兩階層式垃圾郵件過濾機制之研究
A Study of Two-tier Filtering Schemes for Anti-spam
*葉生正
1蘇民揚
2張僩鈞
1 1銘傳大學資訊傳播工程學系所
2銘傳大學資訊工程學系所
*E-mail: [email protected]
摘要
垃圾郵件氾濫至今,造就各種防堵機制群雄並 起,且在內容過濾比對機制中又以機械學習理論的 支援向量機(SVM)與貝氏演算法(Naïve Bayes)最為 著名。故本論文主要擷取 SVM 以超平面快速分類 的特點及貝氏演算法的彈性,研究設計一兩階層式 之垃圾郵件過濾機制。本研究先將中、英文郵件訓 練樣本於中文斷詞與英文斷字後,再以資訊增益 (Information Gain)計算結果決定 SVM 所訓練之關 鍵字。最後,將 SVM 對測試樣本之分類結果,以 本論文提出之 4 種邊界距離挑選出落於模糊區間的 郵件樣本,經由貝氏機率改良模型進行計分以判斷 郵件類別。實驗結果呈現 4 種邊界距離擷取出資料 再計算後的準確率皆有所提升,其中又以最大距離 或平均距離的改善最顯著;且若加上在最佳化模式 的預測下,中、英文郵件整體分類的精確度皆達 97% 以上,因此可驗證本研究提出之兩階層式過濾機制 與貝氏演算法改良模型的可行性。 關鍵詞:支援向量機、貝氏演算法、資訊增益。Abstract
The Support Vector Machine (SVM) and Naïve Bayes are well-known machine-learning algorithms for the application of content filtering against spam. On the basis of fast classification through the hyper-plane of SVM and flexible threshold setting of Bayes, this paper proposes a two-tier filtering scheme which combine SVM and new Naïve Bayes model for anti-spam. In the first tier, Information Gain is the way to decide keywords for training vector of SVM. The paper also provides four kinds of margin of the hyper-plane, and picks out the sampling data which locates on the scope for the second tier Bayesian probability calculation to decide the classification. The experimental results indicate that all kinds of the margin setting bring the improved accuracy about 1% to 4%, especially the Maximum Distance and Average Distance Margin. Additionally, the optimal model performs the total accuracy of Chinese and English sampling mails above 97%. However, the proposed two-tier filtering scheme and new Naïve Bayes model were verified with availability.
Keywords: SVM, Naïve Bayes, Information Gain.
1. 前言
透過電子郵件所衍生出的變相問題,不外乎是 早期的「病毒郵件」以及現今吵得沸沸揚揚的「垃 圾郵件」。且此二者又能相互結合,例如當病毒郵 件感染了某一部電腦後,病毒作者再將中毒電腦名 單販賣給垃圾郵件發送者,使其利用該電腦當作跳 板來發送垃圾郵件形成更大的危害。這種病毒郵件 與垃圾郵件交相賊的情況,令病毒為垃圾郵件創造 更多攻擊機會,至少已有超過 30%的垃圾郵件都是 透過此種中毒電腦的方式來發信[1]。 目 前 各 家 防 毒 廠 商 偵 測 病 毒 的 技 術 日 趨 成 熟,更新病毒碼之效率已臻於快速且穩定,從發現 新 病 毒 到 釋 出 新 病 毒 碼 時 間 相 差 不 會 大 於 八 小 時,故對於病毒信件的攔截,防毒軟體已可做到幾 近完善;但針對「垃圾郵件」的防堵,由於人人對 信件的合法性與非法性的定義不同,因此沒有百分 之百精確的方法。可是對於大多數人而言,只要郵 件信息本身有其「目的」,有想要表達廣告、商業 的意圖和立場,皆會被認定為「垃圾郵件」。然而 在過濾垃圾郵件的方法中,以機器學習理論而言, 由於訓練方式與演算方法的不同,造就出精確率的 結果就不盡相同。本研究主要目的即在於提出結合 支援向量機(Support Vector Machine, SVM)與貝氏 (Naïve Bayes)兩種演算法的特性,先以 SVM 做初步 分類,將落入模糊區的郵件交由 Bayes 進行機率判 斷並給定分數,如此對郵件進行所謂兩階層式的過 濾與分類,以期提高防堵垃圾郵件的精確率,並降 低錯分正常郵件的誤判率[2][3]。 本論文共分 5 個章節,第 1 章簡述本研究之動 機、背景與目的;第 2 章介紹相關的垃圾郵件判別 過濾方法;第 3 章則詳述本研究論文之實驗方法與 步驟;第 4 章將呈現所提出之機制效能分析的結 果。第 5 章則歸納研究結果並提出未來方向。2. 相關研究與技術
本章將介紹目前常見之垃圾郵件判別與過濾 的方法和理論,分別是即時性黑名單(Real Time Black-hole Lists, RBL)、DCC、Razor、Pyzor、支援 向 量 機 (SVM) 和 貝 氏 演 算 法 (Naïve Bayes) 等 [2][5][6]。2.1 即時性黑名單
面對全球 Spammer 每日更迭的 IP 位置、主機 名稱,網路上已有專門收集資訊,建立完整黑名單 資料庫,稱作「即時性黑名單」(Real Time Black-hole Lists, RBL),各郵件伺服器可透過即時查詢 RBL 的 資料以判斷郵件是否為垃圾郵件來源,而後決定是 否拒收相應的郵件。然而目前線上即時黑名單之管 理制度寬鬆不一,較寬者是將對方加入黑名單前會 主動發信通知 SPAM 的郵件主機管理者,要求改 善;若主機管理者遲遲未處理,才會將該主機列入 黑名單;較嚴的作法則為一旦使用者舉報或經主動 偵測認定為可疑對象,一律列入黑名單。這種方法 雖然可有效檔下非常多數的廣告信件,但由於過度 制式,誤攔率必定提高,因此衍生出許多問題。現 今 RBL 服務商大部分是非營利性機構或民間組 織,基本上皆屬免費服務,然而在使用這個技術之 前,還是必須慎選一些聲譽良好且值得信任的服務 網 站 , 如 目 前 公 認 較 準 確 且 免 費 的 ORDB(www.ordb.org)。因為目前各種黑名單資料庫 皆難以保證其正確性和及時性,若使用不完善的資 料庫,如北美的某些 RBL 網站包含了我國大量的主 機名字和 IP 位址,其中有些是早期 Open Relay 所 造成,有些則是由於誤報所造成。這些遲遲不糾正 的資料庫,在一定程度上必定阻礙了我國與北美地 區的郵件聯繫。
2.2 DCC、Razor 與 Pyzor 法
DCC、Vipul's Razor 與 Pyzor 法是將信件內容 取樣,並計算其檢查碼(Checksum),透過網路向 某些集中式資料庫查詢,以辨別此封信件是否已經 遭到其他人提報為廣告信件。此三種技術透過許多 下游裝設收集程式的電子郵件伺服器,取得回報已 知垃圾郵件訊 息的 checksum value 或 密碼雜湊 (Cryptographic Hash),然後製作成該郵件訊息的 特徵或類似指紋的數據供其餘下游的電子郵件伺 服器查詢。在 Spammer 短時間內大量寄發了上千或 上百萬封相同郵件訊息之後,該郵件訊息很容易會 被資料庫端的判斷主機發現,並依特徵被辨識出 來。其中 Razor 是一種線上的垃圾郵件比對資料 庫。如果有一封垃圾信同時寄給上百位使用者,它 會記錄所有的垃圾郵件,計算其指紋碼 (使用 SHA 雜湊演算法),然後存至 Razor 之線上資料庫中。而 事後郵件主機可以經由查詢 Razor 之線上資料庫 來判斷該封郵件是否為垃圾郵件,若是,則會自動 的將這封垃圾信封鎖。DCC 分散式檢查碼交換為一 大宗郵件辨識技術,為免費原始碼。其作法為讓啟 動 DCC 的 Mail Server 在接收到信件時產生信件相 關的檢查碼(Checksum),再將這些 Checksum 通報 至 DCC 伺服器,DCC 伺服器會自動更新並告知郵 件伺服器此檢查碼出現的次數。其中不同內容產生 的 Checksum 會完全不同,其數值代表著此郵件曾 在其它郵件伺服器上被傳送的次數。當伺服器發現 此一次數超過了管理者所設定的門檻時,就可認定 此 一 為 大 宗 寄 發 的 垃 圾 郵 件 。 而 由 於 前 述 之 “Razor”線上垃圾郵件比對資料庫所使用的伺服器 並非免費原始碼,所以“Pyzor”的目的即是要用來取 代 Razor。但上述三種方法最大好處是準確性高以 及節省 CPU 計算資源,因為它僅需針對信件內容 的某幾段取樣,無須逐字比對,對於大量寄送重複 內容的廣告信件(包括電子報),若郵件的特徵符 合了資料庫中的特徵,皆能夠有效大量攔截。此外 由於並不是針對完整信件內容做 checksum,因此即 便廣告信利用一些小技巧更動信件內容,例如:信 件首行的收信者姓名、內容夾雜空白行及無意義單 字等,都不容易影響其算出的 checksum 結果。
2.3 支援向量機
SVM是一種用在機器學習的演算法,其主要的 概念就是針對訓練資料集,利用定義的特徵值,以 訓練函式計算出一個最理想的超平(Hyper-plane), 此後透過此超平面分類測試資料判斷其準確率,當 準確率超過一標準值且具意義時,即可分類新的未 知資料,將所有欲分類的資料快速分類至正確的類 別。SVM 的基本方法論是在建構一個線性分割超 平面(The linear separating hyper-plane),以線性的模 式去執行非線性的分類範圍,而此超平面則是最大 化正集(Positive class)與負集(Negative class)之間的 距離所得出。由於分類垃圾郵件時會有大量的資料 與特徵值,其訓練過程將耗費不少時間,但使用支 援向量機透過數學的方式可以讓事後整體分類速 度大幅提升,達到最佳的分類效果[4][5][8]。2.4 貝氏演算法
貝 氏 演 算 法 運 用 於 垃 圾 郵 件 的 過 濾 效 果 卓 越,Spam Conference 的創辦人 Paul Graham 曾表示 過,使用此方法的過濾軟體 CRM114 一個月內偵測 的精準度達 99.75%,同時 7000 封信件中,只有 8 封有誤判的情形。而 Bayesian Filtering 即是應用機 率學中的貝氏定理來對郵件進行分類,其涵義主要 是假設字與字之間存在著獨立的關係,最早的第一 篇應用在垃圾郵件的論文是在 1998 年由 Sahami 學 者提出,該分類的演算法則說明如下[1]。 給定 N 個文件的種類(在垃圾郵件問題上, N=2,一是正常信件,一是垃圾信件),C1,C2,CN 表示不同文件的種類,以英文字母 d 來表示一個文 件,其中 d 文件包含了W
1,
W
2,
W
m個不同的單字 (Keywords),這裡的目的是在已知 d 文件由不同 單字組成的前提下,該 d 文件屬於C ,jj = 1,2,…, N,去求得一個機率值P(Cj |W1,W2,Wm),其計 算公式如式(1):) , , , ( ) | ( * * ) | ( * ) | ( * ) ( ) , , , | ( 2 1 2 1 2 1 m j m j j j m j W W W P C W P C W P C W P C P W W W C P 1 2 ( | ) * ( ) ( , ... ) i j j i m P W C P C P W W W
1 2 ( ) ( | ) ( , ... ) ( ) j j i i m j P C P C W P W W W P C
(1) 1 2 ( ) ( | ) ( ) ( , ... ) ( ) j j i j i m j P C P C W P C P W W W P C
未知文件的類別則為式(1)中所求得機率值最 大的C
j(意指最可能)。式(1)中P(Cj)代表所有文 件中,Cj類別的可能性,計算上是以「C
j類別文 件的總數」除以「全部的總文件數目」。P(Wk|Cj)則 代表在給定 j C 類別的前提下,Wk出現在C
j類別的 比率(「出現關鍵字 k W 的信件數」除以「該類別的 總信件數」所得的條件機率)。而P
(
W
1,
W
2,
,
W
m)
代表關鍵字Wk出現在全部總文件的機率。 分類器依下式將文件 d 歸類為C
k類(設C
k為 某一已知類別),則從 d 在各類別得到機率的最大 值,來判斷其所屬類別,如式(2)所示: ) , , | ( ) , , | ( 1 2 ... 1 2 1 j m N j m k W W W MaxPC W W W C P (2) 貝氏演算法在郵件系統的應用十分廣泛,許多 著名軟體如 SpamAssassin 已內嵌經此方法作垃圾 郵件的過濾。其最大優點在於經由貝氏演算法計算 後,會針對郵件產生一組易於識別機率分數,屆時 與使用者於郵件伺服器所設定之門檻值比對,若分 數超過門檻值,則判定此文件為垃圾郵件,而門檻 值又可依經驗設定,若發覺過濾器誤刪太多正常信 件,可以將門檻值訂得較為寬鬆,對個人化而言, 貝氏分類法算是較彈性的一種規則[3]。3. 兩階層式的過濾機制
本 研 究 論 文 主 要是 設 計 一兩 階 層 式 垃 圾 郵 件過濾機制,取 SVM 分類演算法所能形成之模 糊 區 間, 及 其快 速分 類 的特 性 ;搭 配 貝氏 演 算 法 透 過樣 本 的大 量建 立 ,提 高 機率 分 數給 予 之 準 確 性, 期 望二 者的 結 合優 於 單一 演 算法 , 展 現更佳的過濾效能。 在 郵 件 樣 本 的 選取 上 , 分為 訓 練 樣 本 與 測 試樣本。訓練樣本旨在做為 SVM 關鍵字之挑選 以 及 貝氏 關 鍵字 資料 庫 的建 立 。挑 選 上依 目 前 一 般 使用 者 收到 信件 類 別的 比 例, 垃 圾郵 件 比 正常郵件為 4:1,故在英文郵件的訓練樣本中 垃圾郵件為 800 封,正常郵件 200 封;中文的 訓練樣本亦以垃圾郵件 800 封,正常郵件 200 封 進 行訓 練 。測 試樣 本 的數 量 ,中 英 文郵 件 皆 為垃圾郵件與正常郵件各 500 封,共 1,000 封進 行 測 試 。 樣 本 來 源 方 面 , 英 文 郵 件 使 用 Ling-spam、TREC Spam Corpus 以及個人收集之 混 合 型樣 本 ;中 文郵 件 則為 收 集多 位 使用 者 信 件 之 混合 型 樣本 ,其 中 測試 樣 本與 訓 練樣 本 為 個 別 收集 , 刻意 避免 文 件之 重 複, 最 後進 行 效 能分析評估。 本機制之流程主要為程式訓練、挑選 SVM 關 鍵字、SVM 分類、決定 SVM 分類後模糊區間範圍, 以及貝氏演算法計算機率分數等,以下將詳述其步 驟程序。3.1 訓練關鍵字
由 於 辭 典 式 斷 詞法 須 具 備一 龐 大 資 料 庫 , 且 須 人工 建 立, 定期 維 護、 更 新, 加 上中 研 院 CKIP 斷詞軟體價格高昂,故本研究訓練關鍵字 的 方 式主 以 統計 式斷 詞 法的 概 念, 於 程式 紀 錄 字 詞 出現 次 數, 包括 在 垃圾 郵 件中 出 現次 數 、 正 常 郵件 出 現次 數、 垃 圾郵 件 中出 現 封數 , 與 正 常 郵件 出 現封 數等 資 訊。 其 中「 出 現封 數 」 為 關 鍵字 在 不同 郵件 類 別出 現 過的 封 數紀 錄 , 可適用於決定 SVM 分類的 Information Gain 關 鍵 字 挑選 條 件, 以及 貝 氏資 料 庫中 關 鍵字 機 率 分數的紀錄[7]。 在關鍵字的擷取方面,中英文樣本方法不一。 英文主要以空白字元或標點符號來決定欲擷取單 字之位置,而後挑選出來做次數、封數的紀錄。由 於語文的特性,英文在資訊索引上較容易識別,且 單字通常即可代表完整意義,故關鍵字的決定則以 其在文件中出現之次數、封數的頻率為主。然而有 些單字出現頻率甚高,但其具備「關鍵」字特性的 地位並不高,例如人稱代名詞、連接詞、定冠詞等, 可濾過不需比對。 至於中文字詞的擷取,由於一個全形中文字大 小為 2bytes,且文句中字與字,或詞與詞間並沒有 明顯的空白或標點符號隔開,加上目前的中文郵件 事 實 上 多 屬 中 英 文 夾 雜 信 件 ( 英 文 字 母 大 小 為 1byte),故在斷詞方法上本研究先以 ASCII 碼比對, 分離出英文或中文字,而後再進行英文關鍵字的訓 練,以及中文字串的斷詞,紀錄其出現次數與封 數。針對中文斷字本研究於程式中並無使用類似 CKIP 的文字資料庫,主要原因在於其所佔空間與 資源量大、申請價格高昂、對詞庫判斷依賴性高(若 詞庫沒有相同的詞句,則全部斷成一個個單獨的中 文字);本研究以每兩個中文字做斷詞,蓋因中文多 以二字組合即具詞意,超過二個字以上的詞句,實 際上也以二個字為基本單位。另外,以每兩個字做 斷詞或許有些詞不具意義,但在樣本數量足夠的訓 練情況下,具備意義的關鍵字排名亦會超越前序。3.2 關鍵字轉換 SVM 特徵向量
經由 Information Gain 計算關鍵字分數後,本 研究分別擷取「垃圾信關鍵字」與「正常信關鍵 字」,而擷取的方向分為二: 1. Overlapping Keywords: 垃圾信關鍵字的條件 為其出現在垃圾信的封數大於在正常信出現之 封數,且依 Information Gain 值由大至小排序,取前 100 名;同樣的正常信關鍵字為其出現在正 常 信 之 封 數 大 於 在 垃 圾 信 出 現 的 封 數 , 依 Information Gain 值排序取前 100 名,然而在訓練 樣本中,正常信為 200 封,加上一般正常信的性 質為字數較少、無特定類別,因此最後訓練出來 符合上述條件的正常信關鍵字自然比垃圾信關 鍵字數量少。故在此中文信件所使用的關鍵字共 132 個,英文信共 136 個。 2) Independent Keywords: 垃圾信關鍵字條件為 其 在 正 常 信 件 中 出 現 次 數 為 0 者 , 再 依 Information Gain 值排序挑選前 100 名;正常信關 鍵字的挑選以此字詞在垃圾信件中出現次數為 0,再依 Information Gain 值排序挑選。如同上述 提及正常信件的性質,符合此條件而產生的中文 郵件關鍵字共 111 個,英文郵件共 109 個。 之後依決定的關鍵字,轉換成SVM向量,由於 本研究以LIBSVM作為第一階段分類工具,故轉出 向量的格式須符合程式要求為:
<label> <index1>:<value1> <index2>:<value2>… 其中 label 為信件所屬類別標籤,若欲分類的資 料集類別為二,則 label 可標示為+1、-1;index 則 為向量編號,視當初所選特徵數目多少而定;而 value 即為特徵向量之值。以本研究將一封信件轉為 向量,垃圾信的 label 值為+1,關鍵字若有 136 個, index 值則為 1~136,而 value 為每個關鍵字在此信 件中出現的次數。
3.3 SVM 設定與訓練
在SVM的使用上,本研究主要以LIBSVM程式 執行,此程式能因應不同資料類型、使用者對於分 類結果之需求,藉由參數設定來達成期望的效果。 在初始環境設定上,首先主要在決定SVM型態與 SVM核心函數。SVM型態主要分為Classification與 Regression。二者間的差別,依定義Classification主 要意圖在產生使未來測試資料錯誤可能性最低的 最佳邊界範圍,而Regression則為計算出未來預測資 料之最佳迴歸數值。本研究「二階層式分類」之主 要目的,即是在SVM首先訓練出最佳超平面,之後 將遺落在正負邊界範圍內的資料挑選出,交由Bayes 進 行 第 二 層 的 過 濾 , 故 在 SVM 型 態 上 選 擇 Classification [4][7]。 初始環境設定的第二部份 kernel_type,在現實 空間中資料並非完全能以線性分類,當遇到無法以 線性分割的資料集時,則須借助核心函數將資料從 Input Space 對應到 Feature Space,核心函數定義為) ( ) ( ) , (x t x t K
。 在 LIBSVM 的核心函數中有以下四種類型,其 中γ、r、d 為核心參數: 1) Linear:K
(
x
i,
x
j)
x
iTx
j 2) Polynomial:0
,
)
*
(
)
,
(
d
j T i j ix
x
x
r
x
K
3) Radial basis function (RBF):
2 i j i j K( x , x )exp(
* x x ) 4) Sigmoid:K( x , x )
i j
tanh( * x x
iT j
r )
本 研 究 使 用 的 SVM 型 態 為 Classification 中 的 C-SVC,而核心函數則選擇RBF。主要目的在於 C-SVC能藉由設定的參數-c與-g,訓練出將錯誤最 小化的超平面,而參數-c和-g的訓練,LIBSVM內所 附的grid.py程式能經由反覆測試,找出最佳的c值與 g值,之後在執行訓練程式時將參數鍵入。 其次RBF為目前較普遍使用的核心函數,能將 極複雜非線性分布的資料轉換至特徵空間,另外學 者亦建議,選擇核心函數時應優先考慮放射型(RBF) 核心函數,因為它具有能分類非線性且高維度的資 料,並僅需調整兩個參數(c和g),不但減少操作上 的複雜性與運算時間,亦能達到較高的預測能力。 故本研究在初始環境設定上以此二者為主。3.4 設定邊界範圍
經由SVM分類後的資料,主要以正、負極區 分,意即y w x b 0計算後大於0者屬於垃圾郵 件,小於0者則判為正常郵件。在實際情形中,待 預測信件通常與資料庫訓練樣本不重複,又很有可 能一封正常信,因出現少許偏向垃圾信的關鍵字, 經計算後結果為+0.002,依SVM分類的精神,將毫 不考慮地將此封郵件歸類為垃圾信,但其所存在於 的平面空間,距離超平面其實是很近的。故為了避 免類似的偶發情形,需要設定一範圍,將落在接近y
w x b
0
兩側模糊區的資料挑選出,交由第 二層貝氏過濾法計算。故本研究採用四種範圍,框 架出需進行第二道過濾的資料: 1) -1 ~ +1: 測試資料經由SVM計算後,其值落在 此範圍者,挑選出予以貝氏計算。 2) -0.5 ~ +0.5: 測試資料經由SVM計算後,其值 落在此範圍者,挑選出予以貝氏計算。 3) Maximum Distance: 額外訓練一組資料集,挑 選其被判錯中正極最大值與負極最小值,以此二 者間距離作為下一組資料在SVM分類後而被挑 選出的範圍。 4) Average Distance: 額外訓練一組資料集,挑選 其被判錯中正極所有值的平均與判錯中負極所 有值的平均值,以此二者間距離作為下一組資料 在SVM分類後而被挑選出的範圍。 上述1)和2)屬於固定且對稱之範圍,3)和4)屬不 對稱且會隨訓練資料改變而更動的邊界範圍,若範 圍距離越大,被挑選出的資料量會越多,造成原先 SVM已正確分類的資料,還會有再次經歷貝氏計算 之機會。決定邊界範圍後,將待測資料交由SVM測 試(predict.exe),分數產生後再將落在範圍內的資料 選取出,不論其當初SVM判別的準確度,最後交給 下一層貝氏法進行雙重過濾。3.5 修改貝氏過濾機制
不同於支援向量機演算法僅需少許特徵值轉 化為向量,並搭配參數設定與核心函數即能找出最 佳分割平面,貝氏過濾垃圾郵件之機制需要龐大的 關鍵字資料庫,紀錄關鍵字屬於郵件類別的機率分 數,提供往後測試信件的機率判定準則。本研究在 實作貝氏資料庫方面,主要將信件斷字、斷詞後的 關鍵字存於資料庫,另外紀錄該關鍵字屬於垃圾郵 件之機率分數,之後針對從SVM模糊區間挑選出的 資料,以貝氏資料庫關鍵字的機率分數作運算,並 預設一門檻值分數,判斷其為垃圾抑或正常郵件。 根據貝氏演算法,任一關鍵字經由計算後所得 之機率分數,可視其為一獨立事件,可對其作數學 運算。以一關鍵字「專業」為例,其在垃圾郵件樣 本中出現的機率為 0.8889,在文件類別只有二種的 情況下,「專業」相對於出現在正常郵件樣本中的 機率即為 0.1111。在此很明顯可看出此關鍵字出現 在垃圾郵件的機率較高,故此關鍵字可獲得一機率 分數 0.8889-0.1111=0.7778,且隸屬於垃圾信的關鍵 字,同樣的方法亦可建立一套正常信的關鍵字機率 分數。 獲得上述貝氏關鍵字機率分數資料庫後,針對 待測郵件的記分,本研究提出四種記分方式,即貝 氏機率演算方式之改良,其中 P (Wi)為垃圾信關鍵 字之機率分數,P (Wi’)為正常信關鍵字之機率分 數,Ni為關鍵字在單一文件中出現之次數: 1) i i i i P(W ) P(W ')
2) i i i i i i P(W )* N P(W ')* N '
3) i i i i P(W ) P(W ')
4) i i i i i i P(W )* N P(W ')* N '
4. 研究結果分析
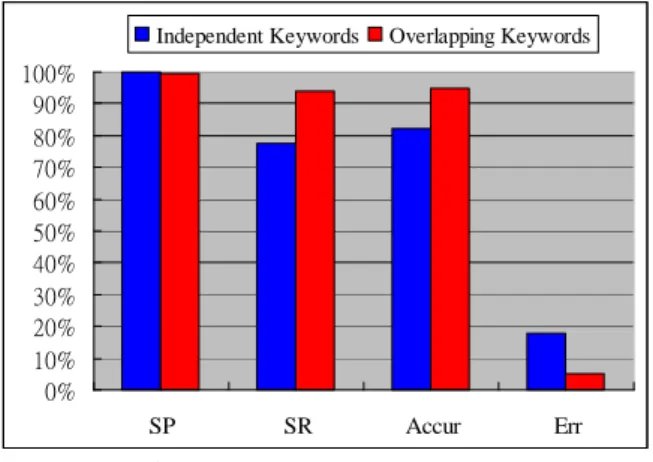
首先對英文郵件之SVM訓練過程為將訓練樣 本 800 封 垃 圾 信 與 200 封 正 常 信 轉 化 為 特 徵 向 量 後,交由grid.py程式訓練,找出最佳c值與g值,以 產生最適之model檔案提供未來測試工作。 第一階段在垃圾郵件關鍵字與正常郵件關鍵 字之間相互獨立情況下(Independent Keywords),以 Information Gain挑選109個特徵值,轉換向量後得 出最佳c值為2048,g值為0.0004882,對負極資料被 錯分的懲罰度為5,之後會產生一個model檔,再將 原本訓練檔案當作測試檔案,以svmpredict.exe程式 進行前測。接著以垃圾信關鍵字與正常信關鍵字間 不相互獨立之關鍵字(Overlapping Keywords)所產 生的136組特徵向量,經由grid.py訓練得出最佳c值 為32,g值為0.001953,同樣w值為5,接續以之產 生 model 檔 , 並 再 次 進 行 前 測 。 分 析 結 果 以 Overlapping Keywords作為特徵向量的分類平均準 確性較高,如圖1所示。其中正確率(Spam Precision, SP)反應了過濾系統「找對」垃圾郵件的能力,正確 率越大,將非垃圾郵件誤判爲垃圾郵件的數量越 少。召回率(Spam Recall, SR)則反映過濾系統發現 垃圾郵件的能力,召回率越高,漏網的垃圾郵件就 越少。準確率(Accuracy)表示對所有郵件(包括垃 圾郵件和正常郵件)的判別正準率。錯誤率(Error) 則是對所有郵件的誤判率。 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% SP SR Accur Err Independent Keywords Overlapping Keywords圖 1 英文關鍵字於 SVM 前測結果比較 至於中文信件則以訓練樣本中垃圾郵件關鍵 字 與 正 常 郵 件 關 鍵 字 相 互 獨 立 的 Independent Keywords 特徵值,轉換為每筆資料 111 向量,以訓 練樣本 1000 筆資料作前測,最佳 c 值為 2048,g 值為 0.0004882,對負極資料被錯分的懲罰度 w 為 5 。 接 著 以 訓 練 樣 本 中 關 鍵 字 不 相 互 獨 立 的 Overlapping Keywords,經 Information Gain 計算找 出 132 個關鍵字,轉化成向量對原本訓練樣本再進 行前測,最佳 c 值為 32768,g 值為 0.000122,w 值 亦 為 5 。 同 樣 地 在 中 文 信 件 的 前 測 結 果 中 , 以 Overlapping Keywords 作為特徵值分類之準確度較 高,如圖 2 所示。 0.00% 10.00% 20.00% 30.00% 40.00% 50.00% 60.00% 70.00% 80.00% 90.00% 100.00% SP SR Accur Err Independent Keywords Overlapping Keywords
圖 2 中文關鍵字於 SVM 前測結果比較
最後,呈現經過 SVM 分類出之後,把所有錯 分 的 信 件 完 全 地 挑 選 出 交 由 貝 氏 法 進 行 機 率 演
算,視其能否驗證兩階層式過濾方法在最佳化的情 況下,準確率能有效提升。 原先 SVM 對 1,000 封測試英文郵件的分類結果 已於圖 2 呈現,在最佳化的前提下,將所有錯分信 件挑選出來,交由第二層貝氏運算,英文郵件即是 以 i i i i i i P(W )* N P(W ')* N '
演算法來進行貝氏機 率分數之判定,其得到效能之提升結果如圖 3 所 示,可明顯看出運用兩階層式過濾法的結果與原本 單一 SVM 相比,各評估指標包括正確率、召回率 與準確率皆有效提升。 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% SVM SVM+Bayes SVM 92.20% 94.60% 93.30% 6.70% SVM+Bayes 96.46% 98% 97.20% 2.80% SP SR Accur Err 圖 3 英文郵件之兩階層式過濾最佳化結果 SVM 對 1,000 封中文測試郵件的分類結果亦如 圖 2 呈現,今將所有由 SVM 錯分的信件挑選出來, 交由第二層貝氏機率分數判定,依中文郵件最佳貝 氏運算結果 i i i i P(W ) P(W ')
演算法,得到最佳化 效能提升結果如圖 4 所示,此結果亦充分表現出在 最佳化之情況下,透過兩階層式過濾機制,對中文 郵件分類的準確性能有顯著的提升,亦證明此方法 針對中文郵件過濾分類之可行性。 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% SVM SVM+Bayes SVM 94.57% 90.60% 92.70% 7.30% SVM+Bayes 98.00% 98% 98.10% 1.90% SP SR Accur Err 圖 4 中文郵件之兩階層式過濾最佳化結果5. 結論與未來展望
以內容比對的垃圾郵件過濾方法而言,特徵 值、關鍵字的選擇與擷取一直是相當重要的一環。 本研究最大的特點在於作為測試之資料集與起始 訓練關鍵字、特徵值的資料集分開收集,使之更符 合「預測」的精神。在關鍵字的訓練與決定方面, 針對不同演算法則有不同的方式,目的亦是希望結 合二者發揮一加一大於二的功效。在樣本獨立、實 驗環境固定的情況下,加上本研究提出貝氏機率演 算的改良模式,驗證了二階層式垃圾郵件分類過濾 的可行性與準確性,未來若有更多特徵明顯、類別 固定之信件樣本,經由Information Gain計算得出更 多屬於正常郵件和垃圾郵件的關鍵字,輸入SVM訓 練向量權重後,相信能提供更佳的準確率。誌謝
本研究感謝國科會專題研究計畫(計畫編號: NSC 94-2622-E-130 -003 -CC3)的經費支持。參考文獻
[1] 吳昭逸,”具垃圾信過濾與安全機制之電子郵件 收發系統”,國立台灣科技大學資訊工程系碩士 論文,民國九十二年。 [2] 謝居呈,”應用機器學習理論改良分類竄改過之 中英文垃圾電子郵件”,國立台灣科技大學電機 工程系碩士論文,民國九十三年。 [3] 蘇士能,”具個人化中文垃圾郵件之過濾設計與 實作”,國立東華大學資訊工程學系碩士論文, 民國九十四年。[4] Chih-Wei Hsu, Chih-Chung Chang, Chih-Jen Lin, “A Practical Guide to Support Vector Classification,” from http://www.csie.ntu.edu.tw/~cjlin/papers/guide/gui de.pdf, 2003.
[5] Harris Drucker, Donghui Wu, Vladimir N. Vapnik,
“Support Vector Machines for Spam
Categorization,” IEEE Transactions on Neural Networks, Vol. 10, No. 5, 1999.
[6] Jenq-Haur Wang, Lee-Feng Chien, “Toward Automated E-mail Filtering –An Investigation of Commercialand AcademicApproaches,”TANET 2003, p687-692, 2003.
[7] Kun-Lun Li, Kai Li, Hou-Kuan Huang, Sheng-Feng Tian, “Active Learning With Simplified SVMsforSpam Categorization,”First International Conference on Machine Learning and Cybernetics, Beijing, 2002.
[8] Pelossof, R. Miller, A. Allen, P. Jebara, T. , “An SVM Learning Approach to Robotic Grasping,” ICRA 2004 IEEE International Conference, Vol. 4, 3512-3518, 2004.