國
立
交
通
大
學
資訊科學與工程研究所
碩
士
論
文
基於最佳停止理論所設計之可調視訊多層編碼
控制的快速編碼模式決策演算法
A Fast Mode Decision Algorithm based on Optimal Stopping
Theory for SVC Multi-Layer Encoder Control
研 究 生:黃嘉彥
指導教授:彭文孝 教授
基於最佳停止理論所設計之可調視訊多層編碼控制的
快速編碼模式決策演算法
研 究 生:黃嘉彥 指導教授:彭文孝
國立交通大學資訊科學與工程研究所 碩士班
摘要
基 於 可 調 視 訊 編 碼 (SVC) 之 多 層 編 碼 控 制 (Multi-layer Encoder Control, MLEC)的架構,本論文提出一個快速編碼模式決策的演算法。此提出的演算法
主要在於改善Zhao’s et al.應用最佳停止理論(Optimal Stopping Theory, OST)所提
出的快速編碼模式決策演算法中所存在的問題。其演算法的問題是將所有編碼模 式(mode)的效益都視為相同,只考慮編碼模式序列中下一個相對更好的編碼模式 的位置和目前在序列中停止的位置相距多遠,但此距離並不能給予任何保證。不 能保證這個相對更好的編碼模式可以得到多少 RD-cost 的下降,而且也不能保證 需要花費多少運算複雜度。因此,本論文將以上兩點加以考慮,設計出一套更有 效率的快速編碼模式決策演算法。 本論文將分析編碼模式配對序列中的不同停止點,若往下找到一組相對更好 的編碼模式配對時能得到多少 RD-cost 下降量,以及分析不同的編碼模式配對在 編碼時各需要多少運算複雜度。再將以上兩項資訊建為表格,提供在計算最佳停 止點時所使用。除此之外,本論文還提出一個精進編碼模式決策的方法,利用統 計與分析 RD 資訊找出較差的編碼模式配對,進一步執行精進程序。實驗結果顯 示,本論文所提出的快速編碼模式決策演算法和徹底式搜尋(exhaustive search)所 需編碼時間相比,節省了編碼時間逾 80%~85%左右且有相當的 RD 效能。此外, 本論文所提出的演算法和其他兩種不同的演算法相比,亦也有更好的穩定性,以 及編碼品質。
A Fast Mode Decision Algorithm based on Optimal Stopping
Theory for SVC Multi-Layer Encoder Control
Student: Jia-Yan Huang Advisor: Wen-Hsiao Peng
Institute of Computer Science and Engineering
National Chiao Tung University
Abstract
This thesis proposed a fast mode decision algorithm for scalable video coding (SVC) multi-layer encoder control (MLEC). The proposed algorithm attempts to improve the problem of the fast algorithm proposed by Zhao’s et al. based on the optimal stopping theory (OST), in which the problem is the benefit obtained of the different mode is regarded as the same and only the distance considered between the stopping point and the position of the next relative best mode in the mode sequence. Unfortunately, this distance cannot guarantee the amount of RD-cost decrease in the next relative best mode; additionally, the amount of required computational complexity to the next relative best mode cannot be anticipated either. Thus, this thesis will take aforementioned points into consideration in order to create a more efficient fast mode decision algorithm.
This thesis analyzed the stopping point in the mode pair sequence, which explore the amount of RD-cost decrease by finding the next relative best mode pair, and analyze the different amount of computational complexity between the different mode pairs. A table containing the above two points will also be provided for calculation of the optimal stopping point. Additionally, this thesis will proposed a more refined encoding method by utilizing statistics and data analysis to identify inferior encoding mode pairs and then refining them. Experimental result demonstrates that the proposed fast mode decision algorithm compares to the method of exhaustive search can achieve time saving about 80% to 85% with negligible quality degradation. Furthermore, the proposed method is superior to those of the other two types because of its stability and encoding quality.
致謝
在兩年的碩士生涯內,首先我要感謝我的指導教授-彭文孝 博士。彭老師 在兩年內不論在學問研究上以及做人處事上都給予我精闢的指導。彭老師教導我 做研究應該要有的態度以及遇到問題如何解決,並且要求我們做於研究生應該有 的態度。在老師細心以及耐心的指導下,讓我能在最有效的時間內完成碩士論文 並且在兩年內受益無窮。在此再一次感謝我的彭老師,並致上無限的敬意。 其次,這篇論文可以完成,我也要感謝林哲永學長和蔡閏旭學長在我的研究 上擔任了啟蒙的指導,不僅在 H.264 和 SVC 的專業領域上,不辭辛勞的與我討論, 更在一開始的研究實作上給予許多珍貴的意見,並且能適時從旁給予建議修正我 已偏差的研究方向,使我在這兩年的碩士生涯,不再舉步維艱。謹此致上由衷的 謝意。 非常榮幸進入 MAPL 實驗室,能夠有熱心與親切的實驗室成員們的切磋與討 論,是我在碩士時期最充實的時光。我要感謝其餘的學長姐們—陳渏紋 博士、 陳俊吉 博士、與詹家欣 博士、王澤瑋、楊復堯、與吳思賢,一步步帶領我進入 這個專業的領域;感謝我的好同學們吳崇豪、李宗霖、陳孟傑和曾于真,不論是 研究上或是生活上,他們總是給予我最直接的協助以及苦樂分享;感謝我的學弟 吳牧軒、陳彥孙,提供我實驗上適時的幫助。 最後,我要感謝我的父母—黃富村 先生、石玉琴 女士的栽培,在取得碩士 學位的路途上,給予精神上和物質上的支持和溫暖,讓我能夠專心的在研究領域 上打拼。感謝我的哥哥—黃嘉維,以及我的姐姐-黃美嘉,也能適時的提供我意 見,並且不斷的鼓勵我繼續向前。感謝你們一路上的陪伴打氣與支持,在此僅將 這篇論文獻給各位,謝謝你們!目錄
摘要... i Abstract ... ii 致謝... iii 目錄... iv 圖目錄... vi 表目錄... vii 第一章 緒論 ... 1 1.1 研究背景... 1 1.1.1 可調視訊編碼之 CGS 架構 ... 1 1.1.2 最佳停止理論-Duration Problem ... 2 1.1.3 Duration Problem in 編碼模式決策 ... 2 1.2 問題闡述與提出解決辦法... 4 1.3 研究貢獻... 5 1.4 論文編排... 5 第二章 相關研究 ... 6 2.1 可調視訊編碼... 6 2.1.1 基本架構... 6 2.1.2 層與層之間預測... 7 2.2 可調視訊編碼之編碼控制... 9 2.2.1 由下而上的編碼控制... 9 2.2.2 多層編碼控制... 10 2.2.3 編碼控制應用於編碼模式決策... 11 第三章 快速編碼模式決策演算法 ... 13 3.1 編碼模式決策的兩項因素... 14 3.1.1 考慮 RD-cost 下降量 ... 15 3.1.2 考慮編碼模式配對的運算複雜度... 17 3.1.3 同時考慮 RD 和運算複雜度,並找出停止點 ... 20 3.2 編碼模式配對的序列產生... 24 3.3 編碼模式決策的精進方法... 26 3.3.1 判定RD效能... 26 3.3.2 精進的方法... 28 3.3.3 精進程序前後差異比較... 30 3.4 快速編碼模式決策演算法的流程... 32 第四章 實驗結果與討論 ... 33 4.1 實驗環境... 334.2 實驗比較與討論... 34 4.2.1 實驗一... 34 4.2.2 實驗二... 38 4.2.3 實驗三... 41 第五章 結論與未來展望 ... 42 參考文獻... 43
圖目錄
圖 1 可調視訊編碼的 CGS 架構 ... 1 圖 2 編碼模式序列... 3 圖 3 可調視訊編碼所提供的三種不同調節性,由左至右分別為(1)空間可調性(2) 時間可調性(3)畫質可調性 ... 6 圖 4 層與層之間的移動向量預測示意圖... 7 圖 5 層與層之間的殘值預測示意圖... 8 圖 6 與層之間的畫面內預測... 8 圖 7 (a)傳統由下而上編碼控制應用於編碼模式決策示意圖 (b) 多層編碼控制應 用於編碼模式決策示意圖... 12 圖 8 編碼模式配對示意圖... 12 圖 9 序列中編碼模式配對的運算時間複雜度示意圖... 17圖 10 reward function-yykk 趨勢示意圖 BLQP=22 , ELQP=18 , W = 0.1 ... 20
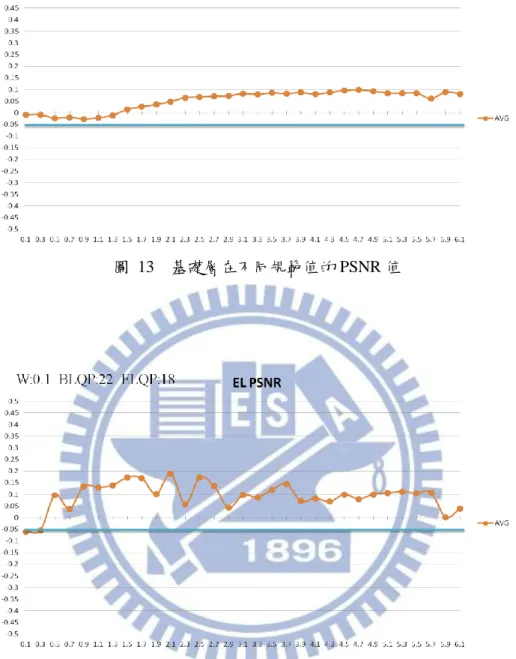
圖 11 基礎層在不同規範值的位元率上升圖 ... 21 圖 12 增進層在不同規範值的位元率上升圖... 21 圖 13 基礎層在不同規範值的 PSNR 值... 22 圖 14 增進層在不同規範值的 PSNR 值... 22 圖 15 在不同規範值的編碼時間節省... 23 圖 16 利用哪些 MB 產生編碼模式配對序列示意圖 ... 25 圖 17 演算法流程步驟圖... 32
表目錄
表 1 測詴的編碼模式種類表... 13 表 2 RD-cost 下降量表 ... 16 表 3 各種編碼模式配對的運算時間表... 18 表 4 不同設定下 yykk 的規範值表 ... 21 表 5 目前編碼的 MB 和周圍 MBs 做相同編碼模式配對的機率表 ... 24表 6 目前編碼 MB pair 和前一張畫面相對位置 MB pair 的 RD ratio 差值 ... 27
表 7 精進方法的編碼模式配對順序表-固定基礎層... 29 表 8 精進方法的編碼模式配對順序表-固定增進層... 30 表 9 序列中編碼模式配對種類的比較... 30 表 10 實驗環境設定... 33 表 11 BLQP = 22 ; ELQP = 18 不同演算法的比較 ... 34 表 12 BLQP = 26 ; ELQP = 22 不同演算法的比較 ... 36 表 13 BLQP = 30 ; ELQP = 26 不同演算法的比較 ... 37 表 14 BLQP = 22 ; ELQP = 18 Zhao's 演算法中加入所提出的精進方法 ... 38 表 15 BLQP = 26 ; ELQP = 22 Zhao's 演算法中加入所提出的精進方法 ... 39 表 16 BLQP = 30 ; ELQP = 26 Zhao's 演算法中加入所提出的精進方法 ... 40 表 17 其他不同的視訊序列 RD 效能 ... 41
第一章 緒論
1.1 研究背景
由於網路傳輸以及多變容量不同設備的蓬勃發展,視訊內容在各種應用上的 可調性已經是需要且非常重要的問題。基於這個理由,Joint Video Team(JVT)以 H.264/AVC 為基礎,制訂了可調視訊編碼(Scalable Video Coding, SVC)[1]。可調 視訊編碼在單一位元串流中提供了不同的調節性,其中包括 1)空間可調性(spatial scalable)、2)時間可調性(temporal scalable)、3)品質可調性(quality scalable)。可調 視訊編碼是由一個基礎層(base layer, BL)和多個增進層(enhancement layer, EL)所 組成,且相較於低層的增進層是相較於高層增進層的基礎層,然而增進層利用層 與層之間預測的方式(inter-layer prediction),盡可能的使用基礎層的資訊來達到 減少壓縮時所需要的位元率。
1.1.1 可調視訊編碼之 CGS 架構
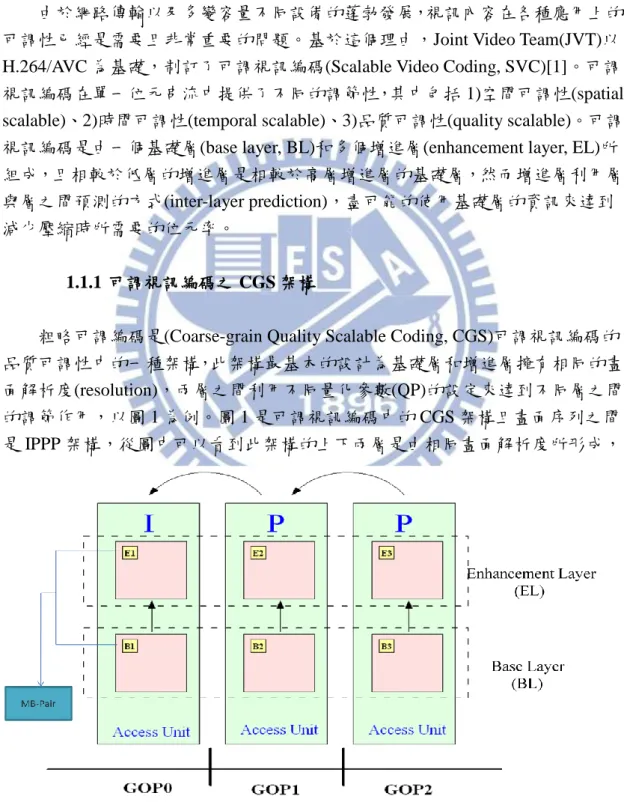
粗略可調編碼是(Coarse-grain Quality Scalable Coding, CGS)可調視訊編碼的 品質可調性中的一種架構,此架構最基本的設計為基礎層和增進層擁有相同的畫 面解析度(resolution),兩層之間利用不同量化參數(QP)的設定來達到不同層之間 的調節作用,以圖 1 為例。圖 1 是可調視訊編碼中的 CGS 架構且畫面序列之間 是 IPPP 架構,從圖中可以看到此架構的上下兩層是由相同畫面解析度所形成,
且基礎層做為增進層的預測。圖中兩層同一張畫面之間相同位置的 MB 稱為一組 MB pair,例如(B1,E1)就是一組 MB pair。這組 MB pair 在可調視訊編碼中扮演非 常重要的腳色,MB pair 中的兩個 MB 之間的編碼資訊有某種程度的相關性,由 於增進層利用基礎層做預測,因此基礎層在編碼時參數的設定亦會牽動增進層的 編碼參數設定。以編碼模式決策(mode decision)為例,兩層之間的編碼模式亦會 有很大的關連性,若基礎層所選擇的編碼模式為 Inter16x8,則增進層的編碼模 式也有較大的機會是相同的,且編碼模式為 Inter8x16 的可能性就非常的小,因 為此兩種編碼模式的分割方式差異較大。 1.1.2 最佳停止理論-Duration Problem
最佳停止理論(Optimal Stopping Theory, OST)[2]中存在一個最佳停止問題, 此問題主要是在說一位決策者如何逐一訪談一連串的物件中,每訪談完一個物件 後決定是否要繼續訪談下一個物件。然而這項理論主要是由兩項物件所形成,1) 一連串的隨機變數、2)一個用來計算分數的函式。以面詴官的例子說明,若有一 連串的人員逐一等著面詴,這裡要被面詴的人員可視為隨機變數,因為每個人擁 有不同的工作經歷或學歷。面詴官想在人群裡挑出一位優秀的人員加入,但又不 想將所有人員都面詴完。此時面詴官利用一套計算分數的函式(稱為 reward function),去計算看說面詴到哪位人員停止,能得到最高的效益。然而在最佳停 止理論中,成功找到最佳停止點的條件只有真的在所有序列中找到最好的物件, 否則都算是失敗的停止點。 然而,並不是所有的問題都是必頇找到最佳的物件。可以依照問題的目的, 找到相對較好的物件即可,這裡以快速編碼模式演算法為例,此問題的目的是為 了節省編碼所需的時間,避免使用完整搜尋的編碼模式決策方法去測詴所有可能 的編碼模式並找出一個最佳的,且在壓縮位元率和畫面品質上不能和完整搜尋法 有太大的差異。簡單的說,快速編碼模式決策演算法是去找出相對較好的編碼模 式即可。因此,基於這些只需要找到相對較好物件的問題,最佳停止理論將這類 型的問題稱為 Duration Problem [3]。在最佳停止理論中的 Duration Problem,其 計算分數的函式是用來計算序列中,下一個會遇到相對更好的物件需要花費多少 代價。因此,在此問題的最佳停止點就是該停止點遇到下一個更好的物件需要花 費最大代價的點即是。所以 Duration Problem 成功找到停止點的定義跟最佳停止 問題不太一樣,這個問題找到的停止點只要能滿足你問題的目的即可。 1.1.3 Duration Problem in 編碼模式決策 在此小節,介紹如何將 Duration Problem 應用於編碼模式決策上,此應用是 由 Zhao’s et al.所提出[4]。Zhao’s et al.[4]利用 Duration Problem 在可調視訊編碼
圖 2 編碼模式序列
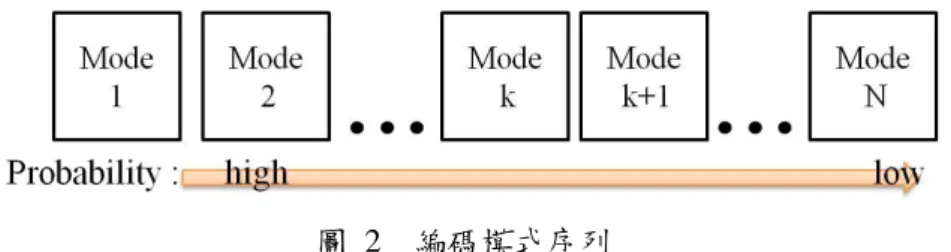
的編碼模式決策上設計出一套編碼模式提前結束的快速演算法,此方法如圖 2 所示。Zhao’s et al. [4] 利用目前要編碼 MB 周圍的資訊產生一組編碼模式序列, 其排序方式是將目前要編碼的 MB 最有可能的編碼模式,依機率由大到小排序。 此排序的目的,是為了讓 reward function 擁有 unimodal function 的特性,也就是 要確保此 reward function 只擁有一個極大值。 在上一小節中提過,Duration Problem 是去找出下一個相對更好的物件時需 要花費多少代價。同樣的,在編碼模式決策時也是如此,在序列中的每一個編碼 模式,都可以利用 reward function 去計算下一個遇到更好的編碼模式需要花費多 少代價。在 Zhao’s et al. [4]所提出的演算法中,此代價是定義為距離目前停止點 多遠的距離,也就是去計算遇到下一個相對更好的編碼模式需要再做多少個編碼 模式。若以方程式來說明 1 ( ) [ ( ) ) ] ( 1) ( 1) N k k k j k E T j P T j N P T N
(1) and ( k) k E T k y N (2) 其中 TTkk 代表目前停在第 kk 個編碼模式且下一個遇到更好的編碼模式是在 序列中的第幾個,特別的是 TTkk = N + 1= N + 1 代表在第 kk 個編碼模式後不會出現相 對應更好的編碼模式。而 E ( TE ( Tkk)) 則是去計算 TTkk 的期望值,yykk 就是所謂的 reward function,去計算下一個預期出現更好的編碼模式位置和目前停止位置 kk 距離多遠。在 Zhao’s et al. [4]所提出的演算法中,在編碼模式序列中每一個位置 都可以去計算一個 yykk,而此演算法停止的位置就是擁有最大 yykk 的編碼模式。1.2 問題闡述與提出解決辦法
在 1.1.3 小節中提到 Zhao’s et al.[4] 將 Duration Problem 應用在編碼模式決策 上並設計出一套快速編碼模式決策的演算法。但是 Zhao’s et al.[4]所提出的演算 法存在了兩項問題,其問題分別為: 沒有考慮停在不同位置的編碼模式時,下一個遇到更好的編碼模式能獲得多 少 RD-cost 下降量。 沒有考慮不同編碼模式的運算複雜度。 因為在Zhao’s et al.[4]所提出的演算法中只是去計算每一個不同停止位置與下一 個相對更好的編碼模式距離多遠,但這個距離並不能給予任何的保證,不能保證 距離越遠就代表能得到越多的 RD-cost 下降量,亦不能保證距離越遠就代表其所 需編碼時間就越長。在Zhao’s et al.[4]所提出的演算法中,每一個不同位置下一 個遇到更好的編碼模式都視為可以得到相同的 RD-cost 下降量,而且不同的編碼 模式,其所需的編碼時間也都視為相同的,但這跟現實情況真的相同嗎。以不同 編碼模式所需的編碼時間為例,在 Inter16x16 和 Inter8x8 兩種不同的編碼模式, 直覺上一定認為 Inter8x8 所需的編碼時間一定比 Inter16x16 所需的多,且實際情 形也是如此,因此怎麼能只考慮下一個遇到更好的編碼模式要再做多少個編碼模 式呢。 基於上述兩個問題點,本篇論文進一步加以考慮並改善 Zhao’s et al.[4]所提 出的方法。首先,因為每一個編碼模式序列中不同的停止位置,可能會依照在序 列中位置的不同而下一個遇到相對更好的編碼模式所得到的 RD-cost 下降量也 有所不同的這一點考慮,作者認為必頇去計算若目前停止位置為kk,則下一個遇 到相對更好的編碼模式會有多少期望的 RD-cost 下降量,這裡記做為E ( R DE ( R DTTkk))。 再來,還要去計算下一個會遇到更好的編碼模式,途中所做過的不同編碼模式總 共需要多少期望的編碼時間,這裡記做為E ( CE ( CTTkk))。然而,這兩個期望值E ( R DE ( R DTTkk))、 E ( CTk) E ( CTk) 分別可以視為下一個遇到更好的編碼模式能獲得多少好處,以及需要花 費多少代價。最後,將這兩個期望值一起考慮為一個比值 yykk = E ( R D= E ( R DTTkk) = E ( C) = E ( CTTkk)), 這個比值稱為獲得好處與需要花費比,作者利用這個比值去找出在編碼模式序列 中,停在哪一個位置能得到最佳的效益。至於如何利用這個比值去找出最佳的停 止位置,將在之後的章節會詳細的說明。
1.3 研究貢獻
在這次的研究工作中,最主要的貢獻是提出一套新的快速編碼模式決策演算 法,其中包含以下幾點: 有效的利用周圍的資訊去產生編碼模式配對序列,以提供目前的 MB 所使 用。 有效的改善原先 Zhao’s et al.[4]所提出演算法中的問題,在此利用統計與分 析的方式成功建立不同位置的 RD 下降表,以及提供不同編碼模式配對的編 碼運算複雜度參考。 有效的提出一套精進編碼模式的機制,不但能在作者所提出的演算法上實施, 在其他的演算法中也能適用。 作者提出的快速演算法能有效的在編碼時間上加速,而且位元率與畫面品質 和完整搜尋法相比,並沒有太大的上升與失真。 實驗結果顯示,作者所提出的快速編碼模式決策演算法和完整搜尋法比較,能得 到 80% ~85%的編碼時間節省,並且擁有相似的位元率-失真效能。並且作者所 提出的精進編碼模式的方式,亦能有效改善 Zhao’s et al.[4]所提出演算法的位元 率-失真效能。1.4 論文編排
本論文之後的組織架構為:第二章包含可調視訊編碼的基本架構與編碼控制 的介紹。第三章呈現作者所提出的快速編碼模式決策演算法。第四章為實驗結果 與討論。最後,第五章為本篇論文的結論以及未來展望。第二章 相關研究
2.1 可調視訊編碼
2.1.1 基本架構
可調視訊編碼 (Scalable Video Coding, SVC) 是 Joint Video Team (JVT) 以 H.264/AVC 為基礎進而延伸出來的另一套標準,讓視訊編碼能附有調節的功能。 可調視訊編碼主要是由一個基礎層(BL)和多個增進層(EL)所組成,且位於較低層 的增進層是位於較高層增進層的基礎層。層與層之間的可調性,能達到提供給各 種不同的環境和不同的機器設備,且在可調視訊編碼的架構下只需將多層不同品 質的視訊編碼成單一位元串流,當環境或機器的限制下,若只需要某層的視訊品 質,只要擷取單一位元串流中部份的位元串流即可得到此層所提供的視訊品質。 因此,可調視訊編碼的可調節性,可以有效的提供給不同的機器設備或環境,然 而在可調視訊編碼中主要支援三種可調性,其中包含: 空間可調性(Spatial Scalability) 不同層之間提供不同畫面解析度來做調節。 時間可調性(Temporal Scalability)
不同層之間提供不同每秒畫面張數來做調節(frame per second)。 畫質可調性(Quality Scalability)
不同層之間提供不同的畫面品質來做調節。
圖 3 可調視訊編碼所提供的三種不同調節性,由左至右分別為(1)空間可調性(2)時間 可調性(3)畫質可調性。
2.1.2 層與層之間預測 在前一小節中說明可調視訊編碼提供的三種主要的可調性,但在不同層之間 是利用什麼方法來達到可調節的好處呢,就是這小節所要介紹的層與層之間預測 方法(Inter-layer prediction)。在前一節中也有提到可調視訊編碼的基本架構是由 基礎層和增進層所組成,增進層利用層與層之間預測的方法,盡可能的利用基礎 層的資訊來達到減少編碼時所需的位元率。在可調視訊編碼中主要有三種層與層 之間預測方法,包括有:
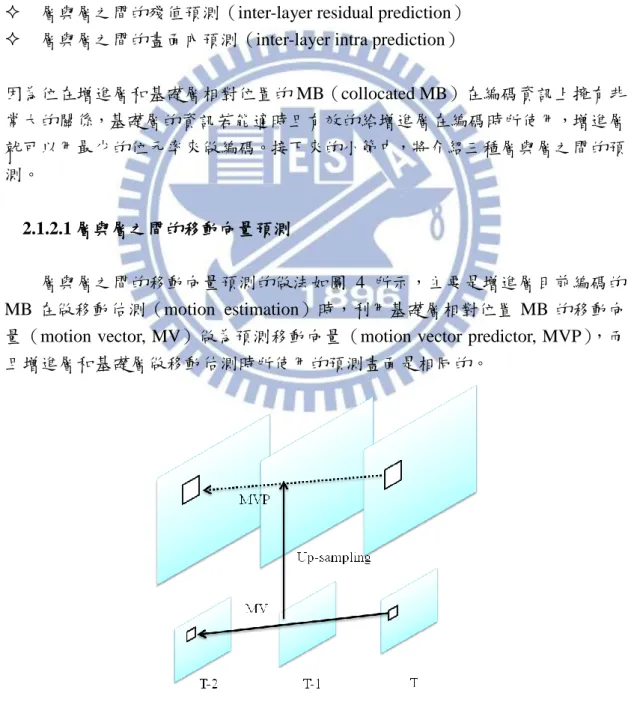
層與層之間的移動向量預測(inter-layer motion prediction) 層與層之間的殘值預測(inter-layer residual prediction) 層與層之間的畫面內預測(inter-layer intra prediction)
因為位在增進層和基礎層相對位置的 MB(collocated MB)在編碼資訊上擁有非 常大的關係,基礎層的資訊若能適時且有效的給增進層在編碼時所使用,增進層 就可以用最少的位元率來做編碼。接下來的小節中,將介紹三種層與層之間的預 測。 2.1.2.1 層與層之間的移動向量預測 層與層之間的移動向量預測的做法如圖 4 所示,主要是增進層目前編碼的 MB 在做移動估測(motion estimation)時,利用基礎層相對位置 MB 的移動向 量(motion vector, MV)做為預測移動向量(motion vector predictor, MVP),而 且增進層和基礎層做移動估測時所使用的預測畫面是相同的。
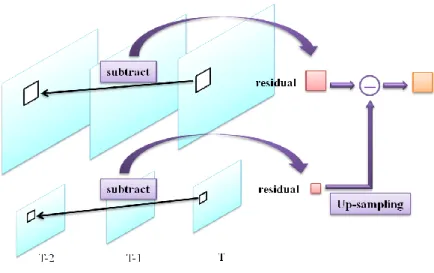
圖 5 層與層之間的殘值預測示意圖 2.1.2.2 層與層之間的殘值預測 如圖 5 所示,增進層在做完移動估測後,原始畫面的 Y 值會和預測畫面的 Y 值相減,此過程稱為移動補償(motion compensation)。在做完移動補償後會得 到一差值,稱做為殘值(residual)。若沒有做層與層之間的殘值預測,則這個殘 值就會在量化(quantization)完後直接去做編碼,但因為兩層之間的資訊關連度 非常的高,兩層間的殘值亦可能非常的接近,因此增進層若有做層與層之間的殘 值預測,增進層會將殘值和基礎層的殘值再做一次相減,使殘值能越少越好,盡 可能減少編碼所需的位元率。 2.1.2.3 層與層之間的畫面內預測 增進層做層與層之間的畫面內預測需要有某種限制,此限制為基礎層相對位 置的 MB 是用畫面內預測(intra prediction)做編碼。然而層與層之間的畫面內 預測如圖 6 所示,基礎層相對位置的 MB 做完畫面內預測編碼且重建後,直接將 此重建後的 MB 做為增進層相對位置 MB 的預測。 圖 6 層與層之間的畫面內預測
2.2 可調視訊編碼之編碼控制
在介紹完可調視訊編碼的三種主要的層與層之間的預測後,接下來將介紹可 調視訊編碼的編碼控制。首先,介紹傳統的可調視訊編碼是做由下而上的編碼控
制(Bottom-up Encoder Control, BUEC),但是傳統的編碼控制在基礎層做編碼時,
完全沒有考慮增進層如何去做編碼。此種做法和可調視訊編碼的基本想法-增進 層盡可能使用基礎層的資訊做編碼的概念有點背道而馳。因為當基礎層在做編碼 時,若完全沒有考慮增進層之後的編碼,增進層後來若想用基礎層的資訊做編碼, 增進層變成只能附和基礎層的編碼去做決策。如此一來層與層之間的可調性就會
變得沒這麼有效率。所以,接下來會介紹Schwarz’s et al. [5]所提出的多層編碼控
制(Multi-layer Encoder Control, MLEC),此種編碼控制是為了解決傳統編碼控 制的問題。最後介紹由 Lin’s et al. [6]所提出的多層編碼控制。 2.2.1 由下而上的編碼控制 傳統的可調視訊編碼在 JSVM[7]中所描述是使用由下而上的編碼控制做編 碼決策,意思是先決定基礎層的編碼參數設定後,再去決定增進層的編碼參數設 定。此編碼決策的方式以公式化表示為: 1 0 0 0 1 1 0 1 0 m i n ( | ... ) . . ( ) ( | ) ... ( | ... ) i i i i i i c i D p p p s t R p R p p R p p p R (3) 在公式(3)中, DDii 和 RRii 分別代表為第 ii 層的失真(distortion)和位元率(rate), pi pi 是第 ii 層設定的編碼參數,RRC iC i 則代表第 ii 層的位元率最大限制。意思就是 在位元率的限制下,如何去設定編碼參數能達到最小的失真,然而上層的編碼參 數會被下層的編碼參數所影響。若以 widely-used Lagrangian approach 來表示兩 層的編碼控制,首先基礎層的編碼參數決策表示為: 0 0 * 0 0 0 0 0 { } a r g m in ( ) ( ) p p D p R p (4) 從公式(4)可以看出在傳統的編碼控制,當基礎層做編碼參數決策時完全不會考 慮增進層的編碼參數設定,也就是盡可能的將基礎層的編碼做到最好。然而,增 進層的編碼參數決策表示為:
* 0 0 1 0 * * 1 1 1 1 1 { | } m in ( | ) ( | ) p p D p p R p p (5) 公式(5)顯示出增進層再做編碼參數決策時,會受到當初基礎層所決定的編碼參 數而有所影響。因此,可以由公式(4)、(5)看出問題的所在,基礎層做編碼參數 決策時只考慮基礎層單一層的結果,增進層會因為基礎層編碼參數的設定而可能 產生較大的編碼失真,因為當初基礎層所選擇的編碼參數可能並不適合增進層所 使用。基於這個理由,Schwarz’s et al.[5]提出了一套權衡基礎層和增進層的方法, 稱做多層編碼控制,而這個方法將在下一小節中詳細的介紹。 2.2.2 多層編碼控制 2.2.2.1 Schwarz’s et al.所提出的多層編碼控制 為了解決傳統由下而上的編碼控制方法在編碼基礎層時只考慮單一層的缺 點,Schwarz’s et al.[5]提出了一種多層編碼控制的方法,這個方法是在編碼基礎 層時也會同時考慮增進層。多層編碼控制在編碼基礎層時在基礎層和增進層中加 入了一個權重(weighting),利用這個權重決定在編碼時要以哪一層為主要考慮的 編碼層。若以公式化表示基礎層的編碼決策為: 0 1 0 0 0 0 0 0 { , | } 1 1 0 1 0 0 1 1 0 m i n (1 ) ( ( ) ( ) ) ( ( | ) ( ( ) ( | ) ) ) p p p w D p R p w D p p R p R p p (6) 這公式(6)中是由公式(4)和公式(5)加上一個權重 ww 演變而來,表示在兩層之間 給予一個權重做權衡,此權重 w 2 [0 ; 1 ]w 2 [0 ; 1 ]。在公式(6)中,若 w = 0w = 0 代表基礎層在 編碼決策時,回歸到傳統由下而上的編碼方法,只考慮基礎層的編碼結果。反之, 當 w = 1w = 1 代表基礎層編碼決策時,完全只考慮增進層的編碼結果,基礎層的編 碼參數設定就變成只針對增進層去做最佳化選擇。然而在 Schwarz’s et al.[5]所提 出的多層編碼控制方法中,增進層在編碼決策時一樣是利用公式(5)去做決策。 對於多層編碼控制決策的方法,也可以轉換成以下敘述的多目標最佳化問題: 0 0 1 1 0 0 0 0 0 1 1 0 m i n (1 ) ( ) ( | ) . . ( ) (1 ) ( ) ( ) ( ( ) ( | ) ) C B C E w D p w D p p s t a w R p R b w R p R p p R (7)
和 分別是基礎層和增進層所限制的最大位元率。公式(7)中的式 子(b),在 w = 0w = 0 時此位元率限制就不存在,但是在 w = 1w = 1 時位元率限制就收斂 到 RRC EC E,因此公式(7)中的目標和限制會隨著權重 ww 的不同而改變。但是此隨 權重不同而目標和限制改變的現象,會造成位元率失真效能得不到預期的結果, 因此 Lin’s et al.[6]為了解決此問題而提出了改善方法,將在下一小節中提及。 2.2.2.2 Lin’s et al.所提出的多層編碼控制 為了解決公式(7)中存在多目標限制會隨著權重 ww 而改變的問題,Lin’s et al.[6]提出了另一個多層編碼控制的多目標最佳化問題式子: 0 0 1 1 0 0 0 0 0 1 1 0 m i n (1 ) ( ) ( | ) . . ( ) R ( ) ( ) ( ) ( | ) C B C E w D p w D p p s t a p R b R p R p p R (8) 在公式(8)中(a)和(b)的限制已不受到權重的影響,但是權重 ww 在於權衡基礎層 和增進層方面依然是存在的。如此一來原先存在因改變權重 ww 而改變目標限制 的問題就不存在,也不會產生不可預期的位元率-失真效能。 然而,在 Lin’s et al.[6]所提出的多層編碼控制方法中,最大的不同點在於基 礎層和增進層在決策編碼參數時,只使用一個式子去做決策: 0 1 0 ~ 0 0 0 0 0 { , | } ~ 1 1 1 0 0 0 1 1 0 m i n (1 ) ( ) ( ) ( | ) ( ( ) ( | ) ) p p p w D p R p w D p p R p R p p (9) 基礎層和增進層從公式(9)中就決定好兩層的編碼參數,這個想法是因為原先 Schwarz’s et al. [5]所提出的方法在增進層是用公式(5)去做決策,但此舉像是多餘 的。因為在公式(9)中,兩層的編碼參數應該就已經是確定的,增進層並不需要 再做一次決策動作。 2.2.3 編碼控制應用於編碼模式決策 由於此篇論文是提出一套新的快速編碼模式決策演算法,因此在此小節中將利用 編碼模式決策來介紹並比較兩種編碼控制方法。在此小節中都假設式應用在兩層
的可調視訊編碼架構上,且增進層和基礎層各有 N 種編碼模式需要做決策。先 以傳統的由下而上的編碼控制為例: (a) (b) 圖 7 (a)傳統由下而上編碼控制應用於編碼模式決策示意圖 (b) 多層編碼控制應用於 編碼模式決策示意圖 如圖 7(a)所示,在不同層同一張畫面相對位置的 MB 稱做為一組 MB 配對(MB pair),在傳統由下而上的編碼控制方法中,這組 MB 配對的編碼模式是先從基礎 層做決策,決定完基礎層的編碼模式後再去決定增進層的編碼模式。若兩層各有 N 種編碼模式可以選擇,這種由下而上的編碼方式總共需要 2N 次的編碼模式決 策運算量。再來考慮多層編碼控制方法應用在編碼模式決策上,由圖 7(b)所示, 這組 MB 配對的編碼模式是同時考慮的,若上下兩層都有 N 種編碼模式,在多 層編碼控制方法中則需要 N2種編碼模式配對的決策運算量,這裡所說的編碼模 式配對是上下兩層中各一個編碼模式可以形成一個配對,如圖 8 所示,若上下兩 層各有 N 種編碼模式,則在基礎層的第一種編碼模式會和增進層的 N 種不同的 編碼模式形成 N 種不同的編碼模式配對,因此在多層編碼控制時總共有 N2種編 碼模式配對需要去考慮。 由上述所提到多層編碼控制做編碼模式決策時,若考慮所有的編碼模式進行 決策則需要非常大的計算量,基於這個理由,作者接下來所設計的快速編碼模式 決策演算法就是為了節省在多層編碼控制做編碼模式決策時所需的編碼時間,並 且在位元率-失真效率方面盡可能的接近完整搜尋法。 圖 8 編碼模式配對示意圖
第三章 快速編碼模式決策演算法
在第二章最後一小節提過,多層編碼控制在編碼模式決策時若考慮所有的編 碼模式做決策需要花費非常大的計算量。因此為了提供一個更省時且有效率的編 碼模式決策方法,作者在接下來的章節內將介紹一套新的快速編碼模式決策演算 法,此方法是改善當初 Zhao’s et al.[4]所提出演算法所存在的問題,並加上一套 精進編碼模式決策的方法來提高位元率-失真的效能。 本篇論文所提出的快速編碼模式決策演算法是建立在可調視訊編碼的 CGS 架構且編碼控制方法是使用多層編碼控制方法。然而在此次演算法中加入編碼模 式決策的編碼模式包括有,基礎層和增進層共有的 Skip、Inter16x16、Inter16x8、 Inter8x16、Inter8x8、Intra4x4 和 Intra16x16,以及只有增進層獨有的 BLSkip 和 IntraBL,建成表格如下 表 1 測詴的編碼模式種類表 編碼模式種類 基礎層(BL) 增進層(EL) Inter MB Type Skip Inter16x16 Inter16x8 Inter8x16 Inter8x8 Skip Inter16x16 Inter16x8 Inter8x16 Inter8x8Intra MB Type Intra16
Intra4
Intra16 Intra4
Inter-layer Prediction Type BLSkip
IntraBL
由此表看來基礎層有 7 種編碼模式需要決策,而增進層有 9 種。但是在增進層獨 有的編碼模式 BLSkip 和 IntraBL 個別是當基礎層相對位置的 MB 是畫面間預測 編碼(inter coded)和畫面內預測編碼(intra coded)時,增進層的 MB 才能選擇做此 兩種編碼模式。因此實際上只有 56 組編碼模式配對頇要考慮。為了接下來的章 節能更清楚明白,在接下來的方法中作者都是一次考慮一組編碼模式配對的 RD-cost 和編碼時間,以此為出發點設計快速編碼模式決策演算法。
3.1 編碼模式決策的兩項因素
在之前提過 Zhao’s et al.[4]所提出的演算法純脆只是去計算下一個更好的編 碼模式配對距離目前在編碼模式配對序列中停止的位置有多遠,但這個距離並不 能有任何的保證,事實上並不是距離越遠所需編碼的時間就越多,距離越遠也不 能保證有越多的 RD-cost 下降量,這兩者個別是由所需編碼的編碼模式配對種類 以及位於編碼模式序列中的位置有所不同。原先 Zhao’s et al.[4]所提出的辦法是 去計算序列中每一個停止點位置的 yykk,如公式(2)所示。但作者認為公式(2)中必 頇多考慮兩項因素,也就是不同位置的 RD-cost 下降量和不同編碼模式配對的運 算時間。 然而編碼模式配對序列中不同位置的 RD-cost 下降量和編碼模式配對所需的 運算時間這兩個因素可以將它們個別視為若停在這個位置之後若碰到更好的編 碼模式配對可以得到多少“好處”和需要付出多少“代價”。因此作者所提出的 演算法是去計算每一個編碼模式配對若下一個碰到更好的編碼模式配對能獲得 多少的好處和需要付出多少代價,作者利用這兩者的比值稱做為“獲得好處與付 出代價比”去找出在序列中的最佳停止點。以公式化來說明: ( ) [ ( ) ] ( ) [ ( ) ] [ ( ) ] ( ) [ ( ) ] k k k k k k k k k a E R D T b E C T E R D T c y E C T (10) 公式(10)(a)是表示停在編碼模式配對序列中第 K 個位置的編碼模式,去計算之後 若碰到更好的編碼模式配對能獲得多少期望 RD-cost 下降的好處。公式(10)(b)表 示需要付出運算時間的代價。公式(10)(c)表示兩者的比值,也就是在第一章節有 提到的 reward function,編碼模式配對序列中的每個位置,都可以去計算 reward function 並利用此去決定序列中最佳的停止位置。為了利用公式(10)去找出最佳 停止位置,必頇先去得到公式(10)中的(a)和(b),因此接下來的兩小節就是去說明 如何去獲得這兩種資訊。3.1.1 考慮 RD-cost 下降量 個別討論如何加入這兩個因素,先討論編碼模式配對序列中不同停止位置, 下一個遇到更好的編碼模式配對能獲得多少期望的 RD-cost 下降量-E ( R DE ( R DTTkk)) 是如何計算,將其公式展開為: 1 1 1 0 0 0 [ ( ) ] [ ( ) | ] ( ) 0 ( 1) 1 1 ( | ) ( )
k k N k k k k k j k N k i j j j k i r r r r E R D T E R D T T j P T j P T N R D T a b l e j k p p p (11) 公式(11)中的機率 P ( TP ( Tkk = j )= j ) 是沿用 Zhao’s et al.[4]所提出的機率計算方式,計 算停止點 K 之後遇到相對更好的編碼模式配對在不同位置的機率是多少。 P ( Tk = N + 1 ) P ( Tk = N + 1 )如前面章節所述是 K 位置之後,不會遇到更好編碼模式配對的機 率,但因為此機率是代表 K 之後不會遇到更好的編碼模式配對,也就是 K 之後沒有更小的 RD-cost,所以此機率前面乘上一個 0。最後可以由公式(11)中看 出,若想要得到E[R Dk(Tk) ]則必頇要先有R D T a b le j k( | )的資訊,此資訊是代 表若停在序列中第 K 個位置,K 之後的編碼模式配對若比 K 位置之前最小的 RD-cost 更小,則這個 RD-cost 下降量有多少。為了得到這個資訊,作者進一步 去統計並建成表格。 因為在原先的 Duration Problem 中,是去計算每個停止位置下一個遇到更好 的編碼模式配對能獲得多少的 RD-cost 下降量,因此在統計資料時也必頇照著這 個想法去做統計,如表 2 就是去統計每一個停止位置下一個遇到更好的編碼模式 配對能獲得多少 RD-cost 下降量。表 2 是利用五種不同的視訊序列-mobile、 football、foreman、harbour 和 crew 在可調視訊編碼的 CGS 架構和利用多層編碼 控制方法,基礎層的 QP=26 和增進層的 QP=22 且權重 W=0.5 的環境下做統計所 得的平均 RD-cost 下降量。表 2 中顯示序列中有 13 個編碼模式配對,綠色數字(縱 排)代表目前在序列中停止的位置,紅色數字(橫排)代表下一個遇到更好的編碼模 式是在序列中的哪一個位置。表中的數字則代表 RD-cost 的下降量。有了這個 RD-cost 下降量的表,就可以輕易的代入公式(11)中去計算每一個停止位置,若 之後會遇到更好的編碼模式配對能得到多少的預期 RD-cost 下降量。表 2 RD-cost 下降量表 BLQP = 26 ELQP = 22 W=0.5 K 2 3 4 5 6 7 8 9 10 11 12 13 1 8631.31 769.07 567.58 432.33 362.01 251.48 242.95 246.25 257.64 212.02 179.4 169.24 2 972.92 566.3 465.48 400.75 273.85 262.65 257.14 234.13 209.17 180.35 175.12 3 563.44 482.07 399.3 289.53 258.84 235.59 225.23 200.43 183.68 168.89 4 476.11 389.45 291.88 248.64 233.65 211.77 187.89 177.82 167.59 5 381.22 287.13 238.67 221.96 201.46 189.62 177.16 170.63 6 281.34 234.62 211.02 191.46 188.84 174.28 167.55 7 224.68 197.66 183.55 182.48 173.91 165.29 8 195.4 178.17 178.65 170.27 161.29 9 173.91 175.71 166.27 164.29 10 171.81 163.06 164.99 11 162.38 164.67 12 165.45 此表可以明顯的看出在同一停止點 K 之後遇到更好的編碼模式配對所能得 到的 RD-cost 下降量會隨著編碼模式配對在序列中位置的編號越大,下降量會越 小。例如停止點 K=1,若下一個遇到更好的編碼模式配對是在位置 3,其 RD-cost 下降量是 769.07;而若下一個遇到更好的編碼模式配對是在位置 12 則 RD-cost 下降量是 179.4。明顯的,位置 3 所得到的 RD-cost 下降量較多。為什麼會有此 種現象?因為上述提過表 2 的統計方式是去計算下一個遇到更好的編碼模式配 對有多少 RD-cost 下降量,遇到更好的定義若以位置 12 為例,代表位置 12 以前 的編碼模式配對都沒有更小的 RD-cost,也就是代表停止點 K 前面最小的 RD-cost 已經很小(代表 K 之前的編碼模式配對的 RD 效能已經很好),因此才會在序列中 後面的位置碰到更好的編碼模式配對。由此點說明表 2 的資訊是符合 duration problem 原先的定義。然而,作者在不同的 QP 設定和不同的權重下都有建立此 表,因此能根據不同的設定去參考不同的表,讓此 RD-cost 下降量表能更具適應 性。
3.1.2 考慮編碼模式配對的運算複雜度 考慮 RD-cost 的因素後,接下來繼續考慮各種不同編碼模式配對的運算時間 複雜度。在原先 Zhao’s et al.[4]所提出的方法中,是去計算下一個更好的編碼模 式配對離序列中停止的點距離多遠。但作者認為不應該是去計算距離多遠,而應 該是去計算下一個更好的編碼模式配對離序列中停止的位置之間所做過的編碼 模式配對需要在付出多少期望的運算時間-E C[ k(Tk) ]才對,若以公式來看: 1 1 1 1 1 [ ( ) ] [ ( ) | ] ( ) ( ) ( 1) ( ) ( ) ( ) ( 1)
k k N N k k k k i k j k i k j N N i k i k j k i k i k E C T E C T T j P T j c P T N c P T j c P T N (12) (a) 1 j i i k c
:編碼模式配對的運算時間總和 公式(12)的機率計算方式和公式(11)的機率相同,一樣是使用 Zhao’s et al.[4] 的方法。其中公式(12)(a)是計算目前停止位置為 K 且下一個遇到更好的編 碼模式配對前,還需要花多少運算時間。以圖 9 為例,假如目前停止的位置是序 列中的第一個位置,其編碼模式配對型態 (mode pair type) 是 A,若下一個相對 更好的是在位置 4,也就是位置 1 之後需要再做第二個到第四個位置的編碼模式配對才會碰到相對更好的。因此公式(12)(a)就是去計算編碼模式配對的型態
為 B、C 和 D 三種不同的編碼模式配對總共需要花費多少的運算時間。所以再計 算 E ( CE ( CTTkk)) 前,必頇先知道各種編碼模式配對的運算時間複雜度是多少。
整個視訊序列只固定做某種編碼模式配對。以表 3 中編號 2 的編碼模式配對 8x8_8x16 為例,在整個視訊序列中基礎層 MB 的編碼模式只做 Inter8x8 且增進 層只做 Inter8x16,然後去計算編碼時間,其他編碼模式配對的運算時間計算亦 是如此。表 3 各個編碼模式配對後面的數字代表這個編碼模式配對的時間運算複 雜度,數字越大代表其運算複雜度越大,這個運算複雜度係數是利用一個最小的 運算時間當作基準和其他編碼模式配對的運算時間所形成的比值。 表 3 將運算複雜度的係數由大到小排序,可以由表中清楚的看出運算時間複 雜度最大的編碼模式配對是 Inter8x8_Inter8x8,且 Inter8x8 的配對組合也都擁有 較高的運算時間複雜度,這對編碼模式運算時間複雜度的認知是符合的,因為現 實上 Inter8x8 是較細的 Inter 編碼模式,其的確需要較多的運算時間。因此在計 算公式(12)的 E C[ k(Tk) ] 時,可以從編碼模式配對序列中知道要做過哪些編 碼模式配對才會遇到一個更好的,這些要做的編碼模式都可以利用表 2 去做查表, 找出相對應編碼模式配對的運算時間複雜度係數,如此一來就可以輕易的算出 [ k( k) ] E C T 。 讀者可能會好奇的問,這種編碼模式配對的運算時間可能並不準確,因為這 種測量方式是去計算整個編碼端的運算時間。作者在這邊的做法只是去給予初步 的計算每種編碼模式配對的運算時間參考值,可能在運算時間上不是完全準確, 但趨勢是正確的。因此作者的想法是,若未來能更準確的計算出每一個編碼模式 配對的運算時間,這套演算法將能提供更準確的停止點。
3.1.3 同時考慮 RD 和運算複雜度,並找出停止點 接下來同時考慮 RD-cost 下降量和運算時間複雜度兩種因素,在前面有提到 作者是將前兩小節所計算的期望值取一個比值 yykk = E [¢ R D= E [¢ R Dkk( T( Tkk) ]= E [C) ]= E [Ckk( T( Tkk) ]) ] 做 為每一個停止位置的 reward function。這個值可以視為序列中的每一個停止點若 之後會遇到相對更好的編碼模式配對能獲得多少 RD-cost 下降量的好處和需要付 出多少運算時間的代價。然而這個 reward function 的趨勢是如何,且如何找到最 佳的停止點呢?先來觀察 yykk 在序列中的趨勢如圖 10 所示:
圖 10 reward function-yykk 趨勢示意圖 BLQP=22 , ELQP=18 , W = 0.1
圖 10 中的縱座標是 yykk 值,橫坐標是序列中不同的停止點 K=0~11。此實驗是在 基礎層的 QP = 22、增進層的 QP = 18 且權重 w = 0.1 設定下統計的平均 yykk 值。 可以從圖 10 中發現,不同的視訊序列的值都有相同的趨勢走向,都是嚴格遞減 的趨勢。其中在 K=1 以前的斜率非常的大,K=1 之後就近趨平緩。 然而 yykk 值也可以視為若停在序列中的這個位置,若之後碰到更好的編碼模 式配對能有多少的好處代價比。若 yykk 值近趨平緩,代表序列中後面的停止點所 能得到的效益比已差不多,因此停在 yykk 值平緩的位置即可。但在平緩的位置上 如何找到停止點呢?作者設計一個在不同的 QP 和不同的權重 w 設定下,規範一 個規範值(threshold),也就是低於此規範值就是序列中的停止點。
的規範值設定方式是去實驗視訊序列在不同的規範值下,找出符合基
礎層和增進層的位元率上升(bit rate increase)和峰值信噪比下降(PSNR decrease)
分別在 2%和 0.05 dB 以內的值。如表 4 就是在不同設定下所找出 yykk 的規範值。 表 4 不同設定下 yykk 的規範值表 BLQP_ELQP W01 W025 W05 W075 W09 22_18 1.5 1.3 1.1 1.3 0.9 26_22 2.5 2.7 1.9 1.9 1.5 30_26 3.7 3.9 3.5 3.1 2.1 然而表 4 中的規範值是個別在不同的設定下,利用不同的視訊序列得到的平均結 果。以基礎層 QP = 22 和增進層 QP = 18 且權重 w=0.1 的設定下舉例,做法如圖 11~圖 15 所示: 圖 11 基礎層在不同規範值的位元率上升圖 圖 12 增進層在不同規範值的位元率上升圖
圖 13 基礎層在不同規範值的 PSNR 值
圖 15 在不同規範值的編碼時間節省 圖 11 和圖 12 分別是基礎層和增進層在不同規範值的編碼位元率上升圖,在此工 作中是以上升在 2%以內為限制並設定規範值。由圖中顯示基礎層和增進層都滿 足此限制的值為 1.5。圖 13 和圖 14 亦是找出滿足峰值信噪比限制在 0.05 dB 最 大下降量的點,圖中顯示基礎層和增進層在所有的規範值幾乎都滿足此種限制, 所以聯集位元率上升和峰值信噪比下降的限制所找出的規範值就是 1.5。圖 15 中也顯示,在此組環境設定值下利用規範值 1.5 所得到的編碼時間節省將近有 81%。在其他的 QP 和權重 w 設定下,規範值的設定也是利用同樣的方法,作 者所建議的規範值設定就是表 4 的結果。 當然 yykk 的規範值可以由使用者所設定,設定滿足使用者本身的需求。表 4 只是作者提出介於此種位元率-失真效能所建議的規範值。
3.2 編碼模式配對的序列產生
由於作者所提出的方法是在於改善 Zhao’s et al.[4] 所提出的演算法,所以基 於原本 Zhao’s et al.[4]所提出的演算法,必頇先產生一組編碼模式配對的序列。 因此在此章節內將介紹編碼模式配對是如何產生的。 因為在參考論文[8]有提到,目前編碼的 MB 所選擇的編碼模式和周圍的 MB 或者和前一張畫面相對位置的 MB 所選擇的編碼模式具有相當大的相似度,也就 是很有可能是用相同的編碼模式做編碼,但由於此次工作是在多層編碼控制方法 的架構下設計快速演算法,因此是要一次考慮一組 MB 配對的編碼模式配對。基 於這個理由,作者再進一步統計目前要編碼的 MB 配對其所選擇的編碼模式配對, 和周圍的 MB 配對或前一張畫面相對應位置及周圍 MB 配對所選擇的編碼模式 配對有多少機率會做到相同的編碼模式配對。如表 5 所示: 表 5 目前編碼的 MB 和周圍 MBs 做相同編碼模式配對的機率表 Sequence 3MBs 7MBs 11MBs 13MBs Football 51% 67% 74% 76% Mobile 48% 65% 72% 74% harbour 57% 71% 76% 78% Crew 55% 70% 76% 79% Foreman 53% 68% 74% 76% Akiyo 90% 93% 94% 94% Avg. 59% 72% 78% 79% 表 5 是去統計目前編碼的 MB 配對和周圍的 MB 配對做相同編碼模式配對的機 率有多少,也就是目前編碼的 MB 配對若和周圍其中一個 MB 配對做相同的編 碼模式配對就會去累加次數。表中 3MBs、7MBs、11MBs 和 13MBs 分別是利用 周圍多少 MB 配對的個數去做實驗。以圖 16 說明,若(x,X)是目前要編碼的 MB 配對,(a,A)~(i,I)是前一張畫面相對位置以及周圍的 9 個 MB 配對, 且(j,J)~(m,M)是同一張畫面周圍 4 個 MB 配對。表中 3MBs 代表是利用 (e,E)、(k,K)和(m,M)這三組 MB 配對做實驗;7MBs 代表是多利用(b, B)、(d,D)、(f,F)和(h,H)這四組 MB 配對做實驗;11MBs 則是多利用(a,A)、(c,C)、(g,G)和(i,I)這四組 MB 配對;而 13MBs 則是利用(a,
A)~(m,M)這 13 組 MB 配對去做實驗。
圖 16 利用哪些 MB 產生編碼模式配對序列示意圖 由表中可以清楚地看到,13 組 MBs 擁有將近 80%的機率有其中一組 MB 配 對和目前編碼的 MB 配對做相同的編碼模式配對。因此作者就利用這 13 個 MB 配對去產生一個編碼模式序列。 然而產生編碼模式序列的方式是先將周圍的 13 組 MB 配對所做的編碼模式 配對形成一組機率,此機率是表示目前編碼的 MB 有多少可能會去做某種編碼模 式配對。因為是用周圍的資訊產生的機率,所以亦稱做為區域機率( local probability)。當然,若只有用區域機率產生編碼模式配對,由表 5 看來只會有將 近 80%的機率會和周圍做相同的編碼模式配對。但仍然還有其餘的 20%不會和 周圍的編碼模式配對相同。因此作者另外加入一組全域機率(global probability), 此全域機率是利用編碼不同的視訊序列,去統計出這些視訊序列做不同的編碼模 式配對其機率各是多少。若用公式表示同時考慮兩組的機率:
(
)
(1
)
(
)
1 ~ 5 6 ,
= 0 .7
i il o c a l P
g l o b a l P
i
(13) 公式(13)中 PPii 代表是某一組編碼模式配對,在前面小節提到作者所考慮的編碼 模式配對總共是 56 組,因此公式(13)也是考慮 56 組的機率。然而 設定為 0.7 是因為表 5 中顯示在大部分的視訊序列中,目前編碼的 MB 配對都有 75%以上 的機率可在周圍找到相同的編碼模式配對。最後利用公式(13)可以將 56 組編碼 模式配對的機率算出。然而作者從 56 組編碼模式配對機率中,挑出前 13 大的機 率組成一個編碼模式序列,其排序方式也是機率由大到小排列。然而每一張畫面 最後一個 MB 配對做完編碼後,會對全域機率進行更新(update),讓全域機率 能更符合不同的視訊序列以及環境。3.3 編碼模式決策的精進方法
在上述的章節以介紹完如何利用區域和全域資訊產生編碼模式配對序列,且 利用考慮 RD-cost 下降量和編碼模式配對的運算時間複雜度找出序列中的停止位 置。但是若快速編碼模式決策演算法只做到上述就停止,將會有一些問題存在, 問題包括有: 在相連畫面相對位置的 MB 幾乎只會產生相似的編碼模式配對序列。 在整個視訊序列中只有少數的編碼模式配對會被測詴。 在位元率-失真效能方面會產生嚴重的失真結果。 為什麼會有這些問題存在?因為若你總是使用區域的資訊和全域的資訊去產生 編碼模式配對序列,而且又給予區域的機率值較高的權重,會使得連續畫面相對 位置 MB 所參考的資訊總是相似的,因此產生的編碼模式配對序列也就會非常相 似,這種現象會一直存在,久而久之相對位置 MB 的編碼模式配對序列都會變成 一樣,也就會形成總是只去測詴相同的編碼模式配對。事實上不同畫面相對位置 的 MB 還是有可能會去做差異非常大的編碼模式配對,因此若發生這種問題,編 碼的位元率-失真效能將會有不可預期的失真產生。 為了解決上述問題,作者提出一個精進編碼模式決策的方法。為了方便起見, 作者將之前章節所提出的辦法稱為第一步驟,然後精進的方法稱為第二步驟。在 第一步驟中,是在編碼模式配對序列中找個停止點,也就 MB 做編碼模式決策是 從序列的起始位置做到停止位置。因此作者所提出的精進方法就是在第一步驟做 過的編碼模式配對中,其中最佳的編碼模式配對其 RD 效能還是不好,就必頇跳 脫原先方法去做一些其他種類的編碼模式配對。然而如何去判斷序列中最佳的編 碼模式配對其 RD 效能好壞與否,而且是要做哪些其他種類的編碼模式配對,這 第二步驟的方法將在之後詳細說明。 3.3.1 判定RD效能 作者所提出判定序列中最佳的編碼模式配對其 RD 效能好壞與否的方法是 利用周圍 MB 配對的平均 RD 做比較,此想法在參考論文[9]~[13]也有被提到, 都是利用周圍 MB 的平均 RD 或是整張畫面的平均 RD 行為做為參考,用來比較 目前編碼 MB 的 RD 效能好壞與否。至於利用哪些周圍的 MB 配對比較 RD 如圖 16 所示,利用已編碼完的(j,J)、(k,K)、(l,L)和(m,M)四組同一張畫 面 MB 配對的平均 RD 和目前編碼 MB 配對的最佳 RD 取一個比值,如公式(14) 所示:( ) ( ) c u r r e n t N e ig h b o r R D M B R D r a t i o R D M B (14) 公式(14)中 R D ( M BR D ( M Bc u r r e n tc u r r e n t)) 是表示目前編碼的 MB 配對在第一步驟中所找到最 佳編碼模式配對的 RD-cost。R D ( M BR D ( M BN e i g h b o rN e i g h b o r)) 則是代表周圍 4 個 MB 的平均 RD-cost,作者接下來對這個 RD 比值進一步分析與討論。作者將前一張畫面相 對位置 MB pair 的 RD 比值和目前編碼 MB pair 的 RD 比值做了一項實驗觀察, 觀察兩個 MB pair 的 RD 比值之間的關係,表 6 顯示實驗結果。
表 6 目前編碼 MB pair 和前一張畫面相對位置 MB pair 的 RD ratio 差值
Ratio(Current MB pair) – Ratio(Collocated MB pair) < 0.3
22_18 mobile football harbour foreman crew akiyo Avg
W01 0.95 0.91 0.97 0.89 0.89 0.95 0.93
W025 0.93 0.91 0.96 0.89 0.87 0.94 0.92
W05 0.89 0.91 0.93 0.88 0.87 0.93 0.9
W075 0.83 0.9 0.87 0.84 0.82 0.93 0.87
W09 0.79 0.88 0.83 0.81 0.82 0.94 0.84
26_22 mobile football harbour foreman crew akiyo Avg
W01 0.9 0.91 0.93 0.9 0.87 0.96 0.91 W025 0.88 0.9 0.9 0.89 0.85 0.95 0.9 W05 0.86 0.9 0.89 0.88 0.85 0.95 0.89 W075 0.83 0.89 0.86 0.85 0.83 0.94 0.87 W09 0.8 0.85 0.8 0.81 0.86 0.95 0.84
30_26 mobile football harbour foreman crew akiyo Avg
W01 0.88 0.89 0.91 0.89 0.86 0.97 0.9 W025 0.88 0.89 0.89 0.9 0.84 0.97 0.89 W05 0.86 0.88 0.89 0.88 0.84 0.96 0.88 W075 0.84 0.86 0.86 0.85 0.84 0.96 0.87 W09 0.81 0.83 0.83 0.83 0.9 0.96 0.86 表 6 統計前後畫面相對位置的 MB pair 其 RD 比值的差,有多少比例是在小 於 0.3 的情況。將近 90%的機率顯示兩個相對位置的 MB pair 的 RD ratio 的差值 小於 0.3。因此作者利用這個結果來判斷目前編碼的 MB pair 在第一步驟獲得的 RD-cost 好壞與否。
3.3.2 精進的方法 上一小節說明如何去判斷在第一步驟中所做的最佳編碼模式配對,其 RD 效 能的好壞與否。接下來的小節將介紹,如何對不好的 RD 效能進一步去做精進的 程序。作者所設計的精進方法是分兩種階級的,限定兩種等級的 RD ratio 差值 -0.3 和 0.5。也就是 RD ratio 差值若超過 0.3 和 0.5 分別會有不同的精進方法。 以公式來說明: _ _ _ _ _ ( ) 0 .3 0 .5 ( ) 0 .5 p r e v io u s fr a m e c u r r e n t fr a m e p r e v io u s fr a m e c u r r e n t fr a m e p r e v io u s fr a m e a R D r a t i o R D r a t i o R D r a t i o b R D r a t i o R D r a t i o (15)
公式(15)中的(a)和(b)代表兩種不同級別的 RD ratio 值,簡稱為級別(a)和級別(b)。 級別(a)代表目前編碼的 MB pair 在第一步驟中獲得的 RD 比周圍的平均差,但差 異較小,因此精進的方法就沒這麼複雜。然而級別(b)則代表差異較大,需要做 較複雜的精進步驟。級別(a)的精進方法為: 1. 在快速演算法的第一步驟中所找到最佳的編碼模式配對,根據不同的權重 w, 固定此最佳編碼模式配對中某一層的編碼模式,並在另外一層測詴不同的編 碼模式。 2. 權重w 0 .5時,固定基礎層的編碼模式;權重w 0 .5時,固定增進層的編碼 模式。另外一層所測詴的編碼模式以表 7 和表 8 做說明,表 7 和表 8 分別是 固定基礎層和固定增進層後,依序由左至右測詴不同的編碼模式,此順序是 經由視訊序列統計在固定某一層的編碼模式後,另外一層所做的編碼模式依 照機率大小由左至右排序。 3. 依序測詴完表 7 和表 8 中另一層的某一個編碼模式後,就會進行評估此編碼 模式配對的 RD 是否符合周圍的平均 RD。測詴方式以公式(16)做判斷, _ _ 0 .3 c u r r e n t fr a m e p r e v io u s fr a m e R a tio R a tio (16) 4. 若符合公式(16),則結束此次編碼模式決策。否則繼續測詴表 7 或表 8 中的 編碼模式。 然而級別(b)精進方法,是在做級別(a)的方法前根據不同的權重 w,個別先去測 詴表 7 和表 8 中固定某一層的編碼模式,另外一層做表中紅色部份的編碼模式。
出規範值太多,認為序列中最佳的編碼模式所得的 RD 效益太差,需要完全的跳 出序列中原先的選擇。以表 7 的 w=0.1 為例,在級別(b)中會先測詴 skip_skip, inter16x16_skip、inter16x8_skip、inter8x16_skip、inter8x8_skip、intra4_skip 和 intra16_skip 這七組編碼模式配對。在七組中挑出一組最佳 RD 的編碼模式配對 並根據權重 w 固定某一層的編碼模式,對另外一層的編碼模式依序測詴不同的 編碼模式,其做法如級別(a)的精進方法。 表 7 精進方法的編碼模式配對順序表-固定基礎層 W=0.1 EL BL
skip skip inter16x16 inter8x8 inter8x16 inter16x8 Blskip intra16 intra4 inter16x16 skip Blskip inter16x16 inter8x16 inter16x8 inter8x8 intra16 intra4 inter16x8 skip Blskip inter16x16 inter16x8 inter8x16 inter8x8 intra16 intra4 inter8x16 skip Blskip inter16x16 inter8x16 inter16x8 inter8x8 intra16 intra4 inter8x8 skip Blskip inter16x16 inter8x16 inter16x8 inter8x8 intra16 intra4 intra4 skip intraBL inter16x16 inter8x16 inter16x8 inter8x8 intra4 intra16 intra16 skip intraBL inter16x16 inter8x16 inter16x8 inter8x8 intra4 intra16
W=0.25 EL
BL
skip skip inter16x16 inter8x16 inter8x8 inter16x8 Blskip intra16 intra4 inter16x16 Blskip skip inter8x16 inter16x16 inter16x8 inter8x8 intra16 intra4 inter16x8 Blskip skip inter16x16 inter16x8 inter8x16 inter8x8 intra16 intra4 inter8x16 Blskip skip inter16x16 inter8x16 inter16x8 inter8x8 intra16 intra4 inter8x8 Blskip skip inter16x16 inter8x16 inter16x8 inter8x8 intra16 intra4 intra4 skip intraBL inter16x16 inter8x16 inter16x8 inter8x8 intra4 intra16 intra16 skip intraBL inter16x16 inter8x16 inter16x8 inter8x8 intra4 intra16
W=0.5 EL
BL
skip skip inter16x16 inter8x16 inter8x8 inter16x8 Blskip intra16 intra4 inter16x16 Blskip skip inter8x16 inter16x8 inter16x16 inter8x8 intra16 intra4 inter16x8 Blskip skip inter16x16 inter8x16 inter16x8 inter8x8 intra16 intra4 inter8x16 Blskip skip inter16x16 inter8x16 inter16x8 inter8x8 intra16 intra4 inter8x8 Blskip skip inter16x16 inter8x16 inter16x8 inter8x8 intra16 intra4 intra4 intraBL skip inter16x16 inter8x16 inter16x8 inter8x8 intra4 intra16 intra16 intraBL skip inter16x16 inter8x16 inter16x8 inter8x8 intra4 intra16
表 8 精進方法的編碼模式配對順序表-固定增進層 W=0.75,
W=0.9 BL
EL
skip skip inter16x16 inter8x16 inter16x8 inter8x8 intra16 intra4
inter16x16 skip inter16x16 inter8x16 inter16x8 inter8x8 intra16 intra4
inter16x8 skip inter16x16 inter16x8 inter8x16 inter8x8 intra16 intra4
inter8x16 skip inter16x16 inter8x16 inter8x8 inter16x8 intra16 intra4
inter8x8 skip inter16x16 inter8x8 inter8x16 inter16x8 intra16 intra4
BLSkip skip inter16x16 inter8x16 inter8x8 inter16x8
intra4 skip inter16x16 inter8x16 inter8x8 inter16x8 intra16 intra4
intra16 skip inter16x16 inter8x16 inter8x8 inter16x8 intra16 intra4
intraBL intra16 intra4
最後在此說明為什麼以權重w 0 .5和w 0 .5為分界點,分別先固定基礎層或增 進層的編碼模式。因為在前面介紹過多層編碼控制是使用權重w來給予層與層之 間做調節,權重小的時候代表是給予基礎層較大的權重,也就是編碼參數設定以 基礎層為考量;反之編碼參數設定是以增進層為考量。基於這個理由,作者認為 在權重w 0 .5時,編碼參數的設定是以基礎層為考慮多一點,因此認定為基礎 層當初選擇的編碼模式是較準確的,因此固定基礎層的編碼模式,並嘗詴增進層 的其他不同的編碼模式,反之在權重w 0 .5時則剛好相反。 3.3.3 精進程序前後差異比較 為了證實精進程序對於作者所提快速演算法的重要性,在此小節提出實驗證 明。此實驗分別在有執行精進方法和沒有執行精進方法中,個別去統計有多少編 碼模式配對的種類會在序列中被測詴。表 9 顯示實驗結果, 表 9 序列中編碼模式配對種類的比較 No Refine Refine mobile 22_18 26_22 30_26 34_30 22_18 26_22 30_26 34_30 W01 13 13 14 14 24 29 30 30 W025 8 15 16 16 14 30 29 29 W05 10 14 16 16 27 26 28 29 W075 13 13 16 14 24 26 27 27 W09 13 14 17 15 26 27 26 23 AVG 11.4 13.8 15.8 15 23 27.6 28 27.6
W01 10 14 16 19 21 25 26 28 W025 8 15 17 16 18 18 24 25 W05 8 17 15 19 18 24 26 29 W075 11 15 16 18 18 21 27 24 W09 13 14 14 16 17 21 25 21 AVG 10 15 15.6 17.6 18.4 21.8 25.6 25.4 harbour W01 11 13 13 14 23 20 26 27 W025 10 14 13 14 15 24 26 26 W05 7 13 13 13 21 27 23 27 W075 10 13 13 14 17 22 25 24 W09 14 13 14 15 22 28 25 18 AVG 10.4 13.2 13.2 14 19.6 24.2 25 24.4 foreman W01 16 17 16 16 30 29 28 30 W025 16 17 20 15 28 28 30 27 W05 19 16 14 15 29 27 29 26 W075 15 16 14 13 29 29 29 27 W09 15 15 14 16 29 29 28 21 AVG 16.2 16.2 15.6 15 29 28.4 28.8 26.2 crew W01 14 18 17 15 26 32 32 30 W025 14 14 16 18 26 30 30 26 W05 13 15 16 17 30 30 32 30 W075 14 14 18 16 29 30 27 22 W09 16 16 17 17 34 21 18 19 AVG 14.2 15.4 16.8 16.6 29 28.6 27.8 25.4 此實驗是在不同的視訊序列在不同的 QP 和不同的權重 w 下測詴,NoRefine 顯 示沒有做精進方法時,序列中的編碼模式配對種類個數;Refine 則是顯示有做精 進方法,時序列中的編碼模式配對種類個數。由表 9 中可以發現有做精進方法的 序列中,其編碼模式配對的種類會多出很多,此實驗結果也能證明此章節開頭所 述若沒做精進程序會形成的問題。因此精進方法在作者所提出的快速演算法中是 非常重要的一環。