Dynamic FEC-Distortion
Optimization for
H.264
Scalable Video
Streaming
Wei-ChungWen andHsu-FengHsiao Jen-Yu Yu
Dept. of Computer Science Information and Comm. Research Labs
National Chiao TungUniversity IndustrialTechnologyResearch Institute
Hsinchu, Taiwan Hsinchu, Taiwan
{wcwen,hillhsiao}@cs.nctu.edu.tw [email protected]
Abstract-Forward error correction codes have been shown adopted in 3GPP [4]. However, unlike Reed-Solomon error to be a feasible solution either inapplication layeror in linklayer erasure code which shows maximum distance separable
to fulfill the need ofQualityof Service for multimediastreaming property,fountain codesgenerallyhave lesscoding efficiency.
over the fluctuant channels. In this paper, we propose FEC- In[5], Tanetal.proposed layeredFECfor sub-band coded
distortion optimization algorithms to efficiently utilize the scalable video multicast
using equation-based
rate controlbandwidth for better video quality. The optimization criterions
are based on theunequal. . errorprotection bytaking account.of ~~~~~~~~that
while daptivF
the distortion functioniop
can be minimized with thetore
theilost
pcts
sothe error drifting problems from both temporal motion
optimized subscription
of video and FEClayers
under ancompensation and Inter-layerpredictionofH1.264/MPEG-4AVC ppyassumption that different frames inavideolayer shall have the
scalablevideocoding. Also, itcanadapttothecontent-dependent samedistortion.
quality contribution of each video frame in a video layer.
Lightweight error-concealment is also incorporated with the In [6], an adaptive FEC scheme as part of the reliable
proposed algorithmsfor better H.264 SVCstreaming. For some layeredmultimediastreaming overeither unicast ormulticast
applicationswhere eithercomputation mightbe the bottleneck or was proposed. The main objective of the FEC scheme is to theupperbound of non-decodableprobabilityof each videolayer maximize the
streaming throughput
whilemaintaining
anis specified, alternative bandwidth allocation algorithm is upperbound of theerrorrate for each scalable videolayerthat
provided with the trade-offofslight quality degradation. FEC fails to decode.
However,
the upper bounds are presetwithout furtherexplanation.
Keywords-FEC optimization;H.264;scalablevideo The impact ofpacketloss and FEC overhead on scalable coding;unequalerrorprotection bit-plane coded video in best-effort networks is analyzed in [7]
Topic area-multimedia communication. and similar optimization algorithm was proposed to allocate the bandwidthresource toFECand videodata, respectively. I. INTRODUCTION In this paper, we propose FEC-Distortion optimization Personal, home, or handheld entertainment systems, such algorithms that take account of the error drifting problems
as DVB-H [1] andIPTVwhich is under construction tobe a from both temporal motion compensation and inter-layer standard by ITU-T, have been an emerging research and prediction of H.264/MPEG-4 AVC scalable video coding, as industrial emphasis due to the great progress of the network well as the content-dependent visual quality contribution of communications and joint multimedia/channel coding each video frame in a video layer toachieve better quality of technologies. It is rather challenging to fulfill the needs for service with the same resource. In case of occasional packet Quality of Service andQuality ofExperience requirements in error that is not recoverable by the FEC scheme, lightweight the mobile environments of such entertainment systems that error-concealment is also incorporated with the proposed mightsuffer fromdynamicchannel fluctuation. algorithms for better quality ofreconstructed video.
Besides Automatic Repeat reQuest (ARQ)whichpossibly The rest of this paper is organizedas follows. In Section II suffers from the intolerable end-to-end packet delay and we modify the FEC optimization algorithm in [5] to be used exacerbated jitter, forward error correction codes have been with H.264 scalable video coding in a non-FEC-layer fashion. shown to be a feasible solution. In DVB-H, Multi-Protocol We present the dynamic FEC-distortion optimization Encapsulated Forward Error Correction (MPE-FEC) is used algorithm in Section III and discuss the error-bounded by interleaving the information packets and the protection optimization algorithm in Section IV, followed by the packetsfrom Reed-Solomon codetodeal with the bursterror. simulation results and concluding remarks in Section V and The error protection strength in MPE-FEC is not really Section VI, respectively.
content-dependent. Besides Reed-Solomon code, rateless
erasure codes (also known as fountain code [2]), such as II. FLAT FEC-DISTORTION OPTIMIZATION
raptor code
[3],
provide virtuallyinfinite
protection symbols I 5,Tne l rpsdlyrdFCagrtmfrsband he mdifedvrsio ofsuchcodehasbeenrecetly band coded scalable
video multicast using equation-based
ratecontrol such that packet loss is one of the parameters to s from thesubscription set M means a vector(n1,
n2,
...lnN). N regulate the sending rate while adaptive FEC is adopted to is the number of thetransmitted video layers (N.<L)andeach recover the lost packets so that the distortion can be vectorelementni
means theoutput symbol number of the FEC minimized with optimized subscription S* as described in (1) erasure code for thei`h
video layer as the n in the (n, k) code. and (2), underan assumption that different frames ina video In addition, ifthe packet loss distribution is modeled by the layer shall have the same distortion measure. Gilbert/Elliot's 2-state Markov chain [11], which is usually St = argminD(s,p),adopted
todescribefading
channel,
therelationship
betweenpi
srM,
R(s)<B
(1)
and p in[6]
is used in(6).
Themodified optimization
L-1
algorithm
isdesignated
as the Flat FEC-DistortionD(s,p),pi
-Di,
(2)Optimization
(FFDO) algorithm.
i=O
where Mis a set of possible subscriptions of video and FEC
layers that fit into the available bandwidth B. p is the average III. DYNAMIC
FEC-DISTORTION
OPTIMIZATION packet loss rate. D(s, p) is the distortion function whilepi isthe decodable probability of only the accumulated i video FFDO is based on the assumption that different frames in
layers
Dis the
associateddistortion, and
L is the total the same video layer exhibitconstant distortion.However,
this ecdlayers
vie . ,tepakto
lose,
are assmed
totbe
isusually
not the case for the real H.264 SVC videos. Thedistortion (or PSNR) depends on the content of each video independent and identically distributed across all the packets frameaswellasthe
quantization
parameter
and mode decision and the relationship betweenpi and p ofthis Bernoulli error used in each block. Due to the error propagation effect modelisshownbelow. resulting from not only theprediction coding across the video layers but also the temporal motion compensation coding in|qi+jf|(-qk)
,O<i<L eachindividual video layer, the distortion caused by different Pi L k=1(3)
frame ofavideo layer can also vary. As a result, the global[17(1
-qk) ,=Loptimal
bit allocation of H.264 SVC and FEC shall be foundk=1 over all the possible bit allocation and packet loss
=p(i
-i
)K-1
(I
py
plf (4)wl combinations.M K
-=P
+Kl(4)
W=0 .. We further propose the
Dynamic
FEC-Distortionwhererecovered
qi
inM,
(3) stands for theis th nubro~-.
probability thatrtcinsmosilayer i can not beEOptimization
further props the Dynamic FE-istortion
(DFDO)algorithm
to perform theoptimization
sessionfre
lais
. notonly
across thevideo
layers
but alsowithin
eachvideo
session for
layer
i.layer.
Since thePSNRvariation of differentpictures
withinaInstead of the sub-band scalablevideo coding with layered video layer is smaller than that across the video layers, the structure on both video and FEC data in [5], our proposed DFDO algorithm first uses FFDO to decide the number of FECoptimization algorithms are based on the H.264/MPEG-4 videolayersNand also the totalamountof protectionpackets AVC scalable extension, which is an amendment to the per GOPfor each video layertosubscribe. Then the algorithm H.264/MPEG-4 AVC standard and it is scheduled to be
finds
the distribution patternSn*
of those protection packets finalized in 2007. The base layer of a Scalable Video Coding among all theFEC sessions in each video layern (1.n
.N) (SVC) bit-stream is usually coded in compliance with H.264 to removethe constantdistortion assumption within the same whilenewscalable toolsareadded forsupporting spatial,SNR, videolayer. The criterion of this search withinavideo layer is andtemporal scalability [8].ForeachGroupof Pictures (GOP) basedonthe FEC-distortionoptimization of the video layeras of a scalable video layer, we apply Reed-Solomon erasure shownin(7) and (8).code [9] to form an (n, k) code which has k symbols of the S
video layer data and theamount of n-kprotection symbols. It =argmax
psnrn(s,p),(7)
will takeafewFECcoding sessionsifthe datarateofavideo
GOPsizeC
layer in the same GOP is high. Sequence Parameter Set
psnrn(s,)
(p psnr+p2 psnr2 i+p3 psnr3n,), (8) Network Abstraction Layer (NAL) units and Picture /=1Parameter Set NAL units [10] have essential header where
psnrn(s,p)
is defined as the PSNR summation of the information inordertodecode the video properlyand they are accumulated videolayers
up tolayer
n among all the video assignedstrongest errorcorrection code (n=256),ascompared frames in each GOP. m is the set of all thepossible
FEC to the other NAL data units. We modify (1) and (2) to distributionpatterns overall the FEC sessions in then`h
video accommodateH.264 SVC and definePSNR function PSNR(s,layer.
p'i
is the decodableprobability
ofith
picture of that GOP p)tobe maximizedasshownin(5) and (6). and all its referencepictures
in thecurrentvideolayer.
psnrI,iis the
PSNR
ofpicture i in the same layer.p2i
is thenon-sMargmaxPSNR(s,p),
(5) decodable probability ofith
picture regardless the successfulL-1
decoding
of its referencepictures
in the current videolayer.
InPSNR(s,p)=
p-PSNZ2veZ
(6)
this case, the implemented error concealment method is toi=o reusethe reconstructed
ith
picture
of then-lth
layer.
psr2n
,iis
where
P'
isthedecodable probability of the error erasure codes the PSNR of picture i in thesame layer andthus it is equal to for only the accumulated i video layers and PSNRaVe i is thepsnr2n i,i. p3,
is the decodable probability ofith picture but not corresponding averagePSNT{,
respectively. Each subscription all of itsreferencepictures in the current video layer.psnr3i~
is thePSNR.
of picture i based on the residual video frame andthe reconstructed reference pictures with the same error
concealmenttechniquementioned above. 40
The three
probabilities
(pi,
,p2i
,p3i)
canbe determinedby
35---(9),
(10),
and(11), respectively.
30 1( r), 25 I~~~~eRdreR~~~~(9)
con~2 26 p2qr)1
1stLayer (10) 15 2nd Layer-reRB 3rdLayer 3 pipi-p2
il 0(11) .1 0.2 0.3 0.4 0.5 6.6 0.7 0.8 0.9 0.95where RA is the set of all the FEC sessions involved for
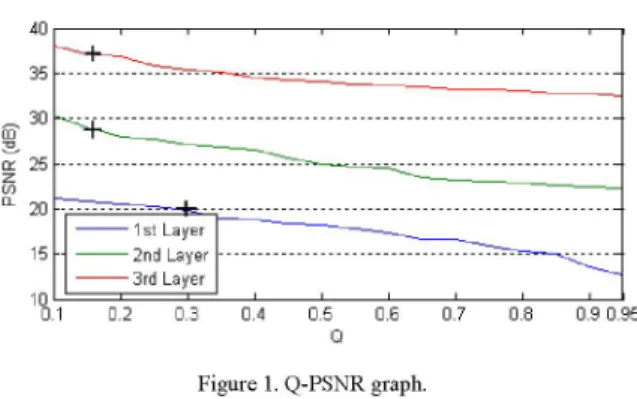
picture i in the current video layer and all the reference Figure 1.Q-PSNR graph. pictures in the samelayer.RBis thesetof all the FEC sessions
involved for picture i in the current video layer. r iS for each Fi. 1ithQ-SRwhtreH.26 SV aeso h
andoevedfory Fire
sio
in thesurrent qideo isyr.
te d evideo
sequencemobile
at4CIFresolution.
In thecaseof basea
ty
oFEC
session r,
.r
. q .layer,
the range of the20%
of thehigher
PSNRvaluesis fromprobability of FEC session r. 19.45 to 21.14
dB,
which isroughly corresponding
toQ
Ifthe packet losses are assumed to be independent and values from 0.1 to 0.3. Within this range, the steepest slop identically distributed with packet loss ratep across all the occurs at Q =0.3 and it is selected as the upperbound -l for
packets,
q,
of FEC session(n, k)is shown in(12). thebase layer. Similarly, 82and83
canbefound inthe samen-I n way.
qr = n, (I
)i
n-i (12)
i= i P V. SIMULATIONS
On the other hand, if the packet loss distribution is We perform simulations for both the flat and dynamic modeled by Gilbert/Elliot's 2-state Markov chain, the FEC-distortion optimization algorithms (noted as FFDO and decodableprobabilityofanFECsessioncanbe found in[6]. DFDO, respectively) as well as the error-bounded allocation algorithm (Error-Bounded). As a comparison, we also show
IV. ERROR-BOUNDEDFEC ALLOCATION the PSNR performance of equally-distributed FEC scheme
Both the flat and dynamic FEC-Distortion optimization (UniformDistribution) among all the video layers.
algorithms compare all thepossiblevideo
layers
and the FEC The video sequence is mobile at 30 fps and the video allocation combinations for each GOP, whichmight require
resolution is 4CIF. The H.264 SVC encoder and decoder are considerable computation effort. In [6], anadaptive
FEC based on the Joint Scalable Video Model (JSVM) reference scheme for reliable layered multimediastreaming
was software and the error concealment technique described in proposed. The main objective of the FEC scheme is to Section III is applied to all the algorithms. For the spatial maximize the streaming throughput whilemaintaining
an scalability, the PSNR is calculated after the picture is up-upper bound of the error rate of each videolayer
that FEC sampled back to its raw video resolution (4CIF in this case).cannot decode. Inspired by this concept, we determine the Some of the encoding parameters for each scalable video layer upper bounds of the non-decodable
probability
of an FEC are listed in Table I and the GOP size is 16. The available session for eachlayer andusethose upper boundsto calculate bandwidth over time is shown in Fig. 2.theprotectionstrengthfor each video
layer
from the baselayer
of H.264 SVC to each enhancement
layer
until all the available bandwidthis consumedasmentioned in[6].
Ifthereis unused bandwidth after all the videolayersareincluded and Layer Resolution QP Bitratekbps
they all satisfy the upper bounds of the
decoding
error 1 QCIF 30 298.80probability, we distribute the remaining bandwidth as 2 CIF 34 872.49
additionalerror
protection equally
amongallthelayers.
3 4CIF 26 3610.09Toderive the upper bound Eifor the
i`h
layer,wedraw theQ-PSNR graph for the
i`h
videolayer, where Q stands for the x1061non-decodable probability ofan FEC session of this video layerwhile all the lower video layers canbe decoded . The upper bound
8i
is defined as theQ
value with thesteepest
slope onthe Q-PSNR
graph
within the range of first20% ofthe
higher
PSNR values, sothat the upper bound will have *reasonable high video quality and it introduces most PSNR *
increase
by
thesameQ
decrease. o 2 3 4 7 ' 11 2 3 4 5 8; 7 8 9 10
Time (sec)
Figure2.Available bandwidth over time.
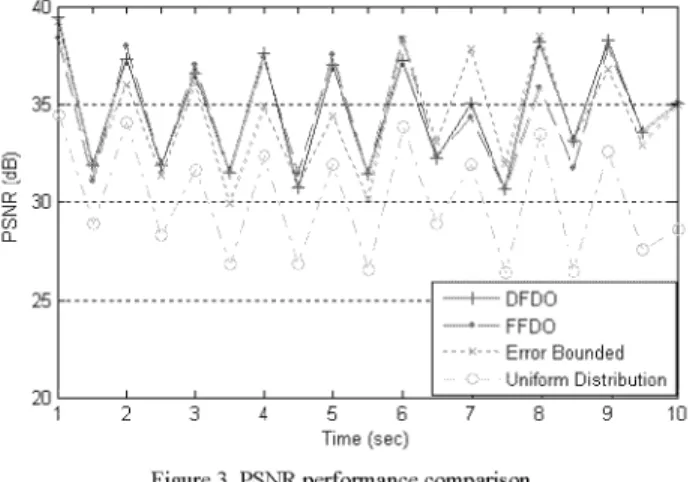
First we consider the packetlosses tobe independent and TABLE III.THEAVERAGEPSNR identically distributed with packet loss ratep=0.25 across all Algorithm Average PSNR(dB)
the packets. The primitive results in terms of the average DFDO 34.65
PSNR of four algorithms are shown in Table II. It clearly FFDO 34.41
shows theimportance of theunequal errorprotectionprovided Error-Bounded 34.23
inDFDO, FFDO, andError-Bounded, when compared to the Uniform Distribution 29.78
equal error protection scheme. The DFDO is always better
than the FFDO even though the PSNR increase is not The availablebandwidth over time is shown in Fig. 4. The significant. Thiscanbe duetotheerrorconcealmenttechnique simulation results are very similar to those in Fig. 3. It which eliminates some of the distortion caused by the error
confirms
that ifwe distinguish the distortion difference with propagation. Fig.3 shows thePSNRperformance. greater details, we canperform
the unequal error protection40______________________________________________________ better.
4 VI. CONCLUSIONS
35 23, 411"
~~~~~~~~~~~In
thispaper,theFEC-Distortionoptimization algorithms
XD/t / i W areproposed. The algorithms take accountof theerrordrifting
problems
from bothtemporal
motioncompensation
andinter-cr 30 -- - - layer prediction of
H.264/MPEG-4
AVC scalable videon coding, as well as the content-dependent visual quality
contribution of each video frame in each video
layer
to25 - - - DFDO achieve better
quality
of service with the same resource. InFFDO case of
occasional
packet errorthat isnot recoverableby
the----ErrorBounded
Uniform
Bistbution
FECscheme,
lightweight
error-concealment is also20 2 3 4 E 9 1
incorporated
with theproposed
algorithms
for better H.264Time(sec)
SVC
streaming.
For someapplications
where eitherFigure3. PSNRperformance
comparison,
computation might
be the bottleneck or the upper bound of error probability for each video layer isrequired,
alternative bandwidth allocation algorithm isprovided
with the trade-offTABLEII. THEAVERAGE PSNR of
slight quality
degradation.
Algorithm Average PSNR(dB) REFERENCES
DFDO 34.70
FFDO 34.53 [1] ETSI, "Digital Video Broadcasting (DVB): Transmission systems for
Error-Bounded 34.36 handheldterminals,"ETSIstandard,EN 302 304VI.1.1,2004.
Uniform Distribution 30.15 [2] J. Byers, M. Luby, and M. Mitzenmacher, "A Digital Fountain
Approach to Asynchronous Reliable Multicast," IEEE Journal on
SelectedAreas inCommunications, 20(8),pp.1528-1540,October 2002. Secondly, we use Gilbert/Elliot's 2-state Markov chain to [3] M. Luby et al., "Raptor Codes for Reliable Download Delivery in
model the packet loss behavior in a fading channel and the WirelessBroadcast Systems," IEEE CCNC, Las Vegas, NV, Jan. 2006. transition probabilities are chosen so that the average packet [4] 3GPP TS 26.346V6.4.0, "Technical Specification GroupServicesand
lost probability is also 0.25 and the available bandwidth System Aspects; Multimedia Broadcast/Multicast Service (MBMS); profile iskept thesame. Thecorresponding results in termsof Protocols andCodecs,"Mar.2006.
averagePSNR for fouralgorithmsareshown in Table III. [5] W.-T.Tan,A.Zakhor,"Video multicastusinglayeredFEC andscalable compression,"IEEE Transactions on Circuits andSystemsfor Video
40 Technology,March2001.
[6] H.-F.Hsiao,A. Chindapol, J.A. Ritcey, andJ.-N.Hwang, "Adaptive
FEC Scheme for LayeredMultimedia Streaming overWired/Wireless Channels," WorkshoponMultimediaSignal Processing, IEEE,pp. 1-4,
35 | ---- 1 Oct. 2005.
[7] S.-R. Kang and D. Loguinov, "Modeling Best-Effort and FEC
+
.. E § '
~~~~~~~~~~~~~~Streaming
of Scalable VideoinLossyNetworkChannels,"IEEEIACM306a-- , - _ Trans.onNetworking,Feb. 2007.
Cn [8] H. Schwarz, D. Marpe, and T. Wiegand, "Overview of the Scalable
H.264/MPEG4-AVC Extension," International Conference on Image Processing, IEEE,Oct., 2006.
25--- DFDO [9] L. Rizzo, "Effective Erasure Codes for Reliable Computer
- FFDO Communication Protocols", Computer Communication Review,
----ErrorBounded
27(2):24-36,
April1997.Uniform
Distribution
[10] ITU-T Rec. &ISO/IEC 14496-10AVC,"Advanced VideoCodingfor1 2 3 4 0 6 7 8 9 16 GenericAudiovisual Services," version3, 2005.
Time (sec) [11] E. Elliot, "Estimates of error rates for codes onburst-noise channels," Figure 4. PSNR performance comparison. Bell SystemTechnique Journal, 1963.