行政院國家科學委員會專題研究計畫 成果報告
基於支撐向量機之細胞神經網路強韌樣板參數設計以實踐
任一給定之布林函數
計畫類別: 個別型計畫
計畫編號: NSC94-2213-E-110-036-
執行期間: 94 年 08 月 01 日至 95 年 07 月 31 日
執行單位: 國立中山大學電機工程學系(所)
計畫主持人: 謝哲光
計畫參與人員: 吳旭焜、陳保戎、徐志廷、招沛宏
報告類型: 精簡報告
處理方式: 本計畫可公開查詢
中 華 民 國 95 年 9 月 22 日
行政院國家科學委員會補助專題研究計畫成果報告
基於支撐向量機之細胞神經網路強韌樣板參數設計
以實踐任一給定之布林函數
計畫類別:■ 個別型計畫 □ 整合型計畫
計畫編號:NSC 94-2213-E-110-036-
執行期間:九十四 年 八 月 一 日 至 九十五 年 七 月 三十一 日
計畫主持人:謝哲光
共同主持人:
計畫參與人員:吳旭焜、陳保戎、徐志廷、招沛宏
成果報告類型(依經費核定清單規定繳交):■精簡報告 □完整報告
本成果報告包括以下應繳交之附件:
□赴國外出差或研習心得報告一份
□赴大陸地區出差或研習心得報告一份
□出席國際學術會議心得報告及發表之論文各一份
□國際合作研究計畫國外研究報告書一份
處理方式:除產學合作研究計畫、提升產業技術及人才培育研究計畫、列
管計畫及下列情形者外,得立即公開查詢
□涉及專利或其他智慧財產權,□一年□二年後可公開查詢
執行單位:國立中山大學
中 華 民 國 九十四 年 九 月 二十 日
1
行政院國家科學委員會專題研究計畫成果報告
題目:基於支撐向量機之細胞神經網路強韌樣板參數設計
以實踐任一給定之布林函數
SVM-based Robust CNN Templates Design Implementing
an Arbitrary Boolean Function
計畫編號:94-2213-E-110-036-
執行期限:94 年 8 月 1 日至 95 年 7 月 31 日
主持人:謝哲光 國立中山大學電機工程學系
計畫參與人員:吳旭焜、陳保戎、徐志廷、招沛宏
一、前言
Cellular neural networks (CNNs), first introduced by Chua and Yang [1]-[2], are large scale nonlinear circuits composed of locally connected cells. CNN has a tremendous variety of applications in the fields of dynamic systems and signal processing. Among the applications, image processing is of great interest since the structures of template operation of CNN are intimately related. Examples of CNN image processing are edge detection, mathematical morphology, and noise filtering [3]-[5]. Advanced applications for image processing using CNN are medical image processing and digital content analysis [6]-[7].
The class of CNNs without feedback interconnections from neighboring cells, namely the uncoupled CNNs, plays an important role in the analysis of the dynamic behavior. Furthermore, the simplicity of the uncoupled CNN circuits renders it attractive in VLSI implementation. The binary steady state output in terms of the binary input of the uncoupled CNN can be represented by a linearly separable Boolean function. Most of the elementary applications can be derived and analyzed via Boolean functions [8]-[10], which is directly related to the CNN template parameters. More complicated tasks can be accomplished by a sequence of uncoupled CNN operations. The architecture of CNN provides both parallel analog processing and local interactions between cells characterizing cellular automata which is intrinsically suitable for VLSI implementations. A typical implementation is the realization of “analogic” programs in the CNN universal machine (CNN-UM) framework [11], so that a fully parallel and high speed device of evolutional computation can be developed [11]-[12].
One of the crucial issues of VLSI CNN chip design is the robustness of a template set for CNN [13]. Analog VLSI implementations of CNN have numerous limitations that need to be taken into account in the theory of CNN in order to guarantee correct and efficient operations. Template parameters can only be realized with a precision of typically 5~10% of the nominal values and usually only a discrete set of possible values is available [14].
The problem of template design or template learning is a key topic in CNN research. The methods investigated since the inception of the CNN may be classified as analytical methods, local learning algorithms, and global learning algorithms [15]-[17]. But these algorithms were not studied concentrating the importance of robustness of the CNN template. It is interesting to find that the geometric margin of a linear classifier with respect to a training data set, a notion borrowed from the machine learning theory, can conveniently be used to define the robustness of an uncoupled CNN implementing a linearly separable Boolean function. Consequently, the so-called maximal margin classifiers can be devised via support vector machines (SVMs) to provide the most robust template design for uncoupled CNNs implementing linearly separable Boolean functions.
SVM is a learning system which was first introduced by Vapnik and coworkers in 1992 [18]. A unique feature of the SVM is that the final discriminant function for classification problem or the predictive function for regression problem can be expanded on a small subset of training data, which is referred to as support vectors [19]-[20]. In the meanwhile, the maximum margin of the optimal separating hyperplane to the nearest vertices can be computed directly by a neat formula. The training algorithm of the SVM to obtain maximal margin design for uncoupled CNN template design can be implemented via sequential minimal optimization (SMO) algorithm [21] with some modification, which provides analytical formulae and efficient convergence [22].
For an arbitrarily given Boolean function, the CFC decomposition method proposed by Crounse, Fung, and Chua [23], can be used to find a sequence of uncoupled CNNs implementing the given Boolean function. In CFC method, the entries of the control templates of the required uncoupled CNNs are restricted to the set of small magnitude, and the thresholds are some integers. The conjunctions of the sequence of CNNs are traditional logic operators. The method is a brute force one, yet it is simple and is easy to be implemented. In our view, the most important thing in the CFC approach is that the uncoupled CNNs they considered are all robust in the sense of geometric margins, though this has
never been clearly pointed out. 二、研究目的
In this project, a general problem of the robust template decomposition with restricted weights for cellular neural networks implementing an arbitrary Boolean function is investigated.
三、研究方法
First, the geometric margin of a linear classifier with respect to a training data set is used to define the robustness of an uncoupled CNN implementing a linearly separable Boolean function. Second, maximal margin classifiers, i.e., robust CNNs, for such Boolean functions can be designed via support vector machines. Finally, for an arbitrarily given Boolean function, we propose an algorithm, which is the generalized version of the well known CFC algorithm, to find a sequence of robust uncoupled CNNs implementing the given Boolean function.
1. Template design for uncoupled CNN
Consider a standard cellular neural network consisting of an M×N rectangular array of cells. Without loss of generality, we will consider in this project exclusively
3
3× neighborhood for each cell C ,
( )
i j , i∈M, j∈N. Thus the CNN parameters are represented by a triple(
A,B,z)
, where A=[ ]
akl and B=[ ]
bkl , k,l∈{
−1,0,1}
,are 3×3 feedback and feedforward templates, respectively, and z is the threshold value. Let xij be
the state of C ,
( )
i j . Then the governing state equation of xij in terms of the input uij and the output yij isgiven by ij k l l j k i kl k l l j k i kl ij ij x a y b u z x =− +
∑∑
+∑∑
+ − = =− + + − = =− + + 1 1 1 1 , 1 1 1 1 , & . (1)The output y is related to the state ij xij by the
standard nonlinearity [10] by
( )
=0.5× +1−0.5× −1= ij ij ij
ij f x x x
y .
In solving the state equation (1), the initial state xij
( )
0 must be given and some proper boundary conditions should be declared.For an uncoupled CNN, the coefficients of the feedback template A is assumed to vanish except the center coefficient a00. Then (1) is reduced to
(
ij ij)
ij( )
ij ij ijij h x w g x w
x& = , := + , (2)
where gij
( )
xij is the driving-point (DP) componentgiven by
( )
ij =− ij+0.5× 00× ij+1−0.5× 00× ij−1ij x x a x a x
g (3)
and wij is the offset level given by
ij k l l j k i kl ij b u z w =
∑∑
+ − = =− + + 1 1 1 1 , . (4)For simplicity, let the terms
[
]
T b b b b b−1,−1, −1,0, −1,1, 0,−1,L, 1,1 in (4) be renamed as[
]
T w w w w w9, 8, 7, 6,L, 1 and[
]
T u u u u u−1,−1, −1,0, −1,1, 0,−1,L, 1,1be renamed as
[
u9,u8,u7,u6,L,u1]
T . Note that thenotation wj has only one subscript, which is different
from the quantity wij with 2 subscripts. Then we have
( )
u f b u w b u w u w wij= 1 1+...+ 9 9+ = , + := ,[
]
T w w w:= 1 ... 9 ,[
]
9 9 1 ... := u u T∈ℜ u .Usually w is called the weight vector and b is called the bias.
With the static binary inputs, i.e., ui∈
{ }
1,−1 , the steady-state output yij( )
∞ of C ,( )
i j can be calculatedexplicitly without integrating (2) with (3) and (4) as follows. See Theorem 6.1 in [10].
If a00>1, then, starting from any xij
( ) (
0 ∈−1,1)
, wehave
( )
[
(
) ( )
ij ij]
ij sign a x w y ∞ = 00−1 0 + . If a00=1, then we have( )
[ ]
ij ij signw y ∞ = , if wij≠0,( )
∞ = ij( )
0∈[ ]
−1,1 ij x y , if wij=0. If a00<1, then we have( )
[ ]
ij ij signw y ∞ = , if wij ≥1 a− 00,( ) (
∞ = 1− 00)
1 ∈(
−1,1)
− ij ij a w y , if wij <1 a− 00.Note that in the a00>1 case, by absorbing the term
(
a00−1) ( )
xij0 into the bias term b or by selecting( )
0 =0ij
x , we have
( )
sign[ ]
w sign[
wu b]
yij ∞ = ij = , + .It is well known that a (local) Boolean function
(
u1,u2,...,u9)
β of nine variables is realizable by every cell of an uncoupled CNN if and only if β
( )
⋅ can be expressed by the formula(
u1,u2,...,u9)
=sign[
a1u1+a2u2+...+a9u9+b]
β ,
where ai, i∈9, b are real constants, and ui∈
{ }
1,−1 ,9 ∈
i , is the ith Boolean variable. See Theorem 6.2 in [10].
It is important to note that the discriminant function
( )
u au au au bf := 1 1+ 2 2+...+ 9 9+ is an affine-linear function of ∈ℜ9
u . Thus implementing a Boolean function by an uncoupled CNN is a linear classification problem.
As pointed out in [10] and [13], since no template parameters can be realized exactly in practice, it is important that the CNN template be designed to be as robust as possible. This guarantees the reliability of CNN hardware implementation. For CNN implementation of a given Boolean function, this robustness can be achieved by designing a maximal margin classifier in the terminology of support vector machine learning theory.
3
2. Linear classification
Let n
X ⊆ℜ and Y:=
{ }
1,−1. Suppose we are given the training set(
)
{
x y}
X YS:= i, i li=1⊆ × . (5)
Note again that xi in (5) is different from the CNN state
ij
x . The training set S is said to be linearly separable if there is a hyperplane of the form
( )
: , 0, x = w x +b=
fwb ,
n
w∈ℜ , b∈ℜ,
that correctly classifies the training data. By treating the truth table of a given Boolean function as the training dataset with l=512 training data, this training set must be linearly separable in order for the Boolean function to be realizable by an uncoupled CNN.
For a given
( )
w,b , where nw∈ℜ and b∈ℜ, define
( )
x w x b fw,b := , + ,( )
x w f( )
x w w x w b gw,b := −1 w,b = −1 , + −1 , n x∈ℜ . Note that the distance of a given point nx'∈ℜ to the hyperplane defined by fw,b
( )
x =0 , or equivalently( )
0, x =
gwb , is given by gw,b
( )
x' . The following definitions are quoted from [20].The functional margin µS
( )
w,b and the geometric margin ηS( )
w,b of( )
w,b with respect to the training set S are defined by, respectively,( )
[
]
i wb( )
i l i i i l i S wb y w x b y f , x 1 1 , min min : , = ⋅ + = ⋅ = = µ ,( )
⎥⎦⎤ ⎢⎣ ⎡ + ⋅ = − − = y w wx w b b w i i l i S 1 1 1 , min : , η( )
i b w i l i1 y g , x min ⋅ = = .The margin γS of a training set S is defined to be the
maximum geometric margin over all hyperplanes, i.e.,
( )
[
i wb i]
l i b w S y g , x 1 , min max := ⋅ = γ ⎥⎦ ⎤ ⎢⎣ ⎡ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + ⋅ = − − = yi w w xi w b l i b w 1 1 1 , min , max .A hyperplane realizing this maximum is called a maximal margin hyperplane or optimal hyperplane. Note that the margin of a linearly separable training set is positive.
Note that in our template design if we choose a00<1, in order for correct binary output, the gray-scale output values must be avoided. This implies that the designed linear classifier must have a functional margin greater than or equal to 1 a− 00. This can easily be solved by
scaling the weight vector and the bias by the same constant, which results in the decision hyperplane and the margin unaltered.
3. SVM for optimal CNN template design
Given a Boolean function of nine variables, we have 512
=
l training data for a binary separation problem. To be realizable by an uncoupled CNN, the training set must be linearly separable. To obtain the maximum
robustness for the input template design, we seek the maximum margin for the training data.
Define
{
: 1}
:= ∈ = + i S i l y I , IS−:={
j∈l:yj =−1}
.It is fairly easy to prove the following fact. Suppose we are given a non-trivial linearly separable training set S. Then the following statements are equivalent:
(a) The margin of S is γS.
(b) There exist w*∈ℜn , w* =1 , b*∈ℜ , and
0 > S γ such that
[
*, + *]
≥ >0 ⋅ i S i w x b y γ for all i∈l, S i b x w*, * + *=γ for some i∈IS+, S j b x w*, * + *=−γ for some j∈IS−. (c) There exist n w0∈ℜ and b0∈ℜ , with 0 := 0 1> − w S γ , such that[
0, + 0]
≥1>0 ⋅ w x b yi i for all i∈l, 1 , 0 * 0 x + b = w i for some + ∈IS i , 1 , 0 * 0 x + b =− w j for some − ∈IS j .The functional margin of hyperplane in (c) with respect to the training set S becomes 1. Such a hyperplane is called a canonical hyperplane.
From the preceding fact, for a given non-trivial linearly separable training set S, maximization of the margin of S is equivalent to minimizing the Euclidean norms of the weight vector w of canonical hyperplenes. Thus consider the following primal optimization problem:
(P) minimize 2−1wTw
subject to yi⋅
[
w,xi +b]
≥1 for all i∈l.Note that the problem (P) is a standard quadratic convex program.
Suppose
(
w*, b*)
solves the (primal) optimization problem (P). Then the maximal margin hyperplane is given by f*( )
x = w*,x +b*=0 with margin1
*− = w
S
γ .
The Lagrangian of problem (P) is given by
(
)
∑
(
)
= − − + − = l i i i T i i T b y x w y z w w z b w L 1 1 1 2 : , , , where[
]
T l l z zz:= 1 L ∈ℜ is the vector of Lagrange multipliers. Maximization of the Lagrangian leads to the following dual optimization problem:
(D) maximize
∑
∑∑
= = − = − l i l j j i j i j i l i i z z y y x x z 1 1 1 1 , 2 subject to 0 1 =∑
= l i i iyz and zi ≥0 for all i∈l. Note that the problem (D) is a standard quadratic concave program.
Suppose z* solves the (dual) optimization problem (D). Define Isv:=
{
i∈l:z*i >0}
. Then we have∑
∑
∈ = = = sv I i i i i l i i i iy x z yx z w * 1 * * ,and the margin is given by γS= w*−1. Moreover, from the Karush-Kuhn-Tuker (KKT) conditions, we have
k I i i i i k k k w x y z yx x y b sv , *, *
∑
* ∈ − = − =∑
∈ − = sv I i k i i i k z y x x y * , , where k∈Isv, i.e., 0 *> kz . The optimal discriminant function is thus given by
( )
*, * * x w x b f = + z*y x ,x b* sv I i i i i + =∑
∈ . (6)Obviously, the Lagrange multiplier *
i
z associated with each point quantifies how important a given training data is in forming the final solution. Points that have zero *
i
z have no influence. Any example xi with sv
I
i∈ is called a support vector. In conceptual terms, the support vectors are those data points that lie closest to the decision surface and are therefore the most difficult to classify.
For a given Boolean function of nine variables, we can use SVM to find the CNN B template and the threshold
ij
z such that the separation margin is maximized. The 512 different inputs and the corresponding outputs are regarded as the training set (5). Then we solve the dual optimization problem (D) to obtain the optimal discriminant function (6).
For CNN template design, we assume the initial state xij
( )
0 to be zero so that the value of a00 wouldnot affect the resulting values of B template and the threshold zij. Note again that once the optimal w*
and b* have been found, if we choose a00<1 in the template design, then, for correct binary output, w*
and b* must be multiplied by the constant 1 a− 00 for
actual template parameters and bias in order to provide a functional margin 1 a− 00.
4. Decomposition Algorithm
Given an arbitrarily Boolean function, linearly separable or not, it is desired to find a sequence of optimal uncoupled CNNs and two-input logic functions as conjunctions [4]. For an uncoupled CNN C(A0,B,z) with binary inputs ui∈{1,−1}, we consider the case of
1 00= a and bi∈{−1,0,1}, i∈9, i.e., 0 0 0 0 1 0 0 0 0 = A , 9 8 7 6 5 4 3 2 1 b b b b b b b b b B= .
Let m be the number of nonzero entries in B. It can be proved that the following threshold values
{
− +1,− +3,− +5, , −3, −1}
∈ m m m m m
z L ,
result in all optimal templates. Denote Ω as the set of all such optimal templates. The (maximal) margin of each template in Ω is given by 1 m, which is the guaranteed robustness.
Now suppose we are given a Boolean function ) , , , , (u1 u2 u3 u9 F L .
We are looking for the solution as a sequence of “ballterms” (k)
b , k∈M, with each selected from Ω and with two-input one-output logic operations Θ(k)
as conjunctions. Each ballterm (k)
b is represented by z b b b b b b b b b b bk ( 1, 2, 3, 4, 5, 6, 7, 8, 9), ) ( = ,
where the last value z is the threshold value and the first nine values b1 to b9 are the entries in B template (the A template has a central nonzero element 1). Note again
that the uncoupled CNN used here all belong to the set Ω. Thus, F is generated as follows
) 0 ( ) 0 ( : b f = , ) 1 ( ) 1 ( ) 0 ( ) 1 ( : f b f = Θ , ) 2 ( ) 2 ( ) 1 ( ) 2 ( : f b f = Θ , M ) ( ) ( ) 1 ( ) ( : M M M M b f f = − Θ , where Θ(k)∈L
and L is the set including 16 two-input one-output logic functions as shown in Table 1.
Table 1. A list of serial number of 16 two-input one-output logic functions (~ means NOT, & means AND, | means OR).
In order to calculate the consecutive terms f(k), we need a distance calculation unit between two Boolean functions f and g, which is defined by
∑
= ⊕ =512 1 ) ( ) ( ) , ( j j g j f g f dist ,where ⊕ is the XOR operation.
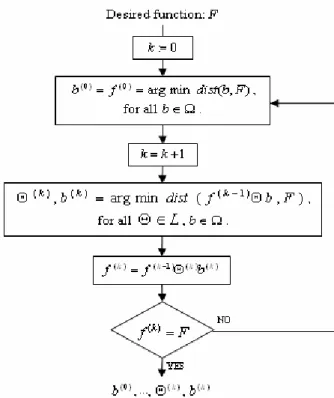
The flow chart for calculating the consecutive (k−1)
f ,
) (k
Θ , and (k)
b is schematically shown in Fig. 1. The modified algorithm is described as follows:
Step 1: Let k=0 . Find (0)
b in Ω of minimum distance from F.
Step 2:k= k+1. Test all the possible combinations of the ballterms in Ω and logic functions in L to find (k)
b and Θ(k)
which minimize the distance between f(k)
5 Step 3: If f(k)=F, then stop, else jump to Step 2.
Fig. 1. Flow chart for modified algorithm.
四、文獻探討
The literature survey has been done in section 1 and will be not be repeated here.
五、結果與討論
In this section, two illustrative examples are provided. One is the famous example of “Game of Life”, and the other is a Boolean function generated by an ugly uncoupled CNN. We wish to point out that when we search in the Ω and L, there may be more than one solution matching the algorithm. When this situation happens, we choose the solution we first meet. The program is implemented using Visual C++ 6.0 running on Microsoft Windows XP, Pentium IV 2.8 GHz platform. In our simulations, one needs about 5 seconds to find the first ballterm and 22 seconds for each consecutive ballterm.
Example 1: Game of life
The Boolean function, which is not linearly separable, is generated from the following local rules:
(a) If there are two neighbors whose state values are 1, then set the state value to 1.
(b) If there are three neighbors whose state values are 1, then retain the state value.
(c) For situations apart from (a) and (b), set the state value to -1.
The algorithm in Fig. 1 results in just two terms 1 ), 1 , 1 , 1 , 1 , 0 , 1 , 1 , 1 , 1 ( ) 0 ( = b− − − − − − − − − b , dist = 46; 4 ), 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 ( ) 1 ( = b− − − − − − − − − − b ,Θ(1)=SN2, dist=0. Example 2:
The Boolean function is generated by the following uncoupled CNN: 0 0 0 0 1 0 0 0 0 = A , 26 20 9 25 8 24 23 19 30 = B , z=37. The results are shown as follows:
2 ), 1 , 1 , 0 , 1 , 0 , 1 , 1 , 1 , 1 ( ) 0 ( = b+ + + + + + + + b ,dist = 29; 3 ), 1 , 1 , 1 , 1 , 1 , 1 , 1 , 0 , 1 ( ) 1 ( = b− − − − − − − − − b ,Θ(1) =SN2,dist=18; 3 ), 1 , 0 , 1 , 1 , 1 , 1 , 1 , 1 , 1 ( ) 2 ( = b− − − − − − − − − b ,Θ(2) =SN2,dist=14; 3 ), 1 , 0 , 1 , 1 , 0 , 1 , 1 , 0 , 1 ( ) 3 ( = b− − − − − − − b ,Θ(3)=SN2,dist=11; 5 ), 0 , 1 , 1 , 0 , 1 , 0 , 1 , 1 , 1 ( ) 4 ( = b− + + + + − + b ,Θ(4)=SN11,dist= 9; 3 ), 1 , 0 , 0 , 1 , 1 , 1 , 1 , 0 , 1 ( ) 5 ( = b− − − − − − − b ,Θ(5)=SN2,dist =7; 2 ), 1 , 1 , 1 , 0 , 0 , 0 , 0 , 1 , 1 ( ) 6 ( = b− − − − − + b ,Θ(6)=SN11,dist = 5; 4 ), 1 , 1 , 1 , 1 , 1 , 0 , 0 , 1 , 1 ( ) 7 ( = b− − − − − − − − b ,Θ(7)=SN2,dist=4; 3 ), 0 , 1 , 0 , 0 , 1 , 0 , 0 , 1 , 1 ( ) 8 ( = b− − − − + b , (8) 11 SN = Θ , dist=3; 1 ), 1 , 0 , 0 , 1 , 0 , 0 , 0 , 1 , 1 ( ) 9 ( = b − − − − + b ,Θ(9)=SN11, dist=2; 5 ), 0 , 1 , 1 , 0 , 1 , 1 , 1 , 0 , 1 ( ) 10 ( = b− − − − − − − b ,Θ(10) =SN2,dist=1; 2 ), 0 , 0 , 0 , 0 , 0 , 1 , 1 , 0 , 1 ( ) 11 ( = b− − − + b , Θ(11)=SN11,dist=0. In this project, we have proposed a modified algorithm to find a sequence of robust uncoupled CNNs implementing the given Boolean functions. In a continuing research [24], the template values are not restricted to
{
±1,0}
, but can be any values in{
±2,±1,0}
or{
±3,±2,±1,0}
.
參考文獻[1] L. O. Chua and L. Yang, “Cellular neural networks: theory,” IEEE Transactions on Circuits and Systems, vol. 35, pp. 1257-1272, Oct. 1988.
[2] L. O. Chua and L. Yang, “Cellular neural networks: applications,” IEEE Transactions on Circuits and
Systems, vol. 35, pp. 1273-1290, Oct. 1988.
[3] I. N. Aizenberg, N. N. Aizenberg, and J. Vandewalle, “Precise edge detection: representation by boolean functions, implementations on the CNN,” in Proc.
IEEE International Workshop on Cellular Neural Networks and Their Applications, London, 1998, pp.
301-306.
[4] I. Szatmári, A. Schultz, C. Rekeczky, T. Kozek, T. Roska, and L. O. Chua, “Morphology and autowave metric on CNN applied to bubble-debris classification,” IEEE Transactions on Neural
Networks, vol. 11, no. 6, pp. 1385-1393, Nov. 2000.
[5] I. N. Aizenberg, “Processing of noisy and small-detailed gray-scale images using cellular neural networks,” Journal of Electronic Imaging, vol. 6, no. 3, pp. 272-285, July 1997.
[6] G. Liszka, T. Roska, Á. Zarándy, J. Hegyesi, L. Kék, and C. Rekeczky, “Mammogram analysis using CNN algorithms,” in Proc. SPIE Medical Imaging, San Diego, 1995, vol. 2434, pp. 461-470.
[7] L. Czúni and T. Szirányi, “Motion segmentation and tracking optimization with edge relaxation in the cellular nonlinear network architecture,” in Proc.
IEEE International Workshop on Cellular Neural Networks and Their Applications, Catania, Italy,
May 2000, pp. 51-56.
[8] Z. Galias, “Designing cellular neural networks for the evaluation of local boolean functions,” IEEE
Transactions on Circuits and Systems II, vol. 40, pp.
219-223, Mar. 1993.
[9] L. Nemes, L. O. Chua, and T. Roska, “Implementation of arbitrary boolean functions on the CNN universal machine,” International Journal
of Circuit Theory and Applications, vol. 26, no. 6, pp.
593-610, Nov. 1998.
[10] L. O. Chua and T. Roska, Cellular Neural Networks
and Visual Computing. Cambridge, United
Kingdom: Cambridge University Press, 2002. [11] T. Roska and L. O. Chua, “The CNN universal
machine: an analogic array computer,” IEEE
Transactions on Circuits and Systems II, vol. 40, no.
3, pp. 163-173, Mar. 1993.
[12] S. Espejo, R. Carmona, R. Domínguez-Castro, and A. Rodríguez-Vázquez, “A CNN universal chip in CMOS technology,” International Journal of Circuit
Theory and Applications, vol. 24, no. 1, pp. 93-109,
Jan. 1996.
[13] P. Kinget and M. Steyaert, “Evaluation of CNN template robustness towards VLSI implementation,”
International Journal of Circuit Theory and Applications, vol. 24, no. 1, pp. 111-120, Jan. 1996.
[14] D. Lím and G. S. Moschytz, “A modular gm-C
programmable CNN implementation,” in Proc.
IEEE International Symposium on Circuits and Systems, Monterey, CA, June 1998, vol. 3, pp.
139-142.
[15] L. O. Chua and P. Thiran, “An analytic method for designing simple cellular neural networks,” IEEE
Transactions on Circuits and Systems, vol. 38, no.
11, pp. 1332-1341, Nov. 1991.
[16] B. Mirzai, Z. Cheng, and G. S. Moschytz, “Learning algorithms for cellular neural networks,” in Proc.
IEEE International Symposium on Circuits and Systems, Monterey, CA, June 1998, vol. 3, pp.
159-162.
[17] M. Hänggi and G. S. Moschytz, “Genetic optimization of cellular neural networks,” in Proc.
IEEE International Conference Evolutionary Computation, Anchorage, Alaska, May 1998, pp.
381-386.
[18] B. E., Boser, I. M. Guyon, and V. N. Vapnik, “A training algorithm for optimal margin classifiers,” in
Proc. The Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, Pennsylvania, United
States, 1992, pp. 144-152.
[19] V. N. Vapnik, The Nature of Statistical Learning
Theory. 2nd ed., New York: Springer, 1999.
[20] N. Cristianini and J. Shawe-Taylor, An Introduction
to Support Vector Machines. Cambridge, United
Kingdom: Cambridge University Press, 2000. [21] J. Platt, “Fast training of support vector machines
using sequential minimal optimization,” in: B. Schölkopf, C.J.C. Burges, A.J. Smola (Eds.),
Advances in Kernel Methods-Support Vector Learning. Cambridge, MA: MIT Press, 1999, pp.
185-208.
[22] W. C. Teng, “SVM-based robust template design for cellular neural networks implementing an arbitrary Boolean function,” M.S. thesis, National Sun Yat-Sen University, 2005.
[23] K. R. Crounse, E. L. Fung, and L. O. Chua, “Efficient implementation of neighborhood logic for cellular automata via the cellular neural network universal machine,” IEEE Transactions on Circuits
and Systems–I, vol. 44, pp. 355-361, 1997.
[24] Y. L. Lin, J. G. Hsieh, and J. H. Jeng, “Robust decomposition with restricted weights for cellular neural networks implementing an arbitrary Boolean function,” International Journal of Bifurcation &