行政院國家科學委員會專題研究計畫 成果報告
以多核心圖形處理器為基礎之並行化正規表示樣式比對演
算法與架構設計(II)
研究成果報告(精簡版)
計 畫 類 別 : 個別型 計 畫 編 號 : NSC 99-2221-E-003-029- 執 行 期 間 : 99 年 08 月 01 日至 100 年 07 月 31 日 執 行 單 位 : 國立臺灣師範大學科技應用與人力資源發展學系(所) 計 畫 主 持 人 : 林政宏 計畫參與人員: 碩士班研究生-兼任助理人員:張浩平 碩士班研究生-兼任助理人員:黃瀚興 大專生-兼任助理人員:蔡睿烝 報 告 附 件 : 出席國際會議研究心得報告及發表論文 處 理 方 式 : 本計畫可公開查詢中 華 民 國 100 年 08 月 30 日
行政院國家科學委員會補助專題研究計畫成果報告
以多核心圖形處理器為基礎之並行化正規表示樣式比對
演算法與架構設計
(II)
計畫類別:
■
個別型計畫 □整合型計畫
計畫編號:NSC 99-2221-E-003-029-
執行期間:99 年 8 月 1 日至 100 年 7 月 31 日
執行機構及系所:國立台灣師範大學科技應用與人力資源發展學系
計畫主持人:林政宏
共同主持人:
計畫參與人員:
成果報告類型(依經費核定清單規定繳交):■精簡報告 □完整報告
本計畫除繳交成果報告外,另須繳交以下出國心得報告:
□赴國外出差或研習心得報告
□赴大陸地區出差或研習心得報告
■出席國際學術會議心得報告
□國際合作研究計畫國外研究報告
處理方式:
除列管計畫及下列情形者外,得立即公開查詢
□涉及專利或其他智慧財產權,□一年□二年後可公開查詢
中 華 民 國 100 年 七 月 卅一 日
一、 中文摘要
由於簡潔和靈活性,正規表示法(regular expression)已被廣泛採用於網路入侵偵測系統 (Network Intrusion Detection System, NIDS)用來描述的網絡攻擊的樣式。然而,正規表示法的 表達能力伴隨著密集的計算和記憶體消耗而導致嚴重的性能退化。近日,圖形處理單位 (graphics processing unit, GPU)由於其低廉的成本和巨大平行計算能力而被採用以加速固定字 串比對。不過,據筆者所知,尚未有研究成果可以處理的已被普遍使用在當前網路入侵偵測 系統和被證實有狀態爆炸(state explosion)問題的正規表示法上。
為了加快正規表示法比對和解決狀態機爆炸的問題,我們提出了一個實現於GPU的分層 並行機(Hierarchical Parallel Machines)架構,可以快速識別含有正規表示法樣式的封包。實驗 結果顯示該分層並行機在處理簡單和複雜的正規表示法,分別達到高達117 Gbps和81 Gbps的 效能。實驗結果顯示該分層並行機不僅可以解決狀態爆炸的問題,但也更加速實現了既簡單 又複雜的正規表示法樣式比對。最後我們公布原始程式並製作成library發佈於google code project (http://code.google.com/p/pfac/)。 研究成果將發表於2011 IEEE Globecom國際會議和第22超大型積體電路設計暨計算機輔 助設計研討會。 關鍵字:正規表示法、樣式比對、多核心圖形處理單元
二、 英文摘要
Due to the conciseness and flexibility, regular expressions have been widely adopted in Network Intrusion Detection Systems to represent network attack patterns. However, the expressive power of regular expressions accompanies the intensive computation and memory consumption which leads to severe performance degradation. Recently, graphics processing units have been adopted to accelerate exact string pattern due to their cost-effective and enormous power for massive data parallel computing. Nevertheless, so far as the authors are aware, no previous work can deal with several complex regular expressions which have been commonly used in current NIDSs and been proven to have the problem of state explosion.
In order to accelerate regular expression matching and resolve the problem of state explosion, we propose a GPU-based approach which applies hierarchical parallel machines to fast recognize suspicious packets which have regular expression patterns. The experimental results show that the proposed machine achieves up to 117 Gbps and 81 Gbps in processing simple and complex regular expressions, respectively. The experimental results demonstrate that the proposed parallel approach not only resolves the problem of state explosion, but also achieves much more acceleration on both simple and complex regular expressions than other GPU approaches. Finally, the library of our proposed algorithm is publically accessible in Google Code (http://code.google.com/p/pfac/).
The research results have been accepted by IEEE GLOBAL COMMUNICATIONS
CONFERENCE (IEEE GLOBECOM 2011) and the 22nd VLSI Design/CAD Symposium.
三、 計畫緣由與目的
Network Intrusion Detection Systems (NIDS) have been widely employed to protect computer systems from network attacks by matching input streams against thousands of predefined attack patterns. Regular expression has been adopted in many NIDS systems, such as Snort [1], Bro [2], and Linux L7-filter [3], to represent certain attack patterns because regular expression can provide more concise and flexible expressions than exact string expressions.
To accelerate regular expression matching, many hardware approaches are being proposed that can be classified into logic-based [4][5][6][7] and memory-based approaches [8][9][10][11][12]. The logic-based approaches which are mainly implemented on the Field-Programmable Gate Array (FPGA), map each regular expression into circuit modules in FPGA. Logic-based approaches are known to be efficient in processing regular expression patterns [4][5] because multiple logic modules can perform their operations simultaneously.
On the other hand, memory-based approaches compile attack patterns into finite state machines and employ commodity memories to store the corresponding state transition tables. Since state transition tables can be easily updated on commodity memories, memory-based approaches are flexible to accommodate new attack patterns. Memory-based approaches have been known to suffer the memory explosion problem for certain types of complex regular expressions. To resolve the memory problem, the rewriting technique [13] converts a regular expression to a new regular expression with smaller DFA. Another research D2FA [20] proposes to reduce the number of state transitions for a regular expression by introducing a new transition called a “default transition.”
Recently, several works [21][22][23][24] have attempted to use Graphic Processor Units (GPU) to accelerate exact and regular expression pattern matching because GPUs provides tremendous computational ability and very high memory bandwidth to process massive input streams and attack patterns. A modified Wu-Manber algorithm [21] and a modified suffix tree algorithm [22] are
However, all of these approaches do not consider the complex regular expressions which can incur state explosion.
In this project, we first explore the parallelism of regular expression matching and discuss the problem of memory explosion. And then, we propose a GPU-based approach which applies hierarchical parallel machines to accelerate regular expression matching and resolve the problem of state explosion. The experimental results show that the proposed parallel algorithm achieves up to 100 Gbps and 81 Gbps in processing simple and complex regular expressions, respectively. The results show that the proposed algorithm has significant improvement on performance than other GPU approaches.
四、 研究方法
This project addresses the algorithm and architecture design of regular expression pattern matching on GPUs. In this section, we first describe the problem of complex regular expression patterns and then propose our hierarchical parallel algorithm and experimental results.
4.1 Complex Regular Expression Patterns
As mentioned above, in this paper, we attempt to reduce all types of complex regular expression into two specific types of complex regular expressions. In this section, we first review these two types of complex regular expressions and explore the reasons that merging such complex regular expressions may lead to large DFAs.
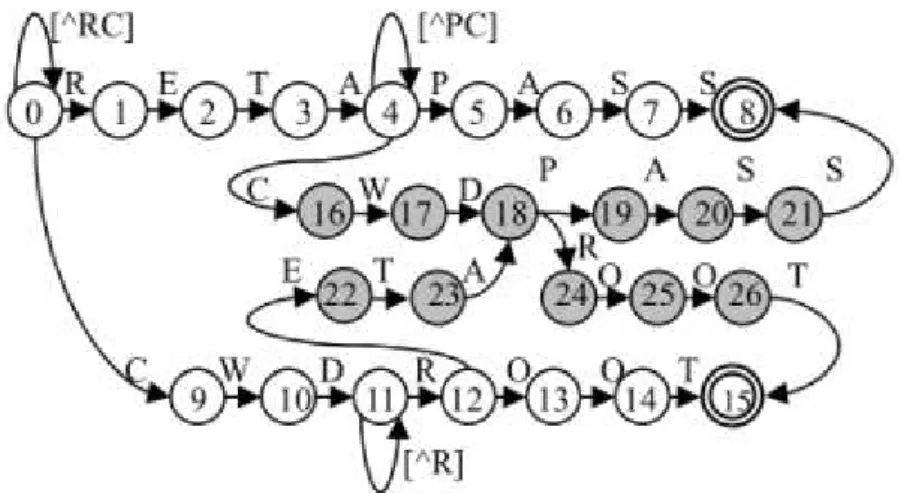
The first type of complex regular expressions is an expression having multiple string sub-patterns divided by the star closure, “.*”. For example, the pattern in Linux L7-filter, “.*membername.*session.*player”, has three string sub-patterns, “membername”, “session”, and “player”. We illustrate the reason of the memory explosion using the following example. Consider to compile two regular expressions, “.*RETA.*PASS” and “.*CWD.*ROOT”. Figure 1 illustrates the composite DFA which attempts to match these two regular expression patterns where partial edges have been omitted for easy description. In Figure 1, states 0 to 8 are used to detect pattern “.*RETA.*PASS”; and states 9 to 15 are used to detect pattern “.*CWD.*ROOT”. In Figure 1, [^RC] means the ASCII character set except for the two characters, „R‟ and „C‟. We need the
additional states, numbered 16 to 26 because any substring containing “RETA” or “CWD” also matches the star closures, “.*”. In this example, the additional states are required because an input stream matches “RETA” or “CWD” also matches “.*”. The phenomenon that an input stream matches multiple sub-patterns simultaneously is called the overlapped matching phenomenon.
Figure 1. Partial DFA of “.*RETA.*PASS” and “.*CWD.*ROOT”.
The second type of complex regular expression is the pattern that has constraint repetitions, such as the pattern for detecting FTP STAT overflow attempt, “.*STAT[^\n]{100}”. The constraint repetitions, “[^\n]{100}”, represents one hundred of non-line-feed characters. Merging such a complex regular expression may also lead to memory explosion. For example, using Flex [15] to compile the single pattern, “.*STAT [^\x0a]{10}” results in a DFA containing 137 states. If we merge this regular expression pattern with the other two patterns “.*USER [^\x0a]{10}” and “.*PASS[^\x0a]{10}”, the number of states increases sharply to 2,498.
Figure 2 shows the partial DFA with respect to the pattern “.*STAT [^\x0a]{10}”. The overlapped matching occurs because an input stream matches “USER” and “PASS” also matches the constraint repetition, “[^\n]{10}”.
Figure 2. Partial state machine of the three regular expressions, “.*STAT[^\n]{10}”, “.*USER[^\n]{10}”, and “.*PASS[^\n]{10}”.
4.2 Hierarchical Parallel Machines
In this section, we propose a GPU-based parallel approach which applies hierarchical state machines to accelerate the matching process of the two complex regular expressions without the problem of memory explosion discussed in Section 2.
For example, in Section 2, the first type of complex regular expressions can be partitioned into two parts, exact string patterns and meta-characters. We can find that the matching of these two types of complex regular expressions can be translated to find the appearance order between exact string patterns. For example, matching the regular expression “.*RETA.*PASS” is equivalent to check whether there is a pattern “RETA” appearing before “PASS” with zero or more instances of any character between “RETA” and “PASS”. Similarly, matching “.*uid.{0,10}gid” is equivalent to check whether “uid” appears before “gid” with at least 0 but no more than 10 instances of any character between “uid” and “gid”.
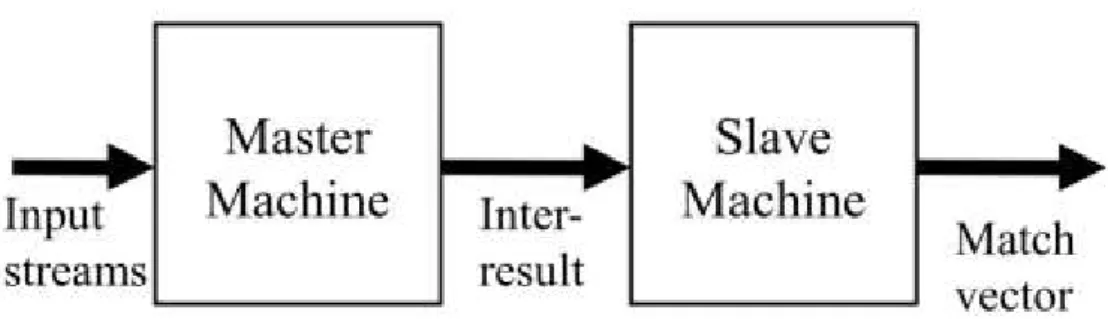
Based on the above observation, the basic idea is that all regular expressions adopted by NIDSs can be reduced to the two specific types of regular expressions which can be decomposed to a sequence of exact string patterns. As shown in Figure 3, we can apply a master machine to identify exact string patterns first; and then, use a slave machine to identify the order relationship of the patterns matched by the master machine. In the following, we describe the construction of the master machine in Section 3.1, and the slave machine in Section 3.2.
Figure 3: Hierarchical Machines 4.2.1 Master Machine
In this section, we describe the construction of the master machine and a novel parallel algorithm for traversing the master machine. In Section 2, we have discussed the memory explosion problem incurred by overlapped matching. To resolve overlapped matching, we extend our previous work, Parallel Failureless Aho-Corasick (PFAC) algorithm [26] which has been released as Google code project [27] to perform regular expression matching. In the following, we first review the PFAC algorithm, and then discuss why the PFAC algorithm can be extended to perform regular expression matching without overlapped matching.
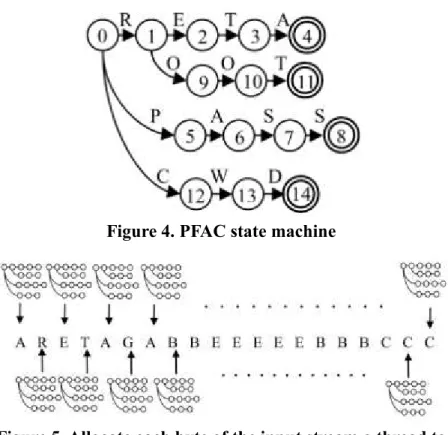
The PFAC algorithm is proposed to accelerate exact string matching by parallelizing the Aho-Corasick (AC) algorithm [14] on GPUs. Using PFAC algorithm has two steps. The first step is to compile multiple string patterns into a PFAC state machine. For example, Figure 4 shows the PFAC state machine for the four patterns, “RETA”, “ROOT”, “PASS”, and “CWD”, where solid lines represent valid transitions. Except for valid transitions, all other invalid transitions leading to trap states are omitted.
In the second step, the PFAC algorithm assigns an individual thread for each byte of an input stream to inspect any pattern starting at the thread‟s starting position by traversing the same PFAC state machine. As shown in Figure 5, the first thread inspects the input stream from the first character „A‟ while the second thread starts from the second character „R‟ and the third thread starts from the third character „E‟. A pictorial demonstration for all other threads is shown in Figure 5.
Figure 4. PFAC state machine
Figure 5. Allocate each byte of the input stream a thread to traverse the PFAC state machine.
During the traversal of a PFAC state machine, if a thread finds a match, the thread reports which pattern is matched, and the starting location corresponding to the thread. When a thread encounters an invalid transition in a PFAC state machine, the thread terminates its computation. For example in Figure 5, traversing the PFAC machine in Figure 4, only the second thread finds a match and reports two information including the match of “RETA” and the starting location of the thread, the second byte. All other threads terminate when they are led to trap states. For example, the first input character taken by the first thread is “A” which has no valid transition for the initial state. Therefore, the first thread terminates immediately after reading the first character. The idea of applying multiple threads to traverse the same PFAC state machine has important implications for efficiency. First, each thread of the PFAC algorithm is only responsible for matching any pattern located at the thread‟s starting location. Second, although the PFAC algorithm applies huge number of threads to perform pattern matching in parallel, most threads have a high probability of terminating early. Therefore, the PFAC algorithm can achieve significant performance gains over the legacy AC algorithm.
character classes with repetitions into a PFAC state machine. Because each thread of the PFAC algorithm is only responsible for identifying the pattern located at the thread starting position, the additional states caused by the overlapped matching are totally removed. For example, Figure 6 shows the state machine for matching the three regular expression patterns, “.*STAT [^\n]{10}”, “.*USER [^\n]{10}”, and “.*PASS [^\n]{10}”. Compared to the traditional DFA state machine as shown in Figure 2, the number of states is significantly reduced from exponential to linear size with respect to the length of constraint repetitions.
Figure 6. A PFAC state machine for the three complex regular expressions, “.*STAT [^\n]{10}”, “.*USER [^\n]{10}”, and “.*PASS [^\n]{10}”. 4.2.2 Slave Machine
Since the master machine can resolve the second type of regular expressions, we now describe how to design the slave machine to consider the first type of regular expressions. Note that the outputs of the master machines include starting locations of master threads and their corresponding matched exact patterns which are translated to encoded symbols. Therefore, the inputs to the slave machine are a set of encoded symbols and their corresponding starting locations. The purpose of the slave machine is to determine the order relationship between encoded symbols using their starting locations.
We demonstrate the construction of the slave machine using the same example of matching two regular expressions “.*RETA.*PASS” and “.*CWD.*ROOT”. As shown in Figure 4, the master machine is used to match the four sub-patterns, “RETA”, “PASS”, “CWD”, and “ROOT” whose encoded symbols are labeled as α, γ, δ, and β, respectively.
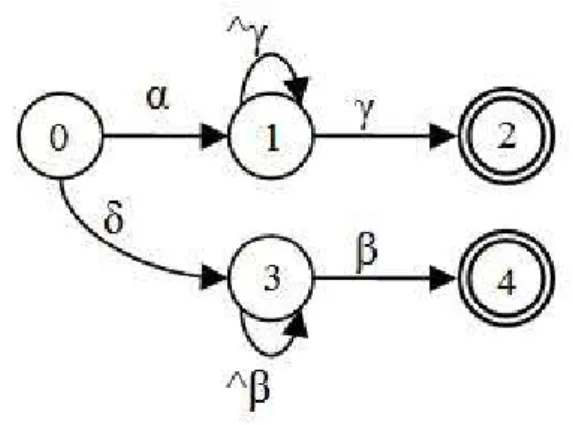
consists of three steps. In the first step, we build the initial machine for each order relation of encoded symbols. The second step is to add a self-loop transition to each internal node. Figure 7 shows the slave machine of “αγ” and “δβ”. We add self-loop transitions labeled as “^γ” and “^β” to state 1 and 3, respectively. These transitions mean that if the next input is not γ and β, the machine stays in state 1 and state 3, respectively. In other words, the self-loop transition represents the meta-character “.*” in the original regular expressions.
Figure 7. Slave machine of “αγ” and “δβ”. 4.2.3 Complete Example
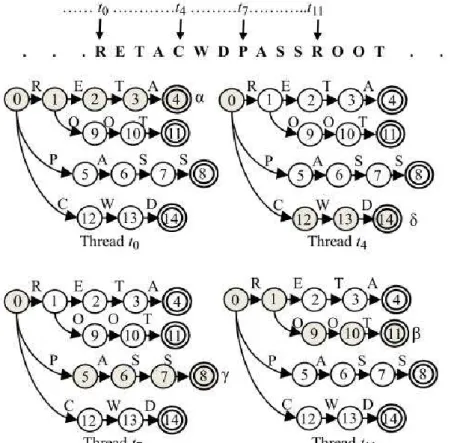
We now use an example to summarize the operation of the master and slave machines. Consider an input stream “RETACWDPASSROOT”. In Figure 8, threads t0, t4, t7, and t11 are
allocated to character „R‟, „C‟, „P‟, and „R‟, respectively. After taking the inputs “RETA”, thread t0 reaches state 4 and outputs α, which indicates the pattern “RETA” is matched. Because there is no valid transition for “R” in state 4, thread t0 terminates at state 4. Similarly, thread t4 reaches final
state 14 and outputs δ. simultaneously, threads t7 and t11 matches the patterns “PASS” and “ROOT”
and output γ and β, respectively. Finally, the master machine outputs the sequence of encoded symbols and their starting locations, (α, 0), (δ, 4), (γ, 7), (β, 11).
Figure 8. Example of master machine where the patterns “RETA”, “CWD”, “PASS”, and “ROOT” are identified by the threads t0, t4, t7, and t11, respectively.
Similar to the master machine, we also apply multiple threads on the slave machine to identify order relationships of the output sequence. As shown in Figure 9, thread t0 allocated to α matches the sequence “αγ” which indicates the regular expression “.*RETA.*PASS” is matched while thread t1 allocated to δ matches the sequence “δβ” which indicates the regular expression “.*CWD.*ROOT” is matched.
4.3 Experimental Results
We have implemented the proposed algorithm on Nvidia® GPUs which offers a parallel programming model via the CUDA™ (Compute Unified Device Architecture) [25]. The experimental configurations are divided into host and device. The host is equipped with an Intel® CoreTM i7-950 running the Linux X86_64 operating system with 12GB DDR3 memory on an ASUS P6T-SE motherboard while the device is equipped with an Nvidia® GeForce® GTX480 GPU in the same CoreTM i7 system with Nvidia driver version 260.19.29 and the CUDA 3.2 version. The network attack patterns consists of 990 simple regular expressions and 88 complex regular expressions extracted from the Bro V1.5.1 rule sets published in 2010. The regular expression matching engine is tested using DEFCON [28] trace files. The DEFCON trace files which contain large amounts of real attack patterns are widely used to test commercial NIDS systems.
We extend our previous work [26], the PFAC library [27] to construct the master and slave machines. The master machine alone can perform simple regular expression matching. The simple regular expressions contain exact string patterns and the second type of complex regular expressions, such as “.*STAT[^\n]{10}”. In order to compare the performance of the master machine, we implement three CPU versions and one GPU version where ACCPU denotes the
implementation of the AC algorithm on the CoreTM i7 using single thread, ACOMP denotes the
implementation of the AC algorithm on the CoreTM i7 with OpenMP [29] library, MASTERCPU
denotes the implementation of the master machine on the CoreTM i7 with OpenMP library, and MASTERGPU denotes the implementation of the master machine on the GTX480. Figure 10 shows
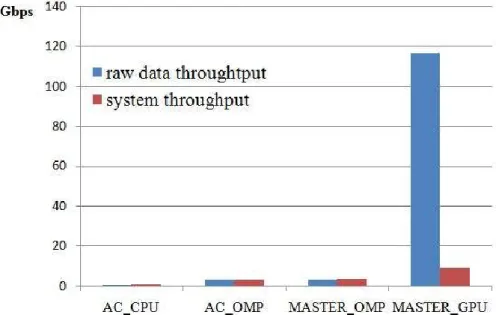
the comparisons of the master machine and the other three CPU versions for processing a DEFCON trace file of 192Mbytes. In Figure 10, the raw data throughput denotes the data throughput without considering the data transfer time via PCIe while the system throughput denotes the data throughput with considering the bandwidth of PCIe transmission. Figure 10 shows that MASTERGPU achieves
maximum raw data throughput of 117 Gbps while ACCPU, ACOMP, and MASTEROMP achieves 0.72,
3.22, and 3.43 Gbps. Compared to ACCPU, ACOMP, and MASTEROMP, MASTERGPU achieves 160x,
effective bandwidth of 6~6.41 GB/s, the system throughput would be much smaller due to PCIe overheads. However, even considering the PCIe overheads, the MASTERGPU still has 2~2.5x times
improvements compared to ACOMP and MASTEROMP.
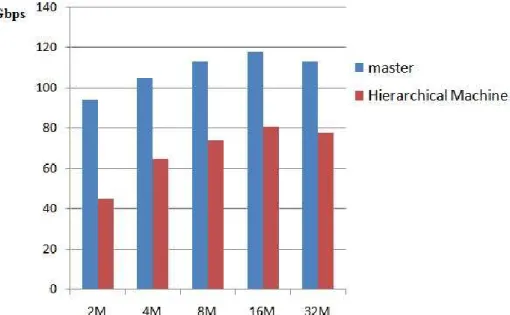
Furthermore, we evaluate the implementation of the hierarchical parallel machines which consists of two state machines running sequentially. Because none of other approaches adopt the same architecture as ours, we only provide the results of the hierarchical parallel machines. Figure 11 shows that the raw data throughput of the master and the hierarchical machines over DEFCON trace files. The hierarchical machines achieve up to 81Gbps for processing 16MBytes DEFCON trace files. Due to the memory limitation of GTX480, the maximum size of the input stream can be processed at a time is 32Mbytes while the master machine alone can support up to 192Mbtyes. We would like to mention that multiple GPUs would be a good solution to improve throughput in the future works.
Figure 10: Raw data and system throughput of ACCPU, ACOMP, MASTEROMP, and
Figure 11: The raw data throughput of the master and hierarchical machines over DEFCON trace files
五、 重要執行成果和價值
In this project, we have explored the parallelism of complex regular expression matching on GPU. Our major contributions are summarized as follows.
1. We have proposed a new architecture which consists of hierarchical parallel machines performed on GPU to accelerate regular expression matching and resolve the problem of memory explosion.
2. We have performed experiments on the Bro V1.5.1. The experimental results show that the proposed approach achieves a significant speedup both on processing simple and complex regular expressions.
3. Finally, the library of our proposed algorithm is publically accessible in Google Code (http://code.google.com/p/pfac/).
All techniques have been accepted and published in international conferences. In the following, we list the related papers of above techniques.
[1] Cheng-Hung Lin, Chen-Hsiung Liu, and Shih-Chieh Chang, "A Novel Hierarchical Machines Algorithm for Accelerating Regular Expression Matching on GPU", 22nd VLSI Design/CAD Symposium, Yunlin, Taiwan, August 2-5, 2011.
[2] Cheng-Hung Lin, Chen-Hsiung Liu, and Shih-Chieh Chang, "Accelerating Regular Expression Matching Using Hierarchical Parallel Machines on GPU", accepted by IEEE GLOBECOM 2011, Houston, Texas, USA, December 5-9, 2011.
[3] Cheng-Hung Lin, Chen-Hsiung Liu, Lung-Sheng Chien, Shih-Chieh Chang, and Wing-Kai Hon, "PFAC Library: GPU-based string matching algorithm", accepted by GPU Technology Conference (GTC 2012), San Jose, California, May 14-17, 2012.
六、 結論
In this project, we have explored the parallelism of complex regular expression matching and proposed a new architecture which consists of hierarchical parallel machines performed on GPU to accelerate regular expression matching and resolve the problem of memory explosion. The experimental results show that the proposed approach achieves a significant speedup both on processing simple and complex regular expressions.
七、 參考文獻
[1] M. Roesch. Snort- lightweight Intrusion Detection for networks. In Proceedings of LISA99, the 15th Systems Administration Conference, 1999.
[2] Bro, http://www.bro-ids.org/
[3] Linux L7-filter, http://l7-filter.sourceforge.net/
[4] R. Sidhu and V. K. Prasanna, “Fast regular expression matching using FPGAs,” in Proc. 9th
Ann. IEEE Symp. Field-Program. Custom Comput. Mach. (FCCM), 2001, pp. 227-238.
[5] B.L. Hutchings, R. Franklin, and D. Carver, “Assisting Network Intrusion Detection with Reconfigurable Hardware,” in Proc.10th Ann. IEEE Symp. Field-Program. Custom Comput.
Mach. (FCCM), 2002, pp. 111-120.
[6] C. R. Clark and D. E. Schimmel, “Scalable Pattern Matching for High Speed Networks,” in
Proc. 12th Ann. IEEE Symp. Field-Program. Custom Comput. Mach. (FCCM), 2004, pp.
[8] M. Aldwairi*, T. Conte, and P. Franzon, “Configurable String Matching Hardware for Speeding up Intrusion Detection,” in ACM SIGARCH Computer Architecture News, 2005, pp. 99–107
[9] S. Dharmapurikar and J. Lockwood, “Fast and Scalable Pattern Matching for Content
Filtering,” in Proc. of Symp. Architectures Netw. Commun. Syst. (ANCS), 2005, pp. 183-192
[10] Y. H. Cho and W. H. Mangione-Smith, “A Pattern Matching Co-processor for Network
Security,” in Proc. 42nd Des. Autom. Conf. (DAC), 2005, pp. 234-239
[11] L. Tan and T. Sherwood, “A high throughput string matching architecture for intrusion
detection and prevention,” in proc. 32nd Ann. Int. Symp. on Comp. Architecture, (ISCA), 2005, pp. 112-122
[12] H. J. Jung, Z. K. Baker, and V. K. Prasanna, “Performance of FPGA Implementation of Bit-split Architecture for Intrusion Detection Systems,” in 20th Int. Parallel and Distributed
Processing Symp. (IPDPS), 2006.
[13] F. Yu, Z. Chen, Y.Diao, T.V. Lakshman, and R.H. Katz, “Fast and Memory-Efficient Regular
Expression Matching for Deep packet Inspection,” in Proc. ACM/IEEE Symp. Architectures
Netw. Commun. Syst. (ANCS), 2006, pp. 93-102
[14] V. Aho and M. J. Corasick. Efficient String Matching: An Aid to Bibliographic Search. In Communications of the ACM, 18(6):333–340, 1975.
[15] Flex, http://flex.sourceforge.net/
[16] PCRE, http://www.pcre.org/
[17] M. Aldwairi, T. Conte, and P. Franzon, “Configurable String Matching Hardware for Speeding up Intrusion Detection,” in Proc. ACM SIGARCH Computer Architecture News, 33(1):99–107, 2005.
[18] F. Yu, R. H. Katz, and T. V. Lakshman, “Gigabit Rate Packet Pattern-Matching Using TCAM,”
[19] N. Tuck, T. Sherwood, B. Calder, and G. Varghese. “Deterministic Memory-Efficient String Matching Algorithms for Intrusion Detection,” in Proc. 23nd Conference of IEEE
Communication Society (INFOCOMM), Mar, 2004.
[20] S. Kumar, S.Dharmapurikar, F.Yu, P. Crowley, and J. Turner, “Algorithms to Accelerate
Multiple Regular Expressions Matching for Deep Packet Inspection,” in ACM SIGCOMM
Computer Communication Review, ACM Press, vol.36, Issue. 4, Oct. 2006, pp. 339-350.
[21] N. F. Huang, H. W. Hung, S. H. Lai, Y. M. Chu, and W. Y. Tsai, “A gpu-based multiple-pattern matching algorithm for network intrusion detection systems,” in Proc. 22nd International Conference on Advanced Information Networking and Applications (AINA), 2008, pp. 62–67.
[22] M. C. Schatz and C. Trapnell, “Fast Exact String Matching on the GPU,” Technical report. [23] G. Vasiliadis , M. Polychronakis, S. Antonatos , E. P. Markatos and S. Ioannidis, “Regular
Expression Matching on Graphics Hardware for Intrusion Detection,” In Proc. 12th
International Symposium on Recent Advances in Intrusion Detection, 2009.
[24] R. Smith, N. Goyal, J. Ormont, K. Sankaralingam, C. Estan, “Evaluating GPUs for network
packet signature matching,” in Proc. of the International Symposium on Performance Analysis
of Systems and Software, ISPASS (2009).
[25] CUDA, http://www.nvidia.com.tw/object/cuda_home_tw.html
[26] Cheng-Hung Lin, Sheng-Yu Tsai, Chen-Hsiung Liu, Shih-Chieh Chang, and Jyuo-Min Shyu,
"Accelerating String Matching Using Multi-threaded Algorithm on GPU," in Proc. IEEE
GLOBAL COMMUNICATIONS CONFERENCE (GLOBECOM), 2010.
[27] PFAC library, http://code.google.com/p/pfac/
[28] DEFCON, http://cctf.shmoo.com [29] OpenMP, http://openmp.org/wp/
國科會補助專題研究計畫項下出席國際學術會議心得報告
日期:100 年 7 月 31 日
It’s a really good experience to attend IEEE GLOBECOM 2010 held on December 6-10,2010 in Miami, Florida, USA. IEEE GLOBECOM is the premier telecommunications event for industry, professionals, and academics from companies, governmental agencies, and universities around the world. IEEE GLOBECOM 2010 covers the entire range of communications technologies, offering in-depth information on the latest developments in voice, data, image, and multimedia.
My paper titled “Accelerating String Matching Using Multi-threaded Algorithm on GPU” was accepted as poster presentation. Because many attendances work on relative researches, I obtained a lot of positive feedback. During my presentation, many professors and students discussed with me about my researches. In addition, I also listened several interesting research topics including network intrusion detection, next generation networks, protocols, and services, and so on.
Finally, I am very thankful for NSC supporting me to attend this conference.
計畫編號 NSC 99-2221-E-003-029- 計畫名稱 以多核心圖形處理器為基礎之並行化正規表示樣式比對演算法與架構設計(II) 出國人員 姓名 林政宏 服務機構 及職稱 國立台灣師範大學科技應用與人力資源 發展學系副教授 會議時間 99 年 12 月 6 日至
99 年 12 月 10 日 會議地點 Miami, Florida, USA
會議名稱 IEEE GLOBAL COMMUNICATIONS CONFERENCE (IEEE GLOBECOM 2010)
發表論文
Accelerating String Matching Using Multi-threaded
Algorithm on GPU
Cheng-Hung Lin*, Sheng-Yu Tsai**, Chen-Hsiung Liu**, Shih-Chieh Chang**, Jyuo-Min Shyu**
*National Taiwan Normal University, Taipei, Taiwan
**Dept. of Computer Science, National Tsing Hua University, Hsinchu, Taiwan
Abstract—Network Intrusion Detection System has been widely used to protect computer systems from network attacks. Due to the ever-increasing number of attacks and network complexity, traditional software approaches on uni-processors have become inadequate for the current high-speed network. In this paper, we propose a novel parallel algorithm to speedup string matching performed on GPUs. We also innovate new state machine for string matching, the state machine of which is more suitable to be performed on GPU. We have also described several speedup techniques considering special architecture properties of GPU. The experimental results demonstrate the new algorithm on GPUs achieves up to 4,000 times speedup compared to the AC algorithm on CPU. Compared to other GPU approaches, the new algorithm achieves 3 times faster with significant improvement on memory efficiency. Furthermore, because the new Algorithm reduces the complexity of the Aho-Corasick algorithm, the new algorithm also improves on memory requirements.
Keywords-string matching, graphics processing unit
I. INTRODUCTION
Network Intrusion Detection Systems (NIDS) have been widely used to protect computer systems from network attacks such as denial of service attacks, port scans, or malware. The string matching engine used to identify network attacks by inspecting packet content against thousands of predefined patterns dominates the performance of an NIDS. Due to the ever-increasing number of attacks and network complexity, traditional string matching approaches on uni-processors have become inadequate for the high-speed network.
To accelerate string matching, many hardware approaches are being proposed that can be classified into logic-based [1][2][3][4] and memory-based approaches [5][6][7][8][9]. Recently, Graphic Processor Unit (GPU) has attracted a lot of attention due to their cost-effective parallel computing power. A modified Wu-Manber algorithm [10] and a modified suffix tree algorithm [11] are implemented on GPU to accelerate exact string matching while a traditional DFA approach [12] and a new state machine XFA [13] are proposed to accelerate regular expression matching on GPU.
In this paper, we study the use of parallel computation on GPUs for accelerating string matching. A direct implementation of parallel computation on GPUs is to divide an input stream into multiple segments, each of which is
processed by a parallel thread for string matching. For example in Fig. 1(a), using a single thread to find the pattern “AB” takes 24 cycles. If we divide an input stream into four segments and allocate each segment a thread to find the pattern “AB” simultaneously, the fourth thread only takes six cycles to find the same pattern as shown in Fig. 1(b).
Figure 1. Single vs. multiple thread approach
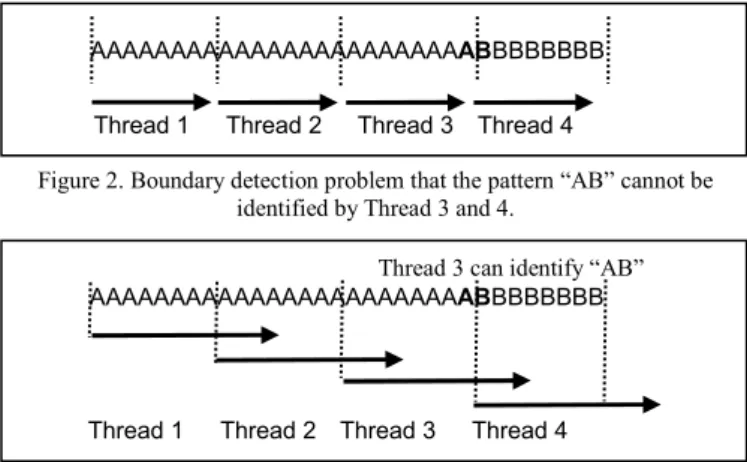
However, the direct implementation of dividing an input stream on GPUs cannot detect a pattern occurring in the boundary of adjacent segments. We call the new problem as the “boundary detection” problem. For example, in Fig. 2, the pattern “AB” occurs in the boundary of segments 3 and 4 and cannot be identified by threads 3 and 4. Despite the fact that boundary detection problems can be resolved by having threads to process overlapped computation on the boundaries (as shown in Fig. 3), the overhead of overlapped computation seriously degrades performance.
Figure 2. Boundary detection problem that the pattern “AB” cannot be identified by Thread 3 and 4.
Figure 3. Every thread scans across the boundary to resolve the boundary detection problem.
In this paper, we attempt to speedup string matching using GPU. Our major contributions are summarized as follows. 1. We propose a novel parallel algorithm to speedup string
matching performed on GPUs. The new parallel Thread 1 Thread 2 Thread 3 Thread 4
AAAAAAAAAAAAAAAAAAAAAAAABBBBBBBB
Thread 1 Thread 2 Thread 3 Thread 4 AAAAAAAAAAAAAAAAAAAAAAAABBBBBBBB
Thread 3 can identify “AB” A A A A A A A A A A A A A A A A A A A A A A A B
(a): Single thread approach
(b): Multiple threads approach
1 thread 24 cycles 4 threads 6 cycles A A A A A A A A A A A A A A A A A A A A A A A B
algorithm is free from the boundary problem.
2. We also innovate new state machine for string matching, the state machine of which is more suitable to be performed in the parallel algorithm.
3. Considering special architecture properties of GPU, we have also described several speedup techniques. 4. Finally, we perform experiments on the Snort rules. The
experimental results show that the new algorithm on GPU achieves up to 4,000 times speedup compared to the AC algorithm on CPU. Compared to other GPU [10][11][12][13] approaches, the new algorithm achieves 3 times faster with significant improvement on memory efficiency. In addition, because the new Algorithm reduces the complexity of the Aho-Corasick (AC) [14] algorithm, we achieve an average of 21% memory reduction for all string patterns of Snort V2.4 [15].
II. PROBLEMS OF DIRECT IMPLEMENTATION OF AC ALGORITHM ON GPU
Among string matching algorithms, the AC algorithm [5][8][9][14][16][17] has been widely used for string matching due to its advantage of matching multiple patterns in a single pass. Using the AC Algorithm for string matching consists of two steps. The first step is to compile multiple patterns into a composite state machine. The second step is to use a single thread to recognize attack patterns by traversing the state machine. For example, Fig. 4 shows the state machine of the four patterns, “AB”, “ABG”, “BEDE”, and “EF”. In Fig. 4, the solid lines represent the valid transitions whereas the dotted lines represent the failure transitions.
The failure transitions are used to back-track the state machine to recognize patterns in different locations. Given a current state and an input character, the AC machine first checks whether there is a valid transition for the input character; otherwise, the machine jumps to the next state where the failure transition points. Then, the machine regards the same input character until the character causes a valid transition. For example, consider an input stream which contains a substring “ABEDE”. The AC state machine first traverses from state 0, state 1, to state 2 which is the final state of pattern “AB”. Because state 2 has no valid transition for the input “E,” the AC state machine first takes a failure transition to state 4 and then regards the same input “E” leading to state 5. Finally, the AC state machine reaches state 7 which is the final state of pattern “BEDE”.
Figure 4. AC state machine of the patterns “AB”, “ABG”, “BEDE”, and “EF”
One approach to increase the throughput of string matching is to increase the parallelism of the AC algorithm. A direct implementation to increase the parallelism is to divide an input stream into multiple segments and to allocate each segment a thread to process string matching. As Fig. 5 shows, all threads process string matching on their own segments by traversing the same AC state machine simultaneously. As discussed in introduction, the direct implementation incurs the boundary detection problem. To resolve the boundary detection problem, each thread must scan across the boundary to recognize the pattern that occurs in the boundary. In other words, in order to resolve the boundary detection problem and identify all possible patterns, each thread must scan for a minimum length which is almost equal to the segment length plus the longest pattern length of an AC state machine. For example in Fig. 5, supposing each segment has eight characters and the longest pattern of the AC state machine has four characters, each thread must scan a minimum length of eleven (8+4-1) characters to identify all possible patterns. The minimum length is calculated by adding the segment length and the length of the longest pattern, and then subtracting one character. The overhead caused by scanning the additional length across the boundary is so-called overlapped computation.
On the other hand, the throughput of string matching on GPU can be improved by deeply partitioning an input stream and increasing threads. However, deeply partitioning will cause the probability of the boundary detection problem to increase. To resolve the boundary detection problem, the overlapped computation increases tremendously and leads to throughput bottleneck.
Figure 5. Direct implementation which divides an input stream into multiple segments and allocates each segment a thread to traverse the AC state
machine.
III. PARALLEL FAILURELESS-ACALGORITHM
In order to increase the throughput of string matching on GPU and resolve the throughput bottleneck caused by the overlapped computation, we propose a new algorithm, called
Parallel Failureless-AC Algorithm (PFAC). In PFAC, we
allocate each byte of an input stream a GPU thread to identify any virus pattern starting at the thread starting location.
The idea of allocating each byte of an input stream a thread to identify any virus pattern starting at the thread starting location has an important implication on the efficiency. First, in the conventional AC state machine, the failure transitions are used to back-track the state machine to identify the virus patterns starting at any location of an input stream. Since in the PFAC algorithm, a GPU thread only concerns the virus pattern starting at a particular location, the GPU threads of B G 0 A 1 2 3 4 5 6 7 9 8 B E D E E F [^ABE] A A A A A A A A A A A A A A A A A A A A A A A A B A A A A A A A
PFAC need not back-track the state machine. Therefore, the failure transitions of the AC state machine can all be removed. An AC state machine with all its failure transitions removed is called Failureless-AC state machine. Fig. 6 shows the diagram of the PFAC which allocates each byte of an input stream a thread to traverse the new Failureless-AC state machine.
Figure 6. Parallel Failureless-AC algorithm which allocates each byte of an input stream a thread to traverse the Failureless-AC state machine. We now use an example to illustrate the PFAC algorithm. Fig. 7 shows the Failureless-AC state machine to identify the patterns “AB”, “ABG”, “BEDE”, and “EF” where all failure transitions are removed. Consider an input stream which contains a substring “ABEDE”. As shown in Fig. 8, the thread
tn is allocated to input “A” to traverse the Failureless-AC state
machine. After taking the input “AB”, thread tn reaches state 2,
which indicates pattern “AB” is matched. Because there is no valid transition for “E” in state 2, thread tn terminates at state
2. Similarly, thread tn+1 is allocated to input “B”. After taking
input “BEDE”, thread tn+1 reaches state 7 which indicates
pattern “BEDE” is matched.
Figure 7. Failureless-AC state machine of the patterns “AB”, “ABG”, “BEDE”, and “EF”.
Figure 8: Example of PFAC
There are three reasons that the PFAC algorithm is superior to the straightforward implementation in Section II. They are described as follows. First, there is no boundary detection problem, as with the straightforward implementation. Second, both the worst-case and average life times of threads in the PFAC algorithm are much shorter than the time needed for the
straightforward implementation. As shown in Fig. 9, threads tn
to tn+3 terminate early at state 0 because there are no valid
transitions for “X” in state 0. The threads tn+6 and tn+8
terminate early at state 8 because there are no valid transitions for “D” and “X” in state 8. Although the PFAC algorithm allocates a large number of threads, most threads have a high probability of terminating early, and both the worst-case and average life-time of threads in the PFAC algorithm are much shorter than the direct implementation. Third, the memory usage of the PFAC algorithm is smaller, due to the removal of failure transitions.
Figure 9. Most threads terminate early in PFAC IV. GPUIMPLEMENTATION
We adopt the Compute Unified Device Architecture (CUDA)[19] proposed by NVIDIA[20] for GPU implementation. In this section, we will discuss several issues to optimize the performance of our algorithm on GPU including group size regulation, thread assignment methodology, and thread number adjustment.
A. Group size regulation
There are two main principles to improve throughput on GPU. One principle is to employ as many threads as possible. The other principle is to utilize the shared memory. In our implementation, 512 threads, the maximum number of threads of a block are employed to process string matching at the same time. The 512 threads traverse the same Failureless-AC state machine. Because multiple threads traverse the same state machine, using shared memory to store the corresponding state transition tables is the most efficient method to improve the latency of accessing state transition tables. However, the size of shared memory is limited and cannot accommodate all virus patterns. In order to utilize the shared memory, we need to divide all virus patterns into several groups and compile these groups into small Failureless-AC state machines to fit into the shared memory.
There are two steps to divide all virus patterns into small groups. The first step is to group these virus patterns by their prefix similarity. By sharing prefixes, the corresponding state machine can be reduced. The second step is to determine the size of a Failureless-AC state machine to fit into the shared memory of a multiprocessor. Given the Snort rules and the size restriction of the state machine, our algorithm can determine the number of the state machine needed to
. . . X X X X A B E D E X X X X X . . . Thread tn~tn+3 Thread tn+6, tn+8 B G B G A B E D E E F tn………tn+3………tn+6 … tn+8 1 2 3 0 4 5 6 7 8 9 0 4 5 6 7 A B E D E E F 1 2 3 8 9 0 A 1 2 3 4 5 6 7 9 8 B G B E D E E F . . . X X X X A B E D E X X X X X . . . …… n n+1 …… Thread n Thread n+1 B G 0 A 1 2 3 4 5 6 7 9 8 B E D E E F B G 0 A 1 2 3 4 5 6 7 9 8 B E D E E F A B E D E G A B B E E E E E B B B C C . . . . . . .
implement all Snort rules. We parameterize the size of the state machine as 1, 2, 3, 4, 5, 6, and 7 KB and find the corresponding number of state machines which are 315, 136, 83, 63, 49, 41, and 35. We find the throughput goes up when the size of a state machine increases. We would like to mention that when the size of a state machine is over 8KB, the corresponding state table cannot fit into the shared memory of our GPU.
B. Thread assignment methodology
As described in section 3, all threads of PFAC traverse the same Failureless-AC state machine and terminate when no valid transition exists. Therefore, it is likely that many threads will terminate very early. To utilize the stream processors, we evaluate two different approaches of thread assignment.
The first approach of the thread assignment is called
Average thread assignment which equally distributes the bytes
of an input stream to each thread of the same block. Supposing we allocate 512 threads to process an input stream of 4,096 bytes, each thread is in responsible for processing eight locations. For example, the first thread processes the bytes starting at locations 0, 512, 1,024, 1,536, 2,048, 2,570, 3,072, and 3,584 of the input stream.
The other approach of the thread assignment is called Boss
thread assignment. The Boss thread assignment declares a
global variable called Boss to assign new jobs to the threads which have already finished their jobs. However, the Boss variable can be accessed by only one thread at a time, which is known as the critical section problem. Therefore, if many threads try to access the Boss variable at the same time, the throughput slows down significantly.
Finally, we choose the average thread assignment to implement our algorithm because the experimental results demonstrate the average thread assignment is much better than the Boss thread assignment.
C. Thread number adjustment
A GPU comprises multiple multiprocessors and an off-chip global memory. Each multiprocessor has 15 KB shared memory, eight stream processors with their register files, an instruction unit, constant cache and texture cache. Multiple blocks are allowed to execute on a multiprocessor which maps each thread to a stream processor. Because the registers and shared memory are split among the threads of blocks, the number of blocks which can be executed simultaneously depends on the number of registers per thread and the number of shared memory per block required for a given kernel function. In order to utilize the eight stream processors of a multiprocessor, we parameterize the thread number of a block as 64, 128, 192, 256, 320, 384, 448, and 512. The experimental results show that 512 threads can achieve the best throughput. Therefore, we choose the thread number of 512 to implement our algorithm.
V. EXPERIMENTAL RESULTS
We have implemented the proposed algorithm on a commodity GPU card and compare with the recent published GPU approaches. The experimental configurations are as follows:
z CPU: Intel® Core™2 Duo CPU E7300 2.66GHz System main memory: 4,096 DDR2 memory z GPU card: NVIDIA GeForce GTX 295 576MHz 480 cores with 1,792 MB GDDR3 memory z Patterns: string patterns of Snort V2.4
In order to evaluate the performance of our algorithm, we implement three approaches described in this paper for comparisons. As shown in Table 1, the CPU_AC denotes the method of implementing the AC algorithm on CPU, which is the most popular approach adopted by NIDS systems, such as Snort. The Direct_AC approach denotes the direct implementation of the AC algorithm on GPU. The PFAC denotes the Parallel Failureless-AC approach on GPU. Table 1 shows the results of these three approaches for processing two different input streams. Column one lists two different input streams, the normal case denotes a randomly generated sequence of 219Kbytes comprising 19,103 virus patterns, whereas the virus case denotes a sequence of 219 Kbytes comprising 61,414 virus patterns.
Column 2, 3, 4, and 5 list the throughput of the three approaches, CPU_AC, Direct_AC, and PFAC, respectively. For processing the normal case of input streams, the throughput of CPU_AC, Direct_AC, and PFAC are 997, 6,428, and 3,963,966 KBps (Kilo Bytes per second), respectively. The experimental results show that the PFAC performs up to 4,000 times faster than the CPU_AC approach while the Direct_AC can only perform 6.4 times as fast. In other words, the PFAC also achieves up to 600 times faster than Direct_AC approach on GPU.
Furthermore, because the new algorithm removes the failure transitions of the AC state machine, the memory requirement can also be reduced. Table 2 shows that the new algorithm can reduce the number of transitions by 50%, and therefore achieve a memory reduction of 21% for Snort patterns. Table 3 compares with several recent published GPU approaches [10][11][12][13]. In Table 3, columns 2, 3, 4, and 5 shows the character number, memory size, the throughput, and the memory efficiency which is defined as the following equation.
Memory efficiency = Throughput / Memory (1)
As shown in Table 3, our results are faster than all [10][11][12][13] with efficient memory usage. We would like to mention that the memory-based approach requires the design and fabrication of a dedicated hardware whereas the GPU approach is more general in the sense that both software and the virus patterns can be easily updated.
TABLE 1:THROUGHPUT COMPARISON OF THREE APPROACHES
Input streams
CPU_AC Direct_AC PFAC
Throughput
(KBps) Throughput (KBps) Throughput (KBps)
Normal Case 997 6,428 3,963,966 Virus Case 657 4,691 3,656,217 Ratio 1 ~6.4 ~4000
TABLE 2:MEMORY COMPARISON
Conventional AC PFAC
states transitions memory (KB) states transitions memory (KB) Reduction
Snort rule* 8,285 16,568 143 8,285 8,284 114 21% Ratio 1 1 1 1 0.5 0.79
* The Snort rules contain 994 patterns and total 22,776 characters. TABLE 3.COMPARISONS WITH PREVIOUS GPU APPROACHES
Approaches Character number of rule set Memory (KB) Throughput (GBps) Memory Efficiency (Throughput/memory) Notes
PFAC 22,776 114 3.9 34,210 NVIDIA GeForce GTX 295 Huang et al. [10] Modified WM 1,565 230 0.3 1,304 NVIDIA GeForce 7600 GT
Schatz et al. [11] Suffix Tree 200,000 14,125 ~0.25 17.7 NVIDIA GTX 8800 Vasiliadis et al. [12] DFA N.A. 200,000 0.8 4 NVIDIA GeForce 9800 GX2
Smith et al. [13] XFA N.A. 3,000 1.3 433 NVIDIA GeForce 8800 GTX
VI. CONCLUSIONS
Graphics Processor Units (GPUs) have attracted a lot of attention due to their cost-effective and dramatic power of massive data parallel computing. In this paper, we have proposed a novel parallel algorithm to accelerate string matching by GPU. The experimental results show that the new algorithm on GPU can achieve a significant speedup compared to the AC algorithm on CPU. Compared to other GPU approaches, the new algorithm achieves 3 times faster with significant improvement on memory efficiency. In addition, because the new algorithm reduces the complexity of the AC algorithm, the new algorithm also improves on memory requirements.
REFERENCES
[1] R. Sidhu and V. K. Prasanna, “Fast regular expression matching using FPGAs,” in Proc. 9th Ann. IEEE Symp. Field-Program. Custom
Comput. Mach. (FCCM), 2001, pp. 227-238.
[2] B.L. Hutchings, R. Franklin, and D. Carver, “Assisting Network Intrusion Detection with Reconfigurable Hardware,” in Proc.10th Ann.
IEEE Symp. Field-Program. Custom Comput. Mach. (FCCM), 2002,
pp. 111-120.
[3] C. R. Clark and D. E. Schimmel, “Scalable Pattern Matching for High Speed Networks,” in Proc. 12th Ann. IEEE Symp. Field-Program.
Custom Comput. Mach. (FCCM), 2004, pp. 249-257
[4] J. Moscola, J. Lockwood, R. P. Loui, and M. Pachos, “Implementation of a Content-Scanning Module for an Internet Firewall,” in Proc. 11th
Ann. IEEE Symp. Field-Program. Custom Comput. Mach. (FCCM),
2003, pp. 31–38.
[5] M. Aldwairi*, T. Conte, and P. Franzon, “Configurable String Matching Hardware for Speeding up Intrusion Detection,” in ACM
SIGARCH Computer Architecture News, 2005, pp. 99–107
[6] S. Dharmapurikar and J. Lockwood, “Fast and Scalable Pattern Matching for Content Filtering,” in Proc. of Symp. Architectures Netw.
Commun. Syst. (ANCS), 2005, pp. 183-192
[7] Y. H. Cho and W. H. Mangione-Smith, “A Pattern Matching Co-processor for Network Security,” in Proc. 42nd Des. Autom. Conf.
(DAC), 2005, pp. 234-239
[8] L. Tan and T. Sherwood, “A high throughput string matching architecture for intrusion detection and prevention,” in proc. 32nd Ann.
Int. Symp. on Comp. Architecture, (ISCA), 2005, pp. 112-122
[9] H. J. Jung, Z. K. Baker, and V. K. Prasanna, “Performance of FPGA Implementation of Bit-split Architecture for Intrusion Detection Systems,” in 20th Int. Parallel and Distributed Processing Symp.
(IPDPS), 2006.
[10] N. F. Huang, H. W. Hung, S. H. Lai, Y. M. Chu, and W. Y. Tsai, “A gpu-based multiple-pattern matching algorithm for network intrusion detection systems,” in Proc. 22nd International Conference on
Advanced Information Networking and Applications (AINA), 2008, pp.
62–67.
[11] M. C. Schatz and C. Trapnell, “Fast Exact String Matching on the GPU,” Technical report.
[12] G. Vasiliadis , M. Polychronakis, S. Antonatos , E. P. Markatos and S. Ioannidis, “Regular Expression Matching on Graphics Hardware for Intrusion Detection,” In Proc. 12th International Symposium on
Recent Advances in Intrusion Detection, 2009.
[13] R. Smith, N. Goyal, J. Ormont, K. Sankaralingam, C. Estan, “Evaluating GPUs for network packet signature matching,” in Proc. of
the International Symposium on Performance Analysis of Systems and Software, ISPASS (2009).
[14] A. V. Aho and M. J. Corasick. Efficient String Matching: An Aid to Bibliographic Search. In Communications of the ACM, 18(6):333–340, 1975.
[15] M. Roesch. Snort- lightweight Intrusion Detection for networks. In Proceedings of LISA99, the 15th Systems Administration Conference, 1999.
[16] N. Tuck, T. Sherwood, B. Calder, and G. Varghese. “Deterministic Memory-Efficient String Matching Algorithms for Intrusion Detection,” in Proc. 23nd Conference of IEEE Communication
Society (INFOCOMM), Mar, 2004.
[17] S. Kumar, S.Dharmapurikar, F.Yu, P. Crowley, and J. Turner, “Algorithms to Accelerate Multiple Regular Expressions Matching for Deep Packet Inspection,” in ACM SIGCOMM Computer
Communication Review, ACM Press, vol.36, Issue. 4, Oct. 2006, pp.
339-350.
[18] F. Yu, R. H. Katz, and T. V. Lakshman, “Gigabit Rate Packet Pattern-Matching Using TCAM,” in Proc. the 12th IEEE
International Conference on Network Protocols (ICNP’04), 2004.
[19] http://www.nvidia.com.tw/object/cuda_home_tw.html [20] http://www.nvidia.com.tw/page/home.html
Bridget Erlikh, Compliance Coordinator, Conference Operations IEEE Communications Society
3 Park Avenue, 17th Floor, New York, NY 10016 USA tel. +1 212 419 7929 - fax +1 212 705 8999
www.comsoc.org - [email protected]
July 12, 2010
Prof. Cheng-Hung Lin 162, Heping E. Rd, Sec.1 Taipei, Taiwan 106 Taiwan
Dear Cheng-Hung Lin:
Your paper, "Accelerating String Matching Using Multi-threaded Algorithm on GPU," has been accepted as part of the technical program for the IEEE Globecom 2010 - Communication & Information System Security, an education conference sponsored by the IEEE Communications Society. GC10 - CIS will be held December 5-10,
2010 in Miami, Florida.
I attest that you are not traveling to the USA to perform work, but to attend an IEEE educational conference. Note: Upon entry into the USA, the IEEE cannot be held accountable for your actions, whereabouts or itinerary.
To further assist you in obtaining a visa, below is a description of the IEEE and of the IEEE Communications Society. The Institute of Electrical and Electronics Engineers (IEEE) is the world's largest technical professional society. Founded in 1884 by a handful of practitioners of the new electrical engineering discipline, today's Institute is comprised of more than 375,000 members who conduct and participate in its activities in 160 countries. The men and women of the IEEE are the technical and scientific professionals making the revolutionary engineering advances, which are reshaping our world today. The IEEE Communications Society embraces all aspects of the advancement of the science, engineering, technology and applications for transfer of information between locations by the use of signals. This includes: sources and destinations involving all types of terminals, computers and information processors; all pertinent systems and operations to bring about this transfer; guided and unguided transmission media; switched and unswitched networks; and network layouts, protocols, architectures and implementations.
If you have any further questions or concerns that I can address, please feel free to contact me by email at [email protected].
Sincerely yours,
Compliance Coordinator, Conference Operations IEEE Communications Society
國科會補助計畫衍生研發成果推廣資料表
日期:2011/08/26國科會補助計畫
計畫名稱: 以多核心圖形處理器為基礎之並行化正規表示樣式比對演算法與架構設計 (II) 計畫主持人: 林政宏 計畫編號: 99-2221-E-003-029- 學門領域: 積體電路及系統設計無研發成果推廣資料
99 年度專題研究計畫研究成果彙整表
計畫主持人:林政宏 計畫編號: 99-2221-E-003-029-計畫名稱:以多核心圖形處理器為基礎之並行化正規表示樣式比對演算法與架構設計(II) 量化 成果項目 實際已達成 數(被接受 或已發表) 預期總達成 數(含實際已 達成數) 本計畫實 際貢獻百 分比 單位 備 註 ( 質 化 說 明:如 數 個 計 畫 共 同 成 果、成 果 列 為 該 期 刊 之 封 面 故 事 ... 等) 期刊論文 0 0 100% 研究報告/技術報告 0 0 100% 研討會論文 1 1 100% 篇 論文著作 專書 0 0 100% 申請中件數 0 0 100% 專利 已獲得件數 0 0 100% 件 件數 0 0 100% 件 技術移轉 權利金 0 0 100% 千元 碩士生 2 2 100% 博士生 0 0 100% 博士後研究員 0 0 100% 國內 參與計畫人力 (本國籍) 專任助理 0 0 100% 人次 期刊論文 0 0 100% 研究報告/技術報告 0 0 100% 研討會論文 2 2 100% 篇 論文著作 專書 0 0 100% 章/本 申請中件數 0 0 100% 專利 已獲得件數 0 0 100% 件 件數 0 0 100% 件 技術移轉 權利金 0 0 100% 千元 碩士生 0 0 100% 博士生 0 0 100% 博士後研究員 0 0 100% 國外 參與計畫人力 (外國籍) 專任助理 0 0 100% 人次其他成果
(
無法以量化表達之成 果如辦理學術活動、獲 得獎項、重要國際合 作、研究成果國際影響 力及其他協助產業技 術發展之具體效益事 項等,請以文字敘述填 列。)原 始 程 式 並 製 作 成 library 公 布 於 Google code project
(http://code.google.com/p/pfac/),除獲得國內外相關研究學者正面回饋, 並預計於 2012 年於美國加州 San Jose 舉辦的 GPU Technology Conference (GTC 2012)發表。 成果項目 量化 名稱或內容性質簡述 測驗工具(含質性與量性) 0 課程/模組 0 電腦及網路系統或工具 0 教材 0 舉辦之活動/競賽 0 研討會/工作坊 0 電子報、網站 0 科 教 處 計 畫 加 填 項 目 計畫成果推廣之參與(閱聽)人數 0
國科會補助專題研究計畫成果報告自評表
請就研究內容與原計畫相符程度、達成預期目標情況、研究成果之學術或應用價
值(簡要敘述成果所代表之意義、價值、影響或進一步發展之可能性)
、是否適
合在學術期刊發表或申請專利、主要發現或其他有關價值等,作一綜合評估。
1. 請就研究內容與原計畫相符程度、達成預期目標情況作一綜合評估
■達成目標
□未達成目標(請說明,以 100 字為限)
□實驗失敗
□因故實驗中斷
□其他原因
說明:
2. 研究成果在學術期刊發表或申請專利等情形:
論文:■已發表 □未發表之文稿 □撰寫中 □無
專利:□已獲得 □申請中 ■無
技轉:□已技轉 □洽談中 ■無
其他:(以 100 字為限)
我們已公布原始程式並製作成 library 公布於 google code project (http://code.google.com/p/pfac/),以為推廣研究成果與學術交流。
3. 請依學術成就、技術創新、社會影響等方面,評估研究成果之學術或應用價
值(簡要敘述成果所代表之意義、價值、影響或進一步發展之可能性)(以
500 字為限)
近兩年著眼於利用多核心圖形處理器(Graphic Processing Unit,簡寫 GPU)龐大的平行 運算能力,發展多執行緒平行演算法(multi-threading parallel algorithm),以加速字 串樣式與正規表示法樣式的比對效能,相關研究成果除發表於與高水準研討會以外,並將 所開法的高效能 GPU 程式製作成 library,發表於 google code project,獲得相關研究 社群的良好回應。研究成果並 submit 至 IEEE Transactions on Computers,目前正進行 major revision. 未來將著眼 GPU 記憶體的優化進行研究。
![Figure 2. Partial state machine of the three regular expressions, “.*STAT[^\n]{10}”, “.*USER[^\n]{10}”, and “.*PASS[^\n]{10}”](https://thumb-ap.123doks.com/thumbv2/9libinfo/7176856.50349/8.892.214.679.87.333/figure-partial-state-machine-regular-expressions-stat-user.webp)
![Figure 6. A PFAC state machine for the three complex regular expressions, “.*STAT [^\n]{10}”, “.*USER [^\n]{10}”, and “.*PASS [^\n]{10}”](https://thumb-ap.123doks.com/thumbv2/9libinfo/7176856.50349/11.892.106.743.371.606/figure-pfac-state-machine-complex-regular-expressions-stat.webp)