A Classifier Learning Scheme based on Rough Membership and Genetic Programming
25
0
0
全文
(2) A Classifier Learning Scheme based on Rough Membership and Genetic Programming. Abstract Classification is one of the important research topics in knowledge discovery and machine learning. A new classifier learning method using genetic programming has been developed for classifying numerical data recently. However, it is difficult for a function-based classifier to classify general nominal data, because nominal data may have possible large distinct values with no ordering values. In this paper, we present a new scheme based on rough set theory and genetic programming to learn a classifier from the data with both nominal and numerical attributes. The proposed scheme first transforms the nominal data into numerical values by rough membership functions. The classification functions then can be generated by genetic programming easily. We use several URI data sets to show the performance of the proposed scheme and make comparisons with other methods. (Keywords: Knowledge discovery, Machine learning, Genetic programming, Classification, Rough set).
(3) 1. Introduction Classification is one of the important tasks in machine learning. A classification problem is a supervised learning that is given a data set with pre-defined classes referred as training samples, then the classification rules, decision trees, or mathematical functions are learned from the training samples to classify future data with unknown class. Owing to the versatility of human activities and unpredictability of data, such mission is a challenge. For solving classification problem, many different methods have been proposed. Most of the previous classification methods are based on mathematical models or theories. For example, the probability-based classification methods are built on the Bayesian decision theory [7][9]. The Bayesian network is one of the important classification methods based on statistical model. Many improvements of Naïve Bayes like NBTree [9] and SNNB [18] also provide good classification results. Another well-known approach is neural network [20]. In the approach of neural network, a multi-layered network with m inputs and n outputs is trained with a given training set. We give an input vector to the network, and an n-dimensional output vector is obtained from the outputs of the network. Then the given vector is assigned to the class with the maximum output. The other type of classification approach uses the decision tree, such as ID3 and C4.5 [16]. A decision tree is a flow-chart-like tree structure, which each internal node denotes a decision on an attribute, each branch represents an outcome of the decision, and leaf nodes represent classes. Generally, a classification problem can be represented in a decision tree clearly. Recently, some active techniques start to be applied by few researchers to develop new classifiers. As an example, CBA [12] employs data mining techniques to develop a hybrid rule-based classification approach by integrating classification rules mining with association. 1.
(4) rules mining. The evolutionary computation is the other one interesting technique. The most common techniques of evolutionary computing are the genetic algorithm(GA) and the genetic programming(GP) [5][8]. For solving a classification problem, the genetic algorithm first encodes a random set of classification rules to a sequence of bit strings. Then the bit strings will be replaced by new bit strings after applying the evolution operators such as reproduction, crossover and mutation. After a number of evolving generations, the bit strings with good fitness will be generated. Thus a set of effective classification rules can be obtained from the final set of bit strings satisfying the fitness function. For the genetic programming, the classifier can be accomplished in either two ways: classification rules [5] or classification functions [8]. The main advantage of classifying by functions instead of rules is concise and efficient, because computation of functions is easier than rules induction. The technique of genetic programming (GP) was proposed by Koza [10][11] in 1987. The genetic programming has been applied to several applications like symbolic regression, the robot control programs, and classification, etc. Genetic programming can discover underlying data relationships and presents these relationships by expressions. An expression is constructed by terminals and functions. There are several types of functions can be applied to the genetic programming: 1. Arithmetic operations: addition, subtraction, multiplication and division. 2. Trigonometric functions: Sine and Cosine, etc. 3. Conditional operators and Boolean operators: IF, ELSE and OR, etc. 4. Other add-on operations: Absolution, negative and other user-specific functions. The algorithm of a genetic programming begins with a population that is a set of randomly created individuals. Each individual represents a potential solution that is. 2.
(5) represented as a binary tree. Each binary tree is constructed by all possible compositions of the sets of functions and terminals. A fitness value of each tree is calculated by a suitable fitness function. According to the fitness value, a set of individuals having better fitness will be selected. These individuals are used to generate new population in next generation with genetic operators. Genetic operators generally also include reproduction, crossover, mutation and others that are used to evolve functional expressions. After the evolution of a number of generations, we can obtain an individual with good fitness value. If the fitness value of such individual still does not satisfy the specified conditions of the solution, the process of evolution will be repeated until the specified conditions are satisfied. The previous researches on classification using genetic programming have shown the feasibility of learning classification functions by designing an accuracy-based fitness function [8] and special evolution operations[2]. However, there are two main disadvantages in the previous work. First, only numerical attributes are allowed in calculating of functions. It is difficult for genetic programming to handle the cases with nominal attributes containing categorical data. The second drawback is that classification functions may conflict each other. In this paper, we propose a new learning scheme that defines a rough attribute membership function to solve the problems of nominal attributes and gives a distance-based fitness function for genetic programming to generate a function-based classifier. Based on the distance-based fitness function, an effective conflict resolution method is developed to overcome the problem of conflicts. More than twenty datasets are selected from UCI data repository to show the performance of the proposed scheme. We also compare the results with other approaches including the statistical model, the decision tree and the association mining.. 3.
(6) This paper is organized as follows: Section 2 introduces the concepts of rough set theory and rough membership functions. In Section 3, we discuss the proposed learning algorithm based on rough attribute membership and genetic programming. In Section 4, we present the conflicts resolution in the classification algorithm. Section 5 shows the experimental results. Finally, conclusions are made in Section 6.. 2. Rough Membership Functions Rough sets introduced by Pawlak [14] is a powerful tool for the identification of common attributes in data sets. The mathematical foundation of rough set theory is based on the set approximation of partition space on sets. The rough sets theory has been successfully applied to knowledge discovery in databases. This theory provides a powerful foundation to reveal and discover important structures in data and to classify complex objects. An attributeoriented rough sets technique can reduce the computational complexity of learning processes and eliminate the unimportant or irrelevant attributes so that the knowledge can be learned from large databases efficiently. The idea of rough sets is based on the establishment of equivalence classes on the given data set S and supports two approximations called lower approximation and upper approximation. The lower approximation of a concept X contains the equivalence classes that are certain to belong to X without ambiguity. The upper approximation of a concept X contains the equivalence classes that cannot be described as not belonging to X. A vague concept description can contain boundary-line objects from the universe, which cannot be with absolute certainty classified as satisfying the description of a concept. Such uncertainty is related to the idea of membership of an element to a concept X. We use the. 4.
(7) following definitions to describe the membership of a concept X on a specified set of attributes B [14].. Definition 1: Let U = (S, A) be an information system where S is a non-empty, finite set of objects and A is a non-empty, finite set of attributes. For each B ⊆ A, a ∈ A, there is an equivalence relation EA(B) such that EA(B) = {(x, x’) ∈ S2 | ∀a ∈ B, a(x) = a(x’)}. If (x, x’) ∈ EA(B), we say that objects x and x’ are indiscernible.. Definition 2: apr = (S, E), is called an approximation space. The object x ∈ S belongs to one and only one equivalence class. Let [x]B = { y | x EA(B) y, ∀x, y ∈ S }, [S]B = {[x]B | x∈S }. The notation [x]B denotes equivalence classes of EA(B) and [S]B denotes the set of all equivalence classes [x]B for x∈S.. Definition 3: For a given concept X ⊆ S, a rough attribute membership function of X on the set of attributes B is defined as. | [ x]B ∩ X | . | [ x]B |. µ BX ( x) = . |[x]B| denotes the cardinality of equivalence classes of [x]B. |[x]B∩X| denotes the cardinality of the set [x]B∩X. The rough membership value µ BX (x) can be interpreted as the. 5.
(8) conditional probability that an object x belongs to X, given that the object belongs to [x]B. The value of µ BX (x) is in the range of [0, 1].. 3. The Learning Algorithm of Classification Functions. 3.1 Classification Functions Consider a given data set S, for a data xj such that xj∈S having n attributes A1, A2, …, An. Let A = {A1, A2, …, An} and Ai∈R, for 1 ≤ i ≤ n . Assume that. x j = (v j1 , v j 2 ,..., v jn ) , where vjt ∈At stands for the t-th attribute of data xj in S. Let C = {C1, C2,…, CK} be the set of K predefined classes. We may say that <xj, cj> is a sample if the data xj belongs to class cj, cj∈C. We define a training set (TS) to be a set of samples, TS = {<xj, cj>| xj ∈S , cj∈C, 1 ≤ j ≤ m}. Where m=|TS| is the number of samples in TS, and mi is the number of samples belonging to the class Ci, K. m = ∑ mi , 1 ≤ i ≤ K. i =1. A classification function for class Ci, fi, is a function fi : R n → R, such that satisfies the following conditions: f i ( x j ) ≥ a, if c j = Ci , where 1 ≤ i ≤ K, 1 ≤ j ≤ m. f i ( x j ) < a, if c j ≠ Ci. A set of classification functions F for the set of class C is defined as 6.
(9) F = { f i f i : R n → R ,1 ≤ i ≤ K }.. 3.2 The Transformation of Rough Attributes Membership. The classification function defined in Section 3.1 has a limitation on attributes. Since the calculation of functions allows only numerical values, it cannot work if dataset contained nominal attributes. In order to apply the genetic programming to train the data set, we make use of rough attribute membership as the definitions in Section 2 to transform the nominal attributes into a set of numerical attributes. For the set of n attributes A = {A1, A2, …, An}, a data xj ∈ S, xj = (vj1, vj2, ... , vjn), vji ∈ Ai. If Ai is a numerical attribute, we have Ãi = {Ai}, let wjk be the value of Ãi, wjk = vji. If Ai is a nominal attribute, we assume that S is partitioned into pi equivalence classes by attribute Ai. Let [sl]Ai denote the l different partitions on attribute Ai, pi is the number of partitions on the attribute Ai. Thus, we have pi. [S]Ai = [ S ] Ai = ∪ [ sl ] Ai , where pi = |[S]Ai|. l =1. We transform the original nominal attribute Ai into a set of K numerical attributes Ãi. Let Ãi = {Ai1, Ai2, ... , AiK}, where K is the number of predefined classes C as defined in Section 3.1. Let the values of Ãi be denoted as (wjk, wj(k+1), ... , wj(k+K-1) ), wik ∈ Aik. For a data xj ∈ S, xj = (vj1, vj2, ... , vjn), vji ∈ Ai is a nominal attribute, we have C C C wjk = µ Ai1 ( x j ) , wj(k+1) = µ Ai2 ( x j ) , ... , wj(k+K-1)= µ AiK ( x j ) ,. where. 7.
(10) | [ s l ] A j ∩ [ x j ]C k |. µ CAik ( x j ) = . | [ sl ] A j |. , if vji ∈ [sl]Ai.. After the transformation, we get the new set of attributes à and the value yj, as follows ~ n ~ A = ∪ Ai , yj = (wj1, wj2, …, wjn’), i =1. where n’ = (n-r) + rK, r is the number of nominal attributes in A. Thus, the new training set becomes TS’ = {<yj, cj>| xj ∈S , cj∈C, 1 ≤ j ≤ m}.. 3.3 The Fitness Function. The fitness value is important for genetic programming to evaluate an individual and generate effective solutions. From the definition of claiming classification functions in Section 3.1, we consider a classification function fi of a class Ci and a specified constant a. For the positive instances <yj, cj>, cj = Ci in the training set TS’, we urge that fi(yj) ≥ a; on the contrary, fi(yj) < a for negative instance <yj, cj>, cj ≠ Ci. To achieve the objective of fi, we define two parameters p and q, let p > a, q < a and p + q = 2⋅a. We measure the error of a positive instance by 0 if c j = C i and f i ( y j ) ≥ a , Dp = 2 [ p − f i ( y j )] if c j = C i and f i ( y j ) < a. and measure the error of a negative instance by 0 if c j ≠ Ci and f i ( y j ) < a . Dn = 2 [ f i ( y j ) − q ] if c j ≠ Ci and f i ( y j ) ≥ a. The fitness value of an individual is then evaluated by the following fitness function:. 8.
(11) m. fitness(hi, TS’) = − ∑ ( D p + Dn ) , j =1. where m is the number of training samples, <yj, cj>∈TS’, 1 ≤ j ≤ m. Since the fitness value of an individual represents the degree of error between target function and the individual, we have the fitness value be as large as possible and approach to zero.. 3.4 The Learning Algorithm. The learning algorithm for classification functions using genetic programming is described in detail as follow: Algorithm: The genetic programming for learning classification functions. Input: The training set TS Output: A function with the best fitness value Step 1: Initial value i = 1, k = 1. Step 2: Transform nominal attributes into rough attribute membership values. For a data xj ∈TS, xj = (vj1, vj2, …, vjn), for all 1≤ j ≤ m, If Ai is a numerical attribute, wjk = vji, k = k + 1. C C C If Ai is a nominal attribute, wjk = µ Ai1 ( x j ) , wj(k+1) = µ Ai2 ( x j ) , ... , wj(k+K-1)= µ AiK ( x j ) ,. k = k + K, repeat Step 2 until yj = (wj1, wj2, …, wjn’) is generated, n’ = (n-r) + rK, r is the number of nominal attributes in A. Step 3: The new training set TS’ = {<yj, cj>| yj = (wj1, wj2, …, wjn’) , cj ∈ C, 1 ≤ j ≤ m}. Step 4: Initialize the population.. 9.
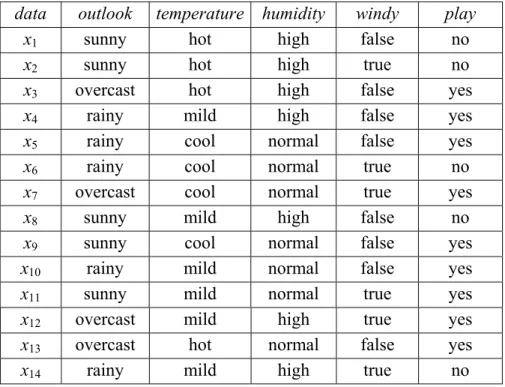
(12) Let gen = 1 and generate the set of individuals Ω1 = { h11 , h21 , …, hq1 } initially, where Ω(gen) is the population in the generation gen and hi( gen ) stands for the ith individual of the generation gen. Step 5: Evaluate the fitness value of each individual on the training set. For all hi( gen ) ∈ Ω(gen), compute the fitness values Ei( gen ) = fitness( hi( gen) , TS’), where the fitness evaluating function fitness() is dependent on the problem and the function is defined by the user. Step 6: Does it satisfy the conditions of termination? If the best fitness value of Ei( gen ) satisfies the conditions of termination or the gen is equal to the specified maximum generation, then the hi( gen ) with the best fitness value is returned and the algorithm halts; otherwise, gen = gen + 1. Step 7: Generate the next generation of individuals and go to Step 5. The new population of next generation Ω(gen) is generated by the ratio of Pr, Pc and Pm, goes to Step 5, where Pr, Pc and Pm represent the probabilities of reproduction, crossover and mutation operations, respectively.. 3.5 An Example. We give an example to explain the above learning algorithm more clearly. The example used in Table 1 is the weather set. This data set concerns the conditions if it is suitable for playing some unspecified game. The conditions consist of four nominal attributes: outlook, temperature, humidity, and wind. The outcome is whether to play or not. The symbolic categories in the four attributes, respectively, are:. 10.
(13) Table 1. The weather data set. data x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 x12 x13 x14. outlook sunny sunny overcast rainy rainy rainy overcast sunny sunny rainy sunny overcast overcast rainy. temperature hot hot hot mild cool cool cool mild cool mild mild mild hot mild. humidity high high high high normal normal normal high normal normal normal high normal high. windy false true false false false true true false false false true true false true. play no no yes yes yes no yes no yes yes yes yes yes no. outlook: {sunny, overcast, rainy}, temperature: {hot, mild, cool}, humidity: {high normal}, windy: {true, false}. We give an example for showing the learning algorithm for the class play = yes. Step 1: Initial value i = 1, k = 1. Step 2: Transform nominal attributes into rough attribute membership values. Let A1 = {outlook}, [s1]A1 be the partition of outlook = sunny, [s2]A1 be the partition of outlook = overcast, and [s3]A1 be the partition of outlook = rainy. [s1]A1 = [x1]A1 = [x2]A1 = [x8]A1 = [x9]A1 = [x11]A11 = {x1, x2, x8, x9, x11}, [s2]A1 = [x3]A1 = [x7]A1 = [x12]A1 = [x13]A1 = {x3, x7, x12, x13}, [s3]A1 = [x4]A1 = [x5]A1 = [x6]A1 = [x10]A1 = [x14]A1 = {x4, x5, x6, x10, x14}.. 11.
(14) [S]A1={{x1, x2, x8, x9, x11}, {x3, x7, x12, x13}, {x4, x5, x6, x10, x14}}, p1 = |[S]A1| = 3. Let A2 = {temperature}, [s1]A2 be the partition of temperature = hot, [s2]A2 be the partition of temperature = mild, and [s3]A2 be the partition of temperature = cool. [s1]A2 = [x1]A2 = [x2]A2 = [x3]A2 = [x13]A2 = {x1, x2, x3, x13}, [s2]A2 = [x4]A2 = [x8]A2 = [x10]A2 = [x11]A2 = [x12]A2 = [x14]A2 = {x4, x8, x10, x11, x12, x14}, [s3]A2 = [x5]A23 = [x6]A23 = [x7]A23 = [x9]A23 = {x5, x6, x7, x9}. [S]A2={{x1, x2, x3, x13}, {x4, x8, x10, x11, x12, x14}, {x5, x6, x7, x9}}, p2 = |[S]A1| = 3. Let A3 = {humidity}, [s1]A3 be the partition of humidity = high and [s2]A3 be the partition of humidity = normal. [s1]A3 = [x1]A3 = [x2]A3 = [x3]A3 = [x4]A3 = [x8]A3 = [x12]A3 = [x14]A3 = {x1, x2, x3, x4, x8, x12, x14}, [s2]A3 = [x5]A3 = [x6]A3 = [x7]A3 = [x9]A3 = [x10]A3 = [x11]A3 = [x13]A3 = {x5, x6, x7, x9, x10, x11, x13}. [S]A3={{x1, x2, x3, x4, x8, x12, x14}, {x5, x6, x7, x9, x10, x11, x13}}, p3 = |[S]A3| = 2. Let A4 = {windy}, [s1]A4 be the partition of windy = true, [s2]A4 be the partition of windy = false. [s1]A4 = [x2]A4 = [x6]A4 = [x7]A4 = [x11]A4 = [x12]A4 = [x14]A4 = {x2, x6, x7, x11, x12, x14}. [s1]A4 = [x1]A4 = [x3]A4 = [x4]A4 = [x5]A4 = [x8]A4 = [x9]A4 = [x10]A4 = [x13]A4 = {x1, x3, x4, x5, x8, x9, x10, x13}. [S]A4={{x2, x6, x7, x11, x12, x14}, {x1, x3, x4, x5, x8, x9, x10, x13}}, p4 = |[S]A4| = 2. For C1: play = yes, [x3]C1 = [x4]C1 = [x5]C1 = [x7]C1 = [x9]C1 = [x10]C1 = [x11]C1 = [x12]C1 = [x13]C1 = {x3, x4, x5, x7, x9, x10, x11, x12, x13}. For C2: play = no, [x1]C2 = [x2]C2 = [x6]C2 = [x8]C2 = [x14]C2 = {x1, x2, x6, x8, x14}.. 12.
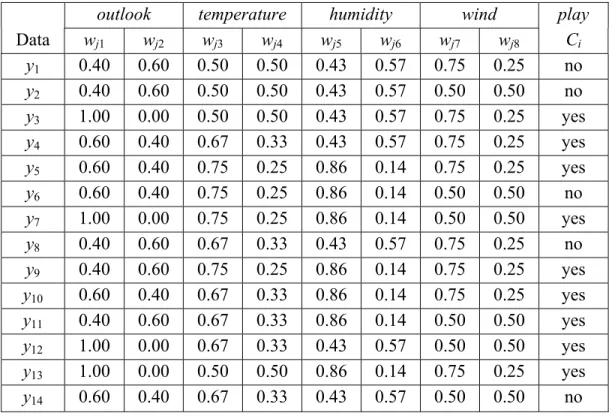
(15) Table 2. The rough attribute membership values of the weather data.. Data y1 y2 y3 y4 y5 y6 y7 y8 y9 y10 y11 y12 y13 y14. outlook wj1 wj2 0.40 0.60 0.40 0.60 1.00 0.00 0.60 0.40 0.60 0.40 0.60 0.40 1.00 0.00 0.40 0.60 0.40 0.60 0.60 0.40 0.40 0.60 1.00 0.00 1.00 0.00 0.60 0.40. temperature wj3 wj4 0.50 0.50 0.50 0.50 0.50 0.50 0.67 0.33 0.75 0.25 0.75 0.25 0.75 0.25 0.67 0.33 0.75 0.25 0.67 0.33 0.67 0.33 0.67 0.33 0.50 0.50 0.67 0.33. humidity wj5 wj6 0.43 0.57 0.43 0.57 0.43 0.57 0.43 0.57 0.86 0.14 0.86 0.14 0.86 0.14 0.43 0.57 0.86 0.14 0.86 0.14 0.86 0.14 0.43 0.57 0.86 0.14 0.43 0.57. wind wj7 0.75 0.50 0.75 0.75 0.75 0.50 0.50 0.75 0.75 0.75 0.50 0.50 0.75 0.50. wj8 0.25 0.50 0.25 0.25 0.25 0.50 0.50 0.25 0.25 0.25 0.50 0.50 0.25 0.50. play Ci no no yes yes yes no yes no yes yes yes yes yes no. The number of nominal attributes n’ = 4×2 = 8.. w11 = µ CA11 ( x1 ) = 0.4 , w12 = µ AC12 ( x1 ) = 0.6 ,. w13 = µ AC21 ( x1 ) = 0.5 , w14 = µ AC22 ( x1 ) = 0.5 , w15 = µ AC31 ( x1 ) = 0.43 , w16 = µ AC32 ( x1 ) = 0.57 , C w17 = µ AC41 ( x1 ) = 0.75 , w18 = µ A42 ( x1 ) = 0.25 .. y1 = (w11, w12, …, w18) = (0.4, 0.6, 0.5, 0.5, 0.43, 0.57, 0.75, 0.25). The final results are listed in Table 2. Step 3: Let TS’={<yj, cj>| yj = (wj1, wj2, …, wj8) , cj ∈ C, 1 ≤ j ≤ 14}, listed as Table 2. Step 4: Initialize the parameters.. 13.
(16) We set m = 14, a = 0, p = 100, and q = 100 for the fitness function. Initially, gen = 1, we generate Ω1 = { h11 , h21 , …, hq1 }. The set of positive instance of TS’ for classification C1 is {y3, y4, y5, y7, y9, y10, y11, y12, y13}, and the set of negative instances is {y1, y2, y6, y8, y14}. Step 5: Evaluate the fitness values of each individual on the training set. Assume that h11 = 50(wj1-wj2), we compute the fitness values E11 = fitness( h11 , TS’). The fitness value of the individual h11 is 14. E11 = fitness (h11 , TS ' ) = −∑ ( D p + Dn ) = -40400. j =1. Step 6: Does it satisfy the conditions of termination? For above case, if the best fitness value of Ei( gen ) does not satisfy the condition of termination, then gen = gen + 1 and go to Step 7. However, if the best fitness value of hi( gen ) satisfies the condition, hi( gen ) is returned and the algorithm halts. After the computing for a finite number of generations, we can get the solution. In this example, the final function is as follows fC1 = 100[(-(wj8-wj7)(wj3-wj4)+(wj1-wj2)+(wj5-wj6))-7. By the same learning procedure, the classification function fC2 can be obtained: f C2 =. 1 wj4 − [54( w j 7 − w j 8 ) + 100( w j1 − w j 2 ) + 12( w j 3 − w j 4 ) + 3]. .. Step 7: Generate the next generation of individuals and go to Step 5. The new population of next generation Ω(gen) is generated by the ratio of Pr, Pc and Pm and goes to Step 5.. 14.
(17) 4. The Classification Algorithm After generating the classification functions, the task of classification becomes straight and simple calculations of mathematical formulas. However, a classifier cannot recognize all objects correctly in real applications generally. Except the case of misclassification, two situations of conflict may occur. The first case is that an object is recognized by two or more classification functions at the same time. The other case is that an object cannot be recognized by any classification function. Under the above both situations, we cannot decide the exact class while classifying an unknown object. A complete classifier will include a conflict resolution method to solve the problem of conflict usually. The resolution in the proposed scheme is based on the distance-based fitness values and Z-score of statistical test. We present the resolution approach in the following. For a classification function fi ∈ F and samples <yj, cj> ∈ TS’ with cj = Ci, let X i be the mean of values of fi(yj), 1 ≤ j ≤ mi. That is,. ∑. Xi =. fi ( y j ) < y j ,c j >∈TS , c j =Ci mi. , 1 ≤ j ≤ mi , 1 ≤ i ≤ K .. For each X i , the standard deviation of values of fi(yj), 1 ≤ j ≤ mi, is defined as. ∑ ( fi ( y j ) − X i )2. σi =. < y j ,c j >∈TS , c j =Ci. , 1 ≤ j ≤ mi , 1 ≤ i ≤ K .. mi. For a data x ∈ S and a classification function fi, let y ∈ S’ be the data with all numerical values after transforming x using rough attribute membership. The Z-value of data y for fi is defined as. 15.
(18) Zi ( y j ) =. | fi ( y j ) − X i |. σi. mi. ,. where, 1 ≤ i ≤ K. If one of the classification functions in F determines the class of the data y uniquely, we complete the classifying task. However, once the data cannot be recognized by any classification function or the data is recognized by more than two classification functions in F, the Z-value will be applied to determine the class to which the data should be assigned. The detailed classification algorithm is listed as follow.. Algorithm: The classification algorithm. Input: A data x Output: The class Ck that x is assigned Step 1: Initial value k = 1. Step 2: Transform nominal attributes of x into numerical attributes. Assume that the data x ∈S, x = (v1, v2, …, vn). If Ai is a numerical attribute, wk = vi, k = k + 1. C. C. C If Ai is a nominal attribute, wk = µ Ai1 ( x) , wj(k+1) = µ Ai2 ( x) , ... , wj(k+K-1)= µ AiK (x) ,. k = k + K, repeat Step 2 until y = (w1, w2, …, wn’) is generated, n’ = (n-r) + rK, r is the number of nominal attributes in A. Step 3: Initially, i = 1 and there exists a set Z such that Z = ∅. Step 4: If fi(y) ≥ 0, that is, the data y is recognized by fi, then Z = {fi}∪Z. Step 5: If i < K, then i = i + 1, go to Step 4. Otherwise, go to Step 6. Step 6: Let |Z| be the number of functions in Z. If |Z| = 1, the unique class Ci corresponding to the function fi in Z will be returned and stop; otherwise, go to Step 7. 16.
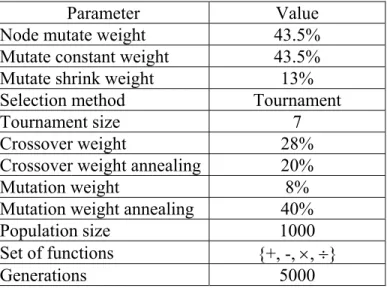
(19) Step 7: If |Z| = 0, Z = F. Step 8: Compute Zi(y), where fi ∈ Z. Step 9: Find the k = arg min{Z i ( y )} , the data x will be assigned to the class Ck. i. f i ∈Z. 5. The Experimental Results The proposed learning algorithm based on genetic programming is implemented by modifying the GPQuick 2.1 [17]. The parameters used in our experiments are list in Table 3. We define only four basic operations {+, -, ×, ÷} for final functions. That is, each classification function contains only the four basic operations. The experimental data sets are selected from UCI Machine Learning repository [1]. We take 20 data sets from the repository totally including 3 nominal data sets, 7 composite data sets (with nominal and numeric attributes), and 10 numerical data sets. For avoiding the missing values in attributes, we modified some of data sets by deleting some objects and attributes with incomplete data into our experimental data sets. The related information of the selected data sets is summarized in Table 4. Table 3. The parameters of GPQuick used in the experiments. Parameter Node mutate weight Mutate constant weight Mutate shrink weight Selection method Tournament size Crossover weight Crossover weight annealing Mutation weight Mutation weight annealing Population size Set of functions Generations 17. Value 43.5% 43.5% 13% Tournament 7 28% 20% 8% 40% 1000 {+, -, ×, ÷} 5000.
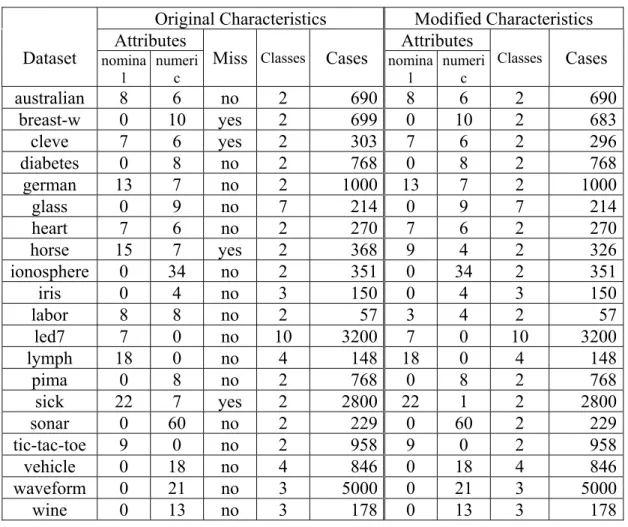
(20) Table 4. The information of data sets. Dataset australian breast-w cleve diabetes german glass heart horse ionosphere iris labor led7 lymph pima sick sonar tic-tac-toe vehicle waveform wine. Original Characteristics Attributes nomina numeri Miss Classes Cases l. c. 8 0 7 0 13 0 7 15 0 0 8 7 18 0 22 0 9 0 0 0. 6 10 6 8 7 9 6 7 34 4 8 0 0 8 7 60 0 18 21 13. no yes yes no no no no yes no no no no no no yes no no no no no. 2 2 2 2 2 7 2 2 2 3 2 10 4 2 2 2 2 4 3 3. 690 699 303 768 1000 214 270 368 351 150 57 3200 148 768 2800 229 958 846 5000 178. Modified Characteristics Attributes Cases nomina numeri Classes l. c. 8 0 7 0 13 0 7 9 0 0 3 7 18 0 22 0 9 0 0 0. 6 10 6 8 7 9 6 4 34 4 4 0 0 8 1 60 0 18 21 13. 2 2 2 2 2 7 2 2 2 3 2 10 4 2 2 2 2 4 3 3. 690 683 296 768 1000 214 270 326 351 150 57 3200 148 768 2800 229 958 846 5000 178. The performance of the proposed classification scheme is evaluated by the average classification error rate for 10 runs of 10-fold cross validation. We figure out the experimental results and compare the effectiveness with different classification models in Table 5. These models include statistical model like Naïve Bayes [4], NBTree[9], SNNB [18]; decision tree based like C4.5 [16], and the association rule-based classifier CBA [12]. Since the proposed GP-based classifier is random based, we also show the standard deviations in the table for reference of readers.. 18.
(21) From the experimental results, we observed that the proposed method obtains lower error rates than CBA in 11 out of the 20 domains, and higher error rates in 9 domains. It obtains lower error rates than C4.5 Rules in 14 domains and higher error rates 6 domains. While comparing our method with NBTree and SNNB, the result is in a tie. While comparing with Naïve Bayes, the proposed method wins 12 domains and loses in 8 domains. Generally, the classification results of proposed method is better than others on an average. However, in some data sets, the test results in GP-based is much worse than others, for example, in the “labor” data, we found that the average error rate is 23.1. The main reason of high error rate terribly in this case is the small size of samples in the data set. The “labor” contains only 57 data totally and is divided into two classes. While the data with small size is tested in 10-fold cross validation, the situation of overfit will occur between the two classification functions easily. The other reason is that we delete some of the attributes for avoiding the problem of missing values in data. Although the data may have missing values in only one or two attributes of some objects, deleting entire the objects or attributes straight will decrease the accuracy of classification. The results of data sets “horse” and “sick“ have the same effect as “labor”. Nevertheless, the proposed GP-based classification scheme still have good results in general.. 19.
(22) Table 5. Experimental results and comparisons. Dataset australian breast-w cleve diabetes german glass heart horse ionosphere iris labor led7 lymph pima sick sonar tic-tac-toe vehicle waveform wine. NB NBTree [18] [18] 14.1 14.5 2.4 2.6 18.1 19.1 24.1 24.1 24.5 24.5 28.5 28.0 18.1 17.4 21.7 18.7 10.5 12.0 5.3 7.3 5.0 12.3 26.7 26.7 19.0 17.6 24.5 24.9 4.2 22.1 21.6 22.6 30.1 17.0 40.0 29.5 19.3 16.1 1.7 2.8. SNNB [18] 14.8 3.0 18.5 24.1 26.2 28.0 18.9 17.4 10.5 5.3 3.3 26.5 17.0 25.1 3.8 16.8 15.4 28.4 17.4 1.7. C4.5 [18] 15.3 5.0 21.8 25.8 27.7 31.3 19.2 17.4 10.0 4.7 20.7 26.5 26.5 24.5 1.5 29.8 0.6 27.4 21.9 7.3. CBA [18] 14.6 3.7 17.1 25.5 26.5 26.1 18.1 17.6 7.7 5.3 13.7 28.1 22.1 27.1 2.8 22.5 0.4 31 20.3 5.0. GP-Based Average S.D. 13.1 0.6 3.1 0.4 20.8 1.3 25.5 1.7 17.3 0.8 27.3 1.3 14.4 0.4 23.2 1.8 4.9 0.5 4.2 0.8 23.1 1.9 23.4 2.1 17.9 1.6 25.5 2.0 11.7 0.7 16.5 0.9 4.2 0.4 31.4 2.2 17.7 1.5 5.3 0.4. 6. Conclusions Classification is an important task in many applications. The technique of classification using genetic programming is a new classification approach developed recently. However, how to handling nominal attributes in genetic programming is a difficult problem. We proposed a scheme based on the rough membership function to classify data with nominal attribute using genetic programming in this paper. Furthermore, we give a conflict resolution. 20.
(23) mechanism for avoiding conflicting among classification functions. The experimental results demonstrate that the proposed scheme is feasible. Although it is not so effective in some cases of datasets, we are trying to find a new fitness function to improve the accuracy for any possible datasets and cope with the data having missing values in the future.. References [1] C. Blake, E. Keogh, C. J. Merz, UCI repository of machine learning database, http://www.ics.uci.edu/~mlearn/MLReopsitory.html, Irvine, University of California, Department of Information and Computer Science, 1998. [2] M. Bramrier and W. Banzhaf, A Comparison of Linear Genetic Programming and Neural Networks in Medical Data Mining, IEEE Transaction on Evolutionary Computation, Vol. 5, No. 1, Feb. pp. 17-26, 2001. [3] B. C. Chien, J. Y. Lin, and T. P. Hong, Learning Discriminant Functions with Fuzzy Attributes for Classification Using Genetic Programming, Expert Systems with Applications, No. 23, pp. 31-37, 2002. [4] R. O. Duda, P. E. Hart, Pattern Classification and Scene Analysis, New York: John Wiley, 1973. [5] A. A. Freitas, A Genetic Programming Framework for Two Data Mining Tasks: Classification and Generalized Rule Induction, Proceedings of the 2nd Annual Conference Morgan Kaufmann, pp. 96-101, 1997. [6] E. H. Han, G. Karypis, V. Kumar, Text Categorization Using Weight Adjusted k-nearest Neighbor Classification, PhD thesis, University of Minnesota, 1999. [7] D. Heckerman, M. P. Wellman, “Bayesian networks”, Communications of the ACM, Vol.. 21.
(24) 38, No. 3, pp. 27-30, 1995. [8] J. K. Kishore, L. M. Patnaik, V. K. Agrawal, Application of Genetic Programming for Multicategory Pattern Classification, IEEE Transactions on Evolutionary Computation, Vol. 4, No. 3, pp. 242-258, 2000. [9] R. Kohavi, Scaling Up the Accuracy of Naïve-Bayes Classifiers: a Decision-Tree Hybrid. Proceedings of the Second International Conference on Knowledge Discovery & Data Mining, AAAI Press/MIT press, Cambridge/Menlo Park, pp. 202-207, 1996. [10] J. R. Koza, Genetic Programming: “On the programming of computers by means of Natural Selection”, MIT Press, 1992. [11] J. R. Koza, Introductory Genetic Programming Tutorial, Genetic Programming 1996 Conference, Stanford University, 1996. [12] B. Liu, W. Hsu, and Y. Ma, Integrating Classification and Association Rule Mining. Proceedings of the Fourth International Conference on Knowledge Discovery and Data Mining, pp. 443-447, 1998. [13] T. Loveard and V. Ciesielski, Representing Classification Problems in Genetic Programming, in Proceedings of the 2001 Congress on Evolutionary Computation, pp. 1070-1077, 2001. [14] Z. Pawlak, Rough Sets, International Journal of Computer and Information Sciences, No. 11, pp. 341-356,1982. [15] Z. Pawlak, A. Skowron, Rough Membership Functions, in: R.R. Yager and M. Fedrizzi and J. Kacprzyk (Eds.), Advances in the Dempster-Shafer Theory of Evidence, pp. 251271, 1994. [16] J. R. Quinlan, C4.5: Programs for Machine Learning, Morgan Kaufmann, 1993.. 22.
(25) [17] A. Singleton, Genetic Programming with C++, Byte, Feb. pp. 171-176, 1994. [18] Z. Xie, W. Hsu, Z. Liu, M. L. Lee, SNNB: A Selective Neighborhood Based Naïve Bayes for Lazy Learning, Proceedings of the sixth Pacific-Asia Conference on Advances in Knowledge Discovery and Data Mining, pp. 104-114, 2002. [19] Y. Y. Yao, S. K. M. Wong, A Decision Theoretic Framework for Approximating Concepts, International Journal of Man-machine Studies, No. 37, pp. 793-809, 1992. [20] G. P. Zhang, Neural Networks for Classification: a Survey, IEEE Transaction on Systems, Man, And Cybernetics-Part C: Applications and Reviews, Vol.30, No. 4, pp. 451-462, 2000.. 23.
(26)
數據
+2
![Table 5. Experimental results and comparisons. GP-Based Dataset NB [18] NBTree [18] SNNB[18] C4.5 [18] CBA[18] Average S.D](https://thumb-ap.123doks.com/thumbv2/9libinfo/8911474.260175/22.918.132.725.129.689/table-experimental-results-comparisons-based-dataset-nbtree-average.webp)
相關文件
Numerical experiments are done for a class of quasi-convex optimization problems where the function f (x) is a composition of a quadratic convex function from IR n to IR and
Particularly, combining the numerical results of the two papers, we may obtain such a conclusion that the merit function method based on ϕ p has a better a global convergence and
• Introduce Computer Graphics Programming with WebGL and J avaScript: WebGL is not only fully shader-based– each applicati on must provide at least a vertex shader and a fragment
In Section 4, we give an overview on how to express task-based specifications in conceptual graphs, and how to model the university timetabling by using TBCG.. We also discuss
This bioinformatic machine is a PC cluster structure using special hardware to accelerate dynamic programming, genetic algorithm and data mining algorithm.. In this machine,
In this thesis, we have proposed a new and simple feedforward sampling time offset (STO) estimation scheme for an OFDM-based IEEE 802.11a WLAN that uses an interpolator to recover
A decision scheme based on OWA operator for an evaluation programme: an approximate reasoning approach. A decision scheme based on OWA operator for an evaluation programme:
In this paper, a decision wandering behavior is first investigated secondly a TOC PM decision model based on capacity constrained resources group(CCRG) is proposed to improve
