SOFTWARE-PRAffICE A N D EXPERIENCE, VOL. 21(1). 35-49 (JANUARY 1991)
A Letter-oriented Perfect Hashing Scheme
Based upon Sparse Table Compression
CHIN-CHEN CHANG
Institute of Computer Science and Information Engineering, National Chung Cheng University, Chiayi, Taiwan 62107, R . O . C .
A N D TZONG-CHEN WU
Institute of Computer Science and Information Engineering, National Chiao Tung University, Hsinchu, Taiwan 30025, R . 0 . C.
SUMMARY
In this paper, a new letter-oriented perfect hashing scheme based on Ziegler's row displacement method is presented. A unique &tuple from a given set of static letter-oriented key words can be extracted by a heuristic algorithm. Then the extracted distinct &tuples are associated with a 0/1 sparse matrix. Using a sparse matrix compression technique, a perfect hashing function on the key words is then constructed. KEY WORDS Perfect hashing functions Letter-oriented hashing Sparse table compression Row displacement method
INTRODUCTION
Hashing is a fast addressing technique for directly accessing data in the memory space. Given a set of keys, one can retrieve the information associated with a key in a very short time through a preconstructed hashing function on keys. A perfect hashing function is defined as a one-to-one mapping from the set of keys into an
address space. There are several methods which have been proposed for constructing perfect hashing functions.'-" By a sparse table, we mean a table in which the number of non-zero elements, as opposed to the zero elements, which are useless or vacant, is much less than the size of the table itself. Also, there are many schemes that can be used to compress a sparse table into a linear array to yield more efficient memory usage.12-1ySome of them are frequently used for storing the parsing tables in compiler design.
Consider the sets of static letter-oriented keys. We present here a new scheme for constructing perfect hashing functions based on Ziegler's row displacement method. One can extract a unique n-tuple on the keys by a heuristic algorithm for a set of
letter-oriented key words. The extracted n-tuples are associated with a 0/1 sparse matrix. We first apply a sparse matrix compression technique to obtain a more compact matrix, and then decompose the compressed matrix into a set of triangular- like row vectors. A row displacement method is employed to compress these decom- OO3&0644/9 1/010035-15$07.50
36 C.-C. C H A N G A N D T.-C. WU
posed row vectors into a more condensed linear array. The displacements of all decomposed row vectors can be determined by applying Ziegler’s row displacement method. Then a perfect hashing function for this set of letter-oriented keys is constructed. In the following sections, we will give detailed descriptions of the construction of perfect hashing functions on sets of static letter-oriented keys. Some discussions about practical implementations of our scheme are also presented.
SPARSE TABLE COMPRESSION
There are several known displacement methods that have been proposed for storing sparse tables.’”’’ Among them, many methods can be used as the bases of con- structing perfect hashing functions. Since Ziegler’s row displacement” is simple, we adopt it to form our perfect hashing functions. Therefore, we give a brief description of Ziegler’s approach in this section. Reviews of some other compression methods for static sparse tables are included in References 15, 16 and 19.
A sparse matrix with non-zero elements in it is given. For convenience, a matrix is regarded as a set of row vectors or a set of column vectors. Ziegler proposed a row displacement method to compress all row vectors of the matrix into a linear array such that all non-zero elements are placed overlapped in the linear array without conflict to yield more efficient memory usage. By applying Ziegler’s row displacement method, the element at the position (i,j) of the matrix can be directly stored at the location BASE(i)+j in memory, where BASE(i) is referred to as the row displacement of the ith row vector. Figure 1 shows a graphical illustration of the row displacement method. Furthermore, Ziegler also gave a suggestion that sorting all the row vectors of the matrix in descending order of the number of non-zero elements in them before placing these row vectors into the linear array will obtain better results. It is known that the problem of computing the optimal displacements of row vectors is NP-complete.’*, *‘I Tarjan and YaoI2 also pointed out that Ziegler’s
method, which is sometimes referred to as a first-fit decreasing method, yields excellent results in practice.
o o x x
[:,.:;
I
x o o o (0 0 x x) (0 0 0 x) l x x O O l (x 0 0 0) (x x x x x XI matrix 1st row-vector 2nd row-vector 3rd row-vector 4th row-vector b e a r array 0 : zero element x : nonzero elementA LETTER-ORIENTED PERFECT HASHING SCHEME 37
Let the sorted row vectors of a compressed matrix be LL and the maximal length of row vector be rn. Ziegler’s row displacement method for placing row vectors into a linear array is described as follows:
Step 1 . Allocate a set of rn free linear locations, denoted by S, in memory.
Step 2 . Get a row vector D from LL.
Step 3. Starting from the head of S, search for a free location from which the non-zero elements of D can be fully placed without conflicting with the non-zero elements of the previously placed row vectors in S. If such a location is not found then allocate rn more contiguous locations from memory; append them to S and repeat this step until such a location is found.
Step 4 . Place D overlapped into S.
Step 5 . Repeat from Step 2 until no row vector remains in LL.
OUR SCHEME
This section presents a new perfect hashing scheme for sets of letter-oriented keys. First, we assume that a unique n-tuple has been obtained on the set of keys by some artificial rules. Then we map the extracted distinct n-tuples to a set of entries of a 011 sparse matrix M , where non-zero elements in M are represented as 1s; others are represented as 0s. Throughout this section, we use a simple example to explain our scheme in finding perfect hashing functions. A general model of our method is also given in the last part of this section.
Consider the case of the twelve months’ identifiers in English listed as below: JANUARY M A Y SEPTEMBER
FEBRUARY JUNE OCTOBER
MARCH JULY N OVE M BE R
APRIL AUGUST DECEMBER
By extracting the second and the third letters, the twelve distinct extracted pairs (2- tuples) are listed as following:
Then we produce a 26 X 26 O / l matrix M associated with the above twelve pairs (see Figure 2). For the sake of readability, the 0s in M are represented as dots.
The reader may notice that the matrix M is rather sparse. Now the problem of our hashing scheme turns out to be how to compress the matrix M of Figure 2 into a more condensed linear array such that the storage used by all extracted n-tuples, i.e. the 1s in the matrix M, is as small as possible. Here we present a straightforward algorithm for compressing a sparse matrix into a more compact one. The compressed matrix is used as the basis of our hashing scheme. First, we shall define some functions which are used later for describing our algorithm more clearly:
38 c d
. . .
1 . . . 1. . .
1 .. . .
l . . . . l l. . .
l . . .. . .
. . .
. . .
. . .
. . .
. . .
. . .
. . .
. . .
. . .
. . .
. . .
l . . . .. . .
l . . .. . .
. . .
. . .
. . .
. . .
1. . . .
1 . 1. . .
. . .
. . .
. . .
. . .
. . .
i -. C.-C. CHANG AND T.-C. WU A 1 B 2 c 3 D 4 E 5 F 6 G 7 H 8 I 9 J 10 K 11 L 12 M = M 1 3 N 14 0 15 P 16 Q 17 R 18 s 19 T 20 u 21 v 22 W 23 X 24 Y 25 Z 26 A B C D E F G H I J K L M N O P Q R S T U V W X Y Z 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 1 2 3 4 S G 7 8 9 0 1 2 3 4 5 6 1 B 9 0 1 2 3 4 5 6 Figure 2 Check Row( M ,i ,j)For the matrix M, if both the ith and the jth row vectors have Is at the same position then return FALSE; otherwise return TRUE.
CheckCol(M ,iJ)
position then return FALSE; otherwise return TRUE.
For the matrix M , if both the ith and jth column vectors have 1s at the same
MoveRow( M,i,j)
elements of the jth row vector to 0.
For the matrix M, move the jth row vector to the ith row vector and set all
MoveCol(M,i,j)
all elements of the jth column vector to 0.
A LETTER-ORIENTED PERFECT HASHING SCHEME 39
MergeRow(M ,iJ)
the ith row vector and set all elements of the jth row vector to 0.
For the matrix M, place all the 1s of the jth row vector into the same position of
MergeCol( M ,i,j)
of the ith column vector and set all elements of the jth column vector to 0. For the matrix M, place all the Is of the jth column vector into the same positions
Example 1
Let the matrix A be
CheckRow(A,1,2) will return FALSE, because both the first and the second row vectors have 1s at the third position in A. Similarly, CheckCol(A,1,2) will return TRUE. MergeRow(A,1,3) will make the first row vector [0 1 11 and MergeCol(A,2,3) will make the second column vector
Again, for the original matrix A, MoveRow(A,1,2) will make A
[A
e
91
Then MoveCol(A,1,2) will make A
Consider a sparse matrix M such as that associated with the example of the twelve months. Let ROW(i) be the index of the row vector into which the ith row vector is merged; let COL(i) be the index of the column vector into which the ith column
40 C.-C. CHANG A N D T.-C. WU
vector is merged. The algorithm to produce a more compact form of the sparse matrix M is stated as follows.
Algorithm COM P R ESS-M ATR I X
Input
An m x n 0/1 matrix M.
output
1. A more compact 0/1 matrix CM with p rows and q columns. 2. The number of rows of CM, p .
3. The number of columns of CM, q.
4. ROW(i) and COLG), for i = l , 2, ..., rn and j=1, 2, ..., n.
Step I [initialization]
For i = l to m do RF(i) := TRUE;
For j = 1 to n do CF(i) := TRUE;
(* RF and CF mean row flag and column flag for indicating if the row and column are available for check, respectively. *)
Step 2 [merge rows]
For i=l to m do
p := 1 ;
If R F ( i ) = TRUE then Begin
For j=i+l to m do
If RFG) = TRUE and CheckRow(M,iJ) = TRUE then Begin MergeRow( M,i,j); RFG) := FALSE; ROWG) := p End; ROW(i) := p ; MoveRow( M ,p,i); p := p + l End;
p := p - 1 ; ( * the number of rows of CM *)
Step 3 [merge columns]
q := 1;
A LETTER-ORIENTED PERFECT HASHING SCHEME 41
If CF(i) = TRUE then Begin
For j = i + l to y1 do
If CFG) = TRUE and CheckCol(M,i,j) = TRUE then Begin M e rg eCo I ( M
,
i ,j) ; CFG) := FALSE; COLO') := q End; COL(i) := q ; q := q + l MoveCol(M ,q,i); End;q := 4-1; (* the number of columns of CM *)
Step 4 [output results] Output CM, p , and q ;
For i = l to m do Output ROW(i); For j = 1 to n do Output COLG);
A graphical illustration of the result produced by the above algorithm is shown in Figure 3.
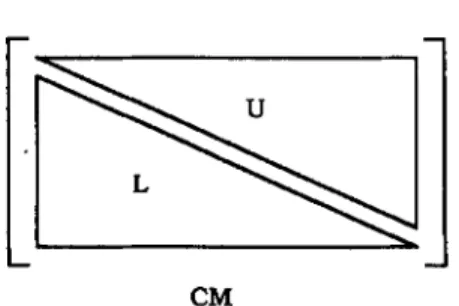
When a more compact matrix CM is obtained, we decompose it into two triangular- like parts, U and L, as shown in Figure 4. Let p be the position (iJ) of CM, if j L
1
q i/p1
then it is in U; otherwise it is in L. That is, some original row vectors are decomposed into two row vectors, one is in U and the other is in L. Now, we define the indices of the decomposed row vectors which will be used for determining the displacements of these row vectors in a contiguous linear array. Let Ri(") be a row vector in U and Ri(L) be a row vector in L which both are contained in the ith original row vector of CM. Define the index of R,Cu) to be i and define the index of Ri(L) tobe (i - 2p / q
1
+
1) row vectors in total.
Reconsider the 0/1 sparse matrix M produced by the example of the twelve months. After executing the algorithm COMPRESS-MATRIX, we obtain a compressed 2 x 8 matrix as follows:
2p / q
1
+
p - 1 ) . Thus, C M can be decomposed into (2p -1
1 1 1 1 1 1 1 1 1 1 1 0 1 0 0 0
Figure
M
42 C . - C . CHANG 'AND T.-C. WU
J
CM
Figure 4. Triangular-like decomposition of the CM matrix
The values of ROW (i) and COL (i) are listed in Table I . Figure 5 depicts the triangular-like decomposition of CM with the index of each decomposed row vector to U and L.
Once the matrix CM is produced, the algorithm for determining the displacements of the decomposed row vectors in CM to a contiguous linear array is given as follows. Algorithm DETERM INE-DISPLACEM ENTS
Input
All decomposed row vectors in the matrix CM.
Output
Displacements of all the decomposed row vectors, BASE(i).
Table I . ROW(i) and COL(i) for the matrix M
1 ROW(i) COL(i) - 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 1 2 3 4 . 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1 1 2 1 1 1 1 1 1 1 2 1 1 1 1 1 1 1 1 2 1 3 1 4 1 5 1 6 1 7 1 1 8 1 ~ - _- - - - ~- index 3 4 - - 4 4 - -
A LElTER-ORIENTED PERFECT HASHING SCHEME 43 Step 1
(a) Record the number of 1s and the index of each row vector.
(b) Sort all row vectors on the number of Is in their descending order. (c) Let LL be the list of the sorted decomposed row vectors.
Step 2
(a) Get a row vector from LL with index i.
(b) Apply Ziegler's first-fit decreasing method to place this vector into a linear array.
Step 3
(a) Record the position k at which the first element of the vector is located. (b) Set BASE(I') = k-1.
Step 4
Repeat from Step 2 until no decomposed row vector remains in LL.
By executing the algorithm DETERMINE-DISPLACEMENTS, all displacements of the decomposed row vectors of the matrix CM, i.e. BASE(i), for the twelve months are listed as in Table 11.
Let the extracted n-tuple be mapped to the position ( r , c) of the original matrix
M. The compressed matrix CM has two rows and eight columns. When all values of ROW(i), COL(1') and BASE(i) are determined, by transforming the position of each non-zero element in the matrix M to the location in the linear array applied by Ziegler's row displacement method, we obtain a perfect hashing function for the twelve months in English as below:
BASE(ROW(r))
+
COL(c) - 4*
ROW(r)+
1 , if COL(c) 2 4*
ROW(r)
h(r,c) =
BASE(ROW(r) 4- 2)
+
COL(c), otherwise44 C . - C . CHANG A N D 1 . - C . WU
For instance, for the key JANUARY in our example of the twelve months, the extracted character tuple is (A, N) which is expressed as (1,14). From Table I , we obtain ROW(1)=1 and COL(14)=3. Since COL(14) < 4 * ROW(1), the hashing value is computed as
h(1,14) = BASE(ROW(1)
+
2)+
COL(1)= BASE(3)
+
3 = 10+
3 = 13For the key OCTOBER, the extracted character tuple is (C, T) which is expressed as (3,20). Again, ROW(3)=1 and COL(20)=6 by Table I . Since COL(20) 2 1 8 * ROW(3) / 2 J, the hashing value is computed as
h(3,20) = BASE(ROW(3))
+
COL(20) - 4 * ROW(3)+
1= BASE(1)
+
6 - 4+
1 = 0+
3 = 3We give the general model of our scheme for constructing perfect hashing functions
on sets of letter-oriented keys in the following. For convenience, we use 2 to denote the lexical order of x . For example, A is 1, B is 2, Z is 26 and so on.
Given a set of letter-oriented keys k , , for i=1,2, ..., N . Let E,=(a,.l, ..., a;.,,)
be an extracted n-tuple from k;. Assume that all N extracted n-tuples are distinct.
Let w be the cardinality of the set of characters appeared in all extracted n- tuples. For instance, if the characters that appeared are the letters from A to Z then w is 26. From all the E j s , an s X t 011 sparse matrix M is produced, and the corresponding entry ( r , c) of M is 1, where s = wl"'*], t = w"--
L""],
Let CM be a matrix with p rows and q columns produced by the algorithm COMPRESS-MATRIX. A perfect hashing function on the given N keys is defined as
BASE(ROW(r))
+
COL(c) -1
q * ROW(r) / p1
+
1, if COL(c) 21
q * ROW(r) / p1
I
(1)h(r,c) =
BASE(ROW(r) - r2 * p / q
1
+
p+
1)+
COL(c), otherwise where the ROW(I') and COL(i) are determined by the algorithm COMPRESS-MATRIX, the BASE(i)s are determined by the algorithm DETERMINE-DISPLACEMENTS, p is the number of rows of CM and q is the number of rows of CM.One may ensure the correctness of formula (1) by transforming the position of a non-zero element in a matrix to the location in a linear array.x The following example illustrates how to map a set of keys with distinct extracted n-tuples to a 0/1 matrix. Example 2
Let w be 26. Assume that a three-tuple is used to map the set of keys to a matrix distinctly. Then a 26 x 676 matrix M is produced since s = 26 and t = 676. Suppose
A LElTER-ORIENTED PERFECT HASHING SCHEME 45
that one of the three-tuples is (A, C, E). Since r = 1 and c = 26x3
+
5 = 82, thecorresponding entry ( 1 , 82) of M will be set to 1. In the same way, assume that a four-tuple is used to map the set of keys to a matrix distinctly. Then a 676 X 676
matrix M is produced since s = 676 and t = 676. Suppose that one of the four-tuples is (A, C, E, F). Since Y = 26
+
3 = 29 and c = 26x5+
6 = 136, the corresponding entry (29, 136) will set t o 1 .In general, the algorithm for constructing a perfect hashing function for a set of
N keys is stated as follows.
Algorithm CONSTRUCT-PH F Input
A set of N keys.
output
p , q , ROW(i)s, COL(i)s and BASE(i)s such that formula ( 1 ) is a perfect hashing function.
Step I
Extract N distinct n-tuples on keys artificially.
Step 2
Produce an s x t 011 matrix M associated with all distinct extracted n-tuples, where s=wL"'*J,
~ = W ' ~ - L ' ~ ' ~ J
and w is the cardinality of the set of characters appeared in all extracted n-tuples.Step 3
Call the algorithm COMPRESS-MATRIX to compress the matrix M into a compact matrix C M with p rows and q columns and determine the values of ROW(i) and CO L ( i ) .
Step 4
the decomposed row vectors with their indices.
Decompose C M into two triangular-like parts U and L as shown in Figure 2. Record
Step 5
46 C . - C . CHANG A N D T . - C . WU
Step 6
Output p , q , ROW(i), COL(i) and BASE(i).
Here, we give two examples to explain how the algorithm CONSTRUCT-PHF works.
Example 3
Consider the C D C PASCAL reserved words listed as below:
AND ARRAY BEGIN CASE CONST DIV
DO DOWNTO ELSE END FILE FOR
FUNCTION GOT0 IF IN LABEL MOD
NIL NOT OF OR OTHERWISE PACKED
PROCEDUREPROGRAM RECORD REPEAT SEGMENT SET
THEN TO TYPE UNTIL VALUE VAR
WHILE WITH
For Step 1, let ( a , b ) be the extracted two-tuple of each reserved word k by the following rules:
1. If length(k) 5 3 then a is the first character of k and b is the last character
of k .
2. If length(k)
>
3 then a is the first character of k and b is the fourth character of k .Thus, there are 38 distinct extracted two-tuples as below:
By executing Step 3 to compress the original 26 x 26 0/1 matrix M produced in Step 2, we obtain a 7 X 15 compressed matrix CM for which p is 7 and q is 15, and
parameters ROW(Z) and COL(i). By executing Step 4 and Step 5, the parameters BASE(i) are determined. The compressed matrix CM, the parameters ROW(i). COL(i) and BASE(i) are shown in Figure 6.
Example 4
(A, D), which corresponds to (1, 4). Thus the hashing value is computed as
Reconsider Example 3. For instance, for the key AND, the extracted two-tuple is h(1, 4) = BASE(ROW(1) - [ 2 x 7 / 151
+
15+
1))+
COL(4)A LE'ITER-ORIENTED PERFECT HASHING SCHEME i ROW(i) COL(i) 47 1 1 1 1 I 1 1 1 1 1 2 2 2 2 2 2 2 I 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 1 1 1 1 2 3 2 1 2 1 1 4 3 1 2 1 1 6 2 7 2 1 2 1 I I 1 1 2 3 4 1 5 2 6 I 7 8 5 9 10 1 1 I 1 12 13 14 15 1 1 I 1 CM = i BASE(i) 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0 0 1 0 0 0 1 1 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0
(a) t h e compressed matrix CM
-
0 0 0 1 0 0 0 0 1 1 0 0 0 0 0I
1 1 1 1 1
I 2 3 4 5 6 7 8 9 0 1 2 3 4
0 14 12 0 17 0 0 22 24 26 30 31 29 27
DISCUSSION
Recently, Sager"' proposed an efficient minimal prefect hashing scheme. Later, Fox
et al.' presented another effective scheme. Sager's algorithm applied his scheme on sets up to 512 words, whereas Fox et al., using an improvement of Sager's algorithm, formed a minimal perfect hashing function for up t o 1000 words; however the size of the set of key words that can be hashed by our near minimal perfect hashing scheme depends on the length of the extracted unique n-tuples and the available memory in a practical implementation.
For the space requirements, the two methods proposed individually by Sager and Fox et al. require only two words of storage per word hashed. In our method, for the 38 reserved words of the CDC PASCAL programming language, we need 26 x 2
+
14 = 66 words, o r about 1-7 words of storage per word hashed, where 26 X 2= 52 words are used for ROW(i) and COL(i) and 14 words are used for BASE(I'). In general, the number of storage per word required, NSPW, by our method is
number of ROW(i)s
+
~ number of COL(i)s+
number of BASE(i)sN ~~ .. ~ NSPW = L"'2J + - L"'21 + 2w L"'2] 4 0
y 1
~~ ~ < ~ N - N I48 or about
C.-C. CHANG A N D T.-C. WU
where o is the cardinality of the set of characters appearing in all extracted n-tuples,
N denotes the number of key words hashed and n is the tuple length. Note that the
magnitude of n highly depends on the intelligence of the above-mentioned algorithm for extracting distinct n-tuples. Thus, the space needed by our method is dominated by the extracted n-tuples.
Since the time spent in finding a perfect hashing function for a set of N keys is
based on the time complexity of the algorithm DETERMINE-DISPLACEMENTS, we analyse the time required to execute the algorithm. Let the compressed matrix C M have p rows and q columns. We have Nlpq = p, the compression rate, where 0
< p 11. That is, N = ppq. The time complexity of the algorithm DETERMINE- DISPLACEMENTS is
Thus, our method has a worst-case time complexity of O(W/p2).
CONCLUSIONS
We have presented a near minimal perfect hashing scheme for letter-oriented sets of key words. Our scheme uses Ziegler's row displacement compression technique for producing the parameters of hashing functions. Furthermore, two advantages are achieved:
1. The extracted distinct n-tuples can be represented by a 0/1 matrix and it is suitable for bit-string operations during the construction of hashing functions.
2. The computation of the hashing value for addressing a key is simple.
However, for the space requirement of our method, the sizes of ROW(i) and COL(i) fully depend on the length of the extracted n-tuples from keys and the size of BASE(i) heavily depends on the compactness of the compressed matrix resulted from the adopted scheme for matrix compression. There are still many good methods for static sparse matrix compression. For example, the method proposed by Durre'' based on Ziegler's row displacement method was applied well with large dictionaries. It is worth while investigating further the choice of a more suitable compression method as a good basis for a perfect hashing scheme on large word sets. U p to now, researchers have proposed many perfect hashing schemes using extracted n-tuples.2-' I
They all used trial and error to find the needed n-tuples. How to find a good heuristic algorithm to extract a unique n-tuple for an arbitrary list of word sets with the least amount of required time still remains open.
A LETTER-ORIENTED PERFECT HASHING SCHEME 49 ACKNOWLEDGEMENTS
The authors would like to thank the referees for their very useful comments which improved the presentation of this paper.
REFERENCES
1. R. Sprugnoli, ‘Perfect hashing functions: a single probe retrieving method for static sets’, C A C M , 2. C. C. Chang. C. Y. Chen and J. K. Jan. ‘On the design of a machine-independent perfect hashing 3. C. C. Chang and R. C. T. Lee, ‘A letter-oriented minimal perfect hashing scheme’, The Computer 4. C. C. Chang and J. C. Shieh, ‘On the design of letter-oriented minimal perfect hashing functions’,
5 . R. J. Chichelli, ‘Minimal perfect hashing functions made simple’, C A C M , 23, (1). 17-19 (1980). 6. C. R. Cook and R. R. Oldehoeft, ‘A letter oriented minimal perfect hashing function’, SIGPLAN 7. E. A . Fox, Q. F. Chen, L. S. Heath and S. Datta, ‘A more cost effective algorithm for finding 8. J. K. Jan and C. C. Chang, ‘Addressing for letter-oriented keys’, Journal of the Chinese Institute 9. G. Jasechke and G. Osterburg, ‘On Chichelli’s minimal perfect functions method’, CACM, 23,
10. T . J. Sager, ‘A polynomial time generator for minimal perfect hash functions’, C A C M , 28, ( 5 ) ,
11. M. D. Brain and A . L. Tharp, ‘Near-perfect hashing of large word sets’, Software-Practice and 12. R. E. Tarjan and A. C. Yao, ‘Storing a sparse table’, C A C M , 21, ( l l ) , 606-611 (1977). 13. A. C. Yao, ‘Should table be sorted?’, JACM, 28, (3), 615-628 (1981).
14. M. L. Fredman, J. Komlos and E. Szemerdi, ‘Storing a sparse table with 0 ( 1 ) worst case access 15. K. Durre, ‘Storing static tries’, in U. Pape (ed.), Graphtheoretic Concepts in Computer Science, 16. K. Durre and G . Fels, ‘Efficiency of sparse matrix storage techniques’, in U. Pape (ed.), Discrete 17. S . F. Ziegler, ‘Smaller faster table driven parser’, Madison Academic Computing Center, University 18. A. V. Aho and J. D. Ullman, Principles of Compiler Design. Addison-Wesley Publishing Co.,
19. P. Dencker, K . Durre and J. Heuft, ‘Optimization of parser tables for portable compilers’, ACM 20. M. R. Garey and D. S . Johnson, Computers and Intructability-A Guide to the Theory of NP-
20, ( l l ) , 841-850 (1977).
scheme’, to appear in The Computer Journal (1990).
Journal, 29, (3), 277-281 (1986).
Journal of the Chinese Institute of Engineers, 8 , (3), 285-297 (1985).
Notices, 17, (9), 18-27 (1982).
minimal perfect hashing functions’, ACM Conference Proceedings, 1989, pp. 114122.
of Engineers, 11, (3), 279-284 (1988). (12), 728-729 (1980).
523-532 (1985).
Experience, 19, (lo), 967-978 (1989).
time’, JACM, 31, (3), 538-544 (1984).
Universitats-Verlag, Rudolf Trauner. Linz, 1984, pp. 125-134.
Structures and Algorithtns, Hanser-Verlag, 1980, pp. 209-221.
of Wisconsin, Madison, Wisconsin, 1977. Reading, Mass., 1977.
Transactions on Programming Languages and Systems, 6 , (4). 546-572 (1984).