Symbolic
Gray
Code
as a
Perfect
Multiattribute
Hashing Scheme
for
Partial Match
Queries
C.C. CHANG,R.C.T. LEE,MEMBER,IEEE, AND M. W. DU,MEMBER,IEEE
Abstract-In this paper, we shall show that the symbolicGraycode hashing mechanism isnotonlygoodfor best matching,butalsogood for partial match queries. Essentially, weshallpropose anewhashing scheme, called bucket-oriented symbolic Gray code,whichcanbeused toproduce anyarbitrary Cartesian product file, which has been shown to begood for partial match queries. Many interesting properties of this newmultiattributehashing scheme,including the property that it isaperfecthashing scheme, have been discussed and proved.
Index Terms-Bucket-orientedsymbolic Gray code, Cartesian product file,multiattribute fileorganization, partialmatch query,perfect hash-ing, symbolicGraycode.
I. THE PARTIAL MATCHING PROBLEM
IN
this paper, we are concerned with partial match query systems[1], [3], [5],
[6],
[10], [18]-[21],
[23].
We assume that we aredealingwith amultiattribute file consisting ofasetofmultiattribute records.Each
recordischaracterized by attributesAl,
A2, -- ,AN. A partial match query is aquery of the
following
form: retrieveall records whereAi,
=all,
* * *,Aik
=aik
where O< k<N.We shall assumethatalloftherecordsaredividedinto buck-ets and stored in disks. Each time a partial match query is processed, one or morediskaccesses areperformed. Since the disk accessing is much more time-consuming than any other processing in the internal mainmemory, we shallmeasurethe performance of our file system by the number of buckets necessarytobe examined.
Let us consider Tables I and II. In both tables, a query
(A
I =a,A2 = *) denotesapartial matchquerywhich retrievesall of the records withA equal toaandA 2 canbeany
value,
i.e., a don't care condition. It can be seen that the average number of buckets to be examined, over all possible partial match queries, is 2forthe
file
systeminTableII and4 for file system inTableI.Thus, our multiattribute file system design problem for partlal match queries can be stated as follows: given a set of multiattribute records, the problem is to arrange the records in such a way that theaveragenumberof bucketstobe exam-ined, overallpossible partial matchqueries, isminimized.
Unfortunately, a solution to the above stated problem is still at large. In other words, given an arbitrary set of multi-attribute records, there is no efficient algorithm to
fimd
anManuscript received April 24, 1981; revised July 8, 1981.
C. C.Changand M. W. Du arewith the InstituteofComputer Engi-neering, NationalChiao-Tung University, Hsinchu, Taiwan.
R.C.T. Lee is with theInstituteofComputer andDecision Sciences, National Tsing Hua University, Hsinchu, Taiwan.
TABLE I
(A)ANARRANGEMENTOF16 RECORDSINTOFOURBUCKETS. (B) BUCKETSTO BEEXAMINEDFORALLPOSSIBLE QUERIESFOR(A)
(A) Bucket 1 Bucket 2 Bucket 3 Bucket 4
(a,a) (a,b) (a,c) (a,d)
(b,b) (b,c) (b,d) (b,a)
(c,c) (c,d) (c,c) (c,b)
(d,d) (d,a) (d,b) (d,c)
(B) Queries Buckets to be examined
(a,TM) 1,2,3,4 (b,*) 1,2,3,4 (c,T) 1,2,3,4 (d,*) 1,2,3,4 (T,a) 1,2,3,4 (*,b) 1,2,3,4 (c,C) 1,2,3,4 (*,d) 1,2,3,4 TABLE II
(A)ANOTHER ARRANGEMENTOF 16 RECORDSINTOFOURBUCKETS. (B) BUCKETSTO BEEXAMINEDFORALL POSSIBLEQUERIESFOR(A)
(A) Bucket 1 Bucket 2 Bucket 3 Bucket 4 (a,a) (a,c) Cc,a) (c,c) (a,b) (a,d) (c,b) (c,d) (b,a) (b,c) (d,a) (d,c) (b,b) (b,d) (d,b) (d,d) (B) Oueries Buckets to be examined
(a,*) 1,2 (b,T*) 1,2 (c,*) 3,4 (d,*) 3,4 (M,a) 1,3 (T,b) 1,3 (*c) 2,4 d) 2,4
optimal arrangement of recordsinto buckets.
However,
ifall records are present, under certain conditions, it ispossible to have anoptimalsolution.We shall elaborate this in the
following
section. II. THE CARTESIAN PRODUCT FILECONCEPT Before presenting the Cartesian productfile concept, let usassume that each record is characterized
by
N attributesAl,A2,
*- -,AN.
EachAi
is associated with a setDi,
which is the domain ofAi.
The size of domainDi
is denoted asqi.
The domain of the file F, consisting of all
possible
records,
isthus
DI
XD2 X * * -XDN. The total numberofrecords,orthesizeof F, denotedasNR,isq, q2 ...
qN.
Weshallassumethatthe entirefile isdividedinto NB buckets:B1,B2, ,
BNB.
Definition: A file system is called aCartesian product file if all records in every bucket are in the form ofD1SI,
D2S2,
DNsN
whereDi.1
is a subset ofDi.
This bucket isde-note4das
[sI,s2,
SNExample 2.1: Let D1 {a, b, c, d} D2 .
LetD1I
=D21 = {a, b} andD12 =D22 = {c, d}. Then thefollowingfile systemis aCartesian product file:
Bucket [1, ] =
DI
XD21 = {(a, a),(a, b), (b, a), (b, b)}Bucket
[1,2]
=DII
XD22 ={(a,c),(a,d),(b,c),(b,d)}
Bucket [2, 2] =D12
XD22 = {(c, c),(c, d), (d, c), (d, d)} Bucket [2,11
=D12 XD21l
={(c,
a),(c,
b), (d, a), (d,b)}.
The reader should note that the above file system isexactly the same as that shown in Table II. This is not accidental. As first pointed out by Lin et al.
[19],
many good file sys-tems, such as those designed by Rivest[211,
Rothnie and Lozano[23],
aswell as Liou andYao[20],
are all Cartesian product files. Aho and Ullman[1] explored
the problem of designing optimal multiattribute file systems whoseprobabili-ties of an attribute being specified are not
equal.
This file systemisalsoaCartesianproduct file. In[6],
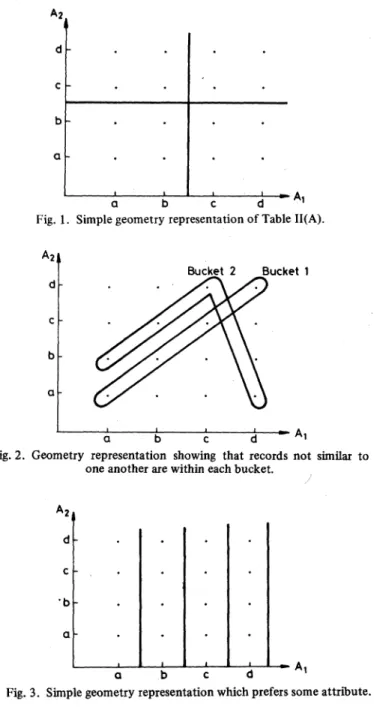
moreproperties of Cartesianproduct fileswerediscussed.The physicalmeaning of a Cartesianproduct file discussedin Example 2.1 can be vi-sualized by considering Fig. 1 where each dot represents a record. In
Fig. 1,
each bucket corre-sponds to a square. In this case, it is easy to see that this Cartesian product file divides records into natural clusters. If we want to retrieve all records withA.,
equal toa, only twobuckets
(Bucket
[1,
1] and Bucket[1,
2])
havetobeaccessed.Similarly,
ifwe want to retrieveall records withA2
=b, again,only twobuckets
(Bucket
[1,
1] and Bucket[2,
1])
have to beretrieved.If we do notuse the Cartesian product file concept and in-steadwe use the file system shown in Table I, the reader can
verify for himself that within each bucket, records are not similartoone anotherat
all,
asshowninFig.
2.In
[19],
it was pointed out that good multiattribute file systems all exhibit some kind ofclustering
property. That is, within each bucket, records should be similar to one an-other. It just happens that Cartesian product files do cluster similar records together.Example 2.2: Cartesian product files do not necessarily group records into squares, as shown in
Fig.
2. For the case .inExample
2.1,
we may also have the following Cartesianproductfile:
DI,
={a},
D12 ={b},
D13 ={c},
D14 ={d}.
D21 =D2 =
{a,b,c,d}.
Bucket
[1,1]
={(a,a),
(a, b), (a, c), (a,
d)}
Bucket
[2,1]
={(b,
a),
(b, b), (b, c), (b, d)}
Bucket
[3,1]
{(c, a), (c, b), (c, c), (c, d)}
Bucket
[4,
1]
={(d,
a),
(d, b), (d, c), (d, d)}.
The above file system is shown in Fig. 3, where each long strip corresponds to a bucket. This file systemperformsvery well if the user
specifies
AI
and verypoorly
if theuser speci-fiesA2 -A2 d C b a a b c d -1Fig. 1. Simple geometryrepresentationofTableII(A). A2~ d c b a I. I ~ -A a b c d At
Fig. 2. Geometry representation showing that records not similar to
oneanotherarewithin eachbucket.
A2
d
a
Fig. 3.
a b c d
Simplegeometryrepresentationwhichpreferssomeattribute.
Because of the clustering properties of Cartesian product files, they are also
useful
for nearestneighbor searching[2],
[41,
[9], [14], [17], [22],
[24]. Du and Sobolewski [10] used the Cartesian product files for parallel processing in multiple disksystems.Given two
records
R1 =(rI1,
rI2,
,rlN)
and R2 =(r2I,
r22 ,
r2),
the Hamming distance betweenRI
and R2 isdefinedasfollows: N
d(Ri,R2)
L6(rj1,r21)
i -1
where
6(r1i,r2
) 1ifr1i
r2i
=0
ifrli
r2i.
One of the most important properties ofCartesian product files is that it is possible to arrange records in a Cartesian product file such that the Hamming distance
[19]
betweenI L I ,A.
L
TABLE III
USING INDEX PAIRSTODENOTE EACH BUCKETNUMBEROFTABLEII(A) (a,a) Bucket (ci,b) [1,1]
J(b,
b) (b,a) (b, c) Bucket (b,d) [1,2] (a ,d) i (a,c) (c,c) Bucket (c,d)[2,21
(d,d) (d,c) (d,a) Bucket (d,b) [2,1] (c, b) (c,a)USINGINDEX PAIRS
Bucket I
Bucket I
Bucket I
TABLE IV
TODENOTEEACHBUCKET NUMBER
Bucket [4,1] (a,a) (a, b) (a,c) (a,d) (b,d) (b,c) (b,b) (b,a) (c,a) (c,b) (c, c) (c,d) (d,d ) (d,c) (d b) (d,a)
two consecutive records in the file is equal to one. For
ex-ample, consider the two files in Examples 2.1 and 2.2, respec-tively. TheycanbedisplayedinTables III and IV. The reader
may verify that in both files, for any pair ofconsecutive
rec-ords, the Hamming distance between them is equal to one.
Thus Cartesian product files exhibit the consecutive retrieval
propertyadvocatedbyGhosh [16].
Note that the Cartesian product fileconcept isonlyamethod
to organize records physically. We still need an indexing
scheme to locate the records. Since this indexing scheme
occupies memory space, it will be desirable to eliminate it. This can only be achieved by using some kind of
multiattri-bute hashing scheme [9], [23] which maps a record directly
toits address spacewithout thehelpofanyindexing file. In this paper, we shall show that wehave amultiattribute
hashing method for Cartesian product files. That is, forevery
Cartesian product file, we can easily design a multiattribute
hashing which produces such afile. Thishashing method has
the property ofbeingaminimumperfect hashing method [8],
TABLE V
USING SYMBOLICGRAY CODETOHASHALLOF THEPOSSIBLE RECORDS
OFEXAMPLE 3.1 Records (a,a) (a, b) (a,c) (a,d) (b,d) (b,c) (b,b) (b,a) (c,a) (c,b) (c,c) (c,d) (d,d) (d,c) (d,b) (d,a) Location 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
[11
],
[25] inthe sensethatnocollisionoccursandnomemory space is wasted. Our hashing scheme is based uponsymbolic Graycode[9]
whichwillbe discussed in the next section.III. SYMBOLIC GRAY CODE
The symbolic Gray code concept was proposed by Du and Lee
[9].
While the exact algorithmofthis hashing function israther complicated, its meaning is easy to understand. Con-sider thefollowing example.Example 3.1: Let us assume that
DI
=D2 = {a, b, c, d}. The symbolic Gray code will always hash allof the possible records as shown inTableV.It was shown in [9] that the symbolic Gray code has the followinginterestingproperties.
Property 1-Address to Key Transfornation Property: All hashing functions provide a key to address transformation. But symbolic Gray code hashing also provides the address to key transformation. That is, given an address in the address space, we can calculate the record stored in thatlocation. For
instance,
for location equal to 5, we can easily show that the recordstored there is(b, a).Property 2-The One-to-One Correspondence: Let us de-noteKAT and AKT as the keyto addresstransformation and the address to key transformation, respectively. Property 2 meansthatif KAT(R)=i,thenAKT(i)=R.
Property3-No Collisioninthe Table: Thisis a consequence ofProperty2.
Property 4-No Waste of Memory Space: This is a conse-quenceofProperties 1 and2.
Property
5-The Nearest Neighbor Property: If symbolic Gray code is used, the Hamming distance between every pair oftwo consecutive records in theresulting
fileisalways
equal
to one. This means that they are nearest neighborsto each other.
Property 6-TheMultiattribute
TreeProperty: Foradetailed discussion of thisproperty,consult[9].
From the above properties, one can easily see thatthe sym-bolic
Gray
code hashing is a minimalperfect hashing
[25]
(perfect means no collision and minimal means no waste of memoryspace).
In spite ofthe above desirable properties, the symbolic Gray code nevertheless suffers from onedisadvantage-it is not good for partial match queries. Consider Table V. Let us assume that every fourrecords are stored in one bucket.
Then,
if our query specifies the first attribute, only one bucket has to be examined. On the other hand,if our query specifies the sec-ond attribute, all bucketshave to be examined. We may say that the consecutive retrieval properties among the attributes arenotbalanced.If there arethree attributes, this imbalance is even more pro-nounced. Atypical file produced by symbolic Gray code in-volving three attributesisnowshown inTableVI.
Note that the symbolic Gray code does produce Cartesian product files. The unfortunate thingis thatitcannotbeused to produce a Cartesian product file
specified
byus. Forin-stance,itcannotproducethe fileshowninTable III.
In this paper, we shall propose a new symbolic Gray code, called bucket-oriented symbolic Gray codeas amultiattribute hashing scheme toproduce any Cartesian product filethatwe want, in particular, aCartesianproduct file suitable for partial matchqueries.
IV. BUCKET-ORIENTED SYMBOLIC GRAY CODE We indicated before that symbolic Gray code always pro-duces a special kind of Cartesian product file. This can be modified. Note that for aCartesian productfile, eachbucket is associated with an index and the index itselfcanbe consid-ered as a record. For instance, in Example 2.1, the indexes associated withthefourbuckets are
(1,
1)(2,
2)
(2,
1)
(1,2).
If we consider theabove 2-tuplesasmultiattribute records,we
can use symbolic Gray code toorder them into thefollowing sequence:
(1, 1)
(1,2)
(2,2)
(2, 1).
Forthe first bucket, there are four records:
(a,a)
(b,b)
(a,b)
(b, a).
We can again use symbolic Graycode to order them into the
following
sequence:(a,a)
(a,b)
(b,b)
(b, a).
TABLE VIATHREE-ATTRIBUTEFILE PRODUCEDBYSYMBOLIC GRAY CODE Record RL(ALV.A2.AVA)
(Al1.
A21. A31)(All
A21. A32)
(A1.
A21.
A33)
(A12. A22. A33) (A11' A22f A32) (A12. A22. A31) (A12. A22. A31) (A12. A2n A32) (A12. A221 A33) (A12. A21, A33) (A12. A21, A32)
(A12§A21 A31 (A13. A21 A31) (AW3 A21' A32)
(A13.
A21.
A33)
(A13'
A22. A33)
(An. A22. A32)
(Aa . A22* A3 ),
Now consider the second bucket: recordsare asfollows:
Address L 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Bucket [1, 2]. The four
(a,c)
(a,d)
(b, c)
(b, d).
We can use symbolicGraycode to order them into the follow-ing sequences:
(a,c)
(a,d)
(b,d)
(b,c).
For reasons that willbecome obvious later,wemay reverse the aboveordering withoutaffectingtheconsecutive retrieve prop-erty. Thereversed order will be
(b, c)
(b,d)
(a,d)
(a,
c).
The above process can be applied to each bucket andfinally
we shall obtainthefileinTable VII.
The reader can now see that we can use the
symbolic
Gray
code to obtain a Cartesian product file specified byus. Since
it is not the
symbolic
Gray code asoriginally
proposed byDu and Lee[9],
we shallcall the newcodebucket-oriented sym-bolicGray
code.TABLE VII
USING INDEX PAIRSTO DENOTE EACHBUCKET NUMBER OF TABLEII(A)
(a,Q) Bucket
[1,1]
(a b) (b,b) (b,a) (b,c) Bucket [1,21(a,d)
(a,c) (c,c) Bucket [2,2](2 d) (d,d) (dc (d b) Bucket 12,11 (d,a) __________ (C, b)V. BUCKET-ORIENTED SYMBOLIC GRAY CODING AS A MULTIATTRIBUTE HASHING FUNCTION
In the previous section, we gave an outline about how sym-bolic Gray code can be used as a hashing to create any arbi-traryCartesianproductfile. Inthissection,weshow theexact
algorithm.
We are given a setof records characterized byNattributes
AI, A2,, AN. The domain ofAi isdenoted asDi. The
domain size of
Ai
isqi. Eachrecordisdenoted asR=(Alb1bA2b2
,ANmN)
where 1<bi
qi. Each Di is dividedinto ti subdomains and the size ofeach subdomain is denoted
aszi. Eachbucket is in the form of
D1, D2S2, *, DNSN
where
Disi
is a subdomain ofDi.
Thisbucket will be denoted asBucket [s1,S2, * * * ,SNI
Our algorithm to hasharecord R=(AjiI,
A2iI2,-
,ANiN)to an address consists oftwo main steps. In the first step,we
determine the order of the bucket which will contain this
record. In the secondstep, the exact location of this record
inside thebucketisdetermined.
Given a record R=
(Alb
1, A2b2X*2ANbN)9
the bucket[S1, S2, SN] which will contain this record isdetermined
bythefollowingformula:
Si=[
for 1 SiSNwherezt is thesize ofasubdomain of
Di
and[xI
is the smallestintegergreater thanorequaltox.
The order of [Sl, S2, ,
SN]
is determined throughAlgo-rithm A which is essentiallythekeytoaddress transformation
algorithmof thesymbolicGraycode discussed in [9].
AlgorithmA: TheAlgorithm which Determines the OrderofaBucket[S1,S2, , SN]
Input:
[S1,
S2, ,SN] [tl,t2,* tNwhere
ti
is the number ofsubdomains ofthe domain ofattri-bute
Ai.
Output: The order of the bucket
[SI,
S2,,SN].
Step1: DetermineanN-tuple
(al,
a2, * *',aN)
through the following rules.a) Fori= 1,let
ai
=si- 1. Thatis,a,
=s - 1. b) For I<iN, letL2 =a + I L3 =aIt2 +a2 +
Li
=aI(t2t3
**ti1)
+a2(t3t4
-*ti1)
+**+aj-1
+1LN =al(t2t3 .. .
tN
1)
+a2(t3t4
.. .tN l)+**+aN-l +; if
Li
isodd,ai=
- 1;if
Li
iseven,ai tiSit
Step 2: The order of Bucket
[Sl,
S2, ,SN]
is now calcu-latedasfollows:P=al(t2 tN)+a2(t3t4 tN)+
**+aN-ltN+aN+l.
Example5.1:
Consider Example 2.1 again. Inthiscase we have fourbuckets:Bucket [1, 1] Bucket [1,
2]
Bucket[2,
2]
andBucket [2, 1]
Letus nowdeterminethe order of
Bucket [1,
1].
SinceSI =S2=1 and tl =t2=2 wehave a, =Sl - 1 = 1 - 1 =0 L2=a + 1 0+ I I isodd. Therefore, a2 =S2 - 1 = 1 - 1 =0
(a1,a2)=
(, 0)
P=alt2
+a2 + 1 =0X 2+0+1 = 1.The order of Bucket [1, ] is 1. ForBucket
[2,
1],wehaveand S= 1 a =sl- 1=2- 1 =1 L2 =a1+ 1= 1 + 1 =2 is even. Therefore, a2 =t2 - S2 =2 - 1 = 1
(al,a2)=(1,
1)P=alt2
+a2 + 1 = 1 X 2+ 1 + 1 =4. The orderof Bucket[2,
11
is 4.Having deterrnined the order ofthe bucket whichwill
con-tain the record, we can determine the relative addressofthe record inside the bucket. Again, we apply thesymbolic
Gray
codetoallof therecordsinside the bucket. If theorder ofthe bucket is even, the ordering is reversed. The following
algo-rithm determines the relative address of a record inside the bucket containing it. After determiningboth the orderofthe bucket and the relative address, the absolute address of the record canbeeasily determined.Algorithm B: The Algorithm which Calculates the Absolute Address ofaRecord
Input: Record
R=(Alb1,A2b2 ..,
ANbN)
(Zj,Z2r
,ZN)
(t,t2r ,tN)where zi is the sizeof eachsubdomain of
Di
andti
is the num-ber of subdomains ofDi.
Output: Theabsolute addressofR. Step 1: Fori I toN,
rbil
Si= [i1
Step 2: Fori l toN,
bz bi -
(Si
- 1) XZi.Step3:
a) For i= 1, let as=
b1
1. Thatis,al 1z4 - 1b)
For 1<i<N,let L2 =a + 1L3
=a1z2
+a2 + 1Li
=a1(Z2Z3
...zi-1)
+a2(Z3Z4
...zi-1)
+ -+ai-
+LN aI(Z2Z3 ZN-1) +a2(Z3Z4 ZN-1) + -- *+aN-l + 1; ifLiisodd,ai=b- 1; if
Li
iseven,ai=Zi bs c) m= a1(Z2Z3 *ZN)+
a2(Z3Z4
...ZN)+ +aN-lZN +aN+ 1.Step4: Apply Algorithm Ato
(SI,
S2,* ,SN)
and(t1,
t2, * ,tN)to determine the order P of Bucket[sI,
S2, *, ,SN]-Step S: IfP is even,m'=zlz2 .zN-m+1. IfPisodd, m =m. (Notethatm'isthe relative addressofRinsideBucket
[SI
S2,SN]
whichwillcontainR.)
Step 6: The absolute addressL of R is determined bythe followingformula:
L=(Z1Z2
--ZN)X(P 1)+m.The above procedureiscalledthekeyto address transforma-tion(KAT) ofthebucket-oriented
symbolic
Gray
code.Example 5.2: Consider Example 5.1 again; inthis case we
have fourbuckets: Bucket [1, 1] Bucket [1,
2]
Bucket
[2,
2]
andBucket
[2,
1]Let us nowdetermine theabsoluteaddressofsomerecordin
this filesystem.
Case 1: For the
recordR=(a,c)=(A11,A23),(bl,b2)
(1,3).
After applying Algorithm B
(or
AKT),
sincez1 =Z2=
2 and tl =t2 = 2, wehaveand
b22
S2 = b2 = p3 =2.
Sowe knowthat the recordwillbecontained inBucket
[1,
2].
Next, we have b
b1
-(si
-1)Xz1
= 1 - (1 -1)
X 2 = 1 and 2=b2- (S2 - 1) XZ2=3-(2-
1)X2 =3- 2 = 1.From Step 3, we have a b - 1 = 1- 1=0
L2
=a,
+ 1 1 isodd. Therefore,a2 =b - 1 = 1 - 1 =0
m=az2
+a2 + 1=0X 2+0+1 = 1.By applying Step4 (or Algorithm
A)
to(sI,
s2)=(1, 2)and (t1, t2) = (2, 2), the order of Bucket [1, 2] is determined to be2. That is, P=2.ForP is even, the relative address of R inside Bucket [1, 2]
is
m'
zIz2-m+l=2X2-
1+1=4. Hence, the absolute address L of R isL=Z1Z2 X(P- l)+mt 2X 2X (2- 1)+4
=4+4=8.
That is, Record (a, c) is stored at the eighth address after applying thisKATtechnique.
Case 2: For record R=(c,
d)=(A13,
A24), (bl,
b2)= (3, 4).After
applying Algorithm
B(or KAT),
sincez1=z2=2
andt1=t2=2,
wehave
and
S2=
1
=
]
= 2.
So we know that the record will be contained in Bucket [2,2]. Next we have
b1
=bi
-(s,
-1)Xz
=3-(2-l)X2=1
and
2b
=b2
-(s2
-1)
Xz2 =4-(2
-1)
X 2=2. ForStep 3, we haveaG
=-bl
71 = 1-1=0 L2=a,
+ 1=0+1 = 1 isodd.Therefore,
a2 =
b2f
-1 =2- 1=m
=a1Z2
+a2 + 1 =0X 2+ 1 + 1 = 2.ForBucket [2,
2],
wehave(sI,
s2) =(2, 2).By applyingStep 4
(or
AlgorithmA)
to(si
,s2)
=(2, 2)
and(tl,
t2)
=(2, 2),
the order ofBucket[2,
2]
is determined tobe 3. That is,P=3.
ForP=3 isodd,the relativeaddressofRinside Bucket
(2,
2]
ism'=m =2.
Hence,theabsolute addressL ofR is
L =zIz2 X (P-1)+m'=2X 2X(3- 1)+2=10. That is, Record (c, d) is stored at the tenth address after
applying
this KATtechnique.If the reader consults Example 2.1 with Table III, hewill discover that the addresses of
(a, c)
and(c,
d)
arejustthe sameasthoseinTable III. Infact,ifAlgorithmB isused,all records in
D,
XD2 will beorganized asshown in Table III.Let us now conclude this section by statingthe fact again that givenanarbitraryCartesianproduct file,we canapplythe bucket-oriented symbolic Graycode to determine the address ofevery record in the file. In otherwords, the bucket-oriented symbolic Gray code can be used as a multiattribute hashing functiontoproduceanyarbitrary Cartesian productfile.
VI. SOME PROPERTIES OF USINGBUCKET-ORIENTED SYMBOLIC GRAY CODE TOORGANIZE ANY
CARTESIAN PRODUCT FILE
In this section, we shall present some interesting properties ofusing the bucket-oriented symbolic Gray code to produce Cartesian product file systems.
Property 1-The Address to Key Transformation: While most hashing functions provide "key to address transforma-tion" only, our bucket-oriented symbolic Gray code also provides an "address to key transformation" (AKT) which maps an address to a unique record. Let us note that the total number ofpossible records of a file D1 X D2 X * XDN is q
lq2
* * *qN,
whereqi
is the size ofDi.
Suppose allofthe records are stored in NB buckets. In the following, we shall show that we have an address to key transformation.Algorthm C: To ConvertanAddress
toitsAssociated Record Input:
(Z
1,Z2,,ZN)
(q1,q2c XqN)
L,1.L.q1q2..-qN
where
qi
andzi are the sizes ofDi
andeach subdomain ofDi,
respectively. Output:
(Alb
1j
A2b2
-,ANbN)
where R=
(Alb
, 2b2ANbN)
is arecordwhichisasso-ciated with the addressL. Step 1: Calculate
m
L-
]I
XZ1Z2*-ZN
Z1Z2
ZNwhere m' is the relative address of the recordRL inside the bucketcontaining it.
Step2: Calculate L-P
=;
ZIZ2 . ..ZN ifPisodd, mm'; if Piseven, m Z1Z2 ...ZN-m +.P istheorder of thebucketcontainingRL. Step 3:
a) Determine an N-tuple
(al,
a2, ,aN)
through the followingequation:P=al(t2t3 . . .tN)+ii2(t3t4 ..tN)
+ -+aN* ltN+aN+ I
where
ti
=q/lzi
and PisobtainedinStep2. b) Fori= 1 toN, determineasfollows:p
si
=a +1, if ti ti+1 * *tN isodd.si=t1-a1,
itj+l
tN]
iseven.[S1
, S2,,SNI
isthebucketcontaining
RL.
Step4:a) Determine an N-tuple
(a,,
a2,,aN)
through the followingequation:m=al(Z2Z3 ...ZN)+a2-(Z3Z4
ZN)
+
+aN.lZN
+aN + 1where
a!s
are allintegers and m is obtained in Step 2. b) Fori= 1 toN,determineb'
asfollows:b>.=a,
+ 1, ifziZi+1
[ . l is odd.. ZN
bz=Zi
-ai,
if [ ] iseven.Zi i+1 ..ZN StepS:
Foril=
toN,bi=ziX (s -
1)+b;'
Step 6:
(A blb ,A2b 2'''**
ANfbN)
iSRL*The above procedure is called the addressto key transforma-tion
(AKT)
of thebucket-oriented symbolic Graycode.Now, let usshowhowtheAKT can beapplied to the data in Table III.
Example 6.1: Consider the case where L 10, ql = q2 = 4 andZ1 =Z2 =2. Step 1: m' 10- 2X10 l I1 X 2 X 2= 10- 8=2 Step2:
12X2
==3.
m m=2becausePisodd. Step 3:a)
t1=q1/z =2and t2 =q2/Z2
=2;wehave 3=alt2 +a2 + 1 =2a1
+a2 +1Thisgives
(a,,
a2)
=(1,
0)
b)
Because[k1f21 =[| 21
= 1
isodd,
sl =a1+1=1+
1 =2.Because
t=
[2-
=2
is even, S2 =t2 -a2 =2-0=2. [2,2]
isthebucket inwhichR10 isstored.Step 4:
a) m
=a1z2
+a2 +1.
We have
2=a1
-2+a2 +I Thisgives(a1,
a2) =(0,
1).b) Because 1= [ =1 isodd,
b'
=a +1=0+1= 1.Because
[-]=2[
1 is odd,b2
=a2 + 1 = 1 + 1 = 2. Step5:b,
=z-(s,
-1)+b'1
=22-(2- 1)+1
=3 b2=z2
(s22-
l)+b =2-(2- 1)+2
=4.
Therefore,wehave
RI0
=(A 13,A24).
Property 2-The One-to-OneCorrespondenceProperty: We have shown the key to
address
transformation(KAT)
mecha-nism ofthe bucket-orientedsymbolic Gray
codehashing
func-tion. We have also shown the address tokey
transformation(AKT)
in the hashing function. We now ask: What is the relationship betweenthesetwotransformations?The following theorem depicts that there is a one to one
correspondence
relationship
betweentheaddresses andrecords. Theorem 6.1: For every recordREDI
XD2 X*
XDN,
ifKAT(R)
=L, thenAKT(L)
=R.(The
proof
of this theoremcanbe foundin
Appendix
A.)
The reader canverify this point by checking intoTable
III.
If he applies the AKT to any address ISL
S16,
he will obtainthe record stored in that location and ifheapplies
the KAT to the record already storedthere, he will obtainexactly
thesameaddress.Property 3-No Collisioninthe Hash Table: Formost hash-ing functions, therewill be
collisions
inthehashtable becausetwo distinct records may be hashed into the same address. FromProperty2, we knowthat ifRi isdifferent fromR2, the
address of
R1
will
be different from that ofR2. Thus there will be no collisions in the hash table. We may say that the bucket-orientedsymbolic
Gray
code can be considered as aperfecthash
function[8], [11], [25].
Property 4-No Waste
of
MemorySpace:
Formosthashing
functions, ifwe know that the total number of records to be stored is M and some kind of
hashing
function is used, weusually
must reserve more thanMlocations. It isnotthecasewhen this
hashing
functionisused. BecauseofProperty
2and Property 1, we onlyhavetoreserveexactly
Mlocations. Thus,
the bucket-orientedsymbolic Gray
code is aminimalperfect
Property 5-The Nearest Neighbor Property: For I AL < NR=q1 q2 --
qN,
the Hamming distance betweentherecordRL stored at location L and the recordRL+1 stored at loca-tion L+ 1 is always 1. Because ofthisspecialproperty, every pair of consecutive records in the hash tablearenearest neigh-bors to each other. This is a very desirable property for
or-ganizing records for a best matchsearching system [2], [4],
[9], [12]-[14], [22].
Theorem 6.2: Let there be N sets: D1, D2, ,
DN
whereDi
{Ai1,
Ai2,
* - -,Aiqi}
andqi
> 1. Let RL denote therecord associatedwithLbyapplying AlgorithmB(KAT) to L. LetNR denote the total number of records in
DI
XD2 X ...XDN. Then the Hamming distance between
Ri
andRi+I
is 1, for 1 < i<NR. (The proof ofthis theorem can be found in AppendixB.)Property 6-Appropriate for Partial Match Searching: It was shown in [6] that Cartesian productfilesweresuitable for partial match searching. Since any Cartesian product file can be produced by using the bucket-oriented symbolic Gray code,we shall say that thishashing scheme isgoodforpartial matchsearching.
Property 7-For any Partial Match Query, It isEasy to De-termine All Buckets Necessary to Be Examined: Assume a
partial match query is of the
following
form. Retrieve all records whereA1l
=Aibi,
Ai2
=Ai2bi2
A. =AAfb
j and i1 . i2 ... ii. Assume each Akbik
isinDi 1 Sikk
~lkSik~
k
.j.
The bucketswehavetoexamineare[SI
S2, **N
I 's,where Skisanyvalueranged from 1 to tk,
(tk
isthe numberof subdomains ofthedomainof attributeAk)
ifk *ip,
1 < p.1 andSk=Si
Iifotherwise.Forinstance, inTable III, consider the query
(AI
=c, A2 = *). That is, the query is(A 13,
*).
SinceA 13 isinD12,s1 =2 and S2 can be from 1 to 2. So there are two buckets[2,
1] and [2,2]
tobeexamined. Byapplying AlgorithmAto thesetwo
buckets,WF
have the order ofthese buckets being4 and 3, respectively. Hence we can conclude that bucket 3 and bucket 4mustbe examined forthe query(A1
=c,A2 =*)
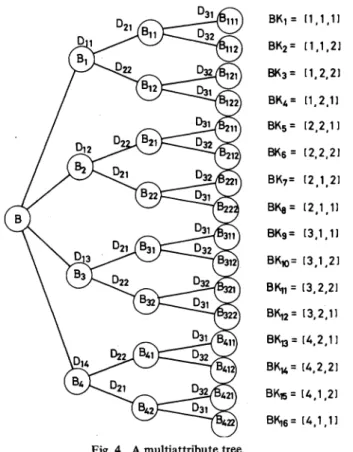
Property 8-The MultiattributeTreeProperty: Assume that
we have asequenceofbuckets, BK1,BK2, andBKNB pro-duced by the bucket-oriented symbolic Gray code. This
se-quence of buckets canbe viewed asa tree whose structure is explainedasfollows.
1)
The topnode ofthetreecorresponds
toall buckets.2)
For level 1 of the tree, there are tl nodes:B,,
B2, **Bt,.
Eachnode corresponds to a set oft2t3 * tN buckets. Thus thefirstnodeonlevel 1 consistsofbuckets ordered from 1 tot2 t3 ...tN. Thesecond nodeconsistsof buckets orderedfromt2 t3 * tN+ Ito
2(t2
t3 * * *tN),
etc.3) Each node on level 1 is split into t2 nodes on level 2. Thus there are t1t2 nodes onlevel 2. Each node corresponds to t3 t4 *
tN
buckets. Thus the first nodeonlevel2consists of buckets ordered from 1 to t3 t4 *. tN. The second node corresponds to buckets ordered from t3 t4 . .tN
+ 1 to2(t3
t4 .tN),
etc.4)
In general, there aretl
t2 *t,
nodes on level i of thetree. Each nodecorrespondsto
ti+1
t4+2
...tN
buckets.5)
Within each node on level i, S1, S2, * * ,si assume thesame
value,
forall bucketsinthis node.B2 =ig3 B31t 2 BK2BK4= l[21
[,1,211
2] BK5= ([2,2,]/X~~~D2
BK7
[2
1
2]2
1 B411 BKu= [4,2,11 \~~~~~~~D~I BK5= [4,2,1]D12B2
BK6
= [4,2,21 B4 D21 ~ 3 421 BK9= 14,1,2]D2B
D31 3 YB422 BK16= [4,1,1]Fig.4. A multiattribute tree.
Example6.2: Consider a three-key records set:
D1={A11,A12,A13,A14,A15,A16,A17,A8}
and
D3={A31,A32,A33,A34,A35,A36}.
LetD1 ={A1A12},D12 = {AD3,A24},D13 = 3,22 ={A17,A
1=
{A21B,A222},D22 ={A23,A24},D31 ={A31,A32,A33jJ,andD32 =
D{A34,A35,A36}1
NR =
q1-*q2-*
q3-8 X 4 X 6 = 192 BZ=z1 *Z2*Z3=2X2X 3=12NB=
t1
* t * t3 = q X2 X =4X 2X 2=16.
z1 z2 z3
The tree corresponding to the buckets in which all the rec-ords in this case is stored is now depicted as in Fig. 4.
For
level
I of the tree, the first node B1 corresponds to buck-ets ordered from 1 to 4. On the second level of the tree, the second nodeB12
corresponds to buckets ordered in 3 and 4. For records in B1,the first key is inD16 ={A
lj,
A 12}
for all records. In B2, the first key is inD11
and the second key isinD22
={A2
3,A24}
for allreords.This kind
of-structure
is called multiple-attribute tree [7],[15].@
VII. CONCLUDING REMARKS
In this paper, we proposed the bucket-oriented symbolic Gray codeas amultiattributeminimal perfect hash function.
Thishashing function can be used to
produce
anyarbitrary
Cartesianproduct
file. Since Cartesianproduct
file systemshave been shown to be appropriate forpartialmatch queries, our bucket-oriented symbolic Gray code is appropriate for partial match queries. Wewould like to emphasize here that hashing is good in this case because no index file is necessary.
Our nextjob is to investigatehowourmultiattribute hashing function can be used to organize files where some possible recordsaremissing.
APPENDIX A PROOF OFTHEOREM 6.1 Definition: Let I.L.qlq2 *
-qN
L=al(q2q3
..*qN)
+a2(q3q4
qN)
+ * * aN-2(qN- 1qN)+aN_ 1qN+aN+ 1 whereai
is aninteger, 0 Sai
<qi.
ThisN-tuple
(a,,
a2, * * *,aN)
is calledtheqi
representation of L. For example, consider the case where q1 =3,q2
=2, q3 =3, and L=6. Thenq2q3 =2X 3 andq3 =3.Therefore,
6=
0(2
X3)
+1(3)
+2 + 1. This means(a1,
a2,a3)
=(0,
1, 2).The
qi
representation of6 is(0,
1,2).Lemma 1: Let A =
(a,,
a2, * * *,aN)
be theqi
representa-tion ofL and B=
(b1,
b2,-** ,bN)
be theqi
representationof L + 1, then the Hamming distance between A and Bis m >1 anda)
ai=bi,
for I.i.N- k,k mb)
aN-k+l + 1 =bN-k+l
c)
ai=qi-
1 forN-k+2SiSN andbi
=OProof: For any integerL, 1 <L< q1 q2 ...
qN,
there isonly one N-tuple
(a1,
a2, ,aN)
such that L =a1q2q3 ...qN+a2q3 -* qN * +a_IqN+aN+
1,whereOSai<qi.
(1)
For integer L + 1, 1 S L+ 1 <
q1
q2 *qN,
there is onlyone N-tuple
(b1,
b2, - ,bN), such thatL + 1=bIq2q3
...QN
+b2q3
*qN+*
+bN-,qN +bN
+1,
where0.bi
Sqi. So,
L=b q2q3 qN +b2q3
** qN+bN-1qN+ bN
(2)
Compare
(1)
and(2)-there
are twopossibilities.
Case 1:
0
<aN
<qN - 1, 0<aN
+ I<qN-Assume bN=aN +l and b1=
ai,
i= 1, 2, - ,N- 1. In thiscase, the Hamming distance between
(a,,
a2,,aN)
and(bC,ba2
bN)
is2
Case 2:aN =qN- l,aNl -qN-l - 1, * ,aN-k+2
=qN-k+2.-
1and
aN-k+l
<qN-k+l
-1, forsomek,
1<
k.N.
Inthiscase,
bN-k+l
=aN-k+l +1,bN-k+2
=bN-k+3
*bN-1 =bN=O
andbi=ai,
i=1,2,- ,N- k.The Hamming distance between
(a,,
a2,- -- ,aN)
and(bI,
b2,- --,bN)is m,where 1 m<k.
Ingeneral, the Hamming distance between
(a,,
a2, - ,a-N)
and(bl,b2,
- --,bN)ism> 1 andai =bi
for 1 i.<N- k, andaN-k+l + 1 =bN-k+l- Q.E.D.
Lemma 2: Let A =
(a,,
a2, * * *,aN)
be theqi
representa-tion ofL where I < L <q1
q2 ...qN.
ThenL |qiqi+l . QN
isequalto
a,(q2q3 * *qi-.) +a2(q3q4 . qi-,1)+* * * +ai-, + 1.
Proof- Since A =
(a,
, a2,- -,aN)
istheqi
representationofL, we have L =
alq2q3
* * * qN + a2q3 ** qN + * +aN.4qN
+aN+ 1,[a L2]
Iqiqi+l 4NiN
_ al
q2q3"
* * qN+a2q3 ...qN + *,+aN-lqN+aN+I =a(q2q3
.-.qi-)
+a2(q3q4
qi-q)
+*+
ai-1
+[aiqi+l
qN+ai+lqI+2
...qN
++aN-lqN+aN+1
qiqi I qN
Since
ai
<qi,
wehaveai
<qi
- 1 and 1.aiqi+l
...qN+ai+lqj+2
qN+ * * *+aN-,qN+aN + I
<
(qi 1)qi+l
- qN +(qi+l
-)q1+2
qN + +(qN-1 - I)qN+(qN- )+ I=qiqi+l
,qN-Hence
aiqi+l
...qN+
ai+lqi+2 qN+-.+aN-qN
+aN
+=1
qiqi+l a +qNThatis,
L q~l is
a,(q2q3
-qi-)
qiqi+l * qN
Wehave theproof. Q.E.D.
Lemma 3: Let A =
(a,,
a2, * * *,aN)
be theqi
representa-tion ofuandB=
(b
I,
b2,* **, bN)betheqi
representationofV.
Let
X=(XI,
X2, * **,XN)
and Y=(Yl,
Y2,
,YN)
betwoN-tuples whicharedefinedasfollows:
xi=-ai + 1, if u isodd,
iqi
[qqi qN
xi=qi-ai, if iseven,
qi qi+1. QN and yi
bi
+ 1, if isodd, qiqi+l ..QN vyi
qi bi, if is even. ,qiqi+l ..qNIfIu- v = 1,theHamming distancebetween X and Yis 1.
Proof: Because Iu- v = 1,wemay supposethatv=u+ 1.
Let A=(a1, a2, * ,
aN)
be the qi representation ofu andB=(b1,
b2,
* * ,bN) be the qi representation ofu+ 1. ByLemma 1, the Hamming distance betweenA andB ism> 1
and
ai=bi
for1.i<N-k,k>m.
aN-k+l + 1 =
bN-k+l
By Lemma 2, wehave
(1) (2)
[qiqi+l ]qN = alq2 ...qi-l +a2q3 * * * qi-l. + --+ai-l +1
=bIq2 - qi-l +
b23
ql[+q--i
biN+
=qiqi+l -fqN N
for Il Ai<N- k+l.
(3)
Equations
(1)-(3)
imply thatYi'xi
for1.i.N-k
and YN-k+l
/ZXN-k+1
Consider [qjqj+i ~ Iand [-1v'
] for N- k+22i.N. Inthiscase,1=alq2
...qi-1 +a2q3 ... qi-qiqi+l ..qN=(alq2
..qi-l+a2q3*..qi-l
+* * +aNkqNk+l . qi-l
+aN-ks qN-k+2 ...qi-l
+
[(qN-k+2
-1)qN-k+3 ...qi-l
+(qN-k+3 -
I)qN-k+4
qi-l(4)
=
Iaq2
...qi-l +a2q3 ...qi-l+- +aN-k+lqN-k+2 qi-l +QN-k +2qN-k+3 ..qi-1
V
qiqi+l...q
b,
q2 ***qi-l +b2Q3 ... qi-l.+-- -+bi-l+I
=[a,q2
...qil
+a2q3...qi-l
+' +aN-kqN-k+l ..qi-l]
+(aN-k+l + I)qN-k+2 ..qi-l +1
=a,q2 -* qi-l +a2q3 * - qi-l
+.. +aN-kqN-k+l qi-l
+aN-k+lqN-k+2 - qi-l
+qN-k+2 ... qi-l + 1 = qiqi+l .. + 1.
Case 1:
[ulqiqi+l
...qyNl
iseven. In thiscase,xi
=qi
-ai
=qi-
(qi
- 1)= 1, since ai=qi- 1. Then[vlqiqi+l
*qN1
isodd. Therefore,yi=
bi
+ 1 =0+1= 1, sincebi
=0. We have xi =yi= 1.Case 2:
[u/qiqi+l
**qN
l isodd. In thiscase,xi
=ai
+1 =(qi
- 1)+ I =qi,
sinceai
=qi
- 1.vlqiqi+l
*...qNl
is odd.Therefore,
yi=qi-bi
=qi
- 0=qi. We have xi=yi qiinthiscase.
Hence,
xi
=yifor N-k+2< i<N.Combining (4)
and(5),
weconcludethat the
Hamming
distancebetween X and Y is 1. Q.E.D. Lemma 4: Let F be afunction,
F:(fi,
f2, fn)
-K,
fi
< qi, definedby
following
equation:
K=
a,(q2q3
...qN)+a2(q3q4 ..qN)where the
N-tuple
(a,,
a2, * * *,aN)
isdeterminedthrough
the followingrules:a)
a=flf
- 1.b) For 1 < i<N L2 =a, + 1
L3 =a,(q2)+a2 + 1
Li
=a,(q2q3
-*qi-1)+a2(q3q4
...qi-.
)
+
-+aj-,+
ILN
=a,(q2
q3 * ** QN-1)
+a2(q3q4
..**QN
-1)
+- - +aN-1 + 1;
if
Li
isodd,ai=fi-
1 ifLi
iseven,ai =qi
-fi.
qlq2 * qN, gi = qi - bi, if
[m/qiqi+l
...qNl is even, gi=bi+ 1, if
[m/qiqi+l
...qNvl
isodd,where theN-tuple(bI,
b2,.* ,bN)isdetermined throughthefollowingequation:
m=bl(q2q3
-*qN)+b2(q3q4
qN)+***+
bN
qN+bN+ IThen G=
F-1.
Proof: For anyN-tuple
(f,
f2,
fN
),F:(fl,
f2,
,fN)
-+K,K=
a1
(q2q3
...qN)+a2(q3q4
*qN)
where
a,,
a2, ,aN
aredeterminedby a) a1=f1-
1b) for 1<iN,
if
al(q2q3
" * *q11j)
+a2(q3q4 **q-)+-
+aj-1+
I isodd,
-ai=fj
- ;(1)
if
al(q2q3
** *qj-.
)+a2(q3q4
...qj_l)
+
--*+ai1
+1
-iseven,ai=qi-
fi.
(2) Weshall showthatG(F(fi, f2,*
,N))
=(fi,f2
,fN)
or
-
G(K) =(fi,
, 2,* *N)-Suppose
G(K)
(gl,
92,*gN)
For i1,
sinceK.
q1q2 * - qN=
q1q1+1
...qN,[K/qiqi+l
...qNl = 1 isodd,
we have g1 =a1 + 1 or a1 =g1 - 1. By Lemma 2, since
(g1
,g2, * *gN)
is theqirepresentation
ofK,wehave [qKqj+i.. =a,(q2q3 *qi-) +a2(q3q4 ...qi-l)qiqj+l qN
Because ofthe conditions ofthe G
function,
if[K/qiqi+1
*..qN] is odd,gi=ai+1.
If[Kf/qiqi+I
*-qN] is even, gi =qi-
ai.
That is, ifal(q2q3
. . .qi-,)
+a2(q3q4
qj-1)
+* +ai- +Iis odd,gi
=a1+1 orai =gi-
1; (3)if
al(q2q3
qi-)
+a2(q3q4
qi-,)
+ +a11 I1+ is even,gi=qi-ai
orai=qi-gi
(4)
Comparing
(1)
and(3), (2)
and(4),
wehavegi
=fi.
So,G(F(fi,
f2,,
fN))
=G(K)
=(fl, f2,
,fN).
Thatis,
G=F'1
.Q.E.D. Theorem 6.1: For every recordR ED1 XD2 X * X
DN,
if
KAT(R)
=L,thenAKT(L)
=R.Proof
Let R=(Alb
1,A2b2
* ANbN) where the ad-dress associated with R is determined bythe KAT(Algorithm
B).
LetKAT(R)
=L. Weshallnowshow that the record(rLl,
rL2, ,
rLN)
associated with L determined through the use ofAKT(Algorithm C)
isexactly(A
1b1,
A2b2
b2 *ANbN)-From KAT, we
finally
haveL=Z1Z2
...ZN(P-
l)+m'.
Let
ZlZ2
*--ZN=C. Then L=C(P-1)+m',
wherem'
is eitherC- m + I or m. By Step 3,m =a1(Z2Z3 * * *ZN) + a2(Z3Z4
ZN)
+.-
+aNlZNN+aN+l,
where O < ai <ziand
ai,
ziareintegers. WehaveO(Z2Z3
...ZN)
+O(Z3Z4
...ZN)
++
OZN
+O+1 <m<-(Z-
1)(Z2Z3
.ZN)
+(Z2
-)(Z3Z4
...ZN)
+
+
(ZN-1
)ZN
+(ZN
-1)
+1.So.1m.zlz2 .zN,i.e.,l.m.C.
Hence,l.m'.C.
Consider L C(P- 1)+m',
and I <m'<
C. WehaveL-C(P-
l)=m',
1 .L -C(P-
1).C.
Therefore, + I+>PL-.
C C SinceP isaninteger,LC |+> >
C-BecauseLC Cl
wehave Lc cL So P= [C- if L C(P- 1)+m' and m'=L - [Li - 1) -C. Inthiscase, =ZJZ2mzz...ZN-+
Z +=C
L+([C]
1)
.C+
1 if[c]
iseven.
m=m' L-(F-1l)
IC(
if[L]
isodd.
Consider theAKTprocedures.
ForanaddressL,
wehavemLL
(ZIZ2
.'ZNl
')ZlZ2 ..ZNr L (rE~L 1) L
if isodd m=m =L ([Cl 1 C.
if C is even, mL =Z1Z2 ZN-mL+
=
[jC-L+1.
CSo,mL
=mandPL
P.Let F:
(b
,b,...
,bXr)
--m,by using
theprocedures
of Step 3 in Algorithm B andG: mL(b51,
Lbl2,
,bL) by
usingtheprocedures ofStep4 in
Algorithm
C.By Lemma 4, we have G=F1. Since mL =m, we have
(14k,
bt
2,.**, bt)
=(b;,
b,
... ,b%).
In similarmanner,let H: (S1,S2
SN)
+Pby
using theprocedures
ofStep
4 in Algorithm B and T: PL -*(SLI,
SL2,
,SLN)
by using
theprocedures ofStep 3 in
Algorithm
C.By
Lemma4,
we have T=H-1
Since PL =P, we have (SL1, SL2,* * ,SLN) =(SI, S2, SN). For Step 1 andStep2in
Algorithm B,
wehavesi
[bi and b=bi
-(si
-l)zi,
respectively.
zi That is,bi
=b'+(Si
-1)
'Zt.Pi=
[]
andP+ =
For [i/Cl and [i+ 1
/CI,
wehave two cases to consider. Case1:[t] =[C 1]= integer.
In this case m + m+ 1 and
Pi+I
=Pi.
IfPi
=Pi,,
is odd,mi
=14 andmj+
=ml+1,
wehavemj+1
=mi
+ 1.For
Pi
=Pi+,
iseven, mi =C-mi
+ andm+=C-m;+
+1,wehavemi=mj+j
+ 1.So we canconcludethat
mi+1
-mi
= 1.If
Pi+1
=Pi,
wehave(SilwSi2,a
*SiN)=(S(i+l)
S(i+n)2ed
S(f+oll)
where
sii's
ands(j+j)j's
aredeflnedasfollows:stat++l tN si=tj- ai, if [
pit1+l
tisodd is even (1)
ForStep S in
Algorithm
C,
wehavebLizl(Ll-1)+b'1 (2)
bLi=_ Zi(SLi ) bLi-(2
Since
b'
= b iandsi
=SLi, comparing(1)
with(2),
we havebLi
=b1.
Inotherwords,(rL1,rL2, ,rLN)=(AIbL
IA2bL2, ANbLN)
-
(A
lbl,A2b,2S, ANbN).
Q.1).D
APPENDIX BPROOFOF THEOREM 6.2
Theorem 6.2: Let there beNsets:
D1, D2,
DN
whereDi
={Ail,
Ai2,, Aiqj}
andqi
> 1. LetRL
denote therecord associated with L. Let NRdenotethetotal number of records in
DI
XD2 X * XDN. Then theHamming
distancebetween
Ri
andRi+j
is 1, for 1 S i <NR.Proof:
(z1z2,- ,ZN)
and(q1,
q2,*,qN)
aregiven.
Let
C=ZlZ2
* ZN- LetRi
=(ri,
ri2,**, rN),
andRi+j
=(r(i+,)l
,r(i+1)2,
*,r(i+,)N)-
;NWe want to show that
d(Ri,
R1+..)
=Sf'
6(rij, r(i+l))
= 1-Byapplying
AKT(or Algorithm
C),
wehaveM~~+,(
Ci
+1 1I)-and
s(i+)j=a(1+l)1+
1, if[ttj
l tN is oddSqE+i)
=s(i+,)j,,
t -a(q+l),
if [~~~tjtj+l
tNI isvee
then
(ail,
ai2,
,a1N)
is thet1
representation ofPi
and(a(il),
a(1+1)2,
** ,a(i
+))
is thet1
representation ofPi+.
SincejmM+l
-m11
= 1, by Lemma 3, wehave(b;1,
b;2,
b;N)
and(b1i+1)1,
b+i)2,
,)N)
as twoN-tuples
which are defined as below and the
Hamming
distance be-tweenthem is 1. * if Z-Z-if' ZN isodd b~--,-z a i1, if is even , j IZjZj+ . ZN andb(i+i
-=a(i+l)i+ 1, if m1+ ZjZj+l ..*ZNo+v=
Zj -a(u+w)1,
if [ * ZZ1 ZNI isodd isevenwhere
(aiI,
ai2,
,ajN)
is the zJrepresentation
ofmi
and(a(i+,)I,
a(i+,)2,
* * -,a(i+)N)
is thez1
representationofmi+
.j = 1, 2, * , N, since the Hamming distance between
(b;I,
Mb2, bN) and(b'i+1)1,
b(1+1)2, * ,b'i+1)N)
is 1,thereexists a k, such that bik b(i+I)k and b, =bi+
1)-
for allj
= 1, 2,*,N,j*k.
Since
si1
=S(i)f, for allj= 1,2,
,N, we have only onebik.:b(i+l)k
andbij=b(i+l)b,
for allj= 1,
2N, j
k. Becauserij
=A1bi
andr(i+1)j
=A1b(i+1)1,
we haverij
=ry+j);
forall j 1, 2,-*
*,
N,j k andrik#
r(i+l)k.
Therefore,N
d(Ri,
Rjj)=
(rij,
r(
+1)i)=1
j=l Case 2:
[ntis]stio and e. Inthis
situation,
forri/Cl
=e,we havee- l<- <e.
C
Ifi/C<e,ori<Ce,wehave 'i+ I
i.Ce-
l,i+1<Ce,
C e.So
[i+
1/Cl
.e,
which is contradict to[i+
1/Cl e+ 1. Hence wehavei/C=e,that is i= Ce.Inthis case, wehavetwopossibilities.
1)
IfPi
=eisodd,thenPi+,
=e+ 1 is even, wehave mi=mi,=i-(e- l)-C=i-eC+C=CMi+l =C-
mt+1
+ 1 C-[(i
+ 1)- eC] + I=C-i+eC=C. That is, Mi=mi+.. =C.
2)
IfPi
=eiseven,thenPi+,
=e+ I isodd,
wehavemi=C-
[i- (e-
1)-C]
+ 1 C-i+(e-
1) *C+
1= 1 andmrn+1
=Mi+
i+ 1 - eC= 1. Thatis,Mi=Mi+1
1.Sowehave concluded that if
[i/Cl
=eand [i+1/Cl
=e+ 1,mi
=mi+l andPi+,
=Pi
+1.For
Pi+l =Pi
+ 1, by Lemma 3, wehave(sil,
sS2,*,siN)
and
(s(i+l)i,
S(i+1)2,
S(i+)N)
or twoN-tuples which are definedasbelow and the Hamming distance between themis 1:1,jtj+l f. tN]
sij=t-a11, if
+Pi
isodd iseven
and
s(i+I)j=a(i+1)j+
1,
if[Pil
tjtj+l ...tN isodd
s(j)j
= t1 -a(j+i)j,
if[t
ti+1
1 isevenwhere
(ail,
ai2
,ajN)
is the t1 representation ofPi
and(a(i+)
I,
a(i+1)2,
,aq+r)
isthet, representationofPi+,.
Formj+j
.mi,
we have(b1, bi2,* b=(b(i+l)i, b(i+l)2,
*,bi+)N),
whereb1 's andbji+1)1's
are definedasfollows: bg =aii
+ 1, if[
Z
isodd ZjZj+I.. ZN b;1=z1-ai,
if rn zN] is even andbl(i+l)
=a(i+l)j+ 1, if [ ZN] ZjZj+l ...ZN isodd is even where(ail, ai2,*
* ,aiN)
is the z; representation ofmi
and(a(i+),
a(i+1)2,
***,a(+)N)
is
thezi
representation
ofmi+,. Forb11
=zj(sij
- 1)+b,'
andb(i+l)1
=zj(s(1+1)i
- 1)+blsince the Hamming distance between
(sil,
Si2 ,siN)
and(s(i+l)
1 iS(i+)2
i+))
is 1,there exists aw, such thatAiw
Aq(i+l)w
andsij
=ss+)j,for
all
j=1, 2,
,N,
j
w.Since
b!
=b(1+1,
for all j=1, 2,* ,N, we havebi
+b(i+l)w
andbij
=b(i+l)j,
for allj 1, 2, ,N, j# w. Sincerij
=Ajb,,
andr(1+1)j
=Ajb(i+)1,
riw
/r(i+l)w.and rij
=r(i+1),
for allj
1,2,
N,
j#w.
Hence,d(Ri, R1+.)
= ir(I+l)1) = 1. Q.E.D.
REFERENCES
11] A. V. Aho and J. D. Ullman, "Optimal partial-match retrieval when fields are independentlyspecified,"ACM Trans. Database Syst.,vol.4,pp. 168-179,June1979.
[2] J. L. Bentley and J. H. Friedman, "Data structures for range searching,"Comput.Surveys,vol.11,pp.397-409,Dec. 1979.
131 W. A. Burkhard, "Partial-match hash coding: Benefits of redun-dancy," ACM Trans. Database Syst., vol. 4,pp. 228-239,June
1979.
141 W. A. Burkhard and R. M. Keller, "Some approaches to best-match file searching," Commun. Ass. Comput. Mach., vol. 16, pp.230-236, Apr. 1973.
S5] C. C. Chang and R.C.T. Lee, "Optimal Cartesian product files for partial match queries and partial match patterns," inProc. NCS1979Conf., Taipei, Taiwan,Dec. 1979,pp.5-27-5-37. 161 C. C. Chang, R.C.T. Lee, and H. C. Du, "Some properties of
Cartesian product files," in Proc. ACM-SIGMOD 1980 Conf.,
SantaMonica, CA, May 1980,pp. 157-168.
171 J. M.Changand K. S. Fu,"On theretrieval time and thestorage space ofdoubly-chained multiple-attribute treedatabase organi-zation,"PolicyAnal.Inform.Syst.,vol. 1,pp.22-48,Jan. 1978.
181 R. J. Cichelli, "Minimal perfect hash functions made simple,"
Commun. Ass. Comput.Mach.,vol.23,pp.17-19,Jan. 1980. 191 H. C. Du and R.C.T. Lee, "Symbolic gray code as a multikey
hashing function," IEEE Trans. Pattern Anal. MachineIntell.,
vol.PAMI-2, pp. 83-90, Jan. 1980.
b(i+
)izi-
=a(i+1),
if1i+
[10] H. C. Du and J. S. Sobolewski, Disk Allocation for Cartesian Product Files onMultiple Disk Systems. Seattle: Univ. Washing-ton,1980.
[11] M. W. Du,K.F. Jea, and D. W. Shieh, "The study ofanew per-fect hash scheme," inProc.COMPSAC1980, pp. 341-347. [12] J. H.Friedman, F.Baskett, and L.J.Shustek,"Analgorithmfor
finding nearest neighbors," IEEE Trans. Comput., vol. C-24, pp.1000-1006,Oct.1975.
[13] J. H. Friedman,J. L. Bentley, and R. A. Finkel, "An algorithm for finding best matches in logarithmic expected time," ACM Trans. Math. Software, vol. 3, pp. 209-226, Sept. 1977.
114] K.Fukunaga andP. M. Narenda,"Abranch and boundalgorithm for computingk-nearest neighbors," IEEE Trans. Comput., vol. C-24, pp.750-753, July1975.
[15] R. L. Kashyap, S.K.C. Subas, and S. B. Yao, "Analysis of the multiple-attribute-tree data-base organization," IEEE Trans. Software Eng., vol.SE-3,pp.451-567,Nov. 1977.
1161 S. P.Ghosh, Data BaseOrganizationfor Data Management. New York: Academic, 1977.
[17] R.C.T. Lee, Y. H. Chin,and S. C.Chang,"Application of princi-pal component analysis to multikey searching," IEEE Trans. Software Eng., vol. SE-2, pp. 185-193, Sept. 1976.
118] R.C.T. Lee and S. H. Tseng, "Multi-key sorting," Policy Anal. Inform. Syst., vol. 3, pp. 1-20, Dec. 1979.
[19] W. C. Lin, R.C.T. Lee, and H. C. Du, "Common properties of some multi-attribute file systems," IEEE Trans. SoftwareEng., vol. SE-5, pp.160-174, Mar. 1979.
[20] J. H. Liou and S. B.Yao, "Multi-dimensionalclustering for data base organizations,"Inform. Syst., vol. 2, pp. 187-198, 1977.
[21] R. L. Rivest, "Analysis of associativeretrieval algorithms," Ph.D. dissertation, Dep. Comput. Sci.,'Stanford Univ., Stanford, CA, 1974.
[22] -,"Partial-match retrieval algorithms," SIAM J. Comput., vol. 15, No. 1, pp.19-50, Mar. 1976.
[231 J. B. Rothnie and T. Lozano, "Attribute based file organization in a paged memory environment," Commun. Ass. Comput. Mach., vol.17,pp.63-69,Feb. 1974.
[24] C. W.Shen and R.C.T.Lee, "A nearest neighbor searchtechnique with short zero-in-time," IEEE Trans. Software Eng., to be published.
[251 R. Sprugnoli, "Perfecthashing functions: Asingle probe retriev-ing method for static sets,"Commun. Ass. Comput. Mach., vol. 20, pp. 841-850, Nov. 1977.
C. C. Chang was born in Taiwan in 1954. He _ received the B.S. degree in applied mathe-matics in 1977and the M.S. degree in computer W and decision sciences in 1979,both from the
4 NationalTsingHuaUniversity.
i
~ : NaHeispresentlyaninstructoraswellas a
Ph.D-r student of theInstitute ofComputer
Engineer-i
mgin NationalChiao-Tung University, Hsinchu, l Taiwan. His research interests are in database w
El design, algorithm analysis, and statistics. R.C.T. Lee (A'74-M'75) received the Ph.D. degree from theUniversityofCalifornia,
Berke-ley,in1967.
He is currently the Director of the Institute of Computer and Decision Sciences, National Tsing Hua University, Hsinchu, Taiwan. He previously worked for NCR (California), Na-tional Institutes ofHealth(Bethesda,MD),and the Naval Research Laboratory (Washington, DC) before joining the National Tsing Hua University in 1975. He is the coauthor of Sym-bolic Logic and Mechanical TheoremProving(New York: Academic), which has beentranslated into bothJapaneseandRussian. His research in clustering analysis will appear as a chapter entitled "Clustering Analysis and its Applications" in Advances in Information Systems Science (New York: Plenum). He is the authorofmorethan 50 papers onmechanical theoremproving, databasedesign,and patternrecognition. M.W.Du(S'70-M'72)wasborninChung-King, China,in1944. He received theB.S.E.E.degree from the National Taiwan University in 1966 and thePh.D.degree fromTheJohns Hopkins University,Baltimore, MD, in 1972.
He is now the Director of the Institute of Computer Engineering, National Chiao-Tung University, Hsinchu, Taiwan. His research interests include fault diagnosis, automata theory, algorithm design and analysis, database design, and Chinesel/O design.