Integration of Likelihood and Transition Measures
for Video-Based Face Recognition
Cheng-Chieh Chiang Yi-Chia Chan Greg C. Lee
Dept. of Information Tech., Takming University of Science & Tech.
Dept. of Comp. Science and Info. Eng., National Taiwan Normal University
Dept. of Comp. Science and Info. Eng., National Taiwan Normal University Email: [email protected] [email protected] [email protected]
Abstract―This paper presents a probabilistic graphical
model to formulate video-based face recognition. There are two main parts involving in our approach: one for likelihood measure and the other for transition measure. The likelihood measure can be viewed as a traditional task of face recognition within a still image, i.e., to recognize who the current observing face image is. Two-dimensional linear discriminant analysis (2DLDA) is employed to judge the likelihood measure. Moreover, the transition measure estimates the probability of the change from the recognized state at the previous stage to each of possible states at the current stage. Our approach for the transi-tion measure can consider both the visual difference of persons according to the training face images and the pose change over time in video frames. We also provide several experiments to show the efficiency of our proposed ap-proach in this paper.
Index Terms ― face recognition, state-space model,
2DLDA, likelihood measure, transition measure. I. Introduction
Video data has been widely used for many kinds of applications in our life, e.g., camera in a hand device for capturing our life, web camera in a lap-top for sending video messages, or surveillance cameras in city streets for security goals. Many kinds of technologies for video data have been de-veloped for their goals of applications. It is an im-portant task to know who appears in a video when we design a video-based application. Thus, face recognition is often a key technology in many vid-eo-based applications, which aims to recognize which persons appear in a video sequence.
In traditional, face recognition is treated as a su-pervised learning, i.e., classifiers are trained by a
set of prepared face images associated with persons and then new face images are recognized by use of the classifiers. It is a long history to develop tech-nologies of face recognition in still images [1][15][20]. Different methods of classifier learning, e.g., eigenface [16], PCA (Principal Component Analysis) and LDA (Linear Discriminant Analysis) [3], LPP (Locality Preserving Projection) [5], and SVM (Support Vector Machine) [6], have been proposed to deal with the problem.
In recent, researchers have paid more attention to the task of video-based face recognition that recog-nizes who appears in a video stream. In principle, video-based face recognition can be regarded as a fusion of recognition results in a set of sequential and consecutive images. However, there are, in fact, more information hidden in video frames. For ex-ample, a face may keep moving in a video so that different face poses should be involved. Incorpo-rating all of recognition results for different face poses appeared in a video could overcome some difficult cases of recognition for special face poses. A face recognition method using temporal voting to incorporate results of still images is proposed for image sequences in [14]. Considering in continuous video frames, visual features extracted from face images could form a manifold in high-dimensional feature space. Thus, we can convert the problem of face recognition to a matching problem between the corresponding manifolds [2][10][17]. Regard-ing the relationship of faces/poses in consecutive video frames, HMM (Hidden Markov Model) is often used for building a face model [9][11]. Another approaches treat face images from video
frames as 3D models and the recognition problem is converted to match and search 3D models for face images [4][7][12].
This work deals with video-based face recogni-tion in a static environment such as a classroom that the members are fixed. We assume there are K persons in the system. In a video, these persons may appear with different face poses, or not appear. Similarly, we have their face and pose images for training. Our goal is to build a model to recognize whose face in a video is.
Our basic idea is like a tracking task: to track the selection in the K candidates over time according to the observations of visual features in video frames. That motivates us to employ the state-space model to construct a probabilistic graphical model for video-based face recognition. Our formulation di-vides video-based face recognition into two parts: likelihood and transition measures. The former is like a traditional task of face recognition in a still image to make a decision who the current observ-ing face image is. The latter estimates the probabil-ity of the change from the recognized state at the previous stage to each of possible states at the cur-rent stage. The transition measure can make it possible to change recognition results from a false to the correction decision.
The rest of this paper are organized as the fol-lows. Section 2 formulates the problem of vid-eo-based face recognition based on a probabilistic graphical model by revising a basic state-space model. Next, in Section 3, we describe how to per-form the face recognition in still images using 2DLDA for the likelihood measure in our formula-tion. Therefore, how to measure the transition probabilities among persons and face poses are presented in Section 4. Section 5 provides several experimental results to show the performance of our proposed approach, and Section 6 draws our conclusion and future works.
II. Formulation A. State-space model
A state-space model is based on Bayesian net-work to analyze dynamic systems, which estimate the states of systems changing over time from a sequence of noisy measurements [8][13]. Here, we
only provide a brief summary of how the posterior probability of a state-space model is inferred.
Figure 1: The graphical structure of a state-space model.
A state-space model in general contains two types of nodes at time t: (i) xt for the system state
and (ii) zt for the observation measurement, whose
probabilistic graphical structure is shown as Figure 1. To simply express the equations, we use the no-tations Xt={x1, ..., xt} and Zt={z1, ..., zt} for all states
and observations, respectively, over time t.
There are two basic assumptions in the model, which can be available by use of the d-separation property [13] of Bayesian Network. The first is the first-order Markov property, i.e.,
) | ( ) | (xt Xt−1 = p xt xt−1 p , (1)
and the second is that the observations are mutually independent: ) | ( ) , | (zt Xt Zt 1 p zt xt p − = . (2)
According to the above two assumptions and Bayes’ rule, the posterior probability of a state xt
given the past observations Zt can be inferred as:
) | ( ) | ( ) | ( ) | ( 1 1 1 − − − = t t t t t t t t Z z p Z x p x z p Z x p , where
∫
− − − − −1)= ( | 1) ( 1| 1) 1 | (xt Zt p xt xt p xt Zt dxt p . (3)Thus, the posterior probability can be computed by:
∫
∫
− − − − − − − − − ∝ = 1 1 1 1 1 1 1 1 1 ) | ( ) | ( ) | ( ) | ( ) | ( ) | ( ) | ( ) | ( t t t t t t t t t t t t t t t t t t dx Z x p x x p x z p dx Z x p x x Z z p x z p Z x p (4)Hence, the posterior probability p(xt|Zt) in a
state-space model can be recursively computed by: (i) a likelihood model, p(zt|xt), which relates the
observation and noise to the state, and (ii) a transi-tion model, p(xt|xt-1), which describes the possibility
of the state change over time. Besides, it is also necessary to define the prior probability of state p(x1) at the beginning of the recursion.
B. Formulation for video-based face recognition A video in general consists of a set of consecu-tive video frames. Hence, to recognize who appears in a video could be considered the recognition in the set of video frames. That means a task of vid-eo-based face recognition could be regarded as a collection of traditional face recognition in many still images from a video. Moreover, there are some temporal relationships among these still images in a video. The situation motivated us to design a state-space model for video-based face recognition to involve the traditional recognition task in a set of video frames and the temporal information over video frames.
Given a set of consecutive video frames denoted as {I1, ..., IN} with N images, assume there are K
persons appeared in the system. We link up the time t in a state-space system with the change of video frames, i.e., frame It is observed at time t in the
system. Following the notation stated in the pre-vious section, hence, a state-space model for vid-eo-based face recognition could be formulated as the follows.
state vector xt: to indicate which person (from 1
to K) observed at time t.
observation zt: the video frame It at time t.
goal: to estimate p(xt|Zt) that recognizes which
person appears at time t according to all (in-cluding current and past) observing video frames.
Summarily, the observation set Zt={z1, ..., zt}
col-lects the face images in video frames, and Xt={x1, ..., xt} shows the recognition results of face
images of these observations.
However, the basic state-space model shown in Figure 1 could not reach an accurate recognition while people are changing their poses in video frames. In order to overcome the change of head poses for face recognition in video frames, our ap-proach, in this paper, is to insert additional pose nodes which express head poses appeared.
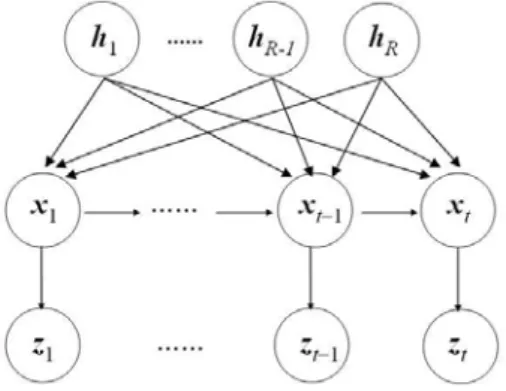
Assume there are R head poses, denoted as
H={h1, ..., hR}, for moving head in video frames.
Then, R extra nodes associated with head poses are appended to our proposed probabilistic model shown as Figure 2. In general, a head can appear with different poses such as rotation and skew, but head poses are limited by the articulation connected with the neck. Similar biomorphic features, e.g., eyes and nose, could be observed with the same head poses even for different people. For example, we may see only one eye of a person through the view of the right-side face. Hence, we can assume these R pose nodes are prior information to the state-space system.
Figure 2: The probabilistic structure of the state-space model for face recognition with pose nodes.
Lemma:
Given the pose information H={h1, ..., hR} and the
set of observations Zt={z1, ..., zt} at time t for the
Bayesian network in Figure 2, the posterior proba-bility of the state xt can be computed as:
1 1 1 1 , ) ( | , ) | ( ) | ( ) , | ( − − − −
∫
∝ t t t t t t t t t dx H Z x p H x x p x z p H Z x p (5) Proof:According to the two assumptions in Eq. (1) and (2), and using the d-separation property [13] of Bayesian network for Figure 2, we could have the following four properties of conditional indepen-dence: ) , | ( ) , | (x X 1 H p x x 1 H p t t− = t t− , (6) ) | ( ) , , | (zt xt Zt 1 H p zt xt p − = , (7) ) | ( ) , | (xt Xt−1 Zt−1 = p xt Xt−1 p , (8) and
) | ( ) , | (H Xt Zt p H Xt p = . (9) Then, 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 ) , | ( ) , | ( ) | ( ) , , ( ) , | ( ) | ( ) , ( ) , | ( ) , | ( ) | ( ) , ( ) | ( ) , | ( ) | ( ) , ( ) | ( ) | ( ) | ( ) | , ( ) , ( ) | ( ) | ( ) ( ) , ( ) , ( ) | ( ) | ( ) | ( ) , ( ) | ( ) , ( ) , | ( ) , , ( ) , | ( − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − −
∫
∫
∫
∫
∫
∫
∫
∫
∫
∫
∝ = = = = = = = = ∝ t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t dx H Z x p H x x p x z p dX Z X H p H X x p x z p dX Z X p Z X H p H X x p x z p dX Z X p X H p H X x p x z p dX Z X p X x p x z p X x p X x H p dX Z X p X x p x z p X p X H p dX Z X p X x p x z p X H p dX Z X p X H p dX Z X p Z X H p dX H Z X p H Z x pand the proof is done. □
That shows there are three factors to determine which person the state xt is: (i) p(zt|xt) means the
likelihood measure for the current observation, (ii) p(xt|xt-1, H) means the transition measure based on
pose information for the previous state, and (iii) p(xt-1|Zt-1, H) is the recursive result at the previous
iteration. Besides, the system needs an initial rec-ognition result, denoted p(x1), of the first face im-age in a video for indicating the prior probability.
In order to more simply achieve face recognition according to Eq. (5) in practice, two assumptions are held in this paper. The first is to assume that face images have been properly cropped in video frames. That can be performed by face detection. The second is to assume that poses of face images are aligned. That is to say, we define R poses for face images and each of training face images can be categorized into a pose. In our work, we apply k-means clustering to roughly divide training face images into R subsets and manually check whether face images are the same pose in the same subset.
III. Face Recognition for Still Images
The likelihood term, denoted as p(zt|xt), in Eq. (5)
measures the possibility of the current observations given a state (i.e., a known person). That can be
estimated by the similarity measure between the face image of the current observation and training images of the given person. Thus, the computation of the likelihood measure for face images in video frames associated with each of time t can be re-garded as face recognition for still images.
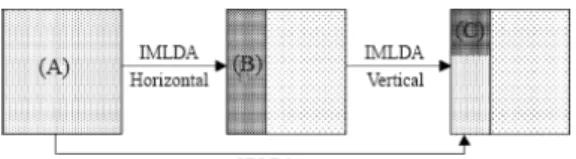
In this work, we adopt 2DLDA (two-dimensional linear discriminant analysis) [19] for performing face recognition in a still image. 2DLDA employs IMLDA (uncorrelated image matrix-based linear discriminant analysis) [18] twice: one for the hori-zontal and the other for the vertical direction shown as Figure 3 which is taken from [19]. In principle, 2DLDA can select most discriminative features learned from training images. We roughly describe the procedure of 2DLDA as the follows.
Assume the image set D consists of K categories of face images, associated with K persons, and suppose the image size, with loss of generality, is m×n. According to the computation of IMLDA presented in [18], a transformation U with size n×d1 can be learned. For each image A in D, we can compute B=AU and collect all matrices B with size m×d1 as the set D'. Similarly, another trans-formation U' with size m×d2 could be learned by use of IMLDA on the dataset D'. Compute BtU
with size d1×d2 for each B∈D' and in final an orig-inal m×n matrix in the image set D can be con-verted to a d1×d2 matrix.
The basic concept of 2DLDA could be shown as Figure 3; that could be viewed as to compress an original image into a compact representation in the up-left corner. Yang et al. [19] also suggested a feature selection strategy to select the most discri-minative features from the compressed corner. In this work, we simply set d=d1=d2 for reducing the dimension of an image as a d×d- dimensional vec-tor and treat it as d2×1-dimensional column vector.
In the 2DLDA plane, suppose that mi is the mean of projected points for training face images asso-ciated with person Mi, i=1 to K. Also, let z't be the
projected point of an observation zt, i.e., a video frame at time t. We can compute (z't-mi) to estimate
the difference between the observing face image and a known person in the 2DLDA plane, and nor-malize it for the approximated likelihood term,
)) ( ) ( 2 1 exp( | | ) 2 ( ) | ( ' 1 ' 2 1 2 i t t i t d i t m z C m z C M z p − − − = − − − π (10)
where C is the covariance matrix of training images associated with the person Mi in the 2DLDA plane.
Thus, the likelihood term p(zt|xt) in Eq. 5 can be
approximated by p(zt|xt=Mi), or simplifying p(zt|Mi),
for each person Mi.
IV. Transition Measure in Video-based Face Rec-ognition
The transition term, denoted as p(xt|xt-1, H), in Eq.
5 measures the transitive possibility from the pre-vious to the current state in the system. That meas-ure can make correction possible while the system sometimes has a false recognition. According to the following equation, ) | ( ) , | ( ) | ( ) ( ) | ( ) ( ) | ( ) , | ( ) , | ( 1 1 1 1 1 1 1 1 1 − − − − − − − − − = = t t t t t t t t t t t t t t x H p x x H p x x p x p x H p x p x x p x x H p H x x p (11)
the transition measure can be divided into two parts described as the follows.
p(xt|xt-1). That term measures the transition
probability of two consecutive states. This part is independent of the persons’ head poses.
p(H|xt, xt-1)/p(H|xt-1). That term measures the
pose-transition likelihood of two consecutive states.
These two terms are described in detail in the fol-lows.
A. Transition among persons
Regarding the first term, p(xt|xt-1), of the
transi-tion measure, it only depends on the recognitransi-tion results of states at each iteration. The transition measure among persons is a fixed table that is built in prior before the system begins evolving. Moreo-ver, the design must provide the ability of correc-tion for false recognicorrec-tion using 2DLDA. Our idea is to compute the similarity measures between any two persons according to their training face images in the 2DLDA plane. That is to say, we estimate the transition measure of any two persons by use of how similar the two persons are in the 2DLDA plane which is also used for the likelihood measure. While two persons are similar observed in the 2DLDA plane, which means it is more possible to false recognize them in our observation measure, and their transition probability should be higher.
Simply following the notations in Section 3, let Di be the dataset of projected points in the 2DLDA
plane for the training face images associated with persons Mi. Then, the similarity of these two
per-sons can be defined as
2 / 1 ) ) ( ) ( ( | | 1 ) , (
∑
∈ − − = i D r j t j i j i r m r m D M M sim (12)where mj are means of projected points in the
2DLDA plane for the training images associated with the person Mj. These similarity measures are
also normalized by Gaussian distribution. Note that
sim(Mi, Mj) is not symmetric, so we define
2 / )) , ( ) , ( ( ) | (xt xt1 sim Mi Mj sim Mj Mi p − = + (13)
for the symmetric property.
B. Transition among poses
Regarding the second term p(H|xt, xt-1)/p(H|xt-1),
it is difficult to induce a closed-form for explaining the term. Observing the sub-terms, p(H|xt, xt-1) and
p(H|xt-1), they can be roughly considered the face
poses at the current and the previous stages, respec-tively. Hence, the second term p(H|xt, xt-1)/p(H|xt-1),
in this work, is approximated to the possibility of the change of the face poses in successive iterations t and t-1.
According to the approximation, there are two tasks to estimate the term of the transition among poses. We first recognize which poses the
ing face images of the current and the previous stages are. We also build a 2DLDA classifier for recognizing face poses of observing images. The 2DLDA classifier for face-pose recognition is sim-ilar to the face classifier described in Section 3. Next, the probabilities of the pose change from the current to the previous stage should be determined. We collect a little of videos which contain different kinds of face moving and then count the actual times of the pose change in each of two consecu-tive frames to compute the probabilities from one to another poses. Note that the counting approach of the pose transition is referred to [10] except our counting is based on all of persons, not on individ-uals.
V. Experimental Results
In our experiments, the Honda/UCSD Video Da-tabase [10][21] is adopted for our training and test dataset to evaluate the performance of our proposed approach. This dataset contains 20 different persons. For each person, there are two videos: one for training and the other for testing. In each video, the person rotates and turns his/her head in his/her own preferred order and speed, and typically in about 15 seconds, the individual is able to provide a wide range of different poses [10]. Sometimes an indi-vidual in the testing video may show some special poses which are not appeared in the training video.
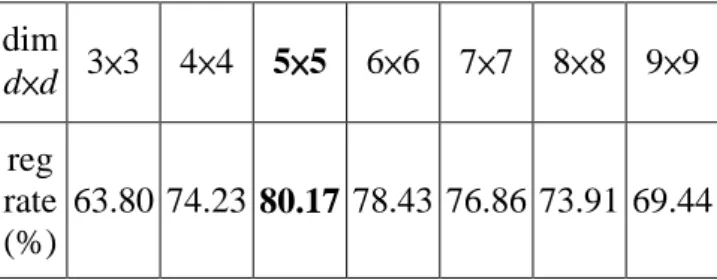
We employ the training part of the dataset to learn a 2DLDA classifier for still-image face rec-ognition and to determine the transition probabili-ties for persons and face poses. The first question is what dimension is feasible in the 2DLDA classifier. We transform each of images to d×d- dimensional feature vectors, stated as Section 3, by trying sev-eral values of d, showing the average rates of face recognition for still images in Table 1. Then, we adopted the d=5 for the highest rate in the follow-ing experiments.
Table 2 shows the average of recognition rates which are based on our proposed approach with three transition cases: without transition, with tran-sition only among persons, and with trantran-sition among both persons and face poses. The case of without transition means the face recognition in video frames is performed only according to the
trained 2DLDA classifier. Table 2 presents a sig-nificant improvement for our approach when the transition information, either on persons or face poses, is incorporated in the model. Moreover, we also list the average rates of face recognition using different well-known methods in Table 3 for com-parison.
Table 1: Recognition rates using 2DLDA for still images of video frames with different dimensions d. dim d×d 3×3 4×4 5×5 6×6 7×7 8×8 9×9 reg rate (%) 63.80 74.23 80.17 78.43 76.86 73.91 69.44
Table 2: The average rates of the face recognition with/without different transition approaches.
without transition transition among persons transition among persons and poses reg rate (%) 80.17 87.33 90.67
Table 3: The average rates of the face recognition using different well-known methods.
Eigen- Face Fisher- Face Nearest Neighbor 2DLDA Our Approach reg rate (%) 69.3 74.5 81.6 80.17 90.67
Next, let us discuss the convergence process with the likelihood and the transition measure over time. Figure 4 illustrates an example of face recognition at time 8, 14, 23, 28. Note that the person of the example is with index “4” in plots. His face poses changed from front to left in this example. The
serving person is identified incorrectly in initial (t=1), but he is recognized correctly in final (t=28). There are five plots at each row. This example only displays the probability values for three persons for simplicity. The first plot shows the likelihood measure of the current observation according to Eq. (10). The second to fourth plots display the proba-bilities of face poses for different persons given the observation. The last plot shows the final probabil-ity of persons given the observing face image. In general, it is difficult to avoid false decision either for face or pose recognition. However, our method makes a possibility converging to the correct deci-sion by aggregating the recognitions in the likelih-ood and the transition measures such as illustrated in the last two iterations.
VI. Conclusion and Future Works
This paper deals with video-based face recogni-tion to determine which persons appear in a video sequence. We formulate the problem using a prob-abilistic graphical model which is based on a state-space model to integrate both the likelihood and the transition measures in recognition. We em-ploy 2DLDA to perform the face recognition in still images to compute the likelihood measure. Also, we design a transition measure to cover the change of persons and face poses appeared in a video. The integration of the likelihood and transition meas-ures in our formulation can improve the perfor-mance of video-based face recognition, as stated in our experiments.
Regarding the future extension of this work, we are performing some detailed experiments on more kinds of datasets to evaluate the abilities of our ap-proach. We also try to revise our model more accu-rately to formulate the problem. Another possible way is to design an incremental learning algorithm with our probabilistic model. That could improve face or pose recognition in the likelihood and tran-sition measures and make our proposed model more robust.
ACKNOWLEDGMENT
This work was supported by National Science Council, Taiwan, under Grant No. NSC 97-2511-
S-003- 007-MY3 and NSC 97-2631-S-003-003 and by Ministry of Economic Affairs, Taiwan, under Grant No. 97-EC-17-A -02-S1-032.
REFERENCE
[1] A. F. Abate, M. Nappi, D. Riccio, and G. Saba-tino , “2D and 3D Face Recognition: a Survey”, Pattern Recognition Letters, Vol. 28, No. 14, pp. 1885-1906, October 2007.
[2] O. Arandjelovic, G. Shakhnarovich, J. Fisher, R. Cipolla, and T. Darrell, “Face Recognition with Image Sets Using Manifold Density Diver-gence,” in Proceedings of CVPR, 2005.
[3] P. Belhumeur, J. Hespanha, and D. Kriegman, “Eigenfaces vs. Fisherfaces: Recognition Using Class Specific Linear Projection,” IEEE Trans. on PAMI, Vol. 19, No. 1, pp. 711–720, 1997. [4] F. B. ter Haar and R. C. Veltkamp, “3D Face
Model Fitting for Recognition,” in Proceedings of ECCV, 2008.
[5] X. F. He, and P. Niyogi, “Locality Preserving Projections.”, In Proceedings of NIPS, 2003. [6] B. Heisele, P. Ho, and T. Poggio, “Face
Recog-nition with Support Vector Machines: Global versus Component-Based Approach,” in Pro-ceedings of ICCV, 2001.
[7] Y.-X. Hu, D.L. Jiang, S.-C. Yan, L. Zhang, and H.-J. Zhang, “Automatic 3D Reconstruction for Face Recognition,” in Proceedings of Interna-tional Conference on Automatic Face and Ges-ture Recognition, 2004.
[8] Z. Ghahramani, “An Introduction to Hidden Markov Models and Bayesian Networks”, In-ternational Journal of Pattern Recognition and Artificial Intelligence, 15(1): 9-42, 2001.
[9] M. Kim, S. Kumar, V. Pavlovic, and H. Rowley, “Face Tracking and Recognition with Visual Constraints in Real-World Videos”, in Pro-ceeding of CVPR, 2008.
[10] K.C. Lee and J. Ho and M.H. Yang and D. Kriegman, “Visual Tracking and Recognition Using Probabilistic Appearance Manifolds,” Computer Vision and Image Understanding, Vol. 99, No. 3, pp. 303-331, 2005.
[11] X. Liu and T. Chen, “Video-Based Face Rec-ognition Using Adaptive Hidden Markov Mod-els”, in Proceedings of CVPR, 2003.
[12] X.-G. Lu, A.K. Jain, and D. Colbry, “Matching 2.5D Face Scans to 3D Models,”, IEEE Trans. on PAMI, Vol. 28, No. 1, pp. 31-43, 2006. [13] K. P. Murphy, “Dynamic Bayesian Networks:
Representation, Inference and Learning”, U. C. Berkeley, PhD. Thesis, 2002.
[14] G. Shakhnarovich, J. W. Fisher, and T. Darrell, “Face Recognition from Long-Term Observa-tions,” in Proceedings of ECCV, pp. 851-865, 2002.
[15] A. S. Tolba, A.H. El-Baz, and A.A. El-Harby, “Face Recognition: a Literature Review”, In-ternational Journal of Signal Processing, Vol. 2, No. 1, pp. 88-103, 2005.
[16] M. Turk and A. Pentland, “Eigenfaces for Recognition”, Journal of Cognitive Neuros-cience, Vol. 3, pp. 72-86, 1991.
[17] R.-P. Wang, S.-G. Shan, X.-L. Chen, and W. Gao, “Manifold-Manifold Distance with Appli-cation to Face Recognition Based on Image Set,” in Proceedings of CVPR, 2008.
[18] J. Yang, J.-Y. Yang, A.F. Frangi, and D. Zhang, “Uncorrelated Projection Discriminant Analysis and its Application to Face Image Feature Ex-traction,” International Journal of Pattern Rec-ognition and Artificial Intelligence, Vol. 17, No. 8, pp. 1325–1347, 2003.
[19] J. Yang, D. Zhang X. Yong, and J. Yang, “Two-Dimensional Discriminant Transform for Face Recognition,” Pattern Recognition, Vol. 38, No. 7, July 2005.
[20] W. Zhao, R. Chellappa, P.J. Phillips, and A. Rosenfeld, “Face Recognition: a Literature Survey”, ACM Computing Surveys, 35(4): 399-458, 2003.
[21] The Honda/UCSD Video Database, http://vision.ucsd.edu/
~leekc/HondaUCSDVideoDatabase/HondaUCS D.html.