應用基因演算法於委外作業專案排程之設計
8
0
0
全文
(2) l 圖形化的專案活動表示。 l 完成專案所需花費時間的預估。 l 專案中各個活動之預定執行起始時間與結 束時間。 l 專案中各個活動之間相對的重要性。 儘管 PERT 與 CPM 可以提供管理者許多 有用資訊,但在對具有並行、反覆與演進式特 性的軟體專案進行規劃與管理時,這兩種工具 在應用上仍有明顯的不足 [4, 11]。舉例來說, 當我們在考慮專案發展過程中有限資源分配 的特性與限制時, CPM 便無法進一步地提供 如何分配資源的相關資訊。為了解決以上的缺 點,我們將在本論文中針對欲求解問題的特性 設計出一個處理委外作業專案排程的演算法。 本文中所提之方法係以基因演算法的架 構為基礎,其目的是協助企業在執行委外作業 專案的過程中產生最佳資源分配與專案時程 管制的決策結果。基因演算法是植基於達爾文 「物競天擇,適者生存」演化理論的概念所發 展出來的方法 [5, 6]。此一方法首先會將吾人 所欲求解之問題以字串的方式編碼成為所謂 的「染色體 (chromosome)」。每個染色體中包 含了數個基因 (gene),不同的基因排列表現出 此一染色體的不同特徵,而這些特徵在經過評 估 (evaluation) 之後便會反映出該染色體對 所在環境的適存程度 (fitness),適存度越高的 染色體表示其所相對應解的品質越高。基因演 算 法 一 般 具 有 「 交 配 (crossover) 」、「 突 變 (mutation)」以及「選擇 (selection)」等三個運 算子。交配運算子的主要目的在於將不同染色 體的部份基因予以交換,進而使得相對應解的 優良特性可以被保留至下一個世代;突變運算 子則是隨機改變染色體中部份基因的內容,用 以在搜尋過程中跳脫局部最佳解的陷阱;至於 選擇運算子則是用以決定哪一個染色體可以 存活至下一個世代。對於環境的適存程度越高 的染色體而言,其在演化過程中得以存活的機 率當然也就越高。如此反覆運作許多世代之 後,我們預期將可以獲致高品質的問題解。 本文在後續的內容中,我們首先就所要處 理 之 委 外 作 業 專 案 排 程 問題 加 以 描 述 且 定 義;之後,我們將詳細說明所提出方法的設計 細節並進一步探討其特性;接著我們會針對演 算法的效能進行評估,然後再藉由一個協同式 委外作業專案管理系統的實作以驗證設計方 法的可行性。最後,我們將為本文的內容進行 總結並說明未來相關的研究工作。. 二、問題塑模 本論文中,我們利用一個有向非循環圖 (directed acyclic graph,DAG) 來表示一個專. 案。在任一特定的 DAG 中,節點係用來表示 專 案 中 的 工 作 (task) 或 活 動 (activity); 而 DAG 中的有向邊則係用來表示工作與工作之 間 的 執 行 先 後 順 序 關 係 (precedence relation)。若吾人在開始執行工作 tj 之前必須 先將工作 ti 完成,則 DAG 中代表工作 ti 與 tj 的節點之間必定存在著一個有向邊。為了方 便說明起見,我們將本文中所將探討的專案抽 象化為一個具有 5 維度特性的系統 -- (T, E, l, r, p)。系統中各個維度的定義說明如下: l T = {t1 , t2 , ..., t|T|} 為專案中所有工作的集 合,|T| 則表示為此集合中所有工作個數。 l E = {eij } 為 DAG 中所有有向邊的集合, eij 表示工作 ti 與工作 tj 之間具有先後順 序關係之限制。在此限制條件下,我們稱 ti 為 tj 的立即前置工作,而 tj 則被稱為是 ti 的立即後繼工作。對於所有屬於工作 ti 的 立即前置工作所成的集合,我們以 PREDi 表示;而 SUCCi 則用以表示工作 ti 的所 有立即後繼工作所成的集合。若有一工作 ti ,其 SUCCi 的內容為空集合,我們稱之 為起始工作。若有一工作 tj,其 PREDj 的 內容為空集合,我們稱之為結束工作。在不 失一般性的情況下,我們假設每一個 DAG 中都各只有一個起始工作與結束工作,並將 之分別表示為 tentry 與 texit。顯而易見地, texit 的完成時間即代表整個專案的完成時 間。 l l 為整個專案的完成期限。 l r 為在期限內完成專案所能獲致的收益。 l p 用以表示專案延遲時每一單位延遲時間 所必須付出的成本。 一般而言,在專案起始之初,專案經理可 先決定出如表 1 所 示 之 專 案 中 所 包 含 的 工 作,以及各個工作之間執行先後順序的限制。 根據表 1 所獲得之相關資訊,我們可以得到 如圖 1 所示之相對應的 DAG。 由於我們必須將專案中的工作分派給最 為合適的工作團隊來執行,因此除了考慮專案 中各個工作彼此之間的執行順序限制條件之 外,我們還必須進一步地針對工作團隊之間的 關係予以抽象化的定義。吾人可將所有意欲參 與專案執行的工作團隊描述成一個具有 3 維 度特性的系統 -- (G, [d ij ], [cij ])。此一系統中各 維度特性與相關定義說明如下: l G = {g 1 , g 2 , ..., g |G|} 為專案中所有參與工 作團隊的集合, |G| 表示為此集合中所有工 作團隊的個數。 l [d ij ] 為一 |T|×|G| 大小的矩陣,d ij 表示工作 團隊 g j 執行工作 ti 所耗費的時間。 l [cij ] 為一 |T|×|G| 大小的矩陣, cij 表示工作 團隊 gj 執行工作 ti 所必須支付的成本。.
(3) 當 g j 無法勝任 ti 時,則令 cij 為無限大。 現假設 s 為某專案在排程之後所得的結 果,則該專案中的工作 tj 基於 s 所得到的完 成 時 間 finifh(tj ) 在 數 學 上 的 定 義 可 被 表 示 為: | G|. finish (t j ) = max ( finish (t i )) + ∑ d jk x jk (1) ∀t ∈PRED i. j. k =1. 其中, xjk=1 表示 s 將工作 tj 分派給團隊 g k 執行,反之, xjk=0。基於以上所描述的符號與 定義,我們可以進一步地得出求解此一問題的 目標函式如下: n. m. maxZ ( s) = r − ∑ ∑ cij xij − p [ finish (t exit ) − l ] + s. i= 1 j= 1. (2). 其中, [a]+ 表示 max{0, a}。本文之目的便在 於根據上述的目標函式設計出適宜的演算法 則,進而找出合乎要求的工作排程結果,使得 專案收益在扣除各個工作執行成本以及懲戒 金額之後可以達到最大值。. 三、設計方法 本節在一開始將先就我們所提出的演算 法做概要性的說明,其內容包括問題編碼的方 式、初始解的產生、適存度的定義、交配與突 變程序的特性、以及選擇機制的設計等相關議 題介紹。接著,我們將詳細說明我們所提出的 交替式順序交配運算子的運作方式,並就其特 性進行分析。最後,我們將說明如何將模擬退 火方法 (simulated annealing,SA) [8] 的精神 整合於突變程序的設計之中,用以強化突變運 算的效能。 (一) 設計方法綜覽 本論文中,我們以基因演算法的基本架構 來解決委外作業專案管理的工作匹配與排程 問題。我們藉由排程字串 (scheduling string, SS) 與匹配字串 (matching string,MS) 二者 的組合來表示一個染色體 [13]。其中,排程字 串係用來表示 DAG 中各個工作節點的執行 先後順序;而匹配字串則是表示某一工作交由 哪一個特定的工作團隊所執行。圖 2 是根據 圖 1 所產生出的一個染色體實例。由圖中我 們可以得知各個工作的執行順序以及分派執 行的狀況。例如:工作 t1 和 t2 之執行係各由 工作團隊 g 1 和 g3 所負責;而工作團隊 g2 則是以循序的方式依次執行工作 t3 、t5 、t9 以 及 t12 。 一旦決定了染色體的編碼方式之後,下一 步便是進行初始族群的建構。在我們建構初始. 族群的過程中,每一個染色體中的排程字串內 容是經由隨機產生一組符合 DAG 拓撲排序 的工作順序所決定;而每一個染色體中的匹配 字串內容則是利用隨機的方式將每一個工作 指派給任意的工作團隊而產生。透過這樣的機 制,我們不但可以保證初始族群中的每一個成 員均為合法表示的染色體,同時也可以確保問 題領域中所有的解都有被產生的可能。此一表 示法具有以下的性質: 性質1. 排程字串中基因內容的排列順序必須 與 DAG 中 工 作 節 點 的 拓 撲 順 序 相 符合。 性質2. 排程字串中的每一個基因內容在該字 串中僅能出現一次。 性質3. 匹配字串中的每一個基因內容允許與 該字串中其他基因的內容相同。 性質4. 排程字串與匹配字串的長度與 DAG 中工作節點的數目相同。 在以上的這些特性中,性質 1 利用拓撲排序 的特性讓工作的執行不會違反執行先後順序 的限制條件;性質 2 則是說明了一個工作僅 能夠讓一個處理單元執行,而一個處理單元在 同一時間內也僅能執行一個工作;性質 3 表 示每個處理單元在完成它所執行的工作後,可 以再被指派處理其它工作;性質 4 則是確保 在排程的過程中每一個工作只被執行一次。 我們還針對問題的特性提出一個名為交 替式順序交配 (Alternative Order crossover, AOX) 運算子。AOX 運算子比傳統的單一切 點順序交配 (order crossover,OX) 運算子 [10] 具備較高的有效性,可避免無效的交配運算。 除此之外,為了避免染色體在突變之後因為解 的品質不佳而無法存活至下一世代 (亦即,產 生無效的突變運算),我們在突變程序的設計 中採用了模擬退火方法的概念,用以強化突變 程序的效能。 當交配與突變程序進行完成,我們必須根 據每一個染色體的適存度對所有的染色體進 行評估。我們利用以下的定義決定染色體 S 的適存度: fitness (S ) =. Z (S ) avg Z (S). (3). 其中, Z(S)avg 是族群中所有染色體相對應於 問題特性所獲致利益的平均值。之後,我們採 用輪盤法則 (roulette wheel selection) 來決定 哪些染色體將會存活至下一個世代。我們也藉 由精英策略 (elitist selection) 的原則來確保每 個世代中最好的一個染色體必定會被選取而 進入下一個世代。當某一個染色體已經被選取 進入下一個世代之後,它將不會於本世代中再 次被選取,以避免在該染色體在下一個世代中.
(4) 重複出現,進而降低了下一世代族群的多樣 性。 (二) 交配程序設計 在委外作業專案排程問題的求解過程 中,本文所提出的 AOX 運算子主要是針對染 色體中的排程字串加以操作。此一運算子必須 要能確保交配之後所產生的子代能滿足工作 執行先後順序的限制條件。此一運算子的運作 流程如下: 步驟1. 由族群中隨機取出兩個參與交配的父 染色體 P0 與 P1,並令交配後所產生 的子代分別為 C0 與 C1 。 步驟2. 藉由隨機的方式決定交配切點的個數 k (2 ≤ k < n ),並以 CP1、CP2、 ...、CPk 分別表示依排列順序先後出現的交配 切點。其中,CP1、CP2 、 ...、CPk-1 在 染色體中的位置係以隨機的方式決 定;而 CPk 的位置則是固定於染色體 中最後一個基因的位置。 步驟3. 令 i = 1,反覆執行以下步驟直到 i > k 為止: (1) 將 P1-i\2 與 Pi\2 中位於 CPi 之 前 尚未出現於子染色體中的基因分別 複製並依序加入 C0 與 C1 之中。 (2) i = i + 1。 步驟4. 產生出新的子代染色體 C0 與 C1 。 根據 AOX 的運作方式,我們可以得到以 下的論證結果: [定 理 ] 在父染色體 P1 與 P2 皆為合法表示 的前提之下,經由 AOX 運算子的操作而產生 的子染色體 Coffspring 必定符合工作執行先後 順序的限制條件。 [證 明 ] 隨機選取 Coffspring 中 的 兩 個 基 因 g i 與 g j ,並假設 g i 的位置在 g j 之前,若吾人 以 pos(Coffspring.gi ) 表 示 基 因 內 容 gi 在 Coffspring 中的位置,則可得知 pos(Coffspring .g i ) < pos(Coffspring .g j )。同時,我們也假設基因 g i 在 父染色體中隸屬於交配切點 CPm 的區段;而 基因 g j 在父染色體中則是隸屬於交配切點 CPn 的區段。以下,我們分兩種情況探討 gi 與 g j 之間的關係。 Case 1. g i 與 g j 源自於相同的父染色體。 假設 gi 與 g j 源自於相同的父染色體 P0。在 pos(P0 .CPm ) = pos(P0 .CPn ) 的 情 況 下 , 如 果 pos(P0 .g i ) > pos(P0 .g j ),則因為隸屬於相同區段 的基因係由前往後依序加入子染色體中,所以 可得出 pos(Coffspring .gi ) > pos(Coffspring .g j ) 的結 果。此與已知條件相互矛盾。因此,必定存在 pos(P0 .g i ) < pos(P0 .g j ) 。 另 一 方 面 , 在 pos(P0 .CPm ) <> pos(P0 .CPn ) 的情況下,如果 pos(P0 .CPm ) > pos(P0 .CPn ),則因為 pos(P0 .CPm ) ≥ pos(P0 .g i ) > pos(P0 .CPn ) ≥ pos(P0 .g j ),最後將. 得 到 pos(Coffspring .g i ) > pos(Coffspring .g j ) 的 結 果。此亦與已知條件相互矛盾。因此,必定存 在 pos(P0 .CPm ) < pos(P0 .CPn ) 。 又 因 為 pos(P0 .g i ) ≤ pos(P0 .CPm ) < pos(P0 .gj ) ≤ pos(P0 .CPn ) , 於 是 可 推 導 出 pos(P0 .gi ) < pos(P0 .g j )。 Case 2. g i 與 g j 源自於不同的父染色體。 在此一情況下,我們可以得知 pos(P0 .CPm ) <> pos(P0 .CPn )。現假設 gi 與 g j 分別源自於不同 的父染色體 P0 與 P1。若 CPm < CPn,則必 定存在 pos(P0 .g i ) < pos(P0 .g j );否則當吾人依 序 將 基 因 加 入 Coffspring 之 中 時 , 將 會 出 現 pos(Coffspring .g i ) > pos(Coffspring .g j ) 的結果,此與 已知條件相矛盾。在另一方面,若 pos(P0 .CPm ) > pos(P0 .CPn ) , 則 必 定 存 在 pos(P1 .gi ) < pos(P1 .g j ),其原因如前所述。 根據以上之論述,我們可以歸納出子染色體中 任意兩個基因之間的先後順序關係必存在於 某一個父染色體之中。亦即,Coffspring 最後呈 現的排程結果必定符合工作執行先後順序的 限制條件。 □ 相較於傳統的交配法則 (例如:局部對應 交配 (partially-mapped crossover,PMX) 與循 環交配 (cycle crossover,CX)) [10],AOX 的 優點在於交配後所產生子代的基因內容必定 符合拓樸順序,因此不需要再進一步地調整內 容。故而在執行效能上, AOX 預期會有較佳 的表現。 再者,相較於單一切點的 OX 運算 子,本文中所提出的 AOX 運算子係以多重切 點的方式處理染色體的交配程序。此一處理方 式的優點在於交配後所產生出來的子代與父 染色體相同的機率較低,可提昇交配運算的有 效性。 (三) 突變程序設計 由於 AOX 交配運算子只是針對工作的 執行順序予以考量,因此在突變程序的設計部 分我們採用兩種機制來加以處理。其中,第一 種機制係採用模擬退火方法的概念來處理工 作指派問題。假設欲進行退火處理的染色體為 S,其所具有之能量為 Z(S),此一機制的運作 流程如下: 步驟1. 設定初始溫度 H0 、循環次數 N,最終 溫度 Hend,並且讓目前溫度 H = H0 。 步驟2. 令 n = 0,執行以下步驟直到 n ≥ N 為 止: (1) 以隨機的方式由 S 中的 MS 字串 選取一個基因並改變其值。將所得之 結果視為 S’。 (2) 計 算 S 與 S’ 二 者 之 間 的 能 量 差 ∆E = Z(S’) - Z(S)。若∆E ≦ 0,則令 S = S’;反之,則由機率 exp(-∆E/kB T) 決定是否接受 S = S’。其中,kB 為.
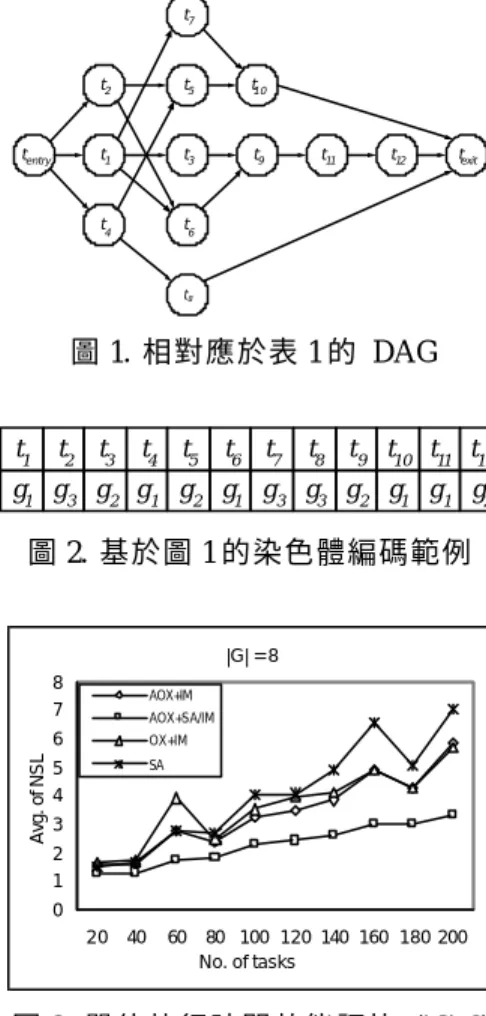
(5) 波茲曼常數。 步驟3. 令 H’ = αH (α 為降溫速率, 0<α<1)。 步驟4. 檢查 H’ 是否大於 Hend。若是,則令 H = H’ 並執行步驟 3;反之,獲得 S 為 最終解。 根據以上的運作方式,我們不難發現:在 模擬退火方法中所欲搜尋的解空間大小為 |G||T|。為了避免此一過程所花費的時間隨著處 理單元或工作節點個數的增加而急遽增加,我 們將初始溫度 H0 設定為. | T | ln | G | 。此一. 動態初始溫度設定的最大優點在於當 DAG 圖形愈趨複雜時,我們可以有效地避免 H0 溫 度過大,造成整個演算法中退火過程所花費的 時間過長;而當 DAG 圖形較為簡單時,此一 設定也能確保 H0 的溫度不會過小,導致退火 過程無法發揮功用。除此之外,為了彌補模擬 退火方法只考量工作匹配情形的不足,我們則 是在第二種突變機制中採用 傳統的插入式突 變 (insertion mutation,IM) 運算子 [13]。其 具體作法是將我們在退火程序所新產生出來 染色體的 SS 字串中隨機選取一個基因進行 移動。在移動的過程中,我們必須判斷所得之 結果是否符合拓撲排序,如果符合,即產生新 的子代。. 四、效能評估. 言,我們以. | T | ln | G | 之值作為每個演算. 法執行該測試案例的單位時間。在後續的實驗 中,我們將分別紀錄各演算法對每個測試案例 執行不同單位時間後所得之結果。吾人亦可由 此觀察執行時間的長短對不同演算法的影 響。此外,我們針對基因演算法所設定之交配 機率為 0.8,突變機率為 0.05,族群大小為 20。 本實驗中所欲評估之演算法,除了我們所 提出的方法 (TOX+SA/IM) 之外,還包括了模 擬退火方法 (SA) 以及兩種不同的基因演算 方法。其中一種以 GA 為基礎之方法相類似 於我們所提出的演算法,但其突變程序卻只包 含了 IM 運算子的運作功能。此一方法主要 是用來衡量使用模擬退火程序於遺傳演算法 中對解決委外作業專案排程問題之影響,在此 我們以 "AOX+IM" 表示之。另一種則為一般 常見之遺傳演算法,其交配程序所使用的運算 子為順序交配,突變程序則為插入式突變,我 們以 "OX+IM" 符號表示之。在這兩種基因演 算法中,其所使用的選擇與評估等其它程序均 和我們提出之演算法相同。另一方面,我們所 欲評估之模擬退火方法則是以一個初始解為 起點開始尋找其鄰近解,產生鄰近解的作法為 改變問題解中執行某一工作之工作團隊或改 變其中一工作之執行順序 (此類似於遺傳演 算法中之插入式突變)。. 我們以專案時程管控為目標設計了一個 測試案例產生器,用以根據各種不同的參數來 產生各種不同類型的專案,進而產生實驗所必 須的測試案例以有效評估我 們所提出演算法 之效能。此一產生器允許使用者輸入以下相關 參數用以建構出所需要的測試案例: l |T|:工作節點數目。 l |G|:工作團隊數目。 l Degavg:工作節點的平均分支度。亦即,所 有工作節點平均的子節點個數。 l Degsd :平均分支度之標準差。 l Poweravg:工作團隊之平均執行能力。 l Powersd :工作團隊執行能力之標準差。. 在實驗的過程中,我們會計算每一個測試 案例由不同演算法執行經過單倍、十倍與二十 倍單位時間後的排程結果。我們以正規排程長 度 (normalized scheduling length,NSL) 作為 衡量演算法優劣的基準。所謂的正規排程長度 係指測試案例經排程後所得的排程長度與該 案例之排程長度下限的比值;而排程長度下限 則是指在 DAG 中選取一條包含起始工作與 結束工作且工作量總和最大之路徑,然後將此 路徑上所有工作的工作量加總後除以工作團 隊中最大工作能力所得到的值。圖 2 至 圖 7 所呈現之內容係各種演算法在不同參數的影 響下所評估而得的效能。. 藉由此一測試案例產生 器為工具,我們依 據表 2 所列的相關參數值產生 60 種不同的 參數組合。針對每一種參數組合,我們以隨機 的方式產生 5 個測試案例,所有共有 300 個 不同情況的工作匹配與 排程案例,用以做為我 們在進行演算法效能評估時的測試資料。. 除了以上的實 s 驗之外,我們也將所有測 試案例在排程後所得之結果加以統計,以便進 行不同演算法之間的全面性比較。我們在表 3 中標示出比較之後的結果。矩形中所表示的數 據為矩形上方與矩形左方演算法的比較結 果。">"、"=" 和 "<" 分別表示左方演算法優 於、等於、劣於上方演算法的測試案例個數。 以 AOX+ IM 和 OX+IM 為例,AOX+ IM 所 得之結果計有 186 次優於 OX+IM、 1 次與 OX+IM 所得之結果相同、其中有 113 次所 得的結果較差。整體而言,我們所提出的方法 遠遠優於 AOX+IM、OX+IM 和 SA。. 由於每個演算法執行一個迭代所需要耗 用的時間不盡相同,若以每次執行演算法之迭 代數作為演算法停止的依據,將失去其公平 性。因此,我們在此以設定演算法之執行時間 作為演算法停止之標準。對每一個測試案例而.
(6) 五、系統實作 為了驗證本文所提出方法的實用性,我們 建構了一個名為 CPMS 的協同式專案管理系 統 (Collaborative Project Management System)。CPMS 允許使用者透過瀏覽器從不 同的機器經由網路鏈結至系統所提供之一致 化使用者介面。在此一介面中,企業組織之專 案經理及相關人員可藉由系統所提供之協同 處理功能,根據其需要建立一個圖形化表示之 專案,並針對專案中之相關工作是否為委外作 業進行設定。一旦設定完成,提供服務的供應 商便可藉由全球資訊網瀏覽該專案所包含的 委外作業工作內容,進而根據該工作團隊之專 長、能力及意願,針對意欲承接之委外作業透 過系統所提供的操作介面提出申請並提供完 成該委外作業所需之相關資訊。最後,系統將 彙整所有供應商所提供的相關資訊進行評 估,針對專案發展時所必須考慮的各個因素 (例如:成本、專案發展時程、人力因素等 ), 擇優選出合適的承包廠商,以支援企業組織決 策管理之用。圖 8 與圖 9 所示分別為 CPMS 的概念模型與實作執行範例。. 六、結論 本論文中,我們提出了一個在解決委外作 業專案排程問題的演算法。此一方法結合了基 因演算法與模擬退火方法的概念,用以確保我 們在處理各種不同類型的專案時可以有效率 的獲得高品質的解。 我 們 設 計 出 一 個 名 為 AOX 的 交 配 法 則。此一交配法則不論是在理論上或是在實際 實驗中所得到的結果均優於傳統的 OX 交配 法則。其原因在於 AOX 運算子所產生子代的 多樣性較高,因此有較高的機率可避免產生與 父染色體具有相同基因內容的子代。除此之 外,我們還將模擬退火方法引入基因演算法的 突變程序之中。藉由模擬退火程序優異的區域 搜尋能力,我們可以避免染色體在經過突變程 序後的解的品質變差,導致在選擇程序時未被 挑選到進入下一世代,喪失突變程序原本跳脫 局部最佳解的用意。根據實驗結果顯示,我們 所提出的方法有高達 94.8% 的機率能獲得較 其他方法為佳的排程效果。AOX+SA/IM 不似 其它方法必須經過長時間的收斂程序,其在短 時間內就能夠產生效果極佳之排程結果。同 時,我們也利用全球資訊網為平台建構了一個 協同式委外作業專案管理系統。此一系統驗證 了本文所提出方法在實際應用上的可行性。 有鑑於在逐漸全球化的經濟體系中,未來 執行不同專案工作的團隊其所在地點也不盡. 相同。因此,在專案工作執行的過程中,吾人 應將工作之間所需知識移轉的依賴程度納入 專案排程時的考量。此一依賴程度可由應用軟 體、品質管理、開發標準、企業文化等因素來 加以衡量。我們未來將針對此一議題加以研 究,並將研究所得結果整合於 CPMS 中,俾使 CPMS 的功能更加完善。. 七、誌謝 本 文 之 成 果 承 蒙 國 科 會 (NSC 91-2213-E-212-012) 專案研究經費補助,深表 感謝。. 八、參考文獻 [1]. 李永山 , "台灣中小型企業資訊作業委外 決策之探討 ," 台灣大學商學研究所碩士 論文, 1999.. [2]. 林信惠 , 黃明祥 , 王文良, 軟體專案管理 , 智勝出版社, 2002.. [3]. 蘇祐毅 , "資訊委外關鍵因素之探討," 台 灣大學商學研究所碩士論文, 1999.. [4]. B. I. Blum, Software Engineering: A Holistic View, Oxford Univ. Press, 1992.. [5]. M. Gen, and R. Cheng, Genetic Algorithms and Engineering Design, Wiley, 1997.. [6]. J. H. Holland, Adaptation in Natural and Artificial Systems, Univ. of Michigan Press, 1975.. [7]. H. Kerzner, Project Management: A Systems Approach to Planning, Scheduling, and Controlling, Van Nostrand Reinhold, 1995.. [8]. S. Kirkpatrick, C. D. Gelatt, and M. P. Vecchi, "Optimization by Simulated Annealing," Science, 220, pp. 671-680, 1983.. [9]. R. Klepper, and W. O. Jones, Outsourcing Information Technology, Systems, and Services, Prentice Hall, 1999.. [10]. Y. Kwok and I. Ahmad, "Efficient Scheduling of Arbitrary Task Graphs to Multiprocessors Using a Parallel Genetic Algorithm," J. Parallel and Distributed Computing, vol. 47, no. 1, pp.58-77, November 1997.. [11]. L. C. Liu and E. Horowitz, "A Formal Model for Software Project Management," IEEE Trans. Software Eng., vol. 15, no. 10, pp. 1280-1293, October 1989..
(7) W. J. Stevenson, Production/Operations Management, McGraw Hill Company, 1999.. [12]. L. Wang, H. J. Siegel, V. P. Roychowdhury, and A. A. Maciejewski, "Task Matching and Scheduling in Heterogeneous Computing Environments Using a Genetic-Algorithm-Based Approach," J. Parallel and Distributed Computing, vol. 47, no. 1, pp.8-22, November 1997.. [13]. 表 1. 專案工作列表. Degavg. T 、 T、2 T 2 0.2 × Degavg 8、16 1 0.4. Degsd |G| Poweravg Powersd. t2. t5. t10. t1. t3. t9. t4. t6. t11. t12. texit. t8. 圖 1. 相對應於表 1 的 DAG t2. t3. t4. t5. t6. t7. t8. t 9 t10 t11 t12. g1 g 3 g 2 g 1 g 2 g1 g 3 g3 g 2 g1 g 1 g2. 圖 2. 基於圖 1 的染色體編碼範例. |G| = 8 8. Avg. of NSL. 表 2. 測試案例相關參數設定 參數數值 20、40、...、200. tentry. t1. 工作 立即前置工作 工作 立即前置工作 t1 -t7 t1 t2 -t8 t4 t3 t1 t9 t3, t6 t4 -t10 t5, t7 t5 t2, t4 t11 t9 t6 t1, t2 t12 t11. 參數名稱 |T|. t7. AOX+IM. 7. AOX+SA/IM. 6. OX+IM. 5. SA. 4 3 2 1 0 20. 40. 60. 80 100 120 140 160 180 200 No. of tasks. 圖 2. 單倍執行時間效能評比 (|G|=8). |G| = 8 8 AOX+IM. 7. 表 3. 測試案例排程結果之全面性比較 OX+IM. SA. ALL. > 300 =0 <0. > 300 =0 <0. > 299 =1 <0. > 899 =1 <0. > 186 =1 < 113. > 173 =1 < 126. > 359 =2 < 539. > 144 =0 < 156. > 257 =1 < 642. Avg. of NSL. AOX+IM. AOX+SA/IM OX+IM. 6. SA. 5 4 3 2. AOX+SA/IM. AOX+IM. OX+IM. 1 0 20. 40. 60. 80 100 120 140 160 180 200 No. of tasks. 圖 3. 十倍執行時間效能評比 (|G|=8). |G| = 8 8 AOX+IM. > 282 =2 < 616. 7. AOX+SA/IM OX+IM. 6 Avg. of NSL. SA. SA. 5 4 3 2 1 0 20. 40. 60. 80 100 120 140 160 180 200 No. of tasks. 圖 4. 二十倍執行時間效能評比 (|G|=8).
(8) |G| = 16 8. Avg. of NSL. AOX+IM. 7. AOX+SA/IM. 6. OX+IM SA. 5 4 3 2 1 0 20. 40. 60. 80 100 120 140 160 180 200 No. of tasks. 圖 5. 單倍執行時間效能評比 (|G|=16) 圖 9. CPMS 執行範例 |G| = 16 8. Avg. of NSL. AOX+IM. 7. AOX+SA/IM. 6. OX+IM SA. 5 4 3 2 1 0 20. 40. 60. 80 100 120 140 160 180 200 No. of tasks. 圖 6. 十倍執行時間效能評比 (|G|=16). |G| = 16 8. Avg. of NSL. AOX+IM. 7. AOX+SA/IM. 6. OX+IM SA. 5 4 3 2 1 0 20. 40. 60. 80 100 120 140 160 180 200 No. of tasks. 圖 7. 二十倍執行時間效能評比 (|G|=16) Site A. Site B. Site C. Project Manager. Team #1. Team #2. Collaborative Project-Management System Local OS. Local OS. Local OS. Network. 圖 8. CPMS 之概念模型.
(9)
數據

相關文件
The min-max and the max-min k-split problem are defined similarly except that the objectives are to minimize the maximum subgraph, and to maximize the minimum subgraph respectively..
Experiment a little with the Hello program. It will say that it has no clue what you mean by ouch. The exact wording of the error message is dependent on the compiler, but it might
When we know that a relation R is a partial order on a set A, we can eliminate the loops at the vertices of its digraph .Since R is also transitive , having the edges (1, 2) and (2,
The proof is based on Hida’s ideas in [Hid04a], where Hida provided a general strategy to study the problem of the non-vanishing of Hecke L-values modulo p via a study on the
In this paper, we have studied a neural network approach for solving general nonlinear convex programs with second-order cone constraints.. The proposed neural network is based on
We investigate some properties related to the generalized Newton method for the Fischer-Burmeister (FB) function over second-order cones, which allows us to reformulate the
For the proposed algorithm, we establish its convergence properties, and also present a dual application to the SCLP, leading to an exponential multiplier method which is shown
In order to establish the uniqueness of a prime factorization, we shall use the alternative form of the Principle of Mathematical Induction.. For the integer 2, we have a unique
