應用多重支持之廣義關聯分類法建構大學休退學預測系統
60
0
0
全文
(2) 應用多重支持之廣義關聯分類法建構大學 休退學預測系統. 指導教授:林文揚 博士(教授) 國立高雄大學資訊工程學系(研究所). 學生:鄭光盛 國立高雄大學資訊工程學系(研究所). 摘要 學生休退學預測問題是教育資料探勘研究領域中很受重視的問題,因為社會 結構的轉變,台灣的出生人口數逐年減少。再加上一般大眾收入的減少、工時增 長、物資價格的調升,以及高學歷畢業生失業率逐年攀升,使得民眾不再信任高 學歷是獲得工作的保證。進而造成大專院校招生不足的現象愈趨嚴重。為維持一 定的學生人數與學校辦學的品質,如何事先查覺學習不太佳的學生,對可能會休 學或退學的學生進行早期的輔導與補救措施,就成為各大學普遍關注的問題。 因為教育的多元化,學生休退學不再如過去只是單純的成績或是經濟問題所 造成,大多數都是零散但具有關聯性的成因。過去以人工一一來判讀這些原因, 曠日廢時且不具成效。本研究的主要目的即在發展一個適用於大學生休退學的預 測系統,本系統預測方法採用我們設計的多重支持之廣義關聯分類法(GACMS)。 我們的 GACMS 方法,以關聯分類法中的 CMAR 方法為基礎,輔以多重支持 度機制讓支持度不高卻很重要的規則可以被系統學習到,再加上納入資料項目間 存在的階層式資訊,讓適用性較窄的規則有機會彙總為強度夠的廣泛規則。 經由實驗結果,GACMS 方法可以得到比現行採用的預測方法更高的精準度。 且能找出重要但容易被其他方法忽略的規則。 關鍵字:廣義關聯分類規則,多重支持度,階層架構關聯規則,學生休退學預測, 關聯分類法 II.
(3) Applying Generalized Associative Classification for Constructed Undergraduate Student Dropout Prediction System. Advisor(s): Dr. (Professor) Wen-Yang Lin Institute of Computer Science and Information Engineering National University of Kaohsiung Student: Kuang-Sheng Jeng Institute of Computer Science and Information Engineering National University of Kaohsiung ABSTRACT. Since the birth rate decreasing is changing the civilian age structure in Taiwan, the student dropout prediction has become an important issue in the educational data mining research community. The income cutback, long working hours, inflation and unemployment rate waiting in the society for university graduate and under graduate students are making students no longer trust that the university diplomas are guarantee for better working opportunities, and it makes the universities not easy to enroll enough new students. In order to keep the student number and education quality to a competitive level, all of the universities are concerning about how to discover the students with learning problems and then engage consolation and compensation works in the early stage. The reasons for student dropout are no longer caused only by academic grades or personal financial problems, since the modern university education is taking routes in III.
(4) various directions. The reasons are diverse yet still event related. In the past, they are examined case by case through manpower that is time consuming and ineffective. This research is to develop a system suitable for university dropout prediction by adopting our Generalized Associative Classification with Multiple Minimum Supports (GACMS). Our GACMS method is based on the CMAR method, a well known associative classification method. With the help of multi-supported method, the system can learn less-supported but important rules. Adding the taxonomy information existed in the data items, the less adoptable rules could become dominating common rules. According to the experimental results, GACMS is capable of acquiring better precision in dropout prediction compared to using the traditional prediction methods, and it also finds important rules that are usually to be ignored by other methods.. Keywords: Generalized Associative Classification, Multiple Minimum Supports, Hierarchy, Student Dropout Prediction, CMAR. IV.
(5) 致謝 兩年的研究所生涯,除了加強了我的研究能力也訓練我報告的技巧,讓我的 表達能力更上一層樓。 首先要感謝我的指導老師林文揚博士,在我研究的問題上提供相當多的技術 指導與專業見解,也適時的修正研究的方向。並在我遇到瓶頸的同時,給予我許 多的鼓勵與幫忙,讓我能在短時間內可以完成此一問題的研究。 同時,我也要感謝洪宗貝教授讓我每週參與 AI meeting,不但指導我的報告 技巧,也同時讓我接觸到不同領域的相關研究,拓展了我的視野。也感謝口試委 員高雄醫學院何文獻教授對論文提出的修正建議,讓論文內容對研究問題的表達 更完整。 最後要感謝我的家人的支持,特別是我哥哥鄭光程在我的英文翻譯上的協助 與指導。. V.
(6) 目錄 摘要 ................................................................................................................................... II ABSTRACT ..................................................................................................................... III 致謝 ................................................................................................................................... V 目錄 .................................................................................................................................. VI 圖目錄 ........................................................................................................................... VIII 表目錄 ............................................................................................................................... X 第一章 緒論 .................................................................................................................... 11 1.1 研究動機與目的 ....................................................................................................... 11 1.2 研究貢獻 .................................................................................................................... 12 1.3 章節架構 ................................................................................................................... 13 第二章. 背景知識與相關研究 ...................................................................................... 15. 2.1 學生休退學預測 ........................................................................................................ 15 2.2 關聯規則探勘 ............................................................................................................ 17 2.2.1 Apriori 演算法 ........................................................................................................ 18 2.2.2 FP-Growth 演算法 ................................................................................................. 20 2.2.3 具有多重支持度的關聯規則探勘 ........................................................................ 22 2.2.4 廣義關聯規則探勘 ................................................................................................. 23 2.3 關聯式分類方法 ........................................................................................................ 25 3.1 系統架構 ................................................................................................................... 28 3.2 資料來源 ................................................................................................................... 29 3.3 資料前置處理 ........................................................................................................... 31 第四章. GACMS 方法 ................................................................................................ 35 VI.
(7) 4.1 基本構想 .................................................................................................................... 35 4.2 預測模型的建立 ........................................................................................................ 36 4.2.1 多重支持度的設定 ................................................................................................. 36 4.2.3 模型建立 ................................................................................................................. 40 4.3 未知資料的預測 ........................................................................................................ 44 第五章 實驗與結果 ........................................................................................................ 44 5.1 實驗設計 .................................................................................................................... 45 5.2 系統說明 ................................................................................................................... 45 5.3 實驗結果分析 ............................................................................................................ 51 5.3.1 預測準確度分析 ..................................................................................................... 51 5.3.2 執行速度分析 ......................................................................................................... 54 第六章 結論與未來研究 ................................................................................................ 55 6.1 結論 ........................................................................................................................... 55 6.2 未來研究工作 ............................................................................................................ 56 參考文獻 .......................................................................................................................... 57. VII.
(8) 圖目錄 圖 2.1 Apriori 原理示意圖 ............................................................................................. 19 圖 2.3 FP-tree 範例 ........................................................................................................ 22 圖 2.4 行政區域劃分圖 .................................................................................................. 25 圖 2.5(a) 強化 FP-tree.................................................................................................... 27 圖 2.5(b) CR-tree ............................................................................................................ 27 圖 3.1 休退學預測系統基本架構圖 .............................................................................. 30 圖 3.3 戶籍地區階層圖 .................................................................................................. 33 圖 3.4 曠課週數階層圖 .................................................................................................. 34 圖 3.5 科系學院階層圖 .................................................................................................. 34 圖 4.1 學生休退學資料範例 ........................................................................................... 36 圖 4.2 GACMS 演算法 3.1 範例-產生頻繁項目及標頭表格 ....................................... 39 圖 4.3 GACMS 演算法 3.1 範例-產生增強型 FP-tree ................................................ 40 圖 4.4 GACMS 演算法 3.1 範例-刪除 d2 後的增強型 FP-tree ................................... 40 圖 4.5 GACMS 演算法 3.1 範例-產生的規則 ............................................................... 41 圖 4.6 GACMS 演算法 3.2 範例-CR-tree ..................................................................... 43 圖 4.7 GACMS 演算法 3.2 範例-最終建立的 CR-tree ................................................ 44 圖 5.1 系統設定畫面 ...................................................................................................... 46 圖 5.2 訓練資料檢視畫面 .............................................................................................. 46 圖 5.3 測試資料檢視畫面 .............................................................................................. 47 圖 5.4 欄位選擇畫面 ...................................................................................................... 48 圖 5.5 條件&階層設定畫面 ........................................................................................... 48 圖 5.6 階層樹畫面 .......................................................................................................... 49 VIII.
(9) 圖 5.7 預測模型建模畫面 .............................................................................................. 50 圖 5.8 測試結果畫面 ...................................................................................................... 51 圖 5.9 分類清單 ............................................................................................................... 51 圖 5.10 各演算法精確度比較 ........................................................................................ 53 圖 5.11 不同多支持度權重參數比較 ............................................................................ 54. IX.
(10) 表目錄 表 2.1 資料探勘於休退學問題之相關研究總覽 ............................ 16 表 5.1 各種演算法精確度比較 .......................................... 52. X.
(11) 第一章 緒論 1.1 研究動機與目的 台灣社會近幾年來因為少子化的趨勢,造成各級教育機構入學人數普遍下 滑,對於在教育階層末端的高等教育機構影響更為巨大。再加上經濟不景氣的影 響,高等教育的費用成為一般家庭沉重的負擔。此外,近年台灣職場需求架構上 的調整,造成高學歷已不再是就業與高薪的保證。基於這些原因,高等教育對許 多學生而言,已不再是必要的選項,因此嚴重影響教育機構的存續問題。教育部 也於民國 102 年推動大學整併計畫,針對一個縣市有兩所以上公立大學,而單一 學校學生人數在一萬人以下的國立大學推動整併;私立大學的學生人數 在兩千人 以內,則推動退場機制。[31]為了能維持學校的規模,各校除了積極開發學生來源 外,也愈來愈重視學生的休退學問題。特別是如何早期預測學生休退學的可能性, 儘早採取輔導措施,以減少休退學的比例。早期關於休退學預測的作法,大多是 以簡單的專家判定來做為找出休退學生的條件,而且多是單一條件。然而這些條 件實際測試後,往往與事實有一段距離。單純以曠缺、學業成績、戶籍地離校的 遠近、獲得的證照數目多寡、參賽得獎的次數等,並無法得出較準確的分類條件。 此乃因導致學生休退學的因素,極有可能是多個因素的組合導致。 例如,以下列學生的休退學規則為例{第 4~8 週曠課,期中考不及格科目超過 三科 休學},在過去可能只能概括的抓取第 4~8 週曠課,或是期中考不及格科目 超過三科者可能休學。這樣的預測結果,經常誤判。但若把條件組合起來,是可 以得到更高的精準度的判別條件。況且對於一個學期有 18 週的出席記錄,其往往 涵蓋重要的期程(如期中考週),若是可以用更精準的條件範圍來組合,應可以得到 更好的預測規則,但光是這些條件的組合就足以叫專家們手忙腳亂。 11.
(12) 有鑒於此,近年來隨著資料探勘技術的發展,有愈來愈多的學者研究如何將 資料探勘的方法運用在學生的休退學預測,例如有神經網絡決策樹(decision tree neural networks)[4], 貝葉氏分類法(naive Bayes)[4], instance-based learning[4], 迴歸 分析(logistic regression)[4] 和 向量支持機(support vector machines)[4] 。 上述方法大都為分類方法,由於學生的休退學預測問題,本質上可視為一種 分類問題,在眾多的分類方法中,關聯式分類法是近年來新發展的方法。其概念 是將分類規則,視為一種特殊的關聯規則。故可利用原本用來產生關聯規則的演 算法,稍加修改後變成探勘分類規則。再由這些分類規則組成分類模型,對未知 的資料進行分類。許多研究都顯示[22],此種分類方法通常優於傳統的分類方法, 如決策樹...等。然而,就我們所知,目前仍未見採用關聯式分類法於預測學生的休 退學之研究。因此,本論文的主要目的,在嘗試運用關聯分類法預測學生的休退 學,並進而建構一套針對大學學生的休退學預測系統。. 1.2 研究貢獻 本論文主要採用關聯式分類探勘的方法,從有限的資料找出更準確預測學生 休退學的關聯式分類規則。我們提出一個結合多支持度與項目階層知識的關聯分 類 法 , 稱 之 為 具 多 重 持 度 之 廣 義 關 聯 分 類 方 法 , 簡 稱 GACMS(Generalized Associative Classification with Multiple Minimum Supports)此方法具有下列優點: A. 通過多重支持度門檻的機制,讓重要卻不常出現的分類條件,在層層以支持度 做篩選的方法中,得以被保留,形成好的分類規則,進入被納入建構模型之中。 B. 有效結合好用屬性值(項目)之間存在的階層資訊,在不降低規則信賴度的前提 下,提高找到的分類規則的支持度,並提高分類模型整體的準確度。 我們以 GACMS預測方法為核心,實際開發了一套針對大專院校學生休退學的預 測輔助系統。經由此系統訓練出來的分類規則模型,可以提供給不具資料庫和資 12.
(13) 料探勘相關基礎知識的教育專家,使其更容易找出休退學的學生族群,進而在學 生休退學事件發生前,施行相關輔導措施和教學策略。以期減少學生人數流失, 減少對教育機構產生的衝擊。. 1.3 章節架構 本論文其餘章節內容介紹如下: 在第 2 章,我們將介紹與本研究有關的背景資知識與相關研究。在 2.1 節我們 首先回顧過去其資料探勘應用關於教育領域方面的研究,採用過哪些方法。2.2 節 則介紹關於關聯式規則及其代表性的探勘方法,如 Apriori 和 FP-Growth 這些方 法。為了讓系統不在建構模型的過程中,不慎過濾掉重要但支持度卻不高的規則 條件,我們也引用了多重支持度關聯規則探勘的技術[26],這將在 2.2.1 節中介紹。 在 2.2.2 節,我們將介紹結合階層關係的廣義關聯規則探勘。 在第 3 章,我們會先說明高等教育中,學生休退學預測的問題,並對我們所 建構的預測系統的架構及主要的功能,作概略性的說明。 第 4 章,我們將詳 細說明我們提出的具 多重支 持度之廣義關 聯分類法 (GACMS)。首先在 4.1 節 我們將介紹 GACMS 的基本構想及大概的流程;在 4.1.1 節介紹我們如何用 CMAR 方法來產分類規則,4.1.2. 是講述多重支持度資料探勘 在 GACMS 中的運用。另外我們還要介紹樹狀階層結構如何節省運算時間和提高 規則的支持度,這也會在 4.1.3.中詳述。 在第 5 章,我們將本論文所提的 GACMS 方法應用於學生的休退學預測,驗 證是否可以在此一問題得到較佳的關聯式分類規則。在 5.1 節 中先描述本實驗的 設備及資料來源。接著在 5.2 節中,說明實驗的結果及我們的分析。在 5.2.1 節 中,我們將比較有無使用多重支持度資料探勘,以及有無使用預先定義樹狀結構 對結果所造成的影響。在 5.2.2 節 中會探討有無使用階層式樹狀結構的執行速度。 13.
(14) 在第 6 章,我們將對本篇研究做一總結,並探討此一主題未來可能研究和發 展的方向。. 14.
(15) 第二章 背景知識與相關研究 2.1 學生休退學預測 有關學生的學習成效的預測,一直是教育界關注的問題,這其中又以學生是 否中途輟學、休學、成績不及格或甚而退學最引起廣泛的研究[22]。近幾年來隨著 資料探勘技術的快速發展與日趨廣泛的應用,有愈來愈多的學者提出各種不同的 方法預測學生的學習成效[16]。這些研究大致上可以從下列幾點觀點加以分析整 理: (1) 研究目的 : 可分為分析原因、結果預測兩種。 (2) 研究對象 : 分為大學生、大專生、遠距教學學生和中小學生。 (3) 採用方法 : 有的用機率的方法,有的用統計分析的方法來解決。 上述的整理比較彙整表在表 2。由這些比較可以發現目前的這些研究皆未討論 關聯分類法,也未考慮資訊集之中存在的階層資訊。更未考慮各分類條件出現的 機率差異極大的現象。. 15.
(16) 表 2.1 資料探勘於休退學問題之相關研究總覽 採用方法 研究目的 研究對象 機器學習. 作 者 年 代. Araque,2009[3]. 分 析 原 因. 結 果 預 測. ✔. 類 神 經 網 路. 貝 氏 推 論. 隨 機 樹 叢. 相 關 分 析. 迴 歸 分 析. ✔. 大學生 ✔. Dekker,2009[4]. 決 策 樹. 統計分析. 大學電機 ✔ 系學生. Kotsiantis ,2009[8]. ✔. 大學生. Kotsiantis,2010[9]. ✔. 遠距學生. Kotsiantis,2005[10]. ✔. Lykourentzou,2009[15]. ✔. 大專生. M´arquez-Vera,2011[17]. ✔. 中學生. ✔ ✔. ✔. Mart´ınez,2001[18]. ✔. 大學生. Mendez,2008[19]. ✔. 大學生. Parker,1999[20]. ✔. 遠距學生. Quadril ,2010[21]. ✔. 中小學生 ✔. Superby,2006[24]. ✔. 大學生. Veitch ,2004[28]. ✔. 中學生. Wegner ,2008[29]. ✔. 中學生. 16. ✔. ✔. ✔ ✔. ✔ ✔. ✔. ✔. ✔ ✔.
(17) 2.2 關聯規則探勘 關聯規則是在大量資料當中,找出其彼此間有用關係的重要資訊。其最早是 由 Agrawal[1]提出。一般關聯式分類規則的表示如下 AB 其中 A, B 代表交易資料中的兩個項目集合。例如,每週曠課 10 節以上,則期中考 會有三科以上不及格,可以寫成下式 每週曠課 10 節 期中考有三科以上不及格 [支持度=10% 信賴度=80%] 這規則顯示 每週曠課 10 節 和期中考有三科以上不及格 之間有很強的關聯,因 為這些學生不在乎上課也不在乎成績。此一資訊可以提供給教育機構的決策者, 訂定相關規定或輔導措施來矯正這些學生。 支持度(support,簡稱 sup)和信賴度(confidence,記成 conf)是關聯規則的兩大重 要指標,也代表了這規則的強度。支持度泛指規則在這些資料出現的機率,也就 是它所涵蓋的範圍所佔的比例,其定義為 sup(A B) = P(A, B) = sup(A∪B) 其中 P(A, B)表示 A 及 B 在資料集中一起出現的機率,而 sup(A∪B) 表示 A∪B 這個項目級的支持度。信賴度則是泛指準確率,其定義如下 conf(A B) = sup(A∪B) / sup(A) = P(A, B) / P(A) 在前述例子中也就是當我們猜測 ”每週曠課 10 節以上,期中考會有三科以上 不及格”的準確率可達八成。每一條規則的支持度和信賴度都需分別高於使用者制 定的最小支持度(minimum support, 記為 ms)和最小信賴度(minimum confidence, 記為 mc)這兩個門檻值,這樣保留下來的關聯規則的強度才夠。 一般由交易資料中,探勘關聯規則的方法皆遵行一個二階段的架構: 17.
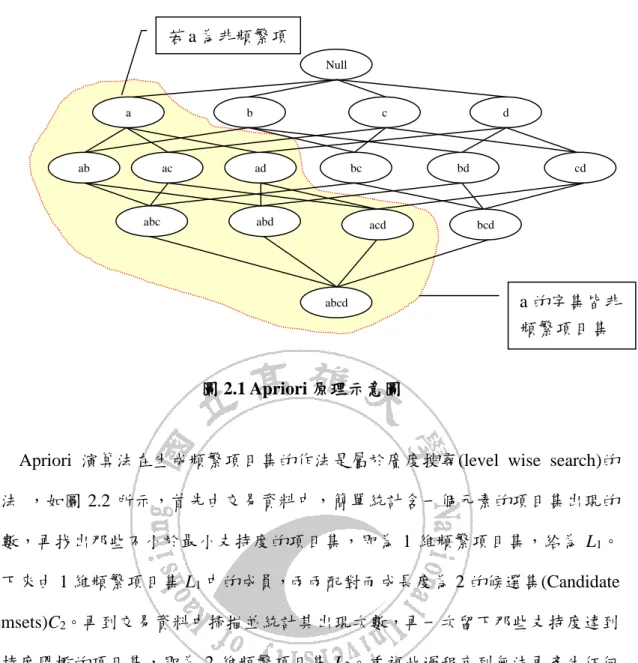
(18) (1) 先由交易資料中生成頻繁項目集,即所有支持度超過最小支持度 ms 的項 目集。 (2) 再由這些頻繁項目集組合成關聯規則,計算其信賴度後,留下超過最小信 賴度 mc 的規則即為所求。 上述二個步驟,以第一階段最耗費時間,故幾乎所有的關聯規則探勘方法的 設計皆只談論如何生成頻繁項目集。接下來我們將會介紹兩個最具代表性的演算 法, Apriori 及 FP-Growth,另外再介紹與我們方法有關的具多重支持度的關聯 規則探勘,以及廣義關聯規則探勘。. 2.2.1 Apriori 演算法 Apriori 是所有探勘規則方法中最具影響的演算法,是由 Agrawal 和 Srikant [2] 提出的方法, Apriori 方法的主要基礎是,當一項目集 A 不是頻繁項目集 B 時, 則所有包含 A 的宇集 B(A⊂B)都不是頻繁項目集。如圖 2.1 所示,當{a}不是頻繁項 目集時,則包含 a 的所有宇集合(Superset)都不是 頻繁項目集,故可減少大量的計 算。. 18.
(19) 若 a 為非頻繁項 Null. a. b. ab. ac. c. ad. abc. bc. abd. d. bd. acd. cd. bcd. abcd. a 的宇集皆非 頻繁項目集. 圖 2.1 Apriori 原理示意圖. Apriori 演算法在生成頻繁項目集的作法是屬於廣度搜尋(level wise search)的 作法 ,如圖 2.2 所示,首先由交易資料中,簡單統計含一個元素的項目集出現的 次數,再找出那些不小於最小支持度的項目集,即為 1 維頻繁項目集,給為 L1。 接下來由 1 維頻繁項目集 L1 中的成員,兩兩配對而成長度為 2 的候選集(Candidate itemsets)C2。再到交易資料中掃描並統計其出現次數,再一次留下那些支持度達到 支持度門檻的項目集,即為 2 維頻繁項目集 L2。重複此過程直到無法再產生任何 的頻繁項目集。詳細的步驟如演算法 2.1 所示。. 演算法 2.1 Apriori 演算法 步驟: 1.. 設 k =1;. 2.. 產生長度 1 的頻繁項目集 L1;. 3.. (Repeat) 重複步驟 4~7 直到沒有頻繁項目集再被識別出來. 4.. 從長度 k 的頻繁項目集 Lk,生成長度 k +1 的候選項目集 Ck+1; 19.
(20) 5.. 修剪長度 k+1 的候選項目集 Ck+1;. 6.. 掃描資料庫,計算候選項目 Ck+1 的支持度;. 7.. 評估候選項目,留下頻繁的候選項目 Lk+1;. 最小支持度 = 2 Itemset Sup Tid 10. Items. {A}. 2. {A}. 2. A,C,D. {B}. 3. {B}. 3. {C}. 3. {C}. 3. {D}. 1. {E}. 3. 20. B,C,E. 30. A,B,C,E. 40. Itemset Sup. st. 1 Scan. {E} 3 長度 1 項目的 支持度. B,E. Database DB. 長度 1 的 頻繁項目集 L1 Itemset. Itemset Sup Itemset {A,C} {B,C} {B,E}. Sup. {A,B}. 1. 2. {A,C}. 2. 2. {A,E}. 1. 3. {B,C}. 2. {B,E}. 3. {C,E} 2 長度 2 的 頻繁項目集 L2. {A,C} {A,E} nd. 2 Scan. Itemset rd. 3 Scan. {B,C} {B,E}. {C,E} 2 長度 2 項目的 支持度. Itemset {B,C,E} 長度 3 的 候選項目集. {A,B}. Sup. {B,C,E} 2 長度 3 項目的 支持度. C3. {C,E} 長度 2 的 候選項目集 C2. Itemset. {B,C,E} 2 長度 3 的 頻繁項目集 L3. 圖 2.2 Apriori 演算法執行過程範例. 2.2.2 FP-Growth 演算法 20. Sup.
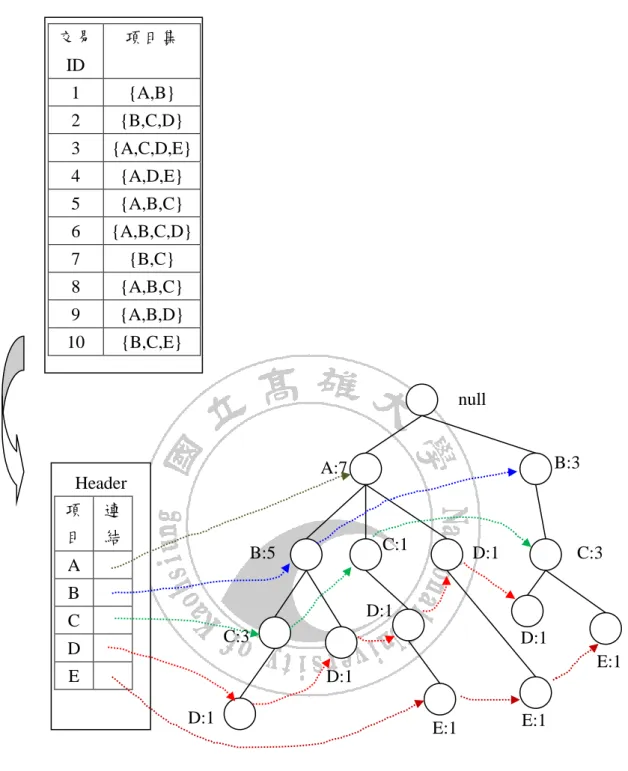
(21) Aprori 演算法的主要缺點在於需產生候選項目集,並多次掃描資料庫,針對 Apriori 演算法的性能瓶頸問題, Han 等人於 2000 年[7]時提出了基於 FP-tree 生成 頻繁項集的 FP-growth 演算法。其方法的主要想法是直接將交易資料壓縮成 FP-tree,再透過這顆樹生成關聯規則。FP-Growth 只對資料庫進行 2 次掃描,而且 其不須產生侯選項目集。FP-growth 第一次做資料庫掃描時,得到 1 維的頻繁資料 集(Frequent itemset)。第二次掃描資料庫時利用 1 維的頻繁資料集篩選出頻繁資料 項,再製成 FP-tree。如圖 2.3 顯示經過 FP-tree 的範例,其中標頭表記錄 1 維的頻 繁項目集,並依項目的出現頻率,由高而低排序。 接下來第二階段,FP-growth 再由 FP-tree 中,由出現次數最低的項目開始, 先產生所有包含此項目的頻繁項目集,將此項目從 FP-tree 中移除,再進行下一個 項目。依此過程持續進行,直到處理完所有的頻繁項目為止。. 21.
(22) 交易. 項目集. ID 1. {A,B}. 2. {B,C,D}. 3. {A,C,D,E}. 4. {A,D,E}. 5. {A,B,C}. 6. {A,B,C,D}. 7. {B,C}. 8. {A,B,C}. 9. {A,B,D}. 10. {B,C,E} null. B:3. A:7. Header 項 連 目 結. C:1. B:5. A. D:1. C:3. B D:1. C. C:3. D. D:1. E. E:1. D:1 D:1. E:1. E:1. 圖 2.3 FP-tree 範例. 2.2.3 具有多重支持度的關聯規則探勘 具多重支持度的關聯規則探勘(Association rule mining with multiple minimum supports),最早是由 Liu[13]提出,並提出建構於 Apriori 演算法上的多重最小支 22.
(23) 持度關聯規則演算法。例如,大型購物中心的交易資料中,有些像是購買珠寶首 飾手錶這些交易,雖然支持度較低,但卻是利潤很高的重要資訊。如果要找出這 些交易資訊,而把支持度門檻降低,會造成讓過多不重要的交易資訊也被涵蓋進 來。但若支持度門檻過高,又很可能找不出這些涵蓋高利潤商品的規則。所以需 要訂定不同的支持度,讓真正有用的交易資訊可以被保留。其多支持度定義如下: 給定一組由項目 I ={a1, a2, a3, ..., an}組成的交易資料集 D,首先要定義最小信 賴度 mc,以及每個項目的最小支持度,令為 ms(a1), ms(a2), ..., ms(an)。則一個項 目集 B = {b1, b2, …, bm}, bi ∈ I, 1 ≤ i ≤m 的最小支持度為. sup(B) ≥. ms(bi). 根據上述定義,ㄧ個由 A∪B 組成的關聯規則 A B,必須符合以下兩個條 件,才是強度夠的規則。 1.. sup(A B) ≥. 2.. conf(A B) ≥ mc. ms(ai). 2.2.4 廣義關聯規則探勘 在真實世界中,大多數的項目之間都存在有所謂的分類關係(taxonomy)或階層 關係(hierarchy)。例如圖 2.4 的住址,即可根據行政區域的劃分,得到類似分類樹 或階層樹。若是能將此種資訊納入探勘的交易資料中,則可找出更佳的關聯規則。 例如. 南部地區學生 缺席次數較少 但如果僅看資料的地址項目,因只有居住的縣市及鄉鎮區等項目,範圍較窄, 所以在相同支持度的門檻限制下,有可能較難發現類似的居住地區與缺席狀況的 23.
(24) 關聯規則。此種將項目的階層分類資訊納入關聯規則的概念就稱為廣義關聯規則 (Generalized association rule)[23] 簡而言之,所謂的廣義關聯規則探勘,是給定一組交易資料集 D 和項目的分 類樹 T,然後找出所有的關聯規則,且其支持度和信賴度也分別高於使用者設定的 門檻,其規則同樣可表示如下: AB 其中 A, B 代表項目集,其成員不僅是由分類樹的葉節點構成,也會由其更高階層 的項目組成。此外,任何右項目集 A 的成員如 a1, a2, …, ai 的祖先,不可以出現 在 B 中。否則會出現如 a ancestor(a),這樣的信賴度一定會是 100%,並無任 何意義。 最早提出此概念的是 Srikant 和 Agrawal [23],但在同時間, Han 和 Fu [6] 也提出類似的概念,稱之為多階層關聯規則,其差異在於構成同一規則的項目必 須都位於階層樹的同一階層,故又視為是廣義關聯規則的特例。此外,還有學者 提出多支持度的廣義關聯規則探勘,如 Lui 和 Chung[14]。. 24.
(25) 離島. 本島. 中台灣. 北台灣. 南臺灣. 金 門 縣. 台 北 市. 大 安 區. 新 北 市. 信 義 區. 台 中 市. 雲 林 縣. 台 南 市. 南 投 縣. 高 雄 市. 三 民 區. 。。。. 連 江 縣. 屏 東 縣. 鳳 山 區. 。。。. 圖 2.4 行政區域劃分圖. 2.3 關聯式分類方法 關聯規則分類法是把關聯規則的方法應用在分類問題上。其原理是分類規 則,在形式上可視為一種受限制的關聯規則。在規則的左項的項目為分類的各種 條件項目,而規則的右項只能是類別的標籤。故理論上,原來用來探勘關聯規則 的演算法應可以稍加修改,即可用來探勘分類規則,此概念最早是由 Liu 等人於 1998 年[12]提出。他們提出的 CBA(Classification Base on Association)演算法,主 要由規則產生器(CBA_Rule Generator, 簡稱 CBA_RG)和分類器(CBA_Classifier Builder)兩個部分構成。規則產生器主要是以 Apriori 演算法為基礎,進行修改主 要不同的是,採用 Apriori 產生頻繁項目集,CBA_RG 還加入了類別標籤這個屬性 25.
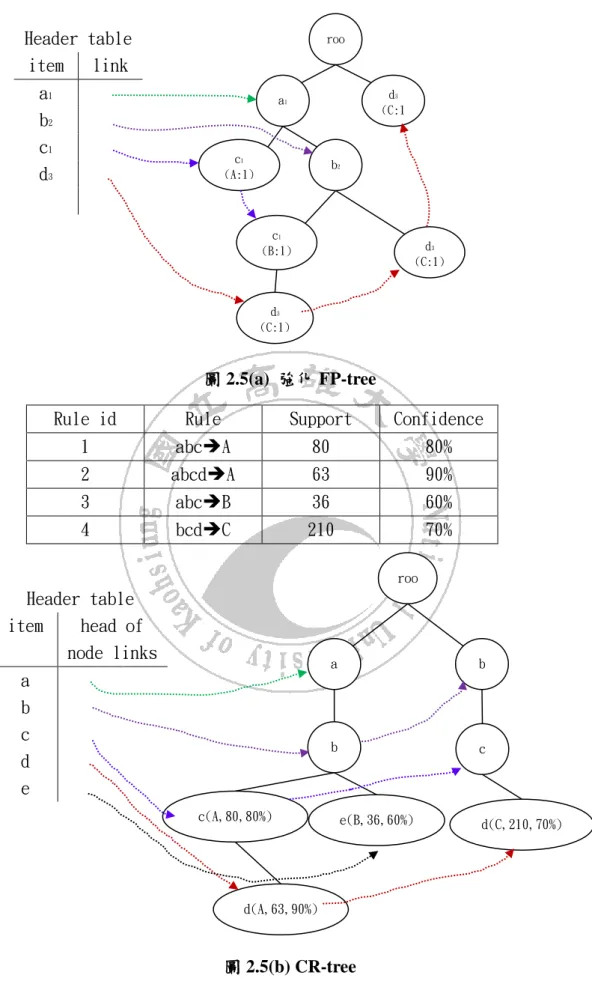
(26) 所產生的集合。例如若 Apriori 產生的頻繁項目集為 A,則 CBA_RG 會產生<A, B> ,A 表示頻繁項目集(成員為其它非類別標籤屬性所構成的條件),B 表示類別 標籤。 也就是說 <A, B>是指 A 屬於類別 B,可以表示成 A B。 分類器這部分,是將 CBA_RG 所產生的規則進行修剪。修剪方法如下: 假設有兩條分類規則. R1, R2 符合下面三點時 R1 優先權高於 R2. 1.. R1 的信賴度高於 R2。. 2.. 當 R1, R2 信賴度一樣時,R1 的支持度高於 R2。. 3.. 當 R1, R2 的信賴度和支持度都一樣時,但 R1 產生時間比 R2 早。. 經過修剪後的規則就是分類器,然後再利用測試資料對分類器的精準度進行 測試。 CBA 是針對單一分類關聯規則的分類方法,即每條規則的右項只允許一個分 類標籤,後來 Li 等學者於 2001 年[11]又提出 CMAR(Classification based on Multiple Association Rules)演算法。主要不同點為(1) CMAR 分類規則右項允許多個 類別標籤;(2) CMAR 在多分類時採用多個分類規則。CMAR 生成頻繁項目集的方 法,是採用改良的 FP-Growth 演算法,把 FP-tree 結構修改為在每一條路徑上同 時記錄該筆資料所屬的類別標籤,如圖 2.5(a)所示。此種改良後的 FP-tree,我們 稱為強化的 FP-tree(Enhance FP-tree). 並採用更有效率的探勘過程來產生頻繁樣. 式及對應的分類規則。 CMAR 在每產生一條分類規則,就將之存入另一資料結構,稱值為 CR-tree, 其形式很像強化的 FP-tree,如圖 2.5(b)所示。每當一條規則存入時,就對規則進 行修剪。與 CBA 不同的是,當信賴度和支持度都一樣時,再比的是項目的多寡(長 度),留下項目較少(長度較短)的規則。. 26.
(27) Header table item link. roo t. a1 b2 c1 d3. d3 (C:1 ). a1. c1 (A:1). b2. c1 (B:1). d3 (C:1). d3 (C:1). 圖 2.5(a) 強化 FP-tree Rule id. Rule. Support. Confidence. 1. abcA. 80. 80%. 2. abcdA. 63. 90%. 3. abcB. 36. 60%. 4. bcdC. 210. 70% roo. Header table item head of node links. t. a b c d e c(A,80,80%). a. b. b. c. e(B,36,60%). d(A,63,90%). 圖 2.5(b) CR-tree. 27. d(C,210,70%).
(28) 第三章 休退學預測系統架構 在本章中,我們將描述我們建構的大學休退學預測系統。此系統是以台灣某 大學為例,主要的目的有二 : (1) 建構一預測模型,可以預測每位學生該學期可能會休學、退學或繼續在 學,即給定一位仍在學學生本學期的學習資料表現,我們希望能決定此學 生在學期末前,最終會屬於退學、休學或正常。亦即此問題視為一分類問 題,將學生分為退學、休學與正常三種類別。 (2) 藉由建構的預測模型,提供重要且關鍵的規則給相關的行政人員做決策參 考。例如,女性比例極低的科系 女學生高退學率,這可以給導師去輔 導與關懷以降低退學率。. 3.1 系統架構 此系統的基本架構,大致可分成三個大的部份 (1) 資料來源 : 用以儲存此系統所需的資料,詳細內容於 3.2 節中說明。 (2) 資料前置處理 : 此部份主要在產生建構預測模型所需的訓練資料,包含必要 的資料前置處理,專家協助建置的項目階層分類樹,詳細內容於 3.3 節中描述。 (3) 預測模型的建構與休退學預測 : 此部份是整個系統的核心,用以建構預測的 模型,並使用此模型進行學生的休退學預測,產生關鍵而重要的規則,針對此 部分我們提出一個結合多重支持度與階層資訊的關連分類法,稱之為具多重支 持度之廣義關聯分類法(Generalized Association Classification with Multiple Minimum Supports, 簡稱為 GACMS 方法)。關於此方法我們將在第四章中詳 28.
(29) 細說明。 如圖 3.1 所示。此系統的運作流程大致如下: 首先,資料前置處理部分,先將異常資料排除。再將數據的欄位作彙總的處 理。得到作為訓練資料的交易資料集。 將交易資料集依條件判斷式將之變成分類項目集,並於此同時將階層樹中的 高階層項目加入,使未出現在分類項目集中專家定義的條件也可以出現在項目集。 接下來,依 執行 GACMS 的方法產生分類規則。並建立初始預測模型。 之後,把測試資料導入,以驗證此模型中的關聯式分類規則,剔除掉準確率 過低的規則。到此,完成預測模型。 再把現行的學籍、曠缺、成績等相關資料輸入,便可以使用此模型預測未來 可能休退學的學生,並由專家針對鎖定這些學生的規則成因,研擬出相關對策或 措施以期減少學生休退學的比例。. 3.2 資料來源 如 3.2 節所言,我們將以台灣某大學的學生資料作為資料來源,這些資料是由 基本資料、活動資料(曠缺、考證照)、成績資料等構成,主要分三個部份: A. 學籍資料表 : 記錄學生基本資料,包含部別、科系、年級、班級、入學方式、 來源、住址…等。 B. 活動資料表 : 記錄學生出缺勤、證照考取數。 C. 成績資料表 : 記錄學生期中、期末考的不及格科目數與總科目數。 結構如圖 3.2 資料綱要結構所示. 29.
(30) 學籍資料. 資料前 置處理. 交易資料 集 (訓練資料) 專家. 曠缺資料. 成績資料. 前置處理. 樹狀階層 項目處理. 。 。 。 資料來源. 階層樹. 生成規則. 重要規則. 預測模型. GACMS 方法. 決策者. 學籍資料 (現行資 料). 學生休退 學預測. 高危險群 學生名單. 輔導員. 圖 3.1 休退學預測系統基本架構圖. 30.
(31) 活動資料表一 學期. 學籍資料表. 週. 部別. 曠課數. 科系. 學號. 年級 班級. 活動資料表二. Foreign key. 來源 住址. 學期 證照數. 入學方式. Foreign key. 學號. 學號. 成績資料表. Foreign key. 學期 期中考不及格科目數 期中考總科目數 期末考不及格科目數 期末考總科目數 學號. 圖 3.2 資料綱要結構. 3.3 資料前置處理. 資料的前置處理方面,我們首先排除了跨校選修的學生。因為跨校選修的學 生,其學籍不在跨校選課的學校,所以資料不齊備。故不列入本研究的資料中。 此外,基於個人資料保護法限制,所有足以辨識個人身分的資料在我們研究中也 一律移除。唯一的外鍵(Foreign key),我們也透過對應表變造成無可辨識個人的一 31.
(32) 組序號。 針對數量形態欄位,為方便轉成關聯式資料探勘的項目,我們把數量值轉換 成 NA(無)、S(輕微或少量)、M(中等)、L(嚴重)四個代表等級的值。包括曠課數、 不及格科目數、證照數...等,都依此轉換成文字,如下所示 每週曠課部份,依程度分 NA(無)、S(1~3 節)、M(4~6 節)、L(6 節以上) 每月曠課部份,依程度分 NA(無)、S(4~12 節)、M(13~24 節)、L(24 節以上) 證照數量,依程度分 NA(無)、S(1 張)、M(2 張)、L(3 張以上) 期中考或期末考不及格部份,依程度分 NA(無)、S(1/3 以下不及格)、M(1/3~2/3 不及格)、L(超過 2/3 以上不及格) 如圖 3.4,我們把曠課週數也階層化,分成 1~4 週、5~8 週、9~12 週、13~16 週、17~18 週,最上層再以 1~18 週匯總。如圖 3.3,我們把台灣的行政區域再依 離島或外島,北、中、南和東台灣來畫分階層。最後如圖 3.5,我們也把科系和學 院依階層來架構連結。. 32.
(33) 本島. 北 台 灣. 中 台 灣. …. 台 北 市. 大 安 區. 離島. 南 臺 灣. …. 台 中 市. …. 南 屯 區. 東 台 灣. …. 高 雄 市. …. 澎 湖. 三 民 區. …. 花 蓮 縣. …. …. 澎 湖 縣. …. 富 里 鄉. 西 嶼 鄉. 圖 3.3 戶籍地區階層圖. 33. …. 馬 祖. 金 門. …. 金 門 縣. 烈 嶼 鄉. …. 連 江 縣. …. 南 竿 鄉. ….
(34) 本學期一至十八週曠課. 第 一 至 四 週 曠 課. …. …. 第 一 週 曠 課. 第 三 週 曠 課. 第 二 週 曠 課. 第 十 三 至 十 六 週 曠 課. 第 九 至 十 二 週 曠 課. 第 五 至 八 週 曠 課. 第 十 七 至 十 八 週 曠 課. …. …. 第 四 週 曠 課. 圖 3.4 曠課週數階層圖. 人 文 管 理 學 院. 工 學 院. 創 意 學 院. …. 營 建 工 程. 建 築 工 程. …. …. 數 位 內 容. 經 營 管 理. 圖 3.5 科系學院階層圖. 34.
(35) 第四章 GACMS 方法 4.1 基本構想 我們提出的 GACMS 方法是一種改良的關聯式分類法,特點是加入項目的階 層關係以及多重支持度的機制,為方便說明我們考慮如圖 4.1 的例子。 程序 1(建立延伸訓練資料集):首先利用項目階層樹擴充訓練資料的條件屬性 及其內容,令為 D*。意即,若 b1, b2,..., bf 為項目 a 的祖先,則將 b1, b2,..., bf 加入凡 是 a 出現的案例資料中。例如,原訓練資料的第一筆案例將變成. 延伸欄. 欄1. 欄2. 欄3. 欄4. 類別. A. a1. b1. c3. d1. 甲. 程序 2(建立預測模型):接下來由延伸的訓練資料集 D*,根據使用者設定的多重支 持度規則的信賴度,產生符合的分類規則,並建立預測模型。此程序為 GACMS 方法的核心,在方法上我們以著名的關聯分類法 CMAR 為基礎將之修改,加入多 重支持度的機制,並考慮項目間的階層關係。詳細的描述將在 3.2 節中說明。 程序 3(未知資料的預測):當一筆未知資料(如學生的資料)進來時,利用程序 2 建 立的模型來預測此案例的類別(即此學生為休學、退學或正常),詳細過程在 3.3 節 中說明。. 35.
(36) nul l 北臺灣 a1 新北市. A. B 南台灣. a3 台北市. b1 三芝鄉. a2 高雄市 b2 鳳山市. 每週曠 TID. 縣市. 鄉鎮區. 科系. 類別 缺節數. 1 2 3 4 5. 新北 新北 新北 高雄 高雄. 三芝. 資工系. S. 正常. 三芝. 資工系. M. 正常. 三芝. 資管系. S. 退學. 鳳山. 資管系. M. 退學. 鳳山. 電機系. S. 休學. 圖 4.1 學生休退學資料範例. 4.2 預測模型的建立 在這一節中,我們首先說明如何設定各項目的支持度門檻,接下來描述 如何由延伸訓練集 D*中產生所有符合多重支持度及信賴度的規則,以及預測模型 的建立。. 4.2.1 多重支持度的設定 此程序的目的是由延伸的訓練資料集 D*中,根據使用者給定的最低支持度門檻、 權重參數、信賴度等所產生的規則。作法是採用 CMAR 的增強型 FP-tree 的資料 36.
(37) 結構,先將延伸資料集 D*存入此增強型 FP-tree 中,再由其產生分類規則。詳細的 演算步驟描述在演算法 3.1。. 演算法 3.1 規則探勘. 輸入: 延伸的訓練資料資料集 D*、項目階層樹 T、最低支持度門檻、權重參數、 信賴度門檻 mc 輸出: 符合的分類規則集合 R. 步驟: 1. 掃描延伸訓練資料集 D*,計算每個項目的支持度門檻,並清除低於支持度的項 目。 2. 建立增強型 FP-tree。 2.1 以步驟 1 存留下來的項目,依每一個項目的出現次數,由高至低排序當成 增 強型 FP-tree 的標頭表。 2.2 依序讀取每筆案例,並依標頭表中項目的次序,將此案例由根節點(null)向子 節點加入增強型 FP-tree 中。 2.3 在每一案例最後一個子節點加入後,在該節點記錄該筆案例的分類結果及出現 的次數。 3. 依項目在標頭表的次序,由出現最低的項目開始,反覆執行下列步驟,直到所 有項目皆處理完為止。 3.1 令 a 為目前的項目,由增強型 FP-tree 產生。所以項目 a 為節點的路徑,型成 一個項目 a 的投影樹(projected subtree)。 3.2 由 3.1 的投影樹,對每一條路徑產生 p = (a1,a2,…,a),計算 p 項目集的支持度 若低於支持度門檻則刪除此路徑。 37.
(38) 3.3 產生下列分類規則 a1, a2,…, a l 其中 l 為與項目在一起的類別標籤,並計算此規則的信賴度,若信賴度低於信賴度 門檻,則將此規則刪除。否則將此規則加入 R 中。 3.4 完成包含項目 a 的所有分類規則的生成後,將項目 a 從增強型 FP-tree 中刪除, 並將所有包含項目 a 的節點中的類別標籤往上合併到靠近的節點中。. 接下來我們以圖 1 的例子為例,說明演算法 3.1 的重要步驟的執行結果。首 先,圖 2 展示步驟 1 執行後的結果,為簡化起見,圖 2 中的資料項目皆以符號來 代表。因最低支持度門檻 σ 設為 25%,權重參數 = 0.5,信賴度門檻 mc = 50%, 故項目 c1 被排除。 接著圖 3 顯示步驟 2 執行後,所產生的增強型 FP-tree,其中可產生所有包 含項目 d2 的分類規則為 R1: A, a1, b1, c3, d2 甲 R2: B, a2, b2, c2, d2 乙. 最後圖 4 顯示項目 d2 移除後,新的增強型 FP-tree 的結果。圖 5 則顯示最後 最後圖 4 顯示項目 d2 移除後,新的增強型 FP-tree 的結果。圖 5 則顯示最後 產生的所有分類規則,其中具紅色刪除線的即為被刪除的規則。. 38.
(39) 每週曠 TID. 區域. 縣市. 鄉鎮區. 科系. 類別 缺節數. 1 2 3 4 5. A. a1. b1. c3. d1. A. a1. b1. c3. d2. A. a1. b1. c2. d1. B. a2. b2. c2. d2. B. a2. b2. c1. d1. Id. item. Sup (%). 1 2 3 4 5 6 7 8 9 10. A a1 b1 d1 B a2 b2 c2 c3 d2. 60 60 60 60 40 40 40 40 40 40. 圖 4.2 GACMS 演算法 3.1 範例-產生頻繁項目及標頭表格. 39. 甲 甲 乙 乙 丙. link.
(40) 圖 4.3 GACMS 演算法 3.1 範例-產生增強型 FP-tree. 圖 4.4 GACMS 演算法 3.1 範例-刪除 d2 後的增強型 FP-tree. 4.2.3 模型建立 接下來我們將前述步驟產生的規則逐一地加入 CR-tree,即構成我們的預測模 型。由於前述步驟所產生的分類規則存在許多不一致或重複的狀況,且數量過於 龐大,故接下來我們依下列的方式,在規則加入到 CR-tree 的時候,對規則進行 修剪。. 40.
(41) 信賴度. 支持度(左. 支持度門檻. 規則 (%). 項,%). (左項,%). A, a1, b1, c3, d2 甲. 100. 20. 20. B, a2, b2, c2, d2 乙. 100. 20. 20. A, a1, b1, d1, c3 甲. 100. 20. 20. A, a1, b1, c3 甲. 50. 40. 20. A, a1, b1, d1, c2 乙. 100. 20. 20. B, a2, b2, c2 乙. 100. 20. 20. B, a2, b2 乙. 50. 40. 20. d1, B, a2, b2 丙. 100. 20. 20. B, a2 乙. 50. 40. 20. d1, B, a2 丙. 100. 20. 20. B 乙. 33. 60. 20. d1, B 丙. 100. 20. 20. A, a1, b1, d1 甲. 50. 40. 30. A, a1, b1, d1 乙. 50. 40. 30. d1 丙. 33. 60. 30. A, a1, b1 甲. 67. 60. 30. A, a1, b1 乙. 33. 60. 30. A, a1 甲. 67. 60. 30. A, a1 乙. 33. 60. 30. A 甲. 67. 60. 30. A 乙. 33. 60. 30. 圖 4.5 GACMS 演算法 3.1 範例-產生的規則 41.
(42) 首先我們考慮規則的關聯性。考慮任一規則 R: P C,我們計算此規則的提升 度(lift) lift (R) . sup( P C ) conf ( R) sup( P) sup(C ) sup(C ). 當 lift > 1,表示此規則的條件 P 與類別 C 為正相關。依分類的目的,規則的提升 度應呈現正相關,且愈高愈好,故當規則 R 的 lift 1,則刪除此規則。 接下來考慮任兩條規則 R 及 R’ R: P C R’: P’ C’ 我們首先定義規則通用性的概念。當下列情形成立時,稱 R 為比 R’更通用的規則。 項目集 P 為 P’的部份集合,即 P P’。 P P’,但每個屬於 PP’中的條件項目 a,皆可找到在 P’的某個項目 b,且 a 為 b 的祖先項目。 當已知 R 為比 R’更通用的規則,而下列條件成立時,則我們保留 R、刪掉 R’。 conf(R) > conf(R’) conf(R) = conf(R),且 sup(R) sup(R’) 最後我們依據階層關係,對規則 R: P C 的左項進行化簡,其原則如下:若左項 的項目集 P 中存在任兩個條件項目 c 及 d,而 c 為 d 的祖先項目,則將 c 移除。此 乃因項目 c 根據階層關係,得知當項目 d 條件成立時,必可推知項目 c 也必成立。 故項目 c 便成為多餘的分類條件。 詳細演算法如演算法 3.2 所示。. 演算法 3.2 模型建立 輸入:分類規則集合 輸出:預測模型 CR-tree 步驟: 1. 先依構成規則的條件項目的出現次數由高而低排序,當成 CR-tree 的標頭表。 2. 將所有的規則依照信賴度、支持度和條件個數排序,依下列步驟逐一加入 CR-tree。 2.1 計算規則的 lift,若 lift 1,則刪除此規則。 2.2 將規則 R:P C 依標頭表中項目的次序,由根節點(null)向子節點,加入 CR-tree 中。加入時,同時檢查已存在規則與 R 的通用性。若已存在的規則比 R 的 通用性更高,且排序較佳,則刪除 R。 2.3 在每一組最後一個子節點加入後,在該節點記錄該規則的類別、支持度和信任 42.
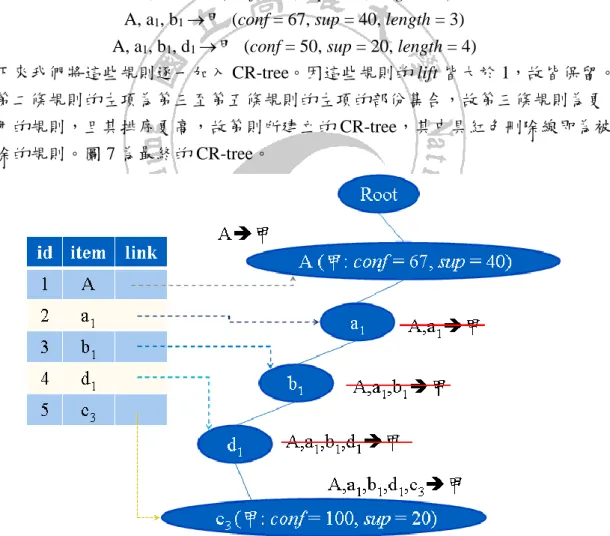
(43) 度。 3. 對所有的規則進行化簡,即若規則左項的項目集中存在任兩個項目 c 及 d,而 c 為 d 的祖先項目,則將 c 移除。 我們以前述的範例,說明演算法 3.2 的主要步驟。考慮下列規則: A, a1, b1, d1, c3 甲 (conf = 100, sup=20, length = 5) A, a1, b1, d1 甲 (conf = 50, sup = 20, length = 4) A, a1, b1 甲 (conf = 67, sup = 40, length = 3) A, a1 甲 (conf = 67, sup = 40, length = 2) A 甲 (conf = 67, sup = 40, length = 1) 經過步驟 2 排序後,其次序如下: A, a1, b1, d1, c3 甲 (conf = 100, sup=20, length = 5) A 甲 (conf = 67, sup = 40, length = 1) A, a1 甲 (conf = 67, sup = 40, length = 2) A, a1, b1 甲 (conf = 67, sup = 40, length = 3) A, a1, b1, d1 甲 (conf = 50, sup = 20, length = 4) 接下來我們將這些規則逐一加入 CR-tree。因這些規則的 lift 皆大於 1,故皆保留。 但第二條規則的左項為第三至第五條規則的左項的部份集合,故第三條規則為更 通用的規則,且其排序更高,故第則所建立的 CR-tree,其中具紅色刪除線即為被 刪除的規則。圖 7 為最終的 CR-tree。. 圖 4.6 GACMS 演算法 3.2 範例-CR-tree. 43.
(44) 圖 4.7 GACMS 演算法 3.2 範例-最終建立的 CR-tree. 4.3 未知資料的預測 當未知的資料輸入時,GACMS 方法先預測模型中尋找所有符合資料條件的規模, 並依據模型中的規則的強度由強至弱(先考慮信類度,再考慮支持度)、逐一與該筆 未知資料的條件比對,直到符合為止;也就是該筆資料會由符合條件中,強度最 強的一條分類規則決定其分類結果。例如 未知資料: {高雄市,資工系,每週曠課程度 s } 模型中的規則: {高雄市,資工系,每週曠課程度 s 休學} (conf = 40%, sup = 80%) {高雄市,資工系,每週曠課程度 s 退學} (conf = 40%, sup = 30%) {高雄市,資工系,每週曠課程度 s 正常} (conf = 10%, sup = 95%) 分類結果:休學. 第五章 實驗與結果 在本章中,我們將會說明 GACMS 演算法的實作,並且進行演算法的效能比 較。 44.
(45) 5.1 實驗設計 首先在實作的平台,我們使用一台個人電腦,其作業環境如下: 作業系統:Windows 7 處理器:Intel® Core™ i5 M430 @ 2.27GHz 主記憶體:DDR3 8192Mbytes 硬碟:Intel SSD 480GB 另外在資料庫方面,我們選用微軟 SQL Server 2008,所有的程式及系統介面 以 c#(Windows form)、WEKA 3.6.6 進行開發。 訓練資料的詳細內容如第二章所述,並參考專家的意見,建構了三個階層樹 狀資訊,為住址、科系及曠課週數,詳如圖 3.3、3.4 及 3.5。 此外,特別值得一提的是,此休退學資料本質上屬於類別分佈極度不平均的 資料,絕大部分的案例屬於正常,休學和退學的案例僅佔不到二成。因此,資料 的選取我們等量擷取三個類別的資料,因為如果數量不相等,會造成系統習得的 分類規則都偏向最大的那一群,導致最後無法有效的分類。. 5.2 系統說明 如圖 5.1,系統基本設定如資料庫連結、訓練資料條件、測試資料條件、最小 支持度調整參數、項目出現次數最低門檻、規則排序…等,都可透過 Setup 這個頁 面進行設定。. 45.
(46) 圖 5.1 系統設定畫面 設定完後進入訓練資料檢視畫面(如圖 5.2),可以檢視訓練資料是否正確。也 可到測試資料檢視畫面(如圖 5.3)檢視測試資料。. 圖 5.2 訓練資料檢視畫面 46.
(47) 圖 5.3 測試資料檢視畫面. 在欄位選擇頁面(Feature Selection)可以選擇要拿來建模型的資料欄位(如圖 5.4),接下來到條件與階層設定頁面(如圖 5.5)可以設定判別項目的條件與階層關 係。再到階層樹頁面(圖 5.5)就可以看到這個項目的階層關係。這個頁面功能還可 供專家來加入不存在於資料中的項目到階層樹中,例如把高雄市歸入南台灣的下 層項目中。. 47.
(48) 圖 5.4 欄位選擇畫面. 圖 5.5 條件&階層設定畫面. 48.
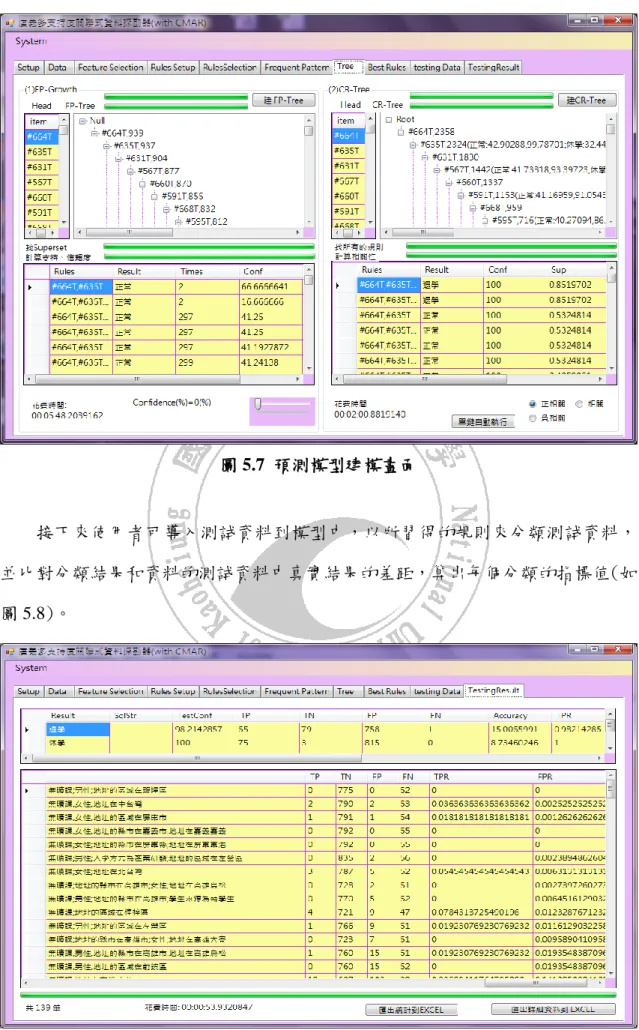
(49) 圖 5.6 階層樹畫面. 接下來開始導入訓練資料以 GACMS 演算法來建立模型(如圖 5.7)。在這個頁 面中,系統會列出增強型的 FP-tree、CR-tree 和學到的規則的資訊,並依之前設定 的排序方式(如圖 5.1)來修剪規則。. 49.
(50) 圖 5.7 預測模型建模畫面. 接下來使用者可導入測試資料到模型中,以所習得的規則來分類測試資料, 並比對分類結果和資料的測試資料中真實結果的差距,算出每個分類的指標值(如 圖 5.8)。. 50.
(51) 圖 5.8 測試結果畫面. 分類清單如圖 5.9 所示,系統將列出由 GACMS 分類後的結果於”預測類別” 欄位,兩個短破折號”—“表示此筆資料以模型中的分類規則無法將其分類。. 預測類別. 圖 5.9 分類清單. 5.3 實驗結果分析 5.3.1 預測準確度分析 本實驗採用 ‘建築工程’、’經營管理’、’營建工程’和’數位內容’等四個科系資 料來實驗,其分別隸屬三個學院(如圖 3.5)。 在精準度上,我們與過去常用在休退學分類上的四種演算法比較,分別是 51.
(52) NaiveBayes、Logistic、JRip 和 DecisionTree (NB-Tree)。這四種方法分別以 WEKA (3.6.6 版) 執行,測試的方式是將 96~100 學年度 5687 筆資料作為訓練資料,將 101 學年度 893 筆資料作為測試資料。而我們的 GACMS 方法也是取 96~100 學年度學 生資料,並平均取每個類別等筆數的資料共 939 筆,項目最低出現次數的門檻為 訓練資料 1%的資料筆數,信賴度門檻設定為 15,再分別以多支持度權重 0.1、0.3、 0.6 和 1.0 來建立模型,程式再以此訓練後的模型對 893 筆測試資料做驗證,並以 測試資料各類別的筆數當權重求出 precision 和 recall 來和其它方法比較。 例 如 測 試 資 料 中 的 類 別 有 {C1,C2,C3...,Cn} 且 權 重 分 別 為 {W1,W2,W3...,Wn} , Precision(在此以ρ表示)和 Recall(在此以γ表示),則可分別以下列方式算出加權平 均。 Wn=Cn 測試資料筆數/測試資料總筆數. ρ加權平均=ρC1×W1+ρC2×W2+ρC3×W3+...+ρCn×Wn γ加權平均=γC1×W1+γC2×W2+γC3×W3+...+γCn×Wn 而結果如表 5.1 與圖 5.10 所示。. 表 5.1 各種演算法精確度比較 方法 Jrip. Logistic. NBTree. BayesNet. Precision 加權平均. Recall. 正常. 0.871. 休學. 0.324. 退學. 0.153. 0.217. 正常. 0.868. 0.942. 休學. 0.172. 退學. 0.375. 0.054. 正常. 0.878. 0.911. 休學. 0.133. 退學. 0.536. 0.268. 正常. 0.938. 0.871. 休學. 0.278. 退學. 0.176 52. 加權平均 時間(秒). 0.896 0.777. 0.779. 0.794. 0.835. 0.147. 0.133. 0.133. 0.56 0.107. 0.791. 2.07. 0.819. 17.46. 0.805. 20.64. 0.797. 0.11.
(53) GACMS(0.1). GACMS(alpha=0.3). GACMS(alpha=0.6). GACMS(alpha=1.0). 正常. 0.926. 休學. 0.25. 退學. 0.196. 0.643. 正常. 0.923. 0.878. 休學. 0.444. 退學. 0.226. 0.643. 正常. 0.974. 0.583. 休學. 0.909. 退學. 0.115. 0.875. 正常. 0.98. 0.503. 休學. 0. 退學. 0.102. 0.852 0.823. 0.839. 0.914. 0.842. 0.027. 0.053. 0.133. 0. 0.769. 76. 0.794. 72. 0.563. 70. 0.486. 69. 0.911. 圖 5.10 各演算法精確度比較 由表 5.1 的數據可以看出,所有的方法在休學與退學這兩類的預測效果普遍 不佳,這是因為實務上造成學生休退學的原因複雜,在有限的資料屬性與樣本下,. 高,正常的精確率提高、但召回率降低,休學的精確率與召回率皆提高,休學的 精確率降低、 圖 5.10 整理各方法在整體的精確率與召回率的比較,可以看出,我們的方法 較其他有較高的精確率表現,但召回率則受α值的影響極大。如圖 5.11 所示,在 53.
(54) 此實驗 α= 0.3 的表現最佳。. Precision 或 Recall 值. 多支持度 權重參數. 圖 5.11 不同多支持度權重參數比較. 5.3.2 執行速度分析 這 一小節我們將針對執行速度來探討,首先我們一樣要和 NaiveBayes 、 Logistic、JRip和DecisionTree比較。 我們針對執行速度進行比較。如表 5.1 所示,我們的方法耗時最長,這是因 為我們學習的規則比較零散,而且我們的程式只以單一執行緒執行,導致建立模 型的時間比 Weka 提供的方法普遍運用多執行緒的執行技巧慢了許多。未來我們 也將採用多執行緒的方法實作我們的方法。. 54.
(55) 第六章 結論與未來研究 6.1 結論 在本研究中,針對大學生的休退學預測問題,我們建構了一個休退學預測系 統,此系統能有效預測在學學生每學期結束後是否休退學或繼續在學。另外,此 系統也能分析探勘所得的分類規則,將最重要關鍵的規則產出,提供給相關的人 員進行決策參考。在這個系統中,我們發展一種新的分類方法,稱為 GACMS 方 法。此方法以關聯分類方法為基礎,加入多重支持度的機制,可有效解決出現頻 率少,但很重要的分類條件被單一支持度過濾掉的問題,讓更多有用的分類資訊 得以保留到模型的產生,提高了模型的預測準確度。另外此方法還利用專家定義 的階層樹,讓零散且有用的規則有機會彙整為強度足夠的分類規則,並有效修剪 訓練後的模型裡規則中多餘的條件,讓分類規則更精實。 在實驗部份,雖然我們的運算速度不比其它演算法。但我們獲得的規則經測 試資料試驗後,證實可獲得精確度遠高於其他方法的分類規則。 綜合以上,我們提出的 GACMS 方法,極適合用資料集中,各種條件出現頻 率差異極大,且又具有豐富階層分類資訊的問題。例如除了做學生休退學研究, 也可做學生未來就業研究,或是將之應用到其它領域去探勘有用的分類規則。. 55.
(56) 6.2 未來研究工作 學生的休退學預測問題,過去已有相當多的研究,但利用關聯式分類法的作 法,就我們所知是種新的嘗試。位來我們將以此研究為基礎,繼續朝向下列幾個 方向進行研究 : (1) 此次研究,發覺有些規則是有時序性的休退學規則。例如,有六成以上的退學學 生是曾經休學。可經由增加時序性的分類規則探勘法找出這類的規則,以增加分 類模型的準確度。 (2) 本論文採用的多重支持度關聯規則探勘,其所設定的權重參數扮演相當重要的角 色。有研究[25]提出以信賴度調整此參數,未來也可參考此一方法找出更好的參數 調整方法,以有效提升訓練模型時的運算速度。 (3) 本研究因採用多重支持度關聯規則探勘,讓許多有用資訊得以保留,但也相對大 幅降低運算速度,如果能有效運用多工處理,應能解決此一問題。如何將本文中 所提方法切分為多個線程(Threads)來執行而不互相干擾,也是接下來可以研究的方 向。目前比較可行的是在 GACMS 作規則排序和修剪時,因為每條規則出現時就 做排序和修剪,所以這邊極有機會可以切分多工模式,只要能有效控制每個線程 不互搶資源即可。. 56.
(57) 參考文獻 [1]. R. Agrawal, T. Imielinski, and A. Swami, “Mining association rules between sets of items in large databases,” in Proceedings of the ACM SIGMOD International Conference on Management of Data, pp. 207-216, 1993.. [2]. R. Agrawal and R. Srikant, “Fast algorithms for mining association rules,” in Proceedings of the 20th International Conferences on Very Large Data Bases, pp. 487-499, 1994.. [3]. F. Araque, C. Roldan, and A. Salguero, “Factors influencing university drop out rates,” Computers & Education, vol. 53, pp. 563–574, 2009. [4]. G.W. Dekker, M. Pechenizkiy, and J.M. Vleeshouwers, “Predicting students drop out: A case study,” in Proceedings of the 2nd International Conference on Educational Data Mining, pp. 41–50, 2009.. [5]. M. Feng, N. Heffernan, and K. Koedinger, “Looking for sources of error in predicting student’s knowledge,” in Proceedings of AAAI Workshop on Education Data Mining, pp. 1–8, 2005.. [6]. J. Han and Y. Fu, “Discovery of multiple-level association rules from large databases,” in Proceedings of the 21st International Conference on Very Large Data Bases, pp. 420-431, 1995.. [7]. J. Han, J. Pei, and Y. Yin, “Mining frequent patterns without candidate generation,” in Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, pp. 1-12, 2000.. [8]. S. Kotsiantis, “Educational data mining: A case study for predicting dropout-prone students,” International Journal of Knowledge Engineering and Soft Data Paradigms, vol. 1, no. 2, pp. 101–111, 2009. 57.
(58) [9]. S. Kotsiantis, K. Patriarcheas, and M. Xenos, “A combinational incremental ensemble of classifiers as a technique for predicting students performance in distance education,” Knowledge Based Systems, vol. 23, no. 6, pp. 529–525, 2010.. [10] S.B. Kotsiantis and P.E. Pintelas, “Predicting students’ marks in Hellenic Open University,” in Proceedings of IEEE International Conference on Advanced Learning Technologies, pp. 664–668 , 2005. [11] W. M. Li, J. W. Han, and J. Pei, “CMAR: Accurate and efficient classification based on multiple class-association rules,” in Proceedings of IEEE International Conference on Data Mining, pp. 369-376, 2001. [12] B. Liu, W. Hsu, and Y. Ma, “Integrating classification and association rule mining,” in Proceedings of the 4th International Conference on Knowledge Discovery and Data Mining, pp. 80–86, 1998. [13] B. Liu, W. Hsu and Y. Ma, “Mining association rules with multiple minimum supports”, in Proceedings of SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 337-341, 1999. [14] C. L. Lui and F. L. Chung, “Discovery of generalized association rules with multiple minimum supports,” in Proceedings of 4th European Conference on Principles and Practice of Knowledge Discovery in Databases, pp. 510-515, 2000. [15] I. Lykourentzo, I. Giannoukos, V. Nikolopoulos, G. Mpardis, and V. Loumos, “Dropout prediction in elearning courses through the combination of machine learning techniques,” Computers & Education, vol. 53, pp. 950–965, 2009. [16] C. Márquez-Vera, A. Cano, C. Romero, and S. Ventura, “Predicting student failure at school using genetic programming and different data mining approaches with high dimensional and imbalanced data,” Applied Intelligence, vol. 16, pp. 315-330, 58.
(59) 2003. [17] C. Marquez-Vera, C. Romero, and S. Ventura, “Predicting school failure using data mining,” in Proceedings of 4th International Conference on Educational Data Mining, pp. 271-276, 2011. [18] D. Martinez, “Predicting student outcomes using discriminant function analysis,” in Proceedings of Annual Meeting of the Research and Planning Group, pp. 163–173, 2001. [19] G. Mendez, T.D. Buskirk, S. Lohr, and S. Haag, “Factors associated with persistence in science and engineering majors: An exploratory study using classification trees and random forests,” Journal of Engineering Education, vol. 9, no. 1, pp. 57-70, 2008. [20] A. Parker, “A study of variables that predict dropout from distance education,” International Journal of Educational Technology, vol. 1, no. 2, pp.1–11, 1999. [21] M.N. Quadril and N.V. Kalyankar, “Drop out feature of student data for academic performance using decision tree techniques,” Journal of Computer Science and Technology, vol. 10, pp. 2–5, 2010. [22] C. Romero and S. Ventura, “Educational data mining: A review of the state of the art,” IEEE Transactions on Systems, Man, and Cybernetics, vol. 40, no. 6, pp. 601-618, 2010. [23] R. Srikant and R. Agrawal, “Mining generalized association rules,” in Proceedings of the 21st International Conference on Very Large Data Bases, pp. 407-419, 1995. [24] J.F. Superby, J.P. Vandamme, and N. Meskens, “Determination of factors influencing the achievement of the first year university students using data mining methods,” in Proceedings of AAAI Workshop on Educational Data Mining, pp. 59.
(60) 1–8 , 2006. [25] M.C. Tseng and W.Y. Lin, “Maintenance of generalized association rules with multiple minimum supports,” Intelligent Data Analysis, vol. 8, pp. 417-436, 2004. [26] M.C. Tseng and W.Y. Lin, “Efficient mining of generalized association rules with non-uniform minimum support,” Data and Knowledge Engineering, vol. 62, no. 1, pp. 41-64, 2007. [27] T.Y. Tang and G. Mccalla, “Student modeling for a web-based learning environment: A data mining approach,” in Proceedings of the 18th National Conference on Artificial Intelligence, pp. 967–968, 2002. [28] W. Veitch, “Identifying characteristics of high school dropouts: Data mining with a decision tree model,” in Proceedings of Annual Meeting of the American Educational Research Association, pp. 1–11, 2004. [29] L. Wegner, A.J. Flisher, P. Chikobvu, C. Lombard, and G. King, “Leisure boredom and high school dropout in Cape Town, South Africa,” Journal of Adolescence, vol. 31, pp. 421–431, 2008. [30] M.V. Yudelson, O. Medvedeva, E. Legowski, M. Castine, D. Jukic, and D. Rebecca, “Mining student learning data to develop high level pedagogic strategy in a medical ITS,” in Proceedings of AAAI Workshop on Educational Data Mining, pp. 1–8, 2006. [31] ETToday 東 森 新 聞 雲 - 教 育 部 102 年 推 方 案 整 併 6 所 國 立 大 學 http://www.ettoday.net/news/20121119/129267.htm [32] P.N. Tan, M. Steinbach, and V. Kumar, Introduction to Data Mining: Pearson, 2005, pp. 373-374.. 60.
(61)
數據

+6


相關文件
Proceedings of the 19th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval pp.298-306.. Automatic Classification Using Supervised
A dual coordinate descent method for large-scale linear SVM. In Proceedings of the Twenty Fifth International Conference on Machine Learning
Hofmann, “Collaborative filtering via Gaussian probabilistic latent semantic analysis”, Proceedings of the 26th Annual International ACM SIGIR Conference on Research and
Mehrotra, “Content-based image retrieval with relevance feedback in MARS,” In Proceedings of IEEE International Conference on Image Processing ’97. Chakrabarti, “Query
in Proceedings of the 20th International Conference on Very Large Data
(1999), "Mining Association Rules with Multiple Minimum Supports," Proceedings of ACMSIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego,
Lange, “An Object-Oriented Design Method for Hypermedia Information Systems”, Proceedings of the Twenty-seventh annual Hawaii International Conference on System Sciences, 1994,
Proceedings of the Fifth International Conference on Genetic Algorithms, Morgan kaufmann Publishers, San Mateo, California, pp.110~117, 1996. Horn, J., “Finite Markov Chain Analysis
