Increamental Learning for Robot Control
I-Jen Chiang
Jane Yung-jen
Hsu
chiang@robot .csie.ntu.edu.tw
yjhsu@csie.ntu.edu.tw
Department of Comuter Science and Information Engineering
National Taiwan University
Taipei, Taiwan 106, R.O.C.
Abstract
A robot can learn t o act by trial and error in the world. A robot continues t o obtain information about the environment from its sensors and t o choose a suit- able action t o take. Having executed an action, the robot receives a reinforcement signal from the world indicating how well the action performed in that sit- uation. The evaluation is used t o adjust the robot’s action selection policy for the given state. The pro-
cess of learning the state-action function has been ad- dressed by Watkins’ &-learning, Sutton’s temporal- difference method, and Kaelbling’s interval estima- tion method. One common problem with these rein- forcement learning methods is that the convergence can be very slow due t o the large state space. State clustering by least-square-error or Hamming distance, hierarchical learning architecture, and prioritized swap- ping can reduce the number of states, but a large por- tion of the space still has t o be considered. This paper presents a new solution t o this problem. A state is taken t o be a combination of the robot’s sensor status. Each sensor is viewed as an independent component. The importance of each sensor status relative t o each action is computed based on the frequency of its oc- currences. Not all sensors are needed for every action. For example, the forward sensors play the most im- portant roles when the robot is moving forward.
1
Introduction
A robot can learn to act by trial and error in the world. The robot obtains the environment informa- tion form its sensors and chooses an action to take. Having executed an action, the robot will indicate how well the action was performing at that situation. From those state-action performing evaluation, the robot will gradually improve its action choosing pol- icy for every states. For the robot control, all we need t o do is t o construct its state-action control function. It is not a easy work in the nonlinear domain. We need a refinement process t o rectify the stateaction
[l] [2] t o make i t adaptive t o the real world. The pro-
cedure of the state-action choosing policy refinement is a learning process. How t o quickly and concisely
create a state-action controller for the robot in dy- namic environment by a learning process is the main purpose in this paper.
The reinforcement learning method [3] [4] [5] [SI [7] [8] [9] [lo] 1121 [13] E141 [15] has been addressed to construct the state-action function for the robot con- trol, such as Watkins’ Q-learning [15] [8] [9], Sutton’s temporal-difference method [12] [13], and Kaelbling’s interval estimation method [5] [6] [7]. One common problem with these reinforcement learning methods is that the convergence can be very slow due to the large state space. State clustering by least-square- error or Hamming distance [14], hierarchical learning architecture [8] [9], and prioritized swapping can re- duce the number of states, but a large portion of the space still has t o be considered.
This paper presents a new solution t o this prob- lem. A state is taken to be a combination of the robot sensor status. Each sensor is viewed as an inde- pendent component. The sensors on different states play different roles in performing an adion. For a sensor-based robot, it is difficult t o enumerate all the mappings of the states and the actions t o construct the robot controller. In order t o simplify all the state- action mappings, the learning process needs to iden- tify which the robot sensor status play the roles of as- sistant, the resistant, or don’t care of executing that action. As we seen, while a robot executing a for- ward action, the forward sensors of it play the most important roles t o govern such operation. When the forward sensors sense that the robot is approximate t o an obstacle, i t is not difficult t o understand that the robot needs t o change the forward action; that is, those sensors status are the resistant to the for- ward action, but if they sense the robot is far from an obstacle it is easy to perform the forward action; that is, those sensors states are the assistants t o the forward operation. If we can clearly identify the sen- sors’ characteristics for each robot action, the consid- eration of sensor status for the action choosing policy will be simplified. The different roles of sensor sta- tus are represented as sensor status-action preference 0-7803-2559-1195 $4.00 0 1995 IEEE
values. The sensor status-action preference values for all sensor status and actions will demonstrate their effects in the action-selection policy. The bigger the preference value of a sensor status t o an action, the more important the sensor status t o assist it. The value of the resistant is the minus sign value and the preference value of the don't care status is zero.
This paper presents an unsupervisory, incremental learning method t o adapt robot operation in the envi- ronment. In our framework, there are some primitive actions given t o the robot. The controller is a state- action mapping function, which utilizes the previous performing evaluation and the sensor status-action preference values of the state, t o determine which action is the most adaptive. The learning process is based on the reinforcement learning methodology, which includes three main procedures: (1) observe the environment information from the robot sensors; (2) choose the most suitable action according t o state- action performing evaluation; (3) cluster and adjust the values of the evaluation function and the sensor status-action preference function for each robot state and action.
At each moment in time, the robot gets informa- tion about the world form its sensors. According t o those sensor status and the current sensor status- action preference values, we can sum up all the values for each action individually t o determine which action is the most suitable, and perform that action. If the robot succeeds t o perform that action, all the sensor status-action preference values will be increased by a reward; otherwise, all of them get the punishment. After the status-action preference refining process has proceeded, we make a normalization on it. If a sensor status has the role of assistant and resistant concur- rently, plus these two different values t o make it play only one role. It is called the normalization. The reward or the punishment given is according t o the error rate and the learning time it takes. The lower the error, the smaller the reward and the punishment. The reward and the punishment will approach t o con- stant values in a long run. Initially, the reward and the punishment are constant values. As by the simu- lated annealing procedure, they approach to zero.
Our method avoid the credit assignment problem. It is difficult t o determine the values of the reward and the punishment in the reinforcement learning process. With unsuitable reward or punishment, the learning could bring t o no effect. In our learning method the reward and punishment, which are initially constant, are decreased by the error and the learning dura- tion, and applied to each sensor status individually at any moment. By the normalization process, we can quickly identify the sensor status t o be the assis-
tant, the resistant, or the don't care status.
In our experiments on mobile robot, we take 16 sonic sensors, which are independent one another around the robot, and divide their sensed range into four fixed status. And there are four primitive actions, such as moving forward, moving backward, turning right, turning left, given t o the robot. We want t o use those sensory information and those basic actions t o construct a controller for mobile behavior, such as following the wall, moving in the corridor, avoiding the fixed and moving obstacle. As t o the simulated mobile robot process on SPARC I, let the robot self- organize the behavior controller by our learning pro- cess in some different generated areas. The error rate can reduce t o 1% within in five minutes at hundreds of steps.
Based on the reinforcement learning method to carry a conceptual learning [ll] into effect, we can identify the feature of every sensor status for each action. By the normalization process, we can quickly distinguish what sensor status is no use for each action. When getting the environment information in the world, the robot can quickly and easily choose an action from the sensory information by referring t o their prefer- ence values for every actions.
Section 2 will describe our definition and method. The simulated experiment is presented in Section 3. Section 4 will make a conclusion about our work.
2
Definition and Method
Let S be the state space, A be the set of actions, The
evaluation function f is a mapping from the state- action pairs into real number, i.e. f : S x A
-+
R. Assume that each sensor affects the choices on ac- tions independently, the function can be decomposed as f = E?==, f i ( s ; , a ) , where s=<
sl, s 2 , . " , s,,>,
and f; : S; x A
+
R is called the preference value for the i t h sensor.During the learning process, the preference values are adjusted according t o the following procedure:
Sensor-differential l e a r n i n g a l g o r i t h m
Observing D
Get sensory information s
Choosing D
Perform the action that maximizes f ( s , a) Adjusting D
frequency(si) t
frequency(si)
+
I, Vs,If the action succeeds,
success(si,
a) t SUCceSS(Si, a)+
1, v s i Total success count 9 t G+
1 OtherwisefaiZure(si, a) t faiZure(si, a)
+
1, Vsi Total failure count !€'e
Q+
1 if success(si,a)-
faiZure(si,a)>
0, s u c c e s s ( s i ,a)-failure(s; ,a) f r e q u e n c y ( s i ) 0 fi(si, a) = foilure(si , o ) - a u ~ ~ e e e ( a i , ~ ) fregu.noy(si) otherwise, f i ( s i , a ) =-
*
f(s,4
+
a * f(s, a)+
(1-
a) * = q = = , f i ( S i , a)The evaluation function f ( s , a) is used for the robot t o determine which action a is the most suitable ac- tion t o perform while the current state is s. Initially, f(s, a) is zero for each primitive action a and all the preference values of its sensor status are zero. The robot randomly selects a n action t o perform, and then rectifies the value of the evaluation function for this action. The rectification process depends on whether this action is succeeded in performing the behavior or not. Importantly, we make a sensor differentiat- ing process for the sensor status in the rectification process, seen in the adjusting procedure of the al- gorithm. We keep recording the number of success and failure for each individual sensor status while the robot is performing a n action, which are success(., .) and failure(.,.). We divide them by the number of the sensor status t h a t has happened t o obtain the fre- quency of success and failure of that action. Then we divide the difference of those two frequency by the total success count t o obtain the sensor status-action preference value if the frequency of success is bigger than the frequency of failure; otherwise, divide it by the total failure count.
The sensor status-action preference values are used t o determine the sensor status classification. If we take the actions to be the concept on learning, the sensors will be the attributes for classification, and the sensor status are their values. For each sensor status and each action, there exists a sensor status- action preference value. The sensor status-action pref- erence value demonstrates the degree that a sensor status belongs t o a concept which is an action. A ac- tion is said t o have the high probability t o be chosen t o perform when the robot state is with much more sensor status having high preference values of that ac- tion than the others, and the value of the arbitration rate, a, is much small.
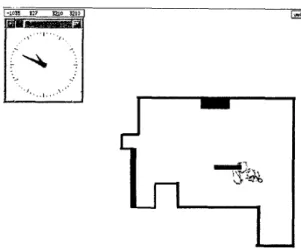
Figure 1: In the initial stage, the robot wandered in the map t o learn the wall-following behavior
Figure 2: After about 15 minutes, the robot followed the left wall under a lower error rate.
At each moment in time, the robot gets informa- tion about the world from its sensors. According t o those sensor status and the current sensor status- action preference values (fi(., .), V i ) , we integrate all
the values t o determine which action is the most suit- able and execute that action. The action which is most suitable for current robot state is the action with the maximum evaluation function value. If the robot succeeds in performing that action, all the sen- sor status-action preference values for the state will be increased by a reward; otherwise, all of them get a punishment. The preference values are then normal- ize for more efficient computation.
3
Experiment
In our experiments using a Nomad 200 mobile robot,
16 sonar sensors around the robot are taken. The sen- sor readings are divided into four states along each
di-
0.6 ; 0.5 . 0.4 0.3 ' . 0.2 ' 0.1
.
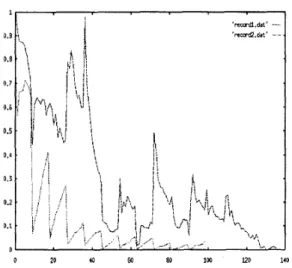
Figure 3: The error rates of two variants of our method.
rection. There are four primitive actions, moving for- ward, moving backward, turning right, and turning left, for the robot. The robot was trained t o perform several behaviors, such as following the wall, moving along the corridor, and avoiding static obstacles in randomly generated simulation environment. After 15 training episodes on the SPARC IPX, the error rate can be reduced t o 1% within ten minutes for the wall-following behavior. On average, each training experiment takes hundreds of steps when a: is zero. The learned data can be used by the real robot with good performance. After learning, the role of each sensor status t o each action is distinct.
For example, as seen in Figure.1 and Figure.%, with- out any prior knowledge of a given map and the rules of performing the wall-following behavior, the robot started from wandering in the map t o following the wall by learning. Incrementally, the robot can correct the stateaction function of doing the wall-following behavior. And inductively, the robot can extract the features of the robot sensors t o deal with the wall- following behavior. It demonstrates that the robot can perform the wall-following behavior quite well within about fifteen minutes.
The error rate can be reduced t o 1% within ten minutes by hundreds of steps, as shown in Figure.3 (The z-coordinate represents the number of learning phases. Each sample is taken at every ten steps of the robot operations.) On average, after about thirty minutes, it is almost nearly error-free. But the error rate is risen when the robot at a concave position, as seen in Figure.4.
The robot was always wandering at a small con-
Figure 4: After about 30 minutes, the robot can per- form the wall-following behavior quite well.
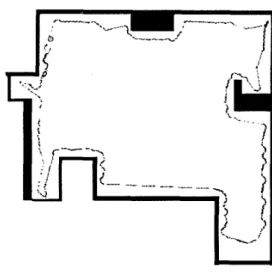
Figure 5: Partition range for robot's sensors.
cave area. That is because each sonic sensor of the robot is constantly partitioned into four status. All the sensor status can be drawn as four concentric cir- cles around the robot as Figure.5. The robot situa- tion is not enough t o be represented by using the fixed partition. It needs a more precise partition. One is t o increase the number of partition, but it will make the convergent rate of leaning increase. Since the learn- ing speed is reverse proportional t o the number of the robot states. The other is t o make all robot sonar sen- sors with variable partition range. According t o the sensors' characteristics for the wall-following behav- ior, we divide them into a fixed number but different partition boundary as the elliptical curves in Figure.5. As we known, different robot behaviors have their different characteristics. In order t o learn different behaviors, we need t o differentiate the robot sensors and make each robot sensor with different partition boundary for each behavior. It is not an easy and eco- nomic work. Dynamical adjustment may be a good idea for the robot behavior learning.
There are two variants of our method in this pa- per. Seen in Figure.3, they have very different learn- ing performance. One is that we neglect the effect
of the state that is reappeared again in the current stage and the robot choose the same action t o per- form, we do not adjust the status-action preference function value of each robot sensor. The other is that we repeatedly increase the success function values of current robot sensory status, if the robot can suc- ceed t o execute the same action; otherwise, increase the failure function values of them. The former is much better than the latter. That is because the for- mer can avoid the over-rewarding and over-punishing. Since we have given the reward or the punishment t o the state-action function, so it is not necessary to distribute the effect of the success or the failure t o each robot sensor. The time that needs t o con- verge is also enlarged. The curves of the error rates of those two methods are fluctuating periodically. This is because the fixed partitions of the robot sensors are not enough t o represent their situation for the wall-following behavior. That makes the robot stuck at local minimum of the state-action function at the concave region in our environment.
Average error rate after 300 steps
The table below shows part of the results from our experiments, which indicates that different values of a results in different convergence speeds and errors in the learned behavior. a is called the arbitration rate. It is used t o adjust the reference degree between the values of the robot state-action evaluation function and the robot sensor status-action function.
0.321 0.0234 0.247 Table. Performance of learning the wall-following
behavior.
I
aI
0.76I
0.6I
0.261 7 1
The smaller the value of the a, the less the elapsed time when error 2 0,Ol. But the vibration of the error rate is reverse proportional t o the value of a. Because if a is approximate t o zero means that the sensor status-action preference values are more im- portant than the value of the previous stateaction evaluation function. That is, the action selection pol- icy almost full depends on the sensor status classifi- cation information. It is dangerous t o determine the sensor status classification according t o a few learn- ing steps at the beginning. Those training examples are not enough t o classify all the sixteen sonic sensor status. Some of sensor status will be classify t o the wrong concept. More examples are needed t o adjust it. In our experiments, it does not need much time t o collect enough examples.
In our experiments, while we dynamically were adding or removing obstacles in our map, the robot was not burdened with the new situation, as shown in Fig- ure.6. The robot can deal with the new environment
Figure 6: Dynamically add an obstacle t o the envi- ronment.
according t o its learned knowledge.
4
Conclusion
This paper presents a new approach t o reinforcement learning for the robot control that differentiates the roles of multiple sensors in action selection. The ap- proach assumes that each sensor can independently contribute t o the action selection policy.
By incrementally updating the preference value of each sensor t o each action, the proposed method can
differentiate important sensors from irrelevant ones; reduce the state space and thereby enabling train- ing t o converge quickly;
and achieve learned behaviors for the robot with low error rate.
Indirectly, the concept classification has been con- structed by the sensor-differentiating process. Each action of a behavior is viewed as a concept. Associ- ated with the reinforcement learning, the role of the sensor status for an action can be clearly differenti- ated by the sensor-differentiating process. Since the sonic sensors around our robot are independent, by our method, we can quickly and correctly identify their effects on performing that action without much space. The only data structure that needs t o maintain is the sensor status-action preference value function. By integrating all the sensor status-action preference values for all actions, we can easily choose the most
suitable action.
In our experiments, t o differentiate the roles of mul- tiple sensors for a action is a helpful method for the robot control. It can quickly achieve the learned be- haviors with low error rate. In our framework, all the sensors are taken t o be independent, but how t o do when some of them are relevant is a n interesting problem. In our future work, we t r y t o establish a in- cremental learning method for the robot control with the relevant sensors.
In the future, we t r y t o add the classification of the relevant sensory information and the automatic adjustment of the sensors' partition for different be- havior in our learning process. This paper has shown that the incremental learning by associating the con- ceptual classification with reinforcement learning for robot control can obtain a quite well performance.
References
[l] R.A. Brooks, "A robust layered control system for a mobile robot," IEEE J. Rob. Autom., 2(1), 1986, pp. 1423.
[2] R.A. Brooks, "Elephants don't play chess," Robotics and Autonomow Systems, 6 , 1990, pp. 3-15.
[3] A.G. Barto, R.S. Sutton, andP.S.Brouwer, "As- sociative search network: a reinforcement learn- ing associative memory," Biological Cybernetics, 40, 1981, pp. 201-211.
141
D.
Chapman and L. Kaelbling, "Learning from delayed reinforcement in a complex domain," in: Proceedings IJCAI-91, Sydney, NSW, 1991. [5] L. Kaelbling, Learning in embedded systems,Ph.D. Thesis, Stanford University, Stanford. CA, 1990.
[SI L. Kaelbling, "Associative reinforcement learn- ing: function in k-DNF," Machine Learning, 15, 1994, pp. 279-298.
[7] L. Kaelbling, "Associative reinforcement learn- ing: a generate and test algorithm," Machine Learning, 15, 1994, pp. 299-319.
L. Lin, Self-improving reactive agents: case stud- ies of reinforcement learning frameworks, Tech. Rept. CMU-CS-90-109, Carnegie-Mellon Univer- sity, Pittsbugh, PA, 1990.
L. Lin, "Programming robots using reinforce- ment learning and teaching," in: Proceedings AAAI-91, Anaheim, CA, 1991.
[8]
[9]
[lo]
P. Maes and R.A. Brooks, "Learning t o CO-ordinat e behaviors
," in:
Proceedings A AAI- 90, Boston, MA, 1990, pp. 796-802.[113 J.R. Quinlan, "Induction of decision trees," Ma- chine Learning, 1991, pp. 338-342.
[12] R.S. Sutton, Temporal credit assignment in re- inforcement learning, Ph.D. thesis, University of Massachusetts, Amherst, MA, 1984
[13] R.S. Sutton, "Learning t o predict by the method of temporal differences," Machine Learning, 3(1), 1988, pp.9-44.
[14] S. Mahadevan and J. Connell, "Automatic pro- gramming of behavior-based robots using rein- forcement learning," Artificial Intelligence, 55, 1992, pp. 311-365.
[15] C. Watkins, Learning from delayed rewards, Ph.D. Thesis, King's College, 1989.