1200 IEEE TRANSACTIONS ON COMPUTERS, VOL. 45, NO. 10, OCTOBER 1996
Harvest Rate
of
Reconfigurable Pipelines
Weiping Shi, Member, IEEE, Ming-Feng Chang, and W. Kent Fuchs, Fellow, IEEE
Abstract-For a reconfigurable architecture, the harvest rate is the expected percentage of defect-free processors that can be connected into the desired topology. In this paper, we give an analytical estimation for the harvest rate of reconfigurable multipipelines based on the following model: There are n pipelines each with m stages, where each stage of a pipeline is defective with identical independent probability 0.5 and spare wires are provided for reconfiguration. By formulating the "shifting" reconfiguration as weighted chains in a partial ordered set, we prove when n : @(m), the harvest rate is between 34%
and 72%.
Index Terms-Harvest rate, yield, reconfigurable arrays, defect tolerance, pipelines, random graphs, percolation.
+
1
INTRODUCTION
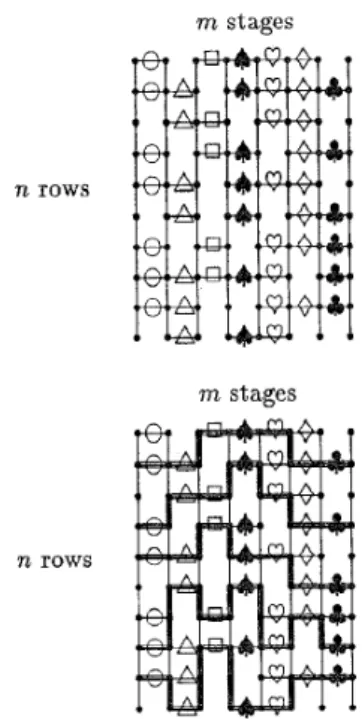
A multipipeline processor array is a set of one-dimensional pipe- lines running in parallel, where processors at different stages of the pipeline may be different; see Fig. 1. Multipipeline processor arrays are important for highly parallel architectures and vector supercomputer architectures [61. VLSI and WSI technology makes it possible to fabricate a multipipeline processor array on a single chip or wafer. However, since it is likely that some processor ele- ments will be defective, defect-tolerance for pipeline processor arrays can be important.
Harvest rate analysis for reconfigurable processor arrays is of- ten difficult for two reasons. The first reason is that for most structures, it is NP-hard to compute the reliability; see Provan and Ball [SI. The second reason is that the reconfiguration algorithm may use complicated procedures to configure the system thereby making the resulting structure highly irregular. When all proces- sors are of the same type, Greene and Gamal 121, Leighton and Leiserson [7], and other researchers have developed algorithms to reconfigure a single-pipeline array from a two-dimensional wafer. Their harvest rate analysis is only for extreme cases where the harvest rate either goes to 0 or goes to 1. Stornetta, Huberman, and Hogg [ll] analyzed the harvest rate of multipipeline arrays, but since the problem is difficult, they used a phenomenological the- ory, combining analytical scaling equations with experimental measurements. Gupta, Zorat, and Ramakrishnan published an analysis of multipipeline processor arrays [51 based on the fol- lowing technical assumption. They not only assumed each proces- sor is defective with independent identical probability, but also assumed each processor is utilized with independent identical probability. They concluded that the harvest rate is independent of the shape of the array. To see the probability that one processor is utilized
is
related to the probability that an adjacent processor is utilized, consider the simplest example where the multipipeline array is a single pipeline with many stages. Therefore, one stageW. Shi is with the Department of Computer Science, University of North Texas,
Denton, T X 76203. E-mail: [email protected].
M.-F. Chang is with the Department of Computer Science and Information Engineering, National Chiao-Tung University, Taiwan, Republic of China. e W.K. Fuchs is with the School of Electvical and Computer Engineering, Purdue
University, West Lafayetfe, IN 47907.
Manuscript received June 17,1994; revised June 8,1995.
For information on obtaining repvints of this article, please send e-mail to: [email protected], and reference IEEECS Log Number C95161.
n rows
n rows
m stages
m stages
Fig. 1. A multipipeline array before and after reconfiguration
can be utilized if and only if all other stages can be utilized. Other examples can be constructed accordingly. As a result, the prob- ability that each stage is used is dependent on the probability that other stages can be used, no matter how one defines the probabil- ity space.
In this paper, we study the harvest rate of multipipeline processor arrays. There are n 2 1 pipelines each with m 2 1 stages. Each stage of a pipeline is defective with identical independent probability p. (This assumption, also used by 151 and [lll, is a re- striction of this model. However, we can take the maximum yield of all stages as p to get an upper bound on the harvest rate of the array using the result of this paper. Similarly, we can take the minimum yield of all stages to get a lower bound on the harvest rate.) Vertical wires are provided for reconfiguration. We assume wires and switches are defect-free, an assumption also used by Greene and Gamal [2], Leighton and Leiserson [7], Gupta, Zorat, and Ramakrishnan [5], and many other researchers. The recon- figuration is done by routing around defective stages using verti- cal wires, and each vertical wire and switch can be used only once. Fig. 1 shows five horizontal pipelines before and after an example reconfiguration.
Our main focus is to analyze how many pipelines we can har- vest on average if processors are defective at random. We will show the harvest rate h(m, n), defined as the percentage of defect-
free processors that can be connected into pipelines through the optimal reconfiguration, is between 34% and 72%, when ?I is the
same order as m. We formulate the "shifting" phenomenon of reconfiguration (some researchers call it fault stealing or compen- sation paths) as maximum weighted chains in a partial ordered set with random weights. Then, we use a mathematical result on the size of the chain to get our final result. Since the shifting phe- nomenon appears in many reconfiguration problems, we expect the method of analysis can be applied to other reconfigurable structures as well.
2
ANALYSIS
To formulate the problem, define a rectangular graph R(m
+
1, n ) = ( V , E), whereIEEE TRANSACTIONS ON COMPUTERS, VOL. 45, NO. 10, OCTOBER 1996
Y,]
= 1201 XI,, 1 1 1 + ma~{Yl,!-l~~t+l,l-l} i f j > l,i = 1 ',I +max{Y,,;-l~Y~~r,i-r.Y,+l,il} i f i > 1rm > i > 1 %,] + max{Yt,/-lJ-l,/-l} i f j > l,i = m V = {(i,j):1<
i<
m + l and 1 2 j I n},The set ((1, j ) : 1 5 j 5 n) is called the left side, and the set { ( m
+
3, j ) : 1 2 j 5 n ] is called the right side.Define X , , ( m
+
1, n ) as a random graph, where each horizontal edge appears with probability p , and each vertical edge appears with probability 1. Fig. 2 is an instance of Xp,1(8, 10). It is clear that the number of pipelines we can harvest equals the maximum number of mutually vertex-disjoint paths from the left side to the right side in Xp,l(m+
1, n). In contrast to our Manhattan model,Gupta, Zorat, and Ramakrishnan [51 assumed a knock-knee model. However, the results for the two models are within a con- stant factor of 2.
left side right side
Fig. 2. An R(8, 10) with some horizontal edges missing.
REMARK. The random graph X p , p ( ~ , n ) is known in percolation
theory as the Bernoulli Square Lattice Bond Model [3].
However, since the vertical edge probability is 1, our prob-
Therefore,
&
lim h(m,n) 4 - = 0
ni,n--fm + n
Now we present our main result. The reconfiguration shown in Fig. 1 is obtained by the greedy algorithm that always takes the bot- tom edge whenever possible, that is, if neither of the vertices on the left and right side of the edge was required in a previously built path. The following lemma proves the greedy reconfiguration always gives us the maximum number of pipelines after reconfiguration. Notice that we can obtain less interstage delay by distributing the pipeline stages evenly. However, since we are only concemed with the maxi- mum number of pipelines, we use the greedy algorithm. See Libesk- ind-Hadas 181 for algorithms on reducing interstage delays.
LEMMA 1. The greedy algorithm defined below can always find a maxi-
mum set of vertex-disjoint L-R paths. Algorithm.
Repeat
1) Take the lowest horizontal edge at each column; 2) Connect these edges into a path P;
3) Delete all horizontal edges in P from the graph; 4) Delete all horizontal edges ((i, j ) , (i
+
1,j)) from theUntil step 1 fail.
graph if vertex (i, j ) or (i
+
1, j ) is in P. lem is different from those studied in percolation theory.PROOF. The proof is by induction on k, the number of vertex-disjoint
paths in the graph. We also keep an invariant assertion that for every vertex (i, I ) E P , if there is no vertex (i,
7 )
E P such The harvest rate k(m,n )
is defined as follows:-/number of vertex - disjoint')
'(L - R paths in X,,,(m +.l,n)) p . n
k(m, n ) =
The function h(m, n) is well defined for all m, n 2 1. It is easy to show 1 2 h(m, n ) 2 0 and h(m, n ) is monotonically decreasing in m,
and monotonically increasing in n. We are interested in the as- ymptotic value of k(m, n). The existence of the limit can be proved
using a similar argument by Grimmett and Kesten [41. Grimmett and Kesten proved that when both horizontal edges and vertical edges appear with probability p , then the limit exists 141. However, estimating the limit is still an open problem in percolation theory.
For simplicity, we assume p = 1/2. The proof can be easily changed for any value of p . We first show that when the number of stages is too large compared to the number of pipelines, then the harvest rate is 0.
THEOREM 1. For any constant k, if m = Q ( 2 " / n k ) , then lim,fl,,,, h(m, 72) = 0.
PROOF. The probability that at least
f i +
1 edges in stage 1 are good isTherefore, the probability that each of the m stages contains at least f i
+
1 edges is at most1202 # of Stages m 10 20 30
IEEE TRANSACTIONS ON COMPUTERS, VOL. 45, NO. 10, OCTOBER 1996
# of Pipelines Harvest Rate
n h(m, n)
10 0.483
20 0.484
30 0.51 3
Fig. 3. Random variables of two lowest paths.
Pr{x,,/ = k } =
('1,
T
fork = 1, 2,Intuitively, xi] is the distance we have to move up to find the ith
stage of the jth path, from the
(j
- 1)th path. Let Yk = max::,{y,,,),then there are k vertex-disjoint L-R paths if and only if
Y,
5 n. Therefore the problem of estimating the number of pipelines be- comes the problem of estimating the random variable y,.To estimate
Yk
directly is hard, because yIds are not mutuallyindependent, and are defined recursively. However, since x,,/s are
mutually independent, we construct a directed graph D ( k ) =
(X,
E ) , where X = (x~,,: 1<
i<
m and 1 2j
5 k) and E is a set of directed edges defined as follows. For every vertex x,,], there are edges fromX,,] to
if j = lc
xz,/+l X r + l , j + ~ i f j < k a n d i = l
X , - ~ , ~ + , , X , ,/,. l,xt+,,j+l i f j < /candl < i <
m
1
x,-l,/+lfxi,,+l if j < ic and i =m.
See Fig. 4. Now, y,,] becomes the value of the maximum-weighted directed path to x,,] in the graph D ( k ) , where each vertex x,,, has a geometrically distributed weight w(x,,), and
maximum weighted directed path in D ( k )
"1,2 "2,2 "3,2 "4,2 "5,2 "6,2 "7,2
X l J X 2 , l x3,l 24,l 25,l 26,l 27,1
Fig. 4. Directed graph D(k) with k = 4
To estimate the maximum-weighted path in D(k), it first seems that
if we add the maximum xi,/ from each row, it might give us an upper bound. Unfortunately, this bound will not be good enough. The key here is to use the underlying combinatorial structure to argue that the maximum weighted directed paths cannot be too large.
Embed D ( k ) into grid L(m
+
k - 1, m+
k - 1), see Fig. 5, and as-sign each element x in L with an integer random variable w(x) that has a geometric distribution with parameter 1 /2. The grid L(m
+
k - 1,m
+
k - 1) = {(i, j ) I 1<
i, j<
m
+
k ~ 11 is a special kind of partiallyordered set. A partially ordered set, or poset, is a set of elements and a binary relation
>
that is reflexive, antisymmetric, and tran- sitive. In L, two elements, a = (xa, ya) and b = (xb, yb), have the bi- nary relation az
b if x, 2 xb and ya 2 yb. A chain in a poset is a set ofpairwise comparable elements. In L, a chain is a set of elements
0 0 0 0
0 0 0
3
7
>
IEEE TRANSACTIONS ON COMPUTERS, VOL. 45, NO. I O , OCTOBER 1996
1203
3
CONCLUSION
In this paper, we analyzed the harvest rate of reconfigurable mul- tipipeline processor arrays. We showed that the ”shifting” or ”fault stealing” phenomenon during reconfiguration can be de- scribed as the maximum weighted chains in a poset with random weights, and we used a combinatorial argument to give a bound on the size of the maximum weighted chain. Our method is the first purely analytical approach to analyzing reconfiguration of linear arrays. We propose as an open problem to find the exact value of h(m, n).
Load Sharing
in Hypercube-Connected Multicomputers
in the Presence of Node Failures
ACKNOWLEDGMENTS
The authors thank Douglas B. West for valuable discussions con- cerning this research, Ran Libeskind-Hadas for suggestions, Harry Kesten, Peter Winkler for providing references, and an anonymous referee (D) for improving the presentation. This research was sup- ported in part by the SDIO/IST and managed by the U S . Office of
Naval Research under contract N00014-89-K-0070. Weiping Shi was also supported in part by the US. National Science Founda- tion under grant MIP-9309120.
REFERENCES
M. Aigner, Combinatorial Theory. Springer-Verlag, 1979.
J.W. Greene and A. Gamal, ”Configuration of VLSI Arrays in the Presence of Defects,” 1. ACM, vol. 41, no. 4, pp. 694-717, 1984. G. Grimmett, Percolation. New York: Springer-Verlag, 1989.
G. Grimmett and H. Kesten, “First Passage Percolation, Network Flows and Electrical Resistances,” Z . Wahrscheinlichkeitstheor.
Verw 66, pp. 3355366,1984,
R. Gupta, A. Zorat, and 1. V. Ramakrishnan, ”Reconfigurable Multipipelines for Vector Supercomputers,” I E E E Trans. Comput-
ers, vol. 38, no. 9, pp. 1,297-1,307, Sept. 1989.
K. Hwang, Advanced Computer Architecture: Parallelism, Scalability, Programmability. New York: McGraw-Hill, 1993.
F.T. Leighton and C.E. Leiserson, “Wafer-Scale Integration of Systolic Arrays,” I E E E Trans. Computers, vol. 34, no. 5, pp. 448- 461, May 1985.
R. Libeskind-Hadas, ”Reconfiguration of Fault Tolerant VLSI Systems,” PhD thesis, Dept. of Computer Science, Univ. of Illinois at Urbana-Champaign, Oct. 1993.
J.S. Provan and M.O. Ball, ”The Complexity of Counting Cuts and of Computing the Reliability That a Graph Is Connected,” S I A M J. Computing, vol. 12, no. 4, pp. 777-788, Nov. 1983.
W. Shi, ”Design, Analysis and Reconfiguration of Defect-Tolerant VLSI and Parallel Processing Arrays,” PhD thesis, Dept. of Com- puter Science, Univ. of Illinois at Urbana-Champaign, June 1992. Coordinated Science Laboratory Technical Report CRHC-94-21, Sept. 1994.
W.S. Stornetta, B.A. Huberman, and T. Hogg, ”Scaling Theory for Fault Stealing Algorithms in Large Systolic Arrays,” IEEE Trans. Computer-Aided Design, vol. 9, no. 3, pp. 290-298, Mar. 1990.
Yi-Chieh Chang and Kang G. Shin, Fellow, IEEE Abstract-This paper addresses two important issues associated with load sharing
(LS)
in hypercube-connected multicomputers: 1) ordering fault-free nodes as preferred receivers of “overflow” tasks for each overloaded node and 2) developing an LS mechanism to handle node failures. Nodes are arranged into preferred lists of receivers of overflow tasks in such a way that each node will be selected as the Mh preferred node of one and only one other node [l]. Such lists are proven to allow the overflow tasks to be evenly distributed throughout the entire system. However, the occurrence of node failures will destroy the original structure of a preferred list if the failed nodes are simply dropped from the list, thus forcing some nodes to be selected as the Mh preferred node of more than one other node. We propose three algorithms to modify the preferred list such that its original features can be retained regardless of the number of faulty nodes in the system. It is shown that the number of adjustments or the communication overhead of these algorithms is minimal. Using the modified preferred lists, we also proposed a simple mechanism to tolerate node failures. Each node is equipped with a backup queue which stores and updates the information on the tasks arrivingkompleting at its most preferred node. Index Terms-Load sharing, hypercube-connected multicomputers, real-time systems, node failures, backup queues.1
INTRODUCTION
LOAD sharing (LS) in general-purpose distributed systems has been studied extensively by numerous researchers and many LS algorithms proposed [2], [3], 141, [ 5 ] . These LS algorithms are usu- ally designed to minimize the average task-response time. By con- trast, LS in distributed real-time systems has been addressed far less than that in general-purpose distributed systems.
In [61, we have proposed a decentralized, dynamic LS method for real-time applications. In this method, each node maintains the state of a set of nodes in its proximity, called a buddy set. Three thresholds of queue length (QL), denoted by TH,,, THf, and TH,,
are used to define the (load) state of a node. A node is said to be
underloaded if Q L 5 TH,, medium-loaded if T H , < Q L 5 THp fully- loaded if THf < Q L 2 TH,, and overloaded if Q L > TH,. Whenever a node becomes fully-loaded due to the arrival and/or transfer of tasks, it will broadcast this change of state to all the nodes in its buddy set; so will it when a node becomes underloaded as a result of completing the execution of tasks. Every node that receives this state-change broadcast will update its state information by mark- ing the node as fully-loaded or underloaded in its ordered list (called a preferred list) of available receivers. When a node becomes overloaded, it can then select, without probing other nodes, the first underloaded node from its preferred list. Note that the pre- ferred list of each node does not change over the time, but the nodes will be dynamically marked as underloaded or overloaded according to their load states, so that an overloaded node may select the first underloaded node from its preferred list.
The authors are with the Real-Time Computing Laboratory, Department of
Electrical Engineering and Computer Science, University of Michigan, A n n Arbor, MI 48109-2122. E-mail: [email protected].
Manuscript Yeceived July 11,1994; revisedJuly 10,1995.
For information on obtaining Yeprints o f this article, please send e-mail to:
transcom~comyuter.org, and reference IEEECS Log Number C95165.