H
IDING
P
REDICTIVE
A
SSOCIATION
R
ULES ON
H
ORIZONTALLY
D
ISTRIBUTED
D
ATA
Shyue-Liang Wang1, Ting-Zheng Lai3, Tzung-Pei Hong2, Yu-Lung Wu3
Department of Information Management1
Department of Computer Science and Information Engineering2 National University of Kaohsiung
Kaohsiung, Taiwan 81148 Institute of Information Management3
I-Shou University Kaohsiung, Taiwan 84001
Abstract. Increasing concerns about privacy breaches have caused extensive studies of privacy preserving data mining in recent years. Association rule hiding in which some of the association rules are suppressed in order to preserve privacy has been identified as a practical privacy preserving application. Most current association rule hiding techniques assume that the data to be sanitized are in one single data set. However, in the real world, data may exist in distributed environment and owned by non-trusting parties that might be willing to collaborate. In this work, we propose a framework to hide Collaborative Recommendation Association Rules (CRAR) where the data sets are horizontally distributed and owned by non-trusting parties. Algorithms to hide the collaborative recommendation association rules and to merge the sanitized data sets are introduced. Performance and various side effects of the proposed approach are analyzed numerically. Comparisons with trusting-third-party approach are reported. The proposed approach shows better processing time, with similar side effects.
Keywords: Privacy preserving, data mining, collaborative recommendation, association rule, horizontally distributed.
1 Introduction
Recent developments in privacy preserving data mining have proposed many efficient and practical techniques for hiding sensitive information that could have been discovered by data mining algorithms. There are four broad areas of research in the field of privacy preserving data mining: privacy preserving data publishing, privacy preserving applications, utility issues, and distributed privacy with adversarial collaboration [1]. In privacy preserving data publishing area, the proposed techniques tend to sanitize the data, by different transformation methods, so that its privacy remains preserved. For example, the
k-anonymity methods try to prevent privacy de-identification. In privacy-preserving applications area, it corresponds to designing data management and mining algorithms in such way that the results of association rule or classification rule mining can preserve the privacy of data. A classic example of such technique is association rule hiding, in which some of the association rules are suppressed in order to preserve privacy. The utility-based privacy preservation has two goals: protecting the private information and preserving the data utility as much as possible. In the distributed privacy area, multiple parties may wish to share aggregate private data, without leaking any sensitive information at their end. For example, different companies with sensitive sales data may wish to collaborate among themselves in knowing aggregate trends without leaking the trends of their individual company.
For a single data set, given specific rules or patterns to be hidden, many data altering techniques for hiding association, classification and clustering rules have been proposed. For association rule hiding, three basic approaches have been proposed. The first approach [3,12] hides one rule at a time. The second approach [9,10] deals with groups of restricted patterns or sensitive association rules at a time. The third approach [13,14] deals with hiding certain constrained classes of association rules. Once the proposed hiding items are given, the approach integrates the rule selection process into the hiding process. All these techniques can be considered as output privacy hiding on single data set. The objective of
output privacy is that the data set is minimally altered so that the mining result will not
disclose certain privacy.
In contrast, the objective of input privacy is that the data is manipulated so that the mining result is not affected or minimally affected. For example, the randomization-based techniques [4] and the cryptography-based techniques are some recently proposed techniques for input privacy. These techniques can be considered as input privacy hiding on single data set.
For multiple data sets with adversarial collaboration, the cryptography-based technique such as secure multiparty computation have shown that non-trusting parties can jointly compute functions of their different inputs while ensuring that no party learns anything but the defined output of the function [8,11]. These techniques can be considered as input
privacy hiding on distributed data set.
However, very few works have been proposed on output privacy hiding on distributed
data sets. As demonstrated in the motivating example in this section, non-trusting parties
may possess data sets that contain same attributes (horizontally distributed data) and are willing to collaborate and discover patterns from the jointed data set. Nevertheless, they would like to hide certain sensitive association rules before combining the data sets.
In this work, we first propose a framework to hide collaborative recommendation association rules where the data sets are horizontally distributed and owned by non-trusting parties. Algorithms to hide the collaborative recommendation association rules and to merge the sanitized data sets are introduced. Various characteristics of the proposed algorithms are analyzed. Numerical experiments show that the proposed approach performs better than the trusting-third-party approach, with similar side effects.
2 Problem Statement
Association rule mining was first introduced in [2]. Let
I
=
{
i
1,
i
2,
,
i
m}
be a set of literals, called items. Given a set of transactions D, where each transactionT
in D is a set of items such thatT
⊆
I
,
an association rule is an expressionX
⇒
Y
whereX
⊆
I
,
,
I
Y
⊆
andX
∩ Y
=
φ
.
As an example, for a given database in Table 1, a minimum support of 33% and a minimum confidence of 70%, nine association rules can be found as follows: B=>A (66%, 100%), C=>A (66%, 100%), B=>C (50%, 75%), C=>B (50%, 75%),AB=>C (50%, 75%), AC=>B (50%, 75%), BC=>A(50%, 100%), C=>AB(50%, 75%), B=>AC(50%, 75%), where the percentages inside the parentheses are supports and
confidences respectively.
However, mining association rules usually generates a large number of rules, most of which are unnecessary for the purpose of collaborative recommendation. For example, to recommend a target item {B} to a customer, the collaborative recommendation association rule set that contains only two rules, C=>B (50%, 75%) and AC=>B(50%, 75%) will generate the same recommendations as the entire nine association rules found from Table 1. This means that if the new customer has shown interests in purchasing item {C} or items
{AC}, then the collaborative recommender will recommend the new customer to purchase
target item {B}. Therefore, a collaborative recommendation association rule set can be informally defined as the smallest association rule set that makes the same recommendation as the entire association rule set by confidence priority.
The following is the definition of collaborative recommendation association rule set. Definition Let RA be an association rule set and RA1 the set of single-target rules in RA. A
set Rc is a collaborative recommender over RA if (1) Rc ⊂ RA1, (2) ∀ r ∈ Rc, there does not
exist r’ ∈ Rc such that r’ ⊂ r and conf(r’)> conf(r), and (3) ∀ r’’ ∈ RA1 –Rc, ∃ r ∈ Rc such
that r’’ ⊃ r and conf(r’’) < conf(r).
Several association rule hiding techniques have been proposed in recent years. In this work, we assume that data are horizontally distributed and stored in distributed locations. Given a set of transaction data sets D1, D2, …, Dn, minimum supports and minimum
confidences and sets of recommended items Y1, Y 2, …, Y n for each data set, the objective is
to minimally modify the data sets D1, D2, …, Dn, such that no collaborative
recommendation association rules containing Y1, Y 2, …, Y n, on the right hand side of the rule will be discovered from the jointed sanitized data set.
As an example, for two given horizontally distributed data sets in Table 1 and Table 2, with minimum support of 33%, minimum confidence of 70%, and hidden item Y = {C} for both data sets, if transaction T1 in D1 is modified from ABC to AB and transaction T7 in D2 is
modified from BC to B, then the following rules that contain item C on the right hand side will be hidden: A=>C (44%, 57%), B=>C (33%, 50%), AB=>C (33%, 60%). However,
C=>B (33%, 60%) will be lost as side effect. The result of the jointed sanitized data set is
3 Proposed Framework and Algorithms
Given a set of horizontally partition data sets, D1, D2, …, Dn, that are owned by non-trusting
collaborative parties, if a trusting third party existed, a simple solution to publish jointed but sanitized data set is to submit all data sets to this trusted third party. The third party hides the specified association rules then publishes the sanitized data set, (D1 + … + Dn)’, this is
referred to as Merge-Then-Hide (MTH) approach or trusting-third-party approach. However, if a trusting third party did not exist, an alternative is to hide designated rules in each data set independently, (D1’ , … , Dn’). The sanitized data sets are then submitted to
the third party. The third party then merges the individually sanitized data sets and publishes the results, (D1’ + … + Dn’), this is referred to as Hide-Then-Merge (HTM)
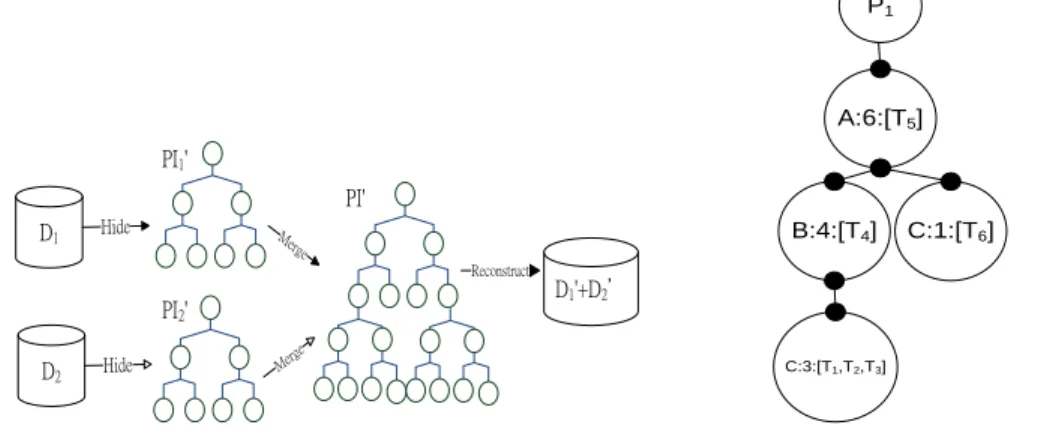
approach or non-trusting-third-party approach. Figure 1 shows the schematic of the proposed non-trusting approach of hiding collaborative recommendation association rules on horizontally distributed data sets.
To hide an association rule, X=>Y, the strategy in the support-based and confidence-based distortion schemes is to either decrease its supports to be smaller than pre-specified minimum support or decrease its confidence to be smaller than pre-specified minimum confidence. In this work, we adopt a similar strategy.
To reduce the number of database scanning, many techniques have been proposed. Based on FP-tree [5] and P-tree [6], we have proposed a similar structure called PI-tree [14]. A PI-tree is an extended prefix-tree structure for storing compressed, crucial information about frequent patterns in less space. A PI-tree is similar to a P-tree except the following. Each node in a PI-tree contains three fields: item name (or item number), number of transactions containing the items on the path from the root to current node (frequency), and a list of transaction ID that contains all the items on the path from the root to current node (TID). For example, the PI-tree for the six transactions in Table 1 is shown in Figure 2. The frequency list is L = < (A:6), (B:4), (C:4)>.
Based on the proposed collaborative recommendation association rule hiding framework, we proposed two algorithms to perform the two major tasks in the process. The PI-tree
Hiding (PIH) algorithm builds a PI-tree and sanitizes the transactions to hide collaborative
recommendation association rules. The PI-tree Merging (PIM) algorithm merges all PI-trees into one PI-tree. The pseudo codes of the proposed algorithms are described as follows.
Algorithm PI-tree Hiding Input: (1) a source data set D,
(2) minimum support, (3) minimum confidence,
(4) a set of hidden (recommended) items Y, Output: a sanitized PI-tree PI’ and frequency list L’. 1. Build initial PI-tree from D;
1.1 Loop until no transactions in D; 1.1.1 Read a transaction from D;
1.1.2 Sort according to item name (or item number);
1.1.3 InsertTran(t, PI-Tree); //insert transaction t to a PI-tree 1.1.4 Update item frequency list L;
1.2 Sort the updated frequency list L; 2. Restructure the PI-tree
2.1 Loop until PI-tree is empty;
2.1.1 Extract(path, PI-tree); //extract a path from PI-tree;
2.1.2 Sort(path, L); //Sort each path according to frequency list L; 2.1.3 InsertPath(path, PI-tree); //insert a path to a new PI-tree 3. Sanitization //find x -> y and reduce confidence/support 3.1 Loop until no more hidden item y;
3.2 For each large 2-itemsets containing y in PI-tree; 3.2.1 Sanitize(y, PI-tree);
4. Output sanitized PI-tree PI’ and frequency list L’;
Algorithm PI-tree Merging Input: (1) a set of PI-trees,
(2) a set of frequency lists, Output: a merged PI-tree.
1. Combine all frequency lists into L’ and sort the list;
2. Sort PIi’ trees in descending order according to the highest item frequency in the
frequency lists of PI trees; 3. Merge all PI-trees
3.1 Loop until each PIi’ tree is empty;
3.1.1 Extract(path, PIi’), i >= 2; //extract a path
3.1.2 InsertPath(path, PI1’); //insert a path to PI1’
4. Restructure the tree according to frequency list L’; 4.1 Loop until the PI1’ tree is empty
4.1.1 Extract(path, PI1’) // extract a path from PI1’
4.1.2 Sort(path, L’);
4.1.3 InsertPath(path, PI’); //insert a path to PI’ 5. Return PI’;
In function InsertTran([t1 | Ti], P), a transaction t is sorted into [t1 | Ti] in alphabetical order.
Here in each sorted transaction, t1 is the first item of the transaction and Ti is the set of
remaining items in the transaction. The Extract function extracts a path from PI-tree. The
Sort function sorts the nodes in a path according to the frequency list L. The Sanitize
function sanitizes a PI-tree such that rule x -> y is hidden when y is a hidden item, based on the strategy presented in this section.
4 Numerical Experiments
This section reports the numerical performance and characteristics of the proposed
Hide-Then-Merge approach and compares with the Merge-Then-Hide approach. Two data
sets were tested: an artificial data set generated from IBM synthetic data generator [7] and a real world data set, BMS-WebView-1, provided by Blue Martini Company and used in the KDD cup contest [15]. The IBM artificial data set has 40,000 transactions, 50 distinct items, with maximum transaction size 11, and average transaction size 5. The BMS-WebView-1 has 59,602 transactions, 497 distinct items, with maximum transaction size 267, and average transaction size 2.5. For each data set, the minimum supports we tested range from 0.5% to 30%. The minimum confidence range is from 5% to 40%. For IBM artificial data set, the total number of association rules ranges from 6 to 404 and the number of hidden rules ranges from 0 to 73. For BMS-WebView-1 data set, the total number of association rules ranges from 528 to 1,499 and the number of hidden rules range from 0 to 137. The number of recommended items considered here are one and two items. The experiments are performed on a PC with AMD 1.66 GHz processor and 1 GB RAM running on Windows XP operating system.
To compare the performance and characteristics, we consider the following effects: time effect, data set effect, and side effects. For time effect, we measure the running time required to hide one and two recommending items, i.e., one and two collaborative recommendation association rule sets respectively. For data set effect, we measure the percentage of altered transactions versus all transactions in the original data set (AT%). For side effects, we measure the percentages of hiding failure, the new rules generated, and the lost rules respectively. The hiding failure side effect measures the percentage of the number of collaborative recommendation association rules that cannot be hidden over the number of rules to be hidden (HF%). The new rule side effect measures the percentage of the number of new rules appeared in the sanitized data set, but not in the original data set, over the number of total association rules in the original data set (NR%). This measure quantifies the percentage of the discovered rules that are artifacts. The lost rule side effect measures the percentage of the number of non-sensitive rules that are in the original data set but not in the sanitized data set over the number of association rules in the original data set (LR%).
Figure 3 shows the processing times required for MTH and HTM approaches to hide collaborative recommendation association rule sets for one and two recommended items on IBM artificial data sets. Figure 4 shows the percentages of transactions altered (AT%) for
MTH and HTM approaches on IBM artificial data set. Figures 5 and 6 show the hiding
failure (HF%), new rule (NR%), and lost rule (LR%) side effects of MTH and HTM approaches for hiding one recommended item on IBM artificial data set respectively. For
MTH approach, on the average, there is 2.88% of hiding failures, 1.19% of new rules
generated but no lost rules. For HTM approach, on the average, there is no hiding failure, 1.05% of new rules generated, and 0.98% of lost rules. Notice that the percentages of hiding failure look relatively high for some data sizes. This is due to the number of rules to
be hidden is relatively small. For example, for 5k IBM artificial data set, there are 13 rules to be hidden. But with only one hiding failure, the HF% = 1/13=7.69% looks relatively high comparing to NR% and LR%.
In summary, to compare the average performance and effects of the two strategies, Table 4 shows some average statistics on both data sets. For IBM artificial data set, the average processing time refers to average of 10k, 20k, 30k, and 40k processing times. For BMS-WebView-1 data set, the average processing time refers to average of 10k, 20k, 30k, 40k, 50k, and 60k processing times. The averages of other effects are calculated similarly. The following observations can be made.
Processing time: On both data sets, the HTM approach requires less processing time to hide collaborate recommendation association rules. This is mainly due to sanitization on two smaller PI-trees requires much less computation time than on larger PI-tree, even with the added cost of merging.
Data set effect: The difference between average altered transaction percentages AT% on IBM data set is 0.09% and is 0.07% on BMS-WebView-1 data set. To hide two recommended items, the differences are 1.16% and 1.51% respectively. This indicates that number of transactions altered for both approaches are about the same.
Side effects: Three main effects are measured and each approach shows different strength and weakness. For hiding failure, the proposed HTM approach can hide more targeted collaborative recommendation association rules. The effect of creating new non-sensitive rules is about the same for both approaches. However, the proposed
HTM approach has a drawback of losing more non-sensitive rules than MTH
approach.
5 Conclusions
Recent development in privacy preserving data mining has proposed many sophisticated data mining techniques that can preserve data and knowledge privacies. However, the problem of preserving output privacy on multiple/distributed data set is not well studied. In this work, we study such a problem and propose a Hide-Then-Merge approach to hide collaborate recommendation association rules from data sets that are horizontally distributed and owned by non-trusting parties. This approach is based on the assumption that merging is performed by a non-trusting third party. To evaluate the performance and characteristics of such approach, we numerically compare with a Merge-Then-Hide approach, which assumes that a trusting third party exists. The results show that the
Hide-Then-Merge approach requires less processing time but has similar side effects as Merge-Then-Hide approach. In the future, we will continue to investigate on hiding other
References
1. C. Aggarwal, P.S., Yu, Privacy-Preserving Data Mining: Models and Algorithms, Springer, 2008.
2. R. Agrawal, T. Imielinski, and A. Swami, “Mining Association Rules between Sets of Items in Large Databases”, Proceedings of ACM SIGMOD International Conference on Management of Data, 207-216, Washington DC, May 1993.
3. A. Atallah, E. Bertino, A. Elmagarmid, M. Ibrahim, and V. Verykios, “Disclosure Limitation of Sensitive Rules”, Proceedings of IEEE Knowledge and Data Engineering Workshop, 45-52, Chicago, Illinois, November 1999.
4. A. Evfimievski, “Randomization in Privacy Preserving Data Mining”, SIGKDD Explorations, 4(2), Issue 2, 43-48, Dec. 2002.
5. J. Han, J. Pei, and Y. Yin, “Mining Frequent Patterns without Candidate Generation”, Proceedings of ACM International Conference on Management of Data (SIGMOD), 1-12, 2002.
6. H. Huang, X. Wu, and R. Relue, “Association Analysis with One Scan of Databases”, Proceedings of IEEE International Conference on Data Mining, 629-632, Maebashi City, Japan, December, 2002.
7. IBM. Almaden. Quest Synthetic Data Generation Code. http://www.almaden.ibm.com/cs/disciplines/iis/.
8. M. Kantarcioglu and C. Clifton, “Privacy-preserving distributed mining of association rules on horizontally partitioned data”, ACM SIGMOD Workshop on Research Issues on Data Mining and Knowledge Discovery, 24-31, June 2002.
9. S. Oliveira, O. Zaiane, “An Efficient On-Scan Sanitization for Improving the Balance Between Privacy and Knowledge Discovery”, Technical Report TR 03-15, Department of Computing Science, University of Alberta, Canada, June 2003. 10. S. Oliveira, O. Zaiane, “A Unified Framework for Protecting Sensitive Association
Rules in Business Collaboration”, Int. J. Business Intelligence and Data Mining, Vol. 1, No. 3, 247-287, 2006.
11. J. Vaidya and C. Clifton. “Privacy Preserving Association Rule Mining in Vertically Partitioned Data”, Proceedings of the 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 639-644, Edmonton, Canada, July 2002. 12. V. Verykios, A. Elmagarmid, E. Bertino, Y. Saygin, and E. Dasseni, “Association
Rules Hiding”, IEEE Transactions on Knowledge and Data Engineering, Vol. 16, No. 4, 434-447, April 2004.
13. S.L. Wang, D. Patel, A. Jafari, and T.P. Hong, “Hiding Collaborative Recommendation Association Rules”, Applied Intelligence, Vol. 26, No. 1, 66-77, 2007.
14. S.L. Wang, H.P. Hong, “One-Scan Sanitization of Collaborative Recommendation Association Rules”, Proceedings of National Computer Symposium, 170-176, Taichun, Taiwan, November, 2007.
15. Z. Zheng, R. Kohavi, L. Mason, “Real World Performance of Association Rules Algorithms”, Proceedings of the 7th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 401-206, San Francisco, CA, USA, August, 2001.
Table 1 Data set D1 Table 2 Data set D2
Table 3 Jointed Data set
Table 4 Comparisons of Average Effects
Characteristic IBM-Artificial IBM-Artificial BMS-WebView-1 BMS-WebView-1
HTM MTH HTM MTH Processing Time 54 147 220 396 Altered Transaction 4.95% 5.54% 0.42% 0.35% Hiding Failure 0% 2.9% 2.73% 7.11% New Rule 1.05% 1.19% 0.40% 0.7% Lost Rule 6.98% 0% 55.99% 0.25% TID D 2 T7 BC T8 C T9 ABC TID D1 T1 ABC T2 ABC T3 ABC T4 AB T5 A T6 AC TID D 1+D2 D1’+D2’ T1 ABC AB T2 ABC ABC T3 ABC ABC T4 AB AB T5 A A T6 AC AC T7 BC B T8 C C T9 ABC ABC
D1 Hide D2 Merge Merge D1'+D2’ Reconstruct PI1' PI' Hide PI2' A:6:[T5] B:4:[T4] C:3:[T1,T2,T3] P1 C:1:[T6]
Figure 1 A framework of hiding CRAR Figure 2 The PI-tree for data set D1
Figure 3 Time Effects Figure 4 Data Set Effects