國
立
交
通
大
學
電機與控制工程學系
碩
士
論
文
針對嵌入式處理器之原始碼能量最佳化的實驗性分析
An Empirical Analysis of Source-level Energy Optimization for
Embedded Processors
研 究 生:黃詠文
指導教授:黃育綸 博士
針對嵌入式處理器之原始碼能量最佳化的實驗性分析
An Empirical Analysis of Source-level Energy Optimization for
Embedded Processors
研 究 生:黃詠文 Student:Yung-Wen Huang
指導教授:黃育綸 博士 Advisor:Dr. Yu-Lun Huang
國 立 交 通 大 學
電 機 與 控 制 工 程 學 系
碩 士 論 文
A Thesis
Submitted to Department of Electrical and Control Engineering College of Electrical and Computer Engineering
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master
in
Electrical and Control Engineering September 2007
Hsinchu, Taiwan, Republic of China
針對嵌入式處理器之原始碼能量最佳化的實驗
性分析
學生:黃詠文 指導教授:黃育綸 博士
國立交通大學電機與控制工程學系(研究所)碩士班
摘 要
適度地轉換程式原始碼可以有效地減少處理器執行指令的數量、降低指令或資料快 取失敗的機會,進而降低存取外部記憶體的次數與所需的能量消耗。程式原始碼的轉換 概念始於保持轉換前後原始碼的執行結果,但卻可以節省整個程式執行所需耗費的能 量。近年來嵌入式系統的市場需求趨勢,強力地引導產業提供更省能的應用與產品,除 了電力電子方面的相關研究,在軟體模組能量最佳化方面,由於其不用變動硬體電路的 優點,使得許多研究學者投注其相關研究,例如,改變資料結構、迴圈、函式、控制流 程與運算子等。然而,在嵌入式處理器日漸普及的趨勢下,我們發現軟體模組能量耗損 情形與其所在嵌入式處理器的指令集架構(Instruction Set Architecture,ISA)亦有著密不 可分的關係。換言之,程式原始碼的轉換對軟體能量消耗產生的影響會隨著指令集架構 的不同,而有所差異。此差異甚至可能改變套用早期程式原始碼轉換所預期的能量耗 損,使得轉換後的能量消耗不降反升。因此,在本論文中,我們針對各種軟體能量最佳 化轉換方法,加以重新分類,增加了與處理器指令集架構相關的類別,並以ARM 處理 器指令集架構提出兩種新的轉換方法,包括插入冗餘變數、重新排列陣列宣告,嘗試減 少存取陣列變數時,計算陣列基底位址時所需的指令個數,藉以降低能量的消耗。此外, 為了驗證各種轉換方法所能貢獻的能量最佳化程度以及邊際效應,我們設計了一連串的 實驗,以EMSIM 作為我們的 StrongARM 處理器的能量模擬器,對特定形式的軟體程式 碼進行不同的轉換。透過這些實驗,可以取得各種轉換方法所能得到的能量消耗情形, 並探討各種轉換所帶來的成本效應,如程式碼大小及程式執行效率的變化等影響。An Empirical Analysis of Source-level Energy
Optimization for Embedded Processors
Student: Yung-Wen Huang Advisor: Dr. Yu-Lun Huang
Department of Electrical and Control Engineering
National Chiao Tung University
Abstract
Source-level transformations can reduce the number of assembly instructions and the miss rate of instruction or data cache, resulting in an optimization of energy consumption and retaining the same execution results for software modules. Recently, the increasing market demand has become major a driving force for industries to create more energy-efficient applications and products. In addition to power electronics, because of the advantage of hardware circuit remaining unchanged researchers also devote a lot to energy optimization in software modules, such as applying the source-level transformations to data structures, loops, procedures, control structures, operators and so on. We found that energy consumption of software modules is highly related to the instruction set architecture (ISA) of the embedded processors, which means that the expected energy consumption is affected by the ISA of the processors. The result might not be what we expected upon applying the source-level transformations. In this thesis, we re-classify the source-level transformations, and add a new ISA-specific sub-category. Based on ARM ISA, we propose two transformations for energy optimization, called dummy variables insertion and arrays declaration permutation, to reduce the instructions in calculating the base addresses of the arrays. These transformations are verified via a series of experiments based on the EMSIM, the energy simulator of StrongARM. From these experiments, the energy optimization for each transformation can be analyzed and the side effects, such as code size and executing performance, can also be evaluated.
誌 謝
這篇論文能順利完成,首先最要感謝的是我的指導教授黃育綸老師,在研究方 面的指導、教誨與鼓勵。在我遇到問題與挫折時,能給予我一盞明燈,指引我明確 的道路,以及繼續往前進的動力。感謝您隨和的個性、不給予我們壓力,也讓我們 可以在良好的環境下進行研究。感謝您對我匱乏的表達及語文能力,給予的幫助與 提醒。而在為人處事方面,也作為我們的楷模,使我們獲益匪淺。在此再度致上萬 分的感謝與敬意,謝謝您!除此之外,也感謝我的口試委員,楊武教授、陳右穎教 授以及何福軒博士對本篇論文的建議與指教,使我可以了解不足的地方,並對此進 行改善。 另外,也感謝「即時嵌入式系統實驗室」的全體成員,雖然相處只有短短一年 的時間,但在學業上的切磋與休息時候的抬摃及娛樂,讓我可以在活潑、有趣的環 境下進行研究,真的很開心能夠認識你們;也感謝608 實驗室的老師、學長、同學 及學弟們陪伴我一年半的研究生活;也感謝其他交大的師長、同學、朋友們,在學 習道路上的指引與陪伴;也感謝大學時代的同窗好友,在研究方面能提供他們的經 驗與我分享,在閒暇之餘,陪我聊天、玩遊戲,舒解平日的壓力。 感謝我的家人,父、母以及常常一起出門逛街的大姊跟二姊,從出生開始就一 路陪我走來。 最後,向在我人生道路上,一路陪伴我走來的所有人們,獻上最誠摯的祝福與 感謝。Table of Contents
摘 要 ...i
Abstract ...ii
誌 謝 ...iii
Table of Contents ...iv
List of Tables ...vii
List of Figures ...viii
Chapter 1 Introduction ... 1
1.1 Background ... 1
1.2 Contribution... 3
1.3 Synopsis ... 3
Chapter 2 Related Work ... 5
2.1 Transformations in Source Code Level ... 5
2.2 ISA on Energy Consumption ... 7
2.2.1 Data Processing Instructions of ARM ... 8
2.2.2 Load and Store Instructions of ARM... 9
2.3 APCS on Energy Consumption ... 10
2.4 Compiler Options that Control Optimization... 11
2.5 Evaluation of Energy Consumption... 12
2.6 SUIF2 Compiler System... 15
Chapter 3 Transformations ... 17
3.1 Classification / Category ... 17
3.2 Data Transformations ... 18
3.2.1 Scratch-pad Array Introduction ... 18
3.2.2 Local copy of global variable... 18
3.2.3 Common Sub-expression Elimination ... 18
3.2.4 Miscellany... 19 3.3 Loop Transformations... 19 3.3.1 Loop Fusion... 19 3.3.2 Loop Fission ... 20 3.3.3 Loop Reversal ... 20 3.3.4 Loop Inversion ... 20 3.3.5 Loop Interchange... 21 3.3.6 Loop Unrolling... 21 3.3.7 Loop Unswitching ... 22 3.3.8 Miscellany... 22
3.4 Control Structures and Operators Transformations... 23
3.4.2 Special Cases Optimization ... 23
3.4.3 Special Cases Pre-evaluation ... 24
3.5 Procedural Transformations... 24 3.5.1 Procedure Inlining ... 24 3.5.2 Procedure Integration ... 24 3.5.3 Procedure Sorting... 25 3.5.4 Procedure Cloning ... 25 3.5.5 Loop Embedding ... 25
3.5.6 Substitution of a Variable Passed as an Address with a Local Variable... 26
3.5.7 Miscellany... 26
3.6 ISA-specific Transformations ... 26
3.6.1 Arrays Declaration Sorting... 26
3.6.2 Dummy Variables Insertion... 27
3.6.3 Arrays Declaration Permutation... 29
3.7 Summary ... 32
Chapter 4 Experiments ... 33
4.1 Experimental Framework... 33
4.2 Data Transformations ... 37
4.2.1 Common Sub-expression Elimination ... 37
4.3 Loop Transformations... 38 4.3.1 Loop Fusion... 38 4.3.2 Loop Fission ... 38 4.3.3 Loop Reversal ... 39 4.3.4 Loop Inversion ... 40 4.3.5 Loop Interchange... 40 4.3.6 Loop Unrolling... 41 4.3.7 Loop Unswitching ... 42
4.4 Control Structures and Operators Transformations... 43
4.4.1 Conditional Sub-expression Reordering ... 43
4.5 Procedural Transformations... 43
4.5.1 Procedure Inlining ... 44
4.5.2 Procedure Integration ... 45
4.5.3 Loop Embedding ... 46
4.6 ISA-specific Transformations ... 46
4.6.1 Arrays Declaration Sorting... 46
4.6.2 Dummy Variables Insertion... 47
4.6.3 Arrays Declaration Permutation... 48
Chapter 5 Results and Analyses ... 49
5.1.1 Common Sub-expression Elimination ... 50 5.2 Loop Transformations... 51 5.2.1 Loop Fusion... 51 5.2.2 Loop Fission ... 52 5.2.3 Loop Reversal ... 53 5.2.4 Loop Inversion ... 54 5.2.5 Loop Interchange... 54 5.2.6 Loop Unrolling... 56 5.2.7 Loop Unswitching ... 59
5.3 Control Structures and Operators Transformations... 60
5.3.1 Conditional Sub-expression Reordering ... 60
5.4 Procedural Transformations... 60
5.4.1 Procedure Inlining ... 61
5.4.2 Procedure Integration ... 62
5.4.3 Loop Embedding ... 63
5.5 ISA-specific Transformations ... 64
5.5.1 Arrays Declaration Sorting... 65
5.5.2 Dummy Variables Insertion... 67
5.5.3 Arrays Declaration Permutation... 69
5.6 Summary ... 71
Chapter 6 Conclusion and Future work... 73
List of Tables
Table 2-1 ARM Data processing instructions (Seal [27])...8
Table 2-2 General and program counter registers [28]... 11
Table 2-3 The optimization levels of gcc 2.95.3 [30]...12
Table 3-1 Sub-categories of code transformations ...17
Table 4-1 The ARM toolchain ...34
Table 4-2 The target architecture of our experimental framework...37
Table 5-1 The definition of notations ...49
Table 5-2 The result of Exp#1.1 ...50
Table 5-3 The definition of notations used in Section 5.1.1...50
Table 5-4 The result of Exp#2.1 ...51
Table 5-5 The definition of notations used in Section 5.2.1...52
Table 5-6 The result of Exp#2.2 ...53
Table 5-7 The result of Exp#2.3 ...53
Table 5-8 The result of Exp#2.4 ...54
Table 5-9 The result of Exp#2.5.a ...55
Table 5-10 The result of Exp#2.5.b ...55
Table 5-11 The result of Exp#2.7.a...59
Table 5-12 The result of Exp#2.7.b ...59
Table 5-13 The result of Exp#3.1 ...60
Table 5-14 The definition of notations used in Section 5.4...61
Table 5-15 The result of Exp#4.1 ...62
Table 5-16 The result of Exp#4.2 ...62
Table 5-17 The result of Exp#4.3 ...64
Table 5-18 The definition of notations used in Section 5.5...65
Table 5-19 The result of Exp#5.1.a ...66
Table 5-20 The result of Exp#5.1.b ...66
Table 5-21 The result of Exp#5.2 ...68
Table 5-22 The result of Exp#5.3 ...69
Table 5-23 The results after transformation in our experiments...71
List of Figures
Figure 2-1 Data processing operands - Immediate (Seal [27])...9
Figure 2-2 Modeled embedded system in EMSIM (Tan et al. [32]) ...13
Figure 2-3 Energy analysis framework of EMSIM (Tan et al. [32])...14
Figure 2-4 The 32-way set-associative cache in EMSIM...14
Figure 2-5 The SUIF system architecture (Aigner et al. [35]) ...15
Figure 2-6 A typical SUIF compiler (Aigner et al. [35])...16
Figure 3-1 Some examples of macro definition for procedures (Brandolese et al. [16])...24
Figure 3-2 A linked list L used by the algorithm of dummy variables insertion ...28
Figure 4-1 The execution results of EMSIM...34
Figure 4-2 The overall experimental framework...35
Figure 4-3 The execution result of the Energy Report program...36
Figure 4-4 C source code of common sub-expression elimination for Exp#1.1 ...37
Figure 4-5 C source code of loop fusion for Exp#2.1 ...38
Figure 4-6 C source code of loop fission for Exp#2.2...39
Figure 4-7 C source code of loop reversal for Exp#2.3...39
Figure 4-8 C source code of loop inversion for Exp#2.4 ...40
Figure 4-9 C source code of loop interchange for Exp#2.5.a...40
Figure 4-10 C source code of loop interchange for Exp#2.5.b...41
Figure 4-11 C source code of loop unrolling for Exp#2.6...42
Figure 4-12 C source code of loop unswitching for Exp#2.7.a...42
Figure 4-13 C source code of loop unswitching for Exp#2.7.b...42
Figure 4-14 C source code of conditional sub-expression reordering for Exp#3.1...43
Figure 4-15 C source code of procedure inlining for Exp#4.1...44
Figure 4-16 C source code of procedure integration for Exp#4.2...45
Figure 4-17 C source code of loop embedding for Exp#4.3 ...46
Figure 4-18 C source code of arrays declaration sorting for Exp#5.1.a...47
Figure 4-19 C source code of arrays declaration sorting for Exp#5.1.b...47
Figure 4-20 C source code of dummy variables insertion for Exp#5.2...48
Figure 4-21 C source code of arrays declaration permutation for Exp#5.3 ...48
Figure 5-1 The results of the code size in Exp#2.6 ...56
Figure 5-2 The results of the instruction cache misses in Exp#2.6 ...56
Figure 5-3 The results of the CPU cycles in Exp#2.6 ...57
Figure 5-4 The results of the energy consumption in Exp#2.6...57
Figure 5-5 The stack content of Exp#5.1.a...67
Figure 5-6 The stack content of Exp#5.1.b ...67
Figure 5-7 The stack content of Exp#5.2 ...68
Chapter 1
Introduction
Recently, energy consumption in design of embedded systems has become a major issue due to the popularity of portable and mobile products. In software aspect, several approaches are proposed to reduce energy consumption. Transformations in source code level among these approaches are weakly tied to target architecture and are application-independent, so it attracts many researchers’ interesting. However, there are many impact factors for transformations and it usually accompanies side effects by using transformations. Hence, it is important to understand these impact factors and evaluate the side effects to get a better trade-off between energy consumption savings, code size and performance.
1.1 Background
With the arrival of mobile generation, there are more and more mobile and portable products of embedded systems on the market. In order to lengthen lifetime of batteries in such products; therefore, energy consumption savings of embedded systems becomes a very important issue. Researches of energy consumption savings are divided into two aspects: hardware and software. Because software programs control the behavior of hardware, energy consumption of the overall embedded systems depend heavily on software design.
It is a critical step to evaluate software energy consumption prior to low energy software design. There are a number of researches about software energy evaluation. Some researches evaluate energy consumption based on physical measurements [1]-[3], and some do it based on simulation [4]-[6].
level, program or source code level, and algorithm level [7], [8]. There are different research groups devoted to investigation on different levels, respectively. It is natural to hypothesize that the efficiency of analysis, and the amount of energy savings obtainable, are much larger at higher levels [9].
Instruction level approaches focus on better code generation for a program by using energy consumption as the design metric. Such approaches include register allocation to minimize memory access, register relabeling to minimize the switching cost in the instruction register and the decoder [10], and instruction reordering to minimize the switching on the control path [1], etc. Although these approaches can be implemented automatically (the back-end of most compiler can implement many performance-oriented optimizations), the overall energy consumption savings is not remarkable and is strongly tied to the target architecture.
In algorithm level, it can get the highest energy consumption savings by selecting appropriate algorithms in software. For example, Mehta et al. [10] evaluated several sorting algorithms, including quicksort, heapsort and bubblesort. They observe that quicksort has less energy consumption than heapsort by using less pointer arithmetic. But algorithm selection is strongly based on programmers’ experience and knowledge, it is difficult to implement automatically and needs very large manual effort.
In source code level, it reduces energy consumption by restructuring program code. It also gets balance between efficiency and energy savings. It is weakly target architecture-dependent and is easy to be implemented automatically. There are many approaches in source code level. Tan et al. [9] proposed software architectural transformations based on OS-driven multi-process. By analyzing and macro-modelling the energy consumption of various components in an embedded OS [11], they can optimize the energy consumption of embedded software by performing a series of selected software architectural transformations. Peymandoust et al. [12] proposed a new methodology based on symbolic
manipulation of polynomials and energy profiling. They use floating-point to fixed-point data conversion and polynomial approximation to achieve a new embedded software optimization methodology. Simunic et al. [5] proposed data optimization to match the characteristics of the target architecture with the processed data. They developed a fixed-precision library for processor SA-1100 to replace floating-point arithmetic operations. In [15]-[21], a series of transformations in source code level were presented to reduce energy consumption. This technique is application-independent and can be implemented automatically. The basic principle of transformations is to transform the source code of program such that the transformed result is functionally identical to the original but is much more energy-efficient. In this thesis, we focus on transformations in source code level due to the feature of application-independent and being implemented automatically.
1.2 Contribution
In this thesis, we collect a series of transformations in source code level. Because the impact of ISA on transformations was not considered in previous work, we re-classify the transformations and propose new ones which are ISA-specific on the ARM. We also present an experimental framework and design a number of experiments to verify energy-efficiency of the transformations presented and proposed. The side effects after transformation are also evaluated and discussed.
1.3 Synopsis
The remainder of this thesis is organized as follows. Chapter 2 discusses related work. In Chapter 3, we redefine categories of transformations in source code level and detail the transformations presented. In Chapter 4, an experimental framework is presented and a number of experiments of the transformations are designed to verify their energy-efficiency,
followed by the results and analyses in Chapter 5. Finally the conclusion and future work are given in the last chapter.
Chapter 2
Related Work
As energy consumption in design of embedded systems becomes more and more important, several transformations in source code level [13]-[26] have been proposed to achieve the goal of low energy software design. A number of transformations have been proposed by using different evaluation metrics, such as performance and energy consumption, etc. Besides, researchers don’t consider the impact of instruction set architecture (ISA) on energy consumption. In our research, we adopt StrongARM as our target processor and do a number of experiments for the transformations to check if they can be used for energy consumption savings. The impacts of ISA and APCS on energy consumption are discussed, too. Besides, we also find that the optimization levels and options of compiler impact on energy consumption. In order to evaluate energy consumption of software programs, we adopt EMSIM energy simulator [31] as a part of our framework. Finally, the SUIF compiler system [34] which is a compiler infrastructure is discussed. In the system, passes can be developed to do transformations automatically. We use some passes released by other researchers’ groups in our experiments.
2.1 Transformations in Source Code Level
According to different requirements such as better performance, smaller code size or lower energy consumption, several transformations in source code level are presented and proposed in [13]-[26]. Russell et al. [2] concluded that minimizing software execution time (i.e. improved performance) results in minimized energy consumption. Although it is not always true, we find that improved performance usually accompanies energy consumption
savings.
Optimization is the heart of advanced compiler design. A number of optimizations which may be valuable in improving the performance of the object code produced by a compiler were presented in [13], [14]. Muchnick [13] divided compiler optimizations into two mainly areas: intraprocedural and interprocedural optimizations. Intraprocedural optimizations include redundancy elimination, loop optimizations, procedure optimizations, register allocation, code scheduling, and control-flow and low-level optimizations, etc. Optimization for the memory hierarchy was also presented. Morgan [14] pointed out that the optimizing compiler attempts to use all of the resources of the processor and memory as effectively as possible in executing the application program. Hence, a number of optimizations which are used for transforming the program to get better performance were presented. The optimizations include dominator optimization, interprocedural optimization, dependence optimization, global optimization, instruction scheduling, register allocation, and instruction rescheduling, etc. Compiler optimizations in [13], [14] included many transformations which may reduce energy consumption in source code level.
Brandolese et al. [15], [16] presented a methodology and a set of models supporting energy-driven source to source transformations. They grouped source to source transformations into four main categories according to the code structures they operate on: loops, data structures, procedures, and control structures and operators. And a number of transformations in different categories were presented.
Chung et al. [17] proposed a new transformation which reduces computational effort by using value profiling and specializing a program for highly expected situations. The goal of this technique is to improve energy consumption and performance by reducing computational effort.
In [18]-[21], a number of transformations which are expected to reduce energy consumption were presented for the purpose of system level power optimization, compiler
optimizations for low power systems, reducing instruction cache energy consumption, and iterative compilation for energy reduction, respectively.
Besides, some transformations presented for different purpose are still useful for energy consumption savings, such as improving data locality with loop transformations [22], augmenting loop tiling with data alignment for improved cache performance [23], optimization of computer programs in C [24], writing efficient C for ARM [25], and transforming and parallelizing ANSI C programs using pattern recognition [26], etc.
2.2 ISA on Energy Consumption
Different ISA of target machine may impact on energy consumption because the source code of program needs to be compiled and assembled to object code according to the instruction set of target machine. The number of instructions generated and which style instructions executed will impact on energy consumption.
In this thesis, we focused on the impact of ARM ISA on energy consumption after transformations, so ARM ISA will be discussed below. The ARM instruction set can be divided into six broad classes of instruction [27]:
z Branch instructions
z Data processing instructions z Status register transfer instructions z Load and store instructions
z Coprocessor instructions
z Exception-generating instructions
In our research, we find that data processing, and load and store instructions will impact on energy consumption, so we will detail the two groups later. Based on the following
discussions, we propose new transformations tied to ARM ISA in the ISA-specific transformations section.
2.2.1 Data Processing Instructions of ARM
ARM has 16 data processing instructions as shown in Table 2-1.
Table 2-1 ARM Data processing instructions (Seal [27])
Mnemonic Opcode Action
AND 0000 Rd := Rn AND shifter_operand
EOR 0001 Rd := Rn EOR shifter_operand
SUB 0010 Rd := Rn - shifter_operand
RSB 0011 Rd := shifter_operand – Rn
ADD 0100 Rd := Rn + shifter_operand
ADC 0101 Rd := Rn + shifter_operand + Carry Flag SBC 0110 Rd := Rn - shifter_operand – NOT(Carry Flag) RSC 0111 Rd := shifter_operand –Rn – NOT(Carry Flag) TST 1000 Update flags after Rn AND shifter_operand TEQ 1001 Update flags after Rn EOR shifter_operand CMP 1010 Update flags after Rn - shifter_operand CMN 1011 Update flags after Rn + shifter_operand
ORR 1100 Rd := Rn OR shifter_operand
MOV 1101 Rd := shifter_operand (no first operand)
BIC 1110 Rd := Rn AND NOT(shifter_operand)
MVN 1111 Rd := NOT shifter_operand (no first operand)
There are 11 addressing modes used to calculate the shifter_operand in an ARM data processing instruction. The impact of the immediate addressing mode on energy consumption is discussed below. As shown in Figure 2-1, this data processing operand provides a constant operand to a data processing instruction. It is encoded in the instruction as an 8-bit immed_8 and 4-bit rotate_imm, so that immediate value is equal to the result of rotating immed_8 (which will be zero extend to 32-bit firstly) right by twice the value in the rotate_imm. Hence,
immediate value must be the value as follows:
z <= 255
z a multiple of 4 between 256 and 1023; z a multiple of 16 between 1024 and 4095 z a multiple of 64 between 4096 and 16383
z …
If you want to assign a value which is not equal to the above value, you will need more than one instruction to complete your operation.
Figure 2-1 Data processing operands - Immediate (Seal [27])
2.2.2 Load and Store Instructions of ARM
Load and store register instructions of load and store instructions are discussed in this section. They use a base register and an offset specified by the instruction. In offset addressing, the memory address is formed by adding or subtracting an offset to or from the base register value. The offset can be either an immediate or the value of an index register. Register-based offsets can also be scaled with shift operations. For the word and unsigned byte instructions, the immediate offset is a 12-bit number. For the halfword and signed byte instructions, it is an 8-bit number. From the above information, we can find that for the word and unsigned byte instructions (or for the halfword and singed byte instructions), if the absolute value of the offset of the memory address from the base address is greater than 4095 (or 255), it can not use an immediate offset and needs another instruction to store the offset to a register; as a result, it needs more than one instruction to load or store the value of a single register from or to memory.
2.3 APCS on Energy Consumption
The APCS (ARM Procedure Call Standard) is a set of rules which regulate and facilitate calls between separately compiled or assembled program fragments [28]. It defines constraints on the use of registers, stack conventions, the format of a stack-based data structure, the passing of machine-level arguments and the return of machine-level results at externally visible procedure calls, and support for the ARM shared library mechanism.
In this section, we discuss that the rules in the APCS that may impact on energy consumption. The ARM has fifteen visible general registers, a program counter register and eight floating-point registers. As shown in Table 2-2, the role of general and program counter registers in the APCS is described. The APCS defines that each contiguous chunk of the stack shall be allocated to activation records in descending address order. At all instants of execution, sp shall point to the lowest used address of the most recently allocated activation record. The value of sl, fp and sp shall be multiples of four.
It is noted that the mapping from languages-level data types and arguments to APCS words is defined by each language implementation, not by the APCS. Because our research about transformations is focused on C language, C language calling conventions in the APCS are discussed. In an argument list, char, short, pointer and other integral values occupy one word. Char and short values are widened by the C compiler during argument marshalling. Argument values are marshalled in the order written in the source code of programs. The first four of the remaining argument words are loaded into a1-a4, and the remainder are pushed on to the stack in reverse order. A structure is called integer-like if its size is less than or equal to one word, and the offset of each of its addressable sub-fields is zero. An integer-like structured result is returned in a1.
Now the APCS is obsolete, and the AAPCS (Procedure Call Standard for the ARM Architecture) should be noted. The AAPCS embodies the fifth major revision of the APCS
and third major revision of the TPCS (Thumb Procedure Call Standard). It forms part of the complete ABI (Application Binary Interface) specification for the ARM architecture [29].
Table 2-2 General and program counter registers [28]
Register Name APCS Role
r0 a1 argument 1 / integer result / scratch register
r1 a2 argument 2 / scratch register
r2 a3 argument 3 / scratch register
r3 a4 argument 4 / scratch register
r4 v1 register variable
r5 v2 register variable
r6 v3 register variable
r7 v4 register variable
r8 v5 register variable
r9 sb/v6 static base / register variable
r10 sl/v7 stack limit / stack chunk handle / register variable
r11 fp frame pointer
r12 ip scratch register / new-sb in inter-link-unit calls
r13 sp lower end of current stack frame
r14 lr link address / scratch register
r15 pc program counter
2.4 Compiler Options that Control Optimization
In this thesis, gcc 2.95.3 is used as our cross compiler to compile our C source code. Because optimization level and options of compiler impact on energy consumption remarkably, we need to decide what optimization level and options to be used firstly. Optimization levels of gcc 2.95.3 are shown in Table 2-3.
In embedded systems, there are three optimization levels used frequently, -O0, -O2 and -Os. We use -O0 as our optimization level due to stable consideration in embedded systems and clear analysis of the impact of transformations. Besides, we also use -fomit-frame-pointer option to avoid keeping the frame pointer in a register for procedures that don’t need one and
avoid the instructions to save, set up and restore frame pointers; as a result, it makes an extra register available to be used. It also makes debugging impossible on ARM.
Table 2-3 The optimization levels of gcc 2.95.3 [30]
Optimization Level Description
-O0 (default) This is the default. Do not optimize. In this level, the compiler’s goal is to reduce the cost of compilation and to make debugging produce the expected results. The compiler only allocates variables declared register in registers. -O1 (-O) Optimize. The compiler tries to reduce code size and execution time.
-O2 Optimize even more. GCC performs nearly all supported optimizations that do not involve a space-speed trade-off. It turns on all optional optimizations except for loop unrolling, function inlining, and strict aliasing optimizations. It also turns on the ‘’ option on all machine.
-O3 Optimize yet more. It turns on all optimizations specified by ‘-O2’ and also turns on the ‘inline-functions’ option
-Os Optimize for size.
2.5 Evaluation of Energy Consumption
In order to analyze the impact of transformations on energy consumption, we need to find a way to evaluate software energy consumption. Tan et al. [31] presented an energy simulation framework that can be used to analyze the energy consumption characteristics of an embedded system featuring the embedded Linux OS running on the StrongARM processor.
As shown in Figure 2-2, the simulator includes the following component:
1) a model for the StrongARM SA-1100 core, consisting of an instruction set simulator
(ISS), simulation models for the instruction cache and data cache and a memory management unit (MMU);
2) a simulation model for 32 MB of system memory; 3) a simulation model for an interrupt controller; 4) simulation models for two timers;
5) simulation models for two UARTs conforming to the Intel 8250 series.
Figure 2-2 Modeled embedded system in EMSIM (Tan et al. [32])
The simulation models are shown on the right half of Figure 2-3 and the sequence of steps involved in using the simulation framework is show on the left. The energy accounting mechanism of EMSIM is task-based. And a function energy stack for each task is used for evaluating the energy consumption of every function in the task. From energy profiling report, we can get information about the number of invoked times, CPU cycles consumed and energy consumption of every function.
The SA-1100 microprocessor is a general-purpose, 32-bit RISC microprocessor with a 16 Kbytes instruction cache, an 8 Kbytes write-back data cache, a minicache, a write buffer, a read buffer, and a memory management unit (MMU) combined in a single chip [33]. Besides, it is software compatible with the ARM V4 architecture processor family. In EMSIM, the 8 Kbytes write-back data cache is replaced by 16 Kbytes one and it doesn’t simulate a minicache. As shown in Figure 2-4, the size of the cache line (block) is 32 bytes and the
caches are 32-way set-associative caches. Replacement policy is round robin within a set.
Figure 2-3 Energy analysis framework of EMSIM (Tan et al. [32])
24 bits Tag memory 32 bytes 0 1 2 3 4 11 12 13 14 15 0 ... 31 0 ... 31 4 Main memory address :
0 1 2 3 4 11 12 13 14 15 16 17 18 19 20 27 28 29 30 31 Cache memory 32 33 34 35 36 43 44 45 46 47 48 49 50 51 52 59 60 61 62 63 0 1 2 3
Main memory Tag number
23 5 Byte Set Tag . . . . . . . . . . . . . . . . . . . . . . . .
Tag bits + valid flag bit
... ...
... .
. .
2.6 SUIF2 Compiler System
The SUIF (Stanford University Intermediate Format) system [34] was developed by Stanford Compiler Group. It is a free compiler infrastructure designed to support collaborative research in optimizing and parallelizing compilers, based upon a program representation, SUIF. It maximizes code reuse by providing useful abstractions and frameworks for developing new compiler passes and by providing an environment that allows compiler passes to inter-operate easily. Now the SUIF group has moved its effort on from SUIF1 to SUIF2.
It also supports some useful tools, such as front ends, converters from SUIF1 to SUIF2 and vice versa, and converters from SUIF2 back to C, etc. Hence, we can write our SUIF compiler to do operations between SUIF intermediate representations (IRs).
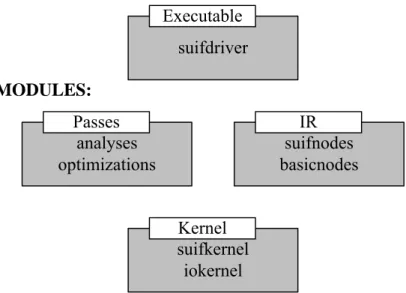
Figure 2-5 shows the SUIF system architecture. The components of the architecture are described as follows.
1) Kernel provides all basic functionality of the SUIF system.
2) Modules can be one of two kinds: a set of nodes in the intermediate representation and a
program pass.
3) Suifdriver provides execution control over modules.
suifdriver analyses optimizations suifnodes basicnodes suifkernel iokernel Executable Passes Kernel IR MODULES:
Passes are the mainly part of a SUIF compiler. It typically performs a single analysis or transformation and then writes the results out to a file. To create a compiler or a standalone pass, the user needs to write a “main” program that creates the SuifEnv, imports the relevant modules, loads a SUIF program and applies a series of transformations on the program and eventually writes out the information, as show in Figure 2-6.
Some passes which do transformations were implemented and released in [36], [37]. We would like to thank for their release, so we can use the passes to do some transformations for our experiments.
initialize & load SUIF environment
save & delete SUIF environment ...
passes (easy to reoder)
Chapter 3
Transformations
A series of transformations operating in source code level were presented in [13]-[25]. In the first section, we firstly explain how we classify transformations, followed by the detail of the transformations in different categories in section 3.2-3.6. Finally the summary of the transformations is given in the last section.
3.1 Classification / Category
According to transformations operating on data or code segments, we firstly divide transformations into two main categories, data and code transformations. In [16], code transformations were grouped into three sub-categories according to the code structures they operate on, including loop, procedural, and control structures and operators transformations. But they don’t consider the influence of ISA on energy consumption.
Table 3-1 Sub-categories of code transformations
Sub-category of code transformations Description
Loop transformations Modify either the body or control structure of
the loop
Control structures and operators transformations Change either specific control structures or operators
Procedural transformations Modify the interface, declaration or body of
procedures
ISA-specific transformations Transformations are impacted by ISA
In our research, we find that some code transformations are strongly tied to ISA of target machine. Therefore, our code transformations will include four sub-categories: loop, control
structures and operators, procedural, and ISA-specific transformations. Sub-categories of code transformations are described in Table 3-1.
3.2 Data Transformations
In this section, we present a series of transformations used in modifying data segment of source code. These transformations may result in reduced data cache misses and memory access, etc., and then energy consumption savings is expected.
3.2.1 Scratch-pad Array Introduction
Allocating a smaller array is used in storing the most frequently accessed elements of the larger array [16]. It is expected that spatial locality is improved contributing to reduced data cache misses. It is noted that the increased instructions which are used in refreshing the elements of arrays may reduce performance and increase code size (i.e. instruction cache misses). As a result, it may not reduce energy consumption.
3.2.2 Local copy of global variable
In the procedure which needs to operate on global variables, we can declare local variables and assign the value of global variables to them before the procedure invoked [15]. We then refresh global variables after leaving the procedure. In such a way, this transformation can increase the possibility for compiler to store variables in registers instead of memory (i.e. it reduces data cache misses). But it has the same side effects as above transformation, it may not reduce energy consumption.
3.2.3 Common Sub-expression Elimination
another existence of the expression whose evaluation always precedes this one in execution order and if the operands of the expression remain unchanged between the two evaluations [13]. Common sub-expression elimination is a transformation which stores the same computation results of common sub-expressions into variables and assigns the value of variables to replace common sub-expressions.
It is noted that this transformations may not always be valuable, because it may be less energy consumption to recompute, rather than allocate another register (or memory) to hold the value. As a result, it does not always reduce energy consumption.
3.2.4 Miscellany
In [15], [16], there are still a number of data transformations presented. Scalarization of array elements introduces temporary variables as a substitute of the most frequently accessed elements of an array. Multiple indirection elimination finds common chains of indirections and uses a temporary variable to store the address. At present, researches about code transformations are still continued proceeding.
3.3 Loop Transformations
Loop transformations operate on the statements which comprise a loop (i.e. these transformations modify either the body or control structure of the loop). Because a large percentage of the execution time of programs is spent in loops, these transformations can have a very remarkable impact on energy consumption. Hence, there are a number of researches and approaches based on loop transformations because of the importance of loop transformations.
This transformation combines one or more loops with the same bounds into a single loop [21]. It reduces loop overhead; as a result, the number of the instructions executed is reduced. Besides, it can also be used for improving data cache locality by bringing the statements that access the same set of data to the same loop [20]. But it is noted that if the increased loop body becomes larger than instruction cache, it will increase instruction cache misses; as a result, energy consumption will be increased.
3.3.2 Loop Fission
Loop fission does the opposite operation to loop fusion [21]. The goal of this transformation is to break down larger loop body into smaller ones to reduce the size of loop body to fit into instruction cache, and then it reduces instruction cache misses. It is noted that computation energy is increased due to the new loop overheads. Therefore, we need to be careful to decide that loop fusion or loop fission should be applied to loops in order to reduce energy consumption effectively.
3.3.3 Loop Reversal
This transformation reverses the order in which a specific loop’s iterations are performed [13]. In some loops of which loop body exists dependence, loop reversal may eliminate the dependence; as a result, it allows other transformations to be applied. Besides, a special case of loop reversal which is useful in ARM architecture was presented in [25]. To apply loop reversal transformation makes an incrementing loop to a decrementing loop which becomes a count-down-to-zero loop. It causes the original ADD/CMP instruction pair to be replaced by a single SUBS instruction; because of this, it saves compares in critical loops, leading to reduced code size, increased performance and reduced energy consumption.
Loop inversion transforms a while loop to a repeat loop (i.e. it moves the loop conditional test from before the loop body to after it) [13]. It results in only one branch instruction needed to be executed to leave the loop, rather than one needed to return to the beginning and another needed to leave after the loop conditional test at beginning. Hence, it is expected that energy consumption is reduced due to the reduced number of the instructions executed. It is noted that this transformation is only safe when the loop body is executed at least once.
3.3.5 Loop Interchange
This transformation reverses the order of two adjacent loops in a loop nest to change the access paths to arrays [14]. It improves the chances that consecutive references are in the same cache line, leading to reduced data cache misses. Hence, reduced energy consumption can be expected.
3.3.6 Loop Unrolling
Loop unrolling replaces the body of a loop by U (the unrolling factor) times copies of the body and modifies the iteration step from 1 to U [13]. The original loop is called the rolled loop. Loop unrolling reduces the overhead of a loop by performing less compare and branch instructions (i.e. better performance) and may improve the effectiveness of other transformations, such as common-sub-expression elimination and software pipelining, etc. It also allows the compiler to get a better register usage of the larger loop body.
On the other hand, the unrolled loop is larger than the rolled loop, so it increases code size and may impact the effectiveness of the instruction cache, leading to increased instruction cache misses. So deciding which loops to unroll and by what unrolling factors is very important.
counting loop [14]. It can unroll the loop and leave the termination conditions in place. This technique has benefits when dealing with a while loop in which later transformations can be used.
3.3.7 Loop Unswitching
This transformation moves loop-invariant conditional branches to the outside of loops [13]. It reduces the number of the instructions executed due to the reduced number of codes executed in the loop body. If the conditional only has if part, loop unswitching has little impact on code size. But if the conditional has else parts, it will need to copy the loop into every else parts of conditional. Hence, it increases code size and instruction cache misses.
3.3.8 Miscellany
In addition to the above loop transformations, other energy-efficiency strategies on loop transformations can be envisioned.
Loop permutation is a general version of loop interchange [13]. It allows more than two loops to be reordered to reduce data cache misses; as a result, it is expected to reduce energy consumption.
Loop tiling achieves the goal of reduction of capacity and conflict misses which are resulted from cache size limitations [21]. It improves cache performance by dividing the loop iteration space into smaller tiles. This also results in a logical division of arrays into tiles, so it may increase reuse of array elements within each tile. By the correct selection of tile sizes, conflict misses which occur when several data elements compete for the same cache line can be eliminated. But it also increases the number of instructions executed and code size because of the increased nesting loops.
Software pipelining can improve the execution performance of loops [16]. It eliminates the dependences between adjacent statements by breaking the operations of single loop
iteration into S stages, and arranges the code in such a way that stage 1 is executed on the instructions originally belonging to iteration i, stage 2 on those of iteration i-1, etc. It makes pipeline performance better through pipeline stalls reduction. Hence, CPU cycles consumed are expected to reduce. But it may increase the number of instructions executed due to the calculation of iteration i. It also increases code size because startup code is generated before the loop to initialize and cleanup code is generated after the loop to finish operations.
3.4 Control Structures and Operators Transformations
In this section, we present a series of transformations which modify control structures and operators of source code to reduce energy consumption.
3.4.1 Conditional Sub-expression Reordering
It is possible to reorder sub-expressions in conditional to reduce energy consumption [16]. In OR conditions, we can sort the sub-expressions in which the possibility of being true in front of others. In AND conditions, we can sort the sub-expressions in which the possibility of being false in front of others. By using this transformation, it reduces the number of the instructions executed; as a result, it reduces energy consumption. It has no side effects.
3.4.2 Special Cases Optimization
Brandolese et al. [16] presented special cases optimization transformation which replaces
calls to generic library or user-defined functions with optimized ones. For example, someone needs to call mathematic functions of which arguments need floating-point variables, but he only wants to do operations for integers. Hence, he can re-write optimized ones for integers to reduce energy consumption. This transformation is only a suggestion, and it can not be implemented by an automation tool.
3.4.3 Special Cases Pre-evaluation
Some functions would return a known value when a special value for an argument is passed. So we could avoid real calls to the functions by defining suitable macros testing for the special cases [16]. Hence, it may reduce real function calls (i.e. the number of the instructions executed) but increases code size. Figure 3-1 shows some examples.
Figure 3-1 Some examples of macro definition for procedures (Brandolese et al. [16])
3.5 Procedural Transformations
Procedural transformations are used for modifying the interface, declaration or body of procedures. There are also a number of researches in this sub-category for the purpose of performance improved and energy consumption savings.
3.5.1 Procedure Inlining
This transformation is supported by many compilers. It replaces the invoked procedure with the procedural body [16]; as a result, it increases the spatial locality and decreases the number of procedure invoked. But it increases the code size which will result in increased instruction cache misses.
3.5.2 Procedure Integration
It has almost the same behavior as procedure inlining [13], but procedure inlining does not consider the call site. This transformation can differentiate among call sites which invoke
the same procedure and decide which call site is need to do procedure integration or only invokes the original procedure. As a result, it may get a better trade-off between code size and energy consumption than procedure inlining.
3.5.3 Procedure Sorting
This transformation is the easiest instruction cache optimization approach to implement. It sorts the statically linked procedures according to the call graph and frequency of use [13]. This transformation has two advantages. Firstly, it places procedures near their callers in virtual memory so as to reduce paging traffic. Secondly, it places frequently used and related procedures so they have less possibility to collide with each other in the instruction cache. To implement this transformation, we only need to reorder the procedural declarations.
3.5.4 Procedure Cloning
This transformation is based on procedural parameters which are constant at one or more call sites. For every call site that calls the same procedure and passes the same constant values of parameters, we clone a copy of the procedure and rename its procedural name [13]. The new version of the procedure has reduced parameters and in the body of which constant parameters are replaced by constant values; as a result, it allows compilers to do advanced optimization.
3.5.5 Loop Embedding
Loop embedding is an interprocedural transformation which moves the loop from the outside of a procedure to the body of the procedure [26]; as a result, it reduces the overhead of the procedure call. The original procedure is needed to be reserved if it is called from more than one call site.
3.5.6 Substitution of a Variable Passed as an Address with a Local Variable
This transformation replaces a procedural argument passed as an address with a local copy of variable [15]. In optimization level of compilers, compilers tend to allocate local variables in registers instead of memory. Hence, it reduces the number of memory access and the data cache misses. But it increases the number of codes which assigns and restores values, it will increase the number of the instructions executed; as a result, it may not reduce energy consumption.
3.5.7 Miscellany
Other transformations which operate on procedure include soft inlining which replaces calls and returns with jumps [16], and procedure splitting which divides each procedure into a primary and a secondary component [13], etc.
3.6 ISA-specific Transformations
Some transformations are dependent to what ISA you operate on. In this section, we present one transformation which is not independent of ISA of target machine. We also propose two transformations which are specific to ARM ISA, including dummy variables insertion and arrays declaration permutation transformations. It is noted that the proposed ones are also strongly tied to the strategies of calculating base addresses of compilers.
3.6.1 Arrays Declaration Sorting
This transformation is to modify the order of local arrays declaration, so that the most frequently accessed array is allocated on the top of the stack; in such a way, the memory locations frequently accessed by exploiting direct access mode [15]. It is less energy expensive in this access mode. When using this transformation, you need to know the stack
allocation strategies of local arrays implemented by compliers.
3.6.2 Dummy Variables Insertion
This transformation proposed is based on the feature of ARM ISA. When elements of arrays are accessed, it is necessary to calculate the base addresses of the arrays firstly. This transformation tries to reduce the number of the instructions executed for calculating the base addresses by inserting dummy variables which are declared as volatile ones between the arrays. In such a way, the offsets of the base addresses of arrays from the stack are changed, so that it is possible to use one instruction to get the base addresses of arrays. Because the order of array declarations is changed and the size of stack allocation is increased, it might increase data cache misses and page fault slightly. It is expected that code size and energy consumption will be reduced because of the reduced number of the instructions executed. It is noted that we need to take care of checking if stack overflow will happen after dummy variables insertion.
In this thesis, we follow the pseudocode writing rules in [38] to write our algorithms. We design an algorithm for dummy variables insertion transformation, and we also take some assumptions as follows.
1) Offset is equal to or less than 226 (for the procedure DUMMY-VARIABLE-SIZE(offset) to
operate correctly).
2) We suppose that compilers only use ‘add’ instruction to calculate the base addresses of
arrays, and the immediate value of the instruction must not be negative value.
3) In order to simplify our algorithm, we also suppose that initial offset passed to the
procedure DUMMY-VARIABLES-INSERT(L, init_offset) is equal to or less than 1024 (because the initial offset is a multiple of 4, we don’t need to insert dummy variable in the above situation). It is large enough in general cases.
List L passed to the procedure DUMMY-VARIABLES-INSERT(L, init_offset) is used in
storing attributes of local array variables by the reverse order of declaration (i.e. the first element of list L stores the attributes of the rightmost array variable, and the last element of list L stores those of the leftmost one). As shown in Figure 3-2, each element of a linked list L is an object with a string field: var_name, two integer fields: sizeof_type and no_elements, and a pointer field: next. Given an element x in the list, var_name stores the name of the array variable, sizeof_type stores the size of the element of that, no_elements stores the number of the elements stored in this array, and next[x] points to its successor in the linked list. Besides, an attribute head[L] points to the first element of the list and an attribute length[L] stores the number of elements of the list.
Because compilers will allocate memory space on the top of stack, when the procedure invokes other procedures of which the numbers of the arguments are greater than 4, the initial offset from the top of stack may not be zero. We pass the integer init_offset to the procedure DUMMY-VARIABLES-INSERT(L, init_offet) to point out this offset.
And the procedure DUMMY-VARIABLE-SIZE(offset) is used in calculating the size of dummy array variable which needs to insert between arrays.
Figure 3-2 A linked list L used by the algorithm of dummy variables insertion
The following is the algorithm of dummy variables insertion. Algorithm 3.1 Dummy Variables Insertion
DUMMY-VARIABLES-INSERT(L, init_offset) 1 no_dummy_vars ← 0
3 sizeof_type[y] ← 4 4 x ← head[L]
5 n ← length[L] ﹣ 1 6 for i ← 1 to n
7 do sizeof_array ← sizeof_type[x] × no_elements[x] 8 remainder ← sizeof_array mod 4
9 if remainder ≠ 0
10 then padding ← 4 ﹣ remainder 11 else padding ← 0
12 offset ← offset + sizeof_array + padding
13 dummy_size ← DUMMY-VARIABLE-SIZE(offset) 14 if dummy_size ≠ 0
15 then no_dummy_vars ← no_dummy_vars + 1 16 offset ← offset + dummy_size
17 var_name[y] ← “dummy” + to_string(no_dummy_vars) 18 no_elements[y] ← dummy_size / 4 19 next[y] ← next[x] 20 next[x] ← y 21 x ← next[y] 22 else x ← next[x] DUMMY-VARIABLE-SIZE(offset) 1 if offset < 256 2 then return 0 3 bound ← 1024 4 mul ← 4 5 while TRUE 6 do if offset < bound
7 then return mul ﹣ (offset mod mul) 8 else bound ← bound × 4
9 mul ← mul × 4
3.6.3 Arrays Declaration Permutation
This transformation uses arrays declaration permutation instead of dummy variables insertion to try to reduce the number of the instructions executed for calculating the base addresses of arrays. It modifies the order of local arrays declaration to change the offsets of
the base addresses of arrays from the stack.
We design an algorithm for arrays declaration permutation transformation, and we take the same assumptions used in Algorithm 3.1 (but the procedural names in the assumptions must be replaced suitably). In addition, in order to simplify this algorithm, we use the procedure ENERGY-COST(offset) to get energy cost for calculating base address of an array; in the procedure, if we only need one instruction for calculating base addresses it will return 1 and if we take more than one instruction for calculating base addresses it will return 2 simply.
We refer to the recursive algorithm of permutation algorithms in [39] to design the procedure PERMUTATION(V, k, A, init_offset). In Algorithm 3.2, we use G_varname to indicate that this variable is a global variable.
Comparing with Section 3.6.2, list L used in this section is similar except that the object of the element of a linked list L has an extra integer field: no_cal_base_address. It stores the number of calculating base address of an array.
The following is the algorithm of arrays declaration permutation. Algorithm 3.2 Arrays Declaration Permutation
ARRAYS-DECLARATION-PERMUTATION(L, init_offset) 1 G_min_t_energy_cost ← ∞ 2 G_n ← length[L] 3 G_level ← -1 4 x ← head[L] 5 for i ← 1 to G_n 6 do V[i] ← 0 7 A[i] ← x 8 x ← next[x] 9 PERMUTATION(V, 1, A, init_offset) 10 head[L] ← A[G_min_V[1]] 11 for i ← 1 to G_n ﹣ 1 12 do x ← A[G_min_V[i]] 13 y ← A[G_min_V[i+1]] 14 next[x] ← y 15 x ← A[G_min_V[G_n]]
16 next[x] ← NIL
PERMUTATION(V, k, A, init_offset) 1 G_level ← G_level + 1
2 V[k] ← G_level 3 if G_level = G_n
4 then t_energy_cost ← TOTAL-ENERGY-COST(V, A, init_offset) 5 if t_energy_cost < G_min_t_energy_cost
6 then G_min_t_energy_cost ← t_energy_cost 7 for i ← 1 to G_n
8 do G_min_V[i] ←V[i] 9 else for i ← 1 to G_n
10 do if V[i]=0
11 then PERMUTATION(V, i, A, init_offset) 12 G_level ← G_level ﹣ 1 13 V[k] ← 0 TOTAL-ENERGY-COST(V, A, init_offset) 1 offset ← init_offset 2 t_energy_cost ← 0 3 for i ← 1 to n 4 do x ← A[V[i]]
5 t_energy_cost ← t_energy_cost + no_cal_base_address[x] × ENERGY-COST(offset)
6 sizeof_array ← sizeof_type[x] × no_elements[x] 7 remainder ← sizeof_array mod 4
8 if remainder ≠ 0
9 then padding ← 4 ﹣ remainder 10 else padding ← 0
11 offset ← offset + sizeof_array + padding
ENERGY-COST(offset) 1 if offset < 256 2 then return 1 3 bound ← 1024 4 mul ← 4 5 while TRUE 6 do if offset < bound
8 then return 2 9 else return 1 10 else bound ← bound × 4 11 mul ← mul × 4
3.7 Summary
Some transformations are strongly tied to which optimization level of the compiler used. For example, because the gcc compiler only allocates variables declared register in registers. When optimization is not enabled [30], transformations such as local copy of global variable and substitution of a variable passed as an address with a local variable are useless in this case. In addition, some transformations have better energy-efficiency when optimization is enabled.
Besides, some transformations may have no impact on energy consumption, but they can reduce dependency for other transformations to be applied. Or after doing some transformations, it is possible to increase the energy-efficiency by using other transformations.
Although a number of transformations can reduce energy consumption remarkably, it is not easy to find which transformations should be used, in which order to apply, and to which code sections [21]. This long standing open problem is called the phase-order problem. In this thesis, we mainly focus on applying one transformation to the source code every time and evaluate the impact on energy consumption on our target architecture.
Chapter 4
Experiments
Hill et al. [40] subdivided set-associative misses into three categories: (set-)conflict misses (due to too many active blocks mapping to a fraction of the sets), capacity misses (due to fixed cache size), and compulsory misses (those necessary misses caused by the first data access). In Chapter 4 and 5, we use their categories of set-associative misses to explain the experiments designed and the impact of different categories of cache misses on energy consumption respectively.
In Chapter 3, we collect a series of transformations in source code level. The efficiency of the transformations is needed to be evaluated and verified on our target architecture by doing experiments. In this chapter, we design an experimental framework to profile the experimental results in the first section. In the last five sections, the experiments of different categories are designed and completed.
4.1 Experimental Framework
EMSIM 2.0 energy simulator of StrongARM is adopted as a part of our experimental framework to get the energy information of the experiments.
In addition to energy consumption, we need other information to analyze and evaluate side effects when every time simulation functions run. Because the main impact factors on energy consumption include CPU cycles consumed, and the number of instruction and data cache misses, we modify EMSIM energy simulator to get such information. The addresses of instruction and data cache miss are outputted to verify the correctness of cache misses. In addition, in order to get more accurate information about cache misses, we detect if
simulation function will be executed. Before being executed, we flush instruction and data caches. The execution results of EMSIM before and after modified are shown in Figure 4-1. And the information about function code size is got by using arm-linux-objdump program of the GNU Binutils which are a collection of binary tools.
Figure 4-1 The execution results of EMSIM
Since the EMSIM simulation framework is about running the Linux OS in a StrongARM simulator, several Linux and StrongARM related components are needed [31], including Linux OS kernel and the ARM toolchain. Linux 2.4.18 and patch-2.4.18-rmk3 are used in building our Linux kernel. Besides, the ARM toolchain which we build are listed in Table 4-1.
Table 4-1 The ARM toolchain
binutils 2.11 gcc 2.95.3 glibc 2.2.3
The ARM toolchain
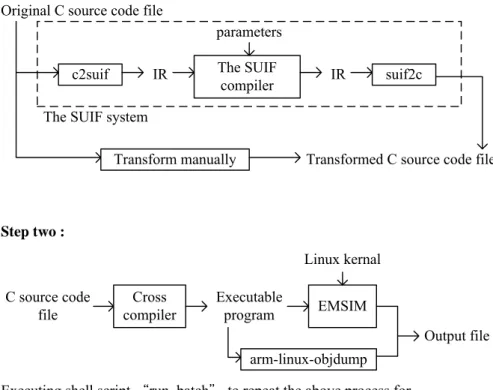
Step one :
Original C source code file
The SUIF compiler
c2suif suif2c
The SUIF system
IR IR
Transformed C source code file Transform manually Step two : parameters C source code file Cross compiler Executable program EMSIM Output file arm-linux-objdump Step three : Output files Energy Report program Experimental result
Executing shell script “run_batch" to repeat the above process for every C source code file in the same directory
Linux kernal
Figure 4-2 The overall experimental framework
Our experiments for every transformation involve three steps, comprised of generating C source code files in the same directory, generating output files which record execution results of EMSIM and arm-linux-objdump, and executing “Energy Report” program to profile energy consumption and side effects by parsing output files. The overall experimental framework is shown in Figure 4-2. In step one, we firstly design an original C source code file and use two ways to generate transformed ones, including using SUIF passes which do transformations, and transforming manually. In step two, in order to get the simulation results for every source code file, we write a shell script, namely “run_batch”, to repeat the process of generating
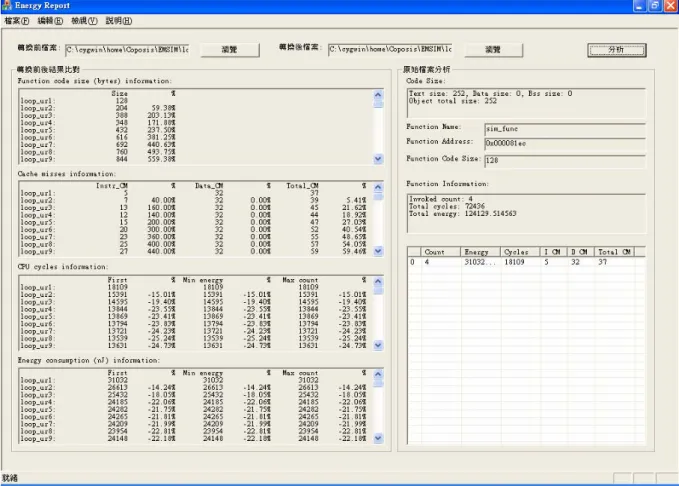
executable program, running simulation and writing out information to output file. In the last step, an “Energy Report” program is designed to parse output files, and to calculate and show the results in GUI, as shown in Figure 4-3.
Figure 4-3 The execution result of the Energy Report program
Transformations in source code level lead to very different results depending on a number of factors, including the specific structure of code, the target architecture, and the parameters of the transformations, etc. [16]. But what compiler you use and of which the options you choose also have a significant impact. Because the EMSIM energy simulator is adopted, the target architecture is fixed in our experimental framework. Table 4-2 shows the target architecture in our experimental framework. In addition, we adopt gcc 2.95.3 as our cross compiler and use optimization level -O0 and option -fomit-frame-pointer to compile the
source code files of our experiments. Hence, the experiments of the transformations are designed to observe the results between the specific structure of code and the different parameters of the transformations in this thesis.
Table 4-2 The target architecture of our experimental framework
The component of the target architecture Description
The processor StrongARM SA-1100 (CPU clock: 206 MHz) The cache architecture 32-way set-associative instruction cache:
Cache size: 16 KB Cache line size: 32 bytes Replacement policy: round robin 32-way set-associative write-back data cache:
Cache size: 16 KB Cache line size: 32 bytes Replacement policy: round robin
4.2 Data Transformations
In this section, the experiment of only one data transformation which is common sub-expression elimination is designed to verify its energy-efficiency.
![Table 2-1 ARM Data processing instructions (Seal [27])](https://thumb-ap.123doks.com/thumbv2/9libinfo/8746620.205107/18.892.223.718.389.872/table-arm-data-processing-instructions-seal.webp)
![Figure 2-2 Modeled embedded system in EMSIM (Tan et al. [32])](https://thumb-ap.123doks.com/thumbv2/9libinfo/8746620.205107/23.892.126.809.197.685/figure-modeled-embedded-system-in-emsim-tan-al.webp)
![Figure 2-3 Energy analysis framework of EMSIM (Tan et al. [32])](https://thumb-ap.123doks.com/thumbv2/9libinfo/8746620.205107/24.892.133.806.200.1017/figure-energy-analysis-framework-emsim-tan-et-al.webp)