Tao, Y.-H., Wu, Y.-L.. and Chang, S..-I., An SPRT-based Adaptive Testing Approach for Practical Business Applications, DSI Annual Meeting, Boston, Massachusetts, November 20-23, 2004.
AN SPRT-BASED ADAPTIVE TESTING APPROACH FOR
PRACTICAL BUSINESS APPLICATIONS
Yu-Hui Tao, National University of Kaohsiung, Kaohsiung, Taiwan, R.O.C., ytao@nuk.edu.tw
Yu-Lung Wu, I-Shou University, Kaohsiung County, Taiwan, R.O.C., yuwu@isu.edu.tw
Hsin-I Chang, I-Shou University, Kaohsiung County, Taiwan, R.O.C., grace520@mail.nkmu.edu.tw
Abstract
Many businesses conduct tests to evaluate employees’ knowledge, skills, abilities and other characteristics during selection and training. The evolving technologies have moved the traditional pencil-and-paper testing toward a computer-based, or even a computer adaptive testing (CAT) scenario. CAT is theoretically sound and efficient, and is commonly seen in educational settings. However, it is not yet seen in business daily routines. One major cause for this phenomenon is that the well-known and popular IRT (Item Response Theory, the most adopted CAT model) is too rigorous to implement in business environment. While SPRT (Sequential Probability Ratio Test) model is less complicated, it only provides the examinee’s mastery result and cannot
compete with the score that IRT offers for flexible business decision-making. To address these issues, we proposed an SPRT-based adaptive testing approach that is simpler to implement while still able to approximate IRT scores in semantic or rank levels for business needs. Most importantly, the proposed model eliminates the requirement of conducting at least 200 parameter-adjusting tests in an IRT model each time the test item bank changes. In order to validate the performance of this proposed model, an English adaptive testing prototype was implemented and benchmarked to the TOEFL testing results. Sixty professionals who had attained a TOEFL score participated in the experiment. Benchmark results showed our prototype has similar discriminating power on subjects’ English ability as TOEFL. The experiment demonstrated that the proposed SPRT-based model is effective and adaptive to meet the business testing needs.
INTRODUCTION
Many businesses conduct tests to evaluate employees’ knowledge, skills, abilities and other characteristics (KSAO’s) during selection and training. These activities are increasing as employees are gaining more attention from corporate executives in the new economy era. The development of information technology (IT) in the last two decades has made computer-based testing (CBT) feasible in educational research and
practice (Bunderson, Inouye & Olson, 1989). Furthermore, recent development of e-learning enabled corporations adopting online e-learning as well as online testing. The evolving technologies have moved the traditional pencil-and-paper testing toward a computer-based, or even a computer adaptive testing (CAT) scenario.
Simple transformation of a fixed length test from pencil-and-paper to CBT is easy and quick with the existing advances in Web programming techniques. On the other hand, CAT has been researched and applied extensively in educational institutes, certified or licensing centers (Olson, 1990), but it has not seen in the daily routines in business organizations. One major cause for this phenomenon is that the most adopted CAT model - Item Response Theory (IRT) - is too rigorous to implement and maintain in business environment. Wise and Kingsbury (2000) listed item pools, test administration, test security and examinee issues as the four general areas of practical issues in developing and maintaining IRT-based CAT programs. In particular, the item pools area includes pool size and control, dimensionality of an item pool, response models, item removal and revision, adding items to the item pool, maintaining scale consistency, and using multiple item pools. The rigorous IRT requires a large number of examinees for estimating item parameters and special expertise in item-pool maintenance, which made it only possible in educational institutes or professional testing centers (Frick, 1992).
Sequential Probability Ratio Test (SPRT) model is another CAT model that is less adopted because it only provides the examinee’s mastery result and cannot compete with the score that IRT offers for flexible business decision-making. Nevertheless, SPRT waives the maintenance requirements to retain the CAT or item-pool expertise once the system is in place, which solves the issues in regular business CAT implementations.
In order to clear the obstacles for businesses to adopt CAT in their daily routines, this paper proposed an SPRT-based CAT approach that inherits SPRT strength in the maintenance-free item pool, and approximates the IRT spirit in grade classification. Criterion validity (Zikmund, 1997) is used to predictive the validity of our proposed approach by implementing an English CAT prototype system that is benchmarked with the TOEFL (Test of English as a Foreign Language) standard.
COMPUTER ADAPTIVE TESTING
CAT differs from the traditional pen-and-paper testing in that an evaluation is done with a possible minimum number of questions adaptive to the ability of the examinee (Welch and Frick, 1993). Because IRT and SPRT are the two fundamental theories in adaptive testing, and TOEFL is the benchmarking standard in our experiment, they are all briefly introduced below.
IRT
Lord (1980) invented IRT in the early 1950s, which utilized probability to explain the relationship between examinee’s ability and the question item response. In other words, a mathematical model, called Item Characteristic Function (ICF) that derives a continuous increasing curve (Item Characteristic Curve, ICC) for predicting the ability and test performance, was developed to infer the examinee’s ability or potential quality.
ICF can be classified into different variations based on the different number of parameters adopted within the mathematical model. Three often-used models include single-parameter, two-parameter, and three-parameter models as shown in Formulas below: Single-parameter model ( ) 1 1 1 ) ( pij j D b j e , Two-parameter model ( ) 1 1 1 1 ) ( pij j D b j a e , Three-parameter model ( ) 1 1 1 1 ) 1 ( ) ( pij j i i D b j a e C c , where D=1.702, e: natural Log, 2.71828,
i: item number; i=1,2,3,…,N, and N is the total number of items, j: examinee; j=1,2,3,…,K, and K is the total number of examinees, j: jth examinee’s ability,
ai: discrimination parameter of item i,
bi: difficulty parameter of item i, and
ci: guess parameter of item i.
Most CATs were established upon the three-parameter model (Ng, Leung, Chan & Wong, 2001). IRT has a few basic assumptions, including unidimensionality, local independence, non-speeded test, and know-correct assumption that need to be sustained before the model can be used to analyze the data (Lord, 1980; Ackerman, 1989). Unidimensionality is a common assumption among IRT models. All items measuring the same ability that must be included in the assumption of the test items. In reality, however, an examinee’s performance may be subject to other factors, such as anxiety and techniques. Therefore, as long as the test qualified to affect one major factor or component of the test result, the unidimensionality assumption is met. Local independence is defined as when the ability affecting the test performance is fixed, any item response is treated as statistically independent. That is, an examinee shows no correlations between test items. Non-speeded test is defined as IRT includes a hidden basic assumption that indicates the test completion is not limited by time. In other words, if an examinee performed poorly, it was due to the incompetent ability
instead of the time availability. Know-correct assumption assumes that if an examinee knew the correct answer of an item, then he or she would have responded to the item correctly.
In IRT theory, item is treated as the basic unit for measuring the examinee’s ability through the parameters. The execution is according to a simple principle: if an examinee responded correctly to an item, then the next item will be a level up in its difficult, and vice versa. For each item responded, the examinee’s estimated ability will be reevaluated, and then the appropriate level of item is given. The process repeats until a pre-set reliability level or stopping rule is triggered. (Ho, 2000)
SPRT
SPRT is applied to criterion-referenced test and license test. It judges the mastery level of an examinee in certain domain knowledge (Li, 1995). Wald originally developed SPRT in 1947 for controlling the quality of military manufacturing in World War II. Ferguson adopted SPRT in education testing for the pass-or-fail decision. However, most educational application adopted IRT theory, and SPRT is not commonly implemented. (Frick, 1990)
In the standard SPRT execution, items were randomly selected and sequential probability ratio testing (Chung, 2000; Li, 2001)。Related definitions of terminology are as follows::
Probability of correct item response: f nm s nm on f m s m om P P P P P P PR ) 1 ( ) 1 ( where
Pom = Probability of previously mastery Pon = Probability of previously non-mastery
Pm = Probability of mastery with correct item response Pnm = Probability of non-mastery with correct item response α = Type I error, judging mastery, but in fact non-mastery β = Type II error, judging non-mastery, but in fact mastery s = number of correct item responses
f = number of wrong item responses LBM (Lower Bound Mastery) = (1-β)/α
UBN (Upper Bound Nonmastery) = β/(1-α)
Frick pointed out that SPRT will generate better efficiency ifαandβwere setup conservatively, such asα=β=0.025. When an examinee finished an item and the system-calculated PR is greater than or equal to LBM, then the examinee is judged to be mastery and the test can be terminated. Or if the result is undetermined or non-mastery with UBN < PR < LBM, then the test goes on with a new randomly selected item. Otherwise, if PR≦UBN, the examinee is judged to be non-mastery (Frick, 1989) Although SPRT does not involve complicated mathematical formula, there are
still two basic assumptions. First, item is randomly selected from the item bank and cannot be repeated. Second, it has local independence like the IRT. Two additional constraints exist when executing SPRT: it is only suitable for mastery learning, and no concrete achievement level can be evaluated; measurement error exists when examinees’ abilities shown non-normal distributed. (Chung, 2000)
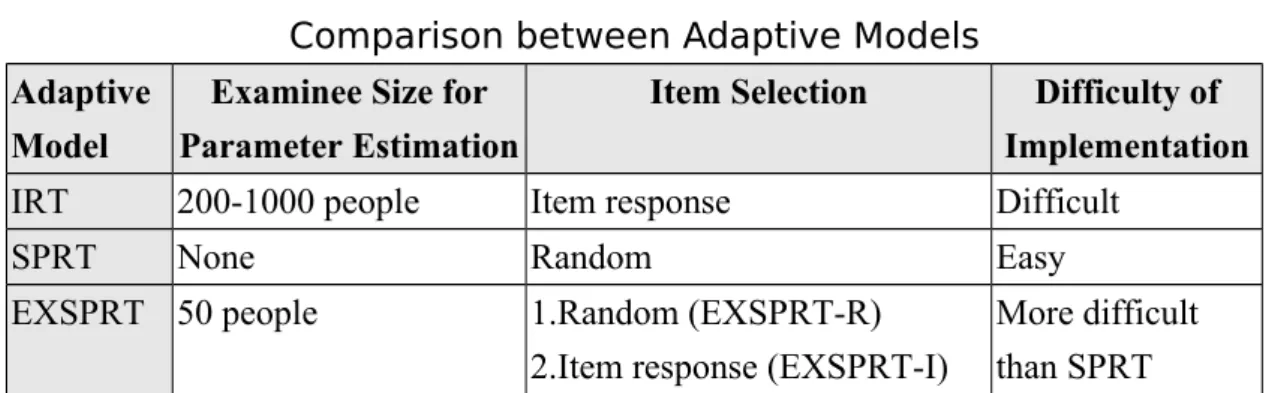
Frick (1992) reported IRT requires 200 to 1000 examinees to adjust the parameters, which consumes more time and human resources in preparation. Moreover, IRT involves complex mathematical formula. These two requirements may prevent instructor from developing the item pool.
Comparing to the complexity of IRT execution, SPRT is a simpler adaptive model to implement. But, its potential drawbacks are not considering item difficulty, discrimination and guess degree. Therefore, Frick mixed these two theories and developed an expert system-based SPRT (EXSPRT). The application of EXSPRT is similar to SPRT, but EXPSRT weighted differently on the items in the item pool. Therefore, EXSPRT requires only 50 examinees to adjust the item bank (Frick, 1992.) A comparison between IRT, SPRT and EXSPRT is listed as in Table 1.
TOEFL
TOEFL is provided by ETS (Educational Testing Service) to non-native English speakers as an English proficiency proof for applying universities or graduates
schools in Canada and the United States. Since 1964 nearly 20 million students have taken the TOEFL test in more than 165 countries, and over 4,500 institutions worldwide use scores from TOEFL tests (TOEFL, 2003).
Historically, Taiwan has been one of the main sources of foreign students among other counties in the U.S.A.. Accordingly, TOEFL exam has been a popular English proficiency test for Taiwan’s students. Many corporations have also adopted TOEFL scores for selecting their new employees by setting appropriate minimum hurdles for different job positions. Recently, even Taiwan’s universities start requiring their students to fulfill a certain TOEFL standard before graduating.
There are two ways to take a TOEFL test, either the pencil-and-paper or the computer-based TOEFL test. Taiwan’s TOEFL has implemented the CAT since October 2000 and every examinee is equipped with a computer and a set of earphone in the test site.
TOEFL test includes Listening, Grammar, Reading and Composition. Listening and Grammar adopt adaptive CAT, which only allow the examinee seeing one item on screen at a time. After the examinee pressing the enter key, the computer will evaluate the response and select the next item with an appropriate difficulty. The examinee can neither skip any item nor go back to previous items. The initial item is usually at the middle-level of difficulty among the items in the test bank. The
examinee, however, has to control the speed of responding since there is a time limit for all items (TOEFL, 2003)
Reading, on the other hand, adopts the traditional linear testing, which does allow the examinee to skip items and return to previous items for modifications. The scores for listening and reading can be viewed immediately after finished the test, but grammar/composition and the total score cannot because the composition requires an ETS professional staff to evaluate at a later time (The Language Training and Testing Center, 2003).
THE PROPOSED SPRT-BASED CAT APPROACH
The main objective of this research is to promote CAT in business organizations by proposing a solution that is feasible to clear the obstacles. We adopted an approach described by Liang (1997) that when an innovative new idea or theory is generated, researcher can construct a prototype to validate its feasibility and correctness. Therefore, after defining the SPRT-based CAT approach, we will briefly introduce the prototype system and the experiment design.
The Approach
The idea of the proposed approach is that it is SPRT-based and adopts the IRT sprit of non-mastery result. As a base, SPRT provides its simplicity in the item pool
that consists of equal difficulty level of items only. The IRT spirit of non-mastery result is achieved by expanding the SPRT-based item pool into an N-tier item pool. In other words, each tier of the item pool contains only the same difficult level of items, so that an examinee’s ability can be identified as up to one of the N levels. The rationale behind this design is that the domain experts in charge can easily maintain the N-tier item pool based only on their professional expertise. No additional expertise in testing theory and no process of brining 50, 200, or 1000 subjects to estimate the parameters as EXSPRT or IRT do.
In order to illustrate this idea more clearly, Figure 1 shows a simplified diagram of a typical IRT-based CAT mechanism while Figure 2 shows the proposed SPRT-based CAT mechanism as a contrast. Two major differences can be easily identified from these two mechanisms: IRT mechanism includes an additional parameter-estimation pre-test task by its theoretical nature, and SPRT-based mechanism has the item pool divided into N tiers by splitting the different difficult-level of IRT items into cohesive groups.
In creditable certified or license centers, even the SPRT item pool is required to be rigorously verified against 3-PLM IRT model as suggested by Kalohn and Spray (1999). However, in order for this SPRT-base CAT approach to be easily adopted in business daily routines, the tedious parameter-estimation task can be exchanged as
long as certain validity retains in it.
Therefore, a question remains to be answered: how is the outcome compared to IRT score? Because each tier of the item pool represents a different scale of ability, an examinee goes through the SPRT item pool from a certain ability level and up, and stops at the first tier judged to be non-mastery or undetermined. Then, the examinee obtains a semantic label of ability, such as medium or proficient, or an ability level, such as level 1 or level 3. For example, if an item pool is 5-tier, then the semantic labels for each tier can be beginner, novice, medium, proficient, and advanced. This type of semantic testing results is actually used in many evaluation or measurement in practice because a 0-100 score presents some trouble in distinguishing closed scores between, say 89 and 82. Nevertheless, this potential advantage of score-to-scale transformation still needs to be validated with some experiment.
To implement the design of the SRPT-based CAT approach, an integrated process for the CAT example is illustrated in Figure 3. The upper half of Figure 3 depicts a single SPRT process cycle while the lower half represents the N-tier SPRT algorithm that determine how to repeat the single SPRT process cycle. In our CAT scenario, three objectives of items include Listening, Grammar, and Reading each has six difficulty levels, which are setup in the first two actions in the SPRT base of Figure 3.
For the most complex situation, the appropriate ability levels of all three objectives for an examinee need to be identified. If an examinee starts with Grammar, the default tier is level 3 and an item is randomly selected from the 3rd tier item pool. When an item response is evaluated to be PR≧LBM, then level 3 is judged to be mastery and level 4 is triggered. Or if PR≦UBN, then level 3 is judged to be non-mastery and level 2 is trigger. Otherwise, UBN≦PR≦LBM means level 3 is undecided, next item will be randomly selected again for the examinee to answer if the stopping condition is not yet met. When the ability level of Grammar is determined, then either listening or reading is triggered. This complex scenario does imply a tradeoff of this SPRT-based CAT approach for business flexible decision needs. That is, it takes longer than the IRT CAT to decide the examinee’s ability due to the N-tier structure that repeats the SPRT test as many as N times.
The simplest scenario would be to determine whether an examinee is mastery on a certain level in one of the Grammar, Listening, or Reading objectives? The process is similar to what has described in the most complex scenario except that no other level will be triggered when a mastery level is decided.
Prototype System
In order to conduct the experiment, the web-based English CAT prototype system was designed as shown in Figure 4. Four basic modules are included - user,
item pool, test setup and test modules. User module contains basic data for the human-resource (HR) staff who manages the test process, the employee or applicant who takes the test, and the domain expert who maintains the test item pool, such as name, account number and password, and job title.
Item pool module provides maintenance functions for adding, editing, deleting, or previewing test items by the domain expert and/or the HR staff. This module supports the domain experts to easily maintain the quality of the item pool without CAT or IT expertise. Test setup module supports the HR stuff to setup the online adaptive test for particular job openings for English qualifications. Theoretically speaking, the scope of the test can be setup for all applicants, group applicants, or individual applicant. Examples of the setup can be only for English reading mastery on “average” skill level for a software engineer, or the highest skill levels of English Grammar, Reading, and Listening for an English secretary. Test module accepts employee or application login to proceed a pre-set personalized test session. All the testing history and records are automatically stored for query on a needed basis.
The prototype system was developed on a Windows 2000 server running a Java-based Web server Resin 2.1 and a Microsoft ACCESS 2000 database. The Web programming language Java Server Page (JSP) was used to implement the interactive programming logic. The purpose of the interactive screens are to illustrate how easy
the domain expert or the HR staff can maintain the item pool or administrate a test, and the how the examinee is taking the test. All users can interactive with the CAT system easily for their tasks.
Experiment Design
In order to validate the proposed SPRT-based CAT approach, a prototype system was developed. A pre-test was conducted to four subjects for assessing the appropriateness of the system and interface designs. Consequently, the formal experiment was conducted only after the opinions and suggestions collected from the pre-test were adjusted in the prototype system. Because the pre-test followed the exact same procedure as the formal experiment, only the design of the formal experiment is summarized below.
The goal of this experiment is to evaluate the effectiveness of the proposed approach by benchmarking our English CAT prototype system with the well-established TOEFL test, which belongs to the predictive validity method in criterion validity (Zikmund, 1997). The convenient sampling method is used to locate sixty working professional and graduating senior students with TOEFL scores attained before this experiment. Each experiment session starts with a 20-minute brief introduction of this experiment and a warming up practice of the English CAT prototype system. Then, an official online CAT test session of 80 minutes on English
Grammar, Listening, and Reading is given to the examinee.
3.4 Experimental Setting
In the experimental process, where did the item pool come from? How were the parametric values determined? What are the stopping conditions? These three important questions of the experimental settings are briefly described below.
Test item pool. Because the benchmark test is against the TOEFL standard, the
test item pool needs to contain TOEFL-like objectives and corresponding items. We acquired a 900-item test pool from the English department of I-Shou University, which was used to experiment a fixed-length test of pencil-and-paper format for classifying freshman English abilities. Like the TOEFL test, the item pool contains 300 items each for Grammar, Reading, and Listening. All three objectives are further classified into six difficulty levels as 1 (beginner), 2 (novice), 3 (median), 4 (proficient), 5 (advanced), and 6 (most advanced).
Parameters settings. Frick (1989) indicated that conservative Type I and Type II
error rates,α andβ values, will achieve relative effective judgmental result. This prototype system adopted 0.25 of Frick’s research, and thus LBM = (1-β)/α=39 and UBN=β/(1-α) =0.02564. As for the probabilities of responding correctly on a test item for the mastery examinee (Pm) and for the non-mastery examinee (Pnm), we took the suggested values of 0.85 and 0.55, respectively, from the domain experts at I-Shou
University. The rationale is that a mastery examinee at any ability level is similar to the traditionally perceived score in class, which is around 85 or higher in Taiwan. On the other hand, for the non-mastery examinee, there is a 50 percept of chances to correctly guess any test item. Therefore, 5% was added to make it more than a wild-guess of non-mastery response.
Stopping condition. Frick (1989) pointed out that for any mastery or non-mastery
examinee, there is a high chance in completing the adaptive testing process with a smaller number of items. However, it may consume all items in the item pool before a medium-ability examinee can be decided. To avoid such situation, we performed a simple simulation using the random number generators in Microsoft Excel 2000 to simulate 40 adaptive testing sessions as shown in Table 2. As seen in Table 2, in two of the extreme situations of P=0.55 and P=0.85, the mastery sessions required much less number of items before determination. Between the two non-master situations, average 16 items were needed to reach the non-mastery decision. To be conservative, we set the stopping condition to be 25 items for an un-decided result.
DATA ANALYSIS AND DISCUSSION
The data analysis proceeded in two steps. First, the subjects were divided into six groups based on their TOEFL scores, which were double validated by the
independent T test for their significant differences. Then, with the same groups, the average ability levels attained from our experiment were calculated and the independence T test was used to test the significance of their differences. If the new average ability levels were significantly different, then we could claim that the English adaptive system based on the proposed approach delivered the same testing effect as the TOEFL did in the semantic representation.
In the New TOEFL, Reading, Listening and Grammar each are 30 points, where Composition has 6 points that are included in Grammar’s 30 points. Although Taiwan has implemented the new TOEFL test for some years, a few subjects attained the old TOEFL test scores, which were transferred to the new test scores before the analysis. Because Reading and Listening each has 30 points, the subjects were divided into 6 groups based on their scores in even distances. The Grammar was divided into 5 since it has only 24 points excluding the 6 points from Composition. Table 3 lists the group segments for Reading, Listening and Grammar in details.
In the first step, the independent T test was used to validate whether the group segments could significantly discriminate the average group TOEFL scores. As seen in Tables 4-6, the P values were all smaller than 0.01, which sustained the group segments were divided correctly in terms of the TOEFL scores.
group ability levels of our prototype CAT system. Similarly, the independent T test was used to examine the significant differences of the average group ability levels. Tables 7- 9 showed that except for the SPRTr4 in reading and SPRTl5 in listening, all other group comparisons were significant at P-values smaller than 0.05.
According to our after-test interviews, the very possible reasons why SPRTr4 of Reading and SPRTl5 of Listening were insignificant maybe due to one-sixth of the subjects were nervous while taking this online adaptive tests, which greatly affected their test performance.Anxiety is one of the issues CAT is still facing as investigates in many studies (Lord and Gressard, 1984) Also, the N-tier SPRT item pool was not as rigorously tested against IRT 3-PLM model as suggested by Kalohn and Spray (1999) for certified or license centers may be another possibility. However, the benchmark test with only 60 subjects is in general very positive to this criterion validity test against TOEFL. Generally speaking, we think the proposed approach can effectively evaluate the employee capability appropriately while meeting business decision needs flexibly.
CONCLUSIONS AND IMPLICATIONS
In order to promote various benefits of the adaptive testing in business daily routines, we have proposed an SPRT-based CAT approach that can not only avoid the
tedious pre-test procedure for maintaining the item pool but also produce a more distinguishable level of examinee’s ability instead of a pass-or-fail decision. Furthermore, we have demonstrated its technical feasibility by implementing an English CAT prototype system as well as its criterion validity by a benchmark test against the well-validated TOEFL test.
There are two major business implications. First, because this SPRT-based approach is sound in theory, effective in performance, and efficient in implementation, it can become an IT proven innovation strategy in today’s new economy era as a cost-effective tool. In other words, this approach prolongs the life cycle of an adaptive testing system by having the HR staff, the domain experts, and the employee or job applicants focus only on their designated routines in process administration, item pool maintenance and test taking, respectively, without additional IT or adaptive-testing expertise.
Another implication is that the certified or license centers can provide this adaptive testing approach as a new business model to their business clients. That is, an application service provider (ASP) leases the testing software and/or system as a package to the business clients and let the clients operate and maintain the testing process. In this scenario, adaptive testing systems can be more affordable and flexible to meet business versatile needs, which provides a good motive and win-win
situations for both the ASP and the business clients
REFERENCES
1. Ackerman, T. A. 1989. Unidimensional IRT calibration of compensatory and noncompensatory multidimensional items. Applied Psychological Measurement, vol. 13: 113-127.
2. Bunderson, V., Inouye, D. & Olson, J. 1989. The four generations of computerized educational measurement, in R. L. Linn (Eds.), Educational
measurement, New York: Macmillian.
3. Chung, C. .2000. Impacts of SPRT adaptive testing affecting on the testing
altitude of junior high school students. Unpublished master these in Educational
Technology, Tamkiang University, Taiwan, R.O.C.
4. Frick, T. W. 1989. Bayesian adaptation during computer-based tests and computer-guided practice exercises. Journal of Educational Computing
Research, vol. 5, no. 1: 89-114.
5. Frick, T. W. 1990. A comparison of three decision models for adapting the length of computer-based mastery test. Journal of Educational Computing Research
Systems, vol. 5, no. 1: 89-114.
6. Frick, T. W. 1992. Computerized adaptive mastery tests as expert. Journal of
7. Ho, R.-G. 2000. Customized testing- adaptive testing, Testing and Counseling, vol. 157: 3288-3293.
8. Kalohn, J. C. & Spray, J. A. 1999. The effective of model misspecification on classification decisions made using a computerized test. Journal of Education
Measurement, vol. 36, no. 1: 47-59.
9. The Language Training and Testing Center 2003.
http://www.lttc.ntu.edu.tw/main.htm, accessed on 2003/12/28, Taiwan.
10. Li, M.-N. 2001. Computer adaptive testing- past, current, and future, Taiwan’s
Education, vol. 604: 52-61.
11. Li, Y.-H. .1995. The effect of the properties of item difficulty on the sequential probability ratio test for mastery decisions in criterion referenced test. Journal of
Psychological Testing, vol. 42: 415-429.
12. Liang, T.-P. 1997. Information management research methods, Journal of
Information Management (Taiwan), vol. 4, no. 1.
13. Lord, F. M. 1980. Applications of item response theory to practice testing
problems. Hillsadle, N. J.: Erlbaum Publishers.
14. Lord, B. H. & Gressard, C. 1984. Reliability and factorial validity of computer attitude scales. Educational and Psychological Measurement, vol. 44,no. 2: 501-505.
markup language for adaptive testing. Hong Kong Polytechnics University,
research project code GT 143.
16. Olson, J. 1990. Applying computerized adaptive testing schools, Measurement
and evaluation in counseling and development, vol. 23, no. 1: 31-38.
17. TOEFL, 2003. http://www.toefl.org, accessed on 2003/12/28.
18. Welch, R. E. & Frick, T. W. 1993. Computerized adaptive testing in instructional settings. Educational Technology Research and Development, vol. 41, no. 3.: 47-62.
19. Wise, S. L. & Kingsbury, G. G. 2000. Practical issues in developing and maintaining a computerized adaptive testing program, Psicológica, vol. 21: pp.135-155.
TABLE 1
Comparison between Adaptive Models
Adaptive Model
Examinee Size for Parameter Estimation
Item Selection Difficulty of Implementation
IRT 200-1000 people Item response Difficult
SPRT None Random Easy
EXSPRT 50 people 1.Random (EXSPRT-R)
2.Item response (EXSPRT-I)
More difficult than SPRT
FIGURE 1 IRT CAT Model
i11,i 12,i13,…i1m i21,i 22,i23,…i2n i31,i 32,i3.3,…i3o . . iN1,i N2,iN3,…iNx IRTItemPool IRTAlgorithm ItemSelection StoppingRules Parameters… CATTest ParameterEstimationPre-test >200 a,b,c IRTSystem FIGURE 2
SPRT-Based CAT Approach N-Tier SPRT Item Pool SPRT Algorithm Item Selection Stopping Rules … CAT Test SPRT-Based System i31,i32 ,i33 ,…,i3o i21,i22 ,i23 ,…,i2n iN1,iN2 ,iN3 ,…,iNx i11,i12 ,i13 ,…,i1m …
FIGURE 3
An illustration of the SPRT-based CAT Process
S e l e c t e i t h e r G r a m m a r , R e a d i n g o r L i s t e n i n g S e l e c t D i f f i c u l t L e v e l ( D e f a u l t a t 3 ) R a n d o m l y S e l e c t a n I t e m R e s p o n d E v a l u a t e P a s s ( P R > = L B M ) ? N o ( U B M < P R < L B M )C o n t i n u e T e s t i n g ? N o Y e s Y e s S P R T B a s e C y c l e M o v e U p O n e L e v e l L e v e l = H i g h e s t L e v e l S e t u p ? Y e s N o A l r e a d y P a s s e d O n e L e v e l D o w n ? F i n i s h e d t h e T e s t ! Y e s I R T S p i r i t ( A l g o r i h t m o n N - T i e r S P R T C y c l e s ) M o v e D o w n O n e L e v e l N o L e v e l = L o w h e s t L e v e l S e t u p ? L B M ( L o w e r B o u n d M a s t e r y ) = ( 1 -β ) / α U B N ( U p p e r B o u n d N o n m a t e r y ) = β / ( 1 - α ) P r o b a b i l i t y o f C o r r e c t I t e m R e s p o n s e = f nm s nm on f m s m om P P P P P P PR ) 1( ) 1(
FIGURE 4
System Functional Structure Chart
Online English CAT System
User Item Pool Test Setup Test
Employee or Applicant Domain Expert HR Staff Edit Item Add Item Delete Item Preview Item Test Pool Browse Test Setup & Go Onlive Test Record Information Published Adaptive Testing Record Query TABLE 2
Simulation of Stopping Condition
P=Pnm=0.55 P=Pm=0.85
Outcome Mastery Non-Mastery Un-decided Mastery Non-Mastery Un-decided
Number of Sessions 7 30 3 16 21 3
Average Number of Items
16 13.9 40 13.2 8.7 40
TABLE 3
TOEFL Scores by Group Segments
Reading Listening Grammar
Group Score Range Group Score Range Group Score Range
GroupR1 1~5 GroupL1 1~5 GroupG1 1~5
GroupR2 6~10 GroupL2 6~10 GroupG2 6~10
GroupR3 11~15 GroupL3 11~15 GroupG3 11~15
GroupR4 16~20 GroupL4 16~20 GroupG4 16~20
GroupR5 21~25 GroupL5 21~25 GroupG5 21~24
GroupR6 26~30 GroupL6 26~30
Table 4
Independent T Test on TOEFL Reading Scores Comparison
Code
Pair-wise Groups
Number Average T-Value P-Value
TOEFLr1 GroupR6 GroupR5 12 16 26.083 22.625 6.760 .00000038 *** TOEFL r2 GroupR5 GroupR4 16 13 22.625 17.769 7.370 .00000006 *** TOEFL r3 GroupR4 GroupR3 13 8 17.769 13.625 4.667 .00016783 *** TOEFL r4 GroupR3 GroupR2 8 9 13.625 9.111 5.934 .00002743 *** TOEFL r5 GroupR2 GroupR1 9 2 9.111 4.500 6.510 .00011017 *** *** Significant at P<0.01;**Significant at P<0.05;*Significant at P<0.1
TABLE 5
Independent T Test on TOEFL Listening Scores Comparison
Code
Pair-wise Groups
Number Average T-Value P-Value
TOEFL l1 GroupL6 GroupL5 9 16 26.667 22.875 7.745 .00000007 *** TOEFL l2 GroupL5 GroupL4 16 15 22.875 17.867 10.075 .00000231 *** TOEFL l3 GroupL4 GroupL3 15 12 17.867 13.167 8.303 .00000012 *** TOEFL l4 GroupL3 GroupL2 12 6 13.167 8.667 6.267 .00001124 *** TOEFL l5 GroupL2 GroupL1 6 2 8.667 4.500 4.466 .00400000 *** *** Significant at P<0.01;** Significant at P<0.05;* Significant at P<0.1
TABLE 6
Independent T Test on TOEFL Grammar Scores Comparison
Code
Pair-wise Groups
Number Average T-Value P-Value
TOEFL g1 GroupG5 GroupG4 6 17 21.333 17.294 5.367 .00002567 *** TOEFL g2 GroupG4 GroupG3 17 22 17.294 13.500 7.843 .00000011 *** TOEFL g3 GroupG3 GroupG2 22 9 13.500 7.889 11.729 .00000002 *** TOEFL g4 GroupG2 GroupG1 9 6 7.889 4.667 6.305 .00002722 *** *** Significant at P<0.01;** Significant at P<0.05;* Significant at P<0.1
TABLE 7
Independent T Test on SPRT-Based Reading Ability Levels Comparison
Code
Pair-wise Groups
Number Average T-Value P-Value
SPRT r1 GroupR6 GroupR5 12 16 5.375 4.781 2.079 .048 ** SPRT r2 GroupR5 GroupR4 16 13 4.781 4.039 2.097 .047 ** SPRT r3 GroupR4 GroupR3 13 8 4.039 3.063 2.175 .042 ** SPRT r4 GroupR3 GroupR2 8 9 3.063 2.611 1.304 .212 SPRT r5 GroupR2 GroupR1 9 2 2.611 1.500 2.316 .046 **
*** Significant at P<0.01;** Significant at P<0.05;* Significant at P<0.1
TABLE 8
Independent T Test on SPRT-Based Listening Ability Levels Comparison
Code
Pair-wise Groups
Number Average T-Value P-Value
SPRT l1 GroupL6 GroupL5 9 16 4.778 4.125 2.532 .019 ** SPRT l2 GroupL5 GroupL4 16 15 4.125 3.533 2.093 .045 ** SPRT l3 GroupL4 GroupL3 15 12 3.533 2.792 1.960 .061 * SPRT l4 GroupL3 GroupL2 12 6 2.792 1.919 2.070 .055 * SPRT l5 GroupL2 GroupL1 6 2 1.919 1.75 .207 .843
TABLE 9
Independent T Test On SPRT-Based Grammar Ability Levels Comparison
Code
Pair-wise Groups
Number Average T-Value P-Value
SPRT g1 GroupG5 GroupG4 6 17 5.250 4.353 2.639 .015 ** SPRT g2 GroupG4 GroupG3 17 22 4.353 3.818 2.364 .023 ** SPRT g3 GroupG3 GroupG2 22 9 3.818 3.222 2.181 .037 ** SPRT g4 GroupG2 GroupG1 9 6 3.222 2.333 2.317 .035 **