行政院國家科學委員會專題研究計畫 成果報告
中文詞彙辨識的凝視位置效果之決定因素(第 3 年)
研究成果報告(完整版)
計 畫 類 別 : 個別型 計 畫 編 號 : NSC 96-2413-H-004-018-MY3 執 行 期 間 : 98 年 08 月 01 日至 99 年 08 月 31 日 執 行 單 位 : 國立政治大學心理學系 計 畫 主 持 人 : 蔡介立 共 同 主 持 人 : 李佳穎 計畫參與人員: 博士後研究:顏妙璇 報 告 附 件 : 國外研究心得報告 出席國際會議研究心得報告及發表論文 處 理 方 式 : 本計畫涉及專利或其他智慧財產權,2 年後可公開查詢中 華 民 國 99 年 11 月 29 日
Introduction
Recognition of a visually presented word requires extracting the visual features from the word‟s retina image as the first step. However, encoding the visual information of word is restricted by the density distribution of retinal receptors, in which the visual acuity drops rapidly outside the fixating location. Even in the foveal region, visual acuity reduces to about 60% of maximum at an eccentricity of one degree (Brysbaert & Nazir, 2005). In consequence a reader tends to move eyes to fixate on words to receive high quality image on the retina. Moreover, in the foveal visual field, the information at different positions of a word is not visible in the same quality. In such situation, the best strategy to identify a word is fixating at the location where can maximize the useful information covered by the small region of high visual acuity.
The drop of visual acuity away from fixation implies that word recognition depends on the fixating position within word. This argument is supported by showing that there is a location in a word where the recognition time is minimized, referred as the optimal viewing position (OVP) (O'Regan & Levy-Schoen, 1987). Many studies have
investigated the OVP effect by the manipulation of the initial fixation position within a word, using the tasks of word naming (O'Regan & Jacobs, 1992; O'Regan, Levy-Schoen, Pynte, & Brugaillere, 1984), lexical decision (Nazir, O'Regan, & Jacobs, 1991; O'Regan & Jacobs, 1992), and perceptual identification (Brysbaert, Vitu, & Schroyens, 1996; Nazir, Heller, & Sussmann, 1992; Stevens & Grainger, 2003). The results consistently showed that the initial fixation curve of recognition time or error rate is U-shaped and typically the OVP is a bit left to the center of the word.
The U-shaped curve of recognition performance across letter positions indicates that recognition difficulty increases as a function of viewing positions in the word. Since
letters further from fixation are less well represented peripherally, the ease of word identification at different fixation position can be estimated by letter perceptibility. In a summed letter information model (McConkie, Kerr, Reddix, Zola, & Jacobs, 1989), the hypothetical word identifiability is the sum of individual letter visibilities, which are calculated according to the distance between the letter position and the initial fixation position. It successfully predicts the viewing position effects of word recognition which is caused by the visibilities of component letters.
However, the asymmetry of the viewing position curve is out of the symmetric prediction simply based on visual acuity. The asymmetry of hemifield acuity has been reported in individual letter perceptibility to account for the asymmetry of the OVP effect (Nazir et al., 1992; Nazir et al., 1991). For example, Nazir et al. (1991) demonstrated that the letter visibility falls away 1.8 times more sharply in the left visual field (LVF) than the right visual field (RVF). However, this RVF advantage can also result from the influence of other factors, likes hemispheric asymmetry and information structure of words. Moreover, a recent study showed a highly symmetrical inverse U curve of letter perceptibility as a function of viewing position (Stevens & Grainger, 2003). Regarding the variation of letter visibility to word eccentricity, it provides weak evidence to explain the asymmetry of the OVP effects.
In addition to letter perceptibility, there are several factors has been suggested to account for the asymmetry, including perceptual learning, hemispheric asymmetry, and the information profile of words (Brysbaert & Nazir, 2005; Rayner, 1998). Perceptual learning refers that the ability to discriminate a target can improve by training of presenting similar stimuli repeatedly at particular position in the visual field (Nazir &
O'Regan, 1990). In reading, the statistics about where the eyes tend to land in a natural reading situation according to the reader‟s experience are critical for retinal training. The landing site distribution can represent the frequency of which words are processed from different locations on the retina (Nazir, Ben-Boutayab, Decoppet, Deutsch, & Frost, 2004). For left-right alphabetic languages, there is a tendency to fixate between the beginning and the middle of the words, referred as the preferred landing position (PLP) (McConkie, Kerr, Reddix, & Zola, 1988; Rayner, 1979). The PLP is mainly determined by the low-level visual and oculormotor factors (Rayner, 1998). Given the observation of that the fixations land on word beginning more frequently than on word ending, word information are processed more efficiency at the PLP. Therefore the recognition performance would show the RVF advantage. The asymmetric OVP effects can reflect the frequency of the training on the retina. It should be noted that, the PLP in Hebrew which is a right-left script has been shown at the right of center (Deutsch & Rayner, 1999). However, the OVP curve for right-left scripts (Hebrew and Arabic) is much more symmetric (Farid & Grainger, 1996; Nazir et al., 2004) than the left-right scripts (English and French). This implies, in addition to perceptual learning, there are other factors contributing in the asymmetry OVP effects.
In addition to the factors aforementioned, lexical structure of words also play an important role to account for the asymmetry of viewing position curve. It highlights the nature of how the lexical processing system encodes the information at different letter positions. As long as a reader recognizes more words in reading experience, the statistics of the learned words about the probability of a letter or letter string appearing in a word can be obtained. This provides an objective method to estimate the ease of identifying
any word on the basis of the partial word information, which is perceived from letter positions with the best visual acuity. The information profile of words can serve as the probabilistic principles which are acquired from lexical knowledge to determine the OVP for word recognition. One source of the information is the entropy on a given position, referring the extent of variance about the information carried on a letter position. The other source is the lexical constraint, referring the probability to recognize a word from the partial word information with high resolution perceived from a fixating position.
In a connectionist model of reading, the entropy values for letter positions in words represent the processing difficulty (Monaghan, Shillcock, & McDonald, 2004). The higher the entropy value for a letter position is, the more information the position carries. The entropy for every letter position in the range of hypothetic reading span could be estimated from all the words with the same length. Monaghan et al. (2004) reported that, in English, the letters at the left side are more varied than those at the right side. This implies the information distribution of letters in words in the lexicon is asymmetric. The OVP at the left of words could be because of the processing efficiency by projecting the denser information with highest resolution.
The second source of the information profile of words is lexical constraint,
reflecting the ease of identifying a word from one or several constituent letters. As more letters of a word are available, the ambiguity of the word is reduced. An analysis of French corpus has shown that more words shared the same final letters than the same initial letters (O'Regan et al., 1984). Clark and O‟Regan (1999) proposed a simple four-letter coding model to estimate word ambiguity when two outer four-letters and two four-letters near to fixation were known. They performed a statistical analysis of English and French
corpuses to obtain word ambiguity as a function of fixation. The plots of ambiguity measurements showed the asymmetry to the left of word center which were similar to empirical viewing position curves. Stevens and Grainger (2003) combined the measures of letter visibility and ambiguity successfully predicted the empirical OVP results of words. Therefore the left-shifted OVP reflects the best position where has the benefit to allow the least ambiguous letters to be projected on foveal region.
Research directly manipulated the lexical informative of words and found the OVP was at the initial letters when words had unique beginning (Brysbaert et al., 1996;
O'Regan & Levy-Schoen, 1987; O'Regan et al., 1984). These studies also showed that the OVP did not be pulled to the opposite side for words with unique ending comparing with unique beginning. It is clear that lexical constraint can influence the OVP effects for some extent. However it interplays with other factors to determine the OVP (Brysbaert & Nazir, 2005; Stevens & Grainger, 2003). One study using Arabic words with different morphological structure showed a reversal in the asymmetry (Farid & Grainger, 1996). They found that the OVP was at the word ending for prefixed word compared with suffixed words. It should be pointed out that Arabic suffixed words actually showed a symmetry OVP curve. These studies consistently demonstrated that the influence of lexical constraint is asymmetry.
Shillcock, Ellison, and Monaghan (2000) proposed a hemispheric processing model of word recognition and the informative distribution of words was taken into account. They argued that, based on the split fovea claim (Lavidor & Walsh, 2004), the OVP phenomenon in English word recognition revealed an optimal division of labor between the two hemispheres. More specifically, they proposed an algorithm to calculate the
optimal splitting point of words in a lexicon, aiming at giving both sides equal probability of identifying the word and maximizing the sum of information on both sides. Their modeling results reflected the fact that the beginning of English words tend to be more informative than the endings, and also resembled the OVP observed in human data (O'Regan, 1990). The results also captured the hypothesis that the distributions of optimal split points for words with more informative beginnings and endings are asymmetrical (O'Regan & Levy-Schoen, 1987): there was a small rightward shift of the OVP for end-informative words.
Moreover, the anatomic constraint of fovea splitting suggests that the word
information split by the fixation is projected to different hemispheres. This provides the ground to explore the possible hemispheric asymmetry of information processing. Recently, Shillcock and his colleague used the split fovea framework to simulate the OVP effect (Shillcock & Monaghan, in prep.). They reported that lateralization of computational resources within the model (i.e., giving more hidden units to one
“hemisphere” of the model) is very effective in skewing the curve to produce the classic shape of the OVP curve.
The considerable research carried out on the OVP effect has variously suggested the roles for hemispheric processing differences, information structure of the words in the lexicon, reading experience, and letter visibility as a function of eccentricity. These factors may have interactions to decide the best letter position for word recognition (see Brysbaert & Nazir, for a review, 2005). The goal of the project is to examine whether the viewing position curve of Chinese word recognition is also asymmetric and how different factors can account for the OVP effect.
There are some features of lexical structure for Chinese written system which are different from alphabetic languages. For reading Chinese, characters are the perceptually prominent units and they usually are also syllables and morphemes. In text the great majority of the characters are actually constituents of compound words rather than being individual words. For these compounds, character meanings are not always transparent to word meaning. According to the Chinese word corpus of Academia Sinica Taiwan (1998), the proportion of one-, two-, three-, and four-character words are 9.5%, 65.6%, 12.4%, and 11.6%, respectively. As the consequence, words with various lengths are mixed in a sentence. However, there is no perceptual indicator of where words begin and end when reading a sentence. It calls into the question of whether word or character is the reading unit and how the „where‟ decision of eye movements can be made in the reading of Chinese.
In reading text, Chinese reader show no preferred landing position on words (Tsai & McConkie, 2003; Yang & McConkie, 1999). Tsai and McConkie (2003) reported that the landing position curve was relatively flat on two-character words, compared with English 7-letter words with the same visual angle. A further regression analysis showed that both character and word frequency of one to two characters next to the current fixation affect the probability of landing on that character position. Another study also showed both character frequency and word frequency effects for fixation time in reading sentences (Yan, Tian, Bai, & Rayner, 2006). These findings imply that word processing plays a role in making eye movement decisions but character processing also has its influence.
Word recognition involves hierarchical processing of sub-lexical units. For example, words in alphabetic scripts are composed of letters and Chinese words are composed of characters, which can be further decomposed into radicals. The order or the configuration of these sub-lexical units can distinguish different words / characters (e.g., act, cat, and cap are different words; 國中 „junior high school‟ and 中國 „China‟ are
different words; 部 „part‟ and 陪 „to accompany‟ are different characters). In addition, letters at different positions (such as initial or final) seem to contribute differently to word recognition. It has been shown that initial letters provide more lexical constraint than final letters (Farid & Grainger, 1996). For example, if the initial letters of a 5-letter word are available (such as FABL_), FABLE is the only candidate word. On the other hand, if the final letters of the same word are available (i.e., _ABLE), there are many candidates (such as CABLE, TABLE, FABLE). Clark and O‟Regan (1999) calculated an ambiguity measure, in which numbers of candidate words were computed given two consecutive internal letters at various positions and the two exterior letters. They found that for words that contain 5 to 11 letters, the ambiguity was the lowest when a two-letter pair to the left of word center was available. These findings suggest that initial letters and those around word center are constraining.
Fraid and Grainger (1996) investigated the causes for the OVP by manipulating lexical constraint and reading direction. In their study, French (read from left to right) and Arabic (read from right to left) were compared. In addition, affixed words were chosen as the material. For prefixed words, the initial letters (i.e., the prefixes) are less constraining than the final letters. In contrast, for suffixed words, the initial letters are more constraining than the final letters (i.e., suffixes). Overall, the curve for Arabic words was symmetric but it depended on the morphological structure. The OVP on prefixed Arabic words was at word ending while that on suffixed words was at word beginning. In contrast, the OVP on French words was generally to the left of word center, with this leftward asymmetry more evident for suffixed words. Thus, depending on the writing system, one factor is more important than the others for the OVP. For example, morphology seems to play a dominant role in recognizing Arabic words.
Besides clarifying the mechanism for the OVP in word recognition, OVP can be used as a tool to investigate how sub-lexical units contribute to word processing. The present project aimed to investigate the influence of the information profile of sub-lexical units (constituent characters and radicals) on Chinese word and character processing by observing the OVP curve.
In Years 1 and 2, the OVP on words was observed when the informativeness of both constituent characters were either matched or varied naturally. Specifically, in Year
1, the OVP curve on isolated two-character words was observed with the lexical decision task. In Year 2, the OVP curve on words (especially two- and three-character words) was observed during normal passage reading. Since there are no visual cues for word boundaries in Chinese sentences, the contribution of a potential statistical cue (i.e., the probability of each character being used as word beginning/ending) to word recognition in continuous text reading was examined. In Year 3, the influence of sub-lexical information profile on word/character recognition was investigated. In Experiment 3-1, neighborhood sizes (defined later) of both constituent characters of two-character words were manipulated orthogonally in addition to the manipulation of fixation positions. If these factors play a role in word recognition, they may influence the OVP. Similarly, in Experiment 3-2, the effects of radical combinability on character recognition was investigated by simultaneously manipulating both the semantic and phonetic radicals.
Year 1: OVP on Words (Lexical Decision Task)
Method
Participants. Twenty-eight male university students at National Yang-Ming University were paid to participate in this experiment. All of them are native speakers of Chinese with normal or corrected-to-normal vision and right-handed.
Design and Materials. A list of 140 Chinese two-character words was used as the stimuli. Word frequencies were controlled in the range of 10 to 100 per million (with an average of 35.54 occurrences per million). The lexical properties of the first and second constituent characters, including number of strokes (11.5 vs. 11.4), subjective familiarity (5.3 vs. 5.4), and word combinability (12.3 vs. 12.0), were matched for all words. The subjective familiarity is based on an unpublished corpus of 5640 Chinese characters. The data were collected from 160 college students by using a 7-point scale for familiarity rating. Word combinability measure was obtained from the corpus by calculating number of two-character words sharing the same first or second constituent character. In addition,
140 pseudowords were created for the lexical decision task. The lexical properties of their constituent characters were matched to those of real words.
Stimulus position was manipulated so that each time a stimulus was presented in one of the seven positions: on the half character position in front of the word (as position -3), on the left half of the first character (as position -2), on the right half of the first character (as position -1), on the middle of the word (as position 0), on the left half of the second character (as position 1), on the right half of the second character (as position 2), and on the half character position behind the word (as position 3). It should be noted that in the position -3 and 3 conditions, the whole character string was presented out of the fixation point, either in the RVF or LVF. The words and pseudowords were randomly divided into 14 lists of twenty words. The lists were distributed over the seven possible display positions according to a Latin square table so that each list was seen in each condition every seven participants.
Apparatus. A video-based eyetracker (iView X Hi-Speed System by SensoMotoric Instruments, Germany) was used to ensure that the eyes of participants were fixating exactly on the central position in each trial. The sampling rate was 500 Hz. The reading material was displayed on a ViewSonic G90fB monitor. The stimuli were presented one at a time for 100 ms in isolation at the center of the display screen and appeared white in a dark background. The size of each character of the two-character string was 40 pixels in the resolution of 1024 x 768 pixels The viewing distance was 80 cm and the width of two-character strings subtended approximately 2.1° of visual angle.
Procedure. In the beginning of the experiment, a nine-point calibration procedure was used for each participant to determine the correspondence between pupil position and gaze position. At the beginning of each trial, a fixation plus sign „+‟ (10*10 pixels) appeared at the center of the screen, and participants were asked to fixate at the center of the plus sign. Once the gaze position remained fixating at the central position (within a range of 5 pixels) for 60 ms, the stimulus was presented at any of the seven positions (positions -3 to 3) for 100ms and followed by a blank screen. Participants were requested to decide whether the stimulus was a „word‟ or „nonword‟ by pressing the assigned
buttons on the response pad (RB-830 by Cedrus Corporation, USA). Positive responses were made with both index fingers, and negative responses with both middle fingers. The participants were instructed to respond as rapidly and accurately as possible. A total of 280 trials were separated into 5 blocks to be completed in the experiment.
Results
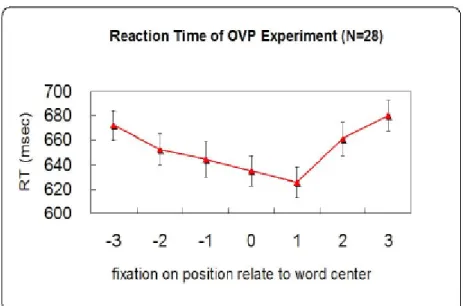
Only correct responses were analyzed with regard to reaction time, which was further restricted to be less than 2000 ms. The reaction time and error rates as a function of viewing positions were shown in Figures 1 and 2. An analysis of variance (ANOVA) was performed on reaction time of words with initial fixation position as the within-subject factor. The main effect of fixation position was significant [F(6,162) = 13.10, p < .05). Post hoc analysis further revealed that position 0 was significantly different from all other positions (ps < .05) except for positions 1 and -1 (ps > .22). Position 1 was significantly different from all other positions (ps < .05) except for position 0. It is worth noting that position 1 had the fastest reaction time 625 ms and it was significantly different from position -1 (p < .05). Position 3 had the slowest reaction time 680 ms and it was significantly different from all other positions except for position -3. An analysis of variance (ANOVA) was also performed on error rates of words with initial fixation position as the within-subject factor. The main effect of fixation position was significant (F(6,162) = 6.09, p < .05). Post hoc analysis showed that position 7 had the highest error rate 8.04% and was significantly different from all other positions (ps <.01). No other comparisons were significantly different.
Figure 1: Mean reaction time as a function of initial fixation position.
Figure 2: Mean percentage of incorrect responses to words as a function of initial fixation position.
Discussion
This experiment showed that response latencies of lexical decision increased when words presented away from the fixation location. Moreover, the optimal viewing position was at the first half of the ending character, which is to the right of the word center. The rightward asymmetric OVP curve cannot be easily explained by reading
direction or hemispheric asymmetry of language processing. One possible explanation for the right-shifted OVP is the reading strategy developed in the normal reading situation. For Chinese readers, fixating on the second character may be more efficient to know where a word is because of the lack of word boundary information in Chinese sentences. Another explanation can be provided by analyzing the lexical information distribution on different character positions.
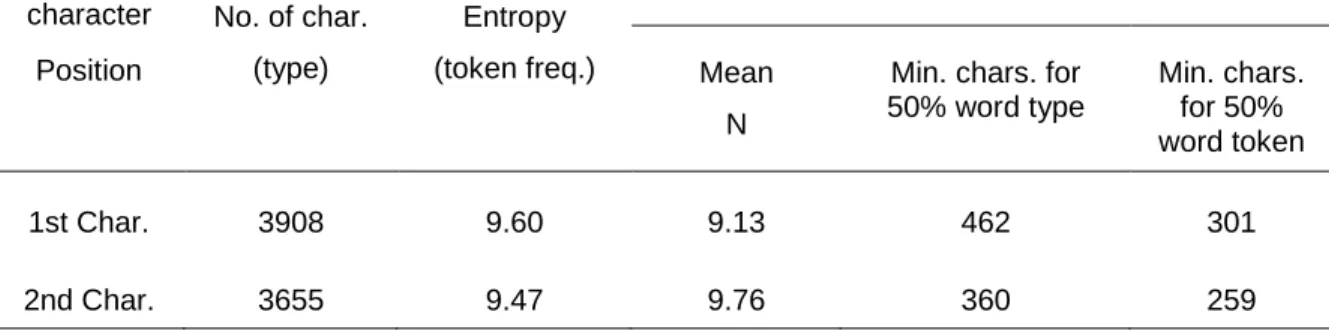
We conducted a complementary analysis on a corpus of 4,020,000 Chinese two-character words (35,673 words in type) to explore the information profile on different character positions (Table 1). The results indicated that the entropy on the first character position is a bit higher than that on the second character position. However, the OVP found here was not on the position where was more informative. When word combinability at different character position was considered, a smaller set of characters in the second character position can be the constituent of 50% word types or tokens in the corpus. Thus, fixating on the second character of word can increase the possibility to have more activation from similar words. We speculate that the tendency to fixate on the second character might have the advantage to determine whether the character string is a word or not in the lexical decision task.
Table 1: The properties of lexical information distribution over two-character words calculated from the Academia Sinica Balanced Corpus
character Position No. of char. (type) Entropy (token freq.) Combinability/Neighborhood Size Mean N
Min. chars. for 50% word type Min. chars. for 50% word token 1st Char. 3908 9.60 9.13 462 301 2nd Char. 3655 9.47 9.76 360 259
Shillcock, Ellison, and Monaghan (2000) proposed a hemispheric processing model of word recognition and the informative distribution of words was taken into
account. They argued that, based on the split fovea claim (Lavidor & Walsh, 2004), the OVP phenomenon in English word recognition revealed an optimal division of labor between the two hemispheres. More specifically, they proposed an algorithm to calculate the optimal splitting point of words in a lexicon, aiming at giving both sides equal probability of identifying the word and maximizing the sum of information on both sides. Their modeling results reflected the fact that the beginning of English words tend to be more informative than the endings, and also resembled the OVP observed in human data (O'Regan, 1990). The results also captured the hypothesis that the distributions of optimal split points for words with more informative beginnings and endings are asymmetrical (O'Regan & Levy-Schoen, 1987): there was a small rightward shift of the OVP for end-informative words.
Experiment 1 in Year 3 was designed to investigate whether lexical constraint can have a direct influence on the OVP by manipulating word combinability at different character positions. In Year 2, the OVP on words during normal passage reading was examined.
Year 2: OVP on Words (Normal Passage Reading)
Chinese sentences are written character-by-character without explicit cues for word boundaries. Probabilities of a character being used as word beginning/ending may be useful statistical cues to identify a word embedded in a series of characters. The OVP of a word during text reading can be inferred from the trough of the curve of refixation probability as a function of initial landing position (McConkie, Kerr, Reddix, Zola, & Jacobs, 1989). It is found that during text reading with alphabetic scripts, refixation probability was the lowest when participants initially fixated to the left of the word center, which is similar to the OVP observed in lexical decision and naming tasks. In the present experiment, the OVP on 2-character words during passage reading and the contribution of information profile within word (in terms of the probability of a character being used as word beginning/ending) was investigated.Method
Participants. Forty-eight college and graduate students at National Yang-Ming University and National Chengchi University were paid to participate in this experiment. All of them are native speakers of Chinese with normal or corrected-to-normal vision.
Materials. Participants read four passages selected from magazines for comprehension. Each passage contained 2008 characters on average (1883 ~ 2163 characters), with each punctuation mark occupying a character space. There were totally 3768 words in the passages, each of which contained 942 words on average. The proportion of words for lengths 1, 2 and more than 2 characters are: 52.1%, 42.5% and 5.5%. The order of four passages was counterbalanced with Latin square assignment.
The probability of a character being used as word beginning/ending was calculated from Academia Sinica balanced corpus (Academia Sinica Taiwan, 1998), which contains more than 9000 segmented passages. Because 2-character words are frequently used, the analysis was restricted to 2-character words. Three types of probabilities of a character being used as word beginning/ending were calculated. First, number of 2-character words in which a particular character is used as word beginning was calculated. Similarly, number of 2-character words in which this character is used as word ending was calculated. Dividing by number of 2-character words that contain this character at either position, the proportion that this character is used as the beginning or ending of 2-character words was calculated. This calculation considered type frequencies. Second, instead of counting number of 2-character words that contain a particular character, the sum of frequencies of these words was used. The probability that a character is used as word beginning/ending was calculated in the similar way as the first calculation, except that token frequencies were considered in the second calculation. Third, sum of frequencies of words, regardless of word length, that contain a particular character was calculated. That is, the denominator was the sum of all words that contain the character. The probability of a character being used as the beginning/ending of 2-character words was calculated in the similar way as the second calculation except that different denominator was used.
Apparatus. Similar to that of Year 1, eye movements were recorded by an iView X Hi-Speed eye tracker and the sampling rate was 500 Hz. The characters were shown in black on a light gray background. All passages were arranged to have 22 characters per line and 4 (horizontal) lines per page. There were totally 93 pages, with 22 to 25 pages per passage. The size of a character was 32 32 pixels. The space between characters was 4 pixels and the space between lines was 50 pixels. The viewing distance was 74 cm, at which each character subtended 0.81.
Procedure. Participants were instructed to read normally for comprehension. They were told that there would be four comprehension questions after reading each passage. After a 13-point calibration and verification for calibration accuracy, a practice passage (4 pages) and two comprehension questions were given.
The experimental phase started with the calibration procedure. Participants read each passage page by page. Before each page, participants were instructed to fixate on a cross presented at the position of the first character (top left). The experimenter pressed a button to accept this calibration check or to recalibrate. Then, participants read the page at their own pace and pressed a button when they finished reading this page. Four yes/no comprehension questions were presented at the end of each passage. Feedback on their responses was given. Participants could take a break after answering the comprehension questions. The next passage started with the calibration procedure. The experiment lasted about 40 minutes to 1 hour.
Results and Discussion
First-pass fixations on words that contain 1 to 3 characters in the four passages were selected for further analysis. First and last words on each line were excluded from analysis. In addition, fixations interrupted by blinks, before and after line crossing (due to oculomotor errors, processing difficulty or after finishing reading each line) were excluded from analysis. Initial landing position (i.e. preferred viewing location, PVL; Rayner, 1979) and refixation probability on words that contain 1 to 3 characters were
calculated to find the OVP during text reading. Then, gaze durations (GD) on 2-character words were calculated. This measure is the sum of durations of all first-pass fixations (independent of number of fixations) on a word before leaving it. The contribution of the probability of a character being used as word beginning/ending to word recognition and OVP was examined.
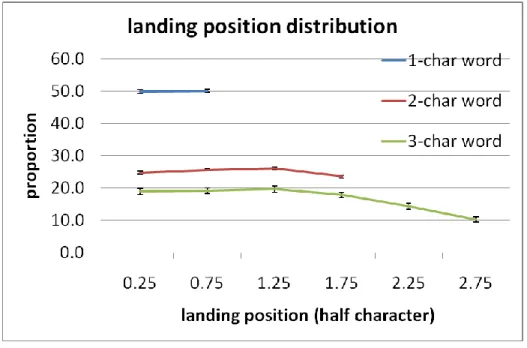
Initial Landing Position and Refixation Probability. Initial landing position on a word was calculated as character position from the word beginning. The space prior to each character was included in calculation. For instance, 1.3 means the participant fixated slightly to the left of the center of the second character of the word. Separately for 1-, 2-, 3-character words, distribution of the initial landing positions (on each half-character) is presented in Figure 3. Separate one-way ANOVA was conducted for each word length. There was no difference in the proportion of landing on either half of a 1-character word (49.9 and 50.1%), F < 1. For 2-character words, the difference in the proportion of landing on each half-character (24.7, 25.6, 26.1, and 23.5%) was significant, F(3,141) = 6.71, p < .001. There was a significant quadratic trend, F(1,47) = 17.75, p < .001. The linear trend was not significant, F < 2, p > .21. Post-hoc pair comparisons showed that the probability of landing on word ending (1.75) was significantly lower than the middle of the word (0.75 and 1.25), ps < .05. For 3-character words, there was a significant main effect of landing position (18.9, 19.2, 19.6, 17.8, 14.3, and 10.3%), F(5,235) = 13.99, p < .001. Both the linear and quadratic trends were significant, F(1,47) = 32.17, p < .001 and F(1,47) = 22.23, p < .001, respectively. Post-hoc pair comparisons showed that probabilities of landing on the initial three positions (0.25, 0.75 and 1.25) were significantly higher than those of landing on the last two positions (2.25 and 2.75), all ps < .05. The probability of landing on the last position (2.75) was also significantly lower than those of landing on the fourth and fifth positions (1.75 and 2.25), both ps < .01. The difference in the probabilities of landing on the fourth position (1.75) and the fifth position (2.25) was marginally significant, p = .061. To summarize, a preference of landing on word center was found for 2-character words. The preferred landing position on 3-character words was slightly to the left of the word center. This pattern of results was similar to that found in alphabetic scripts and a recent study of Chinese reading (Yan,
Kliegl, Richter, Nuthmann, & Shu, 2010).
Figure 3. Initial landing positions on 1-, 2- and 3-character words.
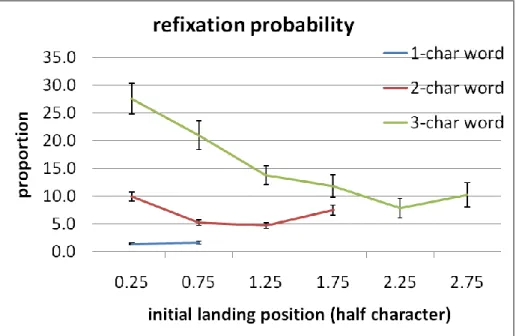
Although the PVL and OVP were found to coincide with each other in reading western languages, they are different concepts. The preferred viewing location is not necessary the optimal viewing position for word recognition. The (preferred) initial landing position is determined by linguistic processing and oculomotor factors as well. In this experiment, the OVP was inferred from the curve of refixation probability as a function of initial landing position. If participants initially fixated at the optimal viewing position for word recognition, the probability of refixating the word should be reduced because recognizing and processing the word was the easiest at this position. The refixation probability is shown in Figure 4. The refixation probability on 1-character word was equally low (1.4 and 1.6%) regardless of the initial landing position, F < 1. For 2-character words, refixation probability was lower when the initial landing position was close to the word center than when it was close to word boundaries, F(3,141) = 19.52, p < .001. Both the linear and quadratic trends were significant, F(1,47) = 5.73, p < .05 and
F(1,47) = 57.99, p < .001, respectively. Post-hoc pair comparisons showed that refixation
probability at the third position (1.25; 4.7%) was significantly lower than those at the first position (0.25; 9.9%), p < .001 and the fourth position (1.75; 7.5%), p < .01. Refixation
probability at the second position (0.75; 5.2%) was also lower than the first and fourth positions, p < .001 and p = .065, respectively. The difference between the second and the third positions as well as the difference between the first and the fourth positions were not significant, both ps > .10. For 3-character words, there were two participants who did not fixate at the last position, thus their data were excluded from analysis. Refixation probability was lower when the initial landing position was around word ending,
F(5,225) = 12.33, p < .001. Both the linear and quadratic trends were significant, F(1,45)
= 41.47, p < .001 and F(1,45) = 6.71, p < .05, respectively. Post-hoc pair comparisons showed that refixation probability was higher at the first position (27.6%) than those at the third to sixth positions (13.8, 11.8, 7.9, and 10.3 %), all ps < .01. Refixation probability was also higher at the second position (21.0%) than those at the fourth to sixth positions, p = .063, .005, and .060, respectively. The differences in refixation probabilities at the third to sixth positions were not significant, all ps > .16. To summarize, for 2-character words, the probability of landing on word center was higher than on word boundaries and the refixation probability was lower when the initial landing position was around word center than word boundaries. This result might suggest that PVL and OVP overlap. However, it is easier to recognize a 3-character word while fixating word ending although the PVL was around word beginning. This is probably due to the fact that Chinese words are not explicitly delineated in sentences. It is not easy to segment a long word from the parafovea; hence, probability of initially fixating word beginning was higher than word ending. However, it is easier to recognize the long word if participants fixated on word ending. The discrepancy between PVL and OVP was interesting in the context of the Chinese writing system in which there is no physical cue for word boundaries. Whether or not Chinese readers are sensitive to the probability of a character being used as word beginning/ending was investigated in the following analysis.
Figure 4. Refixation probability as a function of the initial landing position on 1-, 2- and 3-character words.
Gaze Durations and Statistical Cues for Word Boundaries. The analysis was restricted to 2-character words because their occurrence in the reading material in the corpus and in this experiment was higher than longer words. The probability of a character being used as word beginning/ending was calculated in three ways introduced in the materials section. The congruency of character-to-word assignment was a continuous variable. For the beginning character of a particular 2-character word, it is congruent if the probability of being word beginning is 100%. It is incongruent if the probability is 0%. On the other hand, for the ending character of a particular 2-character word, it is congruent if the probability of being word ending is 100%. Thus, two factors were considered in this analysis, namely, congruency of the first character (C1) and the second character (C2) of any 2-character words. Because congruency is a continuous variable, it is better to investigate its contribution with regression analysis rather than categorizing it into groups (e.g., high, median and low) with the ANOVA. Thus, the linear mixed effects modeling approach (LME; Baayen, 2008; Baayen, Davidson, & Bates, 2008) was used to include random effects from participants as well as auto-correlation within each individual. The LME approach does not require prior averaging across participants; instead, it works with fixation-based data set directly. Various factors can be
added in the model as predictors for a particular dependent variable – gaze duration in this experiment. The statistical procedure was conducted by using the lmer program (lme4 package; Bates, Maechler, & Dai, 2008) in the R system (R Development Core Team, 2008). Both C1 and C2 congruency (the probability of being word beginning and ending, respectively) were centered at 0.5 (i.e., 50%). That is, the regression coefficient should be interpreted as the simple slope (of C1 congruency, for example) when the other factor (i.e., C2 congruency) was set to 0 (50%). The estimated effect size (b), standard error, and t value for each effect were reported. The p values were obtained through Markov Chain Monte Carlo (MCMC) sampling.
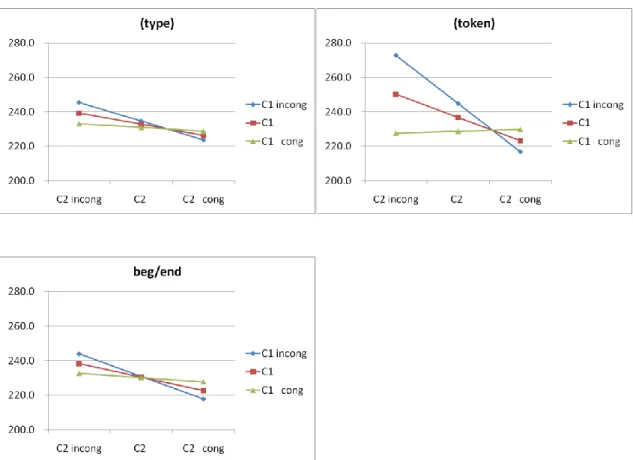
First, when the congruency was calculated with type frequencies of 2-character words, C2 congruency significantly reduced GD on the words (b = -13.0, SE = 4.604, t = -2.82, p < .01). Neither the effect of C1 congruency (b = -3.6, SE = 5.059, t = -0.72, p > .47) nor the interaction (b = 17.5, SE = 20.253, t = 0.86, p > .38) was significant. The higher the congruency of the ending character of 2-character words (i.e., the higher the probability of this character being used as word ending), the shorter the gaze duration was. This pattern did not vary significantly as C1 congruency varied along the continuum although it is almost negligible when C1 was 100% congruent (Figure 5-a).
Second, when the congruency was calculated with token frequencies of 2-character words, C2 congruency again significantly reduced GD on the words (b = -26.9,
SE = 4.697, t = -5.73, p < .001). In addition, C1 congruency also significantly reduced
GD on the words (b = -16.1, SE = 4.481, t = -3.58, p < .001). Furthermore, a significant interaction was also observed (b = 58.2, SE = 16.150, t = 3.61, p < .001). Gaze durations on words were reduced as C1 and C2 congruency increased. However, the slope of reduction in GD as the congruency of a character increased was modulated by the congruency of another character. For instance, as shown in Figure 5-b, the effect of C2 congruency was the highest when C1 was 100% incongruent and was almost negligible when C1 was 100% congruent. The same pattern held for C1 congruency.
Third, when the congruency was calculated with token frequencies of 2-character words divided by sum of token frequencies of all words regardless of word length, C2 congruency significantly reduced GD on the words (b = -15.5, SE = 4.018, t = -3.87, p < .001). However, neither the effect of C1 congruency (b = -0.7, SE = 4.265, t = -0.17, p
> .86) nor the interaction (b = 21.2, SE = 18.534, t = 1.14, p > .25) was significant. The pattern of result was shown in Figure 5-c.
To summarize, the effect of C2 congruency was reliable and robust among all three ways of calculating congruency. Furthermore, the effect was more profound when C1 was incongruent. A smaller and less reliable effect of C1 congruency was also observed. These results indicated that Chinese readers are sensitive to the probability of a character being used as word beginning/ending and word recognition time (in terms of GD) was reduced accordingly. Presumably because the left-side boundary of the fixated word has been determined, it is more important to find out word ending. Thus, the effect of C2 congruency was found to be larger than C1 congruency. Further studies with direct manipulation of C1 and C2 congruency are necessary to clarify the finding of this experiment.
Figure 5. Gaze duration as a function of C2 congruency (C2 incong: 0% congruent; C2: 50% congruent; C2 cong: 100% congruent). The lines were plotted as C1 congruency
varied (C1 incong: 0% congruent; C1: 50% congruent; C1 cong: 100% congruent). The congruency was calculated (a) with type frequencies of 2-character words; (b) with token frequencies of 2-character words; (c) with token frequencies of 2-character words and were divided by sum of frequencies of all words of various lengths.
Year 3-1: OVP on Words (Neighborhood Size Effects)
The purpose of the experiments in Year 3 was to investigate the influence of sub-lexical information profile on word/character recognition. In two experiments, a two-character word or a single two-character was presented in isolation. Participants were instructed to decide whether the presented stimulus was a word/character or not. The fixation position of the stimulus was manipulated. While participants kept fixating the center of the screen, the stimulus was presented at one of five positions relative to the fixation point (Figures 6 and 8). In Experiment 1, number of two-character words that contain the first character of the target word was calculated as the index of neighborhood size 1 (NS1). NS2 was calculated in a similar way in which the second character was taken into consideration. The orthogonal manipulation of NS1 and NS2 (large and small) together with fixation position enabled us to examine the role that informativeness of sub-lexical units plays during word recognition. Similarly, in Experiment 2, number of semantic-phonetic compound characters that contain the semantic/phonetic radical of the target character was computed. The contribution of the informativeness of radicals to character recognition was then investigated.In the classical paper, Coltheart, Davelaar, Jonasson, and Besner (1977) defined orthographic neighbors as words that share all but one letters while keeping word length and letter position constant. Investigating how similar words influence each other sheds light on the organization of the mental lexicon and the process of lexical access. Some researchers observed facilitative effects in which reaction time to target words with more neighbors was faster than those with less neighbors while others observed inhibitory effects (see Andrews, 1997, for a review). Grainger and Jacobs (1996) proposed that there were two mechanisms. First, the activation of neighbors enhanced global lexical activity which in turn facilitated positive response. Second, lexical inhibition between similar
words (especially by higher frequency neighbors) impeded the activation of the target word. The seemly contradictory findings resulted from a combination of these two mechanisms which could be modulated by task-specific criteria (e.g., emphasis on accuracy or speed) and the frequency of neighbors.
A majority of Chinese words are composed of two characters (Academia Sinica Taiwan, 1998). A character can be combined with different characters to form different words. In Chinese, the neighborhood size of two-character words can be calculated separately for each constituent character (Huang, Lee, Tsai, Lee, Hung, & Tzeng, 2006). Neighborhood size 1 (NS1) refers to the number of two-character words that share the beginning character while neighborhood size 2 (NS2) refers to the number of words that share the ending character.
Huang, et al. (2006) found a facilitative neighborhood size effect for high frequency words and an inhibitory effect for low frequency words. In a supplementary regression analysis, they found that word frequency, NS1, and the number of higher frequency neighbors of the first character (HFN1) contributed to the variance in reaction time, while NS2 and HFN2 did not. NS1 had a facilitative effect and HFN1 had an inhibitory effect. This provided an explanation for the inhibitory effect for low frequency words since they have more HFNs than high frequency words. In addition, the result of the regression analysis implies that the first character plays a dominant role in word recognition. In their second experiment, both NS1 and HFN1 were manipulated. The results showed that a facilitative NS1 effect was evident only when the target word had no HFN. Also, when NS1 was large, the inhibitory effect of having HFNs was evident.
In this experiment, NS1 and NS2 of two-character words were manipulated orthogonally in addition to the manipulation of fixation positions. If these factors play a role in word recognition, they may influence the OVP. Furthermore, as observed in the study of Huang et al. (2006), the first character may play a dominant role in word recognition.
Method
University were paid to participate in this experiment. All of them are native speakers of Chinese with normal or corrected-to-normal vision.
Design and Materials. Two hundred and forty two-character strings were chosen as the stimuli. Half of them were real words and the other half were pseudowords. There were three independent variables. First, as is shown in Figure 6, there were five fixation positions. The fixation point was set at the center of the screen, and the two-character string was presented at different position relative to the fixation point according to the condition. The second and third independent variables were neighborhood sizes concerning the first and second constituent characters, respectively. Number of words that share the first character with the target word was calculated as the index NS1 (neighborhood size 1). Similarly, number of words that share the second character was calculated as the index NS2. The sizes of NS1 and NS2 were manipulated orthogonally. In half of the stimuli, NS1 was larger than 40; while in the other half, it was smaller than or equal to 10. The cutoff points for NS2 were the same. The two by two orthogonal manipulation resulted in 4 conditions. As shown in Table 2, there was no difference in word frequency among 4 conditions (F(3,116) = 1.03, p > .38). The difference between NS1-Large and NS1-Small was significant for real words and pseudowords (ps < .001). Similarly, the difference between NS2-Large and NS2-Small was also significant (ps < .001).
Figure 6. Illustration of five fixation positions in Experiment 3-1. Table 2. Mean linguistic properties of the stimuli in each condition.
NS1 Large Large Small Small
NS2 Large Small Large Small
Real Word Word frequency (per million) 2.9 2.4 2.6 2.4 NS1 66.2 71.6 6.5 6.9 NS2 75.7 5.8 70.6 6.3 Pseudoword NS1 62.2 58.8 6.7 6.7 NS2 62.3 6.4 61.8 6.0
Apparatus. Similar to that in Year 1. The characters were shown in black on a light gray background. The characters, which extended 40 40 pixels, were shown at one of the five fixation positions around the center of the screen according to condition. The viewing distance was 74 cm, at which each character subtended 1.02.
Procedure. Participants were instructed to decide whether the stimulus was a legal Chinese word or not by pressing buttons on a response box. After a 9-point calibration and verification for calibration accuracy, there were 10 practice trials.
At the beginning of each trial, a cross was presented at the center of the screen as the fixation point. If the participants‟ eyes remained stable for 60 ms within 5 pixels around the center of the cross, the stimulus was presented. Otherwise, the position of the tracked eye was monitored until it remained stable and met the criterion. If the criterion was not met after 3s, the calibration procedure was repeated. The stimulus was presented for 100 ms. As shown in Figure 6, the stimulus was presented at one of the five positions relative to the fixation point according to the condition. The participants were instructed to respond with both hands as quickly and accurately as possible. The next trial began when the participants pressed a button or after 2 s. There were totally 240 experimental trials divided into 3 blocks. Two filler trials were added to the beginning of each block. Participants could take a break after each block. The experiment lasted about 30-40 minutes.
Results
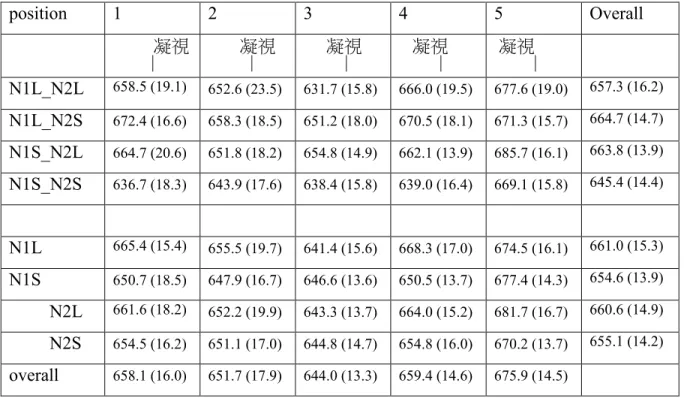
Response time and accuracy were recorded. Only real words and correct responses were analyzed. For each participant, the mean and standard deviation in each condition was calculated. Response time within the mean 2.5 SD was kept for analysis. The means and standard errors of response time on words in each condition are shown in Table 3.
Table 3. Means and standard errors of reaction time in each condition.
position 1 2 3 4 5 Overall 凝視 凝視 凝視 凝視 凝視 N1L_N2L 658.5 (19.1) 652.6 (23.5) 631.7 (15.8) 666.0 (19.5) 677.6 (19.0) 657.3 (16.2) N1L_N2S 672.4 (16.6) 658.3 (18.5) 651.2 (18.0) 670.5 (18.1) 671.3 (15.7) 664.7 (14.7) N1S_N2L 664.7 (20.6) 651.8 (18.2) 654.8 (14.9) 662.1 (13.9) 685.7 (16.1) 663.8 (13.9) N1S_N2S 636.7 (18.3) 643.9 (17.6) 638.4 (15.8) 639.0 (16.4) 669.1 (15.8) 645.4 (14.4) N1L 665.4 (15.4) 655.5 (19.7) 641.4 (15.6) 668.3 (17.0) 674.5 (16.1) 661.0 (15.3) N1S 650.7 (18.5) 647.9 (16.7) 646.6 (13.6) 650.5 (13.7) 677.4 (14.3) 654.6 (13.9) N2L 661.6 (18.2) 652.2 (19.9) 643.3 (13.7) 664.0 (15.2) 681.7 (16.7) 660.6 (14.9) N2S 654.5 (16.2) 651.1 (17.0) 644.8 (14.7) 654.8 (16.0) 670.2 (13.7) 655.1 (14.2) overall 658.1 (16.0) 651.7 (17.9) 644.0 (13.3) 659.4 (14.6) 675.9 (14.5) | | | | |
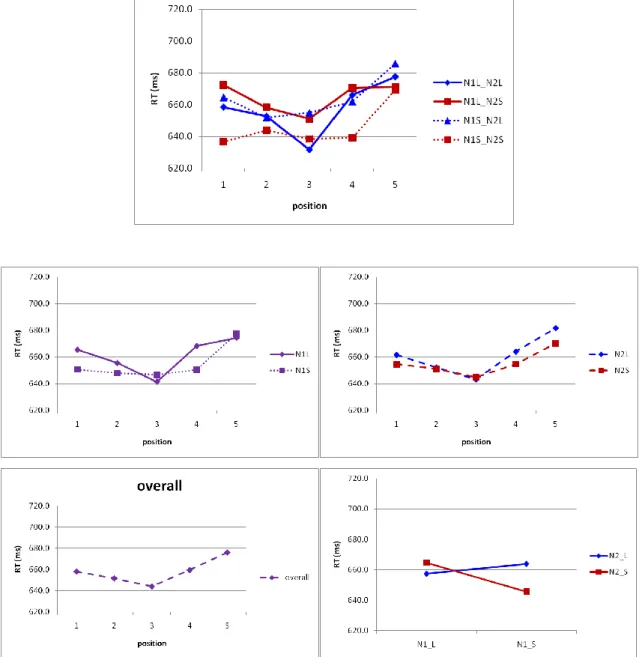
Figure 7. Mean reaction time in (a) all 2 x 2 x 5 conditions; (b) comparison of large and small NS1 at 5 fixation positions; (c) comparison of large and small NS2 at 5 fixation positions; (d) overall effect of fixation positions; (e) effects of NS1 and NS2.
Fixation Position. The effect of fixation position on reaction time was significant [F1(4,76) = 4.06, MSe = 2755, p < .01; F2(4, 464) = 3.74, MSe = 1784, p < .01]. When the
whole word was presented to the left of the fixation point (position 5), reaction time was significantly longer than that when the word was presented at the center of the screen (position 3), ps < .01. All other pairwise comparisons were not significant, ps > .10.
Neighborhood Size. When the manipulation of neighborhood size was considered as one factor with 4 conditions, there was a significant neighborhood size effect [F1(3,57) = 4.98, MSe = 1592, p < .01; F2(3, 116) < 1, MSe = 14820]. The reaction
time in the N1S_N2S condition was the shortest, and it was significantly shorter than that in the N1L_N2S and N1S_N2L conditions by participants, ps < .05.
Interaction Between Neighborhood Size (4) and Fixation Position (5). The interaction between neighborhood size and fixation position was not significant, Fs < 1. However, the effect of fixation positions seems to be different among neighborhood size conditions. In the N1S_N2S condition, there was virtually no difference among positions 1~4. In the other conditions, numerically, reaction time at position 2 was shorter than that at position 4; similarly, reaction time at position 1 was shorter than that at position 5. The pattern of results suggests that the optimal viewing position for two-character word recognition is slightly to the left of the word center.
Neighborhood Sizes 1 and 2. When the manipulation of neighborhood size was considered as two orthogonal factors, there was a significant interaction between NS1 and NS2 [F1(1,19) = 13.13, MSe = 1272, p < .01; F2(1, 116) = 1.47, MSe = 14820, p
> .22]. In the participant analysis, the effect of NS1 was significant only when NS2 was small (p < .01). Similarly, the effect of NS2 was significant only when NS1 was small (p < .01). This pattern resulted from the observation that reaction time in the N1S_N2S condition was the shortest among all conditions. There were no significant main effects of NS1 and NS2, Fs < 2.10, ps > .16.
Simple Interaction of Neighborhood Sizes 1 and 2 (2 × 2) with Fixation Position (5). There was no significant interaction with fixation position. However, the NS1 × NS2 interaction was evident at positions 1 and 4. Concerning the NS1 effect when NS2 was small, the 35 ms and 32 ms difference at positions 1 and 4 were significant, ps < .05. Concerning the NS2 effect when NS1 was small, the 28 ms difference at position 1 was significant, p < .05 while the 23 ms difference at position 4 was not, p = .102.
Simple Main Effect of Neighborhood Size 1 or 2 (2) with Fixation Position (5). The effect size of NS1 at positions 1 to 5 was 15, 8, -5, 18, and -3 ms, respectively, ps > .08. The effect size of NS2 at positions 1 to 5 was 7, 1, -2, 9, 11 ms, respectively, ps > .23.
Discussion
The optimal viewing position on two-character words for word recognition was slightly to the left of the word center. Reaction time was the longest when the whole word was presented in the left visual field (position 5). Numerically, reaction time at positions 1 and 2 was shorter than positions 5 and 4, respectively.
There was a significant interaction between NS1 and NS2. Reaction time to words with small NS1 and small NS2 was the shortest. When NS2 was small, reaction time to words with large NS1 was longer than those with small NS1. When NS2 was large, the effect of NS1 was opposite but not significant. The pattern of the simple effects of NS2 was the same. The observation that NS1 and NS2 had inhibitory effects is consistent with that in the study of Huang et al. (2006). In the present experiment, low frequency words were chosen as the stimuli. In addition, almost all target words had higher frequency neighbors. The larger the neighborhood size was, the more HFNs the target word had. Thus, we observed an inhibitory effect. Alternatively, the inhibitory effect can be interpreted as a constraining effect in which words are easy to recognize if there are only a few orthographic neighbors.
Considering the interaction between neighborhood sizes and fixation position, when NS1 was small, there was virtually no effect of fixation position except when the whole word was presented in the left visual field (position 5). The simple interaction between NS1 and fixation position did not change according to NS2. When NS2 was large, the curve shifted upward, suggesting that words with large NS2 were harder to process than words with small NS2. However, when NS1 was large, the OVP was to the left of word center. This pattern was more evident when NS2 was also large.
was small, reaction time was short regardless of fixation position. This suggests that when a word is easy to recognize, the fixation position does not have an effect. If NS2 was also small, the reaction time was the shortest. This suggests that when both characters are constraining, word recognition benefit the most. When NS1 was large and the word was hard to recognize, fixation position had its effect. Although the observation that OVP located to the left of word center suggests that the first character is important for word recognition, it is puzzling because when NS1 was large, the first character did not provide helpful information, the OVP should locate at the second character. It is also puzzling when NS1 was large, small NS2 did not seem to be constraining. Instead, large NS2 seemed to facilitate word recognition and the OVP curve was more evident in the N1L_N2L condition. The observation that the simple interaction between NS1 and NS2 was evident at positions 1 and 4 may be a complicated by-product.
Year 3-2: OVP on Characters (Radical Combinability
Effects)
Only a few Chinese characters are simple characters, for example, 山 „mountain‟ and 上 „up‟, that cannot be decomposed into smaller parts. Among characters that consist of smaller parts, a majority of them are semantic-phonetic compounds, e.g., 眼 „eye‟. These characters have a semantic radical that signals the semantic category of the character and a phonetic radical that suggests the pronunciation of the whole character. Most semantic-phonetic compounds have the SP structure in which the semantic radical is located at the left-hand side and the phonetic radical is located at the right-hand side (Hsiao & Shillcock, 2006). Similar to multi-character words, whose constituent characters can combine with other characters to form different words, both phonetic and semantic radicals can combine with different radicals to form different characters. The number of characters that share the same semantic radical is referred to as semantic combinability while that share the same phonetic radical is referred to as phonetic combinability.
with a homophone judgment task. During the experiment, electrophysiological responses were recorded. In addition, whether or not the group of characters that share the same phonetic radical with the target character has consistent pronunciation was manipulated. They found a larger N170 component for high combinability than low combinability characters (for highly-consistent characters only) suggesting that a large group of orthographic neighbors elicited greater perceptual-level activation during the initial processing (less than 200 ms). High combinability characters also reduced the P200 component indicating a facilitative effect at the orthographic level. Then, high combinability characters enhanced the N400 component implying a large semantic competition among candidate characters. Thus, high combinability initially increased activation at the perceptual and orthographic levels and facilitated character processing, but later interrupted the process because of competition among characters that share the same radical.
Hsiao, Shillcock, and Lavidor (2006) proposed that small semantic combinability is more informative than large one because only a few characters share the same semantic radical. Also, when the character has a large combinability semantic radical, its phonetic radical becomes more informative than the semantic radical. In their experiment, the target character was presented at the center of the fixation point, so that the semantic radical was presented in the left visual field (LVF) and was projected to the right hemisphere (RH) initially. In contrast, the phonetic radical was presented in the right visual field (RVF) and projected to the left hemisphere (LH). During the experiment, they applied transcranial magnetic stimulation (TMS) over the RH or LH. The reaction to character with large semantic combinability was significantly different when the TMS was applied to the LH than when it was applied to the RH or the control condition. This is because when semantic combinability was large, the phonetic radical played a more important role. Thus, when the TMS was applied to the LH where the phonetic radical was initially projected, it interfered with character recognition. Note, however, the effect of semantic combinability (facilitative / inhibitory) depends on task demand and the types of filler stimuli. Cheng (2006) showed that when pseudo-characters (combining two legal radicals) were used, an inhibitory effect was observed because participants had to examine whether the stimulus was a legal combination or not. When non-characters
(deleting or adding strokes) were used, a facilitative effect was observed because participants can make decision simply based on familiarity.
In the second experiment of Year 3, we aimed to investigate the effects of radical combinability on character recognition by simultaneously manipulating both the semantic and phonetic radicals. In addition, fixation position was manipulated to examine whether one radical play a dominant role or both radicals are important.
Method
Participants. Twenty-five college and graduate students at National Chengchi University were paid to participate in this experiment. All of them are native speakers of Chinese with normal or corrected-to-normal vision.
Materials. One hundred and twenty real characters, sixty pseudo-characters, and sixty non-characters were chosen as the stimuli. Real characters were chosen from the Academia Sinica balanced corpus (1998). The mean character frequency was 5.0 per million (range = 0.34~85.4). The mean number of strokes was 13.4 (range = 7~20). All real characters were semantic-phonetic compounds with their semantic and phonetic radicals located at the left and right hand side, respectively. The combinability of a semantic radical was the number of characters in which this radical serves as the semantic radical. Similarly, the combinability of phonetic radical was the number of characters in which this radical serves as the phonetic radical. Both measures are positively skewed in the corpus. The combinability of semantic radical ranges from 1 (such as 鼻 in 鼾) to 226 (氵 in 汗), with the median of 74. On the other hand, the combinability of phonetic radical ranges from 1 (such as 丞 in 拯) to 20 (such as 非 in 排), with the median of 6. The median of the combinability of semantic and phonetic radicals of the real characters used in this experiment were 71 and 6 (range = 4~226, 3~20), respectively. Pseudo-characters were created by combining a semantic and a phonetic radical but the combination does not exist as a real Chinese character. The mean number of strokes of the pseudo-characters was 13.0 (range = 7~20). The median of the combinability of semantic and phonetic radicals of the pseudo-characters used in this experiment were 42
and 5 (range = 3~226, 3~16), respectively. Non-characters were created by adding/deleting one stroke from real characters. The mean number of strokes of the non-characters was 12.2 (range = 5~24).
Apparatus. Similar to that in Experiment 3-1, except that each character extended 48 48 pixels and subtended 1.22.
Procedure. Similar to that in Experiment 3-1, the stimulus was presented at one of five positions relative to the fixation point according to the condition as shown in Figure 8. Participants were instructed to decide whether the stimulus was a legal Chinese character or not by pressing buttons on a response box. Other procedure was the same as that in Experiment 3-1.
Figure 8. Illustration of five fixation positions in Experiment 3-2.
Results
Response time and accuracy were recorded. Only real characters and correct responses were analyzed. For each participant, the mean and standard deviation in each condition was calculated. Response time within the mean 2.5 SD was kept for analysis. The data set was median split by semantic and phonetic combinability. Characters with
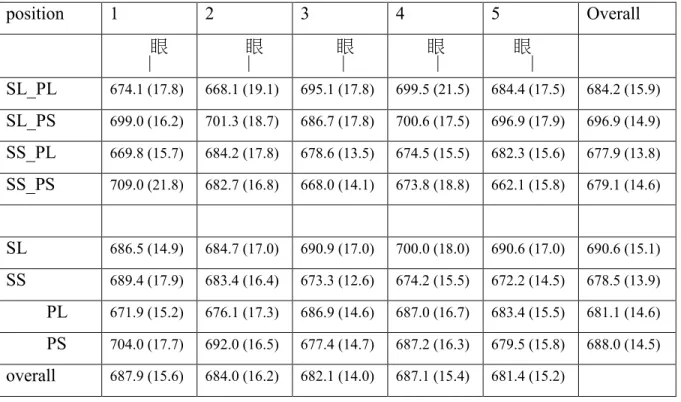
semantic combinability higher than 71 were categorized as the SL group (large semantic combinability), while those lower than 71 were categorized as the SS group (small semantic combinability). Half of the characters fell in each category. Similarly, characters with phonetic combinability higher than or equal to 6 were categorized as the PL group (large phonetic combinability), while those lower than 6 were categorized as the PS group (small phonetic combinability). Sixty-four characters fell in the former group and fifty-six characters fell in the latter group. The categorization results in 4 orthogonal groups. Number of characters in the SL_PL, SL_PS, SS_PL, and SS_PS groups were 25, 35, 31, and 29, respectively. The means and standard errors of response time on real characters in each condition are shown in Table 4.
Table 4. Means and standard errors of reaction time in each condition.
position 1 2 3 4 5 Overall 眼 眼 眼 眼 眼 SL_PL 674.1 (17.8) 668.1 (19.1) 695.1 (17.8) 699.5 (21.5) 684.4 (17.5) 684.2 (15.9) SL_PS 699.0 (16.2) 701.3 (18.7) 686.7 (17.8) 700.6 (17.5) 696.9 (17.9) 696.9 (14.9) SS_PL 669.8 (15.7) 684.2 (17.8) 678.6 (13.5) 674.5 (15.5) 682.3 (15.6) 677.9 (13.8) SS_PS 709.0 (21.8) 682.7 (16.8) 668.0 (14.1) 673.8 (18.8) 662.1 (15.8) 679.1 (14.6) SL 686.5 (14.9) 684.7 (17.0) 690.9 (17.0) 700.0 (18.0) 690.6 (17.0) 690.6 (15.1) SS 689.4 (17.9) 683.4 (16.4) 673.3 (12.6) 674.2 (15.5) 672.2 (14.5) 678.5 (13.9) PL 671.9 (15.2) 676.1 (17.3) 686.9 (14.6) 687.0 (16.7) 683.4 (15.5) 681.1 (14.6) PS 704.0 (17.7) 692.0 (16.5) 677.4 (14.7) 687.2 (16.3) 679.5 (15.8) 688.0 (14.5) overall 687.9 (15.6) 684.0 (16.2) 682.1 (14.0) 687.1 (15.4) 681.4 (15.2)
Fixation Position. These was no effect of fixation position on reaction time [F1(4,96) <1, MSe = 3582; F2(4, 464) < 1, MSe = 3881].