多處理器資料庫系統中利用連續查取特性之多重查詢排程
12
0
0
全文
(2) 性,且符合超大型資料庫的高產能需求 [9,10,17,25]。 在此架構中,每個處理結點 (Processing Node, PN) 含有一或數個處理器,以 及擁有專屬的記憶體與硬碟,而這些處理結點 靠著系統內高頻寬的網路連結。 系統效能在 此多處理器架構中,將取決於有效資源的利用 與查詢負載的排程。 特別是查詢排程(query scheduling),是影響多處理器系統效能的最重 要因素之一。 而到目前為止,絕大部分有關查詢排程 的研究報告,僅注重在每次單一查詢(singlequery)的有效處理[6,7,24]。 然而,每次單一 查詢的處理,在多使用者(multi-user)的系統環 境中,並非最適當的。 特別是大部分的單一 查詢排程研究,嘗試著利用單一查詢的平行處 理(parallel processing) 最佳化,以使回應時間 (response time)的最小化,卻忽略了同時平行處 理 多 個 查 詢 的 多 重 查 詢 排 程(multiple-query scheduling),有著可能潛在優勢。也就是說, 目 前 以 先 做 查 詢 最 佳 化 (Query Optimization)[5,13,14,15,16,17,18,19,20] , 然 後再一次一個查詢的執行[6,24],無法保證達 到最有效率的排程。 例如不同的查詢有可能 是對某一相同資料的查詢,若將不同查詢分開 來執行,則此一資料可能需要做兩次的讀取。 而且未必每個查詢的資料剛好分佈在所有的 處理結點(PNs)裡,而為了達到最大的平行度 (maximum degree of parallism) 與 負 載 平 衡 (workload balance),可能還必須做資料的重分 配。 也就是,有部分資料必須傳送至其他處 理節點處理,否則查詢的執行過程中,可能有 部分處理節點因無資料可處理而遭到閒置。 理想中的多重查詢排程,很有希望可以找出最 佳的查詢組合群組 ,而一次一組查詢同時執 行,儘量避免資料不必要的重分配,嘗試使整 組查詢執行時間的最小化,而此時間當然希望 能小於各別執行一個個查詢所需時間的總 合。 然而,目前還只有很少的研究關注在多 重查詢的排程。 連 續 查 取 特 性 (Consecutive Retrieval Property, C-R property)[11]的應用,是對於查詢 的資料可以重組出某些連續(sequential)關 係 使之 具 有 C-R property(將於文中第三節說 明),再利用此連續特性將資料連續置放於儲 存媒體中,此置放方式可以節省查詢的執行時 間[1,3,4,8,11,12],對系統效能的提升有顯著的 助益。 在本研究報告裡,我們將利用 C-R property 的特性,設計新的多重排程查詢技 術,以促進多處理器資料庫系統之效能與實用 可行。 經過實驗的證明,我們發現此新的技 術確實優於現有的多重查詢排程演算法。 這篇報告的其他章節安排如下,我們在 第二節將現有的多重排程技術做了擇要的介 2. 紹;在第三節,將針對於 C-R property 的應用 做簡單的說明;而於第四節,提出了我們利用 CR-property 所設計的多重查詢排程新技術; 接著在第五節,我們設計實驗以證實所提出的 新技術實用可行;在最後一節,我們將做研究 報告的總結,以及提出未來可能的研究方向。. 二、 現有之研究概況. 於多處理器資料庫系統應用中,相較於 為數眾多的一次執行一個查詢之單一查詢最 佳化研究報告,有關多重查詢排程技術之研究 相對稀少,代表性的研究有 Manish Metha 等 的 Batch Scheduling[22] , 與 Lo 等的 CB Scheduling & PB Schedulings[21]。 分別詳述 如下: Ÿ Mehta、Soloviev 與 DeWitt 發表的 Batch Scheduling[22]:此技術在查詢排程中 , 考量到記憶體(memory)與 I/O 的有效運 用,凡需讀取相同關連之查詢,都儘量 以批次(batch)一起執行,如此可以節省 不少重複讀取之不必要 I/O。 例如有許 多的查詢在等待被執行,查詢 Qi 是 R1 與 R2 兩關連的連結(Join),而查詢 Qk 是 R1 與 R3 兩關連的連結,在記憶體的容量 允許下,可以將 Qi 與 Qk 同時一起執行, 則每一個關連,不管是 R1、R2 或 R3,都 只需要做一次的讀取。 反之如果將 Qi 與 Qk 分開來執行,一次只做一個查詢, 若 Qk 無法於 Qi執行後馬上接著排進去執 行以利用記憶體裡對 R1 的殘留,則 R1 可能無法避免的需要多一次的讀取而為 兩次。 所以多重查詢的效益在此情況下 得以顯現。 此技術之缺點是未把最大平 行度與平衡負載列入考量 ,因此有可能 所選取的查詢局限於使用部分之 處理節 點來執行,而閒置了部分資源與使處理 節點有不平衡負載。 Ÿ. Lo、Hua 與 Tavanapong 於[21]所提出的 Competition-Base (CB) Scheduling 與 Planning-Based (PB) Scheduling: ─ CB scheduling:此術技是放任查詢以 先來後到的方式自由爭取執行所需的 處理節點,一旦都爭取到了處理節點 的查詢,即可立即被執行。 例如:查 詢 Q1、Q2、Q3 依序進入系統,查詢 Q1 需要在處理結點 PN1、PN2 與 PN3 中執 行,查詢 Q2 需要在 PN3 與 PN4,另外 查詢 Q3 則須在 PN4、PN5 與 PN6 中執.
(3) 行。 依先來先搶的規則,查詢 Q1 因 可以馬上爭取到所需的處理節點,將 馬上被執行, 而 查 詢 Q2 雖可占有 PN4,但因 PN3 為 Q1 所占用,需要等 Q1 完成後才能被執行。 至於 Q3,則 因 PN4 被 Q2 佔有,而必須排在 Q2 之 後執行。 而如果 Q3 能在 Q2 前,優先 的搶到 PN4 的話,則 Q1 與 Q3 將有機 會可以同時被執行。. 式,已被研究證實效果比傳統的方式良好。 接 著我們以一簡單的範例來說明 C-R property 的 形成方式: 假設一資料表格有六筆記錄(R1 … R 6),而 有三個查詢(Q1、Q2、Q3)對此資料表格中記錄 的讀取需求如圖 1:. ─ PB scheduling:此技術將現有空閒的 的處理節點,有計畫的做查詢排程。 同樣的被安排到足夠 處理節點的 查 詢,就可以馬上被執行。 如果多個查 詢同時擁有所需的處理節點,則這些 查 詢 可 以 被 同 時 執 行 。 利 用 PB scheduling 的理論發展出 Largest-FitFirst 及 First-Fit-First 兩種演法 ,其說 明如下: Largest-Fit-First 演算法: 主要的精神在於先將等待執行的 查詢依其所需使用到 處理節點數 量由大至小排序,將必須使用較多 處理節點的查詢優先處理。 First-Fit-First 演算法: 依查詢依查詢進入系統的時間由 先至後排序,將較先進入系統的查 詢優先處理。 在這個研究中我們發現,PB 的多重查詢 排程優於 CB 的多重查詢排程,而在 PB 的排 程中 Largest-Fit-First 又略優於 First-Fit-First 模式。 由以上兩個研究的驗證,證實有計畫的安 排多重查詢排程是有其必要而且可行的。 然 對多重查詢排程的設計仍有研究發展的空 間,因不管是使用 Large-Fit-First 或 First-FitFirst,來進行排程仍然可能如[22]一樣,閒置 部分系統資源。. 三. 連續查取特性(C-R Property). Page1. Page2. 3. Q2. Q3. R1:. 1. 0. 0. R2:. 0. 1. 1. R3:. 1. 0. 0. R4:. 0. 1. 1. R5:. 1. 1. 0. R6:. 0. 0. 1. 圖 1、 查詢讀取需求範例 在圖 1 裡,表示查詢 Q1 需讀取記錄 R1、 R3 與 R5,查詢 Q2 需讀取記錄 R2、R4 與 R5, 而 Q3 依此類推。 如果資料是以 I/O 區塊來存 放,如:頁(pages),存於儲存媒體中,而又假 設每一頁只能放置三筆的記錄,則所有資料共 需放置於兩頁之中,假設 R1、R2 與 R3 置於同 一頁 Page1,R4、R5 與 R6 置於另一頁 Page2。 則處理 Q1 需要兩次的 I/O,同樣的 Q2 與 Q3 也 需要兩次的 I/O,而平均查詢所需 I/O 次數為 2。 但如果重組每一頁裡的記錄安排,使每個 查詢所需資料剛好都能連續排列在一起,假設 R1、R3 與 R5 被分配到 Page1 中,而 R2、R4 與 R6 分配於 Page2 中,結果如圖 2 所示,則稱此具 有 C-R property:. Page1. Page2. C-R property 其基本的應用是將資料重 新整理過後,把與一個查詢相關的記錄,存放 在線性儲存媒體(linear storage)裡的連續區域 中,以減少查詢時對資料的讀取時間,相關研 究報告有[4,8,11,12]。 其中 Chang 等,於[4] 中,更將其應用於圖片資料庫的查詢。 而另 一種常見的應用方式,是將資料重組後使其具 有 C-R property,再依序儲存於多重磁碟系統 (multiple-disk system) 中,以加速資料的平行存 取,相關研究有[3]。 這兩種資料存放應用方. Q1. Q1. Q2. Q3. R1:. 1. 0. 0. R3:. 1. 0. 0. R5:. 1. 1. 0. R2:. 0. 1. 1. R4:. 0. 1. 1. R6:. 0. 0. 1. 圖 2 、 具 C-R property 之資料安排 符合 C-R property 的此種資料分配裡,處 理查詢 Q1 與 Q3 只需一次的 I/O,而 Q2 雖然仍 然需要兩次 I/O,但總平均 I/O 需求則為 1.33 次,比之前未具有 C-R property 之資料分配來 得有效率。.
(4) 四、應用 C-R property 之查詢排程 C-R property 雖然至今仍大多被應用於 資料的置放,但在這篇報告裡,於多處理器資 料庫系統中,我們率先將 C-R property 應用在 多重查詢排程的處理中。 在介紹所提出新的 多重查詢排程技術之前,我們將先說明適用於 查詢排程的兩種符合 C-R property 的重組策 略。 (一)C-R property 的重組策略 同樣的先以一範例來說明 C-R property 的兩種重組策略,假設一多處理器資料庫系統 中有七個等待被執行的查詢,在表1 中列出此 七個查詢對系統處理結點的相關需求。 如查 詢 Q1,其可能因資料存放位置的關係,必須 使用到處理結點 PN1、PN2 與 PN;而查詢 Q2, 6 其處理資料則必須使用到處理結點 PN1 與 PN4,等等。 表 1. 查詢對系統處理結點相關需求範例 Q1 Q2 Q3 Q4 Q5 Q6 Q7 PN1 1 1 1 PN2 1 1 1 PN3 1 1 PN4 1 1 1 PN5 1 1 1 PN6 1 1 1 PN7 1 1 PN8 1 1 在不改變查詢對處理結點的需求原則 下,重組表 1 中欄(column)與列(row)的順序, 使重組過後具 C-R property 的排列方式。 基 本上我們可以有兩種重組策略:處理結點需求 數目最小的查詢優先(CRP_Smallest_First),以 及處理結點需求數目最大的查詢優先 (CRP_Largest_First)。 CRP_Smallest_First ─ 處理結點需求數目 最小的查詢優先的策略,其重組結果如表 2 所示,重組過後的查詢與處理結點,具 有 C-R property 的排列方式,其特性說明 如下。 於表 2 中,如果我們將查詢按照其所需 的第一個處理結點出現的列(row)來分層級, 例如:Q4 與 Q6 所需的第一個處理結點,皆為 表中第一列的 PN3,則 Q4 與 Q6 同屬第 1 層; 而又 Q1 與 Q7 所需的第一個處理結點,皆為表 中第三列的 PN6,則 Q1 與 Q7 亦同屬第 3 層; 於此類推,Q2 為第 5 層,Q5 為第 6 層,Q3 為 第 7 層。 如此 CRP_Smallest_First 的特性在於 4. 同一層的查詢中,其排列方式是將查詢依處理 結點的需求數目,按遞增方式排序。 例如於 表 2 的第 1 層中,Q4 需兩個處理結點,而 Q6 需四個處理結點,如此 Q4 排在 Q6 的前面;又 如第 3 層中,Q1 需三個處理結點,而 Q7 需四 個處理結點,則 Q1 排在 Q7 的前面。 表 2. 查詢對系統處理結點需求以 C-R property 重組後範例 層級 1 3 5 6 Q4 Q6 Q1 Q7 Q2 Q5 PN3 1 1 PN8 1 1 PN6 1 1 1 PN2 1 1 1 PN1 1 1 1 PN4 1 1 1 PN5 1 1 PN7 1. 7 Q3. 1 1. CRP_Largest_First ─ 處理結點需求數目最 大 的 查 詢 優 先 的 策 略 恰 好 與 CRP_Smallest_First 相反,顧名思義是將 屬同一層級的查詢,依所需處理結點的數 目,按遞減的方式排序。 將表 1 使用 CRP_Largest_First 策略重組,結果如表 3 所示。 而這次第 1 層中的 Q6 排在 Q4 的前 面,而第 3 層中的 Q7 則排在 Q1 的前面。 表 3. 查詢對系統處理結點需求以 C-R property 重組後範例 1 3 5 6 層級 Q6 Q4 Q7 Q1 Q2 Q5 PN3 1 1 PN8 1 1 PN6 1 1 1 PN2 1 1 1 PN1 1 1 1 PN4 1 1 1 PN5 1 1 PN7 1. 7 Q3. (二)應用 C-R property 之查詢排程演算法 在 此 研 究 中 , 我 們 發 展 出 應 用 C-R property 的 多 重 排 程 演 算 法 (CRP_Scheduling),此排程技術也是利用批次 做查詢執行,原則上有以下四個步驟: (1) 將查詢佇列 (query queue)中的查詢重 組,使重組過後具 C-R property 的排 列方式,使用 CRP_Smallest_First 或 CRP_Largest_First 策略。 (2) 在同一層的查詢中,同時間最多只能 取一個查詢的原則下,找出一個查詢. 1 1.
(5) 組合能使用全部處理結點,或使用最 多數目的處理結點。 (3) 執行所找到的查詢組合,並將查詢從 佇列中移除。 (4) 如果查詢佇列中已無查詢存在,則排 程結束。 如不然,且若又有新的查詢 進入佇列,則重覆步驟(1)~(4)安排下 一批次的查詢;而若未有新查詢進入 佇列,則重覆步驟 (2)~(4)安排下一批 次的查詢。 以下以一 C 程式的虛擬碼來表示我們的 演算法: CRP_Scheduling : WHILE (Query_Queue NOT EMPTY) { IF (there is a new query) CRP_Matrix = Qry_CRP(Query_Queue); /* 步驟(1),結果存於 CRP_Matrix */ Query_Set = Cmp_Comb(CRP_Matrix); /* 步驟(2),結果存於 Query_set */. 列至第 7 列的處理結點。 8. 從第 8 層(列)起,找尋可以與 Q4 及 Q7 同時執行的查詢,但找不到了。 9. 由於所找到的 Q4 及 Q7 僅佔用七個處理 結點,未佔用全部,我們必須嘗試找尋 是否有佔用更多處理結點的查詢組 合。 10. 回溯至上一層,我們發現於第 3 層(列) 尚有一查詢 Q1 可與 Q4 組合,兩查詢 共佔用第 1 列至第 5 列的處理結點。 11. 從第 6 層(列)起,找尋可以與 Q4 及 Q1 同時執行的查詢。 Q5 中選。 12. 此時 Q4、Q1 與 Q5 已可佔用全部的八 個處理結點,執行此三查詢,且將它 們從佇列中移除。 13. 再下一批次的排程,假設仍無新的查 詢加入,則佇列中只剩查詢 Q7。 14. 執行 Q7。 15. 排程結束,綜合排程情形於表 4。 七個查詢共分為三個批次執行,而系統執 行狀況及處理節點使用情況如下:. Run_Queries(Query_Set, Query_Queue); /* 步驟(3),執行並從 queue 中 移除查詢 */. 表 4. 排程結果. } /* 步驟(4),下一輪 */ (三)範例說明 在 這 節 裡 , 我 們 以 重 組 過 後 具 C-R property 的 表 3 做 為 範 例 , 簡 單 說 明 CRP_Scheduling 演算法的執行過程: 1. 考量表 3 中第一個查詢 Q6,所需的處 理結點有 PN3、PN8、PN6 與 PN2,於表 中佔用第 1 列至第 4 列的處理結點。 2. 從第 5 層(列)起,找尋可以與 Q6 同時執 行的查詢,而發現 Q2 可以,且其佔用 第 5 列至第 6 列的處理結點。 3. 再來從第 7 層(列)起,找尋可以與 Q6 及 Q2 同時執行的查詢。 Q3 可以,且其 佔用第 7 列至第 8 列的處理結點。 4. 此時 Q6、Q2 與 Q3 已可佔用全部的八個 處理結點,無須再尋找,這一批次就安 排此三個查詢共同被執行,且將它們從 佇列中移除。 5. 假設沒有新的查詢進入佇列,進入下一 批次的排程。 6. 考量表中剩下的第一個查詢會是 Q4 , 所需的處理結點有 PN3 與 PN8,於表中 佔用第 1 列與第 2 列。 7. 從第 3 層(列)起,找尋可以與 Q4 同時執 行的查詢,發現 Q7 可以,且其佔用第 3 5. 批 查詢 使用的處理節點 次 1 Q2,Q6,Q3 PN1, PN2, PN3, PN4, PN5, PN6, PN7, PN8 2 Q1,Q4,Q5 PN1, PN2, PN3, PN4, PN5, PN6, PN7, PN8 3 Q7 PN1, PN2, PN4, PN5, PN6. 五、 實驗. 為了檢驗所提之新的多重查詢排程演算 法 CRP_Scheduling 的效能,接下來我們設計 了排程實驗系統,模擬 CRP_Scheduling 的排 程,並與現有的多重查詢排程技術做比較,以 確定新排程技術的可行性。 (一) 實驗模型. 在圖 3 中展示出我們的實驗模型。首 先由查詢產生器(Query Generator)利 用 亂數產生查詢,以及其所需使用的處理節 點,接著將所產生的查詢送進查詢佇列 (Query Queue)。 為避免查詢佇列中有過 多的查詢,使得決定排程過於耗時,我們 另 外 設 計 了 一 個 排 程 視 窗 (Scheduling Window)於查詢佇列的前面,唯有進入排.
(6) 程視窗範圍內的查詢,得以被考慮於下一 批次的排程。 再來排程器(Scheduler)利 用所提供的各種排程演算法,從排程視窗 中找尋可共同執行的適當查詢組合,最後 將所選定的查詢送入服務單元 (Serving Unit)進行執行。 為了使排程與執行兩階 段工作能銜接順利,我們建議系統能有一 專屬的協調處理器(coordinator),讓它 只負責排程,而不參與查詢執行,如此當 有查詢正在執行時,協調處理器也利用了 這個時間決定下一批次可以被執行的查 詢組合。 WINDOW. T=. Query set. TQ TT. TQ:Total Number of Queries(處理完的查詢總 數) TT:Total Execution of Time(執行總時間). QUERY GENERATOR. Select Next queries. SCHEDULER. N. Ui:Utilization of the ith PN(每處理節點使用 率) N:Total Number of PNs(處理節點總數). QUERY QUEUE. …. ∑i=1U i N. U =. SERVING UNIT. 圖 3. 實驗模型 於實驗中所使用的各項參數範圍值如表 5,其中處理節點數(Number of PNs)與排程視 窗的大小(Scheduling window size),是主要的 變動參數,我們將利用不同的處理節點數與排 程視窗的大小,來評估對各排程的影響。 而 每次實驗所測試由亂數產生的查詢個數 (Number of queries)必定大於 10,000 個,目的 是為了使實驗結果的誤差值能在 ±1%以內。 此外,查詢所需使用的處理結點數,亦由亂數 產生,可以是 1 個到使用全部的處理結點,而 全部查詢的平均約是使用了三分之一的處理 結點數。 表 5. 各項參數值 PARAMETER VALUES Number of PNs(N) 8,16,32 or 64,128 Number of Queries over 10,000 Query Size(no. of PNs used) 1~N, average (N/3) Scheduling Window Size varied, 16~128 (queries) 除此之外,我們還使用了系統使用率 U (System Utilization),亦即系統中處理結點的平 均 使 用 率 ; 以 及 系 統 產 能 T (System Throughput),系統平均單位時間處理查詢的數 量。 以兩統計值來評估各排程的效能。. 6. 接下來的實驗,對於 CRP_Scheduling 演 算法,我們同時採用了 CRP_Smallest_First 與 CRP_Largest_First,兩種 C-R property 的重組 策略,以瞭解兩者對多重查詢排程的影響,是 否有差異。 在往後的說明,我們將簡單的以 CRP_Smallest_First 與 CRP_Largest_First 來代 表 CRP_Scheduling 的兩種演算法。 另外,為 了評估 CRP_Scheduling 的效能,我們將它與 應 用 性 質 較 接 近 的 PB scheduling[21]中 的 First_Fit_First 以及 Largest_Fit_First 兩演算法 做比較。 因在[21]中已證實了此兩演算法是較 有效率的多重排程技術。 最後附帶一提,在下面的實驗數據中有 所 謂 的 相 對 改 善 率 (Relative Improvement, RI),是指各演算法與 First_Fit_First 比較的結 果。 再下來的是,針對不同參數變化所做的 實驗所得。 (二) 處理結點數的影響(Effect of Number of PNs) 在這個實驗裡我們將排程視窗大小固定 為 32,亦即每一輪排程,必須是在查詢佇列 前 32 個查詢,才有機會被安排去執行。 分別 測試處理節點數為 16、32、64 及 128 的情況 下,對各排程演算法的影響。 首先探討系統使用率,其實驗結果於表 6 與圖 4 中。 不幸的,我們發現,所有的系統 使用率,幾乎是隨著處理結點數的增加而遞 減,究其原因,是因為排程視窗被固定為 32。 如此,當處理結點數增加時,卻無足夠數目的 查詢,可供各排程演算法安排出最理想的查詢 組合。(我們另外有排程視窗大小隨著處理結 點數增加而增加的實驗,將說明於專節五之四 中說明。) 但此實驗的主要目的為比較各排程 演算法,在相同條件設定下的優劣差異。 由 圖 4,我們發現 CRP_Largest_First 有著最佳的 系統使用率,而 CRP_Small_First 只略遜於 CRP_Largest_First,兩者是很接近的。 再來 Largest_Fit_First 與 CRP_Largest_First 已有明 顯 的 差 距, 而 系 統 表 現 最 沒 有 效 率 的 是 First_Fit_First。 另外,CRP_Largest_First 與.
(7) CRP_Small_First 相較於 First_Fit_First,最好 時 有 接 近 12%左右的改善率 (RI) , 而 反 觀 Largest_Fit_First 最多約只有約 7.2%或以下的 改善率。 再由系統產能來討論,相似於系統產能系 統 使 用 率 , 表 現 最 佳 的 還 是 CRP_Largest_First ,而與其很接近的仍然有 CRP_Smallest_First , 再 來 是 Largest_Fit_First , 表 現 最 差 的 仍 舊 是. First_Fit_First No.of PNs U 16 89.19 32 86.33 64 86.05 128 86.27. First_Fit_First。系統產能是系統單位時間處理 查詢的能力,實驗結果表現於表 7 與圖 5。 由 實驗結果顯示,所有演算法的系統產能皆隨著 處理結點數的增多 ,而往下降,然後趨於緩 和,理由同樣是受限於排程視窗固定為 32。 而 CRP_Largest_First 與 CRP_Small_First 相較 於 First_Fit_First,仍有著約 10%左右或高達 11.6%的改善率(RI),而 Largest_Fit_First 卻約 只有 5.9%或以下的改善率。. 表 6. 處理結點數 vs.系統使用率 Largest_Fit_First CRP_Smallest_First U RI U RI 95.6 7.187% 99.13 11.145% 92.18 6.776% 96.04 11.248% 90.19 4.811% 94.41 9.715% 88.97 3.130% 93.66 8.566%. CRP_Largest_First U RI 99.57 11.638% 96.68 11.989% 95.21 10.645% 94.55 9.598%. Effect of no. of PNs. System utilizaion. 100 95 first_fit_first largest_fit_first. 90. crp_largest_first. 85. crp_smallest_first. 16. 32 64 128 No. of PNs. 圖 4. 處理結點數 vs.系統使用率. First_Fit_First T 2.66 2.53 2.54 2.56. Effect of no. of PNs 3.00 2.90 Throughput. No. of PNs 16 32 64 128. 表 7. 處理結點數 vs.系統平均產能 Largest_Fit_First CRP_Smallest_First T RI T RI 2.76 3.759% 2.95 10.902% 2.68 5.929% 2.81 11.067% 2.66 4.724% 2.78 9.449% 2.64 3.125% 2.78 8.594%. 2.80. first_fit_first. 2.70. largest_fit_first. 2.60. crp_largest_first. 2.50. crp_smallest_first. 16. 32. 64. 128. No. of PNs. 圖 5. 系統平均產能 7. CRP_Largest_First T RI 2.97 11.654% 2.82 11.462% 2.80 10.236% 2.81 9.766%.
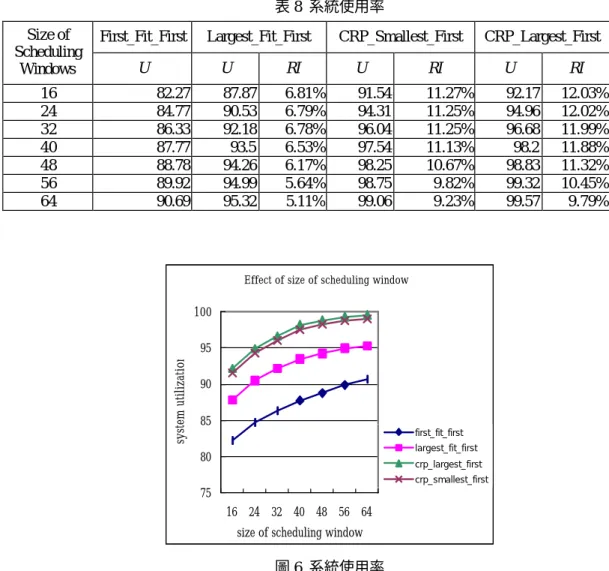
(8) (三) 排程視窗大小的影響(Effect of Size of Scheduling Window). 以上,也就是在多數的情況下可以使用到所有 的處理結點,而甚少有閒置的處理結點。 其次 CRP_Smallest_First 依 舊 緊 跟 著 CRP_Largest_First 之後,表現相差不遠。 而第 三名的還是 Largest_Fit_First,系統使用率最差 的還是 First_Fit_First。 另外,在相對比較於 First_Fit_First 的改善率(RI),其他三個排程技 術皆呈遞減的趨勢,這是因為他們的效能已經 相 當 的 高, 往 上 再 成 長 的 空 間 有 限 ,反觀 First_Fit_First 卻因為原本效能較差,而有較大 的成長空間。 不過令人欣慰的, CRP_Largest_First 與 CRP_Smallest_First 相較 於 First_Fit_First,在多數的情況下大多能有 10%左 右 或 甚 至 高 達 12% 的 改 善 率。 而 Largest_Fit_First 則介於 5%至 7%之間。 接下來探討系統產能,於表 9 與圖 7 中, 所呈現的實驗結果與之前的系統使用率極為相 似,因其受到了相同因素的影響,讀者可自行 參閱,將不再贅述。. 我們設計排程視窗 (Scheduling Window) 的主要目的,是為了避免如果查詢佇列中有著 太多的查詢待排程,則排程演算法於每一批次 的排程,得花很多的時間去決定該有那些查詢 可以被執行,如此可能影響了排程銜接不上執 行的缺點。 而為了解排程視窗大小對系統效率 的影響,在這個實驗裡,我們將處理節點數目 固定為 32,而變化排程視窗大小所得的實驗結 果,表示於表 8、表 9、圖 6、以及圖 7。 再次先從系統使用率來討論,由表 8 與 圖 6 的實驗結果可以看出,四個排程方法的系 統使用率,皆隨著視窗大小的增大,而呈現上 升的趨勢。 這是因為隨視窗大小的增加,排程 有了越來越多的查詢選擇空間,可以找到較佳 的查詢組合所致。 而比較四個排程演算法的優 劣,我們再度的發現,CRP_Largest_First 仍然 表現的最有效率,系統使用率甚至可高達 99%. 表 8 系統使用率. 16 24 32 40 48 56 64. First_Fit_First. Largest_Fit_First. U 82.27 84.77 86.33 87.77 88.78 89.92 90.69. CRP_Smallest_First. CRP_Largest_First. U. RI. U. RI. U. 87.87 90.53 92.18 93.5 94.26 94.99 95.32. 6.81% 6.79% 6.78% 6.53% 6.17% 5.64% 5.11%. 91.54 94.31 96.04 97.54 98.25 98.75 99.06. 11.27% 11.25% 11.25% 11.13% 10.67% 9.82% 9.23%. 92.17 94.96 96.68 98.2 98.83 99.32 99.57. Effect of size of scheduling window. 100 95 system utilization. Size of Scheduling Windows. 90 85 first_fit_first largest_fit_first. 80. crp_largest_first crp_smallest_first. 75 16 24 32 40 48 56 64 size of scheduling window. 圖 6 系統使用率. 8. RI 12.03% 12.02% 11.99% 11.88% 11.32% 10.45% 9.79%.
(9) 表 9 系統平均產能 Size of Scheduling Windows. First_Fit_First T. Largest_Fit_First CRP_Smallest_First CRP_Largest_First T. 16 24 32 40 48 56 64. 2.39 2.47 2.53 2.58 2.63 2.67 2.71. RI 2.54 2.63 2.68 2.73 2.76 2.79 2.8. T. 6.276% 6.478% 5.929% 5.814% 4.943% 4.494% 3.321%. RI 2.65 2.74 2.81 2.86 2.89 2.91 2.92. T. 10.879% 10.931% 11.067% 10.853% 9.886% 8.989% 7.749%. RI 2.67 2.75 2.82 2.87 2.9 2.92 2.93. 11.715% 11.336% 11.462% 11.240% 10.266% 9.363% 8.118%. Throughput. Effect of size of scheduling window. 3 2.9 2.8 2.7 2.6 2.5 2.4 2.3 2.2. first_fit_first largest_fit_first crp_largest_first crp_smallest_first. 16 24 32 40 48 56 64 size of schedulinmg window. 圖 7 系統平均產能. 使用率自然不斷的往上提升。 而於圖 8 中 First_Fit_First 曲線的上揚角度較大,理由與在 五之三節的解釋相同,亦即因其較低的系統使 用率,使得有較大的成長空間。 不過實驗參數 若繼續增大,First_Fit_First 的曲線會漸趨緩 和,逐漸接近其他三條曲線,但不至於超越他 們。 而對於四個排程方法的比較,沒有意外的 還是以 CRP_Largest_First表現出的系統使用效 能最佳,CRP_Smallest_First 的效能其次,再來 才是 Largest_Fit_First,以及系統使用率最差的 First_Fit_First。 對於系統產能的討論,也因實驗所呈現結 果與系統使用率相似,理由相同,不再著墨。 有 關處理節點數目與排程視窗的大小,除 1:1 比 例的實驗外 ,我們也做了 1:1/2、1:3/4、1:1.5 以及 1:2 等的實驗,結果與 1:1 所能呈現的意 義與比較,差別不大,而限於篇幅,不再詳細 討論。 然縱觀所有的實驗結果,隨著處理結點 數的增加,適當的提高排程視窗的大小,是有 其必要性,能增加查詢排程的效能。 但太大的 排程視窗,則只會浪費在決定排程所需的時 間。. (四) 處理結點數與排程視窗大小同步變化 的影響 由於前兩節報告中的實驗探討,每次固定 一個參數(處理結點數或排程視窗的大小),而 只變化另一個參數。 在這節的實驗,我們讓該 兩參數以 1:1 的比例同步的變化,以探討處理 結點數及排程視窗的大小對四個排程演算法的 影響。 我們將系統的處理節點數目與排程視窗 的大小從 16 變化到 128,實驗結果列於表 10、 表 11、圖 8、以及圖 9。 首先探討系統使用率,由表 10 與圖 8 的 實驗結果可以看出,四個排程方法隨著處理節 點數目與排程視窗大小的增加,使用率呈上揚 的趨勢。 由於在五之一節實驗模型的介紹中, 我們有提及,查詢所需的平均處理結點數,約 為全部處理結點數的三分之一。 換個角度來 說,也就是每一批次的排程,不論處理結點數 的多少,平均約只有三個查詢可以被執行。 如 此當處理節點數目與排程視窗的大小等比例成 長,而平均每批次的查詢數不變,這將使得所 有的排程方法都有很大的查詢選擇空間,系統. 9.
(10) 表 10 系統使用率 No. of PNs 16 32 64 128. First_Fit_First U 84.21 86.33 88.74 91.15. Largest_Fit_First CRP_Smallest_First CRP_Largest_First U RI U U U RI 91.18 8.277% 94.92 12.718% 95.33 13.205% 92.18 5.929% 96.04 11.067% 96.68 11.462% 92.9 4.688% 97.01 9.319% 97.95 10.379% 94 3.127% 97.96 7.471% 99.02 8.634%. Effect of no. of PNs. system utilization. 100 95 first_fit_first. 90. largest_fit_first. 85. crp_largest_first crp_smallest_first. 80 16 32 64 128 No. of PNs 圖 8 系統使用率. 表 11 系統平均產能 No. of First_Fit_First PNs T 16 2.41 32 2.53 64 2.63 128 2.72. Largest_Fit_First CRP_Smallest_First CRP_Largest_First T RI T RI T RI 2.57 6.639% 2.71 12.448% 2.72 12.863% 2.68 5.929% 2.81 11.067% 2.82 11.462% 2.74 4.183% 2.87 9.125% 2.9 10.266% 2.8 2.941% 2.92 7.353% 2.95 8.456% Effect of no. of PNs 3 2.9. Throughput. 2.8 2.7 first_fit_first. 2.6 2.5. largest_fit_first. 2.4. crp_largest_first. 2.3. crp_smallest_first. 2.2 16. 32. 64. 128. No. of PNs. 圖 9 系統平均產能. 10.
(11) 六、結論及未來工作. [2] H. Boral, W. Alexander, L. Clay, G. Copeland, S. Danforth, M. Franklin, B. Hart, M. Smith, and P. Valduriez, “Prototyping Bubba, A Highly Parallel Database System,” IEEE Transaction on Knowledge and Data Engineering, 2(1):424, 1990.. 在這篇研究報告中,針對多處理器資 料庫系統的查詢排程 ,我們應用了 C-R property 的 的 兩 種 重 組 策 略 ─ CRP_Largest_First 與 CRP_Smallest_First, 提出了新的多重排程演算法。 此演算法能 從重組過的查詢佇列中,快速的找到佔用全 部或最多處理結點的查詢組合。 我們期望 新的排程技術,能充份發揮多處理器系統的 效能,以加速資料庫查詢的處理。 我們也 建構了一個實驗模型,利用不同參數的變 化,做了一系列的實驗,以評估所提出多重 查詢排程新技術的效能。 在實驗結果裡, 我們發現,應用 C-R property 的多重排程技 術,無論在平均系統的使用率,或所達成的 平均系統產能,皆能明顯的優於現有的多重 查詢排程技術,也證實了新排程技術的可行 性。 而兩種 C-R property 重組策略中,又 以 CRP_Largest_First 略 優 於 CRP_Smallest_First,但差異並不大。 我們的實驗除了考量處理器數目的變 化外,也多了一個排程視窗(Scheduling Window)以規範被考慮排程的查詢數目,其 主要目的,是為了避免查詢佇列中有過多的 查詢,使得決定排程過於耗時。 而實驗結 果也證實了,當排程視窗增加到一定大小以 後,對系統效能的增進是有限的,如此排程 若考量所有在佇列裡的查詢,實質效益是不 大的。 不過根據實驗,我們也建議,隨著 處理結點數目的增加,適度的增加排程視窗 的大小,也有其必要性,可增進排程的效 能。 本研究報告著重於,如何讓每一批次 的排程盡量佔用全部或最多的處理結點 數,以發揮最高的系統使用率。 而已被提 出的多重排程技術,如:Mehta 等[22],則 是考量如何使記憶體與 I/O 的有效運用。 兩種排程技術考量的角度雖然不同,但對增 進資料庫系統效能,與加速查詢處理的目標 卻是一致的。 未來的研究方向,將可嘗試 著如何把多種考量的因素結合在一起,以發 展出考量更為完整,使系統效率更高的多重 排程技術。. [3] Chin-Chen Chang and Jaw- Ji Shen, “Consecutive Retrieval Organization as A File Allocation Scheme on Multiple Disk Systems,” Proceedings of the International Conference on Foundations of Data Organization, Pages 74-80, Kyoto, Japan, May 21-24, 1985.. [4] Chin-Chen Chang, Ji-Han Jiang, and Jau-Ji Shen, “Organization of Pictorial Databases for Spatial Match Retrieval,” Proceedings on International Symposium on Next Generation Database Systems and Their Applications, Pages 205-210, Fukuoka, Japan, 1993.. [5] Chandra Chekuri, Waqar Hasan, and Rajeev MotWani, “Scheduling Problems in Parallel Query Optimization, ” Proceedings of the 14th ACM Symposium on Principles of Database Systems , Pages 255-265, San Jose, California, May 1995.. [6] M. S. Chen, M. Lo, P. S. Yu, and H. C. Young, “Using Segmented Right-deep Trees for the Execution of Pipelined Hash Joins,” Proceedings of International Conference on VLDB, Pages 15-26, Vancouver, Canada, August 1992.. [7] S.. Dandamudi and C-Y Chow, “Performance of Transaction Scheduling Policies for Parallel Database Systems ,” Proceedings of the 11th International Conference on Distributed Computing Systems, Pages 116 –124, 1991.. [8] Jitender S. Deogun, Vijay V. Raghavan and Thomas K. W. Tsou, “Organization of Clustered Files for Consecutive Retrieval,” ACM Trans. On Database Systems, 9(4), Pages 646-671, 1984.. [9] D. DeWitt, R. Gerber, G. Graefe, M. Heytens, K. Kumar, and M. Muralikrishna, “GAMMA – A High Performance Dataflow Database Machine,” Proceedings of the Twelfth International Conference on Very Large DataBase, pages 228-237, Kyoto, Japan, August 1986.. 七、參考文獻 [1] S. S. Al-fedaghi and Y. H. Chin,. [10] D. DeWitt, S. Ghandeharizadeh, D.. “Algorithmic Approach to the Consecutive Retrieval Property,” International Journal of Computer and Information Sciences, Vol. 8, No. 4, Pages 279 - 301, 1979.. Schneider, A. Bricker, H. Hsiao, and R. Rasmussen, “The GAMMA Database Machine Project,” IEEE Transactions on 11.
(12) Engineering,. Engineering, Vol.7, No.6, Pages 900-914, December, 1995.. [11] Sakti P. Ghosh, “File Organization: The. [21] Yu-lung Lo, Kien A. Hua, and Wallapak. Consecutive Retrieval Property,” Communications of the ACM (CACM), Volume 15, Pages 802-808, 1972.. Tavanapong, “Scheduling Queries for Parallel Execution on Multicomputer Database Management System,” Lecture Notes in Computer Science-Database and Expert Systems Applications, Vol. 1134, pp.698-707, September 1996.. Knowledge and 2(1):44-62, 1990.. Data. [12] Sakti P. Ghosh, “Consecutive Retrieval Property,” Data Base Organization for Data Management, Chapter 6, Pages 212268, 1977.. [22] M. Mehta, V. Soloviev, and D. J. DeWitt, “Batch Scheduling in Parallel Database Systems,” Proceedings of the 9th International Conference on Data Engineering, Pages 400 –410, 1993.. [13] W.. Hong and M. Stonebraker, “Optimization of Parallel Query Execution Plans in XPRS, ” Proceedings of International Conference on Parallel and Distributed Information Systems, Pages 218-225, Dec. 1991.. [23] T. H. Merrett and Yahiko Kambayashi, “Join Scheduling in a Paging Environment Using the Consecutive Retrieval Property,” Proceedings of International Conference on Foundations of Data Organization and Algorithms (FODO), Pages 323-347, Kobe, Japan, 1998.. [14] Kien A. Hua and Chiang Lee, “Handling Data Skew in Multiprocessor Database Computers Using Partition Tuning,” Proceedings of the International Conference on VLDB, pages 525-535, Barcelona, Spain, 1991.. [24] S. Takkar. and S. P. Dandamudi, “Performance of Hard Real-time Transaction Scheduling Policies in Parallel Database Systems,” Proceedings of the 6th International Symposium on Modeling, Analysis and Simulation of Computer and Telecommunication Systems, Pages 176 – 184, 1998.. [15] Kien A. Hua, Yu-lung Lo, and Honesty C. Young, “Considering Data Skew Factor in Multi-way Join Query Optimization for Parallel Execution,” VLDB Journal, 2(3):303-330, 1993.. [16] Kien A. Hua, Yu-lung Lo, and Honesty C. Young, “Optimizer-Assisted Load Balancing Techniques for Multicomputer Database Menegement Systems,” Journal of Parallel and Distributed Computing, 25(1):42-57, February 1995.. [25] Teradata. Corporation, Los Angeles, California, Teradata DBC/1012 Data Base Computer Concepts and Facilities, release 3.1 edition, 1988, Teradata Document C02-0001-05.. [17] M. Kitsuregawa, H. Tanaka, and T. Motooka, “Application of Hash to Database Machine and Its Architecture,” New Generation Computing, 1(1):66-74, 1983.. [18] Chiang. Lee and Zue-An Chang, “Workload Balance and Page Access Scheduling for Parallel Joins in SharedNothing Systems,” Proceedings of International Conference on Data Engineering, pages 411-418, 1993.. [19] Chiang Lee and Kien A. Hua, “A Selfadjusting Data Distribution Mechanism for Multidimensional Load Balancing in Multiprocessor-based Database Systems,” Information Systems, 19(7), Pages 549-567, July 1994.. [20] Chiang Lee and Zue-An Chang,"Utilizing Page-Level Join Index for Optimization in Parallel Join Execution," in the IEEE Transactions on Knowledge and Data 12.
(13)
數據

相關文件
A dual coordinate descent method for large-scale linear SVM. In Proceedings of the Twenty Fifth International Conference on Machine Learning
The Performance Evaluation for Horizontal, Vertical and Hybrid Schema in Database Systems.. -A Case Study of Wireless Broadband
in Proceedings of the 20th International Conference on Very Large Data
Lange, “An Object-Oriented Design Method for Hypermedia Information Systems”, Proceedings of the Twenty-seventh annual Hawaii International Conference on System Sciences, 1994,
(1988), “An Improved Branching Sheme for the Branch Bound Procedure of Scheduling n Jobs on m Parallel Machines to Minimize Total Weighted Flowtime,” International Journal of
For better efficiency of parallel and distributed computing, Apache Hadoop distributes the imported data randomly on data nodes.. This mechanism provides some advantages
[16] Goto, M., Muraoka, Y., “A real-time beat tracking system for audio signals,” In Proceedings of the International Computer Music Conference, Computer Music.. and Muraoka, Y.,
Selcuk Candan, ”GMP: Distributed Geographic Multicast Routing in Wireless Sensor Networks,” IEEE International Conference on Distributed Computing Systems,
