應用kNN文字探勘技術於分析新聞評論 影響股價漲跌趨勢之研究 - 政大學術集成
59
0
0
全文
(2) 致謝 在碩士研究生的生涯中,首先要感謝指導老師楊建民教授,每當研究有了 困境,楊教授總是能在學生迷失研究方向時,給予一些建議,循循善誘下幫助 我重新找到研究的本質,除了學業上的教導,在日常上更像個長輩,時常關心 學生,讓遠離家鄉獨自在台北就學的我倍感溫馨。 此外,感謝實驗室的同學 ( 弘業、偉志、珀豪、子洋、柏辰 ) 、助理悅 梣,在研究所學習的過程中,時常互享勉勵支持,給予研究上有用的意見,平 時的吃吃喝喝看電影更是少不了你們,感謝你們這些舒壓的好夥伴! 最後要感謝的是一直在背後默默支持我的爸媽、妹妹,感謝他們不斷的給 予我鼓勵及支持,讓我可以專心的完成碩士班的學業,接下來我將邁向我人生 的下一個階段,祝福所有幫助過我的人。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. I . i n U. v.
(3) 摘要 在網際網路快速發展下,大量使用者在獲取知識與新聞的管道,已由傳統 媒體轉移到網路上。網路活動下使用者互動後所留下的訊息,也就是網路口 碑,也逐漸受到重視。而隨著經濟發展,國人在固定薪資下無法負擔高房價、 高物價的生活,如何透過投資理財來增加自身財富,已是非常普遍,其中又以 股市投資為大眾所重視之途徑。 網路新聞的發布,除了具有網路的即時性外,配合使用者閱讀內化後所留 下的評論,應含有比網路新聞本身內容更多的資訊,投資者便可藉此找尋隱含 之中大量市場消息與資訊。 本研究為了在龐大的資料量中,幫助使用者挖掘其背後之涵義,進而提供 投資預測,將蒐集網路新聞及其閱讀者評論共 1068 篇,並分為訓練資料與測試 資料,使用文字探勘及相關技術做前處理,再透過 kNN 分群技術,計算訓練資 料文件間相似度,將大量未知資料依其相似度做分群後,利用歷史股價訊息對 群集結果之特徵分析解釋之並建立預測模型,最後透過測試資料將模型分群結 果進行評估,進而對股價趨勢做出預測。. 立. 政 治 大. ‧. ‧ 國. 學. 關鍵字:網路口碑、股價趨勢預測、文字探勘、kNN、群集分析. n. er. io. sit. y. Nat. al. Ch. engchi. II . i n U. v.
(4) Abstract With the rapid development of the Internet, the way of user access to knowledge and news transfer from traditional media to the network. Internet word-of-mouth, the message generated from users' interaction on internet, attracts more and more people's attention. With economic development, people in the fixed salary cannot afford high prices and high price in live. People increase their own wealth through investment is very common, among which the stock market is the way to public attention. Internet news has the immediacy of the Internet. And the comments left with the user to read the internalization should contain more information than the Internet news. Investors can find the market news and information by Internet news and comments.. 政 治 大. In this study, in order to help the user to find the meaning behind the huge amount of data, and thus provide investment forecast. We will collect 1068 of internet news and reader reviews to divide into training data and test data using text mining and related technologies to do the pre-treatment, and then calculate the similarity between the training data by kNN, a lot of unknown data according to their similarity clustering. Cluster through the historical share price analysis and modeling. Finally, the model clustering results were evaluated through the test data to predict price trends. The prediction model from training data clustering, use test data to do the evaluation found: k = 15, the similarity threshold value = 0.05, cluster the results of the F-measure performance up to 56% rise in the cluster. K values and the similarity threshold will be adjusted to obtain the most favorable results of the model.. 立. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. Keywords:Internet Word-of-Mouth、The Stock Trend Prediction、Text Mining、 kNN、Cluster Analysis. III .
(5) 目錄 第一章、緒論................................................................................................................ 1 第一節、 研究背景與動機............................................................................ 1 第二節、 研究目的........................................................................................ 2 第三節、 研究步驟與流程............................................................................ 2 第二章、文獻探討........................................................................................................ 4 第一節、 運用新聞資料於預測與口碑........................................................ 4 2.1.1. 新聞資料(消息面)於股價預測之相關研究 ................................. 4 2.1.2. 何謂口碑........................................................................................ 7 2.1.3. 為何口碑會有如此大的效力?.................................................... 8 2.1.4. 何謂網路口碑.............................................................................. 10 2.1.5. 傳統口碑與網路口碑的差異...................................................... 10 第二節、 文字探勘與其相關技術.............................................................. 12 2.2.1. 文字探勘的定義.......................................................................... 12 2.2.2. 文字探勘的架構.......................................................................... 13 2.2.3. 中文斷詞...................................................................................... 14 2.2.4. 中央研究院 CKIP 斷詞系統 ...................................................... 15 2.2.5. 文件特徵值選取.......................................................................... 15 2.2.6. 向量空間模型的運用.................................................................. 17 2.2.7. 文件相似度計算.......................................................................... 19 第三節、 群集分析...................................................................................... 19 2.3.1. k-最鄰近演算法(k-Nearest Neighbor ,kNN) .............................. 20 2.3.2. 分群績效評估.............................................................................. 21 第四節、 文獻探討小結.............................................................................. 22 第三章、研究方法與設計.......................................................................................... 23 第一節、 研究架構...................................................................................... 23 第二節、 資料來源與處理.......................................................................... 25 3.2.1. 資料蒐集...................................................................................... 25 3.2.2. 資料處理模組.............................................................................. 28 第三節、 分群分析...................................................................................... 30 3.3.1. 文件相似度計算.......................................................................... 30 3.3.2. kNN 分群 ..................................................................................... 30 第四節、 分群分類績效評估...................................................................... 32 3.4.1. 分析模組...................................................................................... 32 第五節、 研究流程與預期結果.................................................................. 33 3.5.1. 研究流程...................................................................................... 33 3.5.2. 預期結果...................................................................................... 33 . 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. IV . i n U. v.
(6) 第四章、研究結果...................................................................................................... 34 第一節、 預測模型之建立.......................................................................... 34 第二節、 預測模型之結果 1....................................................................... 37 第三節、 預測模型之累積報酬率.............................................................. 40 第四節、 預測模型之結果 2....................................................................... 42 第五節、 預測模型之結果 3....................................................................... 44 第五章、結論與未來研究方向.................................................................................. 46 第一節、 結論與建議.................................................................................. 46 第二節、 未來研究方向.............................................................................. 46 參考文獻...................................................................................................................... 48 . 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. V . i n U. v.
(7) 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖. 1-1 研究方法與架構圖 ........................................................................... 3 2-1 資訊對事件、新聞、股價之互動關係圖 ....................................... 6 2-2 文字探勘運作架構 ......................................................................... 14 2-3 向量空間模型 ................................................................................. 17 2-4 向量空間模型中的字詞-文件矩陣 ................................................ 18 2-5 二維空間中的餘弦相似度表示法 ................................................. 19 2-6 kNN 說明 ........................................................................................ 20 2-7 評估標準示意圖 ............................................................................. 22 3-1 研究架構圖 ..................................................................................... 24 3-2 上漲、下跌週期圖示 ..................................................................... 25 3-3 反應時間與收盤價變動量圖 ......................................................... 33. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. VI . i n U. v.
(8) 表目錄. 表. 立. 政 治 大. 學. 表 表 表 表 表 表 表 表 表. 2-1 文件分類之情形 ............................................................................. 21 3-1 網路新聞範例 ................................................................................. 26 3-2 新聞評論範例 ................................................................................. 27 4-1 相似度門檻值 0.1 時操作 10 次網路新聞 k 值為 1~30 之平均評 估結果.................................................................................................. 35 4-2 相似度門檻值 0.1 時操作 10 次新聞文件 k 值為 1~30 之平均評 估結果.................................................................................................. 36 4-3 上漲群集之預測正確率 ................................................................ 38 4-4 下跌群集之預測正確率 ................................................................ 39 4-5 新聞文件發布後之兩日累積報酬率示意 .................................... 40 4-6 新聞文件發布後上漲群集之兩日累積報酬率 ............................ 41 4-7 新聞文件發布後下跌群集之兩日累積報酬率 ............................ 41 4-8 上漲群集之預測正確率 ................................................................ 43 4-9 下跌群集之預測正確率 ................................................................ 43 4-10 上漲群集之預測正確率 .............................................................. 44 4-11 下跌群集之預測正確率 .............................................................. 45. ‧. ‧ 國. 表 表 表 表. n. er. io. sit. y. Nat. al. Ch. engchi. VII . i n U. v.
(9) 第一章、緒論 第一節、. 研究背景與動機. 近年來網際網路快速的發展,網路的普及率和使用人數皆大幅增加,使得 網路上的文件在短時間內以驚人的數量增加,而在這樣的環境下,各項產業都 面臨網路數位化的需求,新聞媒體產業也不例外,大量的網路新聞平台開始發 布網路新聞,就連電視新聞媒體也將其電視新聞數位化成網路新聞。根據皮尤 研究中心(2010)的調查數據顯示,美國網際網路的用戶大約占了總人口的 71%,在這些使用者當中,竟然有多達 53%的美國成年人,平時會透過新聞網 站瀏覽新聞,而且這個數據逐年增加,這代表在網際網路時代新聞發展的型 態,有一大部分從傳統的平面電視媒體移轉到網路新聞中,網路新聞已經漸漸 成為多數人瀏覽新聞,藉此了解世界上發生的任何事情,以及獲取知識的最佳 管道,而這更是個股除了大量的基本技術指標分析資料之外,另一個隱含有大 量市場消息與資訊的資料庫,透過這些媒體所發布的相關新聞,更可能足以影 響投資人的下一步決策與預期心理(喻欣凱,2008)。. 立. 政 治 大. ‧ 國. 學. ‧. 在陳均碩(2000) 《農業電子報使用者動機、行為與滿足程度之研究:以資 策會「臺灣農業資訊網(T.As)電子報」為例》的研究中,他發現使用者閱讀網 路新聞的動機中,大家最重視的是「節省時間」,而目前各大入口網站及新聞 網站都有提供線上新聞閱讀的服務,讀者可以照自己的興趣或需要登入這些網 站,不用花費很多時間,便能將一日所發生的重大事件新聞瀏覽完畢,甚至能 依其分類架構找到瀏覽所需的目標新聞事件,並發表自己對於此新聞簡短的評 論。. er. io. sit. y. Nat. al. n. v i n Ch 而陳應強(2005)《影響電子報讀者選擇與閱讀行為之研究》的研究中,發 engchi U 現閱讀電子報的讀者教育程度普遍偏高,且依照教育程度的不同,注重的面向 也不盡相同,教育程度在高中(職)以下的讀者,比較注重電子報的互動性,而 教育程度在大學(專)以下的讀者,比較注重電子報的正確性;這些使用者在閱 讀完網路新聞,了解內化後所留下的互動評論,理應含有比網路新聞本身內容 更正確且更高品質的資訊。又因不同的新聞記者採訪同一事件可能因主觀切入 角度不同,或因所蒐集之資訊未能充分查證,造成單方面主觀報導之事件內 容,可能與實情有所出入,所以使用者在瀏覽完該網路新聞後所留下的互動評 論,理應比網路新聞本身內容更為正確。. 然而,現今這個全球化且瞬息萬變的世界,每天都會有無數的事件發生, 新聞數量當然也跟著大量增加,在這大量的新聞報導中所涵蓋的資訊有大部分 是非使用者所需要或者重複的,過分的資訊過載問題,讓使用者無法快速且正 確地找到自己所需要閱讀使用的資訊,這時便需要一個工具能夠用來整理歸納 1 .
(10) 這些大量的新聞文件,幫助新聞讀者從中找出他們有興趣的主題來閱讀。於是 幫助使用者過濾出所需的資訊,就變成一件相當重要且必需的事情。 第二節、. 研究目的. 依照前述之實驗背景與動機,本研究所需達到之實驗目的分項如下: 1. 將網路新聞及該篇閱讀者之評論合併為一個新聞文件,利用文字探勘技術 對所有新聞文件做斷詞和特徵值選取等資料處理,並應用 kNN 演算法於上 述合併的新聞文件之分群 2. 利用歷史當日交易資料,將新聞文件做分類,分為上漲、持平、下跌三個 類別。 3. 對新聞文件所分群的結果依照歷史交易資料所分出的類別做群集的評估, 驗證上漲、持平、下跌三種分類分群的績效,藉此做為預測漲跌趨勢,投 資者判斷決策的選擇。. 立. 研究步驟與流程. 學. ‧ 國. 第三節、. 政 治 大. 本研究架構主要如下圖所示,主要區分為五個章節。. 程。. ‧. 第一章為緒論,說明本實驗之研究背景與動機、研究目的、研究步驟與流. Nat. y. sit. n. al. er. io. 第二章為文獻探討,針對以往運用新聞資料於預測與口碑的研究、文字探 勘與其相關技術及 k-最鄰近演算法(k-Nearest Neighbor ,kNN)等相關文獻做整理 與探討研究。. Ch. 第三章為研究方法與設計。. engchi. i n U. v. 第四章為研究結果,進行實驗分析與驗證其分群結果。 第五章為結論與建議。. 2 .
(11) 緒論. 文獻探討. 研究方法與設計. 研究結果. 結論與建議 政 治 大 立圖 1-1 研究方法與架構圖. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 3 . i n U. v.
(12) 第二章、文獻探討 第一節、. 運用新聞資料於預測與口碑. 隨著台灣經濟發展,房價居高不下,再加上物價的上漲,造成固定的薪資 逐漸無法負擔,因此現代人對於投資理財的觀念是愈來愈注重,於是開始投資 各種金融性商品,其中又以股市交易為大宗。股價的漲跌變化是許多投資人關 心的議題,以往投資者在預測股市趨勢時僅用技術指標,然而現實是瞬息萬變 的,無法預測的天災人禍更是在所難免,技術指標無法對市場所發出的訊息即 時地做趨勢修正,且由近幾年來爆發的財務危機公司中,時常發現會計師無法 有效查核出財務報表不實的情況,由於新聞資料具備即時性,較能充分反應企 業經營現況,以及整體環境的現況,因此以下將針對以往利用新聞資料於預測 股價趨勢的相關研究探討。 2.1.1.. 政 治 大. 新聞資料(消息面)於股價預測之相關研究. 立. ‧. ‧ 國. 學. 以往針對新聞資料所作的相關股價預測研究不在少數,其中 Wuthrich, Cho, Leung, Permunetilleke, Sankaran, Zhang & Lam(1998)以五個主要股市指數當作 趨勢預測的標的,包含有美國道瓊工業平均指數(Dow Jones Industrial Average) 、香港恆生指數(Hang Seng Index) 、日本日經指數(Nikkie 225 INDEX)、新加坡海峽時報指數(Singapore Strait Times Index)、倫敦金融時報 指數(Financial Times 100 Index)等不同區域之國家股市;透過代理人 (agent)從相關的財經專業網站,在股市開盤前蒐集大量且即時之財經新聞, 以各種文字探勘技術作為分析,如:k-最鄰近演算法、類神經網路,藉此預測 香港當日開盤的股價趨勢和收盤價格,得到下列三種預測結果,股價漲幅超過 0.5%的上漲趨勢、股價跌幅超過 0.5%的下跌趨勢以及股價介於 0.5%~-0.5 的持 平趨勢,最後其研究的結果證實平均準確率比隨機投資策略的效果要好。不過 其研究在分析文件之前,必須先由該領域的專家學者或投資分析師,訂出約 400 個可能與股價漲跌有相關的關鍵字組合,以此作為後續訓練分類器的詞 庫,其實驗結果雖然效果明顯,但事前需耗費時間及人工建立關鍵字組合,成 本付出較大。. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 而 Lavrenko, Schmill, Lawrie, Ogilvie, Jensen & Allan(2000)曾提出語言模 型(Language Model)的概念,藉此辨識出對股價趨勢有相關影響的字詞,例如損 失(loss)、虧損(shortfall)和破產(banruptcy),這些字詞與下跌趨勢有高度的相關 性,反之像企業併購(merger)、收購(acquisition)和企業聯盟(alliance)等字詞則與 上漲趨勢有高度的相關性,證實不同的字詞訊息可能和股價的波動有相關影 響,透過訓練與建立語言模型來辨識這些與股價趨勢相關的詞彙,可協助股價 趨勢之預測。 4 .
(13) 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 5 . i n U. v.
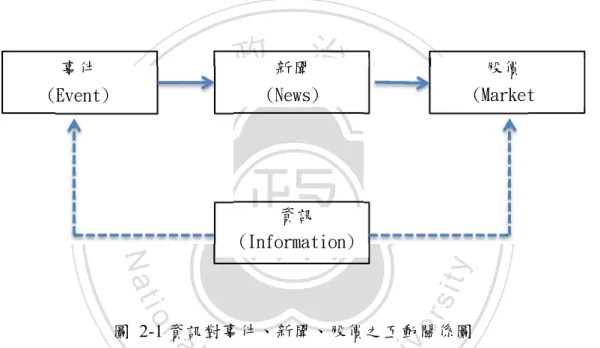
(14) 在新聞影響股價波動方面,Gidófalvi(2001)試圖想要預測當日股價趨勢,他 利用簡單貝氏文字分類器(Naïve Bayes Text Classifier),將新聞區分出上漲和下 跌的分類,研究中指出新聞中所包含的資訊在一定的時間間隔,會對股市造成 相當程度的影響;而新聞造成股票的波動部份,可以透過 ß 值(ß-value)加以 評量與量化新聞對股票的波動影響,該值能透過線性迴歸的方式加以計算而 得,藉此來預測中長期的股價趨勢。 Ahmad, Oliveira, Manomaisupat, Casey & Taskaya(2002)的研究指出,影 響財務市場的資訊通常經由電子郵件、新聞、公司簡報與企業年度報告等形式 發佈,且不論其資訊來源的形式為何,新聞消息中所隱藏的資訊,對制定投資 的決策具有相當重要的地位,如圖 2-1 所示。. 事件 (Event). 立. 政 新聞治 大 (News). . 股價 (Market. Nat. er. io. sit. y. ‧. ‧ 國. 學 資訊 (Information). 圖 2-1 資訊對事件、新聞、股價之互動關係圖. al. n. v i n Ch Fung, Yu & Lam (2002, 2003)則結合各種資料探勘與文字探勘技術來建立預 engchi U 測模型,提出以 t 檢定為基礎(t-test based)的演算法來判斷股價的漲跌趨 勢,其特色為使用兩個 SVM 分類器,一為專門辨識好消息(Good News)的新 聞,另一個則用來辨識壞消息(Bad News)的新聞,剩下的則為影響不大的新 聞文件,並針對以往的權重值計算公式加入群集間的區別係數,以群集內的相 關係數做相似度的判斷,且該預測模型不需要有特定區間的時間序列資料,交 易策略為買進持有(Buy-and-Hold)的投資策略。 Mittermayer(2004)應用支援向量機(Support Vector Machine, SVM)針對新聞 做分類,其主要在預測新聞發布後 60 分鐘內的漲跌幅度與趨勢,並將影響個股 漲跌的新聞分類成好新聞(Good News)和壞新聞(Bad News),其餘的則被分 類成不會對股價造成波動的新聞(No Movers)三種類別,系統會在接受到的分 類結果後,產出對應的交易建議,對個股做買進或買出的操作,結果證實透過 該研究架構交易的平均獲利明顯大於隨機投資的報酬。然而其實驗中,好新聞 6 .
(15) 和壞新聞所包含的關鍵字句有許多重複性,因此造成分類結果的正確性較低。 而鐘任明(2004)以中文新聞和台灣股市為基礎建構一個預測模型,並透過 詞性組合門檻值設定來找出新聞中含有重要資訊的關鍵字詞,其研究發現股價 的漲跌反應和關鍵字詞的組合規則,對其預測的正確率有顯著的影響。 由以上文獻歸納的結果,可以得知新聞與股價波動具有一定的相關性和連 動性,股票交易市場是一個有效率的訊息處理機制,所發生的資訊在吸收消化 後,可以有不同程度地立即反應至股價上,因此本研究假設事件發生所產生的 相關新聞,會有程度地反映在股價的漲跌上,投資者可以透過分析這些資訊,來 執行對自己最有利的決策。 2.1.2.. 何謂口碑. 就經濟學和人類學觀點來看,交易市場上必然充滿著資訊不對稱的問題, 當交易的一方握有另一方所不知道的資訊,如:隱藏的特性(hidden characteristics)和隱藏的行為(hidden actions)時,即產生所謂的「資訊不對稱」問 題,而消費者之間口碑資訊的互相交流,通常被認為是促進整體市場運作和資 訊交流的重要功能之一。透過口碑的傳遞與交流使得消費者之間的資訊分布可 能趨於完全性,這將有助於完全競爭市場的達成。在行銷方面,正面的口碑效 果可作為廠商擴大其市場的最好工具。就社會學觀點來看,口碑傳播行為可使 創新成果擴散,對於社會運動的成型也有所助益(Frenzen&Nakamoto,1993)。 而在消費者行為的研究中,在消費者態度與行為的形成過程中,口碑效果具有 重要的角色地位,這是一個被廣為接受的論點。以下將針對口碑做逐步的探 討。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. i n U. v. 過去的文獻通常將口碑傳播(word of mouth communication)定義為人際間 面對面(face to face)接觸或藉由其他傳播方式,而傳播的目的為非商業目的, 僅傳播自己或他人的產品使用經驗,而傳播的資訊內容可能包含正面或負面的 評價。以下學者分別對口碑做出不同定義,Arndt(1967)將口碑傳播視為一種非 正式的群體影響(informal group influence),而將其定義為「一種口頭的、介於接 收者與非具有商業意圖的傳播者之間,談論有關某一產品、服務或品牌的對話 過程」。Westbrook(1987)則定義口碑為「發生在消費者間有關企業或產品特徵的 非正式溝通」。Bone(1995)在探討口碑行為對產品判斷的影響時,將口碑定義為 「一種人與人之間的溝通,參與溝通的任一方都不是行銷的來源」。Blackwell et al.(2001)則認為口碑是「人與人之問非正式的傳送想法、評論、意見或資訊, 傳送的雙方並非行銷人員」。SiIverlman(2001)定義口碑為「獨立於廠商之外的 消費者與消費者間,透過廠商行銷管道之外的途徑,所進行有關產品與服務的 溝通」。而 Lau&Ng(2001)則認為口碑是指「產品相關的對話、人員推薦、非正 式的溝通與人際溝通」。因此,口碑是人際來源(interpersonal sources)的一種 形式,即以人員為主的資訊傳播方式,為人際間口語上對於產品、品牌或服務. Ch. engchi. 7 .
(16) 非具商業性質的溝通或推薦(Duhan et al.,1997)。 對於產品、品牌及服務相關意見的發展、傳遞與擴散,口碑傳播這種非正 式的對話最早可回溯到 Whyte(1954)的研究,其發現在人與人之間存在著一種巨 大的力量,這種力量發生在「曬衣繩的兩邊(over the clothesline)」與「後院的 籬笆(across the backyard fences)」 ,因為人們在這樣輕鬆的場合下、很自然地 就分享起產品的使用經驗、優缺點之類的意見,在不知不覺的情況下,其消費 行為與決策過程因此而受到影響與改變。後來學者陸續針對不同產品與服務進 行口碑傳播的研究,例如:家庭用品與食物 (Katz&Lazarsfeld,1955;Richins,1983;Bone,1995)、牙醫專業服務(Silk,1966)、內 科專業服務(Duhan et al.,1997)、刮鬍刀(Sheth,1971)、汽車 (Newman&Staelin,1972)、服飾(Asch&Venkatesan,1966)、新產品的採用 (Engel et al.,1969;sheth,1971;Rogers,1983)與服務(Mangold et al.,1999)等。由以上 的研究顯示,口碑對投資者在進行投資決策及選擇行為上,具有相當重要的影 響因素。. 立. 政 治 大. ‧. ‧ 國. 學. 而 Lazarsfeld(1940)則提出口碑傳播在過去都是以二階段傳播理論(two step flow of communication)來描述,他認為資訊是由企業所提供,且企業常是藉由 大眾傳播媒體(如電視廣告、廣播)來散佈資訊,藉此對一般社會大眾進行撒網 式的行銷溝通。並在這樣的行銷溝通傳播過程中,來影響其中某些個人進行股 票投資產品或服務的行為,這群人稱之為早期採用者(early adopter) ,之後透 過這些早期採用者,憑藉其使用經驗再向更多人來散佈有關此項產品或服務的 資訊,而這些早期採用者則扮演著意見領袖(opinion leader)的角色,向其他 人傳播自身使用經驗。. n. al. er. io. sit. y. Nat. 2.1.3.. 為何口碑會有如此大的效力?. Ch. engchi. i n U. v. Silverman(1997)透過文獻的整理與歸納,認為口碑的說服效果主要是來自 於下列四個因素: 1. 相對於企業所提供的正式商業來源(如廣告),口碑的可靠度更高,原因在 於這些口碑主要是透過身邊的親朋好友而來,這些參考來源是我們所信任 的,且其推薦並非作為商業用途(wilkie,1990)。又或者這些口碑來自於客 觀獨立的第三方團,能獲得未失真的事實描述,具有較高的可靠度。 2. 口碑是雙向溝通,而非單向傳播(Wilkie,1990)。 3. 口碑提供潛在顧客使用經驗的參考來源,可以降低投資風險與不確定性 (Murray,1991),所以口碑可以決定產品傳播的速度。 4. 由於口碑是即時的,可馬上進行詢問與回應,所以口碑能提供相關性與完整 性更高的參考價值(Silverman,1987)。 8 .
(17) 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 9 . i n U. v.
(18) 2.1.4.. 何謂網路口碑. 近年來隨著網際網路的普及,口碑資訊在人際間的傳遞不再是只是面對面 的接觸。消費者不僅可藉由不同的網路傳播媒介、網路平台,將個人意見、使 用經驗與評論傳播出去,相對的,也可很輕易地藉由上述的傳播媒介取得口碑 資訊。 Hennig-Thurau et a1.(2004)指出網際網路的出現,使消費者可以透過網頁的 瀏覽,蒐集其他消費者所提供的產品資訊與使用經驗,讓消費者能夠針對特定 主題進行個人經驗、意見、知識的分享形成所謂的電子口碑(electronic word of mouth),又稱為網路口碑(online word of mouth)或鼠碑(word of mouse),並認為 網路口碑的傳遞具有以下等特性: 1. 互動非線性(Interactivity and Non-lieanearlity):溝通是雙向的,每一個人既是 傳播者也是接收傳播者,可以一對一、一對多或多對一甚至是多對多的互 動。. 立. 政 治 大. ‧ 國. 學. 2. 便利性:可以透過搜尋引擎,輕而易舉地取得所需的相關資訊,且網際網路 上所傳播的訊息,可透過數位資料的儲存,因此可以隨時獲取各種歷史資 訊。. ‧. 3. 不受時空限制:無論在任何時間和地方,都可以透過網際網路搜尋資訊或傳 播資訊。. y. Nat. sit. er. io. 4. 匿名性:資訊傳遞者因匿名性的關係,能夠在不會顧及任何情面或利害關係 的狀況下,較願意提供真實的意見與分享第一手經驗,無論是正面或負面評 論。. al. n. v i n Ch 而 Hanson(2000)則認為網際網路上的「口碑傳播」 e n g c h i U ,就是電子口碑傳播或網 路口碑傳播。而網路口碑傳播的形式,主要是透過電子郵件、使用者群組(即新 聞群組)、電子郵件名單服務、線上論壇、產業入口網站討論區、電子佈告欄、 聊天室等網路形式進行資訊的散播。也就是說網路新聞平台上,提供使用者在 網路上散播個人經驗和意見的評論,也算是網路口碑的一種實例。 2.1.5.. 傳統口碑與網路口碑的差異. Kerr et al.(1991)指出實體世界的口碑主要是消費者和自己有關係的朋友, 透過面對面、以口語的方式溝通並分享產品的資訊,而網路上的口碑則訴諸於 文字,將個人的產品經驗和意見傳播出去,雖然面對面的溝通效果能夠更鉅細 靡遺的將資訊表達清楚,較令人信服,但不可否認,網路口碑的文字特性,在 具備一定大規模數量的資料下,所具備的特質也仍具影響。 而 Granitz&ward(1996)認為網路口碑和傳統口碑最大不同之處在於其不受 10 .
(19) 制於彼此之間的背景、長相、地位、住所與工作地方。換句話說,網際網路成 為一個讓消費者得以獲得任何不受時空限制的人所提供的口碑資訊,甚至是匿 名的其他人所提供之大量且互異的產品或服務資訊的平台。 Bickart&Schindler(2001)則認為傳統的口碑包含一個朋友或有關係的人透過 口頭上言詞表達的方式分享產品的相關訊息,而網路口碑則是以文字撰寫的方 式來表達個人的經驗與傳達意見。雖然口頭上的言詞表達可能較具立即的影響 力(Herr et al.,1991),但是文字撰寫卻有其永久存在的優勢,可讓閱讀者依照自 己的需要取得資訊。如此,網路口碑或許可以使得消費者得以吸收更多的私人 資訊並取得較口頭言詞表達更鉅細靡遺的資訊。 費翠(2001)則針對網路口碑傳播與傳統口碑傳播的媒介特性、傳播形 式、傳播對象,與商業性作比較,發現由於網路口碑傳播透過網際網路作為媒 介,故在傳播的形式上,除了傳統口碑常使用的形式之外,更多運用了文字、 聲音、圖片、影像等多媒體形式,相當多元化;且網路口碑的數位化格式透過網 路科技,能夠輕易複製及快速傳遞最完整的二手資訊給很多人,故不是傳統口 碑能夠相提並論的。. 立. 政 治 大. ‧ 國. 學. ‧. 此外,Tanimoto&Fujii(2003)認為透過網際網路而產生的談話內容較面對 面的談話更為開放,議題範圍比人際溝通還要廣泛。由於網路不受時空與地理 位置的限制,加上數位資料的方便性與易複製性,可以不斷經由網路散佈資訊 到所有網路連線能觸及的地方,故網路口碑的能見度與傳播效果遠超過傳統口 碑所能達到的。而留淑芳(2003)透過文獻的整理與歸納,認為傳統口碑與網 路口碑的差異,大致上具有以下三點:. al. er. io. sit. y. Nat. 1.網路口碑較傳統口碑具有較高的說服效果:. n. v i n Ch 網際網路被認知為更能符合消費者需求,具有較其他媒體更高的說服效果 engchi U (Ducoffe,1996)。因為消費者對於網際網路上的資訊乃是基於需要而主動搜尋或 詢問,故資訊接收者對於網路資訊的排斥成及警戒心較低。且網際網路亦被認 知為較不令人厭煩的資訊來源管道,這種遠距的特性有助於提高資訊接收者對 於特定產品的態度,即使網路使用者並未點選該訊息,亦會被消費者認知為更 具有 可信度、相關性的資訊來源 (Miclnnis&Jaworshi,1989;Ducoffe,1996:Briggs&Hollis,1997)。尤其在網際網路的 虛擬空間裡,溝通者問多半為毫不相識、素昧平生的網友,且由於匿名性的關 係,彼此間可在不需顧及任何情面或利害關係的狀況下,往往更能暢所欲言 (Gelb&Sundaram,2002;Ridings et al.,2002),故較傳統口碑具有較高的說服效果。 2.網際網路引發消費者主動搜尋、篩選及傳播資訊的意願: 11 .
(20) 傳統口碑與網路口碑溝通的最大差異在於前者能面對面溝通,產生即時性的溝 通效果,但因受限於時空的限制,對消費者而言,這種口碑資訊的搜尋成本較 高;而網際網路使口碑資訊可藉由文字的方式來傳遞,因此資訊接收者可以主 動去取得所需的資訊,亦即接受者具有較高的主動權與選擇性,完全不受時空 因素的限制,同時也具有快速、低成本的特性,能提高消費者主動搜尋與傳播 的意願(Bickart&Schindler,2001)。此外,網際網路上的虛擬社群功能也有助於激 發消費者傳播網路口碑的意願。因虛擬社群成員為了增強自己對於社群的貢獻 價值,會提供產品或服務的意見與評論給其他社群成員,除了想要幫助擁有相 同興趣的成員能做出更好的投資決策外,還會從過程中獲得社會認同,表示個 人參與並屬於該虛擬社群(McWilliam,2000)。 3.溝通情境的差異: 傳統口碑的傳遞,由於溝通時常須經由面對面的接觸,因此資訊接收者可以明 確的感受到傳遞者的存在,甚至可明確的判斷其身份;然而在網路口碑的溝通 情境中,傳遞者可能是位於地球另一端的異國網友,透過文字在網路上進行資 訊的傳遞,因此接收者較無法感受到對方的存在。. 學. 第二節、. ‧ 國. 立. 政 治 大. 文字探勘與其相關技術. ‧. 因為網際網路的快速發展,大量的資訊內容被置放在網路上供人查詢運 用,藉此做出最正確決策,但每一個使用者的需求都是獨一無二的,為了找尋 最正確的答案,往往得耗費大量心思與時間瀏覽許多資訊內容才能得到符合自 己需求,應該有更好的方法幫助使用者,利用網路上的資訊內容做出正確決 策,而文字探勘技術是一個值得嘗試的方向。. n. al. er. io. sit. y. Nat. 2.2.1.. 文字探勘的定義. Ch. engchi. i n U. v. 文字探勘是編輯、組織以及分析大量文件的一連串過程,提供分析人員或 決策者等需要由資訊中發掘特定資訊特徵及其之間的關聯(Sullivan, 2001),為資 料探勘、知識發現的延伸應用,主要是拿來分析文件內容,從這些雜亂沒有規 則的非結構化文件中,取出隱含在其中有意義、有價值的模型或知識 (Simoudis,1996)-因資料探勘主要是針對結構化的文件作處理分析,但是對非 結構化的文件卻難以處理分析,所以才延伸出處理非結構化文件的文字探勘 (Feldman, 1995;Singh, 1997) ,藉此來發掘文件中隱含有意義且重要的資訊。由 於現實中大部分的資訊多以文字的方式儲存,且過去有研究指出儲存公司資訊 的文件中(E-mail、Office 文件或 PDF 文件等),有 80~98%是重要的資訊 (Cheung, Lee, & Wang, 2005),與資料探勘相較之下文字探勘具有更高的潛在商 業價值(Tan,1999)。文字探勘技術結合了文字分析技術與資料探勘技術,文字分 析技術從語法或語意層面解析文字內容,使得非結構化的文字能夠轉化成結構 化的方式來運用,而資料探勘技術則是用來處理結構化資料之間的關聯、分 12 .
(21) 類、分群問題(國家實驗研究院, 2009)。因此,文字探勘可以說是結合資料探勘 的技術,將非結構化文字資料做前處理後,轉化為資料探勘可以使用的結構化 資料,藉此用來處理大量非結構化的文字分析,舉凡關鍵字關聯、文件分類、 文件分群皆屬文字探勘技術下的議題。 網際網路發達造成的資訊超載,讓使用者難以找到所需之資訊,文字探勘 技術透過電腦的運算能力,能將大量的文字內容過濾並轉化為讓人更有效率的 運用,使得此技術愈來愈受到重視,許多學者將其應用在不同領域上,近幾年 相關應用研究歸納出顧客關係管理、主題分析管理、網站內容管理及趨勢預測 管理等四種類型,此研究即為趨勢預測管理的一種應用。 2.2.2.. 文字探勘的架構. Tan(1999)所提出的文字探勘所運作的架構中主要包含文本萃取(text refining)及知識淨化(knowledge distillation)兩個重要步驟,其中「文本萃取」主 要是把各式各樣不規則的文件轉化為中間形式;而「知識淨化」則是將上述文. 立. 政 治 大. ‧. ‧ 國. 學. 本萃取後的中間形式所呈現的內容歸納出範型或知識。文件所轉化的中間形式 又可以分為文件中間形式(document-based)、概念中間形式(concept-based)兩類, 文件中間形式主要是以一份文件來表示一個分析實體,可以在文件中歸納出範 型或彼此之間的關係,例如: 集群分析、分類分析或視覺化呈現等;而概念中 間形式則是以一個物件或特定領域的概念來表示一個分析實體,分析的結果包 含預測性模型、整合性發現及視覺化呈現等,也可以根據物件或特定領域概念 對文件中間形式進行資訊萃取,轉換成概念中間形式,如圖 2-2 所示。. n. er. io. sit. y. Nat. al. Ch. engchi. 13 . i n U. v.
(22) 群集分析 文件中間格式 分類分析 視覺化呈現 文件 預測性模型 相關性探勘. 概念中間形式. . 立. ‧ 國. 學. 知識淨化. 文本萃取. ‧. 圖 2-2 文字探勘運作架構 (資料來源:Tan, 1999). Nat. y. 中文斷詞. sit. 2.2.3.. 視覺化呈現. 政 治 大. n. al. er. io. 在處理任何文件時,首先必須將文件做斷詞處理,主要目的是為了將文件 內容分割為無數個字詞,這個字詞必須是具有意義,並能自由使用的最小單 位,之後才能做下一步分析處理,因此斷詞處理可以說是語言處理技術中不可 缺少的重要技術。. Ch. engchi. i n U. v. 在字詞的表現方面,中文及印歐語系分屬不同的語系,由於中文裡字詞與 字詞之間並不像印歐語系只要透過明顯的分隔符號(空白符號)就可以斷詞 (Nie,1996),造成中、英文在斷詞處理上產生了極大明顯的差異,而且在中文裡 一個有意義的字詞,可以是一個字,但也可以是由多個字所組成,所以造成斷 詞的困難度增加。比較起來,中文在斷詞上明顯比英文來的複雜許多(喻欣凱, 2008)。而目前國內學者對於中文斷詞主要提出了三個方法,如下: 1. 詞庫斷詞法(Chen, 1992): 詞庫斷詞法主要是利用一個已經建置好的詞庫,將文章的文字資料針對詞庫 裡的字詞做比對,比對過程中會使用「長詞優先法」,以長度較長且具有意義的 字詞作為優先,藉此保留最正確且完整的語意,最後將整篇文章分解出所有具 有意義的最小單位字詞。因詞庫斷詞法利用事先建置的詞庫做為比對依據,所 14 .
(23) 以詞庫的建置與維護就非常依賴具有專業字詞處理經驗人員,長時間地蒐集新 的詞句以維謢詞庫的品質。所以若要使用詞庫斷詞法,依據的詞庫要有相當的 權威性,否則斷詞結果成效不彰。由於新的字詞必須仰賴人工建立,維護所耗 費的時間成本是一個很大的負擔。 2.統計式斷詞法(Fan, 1988;Sproat, 1990): 需要先經由大量文件或大型語言資料庫(Corpus)的訓練,透過統計鄰近字元 同時出現的頻率高低,取得足夠的統計參數作為斷詞的依據,如:詞頻、門檻 值,從各種可能的詞彙組合中找出最可能的斷詞位置。由於透過統計的方式, 不用透過人工定義字詞,所以可以解決複合詞、新生詞的問題。但只靠此方法 統計計算並無法考慮到語意的正確性,因此文句上的表達榮具有錯誤的可能。 且不同領域的語言資料庫,其統計參數無法交互使用。. 政 治 大 此做法結合了詞庫斷詞法和統計斷詞法,首先需對文件做詞庫式斷詞法, 立 比對出許多有意義的字詞,再做統計式斷詞法,利用字詞的統計參數找出文件 3. 混合斷詞法(Nie, 1996):. ‧ 國. 中央研究院 CKIP 斷詞系統. ‧. 2.2.4.. 學. 中最佳的斷詞結果。此方法結合了上述兩個方法的優點,斷詞結果的正確性和 效率較高,然而此方法仍須對詞庫維護和蒐集大量語料來維持此方法的品質。. n. al. er. io. sit. y. Nat. CKIP 斷詞系統是由我國中央研究院所研發,採用混合斷詞法作為斷詞的方 法,其詞庫具有大約 10 多萬個常用中文字詞,並透過統計運算參數得到最佳斷 詞結果,找出新生詞與未知詞。藉由此斷詞系統可以將中文文件中的文字,切 割成數個獨立具有意義的字詞,並透過詞性的標記,標記出字詞的詞性,以供 後續分析運算之使用。 2.2.5.. 文件特徵值選取. Ch. engchi. i n U. v. 將每一篇文件透過斷詞工具斷出所有字詞以後,我們只是將文件拆解出其 組合成分,但還不足以分析出其背後含意和每篇文件的代表性特徵,又因每一 篇文件中的字詞重要性都不同,字詞在該文件的重要性和整個文件集的重要性 也不同,為了能找出能代表此文件的代表性特徵,可以透過計算文件組成的字 詞權重來達成,其中常見的方法如下: 1.. TF(字詞頻率,Term Frequency). 在整個斷過詞的文件集中,每一篇文件中的字詞組合不同,且字詞出現的 頻率也不同,原則上愈重要愈能代表該文件的字詞,理因出現較多次,所以為 了找出能代表此文件的代表性特徵,可以透過計算文件組成的字詞詞頻,也就 是其 TF 值,愈是重要能代表該文件的字詞,在該篇所有字詞中出現的頻率愈 15 .
(24) 高。 2.. IDF(反向文件頻率,Inverse Document Frequency). 愈重要愈能代表該文件的字詞,理應出現較多次這個基本概念,在實際操 作卻會遇到一個嚴重的問題,在自然語言中,有些字詞是基本對話中常用到或 者必定會用到的,所以這些字詞在 TF 的觀念中,必然是該篇文中頻率甚高的 字詞,且在每一篇文件中,也必然都會出現這些高頻率的字詞;而足以代表該 篇文件特徵重要性的字詞,理應只會在這些文件中出現頻率較高,並不會在每 一篇文件都有很高的頻率,於是使用 IDF 反向文件頻率概念修正這些問題,其 主要目的是修正字詞在所有文件和該篇文件中的權重。 3.. TF-IDF. 將 TF 做 IDF 的修正後即為 TF-IDF,其值為 TF 與 IDF 兩者之乘積,所代 表之意義為字詞在文件中的重要性,與其在該文件中出現的頻率成正比,但與 其在所有文件集中出現的文件數量成反比,原因是字詞在該文件中出現頻率愈 高代表其重要性愈高,而該字詞在所有文件集中出現之頻率愈低代表該字詞在 該文件重要性愈高。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 16 . i n U. v.
(25) 4.. Weight 正規畫. 當兩篇文件之其中一字詞分別出現 1 次和 10 次,而文件長度卻分別是 100 字和 1000 字時,字詞之權重有可能受到文件長度而受到影響,為了避免這種情 況發生,須對權重針對其文件長度做正規劃。 2.2.6.. 向量空間模型的運用. 向量空間模型(Vector Space Model,VSM) 是一種簡便且高效率的文件表示 模型,能將非結構化的文件資訊,以向量的形式建構在模型中,為往後的各種 文件資訊處理操作奠定了數學計算的基礎,是目前最廣為使用的資訊檢索模 型。 向量空間模型的關鍵在於特徵向量的權值計算和特徵向量的選取兩個部 分,將使用者的查詢要求(query)和資料庫中的所有文件,依照前述之文件特徵 值選取,依其關鍵字詞之權種所組成的向量,將這些向量建構在模型中,透過 計算向量之間的距離,即可判斷使用者的查詢要求和模型中所有文件的相似程 度,根據相似度查詢結果來做下一步分析計算。下圖 2-3 為一個向量空間模型 基本的呈現方式,並針對其向量表示法和以字詞為單位組成的文件矩陣做說 明。. 政 治 大. 立. ‧. ‧ 國. 學. TERM1. DOC1 = (TERM11, TERM12, TERM13). n. al. er. io. sit. y. Nat. DOC2 = (TERM21, TERM22, TERM23). Ch. engchi. v. i n U. TERM3. DOC3 = (TERM31, TERM32, TERM33) TERM2 圖 2-3 向量空間模型 (資料來源:Salton & Gill, 1983). 17 .
(26) 1.. 向量表示法: 在向量空間模型的概念中,不論文件長短(文章、段落、句子),我們可以. 將每一份文件,以文件為單位分別轉化為向量來表示,一份文件即為空間中的 一個向量,而向量的組成則為其文件中所有字詞的權重值來表示,假設一份文 件用 DOC 表示,而 w1、w2、w3…為其文件組成字詞之權重值,故文件 DOC 的向量可以寫成 DOC = (w1,w2,w3,…,wn)一向量表示。 2.. 字詞-文件矩陣(Term-DocumentMatrix): 當所有文件都轉換為向量呈現以後,為了針對所有文件做分析計算,便將. 所有文件之向量集合以文件矩陣方式呈現,如下圖 2-4 所示(i 篇文件、j 個相異. 政 治 大 相似度;或者在其他文字分析處理中供後續計算,例如:文件的分群和分類處 立. 的字詞特徵權重)。在資訊檢索中,藉此方便計算使用者的查詢要求和文件間的. ‧ 國. 學. 理中,也必須利用此方式計算文件間向量的相似度來進行處理。. ‧. DOC1 W11 W12 … … … W1j. sit. y. Nat. DOC2 W21 W22 … … … W2j. n. al. er. io. … … … … … … …. i n U. v. … … … … … … …. Ch. engchi. … … … … … … … DOCi Wi1 Wi2 … … … Wij. 圖 2-4 向量空間模型中的字詞-文件矩陣 (資料來源:本研究整理). 18 .
(27) 2.2.7.. 文件相似度計算. 如上述所說,在轉換為空間向量模型後,文字探勘為了做後續的文字分析 處理,必須將所有向量組成的字詞-文件矩陣做相似度的計算,而計算兩文件中 的相似度程度,最常使用的方法為計算兩文件向量的餘弦相似度(Cosine Similarity),計算時須以兩組基底和維度相同的文件向量,利用餘弦夾角公式計 算其向量間的角度來度量兩向量間的距離,其計算結果會介於 0 到 1 之間,當 兩個文件向量間的角度愈小時,表示兩項量的餘弦角度愈小,其結果表示兩篇 文件愈相似,而結果值也會愈接近 1;反之,當兩文件愈不相似,其結果值則 會愈接近 0。其二維空間之餘弦相似度如下圖 2-5 所示,A 和 B 兩文件之向量 餘弦相似度為 θ。. 政 A=(X治,Y ) 大 1 1. 立. ‧ 國. 學. Y‐axis. B=(X2,Y2). Nat. X‐axis. n. al. er. io. C=(X0,Y0). sit. y. ‧. θ. Ch. i n U. v. 圖 2-5 二維空間中的餘弦相似度表示法 (資料來源:陳崇正,2009) 第三節、. engchi. 群集分析. 如果我們需要使用大量沒有規則的資料,試圖找出其隱藏在背後的涵義與 知識時,通常需要先將未知資料做分群處理,之後才對其提出解釋並運用,這 連串過程便稱為群集分析。群集分析又被稱為資料切割,因其主要目的為將大 量沒有規則的資料,利用計算資料的相似程度,將相似的資料群聚起來,將原 本的大批資料切割為無數小群集,而群集間的相似度不高,但群集內的相似度 卻很高,透過分析資料間的相似程度與這些群集結果,推論出隱含且令人感興 趣的特徵和現象。由於群集分析的過程中,並沒有任何資訊顯示資料彼此之間 關係,且沒有預先判定資料所屬類別,估屬於非監督式學習的過程。而群集技 術也被廣泛應用在各種領域上,例如:生物學中的物種分群、醫學上的疾病分 群、消費行為的消費型態分群、機器學習、影像處理、基因分析。 19 .
(28) 2.3.1.. k-最鄰近演算法(k-Nearest Neighbor ,kNN). k-最鄰近法是由 T.M. Cover 和 P.E. Hart 兩位學者在 1967 年所提出,在過去 的研究文獻中,經常被拿來使用的一種分類法。kNN 雖然被歸類為分類的演算 法中,但在實作中,如果不用事先設定類別和提供訓練資料,而只透過群集分 析後所得之資料特性,針對其作分析解釋,即可視為分群的一種運用。如 Yang et al.(1999)利用 kNN 於「類別數未知」的新聞事件的偵測追蹤,由於並沒有確 定的類別,所以屬於 kNN 在分群上的應用。 kNN 需要以向量空間模型為基礎進行分群,因此在分群前必須將文件轉換 為空間向量模型,藉由計算所有已知文件向量的相似度和新進文件向量的相似 度,取出前 k 個最相似的文件向量,將這 k 個文件向量所屬群集當作新文件可 能屬於的候選群集,來判斷新進文件可能所屬於的群集,而文件的相似度一般 採用 Cosine 相似度來計算。. 政 治 大. 舉例來說,當文件集中的所有文件皆在向量空間模型中,轉化為特徵值權. 立. ‧. ‧ 國. 學. 重向量,且依照其特徵被分出許多群集,假設有兩個群集,分別是特徵為 B 的 X 群集,以及特徵為 G 的 Y 群集,而一個新進樣本為 S 之文件,進入 kNN 運 算,此時會挑出 k 篇與新進文件最相近的文件,如 k=3,便會找出與新進文件 最相近的前 3 篇文件,藉由這三篇文件所屬群集以及和新進文件間的相似程 度,判斷新進文件究竟屬於 X 群集或 Y 群集,即示意如下圖 2-5。. n. al. 特 徵 B. X. X. Ch X. er. io. sit. y. Nat X. Y. eX n g cY h i . i n UY. vY. Y. S. Y. Y Y. 特徵 G 圖 2-6 kNN 說明 (資料來源:本研究整理) kNN 和其他分群技術相比,因屬於非監督式學習方法,可以省去準備訓練 資料的時間,學習速度快且分群效果佳。但其有兩個困難的問題需要克服,第 20 .
(29) 一個是如何選擇特徵,這是每個機器學習都會遇到的問題,當選擇的特徵不具 有足夠代表性時,其結果將不具意義,像是以頭髮長度和皮膚顏色來讓機器學 習判別性別時,假定男性皆為短髮且皮膚黝黑,此時如果是留長髮的男性與皮 膚較黑的女性,機器學習就無法有效判斷。另一個問題則是文件相似度距離的 制定和語意的問題,如果要判斷兩個字詞是否屬於同一群,只看字詞差別的字 數,用差異的字數來當作距離的差異,其結果也會有問題,像是「巴黎鐵塔」 和「巴黎蛋塔」只差距一個字,和「巴黎聖母院」卻相差了 3 個字,因而將 「巴黎鐵塔」和「巴黎蛋塔」分成一群,實際上「巴黎鐵塔」和「巴黎聖母 院」才是屬於同一群具有建築特性的群集,這樣分出來的群集,就不符合現實 了。(mmdays,2007) 本研究將使用 kNN 群集分析法,將上述新聞文件透過中文斷詞、特徵值選 取將新聞文件轉化為向量,建構在向量空間模型中,進行相似度的比較,藉此 透過 kNN 分群方法將相似度高的新聞文件集群成群間相異大,群內相異小的多 分群,並分析解釋其群內特性,進而評估預測趨勢。 分群績效評估. 立. 學. ‧ 國. 2.3.2.. 政 治 大. ‧. 當把所有的未知文件,經過斷詞系統等等資料的前處理後,依照其特徵值 做 kNN 的分群,並對所分割出許多的群集進一步提出解釋後,通常必須再進行 驗證的步驟,來評估對群集的分群結果之績效,之後針對評估結果再思考分析 解釋,如結果不盡理想,則需要再進行調整(Sebastiani,2002)。我們可利用文字 檢索中常見的評估的方式來評估分群結果之績效,如:精確率(Precision Rate)、 召回率(Recall Rate)等,精確率是指搜尋到的所有結果中,含有正確的結果比 例,而召回率則是所有正確的結果中,被搜尋到的比例,二者間,只要將搜尋 的樣本數縮小即可提升精確率,但也因樣本大幅縮小,造成召回率大幅下降; 而將搜尋的樣本提升,則召回率就會提高,相對地也會搜尋到許多的錯誤結 果,造成精確率下降。因此為了避免造成不同指標之結果不一的情況發生,可 以使用 F-measure 方法改善,F-Measure 是精確率與召回率二個數值的協調平均 值,各取所長之結果,其值介於 0 和 1 之間。. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 表 2-1 為文件分類之結果整理說明,圖 2-6 為文件評估標準如下: 表 2-1 文件分類之情形 分為該類. 未分為該類. 屬於該類別. TP. TN. 不屬於該類別. FP. FN. (資料來源:吳漢瑞, 2011). 21 .
(30) TP:資料屬於該類別,系 統判斷屬於該類別 FP:資料不屬於該類別, 系統判斷屬於該類別 TN:資料屬於該類別,系 統判斷不屬於該類別 FN:資料不屬於該類別, 系統判斷不屬於該類 別 TP+FP:系統分類結果 TP TN 正確的分類結果. FN. TN. TP. FP. 政 治 大 圖 2-7 評估標準示意圖 立(資料來源:陳柏均, 2011). ‧ 國. 學. 第四節、. 文獻探討小結. ‧. 由文獻探討得知新聞與股價波動具有一定的相關性和連動性,且口碑提供 潛在顧客使用經驗的參考來源,以及提供相關性與完整性更高的參考價值,可 以降低投資風險與不確定性,又網路口碑具有即時性無時空限制,可馬上進行 詢問與回應,或歷史資訊也很好取得,而網路新聞之評論屬於網路口碑的一 種,因此本研究將透過網路新聞平台上的新聞文章及其閱讀者的回應,用文字 探勘的相關技術及 kNN 分群技術,配合歷史股價資訊,試圖找出和股價波動的 相關性,進而提出預測。. n. er. io. sit. y. Nat. al. Ch. engchi. 22 . i n U. v.
(31) 第三章、研究方法與設計 本研究將使用文字探勘以及 kNN 群集分析技術建立一個可供預測股價趨勢 的模組,將網路新聞及該篇閱讀者之新聞評論合併為一新聞文件,進行新聞文 件分群,試圖找出能代表群集的關鍵字,並透過歷史之股價交易資料將新聞文 件分類,以判斷群集屬於上漲、持平、下跌何種分類,進而用來預測趨勢。 第一節、. 研究架構. 首先,本研究蒐集網路上新聞平台所發表之網路新聞與其該篇閱讀者之新 聞評論合併為一新聞文件,並利用台灣證券交易所的歷史股價資料對新聞文件 做類別標記,接著透過 CKIP 中文斷詞系統將其進行斷詞後存入資料庫,其中 前三分之二之新聞文件為訓練新聞文件,後三分之一為測試新聞文件。. 政 治 大. 為了考量新聞文件的周延性,能在上漲和下跌這個區間平均挑選出新聞文 件做為訓練文件,因此再由上述的訓練新聞文件隨機挑選出三分之二作為真正 的訓練文件,透過文件特徵值選取中字詞權重的計算方法,計算出新聞文件中 各個字詞的權重,找出能代表文件的關鍵字詞,進而將新聞文件轉換為向量空 間模型,計算出訓練文件之各新聞文件相似度,進行新聞文件分群,之後透過 歷史股價資料對新聞文件的類別標記,計算出各個群集之上漲、持平、下跌幅 度,以此建立預測模型,而剩餘三分之一隻訓練文件則做為評估此模型的回憶 文件。. 立. ‧. ‧ 國. 學. sit. y. Nat. n. al. er. io. 最後再將測試新聞文件依前述建立的模型進行分群,並透過歷史股價資料 對新聞文件的類別標記,評估此模型之正確性,進而提出趨勢預測。. Ch. 本研究之研究架構如圖所示:. engchi. i n U. v. 圖 3-1 研究架構圖 第二節、 3.2.1.. 資料來源與處理 資料蒐集. 本研究的實驗對象為台灣證券交易市場的股票上市公司,本研究先針對鴻 海科技集團進行實驗,日後再增加其他個股。首先,在網路上蒐集該公司之個 股新聞以及該篇新聞之閱讀者所給予之評論。由於 Yahoo 奇摩之新聞平台較具 有能見度,且廣泛蒐集了各種媒體的網路新聞,其中包含了平面、電視以及網 路等媒體的新聞資料,擁有廣大的閱讀群眾,且閱讀者在其新聞平台上閱讀文 章後,所留下之評論數量,明顯高於其他新聞發佈平台,故選擇此新聞平台作 為蒐集網路新聞及評論的資料庫。但因新聞數量太過龐大,且各家媒體對財經 23 .
(32) 領域的專業程度不一,所以只選擇 Yahoo 奇摩新聞平台之財經分類新聞中鉅亨 網的新聞做為資料來源,截至 2012 年 05 月 21 日~2013 年 01 月 24 日止,共計 1068 篇之網路新聞與其閱讀者之評論,為了考量資料的週延性和預測性,這些 資料的前三分之二也就是前 712 篇做為訓練資料之用途,後 356 篇則作為後續 測試資料之預測用途,而訓練資料中,為了確保能在上漲與下跌這個週期中皆 能有資料入選,故接著在訓練資料中,隨機抽取三分之二的資料量作為真正的 訓練資料,而剩餘的資料則可以做為回顧這個模型的資料。新聞與評論之範例 如下頁中表 3-1、表 3-2。 另外,本實驗也同步蒐集個股之歷史股價交易資料,經由台灣證券交易所 的網頁中,擷取存入本實驗資料庫,作為後續計算分類模組的重要資料。. 政 治 大. 圖 3-2 上漲、下跌週期圖示. 立. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 24 . i n U. v.
(33) 表 3-1 網路新聞範例 標題:鴻海 80 元保衛戰!今年市值蒸發 1065 億元 每個交易日少 28 億元... 發布時間:2013-03-05 13:30 蘋果(US-APPL)股價仍未見止跌,續跌 2.4%,在 420 美元附近掙扎,鴻海 (2317-TW)股價也難擺脫蘋果拖累,今天 還是上演開高走低,日線拉出第 7 根黑棒,面臨 80 元關卡保衛戰,早盤並曾 失守 80 元。鴻海今年以來,是讓投資人最傷心的標的之一,今年以來跌幅達 1 成,市值蒸發約 1065 億元,以今年以來 38 個交易日估算,平均每個交易 日市值跌掉 28 億元。 鴻海去年底收盤價為 88.9 元,隨蘋果訂單雜音不斷,蘋果股價持續走軟,鴻 海今年以來,遭到內外資法人聯手砍殺,今年以來,外資共賣超鴻海達 19 萬 張,投信、自營商也聯手賣超 6.7 萬張,三大法人今年以來共賣超鴻海逾 25 萬張。 鴻海今年以來股價跌多漲少,今天盤中曾失守 80 元大關,盤中低點打到 79.7 元,以 80 元估算,鴻海今年以來市值蒸發達 1065 億元,而今年以來僅 38 個 交易日,平均每個交易日鴻海市值徵發達 28 億元。 雖然鴻海今天後半場奮力守住 80 元,但法人對鴻海走勢看法依舊保守,後續 將有 2 大觀察重點,一是 3 月底鴻海公布去 年年報,另一則是期待蘋果發表新產品的訊息,鴻海股價未能站回月線之 前,中線均仍採保守態度。. 立. 政 治 大. ‧. ‧ 國. 學. y. Nat. (資料來源:. sit. al. er. io. http://tw.news.yahoo.com/%E9%B4%BB%E6%B5%B780%E5%85%83%E4%BF%9 D%E8%A1%9B%E6%88%B0-. n. %E4%BB%8A%E5%B9%B4%E5%B8%82%E5%80%BC%E8%92%B8%E7%99% BC1065%E5%84%84%E5%85%83%E6%AF%8F%E5%80%8B%E4%BA%A4%E6%98%93%E6%97%A5%E5%B0% 9128%E5%84%84%E5%85%83...-053010802.html). Ch. engchi. 25 . i n U. v.
(34) 表 3-2 新聞評論範例 標題:鴻海 80 元保衛戰!今年市值蒸發 1065 億元 每個交易日少 28 億元... 發布時間:2013-03-05 13:30 蘋果減單...DELL/惠普訂單殞落大西部成文子館...大電視退禍...歐鐵冰封筆電 運輸受阻...宏夏失戀投資碰壁....種什麼因得什麼果 80 太高貴了 少個 0 或許 較配襯吧...唉 肖掰無落魄的酷! 媚中親日的下場不只有這樣子而已 台灣最好創造一些有研發性的東西,別一直做別人的死代工奴才~ 這代工的勞力錢,賺太多就是剝削廉價勞工。當工資反映回來時,就看得很 清楚. 政 治 大 如果只是代工,只有看人臉色。 立 鴻海高雄的軟體園區,也沒什麼進展?. ‧ 國. 學. 目前 apple 只要一打噴嚏,鴻海就會重感冒.. ‧. 挺馬英九時候挺囂張挺搖擺的~~~. y. Nat. n. 這個姓郭的,生意不乖乖做,還搞政治,死好!. Ch. 老板太關心政治,股價就會跌. engchi. er. io. al. sit. 這種企業根本沒有研發能力!. i n U. v. (資料來源: http://tw.news.yahoo.com/%E9%B4%BB%E6%B5%B780%E5%85%83%E4%BF%9 D%E8%A1%9B%E6%88%B0%E4%BB%8A%E5%B9%B4%E5%B8%82%E5%80%BC%E8%92%B8%E7%99% BC1065%E5%84%84%E5%85%83%E6%AF%8F%E5%80%8B%E4%BA%A4%E6%98%93%E6%97%A5%E5%B0% 9128%E5%84%84%E5%85%83...-053010802.html). 26 .
(35) 3.2.2. 1.. 資料處理模組. CKIP 斷詞. 將新聞平台之網路新聞與該篇閱讀者之評論合併的新聞文件蒐集完成後, 接著便進入文字探勘的資料前處理中,由於文字探勘主要在處理文字運算,因 此必須將其他雜亂之圖片、影音等非文字資料過濾去除,只保留文字的部分, 接著存入資料庫做後續使用。如文獻探討中,為了分析處理非結構化的文件資 料,必須先對文件做斷詞處理,轉化為結構化的資料才能對其做運算,而本研 究使用的斷詞系統為中研院詞庫小組所開發的 CKIP 中文斷詞系統,將文件送 入斷詞系統中,除了回傳文件中所有組成的字詞外,還會在字詞中附加詞性標 記。以下為 CKIP 斷詞系統處理前和處理後的對照範例: 斷詞處理前:. 立. 斷詞處理後:. 政 治 大. ‧ 國. 學 ‧. 當文件斷完詞之後,如果文件長度非常大,則後續的運算效能勢必受到影 響,而在這些字詞的詞性中,名詞、動詞、形容詞等相較其他詞性,較具有實. y. Nat. sit. 質意義,於是我們利用 CKIP 斷詞系統所提供的詞性標記功能,篩選出所需詞. n. 率 2.. al. er. io. 性之字詞,並過濾其他詞性之字詞,藉此減少後續的運算過程,提升執行的效. 權重計算. Ch. engchi. i n U. v. 當斷詞完並篩選一篇文件中所有組成字詞後,便需要計算其字詞的權重, 選出具有代表性的特徵值來代表該文件的特徵,而權重值的計算為經過以下一 連串的修正所求得。. 27 .
(36) 1 TF: 由於愈重要的特徵字詞愈容易重複出現在文件中,故以 TF 值表示該文件中每 一字詞之出現次數,以此作為文件組成的權重值,其公式如下: tf ,. ,. ∑. ,. …………………………………………………………………(式 3-1). 其中,. ,. 是字詞 i 在文件 j 中的出現次數,而∑. ,. 則是文件 j 中所有字詞. 的出現次數之總和。 2 TF-IDF: 當該篇文件出現之字詞,在每一篇文件皆出現,其所能代表文件的重要性與. 政 治 大. 出現在較少文件中的字詞相比,相對少了不少,透過 TF 值做 IDF 之修正即可. 立. 解決此問題。IDF 之運算如下: ………………………………………………………………(式 3-2). ‧. 其中,| |為整個文件集的文件數,而. 為字詞 i 出現在整個文件集中的文. idf. ,. ∑. al. ,. log. | |. sit. tf ,. …………………………………(式 3-3). er. IDF. io. TF. Nat. 件數,而 TF-IDF 值為 TF 與 IDF 相乘而得,公式如下:. y. | |. ‧ 國. log. 學. idf. n. v i n Ch 於是修正後,權重值會因字詞在其文件中出現的次數成正比,因字詞在所 engchi U 有文件集中出現之文件數成反比。 3 Weight: 為了避免文件長度的不同,造成權重值受到影響,故最後針對文件的長度對 TF-IDF 做正規化處理,修正此問題,其公式如下: Weight. ,. ∑. ………………………………………………………(式 3-4) ,. 其中,W , 為該字詞之原始權重,即 TF-IDF,而∑ 始權總之平方總和。. 28 . ,. 為所有字詞原.
(37) 3.. 向量轉換. 計算新聞文件相似度之前,需將新聞文件轉換成能代表其文件特徵的權重 值向量,並將所有向量建構在向量空間模型中,而權重值則為上述斷詞後,不 斷修正計算字詞之權重值,將資料經過這些處理,以便後續作相似度比較運算 及分群分析使用。 4.. 特徵值選取. 文件中每一個字詞都是組成該文件的特徵,當全部選取時必定能完整描述 該文件本身,但當資料量趨於龐大時,愈多的文件特徵便會造成文件向量空間 的維度愈高,分群分析時運算量龐大,因此特徵值的選取便是一個需要取捨的 課題。本研究為了能完整描述該文件之特徵值,減少資料的失真,故選擇全部 的特徵值,作為後續分群分析的運算來源,當日後運算效能明顯無法應付時, 再予以選取特徵值。 第三節、. 立. 文件相似度計算. 學. ‧ 國. 3.3.1.. 分群分析. 政 治 大. 將所有文件轉化為權重值向量,並建構在向量空間模型以後,便可求得字. y. sit. ∑. ∑. ………………………………………(式. er. ∑. io. 3-5). Nat. ∙ | |∙| |. cos. ‧. 詞-文件矩陣,並透過計算向量空間模型中,兩文件所對應向量之餘弦值,以兩 組相同基底與維度之向量夾角差距,來度量兩項量間的距離。餘弦值公式如 下:. al. n. v i n Ch U n 維向量空間。其計算 其中,A、B 兩文件向量間之餘弦相似度為 e n g c h i θ,且為 結果會介於 0 到 1 之間,文件愈相似則結果愈接近 1,反之愈接近 0。 3.3.2.. kNN 分群. 本研究之分群分析是採用 k-最鄰近演算法(kNN)之技術,其在進行新聞文 件分群之前,必須先做上述的向量空間轉換,以及透過計算已分群之相似度(相 似度的計算採用 Cosine 相似度加以計算),來判斷新進文件可能所屬之群集, 其分群步驟如下: 1.. 將新進之新聞文件轉化為向量空間模型表示。. 2.. 將新進新聞文件和已分完群之所有新聞文件做相似度的計算比較,取出和 新進新聞文件最相似的前 k 份文件。. 3.. 將上述取出之 k 份文件之所屬群集,列入新進新聞文件可能所屬於的候選 29 . .
(38) 群集。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 30 . i n U. v.
(39) 4.. P. 將新進新聞文件透過與這 k 份新聞文件之間所屬群集之計算,來判斷新進 新聞文件所屬於之群集,其計算方式為將取出的 k 份新聞文件中,把相同 群集內的所有文件與新進新聞文件的相似度做加總在除以該群集所包含的 文件數,其計算公式如下: ∑. ,. ,. ∈. ,. …………………………………(式 3-6). 其中, 為新進新聞文件之特徵向量, 為第 j 群集所包含的文件數量, , 為相似度的計算公式, , 為判斷群集的屬性函數,當 屬於群 集 時,其函數值為 1,反之則為 0。當計算出新進新聞文件與各個群集之相似 度後,其數值最大的群集就是新近新聞文件所屬於的群集。 第四節、. 分群分類績效評估. 政 治 大 以往預測股價之相關研究中,區分漲跌的方法通常以個股之漲跌變動量作 立 為評估標準,假設某篇新聞事件於 x 日發佈,則其收盤價變動量 x 公式如下: 分析模組. 收盤價. 收盤價. ……………………………………………(式. ‧. 3-7). 收盤價. 學. 收盤價變動量. ‧ 國. 3.4.1.. sit. y. Nat. 而喻欣凱(2008)的研究中發現,當反應時間為前後各兩日,收盤價變動量. io. er. 大於 0.03 時,可將此新聞事件歸類為上漲;當收盤價變動量小於 0.03 時,可將 此新聞事件歸類為下跌;當收盤價變動量界於此範圍之間時則表示此新聞事件. n. al. Ch. i n U. v. 無顯著影響。如下圖 3-3 所示,事件發生的三個時間點,x-2、x、x+2,當五日. engchi. 收盤價變動量大於 0.03 時,我們可以判斷影響 x 日之事件為影響股價上漲;當 收盤價變動量小於 0.03 時,我們可以判斷影響 x 日之事件為影響股價下跌。. 圖 3-3 反應時間與收盤價變動量圖 以反應時間為前後各兩日,所計算收盤價變動量 因此本研究以此為準則,將先前所分割之所有集群,透過蒐集的歷史股價 資料計算並標記其群集內之文件收盤價變動量,試圖分析解釋各個群集之特 徵。. 31 .
(40) 第五節、 3.5.1. 1.. 研究流程與預期結果. 研究流程. 將網路新聞及其評論合併為一個新聞文件,並蒐集存入資料庫,同時也將 台灣證券交易所之個股歷史交易資料存入資料庫供後續使用。. 2.. 取出新聞文件之前三分之二部分,再將其隨機抽取三分之二的資料量作為 訓練資料,而一開始所剩餘三分之一資料量作為未來預測趨勢的測試資 料。. 3.. 將訓練資料送入資料處理模組中進行前處理,之後再進入 Knn 演算法進行 新聞文件分群。. 4.. 分群後透過先前台灣證券交易所之個股歷史交易資料,利用計算收盤價變 動量之方式,對新聞文件做標記,進而對各個集群提出分析解釋。. 學. 3.5.2.. ‧ 國. 5.. 治 政 大 將測試資料放入模型中進行分群,並評估其分析分群結果與實際情況之績 立 效。 預期結果. 蒐集分析新聞和其評論,透過分群分析找出其背後所隱含之意義。. 2.. 透過先前所建立之模型,丟入測試資料進而對股價漲跌趨勢進行預測。. ‧. 1.. n. er. io. sit. y. Nat. al. Ch. engchi. 32 . i n U. v.
數據
相關文件
In this section we define a general model that will encompass both register and variable automata and study its query evaluation problem over graphs. The model is essentially a
MR CLEAN: A Randomized Trial of Intra-arterial Treatment for Acute Ischemic Stroke. • Multicenter Randomized Clinical trial of Endovascular treatment for Acute ischemic stroke in
Promote project learning, mathematical modeling, and problem-based learning to strengthen the ability to integrate and apply knowledge and skills, and make. calculated
“Big data is high-volume, high-velocity and high-variety information assets that demand cost-effective, innovative forms of information processing for enhanced?. insight and
Know how to implement the data structure using computer programs... What are we
• Recorded video will be available on NTU COOL after the class..
—we cannot teach all, but with reading you can learn all 3-6: 3 hour teaching, 6 hour reading/writing after class as important as writing assignments:. some may show up
If we would like to use both training and validation data to predict the unknown scores, we can record the number of iterations in Algorithm 2 when using the training/validation
