Reversible Data Hiding Based on a Sorted VQ Index Table
Cheng-Hsing Yang, Yi-Cheng Lin, Sheng-Chang Wu, Min-Hao Wu
Department of Computer Science, National Pingtung University of Education,
chyang, bm
096114
, bm
097115
, bm
097116
@mail.npue.edu.tw
Abstract
-Recently, a reversible VQ-based data embedding scheme which emphasizes that the original VQ compressed codes can be recovered after data extracting was presented by Chang et al. In their scheme, a sorted VQ codebook is divided into3
2B1 clusters and indexes located in the front one-third clusters are used to embed secret data, where B
denotes the size of secret data embedded into each VQ index. In this paper, a new reversible VQ-based hiding scheme is proposed. In our scheme, a sorted VQ codebook is divided into 2B clusters and half of clusters are used to embed secret data. Strategies of priorities, indicators, and index exchanging are proposed to improve our scheme further. Under the same sorted VQ codebook, experimental results demonstrate that our data hiding algorithm has higher capacity and better compression rate.
Keywords: Data hiding, Reversible embedding, Vector quantization, Data clustering.
1. Introduction
As multimedia and the Internet are popular, the problem of protecting transmitted media becomes more and more important. In order to enhance the safety of transmission, technologies based on data hiding [1] have attracted great attention. Data hiding usually embeds secret data into media, such as images and videos, for the purpose of secret transmission or copyright protection. In this paper, images are used as the embedded media. Images before and after data hiding are called cover images and stego-images, respectively.
In recent years, many hiding technologies have been developed based on the VQ (Vector Quantization) [2-4], and some of them have the character of reversibility [5-11]. The reversible data hiding based on VQ generally refers to owning the ability of extracting hidden data and recovering the images into original VQ coding or SMVQ coding.
According to the developed reversible data hiding technologies based on VQ, we put them into three categories by the characters of outputs as follows.
(1) Images as outputs:
After data hiding, some approaches are limited to producing images as outputs [5, 7]. Literature [5] presents a reversible data hiding scheme based on side match vector quantization (SMVQ). Another
literature [7] presents a reversible information hiding scheme based on VQ.
(2) Legitimate VQ coding or SMVQ coding as outputs:
After data hiding, a formal VQ coding or SMVQ coding is created as outputs [6, 8]. Generally speaking, approaches in this category require more skills. Literature [6] proposes a reversible embedding scheme for VQ-compressed images that is based on side matching and relocation. Also, in literature [8], a reversible data-hiding scheme based on a modified side match vector quantization (SMVQ) technique is proposed.
(3) VQ coding or SMVQ coding with additional control messages as outputs:
Approaches in this category add control messages into the formal VQ coding or SMVQ coding as outputs [9-11]. Therefore, these approaches usually increase the lengths of coding results. Moreover, because the results are not general VQ codes or SMVQ codes, they are easy to cause attentions and expose the fact of data hiding.
In this paper, a new hiding approach of the third category is proposed. Our approaches can not only recovery the original VQ coding, but also flexibility adjusts the embedding capacity. Compared to Chang etal.’smethod [11], our approach has larger capacity. The remainder of this paper is as follows. Chang et al.'s method is introduced in Section 2. Section 3 describes the details of our proposed scheme, and Section 4 shows some experimental results. Finally, some conclusions are given in Section 5.
2. Past Work by Chang et al.
In 2007, Chang et al. provided a VQ-based embedding method which can losslessly recover the VQ index table [11]. In their method, a codebook is partitioned into some clusters and some indexes of the codebook are reserved for acting as indicators. Data are embedded into the VQ index table by transferring index values from one cluster to another cluster and sometimes index values are led by indicators. For a traditional codebook Ψ with N codewords, the codebook is redesigned as codebook Ψ with
N 3 2 2 1 1 B B N 3 2 1 B codewords, where B
denotes the size of secret data embedded into each VQ index. Also, the surplus 2B1 index values are used as the indicators. Some standard images have been used to train the codebook Ψin their paper and
codewords in Ψwere sorted by the referred counts in descending order. Then, codebook Ψ is partitioned into 2B13 clusters with the same size
m B B N 2 2 1
. The front one-third clusters with highest referred counts are used to embed secret data.
1 5 1 2 3 4 5 21 22 23 24 25 11 12 13 14 15 3 2 6 6 7 8 9 10 26 27 28 29 30 16 17 18 19 20 4 I2 I2 I101 I100 01 00 10 11 I110 I111 12 18 1 24 9 6 3 5 21 15 8 26 2 4 || 0 Secret data 14 || 31 18 || 31 0110110001 Index table T Index tableT
Figure 1.Example ofChange etal.’s method for embedding two-bit secret data.
Figure 1 shows an example of Chang et al.’s proposed method for embedding two-bit secret data into each index value in cluster or1 cluster (2 B2). The original codebook Ψconsists of 32 codewords (N32) and the new sorted codebook Ψhas 30 codewords ( N30 ). The new codebook Ψis partitioned into six clusters, each of them has the same number of codewords (m5). In the case that 2-bit secret data is embedded into each index, two indicators are used. Indicator I , valued 0, is carried2 ahead for an index belonging to cluster or5 cluster .6 The other indicator I , valued 31, is carried ahead1 when an index in cluster is embedded 2-bit secret1 data (10)2 or (11)2 and an index in cluster2 is
embedded 2-bit secret data (00)2or (01)2.
For example, the second index 3 in the left table belongs to cluster , and the 2-bit secret data is (10)1 2.
Therefore, index 3 is transformed into index 18 in
4
cluster , and indicator 31 is added in front of the index 18. In Figure 1, the underlined value is the one with no secret data embedded. In this case, to represent an index value, indicator 0, or indicator 31 needs
log2N
bits, except that the length of the index value following indicator 0 is
log22m
bits.3. Our Proposed Method
In this section, a new reversible hiding method based on VQ is proposed. Compared to Chang etal.’s method which uses the front one-third of codebook Ψto embed secret data, our method uses the front half of codebook Ψto embed secret data for the purpose of raising embedding capacity. Firstly, some drawbacks of Chang et al.’s method and their
improvements are pointed out. Then, our proposed method is introduced by showing its data embedding procedure. Finally, the strategies of using indicators flexibly and fully are discussed, and a skill of exchanging indexes in the sorted codebook is proposed to improve embedding results further.
3.1. S
i
mpl
e
i
mpr
ove
me
nt
s
f
or
Chang
e
t
al
.
’
s
method
In this subsection, some drawbacks of Chang et al.’smethod are pointed out and improved. In Figure 2, the left diagram shows part of transformation strategies of Chang et al.’s forB2, where the embedded data and used indicator I are depicted. In1 Chang et al.’s method,indexes in cluster1 and
2
cluster are transferred to cluster4 when the embedded data are (10)2, and indicator I is used in1
the transfer from cluster to1 cluster . However, the4 indexes in cluster containing higher referred counts1 should own higher priorities. Indicator I added to1 indexes of cluster will create more overhead than1 added to indexes of cluster . Therefore, indicator2 I1 should be assigned to the transfer from cluster to2
4
cluster as shown in the right diagram of Figure 2. Similarly, as shown in the bottom of Figure 2, assigning indicator I to the transfer from1 cluster to2
6
cluster is better than assigning to the transfer from
1
cluster to cluster .6
Figure 2. Change the indicator for Chang etal.’s methodof B = 2.
Table 1 shows some common codebook sizes N and their corresponding codebook sizes N for B1
and B2 . Another drawback of Chang et al.’s method is that they do not utilize indicators fully. When B1 and N
128,512
, there is one index value unused. Similarly, when B2 and
256,1024
N , there are two index values unused. However, these unused index values can be used as extra indicators to reduce code length further. Figure 3 shows an example of using an extra indicator I2 for
1
B . If N126 codewords are divided into 3
3
211 clusters, each cluster has m42 codewords.In Changeetal.’smethod,only indicator
1
represent the index value following indicator I .1
However, it needs only 2
log2 m bits if both5 indicators I and1 I2 are used like the strategy shown in Figure 3.
Table 1. Some common codebook sizes N and their N’: (a) B = 1and 1 indicator;
(b) B = 2 and 2 indicators. (a) N 128 256 512 1024 N 126 255 510 1023 (b) N 128 256 512 1024 N 126 252 510 1020
Figure 3. Indicator is used in full for B = 1.
3.2. Our proposed method and the data
embedding procedure
Given a codebook Ψ with size N , a sorted codebook Ψwith size N
B B N 2 2 1 B 2 is created and is divided into 2B clusters, where
B
denotes the number of secret bits embedded into each VQ index. All clusters have the same size
m B B N 2 2 1
. In our approach, half of indexes in Ψwill be used to embed secret data and at least
1
2B indexes are used as indicators. For an image H , each block H is encoded into indexi T by traditionali VQ coding. Then, T is transformed intoi T i , where
i
T is the corresponding index in some cluster and sometimes includes an indicator. In order to describe our approach easily, a function transj(Ti) is used to represent the transformation where index Ti is transformed into the corresponding index in cluster .j Also, if an indicator is carried ahead, transj(Ti) is encoded.
Our method and Chang et al.’s method for embedding 2-bit secret data into a block are shown in Figure 4, where our method is in the right side. In our method, 2-bit secret data is embedded when T is ini
1
cluster or cluster . If2 Ti is in cluster ,1
T
i is transferred to cluster ,1 cluster ,2 cluster , and34
cluster when embedded 2-bit secret data is (00)2,
(01)2, (10)2, and (11)2, respectively. The above
operations will set T to bei trans1(Ti), trans2(Ti), )
(
3 Ti
trans , and trans4(Ti) , respectively. The operations of Ti in cluster2 are similar to Ti in
1
cluster , expect that indicator I1 is additionally carried ahead. If T is ini cluster or3 cluster , no4 secret data is embedded and T is transferred to thei cluster of itself with an indicator I . Here, the2 encoded size of trans3(Ti) or trans4(Ti) is
log22m
.Figure 4. Our proposed method for B = 2 compared with Chang etal.’s method.
1 2 1 2 3 4 5 6 7 8 9 10 11 12 13 14 3 4 15 16 17 18 19 20 21 22 23 24 25 26 27 28 01 00 10 11 I2 I101 I100 I2 I111 I110 12 18 1 24 9 6 3 5 27 Secret data Index table 011011110001 8 17 5 I2||18 26 || 1 I 24 || 2 I I1||9 T Index tableT
Figure 5. Example of our proposed method for embedding two-bit secret data.
Figure 5 shows an example of our proposed method for embedding two-bit secret data into each index belonging to cluster or1 cluster (2 B2). This example has the same VQ codebook and index table as the example shown in Figure 1. The original VQ codebookΨconsists of 32 codewords (N 32) and the new sorted codebook Ψhas 28 codewords (N28). The new codebook Ψis partitioned into four clusters, each of them has the same number of codewords (m7). For simplicity, only indicators I1 and I2 are used in this example despite the fact that four indexes can be used as indicators. Indicator I is1 carried ahead when an index in cluster is embedded2 secret data. Indicator I2 is carried ahead for an index belonging to cluster3 or cluster . Due to our4
proposed method using the front half of the sorted codebook Ψto embed secret data, more indexes can be used for embedding secret data. For example, the forth index 12 in Figure 1 is not embedded secret data, but in Figure 5 is embedded the 2-bit secret data (11)2.
Therefore, under the same codebook and index table, our proposed method can embed more secret data.
In Figure 5, the underlined value is the one with no secret data embedded. The above two-bit embedding example shows that the length of the index value following indicator I is1
log24m
5bits and the length of the index value following indicator I2 is
log22m
4 bits.3.3. Strategies of using indicators flexibly and
fully
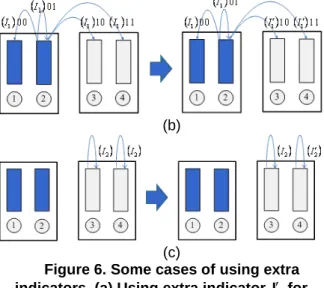
As mentioned in Subsection 3.1, extra indicators can be used to reduce the coding length. Therefore, in our approach, all unused index values are used as extra indicators. That is, our approach uses indicators fully. Figure 6 shows some examples of using an extra indicator to reduce the coding length. In Figure 6 (a), an extra indicator I is used in the transforming1 rule of
cluster
2 when B1. Then, the length of) (
2 Ti
trans is reduced from
log2m
bits to 2 log2 m bits, wherem
is the size of a cluster. When B2, Figure 6 (b) shows the case that an extra indicator I 1 is used in the transforming rule of cluster . Similarly,2 the length of transj(Ti), j1,2,3,4, is reduced from
log24m
bits to
log22m
bits. Finally, the case in Figure 6 (c) reduces the length of trans3(Ti) and) (
4 Ti
trans from
log22m
bits to
log2m
bits. Remention that codebook Ψdivided into 2B clusters has N B B N 2 2 1 B 2 codewords and each cluster has m B B N 2 2 1 codewords. At least 1
2B indicators are needed in our approach. Although the number of indicators can be flexibly adjusted in order to reduce the coding length further, it will reduce the number of codewords in codebook Ψand result in a poor image quality. Therefore, our approach doesn't consider the strategy of flexibly adjusting the number of indicators.
(a)
(b)
(c)
Figure 6. Some cases of using extra indicators. (a) Using extra indicator Ifor1
2
cluster when B = 1. (b) Using extra indicator
1
Iwhen B = 2. (c) Using extra indicator I2 when B = 2.
3.4. Strategies of exchanging indexes in the
sorted codebook
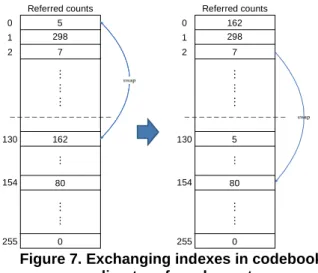
In this section, we proposed the strategies of exchanging indexes in the sorted codebook. Note that the sorted codebook Ψis predesigned from some training images and is fixed for all cover images. Therefore, for any processed cover image H , it would occur the phenomenon that some lower referred count codewords are in the front half codebook and some higher referred count codewords are in the behind half codebook. In our approach, it is better that higher referred count codewords are located in the front half codebook. So, we exchange the lower referred count codewords in the front half codebook with the higher referred count codewords in the behind half codebook. The exchanging process is silently included in the whole embedding procedure, where the sorted codebook Ψis not physically modified and the overhead keeping the exchanging information is embedded too. By the strategies of exchanging indexes in the sorted codebook, we not only increase the capacity, but also decrease the total transformed bits.
Figure 7 shows an exchanging example, where the size of sorted codebook Ψis assumed to be 256 for simple explanation. Firstly, the codeword with the minimum referred count 5 is codeword C0 in the front half of codebook and the codeword with the maximum referred count 162 is codeword C130 in the behind half of codebook. Then, codeword C is0 exchanged with codeword C130 . Ideally, this exchange increases the capacity 1625157 bits. Also, the overhead of recording the exchanging information
0,130
is 14 bits( 2 log2 N 2 log2 N 7714 ). Similarly,
C2, C154
is the next exchange. The numbers of exchanges also need to be recorded. These exchanges are worth if the increased capacity is larger enough than overhead. In our approach, the overhead is embedded using codebook Ψfirstly. Then, a dummy codebook Ψ, which is the exchanging result of codebook Ψ, is used to embed secret data W into the unprocessed blocks of cover image H .298 5 162 0 1 130 255 2 7 80 154 … … … … … … 0 Referred counts 298 5 162 0 1 130 255 2 7 80 154 … … … … … … 0 Referred counts
Figure 7. Exchanging indexes in codebook according to referred counts.
Embedding procedure is as follows:
Input: Cover image H , secret data W , codebook Ψ Output: Transformed index table T
Step1: Encode cover image H by sorted codebook Ψto produce index table T .
Step2: Exchange some indexes in codebook Ψto form a dummy codebook Ψand get the overhead.
Step3: Embed the overhead into index table T by the sorted codebook Ψ.
Step4: Continue to embed secret data W into index table T by the dummy codebook Ψ to produce transformed index tableT .
Extraction procedure is as follows:
Input: Transformed index table T , codebook Ψ Output: Recovered index table T , secret data W Step1: Extract the overhead from transformed index
table T by the sorted codebook Ψ.
Step2: Use the overhead to transform the sorted codebook Ψinto the dummy codebook Ψ. Step3: Continue to extract secret data W from index
table T by the dummy codebook Ψ, and recover index table T from index table T .
4. Simulation and Experimental Results
In this section, some experimental results are demonstrated to show the capacity and VQ rate of Chang et al.’s method and our proposed method.
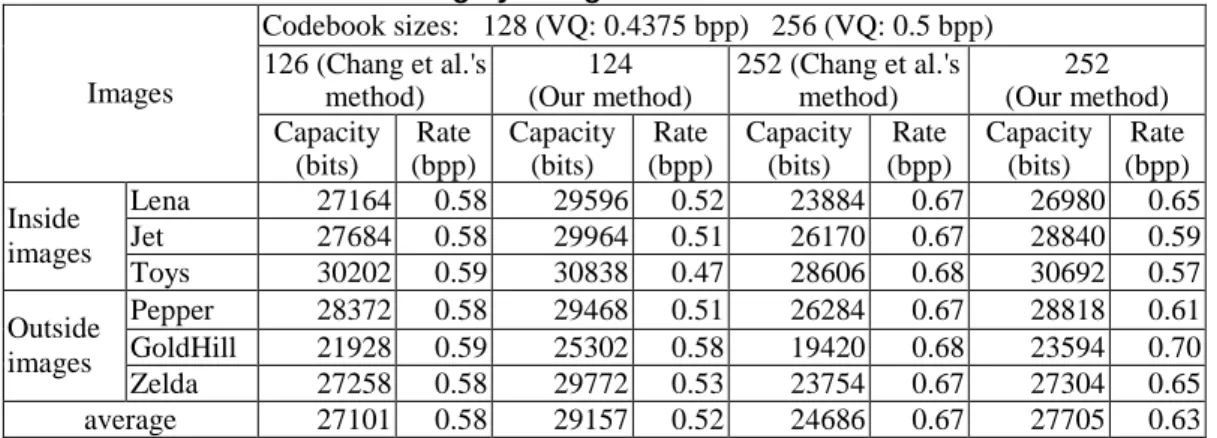
Before starting the test experiments, four kinds of codebooks with sizes of 128, 256, 512, and 1024 codewords were all acquired by the LBG training algorithm, and each codeword was a 16-dimensional vector.Thefivestandard images,‘Lena’,‘Jet’,‘Boat’, ‘Sailboat’, and ‘Toys’, involved in the a bove-mentioned training process are called inside images. To be applied to the experiments of our proposed method, these four codebooks were trained again to generate the appropriate numbers of codewords, such as“124,252,508,1020”forB2, and were sorted according to the referred counts of codewords on the prior five inside images. These derived codebooks were used in the following experiments.
Six popular 512×512 images, Lena, Jet, Toys, Pepper, GoldHill and Zelda, are used as the testing images. By using Chang et al.’s method and our proposed method on these six testing images, Table 2 shows the embedding capacity and VQ rate for B2. Due to the codebook divided into six clusters in Chang et al.’s method forB2 , cluster1 and
2
cluster have 50% probability to add a
log2N
-bit indicator. Due to the codebook divided into four clusters in our proposed method, cluster , which1 contains higher referred count indexes, doesn't add any indicator. As shown in Table 2, our proposed method for B2 has lower VQ rate.Table 3 shows the experimental results for strategies of exchanging indexes in the sorted codebook. When sorted codebook Ψis divided into four clusters for B2, each index in cluster needs1
log24m
bits and each index in cluster2 needs
log2N
log22m
bits, both of them can embed a 2-bit secret data. Also, each index in cluster or34
cluster needs
log2N
log2m
bits and cannot embed any secret data. Due to exchanging some lower referred count codewords in front half of codebook Ψwith some higher referred count codewords in behind half of codebook Ψ, indexes in cluster or34
cluster may be exchanged with those in cluster or1
2
cluster . Hence, our exchange method raises up the embedding capacity, but has the probability of increasing or decreasing the VQ rate as shown in Table 3.
5. Conclusions
Under the same sorted codebook Ψ, this paper presented the strategies of using indicators flexibly and fully and proposed strategies of exchanging indexes in the sorted codebook. Experimental results reveal that our proposed method by using front half of sorted codebook Ψto embed data can raise the embedding capacity than that of Chang etal.’s. Also, the strategies of exchanging indexes in the sorted codebook can enhance the sorted codebook Ψto even more raise the embedding capacity, especially in outside images.
Table 2. Results of the 2-bit hiding by using different initial codebook sizes 128 and 256 Codebook sizes: 128 (VQ: 0.4375 bpp) 256 (VQ: 0.5 bpp) 126 (Chang et al.'s method) 124 (Our method) 252 (Chang et al.'s method) 252 (Our method) Images Capacity (bits) Rate (bpp) Capacity (bits) Rate (bpp) Capacity (bits) Rate (bpp) Capacity (bits) Rate (bpp) Lena 27164 0.58 29596 0.52 23884 0.67 26980 0.65 Jet 27684 0.58 29964 0.51 26170 0.67 28840 0.59 Inside images Toys 30202 0.59 30838 0.47 28606 0.68 30692 0.57 Pepper 28372 0.58 29468 0.51 26284 0.67 28818 0.61 GoldHill 21928 0.59 25302 0.58 19420 0.68 23594 0.70 Outside images Zelda 27258 0.58 29772 0.53 23754 0.67 27304 0.65 average 27101 0.58 29157 0.52 24686 0.67 27705 0.63
Table 3. Results of the 2-bit hiding for the strategy of exchanging indexes in codebook Ψ
Codebook sizes: 128 (VQ: 0.4375 bpp) 256 (VQ: 0.5 bpp) 124 (Our method) 124 (Our swap method) 252 (Our method) 252 (Our swap method) Images Capacity (bits) Rate (bpp) Increasing (bits) Rate (bpp) Capacity (bits) Rate (bpp) Increasing (bits) Rate (bpp) Lena 29596 0.52 1010 0.52 26980 0.65 2574 0.64 Jet 29964 0.51 726 0.50 28840 0.59 1782 0.59 Inside images Toys 30838 0.47 982 0.47 30692 0.57 804 0.57 Pepper 29468 0.51 1240 0.50 28818 0.61 1088 0.61 GoldHill 25302 0.58 4278 0.58 23594 0.70 4694 0.69 Outside images Zelda 29772 0.53 2062 0.52 27304 0.65 4344 0.62 average 29157 0.52 1716 0.52 27705 0.63 2548 0.62
Acknowledgments
This research was partially supported by the National Science Council of the Republic of China under the Grants NCS 97-2221-E-153-001 and the TWISC@NCKU, National Science Council under the Grants NSC 97-2219-E-006 -003.
References
[1] A.P. Fabien, R.J. Anderson, and M.G. Kuhn, “Information hiding –a survey,”Proceedings of the IEEE Special Issue on Protection of Multimedia Content, vol. 87, no. 7, pp. 1062-1078, 1999.
[2] H.C. Huang, F.H. Wang, and J.S. Pan, “Efficient and robust watermarking algorithm with vector quantisation,”IEE Electronics Letters, vol. 37, no. 13, pp. 826-828, 2001.
[3] M. Jo and H.D. Kim, “A digital image watermarking scheme based on vector quantization,” IEICE Transactions Information and Systems, vol. E85-D, no. 6, pp. 1054-1056, Jun. 2002.
[4] H.C. Wu and C.C. Chang, “A novel image watermarking scheme based on the vector quantization technique,”Computers& Security, vol. 24, pp. 460-471, 2005.
[5] C.C. Chang, W.L. Tai, and C.C. Lin, “A reversible data hiding scheme based on side match vector quantization,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 16, no. 10, Oct. 2006.
[6] C.C. Chang and C.Y. Lin, “Reversible steganography for VQ-compressed images using sidematching and relocation,” IEEE Transactions on Information Forensics And Security, vol. 1, no. 4, pp. 493-501, Dec. 2006.
[7] C.C. Chang and W.C. Wu, “A reversible information hiding scheme based on vector quantization,” in Proceedings of Knowle dge-Based Intelligent Information and Engineering Systems (KES 05), Melbourne, Australia, pp. 1101-1107, Sept. 2005.
[8] C.C. Chang, W.L. Tai, and M.H. Lin, “A reversible data hiding scheme with modified side match vector quantization,” in: Proceedings of IEEE 19th International Conference on Advanced Information Networking and Applications, Taipei, Taiwan, pp. 947-952, 2005.
[9] C.C. Chang and C.Y. Lin, “Reversible steganographic method using SMVQ approach based on declustering,”Information Sciences,vol. 177, no. 8, pp. 1796-1805, 2007.
[10] C.C. Chang and T.C. Lu, “Reversible i ndex-domain information hiding scheme based on side-match vectorquantization,”J. of Sys. and Soft., vol. 79, no. 8, pp. 1120-1129, Sept. 2006.
[11] C.C. Chang, W.C. Wu, and Y.C. Hu, “Lossless recovery of a VQ index table with embedded secret data,”Journal of Visual Communication and Image Representation, vol. 18, no. 3, pp. 207-216, June 2007.