A Cooperative Multi-Group Priority MAC Protocol for
Multi-Packet Reception Channels
Wen-Fang Yang, Student Member, IEEE, Jwo-Yuh Wu, Member, IEEE, Li-Chun Wang, Senior Member, IEEE,
and Ta-Sung Lee, Senior Member, IEEE
Abstract—Medium access control (MAC) protocol design for cooperative networks over multi-packet reception (MPR) chan-nels is a challenging topic, but has not been addressed in the literature yet. In this paper, we propose a cooperative multi-group priority (CMGP) based MAC protocol to exploit the cooperation diversity for throughput enhancement over MPR channels. The proposed approach can bypass the computationally-intensive active user identification process. Moreover, our method can efficiently utilize the idle periods for packet relaying, and can thus effectively limit the throughput loss resulting from the relay phase. By means of a Markov chain model, the worst-case throughput analysis is conducted. The results allow us to investigate the throughput performance of the proposed CMGP protocol directly in terms of the MPR channel coefficients. Sim-ulation results confirm the system-wide throughput advantage achieved by the proposed scheme, and also validate the analytic results.
Index Terms—Medium access control, multi-packet reception, cooperative communications.
I. INTRODUCTION
C
OOPERATIVE medium access control (MAC) protocol design can exploit multi-user diversity for network-wide performance enhancement, and has attracted considerable at-tention in the recent years [1]-[5]. Most of the existing works, however, are devised exclusively for the collision channel model and do not exploit the multi-packet reception (MPR) capability at the physical (PHY) layer [6]-[11]. Toward more efficient solutions, one promising approach is thus to further take the MPR advantage into consideration so as to gain full benefits from the PHY-layer processing1. A cooperative MACprotocol design aimed for MPR channels is typically subject to the following challenges. Firstly, the central controller (CC) may require the knowledge of the MPR channels of all links, as well as the traffic conditions of all users, to determine the access set. However, this will call for extra communication overheads, and will degrade the system-wide throughput,
Manuscript received November 19, 2008; revised May 9, 2009 and August 12, 2009; accepted August 16, 2009. The associate editor coordinating the review of this letter and approving it for publication is M. L. Merani.
Some part of this work was presented at IEEE PIMRC 2009. This work is sponsored jointly by the National Science Council under grant NSC-97-2221-E-009-001-MY3, by the Ministry of Education of Taiwan under the MoE ATU Program, by the Academia-Research Cooperation Program of MoEA under grant 98-EC-17-A-02-S2-0050, and by MediaTek Research Center at National Chiao Tung University, Taiwan.
The authors are with the Department of Electrical Engineering and Micro-electronic and Information System Research Center, National Chiao Tung University, Hsinchu 300, Taiwan (e-mail: [email protected];
{jywu, lichun}@cc.nctu.edu.tw; [email protected]).
Digital Object Identifier 10.1109/TWC.2009.081516
1MAC protocol designs for MPR channels in a non-cooperative
environ-ment have been considered in [12]-[16].
especially in a large-scale mobile network. Secondly, when packet reception failure occurs due to collisions, a certain portion of the users may have to serve as the relay for data retransmission. Without properly designed MAC protocols for cooperative user scheduling, there would be a large throughput penalty incurred by the increase of transmission time in the packet relaying phase. To the farthest of our knowledge, cooperative MAC protocol designs for MPR channels have not been found in the literature yet.
Recently, relying on a simple flag-assisted mechanism and an associated multi-group priority (MGP) scheduling strategy, a new MPR MAC protocol was proposed in [16]. The MGP scheme has several distinctive features that make it a potential candidate for cooperative MPR MAC protocol designs. Firstly, in the MGP scheme the users are allowed to access the channel according to some prescribed service priority. There is no need for active user selection through exhaustive search over the channel knowledge and local traffic conditions. This will thus considerably reduce the communication overheads in dense cooperative networks. Secondly, the flag-bit can provide the CC with the knowledge of each user’s buffer status. Combined with the multi-group service priority, the channel access can then be reserved for both direct data transmission and packet relaying in a more balanced fashion. Hence, in a high collision environment, the throughput penalty incurred by the relay phase can be largely reduced. To realize the aforesaid advantages, in this paper we extend the MGP scheme and propose a cooperative MAC protocol for MPR channels. Specific contributions of this paper can be summarized as follows.
1) The proposed protocol is, to our best knowledge, the first cooperative MPR MAC scheme. It is free from any assumptions on the channel characteristics and is applicable to the general heterogeneous environment [5]. 2) The number of users permitted for channel access is deterministically set to attain the MPR channel capac-ity. This prevents the channel from being over-loaded, thereby avoiding irrecoverable packet failure due to collisions.
3) Based on the Markov chain model, the throughput performance in the worst-case scenario is analytically characterized. Specifically, we derive (i) a closed-form upper bound for the throughput penalty of the direct-link user that is incurred by the interference of relay packet transmission; (ii) a closed-form lower bound for throughput gain that a user with packet trnsmission failure can benefit thanks to cooperative packet relaying.
The results allow us to investigate the throughput perfor-mance of the proposed CMGP protocol directly in terms of the MPR channel coefficients. Also, simulation study evidences that the proposed CMGP protocal results in a system-wide throughput advantage.
The rest of the paper is organized as follows. Section II highlights some preliminary results. Section III describes the proposed cooperative MPR MAC protocol. Section IV derives the bounds for throughput penalty and gain. Simulation results are given in Section V to illustrate the performance of the proposed scheme. Section VI concludes this paper.
II. PRELIMINARY
A. System Scenario
We consider the uplink transmission of a centralized co-operative wireless network, in which the CC and the user terminals are equipped with the MPR capability. We assume that the transmission is slotted, and the CC controls the user’s access to a common wireless channel. At the beginning of each time slot the CC determines an access set according to some user scheduling rule to be specified later, and broadcasts this message to initialize data transmission. Assume that, due to the broadcast nature of the wireless medium, the CC and at least one of the inactive users can receive the transmitted packets at the end of the data transmission phase. Depending on whether or not the packet of a particular user is successfully received at the CC, an associated ACK or NAK is sent by the CC over a control channel to all users. When packet reception failure occurs at the CC and none of the inactive users can successfully receive the packet, the source node then retransmits this packet during his/her next channel access phase.
B. MPR Matrix
This section reviews the MPR channel model matrix [13] which specifies the MPR capability at the receiver. Assume that the total number of users is𝑀. Let 𝑈 be a permutation of
the index set{1, 2, ⋅ ⋅ ⋅ , 𝑀} that represents a particular order
of the user service schedule. Then the MPR matrix associated with𝑈 is described as 𝐶 (𝑈)=Δ ⎡ ⎢ ⎢ ⎣ 𝐶1,0(𝑈) 𝐶1,1(𝑈) 𝐶2,0(𝑈) 𝐶2,1(𝑈) 𝐶2,2(𝑈) .. . ... ... 𝐶𝑀,0(𝑈) 𝐶𝑀,1(𝑈) 𝐶𝑀,2(𝑈) ⋅ ⋅ ⋅ 𝐶𝑀,𝑀(𝑈) ⎤ ⎥ ⎥ ⎦ (1)
,where 𝐶𝑛,𝑘(𝑈) = Pr{𝑘 packets are correctly received ∣ 𝑛
packets from first𝑛 users in 𝑈 are transmitted} for 1 ≤ 𝑛 ≤ 𝑀 and 0 ≤ 𝑘 ≤ 𝑛. We note that, according to the setting (1),
different permutation index sets𝑈 in general result in different
MPR matrices. Let 𝐶𝑛(𝑈)=Δ 𝑛 ∑ 𝑘=1 𝑘𝐶𝑛,𝑘(𝑈) (2)
be the expected number of correctly received packets when𝑛
packets are concurrently transmitted. The capacity of an MPR channel for the particular service sequence𝑈 is defined as
𝜂 (𝑈)= maxΔ
𝑛=1,⋅⋅⋅ ,𝑀𝐶𝑛(𝑈) . (3)
Note that the numbers of simultaneously transmitted packets for achieving the channel capacity may not be unique. Let
𝑛0(𝑈)= minΔ { arg max 𝑛=1,⋅⋅⋅ ,𝑀𝐶𝑛(𝑈) } (4) be the minimum amount of capacity-achieving packets. Hence the maximal number of users permitted to access the channel should be𝑛0(𝑈), since there will be no further improvement in
system capacity if more than𝑛0(𝑈) users are simultaneously
served. Note that the MPR matrix (1) can be determined via the physical layer performance metric such as bit error rate; an illustrative example based on CDMA communication can be found in [13].
C. Highlight of the MGP Protocol [16]
The proposed cooperative MPR MAC scheme is based on the MGP method [16], which is highlighted below. As in [13] it is assumed that each user has a buffer of size two for storing two data packets. The central idea behind the MGP scheme is to append a flag-bit at the tail of the transmitted packet to inform the CC about the next buffer status. The flag will be set ON if there is a packet in the next buffer, and is set OFF when otherwise. By exploiting such an on-off flag signature, the MGP scheme classifies the users into three groups with different service priorities: the ACTIVE group consisting of the users with flag-bit ON, the STANDBY group consisting of those with flag-bit OFF, and the PRe-EMptive (PREM) group accommodating those who have stayed in the STANDBY or the ACTIVE group for longer than a certain waiting period
𝑆2. The inclusion of the complementary PREM group is to
avoid unfair service scheduling that can occur in a binary grouping strategy: Without the PREM mechanism, users in the STANDBY group would suffer an unlimited service delay since the channels could be constantly reserved for some ACTIVE links with heavy traffic. Based on the tri-group user classification scheme, the channel access priority (from high to low, respectively) is PREM, ACTIVE, and STANDBY. According to such a service strategy, at the beginning of each time slot a total number of 𝑛0(𝑈) users (for some
𝑈) are selected for data transmission, where 𝑛0(𝑈) is the
minimal number of users that achieves the capacity of the MPR channel. In case that the CC successfully receives the packet sent from, say, user 𝑖, the service priority of this
user is determined by the decoded flag information from the current packet. If, instead, packet reception failure occurs, the CC schedules the service priority of user 𝑖 according to
the previous flag record. We shall note the followings: a) In the MGP scheme the number of users permitted for channel access is deterministically set to attain the MPR channel capacity. This prevents the channel from being overloaded, thereby avoiding irrecoverable packet reception failure due to collisions. b) Under light traffic environments, a significant portion of the users could be in the idle phase (i.e., no data
2Optimal design of the waiting period𝑆 can be done via a similar approach
packets to send). If packet reception failure occurs, the idle periods can then be exploited for packet relaying to reduce the possible throughput loss. This can be effectively accomplished via a natural extension of the MGP protocol, as discussed next. III. COOPERATIVEMULTI-GROUPPRIORITYPROTOCOL
The flag-bit is the instrumental mechanism for facilitating the multi-group priority based user service in the MGP pro-tocol. The central idea of the proposed CMGP scheme is to exploit the flag-bit message for distinguishing the direct links from the relay ones. By assigning different service priority to different types of links, the throughput degradation due to the packet relaying overheads can be limited, and an increase in the network-wide throughput can be achieved.
A. Operation of the Proposed CMGP Protocol
If user𝑖 is permitted to access the channel, as in the MGP
scheme a flag-bit𝑏𝑖 is appended at the tail of the packet upon
transmission. The flag signature is ON (𝑏𝑖 = 1) only if the
second buffer is non-empty and contains a data packet also of user 𝑖. The flag signature is instead OFF (𝑏𝑖 = 0) when
either one of the following cases is true: i) the second buffer is empty, ii) the second buffer is nonempty but the packet therein is received from some other user 𝑗 (∕= 𝑖). Upon successful
packet reception, the CC decodes the flag-bit message and then schedules the user access according to the MGP protocol. If packet reception failure occurs at the CC and user𝑘, who is
not in the access set and has empty second buffer, successfully decodes the transmitted packet from user𝑖, user 𝑘 can serve
as the relay in some upcoming channel access period3. If none
of the users can serve as the relay, which happens when all other users’ buffers are non-empty or none of the users can successfully receive the packet, user𝑖 then re-transmits this
packet during the next channel access. We note the following key features regarding the proposed protocol:
1) The adoption of the flag-bit provides an in-built mech-anism for the CC to dintinguish between the direct and relay-or-idle links for service scheduling. Users with flag-bits ON for direct data transmission will be arranged into either the ACTIVE or the PREM group, and thus enjoy potentially higher channel access priority. This prevents possibly frequent data relaying when col-lision occurs, thereby reducing the throughput penalty incurred by the packet relaying overheads.
2) Thanks to the PREM mechanism, users who are not permitted to access the channel over a time period longer than the threshold 𝑆 will be granted with the highest
service priority. This can limit the service delay of the relay links, and can thus maintain the overall QoS requirement.
3) In the proposed protocol, each user takes his/her turn to access the channel according to the prescribed service priority. There is no need for active user identification, and the protocol complexity can be substantially re-duced.
3The newly generated packets of user𝑘 always enjoy the highest processing
priority and, due to limited buffer size, may cause the dropping of the buffered packet from user𝑖.
B. Algorithm Summary
The flow of the proposed CMGP protocol is summarized as below.
CC-end:
I. Put all users into the PREM group.
II. Select first 𝑛0(𝑈) users (the service priority is PREM,
ACTIVE, and then STANDBY) to access the channel. III. Decode the received packet of each user, and afterwards
schedule him/her as the last one on the service list of the ACTIVE (flag-bit on) or STANDBY (flag-bit off) group.
i. An associated ACK or NAK is broadcast depend-ing on whether or not the packet is successfully decoded.
ii. The counter of each processed user is reset to zero. IV. Increase the counter of waiting slots of all users by one. V. Move the users who have stayed un-served for more
than𝑆 time slots to the PREM group.
VI. Repeat steps II to V. User-end:
I. Upon transmission the user appends a flag bit to the tail of the packet.
II. User 𝑖 will drop his/her packet only when he/she
re-ceives an associated ACK from the CC.
i. There will be no packet drop at user𝑖 even if the
packet is successfully received by some user𝑗 but
has not yet been successfully relayed to the CC. ii. If no associated ACK from the CC is received by
user 𝑖 prior to his/her upcoming channel access,
user𝑖 then retransmits this packet during the next
transmission period.
III. If the packet of user𝑖 is received successfully by some
other user𝑗, then user 𝑗 will store this packet if it has
at least one empty buffer.
IV. If an associated ACK for user𝑖’s packet is received by
user 𝑗, then user 𝑗 will remove user 𝑖’s packet from
his/her buffer.
IV. THROUGHPUTANALYSIS
Recall that the proposed CMGP protocol exploits the idle periods of the MGP scheme for packet relaying. Hence, during each time slot there are in general more concurrently transmitted packets as compared with the MGP method. Even though packet relaying can compensate for the throughput loss due to packet reception failure, the increase in the number of active relay links, however, will introduce stronger interference toward direct data transmissions. The throughput loss caused by the relay-induced interference is thus one major limiting factor for the overall system performance. By regarding the achievable throughput of the MGP scheme as a benchmark, this section aims to characterize the throughput performance of the proposed CMGP protocol. We shall note that the exact analysis for the general case, however, is quite difficult. In this section we will focus on the interference-limited worst case, in which there is only one direct link, and the other𝑛0(𝑈)−1
users serve as the relay. Although the performance evaluation based on such a worst-case scenario could be conservative, our
analyses are quite appealing in that the problem formulation becomes tractable. As will be shown below, we can derive a closed-form upper bound for the throughput penalty incurred by the relay interference, as well as a closed-form lower bound for the throughput gain benefiting from user cooperation, di-rectly in terms of the MPR matrix coefficients. This allows us to deduce several interesting features regarding the proposed CMGP protocol.
A. Upper bound for Worst-Case Throughput Penalty
We shall note that the effective relay candidates are those users with a good link condition and low packet generating probability (or, low packet blocking probability). Based on this observation, we can derive a closed-form upper bound for the worst-case throughput penalty suffered by the direct-link user in terms of the MPR matrix coefficients in (1); the result allows us to further analyze the throughput results under various direct-link channel conditions. In the sequel we let
{𝑢1, ⋅ ⋅ ⋅ , 𝑢𝑛0(𝑈)} be the index set for the active users; without lose of generality we assume that 𝑢1 denotes the direct-link
user.
To proceed, we resort to the Markov chain based analysis. A reasonable model for the evolution of the buffer status is the birth-and-death process with a finite number of states [17]. With the aid of this model, we have the following theorems (the proofs are omitted for brevity).
Theorem 4.1: Assume that, without user cooperation,
the packet blocking probability𝑝𝐵
𝑢1 of user𝑢1is smaller than some positive𝛿, i.e., 𝑝𝐵
𝑢1 ≤ 𝛿 . Then the throughput penalty Δ𝑝
𝑢1 of the direct-link user𝑢1in the CMGP protocol is upper bounded by Δ𝑝 𝑢1 ≤ Δ𝑢1+ 𝛿 (𝐴𝑢1 + 𝐵𝑢1) 𝐴𝑢1+ 𝛿𝐵𝑢1 , (5) where Δ𝑢1 = 𝐶1({𝑢1}) − 𝐶𝑛0(𝑈)(𝑈) + 𝐶𝑛0(𝑈)−1(𝑈∖ {𝑢1}) , (6) and 𝐴𝑢1 and 𝐵𝑢1 are some constants which depend on the packet generating probability and the successful packet transmission probability.
The upper bound in (5) splits into a sum of two terms: the first term Δ𝑢1 is completely characterized by the PHY-layer signal separation capability in terms of the MPR matrix, whereas the second term 𝛿(𝐴𝑢1+𝐵𝑢1)
𝐴𝑢1+𝛿𝐵𝑢1 depends also on the
MAC traffic condition. In the extreme case that 𝛿 → 0
(or 𝑝𝐵
𝑢1 → 0 ), the throughput upper bound (5) is entirely determined by the MPR channel quality as
Δ𝑝
𝑢1≤ Δ𝑢1= 𝐶1({𝑢1}) − 𝐶𝑛0(𝑈)(𝑈) + 𝐶𝑛0(𝑈)−1(𝑈∖ {𝑢1}) . (7)
B. Lower Bound for the Worst-Case Throughput Gain
In the considered worst-case scenario, we can also specify a lower bound for the throughput gain that a user with packet transmission failure can benefit owing to cooperative packet
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6
Packet generating probability p
Thr o u ghput ( p ac k e t/ s lot ) Full cooperation User 2,4,5,7 User 2,4,7 User 2,7 User 2 No cooperation
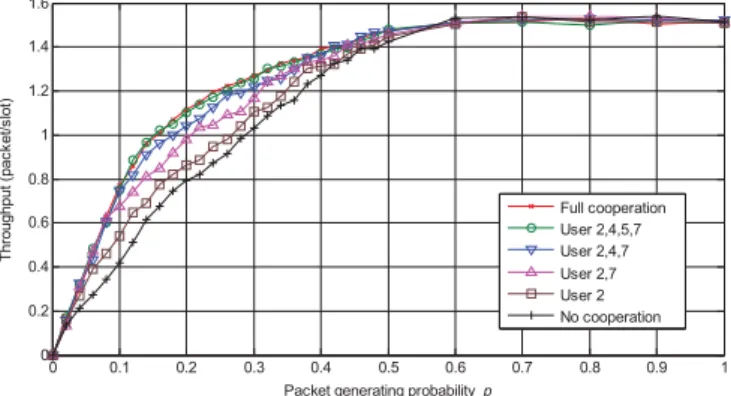
Fig. 1. Throughput performance for different number of users participating in cooperation.
relaying. More specifically, we have the following theorem.
Theorem 4.2: Suppose that the user 𝑢𝑗, where
𝑢𝑗 ∈ 𝑈∖{𝑢2, ⋅ ⋅ ⋅ , 𝑢𝑛0(𝑈)} , suffers from the packet transmission failure. Then, due to cooperative packet relay from some other user 𝑢𝑘 ∈ {𝑢2, ⋅ ⋅ ⋅ , 𝑢𝑛0(𝑈)
}
, at least the user𝑢𝑗 can enjoy a throughput gainΔ𝑔𝑢𝑗:
Δ𝑔 𝑢𝑗 ≥ 𝑝 ( 𝐶𝑛0(𝑈)(𝑈) − min 𝑢𝑘∈{𝑢2,⋅⋅⋅ ,𝑢𝑛0(𝑈)} 𝐶𝑛0(𝑈)−1(𝑈∖ {𝑢𝑘}) ) , (8)
where𝑝 is the packet generating probability.
Based on Theorem 4.2, it can be verified that, even in the interference-limited worst case, the proposed CMGP protocol can still retrieve the maximal achievable throughput advantage (the details are omitted due to space limitation).
V. SIMULATIONRESULTS
We consider a CDMA network with randomly generated spreading codes. The packet length, spreading gain, and number of correctable errors in each packet are, respectively, 200, 6, and 2. We assume that there are a total number of
𝑀 = 8 users in the network, among which users 2, 4, 5, and
7 are nearby the CC and users 1, 3, 6, and 8 are located far away from the CC. The MPR matrix of the considered system scenario can be derived in an analogous way as in [13].
A. Throughput Enhancement due to Cooperation
Fig. 1 compares the throughput performance when the number of the near-end users participating in cooperative communication increases from one to four. The throughput curve when all the eight users are involved for full cooper-ation is also included. In this example the waiting period is determined to be𝑆 = 4. The figure shows that, as the number
of near-end user increases, the throughput performance is improved. This benefits from the increase in the multi-user diversity (or cooperation gain). However, further throughput enhancement is hardly seen if full cooperation is allowed. This is because the inclusion of far-end users can not increase the effective cooperation gain, since they are typically subject to poor channel conditions. We can also see from the figure that cooperation can improve the performance only when the
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6
Packet generating probability p
Thr o ughput (P ac k e t/ S lot )
All users (w/ cooperation) Near users (w/ cooperation) Far users (w/ cooperation) All users (w/o cooperation) Near users (w/o cooperation) Far users (w/o cooperation)
Upper Bound
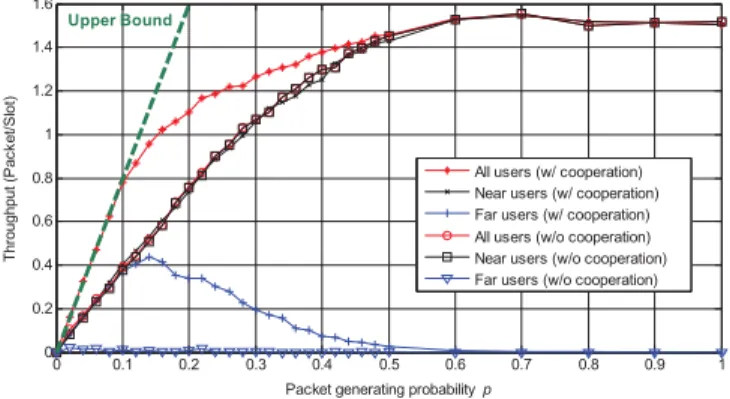
Fig. 2. Average throughput of near, far and all users.
0 0.1 0.2 0.3 0.4 0.5 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4
Packet generating probability p
T h ro ughput gain Simulation Lower bound (8)
Fig. 3. Lower bound of throughput gain derived from Theorem 4.2.
packet generating probability is small (in our case𝑝 < 0.6).
That is because, in a heavy traffic environment (large𝑝), the
channel access phase tends to be fully reserved for direct data transmission, and idle periods are seldom available for cooperative packet relaying.
B. Throughput Results for Near- and Far-End Users
We go on to investigate the throughput results for near-end and far-near-end users in both cooperative and non-cooperative environments. The results are depicted in Fig. 2. As we can see, due to poor channel conditions the average throughput of the far-end users is almost zero without cooperation. However, when cooperation with near-end users is allowed, throughput up to about 0.4 for the far-end users can be achieved when the packet generating probability𝑝 is not large. Also, there is a
significant increase in the overall throughput when compared with the non-cooperative case. For the near-end users, it is important to see that the throughput penalty is almost zero even though a certain portion of the channel access will be dedicated to packet relaying. This is mainly because, in the proposed CMGP protocol, only the idle periods are exploited for the relay phase, and the service priority of the relay users are potentially lower than the direct data transmission links. Finally, we note that the throughput curve of the proposed scheme in the low traffic region is very close to the benchmark result. This implies that, even though multiple relaying of the same packet could occur, the incurred performance degra-dation is negligible. Fig. 3 compares the simulated average throughput gain (per direct link user) with the theoretical lower bound (8). As we can see, the analytic result shows close
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18
Packet generating probability p
T h ro ughput penalty Upper bound (7) Simulation
Fig. 4. Upper bound of throughput penalty derived from Theorem 4.1.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 100 200 300 400 500 600 700 800
Packet generating probability p
D e la y ( S lo t/P a c k e t)
All users (w/o cooperation) Near users (w/o cooperation) Far users (w/o cooperation) All users (w/ cooperation) Near users (w/ cooperation) Far users (w/ cooperation)
Fig. 5. Average delay of near, far and all users.
agreement with the simulated outcome in a low traffic scenario (𝑝 ≤ 0.15). However, there is a large discrepancy as the traffic
load becomes heavy. This is reasonable since the lower bound (8) is derived specifically for the low traffic environment, in which idle periods are available and can be exploited for packet relaying. Fig. 4 further compares the simulated throughput penalty (per direct link user) with the theoretical upper bound (7). The results show that the upper bound (7) tends to be conservative. Actually, the throughput loss due to packet-relaying interference is pretty small (< 0.02) in the
proposed CMGP protocol.
C. Delay and Packet Blocking Performances
Fig. 5 further shows the resultant average delay perfor-mance. It can be seen that, without cooperation, even a small packet generating probability (𝑝 ≈ 0.1) results in severe
delay penalty. However, if cooperation is allowed, the delay performance becomes more robust against the increase in 𝑝.
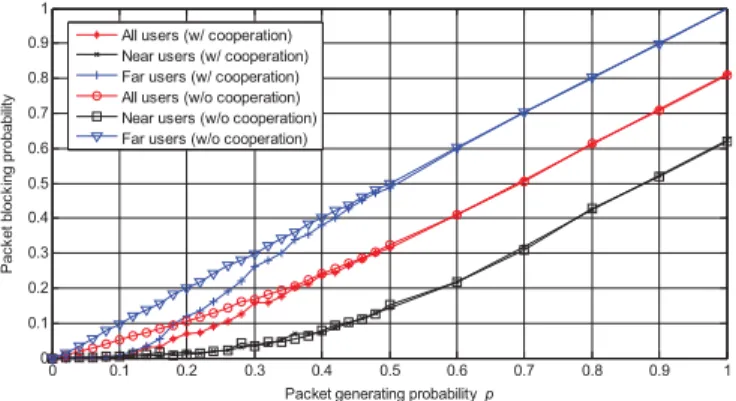
Finally, Fig. 6 depicts the packet blocking probability curves. It can be seen that, for small𝑝 (hence small packet blocking
probability), the blocking probability associated with the near-end users almost diminishes. This reflects the fact that the near-end users typically enjoy good channel conditions, and the MPR capability of these links is strong so that throughput penalty can be kept very small (as evidenced by the analysis in Sec. IV-A).
VI. CONCLUSIONS
Motivated by [16] this paper proposes a cooperative MAC protocol for MPR channels. As far as we know, our scheme is
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Packet generating probability p
P a c k et bloc k ing pr obabilit y
All users (w/ cooperation) Near users (w/ cooperation) Far users (w/ cooperation) All users (w/o cooperation) Near users (w/o cooperation) Far users (w/o cooperation)
Fig. 6. Average packet blocking probability of near, far and all users.
the first proposal which integrates the user cooperation facility and the PHY-layer MPR advantage for MAC protocol designs. The proposed method relies on a priority-based scheduling mechanism, and does not need active user identification: It is thus a promising candidate for the low-complexity protocol implementation in dense cooperative networks. Based on Markov chain models we provide throughput analysis for the proposed protocol. We derive closed-form throughput bounds for the worst case that allow us to investigate the impact of the MPR capability on the system performance. Simulation results confirm the throughput advantage achieved by the proposed method, and validate the presented analytical results.
REFERENCES
[1] F. H. P. Fitzek and M. D. Katz, Cooperation in Wireless Networks:
Principles and Applications. Springer, 2006.
[2] A. K. Sadek, K. J. R. Liu, and A. Ephremides, “Cooperative multiple access for wireless networks: protocols design and stability analysis,”
40th Annual Conference on Information Sciences and Systems, Mar.
2006.
[3] P. Liu, Z. Tao, S. Narayanan, T. Korakis, and S. S. Panwar, “CoopMAC: a cooperative MAC for wireless LANs,” IEEE J. Select. Areas Commun., vol. 7, pp. 340-354, Feb. 2007.
[4] R. Lin and A. P. Petropulu, “A new wireless medium access protocol based on cooperation,” IEEE Trans. Signal Processing, vol. 53, no. 12, pp. 4675-4684, Dec. 2005.
[5] J. Yu and A. P. Petropulu, “Cooperative transmissions for random access wireless networks with MPR channels,” Conference on Information
Sciences and Systems, The Johns Hopkins University, 2005.
[6] S. Verdu, Multiuser Detection. Cambridge University Press, 1998. [7] M. Sidi and I. Cidon, “Splitting protocols in presence of capture,” IEEE
Trans. Inform. Theory, vol. IT-31, pp. 295-301, Mar. 1985.
[8] I. M. I. Habbab, et al., “ALOHA with capture over slow and fast fading radio channels with coding and diversity,” IEEE J. Select. Areas
Commun., vol. 7, pp. 79-88, Jan. 1989.
[9] M. Zorzi, “Mobile radio slotted ALOHA with capture and diversity,”
Wireless Networks, vol. 1, pp. 227-239, May 1995.
[10] L. C. Wang, A. Chen, and S. Y. Huang, “A cross-layer investigation for the throughput performance of CSMA/CA-based WLANs with directional antennas and capture effect,” IEEE Trans. Veh. Technol., vol. 56, no. 5, Sept. 2008.
[11] S. Ghez, S. Verdu, and S. C. Schwartz, “Optimal decentralised control in the random access multipacket channel,” IEEE Trans. Automatic Cont., vol. 34, no. 11, Nov. 1989.
[12] Q. Zhao and L. Tong, “A multi-queue service room MAC protocol for wireless networks with multipacket reception,” IEEE/ACM Trans.
Networking, vol. 11, pp. 125-137, Feb. 2003.
[13] Q. Zhao and L. Tong, “A dynamic queue protocol for multiaccess wireless networks with multipacket reception,” IEEE Trans. Wireless
Commun., vol. 3, no. 6, pp. 2221-2231, Nov. 2004.
[14] M. Realp and A. I. Perez-Neira, “PHY-MAC dialogue with multi-packet reception,” ETSI Workshop on Broadband Wireless Ad-Hoc Networks
and Services, 2002.
[15] X. Wang and J. K. Tugnait, “A bit-map-assisted dynamic queue protocol for multi-access wireless networks with multiple packet reception,”
IEEE Trans. Signal Processing, vol. SP-51, pp. 2068-2081, Aug. 2003.
[16] W. F. Yang, J. Y. Wu, L. C. Wang, and T. S. Lee, “A multigroup priority queueing MAC protocol for wireless networks with multipacket reception,” EURASIP J. Wireless Commun. and Networking, vol. 2008, article ID 970842, 2008.
[17] Z. Wang and X. Yang, Birth and Death Processes and Markov Chains. Springer-Verlag, 1992.