i
國 立 交 通 大 學
資訊科學與工程研究所
碩
碩
碩
碩 士
士
士 論
士
論
論 文
論
文
文
文
基 於 動 態 調 整 權 重 之 c o - c l u s t e r 演 算 法
Co-cluster with dynamic weighting
研究生:張智愷
指導教授:李嘉晃 教授
中
中
中
ii
基 於 動 態 調 整 權 重 之 co-cluster
Co-cluster with dynamic weighting
研 究 生:張智愷 Student:Chih-Kai Chang
指導教授:李嘉晃 Advisor:Chia-Hoang Lee
國 立 交 通 大 學
資 訊 科 學 與 工 程 研 究 所
碩 士 論 文
A ThesisSubmitted to Institute Computer Science and Engineering College of Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master
in
Computer Science Jun 2011
Hsinchu, Taiwan, Republic of China
iv
基於動態調整權重之co-cluster
學生 : 張智愷 指導教授:李嘉晃 教授
國立交通大學資訊學院 資訊科學與工程研究所碩士班
摘要
由於科技的進步,網路的發展,造成資訊量迅速攀升,然而這樣的進步卻相 對的造成使用者必須付出更多的時間去瀏覽所需的文件。有鑒於現今搜尋引擎的 廣泛使用,人們希望以更高的效率與效能取得資訊,其中分群的技術應用,扮演 著重要的角色。在搜尋的過程中,若能先將文件做好適當的分群,則可讓搜尋系 統提供更結構性的結果給使用者。如此一來,不僅可以減少搜尋文件的時間,更 可加快使用者找到自己想要的文件。 本研究利用 Co-Clustering 的分群方法為基底並做更進一步的改良,針對分 群效能的改善以及 feature 權重的增減加以討論,並且以 Reuters、20newsgroup 及 classic3 資料集做分析,萃取出核心關鍵字,並給予適當的權重,進而過濾一 些不必要的雜訊以及加強關鍵字的強度。利用座標的資訊,利用核心關鍵字在距 離群中心的距離為基礎做關鍵字之調整權重。接著,利用 logistic function 的特性 對關鍵字之權重調整到介於 0 與 1 之間,再將關鍵字賦予調整後權重之後,再做 一次 Co-Clustering,重複以上的動作達到收斂後,進而得到較高的分群結果。v
Co-clustering with Dynamic Weighting
Student : Chih-Kai Chang Advisor:Prof. Chia-Hoang Lee Institute Computer Science and Engineering
College of Computer Science National Chiao Tung University
Abstract
This paper proposes a weighted co-clustering algorithm and applies it to document clustering problem. The weighted co-clustering is an extension of co-clustering, and it makes use of co-clustering properties to design a dynamic weighting algorithm for terms. Firstly, co-clustering presents both documents and words on the same coordinate system using spectral embedding technique. Secondly, co-clustering clusters documents and words simultaneously, so the documents that are within the same cluster should be clustered together with their corresponding words. Based on these two properties, the weighted co-clustering changes term weights iteratively. In addition, an outlier detection mechanism is proposed in this paper to eliminate outlier documents from clustering process. When the clustering process is completed, these outlier documents are assigned to appropriate clusters. We conduct experiments on three data sets and the experimental results show that the weighted co-clustering can effectively improve the performance.
vi
誌謝
誌謝
誌謝
誌謝
首先,感謝指導教授李嘉晃老師對我的悉心指導,才能有今日的成果。老師 就像我的良師益友,時而嚴厲,時而慈祥,不論是研究討論或課堂授課時,所教 導我的專業知識和處世道理,都著實讓我獲益良多。這些過程與經驗,都將成為 我一生受用無窮的寶庫。 同時,我亦感謝這兩年來陪伴在我身邊的實驗室同學們、學長以及學弟。尤 其是我的同學們,而益、士元、俊憲,總是不斷的鼓勵我,對我的幫助更是多不 勝數。兩年的時間,雖然不是很長,但是曾經有過的歡笑淚水,這些回憶會一輩 子永存在我的心中。 最後,我要感謝我的家人,感謝你們對我的愛護和包容。謝謝你們在背後默 默的支持,使我能夠順利的完成碩士學位。 心中有太多的感謝不知道如何表達,在此僅以本篇論文表示我對你們最誠摯 的感謝,並祝福你們身體健康、萬事如意,謝謝。 張智愷 謹誌 資訊科學與工程研究所 智慧型系統實驗室 中華民國一百年七月vii
目錄
目錄
目錄
目錄
摘要 摘要 摘要 摘要... iviviv iv Abstract Abstract Abstract Abstract ... vvvv 誌 誌 誌 誌謝謝謝謝... vi... vi... vi... vi 圖目錄 圖目錄 圖目錄 圖目錄 ... viiiviiiviii viii 表目錄 表目錄 表目錄 表目錄 ... ixixix ix 第一章 第一章 第一章 第一章、、、緒論、緒論緒論 緒論 ... 1111 1.1 研究動機... 1 1.2 研究目的... 2 1.3 論文架構... 4 第二章 第二章 第二章 第二章、、、相關研究、相關研究相關研究 相關研究 ... ... 5555 2.1 Co-clustering 概念... 52.2 Spectral Graph Bipartitioning... 6
2.3 Co-cluster Algorithm... 12 第三章 第三章 第三章 第三章、、、、系統設計系統設計系統設計 系統設計 ... ... 151515 15 3.1 概念... 15 3.2 Outlier detection... 16
3.3 Weighted Term Matrix Construction Algorithm... 23
3.4 Merge function... 27
3.5 Co-cluster with Dynamic Weighting... 33
第四章 第四章 第四章 第四章、、、、實驗結果與討論實驗結果與討論實驗結果與討論 實驗結果與討論 ... ... 363636 36 4.1 實驗資料... 36 4.2 實驗設計... 37 4.3 實驗成果... 40 4.4 實驗討論... 42 第五章 第五章 第五章 第五章、、、、結論與未來展望結論與未來展望結論與未來展望 ... 49 結論與未來展望 5.1 研究總結... 49 5.2 未來展望... 49 參考文獻 參考文獻 參考文獻 參考文獻 ... 515151 51
viii
圖目錄
圖目錄
圖目錄
圖目錄
圖3-1 用 co-cluster 降維後點圖... 16 圖3-2 用 co-cluster 降維後點圖利用 k-means 分群的結果 ... 17 圖3-3 用 co-cluster 降維後點圖實際的 label ... 17圖3-4 做 outlier detection 後的點圖,綠色為 outlier ... 18
圖3-5 talk.politics.guns 以及 talk.politics.mideast 執行 outlier detection 的結果 ... 21 圖3-6 內點利用 co-cluster 分群的結果 ... 22 圖3-7 內點實際的 label ... 23 圖3-8 探討點與群中心的距離差所產生的關係性 ... 25 圖3-9 logistic function 示意圖 ... 25 圖3-10 各點尚未進行 outlier detection 之分佈圖 ... 29
圖3-11 各點進行 outlier detection 再進行 co-cluster 後之分佈圖 ... 29
圖3-12 進行相似度計算後的各點之分佈圖 ... 30
圖3-13 Merge 的流程圖 ... 31
圖3-14 Co-cluster with Dynamic Weighting 的流程架構圖 ... 34
圖4-1 進行第二次 iteration 系統分群圖 ... 43
圖4-2 進行第二次 iteration 實際點分佈圖 ... 43
圖4-3 進行第三次 iteration 系統分群圖 ... 44
圖4-4 進行第三次 iteration 實際點分佈圖 ... 44
圖4-5 資料 talk.politics.guns 以及 talk.politics.mideast 各 iteration r 值的變化量 與F1-value 的圖表,其中橫軸為 r 值,縱軸為內點 F1-value 曲線圖 ... 45
圖4-6 資料 crude 及 money-fx 各 iteration r 值的變化量與 F1-value 的圖表,其 中橫軸為r 值,縱軸為內點 F1-value 曲線圖 ... 46 圖4-7 經過 outlier detection 後文章與字的分佈圖 ... 47 圖4-8 權重大於平均值以上文章與字的分佈圖 ... 47 圖4-9 權重大於兩倍平均值以上文章與字的分佈圖 ... 48
ix
表目錄
表目錄
表目錄
表目錄
表 3-2 未做 outlier detection 的文章所對應的 index ... 28
表 3-3 做完 outlier detection 再進行 co-cluster 後的文章所對應的 index ... 29
表 3-4 進行相似度計算後的文章所對應的 index ... 30
表 4-1 20newsgroups 的分群結果,值為 F-1value ... 40
表 4-2 Rruters-21578 的分群結果,值為 F-1value ... 41
表 4-3 Classic3 的分群結果,值為 F-1value ... 41
1
第一章
第一章
第一章
第一章、
、
、
、緒論
緒論
緒論
緒論
1.1
1.1
1.1
1.1
研究動機
研究動機
研究動機
研究動機
現今的社會科技越來越進步,網路在這個社會中已經跟我們的生活密不可分, 隨著網路的蓬勃發展,使得許多資訊的傳遞越來越簡便,從以前的寄信時代到現 在的 e-mail,我們可以了解科技的進步讓我們的生活越來越便利,不論是新聞 或是書本以及報章雜誌都進入了電子化的時代,進而演變出大量的文章該如何分 類的問題,所以如何快速將這些大量的文章做最正確且最有效率的分類,是一個 很重要的課題。 由於電腦的普及化,使得每個人都可簡單且輕鬆的擷取到網路上的文件。面 對如此龐大的文件,進而造成了讀者閱讀上的困擾,面對每天都有成千上萬的文 章在這個網路的世界上發表,這些發表的文章許多都會被拿來當作新聞。然而大 量的新聞資訊所引發的問題往往讓人覺得很頭疼,該如何減低人力來讓系統有個 自動化的方式整理這些龐大的新聞,讓使用者可以快速的找到其喜歡的新聞文章, 這是本研究主要的目的。透過有效率的方式,系統快速且準確的對龐大的文章分 群,如此一來便可以加快搜尋文件的速度,讀者可以快速且便利的找到他們想要 的文章。 分群的方法可以視為一種藝術,透過群與群之間的關係性,除了可以定義群 跟群之間的相似度以外,也可以進階的使用在許多地方,比方說像上敘所說的搜 尋,我們也可以利用在導航、興趣分析,更廣泛的說法,其實不只是只能對文章 做分群,透過分群的概念一樣可以讓許多系統可以達到更高的效能,比方說分散 式系統、多處理器等,在此我們針對文章的分群做研究。我們將針對許多的新聞 文章利用分群的方式來將相似的文章分成同一個群,實驗將用有別於一般傳統的 分群方式,我們會利用 co-cluster[1]的方法除了可以達到不錯的分群效果以外, 我們還可以找到字與文章之間的關係性,藉由此關係聽來做更深一步的探討以及
2 改進效能,已達到更好的精確度。
1.2
1.2
1.2
1.2
研究目的
研究目的
研究目的
研究目的
由於搜尋引擎的廣泛使用,我們希望在搜尋的過程中,先將文件分群好以後, 可以將相關性的文章一併列出,讓使用者除了能夠透過搜尋引擎的搜尋,找出自 己所需要的文章,同時可以了解其他隸屬於同一個群的文章,藉此來達到節省時 間以及迅速找到想要的文章之目的。 透過文章中字與字的關係性,本研究亦可改善許多雜訊的產生,在大量的文 章之中存在許多我們不會去關注甚至於會影響到分群的結果的字,在本研究都會 一一探討,並且透過實驗的方法可以有效的降低不重要字眼的權重,並且提升重 要字眼的權重,進而提升分群的效果。
當我們要對文章做分群時,我們會建立出一個 vector space model[2],在 最基本的概念下,我們會建立一個 word 的 list,這個 list 中的每一個 word 都 是獨立不重複的,然而我們會把每個 word 當成用來表示該篇文章的一種特徵, 許多特徵可以表現出一個特徵的向量,也代表著這篇文章將由這條向量所表現的 特徵空間來表示。 我們考慮到字的分群其實基本的架構在同一篇文章中有多少的文字與其一 起發生,當所有的文章都沒有給定標籤的情況下,該如何利用有效的資訊達到更 高的效果,這是本研究所要探討的目的,目前存在的文章分群法包含以下幾種常 用的演算法,agglomerative cluster[3]、k-means 演算法[4]、
Probabilistic latent semantic analysis(pLSA) [5]、self-organizing maps[6]、multidimensional scaling[7],對於文章的分群,目標是要將一個集 合的文章分到一個群,最近也吸引了越來越多人的興趣,分群可以用來自動檢索 文件組成有意義的清單,這也是一個最廣泛使用的技術以用來進行數據的探勘, 因為它可以捕捉到自然結構的數據,基本上分群是屬於非監督式的學習,所以它
3 不需要事先給定群的類別。 分群的目的是為了將目標對象分配成組,使目標對象在同一個群組中更相似, 並且與不同組不相似。在分群的演算法分成判別性(discriminative)以及生成性 (generative),而判別性的演算法採用兩兩之間的相似性為基礎,以確定一個目 標函數以及優化這個函數來達到目標結果,k-means 是一種典型的判別性演算法, 其目的在於最小化目標對象與群中心之間的平方和,另一方面生成演算法是假定 數據是由一個基本的參數模型,目標是從觀測數據中估計參數,然而群中心可以 進一步的獲得模型與參數,高斯混合模型(The Gaussian mixture mode)是個典 型的生成演算法,其使用一個混合多個高斯分佈的模型,解決多種混合分解已經 被提出,其中許多集中在最大似然法(maximum likelihood methods),如最大化 期望值(EM)[8],或最大後驗估計(MAP)。 目前大多數分群演算法集中在一維度的分群[9],隨著網路速度的發達,以 及電腦的計算速度的增長,許多數據探勘(data mining)的應用已經從對簡單的 資料型態分群延伸到對多類別資料型態作 co-clustering,但是通常都討論高異 質性數據[10]。實際上許多現實例子對象與其相對應的特徵是有互相關聯性的, 在一個語料庫中文章與字就是個典型的例子,因為文章是由字組成的;而將字搜 集起來就成了文章,直觀上一群被分割的文件應該會驅使著一群字被同時的分割, 同樣的當一群字被劃分的同時也意味著一群文章已經被分割了,這也表明了在許 多應用中 co-clustering 比分群更有效率的沿用在單一維度中,因此 co-clustering 已經在許多的應用領域中被廣為研究,例如文件的分析(text mining)[1][11],生物訊息(Bioinformatics)[12][13]、以及資料探勘(data mining)[14]。
4
1.3
1.3
1.3
1.3
論文架構
論文架構
論文架構
論文架構
第一章:前言,敘述本研究之動機與目的。 第二章:相關研究,敘述本研究之相關研究與背景。 第三章:系統設計,將本研究之系統整體架構與概念方法做一個完整介紹。 第四章:實驗結果與討論,將本研究之系統產生的結果根據不同類型的資料 做全面性的分析。 第五章:結論與未來展望,將本研究之系統成果做一總結,並提出結論與探 討未來研究之方向。
5
第二章
第二章
第二章
第二章、
、
、
、相關研究
相關研究
相關研究
相關研究
2.1
2.1
2.1
2.1
Co
Co
Co
Co-
--
-clustering
clustering
clustering 概念
clustering
概念
概念
概念
Co-clustering 的概念在先前就有人提到,其組成與 Hofmann[15]等人提出 的非監督氏學習(unsupervised learning )框架中使用的成對數據(dyadic data) 很相似;一成對的數據會對映至一個由兩種成對關係建立的可見集合,並且將每 個元素對映到其中一個集合之中。成對的概念是常用的數據表示方式,常常用在 許多領域例如:文件分析(text analysis)、電腦視覺、以及計算式的語言學。 比方說在一個語料庫中,文章與字是一個典型的例子,因為文章是由字來組成的, 同時字的組成就成了文章。直觀上,一些被區分好的文章,也應該驅使著字的區 分,同時區分好的字集合應該意味著一些文章已經被區分好了,這樣的原理類似 於 Zhu[16]所提的相互加強原理(mutual reinforcement principle),並且已經
成功的被運用在摘要的系統之中[16][17]。 Co-clustering 或者 bi-clustering 的概念吸引著許多的研究人員開發新的 演算法來執行多類型的文件分群的任務,Dhillon[1]利用了 bi-partite 的圖形 來分別表示文章和字的關係,然後對文章以及字同時進行分群,其理論是架構於 Spectral clustering[18][19][20]之上,實驗結果顯示,co-clustering 方法 可以有效的運用在文件分析的領域。同樣的 Zha[21]等人運用了雙分圖
(bi-partite graph)以及 spectral clustering 來執行分群的目的,利用對象以 及特徵的對偶關係有效的同時針對對象以及特徵分群,Li[22]提出了一個二元的 生成模組,允許模組下的特徵結構(feature structure)與每個群產生連繫,並 且採用優化方法(optimization procedure)優化群的結構以及更新群的資訊。 本質上來說,物件與其特徵可以用矩陣來表示,所以 co-clustering 可以建 構一個模組用來同時將矩陣的行與列進行分群;因此 co-clustering 可以藉由矩 陣的分解[23][24][25]來解決,co-clustering 的模型可以做為優化問題以及涉 及三重(triple)的矩陣分解,Long[26]等人使用了其它的矩陣分解技術,稱做
6
Block Value Decomposition 來分解成對資料的矩陣至一個列系數矩陣、Block
Value 矩陣以及行系數矩陣。
在文件的分析,語料庫常被表示成文章與字組的矩陣,其中列代表了文章, 行代表了在字典裡面的字,許多的文件探勘(text mining)利用 co-clustering 的技術在近期中被開發出來,Mandhani[27]等人提出一個階層式的
co-clustering 演算法,並且運用在文章與字的矩陣;每個 co-cluster 都是一 個子矩陣並且包含了文章所成的群以及與該群有關連的字。Park[28]等人檢視了 spectral clustering 背後的文章以及字,並與 Latent Semantic
Analysis(LSA)[29]做比較,發現 spectral co-clustering 以及 LSA 依照同樣的 執行程序,並且運用不同的正規劃技術以及度量方式。Bisson 以及 Hussain[30]
定義一個相似度的計算稱做*-Sim 迭代的完成物件與特徵的相似度,本篇文章將
Dhillon[1]的 co-clustering 做延伸,提出一個有權重的 co-clustering 演算法, 將不利於分群的字給予較低的權重,同時將那些能夠促進分群的字給予較高的權 重。
2.2
2.2
2.2
2.2
Spectral Graph Bipartitioning
Spectral Graph Bipartitioning
Spectral Graph Bipartitioning
Spectral Graph Bipartitioning
Spectral clustering[18][19][20]是一個分群演算法,它根據點與點之間 的相似度將空間上的結果分群,使得同一個群內的點與點之間的相似度越高越好, 不同群的點與點之間的相似度則越低越好。這類演算法討論到了 graph 的
bipartitioning,是一個有效率的 heuristic,早在 1970 年時就被介紹了 [31][32][33],更進一步在 1990 年被推廣[34]。這一節將簡單說明 spectral graph bipartitioning 的基本原理[18]以及著名的幾個找 graph minimum cut
的方法。
2.2.1
2.2.1
2.2.1
2.2.1
符號定義
符號定義
符號定義
符號定義
7
有權重(weighted),. = {34, … , 36}是點(vertex)所形成的集合,89:為39與3:相 連的邊上的權重。其中,89: ≥ <且89: = 8:9,若89: = <代表39與3:之間無邊相連。 定義 weighted adjacency matrix =:
= = (=9:)9:?4,…,6 G 中的每個點39 ∈ .的 degree 定義為: A9 = B 89: 6 :?4 定義 degree matrix D: C = DA
⋮ ⋱ ⋮
4⋯
< <⋯
A6 H D 為對角矩陣,且對角線上的值為A4, … , A6。 假設有一 假設有一 假設有一假設有一.的子集合的子集合的子集合的子集合I ⊂ .,,,則,則則則I的補集合的補集合的補集合的補集合(KLMNOPMP6Q)標記為標記為標記為標記為IR,,,, 定義 定義 定義 定義indicator vector SI= (S4,…,S6)T ∈ ℝ6為: VSS9 = 4, 9S 39∈ I 9 = <, 9S 39∈ IRW 假設 假設 假設 假設I、、、、X ⊂ .且且且且I ∩ X = ∅ 則定義則定義則定義則定義I、、、、X之間的之間的之間的之間的8P9[\Q為為為為:::: =(I, X) = B 89: 9∈I,:∈X
2.2.2
2.2.2
2.2.2
2.2.2
Laplacian matrix
Laplacian matrix
Laplacian matrix
Laplacian matrix
Laplacian matrix 可以分為 unnormalized 與 normalize。首先說明 unnormalized Laplacian matrix,其定義為:
8 ] = C − = 矩陣]具有下列性質: (1).對於所有的向量S ∈ ℝ6,下列式子成立: ST]S =4 _ B 89:(S9− S:)_ 6 9,:?4
(2). L 是 symmetric 且 positive semi-definite。
因為C與=皆為 symmetric,所以 ] 也是 symmetric。且由(1)可知 L 為 semi-definite。 (3). L 最小的 eigenvalue 為 0,且相對於 0 之 eigenvector 為 1。 由此可知,0 必為 L 之 eigenvalue。且因 L 為 semi-definite,所以所有的 eigenvalue 皆≥ <,由此可知,0 為最小的 eigenvalue。 (4). L 的所有 eigenvalue(n 個)皆為實數,且< = `4≤ `_≤ ⋯ `6。
接下來說明 normalized graph Laplacian。normalized graph Laplacian 分為兩種,其定義分別為: ]bcM= Cd4_]C 4 _ 與 ]e8 = Cd4] 矩陣]bcM與與與與]e8具有下列性質具有下列性質具有下列性質具有下列性質:::: (1). 對於所有的向量S ∈ ℝ6,下式子成立:
9 ST]bcMS =4 _ B 89:fgAS99− S: gA:h _ 6 9,:?4 (2). ]e8i = `i ⟺ ]bcM8 = `8,,,其中,其中其中其中8 = C4/_i。。。。 (3). ]e8i = `i ⟺ ]i = `Ci。。。。 (4). ]bcM與與與與]e8是 positive semi-definite。
由(1)可知Lmno為 semi-definite,接著根據(2)可知,若 λ 是Lmno的
eigenvalue,則 λ 也是Lqr的 eigenvalue,所以Lqr的所有 eigenvalue 皆≥ 0,
由此可知Lqr為 semi-dininite。 (5). ]e8最小 eigenvalue 為 0,且相對於 0 之 eigenvector 為 1。]bcM最小的 eigenvalue 為 0,且相對於 0 之 eigenvector 為C4/_4。 因為]e84 = Cd4]4 = < = < × 4且]e8為 semi-definite,所以 0 為]e8之最 小的 eigenvalue。由(2)與(4)可知,0 也是]bcM最小的 eigenvalue 且]bcM相 對於 0 之 eigenvector 為C4/_4。 (6). ]bcM與與與與]e8的所有 eigenvalue(n 個)皆為實數,且< ≤ `4 ≤ `_ ≤ ⋯ `6。
2.2.3
2.2.3
2.2.3
2.2.3
RatioCut
RatioCut
RatioCut
RatioCut 與
與
與 Ncut
與
Ncut
Ncut
Ncut
給定一個 similarity graph + = (., 0),為了將所有的點.分成任意t群,
首先定義 cut 如下:
KiQ(I4, … , It) =4_ B =(IN, IuuuuN t
N?4
10
其中,I4∪ ⋯ ∪ It= .,,且,,且且且I4∩ ⋯ ∩ It = ∅。
Spectral clustering 的目標就是找出一組分割(partition) I4, … , It,使
得KiQ(I4, … , It)為最小。但是在分群時,有時會希望分群完成之後每一個群的
大小都差不多,所以必須將群的數量也考慮進去,於是就有 RatoiCut 與 Ncut。 分別定義如下:
wxQ9LyiQ(I4, … , It) = BKiQzI|IN, IuuuuN{
N| t
N?4
}KiQ(I4, … , It) = BKiQ(I3LO(IN, IuuuuN)
N) t N?4 其中,|I|代表I中點的數量,3LO(I) = ∑ A9∈I 9。 接下來就可以將重點放在如何找到 RatioCut 與 Ncut 的最小值上面。在這一 小節中,只說明 k = 2 之原理,因為 k 為任意值時,其原理與 k = 2 時是一樣的。 先說明 RatioCut: 根據之前的敘述,目標是要找出:
M96
I⊂. wxQ9LyiQ(I, IR) 首先定義向量S = (S4, … , S6) ∈ ℝ6為:S9 =
|I|uuuu/|I|,,,, 9S 39 ∈ I −|I|uuuu/|I|,,,, 9S 39∈ IR
(_. 4)W 則S具有以下性質: (1). (1). (1). (1). S ⊥ 4 (2). (2). (2). (2). ‖S‖ = √6
11 (3). (3). (3). (3). ST]S = |.| ∙ wxQ9LyiQ(I, IR) 因為|.|為定值,所以找出wxQ9LyiQ(I, IR)的最小值相當於找出S使得ST]S的 值為最小,因此可以將問題重新表現如下:
M96
I⊂. ST]S bi:PKQ QL S ⊥ 4 且且且且 S 9定義於定義於定義於定義於(_. 4),,,,‖S‖ = √6 但是這是一個 NP hard 的問題,沒有辦法有效率的被解決,所以放寬一些限制, 改成S ∈ ℝ6皆可,如此可以將問題簡化成:M96
S∈ℝ6 ST]S bi:PKQ QL S ⊥ 4 ,,,,‖S‖ = √6 由 Rayleigh-Ritz theorem[35]可知: `4≤ S T]S STS ≤ `6 且 f 若取 L 之 eigenvector 即可,但是前面的敘述可知,L 相對於`4之 eigenvector 為 1,但是因為 f 被限制要垂直於 1,所以改取相對於`_之 eigenvector。求得 f後將 f 當成 indicator vector,就可以藉由 f 得到 A,也就是將 V 分成兩群: V339 ∈ I, 9S S9 ≥ < 9∈ I,R 9S S9 < < (_. _)W 接下來說明如何求 Ncut 之最小值,其過程與求 RatioCut 之最小值非常類似。 首先定義向量S = (S4, … , S6) ∈ ℝ6為: S9 = 3LO(IR) 3LO(I) , 9S 39 ∈ I −3LO(IR)3LO(I) , 9S 39 ∈ IR (_. )W 則可求得: (1). (1). (1). (1). (CS)T4 = <
12 (2). (2). (2). (2). STCS = 3LO(.) (3). (3). (3). (3). ST]S = 3LO(.)}KiQ(I, IR) 所以可以將問題表示如下:
M96
I⊂. ST]S bi:PKQ QL CS ⊥ 4 且且且且 S9定義於定義於定義於定義於(_. ),,,,STCS = 3LO(.)同樣可以放寬限制變成:
M96
S∈ℝ6 ST]S bi:PKQ QL CS ⊥ 4 ,,,,STCS = 3LO(.)最後將S = Cd4/_[代入代入代入代入:
M96
[∈ℝ6 [TCd4/_]Cd4/_[ bi:PKQ QL [ ⊥ Cd4/_4 ,,,,‖[‖_ = 3LO(.)其中,Cd4/_]Cd4/_= ]bcM,且如前所述]bcM相對於`4之 eigenvector 為Cd4/_4,
所以根據 Rayleigh-Ritz theorem,取 g 為]bcM相對於`_之 eigenvector,則
S = Cd4/_[。最後如同(2.2),可以利用 f 將 V 分成I與IR。
2.3
2.3
2.3
2.3
Co
Co
Co
Co-
--
-cluster Algorithm
cluster Algorithm
cluster Algorithm
cluster Algorithm
基於 spectral clustering 的架構,Dhillon[1]提供了一個 spectral co-clustering 的演算法,此演算法取左邊以及右邊第二個奇異值向量 (singular vectors)適度的縮放文章及字的矩陣而使其產生更好的二元分割 (bipartitionings)。co-clustering 演算法將使用一個二分的無向圖模組,一 個點的集合包含了兩個獨立的集合,其中一者代表文章,另外則代表字,將文章 以及字進行 co-clustering 必須依照以下準則:一群已經分割好的文章應 該促使著一群字的分群,同樣的當一群字分割好也應意味著一群文章的分群。
13 傳統上,spectral clustering 轉移了分群的問題到解圖的最小分割 (minimum cut)問題,在圖型的分割,如果分群的演算法沒有考慮到群的大小, 不平均的問題就有可能會發生,有一種方法去避免此問題就是限定群的大小,因 此不同的 spectral clustering 演算法的發展也會根據它不同的限制,如上面 2.2.2 小節所述,RatioCut[36]是根據點的數量進行計算,同樣的 Ncut[37]則會 考慮邊的權重,適當的放寬限制後 spectral clustering 演算法可變成解特徵方 程式(eigenvalue equation)的問題,例如 Ncut 可以形成一個廣益的特徵值問題 ] = `C,它提供了一種真正的放寬至離散優化問題去尋找最小且正規劃的切 集。
Dhillon 建議將文章以及字一起進行處理,所以 Laplician matrix 以及對 角矩陣則採用方塊矩陣來一併考慮文章以及字,式子(2.4)將呈現它們的不同 處。 ] = −IC4T −IC _ , C = C 4 < < C_ (_. ) ] = `C可以被改寫為式子(2.5) −IC4T −IC _ c = ` C< C4 <_ c (_. ) 以上兩個式子可以被進一步的改寫成兩個子式子並且正規劃後的矩陣 I6= C4d4/_IC_d4/_正是奇異值分解(singular value decomposition)的定義,
對於分兩群而言,I6的左邊第二以及右邊第二奇異值向量將會產生良好的分割, 對於多群的問題,k-way 分割可以被應用到矩陣I6;首先先完成I6左邊第個以 及右邊第個奇異值,左邊的奇異值向量為i4, … , i4,右邊的奇異值向量為 34, … , 34,而i9以及39代表矩陣I6第左以及第右第 i 大的奇異值所對應的奇異 值向量,第二步將i4, … , i4組成矩陣 U,以及34, … , 34組成組成組成組成.,第三部將資料 及以維度下呈現式子(2.6),最後對維度下資料的 Z 執行 k-means 演算法並獲
14
得 k-way 的多群結果,演算法 1 清楚的呈現 co-clustering[1]的演算法。 = C4d4/_
C_d4/_. (_. )
======== IO[Le9Q\M 4. yL − KOibQPe96[ IO[Le9Q\M ============= 6QNiQ ∶ +93P6 MxQe9 I x6A Q\P 6iMPe LS KOibQPe
iQNiQ ∶ yOibQPe96[ 96AP x6A − A9MP6b9L6 AxQx 4. P[96
_. I6 ← C4d4_IC_d4_
. ← ¡OL[_¢
. yLMNiQP OPSQ x6A e9[\Q b96[iOxe 3PKQLeb LS I6. ]PSQ b96[iOxe 3PKQLeb xeP i4, … , i4 x6A e9[\Q b96[iOxe 3PKQLeb xeP 34, … , 34, 8\PeP i9 x6A 39 ePNePbP6Qb Q\P OPSQ x6A e9[\Q
b96[iOxe 3PKQLeb KLeePbNL6A96[ QL 9Q\ Oxe[PbQ b96[iOxe 3xOiPb LS I6. . ← £i4, … , i4¤
. . ← £34, … , 34¤
¥. ¦LeM Q\P MxQe9 xb b\L86 96 0§ixQ9L6(_. ) ¨. ← t − MPx6b(, )
©. ePQie6 , 4<. P6A
15
第三章
第三章
第三章
第三章、
、
、
、系統設計
系統設計
系統設計
系統設計
3.1
3.1
3.1
3.1
概念
概念
概念
概念
傳統的分群的方法例如 K-means、pLSA[38]往往只考慮到單一維度的關係來 分群,例如在文件分群問題上,只是利用文章裡面的字計算群與群之間的關係性, 但是卻沒有考慮到字跟所在的文章之間具有什麼樣的關係,本論文採用 co-clustering 的方法來做文章分群,同時考慮文章與所含之文字以及文字與所 在的文件關係同時分群;co-clustering 背後是透過 spectral clustering 分群, 在多群分群上,spectral clustering 可以使用 spectral embeddeding 技術做 類似降維之動作;假設當文章被降維到三度空間的情況下,我們可以從三維座標 圖中了解到一篇文章在這個三維的空間所在的位置以及群中心的位置;同樣的, 基於 co-cluster 演算法的架構,我們也可以知道每個字在這三度空間的位置, 這點提供了我們很大的想法來對 co-cluster 的演算法做更進一步的改善。 我們知道群中心往往代表一群裡面最能表現一個群,換句話說當我們知道一 個點如果靠近群中心,我們可以間接的了解到這個點應該具備足夠的特徵可以讓 它表現這個群,同理,如果一個點距離群中心很遠,這個資訊告訴我們它不具足 夠的特徵可以表現這個群,更進一步的推廣,以兩群為例,當我們知道如果一個 點靠近某個群中心,相對的遠離另外一個群中心的話,我們可以知道這個點對於 靠近的那個群而言是相對的重要,反之如果一個點與某兩個群都很靠近,也就是 說他可能介於兩群的中間,我們可以推得這個點並不是一個具備足夠特徵可以將 兩群分開的點,所以具備這樣條件的點,我們可以把它想成是一種雜訊,比方說 當我們要做新聞分群的時候,”新聞”這樣的一個關鍵詞,出現次數很多,但是 他往往不會給我們帶來很大的幫助,因為它可能出現在每一篇文章裡面。 有鑒於上述的種種想法,本論文希望透過一個幾何的距離概念,給予字適當 的權重,經由一個加權的方法讓 co-cluster 這個演算法的效能有更進一步的提 升。
16
3.2
3.2
3.2
3.2
Outlier detection
Outlier detection
Outlier detection
Outlier detection
3.2.1
3.2.1
3.2.1
3.2.1
目的
目的
目的
目的
本節我們討論使用 outlier detection 的目的,首先我們先探討分群的意義, 一個分群的演算法將一些相似的文章分成一群,我們可以將文章所代表的座標點, 例如根據 k-means 的演算法分群到所指定的群裡,首先我們根據 co-cluster[1] 的演算法先將維度降到三維的空間,將所有的點標上去如圖 3-1,這樣的方法可 以將每篇文章與字利用視覺化的技術將每篇文章與字顯示在三維的空間。最後利 用 k-means 做分群得到的結果如圖 3-2,最後我們實際觀察正確答案將原本文章 的標籤標記上去,利用顏色的不同區隔出兩群之間的差異得到圖 3-3,可以了解 到利用 k-means 的演算法得到的結果並不理想,紅色群幾乎一半的點都被分到綠 色的群。 圖3-1 用co-cluster降維後點圖
17 圖3-2 用co-cluster降維後點圖利用k-means分群的結果 圖3-3 用co-cluster降維後點圖實際的label 基於以上的因素,我們試著將 outlier detection 的概念帶入本系統,首先 我們先利用 outlier detection 找出屬於 outlier 的點並標記如圖 3-4,綠色點 標定為 outlier,我們觀察紅色點可以發現大部分的文章都著落在不是屬於
18 outlier 的區塊,也就是說這區塊的文章的相似度相較於 outlier 的文章是比較 接近的。有鑒於此,去除 outlier 除了可以取出大部份的文章以外,點與點之間 的分佈也相較於沒有使用 outlier 還要均勻,進而分析紅色區塊的點我們將這些 點對應回原本的文章篇數,可以找到哪些文章是不屬於 outlier 我們將此定為 inner document。 圖3-4 做outlier detection後的點圖,綠色為outlier
3.2.2 節我們將說明 outlier detection function 的符號定義,藉由計算 covariance matrix 以及利用馬氏距離(Mahalanbios distance)的公式將所有的 點算出其對應的馬氏距離後,對其分佈我們取平均值加減 t 個標準差的範圍當作 inner document,反之在外的即為 outlier document。
19
3.2.2
3.2.2
3.2.2
3.2.2
符號定義
符號定義
符號定義
符號定義
此小節我們針對 Outlier detection 內的符號做一個完善的定義,給定一個 矩陣IM×6其中 m 代表總共有 m 篇文章,n 代表總共有 n 個字,故一個數I9:代表 第 i 篇文章的第 j 個字,其中9 ∈ {4 … … M},,,,: ∈ {4 … … 6},經過 co-cluster[1] 的方法以後,我們可以得到一矩陣 Z 代表著 m 篇文章字在 d 個維度下的座標點, 我們令一矩陣AN(9, :) = ª(9, :)«9 ∈ {4 … … M},,,,: ∈ {4 … … ]}¬,故AN9代表第 i 篇 文章在維度 d 下的點座標,又ANuuuuM代表 m 篇文章的期望值(平均數),.M代表矩
陣 dp 的 covariance matrix,然而 covariance matrix 的算式可以寫成如下: .M =M − 4 BzAN4 9− ANuuuuM{
M 9?4
zAN9− ANuuuuM{T (. 4)
接著利用 covariance matrix 我們可以計算馬氏距離(Mahalanbios distance)9,
其中9 ∈ {4 … … M},馬氏距離的計算公式如下:
9= ®zAN9− ANuuuuM{T.Md4zAN
9− ANuuuuM{¯ 4/_ (. _) 我們取得每個點的馬氏距離以後,計算標準差° = 4 M∑ (M9?4 9− R)_,取9在與 平均值相差 t 個標準的距離外為 outlier 定其為 outlierdoc 反之在與平均值相 差 t 個標準差內的點定其為 innerdoc,其中 t 是一個參數讓用來調整須要幾個 標準差。 如果我們將所有在 Z 上的點表示在三維的空間中,可以發現點跟點的分布在 三維的空間比較可以顯示有 outlier 的點與不是 outlier 的點,為了將所有的點 表現在三度空間下,在此我們定A = 來取 outlier 的點。
20
3.2.2
3.2.2
3.2.2
3.2.2
演算法
演算法
演算法
演算法
根據上一小節的符號定義,本節將寫出完整的實驗演算法。
======== IO[Le9Q\M _. Si6KQ9L6 iQO9Pe APQPKQ9L6 ============= 96NiQ +93P ALKiMP6Q MxQe9 C = {AN4, … ANM}, 8\PeP AN9 ∈ ℝA x6A
Q\P 6iMPe LS bQx6AxeA AP39xQ9L6 Q LiQNiQ 966PeALK,,,,LiQO9PeALK
+93P6 C = {AN4, … , ANM} 4. ANuuuuuuM= MPx6 LS C _. .M =M − 4 BzAN4 9− ANuuuuuuM{ M 9?4 zAN9− ANuuuuuuM{T . SLe 9 = 4 QL M
. 9 = ®zAN9− ANuuuuuuM{T.Md4zAN9− ANuuuuuuM{¯ 4 _ . P6A . R = MPx6 LS ( = {4, … M}) ¥. SLe 9 = 4 QL M ¨. 9S z(R − Q°) ≤ 9 ≤ (R + Q°){ ©. 966PeALK ← 9 4<. P6A 44. 9S z(R + Q°) < 9||(R − Q°) > 9{ 4_. LiQO9PeALK ← 9 4. P6A 4. P6A 在 outlier detection 的演算法中,參數 t 是用以讓我們調整須要多少個標
21
準差,我們實驗不同的標準差來評估最後實驗的效果的好壞,我們選擇了 talk.politics.guns 以及 talk.politics.mideast 這兩筆資料分群,圖 3-5 顯 示出結果。當 t=1 時紅色的點代表著 inner document 的部份,約略有 7%的資料 被我們分到 outlier,當 t=2 時紅色與綠色的點代表 inner document 的部份, 約略有 1.7%得資料被我們分到 outlier,當 t=3 時紅色、綠色以及藍色的點代表 inner document 的部份,約略有 0.9%的點被分成 outlier,當我們選定的資料 非常相似,例如都在 politics 分類下的文章,大部分的點會相當的集中,如果 選定的 t 值太過於大,被定義到 outlier 的點將會非常少,我們也將 t 在不同值 的結果列出如表 3-1。 F1-value t=1 93.21% t=2 63.21% t=3 63% 表 3-1 在 outlier detection 中不同參數 t 所分群的實驗結果。 圖3-5 talk.politics.guns以及talk.politics.mideast執行outlier detection的結果
22
3.2.2
3.2.2
3.2.2
3.2.2
實驗效果分析
實驗效果分析
實驗效果分析
實驗效果分析
首先我們選取 20newsgroups 的 corpus 之中的 talk.politics.guns 以及 talk.politics.mideast 這兩個資料做分析,經過去除 outlier 後我們針對 inner document 我們將其在進行一次 co-cluster 最後利用 k-means 做分群,得到的結 果如圖 3-6,最後比較實際上帶有標籤的點圖 3-7,得到的結果可讓正確率大大 的提升,因為我們將原本分佈比較散亂的圖,經過 outlier detection 以後得到 的點較原本均勻,此時做 k-means 較不會因為原本點圖的分散而找到不恰當的群 中心,當找到恰當的群中心以後,分群的效果自然而然會有顯著的提升,但是針 對傳統的 data mining 方法,我們會將 outlier 的點做刪除的動作,由於本實驗 找出的 outlier 並不是真的雜訊,故我們利用 3.4 節的 merge function 方法將 屬於 outlier 的文章找到其最適合的群,並將他們分到距離最近的群,最後的結 果作為評估最終的效能。
23
圖3-7 內點實際的label
3.3
3.3
3.3
3.3
Weighted Term Matrix Construction Algorithm
Weighted Term Matrix Construction Algorithm
Weighted Term Matrix Construction Algorithm
Weighted Term Matrix Construction Algorithm
3.3.1
3.3.1
3.3.1
3.3.1
目的與概念
目的與概念
目的與概念
目的與概念
分群的概念架構在群與群之間的相似度,很值觀的我們可以認為假如群跟群 之間用字的差異性較大,這樣的分群效果應當是好的,比方說以兩群為例子如果 文章 1、3、5 裡面的字都是 w1、w3、w5 然而文章 2、4、6 裡面的字都是 w2 、 w4、w6 那這樣子可以很清楚的將文章 1、3、5 分成一群,反之文章 2、4、6 可 以分成另一群,但現實生活中文章內容的字往往夾帶著許多的常用字(stop word),除此之外也有許多不是屬於 stop word 但依舊沒有鑑別度的字,比方說 我們探討新聞類的文章,”新聞”這個字眼往往會出現在許多文章中,然而這個 字眼並沒有辦法告訴我們是哪一類的新聞,這樣沒有鑑別度的字其實在每一篇文 章中占很大的篇幅。
24 中 m 代表總共有 m 篇文章,n 代表總共有 n 個字,故每個數I9:代表第 i 篇文章的 第 j 個字,其中裡面的值只考慮出現不出現也就是說指只能填 0 代表不出現 1 代表出現,我們通稱為 0/1 矩陣,以上的方法在語料庫給定以後這樣子的矩陣隨 即可以產生但卻無法做任何的調整,以下我們的方法可以逐步的調整每個字的權 重,透過一個圖型與分群的概念,我們將設計一個調整權重的方法,如此一來便 可以藉調整字的權重來改進實驗的效果。 Co-cluster[1]的好處在於我們可以同時將文章與字做分群,此演算法的架 構在於利用文章來帶動字的分群,亦可利用字來帶動文章的分群,我們的想法在 於將字賦予權重之後將原本的頻率矩陣改變成帶有權重意義的頻率矩陣,透過這 樣子的方式我們可以分析以及改變每個字的權重,最後在 3.5 節我們會說明如何 動態的改變字的權重以及如何評估它的效能 。
3.3.2
3.3.2
3.3.2
3.3.2
公式定義
公式定義
公式定義
公式定義
本小節將會對公式以及我們設計的方法做更完整的解說,在不失一般性的條 件下,我們先取兩群來說明首先我們給定兩個群中心yKP6QPe4以及以及以及以及yKP6QPe_,並假 設有兩個點8N9以及以及以及以及8N9,,,,{9,,,,:} ∈ {4 … … 6},如果說8N9比較靠近yKP6QPe4則依據 分群的概念,8N9會分到yOibQPe4。如果說存在一點8N與yOibQPe4以及以及以及以及yOibQPe_都
相似,則點座標將會靠近yKP6QPe4以及yKP6QPe_,換言之這個點將會介於
yKP6QPe4以及以及以及以及yKP6QPe_之間,因此我們定義一個計算距離的差距來衡量彼此之間的
相似度如下列公式:
∆A9bQ9 = «|8N9− yKP6QPe4| − |8N9−yKP6QPe_|« (. )
透過這個公式我們可以了解假設兩點8N9以及以及以及以及8N:,兩群中心
,,,,∆A9bQ:= |_ − | = 4 較靠近某群,相對的如果值越小代表這點離 因此我們認為值的大小與重要性成正比 圖3-8 為了避免∆A9bQ的值可能很散亂 的值轉到{0,1}區間,logistic function 大時會越靠近 1,根據曲度的斜率我們可以控制當 有多慢(多快)速度的增長 式子: 89 = 4 + P4d∆A9bQ9 25 4,∆A9bQ9 > ∆A9bQ:,並且可以發現當數字越大代表此點 相對的如果值越小代表這點離yKP6QPe4以及以及以及以及yKP6QPe_都相當的靠近 大小與重要性成正比。 探討點與群中心的距離差所產生的關係性 的值可能很散亂,在此我們透過logistic function logistic function的圖如 3-9,我們可以發現當 根據曲度的斜率我們可以控制當∆A9bQ的值越大( 速度的增長,在此我們採用最原始型態的logistic function 圖3-9 logistic function示意圖 並且可以發現當數字越大代表此點 都相當的靠近, 探討點與群中心的距離差所產生的關係性 logistic function將原先 我們可以發現當∆A9bQ越 (越小)我們該 logistic function如下 (. )
26 由式子(3.3)以及(3.4)計算出來的89即代表8N9所應有的權重,在此我們將 進一步的推廣到多群,在分群的效能評估方式常常用兩兩比較的關係性來判斷分 群的效能,F1 value[39]方法採用此種概念,在此我們效仿分群的評估方式,採 用兩兩的計算,因此根據公式(3.3)、(3.4)我們可以改寫如下,其中 times 代表 所執行的次數:
∆A´bQuuuuuu´ = µB B «|8N9− yKP6QPee| − |8N9−yKP6QPeb|« t b?e4 t e?4 ¶ Q9MPb· (. ) 其中 k 代表群數{r,s}∈ {4 … … t},,,,9 ∈ {4 … … 6},而 times 是為了平均所有 的∆A9bQ9所以最後會除以總共的次數,times 的計算方式為:Q9MPb = ∑ ∑t 4 b?e4 t
e?4 ,最後我們將得到的∆A´bQuuuuuu´透過公式(3.4)可以改寫成下式子:
89= 4 + P4d∆A´bQuuuuuuu´ (. )
最後我們令一個對角矩陣 T,使其值為T(:, :) = 8:,,,,: ∈ {4 … … 6},假設一個
矩陣IM×6,,,,其中其中其中其中I9:代表裡面的值代表裡面的值代表裡面的值代表裡面的值,I × T代表對於文章 i 其所對應第 j 個字乘以
它所對應的權重8:,所得到的矩陣是賦有權重的一個新的矩陣,此矩陣包含了新
的文章與字的關係,透過這個關係我們依舊可以再進一步做 co-cluster 的分群, 再透過 Weighted Term Matrix Construction Algorithm 的評估,我們可以在得 到更新一層的關係,在 3.5 節我們將會做更詳細的說明。
3.3.3
3.3.3
3.3.3
3.3.3
演算法
演算法
演算法
演算法
27
最後輸出是一個對角矩陣 T,根據式子(3.5)、(3.6)我們寫出本實驗的演算法如 下:
=== IO[Le9Q\M . =P9[\QPA TPeM xQe9 yL6bQeiKQ9L6 IO[Le9Q\M === 96QNiQ 8N9,,,,yKP6QPe4… … yKP6QPet,,,,t 9b Q\P 6iMPe LS KOibQPe
LiQNiQ T
4. 969Q9xO T 9b x PeL − MxQe9 89Q\ A9MP6Q9L6 6 × 6 _. Q9MPb = B B 4 t b?e4 t e?4 . SLe 9 = 4 QL 6
. ∆A´bQuuuuuu´= µB B «|8N9− yKP6QPee| − |8N9−yKP6QPeb|« t b?e4 t e?4 ¶ Q9MPb· . T(9, 9) = 4 4 + Pd∆A´bQuuuuuuu´ . P6A ¥. ePQie6 T
3.4
3.4
3.4
3.4
Merge function
Merge function
Merge function
Merge function
3.4.1
3.4.1
3.4.1
3.4.1
定義及解說
定義及解說
定義及解說
定義及解說
在 3.2 節我們有提到,雖然我們用了 outlier detection 把 outlier 過濾後, 保留剩下的文章再分群可以達到還不錯的效果,但是面對 outlier 的文章,我們 不能夠將它刪除,這也是有別於先前的 data mining[14]的傳統的方法,給定一
個矩陣IM×6做 co-cluster[1]之後我們將會得到一個降維後的座標系統
(M6)×],其中 Z 的前M × ]的維度代表作標點,後面6 × ],L 代表每個文章或
是字的維度,這個座標系統 Z 我們為了之後會用到先把它叫做LOA,透過 outlier
28
標系統 Z,對 Z 做 k-means 之後每個 innerdoc 皆會有自己的 index,代表該點標
定為哪個群,此 index 我們叫做96AP6P8,代表去除 outlier 後新的矩陣進行
co-cluster 後得到分群的 index。
當我們去除 outlier 後得到新的矩陣進行 co-cluster 得到的座標系統 Z 與
LOA是兩個不同的座標系統,但我們可以確定966PeALK ⊆ xOOALK,alldoc 代表
原本語料庫的所有文章,根據上面的條件,我們可以對每個 innerdoc 找到其在
原本的座標系統LOA中對應的座標點,所以每個 innerdoc 都會有根據去除
outlier 後進行 co-cluster 之新座標系統所產生的96AP6P8以及在尚未去除
outlier 之舊座標系統的LOA,但是屬於 outlierdoc 的文章只保留在舊座標系統
所得到的 index 以及座標LOA,根據 3.1 節我們得知舊座標系統往往會因為
outlier 的影響造成分群效果不佳,故在舊座標系統得到的 index 是錯誤率較高 的,但是如何讓 outlierdoc 的文章產生較正確的 index,我們必須由 innerdoc 的座標點來修正 outlierdoc 的 index。
該如何利用 innerdoc 的座標點來修正 outlierdoc 的 index 首先必須計算在
96AP6P8之中哪些點是屬於第 k 群,將之歸類好以後再去找其在LOA所對應的座
標點,並且計算群中心,在此我們先舉個例子來做解釋,假設存在 10 個點C9,
其所對應的 index 為9A9,,,,9 ∈ {4 … … 4<},尚未進行 outlier detection 以及其 實際的 label 其值如下表: 文章 文章 文章 文章 C4 C_ C C C C C¥ C¨ C© C4< I II
Indexndexndexndex 1 1 1 1 1 1 1 2 2 2 實際
實際實際
實際 1 1 1 1 2 2 2 2 2 2 表 3-2 未做 outlier detection 的文章所對應的 index
圖3-10 透過去除 outlier之後進行 outlier的點其值以及分佈圖如下 文章 文章文章 文章 C4 C_ 6AP6P8 1 1 實際 實際實際 實際 1 1 表 3-3 做完outlier detection 圖3-11 各點進行 對於C¨、、、、C©、、、、C4<這三個點由於其 29 各點尚未進行outlier detection之分佈圖 之後進行co-cluster,我們成功的將正確率提高以及找出 的點其值以及分佈圖如下: C C C C C¥ C¨ 1 1 2 2 2 ? 1 1 2 2 2 2
outlier detection再進行 co-cluster 後的文章所對應的
進行outlier detection再進行co-cluster後 這三個點由於其index 錯誤率較高,所以我們取出 之分佈圖 我們成功的將正確率提高以及找出 C© C4< ? ? 2 2 文章所對應的index 後之分佈圖 所以我們取出
6AP6P8之中label = 1 也對 label = 2的點計算幾何平均得群中心 此的座標系統都是原先尚未進行 在與C¨、、、、C©、、、、C4<存在座標點的系統下討論相似度 別與yKP6QPe4以及以及以及以及yKP6QPe_兩群中心進行相似度的計算 算方式,最後取最小者當作最相似者並且標定與之相同的 後的值如下表: 文章 文章文章 文章 C4 C_ 6AP6P8 1 1 實際 實際實際 實際 1 1 表 3-4 進行相似度計算後的 圖3 整個 Merge的流程圖如下 30 label = 1的點算出其幾何平均得到群中心yKP6QPe4, 的點計算幾何平均得群中心yKP6QPe_,必須注意的一點是我們在 此的座標系統都是原先尚未進行outlier detection 的座標系統, 存在座標點的系統下討論相似度,在將C¨、、、、C©、、、、 兩群中心進行相似度的計算,在此我們取歐式距離的計 最後取最小者當作最相似者並且標定與之相同的label如 C C C C C¥ C¨ 1 1 2 2 2 2 1 1 2 2 2 2 進行相似度計算後的文章所對應的 index 3-12 進行相似度計算後的各點之分佈圖 的流程圖如下: ,同樣的我們 必須注意的一點是我們在 ,因為我們必須 、 、 、 、C4<的座標分 在此我們取歐式距離的計 如圖 3-12,最 C© C4< 2 2 2 2
31
圖3-13 Merge的流程圖
第一次 co-cluster 所得到的座標系統Zº»¼ Outlier detection
Co-cluster with Dynamic Weighting Outlier document Inner document
根據index½¾r以及 backward 找出在Zº»¼的座 標並計算群中心C¿… … CÀ
如果該點屬於 inner document 則直接賦予原本的 label,如果是屬於 outlier document,與各群中心計算歐式距離並取最小者賦予其相同的 label,最後 的值為indexÁ½û
32
3.4.2
3.4.2
3.4.2
3.4.2
演算法
演算法
演算法
演算法
根據圖 3-13 的流程圖,以下的演算法為整個程式執行運作的算式。 ============== IO[Le9Q\M . Pe[P Si6KQ9L6 =============
96QNiQ +93P6 966Pe ALKiMP6Q KOibQPe96[ 96AP6P8、、、、LOA、、、、966PeALK、、、、LiQO9PeALK
LiQNiQ yOibQPe96[ ePbiOQ 96APS96xO
4. P[96
_. yLMNiQP 966Pe ALKiMP6Q KOibQPe KP6QPeb
y4, . . . , yt L6 LOA ib96[ 966PeCLK x6A 96AP6P8 96SLeMxQ9L6
. 96APS96xO= 96AP6P8
. Ibb9[6 PxK\ ALKiMP6Q AL 96 LiQO9PeCLK QL L6P LS Q\P
KOibQPeb y4, . . . , yt xKKLeA96[ QL
y∗ = xe[M96
y ∈{y4,…,yt.}|AL− y| x6A iNAxQP KOibQPe96[ 96APS96xO
. ePQie6 96APS96xO
. P6A
33
3.5
3.5
3.5
3.5
Co
Co
Co
Co-
--
-cluster with Dynamic Weighting
cluster with Dynamic Weighting
cluster with Dynamic Weighting
cluster with Dynamic Weighting
3.5.1
3.5.1
3.5.1
3.5.1
流程架構
流程架構
流程架構
流程架構
本小節將針對本實驗的主要核心的流程做說明,給定一個矩陣IM×6,其中 m 代表文章的篇數,n 代表所有字的數量,根據 3.2 節提到的 outlier detection, 我們針對矩陣 A 進行 outlier 的去除動作,進而得到 inner document 以及 outlier document。得到的 inner document 接下來會在進行一次 co-cluster,
得到新的座標點後取字的座標8N9,,,,9 ∈ {4 … … 6},經過 3.3 節的 Weighted Term
Matrix Construction Algorithm 對所有的字賦予權重之後,透過式子(3.5)、
(3.6)產生矩陣 T,我們將這個 T 的矩陣乘以 A 來對矩陣 A 做更新,即I = I × T再
對更新的矩陣再進行 co-cluster 同樣的依舊可以得到新座標點8N9,然而新的
8N9有著新的分佈,這樣子的分佈我們亦可以在探討每一個字的權重,所以也同
樣的透過式子(3.5)、(3.6)再進行更新而得到 T,如此一來每個字可以經過每次 的 co-cluster、Weighted Term Matrix Construction Algorithm 進行動態的調 整,本次的權重會根據上一次給定的分群所產生的分佈進行調整,最後 output 的結果是 inner document 的 index。我們將根據 3.4 的 merge function 與 outlier document 進行合併,最後的結果再來做評估,整個 Co-cluster with Dynamic Weighting 的流程架構圖如下:
圖3-14 Co-cluster with Dynamic Weighting
34
35
3.5.2
3.5.2
3.5.2
3.5.2
演算法
演算法
演算法
演算法
本小節將列出本實驗的主要演算法,我們將會總合 3.2、3.3、3.4 的方法, 最後在 3.5.3 我們將評估效果。
======== Algorithm 5. Co − cluster with Dynamic Weighting ====== 1. Initial T½ÂÈÂû= Tº»¼= T,r = 1
2. Given A,from A½ = D¿d¿ÊADÊd¿Ê
3. £index, Z¤ = co − cluster(A),and set Zº»¼= Z
4. £innerdoc, outlierdoc¤ = Outlier detection(Zº»¼)
5. A ← innerdoc 6. While(r > 0.1)
7. £index, Z¤ = co − cluster(A),and set Z½¾r ← Z,
which is L − dimension data ,and L = ¡logÊk¢
8. T = weight function(Z½¾r)
9. A ← A × T 10. r = ‖T − Tº»¼‖
11. Tº»¼ ← T
12. end
13. Run k − means algorithm on the L − dimension data Z to obtain
the desired k − way multipartition,L = ¡logÊk¢,and set index → index½¾r
36
第四章
第四章
第四章
第四章、
、
、
、實驗
實驗
實驗
實驗結果
結果
結果
結果與
與
與
與討論
討論
討論
討論
4.1
4.1
4.1
4.1
實驗資料
實驗資料
實驗資料
實驗資料
我們的實驗選取了三個語料庫,在文件分析的實驗中著名的兩個語料庫為 20newsgroups1 以及 Reuters-215782 ,第三個為 Dhillon 發表在 KDD2001 年的論 文[1]中的語料庫(Classic33 )。 (1).20newsgroups 的語料庫中包含了 20,000 篇新聞的文章,其中分成了 20 個 類別,文章中不少類別討論的話題很接近例如:comp.sys.ibm.pc.hardware 以及 comp.sys.mac.hardware 都是在討論有關 hardware 方面的新聞,用詞 上也都比較接近,同樣的也有許多文章討論的話題相對的比較懸殊例如: rec.motorcycles 以及 soc.religion.christian。本實驗取的語料庫為 20newsgroups-bydate 的版本,此版本根據日期作排列並且除了去除了在文 章中組別的編列文字之外(Xref, Newsgroups, Path, Followup-To, Date), 同時也去除了一些重複的文章,經過這樣以上的步驟,實際所剩下的文章數 量為 18,846 篇文章。 (2).Reuters-21578 的語料庫包含了 21578 篇文章,是路透社(Reuters)新聞專 線在 1987 年所蒐集的文件集並編撰定義了它們各自的類別,在許多 information retrieval 的研究上常常用到該語料庫,語料庫中類別與類別 之間的篇章數相當懸殊,最大的類別群(earn)可以到 3753 篇,而最小群可 以到 1 篇,而本實驗取篇章數最大的 10 個類別來做實驗。 (3).Dhillon 在 KDD2001 年所發表的論文之中的語料庫我們選取了其中的一個 (以下稱 Classic3)來做實驗,其中 Classic3 包含了 MEDLINE(經由醫療的期 刊中的摘要部分,共計 1033 筆摘要)、CISI(從 information retrieval 論 1 http://people.csail.mit.edu/jrennie/20Newsgroups/20news-bydate.tar.gz 2 http://www.daviddlewis.com/resources/testcollections/reuters21578/reuters21578.tar.gz 3 ftp://ftp.cs.cornell.edu/pub/smart/
37 文中的摘要部分,共計 1460 筆摘要)以及 CRANFIELD(是有關於空氣動力學 系統的 1400 筆摘要)。
4.2
4.2
4.2
4.2
實驗設計
實驗設計
實驗設計
實驗設計
4.2.1
4.2.1
4.2.1
4.2.1
前處理
前處理
前處理
前處理
首先 Reuters-21578 的語料庫是由 XML 的型式撰寫,本系統將保留<title> 以及<body>內的文字,接下來對所有的語料庫我們會做下列的處理方式: (1).Stop Words 移除 在文章之中,會有許多的介系詞、動詞、語助詞之類的文字,像是 a、the、 an 等等,這些字通常對於分群和分類沒有幫助,也就是 Stop Words,這些 字會造成分群的一些 Noise,因此我們將一些常見的 Stop words 建成一個 table,在將資料做處理的時候,會參照這個表,將不必要的 stop words 去除掉,有利於我們的分群和分類。 (2).統一字母的大小寫一律改小寫、去除特殊符號 在文章中,作者使用的字可能會有大小寫不同的情況,電腦會將大小寫看成 是不同的字,因此我們將其所有的文字都改成小寫,以便判斷字的相同。文 章中還會有許多雜訊的特殊符號,例如標點符號、羅馬符號等等,這些對於 文章的分類、分群是沒什麼幫助的,因此我們會把這些符號刪除,保留對文 章有意義的字。 (3).字頻的次數 文章中出現了許多的稀有字,在所有的字裡面這些字的個數其實已經涵蓋了 一半以上,然而這些稀有字因為出現的次數過少,其實對於文章並沒有太大 的意義,但是過量卻足以影響整個實驗的效果,面對這樣的問題,我們系統 將只保留字頻總次數超過 30 次以上的字,比方說一個字”A”出現在所有的
38 文章的總次數只有 29 次,那這個字將會被刪除,這樣的做法一方面可以減 少稀有字對分群的影響更可以降低矩陣的維度以加快計算的速度。
4.2.2
4.2.2
4.2.2
4.2.2
F1 cluster evaluation measure
F1 cluster evaluation measure
F1 cluster evaluation measure
F1 cluster evaluation measure
Clustering 的部分,本論文採用 F1 cluster evaluation measure[39]來評 估分群結果的好壞。當系統在做分群時,系統並不會知道哪個群是哪個類別,系 統只會將所有的資料分成指定的群數,所以計算效能時,是將分群的結果和真實 的類別作比較,此方法 Ramage[40]等人亦使用過,比較方是下列四種情況: 1. True Positives(TP): 系統將兩篇文章分在同一群,而這兩篇文章真實也是在同個類別內。 2. False Positives(FP): 系統將兩篇文章分在同一群,但是這兩篇文章真實不是在同個類別內。 3. True Negatives(TN): 系統將兩篇文章分在不同群,而這兩篇文章真實也不在同個類別內。 4. False Negatives(FN): 系統將兩篇文章分在不同群,但是這兩篇文章真實是在同個類別內。 F1 cluster evaluation measure 的算法定義如下:
2*
*
1
TP
precision
TP
FP
TP
recall
TP
FN
precision recall
F
precision recall
=
+
=
+
=
+
39
4.2.3
4.2.3
4.2.3
4.2.3
比較方法
比較方法
比較方法
比較方法
實驗除了本實驗的方法外,為了不失公平性,以下幾種是我們實作以用來跟 我們的方法做比較,實作上我們採用y#來做前處理的部分,方法主軸的部分採用 matlab 實作: (1).K-means: K-means[4]是一個被大家廣為比較並列為基準的一個方法,原理很簡單,給 定一個集合其中包含了 n 個點4… 6,其中此 n 個點為 d-dimension 的實 數向量,k-means 演算法目的將 n 個點分成 k 群(t ≤ 6), Ï = {Ï4, Ï_, … , Ït}以 盡量減少點與其所在的群的群中心距離的平方合(within-cluster sum of squares)的方式, 本實驗採用 matlab 內部的 K-means 方法:
[Index]=kmeans(matrix,k),其中我們給定矩陣 matrix 以及目標群 k 經過 此方法會得到各點所對應的 label。
(2).Co-cluster
本實驗採用 Dhillon[1]的方法,在 2.3 節有此方法詳細的介紹。
(3).PLSA:在 PLSA 的實作方面,我們參考此方法[38],從本質上來說,PLSA 是 基於混合式分解(mixture decomposition)進而得到潛在的類別模組
(latent class model) ,它的標準程序為利用 Expectation
Maximization(EM)[8]演算法藉由淺在的變數模組(latent variable models) 估計最大概似(maximum likelihood),此演算法包含了兩個步驟 E-step 以 及 M-step,E-step 會根據目前估計的參數,來計算潛變量 z 的後驗機率, 在 M-step 參數會根據先前 E-step 所獲得的後驗機率來進行更新,當我們給 定 word 8 ∈ = = {84, 8_, … , 8}在文章A ∈ C = {A4, A_, … , A}},E-step 的 公式如下:
40
Ðzt|A9, 8:{ =∑ Ðz8Ðz8:|t{Ð(t|A9) :|O{Ð(O|A9)
O?4 (. 4)
估計Ð(A9) ∝ 6(A9)可以被獨立進行的,而 M-step 用來重新估計參數的算式
如下: Ðz8:|t{ = ∑ 6zA9, 8:{Ðzt|A9, 8:{ } 9?4 ∑M?4 ∑ 6(A}O?4 9, 8M)Ð(t|A9, 8M) (. _) Ð(t|A9) =∑ 6zA9, 8:{Ð(t|A9, 8:) :?4 6(A9) (. )
4.3
4.3
4.3
4.3
實驗成果
實驗成果
實驗成果
實驗成果
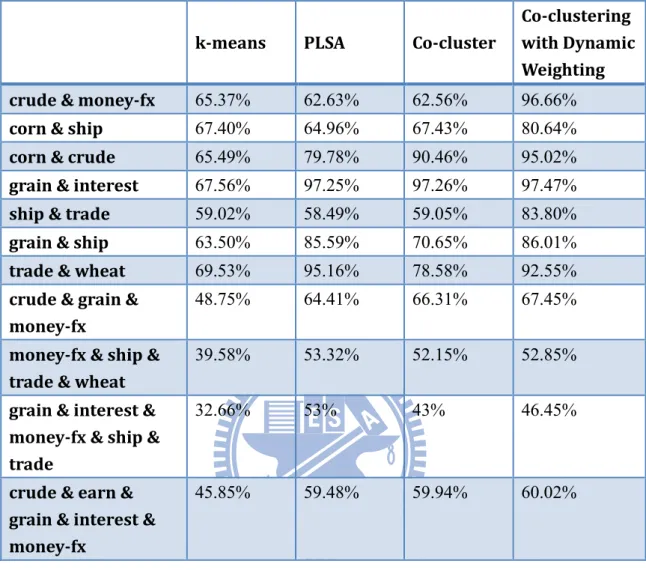
本節將本實驗的結果一一呈現出來,首先在表 4-1 是 20newsgroups 的分群 結果,其中包含 2 群與 4 群的結果,本實驗 F1-value 取最大值作為最後的分數, 其中我們的方法所得到的結果相較於其他方法來的好,表 4-2 是 Reuters-21578 的實驗顯示結果,
k-means PLSA Co-cluster
Co Co Co
Co----clustering clustering clustering clustering
with Dynamic with Dynamic with Dynamic with Dynamic Weighting Weighting Weighting Weighting talk.politics.guns & talk.politics.mideast 66.63% 76.76% 66.63% 93.63% rec.autos & rec.motorcycles 66.62% 69.65% 64.39% 75.85% alt.atheism & comp.graphics 66.75% 96% 94.02% 96% rec_autos & rec_baseball 65.50% 62.08% 89.47% 91.63% alt.atheism & comp.graphics & rec_baseball 50.17% 94.39% 64.91% 94.09% 表 4-1 20newsgroups 的分群結果,值為 F-1value
41
k-means PLSA Co-cluster
Co-clustering with Dynamic Weighting crude & money-fx 65.37% 62.63% 62.56% 96.66%
corn & ship 67.40% 64.96% 67.43% 80.64%
corn & crude 65.49% 79.78% 90.46% 95.02%
grain & interest 67.56% 97.25% 97.26% 97.47%
ship & trade 59.02% 58.49% 59.05% 83.80%
grain & ship 63.50% 85.59% 70.65% 86.01%
trade & wheat 69.53% 95.16% 78.58% 92.55%
crude & grain & money-fx
48.75% 64.41% 66.31% 67.45%
money-fx & ship & trade & wheat
39.58% 53.32% 52.15% 52.85%
grain & interest & money-fx & ship & trade
32.66% 53% 43% 46.45%
crude & earn & grain & interest & money-fx
45.85% 59.48% 59.94% 60.02%
表 4-2 Rruters-21578 的分群結果,值為 F-1value
k-means PLSA Co-cluster
Co-clustering with Dynamic Weighting cisi & med 67.34% 97.62% 93.68% 96.65%
med & cran 60.68% 98.41% 99.20% 99.36%
cisi & cran 66.18% 98.61% 97.58% 97.65%
Classic3 55.84% 97.14% 95.00% 96.38% 表 4-3 Classic3 的分群結果,值為 F-1value