) - ? P E [ Y ( n ) p ( n ) l JA ( 6 ) It can be further simplified as
A ( n + l ) = A ( n ) - ? f l e ( n ) Y ( n ) (7) where
p
is a constant rate of convergence. For each adaptive coefficient, we haveq ( n
+
1) = a,(n)- 2pe(n)emg(n - i ) f o r i = I... M (8) where a@ is the original ARM parameter,p
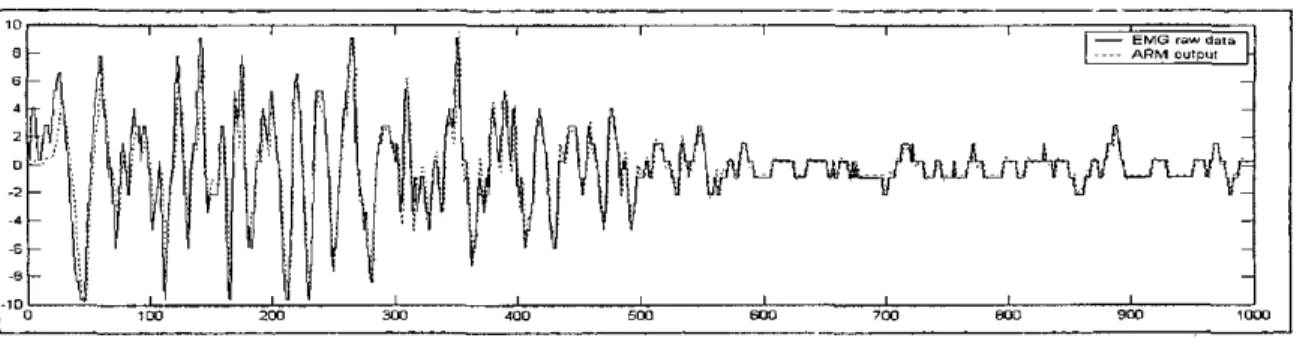
is a constant rate of convergence and e(n) is the difference between the nth sample data of EMG raw data and the nth output of ARM. Hence, we can update the new ARM parameter by Eq.(8). A model order of 4 is adequate for AR time series modeling of EMG signal. The simulation of the original EMG signal using a fourth-order AR model is shown in Fig. 3. Correspondingly, an ARM feature contains four feature components.B. Histogram ofEMG (HEMG)
HEMG is the extension of the ZC and WAMP. It counts how many samples in the particular voltage range and provides the information about the frequency which the EMG signals reach multiple amplitude levels. Similar to the setting in [14], the voltage range
[-IO,
+IO] is divided into nine equivalent intervals and the counts in each voltage interval will be multiplied by 0.01. A HEMG feature contains nine feature componentsFig. 3. The simulation of the original EMG signal using a fourth-order AR model
3.
Cascaded Architecture
of
Neural Network
with Feature Map (CANFM).
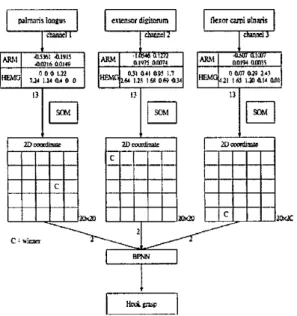
CANFM is a cascaded architecture of neural networks. It is composed of two neural networks. The former is the unsupervised Kohonen's self-organizing map (SOM), the latter is the supervised multi-layer feedforward neural network trained by back-propagation algorithm (BPNN). Fig. 4 shows detailed information of the proposed CANFM, There are three input channels in the CANFM. The three channels receive features extracted from EMG signals of palmaris longus, extensor digitorum and flexor carpi ulnaris, respectively. Each channel sends features as the input of the Kohonen's SOM and the output is the 2-D coordinate
(on
the x and y axes) in the 2-D topological net. A 2-D coordinate is thus a condensed feature for a channel. After the feature map, these condensed features become new input of the BPNN. In this way, there are total six input nodes of the BPNN due to three channels.. . .
. . .
U-
-?."*
Q,",
Fmmi hnm Fea,uJer from
Q
C H Ib , W fmm
calman,laol"s rrrcnm&Jmm I l c r o r ~ i vlnanr
Fig. 4 Detailed information of CANFM
The cascaded architecture can compensate for the inaccuracy of unsupervised neural network and long training time of supervised neural network. Another
important contribution of the proposed cascaded architecture is to reduce the input dimension (feature space) of the post-classifier. Although the concept of cascading a supervised neural network with an unsupervised neural network is not
a
new concept to reduce the training time of a supervised neural network, the proposed architecture is a brand new idea for dealing with the reduction of dimension of feature space in EMG classification research field. In addition, SOM can map a space with variations onto a small cluster in the 2-D map by the concept of neighborhood [Il][lO]. This offers us a great benefit for the EMG classification. Actually, in our previous study [13], we had implemented a similar cascaded architecture of neural networks for handwritten digits recognition. According to the experimental results of handwriting recognition, such classifier can achieve high recognition rate to handwritten features which have large variations due to different styles of people.3.1 Reduction of Input Dimension by 2-D SOM The 2-D Kohonen's SOM can keep the neighborhood relations of the input pattern since it learns under the topologypreserving map [IO]. Therefore, the 2-D SOM is also called a topology-preserving map. The merit is useful for clustering EMG signals. In addition, the Kohonen's SOM can he used to remove the redundancy in feature space or noise information
in
the input pattern, and avoid the trial and error approaches, such as genetic algorithm and KL expansion. In other words, the 2-D Kohonen's SOM reduces the input dimension from a high dimension to a 2-D coordinate.The unsupervised SOM can find a winner on the 2-D map to represent the original pattern which is in high dimension. Let
y,
be the corresponding output neuron (winner node) of a high dimensional vector x on the 2-D output net, the location ofy ,
can be found by the following four steps according to the learning rule of the Kohonen's feature map [ 6 ] .Step 1: Initialization. Choose random values for the initial weight vectors W j ( 0 )
.
The only restriction here is that the initial weight vectors W j ( 0 ) must be different for j = l ,....
/.
where I is the numbers of output neurons.Step 2: Similarity Matching. Find the winning neuron y c at time step 1 by using the
minimum-distance Euclidean criterion:
Step 3: Updating. Adjust the synaptic weight vectors of all neurons by using update rule
wj(t + 1) =
wj(0
+ rl(Ohj,y,(Ob(/)
-w,(t)l
(10) where q(r) is the leaming rate, and( t ) is the neighborhood function centered around the winner; both q ( / ) and
hj,% ( 1 ) are varied dynamically during
leaming for best results.
Step 4: Continuation. Go hack to step 2 until no
changes in the feature map are observed. The leaming rate in step 3 should he time varying. This requirement can he satisfied by choosing an exponential decay for q(t)
where
'rl
is the time constant of the leaming rate. The learning rate begins with a value in (0,l); thereafter it would decrease gradually. But we keep it above 0.01. Correspondingly, the topological neighborhood function is assumed a time-varying form aswhere dj,?, is the lateral distance between winner y ,
and excited neuron j in the two-dimensional output space, and ~ ( t ) is defined as
where r2 is another time constant of the SOM algorithm, and c,, is the value of c at the initiation. Therefore, as time
r
increases, the width u(t) decreases at an exponential rate, and the topological neighborhood shrinks in a corresponding manner3.2
Classification by Back-Propagation Neural NetworkAfter
reductionof
the inputspace
using Kohonen's SOM, the three sets of 2-D coordinates (six newly condensed features) are fed into the BPNN for further classification. Choosing the BPNN as the post-classifier of CANFM is due to its learning ability and fast recall speed. Since there are eight postures to he classified, the BPNN has eight output nodes (see Fig. 4) and one hidden layer in which the number of hidden nodes should he determined based on experimental trail-and-error to achieve near-optimal learning accuracy. Which posture should he executed will depend on which output neuron has the largest value in the recall process of the neural network. In the learning of connected weight vectors, the generalizeddelta learning rule [ I l l for the weight updating is used in this paper. Also, a sigmoid is function is used in a neuron for the nonlinear transformation of aggregated signals from input nodes.
4. EMG
Classification System
The system architecture is shown in Fig. 5 . At first, the EMG signals are acquired from the EMG surface electrodes and sampled by the AD converter AD7874 with sampling frequency 2.5 KHz and then stored in the memory. An EMG raw data has 1000 samples, i.e., an EMG raw data is obtained in 400 ms. Then, the sampled EMG raw data is transferred from the memory to PC by parallel port and recorded in a specified file.
3.chanml EM0 rwfnclauodn
CANE4 W G
rim
Signal FeammuSW" PTCCCSlUC LXtIactiO.
D S P W LWGelarufcz"on ism NIUNaodIV
-
pollyre comvld Fig. 5 Block diagram of the EMG classification system
Feature extraction methods (ARM and HEMG) and classifications (CANFM) are embedded in DSP with its own assembly codes [3].
The on-line EMG signal classification module is developed based on the DSP chip TMS320C31 produced by Texas Insbument. In our experiment, for reducing the effect of noise to the EMG signals, a 60 Hz notch filter is embedded into the module. In addition, for obtaining meaningful EMG signals, a 30-400 Hz band pass filter is embedded. The above are developed with the assembly language of TMS320C3 1. The output of CANFM indicates which posture should he executed and the DSP-based EMG classification system will send the command to NTU-Hand IV. NTU-Hand IV is a five fingered prosthetic hand with 11 degree-of-freedom (DOF) (see Fig. 6). When receiving the posture command, the NTU-Hand JV will generate the actual posture output.
5.
Experimental Results
An illustrative example for the classification of the features
from
three channels using CANFM is shown in Fig. 7, and it gives the details of the system. First, we obtain EMG signals from three channels, and then extract the ARM and HEMG features. For each channel, an ARM feature contains four feature components, while a HEMG feature contains nine feature components. After acquiring the input features, we pass each group of the features (13 feature components per channel) into a Kohonen's SOM. Then, each group of features with high dimension is reduced to 2-D coordinates. We use the three sets of 2-D coordinates as inputs of the supervised BPNN classifier. The result we obtained is the desired class, and its name is Hoop Grasp. Finally, the prosthetic hand, HTU-Hand IV,follows the classification result to perform the posture. EMGsurfaceelectrades(three channels) same
&-&
classification systemI
Fig. 6 Real picture of DSP-Based EMG classification and NTU-Hand IV performing on an amputee
ikxn mi Irinuis
m
Fig.
7.
An illustrative examplefor
classificationof
the features using CANFMIn our experiments, parameters in the unsupervised 2-D SOM are set up as follows. The three 2-D SOMs for all
channels have the same numbers of input nodes (one SOM has 13 input nodes, where 4 input nodes belong to ARM, 9
input nodes belong to HEMG). The output topological net for a SOM is arranged as a 20-by-20 2-D net. The initial neighborhood size is 20. For the learning rule, the initial learning factor q0 is set as 0.9, and time constant 7, is
200. The initial neighborhood size is equal to the number of output neurons, such that all output neurons will have the chance to he the winner of the corresponding input at beginning. Therefore, the initial size u0 is equal to the radius of the 2-D output net (10). The time constant for the
neighborhood f i c t i o n is r2 = 200/logu,
.
Besides, for the neural network BPNN in the CANFM, the number ofinput node of this BPNN is 6 , and number of output node is 8. The number of hidden node is set as 10. The BPNN used here is trained by the standard back-propagation learning [ I l l rule with momentum term, where the leaming rate is set as 0.3, the momentum parameter is set
as 0.9. The network structure, as well as the leaming constants, is determined after thorough trail-and-error testing for achieving the best performance (i.e., lowest MSE). The learning stops when the MSE almost keeps constant (2000 learning cycles used here).
Table 2 . Comparison of the classification results among K-NN, fizzy K-NN, BPNN, and CANFM (%)
PG HG WF LP FH CEG TIC CYG Ave.
K-NN 90 LOO LOO 85 80 95 85 95 91.25
:,
-??
9 0 100 100 85 90 95 85 95 92.50 *.IYLY BPNN 100 100 100 85 100 LOO 95 100 97.50 CANFM 100 100 100 95 100 95 LOO 100 98.75 Table 2 shows the classification results of the K-NN method (For avoiding the existence of a tie [9], the k is setas 5 here, an odd value), fuzzy K-NN algorithm [9], pure
BPNN, and CANFM. Each posture has 20 training patterns and 20 testing patterns. The features used for all classifiers are ARM and HEMG features. Again, by taking trial-end-error to achieve near-optimal structure, the numbers of input node, hidden nodes, and hidden nodes in
this pure BPNN are 39, 20, and 8, respectively. The learning rate and momentum constant of the BPNN are the same as the setting of BPNN in CANFM (0.3 and 0.9).
?em
j?iL-,,,
erx BRNlnCUsM.
~rm am 2w ~ , , * J I o u T n 1 -d Yn l a 0 ?m m rac c-www
Fig. 8. MSE of pure PBNN against BPNN in CANFM Table 2 shows that the CANFM outperforms the K-NN,
fuzzy K-NN, and BPNN in average classification accuracy
by 7.5%, 6.25% and 1.25%, respectively. Fig 8 shows the
MSE of the pure BPNN against BPNN in our CANFM. We can conclude that the pure BPNN is insufficient to reduce learning time and the MSE due to the complexity of the EMG signals and large network structure, but our CANFM can tackle this problem successfully. The learning of pure BPNN appeared slow compared with the learning of BPNN in CANFM (MSE approaches zero). Therefore, by cascading Kohonen's SOMs to reduce the feature space
can actually speed up the learning time of a BPNN and reduce MSE. However, the EMG system does not reset. Namely, the EMG surface electrodes are remaining on the same locations when extracting training patterns and testing patterns.
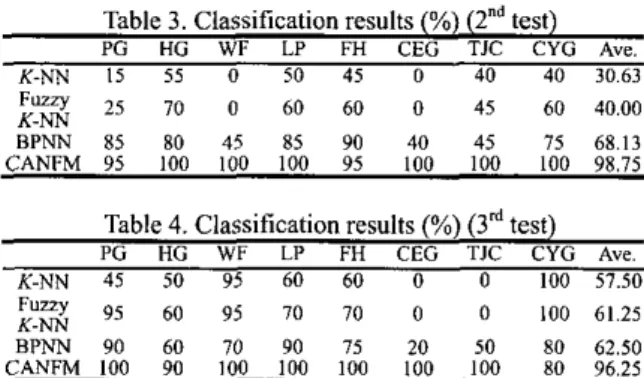
In order to test the robustness of CANFM against the variations of features, except the test data used in Table 2 (the 1" test), we prepare another two test sets (each test set has 160 testing patterns, and each posture has 20 testing patterns too) in different days. It implies that the muscles' conditions may be different, relax or tight. In particular, when re-acquiring a new testing set, the EMG surface electrodes are replaced.
Table 3. Classification results (%) (2"d test) PG HG WF LP FH CEG TJC CYG Ave. K-NN I5 55 0 50 45 0 40 40 30.63
Lyg
25 70 0 60 60 0 45 60 40.00BPNN 85 mo 45 85 YO 40 45 75 68.13 CANFM 95 100 100 100 YS 100 100 100 98.75
Table 4. Classification results (%) (3d test) PG HG WF LP FH CEG TJC CYG Ave. K-NN 45 50 95 60 60 0 0 100 57.50 K-NN 95 60 95 70 70 0 0 100 61.25 Fuzzy .. . .. . BPNN 90 60 70 YO 75 20 50 80 62.50 CANFM 100 YO 100 100 100 100 100 80 96.25 Table 3 and Table 4 show the classification results of the Znd and the 3" tests, respectively. We see that for some postures, K-NN method and fuzzy K-NN show no discrimination abilities. For example, the postures WF and CEG cannot be recognized by K-NN and fuzzy K-NN
(classification rates = 0). Besides, the BPNN shows better classification results than K-NN and fuzzy K-NN in most of postures in lhe Yd and the 3'' test. However, the BPNN gets lower classification rates compared with the results in the 1" test. Moreover, CANFM still gains high classifications rates for all postures no matter how poor the results of the other three classifiers are. Finally, the average classification rates from these three test results are shown in Fig. 9. Clearly, CANFM remains higher average classification rates in the Znd and the 3'' test (above 96.25%), while classification rates obtained from K-NN, fuzzy K-NN and BPNN drop a lot from the 2"' test.
12c ,m
5
; m y/ + P W X ~ r n'W
/Iz/
+ c m P M 20 $ 0 lstfstmg .Znd* lrdleifblpFig. 9. Comparison of average classification rates of different tests among different classifiers
6. Conclusions
In this paper, a cascaded architecture of neural networks with feature map (CANFM) is proposed to enhance and remain the EMG classification accuracy under large variations of EMG signals. Several conclusion remarks are as follows:
1. By using feature set {ARM, IEMG}, we experience three tests to obtain the classification results for eight kinds of prehensile postures by using K-NN, fuzzy K-NN, BP neural network, and CANFM.
Another important contribution of CANFM is that the learning time is reduced substantially because of the reduction of input dimension by cascading SOM for each channel (each EMG surface electrode).
In short, this paper proposes CANFM to approach optimal EMG classification. Moreover, we develop a DSP-based EMG classification system to realize the on-line EMG classification combined with the multi-DOF prosthetic hand, NTU-Hand IV., which had been developed in our Lab.
![Fig. 5 Block diagram of the EMG classification system Feature extraction methods (ARM and HEMG) and classifications (CANFM) are embedded in DSP with its own assembly codes [3]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8857860.244425/4.923.480.792.391.496/diagram-classification-feature-extraction-methods-classifications-embedded-assembly.webp)