An Indexing Method for Supporting Structure Queries on XML Documents
11
0
0
全文
(2) This paper is organized as followings. In. Tuong Dao [6] encodes the structured. Section 2 we describe some related works. document according to the TEI guidelines, and. about. uses. indexing. methods. on. structured. the. extension. of. SCL. (Simple. documents, in Section 3 we discuss how to. Concordance Lists) model to support content,. build the index information, modify the index. structure, and attribute queries on structured. interval method, and reduce the space overhead. document. But, this method does not use the. on index information to improve query. concept of tree structure to handle the index. efficiency and more query types. Section 4 is. information. It uses containment relationships. describing the update method to maintain the. rather than hierarchical relationships to support. integration of index information and original. queries on document structure. The document. XML documents after the structured documents. in Figure 1 is the collection of English classic. had be inserted, deleted, or modified. In section. texts available for public use at the Oxford Text. 5, we discuss the works we are doing follows. Archive which contains three divisions, the. up this paper was published and some future. table of contents and two chapters. In Figure 1,. works that can improve in the information. structural elements are marked up with XML. retrieval system. Section 6 presents concluding. tags and encoded by TEI guidelines.. remarks with the proposed concepts of this 100.1. paper.. 100.2. 101. 102. <doc n=”1975”> <dtitle> Tarzan of 104.2. 105. 103. 104. 104.1. the Apes </dtitle>. 105.1. <div type=”toc”> Contents … </div> 105.2. 2 Related works. 106. 110. 111. <p> …. Let. all. handling structured documents well in terms of. his. 119. 120. 112. 113. respect Tarzan 120.1. 115. of. the Apes. 117. and. 118. Kala,. 120.2. 120.3. documents e.g. SGML or XML documents.. 114. mother … </p> … </div> 121. 122. <div type=”chapter” id=”C11”> King. discuss some indexing methods for structured. 109 116. 109.1. In this section, we. 108. Knowledge …. For years, there has been growing interest in indexing and retrieval.. 107. <div type=”chapter” id=”C7”> The Light of. 124.1. 125. 126. <p>. And. thus. 127. 128. 134. 135. 136. kingship. of. the Apes … </p>. 137.2. the. 129. came the young 137. 123. of. 130. 124. Apes … 131. 132. Lord Greystoke into. 133. the. 137.1. 137.3. … </div> … </doc>. First one is a kind of indexing methods on structured documents by using TEI (Text. Figure 1:Document in the text collection. Encoding for Interchange) guidelines – an encoding standard adopted by the humanities. 2.2 Indexing with UID. desciplines. Second one is uses an m-ary. Lee et al. [7] proposed an indexing structure. complete tree structure to create a document. that is able to reduce the storage overhead. tree and assign a UID for each node of tree. taken to indexing at all levels of document. structure according to the order of the. structure. They first represented a document as. level-order tree traversal in subsection 2.2. In. an m-ary complete tree where m is the largest. subsection 2.3, a method uses the index interval. number of child elements of an element in the. concept to assign each node the step numbers. structure. The result of the mapping is called. for reaching and leaving the node while. ‘document tree’. Secondly they assigned each. traversing by the preorder way.. element a UID (Unique element IDentifier) according to the order of the level-order tree. 2.1 Indexing with TEI guidelines. traversal. For example, the document tree in. 2.
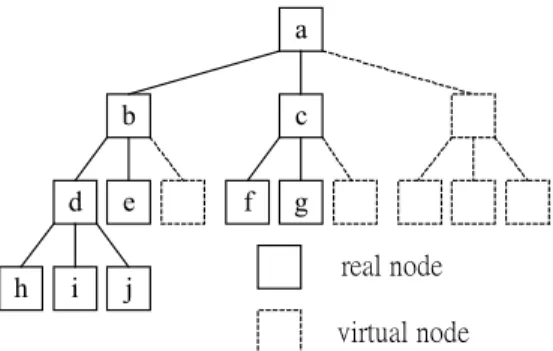
(3) Figure 2, we assign UID’s as shown in the. method by using the index interval concept. Table 1 assuming a 3-ary tree. Here, we can. which assigns each node a pair of interval. consider this document tree as following: the. numbers - <1st_index, 2nd_index> according to. node a is a book, b a chapter, d a section, and h. the step numbers for reaching and leaving the. is a subsection. Because they use the concept of. node while traversing through the DOM tree in. complete tree, there are some virtual nodes. the preorder way. From this index interval. which do not exist.. concept, we can infer the relationship of parent-child in any level and the relationship of sibling in the same level by comparing the. a b. index interval numbers of specified nodes. They also proposed a document updating. c. method – Lazy update by using the index. h. d. e. i. j. f. g. update table to record the index update and index transformation information. This method. real node. lets the system does not need to update the. virtual node. index information immediately and could select suitable time to clean up the index table after. Figure 2:Example of document tree. the document is inserted, deleted, or modified. However, this method does not provide. Table 1:Unique element identifiers Element. UID. Element. UID. complete solution for inserting elements to the. a b c d e. 1 2 3 5 6. f g h i j. 8 9 14 15 16. structured document and deleting elements from the structured document. Furthermore, they do not support the attribute query type for structured documents.. The UID’s of the parent and j-th child of a. 3 The indexing method. node whose UID is i can be obtained by the. Indexing. following two functions. Using these functions we. can. only. decide. the. documents. for. performed in various ways. In traditional text. relationship between two nodes on condition. information retrieval systems, only the queries. that the difference of their level numbers is just. on content are supported. The rich structural. 1. If the condition doesn’t hold, the parent-child. information is contained in documents and the. relationship has no choice to be decided by. attributes of document components are not. these two functions in recursive way.. child (i, j ) = k (i − 1) + j + 1. structured. content, structure and attribute queries can be. parent-child. (i − 2 ) parent (i ) = + 1 k . on. captured in these systems, and the queries on structure and attributes are not supported. For. (1). improving the index interval method [3] and adding the extra index information about the. (2). elements in XML documents, we use a kind of XML parser – DOM (Document Object Model). 2.3 Indexing with index interval. parser to build the index information and. Jyh-Hong Tsay et al. [3] proposed an index. 3.
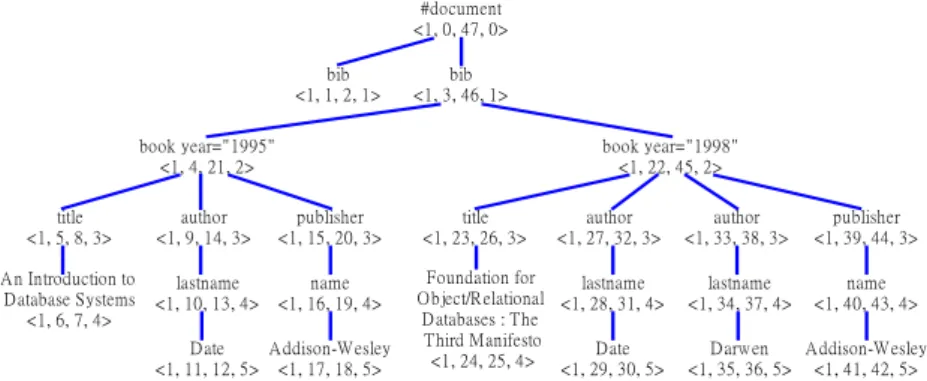
(4) propose five basic query functions to carry out. interval numbers. We assume the two index. the structure queries, provide information. interval numbers of nodes - U and V are U1st,. retrieval efficiently, and support more structure. U2nd and V1st, V2nd respectively. If V1st < U1st,. query types on structure documents.. and U2nd < V2nd, then the node U is a descendent of the node V. If U1st = V2nd + 1 or V1st = U2nd +. 3.1 Building the index information. 1, then the node U is a sibling of the node V.. The main idea of building the index. The document number tells which document. information is that we use the DOM parser to. the element belongs to, and the level number. parse the whole XML document into a tree. informs which level the element belongs to. An. structure, assign associated information (i.e.. example of an XML document and its tree. index information = <document number,. structure are shown in Figure 4 and Figure 5. 1st_index, 2nd_index, level number>) to each. respectively.. node in preordering way, and save the index information. into. three. kinds. of. <?xml version=”1.0”?>. index. <!DOCTYPE bib [. information lists according to the node types –. <!ELEMENT bib (book+) > <!ELEMENT book (title, author+, publisher) >. the element node, the attribute node and the. <!ATTLIST book year CDATA #REQUIRED >. text node. The index information of all element. <!ELEMENT title (#PCDATA) >. nodes is recorded into the ELEMENT list, the. <!ELEMENT author (lastname) > <!ELEMENT lastname (#PCDATA) >. index information and attribute values of all. <!ELEMENT publisher (name) > <!ELEMENT name (#PCDATA) >. element attribute nodes are recorded into the. ]>. ATTRIBUTE list and the index information. <bib> <book year="1995">. and content of all text node are recorded into. <title> An Introduction to Database Systems </title>. the TEXT list. The concept of this processing is. <author> <lastname> Date </lastname> </author> <publisher> <name> Addison-Wesley </name >. shown in Figure 3.. </publisher>. </book> <book year="1998"> <title> Foundation for Object/Relational Databases: The Third Manifesto </title>. XML Documents. <author> <lastname> Date </lastname> </author> <author> <lastname> Darwen </lastname> </author> <publisher> <name> Addison-Wesley </name >. </publisher>. </book>. DOM Parser. index information. ELEMENT list ATTRIBUTE list TEXT list. </bib>. Figure 4:Example document. Figure 3:Building index information After. building. the. index. information,. The two interval numbers (1st_index and. according to the node type number we separate. 2nd_index) of index interval are the step. the index information into three lists –. numbers of reaching and leaving the node of. ELEMENT, ATTRIBUTE, and TEXT. In this. the document tree while traversing in preorder. processing phase, the system does not store the. way. This pair of index interval numbers could. 2nd_index and level number into ATTRIBUTE. be used to determine what kind of relationships. and TEXT lists. Moreover, the system adds the. do specify nodes have by comparing the index. attribute values after the corresponding index. 4.
(5) information of the attribute. The content of. figure out Q-TEXT list for answering query. these lists are shown in Figure 6. There is an. requirements after loading these three index. additional temporary list – Q-TEXT that is not. information lists into the memory.. stored in the storage. We can use TEXT list to #document <1, 0, 47, 0> bib <1, 1, 2, 1>. bib <1, 3, 46, 1>. book year="1995" <1, 4, 21, 2>. book year="1998" <1, 22, 45, 2>. title <1, 5, 8, 3>. author <1, 9, 14, 3>. publisher <1, 15, 20, 3>. A n Introduction to D atabase Systems <1, 6, 7, 4>. lastname <1, 10, 13, 4>. name <1, 16, 19, 4>. D ate A ddison-Wesley <1, 11, 12, 5> <1, 17, 18, 5>. author <1, 27, 32, 3>. author <1, 33, 38, 3>. publisher <1, 39, 44, 3>. Foundation for lastname O bject/Relational <1, 28, 31, 4> D atabases : The Third Manifesto D ate <1, 24, 25, 4> <1, 29, 30, 5>. lastname <1, 34, 37, 4>. name <1, 40, 43, 4>. title <1, 23, 26, 3>. D arw en A ddison-Wesley <1, 35, 36, 5> <1, 41, 42, 5>. Figure 5:Tree structure of example document spaces. In our example document, author and ELEMENT index information:<Doc_No, 1st_index, 2nd_index, level_No> bib > 1 3 46 1 book > 1 4 21 2 > 1 22 45 2 title > 1 5 8 3 > 1 23 26 3 author/lastname > 1 10 13 4 > 1 28 31 4 > 1 34 37 4. lastname elements are combined into one element – author/lastname and stored into ELEMENT list using the index information of. publisher/name > 1 16 19 4 > 1 40 43 4. lastname. The symbol “/” between author and. ATTRIBUTE index information:<Doc_No, 1st_index, Att_Value> year > 1 4 1995 > 1 22 1998. lastname is used to show their parent-child relationship. The index information of TEXT. TEXT index information:<Doc_No, 1st_index> An Introduction to Database Systems > 1 6 Date > 1 11 > 1 29 Addison-Wesley > 1 17 > 1 41 Foundation for Object/Relational Databases: The Third Manifesto > 1 24 Darwen > 1 35. list and Q-TEXT list just includes content of nodes, its document number and first index interval number. Because the second index interval number of TEXT nodes always equals. Q-TEXT index information:<Doc_No, 1st interval> 1 6 > An Introduction to Database Systems 1 11 > Date 1 17 > Addison-Wesley 1 24 > Foundation for Object/Relational Databases: The Third Manifesto 1 29 > Date 1 35 > Darwen 1 41 > Addison-Wesley. to its first index interval number adds one. In this way, we not only reduce some space overhead but also infer the second index interval number of specific node from one’s first index interval number. In order to keep the. Figure 6: The content of listings.. attribute value of the attribute node, the We will discuss the contents of these lists in. ATTRIBUTE list includes the name of attribute. following. In ELEMENT list, it contains the. and its index information – document number,. name of elements and its index information. If. first index interval number, and attribute value.. an element includes only one element, it could. In the ATTRIBUTE list, we just keep the first. combine with its child element and keep the. index interval number, because we can only use. index information of its child. In this way, we. the first index interval number to decide which. can not only store the parent-child relationship. element node includes this attribute node.. of these two nodes but also save some storage. 5.
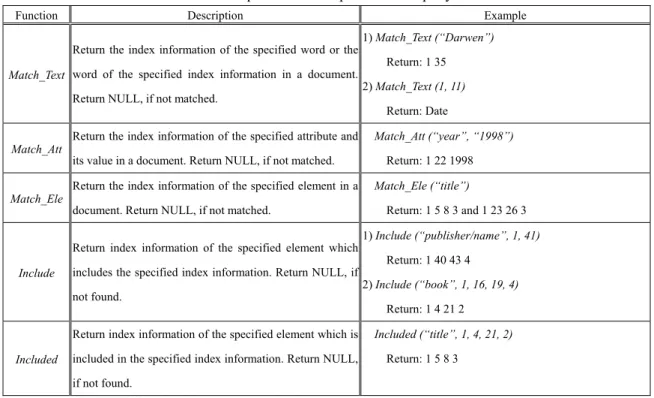
(6) 3.2 Five basic query functions. propose five basic query functions for finding. The XML documents are marked up with. out the index information and inferring. start-tags and end-tags, these markup tags are. relationships of specified elements, attributes,. used to delimit the boundaries of structural. or keywords. The description of these basic. elements or specify the values of attributes. query. associated with structural elements. Based on. examples based on the previous example. these properties of XML documents, we. document are shown in Table 2.. functions. and. the. corresponding. Table 2: The description and examples of basic query functions Function. Description. Example. Return the index information of the specified word or the Match_Text word of the specified index information in a document. Return NULL, if not matched.. Match_Att. Match_Ele. Return the index information of the specified attribute and its value in a document. Return NULL, if not matched. Return the index information of the specified element in a document. Return NULL, if not matched.. 2) Match_Text (1, 11). Match_Att (“year”, “1998”) Return: 1 22 1998 Match_Ele (“title”) Return: 1 5 8 3 and 1 23 26 3. includes the specified index information. Return NULL, if not found.. 1) Include (“publisher/name”, 1, 41) Return: 1 40 43 4 2) Include (“book”, 1, 16, 19, 4) Return: 1 4 21 2. Return index information of the specified element which is Included. Return: 1 35. Return: Date. Return index information of the specified element which Include. 1) Match_Text (“Darwen”). included in the specified index information. Return NULL,. Included (“title”, 1, 4, 21, 2) Return: 1 5 8 3. if not found.. 3.3 Query on content, structure and attributes. attribute as following. The first and second. So far, we have discussed the index method. structure query. The third one is a combination. for. extracting. the. index. information. examples are combinations of content and of structure and attribute query.. of. elements, attributes, and texts in a document. Example 1: Find out the title and author’s name of every book whose publisher’s name is “Addison-Wesley”. Step 1: Call Match_Text (“Addison-Wesley”) Return: 1 17 and 1 41 Call Include (“publisher/name”, 1, 17) Return: 1 16 19 4 Call Include (“publisher/name”, 1, 41) Return: 1 40 43 4 Step 2: Call Include (“book”, 1, 16, 19, 4) Return: 1 4 21 2 Call Include (“book”, 1, 40, 43, 4) Return: 1 22 45 2. Moreover, we have proposed five basic query functions for finding out the index information and inferring the including relationship. Now we will describe how to use the index method and the five basic query functions for processing the higher-level user queries. Based on the previous example document, we take three examples to explain how to find out the results of query on content, structure and. 6.
(7) Step 3: Call Included (“title”, 1, 4, 21, 2) Return: 1 5 8 3 Call Included (“author/lastname”, 1, 4, 21, 2) Return: 1 10 13 4 Call Included (“title”, 1, 22, 45, 2) Return: 1 23 26 3 Call Included (“author/lastname”, 1, 22, 45, 2) Return: 1 28 31 4 and 1 34 37 4 Step 4: Call Match_Text (1, 6) Return: An Introduction to Database Systems Call Match_Text (1, 11) Return: Date Call Match_Text (1, 24) Return: Foundation for Object/Relational Databases: The Third Manifesto Call Match_Text (1, 29) Return: Date Call Match_Text (1, 35) Return: Darwen. function, the system has to add 1 to the each first index interval number of returned index information in Step 3. These index information can be used to extract the corresponding content. For instance, the content of element title>1 5 8 3 is 1 6>An Introduction to Database Systems. Example 2: Find out the title and publisher of every book whose author’s name is “Darwen”. Step 1: Call Match_Text (“Darwen”) Return: 1 35 Call Include (“author/lastname”, 1, 35) Return: 1 24 27 4 Step 2: Call Include (“book”, 1, 24, 27, 4) Return: 1 22 45 2 Step 3: Call Included (“title”, 1, 22, 45, 2) Return: 1 23 26 3 Call Included (“publisher/lastname”, 1, 22, 45, 2) Return: 1 40 43 4 Step 4: Call Match_Text (1, 24) Return: Foundation for Object/Relational Databases: The Third Manifesto Call Match_Text (1, 41). In Step 1, after calling Match_Text(“Addison -Wesley”) function to get index information of keyword “Addison-Wesley”, the system checks to see if the keyword “Addison-Wesley” is a publisher’s name by call Include(“publisher/nme”, 1, 17) and Include (“publisher/name”, 1, 41) functions. The Step 2 is finding out which. Return: Addison-Wesley. book includes the index information of results – 1 16 19 4 and 1 40 43 4 in Step 1 by calling. The Step 1 checks to see if the keyword. Include(“book”, 1, 16, 19, 4) and Include. “Darwen” is a author’s name and the Step 2. (“book”, 1, 40, 43, 4) functions. The Step 3. checks which book includes the author name is. looks for what index information of “title” and. “Darwen”. Step 3 finds out the index. “author/lastname”. index. information of book’s title and publisher’ name. information of element book - 1 4 21 2 and 1 22. and uses these information for answering the. 45 2 by calling Included(“title”, 1, 4, 21, 2),. user’s query in Step 4.. are. included. in. Included(“author/lastname”, 1, 4, 21, 2), Example 3: Find out every book whose publishing year is “1995”. Step 1: Call Match_Att (“year”, “1995”) Return: 1 4 1995 Call Include (“book”, 1, 4) Return: 1 4 21 2 Step 2: Call Included (“title”, 1, 4, 21, 2) Return: 1 5 8 3 Call Included (“author/lastname”, 1, 4, 21, 2) Return: 1 10 13 4 Call Included (“publisher/lastname”, 1, 4, 21, 2) Return: 1 16 19 4. Included(“title”, 1, 4, 21, 2), and Included (“author/lastname”, 1, 4, 21, 2) functions. The last Step, the system uses the document number and the first index interval number of returned index information of Included() functions in Step 3 to extract the content of the title and author’s name for answering the user’s query by call Match_Text() function sequentially. Before the system calls the Match_Text(). 7.
(8) Step 3: Call Match_Text (1, 6) Return: An Introduction to Database Systems Call Match_Text (1, 11) Return: Date Call Match_Text (1, 17) Return: Addison-Wesley. structured documents. We take advantages of Lazy Update and modified the concept of Lazy Update to solve the problem on the validation of the structured documents and let the updating of index information more efficiently. The following are. In Step 1, the system will check the keyword. our different strategies on different cases.. “1995” is included in which book. The Step 2 finds out the index information of book’s title,. (1) Modifying the specific content of some. author, and publisher and uses these index. element. information for answering the user’s query in. First of all, we have to find out the. Step 3.. specific content position of the element in TEXT list and Q-TEXT list that we want to. 4 Update method. modify. Then we use the new data to replace. After on user insert or remove some element. the old data. In this case, we only need to do. of structured document, the document content. this modification immediately, because the. and index information has to be changed. Once. structure of whole XML document does not. the structure changed, we have to do something. be changed.. to maintain the document content and index information integrations. Otherwise, we cannot. (2) Removing some element structure. retrieve the content correctly anymore. One of. In this case, we will use the update table. the update methods is to re-compute the index. to keep the index interval of the removed. information of the document immediately. And. element. For example, we want to remove. then write the new index information back to. the first author of second book of example. the index information storage. This method is. document in Figure 4 (i.e. Date). First, we. called Immediate Update, which can maintain. have to find out which index interval of. the integration on index information of. element includes the author’s name “Date”.. document and the content of document. But. Next, we record it’s index information (i.e.. this way may waste too much overhead for. <1, 27, 32, 3>) in the update table. Using the. frequent updating. Another update methods can. concept of update table a user still could. avoid the expensive update cost and provide. issue the query after this operation, but the. update index information more efficiently is. system needs to check that the element. called Lazy update [3]. Lazy Update use an. structure is removed from the index. index update table to record the index update. information lists or not before outputting the. and index transformation information, it let’s. query result.. the system does not need to update the index. If we issue a query: Find out the title and. immediately. Then, the system can select. author’s. suitable time to clean up the index information.. publisher’s name is “Addison-Wesley” (i.e.. However, Jyh-Hong Tsay et al. did not consider. Example 1 of section 3) after the above. the validation of the structured document after. removing operation, the system will check. inserting. and. removing. the. element. of. 8. name. of. every. book. whose.
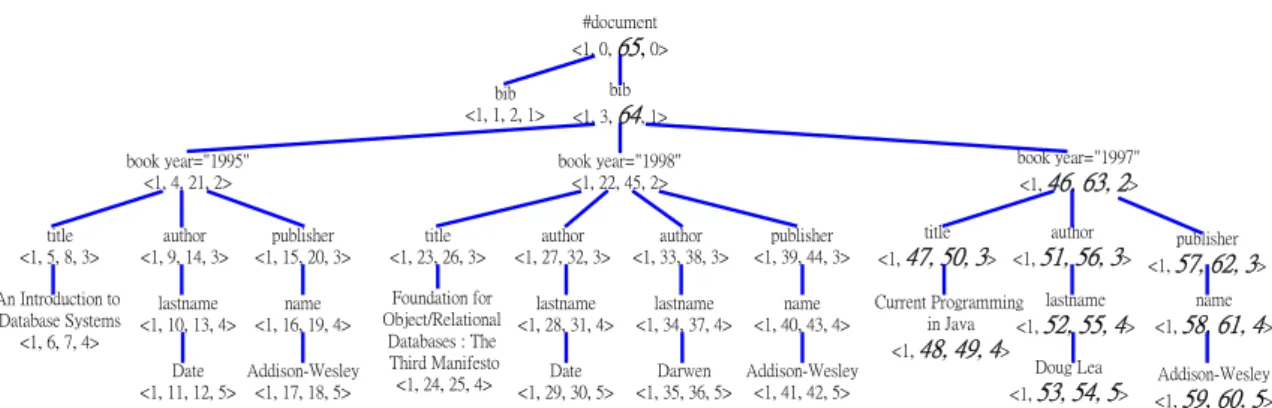
(9) to see if the index interval of result data is. document tree. So the first index interval. included in the index interval which are. number of the root in inserted element. recorded in the update table. So the result of. structure is starting form 46 and it’s level. Example 1 doesn’t contain “Date”.. number is starting form 2. The system will add 46 to each index interval number, add 2 to each level number in the inserted element. (3) Inserting some element structure In this case, the system will insert the. structure, add 18 (i.e. the difference of index. element structure that we want to add into. interval numbers of root node in inserting. the XML document into the last of relative. element structure+1) to each index interval. position of document tree. Because we have. number great than 45 in the original index. to consider the validation of XML document. information lists, and then insert the index. and insert the index information of the. information of the inserted element structure. inserted element structure into the index. into the last of the corresponding position of. information lists easily.. the ELEMENT, ATTRIBUTE, TEXT lists. The new content of all lists after insertion. We will describe the concept of inserting. operation are shown in Figure 10.. an element structure by using the following element structure in Figure 7. Assume that. <book year=”1997”>. we will insert the element structure into the. <title>Current Programming in Java</title>. example document in Figure 4. First of all,. <author><lastname>Doug Lea</lastname></author>. the system has to figure out the index. <publisher><name>Addison-Wesley</name></publisher>. information of tree structure of the inserted. </book>. elements, assign the one to document book year="1997" <1, 0, 17, 0>. number, and calculate the difference of index interval numbers of the root node (i.e.. title <1, 1, 4, 1>. 17-0=17) in the inserted element structure. The concept of insertion operation and the result document tree of insertion operation. author <1, 5, 10, 1>. publisher <1, 11, 16, 1>. Current Programming lastname in Java <1, 6, 9, 2> <1, 2, 3, 2>. name <1, 12, 15, 2>. Doug Lea <1, 7, 8, 3>. are shown in Figure 8 and Figure 9. Addison-Wesley <1, 13, 14, 3>. Figure 7: Inserted element and structure. respectively. The inserted element structure is a sibling of second book in the example #document <1, 0, 47, 0> bib <1, 1, 2, 1> book year="1995" <1, 4, 21, 2>. bib <1, 3, 46, 1> book year="1998" <1, 22, 45, 2>. title <1, 5, 8, 3>. author <1, 9, 14, 3>. publisher <1, 15, 20, 3>. An Introduction to Database Systems <1, 6, 7, 4>. lastname <1, 10, 13, 4>. name <1, 16, 19, 4>. Addison-Wesley Date <1, 11, 12, 5> <1, 17, 18, 5>. book year="1997" <1, 0, 17, 0>. author <1, 27, 32, 3>. author <1, 33, 38, 3>. publisher <1, 39, 44, 3>. Foundation for lastname Object/Relational <1, 28, 31, 4> Databases : The Third Manifesto Date <1, 24, 25, 4> <1, 29, 30, 5>. lastname <1, 34, 37, 4>. name <1, 40, 43, 4>. title <1, 23, 26, 3>. title <1, 1, 4, 1>. author <1, 5, 10, 1>. publisher <1, 11, 16, 1>. Current Programming lastname <1, 6, 9, 2> in Java <1, 2, 3, 2> Addison-Wesley Darwen Doug Lea <1, 35, 36, 5> <1, 41, 42, 5> <1, 7, 8, 3>. name <1, 12, 15, 2>. inserted element. Figure 8: The concept of insertion operation. 9. Addison-Wesley <1, 13, 14, 3>.
(10) #document <1, 0, 65, 0> bib <1, 3, 64, 1>. bib <1, 1, 2, 1> book year="1995" <1, 4, 21, 2>. book year="1997" <1, 46, 63, 2>. book year="1998" <1, 22, 45, 2>. title <1, 5, 8, 3>. author <1, 9, 14, 3>. publisher <1, 15, 20, 3>. An Introduction to Database Systems <1, 6, 7, 4>. lastname <1, 10, 13, 4>. name <1, 16, 19, 4>. Date Addison-Wesley <1, 11, 12, 5> <1, 17, 18, 5>. title <1, 23, 26, 3>. author <1, 27, 32, 3>. author <1, 33, 38, 3>. Foundation for lastname Object/Relational <1, 28, 31, 4> Databases : The Third Manifesto Date <1, 24, 25, 4> <1, 29, 30, 5>. lastname <1, 34, 37, 4>. publisher <1, 39, 44, 3>. author title publisher <1, 47, 50, 3> <1, 51, 56, 3> <1, 57, 62, 3>. Current Programming lastname in Java <1, 52, 55, 4> <1, 48, 49, 4> Doug Lea Darwen Addison-Wesley <1, 35, 36, 5> <1, 41, 42, 5> <1, 53, 54, 5> name <1, 40, 43, 4>. name <1, 58, 61, 4> Addison-Wesley <1, 59, 60, 5>. Figure 9: The result document tree of insertion operation propose the write back strategy to handle the. ELEMENT index information:<Doc_No, 1st_index, 2nd_index, level_No> bib > 1 3 64 1 book > 1 4 21 2 > 1 22 45 2 > 1 46 63 2 title > 1 5 8 3 > 1 23 26 3 > 1 47 50 3 author/lastname > 1 10 13 4 > 1 28 31 4 > 1 34 37 4 > 1 52 55 4. integration problem of the original XML document and it’s index information lists. Moreover, we will use the XML scheme for. publisher/name > 1 16 19 4 > 1 40 43 4 > 1 58 61 4. setting more data types on content of XML. ATTRIBUTE index information:<Doc_No, 1st_index, Att_Value> year > 1 4 1995 > 1 22 1998 > 1 46 1997. document on the document validation, and take the XQL or XML-QL [1] grammar to. TEXT index information:<Doc_No, 1st_index> An Introduction to Database Systems > 1 6 Date > 1 11 > 1 29 Addison-Wesley > 1 17 > 1 41 > 1 59 Foundation for Object/Relational Databases: The Third Manifesto > 1 24 Darwen > 1 35 Current Programming in Java > 1 48 Doug Lea > 1 53. implement the system query language.. 6 Conclusions In order to perform structure queries efficiently on structured documents, we have. Q-TEXT index information:<Doc_No, 1st interval> 1 6 > An Introduction to Database Systems 1 11 > Date 1 17 > Addison-Wesley 1 24 > Foundation for Object/Relational Databases: The Third Manifesto 1 29 > Date 1 35 > Darwen 1 41 > Addison-Wesley 1 48 > Current Programming in Java 1 53 > Doug Lea 1 59 > Addison-Wesley. proposed the new index method that makes the users can issue the content, structure and attribute queries on XML documents. We have shown how to handle these kinds of queries and how to use the strategies of update method for solving the update problem on element’s. Figure 10: The content of lists after insertion. insertion, element’s removing and content’s. operation. modification situations.. 5 Future work. References. So for, we have discussed the update method. [1] Alin Deutsch, Mary Fernandez, Daniela. on the index information lists, but did not. Florescu, Alon Levy, Dan Suciu. XML-QL:. discuss how to update the XML document. A Query Language for XML. March 2001. correspond to the changed index information. http://www.w3.org/TR/1998/NOTE-xml-ql-19. lists. The reason is that we can answer user’s. 980819. queries just by the index information lists, not. [2] Dongwook Shin, Hyuncheol Jang, and. original XML document. Furthermore, we will. Honglan Jin. BUS: An Effective Indexing. 10.
(11) and. Retrieval. Scheme. in. Structured. Documents. Dongwook Shin, Hyuncheol Jang and Honglan Jin; Proceedings of the third ACM Conference on Digital libraries, Pages 235 - 243, 1998 [3] Jyh-Jong Tsay and Gang-Heng Lu. Dynamic Indexing Schemes for Structured Documents. Master Thesis, Department of Computer Science. and. Information. Engineering. National Chung Cheng University. August 31, 2000 [4] S. Park, and Hyoung-Joo Kim. A new query processing technique for XML based on signature. Database Systems for Advanced Applications, 2001. Proceedings. Seventh International Conference, Pages: 22 –29, 2001 [5] Takeyuki Shimura, Masatoshi Yoshikawa and Shunsuke Uemura. Storage and Retrieval of XML Documents using Object-Relational Databases. July 2001. http://citeseer.nj.nec.com/shimura99storage. htm [6] Tuong. Dao.. An. Indexing. Model. for. Structured Documents to Support Queries on Content, Structure and Attributes. Research and. Technology. Advances. in. Digital. Libraries, 1998. ADL 98. Proceedings. IEEE International Forum on 1998 Pages:88-97 [7] Yong Kyu Lee, Seong-Joom Yoo, Kyoungro Yoon.. Index. Structures. for. Structured. Documents. Proceedings of the 1st ACM international conference on Digital libraries, Pages 91-99, 1996 [8] W3C. Document Object Model (DOM). July 2001. http://www.w3.org/DOM/. 11.
(12)
數據


+4

相關文件
The Secondary Education Curriculum Guide (SECG) is prepared by the Curriculum Development Council (CDC) to advise secondary schools on how to sustain the Learning to
好了既然 Z[x] 中的 ideal 不一定是 principle ideal 那麼我們就不能學 Proposition 7.2.11 的方法得到 Z[x] 中的 irreducible element 就是 prime element 了..
Wang, Solving pseudomonotone variational inequalities and pseudocon- vex optimization problems using the projection neural network, IEEE Transactions on Neural Networks 17
volume suppressed mass: (TeV) 2 /M P ∼ 10 −4 eV → mm range can be experimentally tested for any number of extra dimensions - Light U(1) gauge bosons: no derivative couplings. =>
For pedagogical purposes, let us start consideration from a simple one-dimensional (1D) system, where electrons are confined to a chain parallel to the x axis. As it is well known
The observed small neutrino masses strongly suggest the presence of super heavy Majorana neutrinos N. Out-of-thermal equilibrium processes may be easily realized around the
Define instead the imaginary.. potential, magnetic field, lattice…) Dirac-BdG Hamiltonian:. with small, and matrix
incapable to extract any quantities from QCD, nor to tackle the most interesting physics, namely, the spontaneously chiral symmetry breaking and the color confinement..
